3.2. Design of the Reinforcement Learning MPPT System
Sequential decision-making is a common problem in real life, for example, an infant trying to walk by stretching a leg forward and move his body. By taking a series of actions, the infant will have a chance to reach his goal (keep moving forward). The Markov decision process (MDP) provides a systematic framework for describing this sequential decision-making problem. To solve an MDP, a reinforcement learning (RL) method is proposed by [
8]. Learning by interacting with the environment is a human’s intuitive learning skill. When facing an unknown system, the human will interact with it according to their own understanding of the system, and then receive feedback. This feedback signal provides a criterion for judging how “good” or “bad” an action is under a specific circumstance. The actions with better outcomes will have a larger chance to be chosen, i.e., they are reinforced, while the actions with worse outcomes will have smaller chance of being done in the future.
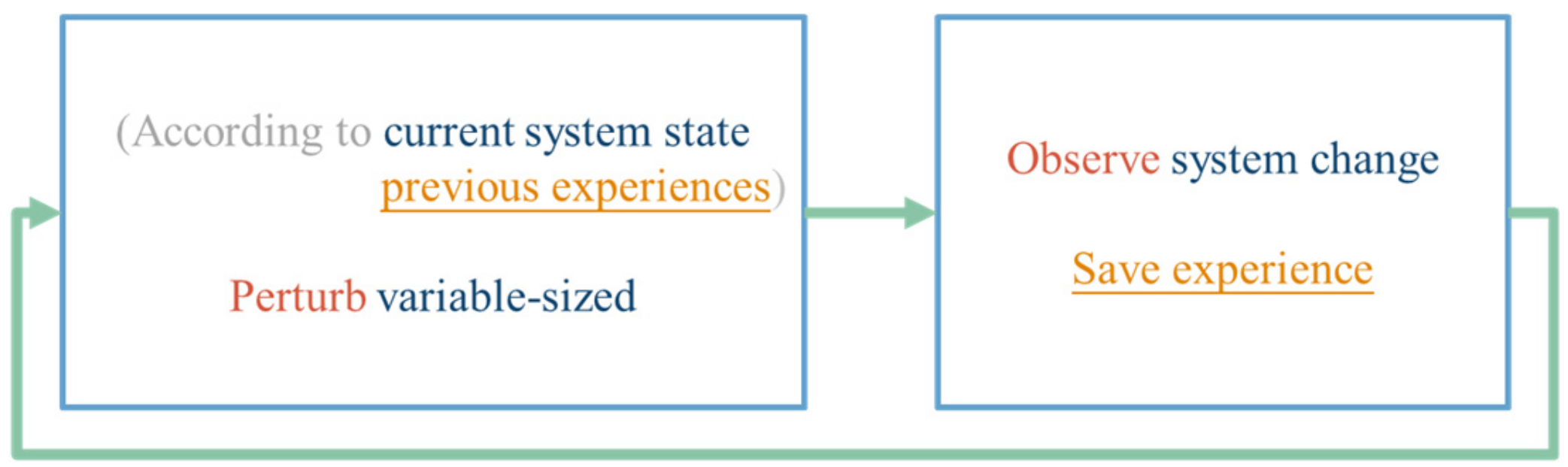
With the description of RL provided above, the concept of the variable step size tracking method based on RL is shown in
Figure 7. The perturbation size can be chosen according to the observed system state and the previous experiences. Once the perturbation is done, the system change including the change of the state and the feedback signal will be observed and the interaction experience will be learned.
To provide a detailed description of the RL MPPT, the background knowledge of RL will be described from
Section 3.2.1 to
Section 3.2.5, including the description of the system, the interaction, and the evaluation of the interaction experience. Finally, the design of the RL MPPT methods, including the RL-QT MPPT method and the RL-QN MPPT method will be proposed in
Section 3.3.
3.2.1. Markov Decision Process and Reinforcement Learning Problem
A Markov decision process (MDP) [
17,
18] consists of
S,
A,
T, and
R, where
S represents the set of environment’s state description, and
A is the set of available actions the agent can take.
T is the transition function, which indicates the system’s probability distribution of jumping from any state to all possible states after applying all available actions, and it is denoted as
. For example, the probability of jumping from the state
to state
after applying the action
can be written as
. For an MDP, the Markov properties hold. Consider a discrete-time series
, the next state
only depends on the current state
and the current action
, as shown below:
A reward R is a scalar numerical signal received from doing an action at a state, and the reward function R can be formally represented as .
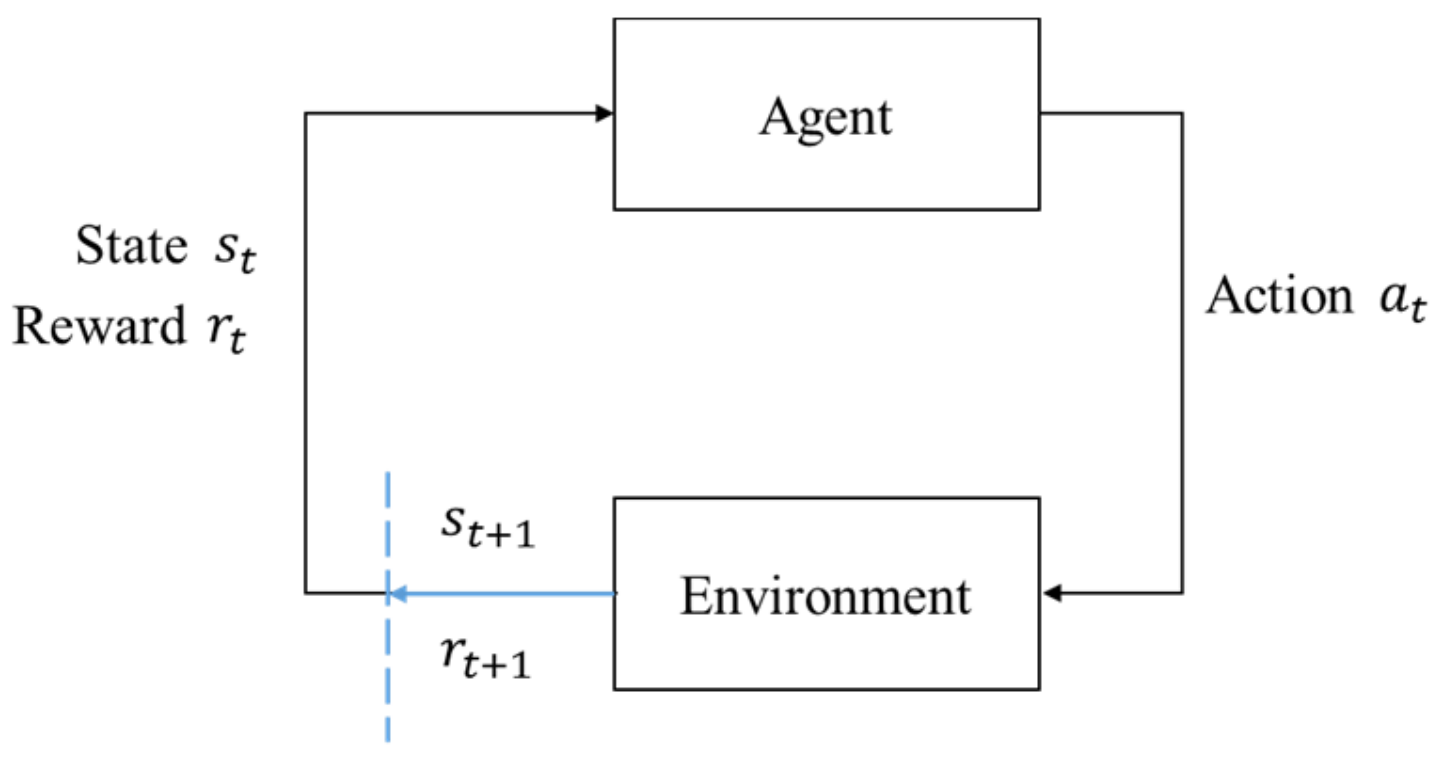
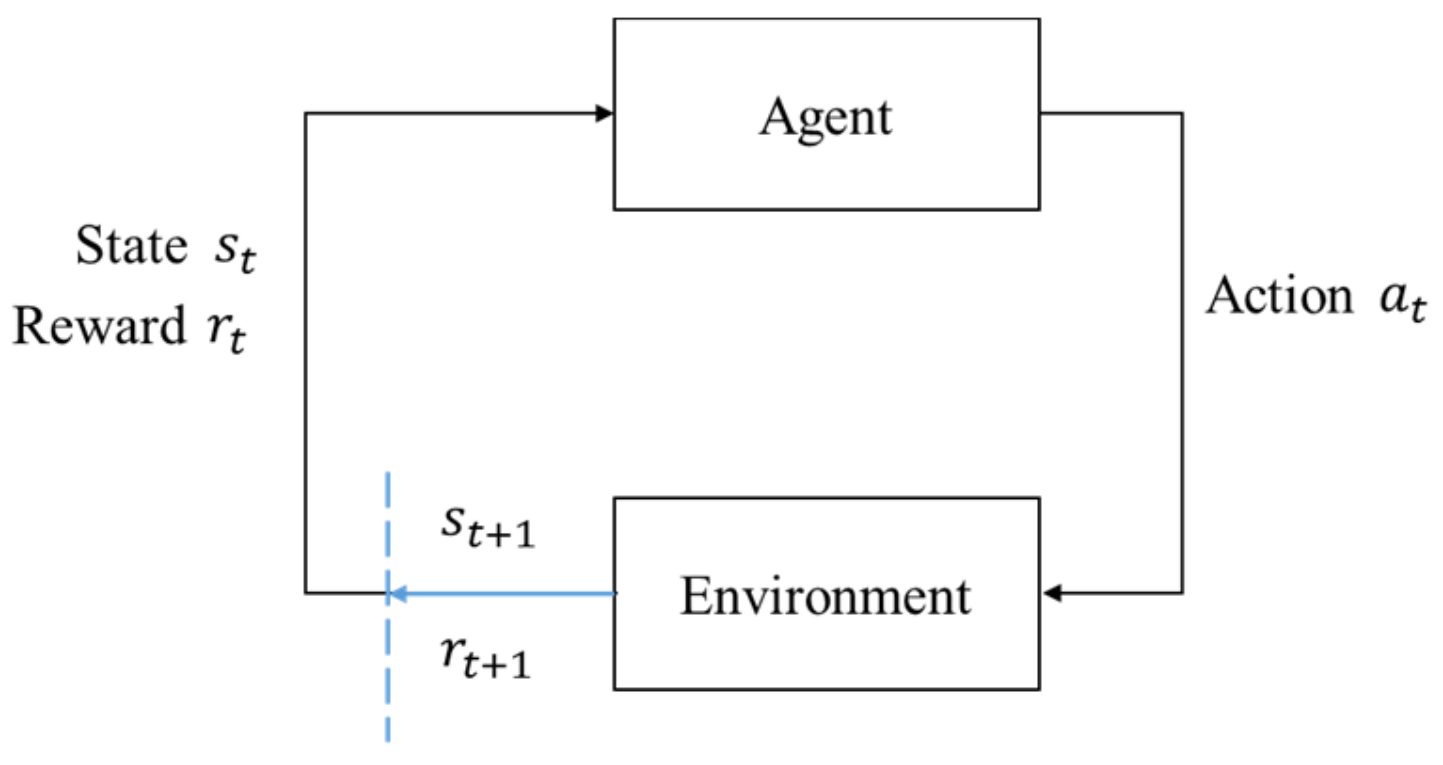
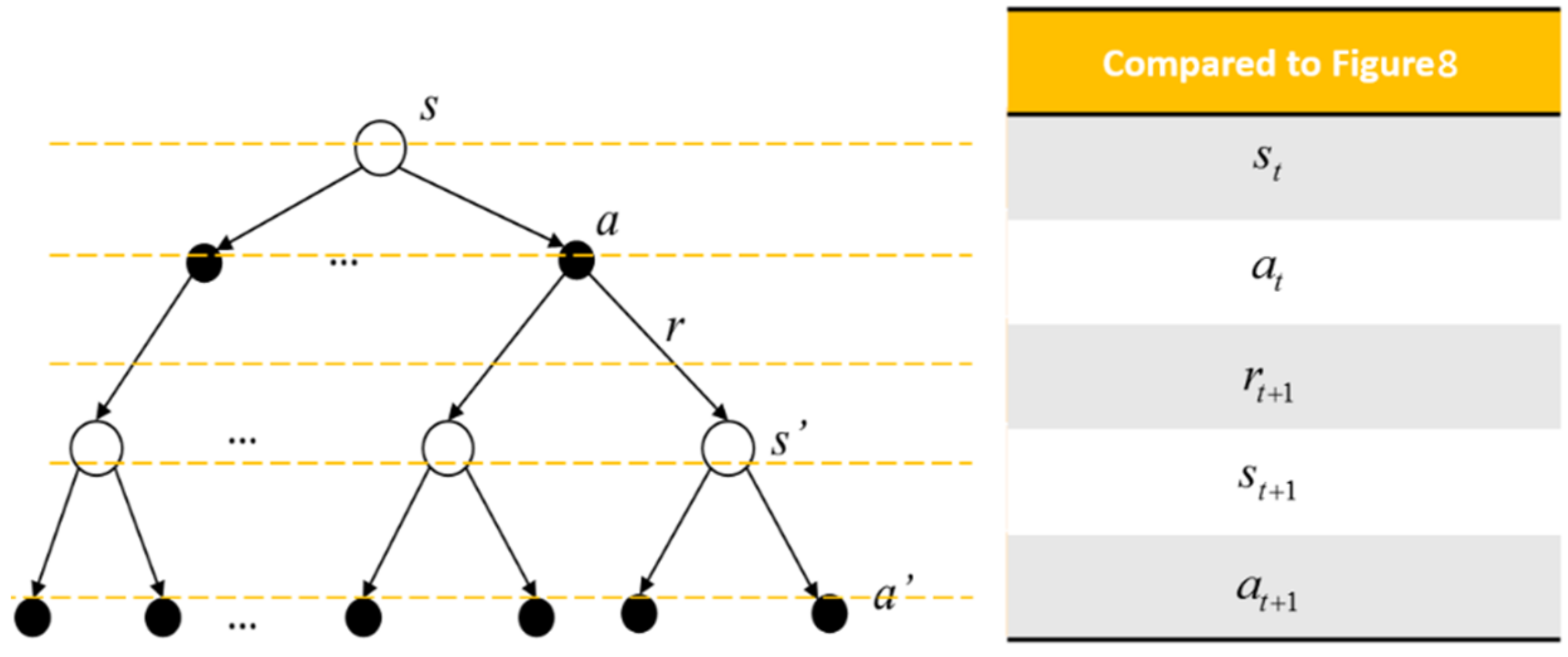
In RL, the one who actively takes actions that affect the environment is called an agent, and the environment is an object that reacts passively to the agent. The interaction between the agent and the environment can be described under the MDP framework. The agent–environment interface is shown in
Figure 8. The agent and the environment interact discretely in a time series
. For each time step
t, the description of the environment’s current condition
is obtained by the agent. The agent will decide which action
should be taken based on some rules. Then a numerical reward signal
and a new state
are brought out by the environment.
Figure 9 is a common representation of describing the interaction between the agent and the environment. The white circles represent the states and the black dots are the actions. The top white circle is the current state, and the middle black dots are all of the available actions. The possible succeeding states are the white circles in the middle, and the corresponding available actions are listed at the bottom of the diagram.
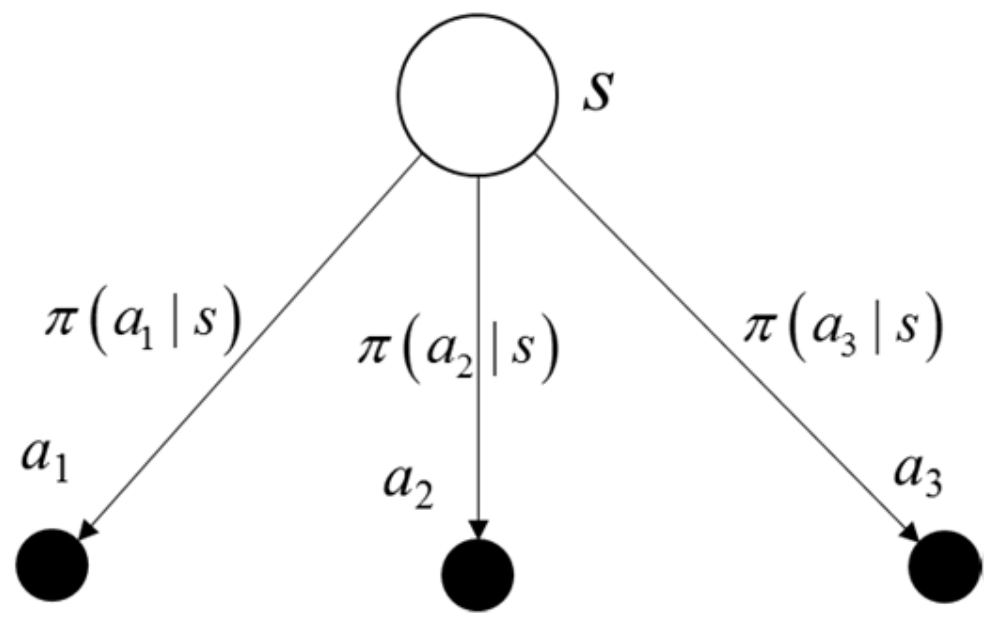
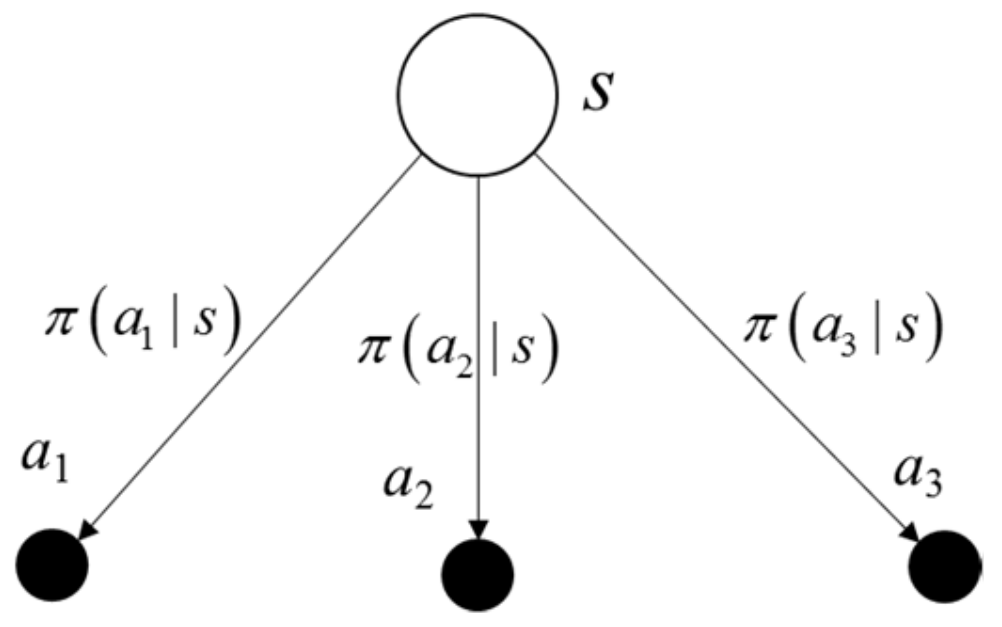
The rule followed by an agent is called a policy. Formally, an agent’s policy
is the mapping of the current state to the selection probability of the available actions. Hence, the probability of selecting
when the agent is at the state
can be denoted as
. For example, under a policy
, the probability of selecting
at state
s can be written as
, as shown in
Figure 10. With the experience (such as the tuple (
)) gathered, the policy can be modified. The goal of reinforcement learning is to obtain a policy, such that the received cumulative rewards are maximized.
