1. Introduction
The term “well-being” is mainly considered as a positive outcome, and refers to the process of evaluating people in terms of being satisfied with their life. Regarding the World Happiness Report, it includes aspects of life on the social and personal levels that comprise health and economy as critical variables for personal well-being [
1,
2]. Diseases are prevented with the help of physical activities, personal behavior, nutrition, and lifestyle. There is also a reduction in treatment cost, leading to gradual improvements in life expectancy, energy level, and good healthy feelings [
3,
4,
5,
6]. In this context, various studies have targeted the effective development of personalized systems for healthcare. Requirements of healthcare systems are found to be increased due to the increased adoption of technologies for an active and healthy lifestyle. An integrated system for healthcare consists of effective capabilities that lead to stability regarding individuals’ awareness of health [
7,
8,
9]. With regard to the advancement of personalized technologies, there has been increased research focusing on the success of digital recommender systems concerned with health. The existing systems for healthcare, which mainly include digital health devices such as Apple Watch, Google Fit, and Samsung Health, effectively operate for individual health and fitness tracking. These devices help by providing efficient and recommended features that work on the effective analysis of the human body, including footsteps, heart rate, and hours of sleep [
10,
11,
12,
13,
14,
15]. These systems have the additional feature of focusing on the tracking of fitness. However, concerning the development of eating habits, these measures are found to be ineffective to sustain a healthy lifestyle. In order for users to develop efficient and healthy habits with these systems, they must generate proper guidance for nutrition based on recommendations of services for well-being [
