Data-Driven Based Approach to Aid Parkinson’s Disease Diagnosis



Abstract
1. Introduction
2. Related Works
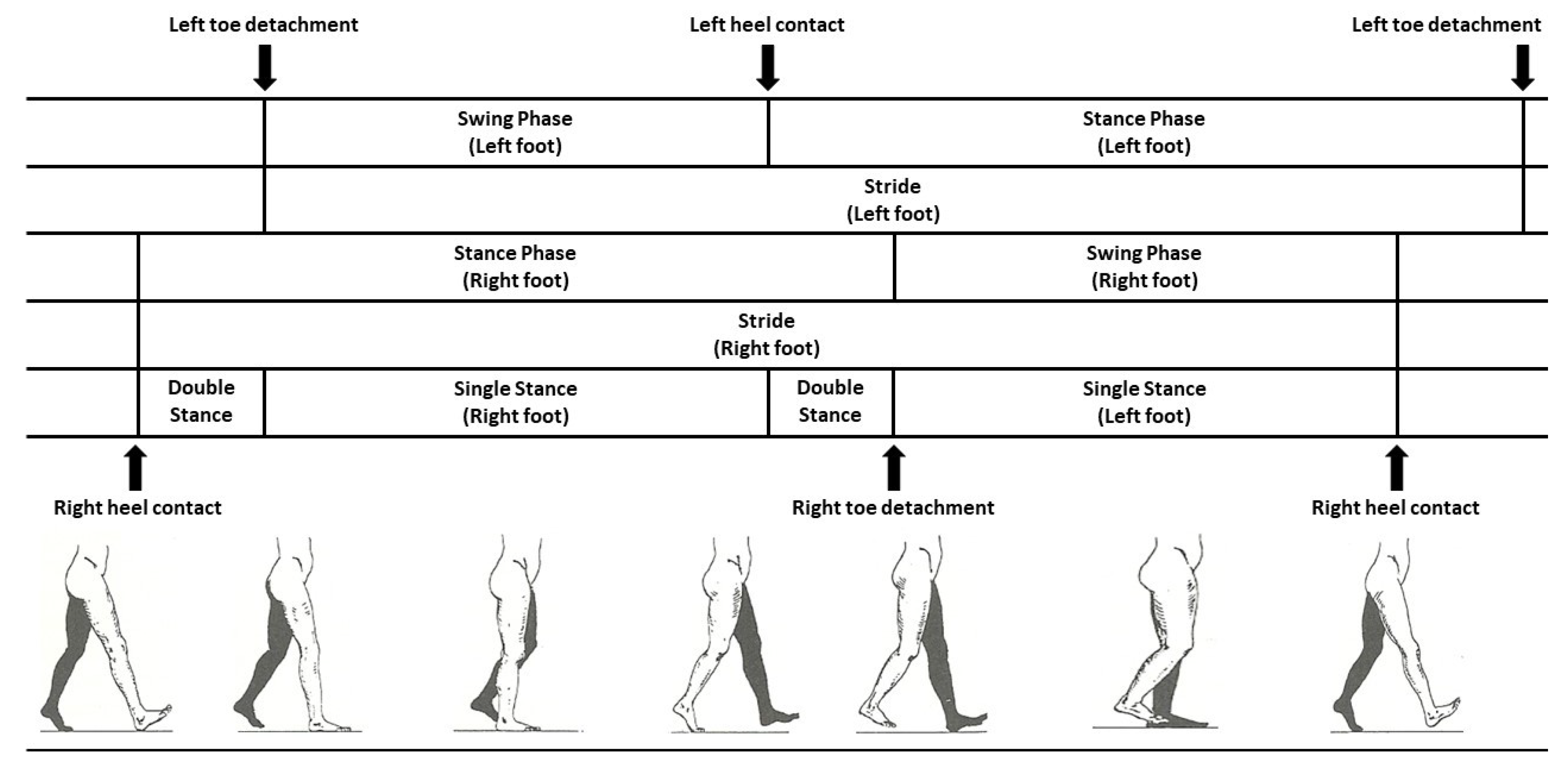
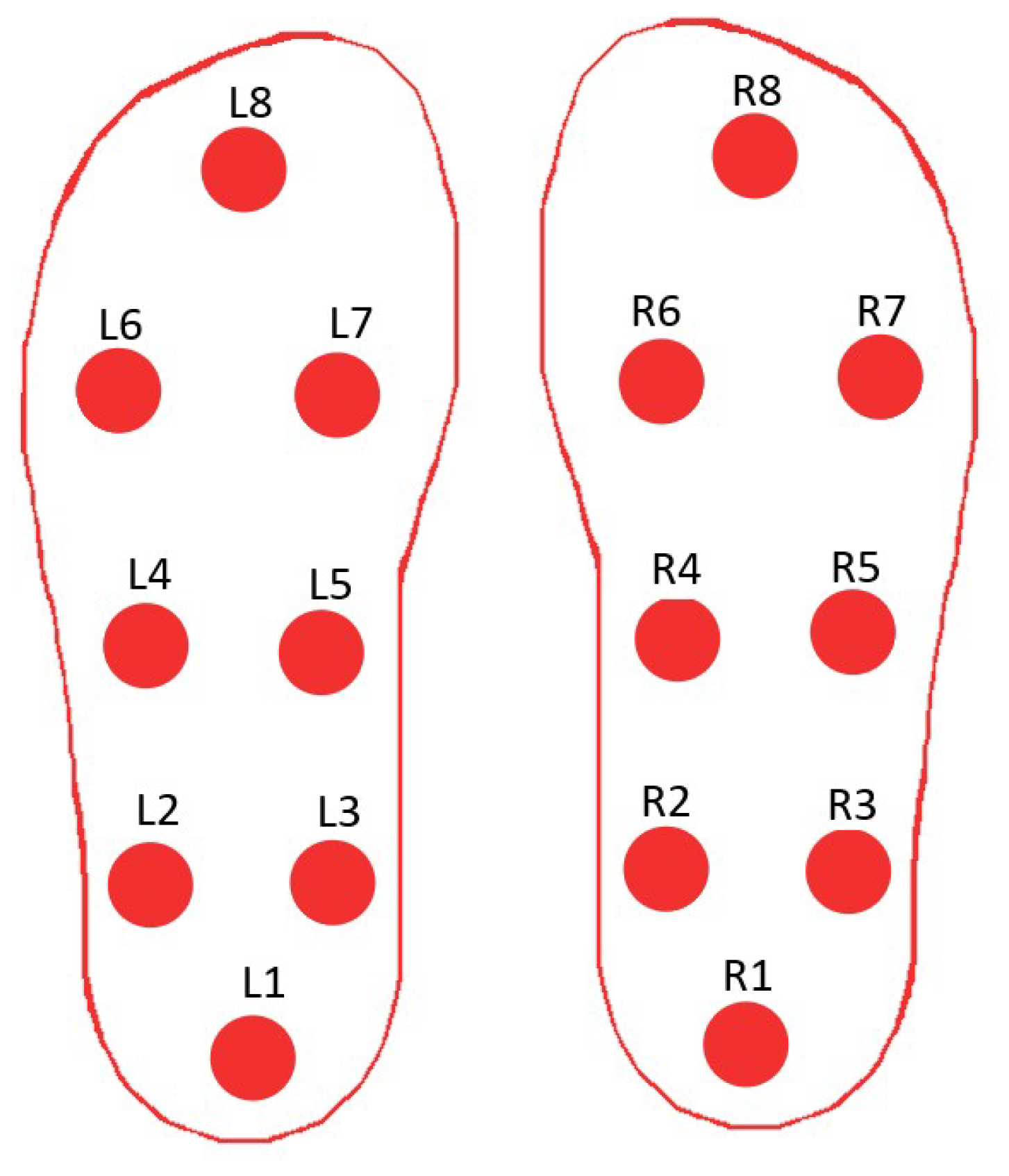
3. Dataset Description
4. Background on Data Processing and Classification Techniques
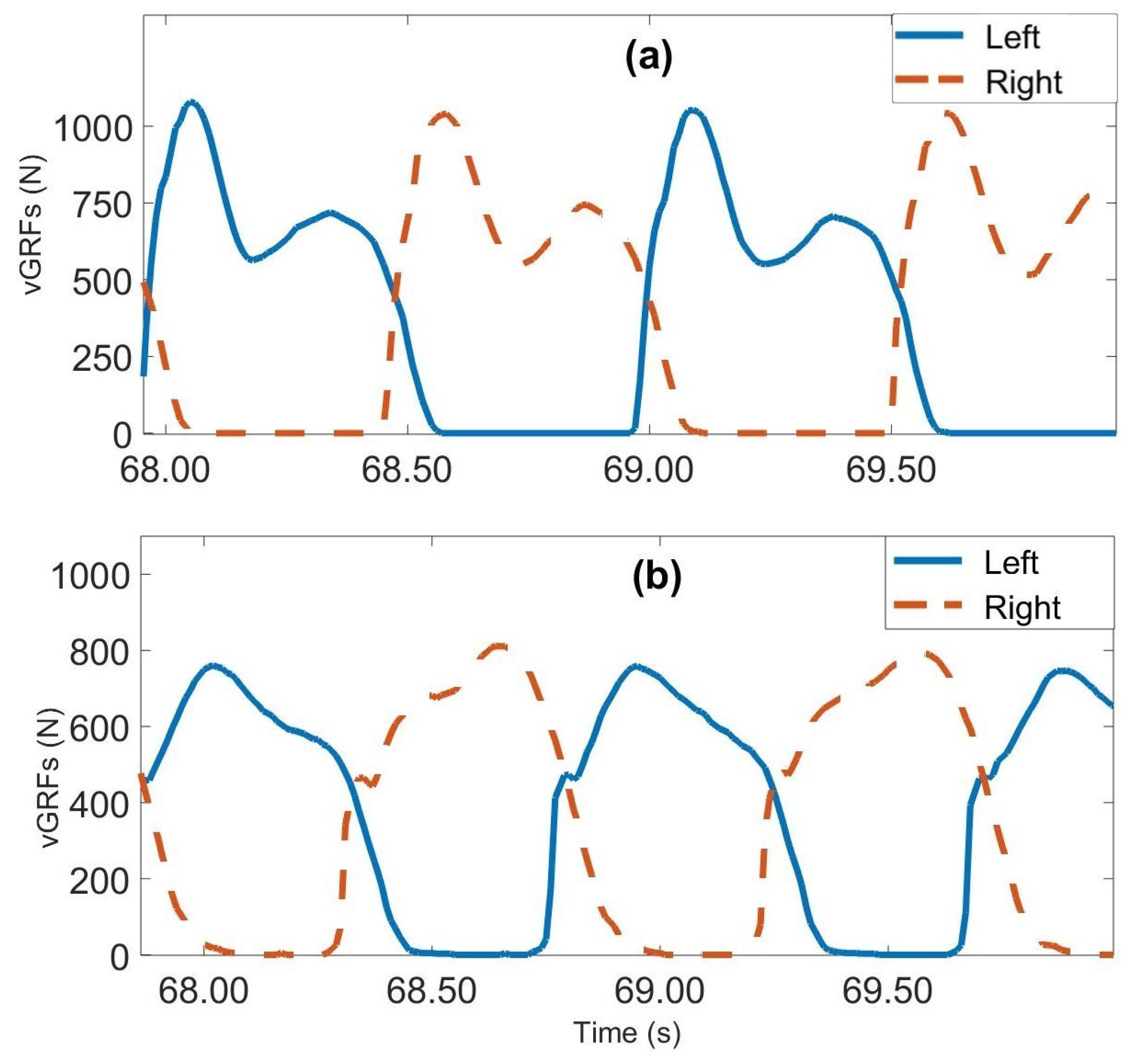
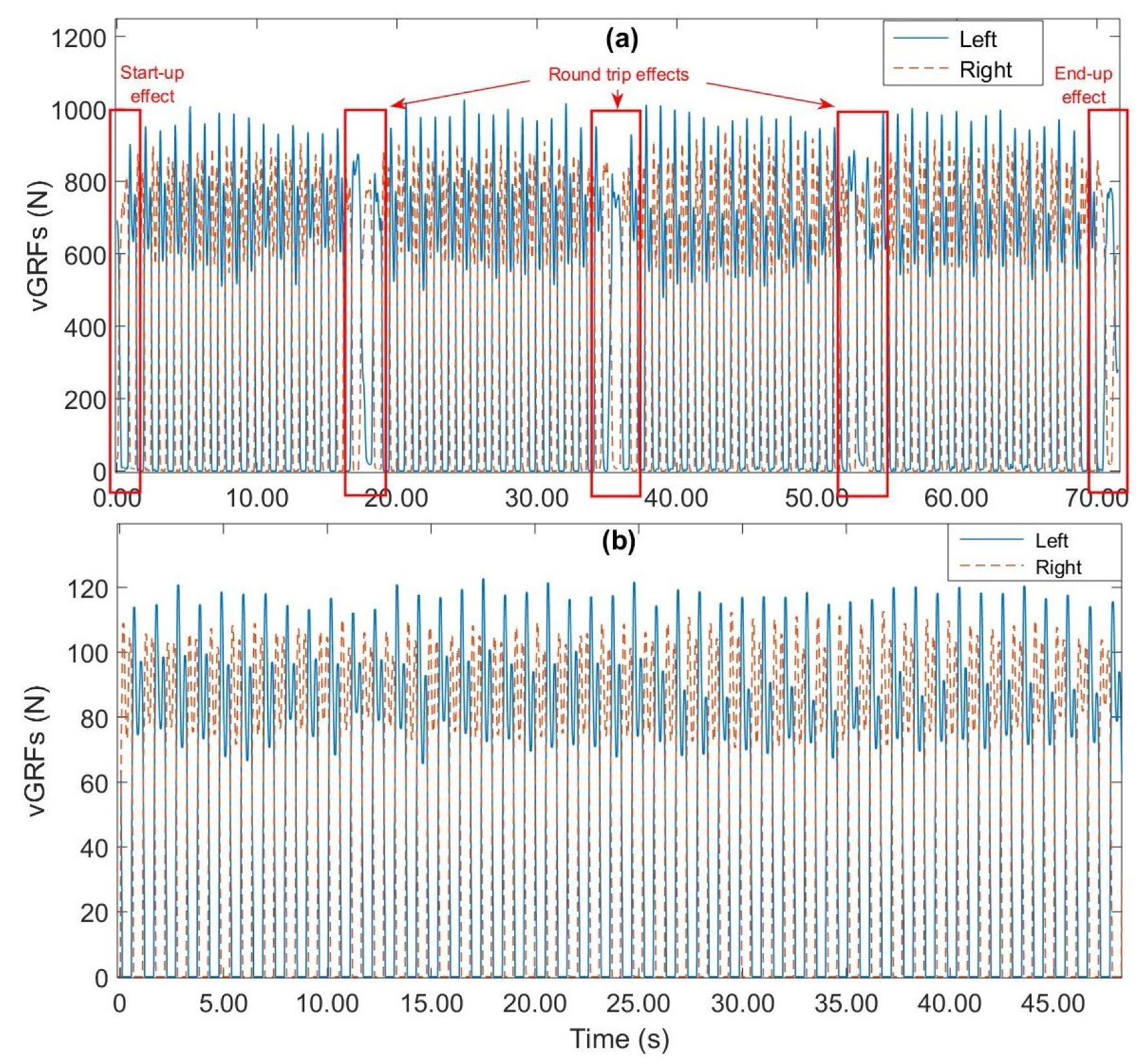
4.1. Data Pre-Processing
4.2. Feature Extraction and Selection
4.2.1. Feature Extraction
4.2.2. Feature Selection
4.3. Classification Techniques
- K-nearest neighbour [88] is one of the simplest supervised classification approaches. It is a non-parametric supervised classification method. In K-NN, no explicit or modelling phase occurs before the classification phase. Classification with K-NN involves two main steps: (1) a distance calculation (usually, Euclidean distance) is made between the new sample and all training samples; (2) the new sample is assigned to the majority class of the nearest samples using the K nearest neighbour selection.
- The support vector machine is a well-known supervised machine learning model [89] that is used primarily for binary prediction problems. The underlying idea of this model is based on the concepts of a hyper-plane and the margin. The learning process consists of finding a linear separator (also called a hyperplane) which separates the training data while maximizing the margin between the hyperplane and these training data. In some cases, SVM cannot directly find a linear separation between the data in its original representation. Thus, to be able to find a linear separator between the groups, a training data transformation proposed by Vapnik [89] is performed from the original space to another higher dimensional space. This transformation can be made using a kernel function such as the Gaussian, quadratic, or polynomial kernel functions.
