1. Introduction
The past couple of years have seen an increase in the amount of research on artificial noses for detecting targeted substances in the atmosphere. While the first generations of sensors were optimized to respond to a particular substance and were designed to detect it within a certain concentration range, sensor sensitivity is not a major problem anymore. But because these sensors can have the same electrical response to many different targeted substances, the necessary chemical selectivity can be hard to achieve. Therefore, research is now shifting towards arrays of an increasing number of sensors that are able to distinguish between a series of different substances in various concentration ranges, as a dog’s nose would. The design of a sensor array depends on the application, for example, [
1] industrial chemicals, such as pollutants, volatile organic compounds, or explosives [
2], or compounds used in environmental monitoring. Often, the applications are in the food and beverage industry [
3,
4], for detecting fruit aromas or determining the ripening status [
5,
6], controlling the quality of vegetable oil [
7,
8], classifying different types of wines [
9] or teas [
10] and in detecting spoilage due to microbiological contamination [
11]. Applications in the field of medicine have been explored as well, for example, in analysing breath [
12] or detecting the volatile organic compounds produced by bacteria in infected wounds [
13]. There are a variety of technologies used in artificial noses. Some of the most common sensors are based on metal oxide semiconductors (MOS), while other types use conducting polymers or employ approaches from optics, mass spectrometry, gas chromatography, or combinations of techniques [
4]. For several applications in food chemistry, a small number of highly sensitive sensors is already sufficient, as we can deduce the state of the sample based on the presence of a small number of compounds [
4]. However, the fundamental question remains, whether a more general system can be built, one that truly mimics a dog’s nose. The long-term vision is an array of thousands of different sensors, integrated onto a single chip, similar to image sensors. Such a system with many sensors that selectively respond to different substances would make the detection of a wider set of substances possible. In addition, such a system would allow us to simultaneously test several different surface modifications, which would mean the faster optimization of an e-nose with a small number of sensors for specific applications. It is important to note that the present system of surface-functionalized micro-capacitors allows for a wide variety of organic receptor molecules to be designed for specific sensing applications.
To date, the number of different sensors in an array is small. The maximum number of different sensors reported in the literature is 18 semiconductor sensors installed in a commercially available e-nose [
10] or 34 in an experimental setup [
13]. We have built a 16-channel e-nose demonstrator [
2] for use in this study. The number of sensors in existing e-noses is small compared to the millions of sensing cells in a dog’s nose. But while increasing the number of sensors is a plausible task and a large number of sensors could be integrated on a chip, similar to CMOS chips for imaging, the real problem is handling, analysing and interpreting the huge amounts of data that are generated from such a sensor array.
Due to the complexity of a sensor array’s output, one option to handle the data is the use of artificial intelligence (AI). The past couple of decades have witnessed remarkable advances in the capabilities of AI to manage large amounts of data in very different scientific fields. AI is successfully used where “big data” is generated, such as in particle physics, astronomy, molecular biology and medicine.
In order to properly interpret the “signal” from a multisensory array, careful data analysis is required. Often, machine-learning methods are employed to help with this task. Typically, the analysis consists of data pre-processing, feature extraction, building classification models, and decision making, which means classifying the input to the correct class. As the sensory system is aimed to tackle a particular task, the methods have to be optimized for the domain in question. Data pre-processing usually removes the corrupted data, filters, segments, and assigns classes to the segments. Feature extraction aims to extract robust information from the sensors’ responses, with common features being the average signal differences, the relative differences, or the different types of array normalizations [
14]. The classification methods can be seen as unsupervised and supervised. Unsupervised methods work on data that have not been labelled and aim to identify commonalities. They usually work by building clusters of data based on the statistical properties. A commonly used technique with unsupervised methods is principal component analysis (PCA) [
15]. On the other hand, supervised methods require both a training dataset, upon which the model is built, as well as a testing set, upon which it is evaluated. Here, both sets are labelled, meaning that the samples are assigned to chosen classes (such as individual chemical compounds). Some successful methods applied to electronic noses include support vector machines (SVMs) [
5,
12], different types of neural networks [
9,
12,
16], as well as different methods based on decision trees. Overall, machine-learning methods usually perform well when assisting with the classification of sensor inputs. Some other algorithm-related tasks with electronic noses include the compensation of sensor drift, an intrinsic feature of the sensor that appears with time [
17], developing approaches to incrementally add classes to the model without having to retrain it for each new class [
18] and knowledge transfer between similar sensors [
19].
The goal of this study is to apply the methods of artificial intelligence to an existing e-nose demonstrator, which is described in our earlier publication [
2]. There are 16 different pairs of sensors in this demonstrator, which are differently chemically surface-functionalized, thereby providing different electrical responses to different vapours. We selected 11 different target substances, which are presented in
Table 1. With many sensors and many different compounds, we want to see which sensors or sensor combinations are appropriate for particular compounds.