3.2.2. Long Term Rewards
The expected return
is the sum of the discounting rewards the agent expected to receive at time
t, as below:
where
is the discounting parameter,
. The rewards are discounted in order to avoid infinite cumulated rewards. With a smaller
, the agent focuses on the recent rewards more, while a larger
will make the agent be farsighted, and thus long term rewards will be considered. Also, the expected return can be written as an iterative form, which indicates that the current return is equal to the sum of the immediate reward
and the successor state return
.
3.2.3. Action Value and Optimal Action Value
The action value is the agent’s expected return starting from the state
s, with the action
chosen and thereafter following the policy
, as described in (10):
where
r is the immediate reward received by doing action
, and
is the discounted action value starting from all possible next states
.
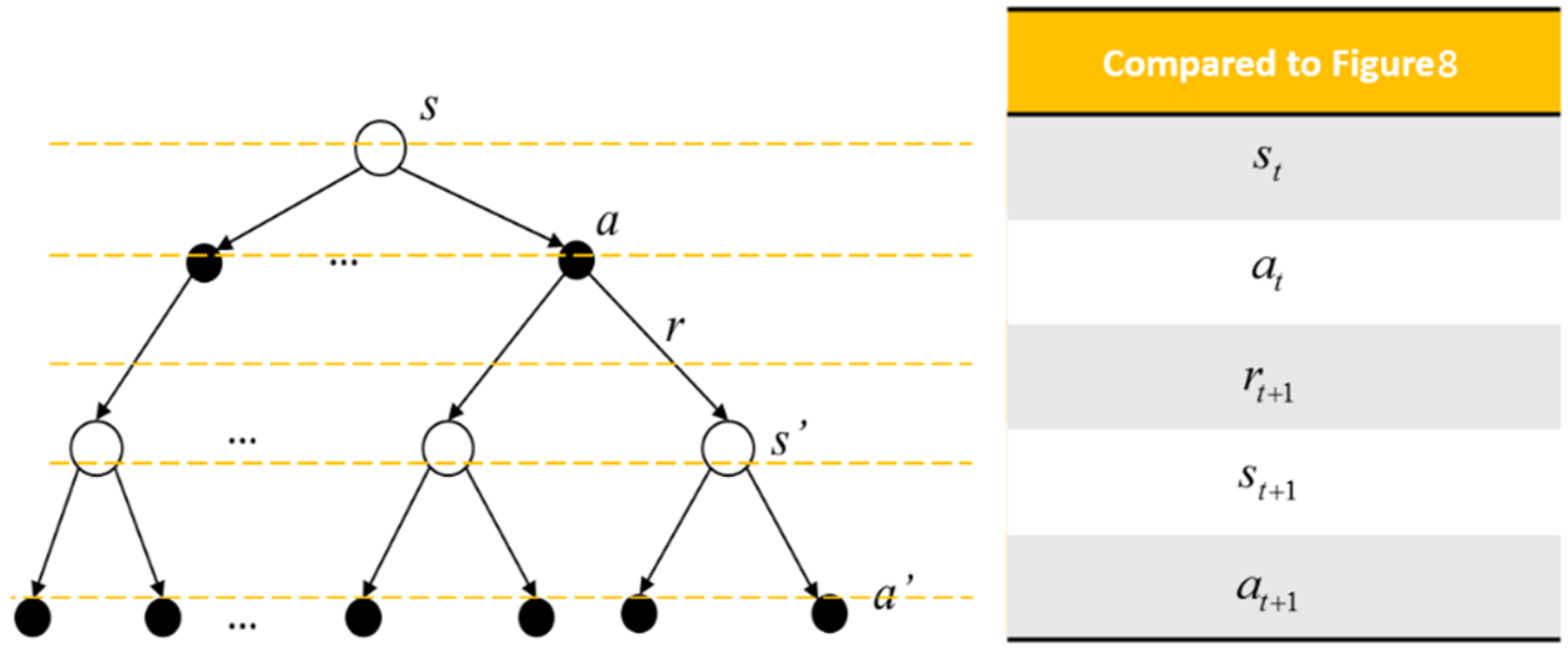
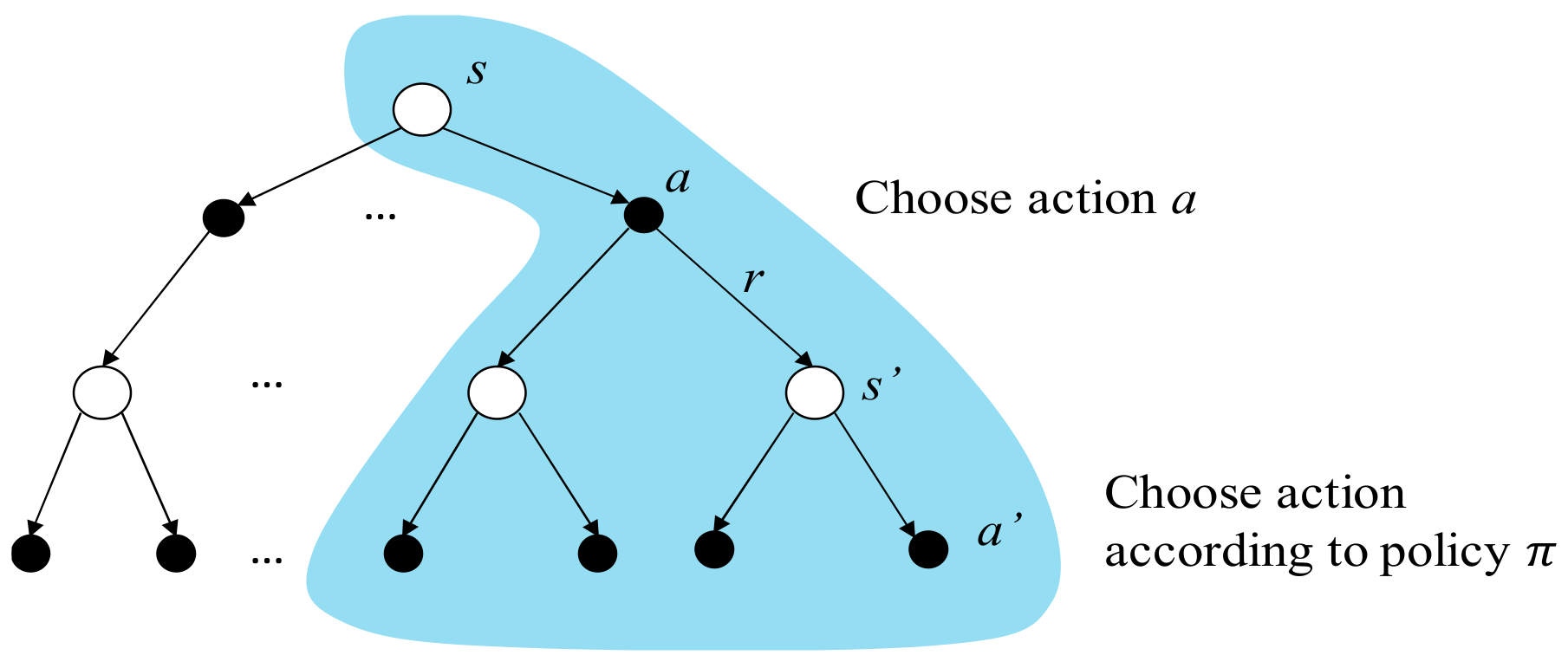
The backup diagram of the action value is shown in
Figure 11. The top white circle and black dot are the state
and the action
being chosen under the state
, respectively.
r is the reward received consequently. The white circles in the middle are the successor states
the agent may obtain after doing action
. After that, the agent does actions according to the policy
, and the black dots in the bottom are the possible actions
being chosen.
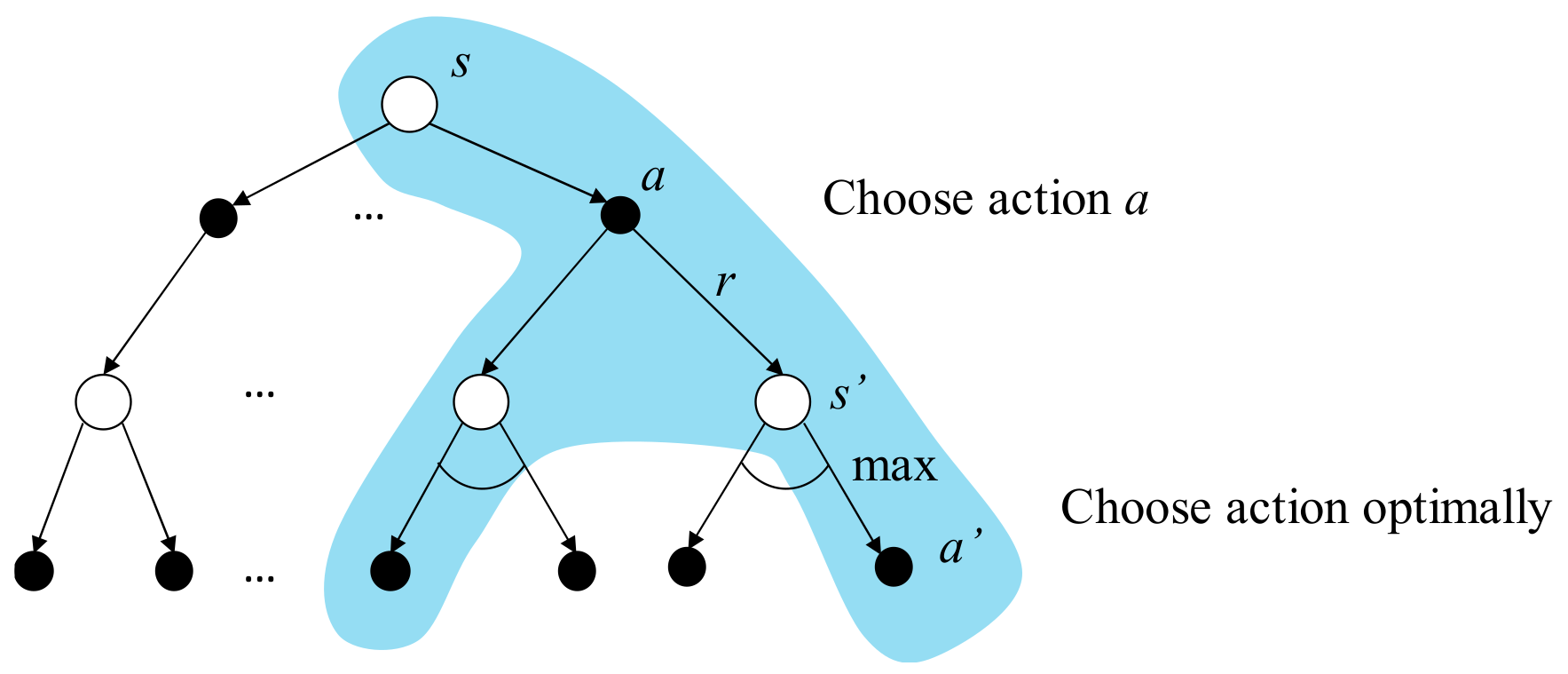
To an action value function, a policy
is better than the other policy
, or
, if and only if
. There always exists a policy that is better or equal to all the other policies and that is an optimal policy. The optimal action value function is defined as the expected return starting from the state
with the action a chosen, thereafter following the optimal policy, such that the expected returns in the following states are maximized, as shown in (11)
where,
is the optimal action value function of the next state
with optimal action
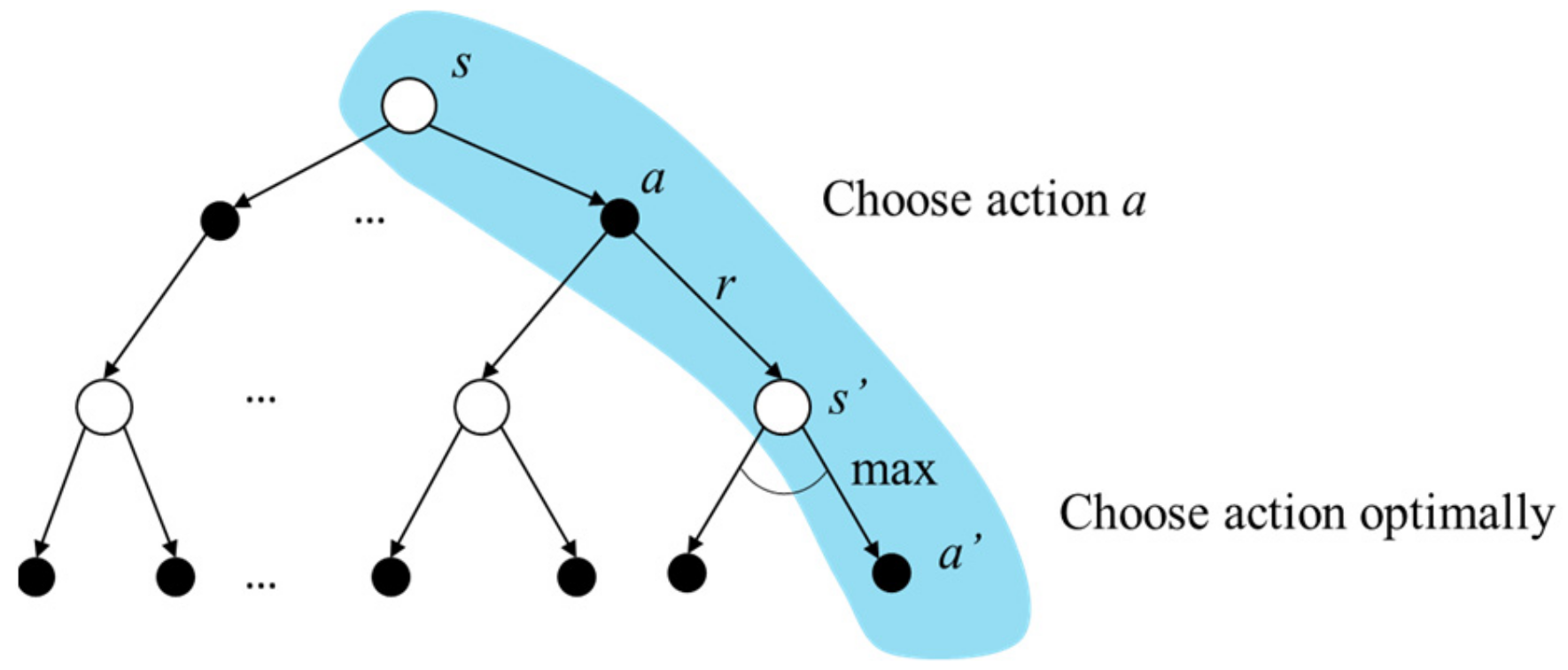
chosen. The backup diagram of the optimal action value function is depicted in
Figure 12 with the blue background. The arc between different
is a representation of choosing the optimal
such that the return starting from
is maximized.
3.2.4. Introduction to Q-learning
Q-learning [
19] is a model free temporal difference (TD) method to perform RL. A Q-table is constructed through bootstrapping to store the optimal action value of any state-action pair. The one-step update of Q-learning is shown as below:
where
directly approximates the optimal action value
and is independent of the policy followed. For the state
, an optimal action
is expected to be selected within action set
A(s’) so that the Q value at
can be maximized, i.e.,
. The updating rate of the
Q value is
,
, and
Q has been proven to converge to
with a probability 1 by [
19]. The backup diagram of Q-learning is depicted in
Figure 13 with a blue background. Through actual interactions, the experiences
can be acquired. According to the interaction experiences, the
Q values can be updated by (12) and stored in a tabular form, which is called a Q-table.
Once the Q-table is fully constructed, the optimal policy can be extracted by greedily choosing the action with the largest optimal action value for each state, i.e.,
.