16]. For effective understanding of the functions of the core system, it is observed that the recommender systems can contribute to the improvement of quality related to the information overload involved in semantic technology.
Primarily, recommender user ratings effectively respond to the functions as vectors [
17]. In this context, the concept of ontology contributes to the matching of similarities with the help of various filtering techniques. In a similar context, collaborative filtering methods are also implemented by researchers involved in the development of recommender systems [
18]. There are various large-scale studies in the literature that focus on hybrid methods using different techniques of filtering, specific health conditions, and healthcare monitoring systems [
19,
20,
21]. As there are various prototypes developed by practitioners and researchers involving well-being factors in the recommender systems, the benefits of learning with the help of the recommendation process are effectively recognized and promoted [
22]. However, the systems cannot be recognized as sufficient to change the impoverished lifestyle of users. To change users’ unhealthy habits, there is a huge requirement that the recommendations be actionable [
16].
The existing research mainly aims at monitoring health and fitness with the help of user devices without considering the contextual information and nutritional components [
22]. To determine the contextual information, various learning methods have been proposed. The existing recommender system method integrates the core functions with the help of collaborative filtering that involves few limitations related to the recommendations for the cold start. Regarding the two types of cold start problems, the new user problem is considered to be more difficult [
23,
24,
25,
26,
27,
28]. Accordingly, some studies have proposed hybrid methods, which mainly combine content-based filtering and collaborative filtering to enhance the limitations with the help of algorithms [
29].
