1. Introduction
A Bayesian network (BN) BBN is a probabilistic graphical model that represents a probability distribution through a directed acyclic graph (DAG) that encodes conditional dependency and independency relationships among variables in the model. BNs are widely applied to various forms of reasoning in many domains such as healthcare, bioinformatics, finance, and social services [
1,
2,
3]. With the increasing availability of big datasets in science, government, and business, BN learning from big datasets is becoming more valuable than learning from conventional, small datasets. BN also has a widespread application in multiple-criteria decision analysis as a graphical model in Anomaly Detection [
4] and Activity Recognition [
5] from sensor data. However, learning BNs from big datasets requires high computational costs [
6], and complexities that are not well addressed with conventional BN learning approaches. One solution is to perform the learning task in a distributed data processing and learning fashion using computation diagrams such as MapReduce [
7,
8]. Several research gaps still exist. It is quite challenging to select a learner from numerous BN structure learning algorithms to consistently achieve good learning accuracy. There are typically two approaches of ensemble learning for big data—algorithm level or data level. However, there is a lack of research that conducts ensemble learning at both the data level and the algorithm level. Furthermore, there is a lack of work for Bayesian Network learning integrated as part of the big data modeling and scientific workflow engine.
There are three main challenges for learning a Bayesian network from big data. First, learning a BN structure from the big dataset is an expensive task that often fails due to insufficient computation power and memory constraints. It is necessary to find an intelligent way to divide the dataset into small data slices suitable for distributed learning. Second, it is difficult to determine which BN learning algorithm would work well on a particular dataset. Lastly, the distributed learned BN structures need to be intelligently merged collectively to form a BN structure that follows the generative distribution of the big dataset.
Facing these challenges, we propose a novel approach called PEnBayes (Parallel Ensemble-based Bayesian network learning) to learn a Bayesian network from big data. The PenBayes approach consists of three phases: Data Preprocessing, Local Learning, and Global Ensemble Learning. In the Data Preprocessing phase, the entire dataset is divided into data slices for the Local Learners. We design a greedy algorithm to intelligently calculate the appropriate size of each data slice, defined as the Appropriate Learning Size (ALS). Then, the entire big dataset is divided into many data slices and sent to the Local Learners. During the Local Learning phase, a two-layered structural ensemble method is proposed to learn a Bayesian network structure from each data slice and then merge the learned networks into one local BN structure. Lastly, in the Global Ensemble Learning phase, PEnBayes uses the same structural ensemble method as in the Local Learners to merge the local BN structures into a global structure. Experimental results on datasets from three well-known Bayesian networks validate the effectiveness of PEnBayes in terms of efficiency, accuracy, and stability for learning a Bayesian network from big datasets. PEnBayes uses the entire big dataset instead of sampling data for learning.
The main contributions of this paper are as follows:
A greedy data size calculation algorithm is proposed for adaptively partitioning a big dataset into data slices of appropriate size for distributed BN learning.
A distributed three-layered ensemble approach called PenBayes is proposed to achieve stable and accurate Bayesian network learning from big datasets at both data and algorithm levels.
PenBayes enables Big Data Bayesian network learning by leveraging the distributed platform [
9] and the scientific workflow system [
10] for advancing big data learning in the graphical model research area.
The remainder of this paper is organized as follows. In the next section, we introduce the background. Related work is in
Section 3. The research problem is formalized in
Section 4. Our approach is described in
Section 5, with workflow integration in
Section 6.
Section 7 and
Section 8 show experimental setups, results, and discussions. Finally, the paper is concluded in
Section 9.
3. Related Work
In the field of BN learning from big data, Chickering et al. [
6] showed that identifying high-scoring BN from a large dataset is NP-hard. Yoo et al. [
1] reviewed bioinformatics and statistical methods and concluded that Bayesian networks are suitable in analyzing big datasets from clinical, genomic, and environmental domains. In recent years, data parallelization techniques have become a key solution for big dataset Bayesian network learning problems. Fang et al. [
7] proposed a Map-Reduce-based method for learning BN from massive datasets. Our previous work [
8] adopted distributed data parallelism techniques and scientific workflow for BN learning from big datasets to achieve better scalability and accuracy. Yue et al. studied a parallel and incremental approach for D ata-Intensive BN learning [
38]. A scalable approach for learning Bayesian network classifiers is proposed in [
39]. It is quite difficult to select a learner from numerous BN structure learning algorithms to consistently achieve good learning accuracy. This is a research gap that needs to be filled. Furthermore, we significantly extend our previous work [
8,
40] in adopting different BN structure learning algorithms in the Local Learner and design a three-layered ensemble approach to ensure learning stability and accuracy. There are three major differences: (1) formalized problem definition and a new theorem are provided; (2) an additional layer of ensemble is added at the data slice level to leverage multiple BN structure learning algorithms for achieving learning stability; (3) extensive experiments and results analyses on much larger datasets on a distributed platform integrating scientific workflow are presented.