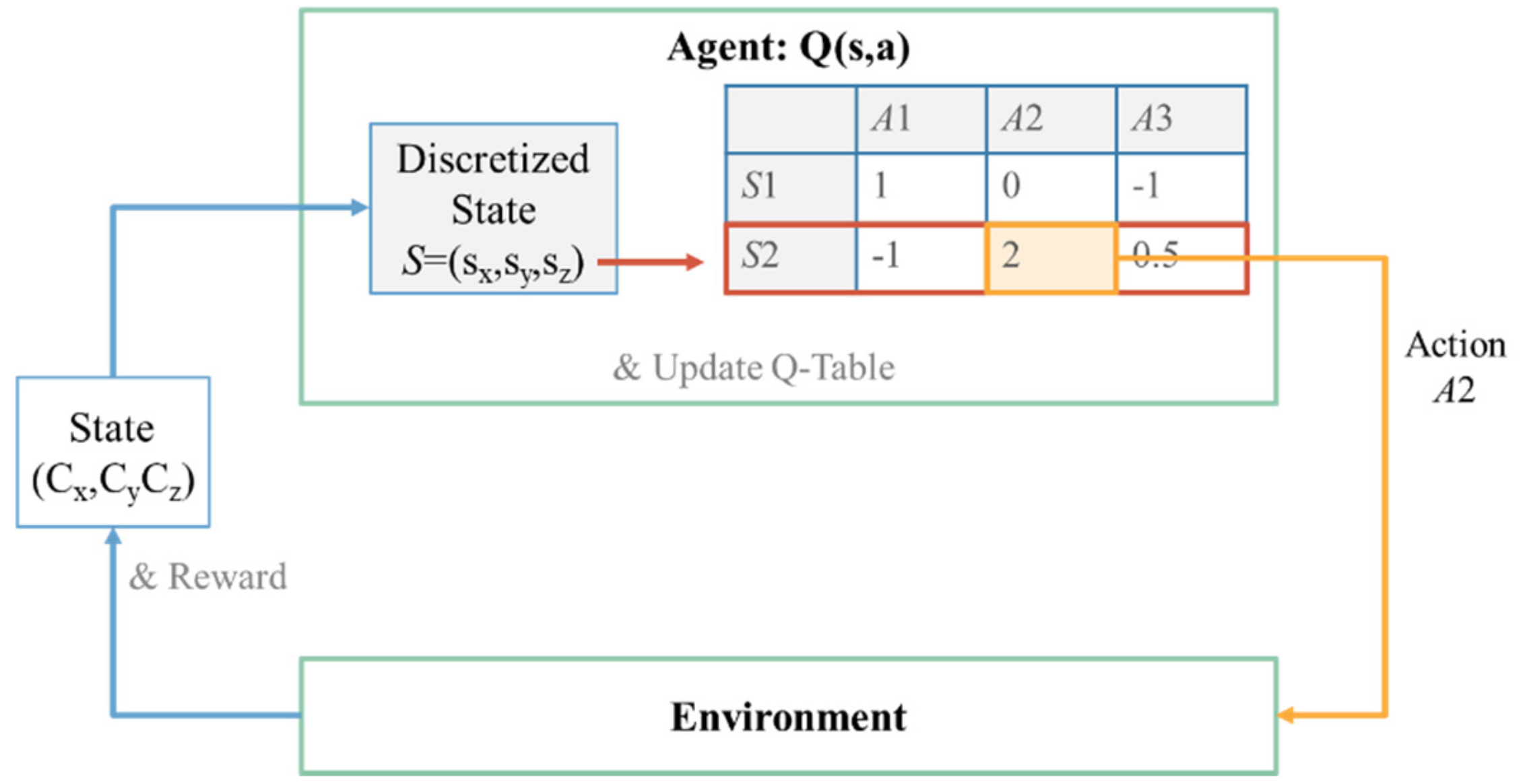
Table 1 is an example of policy extraction from a well-constructed Q-table. The agent will take the action
A3 when it is at the state
S1 since
. Similarly,
A1 should be taken at states
S2 and
S4, and
A2 should be taken at state
S3.
One of the issues in RL is the exploration–exploitation trade-off [
8]. For some RL problems, the policy changes with time, thus off-line learning is not suitable for them. Therefore, for each time step, the system is designed to be
-greedy, i.e., choosing actions randomly to explore new possible rules in a probability
and otherwise following the learned policy and always choosing the action with the largest Q value.
The algorithm of Q-learning is shown in Algorithm 1. First, the elements in the Q-table are initialized. The -greedy, the learning rate and the discount factor are also initialized. Note that for a non-episodic MDP, there is no ending state, therefore, should be less than 1 to avoid infinite expected return.
The agent observes the current state first. With a probability , the agent will randomly choose the available actions, otherwise, it will choose the action with the largest Q value according to the Q-table. After applying the action, the environment will generate the reward signal , and then a new state can be observed. With obtained, the element in the Q-table can be updated using (34). Finally, the current state is replaced by the new state , and one step of an update is completed.
| Algorithm 1: Non-episodic Q-learning algorithm |
| Initialize |
| Initialize |
| Observe |
| Repeat (for each time step t) |
|
| Apply , observe and |
|
|
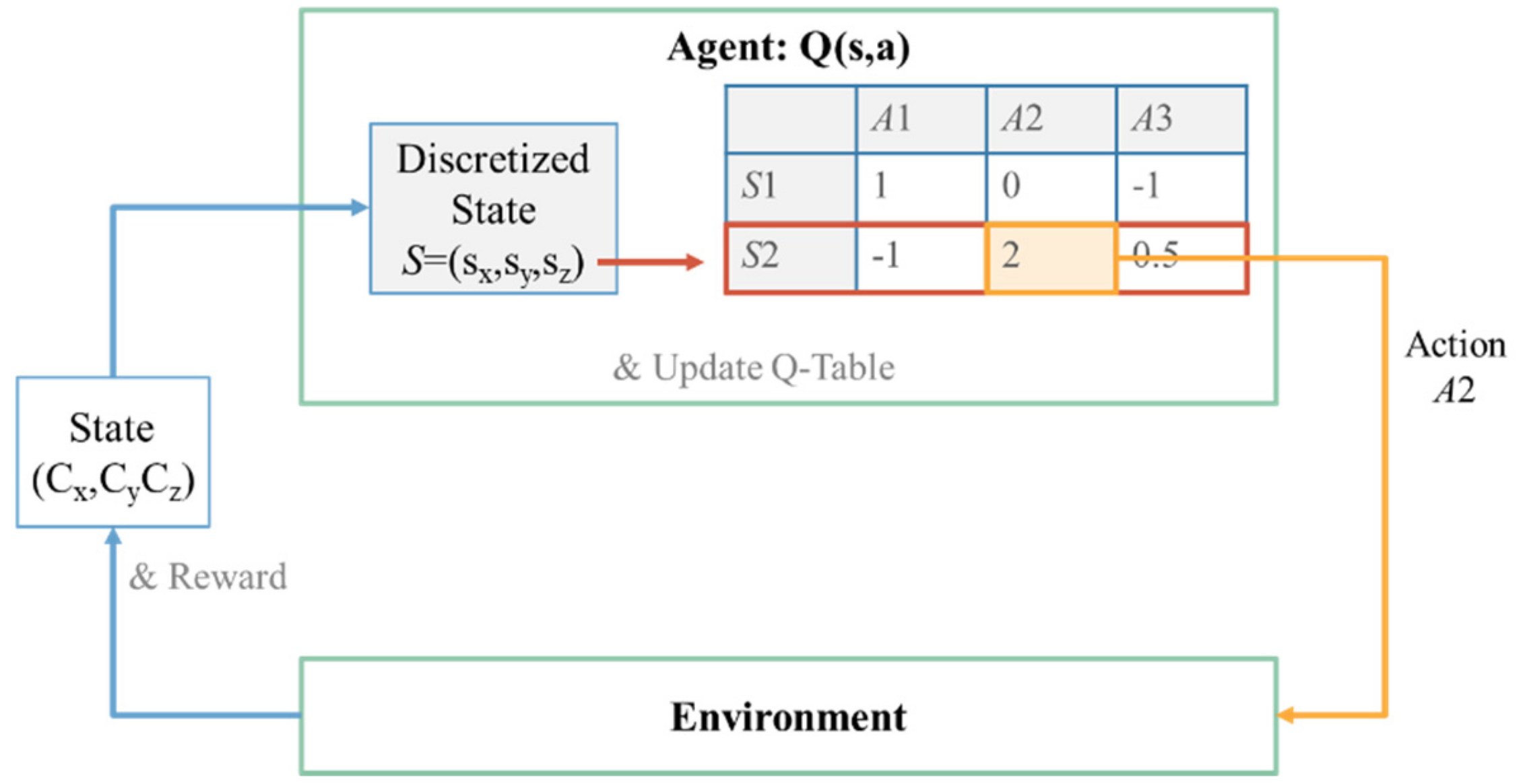
An example of the agent–environment model with the Q-table is illustrated in
Figure 14. The state representation generated by the environment is required to be discretized to perform table lookup on the Q-table, which is impractical in some cases, such as the state space is too large or the state space is continuous. Therefore, an approximation of the Q-table using a neural network, named Q-network [
13], has been implemented in this paper.
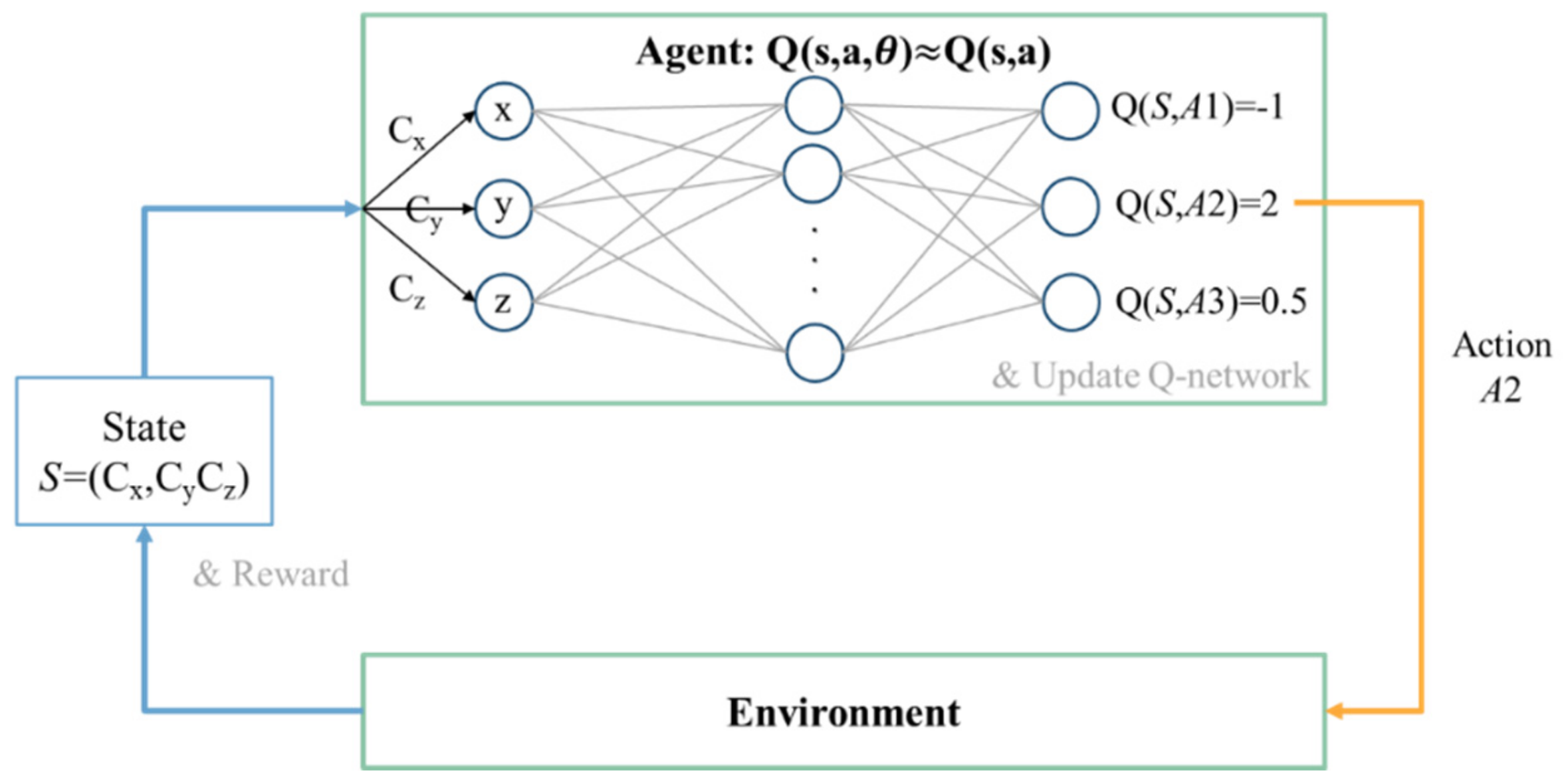
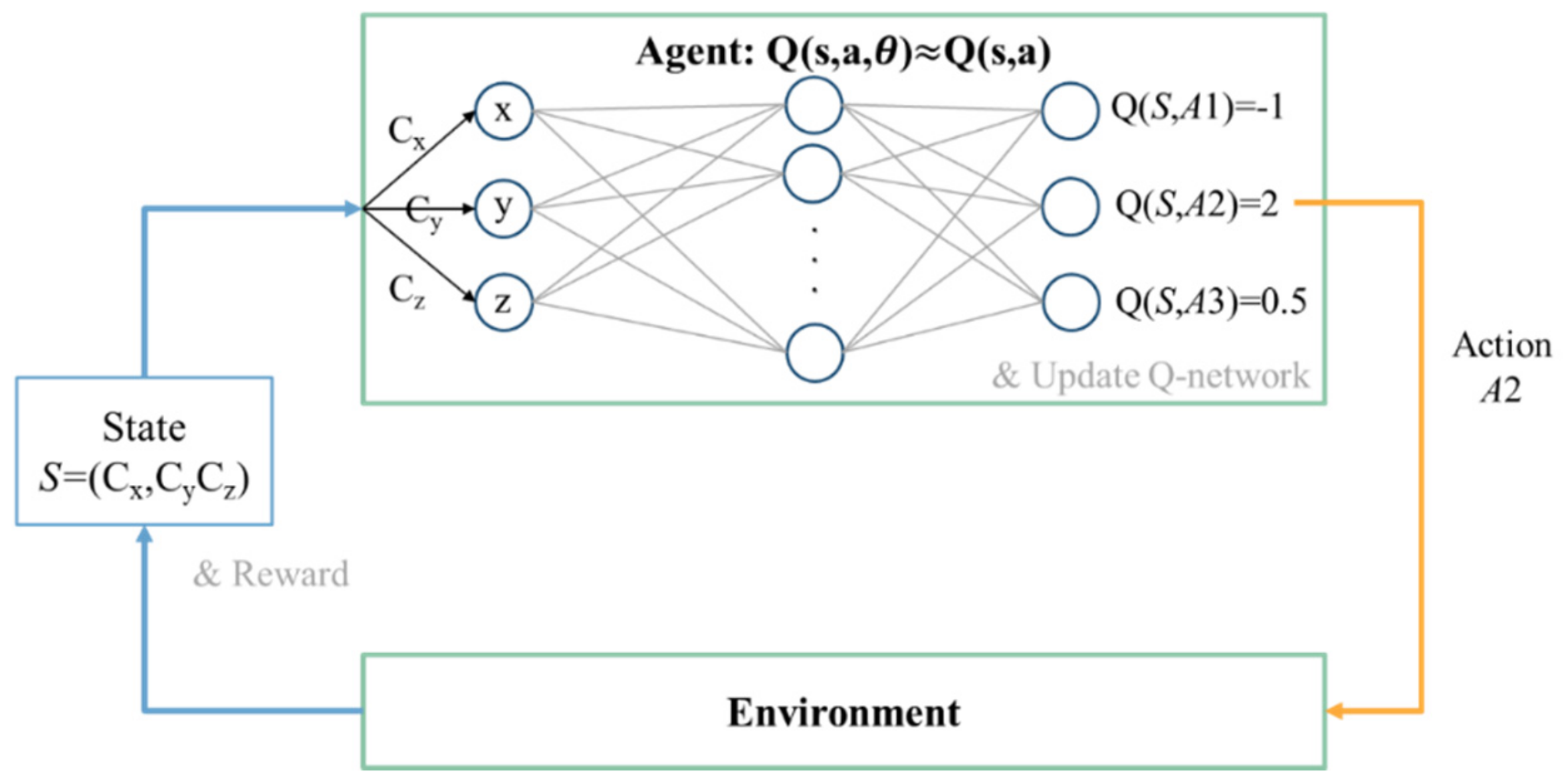
3.2.5. Q-Learning with Neural Network Approximation
The Q-table in
Figure 14 can be approximated as the Q-network in
Figure 15. The state representation can be directly used as the input of the Q-network without discretization. The number of input nodes is the dimension of the state representation. The output of the Q-network
is used to approximate the optimal action value
, where
is the weight of the network, i.e.,
.
The loss function, also known as the cost function [
20], of the Q-network in iteration
is defined as:
where
is the target Q value based on the current reward r and the maximum Q value at the next step
generated by the Q-network in iteration
, and
is the estimated Q value provided by the Q-network in iteration
. For every
, (13) should be minimized in order to approximate the estimate Q value to the target Q value. The target Q-network parameter of the previous iteration,
, should hold fixed during the training in iteration
. This may cause the oscillation or divergence of the policy since the target Q value is affected immediately after updating the Q-network for every iteration.
To stabilize the learning process, a fixed target Q-network technique is proposed by [
13], and the loss function is written as
where
is the old parameter several iterations before, and it will update to the current value for every
iterations,
. Therefore, the frequent update of the Q-network
Q will have less effect on the target Q value
, and the training process will be more stable.