With regard to the rising amount of information and data, various challenges in the filtering methods have been seen to arise, including leanness and scalability [
30]. The latest trends in machine learning employ various layers of processing, which helps in learning from complex contextual features. It has also been observed to be pervasive, as the effective ingredients of the recommender system provide accurate services for users. According to the experts, it has been found that machine learning has the power to determine the factors involved in health and lead to improvements in quality of life with the help of lifestyle health services [
31,
32,
33].
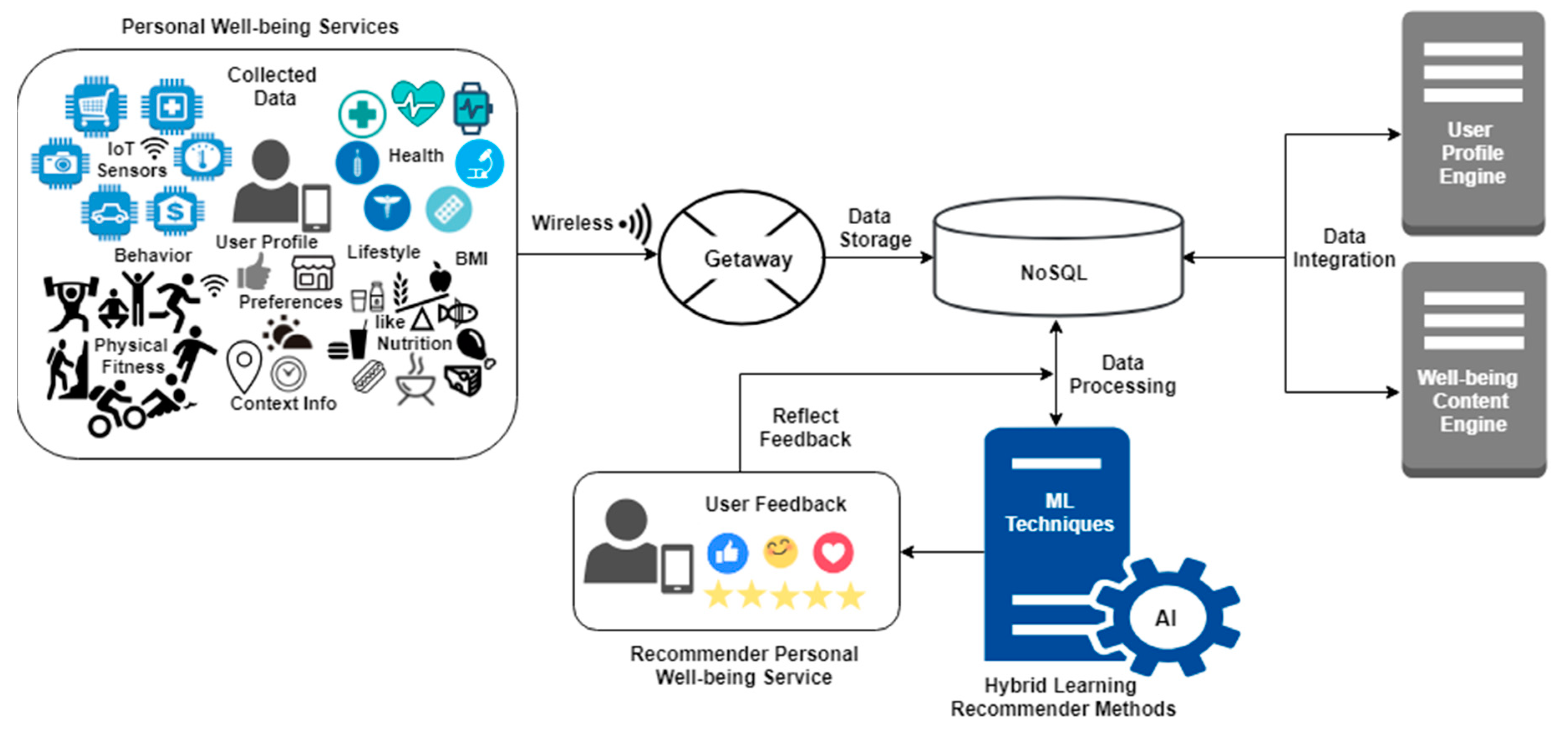
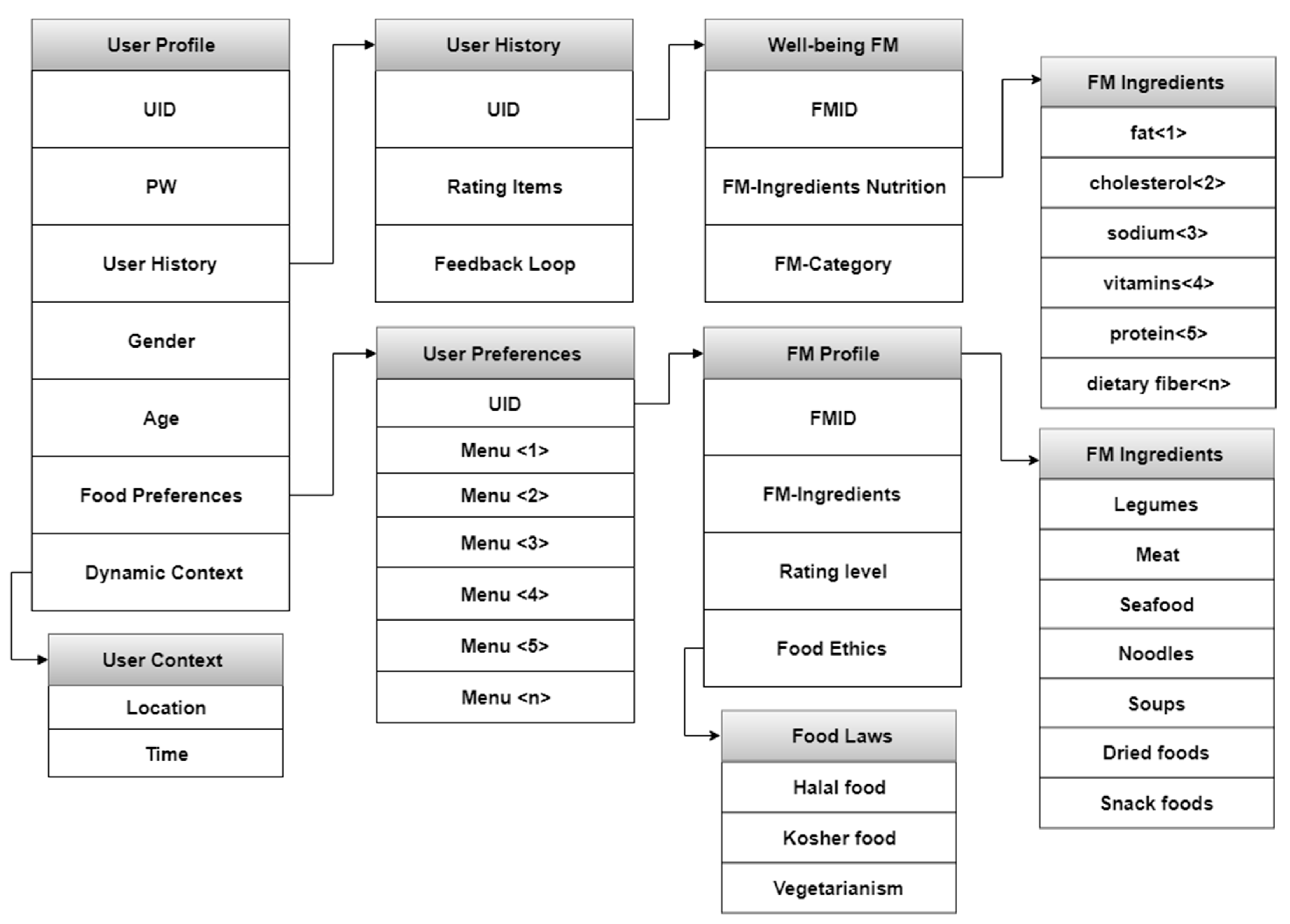
Figure 1 depicts the large set of data that was collected with the help of various types of sensors to address the inefficiency of the technologies and the effective approaches that have been developed by researchers.
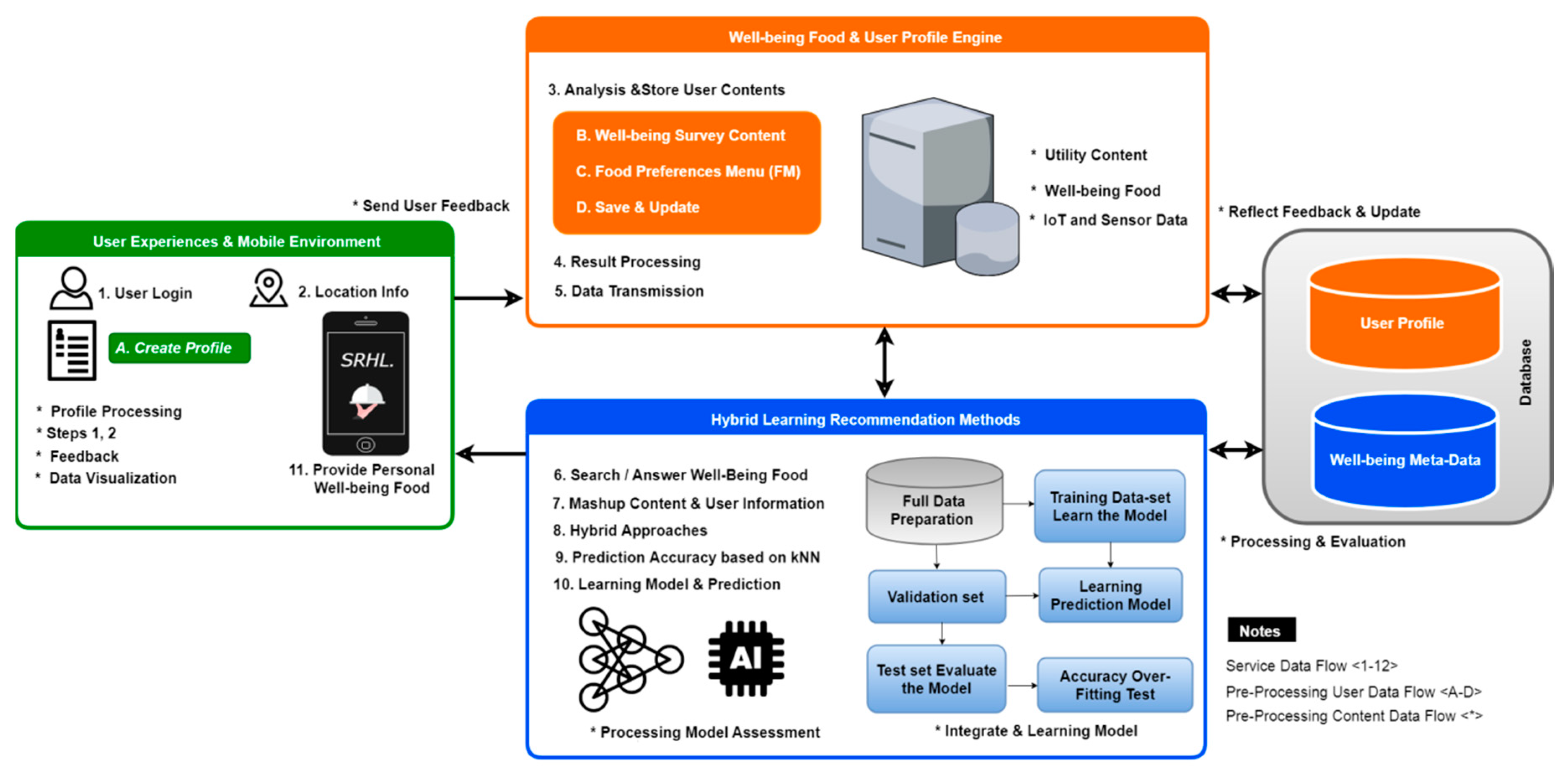
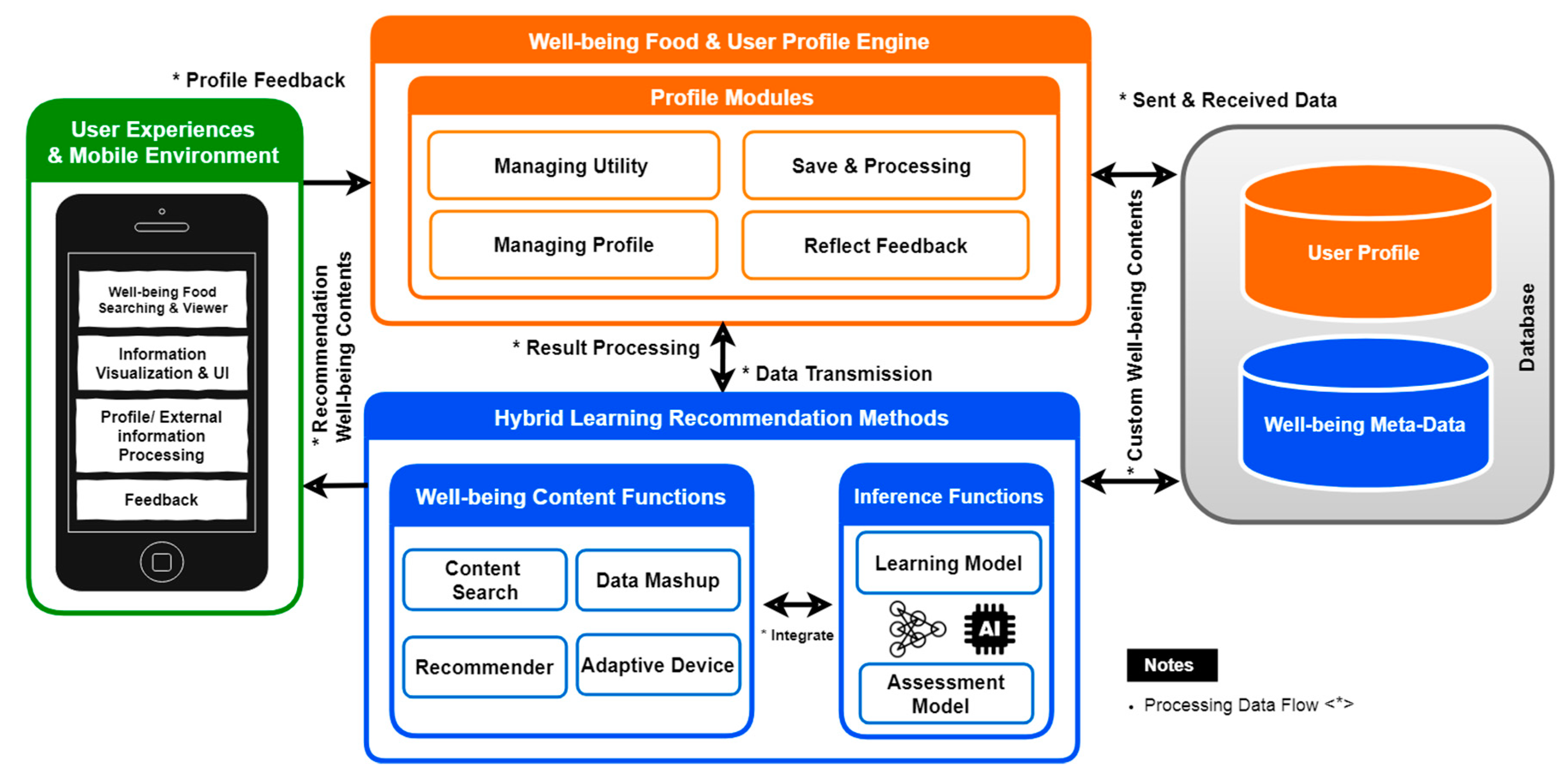
Information in the context of well-being is collected and transformed by connecting personal identities with mobile devices by the use of getaway of wireless nature. NoSQL [
30] is used to store data, which helps in integrating contextual information in two engines, profile engine and well-being content engine. Each technique focuses on different facets by the use of machine learning techniques. Hybrid learning methods give the content of a personalized recommender and are based on feedback of a reflecting nature. There are challenges in recommendation, which can be represented as the estimation of the response of a new user, choosing specific algorithms, learning mechanism, and the evolution of performance [
31]. Well-being content supports recording routine activities and provides the recommender service usage. The handling of data requirements is done with communication of data sources in many aspects. There is integration of data related to the context of users and engines of well-being services.