In machine learning, ensemble methods [
41] use multiple learning methods to obtain better predictive performance than learning from any of the constituent methods. Because the multiple learning methods of ensemble learning can run independently before their results are merged, it is a natural fit to use the MapReduce model for ensemble learning. There are typically two approaches of ensemble learning for big data: (1) data level, where the results of the same learner on different data sets are merged in the end [
42]; (2) algorithm level, where the results of different learning algorithms on the same data are merged in the end. As a data-level approach, Ref. [
43] partitions the data, uses a decision tree method called C4.5 at Map phase for each data partition, and bagging ensemble learning [
44] where individual learner results are assembled during the Reduce phase. As one of the first big data ensemble learning studies of a Bayesian network, our previous work [
8] also uses the data-level approach because it uses the MMHC algorithm. As an algorithm-level approach, Refs. [
45,
46] support parallel ensemble learning of multiple classifiers on the same data. Different from these approaches, in this paper, we conduct ensemble learning at both the data level and algorithm level.
There have been machine learning libraries built on big data engines to support distributed learning. The most popular ones include Spark MLlib [
47], Mahout [
48], H2O [
49], and FlinkML [
50]. Users can build machine learning applications using these libraries and the inherent parallel execution from the underlying big data engines. However, to the best of our knowledge, there is no library built on big data modeling engines for Bayesian Network learning, this research fills this gap. Further, in contrast to these libraries, our approach allows researchers with limited knowledge programming to implement their own learning algorithms, and the parallel computation work is integrated as part of the big data modeling and workflow engine.
4. Problem Formulation
Our goal is to use the big training data to learn an accurate model of the underlying distribution at both data level and algorithm level to achieve better learning accuracy, stability, and usability towards integrating Bayesian network learning as part of the big data modeling and scientific workflow engine. We need to state and elaborate this more precisely using the following definitions and theorem.
Given a very large DAG-faithful dataset, it is desirable to divide it into many slices for distributed learning. The key challenge is to determine the data slice size. A size that is too small breaks the DAG-faithful property of the data slice, resulting in a poor BN structure, whereas a size that is too large may incur a high computation cost. Thus, we introduce a concept called Appropriate Learning Size (ALS), as defined below.
Definition 3. (Appropriate Learning Size)
Given a DAG-faithful and independent identically distributed (iid) big dataset D, its Appropriate Learning Size () is the minimal data slice size that maintains the DAG-faithful property.
Definition 4. (Edge Strength) Given a dataset D containing N records and a Bayesian network B containing M edges, the Edge Strength (ES) of B is the Bayesian score of B given D divided by M and N.
Formally, Edge Strength of
B given
D is calculated by Equation (
3):
Edge Strength (ES) indicates the average contribution of each edge to the overall score of the BN. A lower ES value means higher network quality and structural stability. This paper uses the BDeu score function for Edge Strength calculation throughout the experimental study.
Theorem 1. Given a distribution P, and a sufficiently large DAG-faithful dataset with records and a DAG structure , there exists a DAG-faithful dataset drawn from P, with records and a DAG structure (). The difference of the average Markov blanket size between the and is less than a small threshold β. The absolute value difference of the Edge Strength between the and is less than a small threshold ϵ.
This theorem can be formalized as: Proof. By Definition 1, since
and
are both DAG-faithful datasets, their generative probability distributions
P have unique essential graphs
and
, which encodes the same conditional independences in
P [
23]. Since the essential graphs
and
are drawn from the same distribution
P, then
and
are identical. The only difference between an essential graph and a DAG structure is the edge direction, but because the change of arc direction does not effect the sum of each node’s Markov Blanket, the change of edge direction will not affect the AMBS. Thus, we can transform
and
into two DAGs:
and
, and consequently,
is equal to
. Therefore, there must exist a threshold value
such that
.
Furthermore, since
and
have the same edges, the differences between
and
are determined by the Bayesian score calculation over the different orientation of edges, which is insignificant and converges towards 0 when
and
become sufficiently large [
29]. Therefore, given a distribution
P, and a sufficiently large DAG-faithful dataset
with
records, there exists a small threshold,
, and
such that
and
. □
Based on Theorem 1, we can propose a new greedy method that keeps increasing the size of data slice D until and both converge. In this way, we can quantitatively estimate and verify dataset’s DAG-faithful property for distributed Bayesian network learning on a big dataset. Details of this greedy method can be found in Algorithm 1.
In practice, the underlying network structure of a dataset D is unknown. The only way to estimate the is through learning and obtaining the BN structure from the D. To address this challenge, based on Theorem 1, we propose a greedy algorithm (Algorithm 1) to estimate the value of using and Edge Strength.
Algorithm 1 starts with a small data slice, . It learns the BN from (Step 4) and obtains (Step 5) and Edge Strength() (Step 5). Since may not be large enough to be DAG-faithful, resulting in inaccurate and unstable and . In order to make DAG-faithful, the loop in the algorithm (Steps 7–16) doubles at each iteration, the loop condition ensures that and values converge after each iteration. We choose to double the size because this is a reasonable learning rate that serves as a balanced tradeoff point between quality and efficiency. If the size increases at a lower learning rate, then it will take longer for the algorithm to converge, if the rate is a more significant number such as 3, then the will grow too fast, resulting in a relatively large data slice that may slow down the learning process. The loop stops when both and become stable, which satisfies Theorem 1. This indicates, based on Theorem 1, that the size of is close to (Step 17) and can approximate the real value.
