Spatio-Temporal Attention Model for Foreground Detection in Cross-Scene Surveillance Videos




Abstract
:1. Introduction
2. Related Work
3. The Proposed Approach
3.1. Attention-Guided Weight-Able Connection Encoder-Decoder
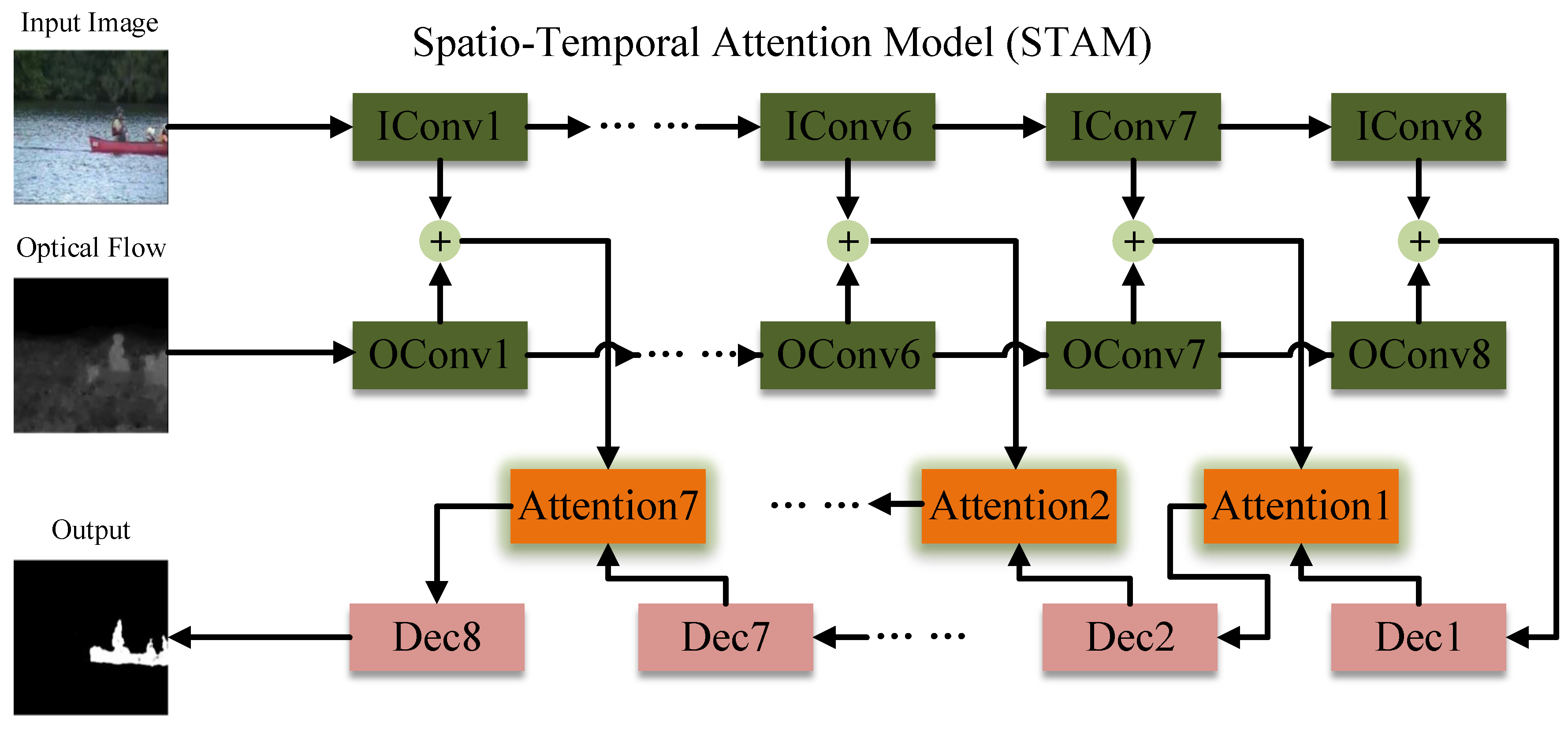
3.2. Model Structure
3.3. The Proposed Attention Module
3.4. Loss Function
3.5. Motion Cue
3.6. Model Training
4. Experiments
4.1. Data Preparing and Experiment Setting
4.2. Results and Evaluation on CDnet 2014
4.3. Cross-Scene Segmentation Results on Wallflower and PETS
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Barnich, O.; Van Droogenbroeck, M. ViBe: A Universal Background Subtraction Algorithm for Video Sequences. IEEE Trans. Image Process. 2011, 20, 1709–1724. [Google Scholar] [CrossRef] [PubMed]
- Elgammal, A.; Duraiswami, R.; Harwood, D.; Davis, L.S. Background and foreground modeling using nonparametric kernel density estimation for visual surveillance. Proc. IEEE 2002, 90, 1151–1163. [Google Scholar] [CrossRef]
- Kim, K.; Chalidabhongse, T.H.; Harwood, D.; Davis, L. Real-time foreground–background segmentation using codebook model. Real-Time Imaging 2005, 11, 172–185. [Google Scholar] [CrossRef]
- Wang, H.; Suter, D. Background subtraction based on a robust consensus method. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 1, pp. 223–226. [Google Scholar]
- Heikkila, M.; Pietikainen, M. A texture-based method for modeling the background and detecting moving objects. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 657–662. [Google Scholar] [CrossRef] [PubMed]
- Learned-Miller, E.G.; Narayana, M.; Hanson, A. Background modeling using adaptive pixelwise kernel variances in a hybrid feature space. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Liao, S.; Zhao, G.; Kellokumpu, V.; Pietikainen, M.; Li, S.Z. Modeling pixel process with scale invariant local patterns for background subtraction in complex scenes. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1301–1306. [Google Scholar]
- Sheikh, Y.; Shah, M. Bayesian modeling of dynamic scenes for object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1778–1792. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Satoh, Y.; Takauji, H.; Kaneko, S.; Iwata, K.; Ozaki, R. Object detection based on a robust and accurate statistical multi-point-pair model. Pattern Recognit. 2011, 44, 1296–1311. [Google Scholar] [CrossRef]
- Huynh-The, T.; Banos, O.; Lee, S.; Kang, B.H.; Kim, E.S.; Le-Tien, T. NIC: A Robust Background Extraction Algorithm for Foreground Detection in Dynamic Scenes. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 1478–1490. [Google Scholar] [CrossRef]
- Chen, M.; Yang, Q.; Li, Q.; Wang, G.; Yang, M.H. Spatiotemporal Background Subtraction Using Minimum Spanning Tree and Optical Flow. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 521–534. [Google Scholar]
- Larochelle, H.; Hinton, G.E. Learning to combine foveal glimpses with a third-order Boltzmann machine. In Advances in Neural Information Processing Systems; MIT Press: Boston, MA, USA, 2010; pp. 1243–1251. [Google Scholar]
