Guava Detection and Pose Estimation Using a Low-Cost RGB-D Sensor in the Field





Abstract
:1. Introduction
2. Materials and Methods
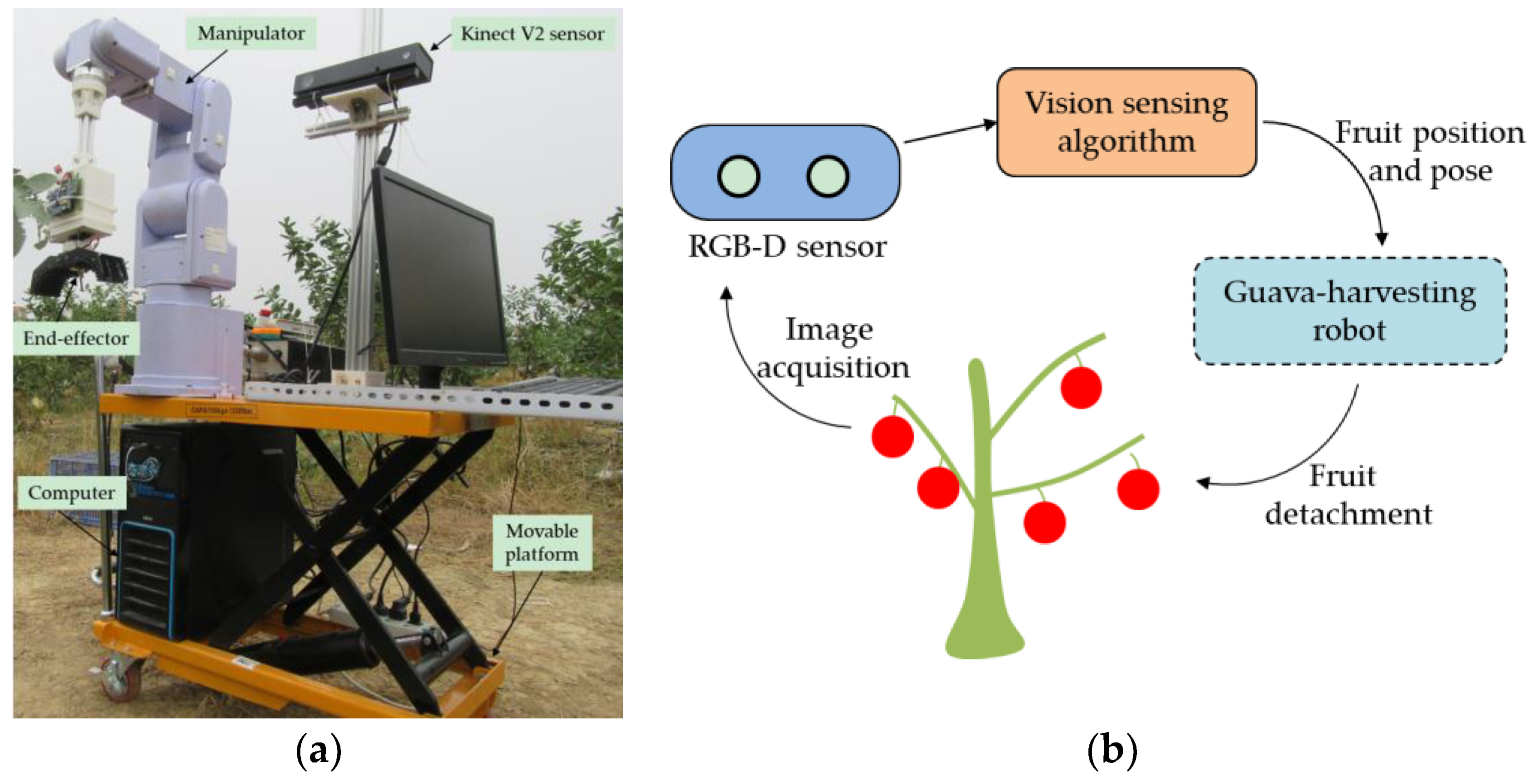
2.1. Vision Sensing System