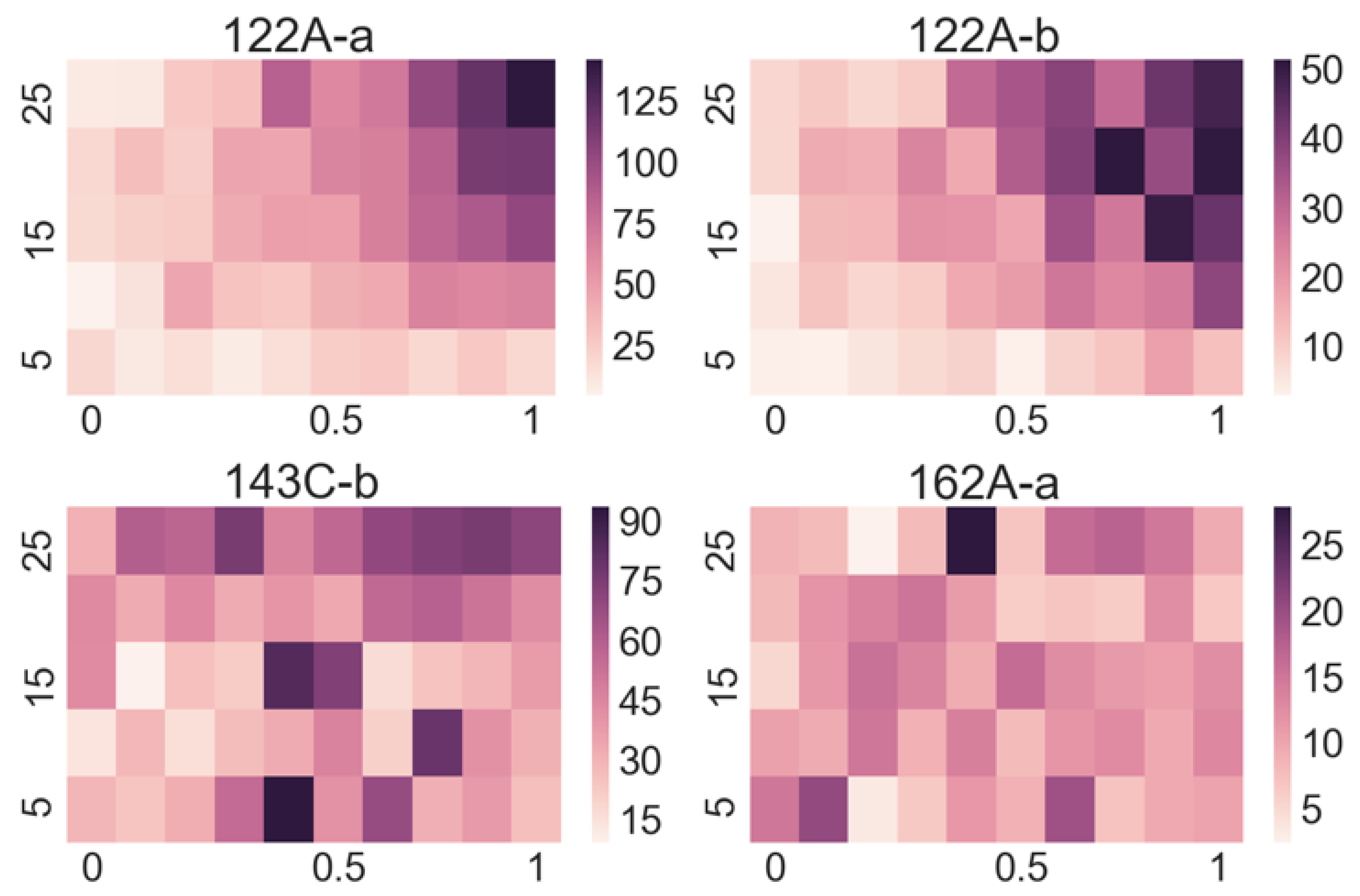
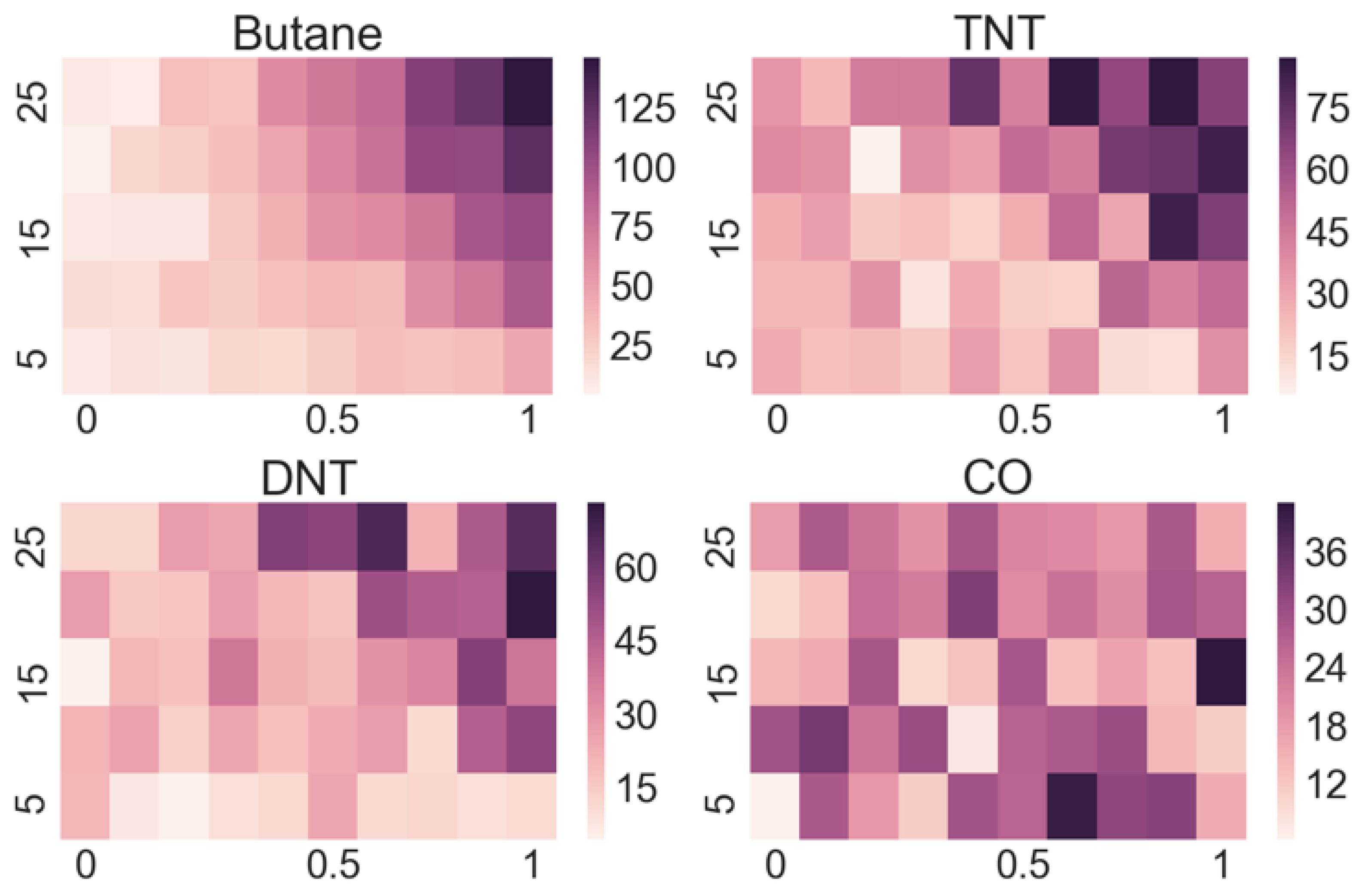
Our approach is to measure the response of each sensor in the array to each targeted substance at different concentrations of vapours and different flow rates, which allows us to gather more data on a single substance in a controlled manner. As a result, we obtain a 2D array of responses for each sensor at different concentrations and flow rates for each targeted substance. For each sensor, this amounts to 50 different responses (all functions of time) for every selected substance. From the stored functional responses, we assign characteristic parameters, e.g., the amplitude of a response for a certain combination of flow rate and concentration, which is a single number. These numbers are then organized into a matrix that is presented with a so-called “heat map”. Such maps give a very informative overview of the response of a certain sensor to a selected substance. As our demonstrator has 16 channels, we obtain 16 such matrices for every substance with 16 × 50 = 800 numbers characterizing the response of the sensor array to that substance.
It has been previously demonstrated that many of the sensors in our demonstrator system react to various substances in a different way; however, several sensors also show a response to more than one substance, which makes the interpretation of the signals non-trivial. Since we are dealing with a new type of sensor, we only use AI methods that are easy to interpret in order to understand which features are the most relevant to differentiating between individual substances. In this paper we explore the use of the Random Forest machine-learning algorithm to distinguish the array responses to different substances. After the algorithm is trained on a set of acquired signals, the question is how well the algorithm recognizes newly acquired signals from one of the substances of the set. At this point we are only interested in identifying individual, “pure” substances, with future work planned to look at mixtures of different vapours.
