2.2. Cognitive Architecture for HALS Protocols
The architecture proposed for HALS protocols follows a cognitive approach (
Figure 2). It is divided into three main systems: perception, cognition, and action. The perception system measures data from the surgical workspace with the aid of two sensors. Firstly, the image analysis of the endoscope camera allows tracking of the tools or any other relevant object in the abdominal cavity. This information is then used by the action system to plan a trajectory for the autonomous tools. Secondly, a smart glove acquires information about the hand pose and orientation, which describes the gesture of the current surgical stage. This information is the input of the HGR algorithm proposed in this paper.
The cognition system is based on production rules to govern the behavior of the architecture. These production rules are supported by a space where the long-term memory information is combined with the working memory. The former encodes the knowledge base acquired through the analysis of long periods of time; the latter includes information about what is currently happening, introducing perception data and the actions to be performed. The cognition system also includes learning algorithms—specifically, reinforcement learning algorithms—to enhance the performance of the architecture.
Finally, the action system oversees execution of the decisions made by the cognition system. These decisions are related to the surgical robot movements to suitably assists the surgeon in each surgical stage. Although the surgical robot is intended to act autonomously, the surgeon may override these movements (or even command an emergency stop) by means of an HMI system.
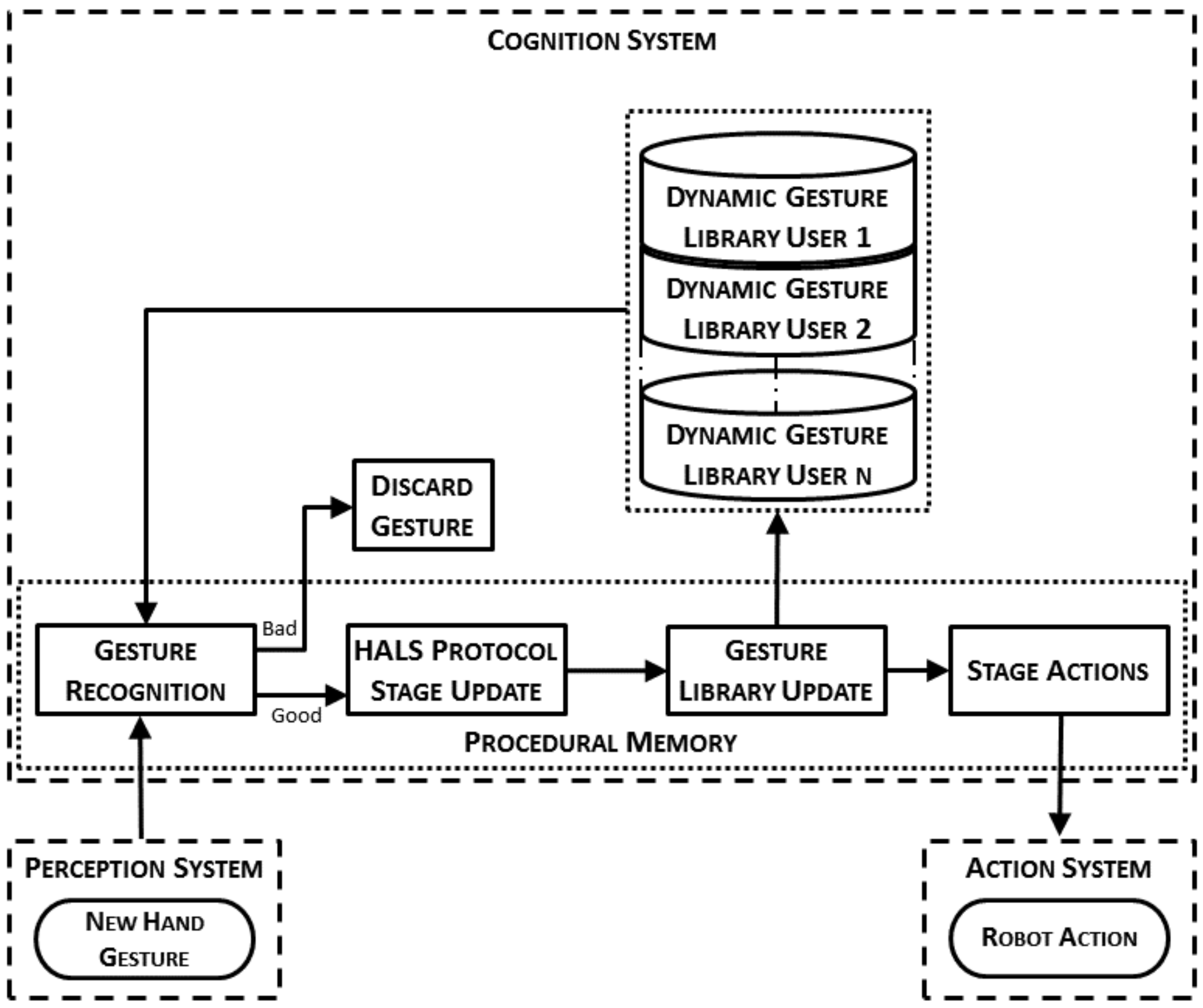
The way a HALS protocol is included into the cognitive architecture is outlined in
Figure 3. This figure shows the general workflow of a protocol for HALS including the hand gesture recognition and the main interactions between the different systems in the architecture. When the perception system detects that a new hand gesture has been made, the gesture recognition algorithm tries to recognize it. The recognition of this gesture makes the HALS protocol evolve from one stage to another. Then, the dynamic gesture library is modified with the information of the newly recognized gesture. Finally, depending on the HALS protocol stage, the actions to be performed by the surgical robot to properly assist the surgeon are communicated to and then executed by the action system.
The different robot actions have been further analyzed and verified in previous works of our group. The endoscope motion combines a reactive behavior based on instrument tracking with a proactive behavior based on the surgery workflow [
26]. This control makes it possible to accommodate the camera view to the current state of the task with enough flexibility enable it to adapt its behavior to unplanned or unforeseen situations.
Regarding the tool movement managed by the robotic assistant, a hybrid force–position controller is implemented based on [
