Video Smoke Detection Method Based on Change-Cumulative Image and Fusion Deep Network



Abstract
:1. Introduction
2. Related Work
3. Our Method
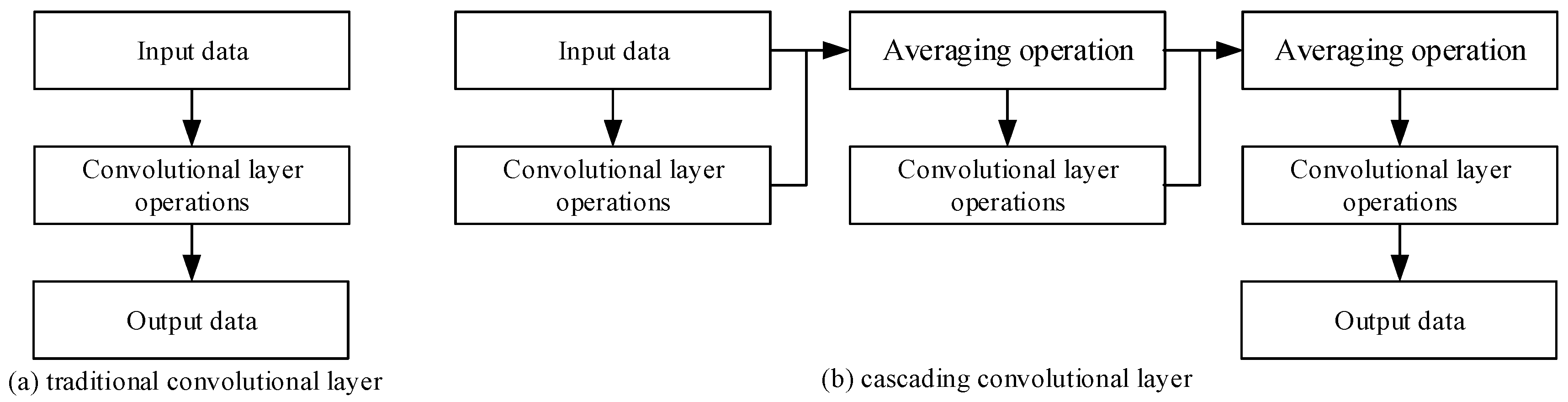
3.1. Change-Cumulative Image
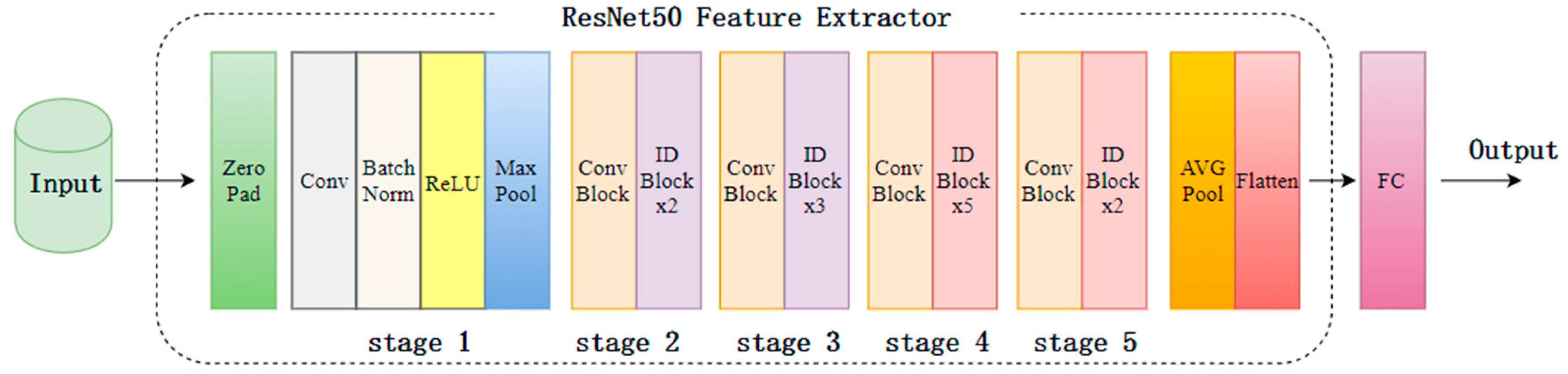
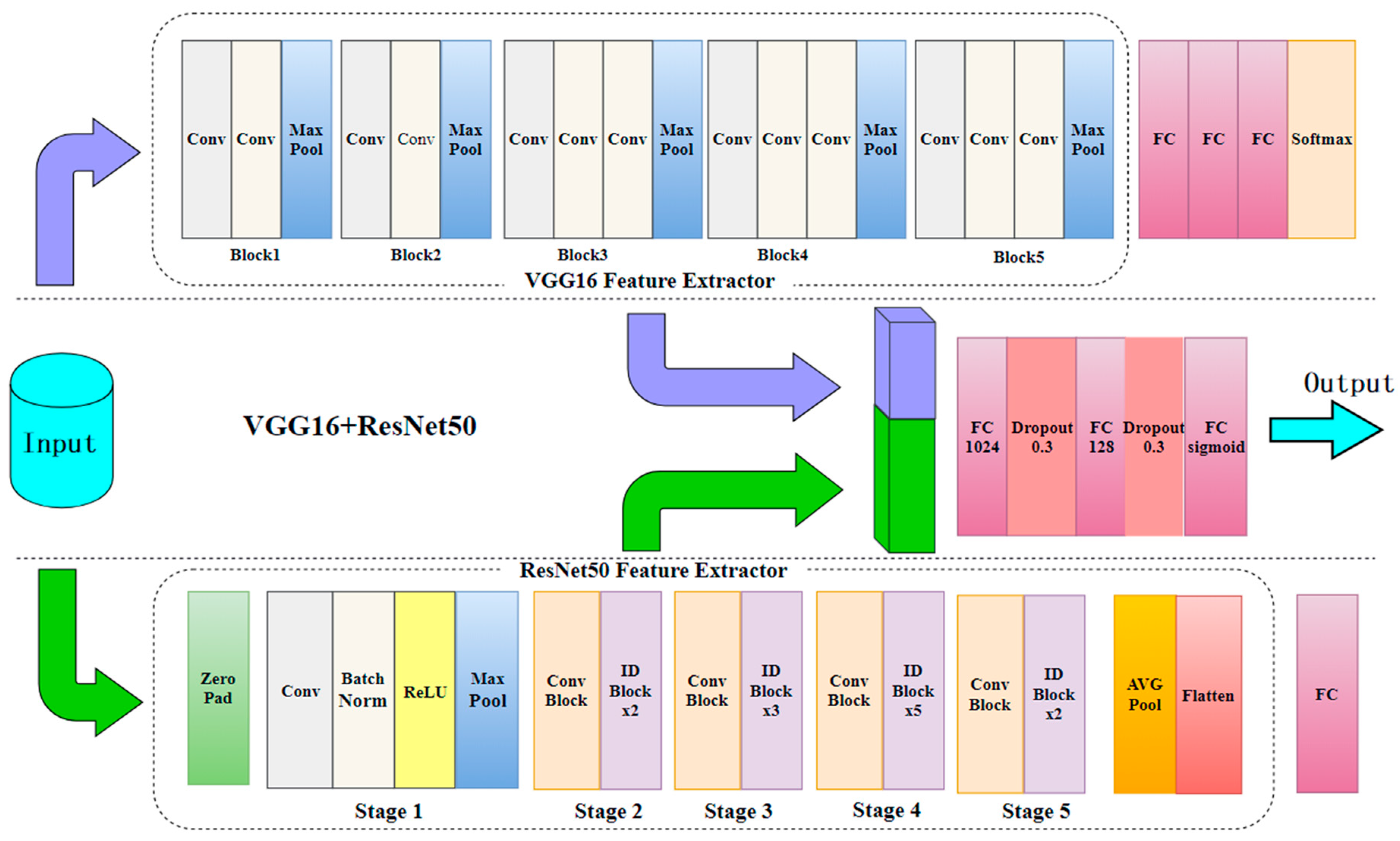
3.2. Fusion Deep Network
| Algorithm 1. Procedure to detect the smoke object in a video. |
| Input: A video. Initialize: k = 1, N = 100. While obtaining a frame from the input video do 1. using bilinear interpolation method to scale the current frame image size to 224 × 224, denoted as . 2. if (k > = N) then, 3. calculating the change-cumulative image of the current frame image according to formulas (1) to (4), denoted as ; 4. calculating the classification score s of the cumulative image after fusion deep network; 5. If (s > 0.5), then 6. outputting the alarm signal of smoke object; 7. End if 8. End if 9. caching images and ; 10. k = k + 1; end while |
4. Experiments and Results
4.1. Experiment Description