2.2. Fruit Detection and Pose Estimation Algorithm
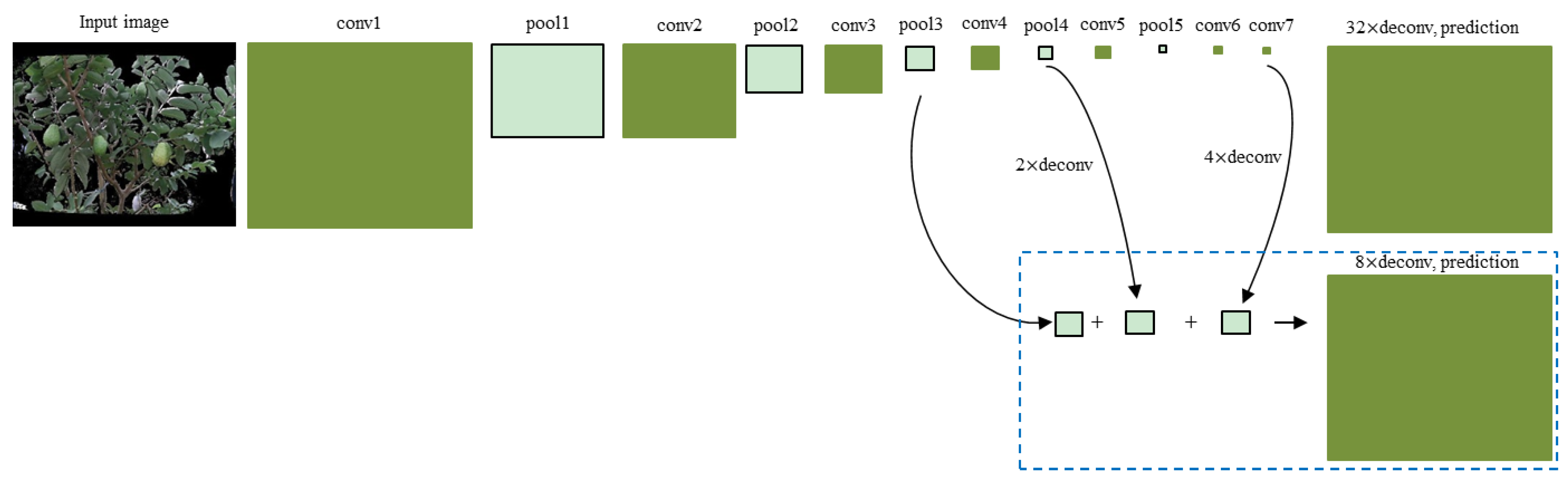
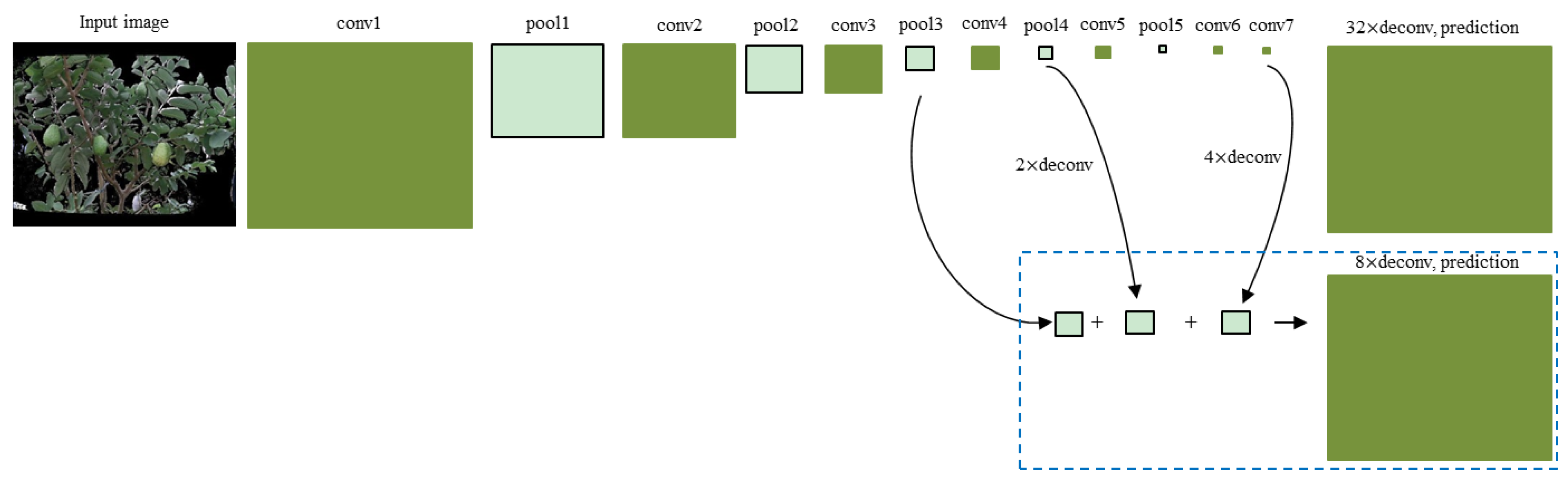
2.2.1. Image Segmentation
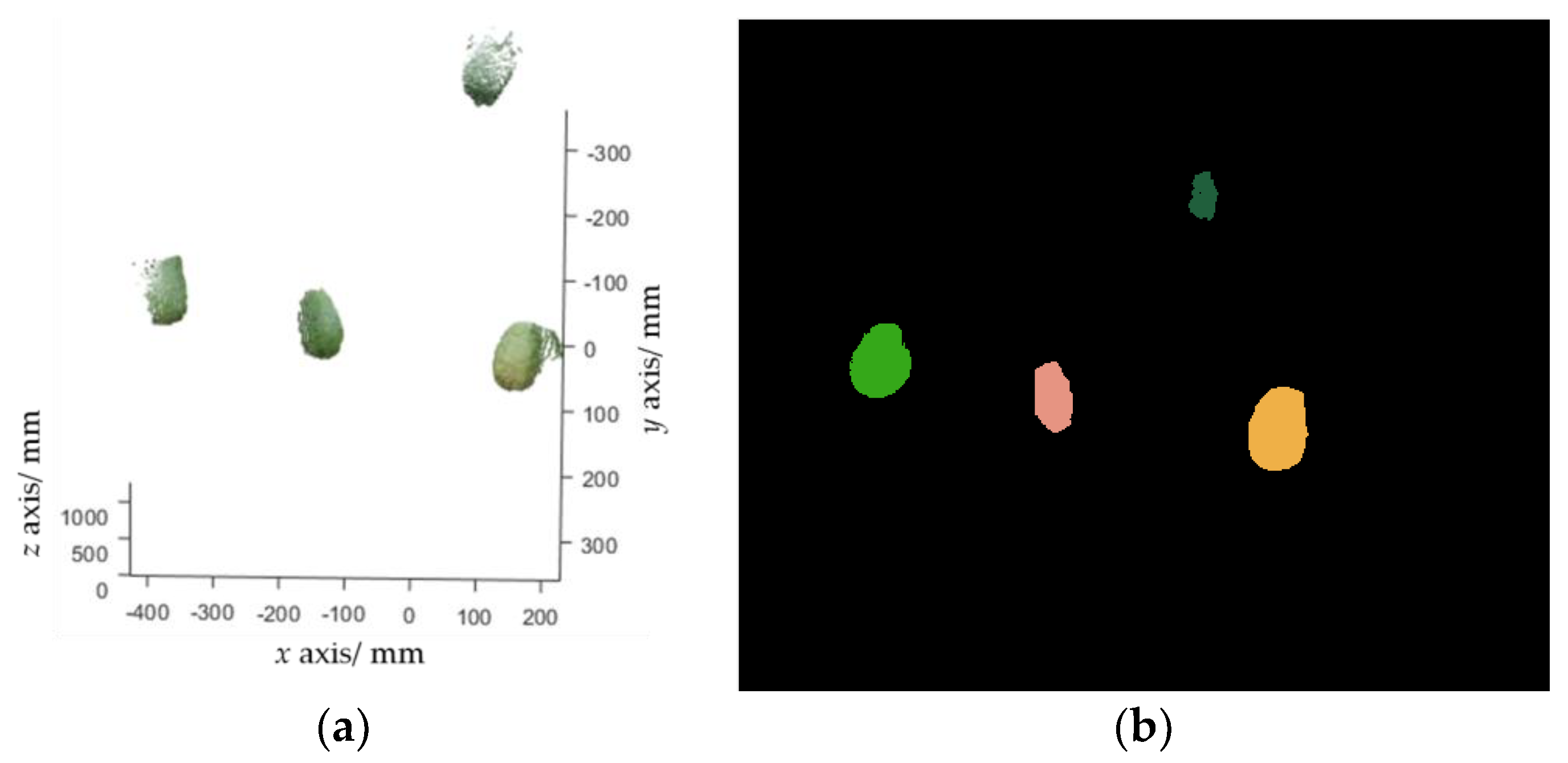