5]. On one hand, the position controller navigates the robot tool, and consists of an artificial potential fields algorithm modified to adapt the velocity depending on the approach to an obstacle (i.e., the surgeon’s hand/tool). On the other hand, the force controller is designed to apply a force with the tool by means of a Proportional-Integrative (PI) controller feedback.
The normal workflow can be altered in case of a bad result of the gesture recognition algorithm. This result may be because of an intentional gesture that was poorly recognized, or an unintentional movement of the hand made by the surgeon, which eventually is considered as a gesture by the recognition algorithm. In both situations, the recognized gesture is labeled as a bad result if the gesture does not correspond to a valid action in the current stage of the surgical protocol. Moreover, if the gesture is the one expected but its confidence index is below a threshold, the system also labels it as bad. When a gesture is labeled as bad, the system will send a voice message to the surgeon. Otherwise, the surgeon may still use a voice command interface to correct an unexpected detection of the recognition system, making use of the voice decoder included in the architecture presented in our previous work [
5]. This command must be explicit enough to avoid confusion when the surgeon talks with the surgical human staff. This action leads to a correction on the detected gesture, which prevents an undesired update of the dynamic gesture library.
2.2.1. Semantic Memory
The semantic memory coupled with the procedural memory form part of the long-term memory of the cognition system. This memory includes concepts, meanings, facts and any other forms of knowledge needed to understand the environment [
27]. More specifically, the knowledge needed to suitably work in a HALS workspace includes (1) the different surgical protocols that the surgical robot is able to assist; (2) the sequence of stages for each of those protocols, and (3) the actions executed in each stage. All the information listed above is modeled as a database with tables or semantic units,
(
), that store the knowledge needed to properly assist the surgeon. Each unit entry includes a set of attributes to suitably define it. The first semantic unit S1 lists all the HALS protocols where the robotic assistant is going to be used. Each entry of this unit consists of two attributes: the protocol name (
protocolName) and the protocol identifier (
). Hence,
is defined as:
The second semantic unit
describes the different stages of each protocol and all the trigger signals (i.e., the events that make the protocol progress from one stage to another). Each stage stored into
is defined by three attributes: the protocol identifier (
), the stage (
), and the trigger (
). Hence, each entry of
is defined as:
For each stage, the semantic unit
stores the corresponding actions that the surgical robot must make to assist the surgeon. Therefore, for each stage there will be as many entries as actions to be executed. More specifically, the HALS clipping protocol presents two different autonomous movements: one for the endoscope, and another for the robot tool. Hence, each entry of
is defined as:
where
action is the action to be performed for each surgical element, endoscope, and/or surgical tool.
