1. Introduction
The Kalman filter is widely used for target tracking due to the low computational complexity for real time processing and the statistic optimality under a linear state space model with Gaussian noises. Because of the model uncertainty of target maneuvering and the heavy-tailed measurement noises deduced by outliers, the performance of Kalman filter may break down dramatically, and even the convergence cannot be guaranteed. Addressing model uncertainty and investigating robust filter against heavy-tailed measurement noises are two important research topics in the target tracking field.
Model uncertainty in maneuvering target tracking exhibits that the motion model of target is time varying and that the switching time between different models is unknown. Due to the model uncertainty, the model used by Kalman filter may not match the actual dynamics so that the filter may gradually diverge. Multiple-model (MM) methods are considered as the mainstream approach to maneuvering target tracking under model uncertainty [
1]. These methods establish a finite set of models to describe the different motion patterns for maneuvering target, and achieve the ultimate estimate of state by a certain combination of the estimates from each model. In the literature, the MM methods can be categorized into two different types: fixed-structure MM (FSMM) methods which use a fixed model set at all times and variable-structure MM (VSMM) methods in which the model set is not fixed. The generalized pseudo-Bayesian estimator of order
n (GPBn) filter and the interacting multiple model (IMM) filter [
2] are the typical FSMM methods. Among them, the IMM filter is considered to be the best compromise between complexity and performance, and has been successfully applied in a large number of tracking applications [
3,
4,
5,
6,
7,
8]. In IMM filter, several sub-filters operate in parallel and cooperate with each other through an interacting strategy, leading to improved performance of estimation. For the FSMM methods, if the model set used does not match the set of actual models of target movement, the performance can be degraded. To cope with this problem, several VSMM methods have been proposed, such as likely mode set (LMS) filter [
9], expected-mode augmentation (EMA) filter [
10], equivalent-model augmentation (EqMA) filter [
11], and hybrid grid multiple model (HGMM) filter [
12]. These filters use different model-set adaptation schemes to adjust the model set. For example, the EqMA filter augments the model set by a new variable model depending directly on the history information from the recent models, while the HGMM filter adapts the model set by the hybrid grid scheme which consists of a fixed coarse grid and an adaptive fine one. In recent years, some researchers have proposed Sequential Monte Carlo (SMC) methods [
13,
14] for dealing with the problem of model uncertainty in target tracking. These methods maintain several particle filters (PFs) in parallel and fuse the results of PFs to provide the posterior probability of model and the posterior distribution of state. In addition, the SMC method in [
14] uses a scale parameter to detect the model change and does not require the mode transition probabilities. This strategy of handling model change is quite different from the above mentioned FSMM and VSMM methods.
Besides the model uncertainty, the outlier measurements existing in real tracking scenarios should also be handled. Outliers can induce heavy-tailed non-Gaussian noises, and the performance of Kalman filter may be seriously degraded since its underlying optimality criterion is minimum mean square error, which is very sensitive to heavy-tailed noises. A large number of robust filters have been proposed to improve the robustness against non-Gaussian noises. The Huber-based filter [
15,
16,
17,
18,
19] is a classical robust method based on a combined minimum
l1 and
l2 norm estimation. The maximum correntropy Kalman filter (MCKF) [
20,
21,
22,
23,
24] is another effective way to suppress the impact of non-Gaussian noises. It uses the robust maximum correntropy criterion (MCC) as the optimality criterion. Simulation experiments show that the MCKF outperforms Huber-based filter in estimation accuracy [
20,
22,
23,
24]. However, neither Huber-based filter nor MCKF takes advantage of the inherent heavy-tailed feature of the noise distribution. Thus, their estimation precision is limited. The Student’s
t-distribution is robust to outliers since it has heavier tail compared with Gaussian distribution. Based on this idea, many robust filters utilizing Student’s
t-distribution has been proposed [
25,
26,
27,
28,
29,
30]. The Student’s
t filter [
25,
26] is derived by modeling the posterior distribution of the state, the heavy-tailed process and measurement noises as Student’s
t-distributions. The filter recursions are designed according to the framework of Bayesian filter. This filter may induce significant bias since an approximated method of moment matching is employed to prevent the growth of the degrees of freedom (dof) of Student’s
t-distribution. The variational Bayesian (VB) based Student’s
t filter [
27,
28,
29,
30] represents the Student’s
t-distribution of noises as an infinite mixture of Gaussians, and employs VB approach to jointly estimate the state and the unknown parameters of the Student’s
t-distribution. This filter can achieve higher estimation accuracy than the Student’s
t filter [
29,
30].