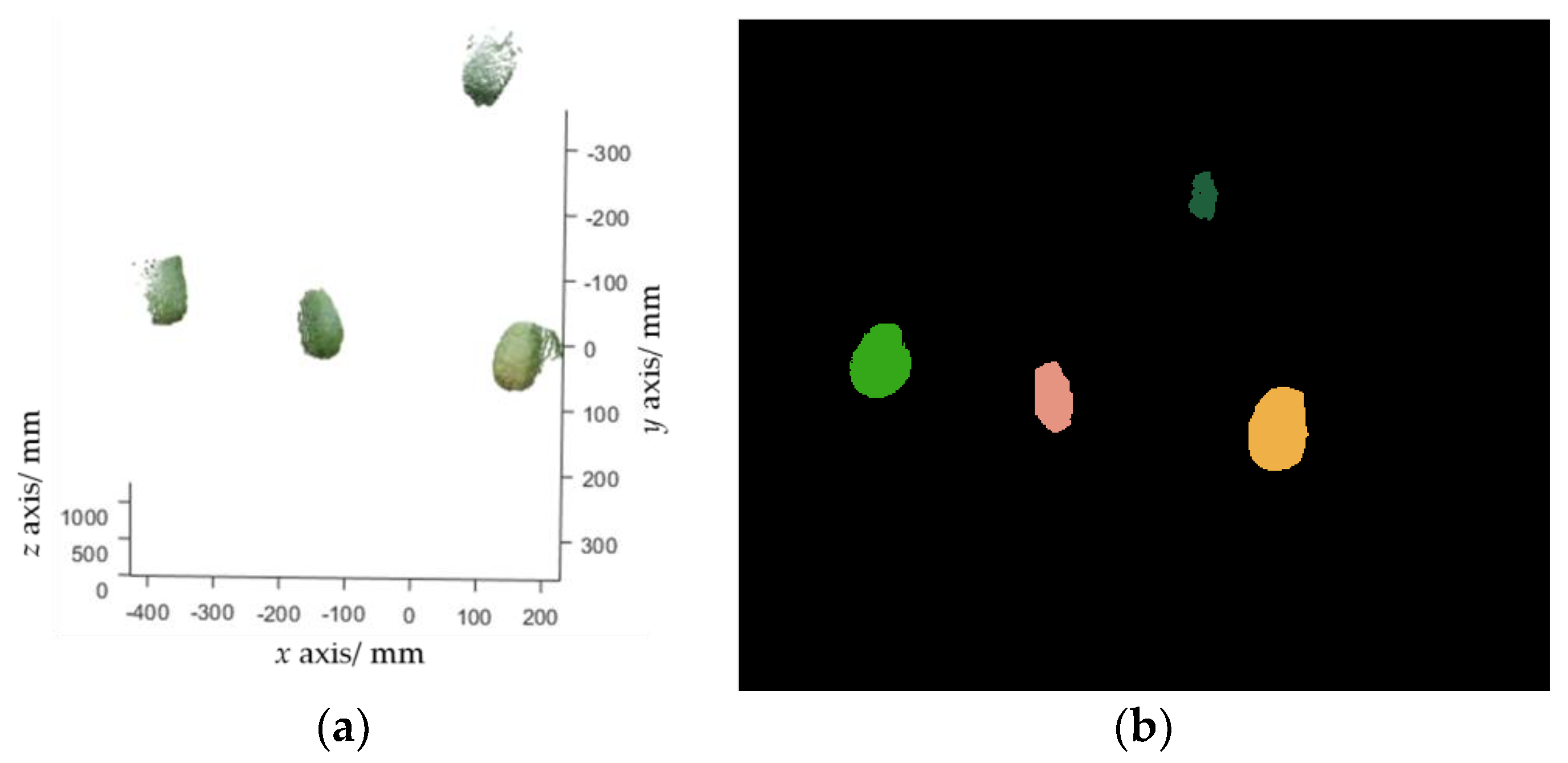
2.2.2. Fruit Detection and Localization
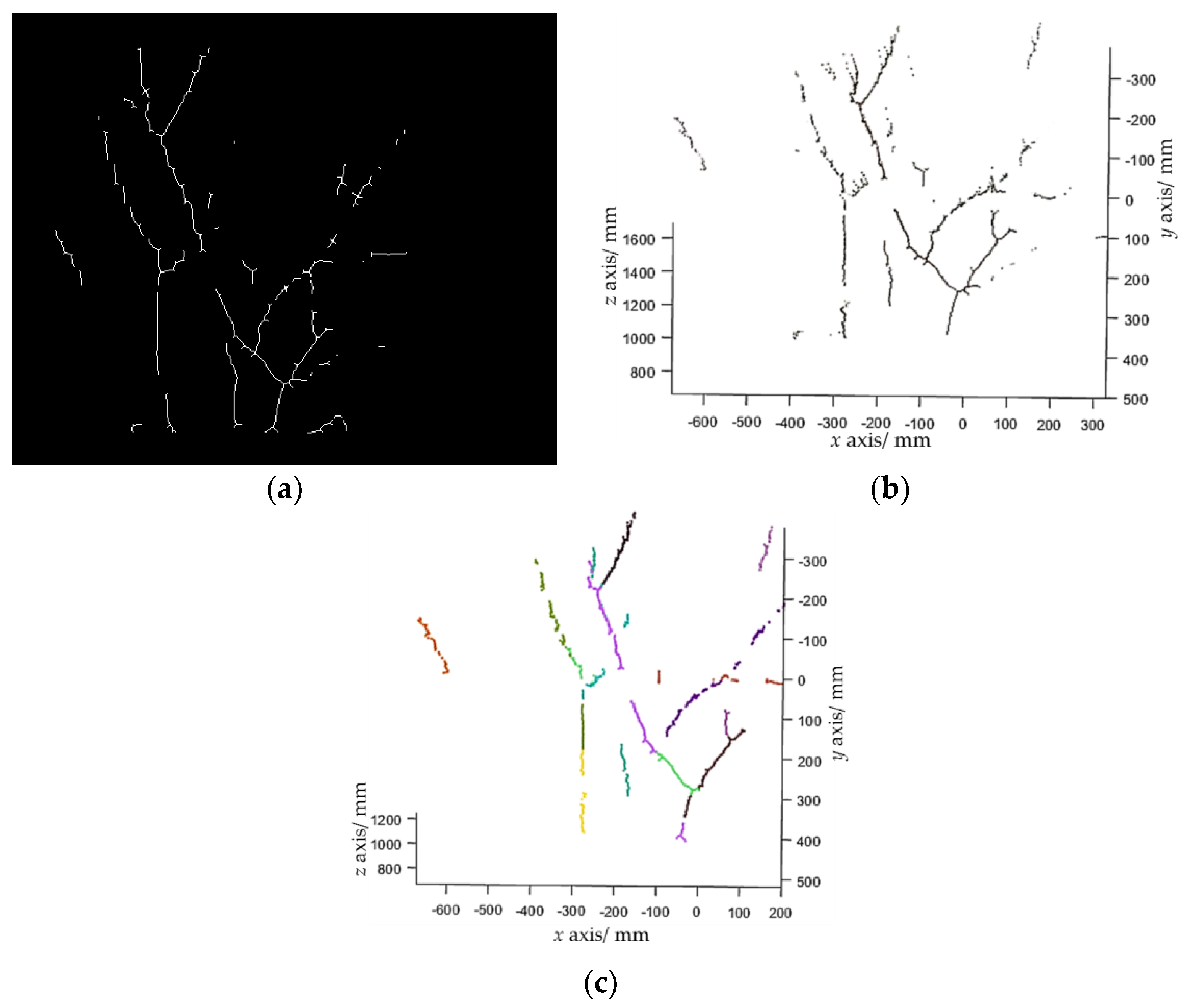
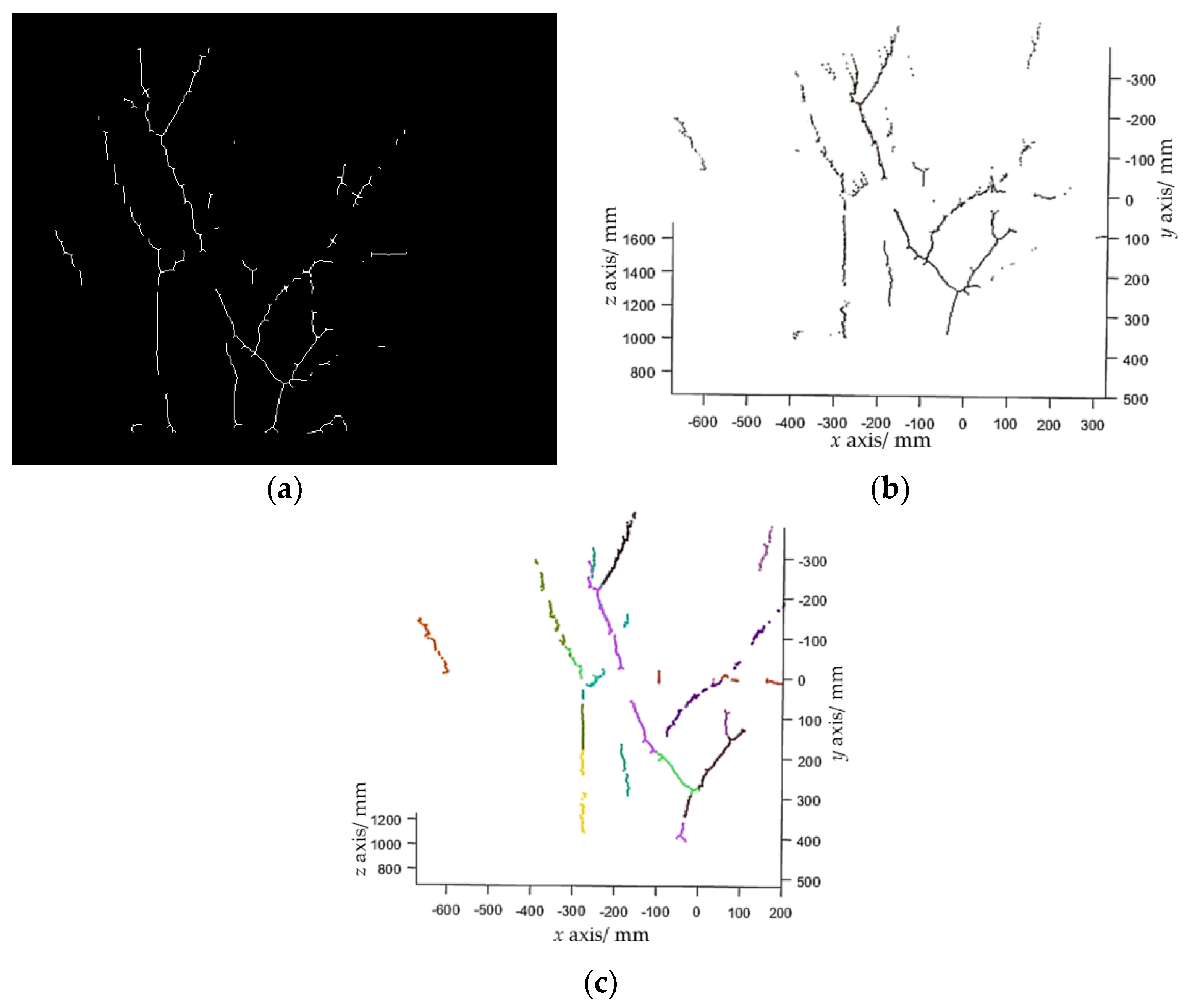
2.2.3. Branch Reconstruction
- Step 1. Randomly select two points, p1 and p2, from the branch point cloud to calculate the parameters of a line candidate as where , then search inliers that fit this line within a threshold. The threshold was set to 15 mm in our experiments.