- Kim, J.; Lee, S.; Kwak, D.; Heo, M.; Kim, J.; Ha, J.; Zhang, B. Multimodal Residual Learning for Visual QA. In Advances in Neural Information Processing Systems; MIT Press: Boston, MA, USA, 2016; pp. 361–369. [Google Scholar]
- Goyette, N.; Jodoin, P.M.; Porikli, F.; Konrad, J.; Ishwar, P. Changedetection.net: A new change detection benchmark dataset. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 1–8. [Google Scholar]
- Spagnolo, P.; D’Orazio, T.; Leo, M.; Distante, A. Advances in Background Updating and Shadow Removing for Motion Detection Algorithms. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Versailles, France, 5–8 September 2005; Volume 6, pp. 2377–2380. [Google Scholar]
- Spagnolo, P.; Orazio, T.; Leo, M.; Distante, A. Moving Object Segmentation by Background Subtraction and Temporal Analysis. Image Vision Comput. 2006, 24, 411–423. [Google Scholar] [CrossRef]
- Wren, C.R.; Azarbayejani, A.; Darrell, T.; Pentland, A.P. Pfinder: Real-time tracking of the human body. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 780–785. [Google Scholar] [CrossRef]
- Stauffer, C.; Grimson, W.E.L. Adaptive background mixture models for real-time tracking. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Cat. No PR00149), Fort Collins, CO, USA, 23–25 June 1999; Volume 2. [Google Scholar]
- Rittscher, J.; Kato, J.; Joga, S.; Blake, A. A probabilistic background model for tracking. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2000; pp. 336–350. [Google Scholar]
- Oliver, N.M.; Rosario, B.; Pentland, A.P. A Bayesian computer vision system for modeling human interactions. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 831–843. [Google Scholar] [CrossRef]
- Hu, W.; Li, X.; Zhang, X.; Shi, X.; Maybank, S.; Zhang, Z. Incremental tensor subspace learning and its applications to foreground segmentation and tracking. Int. J. Comput. Vis. 2011, 91, 303–327. [Google Scholar] [CrossRef]
- Zhao, X.; Satoh, Y.; Takauji, H.; Kaneko, S.; Iwata, K.; Ozaki, R. Robust adapted object detection under complex environment. In Proceedings of the 2011 8th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Klagenfurt, Austria, 30 August–2 September 2011; pp. 261–266. [Google Scholar]
- Liang, D.; Kaneko, S.; Sun, H.; Kang, B. Adaptive local spatial modeling for online change detection under abrupt dynamic background. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2018. [Google Scholar]
- Liang, D.; Kaneko, S.; Hashimoto, M.; Iwata, K.; Zhao, X. Co-occurrence probability-based pixel pairs background model for robust object detection in dynamic scenes. Pattern Recognit. 2015, 48, 1374–1390. [Google Scholar] [CrossRef]
- Zhou, W.; Shun’ichi, K.; Manabu, H.; Yutaka, S.; Liang, D. Foreground detection based on co-occurrence background model with hypothesis on degradation modification in dynamic scenes. Signal Process. 2019, 60, 66–79. [Google Scholar] [CrossRef]
- Dai, J.; He, K.; Sun, J. Instance-Aware Semantic Segmentation via Multi-task Network Cascades. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3150–3158. [Google Scholar]
