Adversarially Learned Total Variability Embedding for Speaker Recognition with Random Digit Strings


Abstract
:1. Introduction
2. Related Work
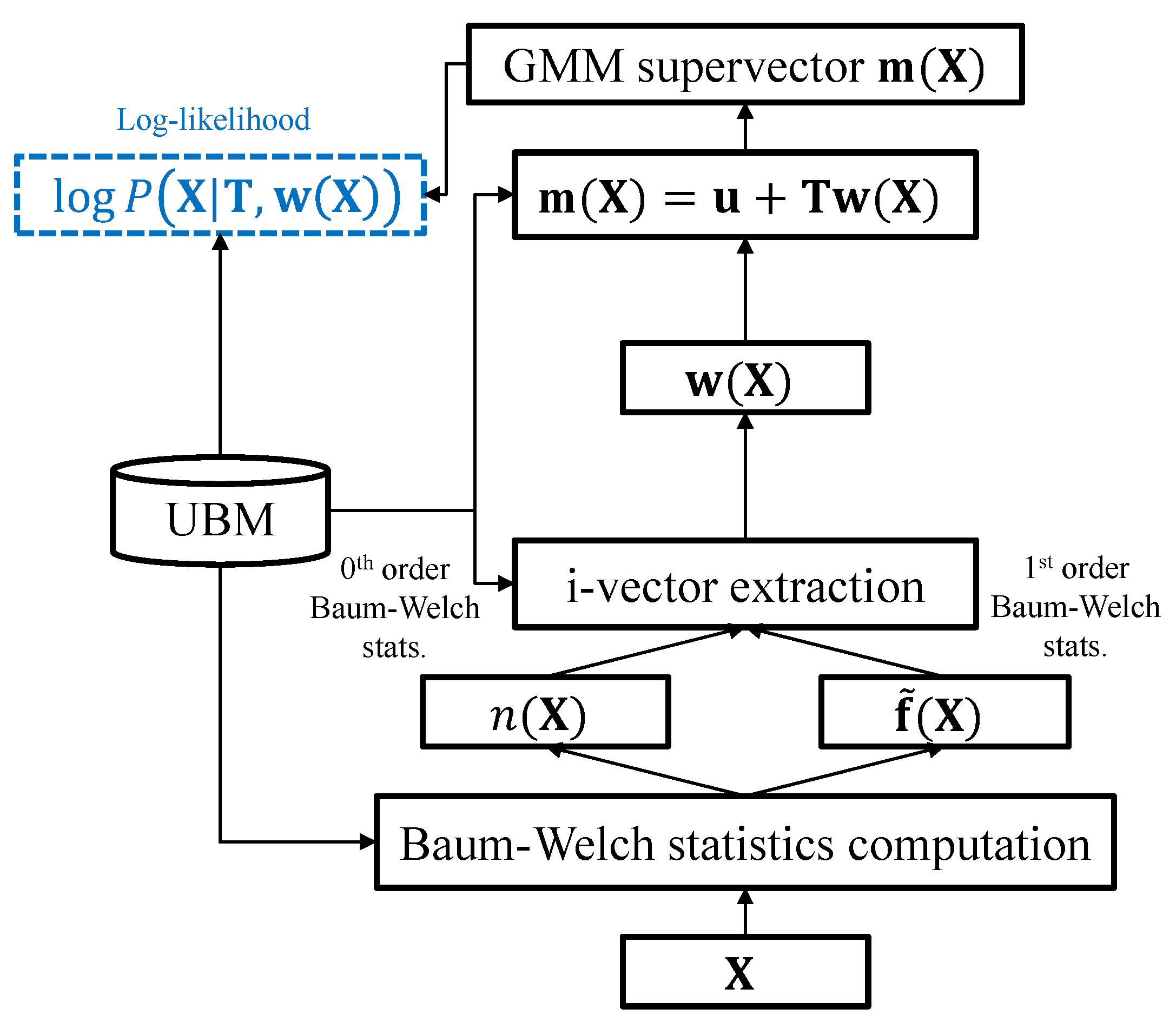
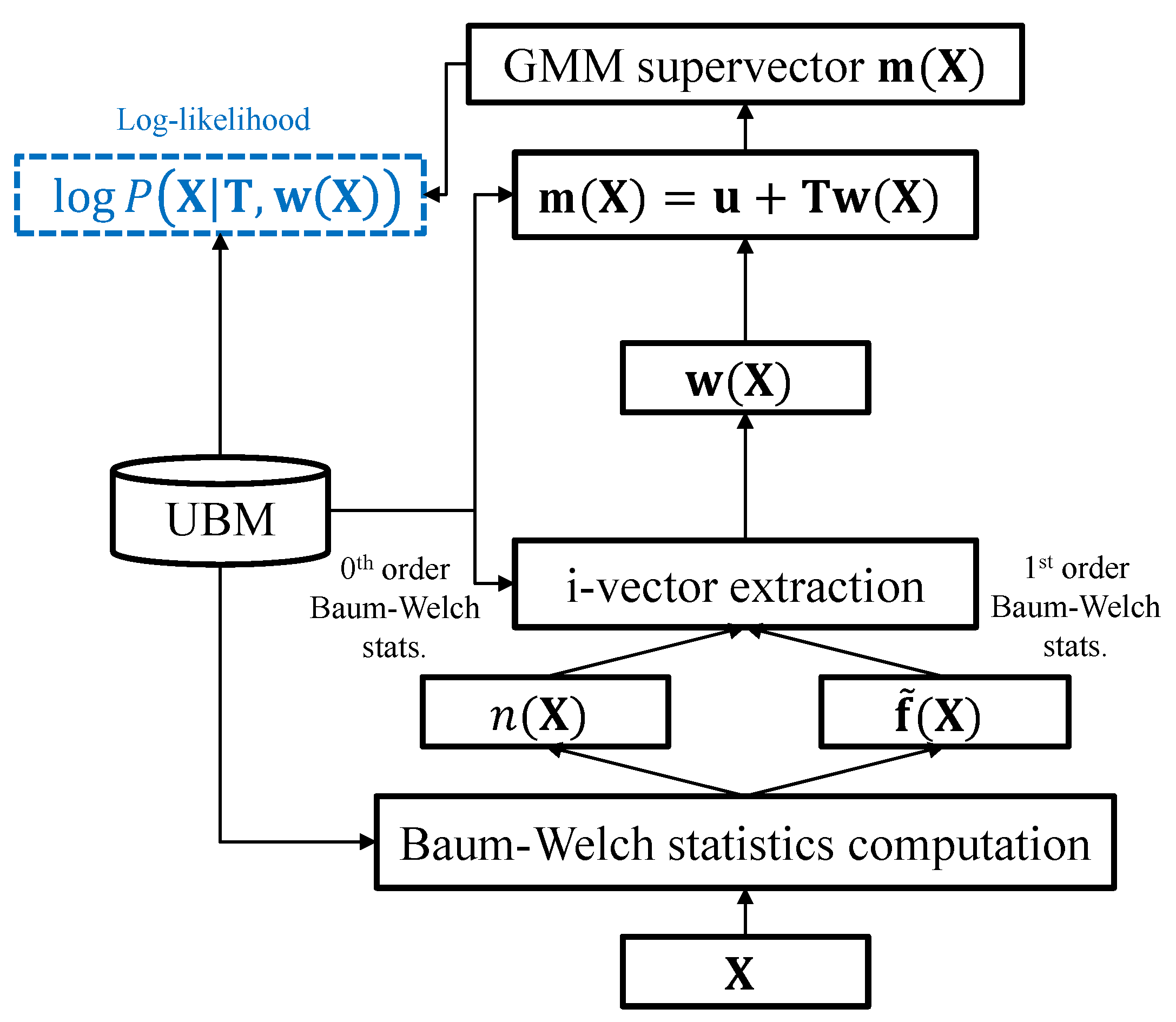
2.1. I-Vector Framework
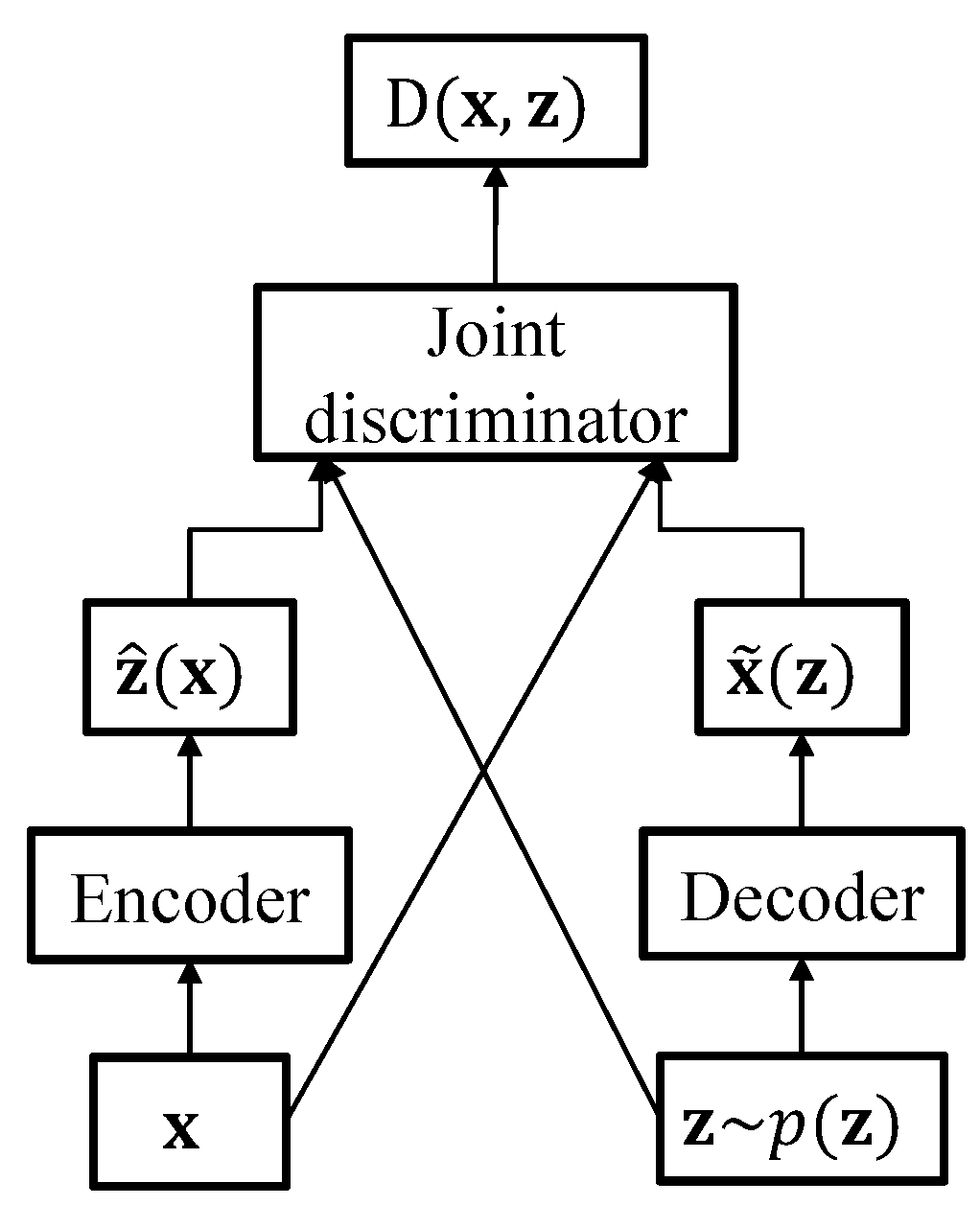
2.2. Adversarially Learned Inference
3. Adversarially Learned Feature Extraction
3.1. Maximum Likelihood Criterion
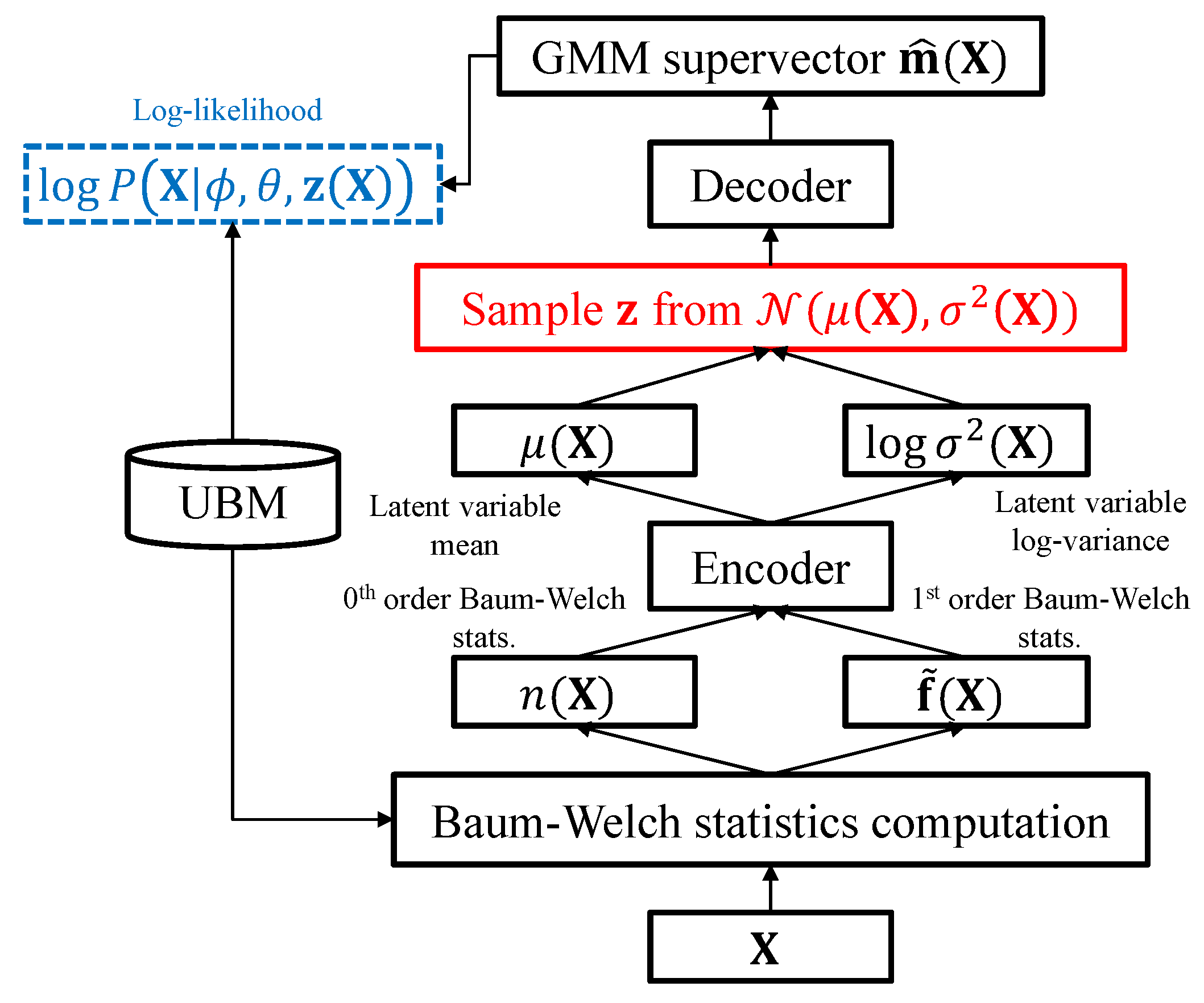
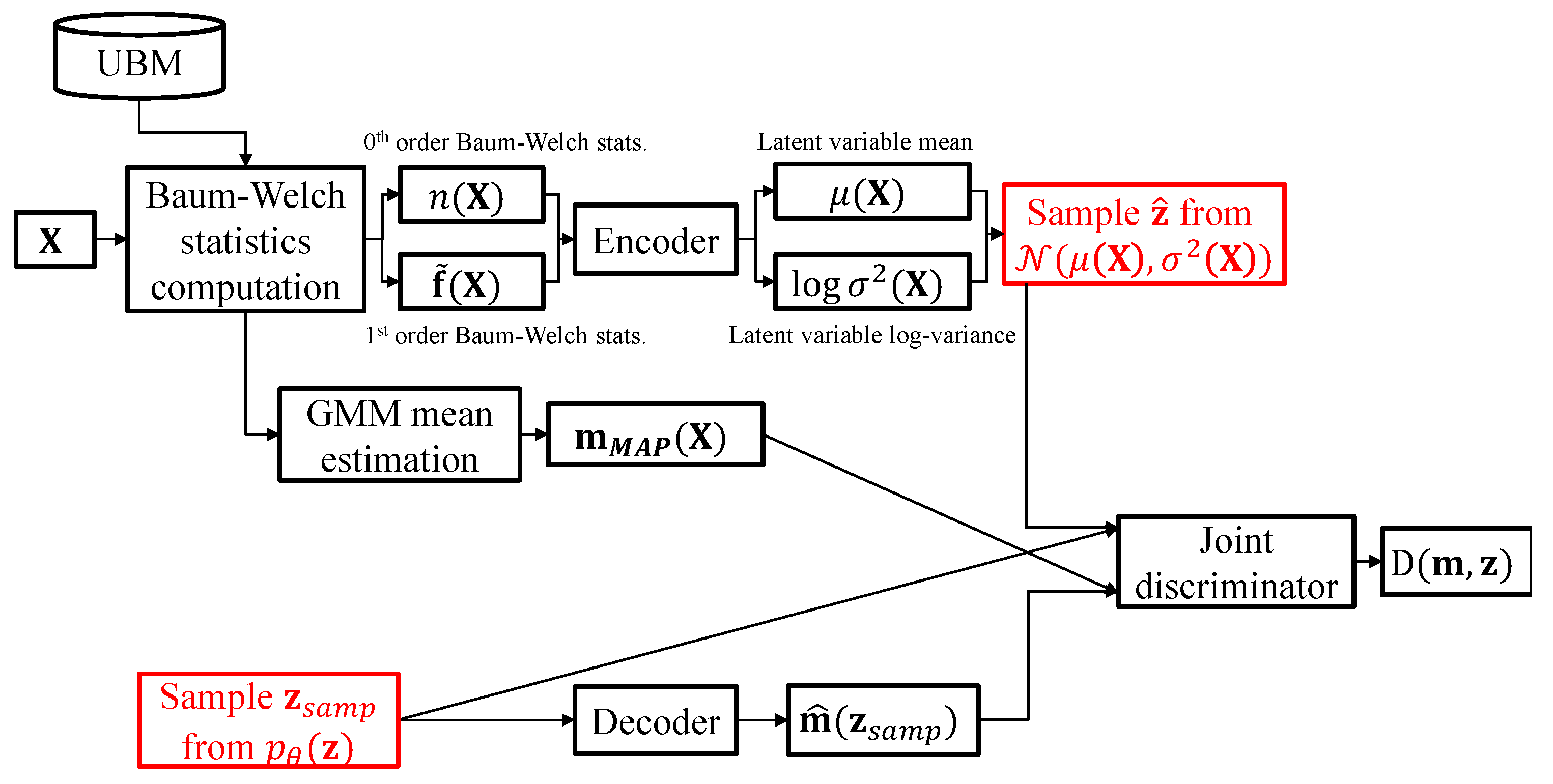
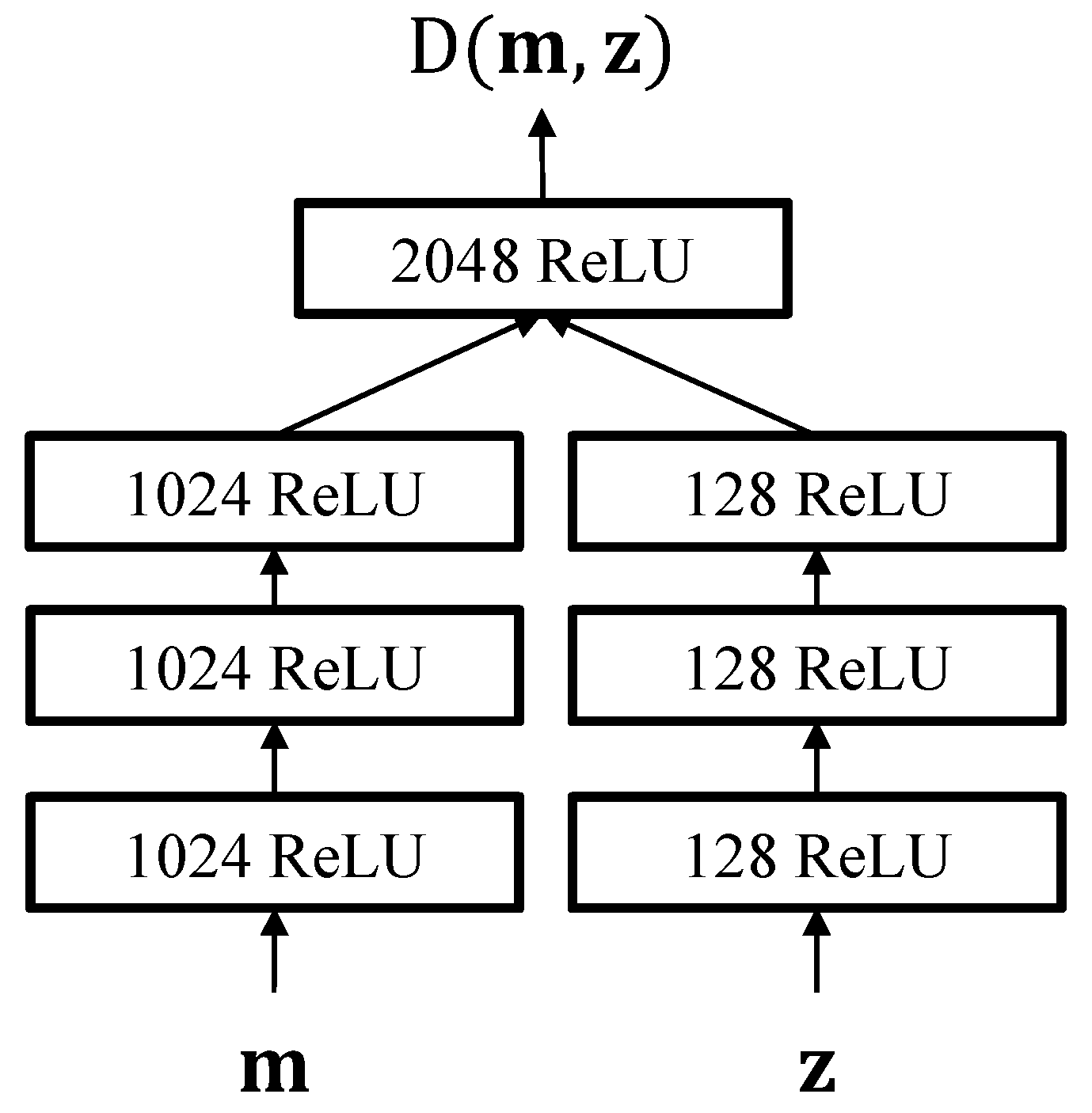
3.2. Adversarially Learned Inference for Nonlinear I-Vector Extraction
3.3. Relationship to the VAE-Based Feature Extractor
4. Experiments
4.1. Databases
4.2. Experimental Setup
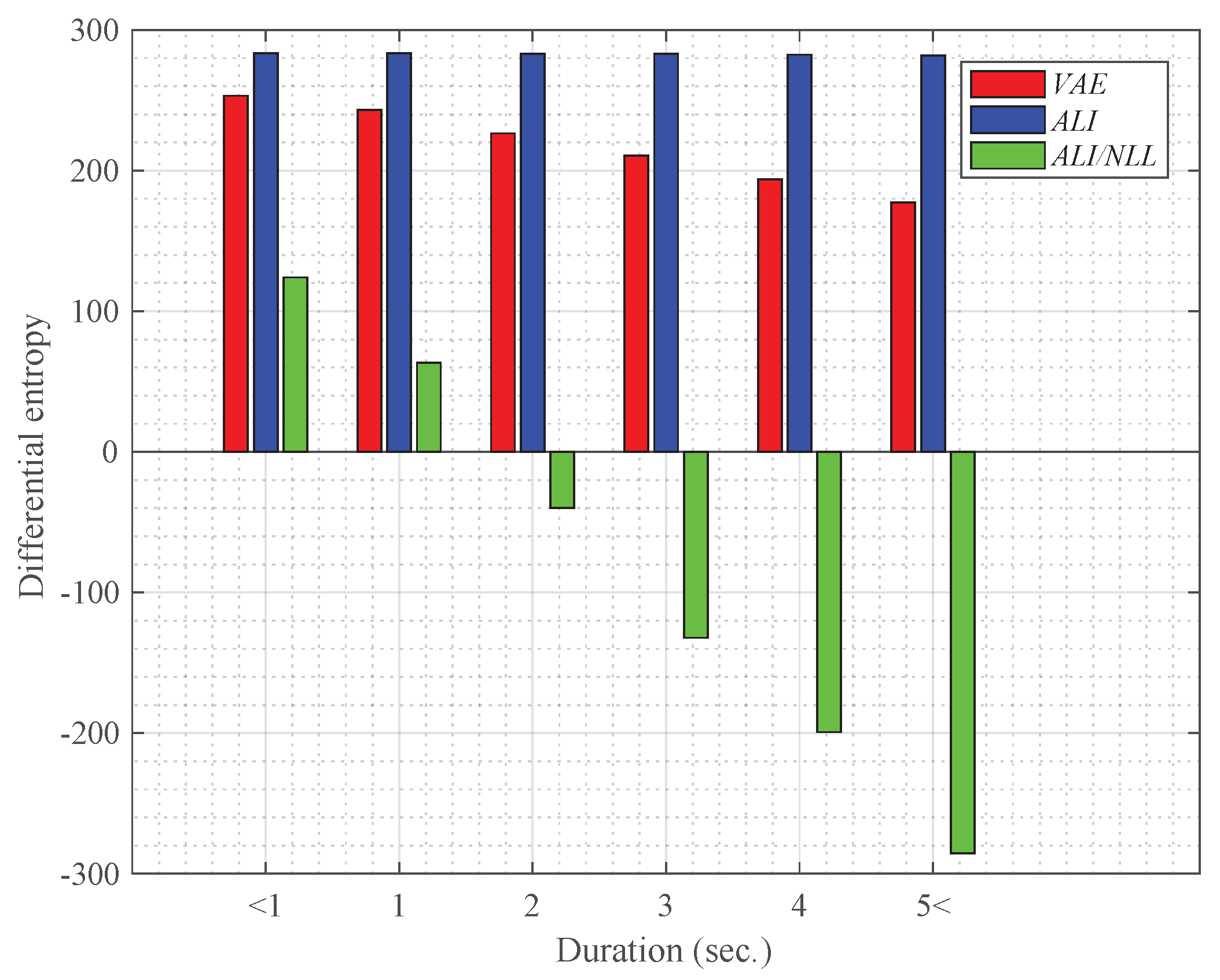
4.3. Effect of the Duration on the Latent Variable
- VAE: the VAE-based feature extraction network trained to minimize (17)
- ALI: the ALI-based feature extraction network trained to minimize the standard GAN objective function (8)
- ALI/NLL: the proposed ALI-based feature extraction network trained to minimize the negative log-likelihood-based objective function (16)
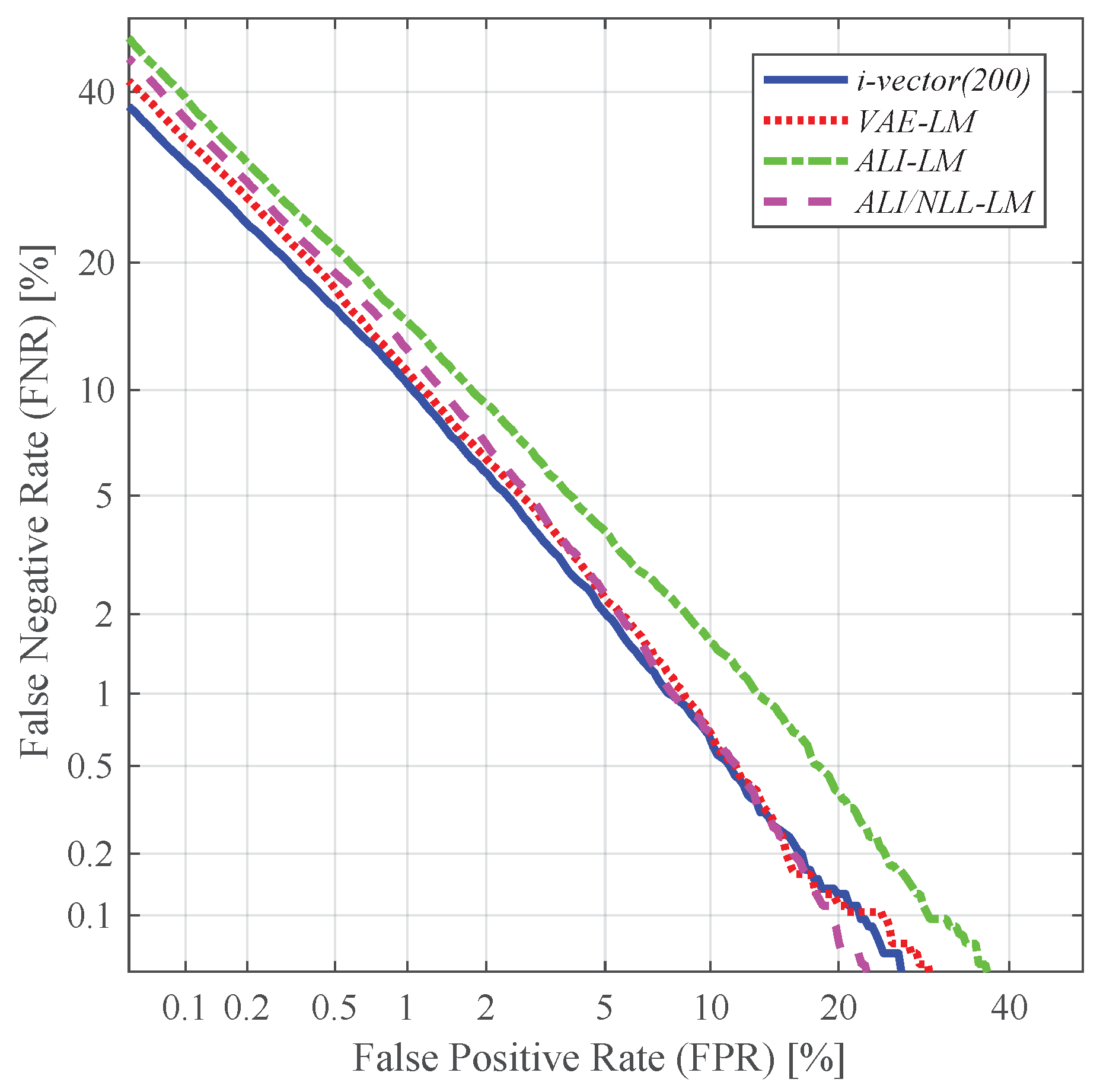
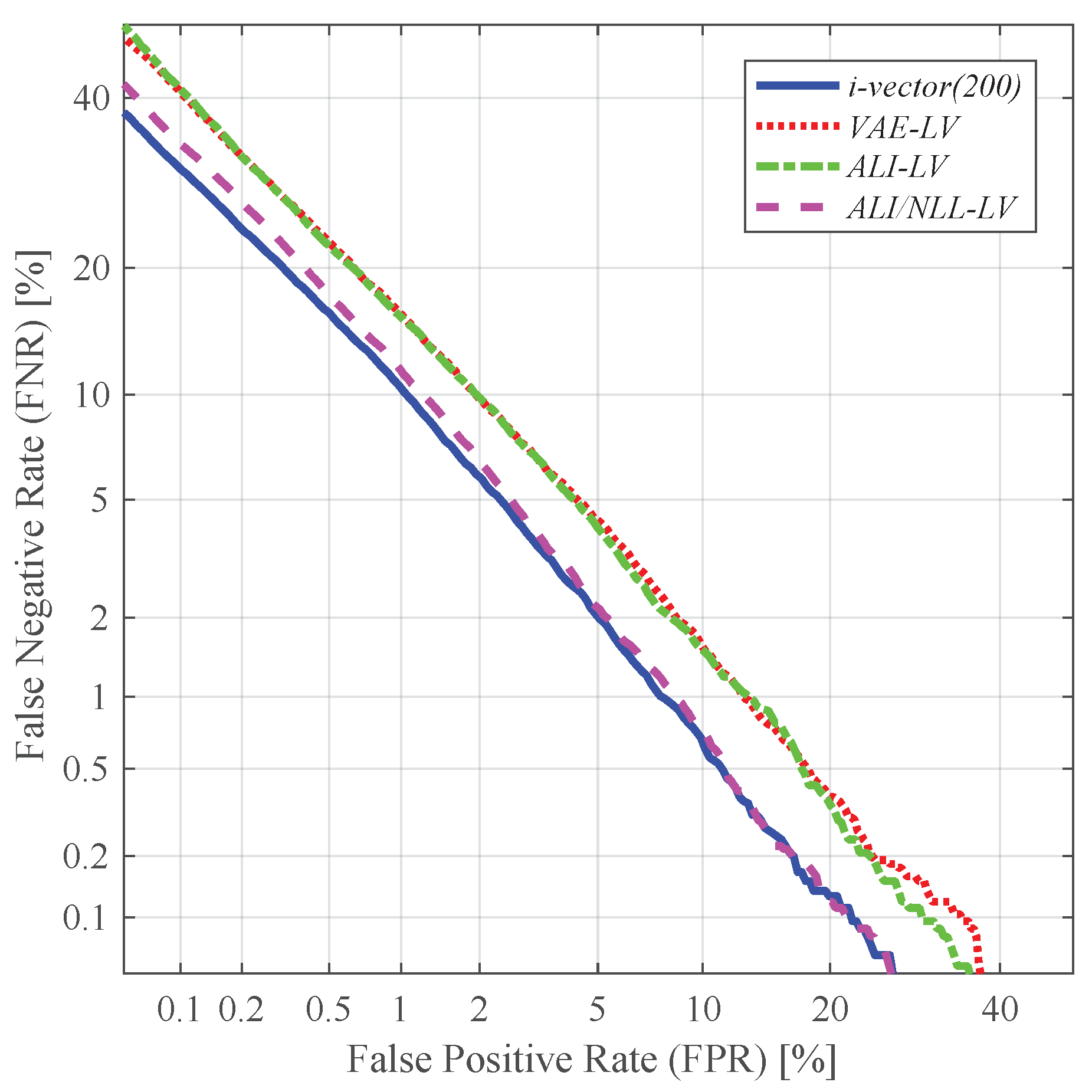
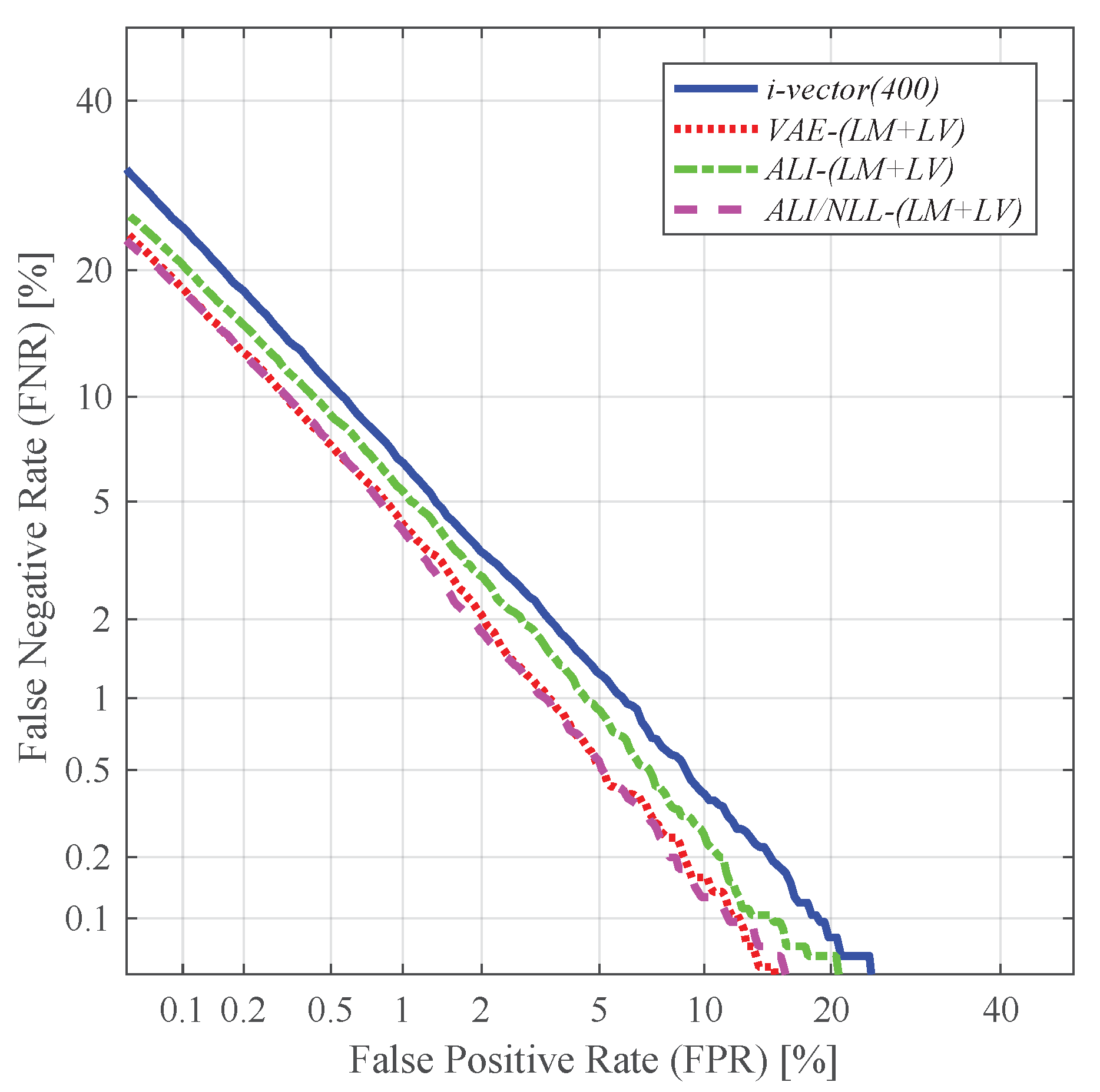
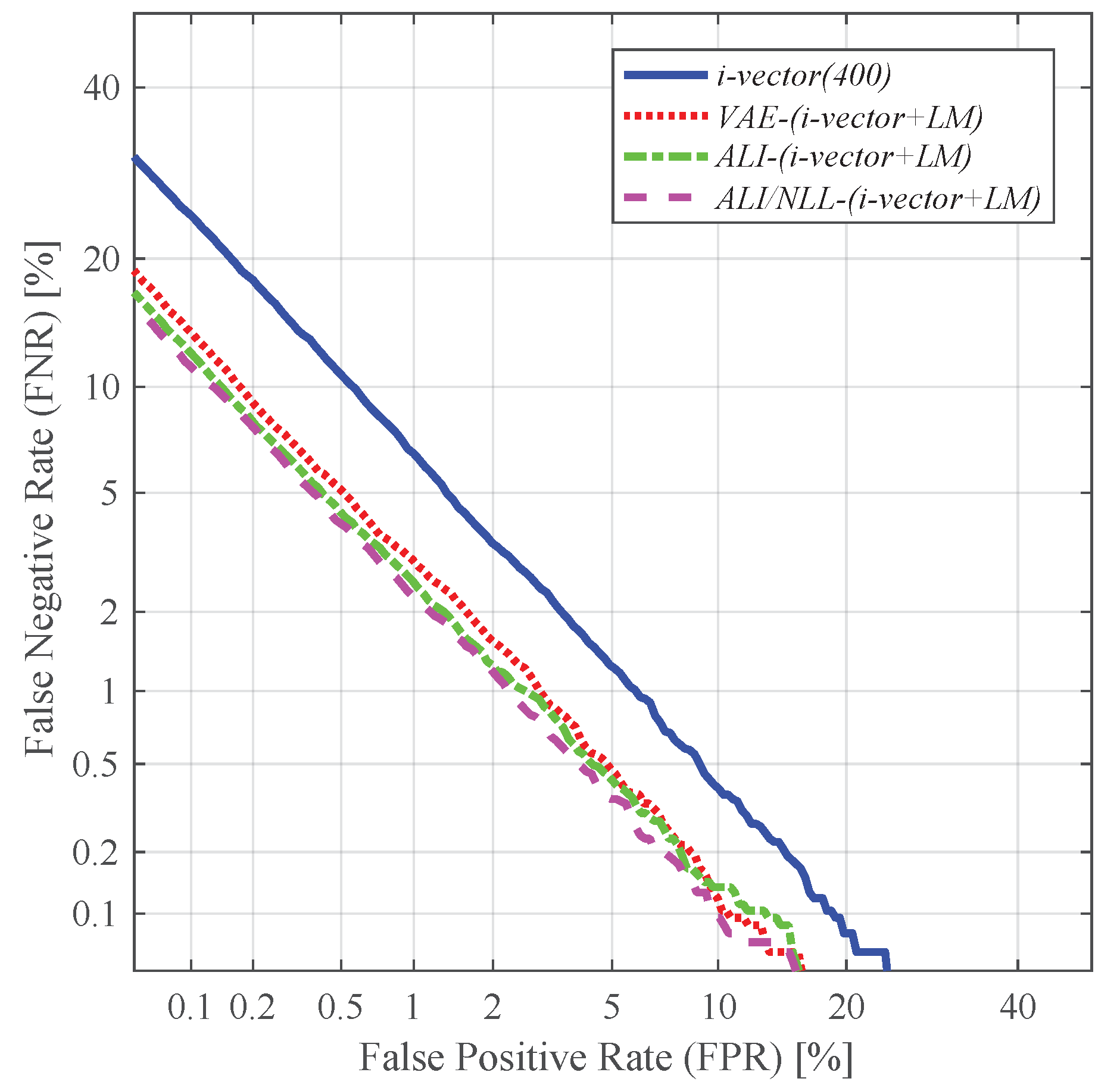