- Step 2. Repeat Step 1 N times (N was set to 4000 in experiments). If the number of inliers of the line model with the largest number of inliers is larger than a predefined threshold (which was set to 40 in the experiments), choose this line model as a line segment, subtract the inliers from , and go to Step 3. Otherwise, stop the line detection.
- Step 3. Repeat Step 2 until the is empty.
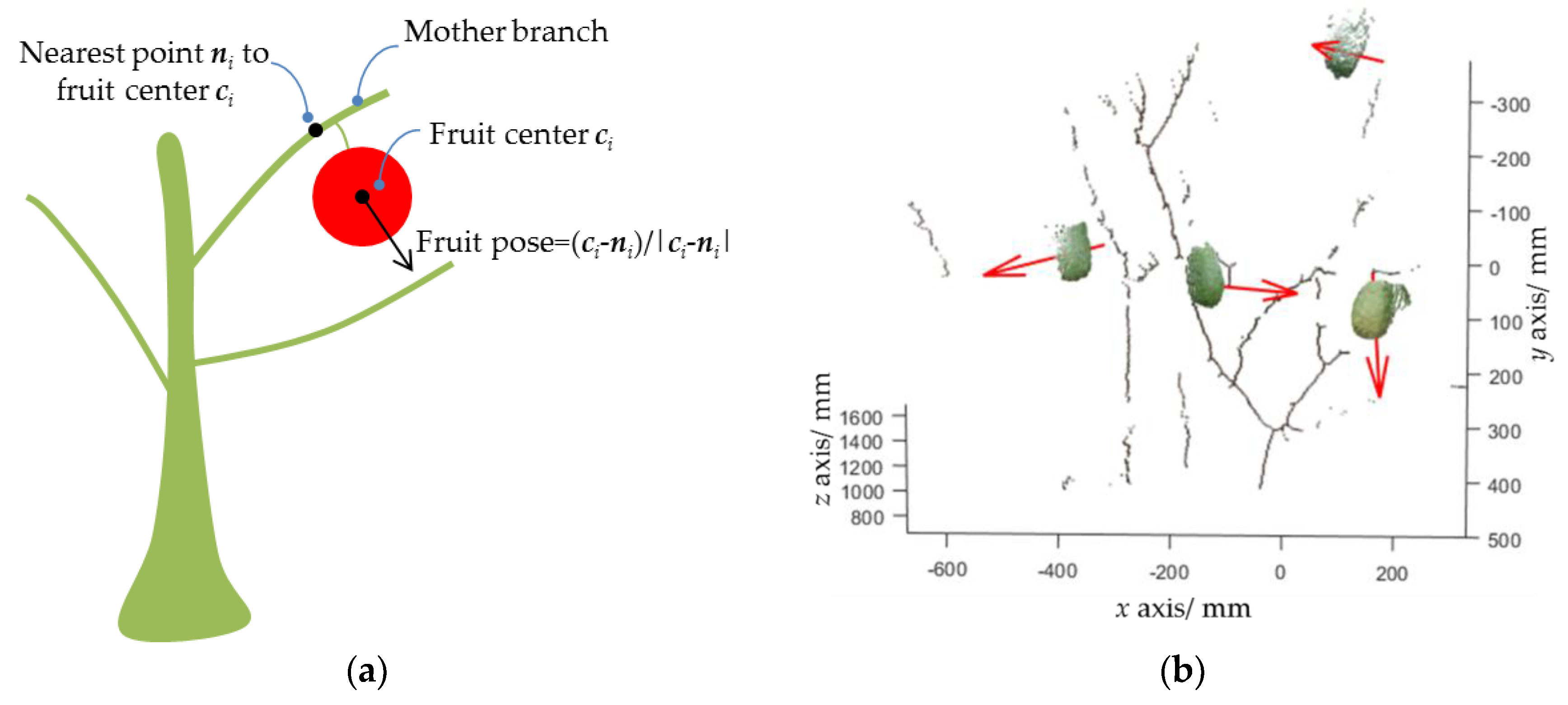
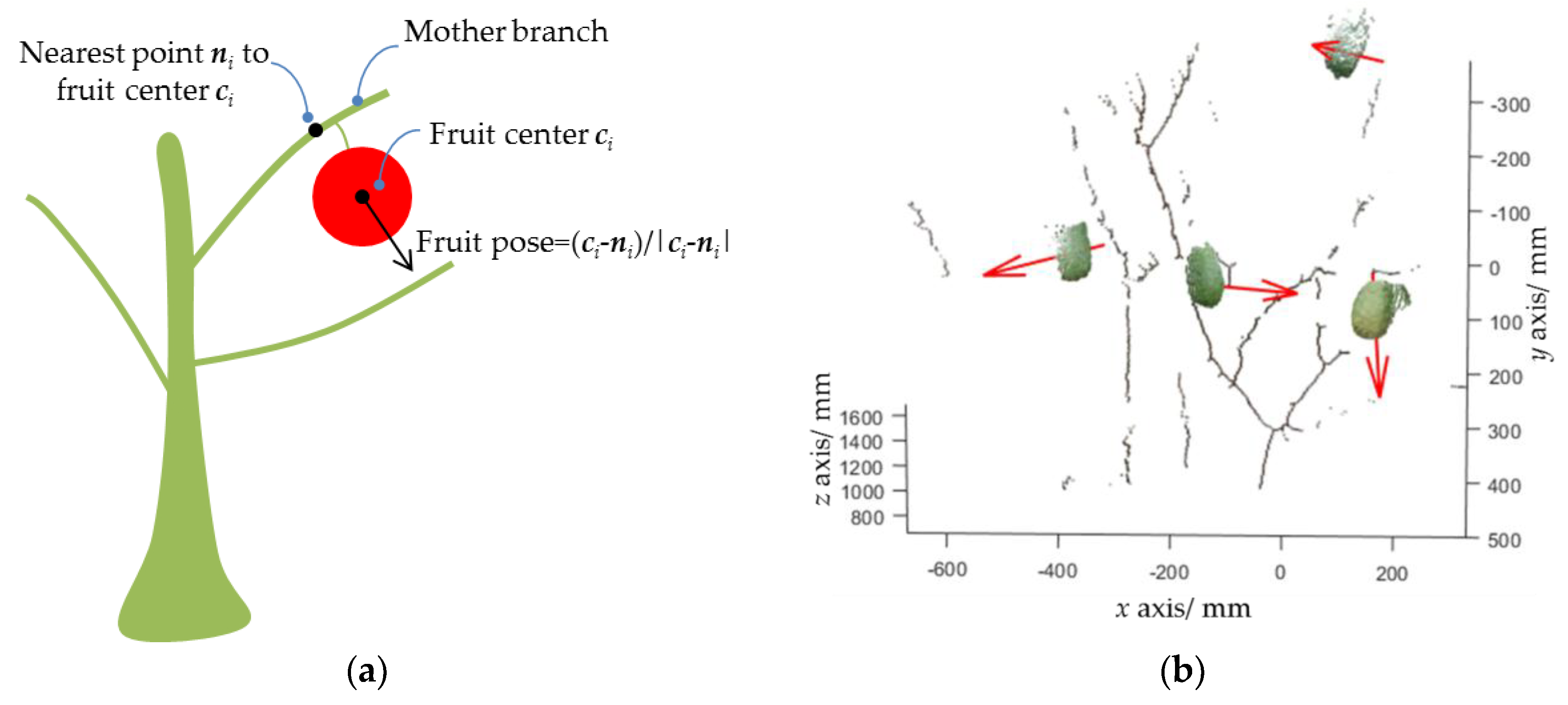
2.2.4. Fruit Pose Estimation
3. Datasets
3.1. Image Acquisition
3.2. Ground Truth
4. Results and Discussions
4.1. Image Segmentation Experiment
4.2. Fruit Detection Experiment
4.3. Pose Estimation Experiment
4.4. Time Efficiency Analysis
5. Conclusions
- (i)
- The FCN model realized a mean accuracy of 0.893 and an IOU of 0.806 for the fruit class, and obtained a mean accuracy of 0.594 and an IOU of 0.473 for the branch class. The result revealed that the guava fruit can be well segmented, but the branch was a little difficult to segment;
- (ii)
- The detection precision and recall of the proposed algorithm were 0.983 and 0.949, respectively. It can be concluded that the proposed algorithm was robust for detecting in-field guavas;
- (iii)
- The pose error of the bounding box-based method was , while that of the sphere fitting-based method was . The results suggested that the sphere fitting method was more suitable for pose estimation;
- (iv)
- The proposed pipeline needs 0.565 s on average to detect a fruit and estimate its pose, which was sufficient for a guava-harvesting robot.
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Dong, Q.; Murakami, T.; Nakashima, Y. Recalculating the agricultural labor force in china. China Econ. J. 2018, 11, 151–169. [Google Scholar] [CrossRef]
- Silwal, A.; Davidson, J.R.; Karkee, M.; Mo, C.; Zhang, Q.; Lewis, K. Design, integration, and field evaluation of a robotic apple harvester. J. Field Robot. 2017, 34, 1140–1159. [Google Scholar] [CrossRef]
- Bac, C.W.; Hemming, J.; Van Tuijl, J.; Barth, R.; Wais, E.; Van Henten, E.J. Performance evaluation of a harvesting robot for sweet pepper. J. Field Robot. 2017, 36, 1123–1139. [Google Scholar] [CrossRef]
- Kusumam, K.; Krajník, T.; Pearson, S.; Duckett, T.; Cielniak, G. 3d-vision based detection, localization, and sizing of broccoli heads in the field. J. Field Robot. 2017, 34, 1505–1518. [Google Scholar] [CrossRef]
- Song, Y.; Glasbey, C.A.; Horgan, G.W.; Polder, G.; Dieleman, J.A.; van der Heijden, G.W.A.M. Automatic fruit recognition and counting from multiple images. Biosyst. Eng. 2014, 118, 203–215. [Google Scholar] [CrossRef]