The processing of data is based on supervised machine learning algorithms that learn from reflective functions, which in turn helps in utility prediction and recommended well-being services for every user. The research work helps in capturing the focus of researchers, because the problem of cold start arises when a user profile does not exist in the system, and there is no available previous rating [
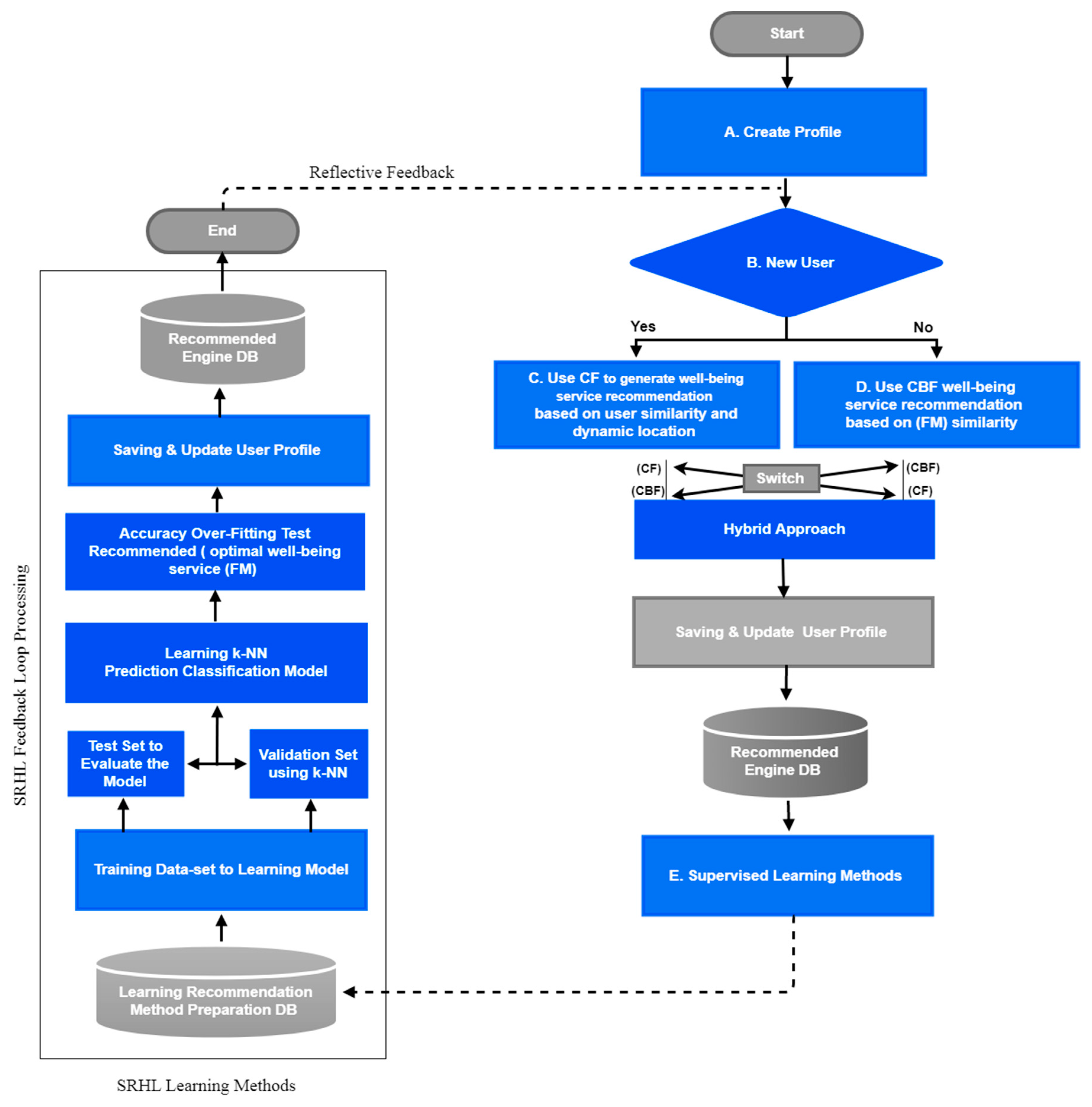
32]. In order to tackle these challenges, in this paper a new learning method based on machine learning is proposed for an advanced recommender, which relies on hybrid learning methods to improve upon current recommender systems using collaborative filtering for better personal well-being services.
The main motivation of this work focuses on solving the cold star and scalability issues in a collaborative filtering method. To effectively address the inefficiencies, this paper presents a hybrid learning methods, SRHL which is a smart recommender system of personal well-being in regard to health food service. SRHL has been designed to examine how combined filtering approach improve crucial issues of cold star problem using a profile learning loop concept, and what kind of user feedback reflected to improves the recommender accuracy and enhance the efficient performance based on machine learning techniques. With regard to the research, the most essential and suitable contextual features used to develop the effective recommendations mainly include time, activity, location, and the composite information related to monetary costs, ingredients, health and nutritional value, availability, and the effects of combining the ingredients. In relation to meeting the requirements, the methods of hybrid learning are integrated with various algorithms, including: (1) switching among content-based and collaborative filtering to resolve the cold start problem for new users; (2) identifying user context within the dynamic filtering; and (3) integrating the profile learner methods to reflect user feedback.
In this regard, the expected and suitable contributions are as follows: (i) improving the new user problem of the cold start; (ii) optimizing the precision of the hybrid recommender system in the domain related to the services of health food for personal well-being; (iii) enhancing the user experience with the help of relevant and effective suggestions depending on the user’s identified context; and (iv) showing evidence of the concept, which involves a learning loop that contributes to continual advancement in the performance of the personalized recommender. All of these contributions lead to effective enhancement of the pre-existing methods of recommender learning and address the extraordinary challenges found in the prediction of well-being services.
The major outcomes of this paper mainly focus on the classes of existing recommender systems. The evaluations of the parameters adopted by efficient supervised learning contribute to the analysis of validity related to the efficiency of methods involved in the prediction of learning methods. The performance is measured using multiple metrics to evaluate the accuracy of recommendations, based on three performance errors: mean squared error (MSE), mean absolute percentage error (MAPE), and mean absolute error (MAE) [
34].
The remaining parts of the paper are mainly structured in sections that include a review of the literature focused on the background for the analysis of the present situation, explained in
Section 2.
Section 3 consists of explanations regarding the proposed methods of hybrid learning, including the system architecture, functional algorithms, and effective parameters. The results of the validation process are explained in
Section 4, and the conclusion along with future work are discussed in
Section 5.
4. Experiment and Evaluation
Experiments were conducted to verify the performance of the proposed SRHL. The experiments were carried out by calculating error values that can be derived from incorrect recommendation results when simulated recommendations were performed using the SRHL model. The calculation of error values is computed similarly to the supervised learning [
52]. The data for the experiment must already have a value for the recommendation result. When analyzing the actual model, it is assumed that there are no correct answers (recommendation results), and the difference between the finally predicted value and the actual correct answer is defined as an error value. A low error value means that the predicted value is close to the correct answer (the predicted value is highly correlated with the recommendation result that is correct, i.e., similar), and a high error value means that the predicted value is far from correct (the predicted value is less relevant to the recommendation result that is the correct answer). The error values of single models CF and CBF and combinations CF + CBF, CF + ML, and CBF + ML were calculated for comparison with the proposed SRHL, and the experiments proceeded in the following environment, shown in
Table 4.