To break down the correlation between training samples, the experience replay technique is proposed by [
12]. For each time step t, an experience sample is gathered and stored by the agent into a data set
, where
. For each learning iteration, several samples are taken randomly as a mini-batch
to perform mini-batch gradient descent [
21], and the loss function can be rewritten as
Finally, a Q learning algorithm using a Q-network as the function approximation is shown in Algorithm 2. The parameter of
Q and
,
and
, are initialized. The target
Q parameter update period
CT, the experience data set
E, the
-greedy policy, the learning rate
, the discount factor
and the experience replay threshold
pth are also initialized. The agent then observed the current state
. With a probability
, the agent will do the action randomly, otherwise, it will choose the action with the largest
Q value according to the output of the Q-network, i.e.,
. After applying an action, the agent observed the reward and the representation of the next state, and
will be stored into
E. After cumulating enough experiences, an experience replay can be performed by sampling a mini-batch of experiences
from E randomly. The mini-batch target Q values
are calculated by the
instead of Q because of the performing of the fixed target Q-network technique, and then a mini-batch gradient descent [
21] is applied to minimize the loss function shown in (37). The target Q-network parameter
will be updated for every
CT iterations. Finally, the state is updated, and a new iteration will begin.
| Algorithm 2: Q-learning using Q-network approximation with fixed target Q-networks and experience replay |
| Initialize CT, E, |
| Observe |
| Repeat (for each time step t) |
|
| Apply , observe and |
| Store in E |
| If |
| Randomly Sample mini-batch from E |
| Calculate loss function as (15) |
| Perform mini-batch gradient descent to optimize the loss function |
| Every CT step update |
|
|