2.2.2. Procedural Memory
The procedural memory is the long-term memory that manages the knowledge of when, how, and what actions have to be executed by connecting internal and external data. The internal data come from the semantic memory, while the external data are provided by the perception and action systems. This knowledge is presented as IF–THEN rules, the so-called production rules, where each production has a set of conditions and a set of actions. The conditions denote the “IF” part of the rule and check the current state of the task, whereas the “THEN” part defines the actions to be executed.
2.2.3. Working Memory
The working memory is the short-term memory of the architecture where the current environment situation is codified. It includes not only the current cognition system situation, but also that of the rest of the architecture (i.e., the perception and action systems). All this information is used by the decision procedure to infer which production rules in the procedure memory must be applied next.
2.3. Offline Gesture Training Process
The first element of the general system workflow introduced in
Figure 3 consists of the gesture recognition. This algorithm requires the initial training of a dynamic gesture library, which is unique for each surgeon as previously described in
Section 2.1. Thus, this section explains the data acquisition and processing steps followed in the present paper to obtain the required model for each gesture within the dynamic gesture library.
The gesture training process has been designed in such a way that only the most relevant information of a gesture is automatically processed and encoded into sequences of tags, as described in
Section 2.3.1. Such data are then processed by the gesture training algorithm (see
Section 2.3.2), which is implemented by means of an HMM network, to obtain a set of patterns for each of the proposed gestures.
2.3.1. Data Acquisition and Processing
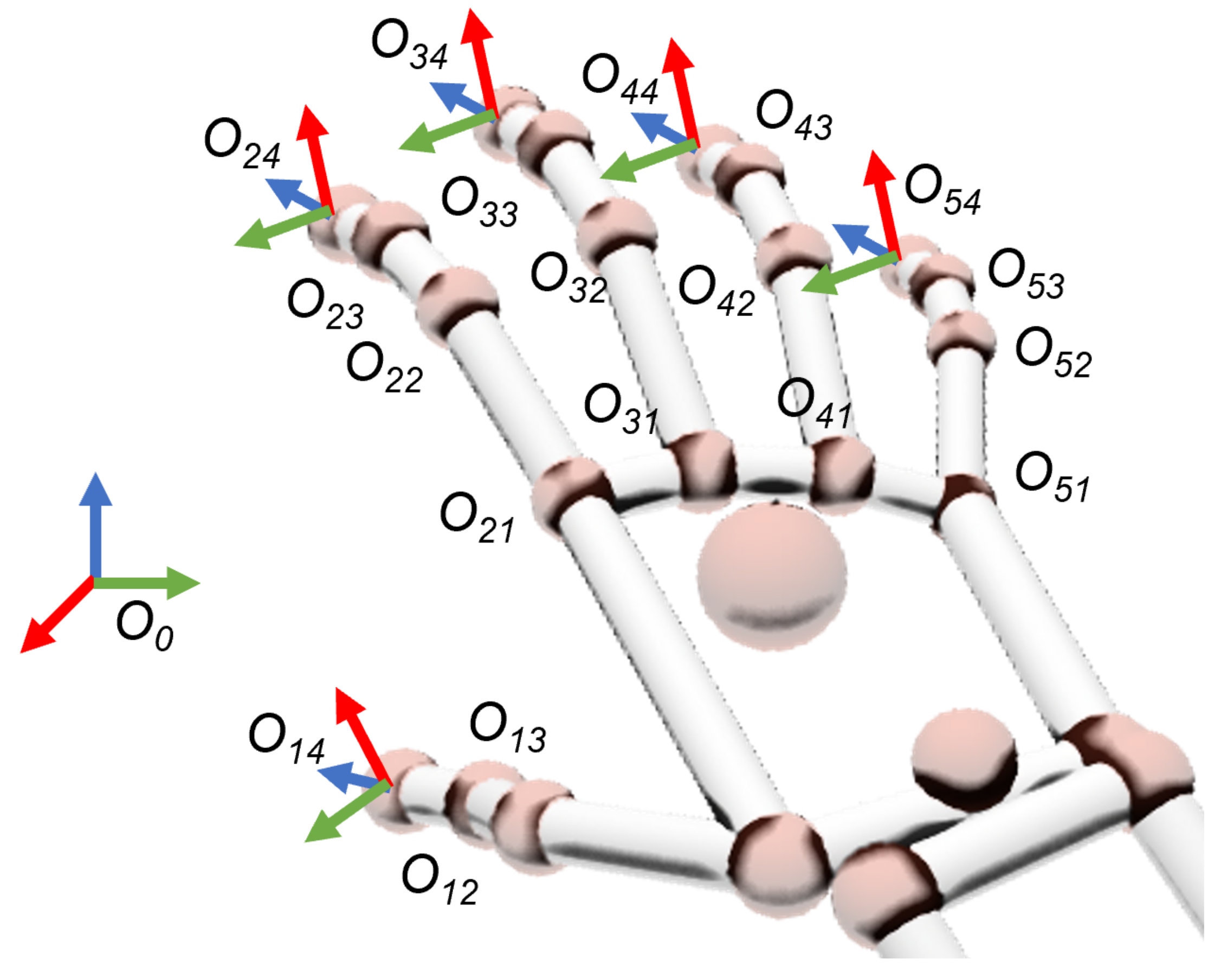
The gesture training process is performed on a patient simulator before the intervention, and begins with the data acquisition of the surgeon’s hand movements by means of a smart glove. This sensor device measures the origin of the coordinate frames
for each of the joints of the surgeon’s fingers relative to the reference frame of the sensor device
(
Figure 4). On each frame, index
i denotes the finger element (1 = thumb; 2 = forefinger; 3 = middle; 4 = ring; 5 = pinky) and
j refers to the joints between their contiguous bones (1 = metacarpal–proximal; 2 = proximal–middle; 3 = middle–distal; 4 = fingertip). All coordinate frames
are oriented in such a way that their
vectors have the direction of the
j phalanx related to finger
i. These frames, defined by their homogeneous transform matrices
related to frame
, can be redefined as a set of geometrical parameters (so-called features) like the joints’ flexion