2. Materials and Methods
2.1. Array of Sensors
An array of 16 micro-capacitive sensors that were chemically functionalized using different receptor molecules was used [
2]. Each sensor is actually a chip, which has a pair of identical, planar, comb-like micro-capacitors with inter-digitated electrodes made of a thin layer of silicon dioxide. Each micro-capacitor has outer dimensions of 350 µm × 300 µm and has 51 fingers, each finger is 300 µm long. The electrodes are made of polysilicon and are 1.5 µm apart and 2.5 µm high. The conductive polysilicon is covered with an approximately 10-nm-thick layer of SiO
2. This layer provides for the good chemical binding of different organic molecules, which serve as a thin receptor layer to attract targeted molecules in the surrounding atmosphere and bind them to the surface. This surface layer of attracted molecules changes the capacitance of the sensor, which is detected by our electronic circuit. After the chip and the pair of micro-capacitors is surface functionalized with different receptor molecules, the receptor layer of one of the micro-capacitors is removed using high-intensity Ar
+ laser illumination. This illumination produces a high surface temperature and the illuminated receptor layer loses its ability to preferentially attract targeted molecules to that surface. In this way the pair becomes chemically different and the preferential adsorption of the targeted molecules on one sensor causes an imbalance in the capacity of the two sensors. This imbalance is then detected as the signal from each sensor pair.
The surfaces of the 15 sensors used in this system were modified with six different silanes: (1) 3-aminopropyl) trimethoxysilane (APTMS), (2)
p-aminophenyltrimethoxysilane (APhS), (3) 1-[3-(trimethoxysilyl)propyl] urea (UPS), (4)
N-(2-aminoethyl)-3-aminopropyltrimethoxysilane (EDA), (5)
N,
N-dimethylaminopropyl)trimethoxysilane (DMS) and (6) octadecyltrimethoxysilane (ODS). After the comb-like micro-capacitors were coated with a specific silane, one of the micro-capacitors in each pair was irradiated with a high-power laser beam to modify the properties of the organic layer. In many cases this irradiated sensor showed different responses than the non-treated and was considered as an independent sensor in our measurements. This means that we actually had 30 different sensors operating in our e-nose demonstrator. The processes of surface modification by these organic molecules and the characterization of the surfaces is comprehensively described in Ref. [
2].
2.2. 16 Channel e-Nose Demonstrator
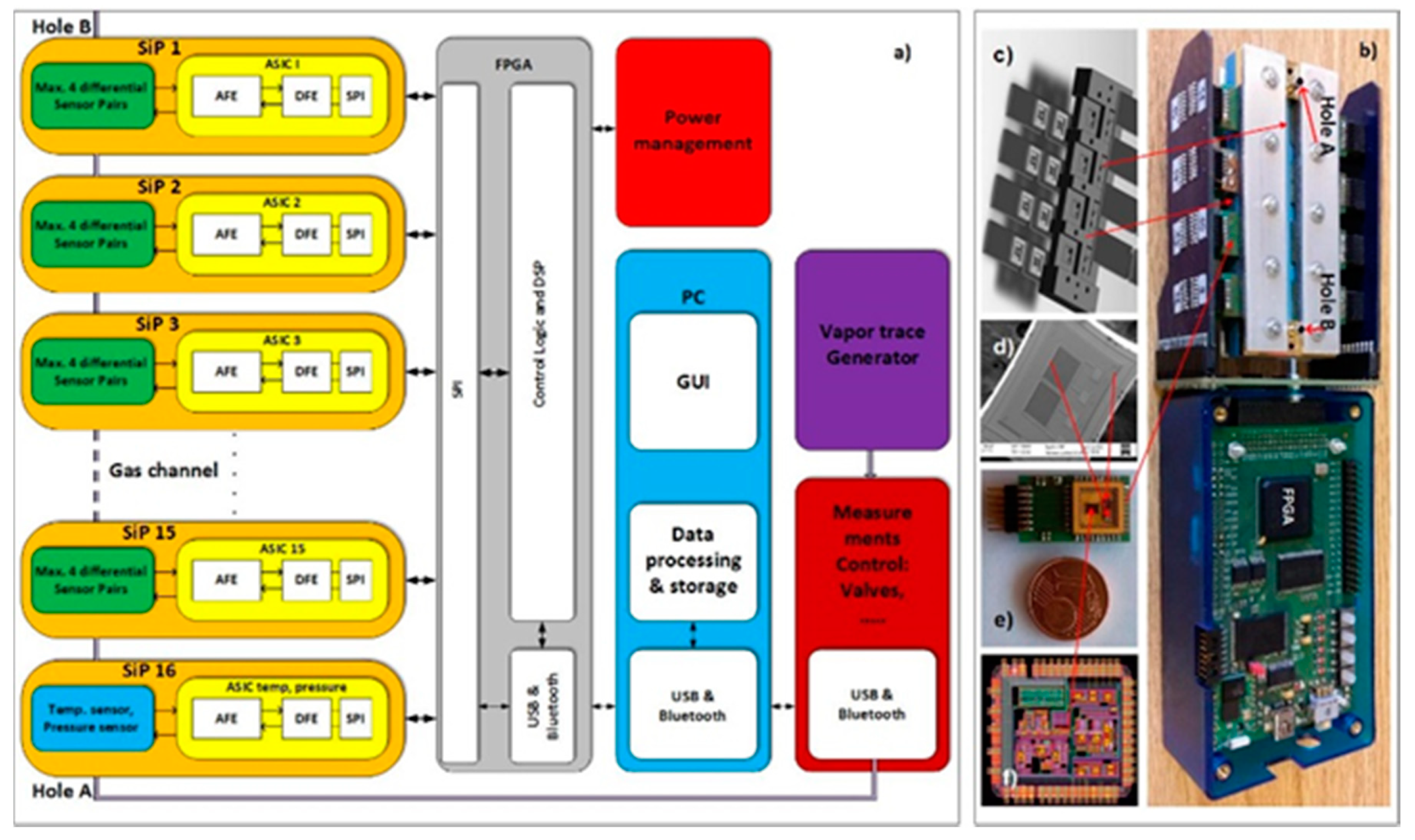
A block diagram of the 16-channel e-nose demonstrator for vapour-trace detection is presented in
Figure 1a. It is composed of 16 differently modified comb capacitive sensors connected to an ASIC with detection electronics. One channel of detection electronics can serve a maximum of four differential sensors. In this experiment we used only two sensors in one channel of electronics. The result of the capacitance-difference measurement of each sensor is A/D converted and further processed in the FPGA [
2]. The last, 16th channel serves for the temperature and humidity measurements. The results are sent to a PC for further processing, storage, eventual display and further signal processing using the methods of machine learning, as described here. The physical implementation of the 16-channel e-nose demonstrator is presented in
Figure 1b, while its building blocks are presented in
Figure 1c,d. The technical details of the demonstrator are explained in the references [
2,
20,
21].
Figure 2 shows a PC interface screen of the 16-channel e-nose demonstrator, where the response of each sensor can be plotted vs. time at a rate of 100 points/minute. At the same time, each sensor’s response is analysed and plotted as a coloured square with a colour corresponding to the magnitude of the response. In this way a matrix of coloured squares is presented, as shown on the bottom-left part of