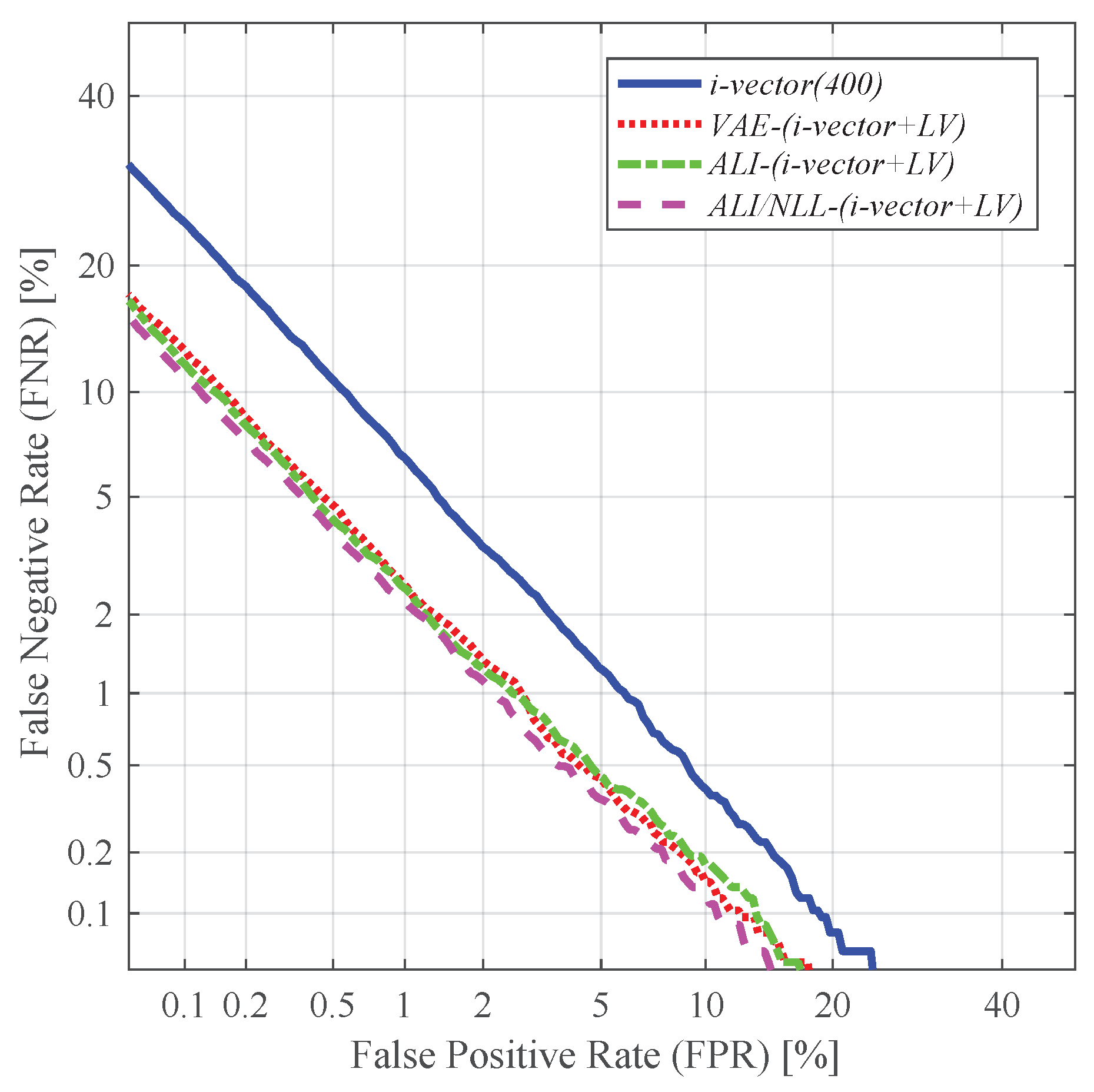
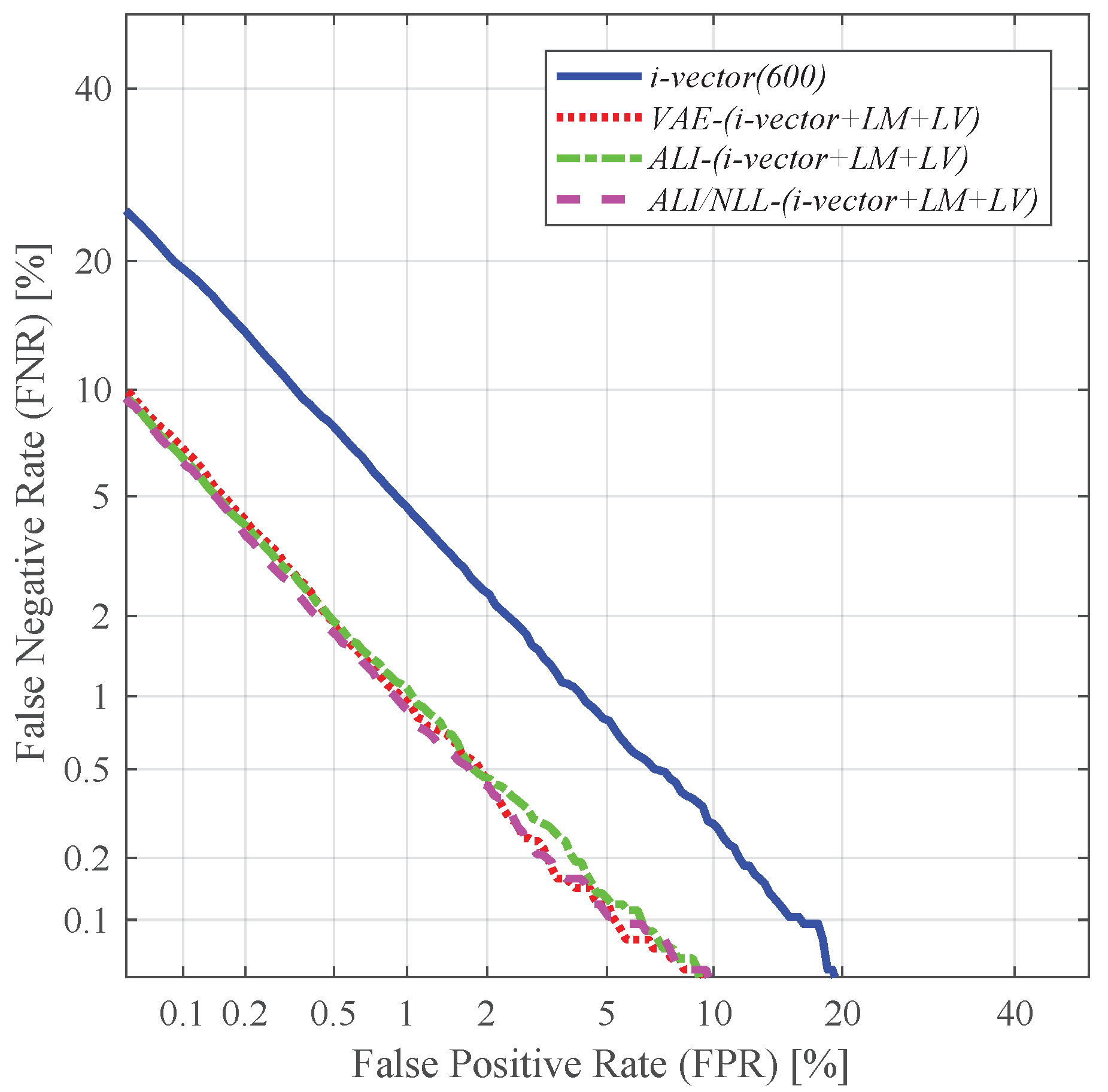
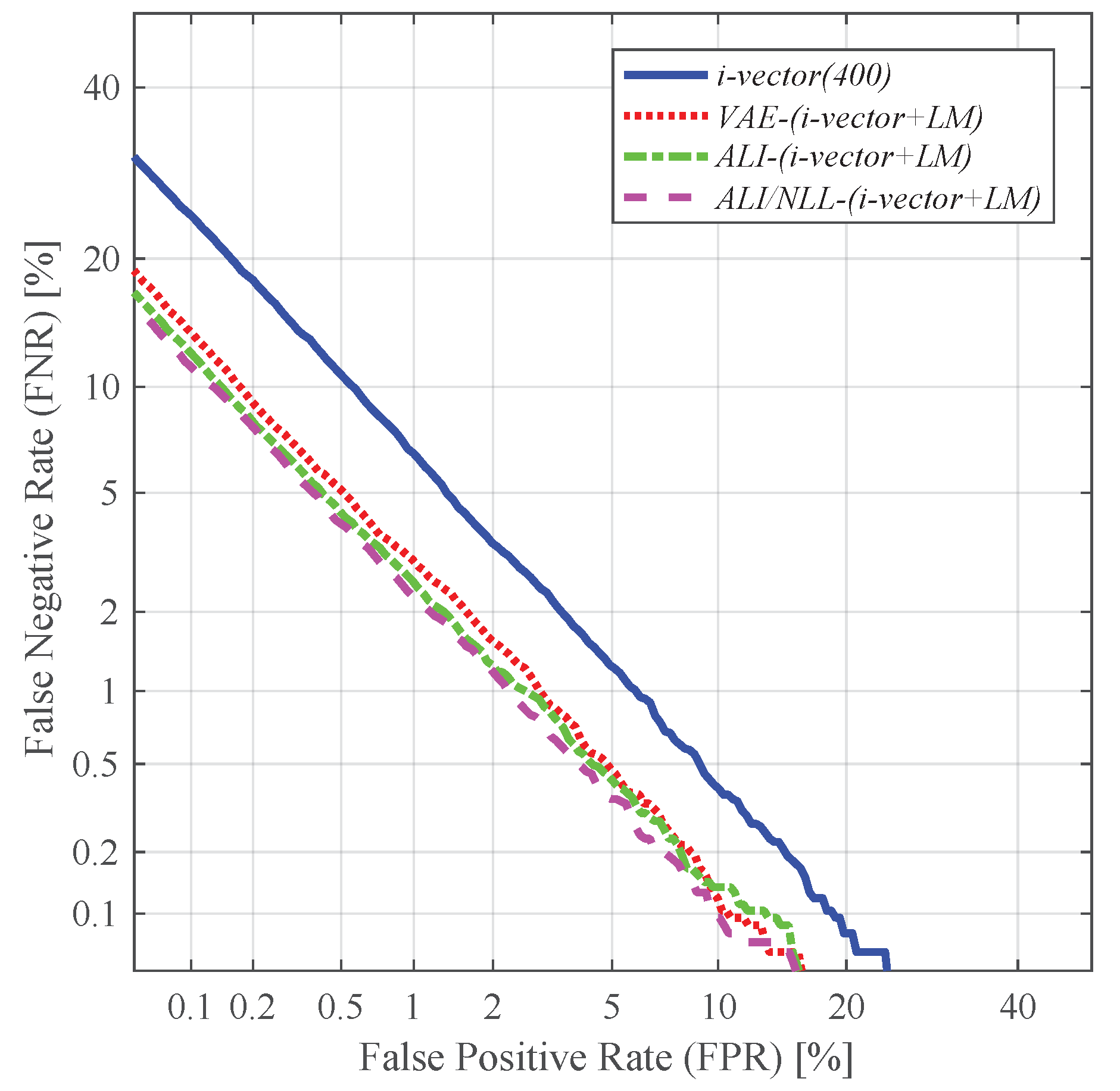
4.4. Speaker Verification and Identification with Different Utterance-Level Features
- i-vector(200): standard 200-dimensional i-vector
- i-vector(400): standard 400-dimensional i-vector
- i-vector(600): standard 600-dimensional i-vector
- LM: 200-dimensional latent variable mean
- LV: 200-dimensional latent variable log-variance
- LM + LV: concatenation of the 200-dimensional latent variable mean and the log-variance, resulting in a 400-dimensional vector
- i-vector + LM: concatenation of the 200-dimensional i-vector and the 200-dimensional latent variable mean, resulting in a 400-dimensional vector
- i-vector + LV: concatenation of the 200-dimensional i-vector and the 200-dimensional latent variable log-variance, resulting in a 400-dimensional vector
- i-vector + LM + LV: concatenation of the 200-dimensional i-vector and the 200-dimensional latent variable mean and log-variance, resulting in a 600-dimensional vector
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Dehak, N.; Kenny, P.; Dehak, R.; Dumouchel, P.; Ouellet, P. Front-end factor analysis for speaker verification. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 788–798. [Google Scholar] [CrossRef]