| Algorithm 1 CalculateALS. |
| Input: |
| | D: Dataset; |
| | ϵ1, ϵ2: Thresholds; |
| | mstep: Maximum loop steps. |
| Output: |
| | AMBS: Average Markov blanket size; |
| | ALS: Appropriate Learning Size. |
| 1: | bestAMBS = 1; bestES = −1; step = 0; |
| 2: | sliceSize = InitialSize * number of attributes in D;// Initial data slice size |
| 3: | Dsliced = read sliceSize rows from D; |
| 4: | BNDS = LearnBNStructure(Dsliced); |
| 5: | currentAMBS = average Markov Blanket size of BNDS; |
| 6: | currentES = Edge Strength of BNDS; |
| 7: | while (step ≤ mstep) AND ((|currentAMBS − bestAMBS| > bestAMBS * ϵ1) OR (|currentES −
bestES| > bestES * ϵ2)) do |
| 8: | sliceSize = sliceSize * 2; |
| 9: | bestAMBS = currentAMBS |
| 10: | bestES = currentES; |
| 11: | Dsliced = readData(D, nrows = sliceSize); |
| 12: | BDDS = learnBNStructure(Dsliced); |
| 13: | currentAMBS = AMBS of BDDS; |
| 14: | currentES = Edge Strength of BDDS; |
| 15: | step = step + 1; |
| 16: | end while |
| 17: | ALS = number of records in Dsliced; |
| 18: | returnALS. |
Definition 5. (Weight of Bayesian network )
Given M Bayesian network structures, each structure denoted as , a dataset D and a Bayesian score function P on and D denoted as , then, the weight of a structure , denoted as , is its score divided by the sum of scores of all the structures.
Formally,
is calculated using Equation (
5):
Definition 6. (Weighted Adjacent Matrix)
Given N Bayesian network structures, each structure denoted as , a dataset D and a score function . The Weighted Adjacent Matrix of the structure , denoted as , is the product of ’s adjacent matrix and .
Formally,
is calculated using Equation (
6):
Definition 7. (Final Weighted Adjacent Matrix)
Given a collection of N weight adjacent matrix , the final weighted adjacent matrix is their sum, denoted as: 5. The Proposed Approach
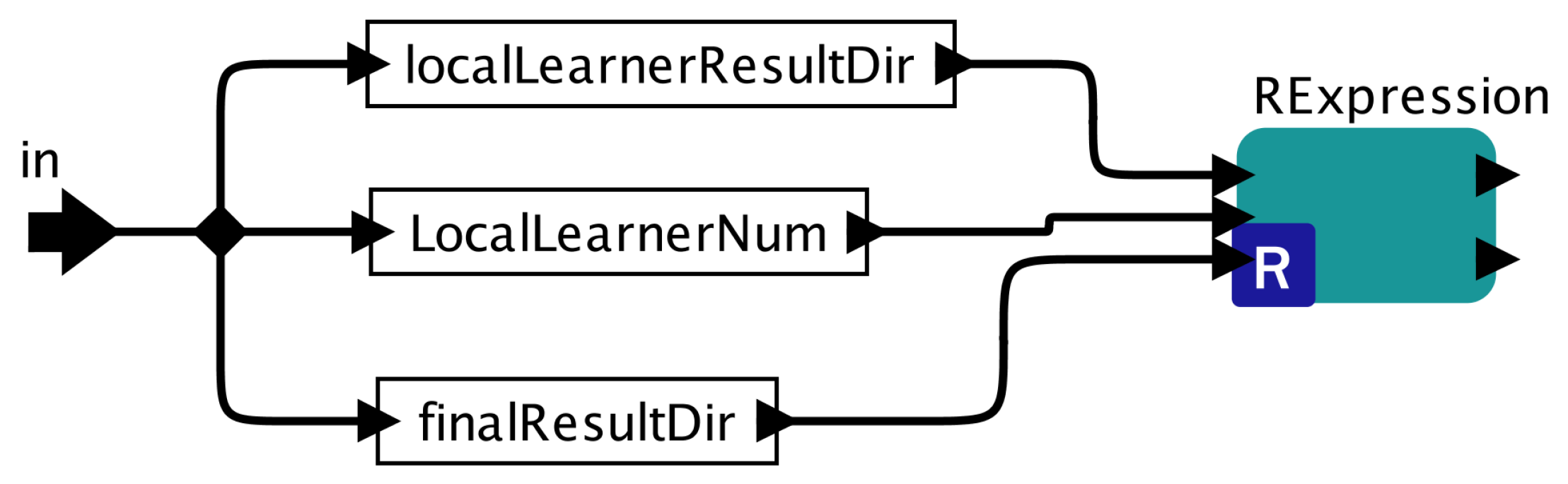
5.1. Overview of PEnBayes
Figure 2 provides an overview of PEnBayes for learning Bayesian network from big data. PEnBayes contains three phases: Data Preprocessing, Local Learner, and Global Ensemble.
5.1.1. Adaptive Two-Stage Data Slicing
Given a big dataset containing
N records and
K local learners, the first step in Adaptive Two-Stage Data Slicing is to perform the global data slicing on the big dataset to allocate data evenly among available local learners for load balancing and consequent learning. Each local learner will receive a global data slice of
rows as the input for local learning. Then, the Appropriate Learning Size (
) value is calculated to obtain the appropriate size of each local data slice using the algorithm proposed in
Section 4. The global data slice on each local learner is adaptively divided into many local data slices of size
for efficient and distributed learning.
