Fruit Detection and Segmentation for Apple Harvesting Using Visual Sensor in Orchards


Abstract
1. Introduction
2. Related Work
3. Material and Methods
3.1. Vision Sensing System
3.2. Network Architecture
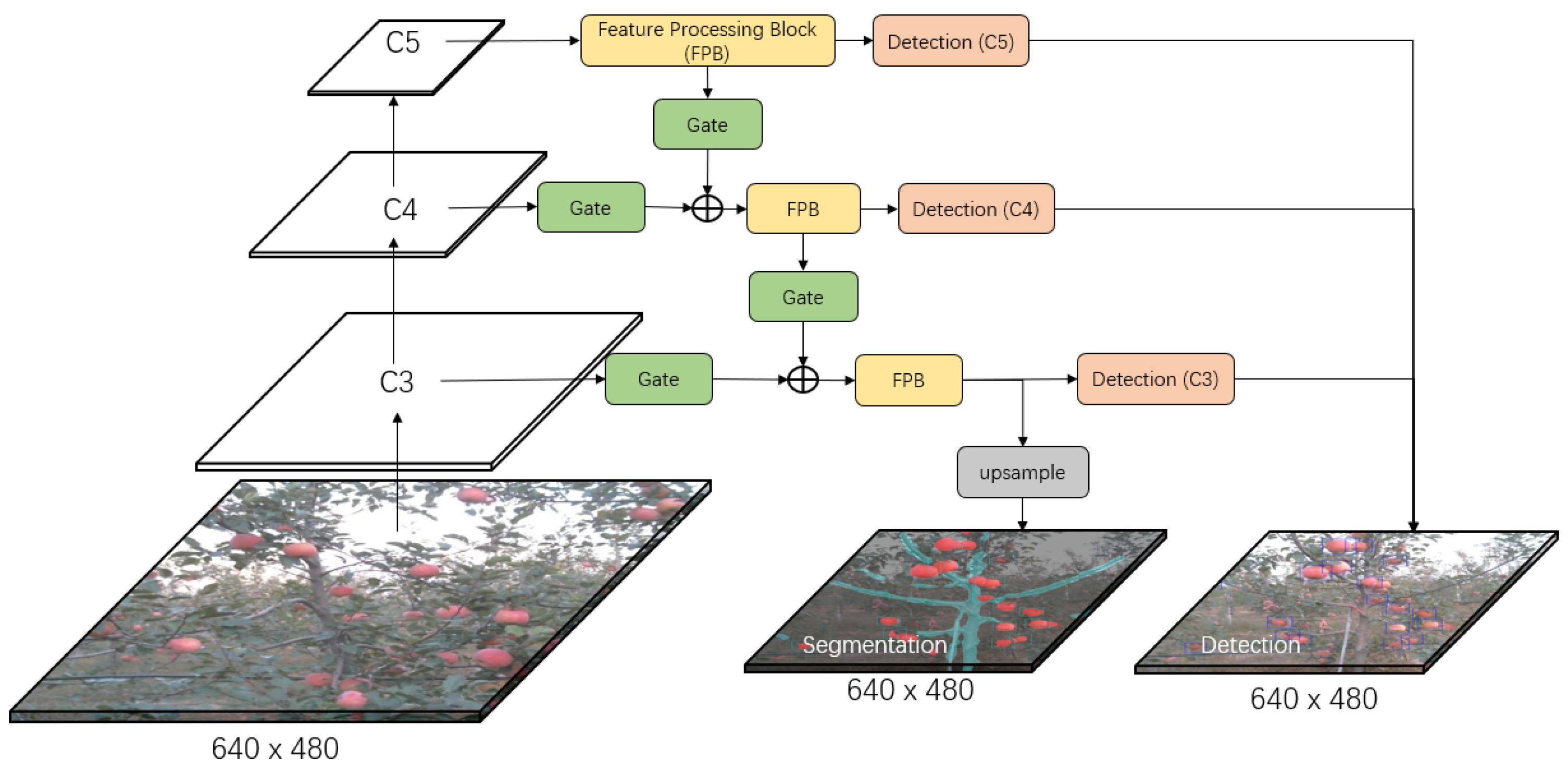
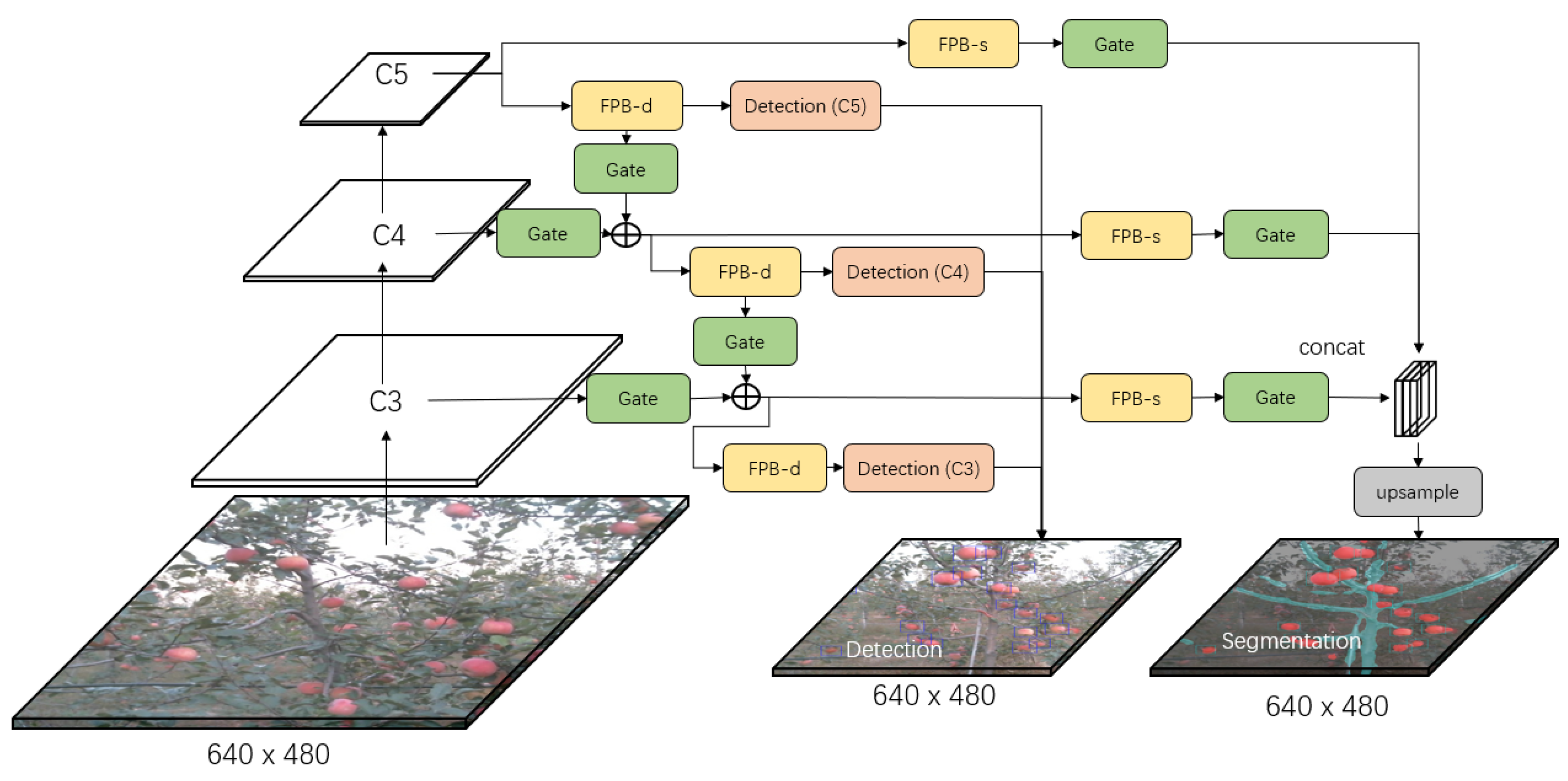
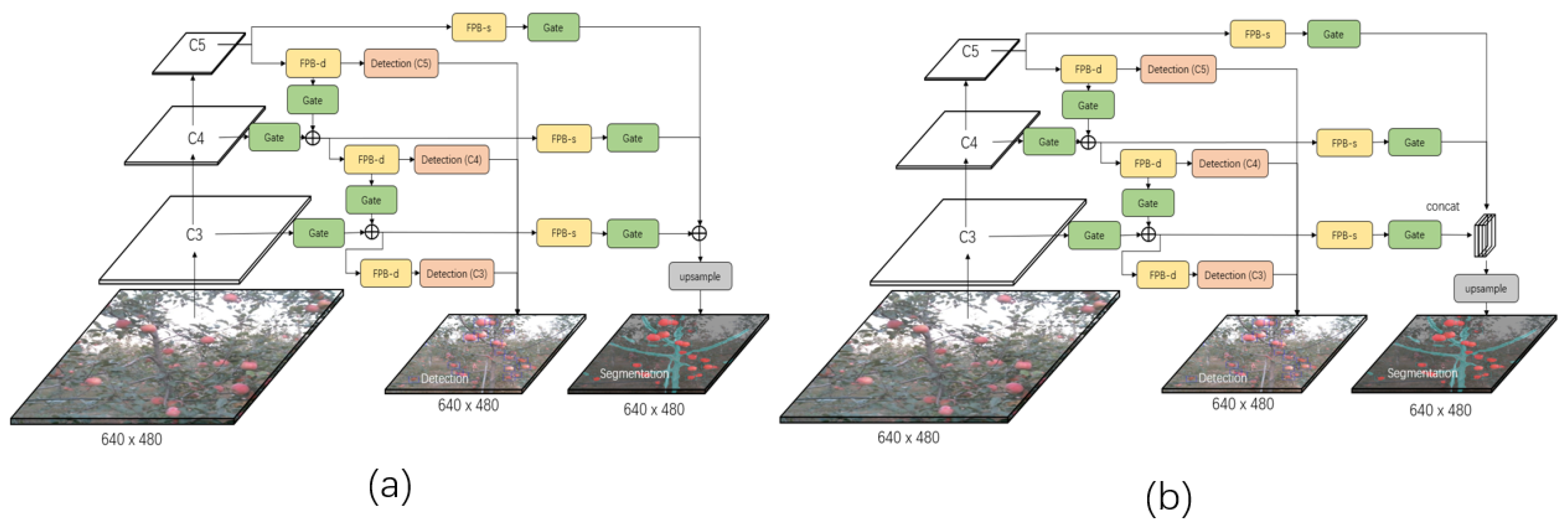
3.2.1. Gated-FPN for Multi-level Fusion