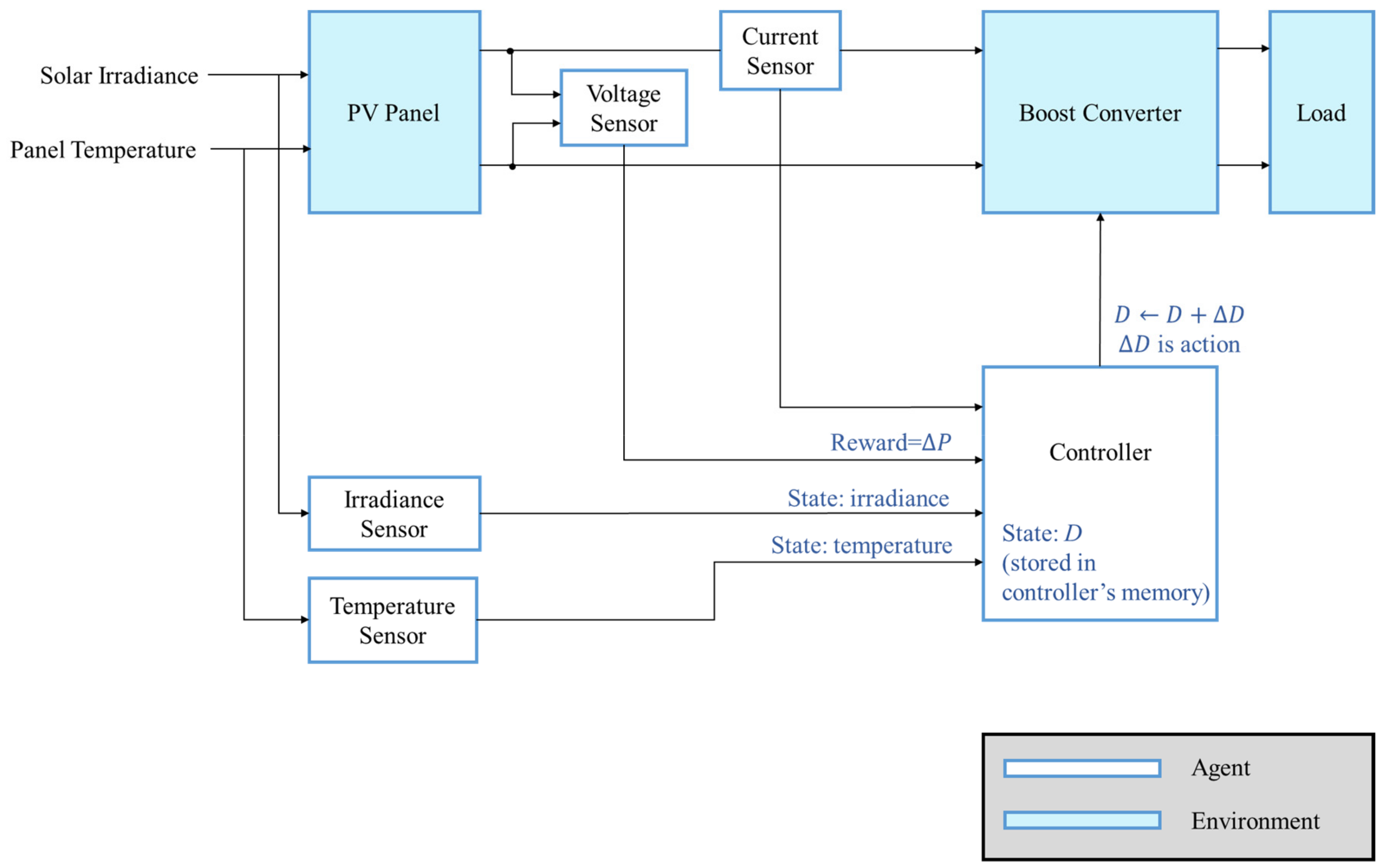
3.3. Design of an RL MPPT System
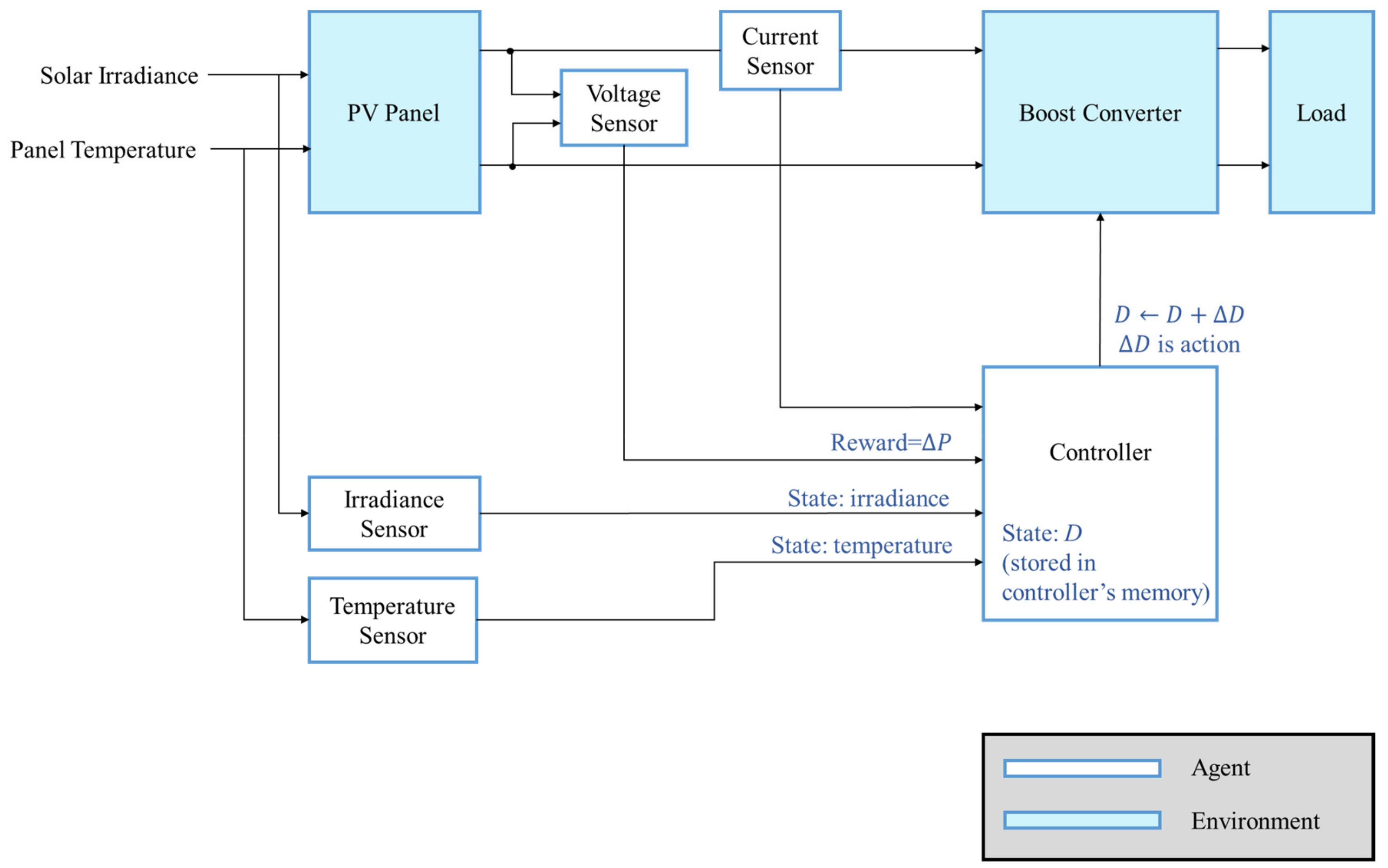
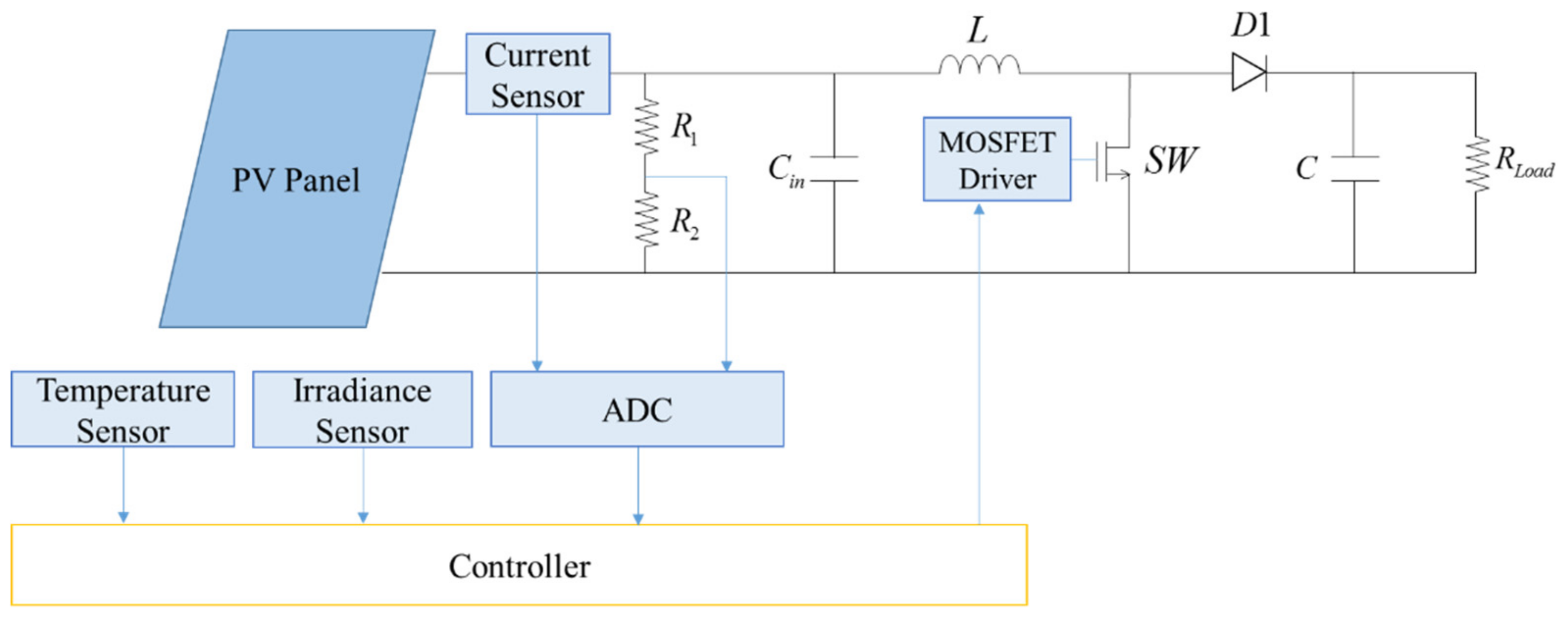
To perform MPPT based on RL, the system must be able to be described by MDP. The element needed in the RL MPPT system is defined in
Table 2. The PV module and the converter can be seen as the environment, and the controller is the agent as depicted in
Figure 16. The goal of the agent is to reach the MPP through interacting with the environment.
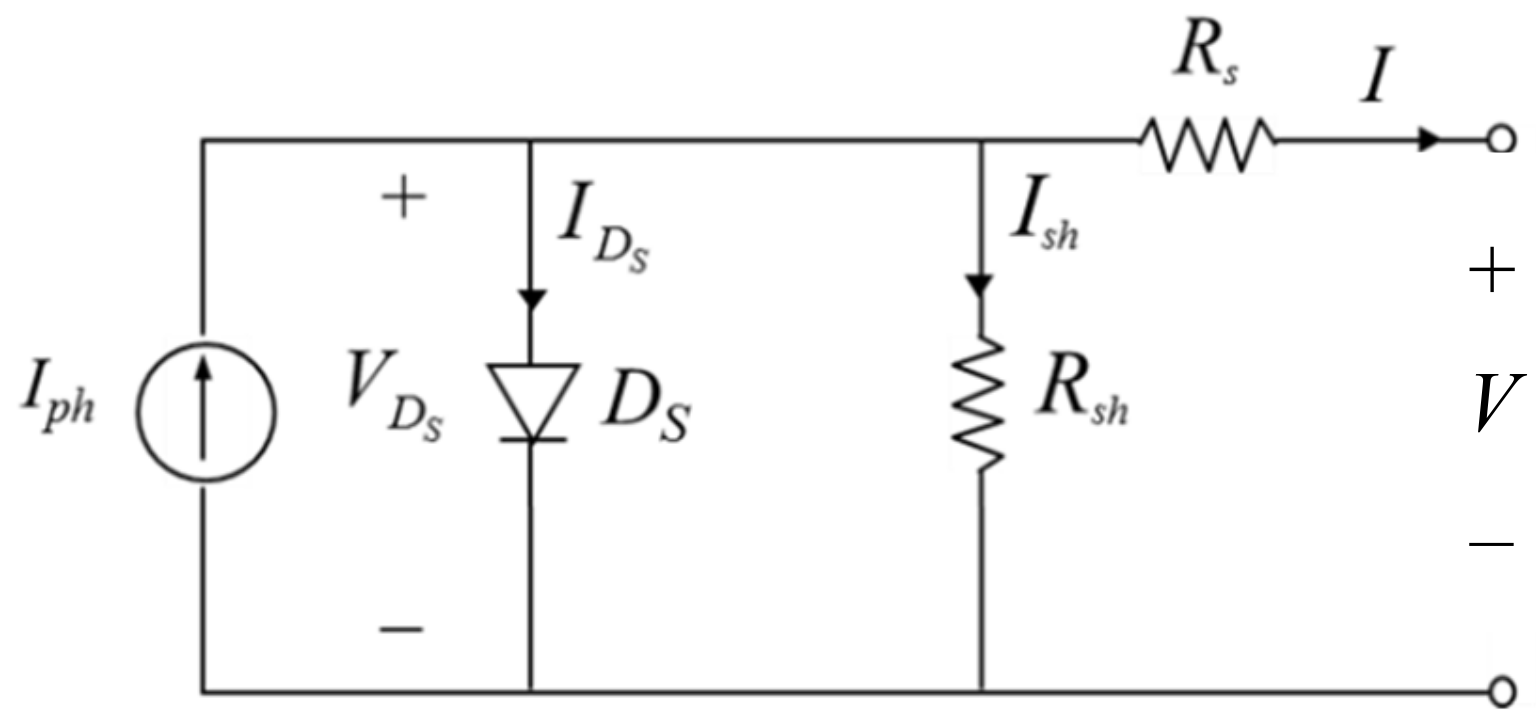
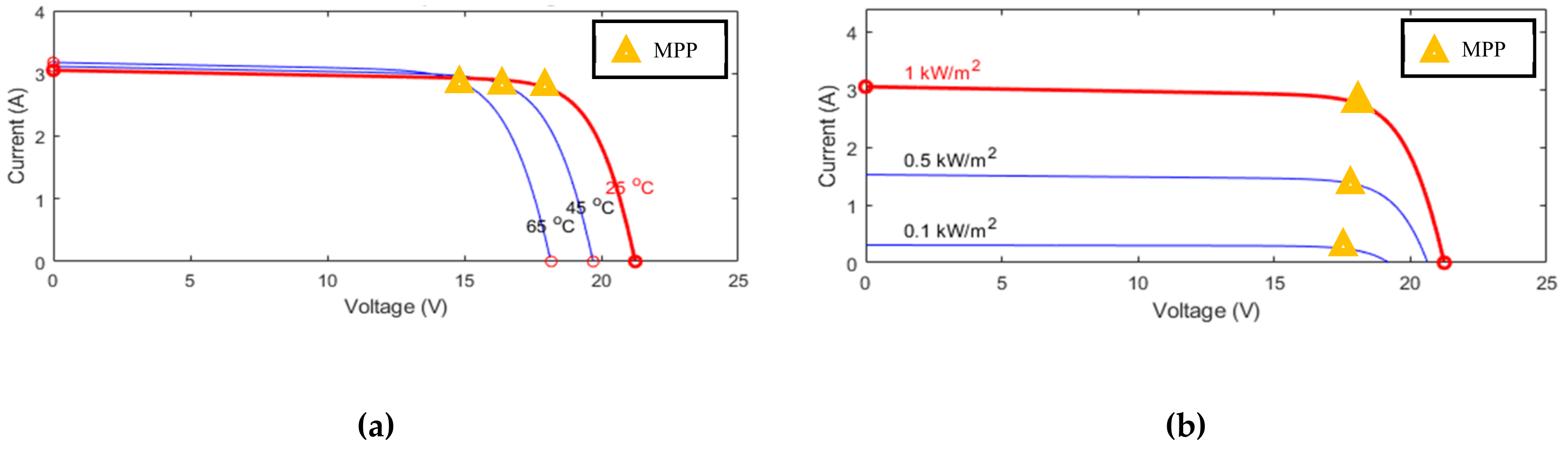
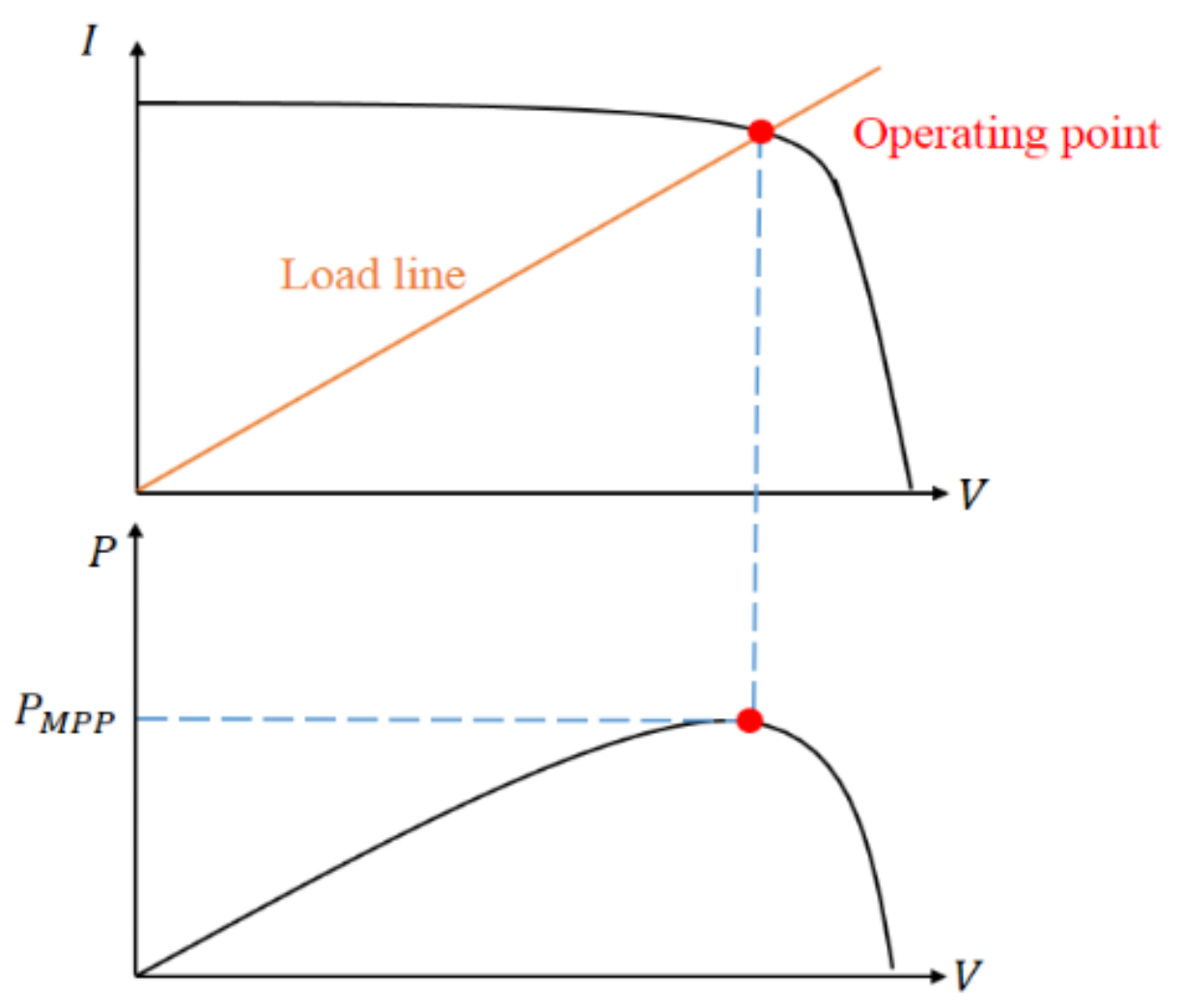
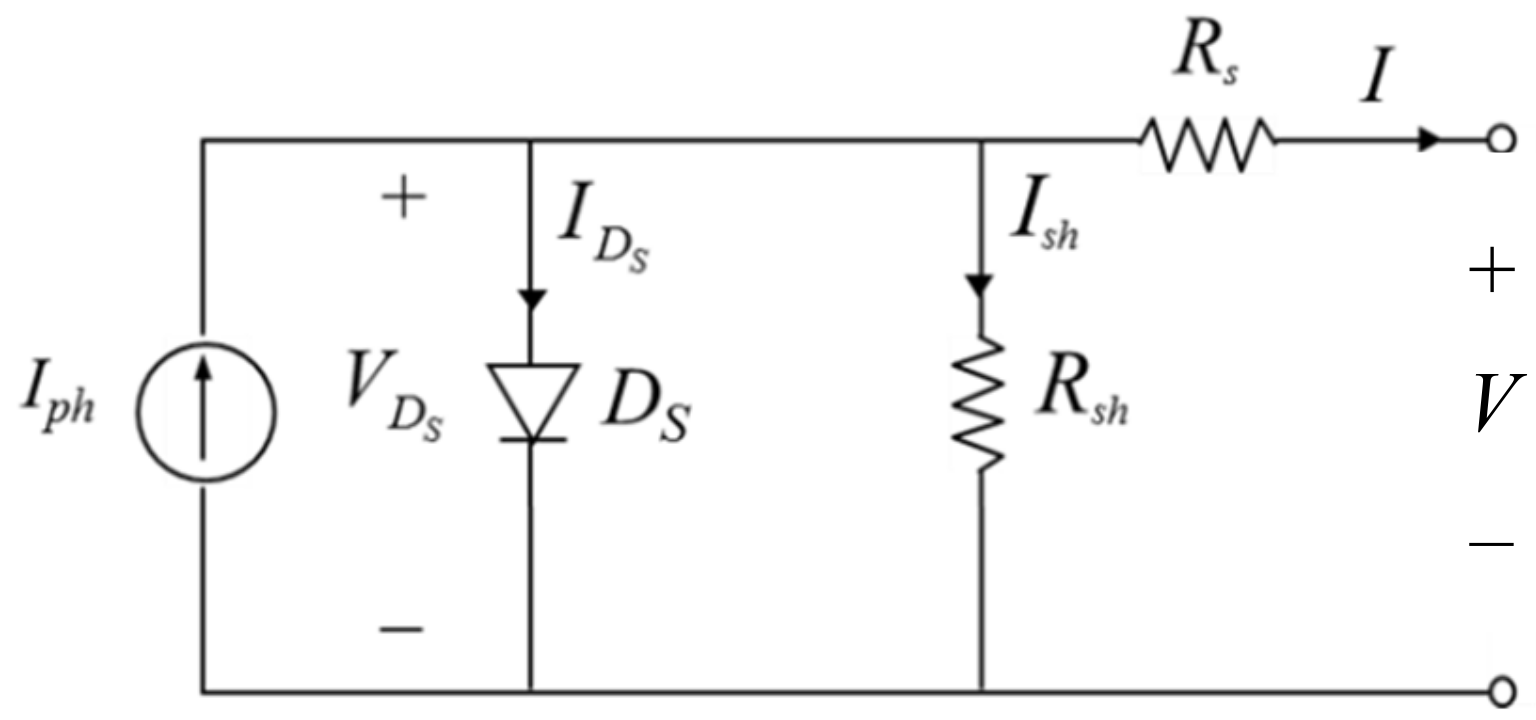
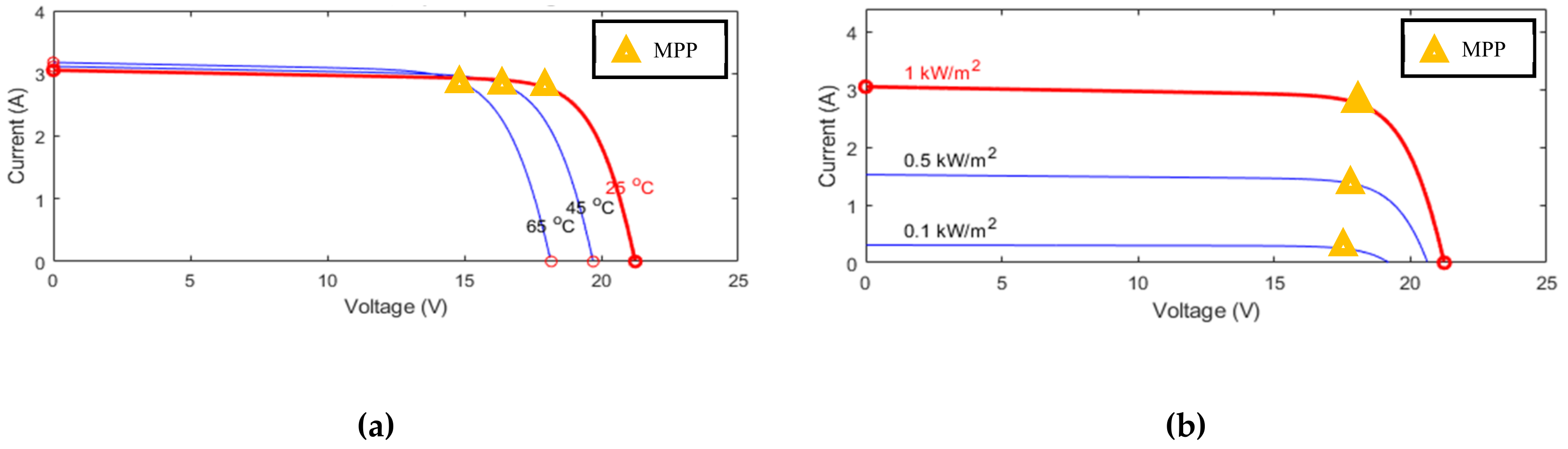
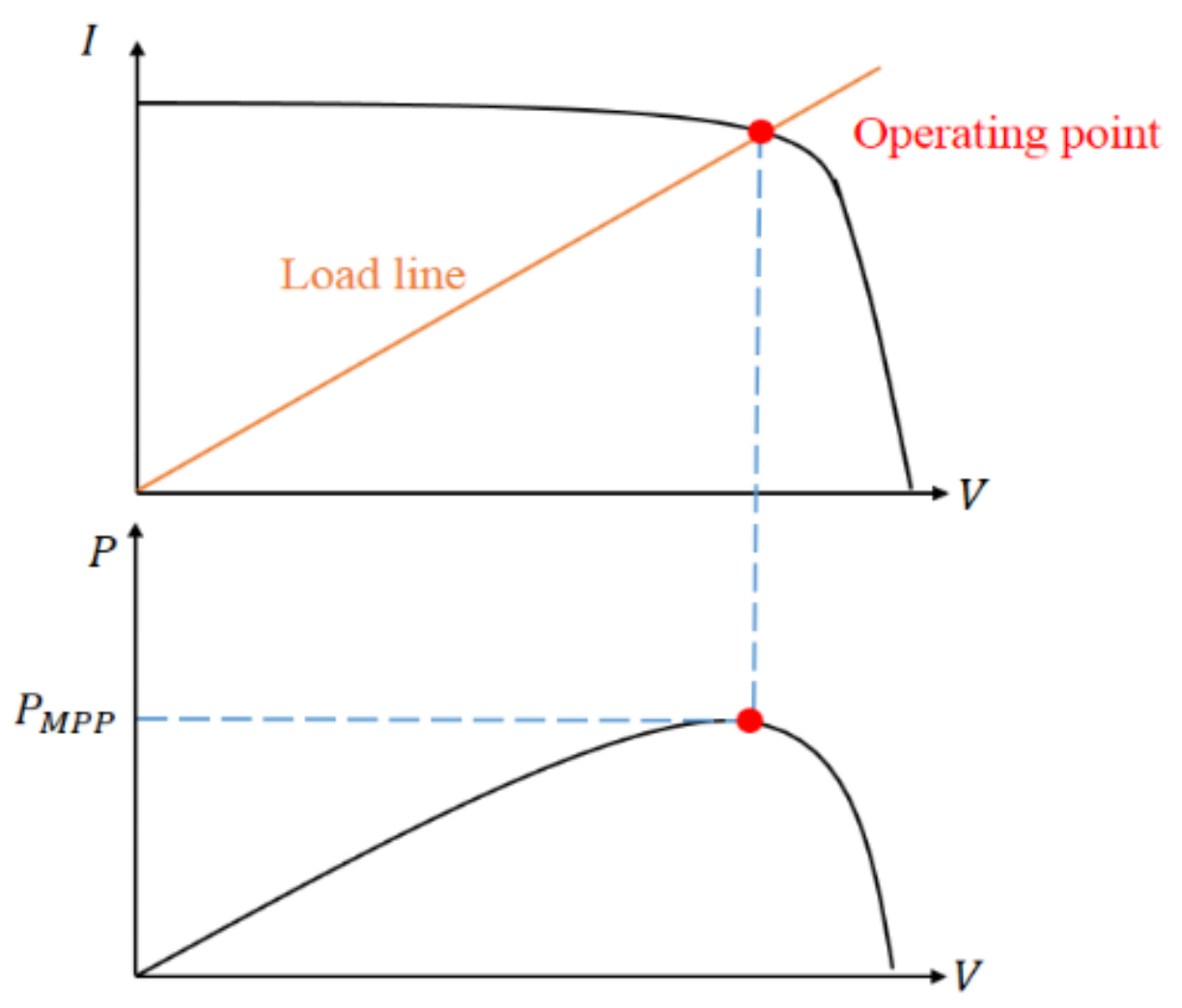
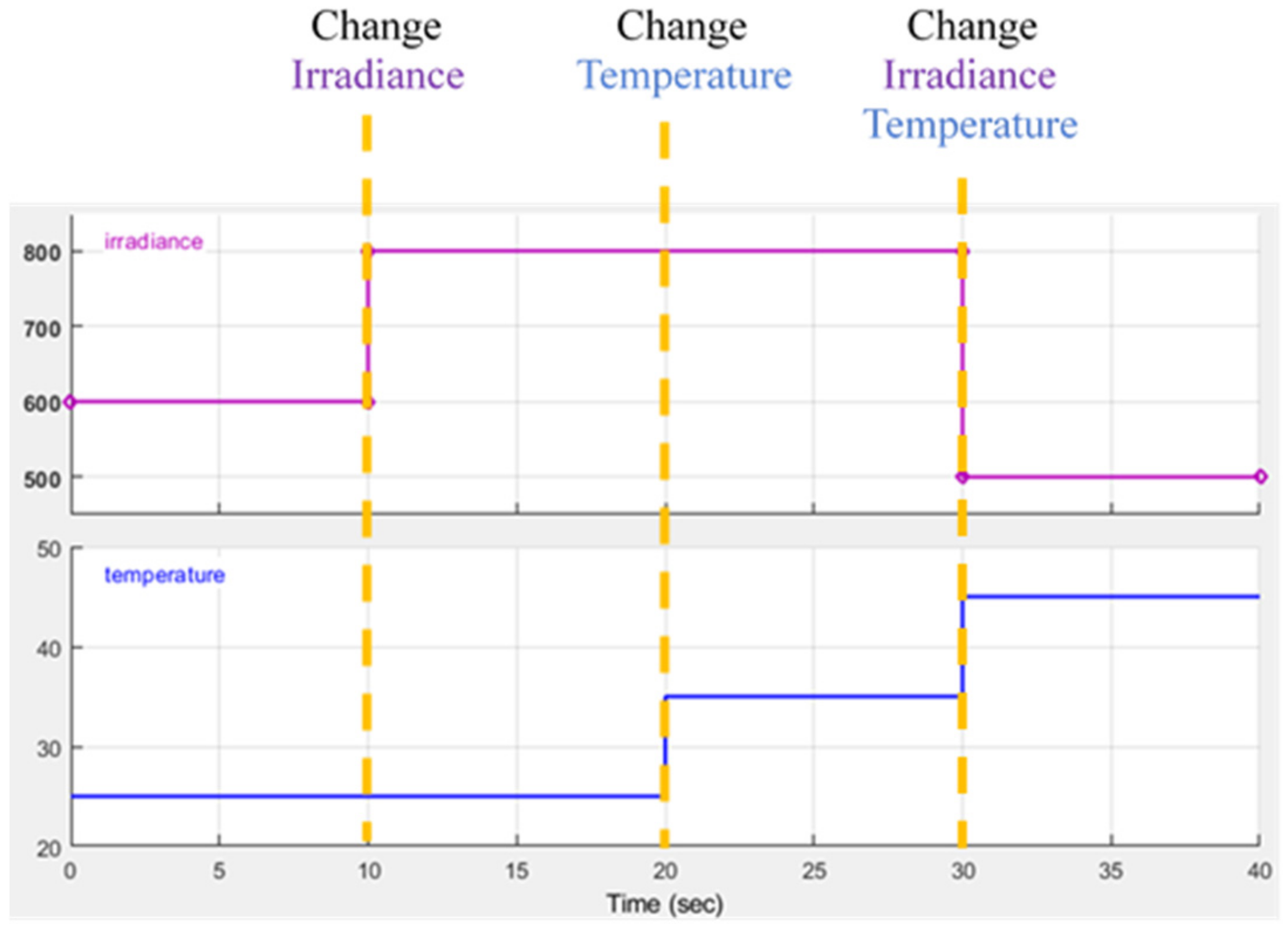
The system’s condition, the state, is described by the solar irradiance, the module temperature and the duty ratio D since the I-V curve is affected by the solar irradiance and the module temperature as mentioned previously. The system’s operating point is at the intersection of the I–V curve and the load line, and the load line is controlled by the duty ratio of the converter.
In this study, the action is defined as a set of duty ratio changing step with different step sizes. Therefore, the tracking progress can be seen as a sequential decision-making problem, i.e., the MPP of the system can be reached by applying a series of variable step sizes appropriately.
The reward is a numerical signal that helps the agent judge how “good” or “bad” an action is. The action that moves the operating point close to the MPP is better than the action that moves the operating point away from the MPP. Therefore, the power difference is defined as the reward since it provides not only the moving direction of the operating point but also the numerical scaling representation of the effect caused by applying the action, for example, a larger step size may lead to a larger power difference.