- The decision tree is a supervised classification method [90] that is simple, effective and easy to interpret. A DT finds nonlinear relationships between the inputs and outputs of the system. A DT is an iterative classifier that separates variables into branches and nodes. The nodes are composed of one root node and diverse inertial nodes and leaves. Several algorithms have been used for DT construction including the Classification and Regression Tree (CART) [90], Iterative Dichotomiser (ID3) [91] and C4.5 [92], etc.
- The random forest is another supervised machine learning introduced by Breiman in [93]. As its name implies, a random forest is constructed from a set of DTs. Each tree is constructed using a training subset generated randomly from the original dataset using the Bootstrap technique. Therefore, the RF model combines the bagging technique and the randomized selection from partitioning the data nodes during DT construction.
- Naïve Bayes (NB) is another simple supervised machine learning model based on the Bayes theorem [94,95] with independence assumptions between observation data. NB’s main advantage is that its learning model is simple and does not require any complicated iterative parameter estimation. Despite its simplicity, the NB model can outperform more sophisticated machine learning models.
- The Gaussian Mixture Model is a supervised and unsupervised probabilistic machine learning model. This model represents the training data as weighted-sum finite Gaussian-component densities. The data are represented according to one or multi-Gaussian distributions and characterized by the covariance matrix and the mean vector. The parameter estimation for this model (the proportions, the covariance matrices of the Gaussian component and the mean vectors) is based on the maximization of the log likelihood using the expectation–maximization (EM) [96] algorithm.
- K-means is still another simple unsupervised machine learning model. This method divides the training data into k homogeneous clusters [97]. The objective is to minimize the total intra-cluster variance and the distortion measure as a cost function. The K-means model finds the cluster centroids iteratively and assigns the data to the various cluster centroids based on their distance (e.g., Euclidean) until convergence occurs.
4.4. Performance Evaluation
- The Precision metric measures the proportion of relevant subjects that are relevant. It measures the ability of the classifier to refuse irrelevant subjects. The Recall metric evaluates the proportion of relevant subjects that are found. It measures the ability of the classifier to provide all relevant subjects. These metrics are expressed as follows:
- The F-measure metric is a combination of precision and recall defined as follows:where is a real positive weighting factor, used to set the degree of importance of the precision and recall. In this study, is set to 1 to assign the same weight to both precision and recall.
4.5. Parameters Setting
4.5.1. Supervised Algorithms
- A K-NN with Euclidean distance is applied to the three sub-datasets (Yogev, Hausdorff, and Frenkel-Toledo). The number of neighbours is determined by varying K from 2 to 10. The optimal K values for the Yogev, Hausdorff and Frenkel-Toledo sub-datasets are, respectively, 7, 2 and 7.
- The CART algorithm is used for the DT model. The CART uses the Gini index (Gini impurity) parameter to find the best construction and the best partition of the tree.
- For the RF model, the number of trees is varied between 10 and 200. The optimal numbers of trees for the Yogev, Hausdorff and Frenkel-Toledo sub-datasets are, respectively, 100, 80 and 150.
- For the NB model, a normal distribution is used to model the conditional probability of the observation data and classes for the three sub-datasets.
- For the SVM model, a nonlinear model with polynomial kernel function (degree 3) is used for the two first sub-datasets, and a linear model is used for the third sub-dataset.
4.5.2. Unsupervised Algorithms
- For the GMM model, the diagonal Gaussian function is used for the Frenkel-Toledo sub-dataset, and the full Gaussian function is used for the other two sub-datasets.
- For K-means, the only parameter to tune is the number of classes, which in this study is two (subjects with PD and healthy subjects).
5. Results and Discussion
5.1. Parkinson’s Disease Classification Results
5.2. PD Discrimination from Other Neurodegenerative Diseases (Amyotrophic Lateral Sclerosis (ALS) and Huntington’s Disease (HD))
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Das, R.A. Comparison of multiple classification methods for diagnosis of Parkinson disease. Expert Syst. Appl. 2010, 37, 1568–1572. [Google Scholar] [CrossRef]
- Hariharan, M.; Polat, K.; Sindhu, R. A new hybrid intelligent system for accurate detection of Parkinson’s disease. Comput. Methods Programs Biomed. 2014, 113, 904–913. [Google Scholar] [CrossRef]
- Pan, S.; Iplikci, S.; Warwick, K.; Aziz, T.Z. Parkinson’s Disease tremor classification–A comparison between Support Vector Machines and neural networks. Expert Syst. Appl. 2012, 39, 10764–10771. [Google Scholar] [CrossRef]
- Dorsey, E.R.; Constantinescu, R.; Thompson, J.P.; Biglan, K.M.; Holloway, R.G.; Kieburtz, K.; Marshall, F.J.; Ravina, B.M.; Schifitto, G.; Siderowf, A.; et al. Projected number of people with Parkinson disease in the most populous nations, 2005 through 2030. Neurology 2007, 68, 384–386. [Google Scholar] [CrossRef] [PubMed]
- Circulaire SG/DGOS/R4/DGS/MC3/DGCS/3A/CNSA no 2015-281 du 7 Septembre 2015 Relative à la Mise en Oeuvre du Plan Maladies Neuro-DéGéNéRatives 2014–2019. Available online: https://solidarites-sante.gouv.fr/fichiers/bo/2015/15-09/ste_20150009_0000_0056.pdf (accessed on 15 October 2015).
- FRANCE PARKINSON et CGE DISTRIBUTION: Un Accord de MéCéNat Pour Faire Connaitre la Maladie dans le Milieu de L’entreprise. Available online: https://www.franceparkinson.fr/wp-content/uploads/2016/10/CP-FRANCE-PARKINSON-et-CGE-DISTRIBUTION.pdf (accessed on 10 January 2019).
- Parkinson et Souffrances de vie. Available online: https://neurologies.fr/parkinson-et-souffrances-de-vie/ (accessed on 25 April 2013).