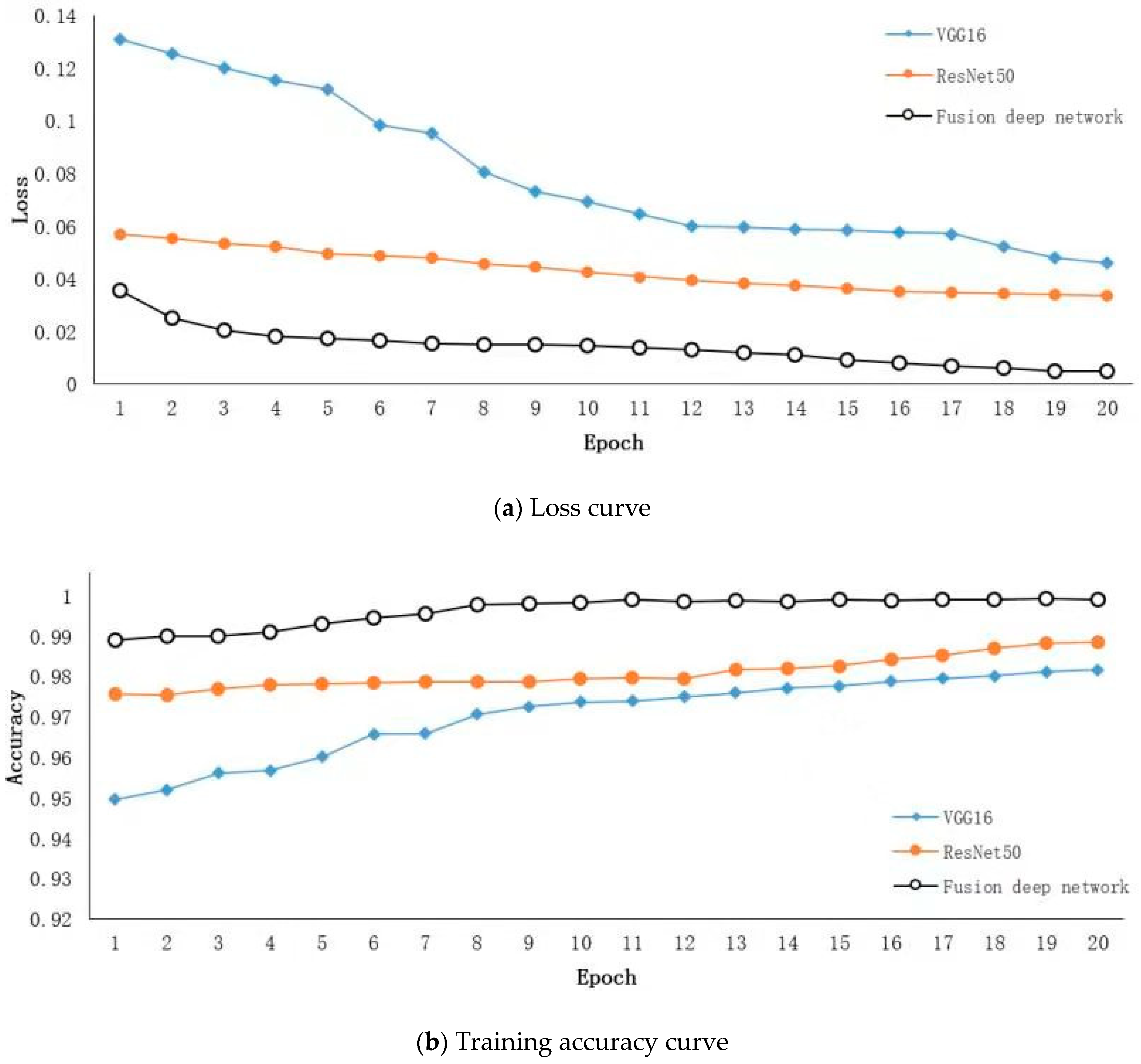
4.2. Model Training
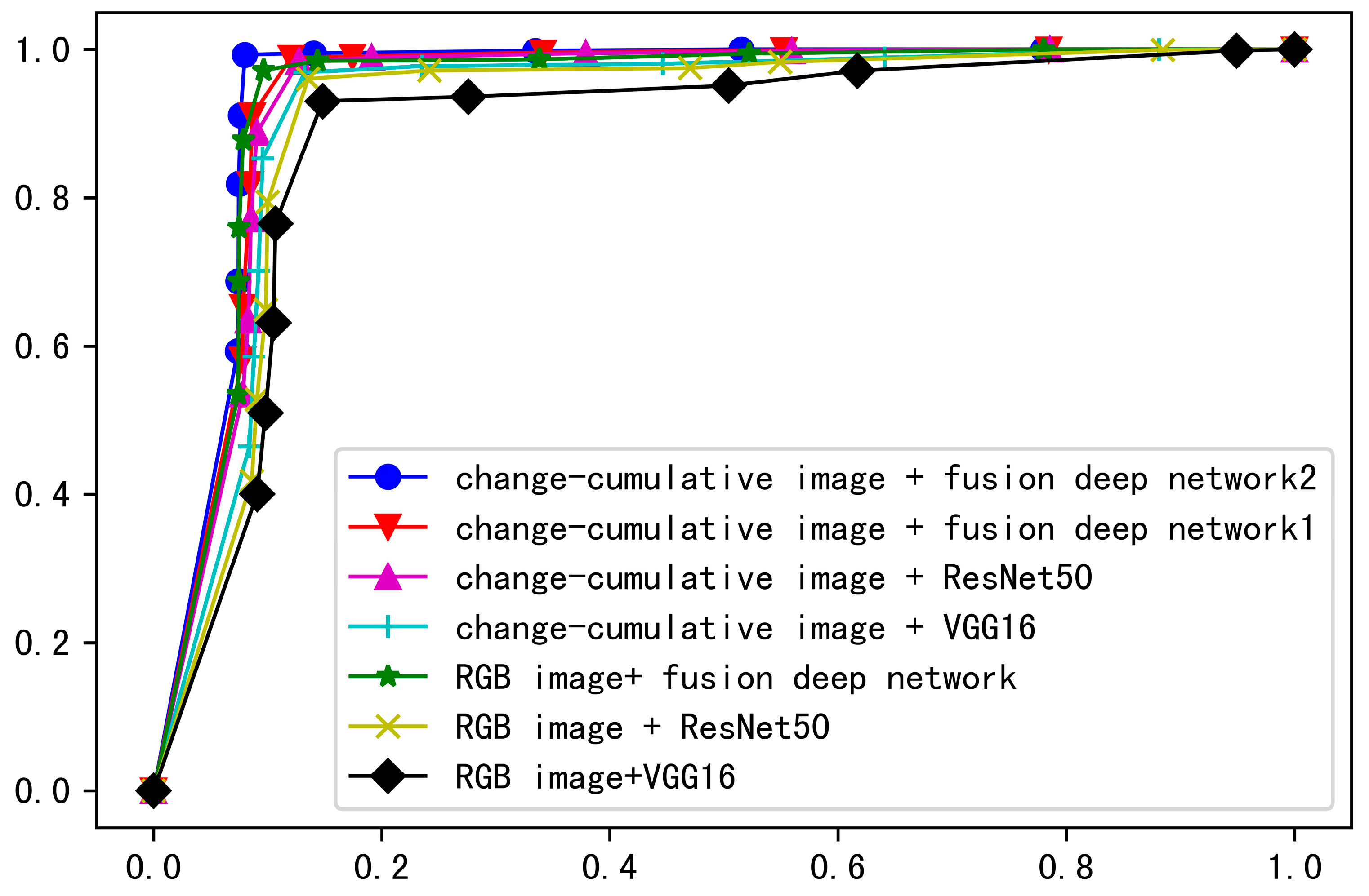
4.3. Performance Comparison
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Shi, J.; Yuan, F.; Xue, X. Video smoke detection: A literature survey. J. Image Graph. 2018, 23, 303–322. [Google Scholar]
- Chen, T.H.; Yin, Y.H.; Huang, S.F.; Ye, Y.-T. The smoke detection for early fire-alarming system base on video processing. In Proceedings of the International Conference on Intelligent Information Hiding and Multimedia, Pasadena, CA, USA, 18–20 December 2006; pp. 427–430. [Google Scholar]
- Krstinić, D.; Stipaničev, D.; Jakovčević, T. Histogram-based smoke segmentation in forest fire detection system. Inf. Technol. Control. 2009, 38, 237–244. [Google Scholar]
- Gubbi, J.; Marusic, S.; Palaniswami, M. Smoke detection in video using wavelets and support vector machines. Fire Saf. J. 2009, 44, 1110–1115. [Google Scholar] [CrossRef]