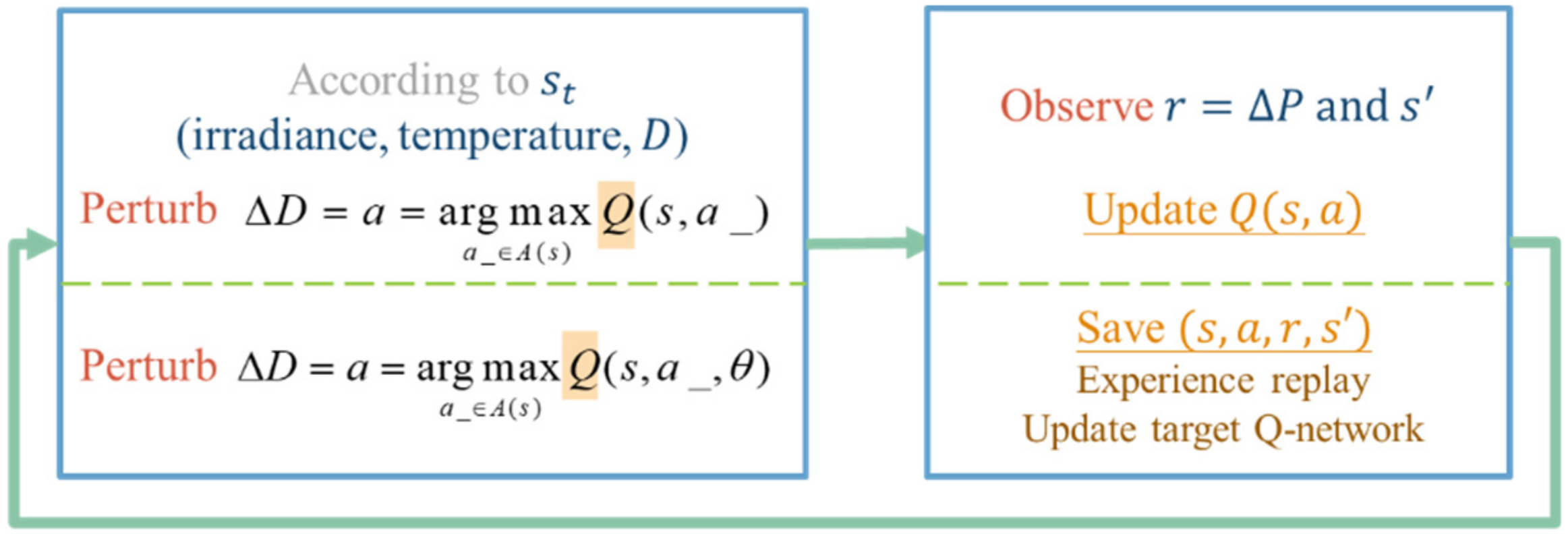
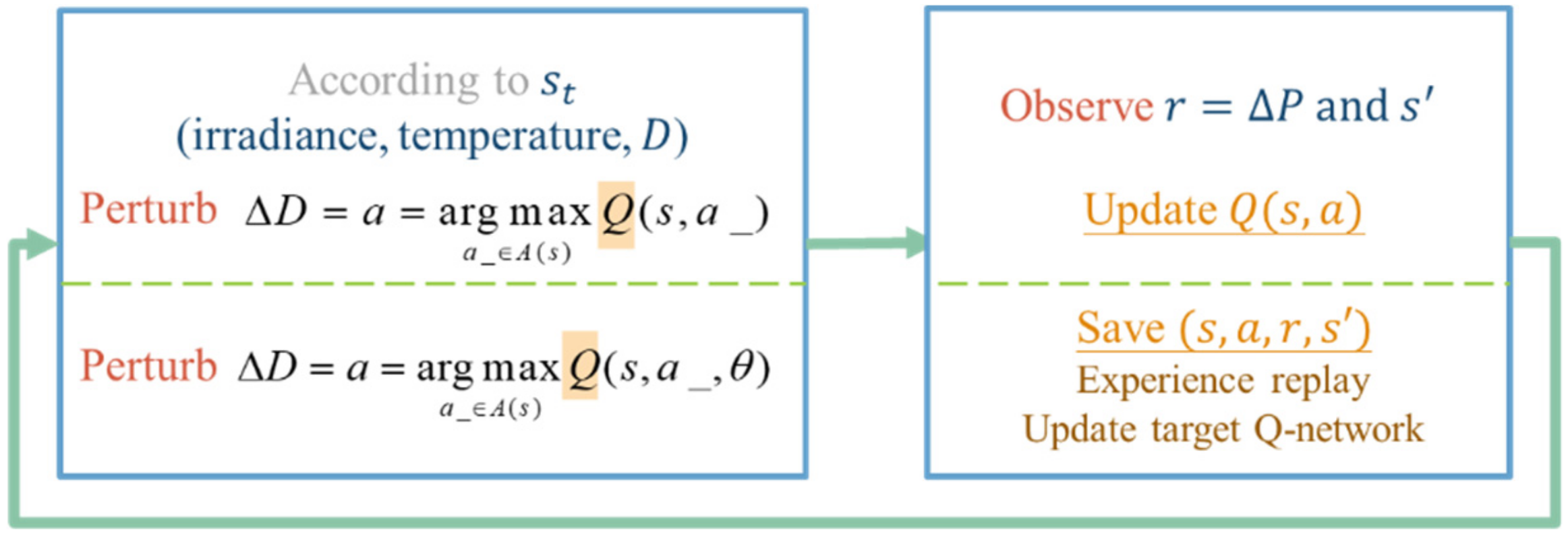
Also, the Markovian property holds since the current state is only affected by the state and the action taken one step before. Through combining the elements of the MDP model designed in
Table 2 and the concept of the RL MPPT shown in
Figure 7, the detail of the RL MPPT can be described as
Figure 17.
The perturbation step size is chosen according to the Q value of the current irradiance, temperature, and duty ratio
D. After applying the change of
D, the power difference
and the new state description
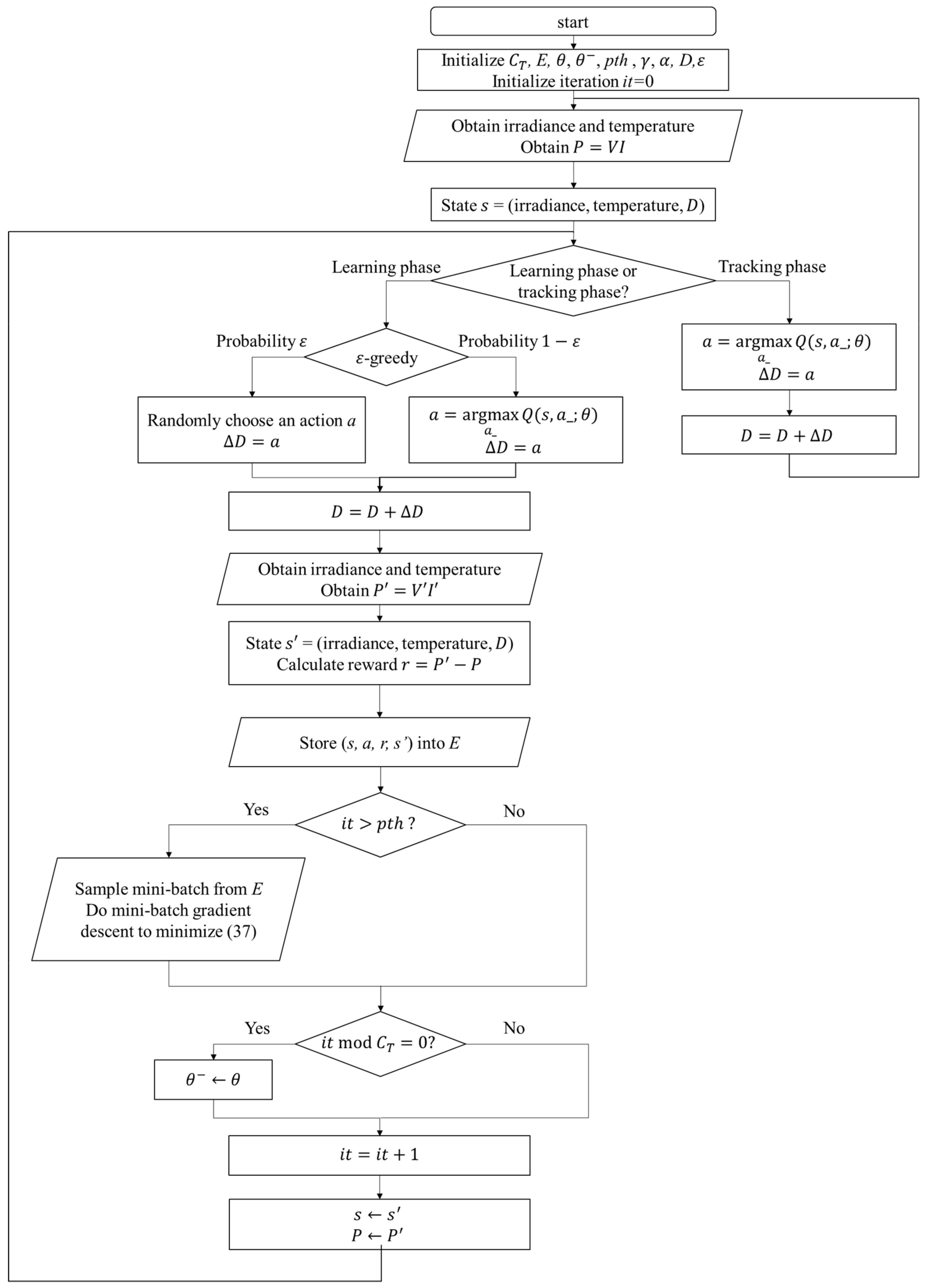
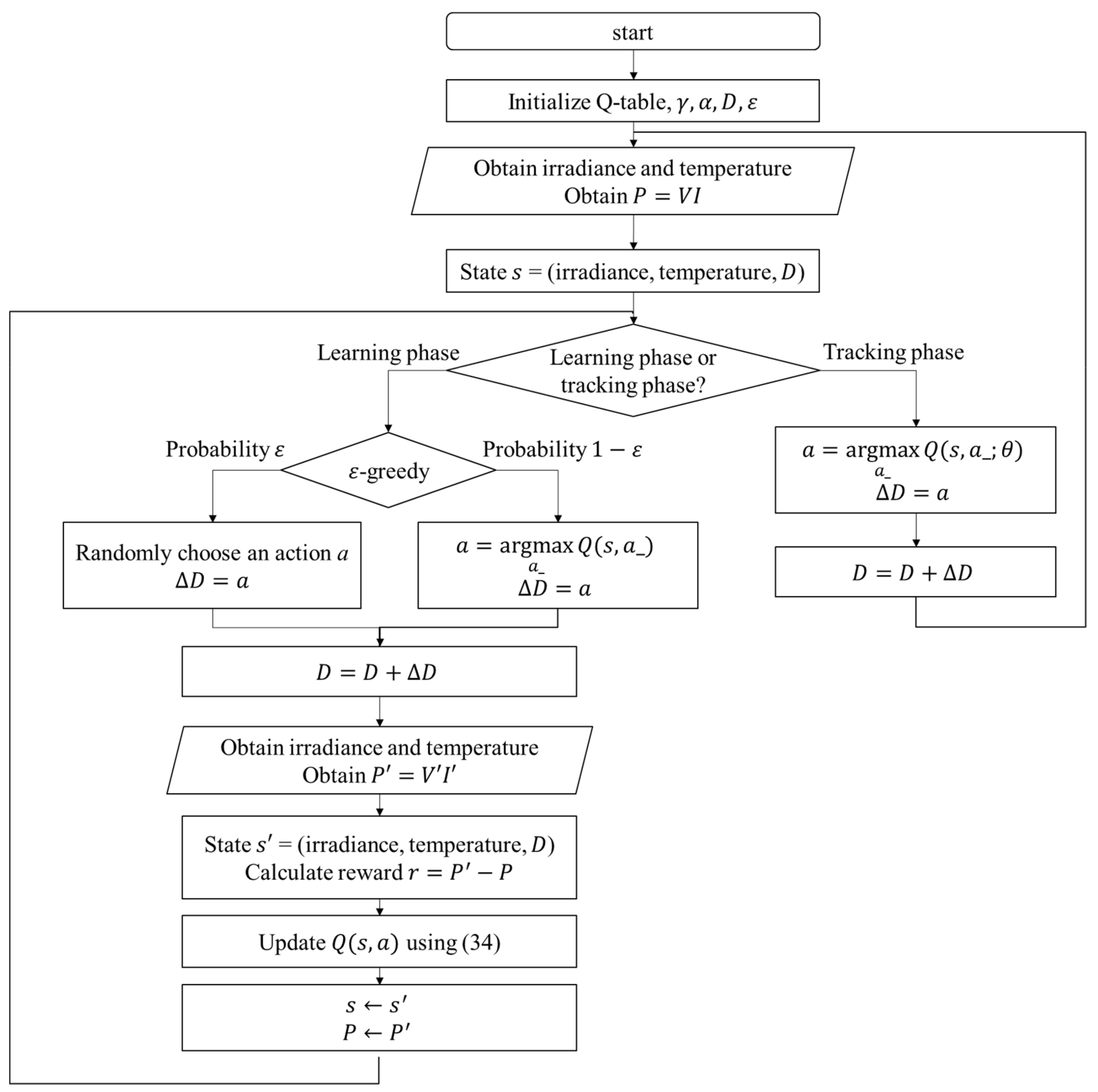
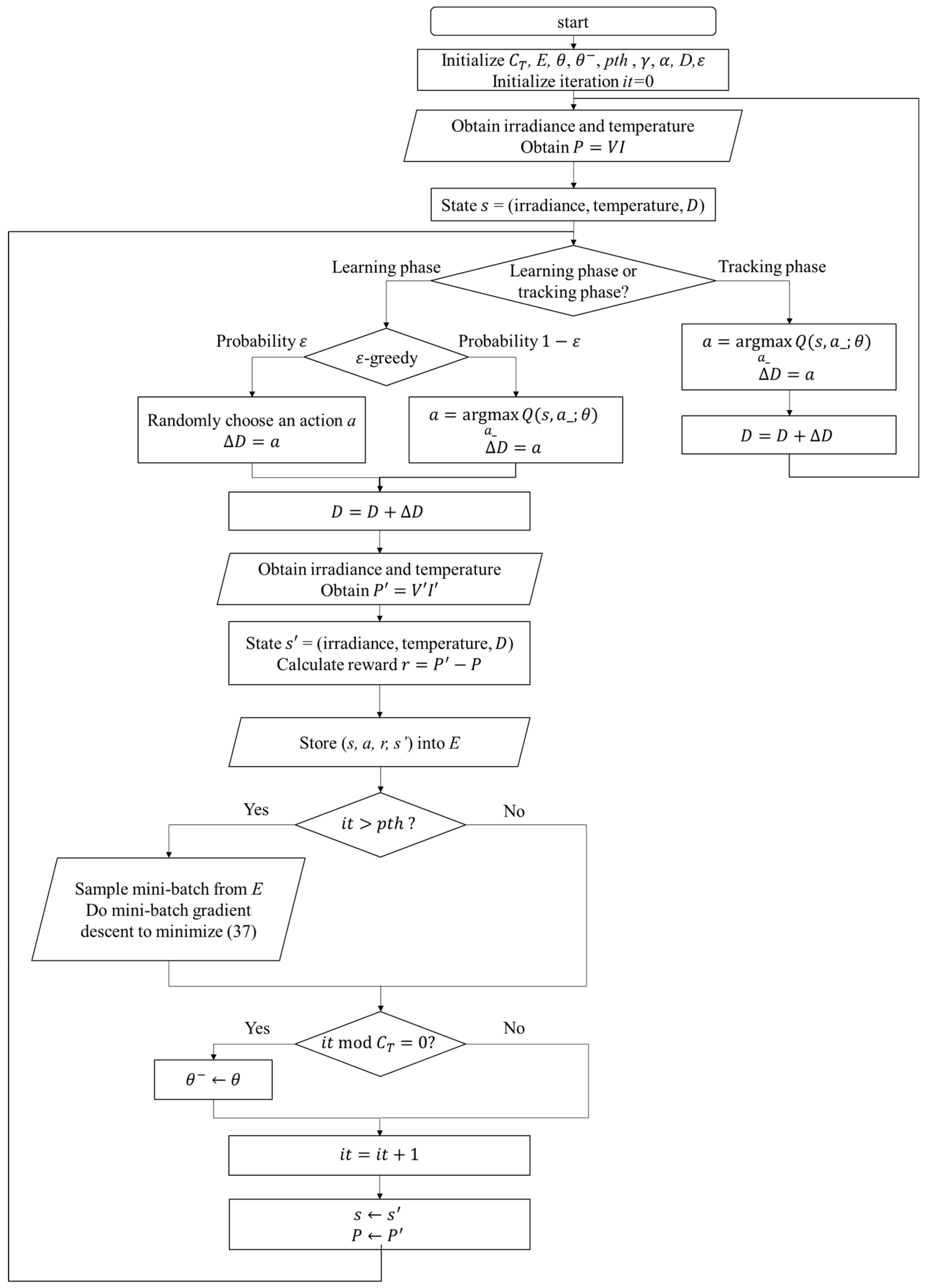
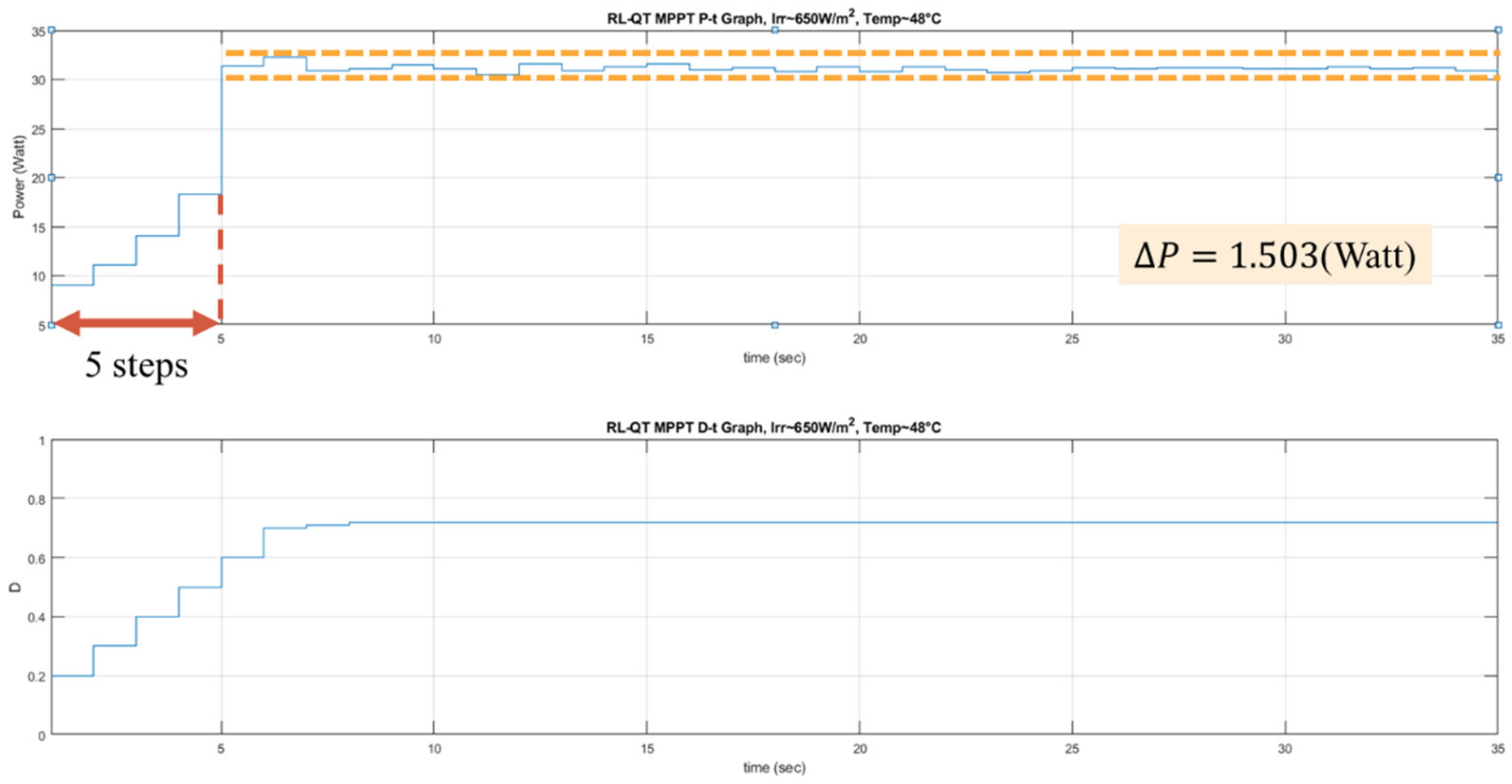
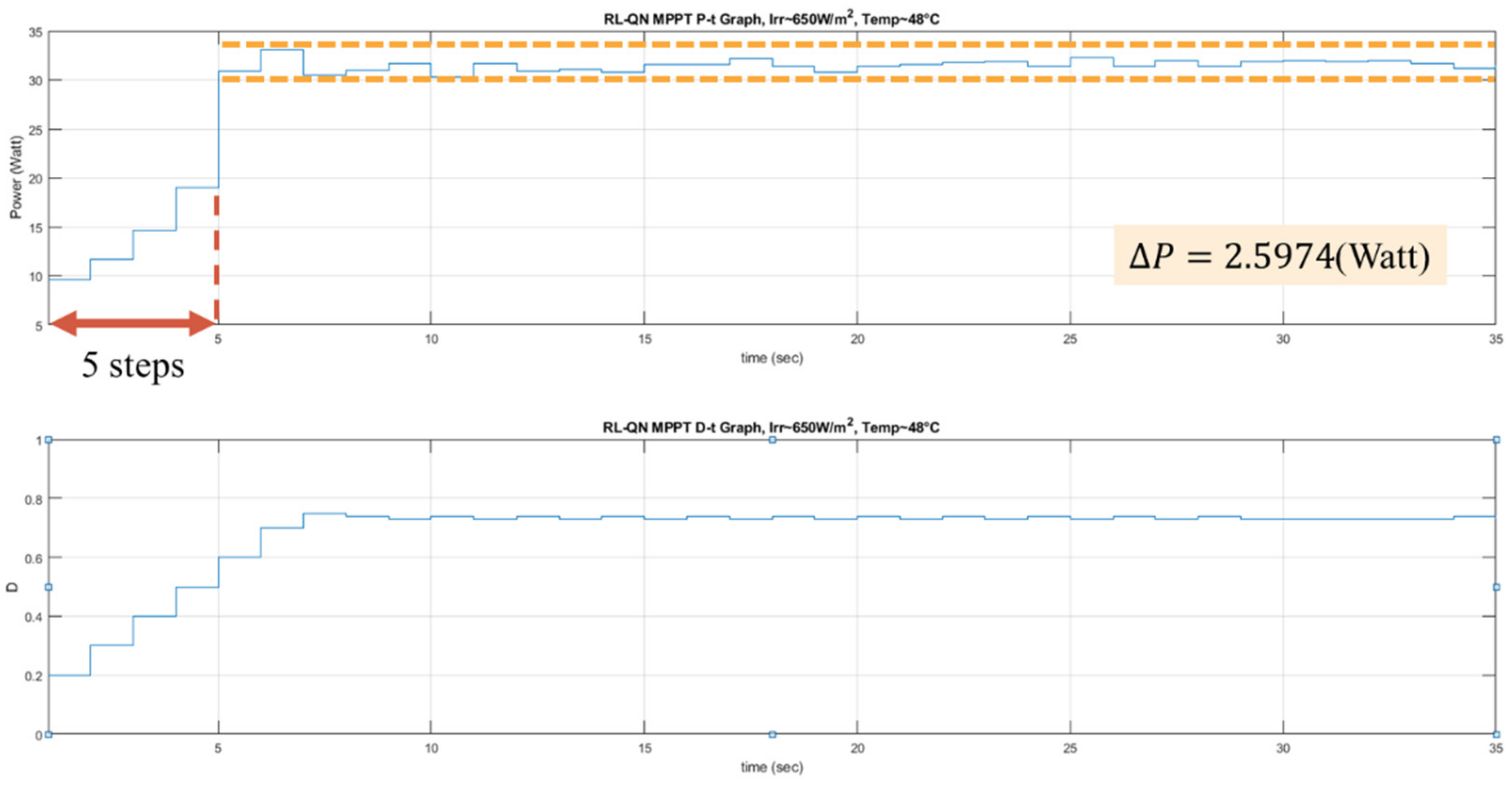
can be observed. In the Q-table approach, the experience will be used to update the Q value immediately, but in the Q-network approach, it will be stored to perform experience replay. With the simple workflow of the RL MPPT described as above, the flowcharts of the RL MPPT using Q-table (RL-QT MPPT) and the RL MPPT using Q-network (RL-QN MPPT) are shown in
Figure 18 and
Figure 19. The flowcharts essentially follow the Q-learning algorithms provided in Algorithm 1 and Algorithm 2, respectively.