- Pinheiro, P.H.O.; Lin, T.; Collobert, R.; Dollar, P. Learning to Refine Object Segments. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Volume 9905, pp. 75–91. [Google Scholar]
- Kirillov, A.; Levinkov, E.; Andres, B.; Savchynskyy, B.; Rother, C. InstanceCut: From Edges to Instances with MultiCut. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7322–7331. [Google Scholar]
- Bai, M.; Urtasun, R. Deep Watershed Transform for Instance Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2858–2866. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R.B. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–26 October 2017; pp. 2980–2988. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE TPAMI 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Braham, M.; Droogenbroeck, M.V. Deep background subtraction with scene-specific convolutional neural networks. In Proceedings of the 2016 International Conference on Systems, Signals and Image Processing (IWSSIP), Bratislava, Slovakia, 23–25 May 2016. [Google Scholar]
- Babaee, M.; Dinh, D.T.; Rigoll, G. A deep convolutional neural network for video sequence background subtraction. Pattern Recognit. 2018, 76, 635–649. [Google Scholar] [CrossRef]
- Wang, Y.; Luo, Z.; Jodoin, P. Interactive deep learning method for segmenting moving objects. Pattern Recognit. Lett. 2017, 96, 66–75. [Google Scholar] [CrossRef]
- García-González, J.; de Lazcano-Lobato, J.M.O.; Luque-Baena, R.M.; Molina-Cabello, M.A.; López-Rubio, E. Foreground detection by probabilistic modeling of the features discovered by stacked denoising autoencoders in noisy video sequences. Pattern Recognit. Lett. 2019, 125, 481–487. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent Models of Visual Attention. In Advances in Neural Information Processing Systems; MIT Press: Boston, MA, USA, 2014; pp. 2204–2212. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.C.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid Attention Network for Semantic Segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Liu, C. Beyond Pixels: Exploring New Representations and Applications for Motion Analysis. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2009. [Google Scholar]
- Hu, M.; Ali, S.; Shah, M. Learning motion patterns in crowded scenes using motion flow field. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–5. [Google Scholar] [CrossRef]
- Lucas, B.D.; Kanade, T. An Iterative Image Registration Technique with an Application to Stereo Vision (IJCAI). In Proceedings of the 7th International Joint Conference on Artificial Intelligence (IJCAI ’81), British, Columbia, 24–28 August 1981; pp. 674–679. [Google Scholar]
- Toyama, K.; Krumm, J.; Brumitt, B.; Meyers, B. Wallflower: Principles and practice of background maintenance. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 1, pp. 255–261. [Google Scholar]
- Performance Evaluation of PETS Surveillance Dataset 2001. Available online: http://limu.ait.kyushuu.ac.jp/en/dataset/ (accessed on 10 November 2015).