- Sengupta, S.; Lee, W.S. Identification and determination of the number of immature green citrus fruit in a canopy under different ambient light conditions. Biosyst. Eng. 2014, 117, 51–61. [Google Scholar] [CrossRef]
- Qureshi, W.S.; Payne, A.; Walsh, K.B.; Linker, R.; Cohen, O.; Dailey, M.N. Machine vision for counting fruit on mango tree canopies. Precis. Agric. 2016, 17, 1–21. [Google Scholar] [CrossRef]
- Luo, L.; Tang, Y.; Zou, X.; Wang, C.; Zhang, P.; Feng, W. Robust grape cluster detection in a vineyard by combining the adaboost framework and multiple color components. Sensors 2016, 16, 2098. [Google Scholar] [CrossRef]
- Wang, C.; Lee, W.S.; Zou, X.; Choi, D.; Gan, H.; Diamond, J. Detection and counting of immature green citrus fruit based on the local binary patterns (lbp) feature using illumination-normalized images. Precis. Agric. 2018, 19, 1062–1083. [Google Scholar] [CrossRef]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; Mccool, C. Deepfruits: A fruit detection system using deep neural networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef]
- Stein, M.; Bargoti, S.; Underwood, J. Image based mango fruit detection, localisation and yield estimation using multiple view geometry. Sensors 2016, 16, 1915. [Google Scholar] [CrossRef] [PubMed]
- Bargoti, S.; Underwood, J. Deep fruit detection in orchards. In Proceedings of the IEEE International Conference on Robotics & Automation, Singapore, 29 May–3 June 2017; pp. 3626–3633. [Google Scholar]
- Bargoti, S.; Underwood, J. Image segmentation for fruit detection and yield estimation in apple orchards. J. Field Robot. 2017, 34, 1039–1060. [Google Scholar] [CrossRef]
- Barnea, E.; Mairon, R.; Ben-Shahar, O. Colour-Agnostic Shape-Based 3D Fruit Detection for Crop Harvesting Robots. Biosyst. Eng. 2016, 146, 57–70. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Vandevoorde, K.; Wouters, N.; Kayacan, E.; Baerdemaeker, J.G.D.; Saeys, W. Detection of red and bicoloured apples on tree with an RGB-D camera. Biosyst. Eng. 2016, 146, 33–44. [Google Scholar] [CrossRef]
- Rusu, R.B. Semantic 3d Object maps for Everyday Manipulation in Human Living Environment. Ph.D. Thesis, Computer Science Department, Technische Universität München, München, Germany, 2009. [Google Scholar]
- Wang, Z.; Walsh, K.; Verma, B. On-tree mango fruit size estimation using RGB-D images. Sensors 2017, 17, 2738. [Google Scholar] [CrossRef]
- Eizentals, P.; Oka, K. 3d pose estimation of green pepper fruit for automated harvesting. Comput. Electron. Agric. 2016, 128, 127–140. [Google Scholar] [CrossRef]
- Lehnert, C.; Sa, I.; Mccool, C.; Upcroft, B.; Perez, T. Sweet pepper pose detection and grasping for automated crop harvesting. In Proceedings of the IEEE International Conference on Robotics & Automation, Stockholm, Sweden, 16–21 September 2016; pp. 2428–2434. [Google Scholar]