, the distance
, and the orientation
between contiguous fingertips:
where
is the distance vector among two contiguous fingertips.
In (
4), all features for a specific gesture
g are gathered as a component
into a feature vector
. This new definition of the full hand pose in terms of features simplifies the training process workflow, which appears in
Figure 5. However, this set of 22 features cannot be used together on the HMM training process because of the exponential growth of their combinations into possible states of the hand. Thus, one major contribution of this work consists of an algorithm which selects the features that best represent each trained hand gesture, discarding the rest of them. The main advantage is its capability of finding the most representative features automatically, regardless of the trained gesture.
As a first step of the process workflow, the feature acquisition element records
N times a specific gesture
g. Each repetition
n stores a feature sequence with the full trajectory of all the feature vectors
discretized with
samples in time intervals of
. Hence, the set of all feature sequences
is (
5):
Both the trajectory and velocity of the hand may change for each repetition
n. Thus, the number of
samples acquired can also be different. The segmentation condition to start and finish the recording of a feature sequence
is given in terms of the energy vector
per second of the feature vector
. More specifically, let
be the frequency of
(number of samples per second). The expression of the energy is (
6):
If the energy of any feature component exceeds a threshold , then the feature acquisition starts recording a new gesture. Each threshold can be automatically determined with a previous experiment, where the sensor reads the features of the hand without any movement of the fingers. In case of a very long sequence of gestures, the reliability of the HMM network may drop significantly. To prevent this issue, a maximum limit for the time frame is imposed.
With the acquisition of
, these raw data must be processed in the following steps of the workflow shown in
Figure 5 to eventually obtain the encoded sequence for an HMM Network:
Feature Fitting. Each feature sequence
of all
N repetitions must be comparable in sampling, time, and size. The dynamic time warping (DTW) algorithm can be used to find an optimal alignment between such feature sequences [
28]. More specifically, DTW corrects the delay, equals the number of samples
, and provides a quantitative value of the similarity
among two different feature sequences
and
, being
. In this way, the closer
is to 0, the more similar are the two sequences. DTW is applied in this step to remove any repetition, which is labeled as dissimilar because of errors in sensor measurements. This process eventually leads to a reduced amount of
valid set of feature sequences
with fixed length of
K samples.