- Kenny, P. A small footprint i-vector extractor. In Proceedings of the Odyssey 2012, Singapore, 25–28 June 2012; pp. 1–25. [Google Scholar]
- Kenny, P.; Boulianne, G.; Dumouchel, P. Eigenvoice modeling with sparse training data. IEEE Trans. Audio Speech Lang. Process. 2005, 13, 345–354. [Google Scholar] [CrossRef]
- Dehak, N.; Kenny, P.; Dehak, R.; Glembek, O.; Dumouchel, P.; Burget, L.; Hubeika, V.; Castaldo, F. Support vector machines and joint factor analysis for speaker verification. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 4237–4240. [Google Scholar]
- Campbell, W.M.; Sturim, D.; Reynolds, D. Support vector machines using GMM supervectors for speaker verification. IEEE Signal Process. Lett. 2006, 13, 308–311. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.; et al. Deep neural networks for acoustic modeling in speech recognition. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Variani, E.; Lei, X.; McDermott, E.; Moreno, I.L.; G-Dominguez, J. Deep neural networks for small footprint text-dependent speaker verification. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4080–4084. [Google Scholar]
- Snyder, D.; G-Romero, D.; Povey, D.; Khudanpur, S. Deep neural network embeddings for text-independent speaker verification. In Proceedings of the INTERSPEECH, Stockholm, Sweden, 20–24 August 2017; pp. 999–1003. [Google Scholar]
- Snyder, D.; G-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-vectors: robust DNN embeddings for speaker recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- Chowdhury, F.A.R.; Wang, Q.; Moreno, I.L.; Wan, L. Attention-based models for text-dependent speaker verification. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5359–5363. [Google Scholar]
- Wan, L.; Wang, Q.; Papir, A.; Moreno, I.L. Generalized end-to-end loss for speaker verification. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4879–4883. [Google Scholar]
- Yao, S.; Zhou, R.; Zhang, P. Speaker-phonetic i-vector modeling for text-dependent speaker verification with random digit strings. IEICE Trans. Inf. Syst. 2019, E102D, 346–354. [Google Scholar] [CrossRef]
- Saeidi, R.; Alku, P. Accounting for uncertainty of i-vectors in speaker recognition using uncertainty propagation and modified imputation. In Proceedings of the INTERSPEECH, Dresden, Germany, 6–10 September 2015; pp. 3546–3550. [Google Scholar]
- Hasan, T.; Saeidi, R.; Hansen, J.H.L.; van Leeuwen, D.A. Duration mismatch compensation for i-vector based speaker recognition systems. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 7663–7667. [Google Scholar]
