EAGLE—A Scalable Query Processing Engine for Linked Sensor Data †

 ,
, 
Abstract
1. Introduction
- A proposed distributed spatio–temporal sub-graph partitioning solution which significantly improves spatio–temporal aggregate query performance.
- An implementation of a comprehensive set of spatial, temporal and semantic query operators supporting computation of implicit spatial and temporal properties in RDF-based sensor data.
- An extensive performance study of the implementation using large real-world sensor datasets along with a set of spatio–temporal benchmark queries.
2. Background and Related Work
2.1. Sensor Ontologies
2.2. Triple Stores and Spatio–Temporal Support
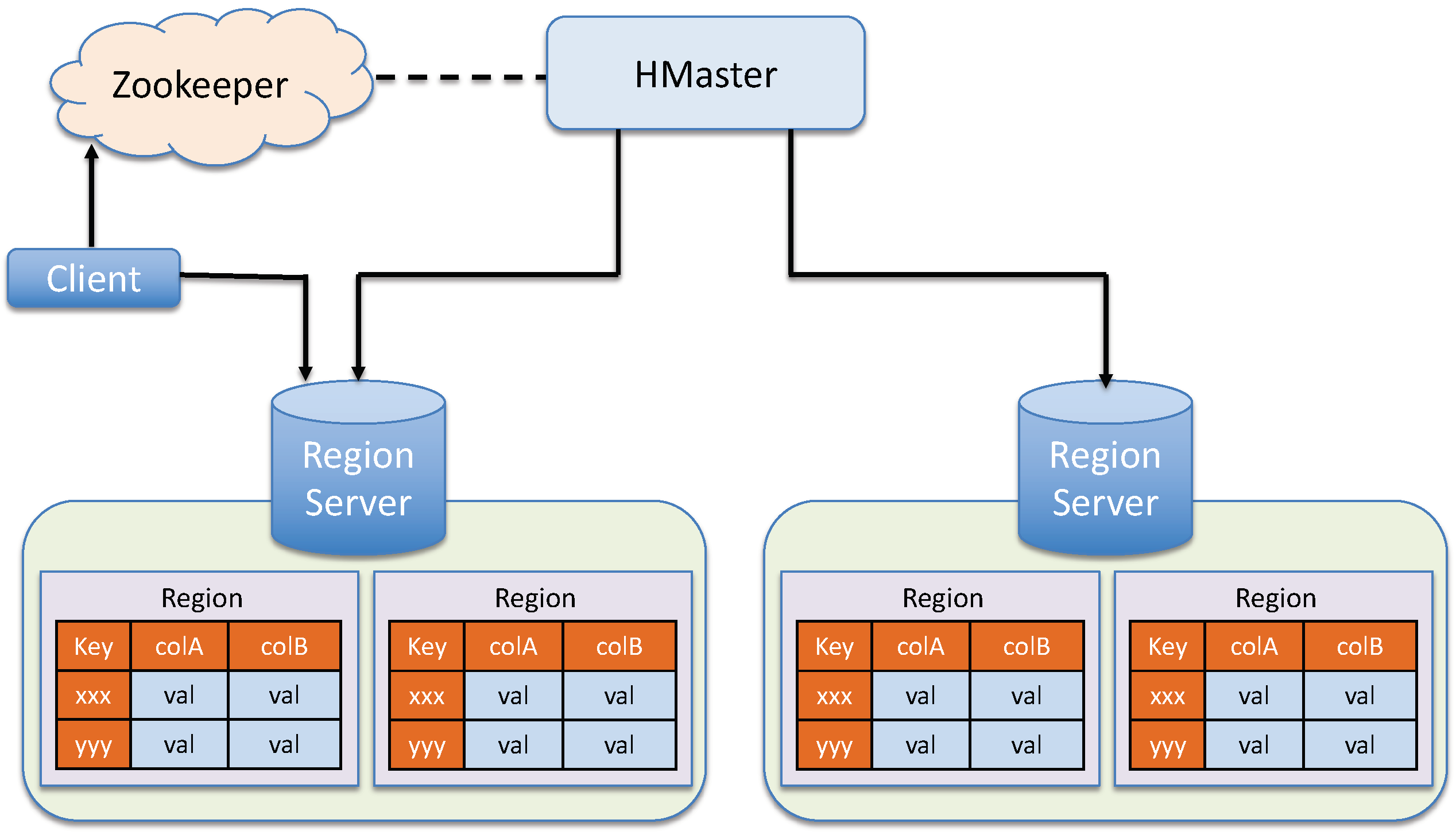
3. System Architecture
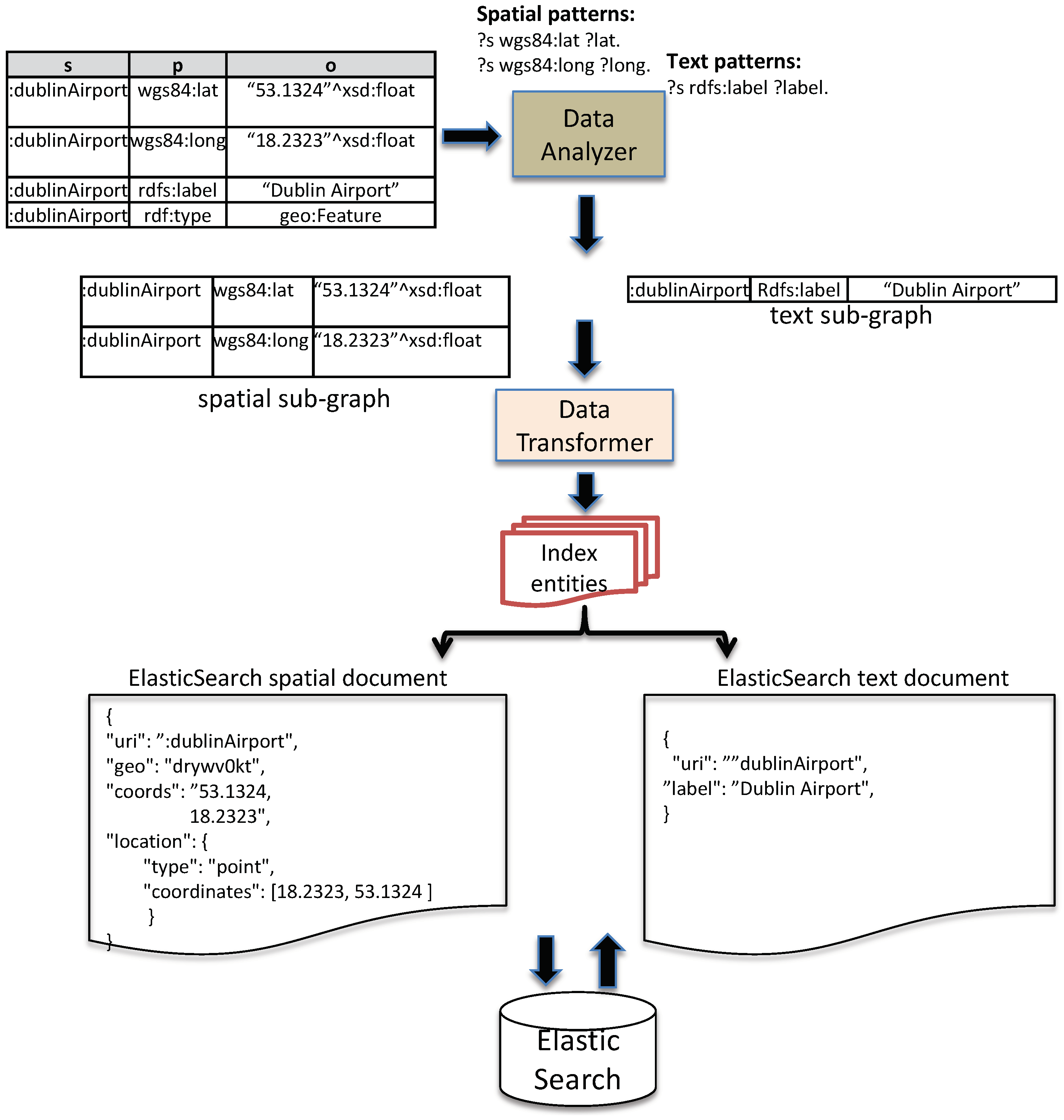
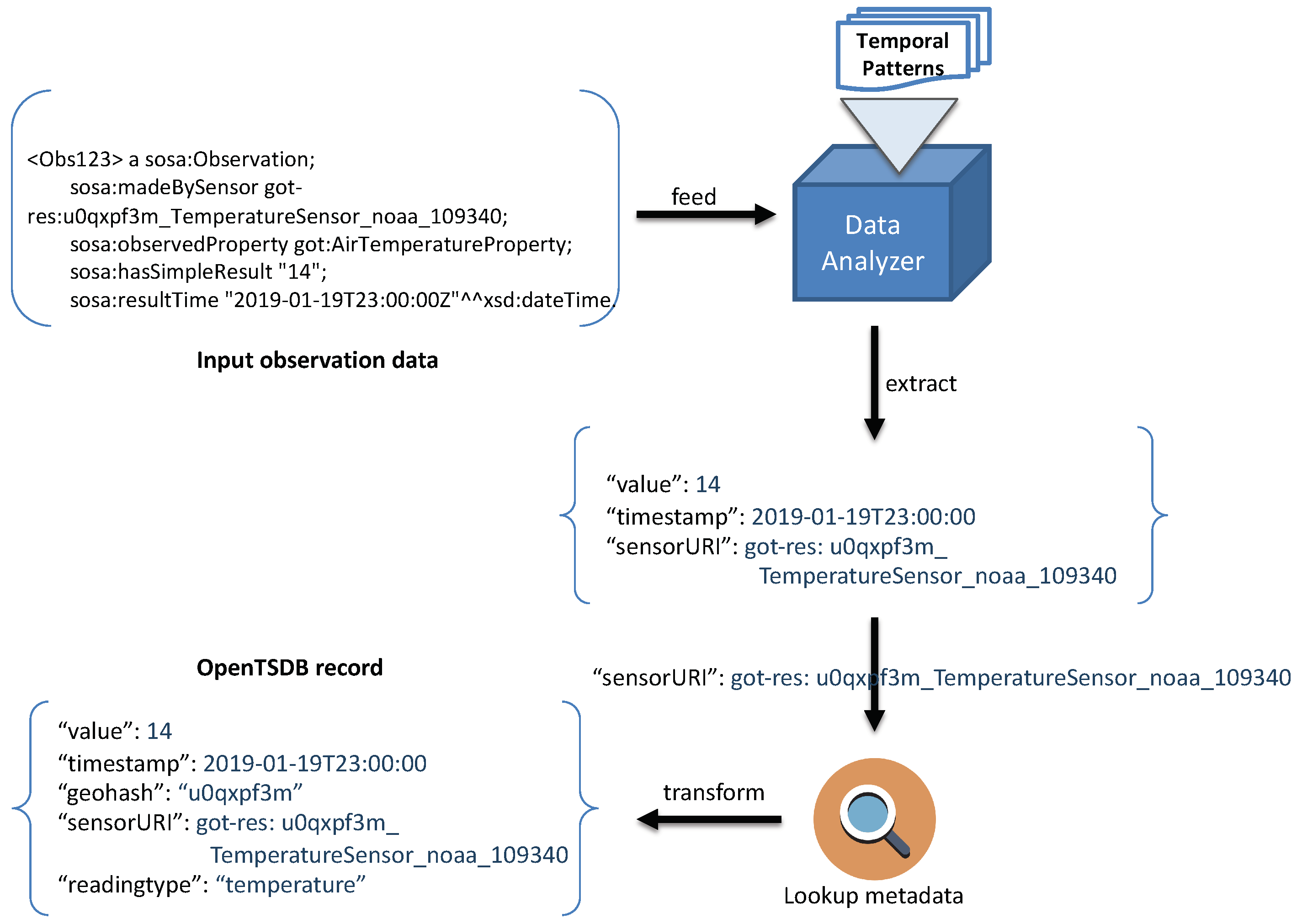
3.1. Data Analyzer

3.2. Data Transformer
3.3. Index Router
3.4. Data Manager
3.4.1. Spatial-Driven Indexing

3.4.2. Temporal-Driven Indexing