Feature Selection. The training of a specific gesture usually requires only a feature subset that precisely defines the meaning of the surgeon’s hand movements. For example, a scissors gesture is performed by the separation of the index and middle fingertips, so most relevant features are , . In this way, a feature selection method is implemented to automatically select these most relevant features based on the following criteria:
Similarity. For each feature component , the DTW is applied with respect to the other features of vector . If two or more components are similar, then only one is used for training the gesture. As before, this comparison is made in terms of the Euclidean distance given by the DTW algorithm.
Relevance. Feature sequences with maximum peaks under a specific threshold are ignored. In other words, features with non-relevant motion are ignored for the training. These relevance thresholds are proportional to the energy thresholds obtained on the equation explained in (
6). The usual values of such thresholds are about 1 cm for distance features
and
for angle features
,
. Such thresholds are considered with the HALS restriction of finger movements in mind.
Discretization. The selected feature sequences,
, are processed by a discretization method, which finds the optimal amount of clusters,
, and stores their locations into a vector of center values,
. The algorithm chosen for this task is the X-means [
29], a variant of the K-means that computes the optimal number of clusters by means of a specific criterion like the Calinski–Harabasz evaluation [
30]. The main advantage for using X-means lies in the automation of the centroids selection process. These center values
are used for discretizing the selected features
into
by means of the Euclidean distance of each feature sample with each component center value (see
Figure 6). Besides, a hysteresis zone near each center value is considered to avoid peak values and minimize unstable oscillations because of noise effects. Final values on each discretized feature component
are integers among 0 and its number of center values (
).
Encoding. All the discretized sequences,
, of each feature component are combined into a single encoded sequence of tags,
, by the encoding method. The tagged sequence,
, is encoded by means of the discretized feature components,
, and the components
of the center values
(
7):
This expression assigns a unique tag for each possible combination of all the discretized features.
In essence, all the steps of the data acquisition and processing were designed to determine the parameters automatically and customized for the user who is training the system. Indeed, the only parameters to be set are the energy thresholds and the relevance thresholds, which are automatically obtained by means of a prior experiment. On the other hand, the vector of center values is also automatically obtained with the X-means algorithm. Therefore, this methodology enhances the adaptation of the algorithm to every single user and their unique way of making hand gestures.
2.3.2. Pattern Training
The encoded set,
, obtained from each repetition of the discretized feature sequences,
, is sequentially sent to the training process step (
Figure 5). The training process constructs an HMM network associated to each of the
g gestures explained in
Section 2 by means of the Baum–Welch algorithm [
31]. Each of these networks consists of a gesture set,
, with the following trained parameters (
8):
In this expression, SQ denotes the states of the HMM; SE is the set of all possible combinations of the encoded sequences, , for each sample, ; the transition matrix, U, is the probability distribution, which indicates the relations between the states; the emission matrix, V, is the probability distribution, which establishes the most probable value of the encoded sequence at each state; and is the initial states distribution. More specifically, this work chose five states SQ for all the trains. The set of encoded sequences, SE, includes all the combinations of for each sample k. diagonal symmetric matrix where the upper and lower diagonals are not null, and the sum by rows (columns) is equal to 1. Likewise, V is initially a matrix, where the sum by row is equal to 1.
After all the N repetitions performed for each gesture g, the resulting gesture sets, , are stored in the dynamic gesture library. These data are used by the gesture recognition process, which is explained in detail in the next section.
2.4. Gesture Recognition Process and Dynamic Gesture Update
The dynamic gesture library that is used during the recognition process is composed of the gesture records that were made during the off-line training process. In order to include new records of the gestures already trained but made during the surgery itself, an on-line procedure to include them was designed. This way, the dynamic gesture library can adapt itself to the smooth changes the surgeon could make in the trained gestures and consequently, to improve the overall performance of the recognition process. In the following, the whole process from the gesture recognition to the update of the library will be detailed (
Figure 7).