- Pierre-Luc, S.C.; Guillaume-Alexandre, B.; Robert, B. SuBSENSE: A universal change detection method with local adaptive sensitivity. IEEE Trans. Image Process. 2014, 24, 359–373. [Google Scholar]
- Bianco, S.; Ciocca, G.; Schettini, R. Combination of Video Change Detection Algorithms by Genetic Programming. IEEE Trans. Evol. Comput. 2017, 21, 914–928. [Google Scholar] [CrossRef]
- St-Charles, P.L.; Bilodeau, G.A.; Bergevin, R. A Self-Adjusting Approach to Change Detection Based on Background Word Consensus. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015. [Google Scholar]
- Hofmann, M.; Tiefenbacher, P.; Rigoll, G. Background segmentation with feedback: The Pixel-Based Adaptive Segmenter. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Details | Encoder1 | Encoder2 | Encoder3 | Encoder4 | Encoder5 | Encoder6 | Encoder7 | Encoder8 |
|---|---|---|---|---|---|---|---|---|
| Filter | 5 × 5 | 5 × 5 | 5 × 5 | 5 × 5 | 5 × 5 | 5 × 5 | 3 × 3 | 3 × 3 |
| Output | 128 × 128 × 64 | 64 × 64 × 128 | 32 × 32 × 256 | 16 × 16 × 512 | 8 × 8 × 512 | 4 × 4 × 512 | 2 × 2 × 512 | 1 × 1 × 1024 |
| Details | Decoder1 | Decoder2 | Decoder3 | Decoder4 | Decoder5 | Decoder6 | Decoder7 | Decoder8 |
| Filter | 3 × 3 | 3 × 3 | 5 × 5 | 5 × 5 | 5 × 5 | 5 × 5 | 5 × 5 | 5 × 5 |
| Output | 2 × 2 × 512 | 4 × 4 × 512 | 8 × 8 × 512 | 16 × 16 × 512 | 32 × 32 × 256 | 64 × 64 × 128 | 128 × 128 × 64 | 256 × 256 × 1 |
| Details | Attention1 | Attention2 | Attention3 | Attention4 | Attention5 | Attention6 | Attention7 | – |
| Filter | 3 × 3 | 3 × 3 | 5 × 5 | 5 × 5 | 5 × 5 | 5 × 5 | 5 × 5 | – |
| Output | 2 × 2 × 1024 | 4 × 4 × 1024 | 8 × 8 × 1024 | 16 × 16 × 1024 | 32 × 32 × 512 | 64 × 64 × 256 | 128 × 128 × 128 | – |
| Method | Recall | Specificity | FPR | FNR | PWC | F-measure | Precision | Single/Scene-Specific |
|---|---|---|---|---|---|---|---|---|
| STAM | 0.9294 | 0.9955 | 0.0045 | 0.0706 | 0.6682 | 0.9030 | 0.8781 | single model |
| STAM | 0.8364 | 0.9977 | 0.0023 | 0.1636 | 0.7698 | 0.8791 | 0.9265 | single model |
| STAM | 0.9458 | 0.9995 | 0.0005 | 0.0542 | 0.2293 | 0.9651 | 0.9851 | single model |
| Cascade CNN [34] | 0.9506 | 0.9968 | 0.0032 | 0.0494 | 0.4052 | 0.9209 | 0.8997 | scene-specific |
| SuBSENSE [46] | 0.8124 | 0.9904 | 0.0096 | 0.1876 | 1.6780 | 0.7408 | 0.7509 | scene-specific |
| GMM [18] | 0.6846 | 0.9750 | 0.0250 | 0.3154 | 3.7667 | 0.5707 | 0.6025 | scene-specific |
| DeepBS [33] | 0.7545 | 0.9905 | 0.0095 | 0.2455 | 1.9920 | 0.7548 | 0.8332 | single model |