In maneuvering target tracking, the problems of model uncertainty and heavy-tailed measurement noises could exist simultaneously. Investigating robust IMM filter to cope with both model uncertainty and heavy-tailed noises is meaningful. As far as we know, Shen et al. [
31] considered utilizing Student’s
t-distribution to improve the robustness of IMM filter for the first time. They modeled the heavy-tailed measurement noises as Student’s
t-distribution and employed IMM and VB approaches to estimate the target state, the probability of motion mode and the parameters of noises. However, the dof of Student’s
t-distribution, which is determined by the estimated parameters of an auxiliary random variable, becomes very large after several filtering steps. Then, the Student’s
t-distribution converges to Gaussian distribution and loses the heavy-tailed property. Therefore, the robustness of this filter against heavy-tailed measurement noises is limited. In addition, the scale matrix of Student’s
t-distribution in this filter is assumed to be known exactly. However, this premise is usually unavailable since the scale matrix is unknown or time varying in many actual applications. Furthermore, this filter is based on linear systems and should be generalized to nonlinear systems which are more common in maneuvering target tracking.
Motivated by the above discussions, we propose a new robust IMM filter to better handle the heavy-tailed measurement noises and the system nonlinearity. The posterior distribution of target state is approximated by Gaussian distribution, and the measurement noises are modeled as Student’s t-distribution. The unknown dof and scale matrix of the Student’s t-distribution are assumed to obey gamma and inverse Wishart distributions, respectively. Then, the state and the parameters of gamma and inverse Wishart distributions for each mode are interacted via IMM mixing, and they are jointly estimated by using VB approach. An approximation method is given to derive the mode-conditioned predicted likelihood which is used for calculating the mode probability. The unscented transform (UT) is employed to tackle the system nonlinearity. The growth of dof estimates is prevented and the estimation accuracy of state is improved over existing filters under heavy-tailed measurement noises as shown in our simulation example.
2. System Model and Assumptions
Consider the following jump Markov system
where
is the scan time index,
and
are the state and measurement vectors respectively,
is the mode of target movement taking value in a finite set
,
is the total number of dynamic models,
and
are the state transition function and measurement function based on the mode
respectively,
is the process noise vector based on the mode
, and
is the measurement noise vector. The mode
is assumed to be a homogeneous Markov chain with the transition probability
, and
is assumed to be uncorrelated zero-mean Gaussian noises with covariance matrix
. Throughout this paper, we abbreviate
,
,
and
by
,
,
and
, respectively. Then, the transition probability density function (PDF) of state is given by
, where
denotes a Gaussian PDF with mean
and covariance matrix
.
When measurement outliers occur, the distribution of measurement noises has heavy-tailed non-Gaussian characteristic. The performance of traditional IMM filter based on Gaussian noise assumption may dramatically degrade since it is very sensitive to heavy-tailed noises. Since the Student’s t-distribution has heavier tail and is more robust to outliers than Gaussian distribution, we model the measurement noises as Student’s t-distribution, i.e.,
, where
stands for a Student’s
t PDF with mean
, scale matrix
and dof
. The Student’s
t-distribution can be represented by an infinite mixture of Gaussian distributions as [
32]
where
is an auxiliary random variable,
denotes a Gamma PDF with shape parameter
and rate parameter
. The expression for
is
where
is the Gamma function. Then, the likelihood PDF conditioned on the mode
can be written as
The tail thickness of Student’s
t-distribution is controlled by the dof. When the dof decreases, the tail becomes thicker. When the dof goes to infinity, the Student’s
t-distribution approaches a Gaussian distribution. Shen et al. [
31] assumed that the posterior distribution of the auxiliary variable
is a Gamma distribution, i.e.,
and used the VB approach to estimate the parameters
and
. However, the estimates of both
and
which determine the dof of Student’s
t-distribution become large after several filtering steps. Thus, the distribution of measurement noises loses the heavy-tailed property and the robustness of the filter cannot be guaranteed. To prevent the growth of the dof estimates, we assume that the posterior distribution of the dof
is a Gamma distribution, i.e.,
, and estimate the parameters
and
instead. Furthermore, in order to deal with the uncertainty of scale matrix
, we choose inverse Wishart distribution as the posterior distribution of
, i.e.,
, where
stands for an inverse Wishart PDF with degree
and inverse scale matrix
. The PDF of inverse Wishart distribution is defined by
where
Then, the unknown statistic of the scale matrix
can be determined by estimating the parameters
and
.