- Li, H.; Zhu, Q.; Huang, M.; Guo, Y.; Qin, J. Pose Estimation of Sweet Pepper through Symmetry Axis Detection. Sensors 2018, 18, 3083. [Google Scholar] [CrossRef]
- Van Henten, E.J.; Van Tuijl, B.A.J.; Hoogakker, G.J.; Van Der Weerd, M.J.; Hemming, J.; Kornet, J.G.; Bontsema, J. An autonomous robot for de-leafing cucumber plants grown in a high-wire cultivation system. Biosyst. Eng. 2006, 94, 317–323. [Google Scholar] [CrossRef]
- Lu, Q.; Tang, M.; Cai, J. Obstacle recognition using multi-spectral imaging for citrus picking robot. In Proceedings of the 2011 3rd Pacific–Asia Conference on Circuits, Communications and System, Wuhan, China, 17–18 July 2011; pp. 1–5. [Google Scholar]
- Noble, S.; Li, D. Segmentation of greenhouse cucumber plants in multispectral imagery. In Proceedings of the International Conference of Agricultural Engineering, CIGR-Ageng, Valencia, Spain, 8–12 July 2012; pp. 1–5. [Google Scholar]
- Bac, C.W.; Hemming, J.; Van Henten, E.J. Robust pixel-based classification of obstacles for robotic harvesting of sweet-pepper. Comput. Electron. Agric. 2013, 96, 148–162. [Google Scholar] [CrossRef]
- Bac, C.W.; Hemming, J.; Van Henten, E.J. Stem localization of sweet-pepper plants using the support wire as a visual cue. Comput. Electron. Agric. 2014, 105, 111–120. [Google Scholar] [CrossRef]
- Zhang, P.; Xu, L. Unsupervised segmentation of greenhouse plant images based on statistical method. Sci. Rep. 2018, 8, 4465. [Google Scholar] [CrossRef] [PubMed]
- Majeed, Y.; Zhang, J.; Zhang, X.; Fu, L.; Karkee, M.; Zhang, Q.; Whiting, M.D. Apple Tree Trunk and Branch Segmentation for Automatic Trellis Training Using Convolutional Neural Network Based Semantic Segmentation. IFAC 2018, 51, 75–80. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for scene segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 22, 1330–1334. [Google Scholar] [CrossRef]
- Simonyan, K.; Andrew, Z. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar]
- GitHub. FCN. 2018. Available online: https://github.com/shelhamer/fcn.berkeleyvision.org (accessed on 15 June 2018).
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Serra, J. Image Analysis and Mathematical Morphology; Academic Press: New York, NY, USA, 1982; pp. 387–390. [Google Scholar]
- Botterill, T.; Paulin, S.; Green, R.; Williams, S.; Lin, J.; Saxton, V.; Mills, S.; Chen, X.; Corbett-Davies, S. A robot system for pruning grape vines. J. Field Robot. 2017, 34, 1100–1122. [Google Scholar] [CrossRef]
- Schnabel, R.; Wahl, R.; Klein, R. Efficient ransac for point-cloud shape detection. Comput. Graph. Forum 2007, 26, 214–226. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Schmid, C. Constructing models for content-based image retrieval. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; pp. 39–45. [Google Scholar]