3.5. Query Engine

4. A Spatio–Temporal Storage Model for Efficiently Querying on Sensor Observation Data
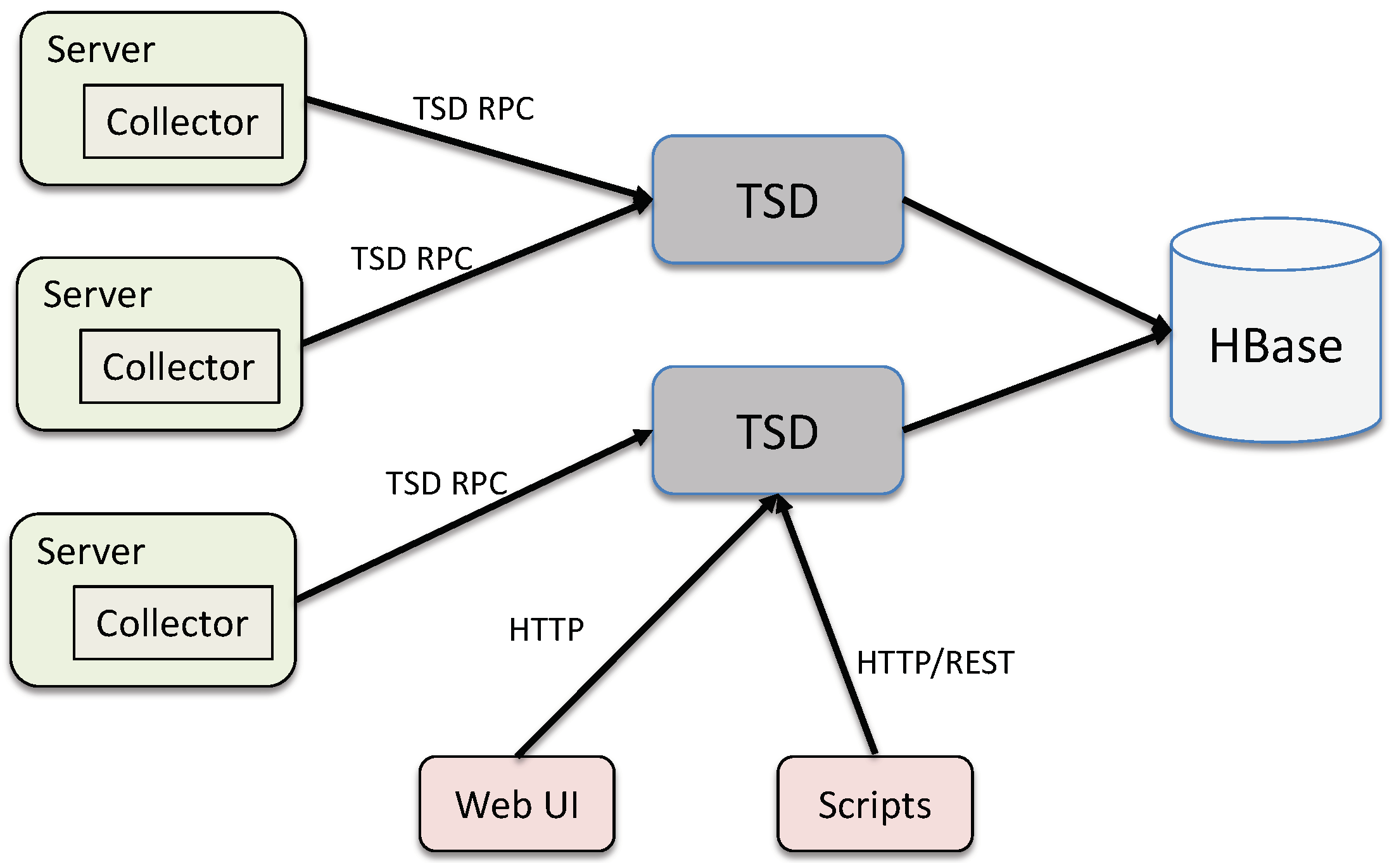
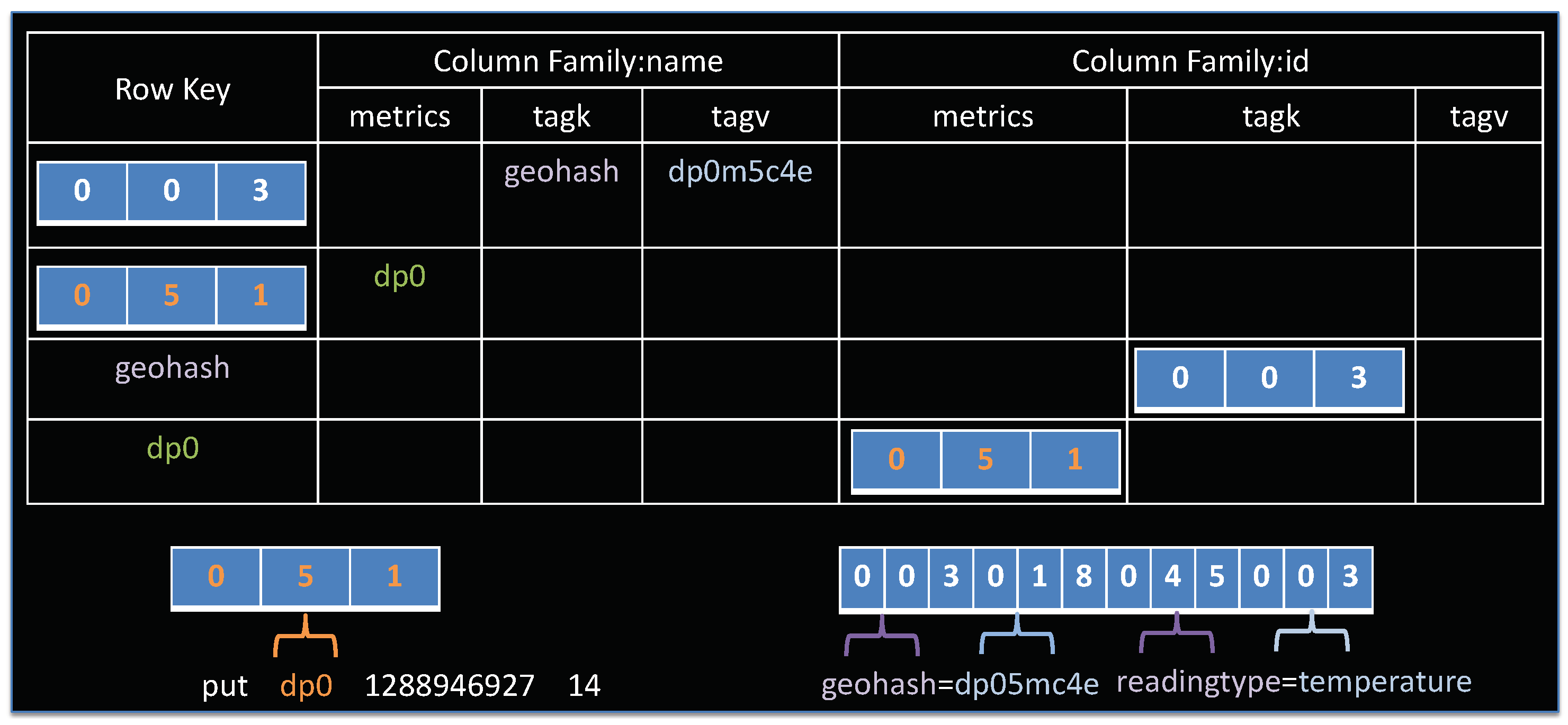
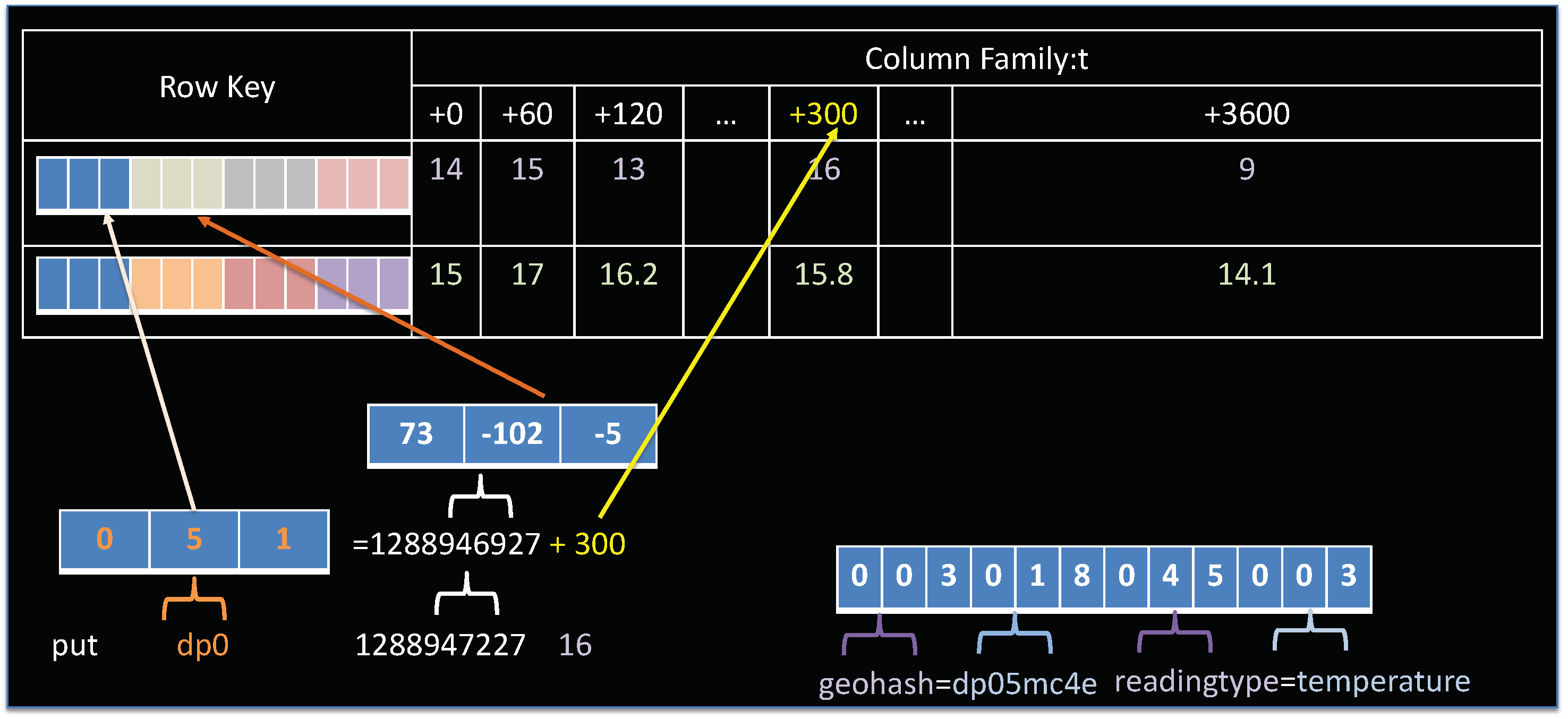
4.1. Opentsdb Storage Model Overview
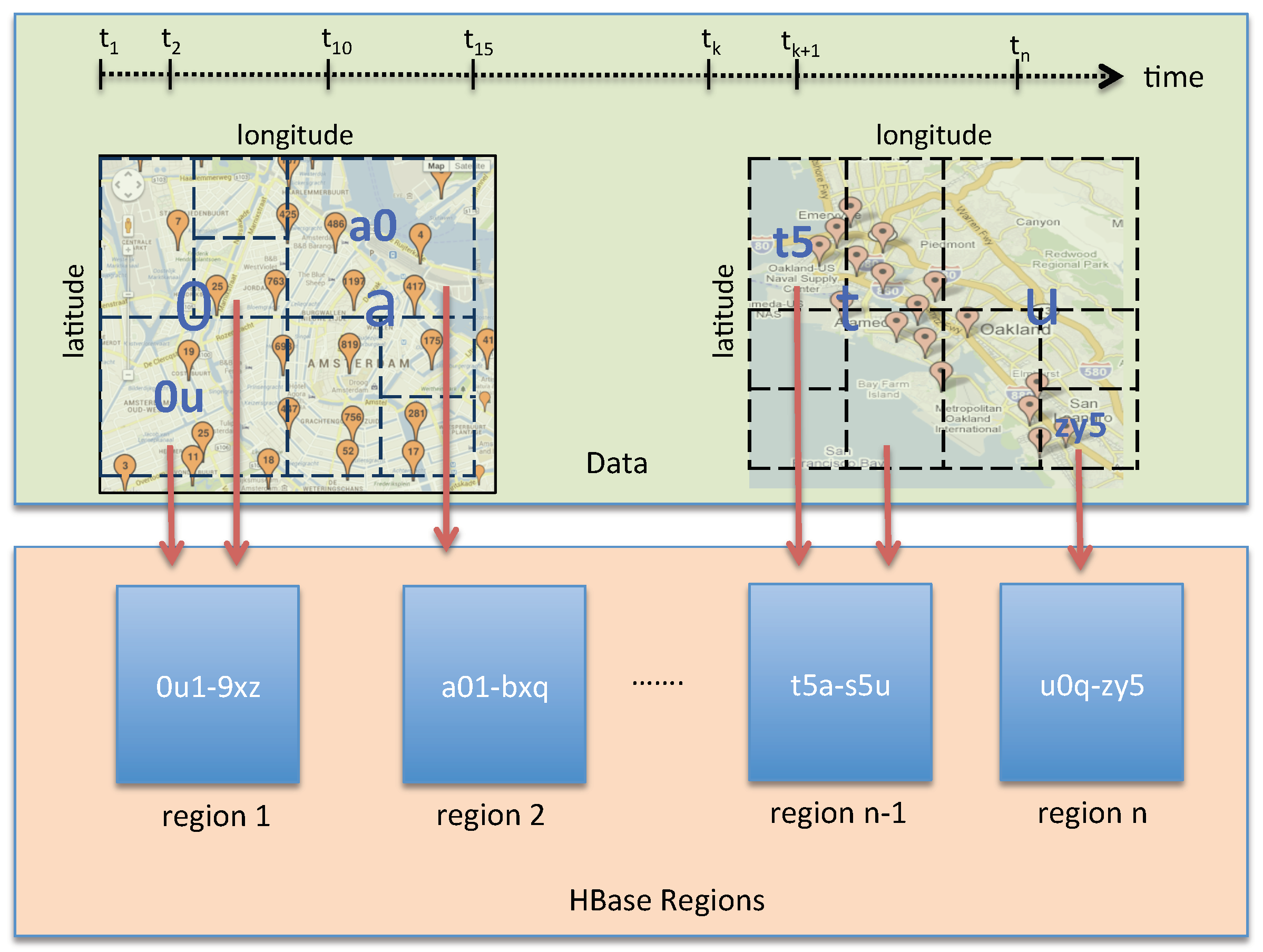
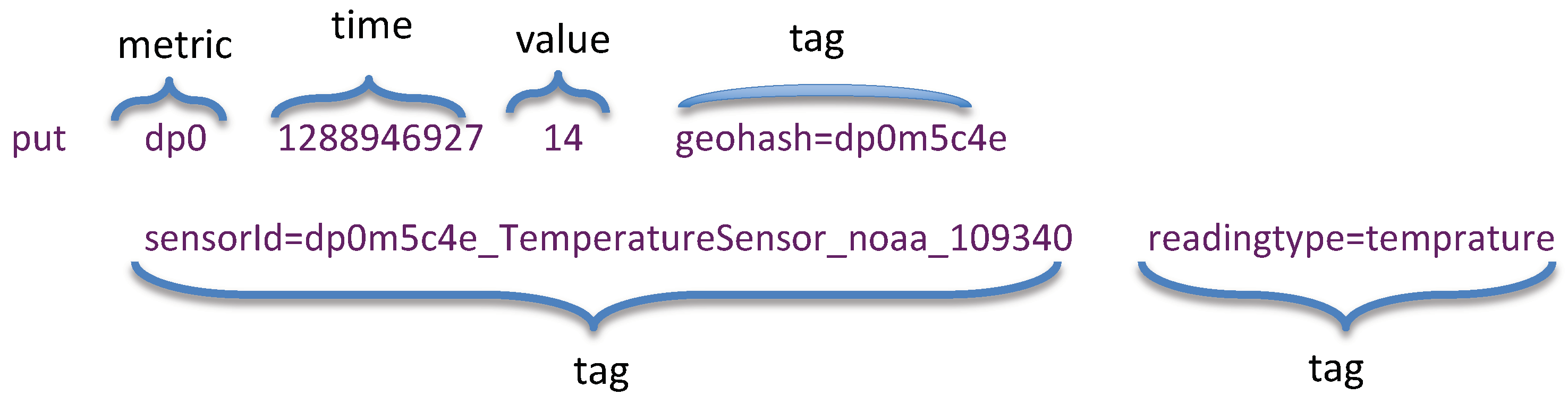
4.2. Designing a Spatio–Temporal Rowkey
- A user may request meteorological information of an area over a specific time interval. The query may include more than one measurement values, i.e., humidity, wind speed along with the temperature.
- A user may request the average observation value over a specific time interval using variable temporal granularity i.e., hourly, daily, monthly, etc.
- A user may request statistical information about the observation data that are generated by a specific sensor station.