3. Design of Robust IMM Filter
3.1. Model Interaction
We assume that the mode-conditioned posterior distributions of the state
, the scale matrix
and the dof
at time
are Gaussian, inverse Wishart, and Gamma distributions, respectively, and that they are mutually independent. Then, the joint mode-conditioned posterior PDF of
,
and
can be expressed as
Let
and
denote the posterior and predicted mode probabilities respectively, and
denote the mixing probability, we have
The mixing PDF of
,
and
is given by
We approximate the above summed PDF in the right side of (6) by a single one as
By matching the first and the second-order moments between (6) and (7) for the state distribution, we obtain the mixing state
and the covariance matrix
as
However, the mixing parameters
and
cannot be computed analytically by matching the first two moments of inverse Wishart distributions between (6) and (7) due to the complexity of second-order moment. We adopt the method of minimizing weighted Kullback–Leibler (KL) divergence in [
33] to overcome this difficulty and derive that
For the Gamma distribution, we also use the method of matching the first two moments like the state. According to (6), the conditional mean and covariance of
are given by
Since the mean and covariance of a Gamma PDF
are
and
respectively, we have
On the other hand, according to (7), we have
By combining (12)–(15), the mixing parameters
and
for the Gamma distribution can be calculated as
3.2. Time Prediction
The time prediction step is to derive the mode-conditioned predicted PDF at time by using the mixing PDF and the dynamical models at time .
The mode-conditioned predicted PDF can be calculated by the following Chapman–Kolmogorov equation:
We assume that the dynamical models of the state, the scale matrix and the dof are independent, i.e.,
According to (7), (18) and (19), we have
We can see that the mode-conditioned predicted distributions of the state, the scale matrix and the dof are also independent. These distributions are assumed to be Gaussian, inverse Wishart and Gamma distributions, respectively, which have the same form of PDF as the posterior distributions. Then, the mode-conditioned predicted PDF can be represented by
By matching the first and the second-order moments between (20) and (21) for the state, we obtain the predicted mean and the covariance matrix as
However, it is hard to compute the predicted parameters of inverse Wishart and Gamma distributions since the dynamical models of the scale matrix and the dof are usually unknown in practice. Here, a heuristic dynamical model is chosen as in [
34] by introducing a forgetting factor
, which indicates the extent of parameter fluctuation. Then, the predicted parameters are given by
When
, the parameters are kept stationary. When
is close to 0, the parameters are high time-fluctuation.
3.3. Measurement Update
We define
. The measurement update step is to compute the mode-conditioned posterior PDF
and the posterior mode probability
when a new measurement
is collected at time
. However, deriving the mode-conditioned posterior PDF is analytically intractable. We employ the VB approach [
35] to obtain an approximated solution.
According to the VB approach, the mode-conditioned posterior PDF is approximated by a free form factored PDF:
The posterior PDFs
,
,
and
are calculated by minimizing the KL divergence as
where
is the KL divergence. The solutions of the above optimal problem satisfy
where
,
,
and
are constants independent of
,
,
and
, respectively.
According to (2) and (21), we have
Substituting (1), (3) and the expression of Gaussian PDF into (32), we obtain the detailed expression of
where
denotes a constant with respect to
.
Substituting (33) into (28) yields
where
is given by
where
denotes the expectation with respect to the PDF
.
can be deemed as modified covariance matrix of measurements taking into account the uncertainty of both and
and
. Then,
According to the construction of nonlinear Gaussian filter in [
36],
can be approximated by a Gaussian PDF, i.e.,
where
Substituting (33) into (29) yields
where
According to (3), we can deduce that
is an inverse Wishart PDF with the following expression:
where
Substituting (33) into (30) yields
According to (1),
is a Gamma PDF as
where
Substituting (33) into (31), and using the Stirling’s approximation
, we obtain
According to (1),
is also a Gamma PDF as
where
The unknown expectations in (34), (41), (44), (46), (47) and (50) are given by
where
is the digamma function.
Combining (36)–(40), (43), (44), (46), (47) and (49)–(56), the fixed point iteration algorithm can be employed to acquire the unknown quantities , , , , , , , and . The iteration is terminated when the variations of these quantities are small enough.