Figure 2, which is helpful for monitoring and comparing the responses of different sensors. In the figure all the squares are green because no thresholds for the measured signal have been defined.
2.3. Generator of Vapours and Measuring Protocols
To measure the response of the 16-channel e-nose demonstrator to different vapours we need different vapours with adjustable and calibrated concentrations for each vapour. We have previously published detailed studies of a reliable generator of vapours for different explosives; this is an important instrument for the development of e-noses [
2,
20,
21]. We used two different vapour generators in this study. For explosives, the setup for generating particular concentrations of molecules of different explosives in the N
2 carrier gas is based on the flow of N
2 through containers with finely dispersed explosives on a fibre carrier, which provides a large surface area of explosive material [
2,
20,
21]. For the remaining substances, gas samples of high purity were prepared commercially by mixing the target substance with nitrogen gas to a selected concentration. These were further mixed with additional N
2 carrier gas to lower the concentration to the required value at a certain total flow and fed into the measuring system. It was noticed in our experiments that humidity fluctuations in the laboratory significantly influenced the sensors’ responses. For this reason, the e-nose demonstrator was enclosed in a metal tube, which had an overpressure of N
2 to minimise any diffusion of water into the system, thereby providing a stable environment. To prevent water diffusing through the exhaust tube, a long exhaust tube with a drying stage and a pump were used.
2.4. Data Acquisition
In total, 11 different chemical substances were used for the measurements, as listed in
Table 1. All the targeted substances were detected in their vapour phase, which was a mixture of known concentrations of molecules of the targeted substance and the carrier gas. Very pure N
2 was as the carrier gas because it is inert and does not interact with the sensors.
For each target substance, we varied both the concentration of the substance and the gas flow during the measurements to increase the diversity of the available dataset in a controlled manner. The concentration was varied by changing the ratio of the sample-containing gas and the pure nitrogen gas, ranging from 10% (one part of sample-containing gas and nine parts of pure nitrogen) to 100% (sample-containing gas only) in steps of 10%. The total gas flows ranged from 5 to 25 mL/min in steps of 5 mL/min and in all cases we observed that the amplitude of the sensors’ responses after a selected time period seemed to depend on the flow rate. The simplest explanation for this behaviour is that small flow rates do not allow the specified concentration to be reached in the pre-set time interval, resulting in a smaller concentration at individual sensor sites and therefore smaller responses. Nevertheless, the use of different flow rates gives us a way to gather more data in a controlled manner. Based on our observations, we only used data gathered at higher flow rates in our final analyses.
For a given concentration and flow rate the measurement started by flushing the sensor array with pure N2 for 5 min, in the case of explosives, and 3 min, in the case of the other substances. This is a “cleaning cycle”, or the “off” cycle, where the remaining molecules, adsorbed on the surfaces of the micro-capacitive sensors and inside the connecting tubes, were removed by the N2. Then, the gas with a chosen concentration flowed through the sensor array for 3 or 5 min, depending on the substance. This is the “on” cycle, which together with the “off” cycle, form a complete cycle. This cycle was repeated 10 times. Afterwards, the array was flushed with nitrogen and the measurement continued for a different combination of flow and concentration.