- A user may ask for statistical information, such as the hottest month over the last year for a specific place of residence. Such queries can become more complex if the residence address is not determined by city name or postal code but by its coordinate.
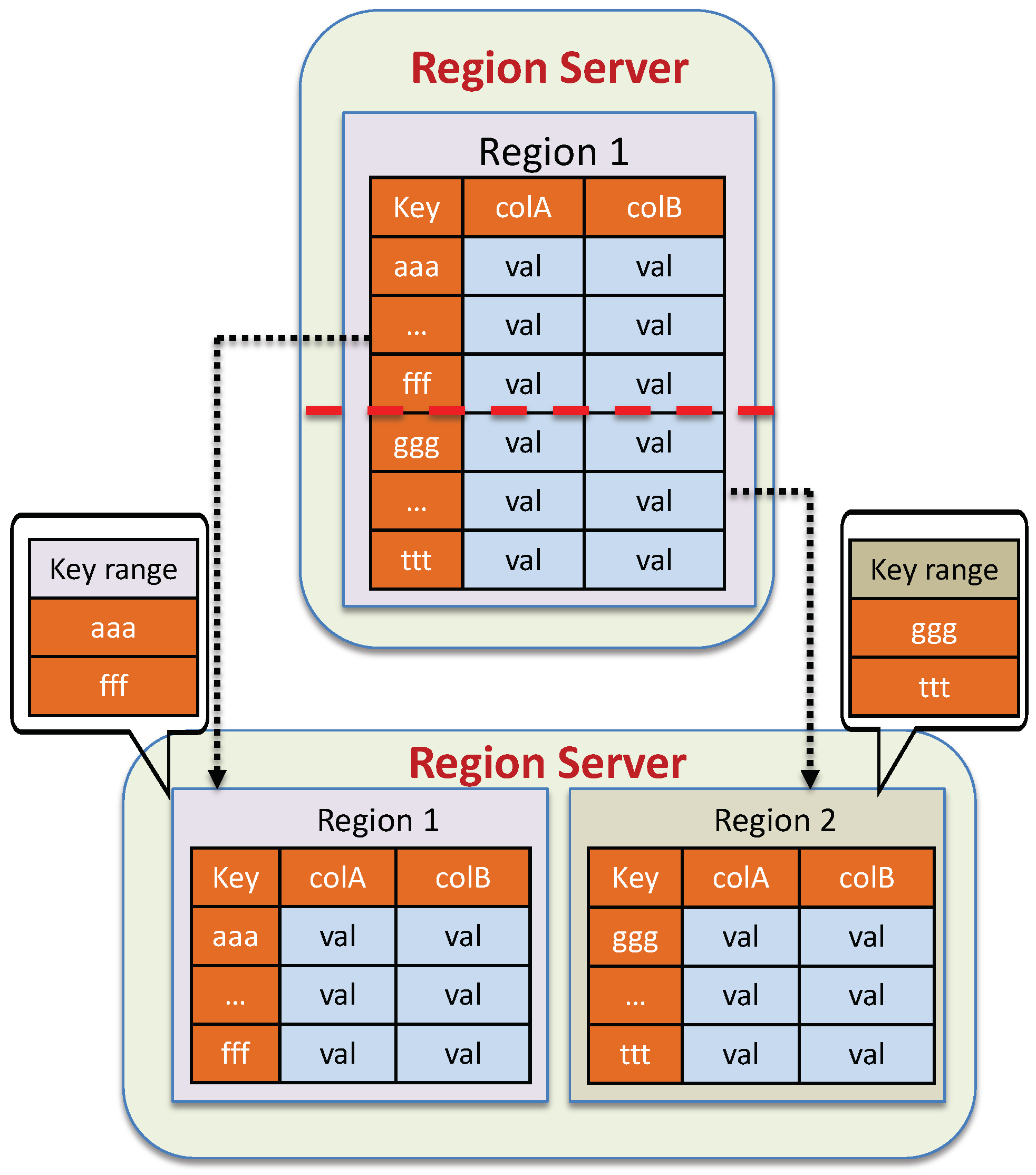
4.3. Spatio–Temporal Data Partitioning Strategy
5. System Implementation
5.1. Indexing Approach
5.1.1. Defining Triple Patterns for Extracting Spatio–Temporal Data


5.1.2. Spatial and Text Index


| Algorithm 1: A procedure that will read a given dataset and index its spatial and text data in ElasticSearch. |
 |
| Algorithm 2: A procedure that will read a streaming triple and index its spatial and text data in ElasticSearch. |
 |
5.1.3. Temporal Index
| Algorithm 3: A procedure that will read an observation data and index its temporal information in OpenTSDB. |
 |
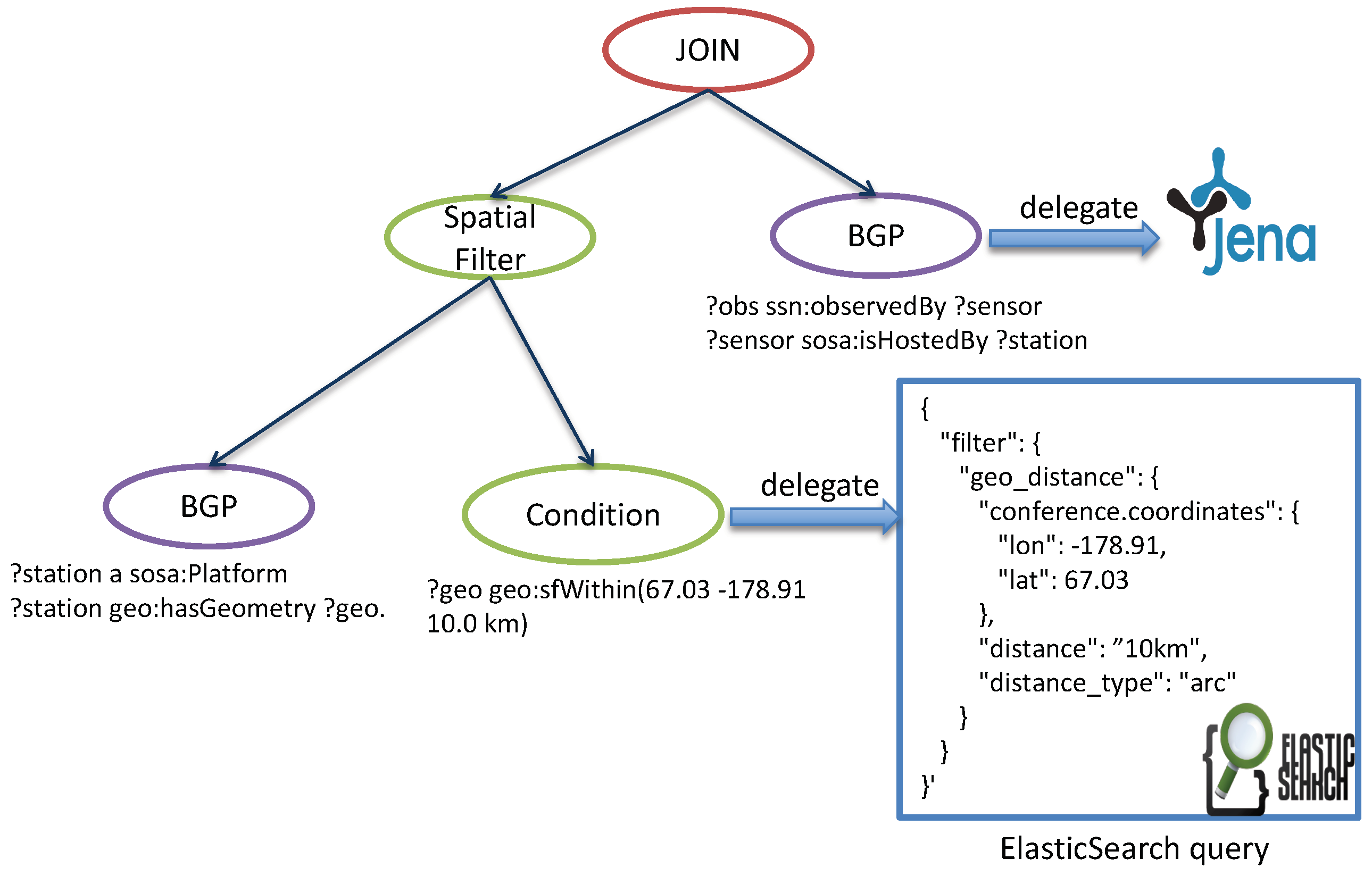
5.2. Query Delegation Model
6. Query Language Support
6.1. Spatial Built-in Condition
- If is a qualitative spatial function, then is a spatial built-in condition.