- Mandasari, M.I.; Saeidi, R.; McLaren, M.; van Leeuwen, D.A. Quality measure functions for calibration of speaker recognition systems in various duration conditions. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 2425–2438. [Google Scholar] [CrossRef]
- Mandasari, M.I.; McLaren, M.; van Leeuwen, D.A. Evaluation of i-vector speaker recognition systems for forensic application. In Proceedings of the INTERSPEECH, Florence, Italy, 27–31 August 2011; pp. 21–24. [Google Scholar]
- Kang, W.H.; Kim, N.S. Unsupervised learning of total variability embedding for speaker verification with random digit strings. Appl. Sci. 2019, 9, 1597. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Doersch, C. Tutorial on variational autoencoders. arXiv 2016, arXiv:1606.05908. [Google Scholar]
- Theis, L.; van den Oord, A.; Bethge, M. A note on the evaluation of generative models. In Proceedings of the ICLR, San Juan, PR, USA, 24 April 2016. [Google Scholar]
- Shang, W.; Sohn, K.; Akata, Z.; Tian, Y. Channel-recurrent variational autoencoder. arXiv 2017, arXiv:1706.03729v1. [Google Scholar]
- Dumoulin, V.; Belghazi, I.; Poole, B.; Mastropietro, O.; Lamb, A.; Arjovsky, M.; Courville, A. Adversarially learned inference. In Proceedings of the ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Reynolds, D.; Quatieri, T.F.; Dunn, R.B. Speaker verification using adapted Gaussian mixture models. Digit. Signal Process. 2000, 10, 19–41. [Google Scholar] [CrossRef]
- Dehak, N.; T-Carrasquillo, P.A.; Reynolds, D.; Dehak, R. Language recognition via i-vectors and dimensionality reduction. In Proceedings of the INTERSPEECH, Florence, Italy, 27–31 August 2011; pp. 857–860. [Google Scholar]
- Goodfellow, I.J.; P-Abadie, J.; Mirza, M.; Xu, B.; W-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. arXiv 2014, arXiv:1406.2661v1. [Google Scholar]
- Salakhutdinov, R. Learning deep generative models. Annu. Rev. Stat. Its Appl. 2015, 2, 361–385. [Google Scholar] [CrossRef]
- Lopes, C.; Perdigao, F. Phone recognition on the TIMIT database. Speech Technol. 2011, 1, 285–302. [Google Scholar]
- Leonard, R.G. A database for speaker-independent digit recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, San Diego, CA, USA, 19–21 March 1984; pp. 328–331. [Google Scholar]
- Gravier, G. SPro: Speech Signal Processing Toolkit. Available online: http://gforge.inria.fr/projects/spro (accessed on 1 July 2019).