The posterior mode probability can be calculated by
In (57), the predicted mode probability
is given by (4), and the predicted likelihood
can be derived by
However, the above integration is computationally infeasible since
,
,
and
are coupled in
according to (32). We use the similar variational approach in [
37] to derive an approximated predicted likelihood. The predicted likelihood can be rewritten as
Since the KL divergence term in the right side of the above equation is minimized by VB approach, the predicted likelihood can be approximated by
Substituting (35), (42), (45), (48) and the expression of
in (32) into (58) yields
The final estimate of the state is given by a probabilistically weighted average of all the mode-conditioned estimates, i.e.,
and the corresponding covariance matrix is calculated as
3.4. Approximated Gaussian Integrations Based on Unscented Transform
Due to the nonlinearity of the state transition function
and the measurement function
, the Gaussian integrations in (22), (23), (37)–(39), (53) and (54) cannot be computed analytically. In this paper, the UT [
38] is employed to calculate the Gaussian integrations approximately.
For the Gaussian integrations in (22) and (23),
sigma points are generated from the mixing state
and the covariance matrix
as
where
denotes the
p-th column of the matrix square root of
,
is a scaling parameter,
controls the divergence of the sigma points and is usually set to a small positive value (e.g., 0.01),
is a secondary scaling parameter which is usually set to zero. Then, the predicted state
and the covariance matrix
are calculated as
where the weights of sigma points are given by
where
is used to incorporate the prior information of the distribution.
is optimal under Gaussian distributions.
For the Gaussian integrations in (37)–(39), the sigma points generated from the predicted state
and the covariance matrix
are given by
Then, the predicted measurement mean
, the covariance matrix
and the cross-covariance matrix
are calculated as
We generate the sigma points from the posterior state
and the covariance matrix
as
Then, the Gaussian integrations in (53) and (54) are calculated as
With the above derivations, the proposed robust IMM filter is summarized as follows:
Step 1: Choose initial estimates , , , , , and for each mode Set and . Let
Step 2: Calculate the predicted mode probability and the mixing mode probability using (4) and (5). Then, calculate the mixing quantities , , , , and for each mode using (8)–(11), (16) and (17).
Step 3: Calculate the predicted quantities , , , , and for each mode using (62), (63) and (24)–(27).
Step 4: Update the posterior quantities , , , , and for each mode through fixed point iterations based on VB approach as follows:
Update and using (43) and (49), and initialize , , , .
Repeat
Update using (67) and (68).
Update and using (46), (47), (52) and (55).
Update and using (44), (50), (51) and (56).
Update and using (34), (36), (40), (51), (52) and (64)–(66).
Until converged
Step 5: Update the posterior mode probability using (57) and (59).
Step 6: Calculate and using (60) and (61). Let , and return to Step2.
4. Simulation Example
This section presents a two-dimensional maneuvering target tracking scenario with a period of 200 s to demonstrate the performance of the proposed filter. A maneuvering target moves following two models: constant velocity (CV) model and coordinated turn (CT) model. The modes representing the CV model and CT model at time