- Beyene, T.J.; Hoek, H.; Zhang, Y.; Vos, T. Global, regional, and national age–sex specific all-cause and cause-specific mortality for 240 causes of death, 1990–2013. Lancet 2015, 385, 117–171. [Google Scholar]
- Vos, T.; Barber, R.M.; Bell, B.; Bertozzi-Villa, A.; Biryukov, S.; Bolliger, I.; Charlson, F.; Davis, A.; Degenhardt, L.; Dicker, D.; et al. Global, regional, and national incidence, prevalence, and years lived with disability for 301 acute and chronic diseases and injuries in 188 countries, 1990–2013: A systematic analysis for the Global Burden of Disease Study 2013. Lancet 2015, 386, 743–800. [Google Scholar] [CrossRef]
- Mosley, A.D. The Encyclopedia of Parkinson’s Disease, 2nd ed.; Facts on File: New York, NY, USA, 2010; p. 89. [Google Scholar]
- Fah, S.; Elton, R.I. Members of the UPDRS Development Committee. In Recent Development in Parkinson’s Disease; Fahn, S., Marsden, C.D., Calne, D.B., Goldstein, M., Eds.; Macmillan Health Care Information: New York, NY, USA, 1987; Volume 2, pp. 153–164. [Google Scholar]
- Hoehn, M.M.; Yahr, M.D. Parkinsonism onset, progression, and mortality. Neurology 1967, 17, 427. [Google Scholar] [CrossRef]
- Schwab, R.S. Projection technique for evaluating surgery in Parkinson’s disease. In Third Symposium on Parkinson’s Disease; Gillingham, F.J., Donaldson, I.M.L., Eds.; Scientific Research Publishing: Wuhan, China, 1969; pp. 152–157. [Google Scholar]
- Mahoney, F.I.; Barthel, D.W. The Barthel Index. Md State Med. J. 1965, 14, 61–65. [Google Scholar]
- Folstein, M.F.; Folstein, S.E.; McHugh, P.R. Mini-mental state. A practical method for grading the cognitive state of patients for the clinician. J. Psychiatr. Res. 1975, 12, 189–198. [Google Scholar] [CrossRef]
- Schmand, B.; Lindeboom, J.; Van Harskamp, F. Dutch Adult Reading Test; Swets & Zeitlinger: Lisse, The Netherlands, 1992. [Google Scholar]
- Lezak, M.D. Neuropsychological Assessment; Oxford University Press: Oxford, NY, USA, 2004. [Google Scholar]
- Peker, M.; Sen, B.; Delen, D. Computer-aided diagnosis of Parkinson’s disease using complex-valued neural networks and mRMR feature selection algorithm. J. Healthc. Eng. 2015, 6, 281–302. [Google Scholar] [CrossRef]
- Kenneth, R.; Gorunescu, F.; Salem, A.M. Feature selection in Parkinson’s disease: A rough sets approach. In Proceedings of the International Multiconference on Computer Science and Information Technology (IMCSIT’09), Mrągowo, Poland, 12–14 October 2009; pp. 425–428. [Google Scholar]
- Yadav, G.; Kumar, Y.; Sahoo, G. Predication of Parkinson’s disease using data mining methods: A comparative analysis of tree, statistical and support vector machine classifiers. In Proceedings of the National Conference on Computing and Communication Systems (NCCCS), Durgapur, India, 21–22 November 2012; pp. 1–8. [Google Scholar]
- Safi, K.; Diab, A.; Albertsen, I.M.; Hutin, E.; Mohammed, S.; Khalil, M.; Amirat, Y.; Gracies, J.M. Non-linear analysis of human stability during static posture. In Proceedings of the International Conference on Advances in Biomedical Engineering (ICABME), Beirut, Lebanon, 16–18 September 2015; pp. 285–288. [Google Scholar]
- Prieto, T.E.; Myklebust, J.B.; Myklebust, B.M. Characterization and modeling of postural steadiness in the elderly: A review. IEEE Trans. Rehabil. Eng. 1993, 1, 26–34. [Google Scholar] [CrossRef]
- Diagnosing Parkinson’s Disease. Available online: https://www.medicalnewstoday.com/articles/323412.php (accessed on 22 October 2018).