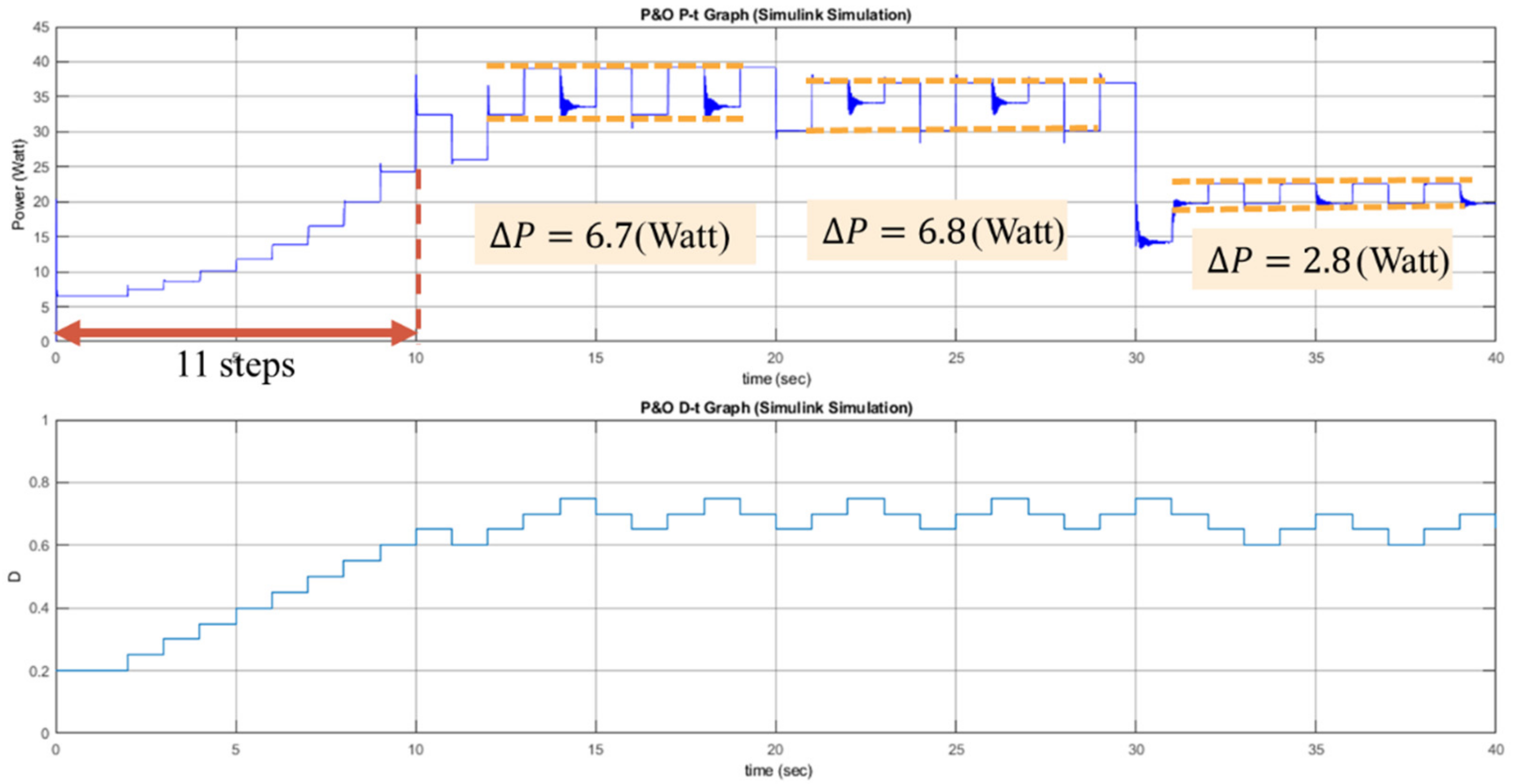
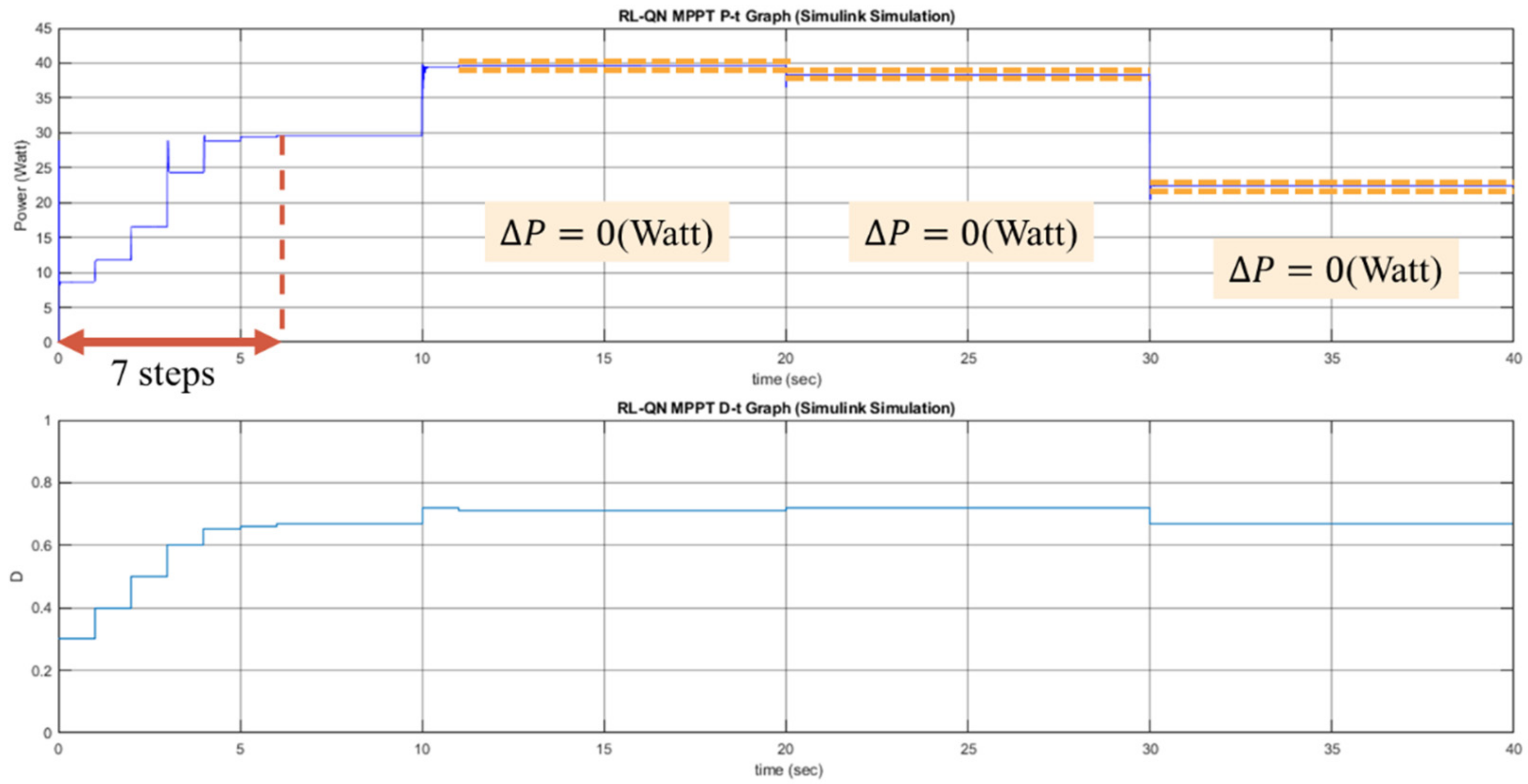
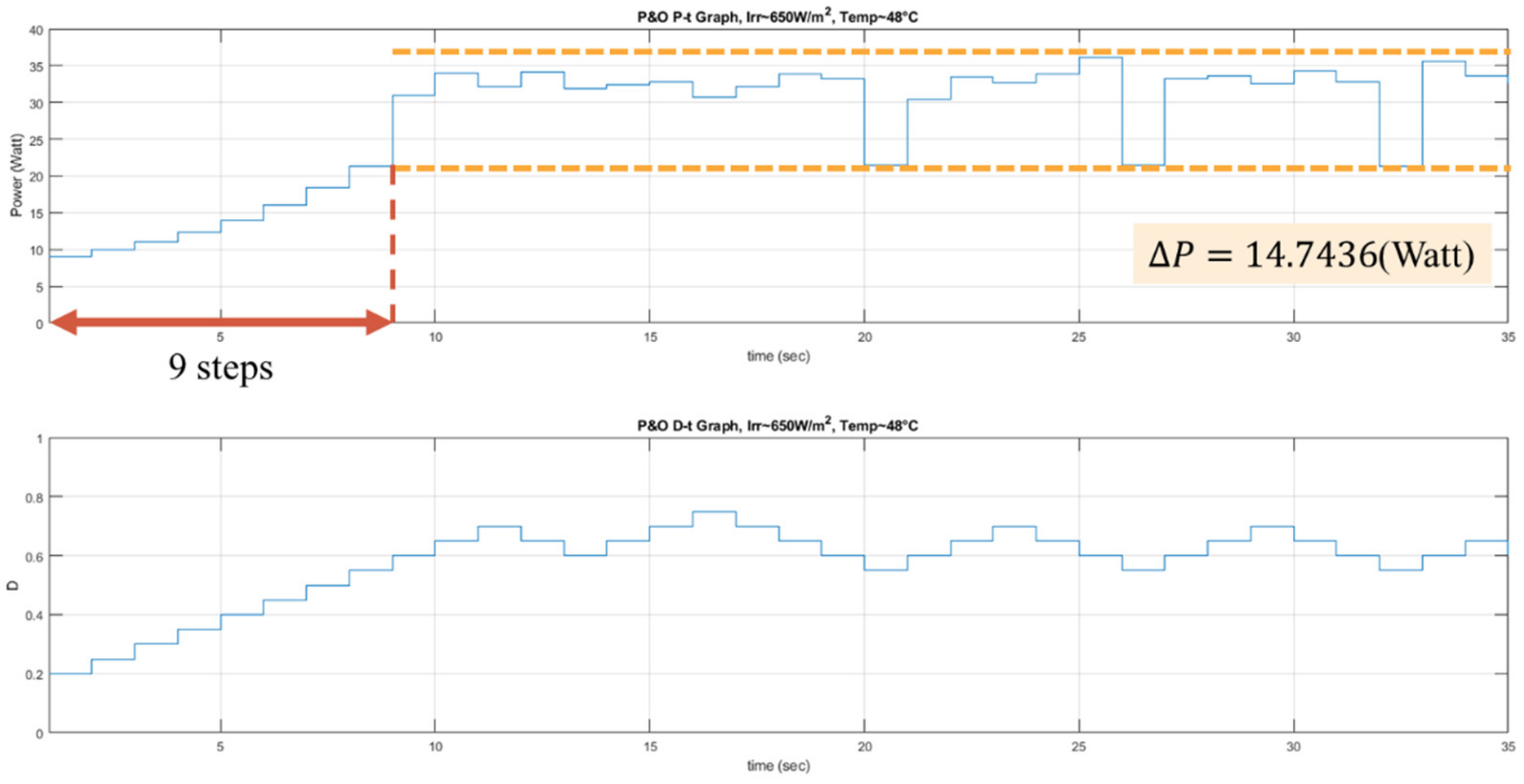
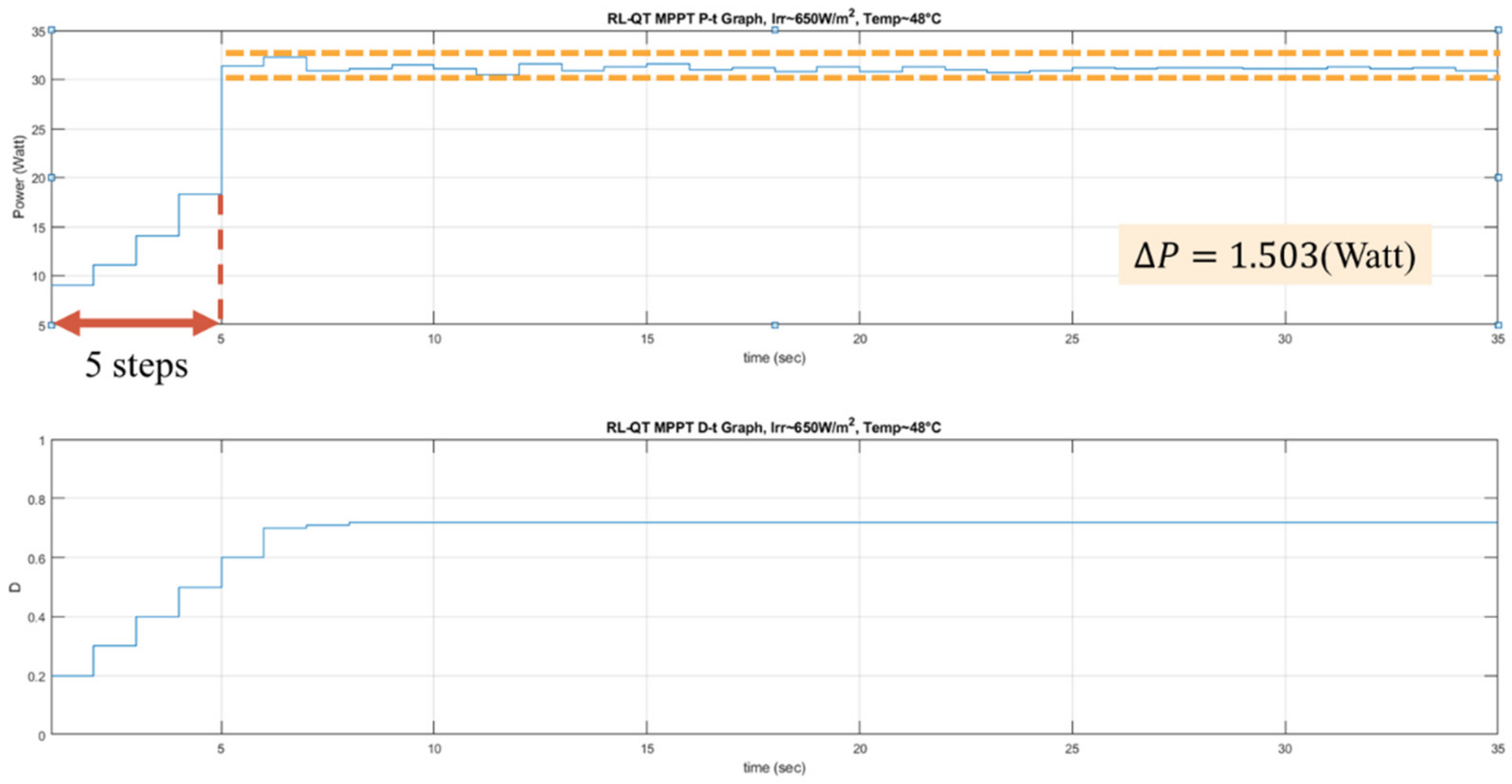
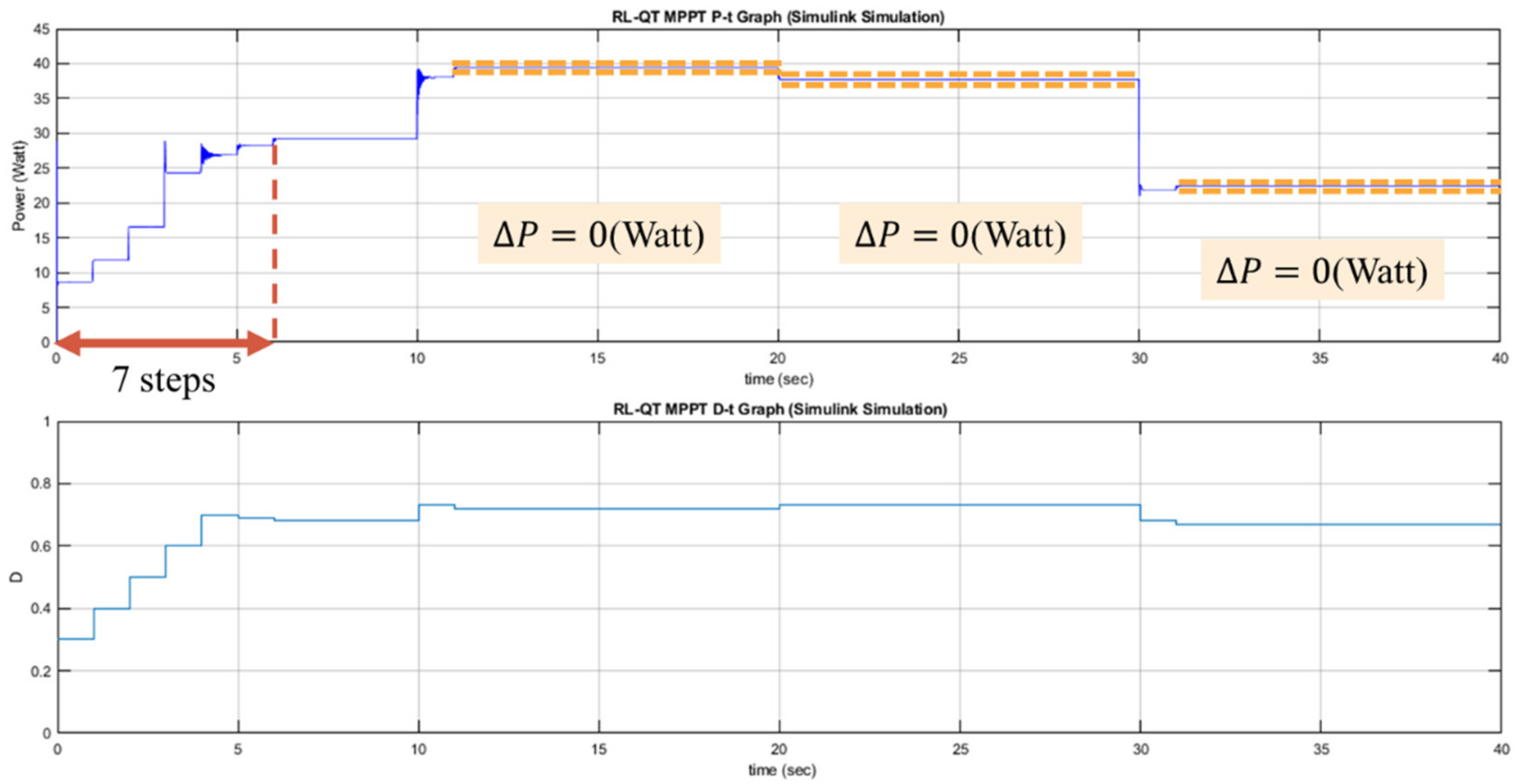
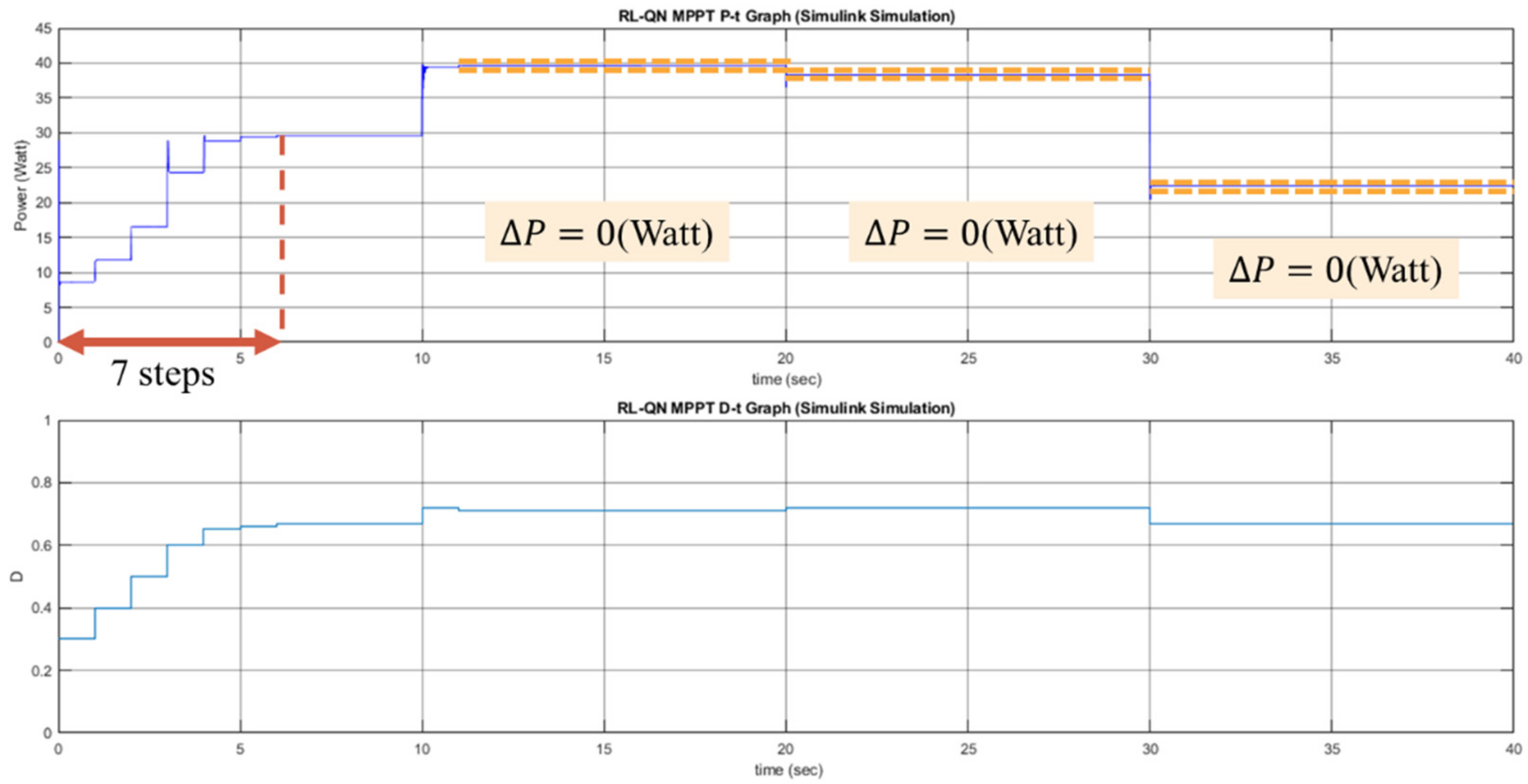
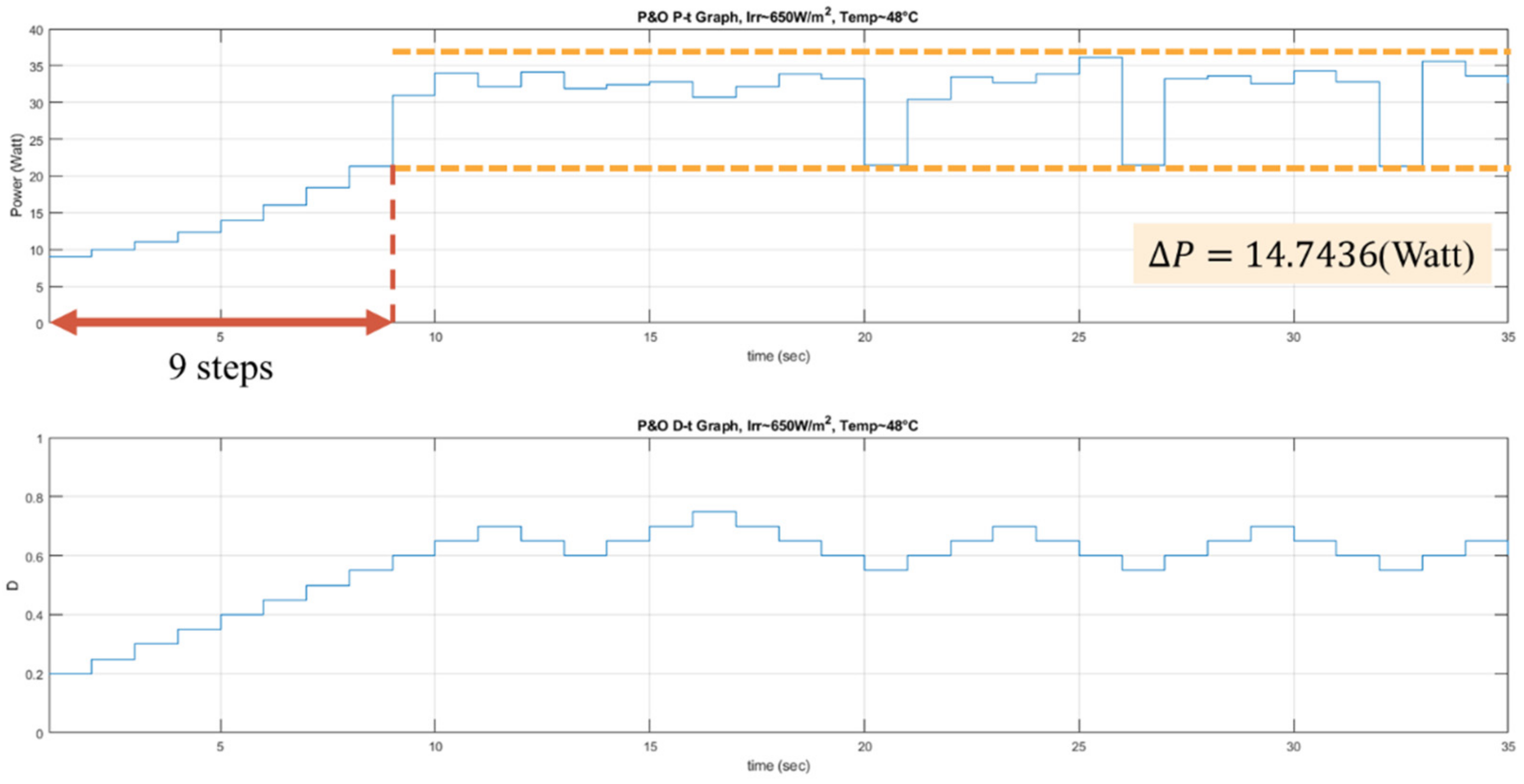
The proposed RL MPPT methods in this paper include two phases, the learning phase and tracking phase. In the learning phase, the experiences are learned, i.e., the Q-table or the Q-network is updated. However, to speed up the tracking speed, the update process is skipped in the tracking phase. The description of the learning phase and the tracking phase of the RL-QT MPPT and RL-QN MPPT are shown below:
(a) Learning Phase of RL-QT MPPT
First, the Q-table, the discount factor , the learning rate , the -greedy policy, and the duty ratio D are initialized, and the solar irradiance and the temperature of the PV module are sensed to form the state representation (irradiance, temperature, D). The output power of the PV module is sensed and stored as P. With a probability of , the agent will randomly choose an action and change the perturbation step size. Otherwise it will follow the Q-table and choose the action with the largest Q value. After applying the new duty ratio, the irradiance, the temperature and the output power are sensed again. Therefore, the succeeding state is obtained, and the reward r can be calculated as . Finally, with , the corresponding element in the Q-table, i.e., , can be updated by (34).
(b) Tracking Phase of RL-QT MPPT