are denoted by
and
, respectively. The state of the CV model is
including the components of the position
and the velocity
. The dynamics of the CV model is given by
where
is the sampling period. The covariance matrix of the process noises
is given by
where
is the power spectral density. The state of the CT model is
, where
is the turn rate. The dynamics of the CT model is given by
and the covariance matrix of the process noises
is given by
where
and
are the power spectral densities corresponding to
and
, respectively.
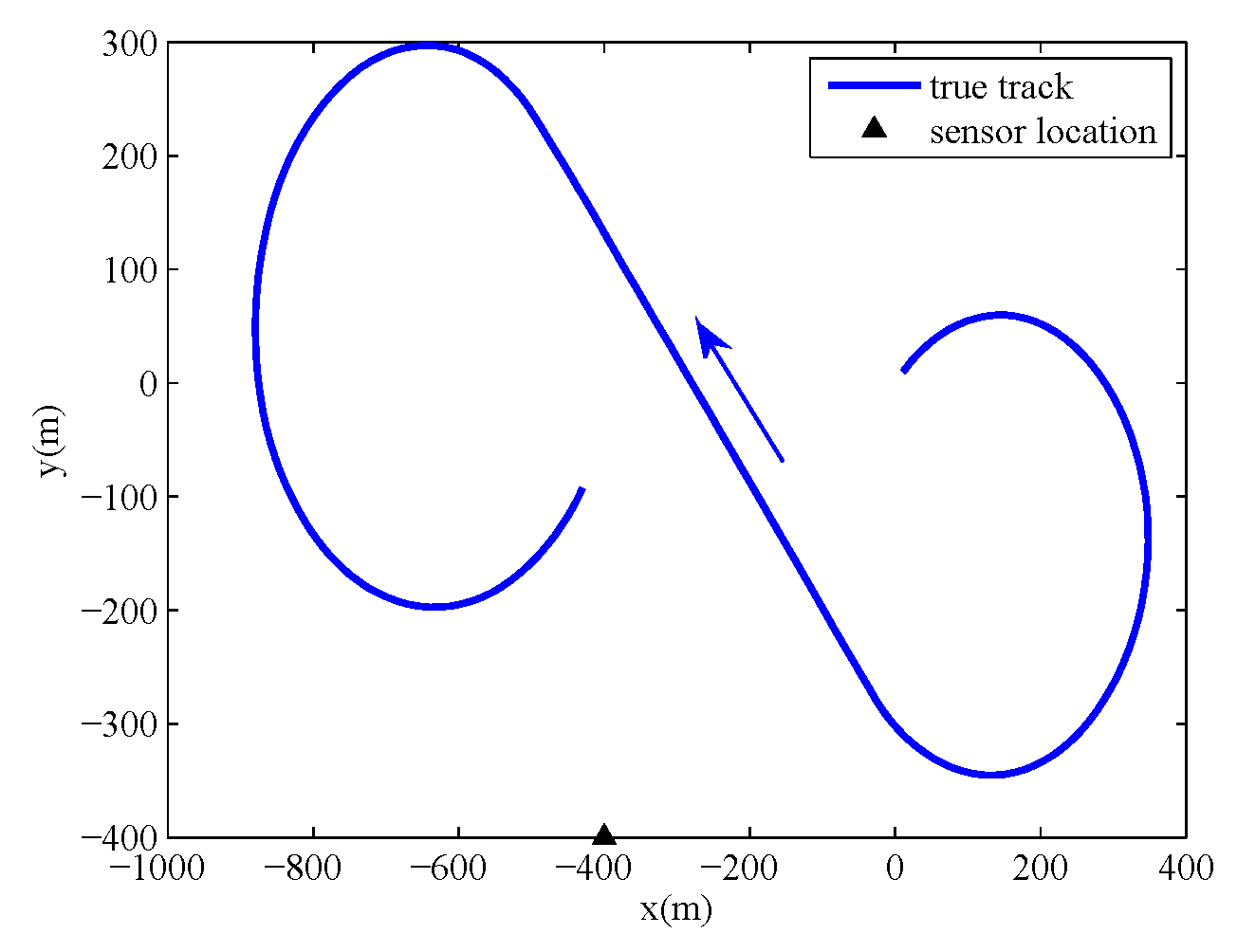
A sensor located at
collects noisy range and azimuth measurements of the target according to the equation
The sampling period is
. The target executes a
coordinated turn from 0 s to 70 s, moves at a constant velocity from 71 s to 120 s, and executes a
coordinated turn from 121 s to 200 s. The power spectral densities are set to
and
. The true initial state of target is
, and the location of the sensor is
. The true track of the target and the sensor location are shown in
Figure 1.
To illustrate the performance of the proposed filter, we consider the following four cases under different conditions of measurement noises:
Case A: Gaussian noises
where
is the known nominal covariance matrix.
Case B: Gaussian noises with time varying covariance matrix
This case is used to simulate the situation that the actual covariance matrix is deviated from the nominal one
.
Case C: Contaminated Gaussian noises
where
can be seen as a normal distribution,
can be considered as a perturbing distribution with much larger covariance matrix due to outliers, and
is a perturbing parameter that represents the extent of the perturbation. This case is used to simulate the corrupted measurements by outliers. We set
.
Case D: Contaminated Gaussian noises with time varying covariance matrix
Both outliers and covariance mistuning are simultaneously simulated in this case.
is also set to 0.1.
Four existing filters including VB based Student’s
t filter (VBStdF) [
30] utilizing only single CT model, IMM filter (IMMF) [
1], VB based IMM filter (IMMVBF) estimating the unknown covariance matrix of measurement noises [
33], and VB based IMM filter modeling measurement noises as Student’s
t-distribution (IMMVBStdF) [
31] are compared with the proposed filter. 1000 Monte Carlo (MC) runs are carried out for each case of measurement noises above. All the filters are implemented in MATLAB on an Intel i7 3.6GHz processor.
The initial estimates of the degree and the inverse scale matrix with respect to the inverse Wishart distribution in VBStdF, IMMVBF and the proposed filter are chosen as and . All the initial estimates of the Gamma distribution parameters in VBStdF, IMMVBStdF and the proposed filter are set to 0.5. For all the VB approach based filters, is used, and the VB iteration is terminated when the difference of position estimates between two adjacent iterations is less than 1e-6. The mode probabilities are initialized as and , and the mode transition probability is set to for all the IMM type filters. The initial covariance matrix of the state estimate is set to , and the initial estimate of the state is chosen randomly from the Gaussian distribution for all the filters.