R language is a powerful tool for data analysis and prediction [
53]. R Studio, an integrated development environment, is compatible with various filtering and analysis libraries such as CF, CBF, ML, and similarity [
54]. The libraries and functions used in these experiments are shown in
Table 5, and a screenshot of the operation code part of the recommendation models is shown in
Figure 6 and
Figure 7, with the results using three matrix error models (MAE, MAPE, and MSE) for evaluating the recommendation results.
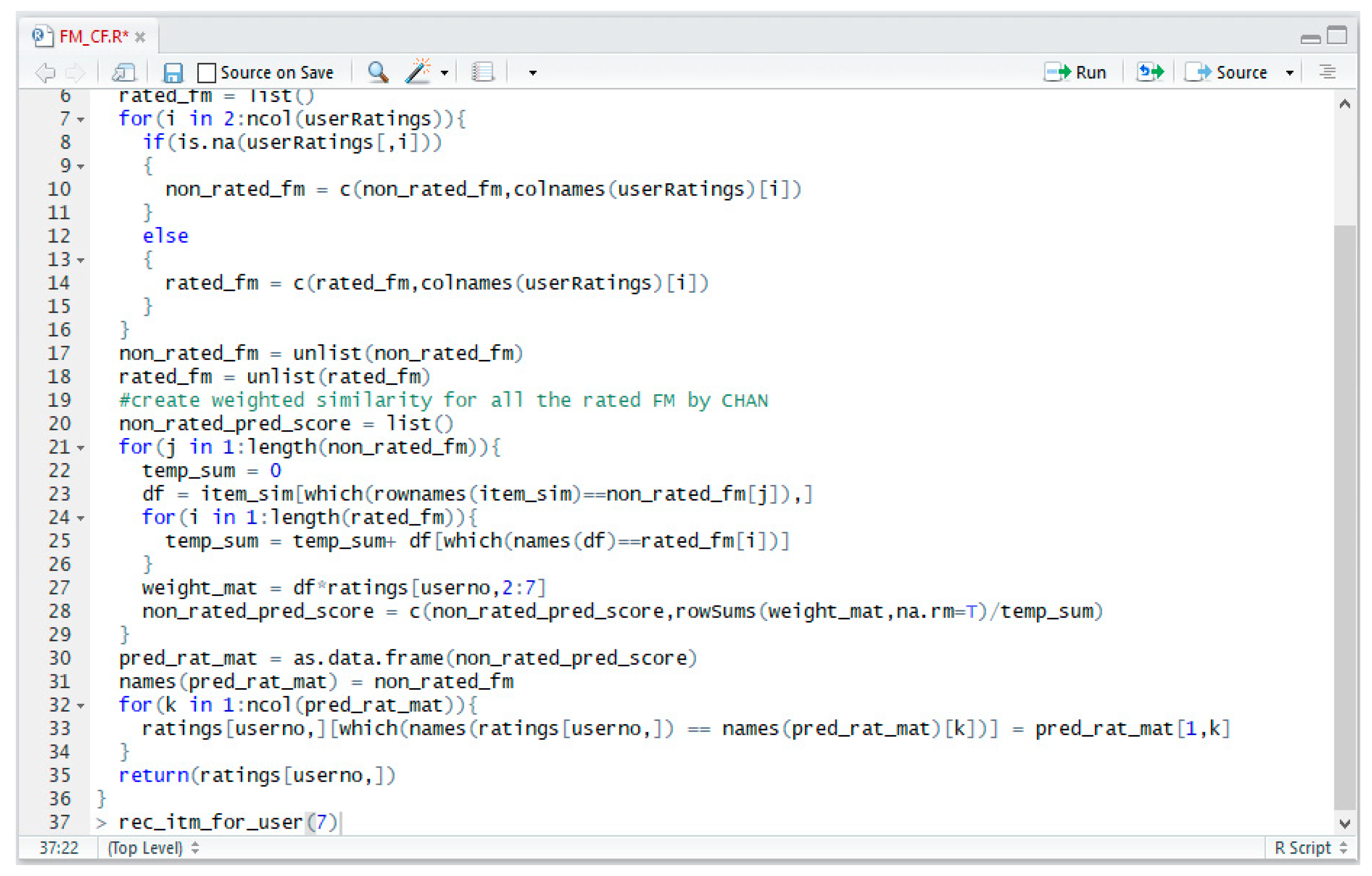
The code shown in
Figure 6 is part of the source code for the CF model of the proposed SRHL, and the console screen in
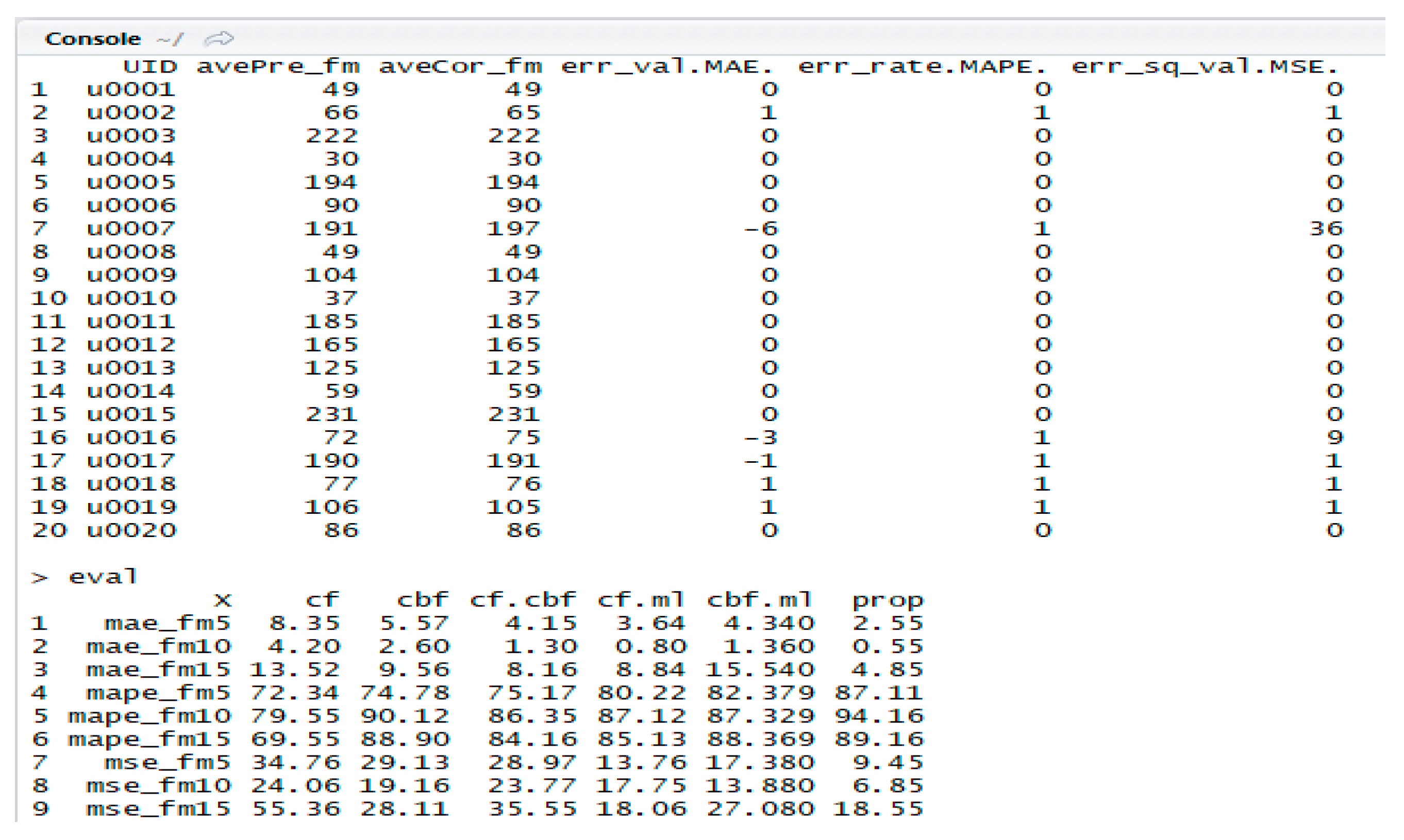
Figure 7 shows the results of MAE, MAPE, and MSE in R. These 20 data points are the result of recommendation results of users and the error values/rates to calculate MAE, MAPE, and MSE when FM = 10.
<avePre_fm> is a predicted recommendation result, and
<aveCor_fm> is a correct recommendation result.
<err_val.MAE.> is a result calculated by the difference between
<avePre_fm> and
<aveCor_fm>, which is the error values of users.
<err_rate.MAPE.> is an error rate for calculating the accuracy through MAPE, which is 1 if there is an error and 0 otherwise.
<err_sq_val.MSE.> is a squared error value for calculating MSE. In
Figure 6, the matrix
<eval> is derived from six models by calculating the average and frequency of the total results and deriving the final analysis results. The final results are analyzed and summarized in
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10, and visualized in
Figure 8,
Figure 9 and
Figure 10.
For the experiment we selected close to the FM dominant, this is explicitly and intrinsically, perhaps even directly, related to personal health. The prediction estimates were done among a set of three evaluation criteria matrix error models, explained in