In order to avoid possible bias due to the slowly shifting background from the water molecules present in the sensor system due to their diffusion from the environment, the combinations of concentration and flow were chosen in a random sequence instead of a gradual one. For explosives, the entire sequence was repeated several times. In addition, subsequent measurements took place after a few weeks or even months. On the other hand, due to the limited number of gas mixtures, the gas samples were measured only once, in some cases with a smaller number of combinations.
2.5. Data Processing and Feature Extraction
Since machine-learning models are usually not built using raw data, such as the recorded time-dependence of a signal from each micro-capacitive sensor, we first process the data to extract meaningful information that will help us distinguish between the different substances. A typical response of an individual sensor from the array for a couple of “on” and “off” states is shown in
Figure 3. When the sensor is exposed to the flow of pure N
2, it takes approximately τ ~ 3 min to reach the steady, “off” state. This time constant τ is determined by the time required for the whole of the tubing and the chamber(s), where the sensors are mounted, to be filled with pure N
2. Should the system be integrated, the response time would be much shorter.
When the target sample-containing gas is introduced into the chamber where the sensor is located, the signal increases to a steady value, which we call the “on” state. When the valve with the sample-containing gas is closed and only pure nitrogen gas flows over the sensor again, the signal returns to the signal value in the “off” state. The signal value in the “off” state is subjected to long-term drifts within the time window of the experiment and has to be set before the measurement begins. Therefore, at the beginning of the measurements we manually adjust this “off” signal within the dynamic range of the detecting electronics to prevent saturation effects when the drift drives the signal to the limits of the electronics.
The difference between the “on” and “off” signals is called the amplitude of the response and is determined automatically for a stored signal using an appropriate algorithm. From the stored signal, we create the
segments that will be used for building and testing the models in the following way: first, we take 100 points of baseline immediately before the opening of the valve (i.e., the “off” state) with the sample-containing gas and the last 100 points of the response to the sample, just before switching back to pure nitrogen (the “on” state, as indicated in
Figure 3). For each sensor and for a single on/off cycle, this means one row with 200 numbers, and since we have 31 sensors (30 functionalized sensors and one for humidity), each
single-cycle segment matrix will consist of 31 rows with 200 numbers. For each measurement cycle on a selected sample, covering all the concentrations and all the flows, generates 10 concentrations × 5 flow rates × 10 repetitions, which equals 500 segment matrices. We should note that the time constant τ related to the transient effects cannot be used to distinguish between different substances, because in our system τ is primarily determined by the design of the chambers where the sensors are installed, the length of the tubing used to supply the gas, and the flow rate of the N
2 carrier gas through the sensing head.
The next step is called feature extraction in machine-learning terminology. Each feature is a mathematical operation upon the segment matrix, which produces a single numerical value and is explained in the continuation. For each segment matrix, we calculate a series of features. The values are then stored in a vector that is called an instance. In a machine-learning approach, it is common to generate a large number of features, especially when it is not immediately clear which features will be the most efficient for classification. In our case, we calculated the following five features:
The amplitude for each functionalized sensor (the difference between the “on” and “off” signals, which makes 30 features in total).
The noise difference for each sensor. We calculated the RMS noise in the “on” state and subtracted the RMS noise in the “off” state. This feature is not a “very strong” one, as it is not much different for different sensors and shows rather random behaviour in the noise heatmaps.
The flow rate. We use the flow-rate value as a feature as we can determine or set it independently. At the same time, we keep the concentration as an unknown variable. This choice can be rationalized if we consider the operation of the algorithm in a real situation with a real demonstrator. If we are seeking for a specific substance, then we do not know the concentration of that substance in the measuring air, but we do know the flow rate of the air entering the detector.
The flow-normalized amplitude, because the amplitude increases with an increasing flow rate.
The amplitude with the subtracted amplitude of the humidity sensor. This is always a positive number and will compensate the signal for possible changes to the humidity during the course of the measurements.
In total, this leaves us with 4 × 30 + 1 (flow is a single feature) = 121 features. In our measurements each instance is therefore a vector with 121 dimensions.
2.6. Machine-Learning and Classification
Machine-learning algorithms are used to recognize patterns in large sets of data. Often, various approaches are tested on the data to assess which performs better in terms of classification accuracy. In addition, different algorithms differ in terms of the comprehensibility to a human user. We decided to use the decision-trees algorithm (J48 algorithm), which is simple to understand. The classification of an instance begins at the root and proceeds along the branches, with each branch corresponding to a particular feature, until a leaf, corresponding to the class, which in our case is the identified substance. When building a decision tree on a training data set, features with the highest information gain are chosen first, being the features that best split the training set into distinct groups. Thus, inspecting the final decision tree provides us with an insight into which features are the most relevant for classification. However, when using decision trees, we can find ourselves in danger of overfitting the tree on the training data set. Random Forest is a further improvement to the decision-tree algorithm, which is aimed at preventing this and improving the classification accuracy. As the name suggests, the algorithm builds several decision trees, each of them on a randomly chosen subset of training data and using a randomly selected subset of features. Each instance in the testing set is then classified using all the trees in the forest and the final class is the one chosen by most trees.