- Russo, A.U.; Deb, K.; Tista, S.C.; Islam, A. Smoke detection method based on LBP and SVM from surveillance camera. In Proceedings of the 2018 International Conference on Computer, Communication, Chemical, Material and Electronic Engineering (IC4ME2), Rajshahi, Bangladesh, 8–9 February 2018; pp. 1–4. [Google Scholar]
- Yuan, F. Video-based smoke detection with histogram sequence of LBP and LBPV pyramids. Fire Saf. J. 2011, 46, 132–139. [Google Scholar] [CrossRef]
- Yuan, F. A double mapping framework for extraction of shape-invariant features based on multi-scale partitions with AdaBoost for video smoke detection. Pattern Recognit. 2012, 45, 4326–4336. [Google Scholar] [CrossRef]
- Gong, Z.; Zhong, P.; Yu, Y.; Hu, W.; Li, S. A CNN with Multiscale Convolution and Diversified Metric for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3599–3618. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, Y.; Zhang, Q.; Lin, G.; Wang, Z.; Jia, Y.; Wang, J. Video Smoke Detection Based on Deep Saliency Network. Fire Saf. J. 2019, 105, 277–285. [Google Scholar] [CrossRef]
- Frizzi, S.; Kaabi, R.; Bouchouicha, M.; Ginoux, J.M.; Moreau, E.; Fnaiech, F. Convolutional neural network for video fire and smoke detection. In Proceedings of the IECON 2016—42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 23–26 October 2016; pp. 877–882. [Google Scholar]
- Zhang, Q.; Lin, G.; Zhang, Y.; Xu, G.; Wang, J. Wildland forest fire smoke detection based on faster R-CNN using synthetic smoke images. Procedia Eng. 2018, 211, 441–446. [Google Scholar] [CrossRef]
- Yin, Z.; Wan, B.; Yuan, F.; Xia, X.; Shi, J. A deep normalization and convolutional neural network for image smoke detection. IEEE Access 2017, 5, 18429–18438. [Google Scholar] [CrossRef]
- Toreyin, B.U.; Dedeoglu, Y.; Cetin, A.E. Contour based smoke detection in video using wavelets. In Proceedings of the 14th European Signal Processing Conference, Florence, Italy, 4–8 September 2006; pp. 1–5. [Google Scholar]