Table 6: mean absolute error (MAE), mean absolute percentage error (MAPE), and mean squared error (MSE). The experimental results indicate that the error correlation was compared with the proposed learning methods in SRHL. The experiment used a precollected dataset that included the user profile and history ratings assuming the user feedback after the algorithm was deployed was the same as in the precollected dataset; first FM size sequentially is 5, 10, 15.
FM is a recommendation list that is derived in CF which is the first step in the proposed algorithm for the recommendation. FM decreases in every step of the algorithm because each step deletes 10 useless items. The final numbers are FM-5. It is essential to know the performance of the SRHL after the experiment to find out if the methods have been successful or not. Many properties can be considered when evaluating the recommendation system. The learning methods’ performance can be measured by testing against different datasets using a machine learning method approach and then comparing the performance of the four algorithms (CF + CBF, CF + ML, CBF + ML, CF + CBF + ML) that use these models to calculate accuracy. The first method is used for collaborative filtering (CF) and content-based filtering (CBF), then two algorithms combined (CF + CBF) are applied to CF + ML, then CBF + ML is combined with the final proposed learning method, and then all algorithms (CF + CBF + ML) are combined to forecast the exchange rates. This way, the proposed methods of SRHL calculate the accuracy and reliability of the performance comparison according to three evaluation criteria matrix error [
34].
The principal properties of recommendation system accuracy are at a tradeoff when the system wants to focus on diversity. In the formula that describes the process,
is the actual rating,
is the predicted rating, and
n is the number of items. Also, the value used in the experiment is the content ID of the FM last selected or purchased by the user, the number of materials used in the test is 232, and the content ID has a value of 1–232. The scope of error calculated by MAE and MSE is shown in
Table 7. MAPE is an accurate value calculated as a percentage, so it has a range of 0 to 100%. The results of MAPE in the experiment were recalculated to deduct the accuracy of the model as 100% MAPE.