Other commonly used algorithms are more complex. For example, Support Vector Machines (SVMs) looks at the data in a multidimensional space, with each dimension corresponding to a feature, and then searches for a hyperplane that best splits the data. Neural networks, which have become popular lately, consist of a complex interconnected network of “neurons”, each representing a mathematical operation on the input data, until the output represents the final class. While often very efficient, these advanced approaches essentially function as “black boxes”, with the classification process incomprehensible to human interpretation. As comprehensibility of the models was one of our main aims, only algorithms based on decision trees were used at this stage.
The classification accuracy of an algorithm is defined as the ratio of true positives (correctly classified examples, where the criteria is either YES or NO) and all the examples in the test set. To evaluate the classification accuracy of our algorithm, the data (from here on, we are only working with the instances) are split into a training set and a testing set. The training set serves for training the classification algorithm, and the testing set serves for testing the classification accuracy of the “as-trained algorithm”. To avoid overfitting, the training and testing sets must be distinct and uncorrelated. In our study, we obtained several runs of measurements from TNT, DNT and RDX, sometimes separated by weeks or months, as the vapour generator is essentially a limitless source for our purpose. Measurements from individual runs were then assigned to one of the sets. For samples from gas cylinders, due to the small amounts available, the measurements were carried out in a single run. The first half was assigned to the training and the second to the learning set, which still preserves sufficient diversity for our purpose.
4. Discussion
Looking at the heatmaps for the individual sensor responses when varying the concentration and flow of the target substance can give us a quick insight into which sensors are appropriate for the detection of particular substances and which ones do not respond. However, as the output of a multi-sensor e-nose is complex, meaning that some sensors respond to several substances and many sensors respond to a particular substance, a manual interpretation is practically impossible.
On the other hand, methods of artificial intelligence are well suited to help us with the classification task. Apart from building the classification model, in our case using Random Forest, we can learn several things about the task by looking at the confusion matrices that have been obtained. In our case, we noticed among the studied substances that TNT and DNT are often misclassified as one another. This is most likely due to the similar chemical structure and the similar affinity of the functionalized surfaces of our sensors to these two substances. However, if we group TND and DNT together (which is reasonable due to their chemical similarity), they are well distinguished from all the other substances. The value of 0.94 for explosives in the classification
Table 4 represents the ratio of correctly classified instances for explosive versus all other substances and is considered a very good result.
This leads to the conclusion that the set of six different silane molecules: (1) 3-aminopropyl) trimethoxysilane (APTMS), (2) p-aminophenyltrimethoxysilane (APhS), (3) 1-[3-(trimethoxysilyl)-propyl] urea (UPS), (4) N-(2-aminoethyl)-3-aminopropyltri-methoxysilane (EDA), (5) N,N-dimethyl-aminopropyl)trimethoxysilane (DMS) and (6) octadecyltrimethoxysilane (ODS) are very appropriate for the selective detection of TNT and DNT molecules in the atmosphere.