| IUTIS-5 [47] | 0.7849 | 0.9948 | 0.0052 | 0.2151 | 1.1986 | 0.7717 | 0.8087 | scene-specific |
| PAWCS [48] | 0.7718 | 0.9949 | 0.0051 | 0.2282 | 1.1992 | 0.7403 | 0.7857 | scene-specific |
| Method | PTZ | BDW | BSL | CJT | DBG | IOM | LFR | NVD | SHD | THM | TBL |
|---|---|---|---|---|---|---|---|---|---|---|---|
| STAM | 0.8648 | 0.9703 | 0.9885 | 0.8989 | 0.9483 | 0.9155 | 0.6683 | 0.7102 | 0.9663 | 0.9907 | 0.9328 |
| Cascade CNN [34] | 0.9168 | 0.9431 | 0.9786 | 0.9758 | 0.9658 | 0.8505 | 0.8370 | 0.8965 | 0.9414 | 0.8958 | 0.9108 |
| SuBSENSE [46] | 0.3476 | 0.8619 | 0.9503 | 0.8152 | 0.8177 | 0.6569 | 0.6445 | 0.5599 | 0.8646 | 0.8171 | 0.7792 |
| GMM [18] | 0.1522 | 0.7380 | 0.8245 | 0.5969 | 0.6330 | 0.5207 | 0.5373 | 0.4097 | 0.7156 | 0.6621 | 0.4663 |
| DeepBS [33] | 0.3133 | 0.8301 | 0.9580 | 0.8990 | 0.8761 | 0.6098 | 0.6002 | 0.5835 | 0.9092 | 0.7583 | 0.8455 |
| IUTIS-5 [47] | 0.4282 | 0.8248 | 0.9567 | 0.8332 | 0.8902 | 0.7296 | 0.7743 | 0.5290 | 0.8766 | 0.8303 | 0.7836 |
| PAWCS [48] | 0.4615 | 0.8152 | 0.9397 | 0.8137 | 0.8938 | 0.7764 | 0.6588 | 0.4152 | 0.8710 | 0.8324 | 0.6450 |
| Category | STAM | DeepBS [33] | SuBSENSE [46] | PBAS [49] | GMM [18] |
|---|---|---|---|---|---|
| Bootstrap | 0.7414 | 0.7479 | 0.4192 | 0.2857 | 0.5306 |
| Camouflage | 0.7369 | 0.9857 | 0.9535 | 0.8922 | 0.8307 |
| ForegroundAperture | 0.8292 | 0.6583 | 0.6635 | 0.6459 | 0.5778 |
| LightSwitch | 0.9090 | 0.6114 | 0.3201 | 0.2212 | 0.2296 |
| TimeOfDay | 0.3429 | 0.5494 | 0.7107 | 0.4875 | 0.7203 |
| WavingTrees | 0.5325 | 0.9546 | 0.9597 | 0.8421 | 0.9767 |
| Overall | 0.7138 | 0.7512 | 0.6711 | 0.5624 | 0.6443 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, D.; Pan, J.; Sun, H.; Zhou, H. Spatio-Temporal Attention Model for Foreground Detection in Cross-Scene Surveillance Videos. Sensors 2019, 19, 5142. https://doi.org/10.3390/s19235142
Liang D, Pan J, Sun H, Zhou H. Spatio-Temporal Attention Model for Foreground Detection in Cross-Scene Surveillance Videos. Sensors. 2019; 19(23):5142. https://doi.org/10.3390/s19235142
Chicago/Turabian StyleLiang, Dong, Jiaxing Pan, Han Sun, and Huiyu Zhou. 2019. "Spatio-Temporal Attention Model for Foreground Detection in Cross-Scene Surveillance Videos" Sensors 19, no. 23: 5142. https://doi.org/10.3390/s19235142
APA StyleLiang, D., Pan, J., Sun, H., & Zhou, H. (2019). Spatio-Temporal Attention Model for Foreground Detection in Cross-Scene Surveillance Videos. Sensors, 19(23), 5142. https://doi.org/10.3390/s19235142