Given
K Local Learners, each local learner will receive
data slices for distributed learning, each data slice is of size
.
calculated by Equation (
8).
5.1.2. Local Learner
Each Local Learner has two components: Data Slice Learner and Local ensemble.
Each Data Slice Learner (DS learner) learns K BN structures from one data slice using K different Bayesian network structure learning algorithms. In the experiment, three BN structure learning algorithms are used, namely MMHC, HC, and Tabu. Therefore, the value of K equals 3. Each DS learner then uses the first layer of the weighted adjacent matrix based structure ensemble method to combine these BN structures into one BN.
Then, the Local Learner uses the second layer of the Structure Ensemble to merge the networks learned from all data slices into one local network. As a result, each Local Learner produces one local BN. Our ensemble method is a bagging strategy based on weighted voting.
5.1.3. Global Ensemble
In this final stage, upon the completion of all Local Learners, PEnBayes uses the third layer of the ensemble method to merge the network structures learned from each Local Learner into one global BN structure, thus achieving the task of learning a complete BN from a big dataset.
5.2. Structure Ensemble Method
The main reasoning for the Structure Ensemble Method (Algorithm 2) is based on Definition 5 and Definition 7. Given N BN structures and a dataset D, the goal is to merge these structures into one network structure . Edge Strength is used as the score function to indicate the quality of a learned structure among all the structures (Definition 5). Then, by modeling the learned structures as the Final Weighted Adjacent Matrix (Definition 7), an edge e should exist in the when e exists in the majority of the learned structures. This is equivalent to the the formalized condition in which is the Structure Ensemble Threshold.
| Algorithm 2 StructureEnsemble. |
| Input: |
| | BN: BN Structures; |
| | D: Data set; |
| | T: Threshold factor. |
| Output: |
| | BNE: Ensembled BN Structure. |
| 1: | Obtain from ; |
| 2: | = ; |
| 3: | = |
| 4: | = ; |
| 5: | ; |
| 6: | , |
| 7: | if and i->j does not form a circle in then |
| 8: | = 1; |
| 9: | end if |
| 10: | return. |
Specifically, the Structure Ensemble Method works as follows: First, the Structure Ensemble encodes each network
into an adjacent matrix
, then, it calculates the weight of each network using Edge Strength as the score function, and obtains the weighted adjacent matrix using Equation (
6) (Steps 2–4). In Step 5, the final weighted adjacent matrix
is obtained.
is the collective voting results of the structures with respect to their weights and is calculated using Equation (
7). Based on majority voting, if a directed edge exists between node
i and node
j in most of the networks, then
should be larger than the Structure Ensemble Threshold
Equation (
9). The basic threshold is equal to the minimal structure weight
. Given that
T is the basic threshold factor, if an entry
is larger than the threshold
, then there are more than
T structures containing the edge
. Therefore, the Structure Ensemble adds an edge between
i and
j in the network
(Step 8). After iterating all the entries in
, a merged network structure
is produced from
.
For example, suppose there is a dataset
D from the Cancer network, and we learned three different networks
,
and
from
D with the following Adjacent Matrix.
The Structure ensemble calculates the Edge Strength of each network
given
D and uses Equation (
5) to calculate the
. In this case, we have
= 0.31,
= 0.34,
= 0.35. Then,
If we set the basic threshold factor T as 2, then the Structure Ensemble Threshold = 0.62, the merged network structure is as follows: = .
is the correct adjacent matrix presentation of the Cancer network. Through this example, we can see that even though , and all miss one edge, the Structure Ensemble can identify all five directed edges and obtain the correct network structure of the Cancer network.
5.3. Data Slice Learner
Data Slice Learner is the first layer of the ensemble method that executes Algorithm 3 to combine BNs learned by different learning algorithms using majority voting. Algorithm 3 invokes three BN learning algorithms (namely MMHC, HC, and Tabu) to learn a BN structure for each data slice . Then, it calls Structureensemble to merge the three learned networks into one network structure . For Data Slice Learner, the basic threshold factor T is set as two for majority voting.
| Algorithm 3 DataSliceLearner. |
| Input: |
| | DS: Data slice. |
| Output: |
| | BNDS: Merged network structure in matrix. |
| 1: | = (); |
| 2: | = (); |
| 3: | = (); |
| 4: | |
| 5: | |
| 6: | ; |
| 7: | return |
5.4. Local Learner
Each Local Learner (shown in Algorithm 4) is given
data slices Equation (
8). Then, the Local Learner learns a network for each data slice using DataSliceLearner (Step 3). The Local Learner keeps track of the data slice
with the best Edge Strength. After completing data slice learning, the Local Learner calls the Structureensemble to merge the learned networks into one local network
. By Definition 5, the weight of each learned network is calculated using one dataset. For the Local Learner, the threshold factor
, this means the Local Learner identifies an edge if that edge exists in more than half of networks learned by the Data Slice Learners. Local Learner is the second layer of the network ensemble scheme.