- Oberg, T.; Karsznia, A.; Oberg, K. Basic gait parameters: Reference data for normal subjects, 10–79 years of age. J. Rehabil. Res. Dev. 1993, 30, 210–223. [Google Scholar] [PubMed]
- Khorasani, A.; Daliri, M.R. HMM for classification of Parkinson’s disease based on the raw gait data. J. Med. Syst. 2014, 38, 147–152. [Google Scholar] [CrossRef] [PubMed]
- Bäzner, H.; Oster, M.; Daffertshofer, M.; Hennerici, M. Assessment of gait in subcortical vascular encephalopathy by computerized analysis: A cross-sectional and longitudinal study. J. Neurol. 2000, 247, 841–849. [Google Scholar] [CrossRef]
- Hausdorff, J.M. Gait dynamics, fractals and falls: Finding meaning in the stride-to-stride fluctuations of human walking. Hum. Mov. Sci. 2007, 26, 555–589. [Google Scholar] [CrossRef] [PubMed]
- Yogev, G.; Giladi, N.; Peretz, C.; Springer, S.; Simon, E.S.; Hausdorff, J.M. Dual tasking, gait rhythmicity, and Parkinson’s disease: Which aspects of gait are attention demanding? Eur. J. Neurosci. 2005, 22, 1248–1256. [Google Scholar] [CrossRef] [PubMed]
- MacLeod, C.M. Half a century of research on the Stroop effect: An integrative review. Psychol. Bull. 1991, 109, 163. [Google Scholar] [CrossRef]
- Langenecker, S.A.; Nielson, K.A.; Rao, S.M. fMRI of healthy older adults during Stroop interference. Neuroimage 2004, 21, 192–200. [Google Scholar] [CrossRef]
- Dwolatzky, T.; Whitehead, V.; Doniger, G.M.; Simon, E.S.; Schweiger, A.; Jaffe, D.; Chertkow, H. Validity of a novel computerized cognitive battery for mild cognitive impairment. BMC Geriatr. 2003, 3, 4. [Google Scholar] [CrossRef]
- Yogev, G.; Plotnik, M.; Peretz, C.; Giladi, N.; Hausdorff, J.M. Gait asymmetry in patients with Parkinson’s disease and elderly fallers: When does the bilateral coordination of gait require attention? Exp. Brain Res. 2007, 177, 336–346. [Google Scholar] [CrossRef]
- Hausdorff, J.M.; Lowenthal, J.; Herman, T.; Gruendlinger, L.; Peretz, C.; Giladi, N. Rhythmic auditory stimulation modulates gait variability in Parkinson’s disease. Eur. J. Neurosci. 2007, 26, 2369–2375. [Google Scholar] [CrossRef] [PubMed]
- Hausdorff, J.M.; Cudkowicz, M.E.; Firtion, R.; Wei, J.Y.; Goldberger, A.L. Gait variability and basal ganglia disorders: Stride-to-stride variations of gait cycle timing in parkinson’s disease and Huntington’s disease. Mov. Disord. 1998, 13, 428–437. [Google Scholar] [CrossRef] [PubMed]
- Frenkel-Toledo, S.; Giladi, N.; Peretz, C.; Herman, T.; Gruendlinger, L.; Hausdorff, J.M. Effect of gait speed on gait rhythmicity in Parkinson’s disease: Variability of stride time and swing time respond differently. J. Neuroeng. Rehabil. 2005, 2, 23. [Google Scholar] [CrossRef] [PubMed]
- Jeon, H.S.; Han, J.; Yi, W.J.; Jeon, B.; Park, K.S. Classification of Parkinson gait and normal gait using spatial-temporal image of plantar pressure. In Proceedings of the 30th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Vancouver, BC, Canada, 20–24 August 2008; pp. 4672–4675. [Google Scholar]
- Andrews, C.J.; Neilson, P.D.; Lance, J.W. Comparison of stretch reflexes and shortening reactions in activated normal subjects with those in Parkinson’s disease. J. Neurol. Neurosurg. Psychiatry 1973, 36, 329–333. [Google Scholar] [CrossRef] [PubMed]
- Ashhar, K.; Soh, C.B.; Kong, K.H. A wearable ultrasonic sensor network for analysis of bilateral gait symmetry. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju Island, Korea, 11–15 July 2017; pp. 4455–4458. [Google Scholar]
- Nieuwboer, A.; Dom, R.; De Weerdt, W.; Desloovere, K.; Janssens, L.; Stijn, V. Electromyographic profiles of gait prior to onset of freezing episodes in patients with Parkinsons disease. Brain 2004, 127, 1650–1660. [Google Scholar] [CrossRef] [PubMed]
- Halliday, S.E.; Winter, D.A.; Frank, J.S.; Patla, A.E.; Prince, F. The initiation of gait in young, elderly, and Parkinson’s disease subjects. Gait Posture 1998, 8, 8–14. [Google Scholar] [CrossRef]
- Hong, M.; Perlmutter, J.S.; Earhart, G.M. A kinematic and electromyographic analysis of turning in people with Parkinson disease. Neurorehabil. Neural Repair 2009, 23, 166–176. [Google Scholar] [CrossRef] [PubMed]
- Saito, N.; Yamamoto, T.; Sugiura, Y.; Shimizu, S.; Shimizu, M. Lifecorder: A new device for the long-term monitoring of motor activities for Parkinsons disease. Intern. Med. 2004, 43, 685–692. [Google Scholar] [CrossRef]
- Hoff, J.I.; Van Den Plas, A.A.; Wagemans, E.A.H.; Van Hilten, J.J. Accelerometric assessment of levodopa-induced dyskinesias in Parkinson’s disease. Mov. Disord. Off. J. Mov. Disord. Soc. 2001, 16, 58–61. [Google Scholar] [CrossRef]
- Salarian, A.; Russmann, H.; Vingerhoets, F.J.; Dehollain, C.; Blanc, Y.; Burkhard, P.R.; Aminian, K. Gait assessment in Parkinson’s disease: Toward an ambulatory system for long-term monitoring. IEEE Trans. Biomed. Eng. 2004, 51, 1434–1443. [Google Scholar] [CrossRef] [PubMed]
- Salarian, A.; Horak, F.B.; Zampieri, C.; Carlson-Kuhta, P.; Nutt, J.G.; Aminian, K. iTUG, a sensitive and reliable measure of mobility. IEEE Trans. Neural Syst. Rehabil. Eng. 2010, 18, 303–310. [Google Scholar] [CrossRef] [PubMed]
- Mariani, B.; Jiménez, M.C.; Vingerhoets, F.J.; Aminian, K. On-shoe wearable sensors for gait and turning assessment of patients with Parkinson’s disease. IEEE Trans. Biomed. Eng. 2013, 6, 155–158. [Google Scholar] [CrossRef] [PubMed]