Once a new record has been recorded and encoded, the recognition process starts. The on-line encoded sequence,
E, is processed by a forward–backward algorithm for each gesture set,
, of trained data. This algorithm computes the probabilities,
, converted into a logarithmic scale, and as a result, it returns the gesture,
g, that has obtained the highest probability
. Additionally, a confidence index (CI) value between 0 (null confidence) and 1 (full confidence) is obtained. This index is computed by means of the two highest probabilities—that of the recognized gesture,
, and that of the gesture recognized in the second position,
(
9):
The dynamic gesture library is updated with the information of the record that has just been recognized through the transition (
U) and emission probability matrices (
V). Each time a new record,
E, has to be recognized, the transition and emission probability matrixes of this new sequence are computed. They are used to obtain the new matrixes of the gesture set
(
7) that was just recognized, using (
10) and (
11):
where
is the new transition probability matrix of the gesture set
;
is the previous transition probability matrix of the gesture set
, and
is the transition probability matrix of the new record. In the same way,
is the new emission probability matrix of the gesture set
;
is the previous one, and
is the emission probability matrix of the new record. Finally,
p is the value used to weight the new record with respect to the old ones. Depending on its value, the gesture library is updated using a different amount of information from the newly recognized record. High values of
p make the gesture library include more information about the new record than of the previous ones. On the contrary, small values of
p mean that the library is barely modified by the new information. Thus, this parameter is chosen so that the CI will be maximized, as explained next.
When the new record has been misrecognized, either because it is substantially different from the ones in the library, or because the surgeon has made a mistake, the surgeon informs the system through a voice command and the value of
p is set to zero (i.e., this record is not used to update the dynamic gesture library). On the contrary, when the system properly recognizes the record,
p must be chosen to improve the overall process. To avoid a static system where the weights,
p, are defined and fixed during the design process, a reinforcement learning (RL) algorithm is used to make the system learn this parameter. This learning technique tries to maximize a reward that is received when the system makes a decision [
24]. Within this work, the goal was to maximize the CI previously defined, so that the overall performance of the recognition process increases. Thus, the reward signal of the RL algorithm will be the confidence index as defined in (
8). On the other hand, the decision to be taken is which weight value,
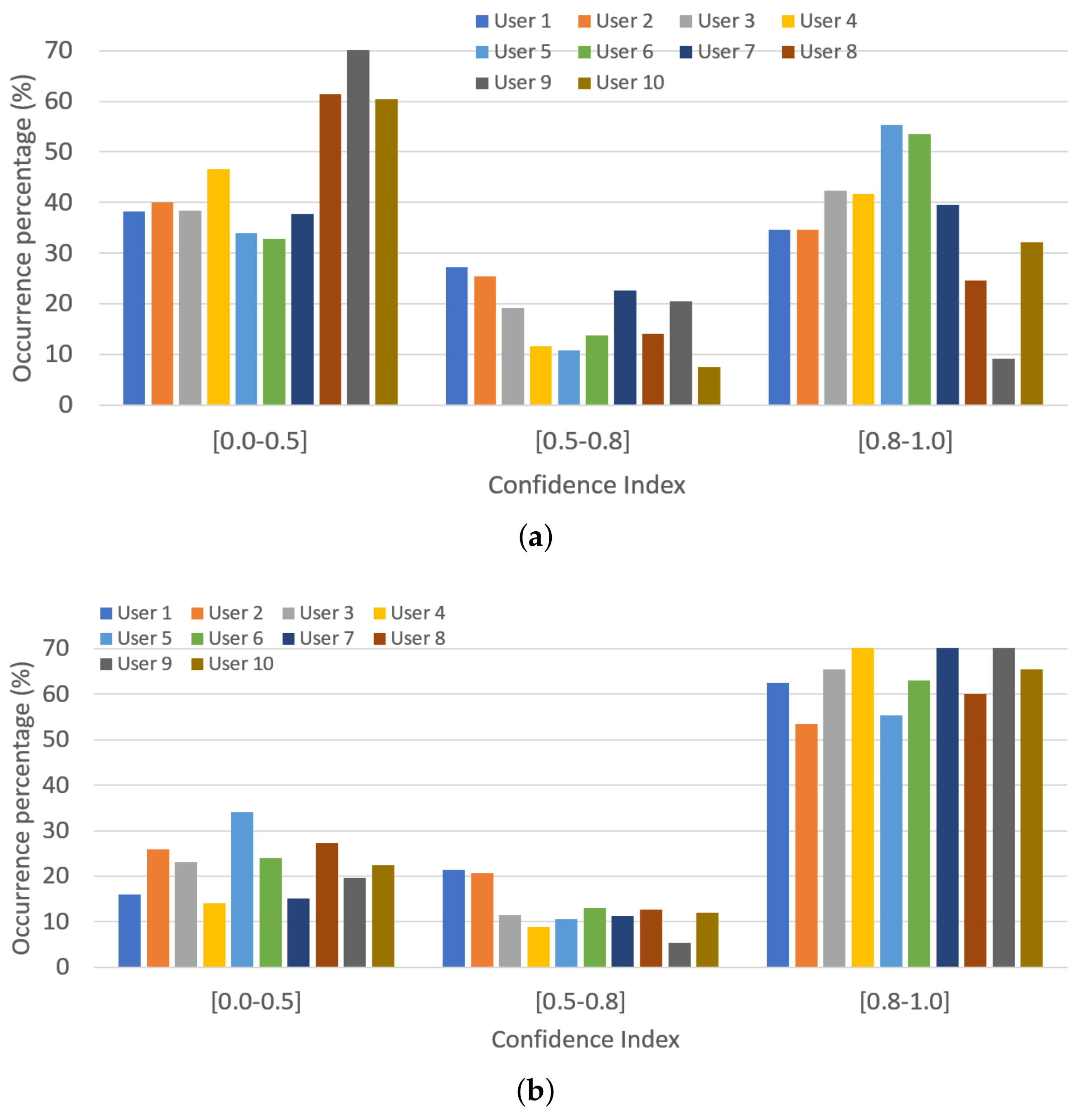
p, will be used to update the dynamic gesture library. As this decision also depends on the CI value, the RL algorithm is organized to make independent decisions according to the level of confidence on the recognition. Thus, records with high CI will tend to higher weighting values than the ones recognized with extremely low CI. Although the CI can take values between 0 and 1, in order to avoid having a different weight value for each possible CI, three different ranges of the CI value are established. This way, only three weight values,