- Sadjadi, S.O.; Slaney, M.; Heck, L. MSR identity toolbox v1.0: A MATLAB toolbox for speaker recognition research. Speech Lang. Process. Tech. Comm. Newsl. 2013, 1, 1–32. [Google Scholar]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the ICML, Bellevue, WA, USA, 28 June–2 July 2011; pp. 689–696. [Google Scholar]
- Abadi, M.; Agarwal, A.; Harham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-Scale Machine Learning Heterogenous Systems. Available online: tensorflow.org (accessed on 1 July 2019).
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradial methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Hansen, J.; Hasan, T. Speaker recognition by machines and humans. IEEE Signal Process. Mag. 2015, 32, 74–99. [Google Scholar] [CrossRef]
- Garcia-Romero, D.; Espy-Wilson, C.Y. Analysis of i-vector length normalization in speaker recognition systems. In Proceedings of the INTERSPEECH, Florence, Italy, 27–31 August 2011; pp. 249–252. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LM | LV | LM+LV | i-Vector + LM | i-Vector + LV | i-Vector + LM + LV | |
|---|---|---|---|---|---|---|
| i-vector(200) | 3.36 | |||||
| i-vector(400) | 2.68 | |||||
| i-vector(600) | 2.17 | |||||
| VAE | 3.61 | 4.65 | 2.03 | 1.78 | 1.65 | 0.97 |
| ALI | 4.39 | 4.56 | 2.32 | 1.59 | 1.55 | 1.03 |