| Algorithm 4 LocalLearner. |
| Input: |
| | DS: Data slices; |
| | Nd: number of data slices. |
| Output: |
| | BNLocal: Local network structure. |
| 1: | For each |
| 2: | ; |
| 3: | = the data slice with the best Edge Strength; |
| 4: | End For |
| 5: | |
| 6: | return. |
5.5. Global Ensemble
Upon the completion of all the Local Learners, each Local Learner sends its local BN and its best data slice to the Global Ensemble for the final merging process (shown in Algorithm 5). Similar to the Local Learner, the third layer of the network ensemble is executed to produce one final network structure using all the local structures and a data slice (denoted as ) as representative for the entire dataset for fast calculation here. For the Global Ensemble, given K Local Learners, the threshold factor is . This means that the Global Ensemble adds an edge in the final network if that edge exists in more than two-thirds of networks learned by all the Local Learners.
| Algorithm 5 GlobalEnsemble. |
| Input: |
| | LS: Local Structures; |
| | DSBG: Data slice with the best global Edge Strength; |
| | K: Number of Local Learners. |
| Output: |
| | BNfinal: Local network structure. |
| 1: | |
| 2: | return. |
5.6. The Time Complexity of PenBayes
Since PEnBayes is a parallel learning algorithm, the time complexity is determined by the local learner. As specified in
Section 5.1, each local learner receives
data slices. Therefore, the time complexity of PEnBayes is defined as:
where T(DS) is the time spent on learning the BN structure from one data slice of size
and can be regarded as a constant value given the learning algorithms in the Data Slice learner and the data slice. Therefore, the time complexity of PEnBayes is linear with the value of
. The learning time will decrease with more local learners and will increase with fewer local learners. The experiment results in
Section 8.3 confirm this theoretical analysis.
8. Experimental Results
This section presents experimental results with our PEnBayes approach.
Section 8.1 discusses evaluation of the ALS calculation algorithms to determine the Appropriate Learning Size for big datasets.
Section 8.2 compares execution time and accuracy for PEnBayes with the baseline algorithms for learning Bayesian networks.
Section 8.3 explores the scalability of PEnBayes. Note that PB16, PB32, PB64 and PB128 refer to results of PEnBayes with 16, 32, 64 and 128 Local Learners, respectively. Based on the setup in
Section 7.3, they each run with 32, 64, 128 and 256 CPU cores.
8.1. ALS Calculation Results
Table 3 shows the computation results for Appropriate Learning Size (ALS) and comparison between the calculated AMBS and actual AMBS from the three known BNs. We observe that the calculated AMBS by Algorithm 1 is very close to the actual AMBS, indicating an accurate estimation of ALS by Algorithm 1.
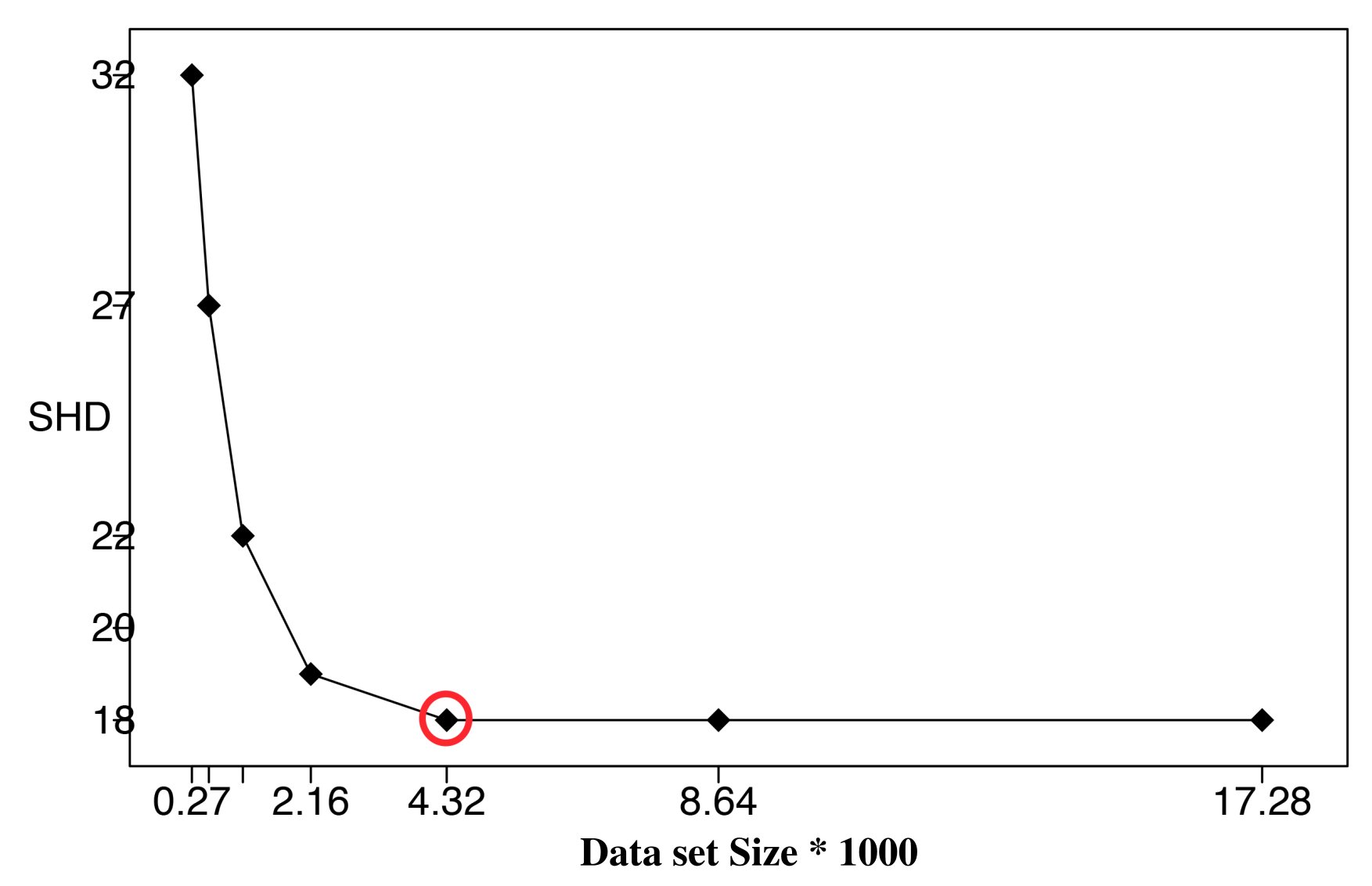
To further verify the correctness of the ALS calculation, we performed BN learning using the calculated ALS values (the second column in
Table 3) as reference values (circled in red). Each reference value was repeatedly halved or doubled to create a new dataset size. For each dataset size, a network was learned using the HC algorithm, and the resulting structural Hamming distance (SHD) between the learned network and the correct network was recorded [
27]. We only use SHD because it can distinguish the differences between the learning results clearly. Bayesian score comparison results are much closer, and differences in the learned network are hard to identify and distinguish.