- If , are spatial built-in conditions, then (), (), and () are spatial built-in conditions.
6.2. Property Functions
6.3. Querying Linked Sensor Data by Examples







7. Experimental Evaluation
7.1. Experimental Settings
7.1.1. Platform and Software
7.1.2. Datasets
7.1.3. Queries
7.2. Experimental Results
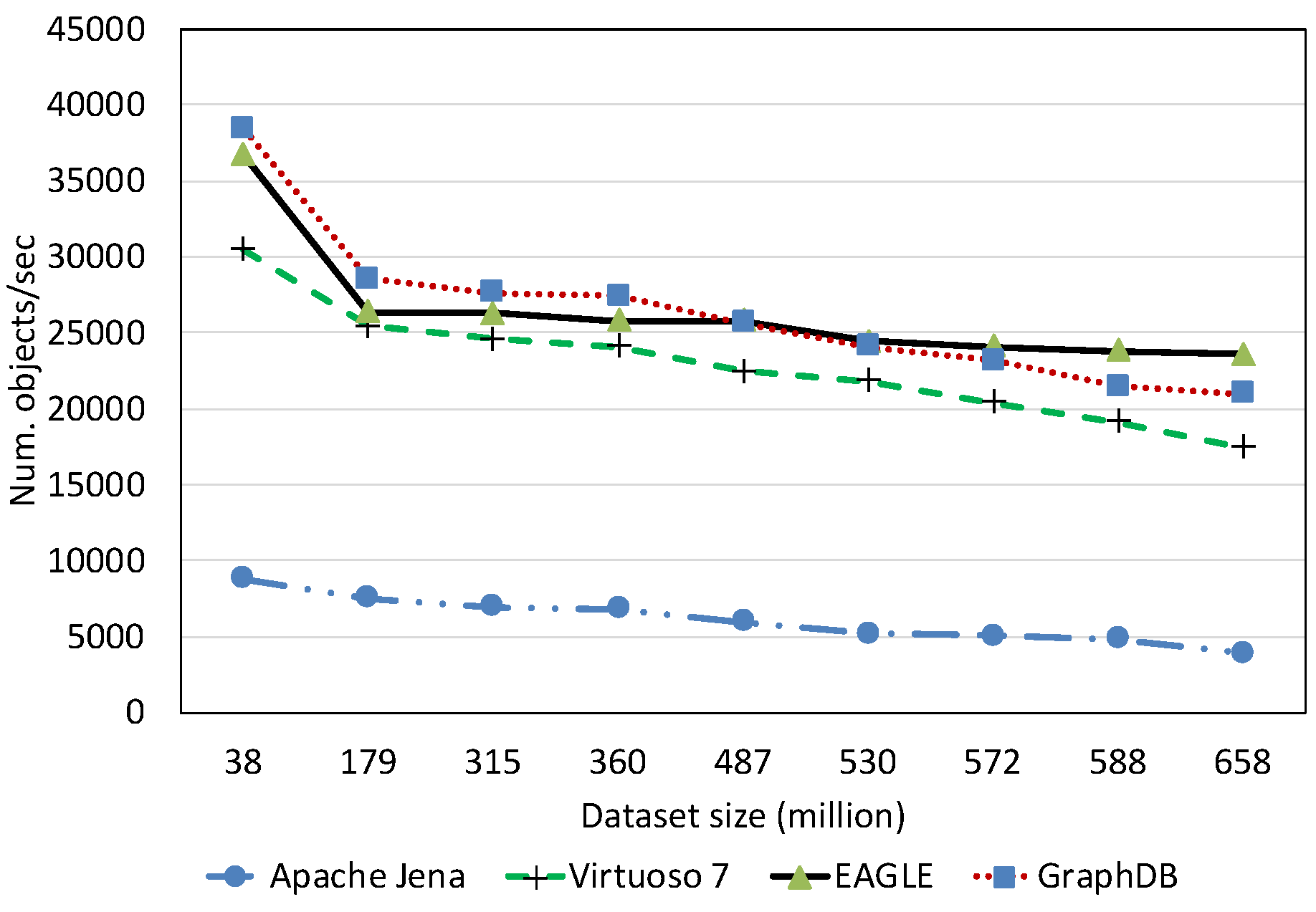
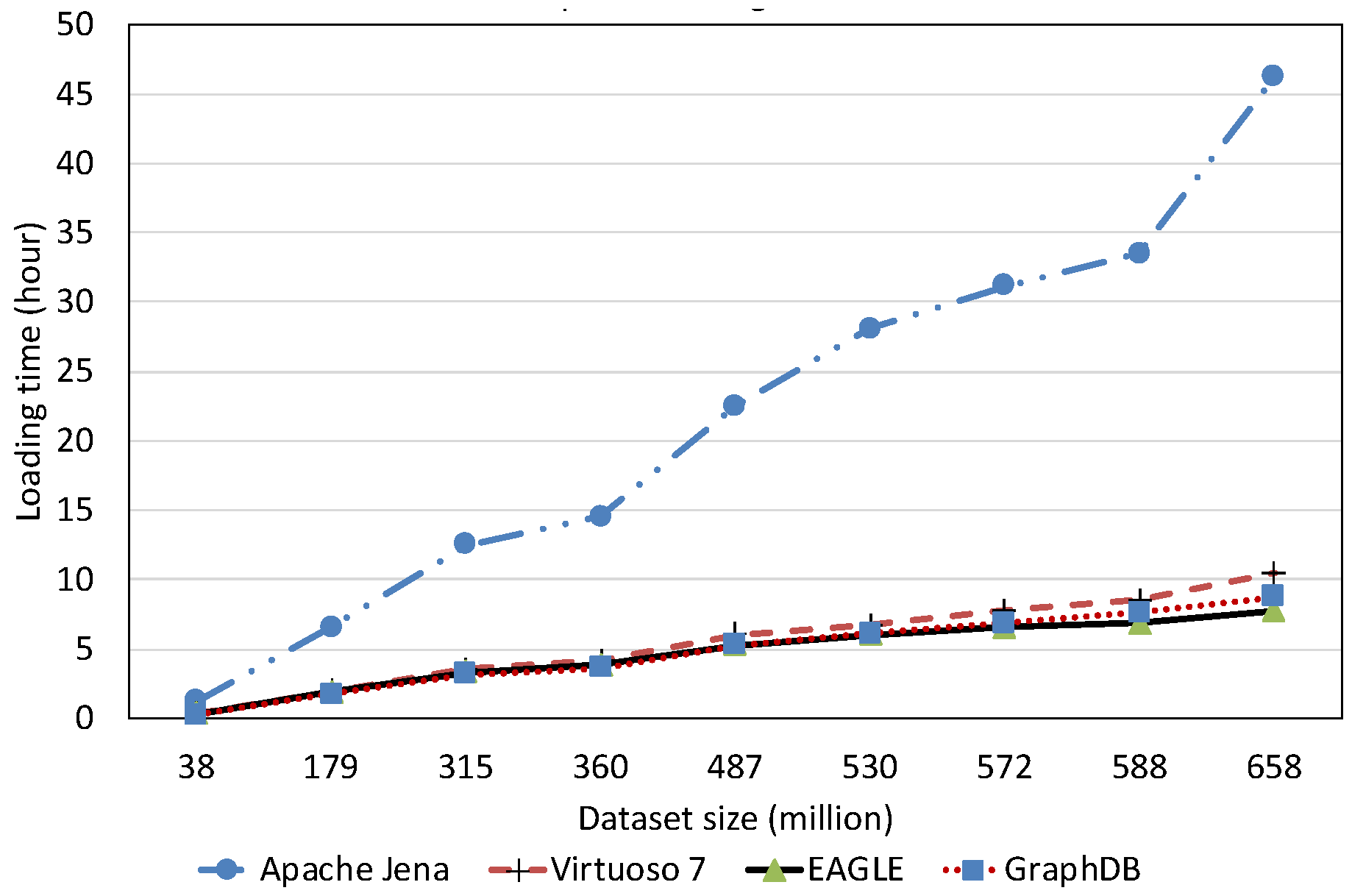
7.2.1. Data Loading Performance
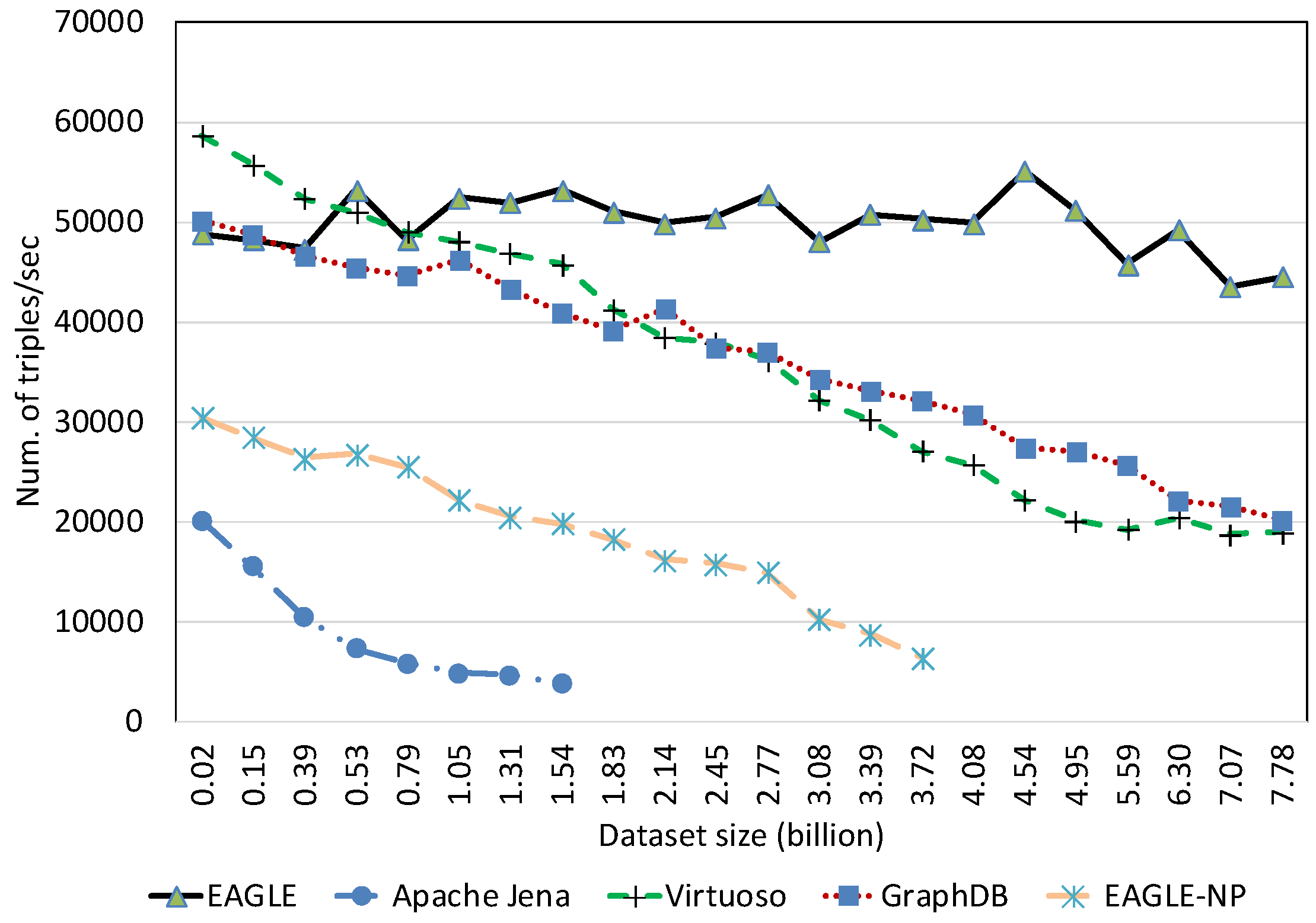
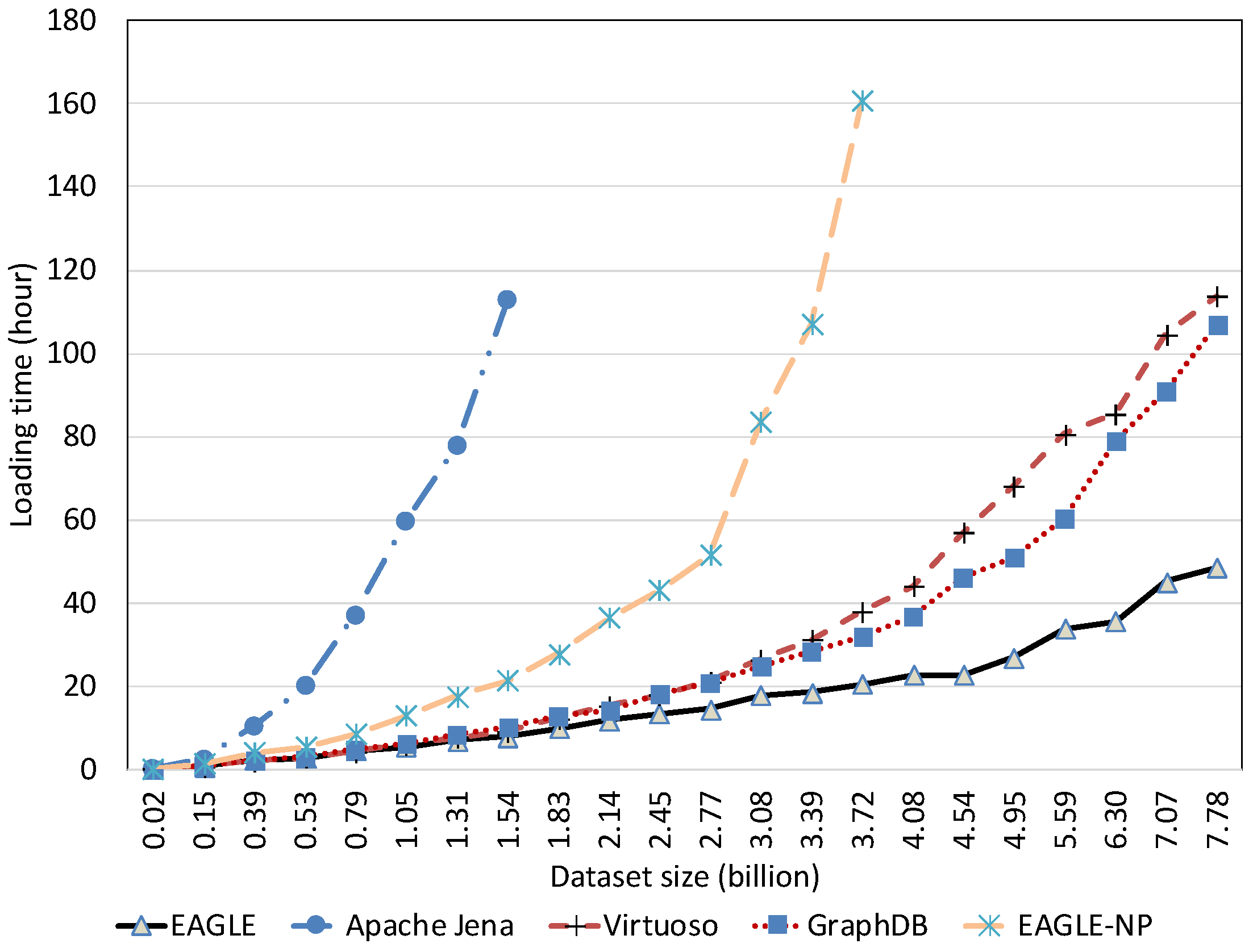
Spatial Data Loading Performance With Respect to Dataset Size
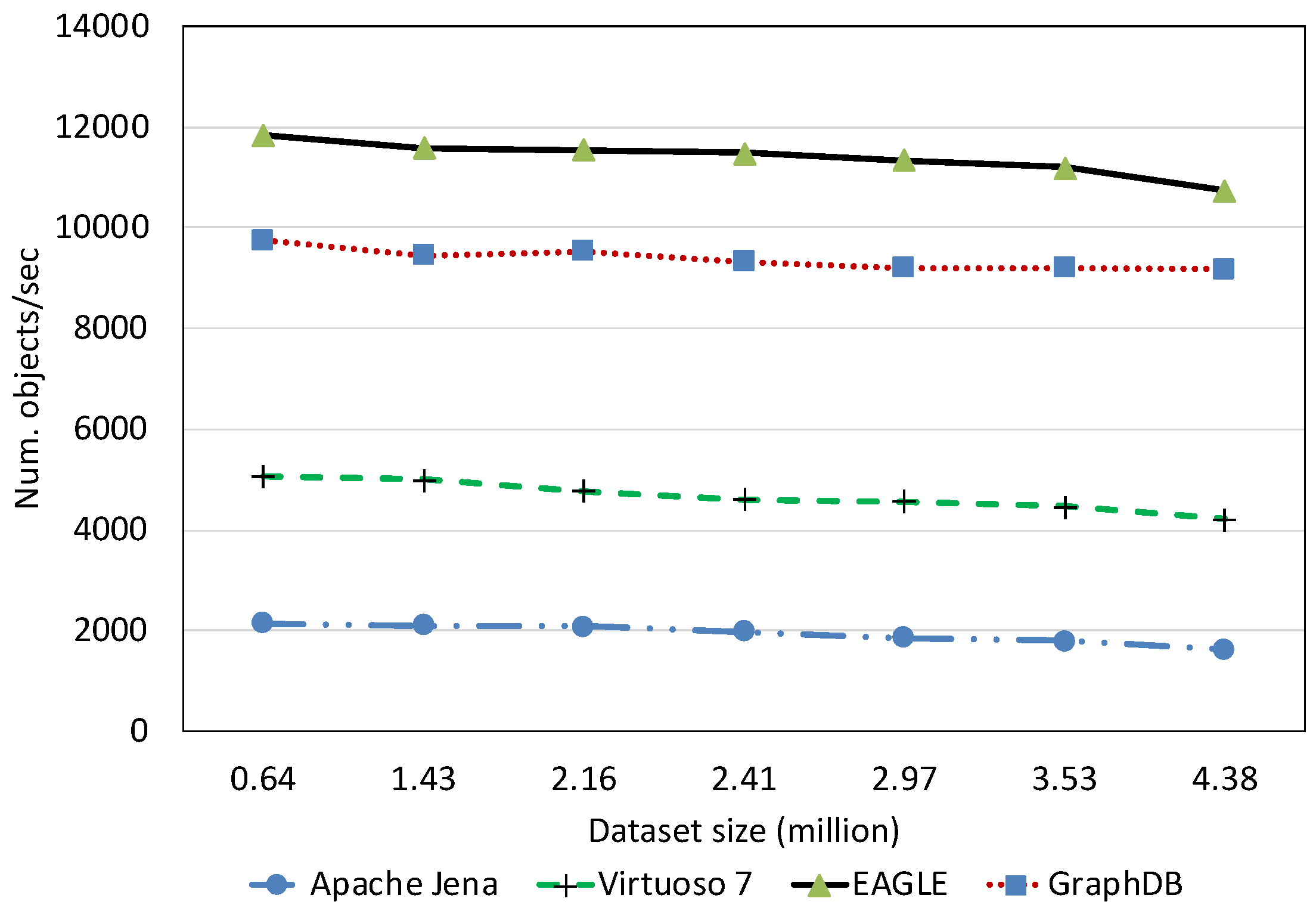
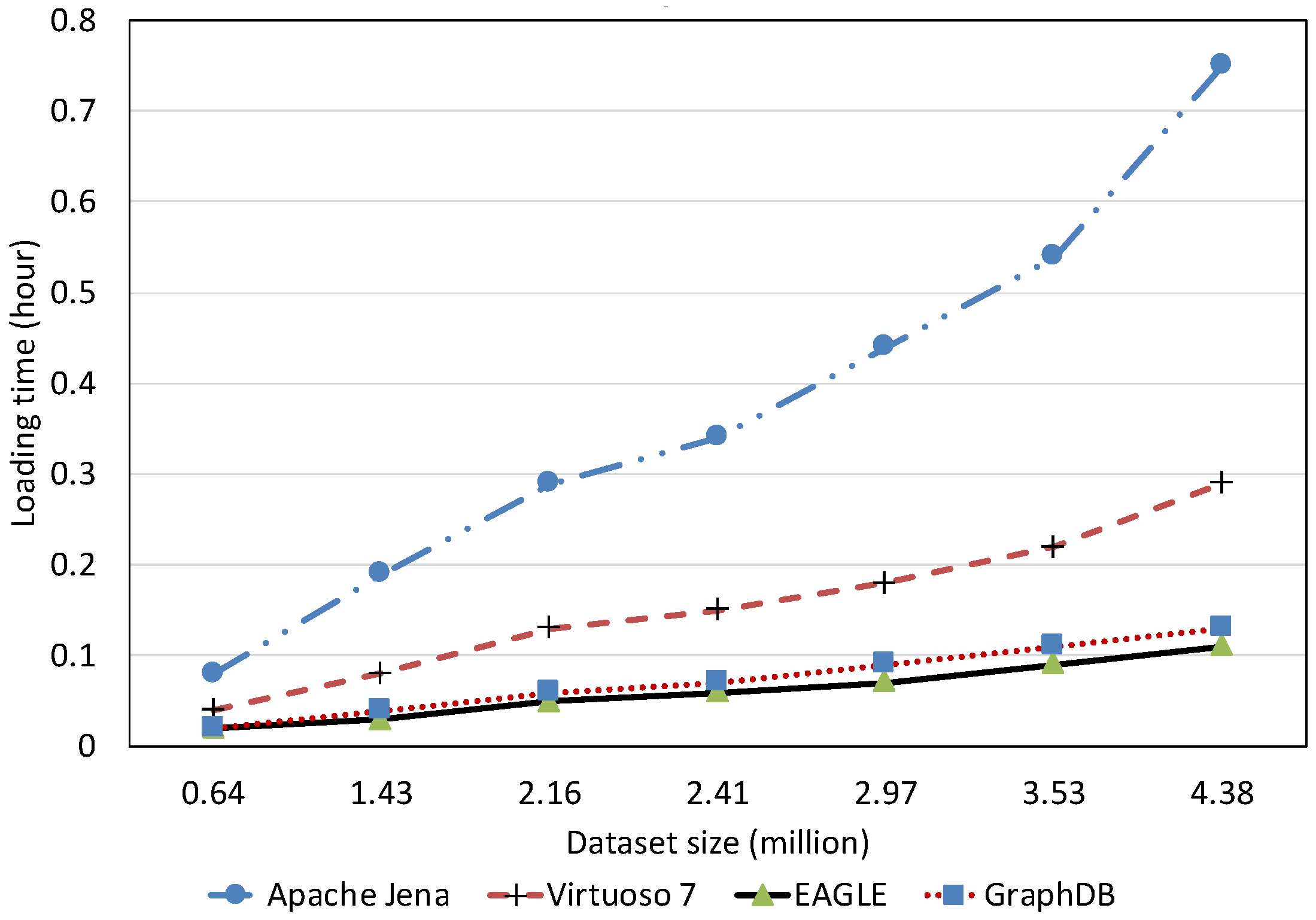
Text Data Loading Performance With Respect to Dataset Size
Temporal Data Loading Performance With Respect to Dataset Size
7.2.2. Query Performance with Respect to Dataset Size
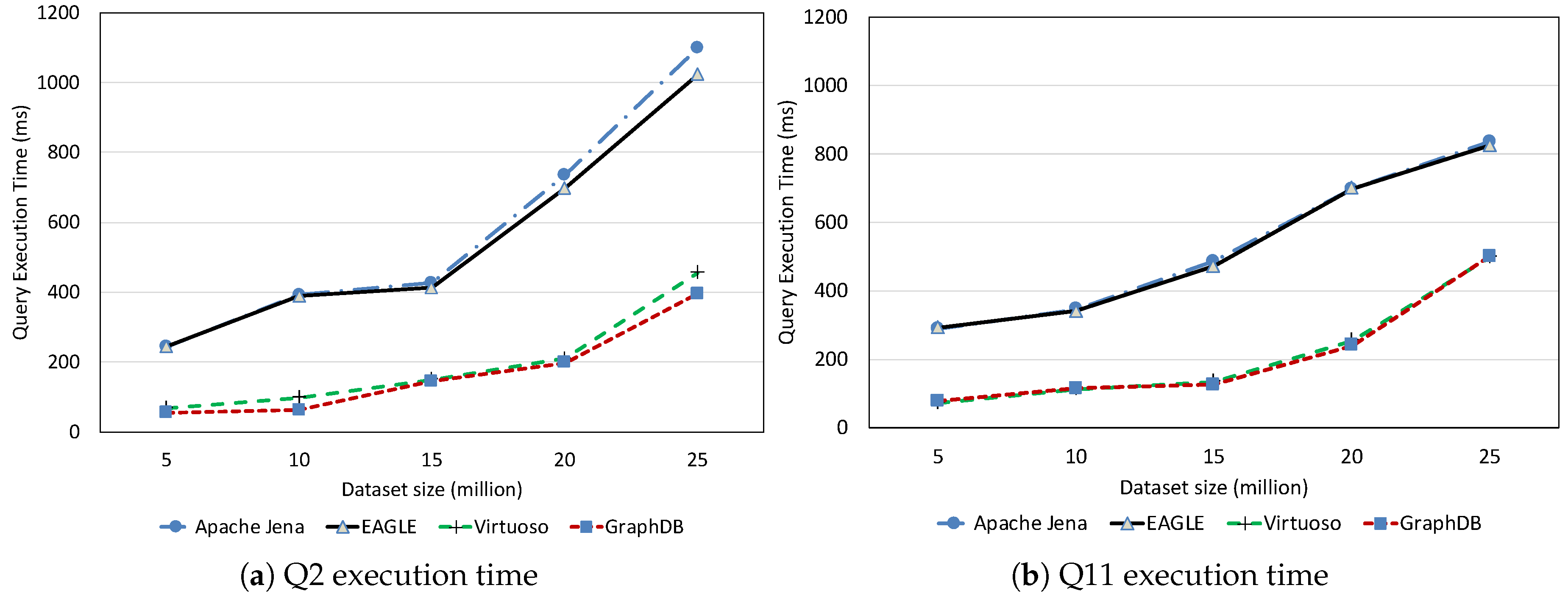
Non-Spatio–Temporal Query Performance
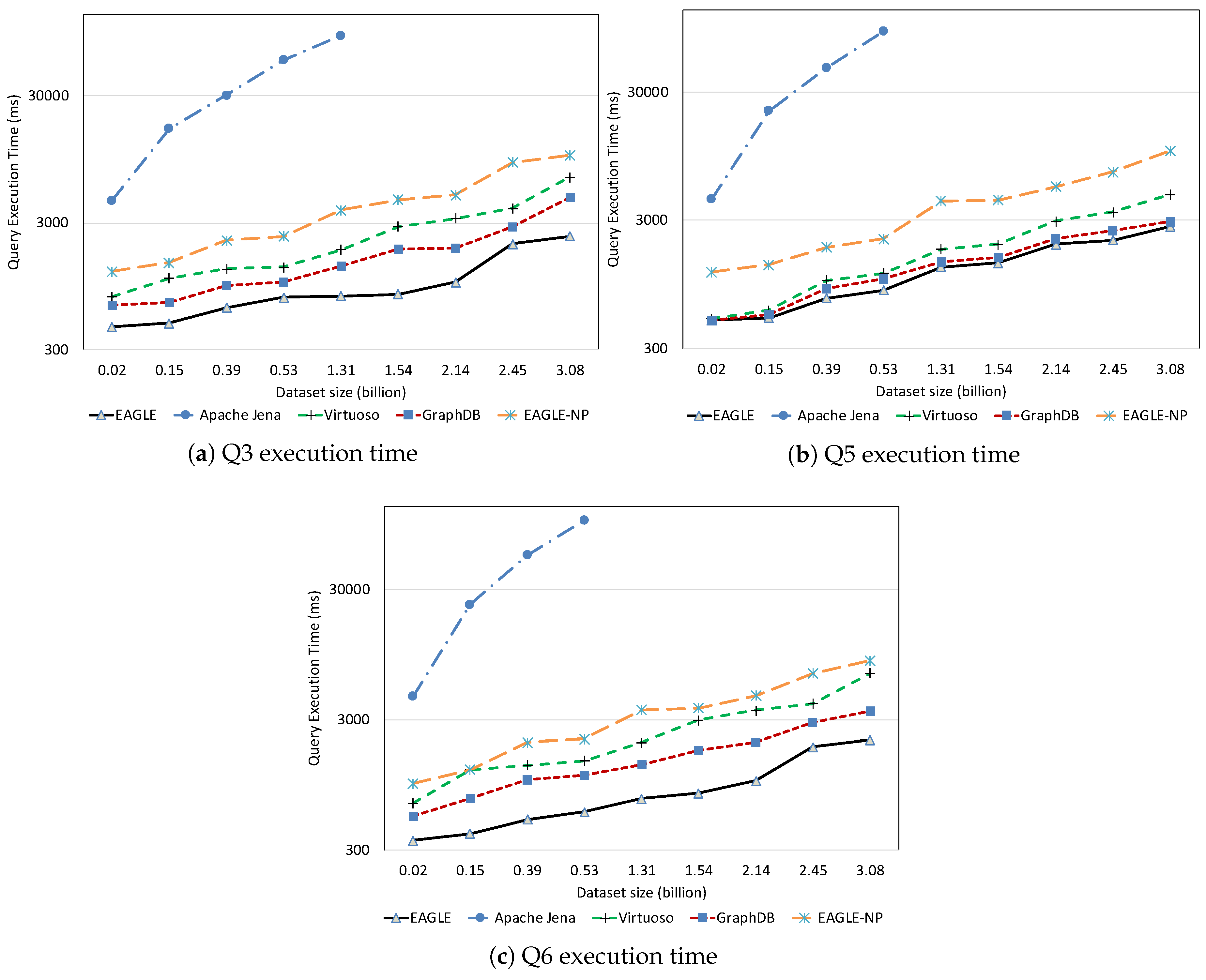
Spatial Query Performance
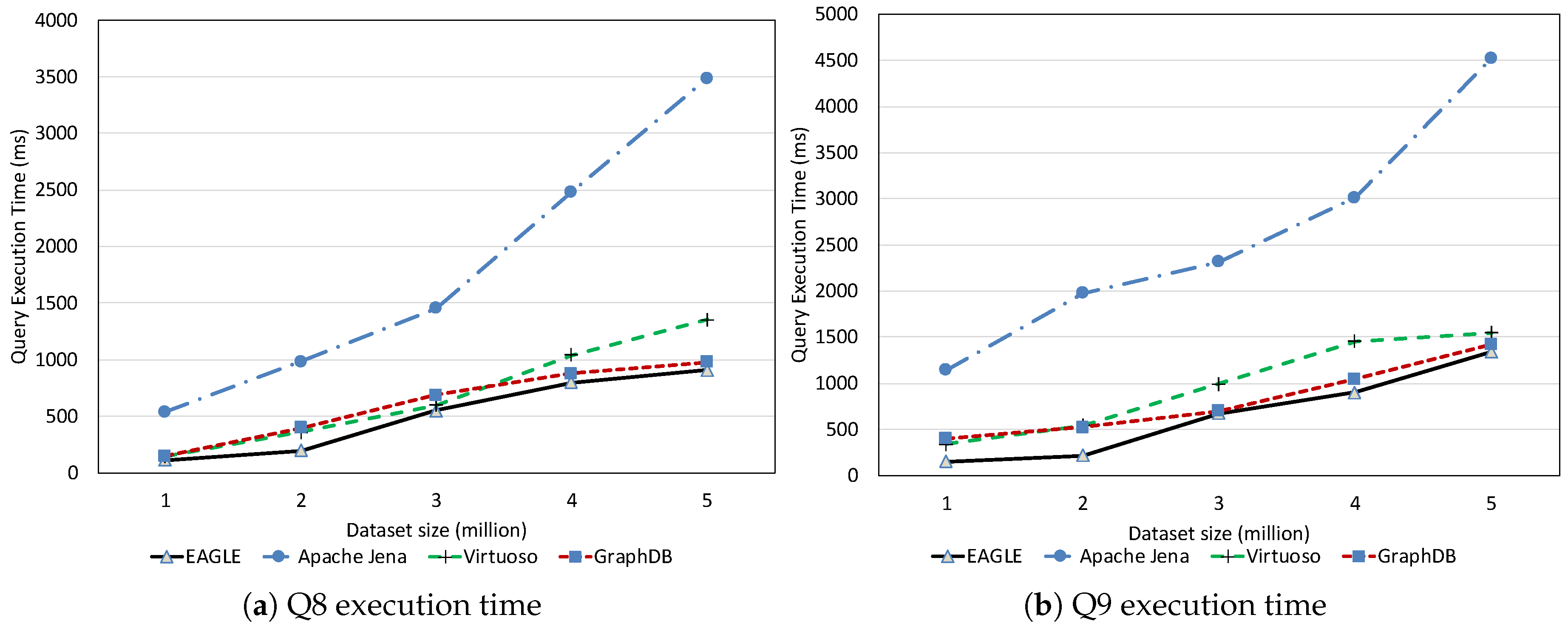