- Latash, M.L.; Aruin, A.S.; Neyman, I.; Nicholas, J.J. Anticipatory postural adjustments during self inflicted and predictable perturbations in Parkinson’s disease. J. Neurol. Neurosurg. Psychiatry 1995, 58, 326–334. [Google Scholar] [CrossRef]
- Cho, C.W.; Chao, W.H.; Lin, S.H.; Chen, Y.Y. A vision-based analysis system for gait recognition in patients with Parkinson’s disease. Expert Syst. Appl. 2009, 36, 7033–7039. [Google Scholar] [CrossRef]
- Galna, B.; Barry, G.; Jackson, D.; Mhiripiri, D.; Olivier, P.; Rochester, L. Accuracy of the Microsoft Kinect sensor for measuring movement in people with Parkinson’s disease. Gait Posture 2014, 39, 1062–1068. [Google Scholar] [CrossRef] [PubMed]
- Pachoulakis, I.; Kourmoulis, K. Building a gait analysis framework for Parkinson’s disease patients: Motion capture and skeleton 3D representation. In Proceedings of the International Conference on IEEE Telecommunications and Multimedia (TEMU), Heraklion, Greece, 28–30 July 2014; pp. 220–225. [Google Scholar]
- Dror, B.; Yanai, E.; Frid, A.; Peleg, N.; Goldenthal, N.; Schlesinger, I.; Hel-Or, H.; Raz, S. Automatic assessment of Parkinson’s Disease from natural hands movements using 3D depth sensor. In Proceedings of the 2014 IEEE 28th Convention of Electrical & Electronics Engineers in Israel (IEEEI), Eilat, Israel, 3–5 December 2014; pp. 1–5. [Google Scholar]
- Dyshel, M.; Arkadir, D.; Bergman, H.; Weinshall, D. Quantifying Levodopa-Induced Dyskinesia Using Depth Camera. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 119–126. [Google Scholar]
- Antonio-Rubio, I.; Madrid-Navarro, C.J.; Salazar-López, E.; Pérez-Navarro, M.J.; Sáez-Zea, C.; Gmez-Miln, E.; Mnguez-Castellanos, A.; Escamilla-Sevilla, F. Abnormal thermography in Parkinson’s disease. Parkinsonism Relat. Disord. 2015, 21, 852–857. [Google Scholar] [CrossRef] [PubMed]
- Song, J.; Sigward, S.; Fisher, B.; Salem, G.J. Altered dynamic postural control during step turning in persons with early-stage Parkinsons disease. Parkinson’s Dis. 2012, 2012, 386962. [Google Scholar]
- Foreman, K.B.; Wisted, C.; Addison, O.; Marcus, R.L.; LaStayo, P.C.; Dibble, L.E. Improved dynamic postural task performance without improvements in postural responses: The blessing and the curse of dopamine replacement. Parkinson’s Dis. 2012, 2012, 692150. [Google Scholar] [CrossRef]
- Muniz, A.M.S.; Liu, H.; Lyons, K.E.; Pahwa, R.; Liu, W.; Nobre, F.F.; Nadal, J. Comparison among probabilistic neural network, support vector machine and logistic regression for evaluating the effect of subthalamic stimulation in Parkinson disease on ground reaction force during gait. J. Biomech. 2010, 43, 720–726. [Google Scholar] [CrossRef]
- Vaugoyeau, M.; Viallet, F.; Mesure, S.; Massion, J. Coordination of axial rotation and step execution: Deficits in Parkinson’s disease. Gait Posture 2003, 18, 150–157. [Google Scholar] [CrossRef]
- Tao, W.; Liu, T.; Zheng, R.; Feng, H. Gait analysis using wearable sensors. Sensors 2012, 12, 2255–2283. [Google Scholar] [CrossRef] [PubMed]
- Su, B.L.; Song, R.; Guo, L.Y.; Yen, C.W. Characterizing gait asymmetry via frequency sub-band components of the ground reaction force. Biomed. Signal Process. Control 2015, 18, 56–60. [Google Scholar] [CrossRef]
- Zeng, W.; Liu, F.; Wang, Q.; Wang, Y.; Ma, L.; Zhang, Y. Parkinson’s disease classification using gait analysis via deterministic learning. Neurosci. Lett. 2016, 633, 268–278. [Google Scholar] [CrossRef] [PubMed]
- Daliri, M.R. Automatic diagnosis of neuro-degenerative diseases using gait dynamics. Measurement 2012, 45, 1729–1734. [Google Scholar] [CrossRef]
- Attal, F.; Mohammed, S.; Dedabrishvili, M.; Chamroukhi, F.; Oukhellou, L.; Amirat, Y. Physical human activity recognition using wearable sensors. Sensors 2015, 15, 31314–31338. [Google Scholar] [CrossRef] [PubMed]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach; Prentice-Hall: Egnlewood Cliffs, NJ, USA, 1995; Volume 25, p. 27. [Google Scholar]
- Lee, S.H.; Lim, J.S. Parkinson’s disease classification using gait characteristics and wavelet-based feature extraction. Expert Syst. Appl. 2012, 39, 7338–7344. [Google Scholar] [CrossRef]
- Daliri, M.R. Chi-square distance kernel of the gaits for the diagnosis of Parkinson’s disease. Biomed. Signal Process. Control 2013, 8, 66–70. [Google Scholar] [CrossRef]
- Wu, Y.; Krishnan, S. Statistical analysis of gait rhythm in patients with Parkinson’s disease. IEEE Trans. Neural Syst. Rehabil. Eng. 2010, 18, 150–158. [Google Scholar]
- Sarbaz, Y.; Banaie, M.; Pooyan, M.; Gharibzadeh, S.; Towhidkhah, F.; Jafari, A. Modeling the gait of normal and Parkinsonian persons for improving the diagnosis. Neurosci. Lett. 2012, 509, 72–75. [Google Scholar] [CrossRef]
- Cuzzolin, F.; Sapienza, M.; Esser, P.; Saha, S.; Franssen, M.M.; Collett, J.; Dawes, H. Metric learning for Parkinsonian identification from IMU gait measurements. Gait Posture 2017, 54, 127–132. [Google Scholar] [CrossRef]
- Jane, Y.N.; Nehemiah, H.K.; Arputharaj, K. A Q-backpropagated time delay neural network for diagnosing severity of gait disturbances in Parkinson’s disease. J. Biomed. Inform. 2016, 60, 169–176. [Google Scholar] [CrossRef] [PubMed]
- Gait in Parkinson’s Disease. Available online: https://physionet.org/pn3/gaitpdb/ (accessed on 10 January 2019).