Figure 7,
Figure 8 and
Figure 9 show SHD trends over varying data slice size on the three synthetic datasets. The reference values are circled in red.
Notice that a lower SHD value indicates a more accurate BN structure. From the figures, we observe that SHD drops sharply as the data slice size increases until the reference value of ALS is reached. We also notice that as the data slice size increases from the reference value, SHD remains stable. In
Figure 9, the calculated
does not achieve the lowest SHD. Further, SHD increases as data size increases, indicating the existence of overfitting with the growth of the data set size. However, we observe that the SHD value of the calculated
is 13, which is very close to the lowest SHD value being 12. This indicates that the calculated
is the smallest data slice size that returns the lowest or close to lowest SHD values, thus optimizing the trade-off between learning accuracy and computation efficiency and avoiding overfitting. These results show the effectiveness of Algorithm 1 for calculating ALS. This empirical study also supports setting the value of thresholds
and
as 0.05.
8.2. PEnBayes and Baseline Experimental Result Comparison
Execution time, as well as accuracy, are compared for different PEnBayes setups (with different numbers of Local Learners) and different baseline Bayesian learning algorithms, namely MMHC, HC, and Tabu.
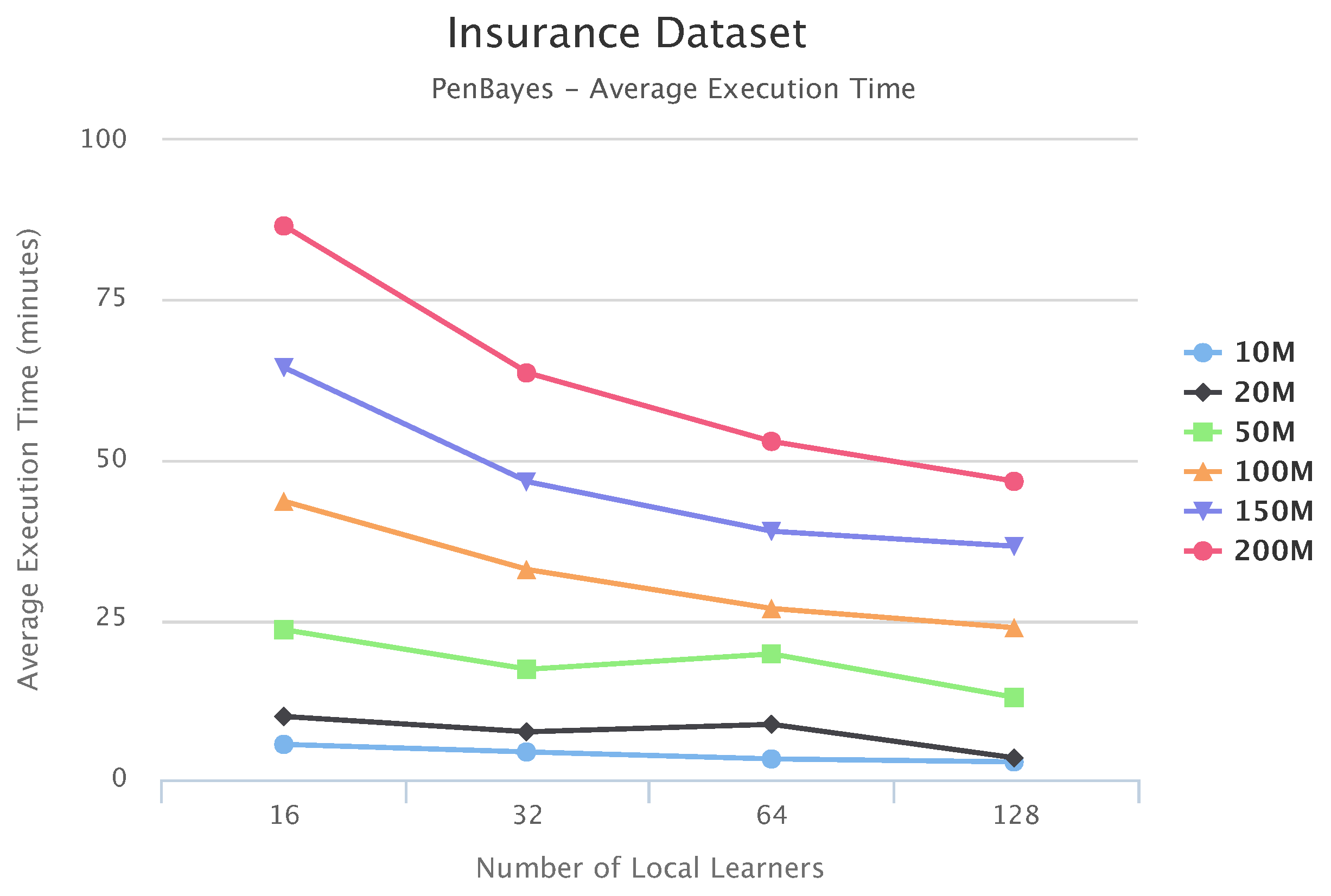
Figure 10,
Figure 11 and
Figure 12 compare execution times of the different setups for the Alarm, Child, and Insurance datasets, respectively. As these figures show, execution times for the baseline algorithms are exponentially higher than for PEnBayes and increase at a much faster rate as the dataset size increases. Note that for the Insurance dataset, MMHC was able to complete learning for only the 10-M dataset. For all other Insurance dataset sizes, MMHC was not able to learn the network within the maximum allotted amount of 12 h for the wall-time. These results demonstrate the significant improvement of computational efficiency of PEnBayes compared with traditional baseline BN learning algorithms.
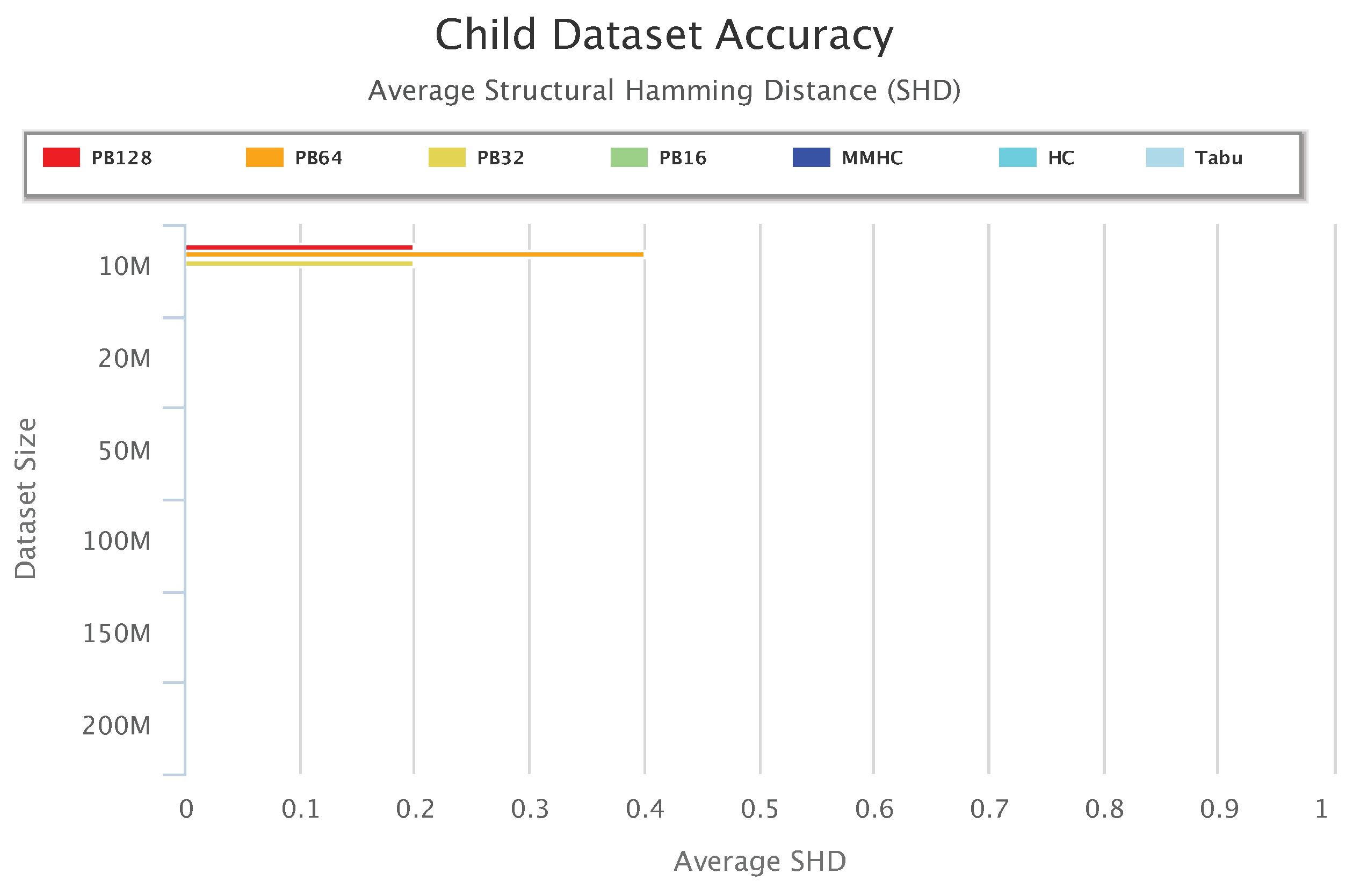
Figure 13,
Figure 14 and
Figure 15 compare accuracy of the different setups for the Alarm, Child, and Insurance datasets, respectively. Accuracy is measured by the structural hamming distance (SHD) between the learned network and the true network structure. Lower SHD indicates a more accurate BN structure. In these figures, a value of zero for SHD indicates that the learned network exactly matches the true network. A negative value for SHD, on the other hand, indicates that network learning was not completed within the maximum allotted amount of 12 h for the wall-time.