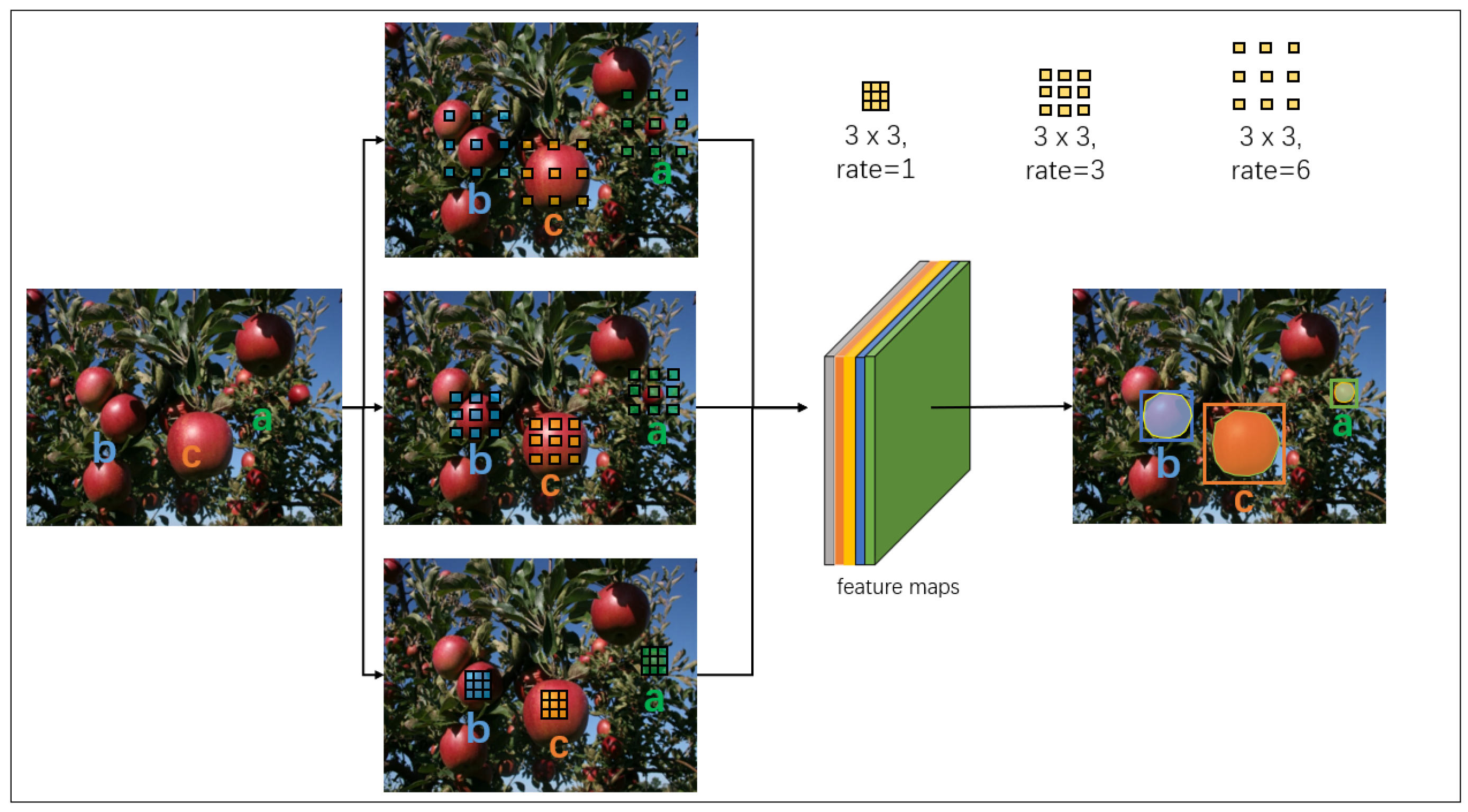
3.2.2. ASPP for Multi-Scale Fusion
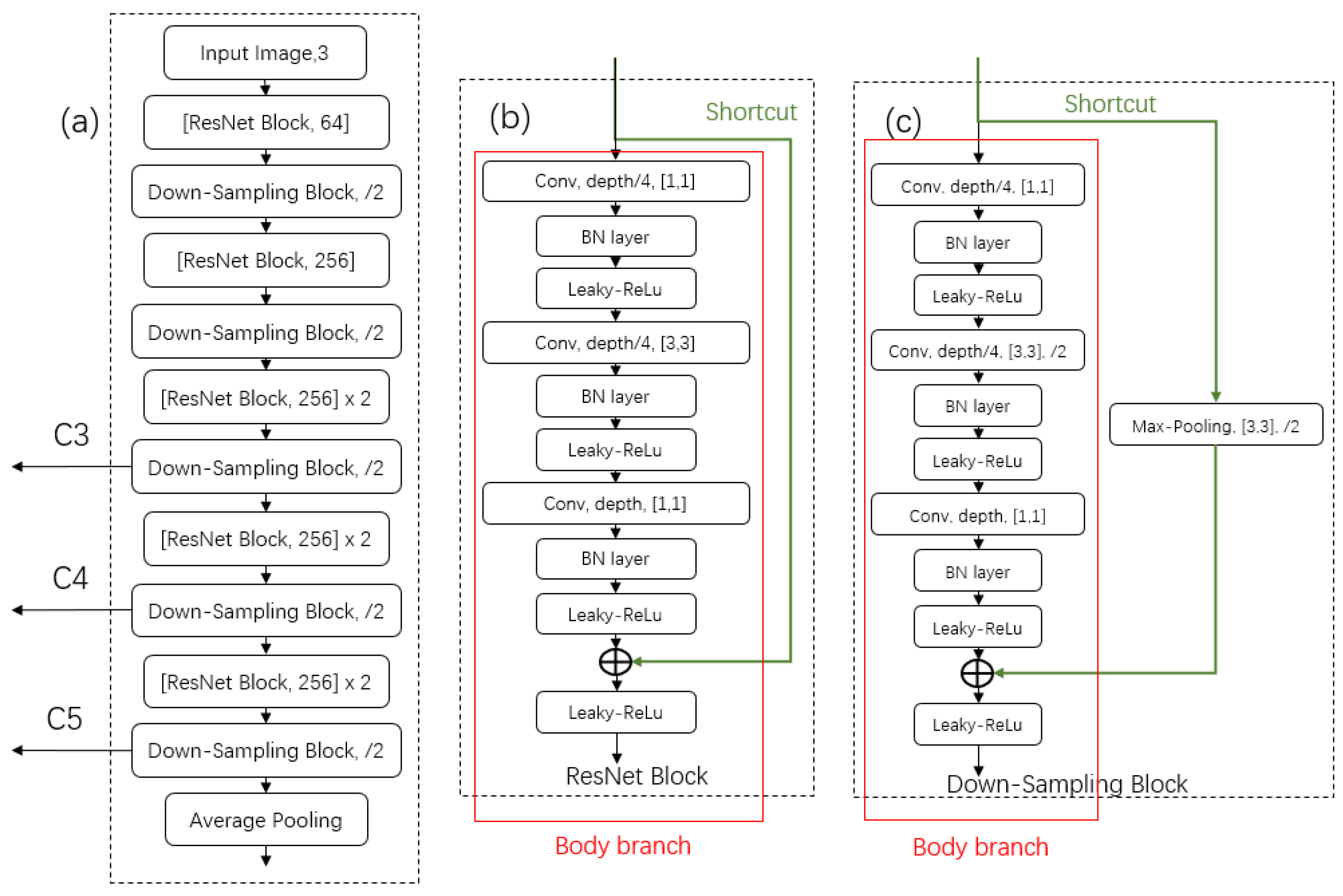
3.2.3. Lightweight Designed Backbone
3.3. Training Data and Method