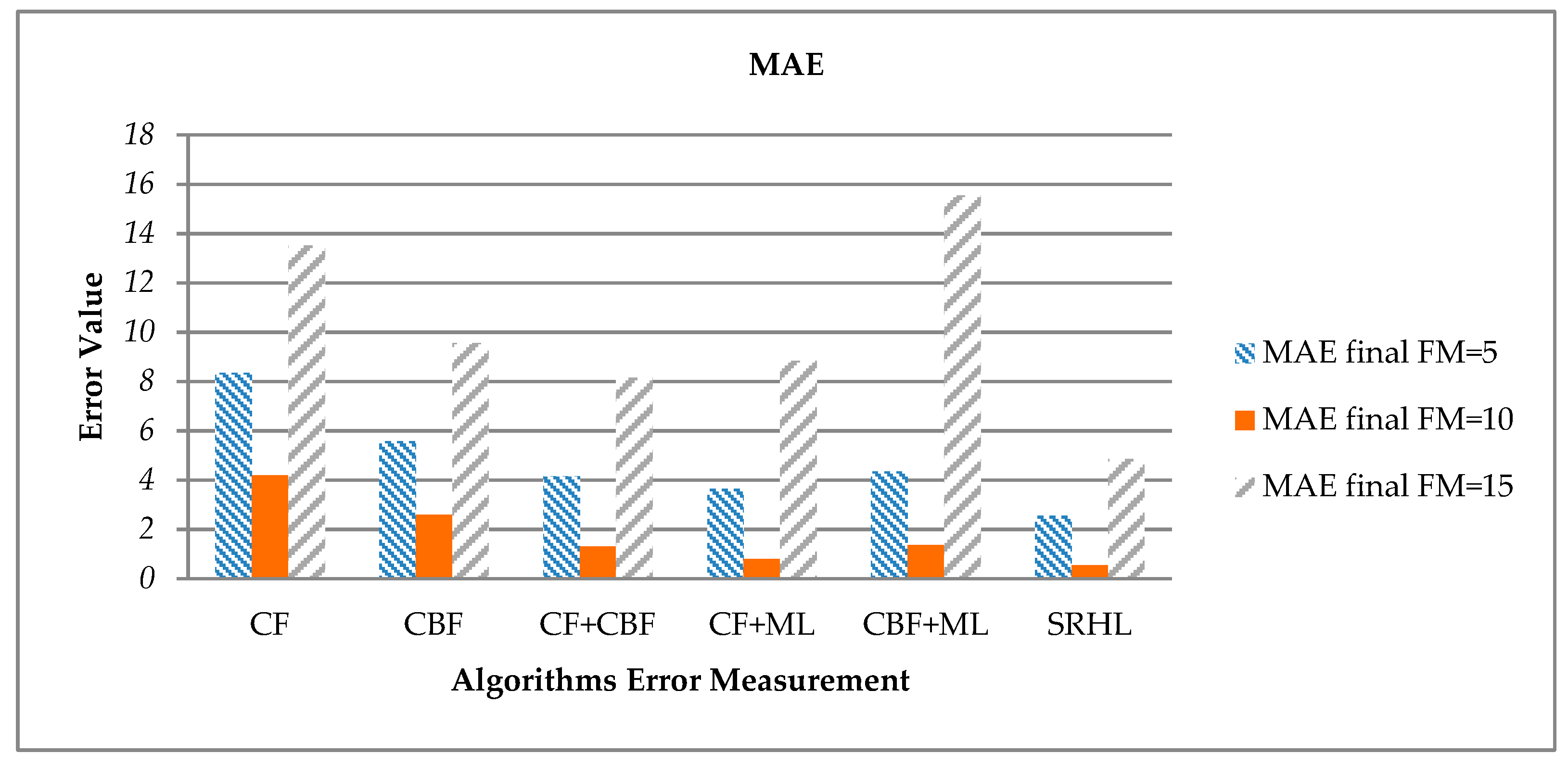
First, the error values derived using MAE are calculated as shown in
Table 8 and
Figure 8. MAE is a formal method for calculating the average error value that is derived when the model predictions are wrong. From the results, the error values of the proposed SRHL are shown to be low overall. Especially when FM = 10, it can be seen that the low error value is derived from the overall algorithms. FM is the number of recommendations. That is, since the number of items to be recommended is low, if just one of the items is a wrong recommendation, it means that the overall error value may go up. On the contrary, if FM is high, the number of recommended items increases, and the probability of error also increases. That means the number of recommendations, FM, should be set to an appropriate number, and in the present experiment, the error value was low when FM had a median value of about 10.
According to the calculated error when FM = 10, see
Table 8 the proposed SRHL showed an error value as low as 3.65 compared to CF. This reduction is the most when compared to all models, because CF shows low recommendation accuracy because of its critical cold start problem. CF + ML showed lower error value than the other models, but the error value was as high as 0.25 compared to the proposed SRHL.
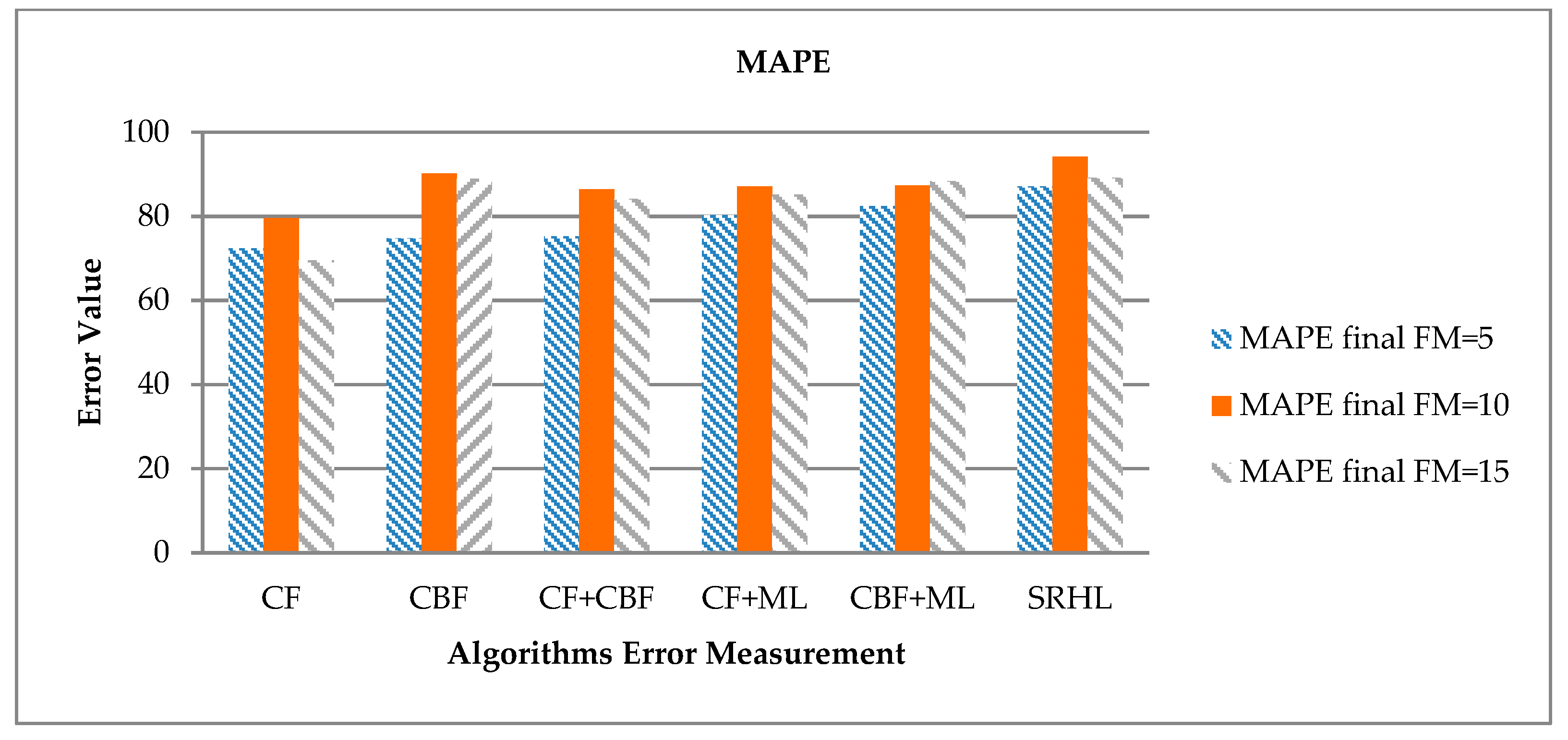
Next, the accuracy calculation results of recommendation using MAPE are shown in
Table 9 and
Figure 9. MAPE uses the error computed by MAE to convert to a percentage, which is used to indicate the ratio between the zero error value and the others. In this experiment, 100% MAPE is calculated and normalized to express the accuracy of the recommendation rather than the frequency of error that is originally calculated by MAPE. As with MAE, when FM = 10, each model showed the highest recommendation accuracy.