p, are learned—one per CI group (i.e., CI = [0.0–0.5), [0.5–0.8), [0.8–1.0]). As can be observed, the size of each group decreases as the CI value increases (i.e., recognitions with CI ∈ [0.8–1.0] are more relevant than the ones in [0.5–0.8) and even more than the ones in [0.0–0.5)). This makes it so that only the best recognitions (higher CI) have a high impact on the dynamic gesture library update.
On the other hand, the weight values, p, have to be discretized in order to be used in the RL process (i.e., the decision has to be made within a finite set of predefined values. To make the process converge in a reasonable number of detections, it has to be reduced. Thus, it is discretized, taking the following considerations into account: (1) New recorded matrices cannot completely substitute the previous ones in the gesture set because all the historic information would be lost; thus is discarded. (2) New record matrixes cannot be rejected if the gesture has been correctly detected, thus is discarded. (3) The gesture set has to include plenty of information from several sources, that is, different gesture records. To achieve this, the values of p are preferred not to be too high because higher values imply the loss of information of the previous records. Consequently, the possible values of p are discretized into: .
According with the discretization and aggrupation that has been made, the RL algorithm has different weight values to choose per CI group. That is, for each CI value within a group, the RL algorithm has five different
p values to choose. This range of possibilities constitute the set of state–action pairs that defines this kind of algorithm and are implemented as any other production rule in the procedural memory. The states are the different CI groups and the action is the weight value selection (Table “
Pairs” in
Figure 7).
To be able to make the decision, that is, to choose a
p value within the five possible ones within a CI group, these action–state pairs (CI group—
p) are weighted. Each pair is associated to a
Q-value that will be used by the RL algorithm to make the decision. The
Q-value is updated when the reward is received, following (
12) (SARSA algorithm):
where
is the
Q-value in the
th iteration;
is the reward collected in this iteration (i.e., the CI);
is the learning rate; and
is the discount rate. The learning rate determines the importance of new knowledge over old information, while the discount factor determines the importance of future rewards [
32]. The last two parameters are considered as initial conditions of the RL algorithm and are set as preconditions in the experiments.
As the RL technique is based on discovering which actions are the most rewarded by trying them [
24], this kind of algorithm is a trade-off between exploration and exploitation: the system has to exploit what it already knows, but it also has to explore new actions. To determine how the rules are selected based on their
Q-value, the
exploration strategy [
33] is used. This strategy randomly selects a pair (CI group—
p) with
probability, while the pair with the highest
Q-value is selected with
probability.