The root mean square errors (RMSEs) and average RMSEs (ARMSEs) of position, velocity and turn rate are used to evaluate the estimation accuracy of the filters. The RMSE and ARMSE of position are defined as
where
is the total count of MC runs,
and
are true position and estimated position for the
i-th MC run, and
is the total count of samples. The RMSEs and ARMSEs of velocity and turn rate are defined similar.
The RMSEs of position, velocity and turn rate in four cases are shown in
Figure 2,
Figure 3,
Figure 4 and
Figure 5, and the corresponding ARMSEs are listed in
Table 1. The overall performance of VBStdF in estimation accuracy is the worst among the filters for all cases. We do not plot the entire RMSE curves of position for VBStdF to show other curves distinctly. The largest RMSE of position for VBStdF under four cases are 53.03 m, 50.19 m, 99.82 m and 98.30 m, respectively. The reason for the poor performance of VBStdF is that the single-model based filter is less adaptive to target maneuvering compared with multiple-model based filter.
In Case A, the estimation accuracy of the proposed filter is lower than IMMF and IMMVBF. The reason is that the assumed Student’s t-distribution for measurement noises deviates from the actual Gaussian distribution. The performance of the proposed filter in estimation accuracy is also poorer than IMMVBStdF. That is because the scale matrix of Student’s t-distribution is required to be estimated additionally for the proposed filter, while the scale matrix is known exactly for IMMVBStdF. However, the accuracy degradation of the proposed filter is not obvious compared with IMMF, IMMVBF, and IMMVBStdF.
In Case B, IMMF has larger RMSEs than IMMVBF, IMMVBStdF, and the proposed filter since IMMF utilizes mistuned covariance matrix of measurement noises, while the IMMVBF and the proposed filters can learn the covariance matrix adaptively. The IMMVBStdF seems to have the ability of capturing the unknown covariance matrix either. The performance of the proposed filter in estimation accuracy is also slightly worse than IMMVBF and IMMVBStdF as Case A.
In Case C, the proposed filter outperforms other filters obviously in estimation accuracy. IMMF and IMMVBF are based on the assumption of Gaussian noises so that they cannot cope with heavy-tailed measurement noises.
Figure 6 shows the estimates of the dof parameters
,
,
and
versus time for IMMVBStdF and the proposed filter in one MC run. We can see that the estimates of dof parameters for IMMVBStdF become large after several time steps. Therefore, the distribution of measurement noises converges to a Gaussian distribution and loses the heavy-tailed property. The estimates of dof parameters for the proposed filter maintain small values overall, except some high peaks for
and
curves caused by outliers. Therefore, the proposed filter is more robust against heavy-tailed measurement noises than IMMVBStdF. In addition, we can see that the IMMVBF and IMMVBStdF are more robust than IMMF.
The results under Case D are similar to Case C.
The 1000 MC runs averaged estimates of mode probabilities for CV model are shown in
Figure 7. In Case A, we can see that the estimation results are nearly the same for all the filters. In Case B, the accuracy of IMMF estimates is lower than other filters and the response to mode changes for IMMF is more lagging than other filters. The reason is also that the covariance matrix of the measurement noises utilized by IMMF is mistuned. In Case C and D, the proposed filter achieves more accuracy estimates of mode probabilities than other filters, indicating that the proposed filter can also improve the estimation accuracy of mode probability under heavy-tailed measurement noises.
We use the number of floating points operations (flops) [
39] to measure the computational complexity of filter. The computational complexity of VBStdF, IMMF, IMMVBF, IMMVBStdF and the proposed filter are listed in
Table 2. We can see that the proposed filter has the highest computational complexity among the filters. According to
Table 2, the computational complexity of proposed filter is higher than VBStdF mainly because of multiple model operations, and is higher than IMMF mainly because of fixed point iterations. The proposed filter requires more flops compared with IMMVBF and IMMVBStdF since the proposed filter involves more parameters to be estimated in the filter recursions.
We further test the computational cost of filters for the above tracking scenario. The 1000 MC runs averaged computation time in four cases are shown in
Table 3. It can be seen that the proposed filter expends more computational cost than other filters, demonstrating that the proposed filter has higher computational complexity than other filters.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}