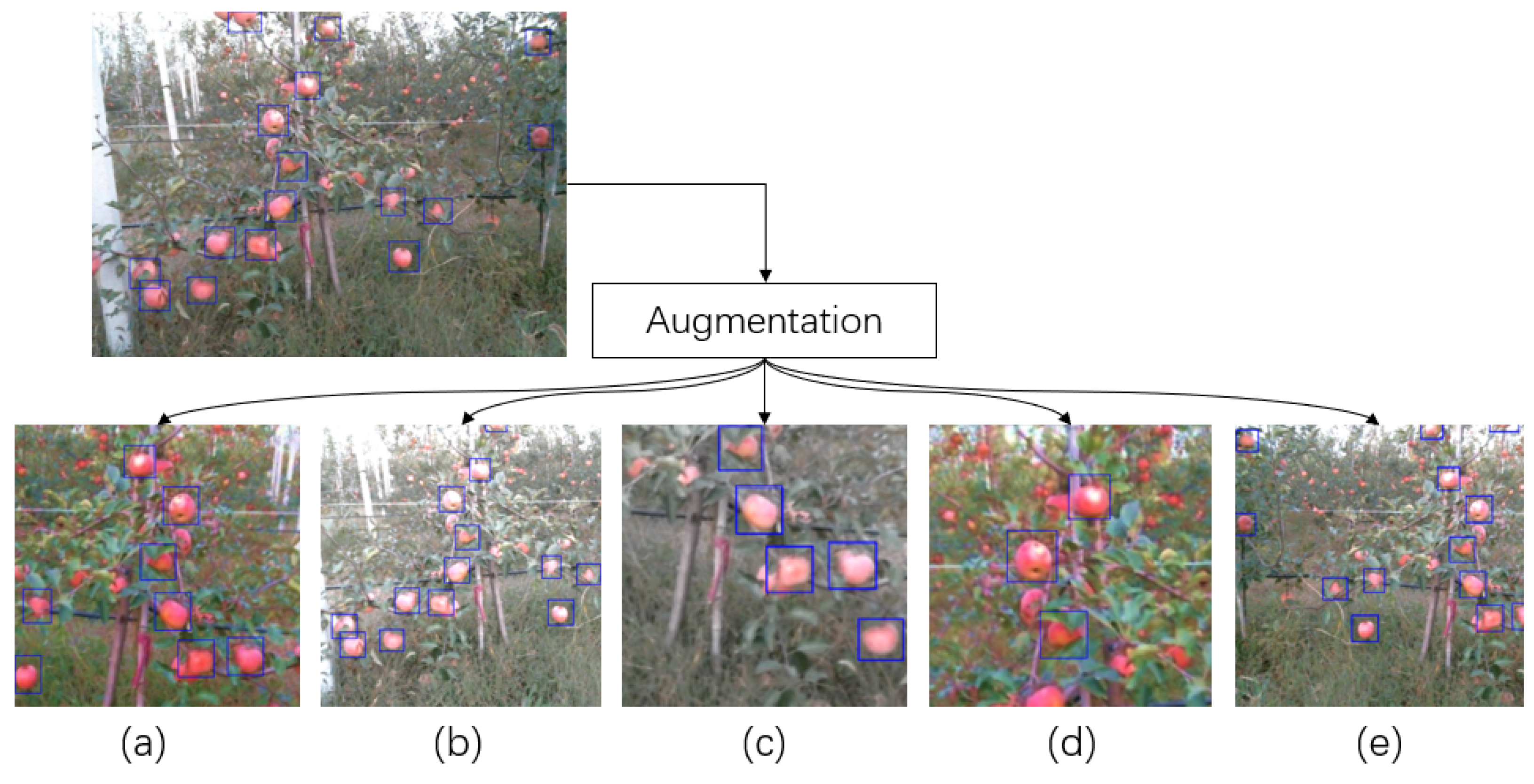
3.3.1. Data Collection
3.3.2. Training Method
4. Experiment and Discussion
4.1. Experiment on Network Architecture and Training
4.1.1. Experiment on Network Architectures
4.1.2. Experiment Results and Discussion
4.2. Experiment on Detection Performance
4.3. Experiment on Segmentation Performance
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- ABARES. Australian Vegetable Growing Farms: An Economic Survey, 2016–17 and 2017–18; Australian Bureau of Agricultural and Resource Economics (ABARE): Canberra, Australia, 2018.