2.5. Co-Worker Robotic Scenario for HALS Kidney Resection
The HGR system proposed by this work was tested on a HALS protocol of a total kidney resection, where the ureter and blood vessels were clipped. The experimental setup, which is shown in
Figure 8a, emulated a HALS co-worker robotic surgery scenario, using commercial devices. It included two robots: a WAM manipulator from Barret Technology that magnetically handled a stereoscopic mini-camera [
26], and a UR3 manipulator from Universal Robots that controlled a surgical tool. The abdominal simulator dimensions were
cm
, which is in the range of the commercial ones found in the market for abdominal laparoscopic training [
34]. The surgeon managed one conventional surgical tool with one hand. The surgeon’s other hand ws introduced into the abdominal simulator through a HandPort [
35], as shown in
Figure 8b,c. This HandPort is a commercial tool from Endopath Dextrus that allows up to 4 cm abdominal wall thickness [
36]. Moreover, the surgeon’s hand was equipped with a smart Data Glove Ultra from Fifth Dimension Technology. This glove gives the position of the fingertips as well as the flexion of the finger joints. The fingertips are open, so the surgeon can have the same tactile sensation as without the glove. Although this configuration has only been tested on in-vitro experiments, the glove could be protected with an extra surgical glove, so it can be isolated from the patient, which prevents a further sterilization of the device.
The stages of the total kidney resection of the HALS co-worker scenario proposed in this paper are shown in
Table 1. Although there is no limit to the number of gestures managed by the proposed algorithm, the kidney resection protocol only needs three different gestures. Each stage of this protocol can be described by the recognition of a set of surgical gestures made by the surgeon’s hand (
Figure 9). The selection of these gestures considers that the surgeon is able to make their related finger displacement in a HALS in-vitro environment (
Figure 8):
Grabbing. This gesture consists of opening and closing the hand. It is useful to detect surgical situations like grabbing a big mass of tissue or an organ, although it can also be made for separating adhesions (stages 1 and 6).
Scissors. With the index and middle fingers extended, the surgeon separates and joins their tips like a scissor mechanism. This can be used to order the robot tool to make an action with its tool (stage 4).
Forceps. The thumb and index fingertips get closer and retreat like forceps. This may apply to detecting when the surgeon’s hand is pulling a thin tissue or vessel (stage 3).
As shown in
Figure 3, the recognition of a new gesture makes the system progress to the next stage. Then, the gesture library is updated through the process explained in
Section 2.4 and a new action is commanded to the endoscope and/or the robotized surgical tool, as described in
Section 2.2.
This protocol and the gesture recognition process itself entails knowledge that has to be included into the semantic memory. Specifically, related to the protocol, the first semantic unit has to include the HALS protocol, so it is encoded as
. The information about the protocol stages and the triggers that make the protocol to progress from one stage to the next is codified in the second semantic unit as:
Finally, the semantic unit
stores the robot actions as follows:
Related to the gesture recognition process, in order for each type of gesture to be recognized, its set, , has to be included. Likewise, the discretization of the weight values and the aggrupation of the CI, needed for the on-line update of the dynamic gesture library, must also be included.
Three new semantic units are needed to codify this information, what makes the semantic memory finally have a total of six units.
Specifically,
includes the gesture type and the parameters included in its set:
where for each gesture,
denotes the states of the HMM,
is the set of all possible combinations of the encoded sequences,
is the transition matrix,
is the emission matrix, and
is the initial states distribution as defined in
Section 2.4. For the HALS protocol defined in
Table 1, this semantic unit will be encoded as:
includes the discretization of the weighting factor,
p, of the on-line process:
Finally,
contains the aggrupation of the CI.
On the other hand, the entire gesture recognition process and the dynamic gesture library update process form part of the procedural memory (
Section 2.2.2). Thus, the whole HALS workflow shown in
Figure 3 is encoded into the production rules (
) shown in
Table 2. The first one,
, is devote to the recognition of a new gesture. When the perception system detects a new record,
E obtained with (9), the gesture recognition process explained in
Section 2.4 starts (
). Once a new gesture,
g, has been recognized, two actions are made: (
) the HALS protocol stage is updated (
) and (
) the RL algorithm selects a new weight,
, to later (
) update the dynamic gesture library with the information of the recently recognized gesture
. When a new stage is detected, (
) is performed by the surgical robot to properly assist the surgeon, executed by the action system (
). Finally, if there is nothing new (
) the cognitive system enters into a waiting state. Each of these six productions are codified as a larger number of rules.

 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}