Full-Text Search Query Performance
Temporal Query Performance
Mixed Query Performance
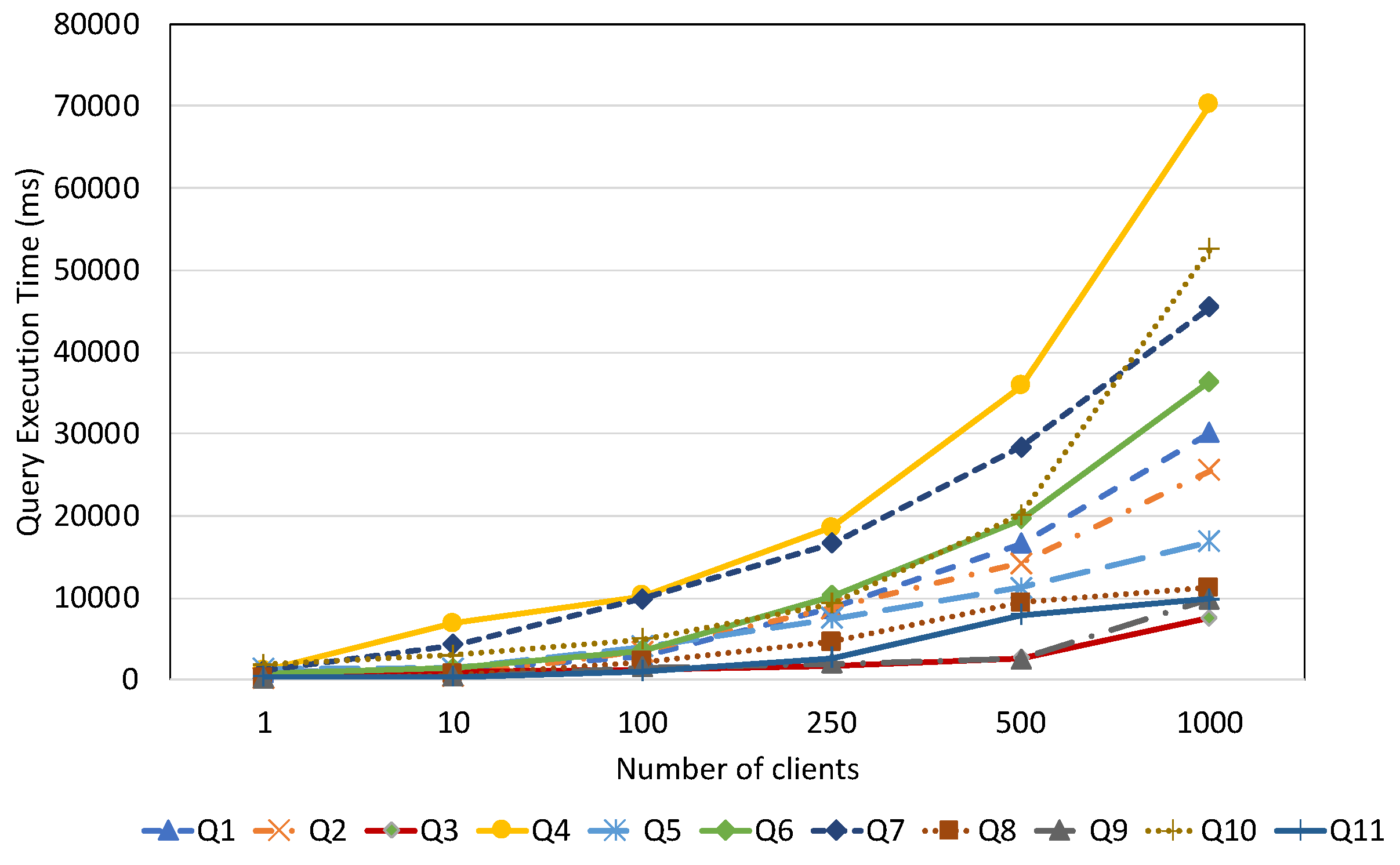
7.2.3. Query Performance with Respect to Number of Clients
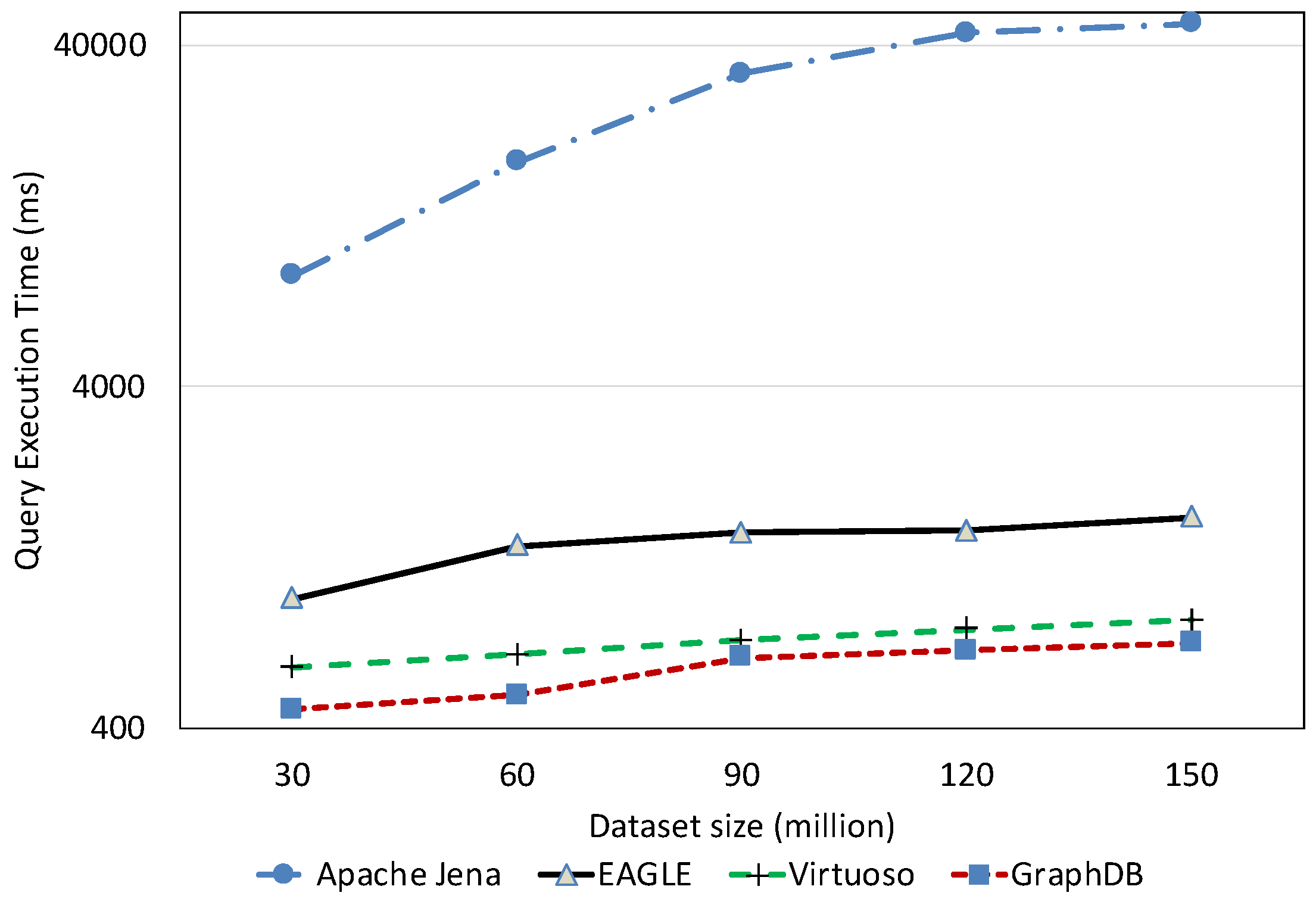
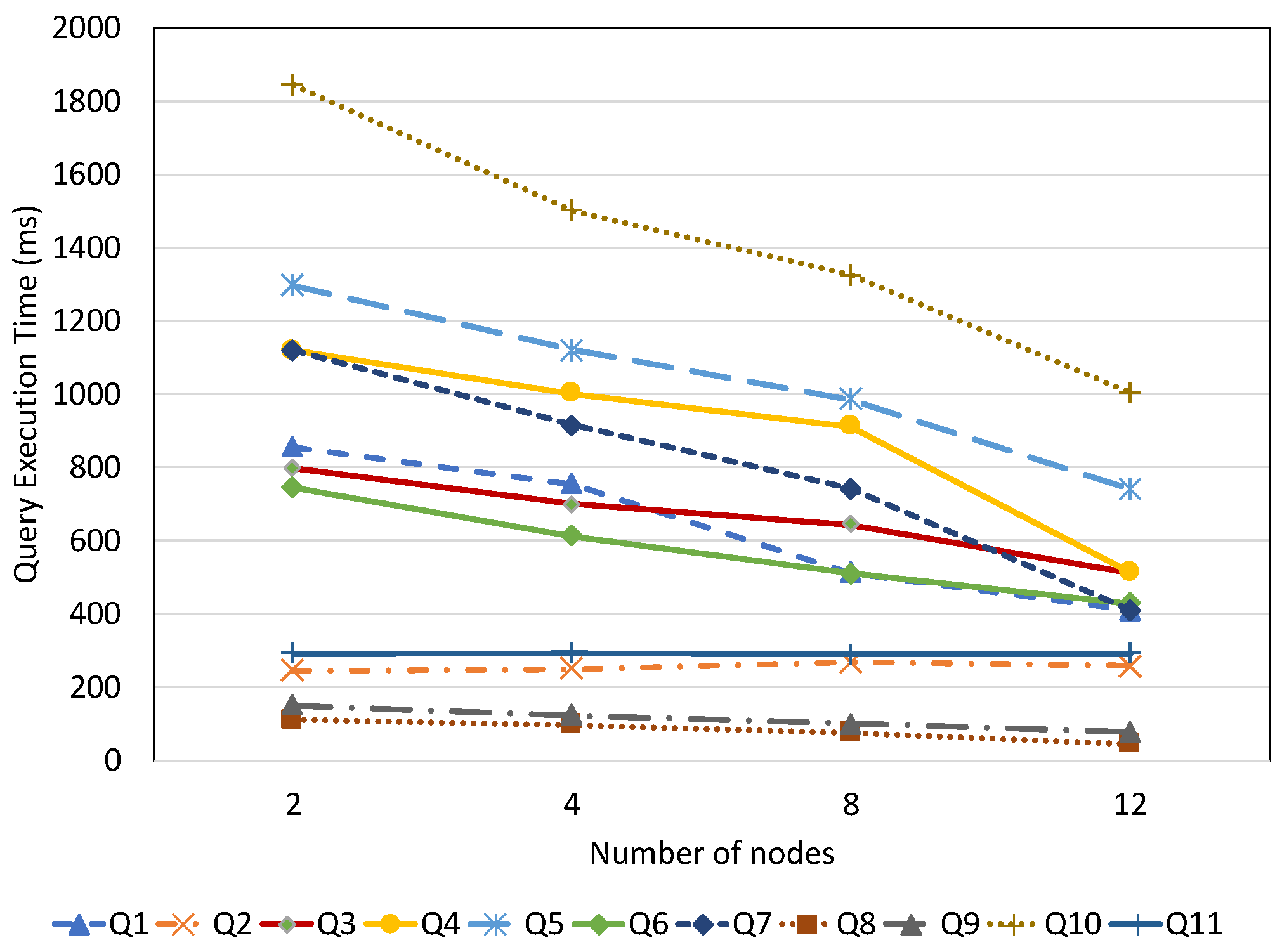
7.2.4. System Scalability
7.3. Discussion
8. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Appendix A. Query Characteristics

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Query | Parametric | Spatial Filter | Temporal Filter | Text Search | Group By | Order By | LIMIT | Num. Variables | Num. Triple Patterns |
|---|---|---|---|---|---|---|---|---|---|
| 1 | ✓ | ✓ | 3 | 3 | |||||
| 2 | ✓ | 3 | 4 | ||||||
| 3 | ✓ | ✓ | 7 | 8 | |||||
| 4 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 7 | 8 | |
| 5 | ✓ | ✓ | ✓ | ✓ | 4 | 5 | |||
| 6 | ✓ | ✓ | 5 | 8 | |||||
| 7 | ✓ | ✓ | ✓ | ✓ | ✓ | 7 | 8 | ||
| 8 | ✓ | ✓ | 3 | 4 | |||||
| 9 | ✓ | ✓ | 6 | 7 | |||||
| 10 | ✓ | ✓ | ✓ | ✓ | 7 | 9 | |||
| 11 | ✓ | 2 | 1 | ||||||