| ALI/NLL | 3.64 | 3.46 | 1.91 | 1.55 | 1.51 | 0.94 |
| LM | LV | LM + LV | i-Vector + LM | i-Vector + LV | i-Vector + LM + LV | |
|---|---|---|---|---|---|---|
| i-vector(200) | 12.62 | |||||
| i-vector(400) | 7.67 | |||||
| i-vector(600) | 5.07 | |||||
| VAE | 11.89 | 17.78 | 6.94 | 5.36 | 4.99 | 2.75 |
| ALI | 16.62 | 17.31 | 8.54 | 5.10 | 4.79 | 2.79 |
| ALI/NLL | 12.56 | 12.38 | 6.76 | 3.97 | 4.18 | 2.49 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, W.H.; Kim, N.S. Adversarially Learned Total Variability Embedding for Speaker Recognition with Random Digit Strings. Sensors 2019, 19, 4709. https://doi.org/10.3390/s19214709
Kang WH, Kim NS. Adversarially Learned Total Variability Embedding for Speaker Recognition with Random Digit Strings. Sensors. 2019; 19(21):4709. https://doi.org/10.3390/s19214709
Chicago/Turabian StyleKang, Woo Hyun, and Nam Soo Kim. 2019. "Adversarially Learned Total Variability Embedding for Speaker Recognition with Random Digit Strings" Sensors 19, no. 21: 4709. https://doi.org/10.3390/s19214709
APA StyleKang, W. H., & Kim, N. S. (2019). Adversarially Learned Total Variability Embedding for Speaker Recognition with Random Digit Strings. Sensors, 19(21), 4709. https://doi.org/10.3390/s19214709