- Yuan, P.; Hou, X.; Pu, L. A Smoke Recognition Method Combined Dynamic Characteristics and Color Characteristics of Large Displacement Area. In Proceedings of the 2018 2nd IEEE Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Xi’an, China, 25–27 May 2018; pp. 501–507. [Google Scholar]
- Kopilovic, I.; Vagvolgyi, B.; Szirányi, T. Application of panoramic annular lens for motion analysis tasks: Surveillance and smoke detection. In Proceedings of the 15th International Conference on Pattern Recognition, Barcelona, Spain, 3–7 September 2000; pp. 714–717. [Google Scholar]
- Tung, T.X.; Kim, J.-M. An effective four-stage smoke-detection algorithm using video images for early fire-alarm systems. Fire Saf. J. 2011, 46, 276–282. [Google Scholar] [CrossRef]
- CVPR Lab. Available online: https://cvpr.kmu.ac.kr/ (accessed on 21 August 2014).
- Brahimi, S.; Ben Aoun, N.; Ben Amar, C. Boosted Convolutional Neural Network for object recognition at large scale. Neurocomputing 2019, 330, 337–354. [Google Scholar] [CrossRef]
- Vido smoke dection. Available online: http://staff.ustc.edu.cn/~yfn/vsd.html (accessed on 10 May 2015).