| 12 | ✓ | ✓ | |||||||
| 13 | ✓ | ✓ |
Appendix B. Sparql Representation












References
- Evans, D. The Internet of things: How the next evolution of the internet is changing everything. CISCO White Paper 2011, 1, 1–11. [Google Scholar]
- Sheth, A.; Henson, C.; Sahoo, S.S. Semantic Sensor Web. IEEE Internet Comput. 2008, 12, 78–83. [Google Scholar] [CrossRef]
- Compton, M.; Barnaghi, P.; Bermudez, L.; GarcíA-Castro, R.; Corcho, O.; Cox, S.; Graybeal, J.; Hauswirth, M.; Henson, C.; Herzog, A.; et al. The SSN ontology of the W3C semantic sensor network incubator group. Web Semant. Sci. Serv. Agents World Wide Web 2012, 17, 25–32. [Google Scholar] [CrossRef]
- Patni, H.; Henson, C.; Sheth, A. Linked sensor data. In Proceedings of the 2010 International Symposium on Collaborative Technologies and Systems (CTS), Chicago, IL, USA, 17–21 May 2010; pp. 362–370. [Google Scholar]
- Le Phuoc, D.; Nguyen Mau Quoc, H.; Tran Nhat, T.; Ngo Quoc, H.; Hauswirth, M. Enabling Live Exploration on The Graph of Things. In Proceedings of the Semantic Web Challenge Conference, Trentino, Italy, 19–23 October 2014. [Google Scholar]
- Botts, M.; Percivall, G.; Reed, C.; Davidson, J. OGC® sensor web enablement: Overview and high level architecture. In Proceedings of the International Cconference on GeoSensor Networks, Boston, MA, USA, 1–3 October 2006; pp. 175–190. [Google Scholar]
- Botts, M. Ogc Implementation Specification 07-000: Opengis Sensor Model Language (Sensorml); Open Geospatial Consortium: Wayland, MA, USA, 2007. [Google Scholar]
- Cox, S. Observations and Measurements; Open Geospatial Consortium Best Practices Document; Open Geospatial Consortium: Wayland, MA, USA, 2006; p. 21. [Google Scholar]
- Cox, S. Observations and Measurements-XML Implementation; Open Geospatial Consortium: Wayland, MA, USA, 2011. [Google Scholar]
- Sheth, A.P. Semantic Sensor Web. Available online: https://corescholar.libraries.wright.edu/cgi/viewcontent.cgi?article=2128&context=knoesis (accessed on 5 October 2019).