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Bac, C.W.; Hemming, J.; Van Tuijl, B.; Barth, R.; Wais, E.; van Henten, E.J. Performance evaluation of a harvesting robot for sweet pepper. J. Field Robot. 2017, 34, 1123–1139. [Google Scholar] [CrossRef]
- Li, J.; Karkee, M.; Zhang, Q.; Xiao, K.; Feng, T. Characterizing apple picking patterns for robotic harvesting. Comput. Electron. Agric. 2016, 127, 633–640. [Google Scholar] [CrossRef]
- Lin, G.; Tang, Y.; Zou, X.; Xiong, J.; Li, J. Guava detection and pose estimation using a low-cost RGB-D sensor in the field. Sensors 2019, 19, 428. [Google Scholar] [CrossRef]
- Vit, A.; Shani, G. Comparing RGB-D Sensors for Close Range Outdoor Agricultural Phenotyping. Sensors 2018, 18, 4413. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Gong, L.; Huang, Y.; Liu, C. A review of key techniques of vision-based control for harvesting robot. Comput. Electron. Agric. 2016, 127, 311–323. [Google Scholar] [CrossRef]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the 2014 Science and Information Conference, London, UK, 27–29 August 2014; pp. 372–378. [Google Scholar]
- Ke, Y.; Sukthankar, R. PCA-SIFT: A more distinctive representation for local image descriptors. CVPR (2) 2004, 4, 506–513. [Google Scholar]
- Pass, G.; Zabih, R.; Miller, J. Comparing Images Using Color Coherence Vectors. In Proceedings of the Fourth ACM International Conference on Multimedia, Boston, MA, USA, 18–22 November 1996; pp. 65–73. [Google Scholar]
- Ahonen, T.; Hadid, A.; Pietikainen, M. Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef]
- Zhou, R.; Damerow, L.; Sun, Y.; Blanke, M.M. Using colour features of cv.‘Gala’apple fruits in an orchard in image processing to predict yield. Precis. Agric. 2012, 13, 568–580. [Google Scholar] [CrossRef]
- Song, Y.; Glasbey, C.; Horgan, G.; Polder, G.; Dieleman, J.; Van der Heijden, G. Automatic fruit recognition and counting from multiple images. Biosyst. Eng. 2014, 118, 203–215. [Google Scholar] [CrossRef]
- Luo, L.; Tang, Y.; Zou, X.; Wang, C.; Zhang, P.; Feng, W. Robust grape cluster detection in a vineyard by combining the AdaBoost framework and multiple color components. Sensors 2016, 16, 2098. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Lee, W.S.; Zou, X.; Choi, D.; Gan, H.; Diamond, J. Detection and counting of immature green citrus fruit based on the local binary patterns (lbp) feature using illumination-normalized images. Precis. Agric. 2018, 19, 1062–1083. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Georgiou, T.; Lew, M.S. A review of semantic segmentation using deep neural networks. Int. J. Multimed. Inf. Retr. 2018, 7, 87–93. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, L.T.; Chen, Z.; Li, P. A survey on deep learning for big data. Inf. Fusion 2018, 42, 146–157. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 91–99. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. Deepfruits: A fruit detection system using deep neural networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef]
- Bargoti, S.; Underwood, J. Deep fruit detection in orchards. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3626–3633. [Google Scholar]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN. Comput. Electron. Agric. 2019, 163, 104846. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Koirala, A.; Walsh, K.; Wang, Z.; McCarthy, C. Deep learning for real-time fruit detection and orchard fruit load estimation: Benchmarking of ‘MangoYOLO’. Precis. Agric. 2019, 20, 1107–1135. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- McCool, C.; Sa, I.; Dayoub, F.; Lehnert, C.; Perez, T.; Upcroft, B. Visual detection of occluded crop: For automated harvesting. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 2506–2512. [Google Scholar]
- Bargoti, S.; Underwood, J.P. Image segmentation for fruit detection and yield estimation in apple orchards. J. Field Robot. 2017, 34, 1039–1060. [Google Scholar] [CrossRef]
- Li, Y.; Cao, Z.; Xiao, Y.; Cremers, A.B. DeepCotton: In-field cotton segmentation using deep fully convolutional network. J. Electron. Imaging 2017, 26, 053028. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Yao, J.; Yu, Z.; Yu, J.; Tao, D. Single Pixel Reconstruction for One-stage Instance Segmentation. arXiv 2019, arXiv:1904.07426. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Silberman, N.; Guadarrama, S. TensorFlow-Slim Image Classification Model Library. Available online: https://github.com/tensorflow/models/tree/master/research/slim (accessed on 21 May 2019).