Building classification algorithms can provide an insight into which sets of substances can be distinguished well among themselves, as demonstrated in
Table 2,
Table 3 and
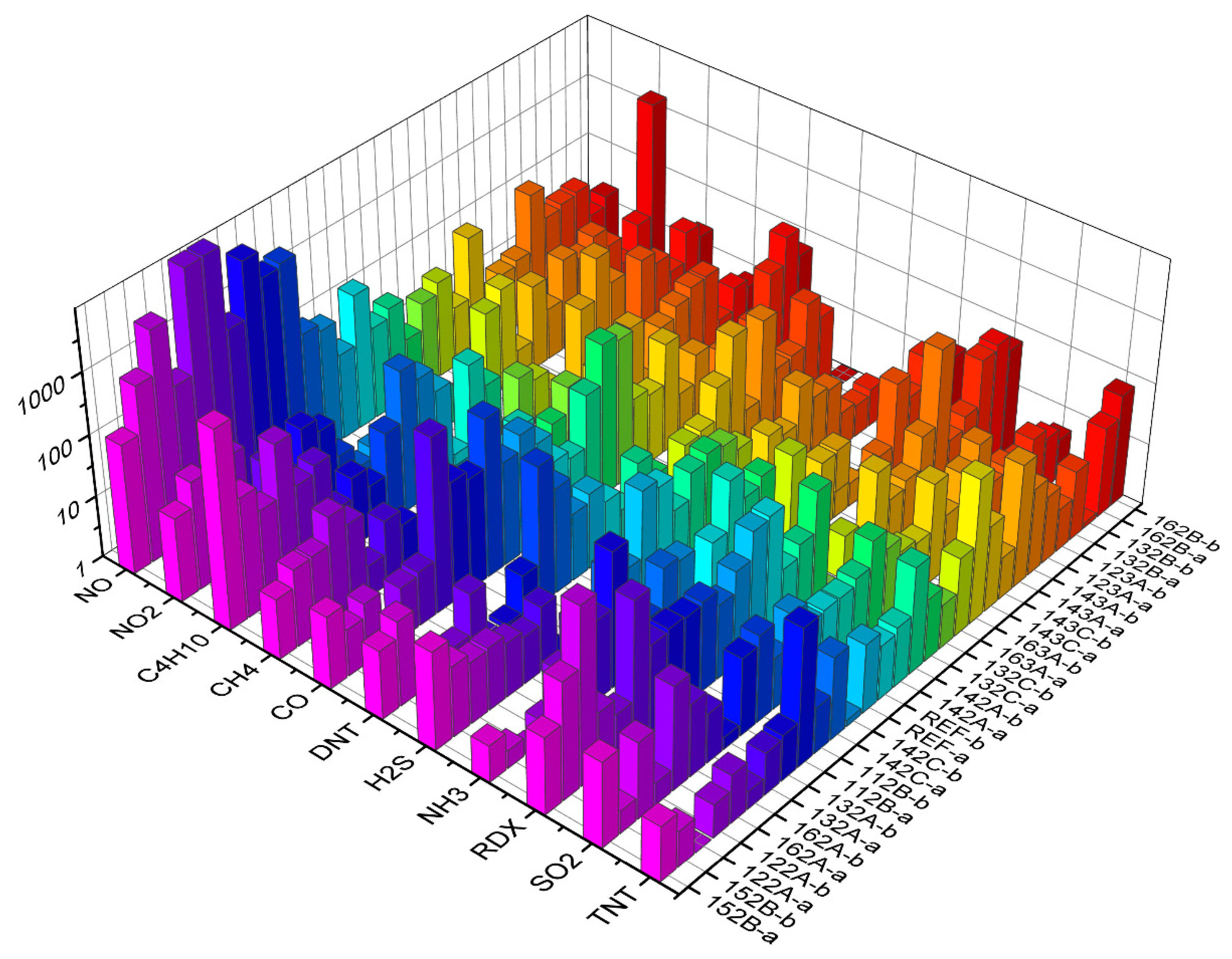
Table 4. In addition, models based on decision trees are easy to interpret, allowing us to see which features are more important and which are not—if features related to a particular sensor do not appear in decision trees, the sensor can be discarded altogether when optimizing the sensor array for a particular application. For example, in the case where we distinguish explosives from other substances, an inspection of some decision trees generated by the algorithm shows that sensors REF-B, 143C-a and 132A-b play the most prominent role in the classification (they appear at the initial nodes of several trees). Looking at the responses of all the sensors to all the substances at the maximum concentration and flow (
Figure 6), this is reasonable, since these sensors respond to TNT, DNT and RDX better than to some other substances.
One of the key steps in improving the classification accuracy of our algorithm was to focus only on the subset of the data with stronger signals, i.e., the measurements with higher concentrations and flows. While this might appear to be a drawback, we should remember that the initial concentration (especially for explosives) was already very low—increasing the concentration to higher values would likely result in a much higher response, making the classification task easier.
From the algorithm point of view, there are several ways to improve the accuracy, such as including additional features that are calculated as combinations of more than one sensor, or using advanced methods such as neural networks. However, as we already pointed out at the beginning, the goal was to demonstrate the feasibility of the approach and to see how machine-learning can guide us to improve and optimize the sensor array itself. Neural networks were previously used in e-noses [
3,
5,
8,
10]; however, as they are essentially “black boxes” that only produce results without an intuitive interpretation, they are only suitable for a “final” application and not for our case, where we are still in the development and optimization phase. The main takeaway from the experiments should then be seen as an insight into how to assemble sensors to work well on a chosen set of substances—which sensors to keep and whether we should add additional sensors that react to substances to which the current system responds poorly (as seen with H
2S and SO
2 in our case). Alternatively, if we want to distinguish between TNT and DNT, we should focus on a sensor functionalization that will exploit the difference between the two.
There are two important problems to consider for future work from the computer-science point of view. First, let us imagine a situation where the system is trained to work on a specific set of substances. Now, we want to expand the functionality of the system to work on additional classes, but we do not have the original training set (perhaps we are an end user and the manufacturer is unwilling to share the data) that would allow us to straightforwardly train the new model. Second, due to the nature of the manufacturing of individual sensors, which includes coating with a functionalized layer followed by laser abrasion, no two sensors of the same type will be identical—thus the classification model trained on the data obtained on one setup might not work with the same accuracy on another one. The task here is to optimize the classification model to work on the second setup without having to repeat all the measurements for the training set. In computer science, both of these two problems can be viewed as tasks for the transfer-learning domain [
23].

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}