Figure 13 shows that for the Alarm 50-M dataset, MMHC was able to identify the structure of the true network. For the Alarm 100 M dataset, both MMHC and Tabu were able to achieve this. However, for the Alarm 150-M and 200-M datasets, none of the baseline learning algorithms was able to learn a network at all within the maximum allotted time. Only PEnBayes was able to learn a BN structure from these very large datasets. Among the baseline algorithms, MMHC achieved the best learning accuracy. On 20-M, 50-M and 100-M datasets, PEnBayes achieves better accuracy than whole dataset learning by HC and Tabu algorithms. This indicates the effectiveness and robustness of PEnBayes in obtaining more consistent and accurate BN structures through multi-layered ensembles.
Figure 14 shows accuracy results for the Child data. All setups achieved a perfect SHD value of zero, except for PB128, PB64, and PB32 on 10 million datasets. Note that PB16 achieved 100% learning accuracy with 0 SHD.
Figure 15 summarizes accuracy results for the Insurance data. Note that for Insurance 200 M, none of the baseline algorithms was able to learn a network. An important observation from this plot is that MMHC performed very poorly on the Insurance data. MMHC learned a network with very high SHD for Insurance 10 M, and was not able to complete network learning for all other Insurance datasets. However, with the multi-layered ensemble approach, PEnBayes was not affected by the poor performance of MMHC. In contrast,
Figure 15 shows that PEnBayes achieved a slightly higher learning accuracy than all baseline algorithms, with smaller SHD values on all Insurance datasets.
We also noted that for the same big dataset, different numbers of Local Learners may result in different learning accuracies. This is because the Bayesian networks learned by the Local Learners are different in number and structurally varied, thus resulting in different final network structures, and consequently, slightly different accuracy results. In addition, we observe that there is no optimal number of Local Learners for learning accuracy in general.
To study the accuracy and the stability of PenBayes, we compared the SHD standard deviation of PenBayes vs. the baseline algorithms.
Figure 16 shows the standard deviation of the SHD for Alarm for different dataset sizes. As with previous figures, negative values indicate that the algorithm was unsuccessful in learning a network for the dataset. We observe that even though the SHD standard deviation of PenBayes was not always the lowest, it was more consistent across all dataset sizes compared to the baseline algorithms. For example, even though MMHC obtained lower SHD standard deviation values than PenBayes for the smaller datasets, it was not able to learn a network for dataset sizes 150-M and 200-M. Tabu had higher SHD standard deviation values than PenBayes for dataset sizes 10 M to 50 M, then abruptly dropped to 0 for 100-M, and was not able to process dataset sizes 150-M and 200-M. This indicates that PenBayes achieves more stable learning accuracy than any individual baseline algorithm alone.
In summary, compared with the baseline learning algorithms, these experimental results indicate that PEnBayes is more stable and robust regarding learning BN structures from big datasets than traditional learning algorithms.
8.3. PEnBayes Scalability Experiments
Figure 17,
Figure 18 and
Figure 19 show the scalability of our workflow with different Local Learner number and distributed nodes. We always allocate eight Local Learners on one compute node. Therefore, more Local Learner means the execution runs on more compute nodes. We can see that most of the execution times decreased with more Local Learners, showing a linear relationship between the number of Local Learners and the execution time. This indicates that PenBayes can scale well, achieving better execution performance with more computation nodes.
We observe that there were a few cases where the execution times increased with more Local Learners. We investigated the logs on these cases and found that while more Local Learners decreased learning time for each Local Learner, data reading times by the Local Learner program were nearly constant. In the experiments, data was read from a shared data node with a Lustre parallel file system. The reason for the constant data reading time is because more Local Learners will have fewer data to be read for each Local Learner, but more reading competition among more simultaneous data readers. This means that data reading became more and more dominant in the overall execution time. Also, the same amount of data sent to the Local Learners does not mean the same local learning time because learning time, especially its convergence, depends on both data content and data size. Data content affects how samples for different dependency relationships are distributed among different data slices. Therefore, if the jobs scheduled on one compute node by Spark happen to have more data reading time and learning time, the node becomes a straggler [
56] and slows down the overall execution time. Additionally, these experiments were conducted in a shared cluster environment where network congestion varies depending on the load. Due to these reasons, we do not always see the overall times decrease with more Local Learners. This abnormal behavior occurred more with the Child datasets since their learning times are relatively shorter compared to Alarm and Insurance.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}