- Tensorflow-yolo-v3. Available online: https://github.com/mystic123/tensorflow-yolo-v3 (accessed on 17 January 2019).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Py-Faster-Rcnn. Available online: https://github.com/rbgirshick/py-faster-rcnn (accessed on 29 December 2018).
- TF Image Segmentation: Image Segmentation Framework. Available online: https://github.com/warmspringwinds/tf-image-segmentation (accessed on 14 March 2018).
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- Wang, Q.; Zhang, Q. Three-dimensional reconstruction of a dormant tree using rgb-d cameras. In Proceedings of the 2013 Kansas City, Kansas City, MI, USA, 21–24 July 2013; p. 1. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Iteration | If Augmentation | Small | Median | Large |
|---|---|---|---|---|---|
| 1 | 100 | Yes | 67% | 32% | 1% |
| 2 | 100 | No | 87% | 13% | 0% |
| 3 | 1K | Yes | 58% | 37% | 5% |
| 4 | 1K | No | 85% | 12% | 1% |
| 5 | 10K | Yes | 51% | 40% | 9% |
| 6 | 10K | No | 89% | 11% | 0% |
| Index | Model | Method | ||||
|---|---|---|---|---|---|---|
| 1 | DaSNet-A(G) | M1 | ||||
| 2 | DaSNet-B(G) | M1 | ||||
| 3 | DaSNet-C(G) | M1 | ||||
| 4 | DaSNet-B(G) | M2 | 0.827 | |||
| 5 | DaSNet-C(G) | M2 | ||||
| 6 | DaSNet-B(FPN) | M2 |
| Index | Model | Inference Time | Weights Size |
|---|---|---|---|
| 1 | DaSNet-A(G) | 30 ms | M |
| 2 | DaSNet-B(G) | 32 ms | M |
| 3 | DaSNet-C(G) | 40 ms | M |
| Index | Model | Weights Size | Time | ||
|---|---|---|---|---|---|
| 1 | DaSNet-B(lw-net) | M | 32 ms | ||
| 2 | DaSNet-B(ResNet-50) | 112 M | 47 ms | ||
| 3 | DaSNet-B(ResNet-101) | 0.836 | 188 M | 72 ms | |
| 4 | DaSNet-B(Darknet-53) | 176 M | 50 ms | ||
| 5 | YOLO-V3(Darknet-53) [31] | 248 M | 48 ms | ||
| 6 | YOLO-V3(Tiny) [31] | M | 38 ms | ||
| 7 | Faster-RCNN (VGG-16) [22] | 533 M | 136 ms |
| Index | Model | ||
|---|---|---|---|
| 1 | DaSNet-B-Add(lw-net) | ||
| 2 | DaSNet-B-Concat(lw-net) | ||
| 3 | DaSNet-B-Concat(ResNet-50) | ||
| 4 | DaSNet-B-Concat(ResNet-101) | 0.876 | |
| 5 | DaSNet-B-Concat(Darknet-53) | ||
| 6 | FCN-8s(ResNet-50) [36] | ||
| 7 | FCN-8s(ResNet-101) [36] |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, H.; Chen, C. Fruit Detection and Segmentation for Apple Harvesting Using Visual Sensor in Orchards. Sensors 2019, 19, 4599. https://doi.org/10.3390/s19204599
Kang H, Chen C. Fruit Detection and Segmentation for Apple Harvesting Using Visual Sensor in Orchards. Sensors. 2019; 19(20):4599. https://doi.org/10.3390/s19204599
Chicago/Turabian StyleKang, Hanwen, and Chao Chen. 2019. "Fruit Detection and Segmentation for Apple Harvesting Using Visual Sensor in Orchards" Sensors 19, no. 20: 4599. https://doi.org/10.3390/s19204599
APA StyleKang, H., & Chen, C. (2019). Fruit Detection and Segmentation for Apple Harvesting Using Visual Sensor in Orchards. Sensors, 19(20), 4599. https://doi.org/10.3390/s19204599