- NASNet, DenseNet. Available online: https://github.com/fchollet/deep-learning-models/releases (accessed on 18 January 2019).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Layer (None, 224, 224, 3) | |||||
|---|---|---|---|---|---|
| VGG FEATURE Extractor | ResNet50 Feature Extractor | ||||
| Block | Layer (type) | Output Shape | Stage | Layer (type) | Output Shape |
| Block 1 | Conv2D * 2 | (None, 224, 224, 64) | Stage 1 | ZeroPadding | (None, 230, 230, 3) |
| Conv2D | (None, 112, 112, 64) | ||||
| MaxPooling | (None, 112, 112, 64) | BatchNormalization | (None, 112, 112, 64) | ||
| MaxPooling | (None, 56, 56, 64) | ||||
| Block 2 | Conv2D * 2 | (None, 112, 112, 128) | Stage 2 | (None, 56, 56, 256) | |
| MaxPooling | (None, 56, 56, 128) | ||||
| Block 3 | Conv2D * 3 | (None, 56, 56, 256) | Stage 3 | (None, 28, 28, 512) | |
| MaxPooling | (None, 28, 28, 256) | ||||
| Block 4 | Conv2D * 3 | (None, 28, 28, 512) | Stage 4 | (None, 14, 14, 1024) | |
| MaxPooling | (None, 14, 14, 512) | ||||
| Block 5 | Conv2D * 3 | (None, 14, 14, 512) | Stage 5 | (None, 7, 7, 2048) | |
| MaxPooling | (None, 7, 7, 512) | ||||
| Concatenate (None, 7, 7, 2560) | |||||
| Flatten (None, 125400) | |||||
| Fc & dropout 0.3 (None, 1024) | |||||
| Fc & dropout (None, 128) | |||||
| Output Fc & sigmoid (None, 1) | |||||
| Dataset | Description | Names |
|---|---|---|
| training dataset | smoke videos | Dry_leaf_smoke_02.avi [19] wildfire_smoke_1.avi [17] |
| non-smoke videos | Waving_ leaves_895.avi [19] smoke_or_flame_like_object_1.avi, smoke_or_flame_like_object_2.avi, smoke_or_flame_like_object_3.avi [17] | |
| testing dataset | smoke videos | Cotton_rope_smoke_04.avi, Black_smoke_517.avi [19] wildfire_smoke_2.avi, wildfire_smoke_3.avi, wildfire_smoke_4.avi [17] |
| non-smoke videos | Traffic_1000.avi, Basketball_yard.avi [19] smoke_or_flame_like_object_4.avi, smoke_or_flame_like_object_5.avi, smoke_or_flame_like_object_6.avi, smoke_or_flame_like_object_7.avi, smoke_or_flame_like_object_8.avi, smoke_or_flame_like_object_9.avi, smoke_or_flame_like_object_10.avi [17] |
| Hyper-Parameters | α | β1 | β2 | ε |
|---|---|---|---|---|
| Value | 0.001 | 0.9 | 0.999 | 10e-8 |
| Input Image | Network | AR/% | FPR/% | FAR/% |
|---|---|---|---|---|
| RGB image | VGG16 | 88.06 | 14.82 | 6.97 |
| RGB image | ResNet50 | 89.98 | 13.54 | 3.94 |
| RGB image | fusion deep network | 92.86 | 9.64 | 2.82 |
| change-cumulative image | VGG16 | 90.48 | 13.24 | 3.09 |
| change-cumulative image | ResNet50 | 91.33 | 12.74 | 1.64 |
| change-cumulative image | fusion deep network (without pre-trained ImageNet weights) | 91.96 | 12.05 | 1.12 |
| change-cumulative image | fusion deep network (with pre-trained ImageNet weights) | 94.67 | 7.99 | 0.73 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, T.; Cheng, J.; Du, X.; Luo, X.; Zhang, L.; Cheng, B.; Wang, Y. Video Smoke Detection Method Based on Change-Cumulative Image and Fusion Deep Network. Sensors 2019, 19, 5060. https://doi.org/10.3390/s19235060
Liu T, Cheng J, Du X, Luo X, Zhang L, Cheng B, Wang Y. Video Smoke Detection Method Based on Change-Cumulative Image and Fusion Deep Network. Sensors. 2019; 19(23):5060. https://doi.org/10.3390/s19235060
Chicago/Turabian StyleLiu, Tong, Jianghua Cheng, Xiangyu Du, Xiaobing Luo, Liang Zhang, Bang Cheng, and Yang Wang. 2019. "Video Smoke Detection Method Based on Change-Cumulative Image and Fusion Deep Network" Sensors 19, no. 23: 5060. https://doi.org/10.3390/s19235060
APA StyleLiu, T., Cheng, J., Du, X., Luo, X., Zhang, L., Cheng, B., & Wang, Y. (2019). Video Smoke Detection Method Based on Change-Cumulative Image and Fusion Deep Network. Sensors, 19(23), 5060. https://doi.org/10.3390/s19235060