- Russomanno, D.J.; Kothari, C.R.; Thomas, O.A. Building a Sensor Ontology: A Practical Approach Leveraging ISO and OGC Models. In Proceedings of the 2005 International Conference on Artificial Intelligence, ICAI 2005, Las Vegas, NV, USA, 27–30 June 2005. [Google Scholar]
- Niles, I.; Pease, A. Towards a standard upper ontology. In Proceedings of the International Conference on Formal Ontology in Information Systems, Ogunquit, ME, USA, 17–19 October 2001. [Google Scholar]
- Soldatos, J.; Kefalakis, N.; Hauswirth, M.; Serrano, M.; Calbimonte, J.P.; Riahi, M.; Aberer, K.; Jayaraman, P.P.; Zaslavsky, A.; Žarko, I.P.; et al. Openiot: Open source internet-of-things in the cloud. In Interoperability and Open-Source Solutions for the Internet of Things; Springer: Cham, Switzerland, 2015; pp. 13–25. [Google Scholar]
- Agarwal, R.; Fernandez, D.G.; Elsaleh, T.; Gyrard, A.; Lanza, J.; Sanchez, L.; Georgantas, N.; Issarny, V. Unified IoT ontology to enable interoperability and federation of testbeds. In Proceedings of the 2016 IEEE 3rd World Forum on Internet of Things (WF-IoT), Reston, VA, USA, 12–14 December 2016; pp. 70–75. [Google Scholar]
- Ibrahim, A.; Carrez, F.; Moessner, K. Geospatial ontology-based mission assignment in Wireless Sensor Networks. In Proceedings of the 2015 International Conference on Recent Advances in Internet of Things (RIoT), Singapore, 7–9 April 2015; pp. 1–6. [Google Scholar]
- Janowicz, K.; Haller, A.; Cox, S.J.; Le Phuoc, D.; Lefrançois, M. SOSA: A lightweight ontology for sensors, observations, samples, and actuators. J. Web Semant. 2018, 56, 1–10. [Google Scholar] [CrossRef]
- Le-Phuoc, D.; Parreira, J.X.; Hauswirth, M. Linked Stream Data Processing; Springer: Berlin, Germany, 2012. [Google Scholar]
- Le-Phuoc, D.; Quoc, H.N.M.; Quoc, H.N.; Nhat, T.T.; Hauswirth, M. The Graph of Things: A step towards the Live Knowledge Graph of connected things. J. Web Semant. 2016, 37, 25–35. [Google Scholar] [CrossRef]
- Perry, M.; Jain, P.; Sheth, A.P. Sparql-st: Extending sparql to support spatiotemporal queries. In Geospatial Semantics and the Semantic Web; Springer: Boston, MA, USA, 2011. [Google Scholar]
- Koubarakis, M.; Kyzirakos, K. Modeling and querying metadata in the semantic sensor web: The model strdf and the query language stsparql. In Proceedings of the Extended Semantic Web Conference (ESWC), Heraklion, Greece, 30 May–3 June 2010; Volume 12, pp. 425–439. [Google Scholar]
- Gutierrez, C.; Hurtado, C.A.; Vaisman, A. Introducing Time into RDF. IEEE Trans. Knowl. Data Eng. 2007, 19, 207–218. [Google Scholar] [CrossRef]
- Quoc, H.N.M.; Serrano, M.; Han, N.M.; Breslin, J.G.; Phuoc, D.L. A Performance Study of RDF Stores for Linked Sensor Data. vixra:1908.0562v1. Available online: http://xxx.lanl.gov/abs/vixra:1908.0562v1 (accessed on 28 July 2019).
- Owens, A.; Seaborne, A.; Gibbins, N.; Schraefel, M.C. Clustered TDB: A Clustered Triple Store for Jena. In Proceedings of the 18th International Conference on World Wide Web, WWW 2009, Madrid, Spain, 20–24 April 2009. [Google Scholar]
- Miller, L. Inkling: An RDF SquishQL implementation. In Proceedings of the International Semantic Web Conference (ISWC), Sardinia, Italy, 9–12 June 2002; pp. 423–435. [Google Scholar]
- McBride, B. Jena: Implementing the RDF Model and Syntax specification. In Proceedings of the Semantic Web Workshop, Hong Kong, China, 1 May 2001. [Google Scholar]
- Brodt, A.; Nicklas, D.; Mitschang, B. Deep integration of spatial query processing into native rdf triple stores. In Proceedings of the 18th SIGSPATIAL International Conference, San Jose, CA, USA, 2–5 November 2010; pp. 33–42. [Google Scholar]
- Kiryakov, A.; Ognyanov, D.; Manov, D. OWLIM—A pragmatic semantic repository for OWL. In Proceedings of the International Conference on Web Information Systems Engineering, New York, NY, USA, 20–22 November 2005; pp. 182–192. [Google Scholar]
- Singh, R.; Turner, A.; Maron, M.; Georss, A.D. Geographically encoded objects for rss feeds 2008. Available online: http://georss.org/gml (accessed on 25 July 2019).
- Le-Phuoc, D.; Nguyen-Mau, H.Q.; Parreira, J.X.; Hauswirth, M. A middleware framework for scalable management of linked streams. Web Semant. Sci. Serv. 2012, 16, 42–51. [Google Scholar] [CrossRef]
- Le-Phuoc, D.; Parreira, J.X.; Hausenblas, M.; Han, Y.; Hauswirth, M. Live linked open sensor database. In Proceedings of the 6th International Conference on Semantic Systems, Graz, Austria, 1–3 September 2010; ACM: New York, NY, USA, 2010. [Google Scholar]
- Nguyen Mau Quoc, H.; Le Phuoc, D.; Serrano, M.; Hauswirth, M. Super Stream Collider. In Proceedings of the Semantic Web Challenge, Boston, MA, USA, 11–15 November 2012. [Google Scholar]
- Quoc, H.N.M.; Le Phuoc, D. An elastic and scalable spatiotemporal query processing for linked sensor data. In Proceedings of the 11th International Conference on Semantic Systems, Vienna, Austria, 16–17 September 2015; ACM: New York, NY, USA, 2015; pp. 17–24. [Google Scholar]
- Quoc, H.N.M.; Serrano, M.; Breslin, J.G.; Phuoc, D.L. A learning approach for query planning on spatio-temporal IoT data. In Proceedings of the 8th International Conference on the Internet of Things, Santa Barbara, CA, USA, 15–18 October 2018; p. 1. [Google Scholar]
- Sigoure, B. Opentsdb Scalable Time Series Database (tsdb). Stumble Upon. 2012. Available online: http://opentsdb.net (accessed on 25 June 2019).
- George, L. HBase: The Definitive Guide: Random Access to Your Planet-Size Data; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2011. [Google Scholar]
- Chang, F.; Dean, J.; Ghemawat, S.; Hsieh, W.C.; Wallach, D.A.; Burrows, M.; Chandra, T.; Fikes, A.; Gruber, R.E. Bigtable: A distributed storage system for structured data. ACM Trans. Comput. Syst. (TOCS) 2008, 26, 4. [Google Scholar] [CrossRef]
- Dimiduk, N.; Khurana, A.; Ryan, M.H.; Stack, M. HBase in Action; Manning Publications: Shelter Island, NY, USA, 2013. [Google Scholar]
- Le-Phuoc, D.; Quoc, H.N.M.; Parreira, J.X.; Hauswirth, M. The linked sensor middleware–connecting the real world and the semantic web. Proc. Semant. Web Chall. 2011, 152, 22–23. [Google Scholar]
- Lefort, L.; Bobruk, J.; Haller, A.; Taylor, K.; Woolf, A. A linked sensor data cube for a 100 year homogenised daily temperature dataset. In Proceedings of the 5th International Conference on Semantic Sensor Networks, Boston, MA, USA, 11–15 November 2012; pp. 1–16. [Google Scholar]
- Jena Assembler Description. Available online: http://jena.apache.org/documentation/assembler/assembler-howto.html (accessed on 25 June 2019).
- Hartig, O.; Heese, R. The SPARQL query graph model for query optimization. In Proceedings of the ESWC’07, Innsbruck, Austria, 30 May 2007. [Google Scholar]
- Battle, R.; Kolas, D. Geosparql: Enabling a geospatial semantic web. Semant. Web J. 2011, 3, 355–370. [Google Scholar]
- Pérez, J.; Arenas, M.; Gutierrez, C. Semantics and Complexity of SPARQL. In Proceedings of the International Semantic Web Conference, Athens, GA, USA, 5–6 November 2006; pp. 30–43. [Google Scholar]
- Quoc, H.N.M.; Han, N.M.; Breslin, J.G.; Phuoc, D.L. A 10 Years Global Linked Meteorological Dataset. 2019. Unpublished Work. [Google Scholar]
- Ladwig, G.; Harth, A. CumulusRDF: Linked data management on nested key-value stores. In Proceedings of the 7th International Workshop on Scalable Semantic Web Knowledge Base Systems (SSWS 2011), Bonn, Germany, 24 October 2011; Volume 30. [Google Scholar]
- Aasman, J. Allegro Graph: RDF Triple Database; Franz Incorporated: Oakland, CA, USA, 2006; Volume 17. [Google Scholar]


























| Element Name | Size |
|---|---|
| Metric UID | 3 bytes |
| Base-timestamp | 4 bytes |
| Tag names | 3 bytes |
| Tag values | 3 bytes |
| ... | ... |
| Spatial Function | Description |
|---|---|
| <feature> geo:sfIntersects (<geo> | <latMin> <lonMin> <latMax> <lonMax> [ <limit>]) | Find features that intersect the provided box, up to the limit. |
| <feature> geo:sfDisjoint (<geo> | <latMin> <lonMin> <latMax> <lonMax> [ <limit>]) | Find features that intersect the provided box, up to the limit. |
| <feature> geo:sfWithin (<geo> | <lat> <lon> <radius> [ <units> [ <limit>]]) | Find features that are within radius of the distance units, up to the limit. |
| <feature> geo:sfContains <geo> | <latMin> <lonMin> <latMax> <lonMax> [ <limit>]) | Find features that contains the provided box, up to the limit. |
| URI | Description |
|---|---|
| units:kilometre or units:kilometer | Kilometres |
| units:metre or units:meter | Metres |
| units:mile or units:statuteMile | Miles |
| units:degree | Degrees |
| units:radian | Radians |
| Temporal Function | Description |
|---|---|
| ?value temporal:sum (<startTime> <endTime> [<‘groupin’ down sampling function> <geohash prefix> <observableProperty>]) | Calculates the sum of all reading data points from all of the time series or within the time span if down sampling. |
| ?value temporal:avg (<startTime> <endTime> [<‘groupin’ down sampling function> <geohash prefix> <observableProperty>]) | Calculates the average of all observation values across the time span or across multiple time series |
| ?value temporal:min (<startTime> <endTime> [<‘groupin’ down sampling function> <geohash prefix> <observableProperty>]) | Returns the smallest observation value from all of the time series or within the time span |
| ?value temporal:max (<startTime> <endTime> [<‘groupin’ down sampling function> <geohash prefix> <observableProperty>]) | Returns the largest observation value from all of the time series or within a time span |
| ?value temporal:values (<startTime> <endTime> [<‘groupin’ down sampling function> <geohash prefix> <observableProperty>]) | List all observation values from all of the time series or within the time span |
| Sources | Sensing Objects | Historical Data | Archived Window |
|---|---|---|---|
| Meteorological | 26,000 | 3.7 B | since 2008 |
| Flight | 317,000 | 317 M | 2014–2015 |
| Ship | 20,000 | 51 M | 2015–2016 |
| – | 5 M | 2014–2015 |
| Category | Non Spatio–Temporal Query | Spatial Query | Temporal Query | Full-Text Search Query | Mixed Query |
|---|---|---|---|---|---|
| Query | Q2, Q11 | Q1 | Q5, Q6 | Q8, Q9 | Q3, Q4, Q7, Q10 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen Mau Quoc, H.; Serrano, M.; Mau Nguyen, H.; G. Breslin, J.; Le-Phuoc, D. EAGLE—A Scalable Query Processing Engine for Linked Sensor Data. Sensors 2019, 19, 4362. https://doi.org/10.3390/s19204362
Nguyen Mau Quoc H, Serrano M, Mau Nguyen H, G. Breslin J, Le-Phuoc D. EAGLE—A Scalable Query Processing Engine for Linked Sensor Data. Sensors. 2019; 19(20):4362. https://doi.org/10.3390/s19204362
Chicago/Turabian StyleNguyen Mau Quoc, Hoan, Martin Serrano, Han Mau Nguyen, John G. Breslin, and Danh Le-Phuoc. 2019. "EAGLE—A Scalable Query Processing Engine for Linked Sensor Data" Sensors 19, no. 20: 4362. https://doi.org/10.3390/s19204362
APA StyleNguyen Mau Quoc, H., Serrano, M., Mau Nguyen, H., G. Breslin, J., & Le-Phuoc, D. (2019). EAGLE—A Scalable Query Processing Engine for Linked Sensor Data. Sensors, 19(20), 4362. https://doi.org/10.3390/s19204362