MAPE also showed the lowest accuracy of 79.55% for CF and the proposed SRHL showed the highest recommendation accuracy of 94.16%, which is 14.61% higher than CF. The next highest accuracy for SRHL was 90.12% for CBF. This result was calculated differently from the result of MAE. That means the actual error value of CBF is highly measured, but the percentage of accurate recommendations is high. In other words, CBF is less likely to make a false recommendation, but if it is incorrect, it is accompanied by high error values.
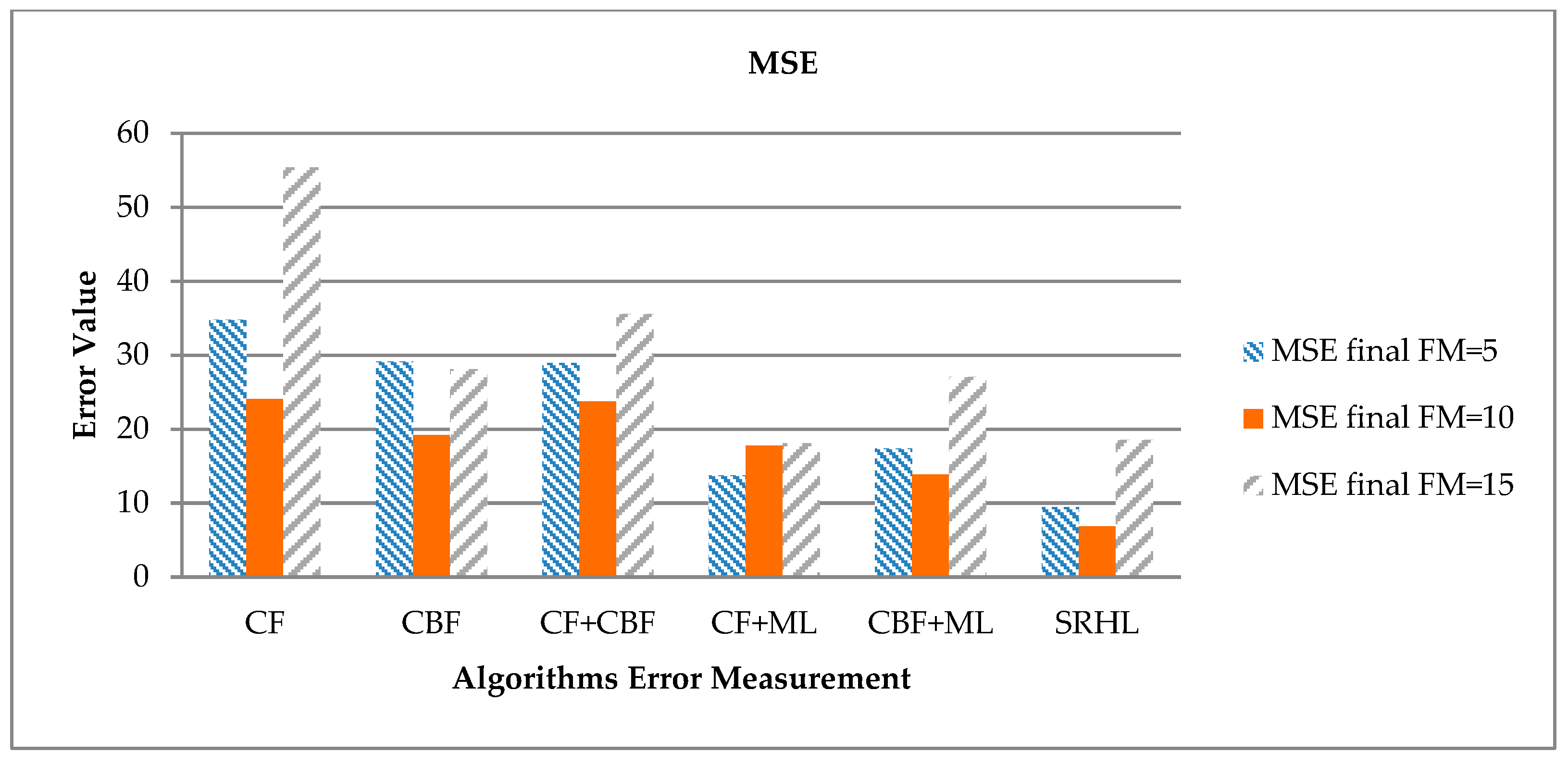
Finally, the calculation results of error numbers using MSE are shown in
Table 10 and
Figure 10. MSE is a way to calculate error values like MAE. Unlike MAE, it performs a squaring operation on error values to weight against high error values. That is, higher error values are reflected more and lower error values are reflected less.
According to the results, the lowest error value was observed when FM = 10, which showed good results as with MAE. The proposed SRHL showed the lowest error value of 6.85 and the highest error value of 24.06 in CF as well as MAE and MAPE. The proposed SRHL improved the error value by an average of 12.87 over all models when FM = 10. The error value was improved by 17.21 compared to CF, with the highest error value of 24.06, and by 7.03 from 13.88 for CBF+ML, which is the next lowest error value for the proposed SRHL.
According to the analysis carried out above, the best performance was obtained when FM = 10, and a summary of the experimental results is shown in
Table 11.
Finally, the three-criteria evaluation matrix, MAE, MAPE, and MSE, were used to measure the performance of the proposed hybrid learning algorithms. The prediction accuracy result of MAE compared to SRHL showed an improvement in performance at approximately 0.55. Furthermore, with MAE the results show a lower value, which is validated as the better result. However, the MAPE result shows an approximately 94.16% higher value, which confirms the better result, while the MSE model’s increase of about 6.85 in value of accuracy over time has become low compared with MAPE, which is stable and the best average model for improved prediction and performance. The proposed SRHL can complement the cold-start problem of CF and the fact that it does not reflect the user’s preference and dynamic profile, which is a disadvantage of CBF, and can recommend items by learning the user’s real-time change through ML. The experimental results show that the performance of the proposed SRHL is better than that of the two single models, CF and CBF, and combinations of the models, CF + CBF, CF + ML, and CBF + ML.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}