- Fankhauser, P.; Bloesch, M.; Rodriguez, D.; Kaestner, R.; Hutter, M.; Siegwart, R. Kinect v2 for Mobile Robot Navigation: Evaluation and Modeling. In Proceedings of the International Conference on Advanced Robotics (ICAR), Istanbul, Turkey, 27–31 July 2015; pp. 388–394. [Google Scholar]
- Cao, X.; Zou, X.; Jia, C.; Chen, M.; Zeng, Z. RRT-based path planning for an intelligent litchi-picking manipulator. Comput. Electron. Agric. 2019, 156, 105–118. [Google Scholar] [CrossRef]
- Bac, C.W.; Van Henten, E.J.; Hemming, J.; Edan, Y. Harvesting robots for high-value crops: State-of-the-art review and challenges ahead. J. Field Robot. 2014, 31, 888–911. [Google Scholar] [CrossRef]
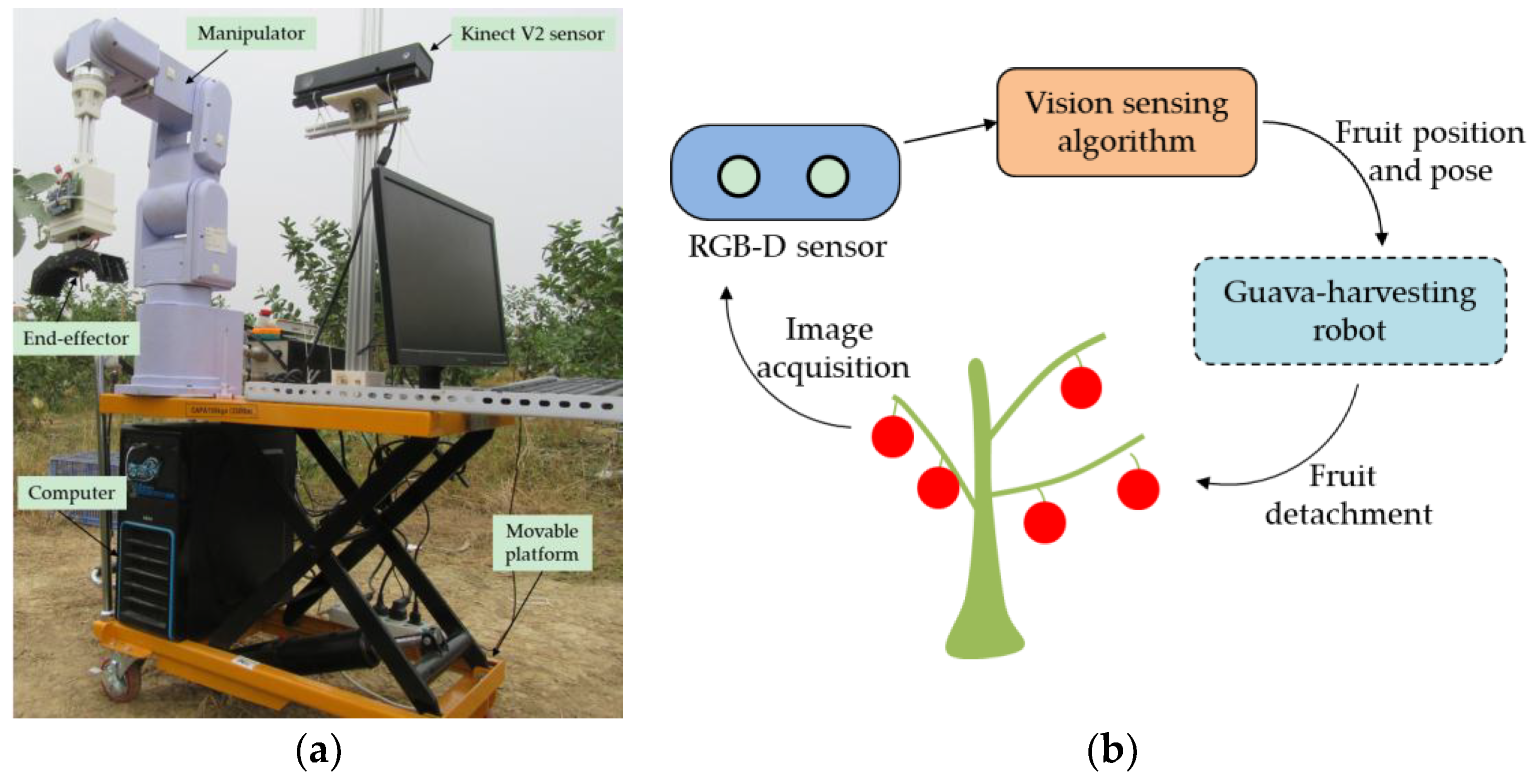







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fruit | Branch | |||
|---|---|---|---|---|
| Mean Accuracy | IOU | Mean Accuracy | IOU | |
| FCN | 0.893 | 0.806 | 0.594 | 0.473 |
| SegNet | 0.818 | 0.665 | 0.642 | 0.389 |
| CART | 0.264 | 0.235 | 0.071 | 0.067 |
| Algorithm | # Images | # Fruits | # True Positives | # False Positives | Precision | Recall |
|---|---|---|---|---|---|---|
| Proposed | 91 | 237 | 225 | 4 | 0.983 | 0.949 |
| method in [4] | 91 | 237 | 159 | 10 | 0.941 | 0.671 |
| Method | MEDE (degree) | MAD (degree) |
|---|---|---|
| Bounding box | 25.41 | 14.73 |
| Sphere fitting | 23.43 | 14.18 |
| Bounding Box (%) | Sphere Fitting (%) | |
|---|---|---|
| 70.45 | 74.24 | |
| 62.88 | 63.64 | |
| 49.24 | 53.79 |
| Subtasks | Average Time (s) | Standard Deviation (s) |
|---|---|---|
| Segmentation | 0.165 | 0.076 |
| Fruit detection | 0.689 | 0.368 |
| Branch reconstruction | 0.543 | 0.397 |
| Pose estimation | 0.000 | 0.000 |
| Total | 1.398 | 0.682 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, G.; Tang, Y.; Zou, X.; Xiong, J.; Li, J. Guava Detection and Pose Estimation Using a Low-Cost RGB-D Sensor in the Field. Sensors 2019, 19, 428. https://doi.org/10.3390/s19020428
Lin G, Tang Y, Zou X, Xiong J, Li J. Guava Detection and Pose Estimation Using a Low-Cost RGB-D Sensor in the Field. Sensors. 2019; 19(2):428. https://doi.org/10.3390/s19020428
Chicago/Turabian StyleLin, Guichao, Yunchao Tang, Xiangjun Zou, Juntao Xiong, and Jinhui Li. 2019. "Guava Detection and Pose Estimation Using a Low-Cost RGB-D Sensor in the Field" Sensors 19, no. 2: 428. https://doi.org/10.3390/s19020428
APA StyleLin, G., Tang, Y., Zou, X., Xiong, J., & Li, J. (2019). Guava Detection and Pose Estimation Using a Low-Cost RGB-D Sensor in the Field. Sensors, 19(2), 428. https://doi.org/10.3390/s19020428