In the tracking phase, the agent selects the action by looking up the Q-table, and D is changed accordingly. Then the iteration ends without updating the Q-table.
(c) Learning Phase of RL-QN MPPT
The RL-QN MPPT is similar to the RL-QT MPPT. First, the fixed target Q-network update iteration , the experience dataset E, the network parameters and , the experience replay threshold pth, the discount factor , the learning rate , the -greedy policy, and the duty ratio D are initialized, and the iteration counter is also initialized. Then the state (irradiance, temperature, D) is obtained by acquiring the solar irradiance data and the module temperature data. The output power of the PV module is calculated as . Under the -greedy policy, the action will be chosen randomly in a probability , otherwise the action with the largest Q value will be taken. The subsequent state representation and the reward r can be obtained after changing the duty ratio of the converter. The experience is stored in E, and if the experiences in E are enough, the experience replay techniques will be performed. For every CT step, the fixed target Q-network weight will be updated, and finally, it will be increased to move onto the next iteration.
(d) Tracking Phase of RL-QN MPPT
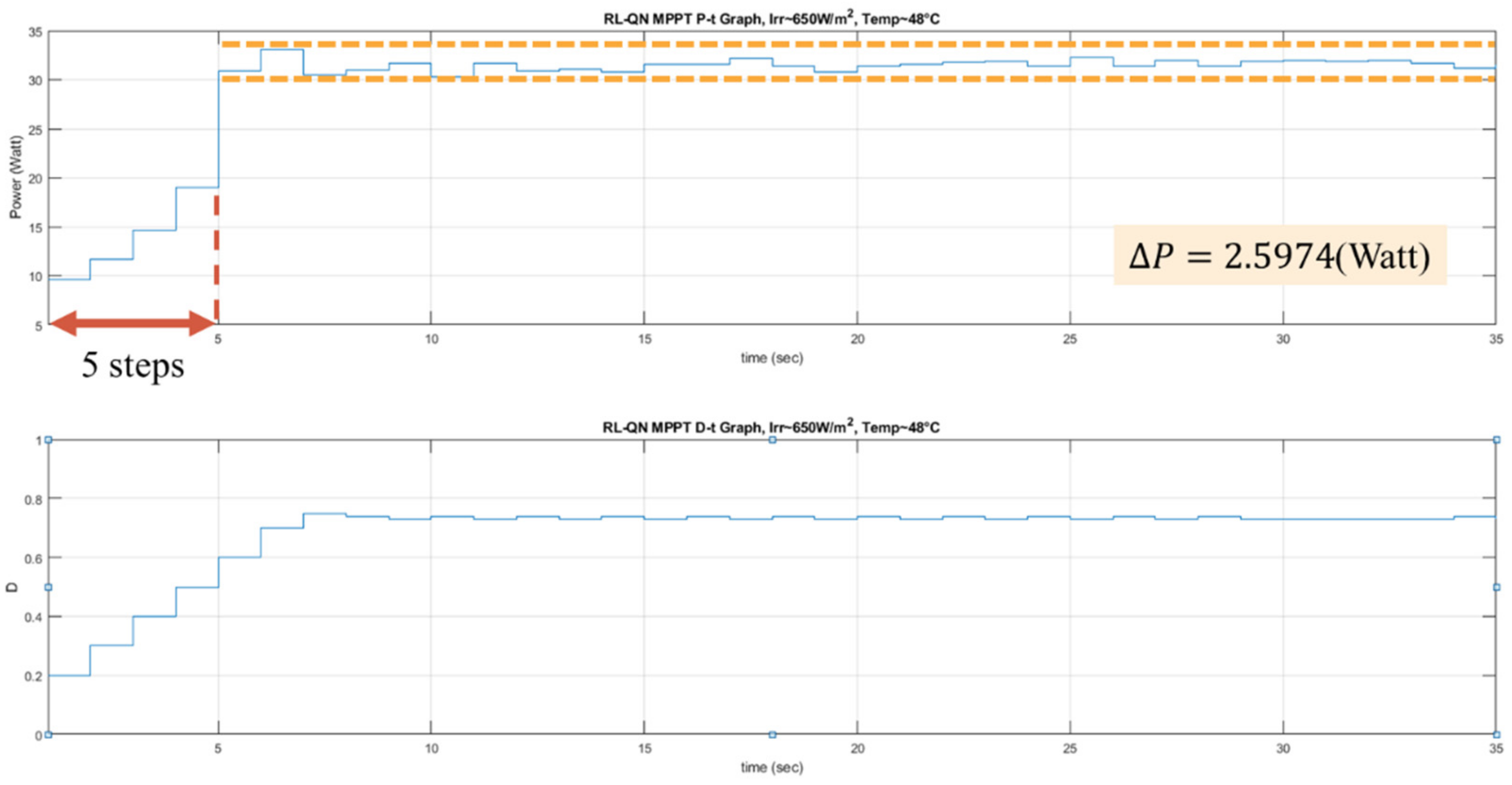
In the tracking phase, the agent follows the policy approximated by the Q-network, i.e., always choose the action with the largest Q value. Then D is modified by . The system’s operating point is changed, but the experience is not stored to speed up tracking. Then a new iteration will begin.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}