- Ertuğrul, Ö.F.; Kaya, Y.; Tekin, R.; Almalı, M.N. Detection of Parkinson’s disease by shifted one dimensional local binary patterns from gait. Expert Syst. Appl. 2016, 56, 156–163. [Google Scholar] [CrossRef]
- Açici, K.; Erdaş, Ç.B.; Aşuroğlu, T.; Toprak, M.K.; Erdem, H.; Oğul, H. A Random Forest Method to Detect Parkinson’s Disease via Gait Analysis. In Proceedings of the International Conference on Engineering Applications of Neural Networks, Athens, Greece, 25–27 August 2017; Springer: Cham, Switzerland, 2017; pp. 609–619. [Google Scholar]
- Joshi, D.; Khajuria, A.; Joshi, P. An automatic non-invasive method for Parkinson’s disease classification. Comput. Methods Programs Biomed. 2017, 145, 135–145. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Chen, P.; Luo, X.; Wu, M.; Liao, L.; Yang, S.; Rangayyan, R.M. Measuring signal fluctuations in gait rhythm time series of patients with Parkinson’s disease using entropy parameters. Biomed. Signal Process. Control 2017, 31, 265–271. [Google Scholar] [CrossRef]
- Alam, M.N.; Garg, A.; Munia, T.T.K.; Fazel-Rezai, R.; Tavakolian, K. Vertical ground reaction force marker for Parkinson’s disease. PLoS ONE 2017, 12, e0175951. [Google Scholar] [CrossRef] [PubMed]
- Khoury, N.; Attal, F.; Amirat, Y.; Chibani, A.; Mohammed, S. CDTW-based classification for Parkinson’s Disease diagnosis. In Proceedings of the 26th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN 2018), Bruges, Belgium, 25–27 April 2018; pp. 621–626. [Google Scholar]
- Bhoi, A.K. Classification and Clustering of Parkinson’s and Healthy Control Gait Dynamics Using LDA and K-means. Int. J. Bioautom. 2017, 21, 19–30. [Google Scholar]
- Aharonson, V.; Schlesinger, I.; McDonald, A.M.; Dubowsky, S.; Korczyn, A.D. A Practical Measurement of Parkinson’s Patients Gait Using Simple Walker-Based Motion Sensing and Data Analysis. J. Med. Devices 2018, 12, 011012. [Google Scholar] [CrossRef]
- Haji Ghassemi, N.; Hannink, J.; Martindale, C.F.; Gabner, H.; Muller, M.; Klucken, J.; Eskofier, B.M. Segmentation of Gait Sequences in Sensor-Based Movement Analysis: A Comparison of Methods in Parkinson’s Disease. Sensors 2018, 18, 145. [Google Scholar] [CrossRef]
- Frenkel-Toledo, S.; Giladi, N.; Peretz, C.; Herman, T.; Gruendlinger, L.; Hausdorff, J.M. Treadmill walking as an external pacemaker to improve gait rhythm and stability in Parkinson’s disease. Mov. Disord. 2005, 20, 1109–1114. [Google Scholar] [CrossRef]
- Hausdorff, J.M.; Rios, D.A.; Edelberg, H.K. Gait variability and fall risk in community-living older adults: A 1-year prospective study. Arch. Phys. Med. Rehabil. 2001, 82, 1050–1056. [Google Scholar] [CrossRef]
- Hausdorff, J.M.; Lertratanakul, A.; Cudkowicz, M.E.; Peterson, A.L.; Kaliton, D.; Goldberger, A.L. Dynamic markers of altered gait rhythm in amyotrophic lateral sclerosis. J. Appl. Physiol. 2000, 88, 2045–2053. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Motoda, H.; Setiono, R.; Zhao, Z. Feature selection: An ever evolving frontier in data mining? In Proceedings of the Fourth Workshop on Feature Selection in Data Mining, Hyderabad, India, 21 June 2010; pp. 4–13. [Google Scholar]
- Liu, H.; Yu, L. Toward integrating feature selection algorithms for classification and clustering. IEEE Trans. Knowl. Data Eng. 2005, 17, 491–502. [Google Scholar]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intel. 1997, 97, 273–324. [Google Scholar] [CrossRef]
- Das, S. Filters, wrappers and a boosting-based hybrid for feature selection. In Proceedings of the Eighteenth International Conference on Machine Learning (ICML 2001), Williamstown, MA, USA, 28 June–1 July 2001; pp. 74–81. [Google Scholar]
- Attal, F. Classification de Situations de Conduite et Détection des Événements Critiques d’un Deux Roues Motorisé. Ph.D. Thesis, Université Paris-Est, Champs-sur-Marne, France, 2015. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbors pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2014. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Neapolitan, R.E. Learning Bayesian Networks; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2004; Volume 38. [Google Scholar]
- Nielsen, T.D.; Jensen, F.V. Bayesian Networks and Decision Graphs; Springer: Berlin, Germany, 2009. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–38. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Goldberger, A.L.; Amaral, L.A.; Glass, L.; Hausdorff, J.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a New Research Resource for Complex Physiologic Signals. Circulation 2000, 101, e215–e220. [Google Scholar] [CrossRef]
- Rayhan, F.; Ahmed, S.; Mahbub, A.; Jani, M.; Shatabda, S.; Farid, D.M. CUSBoost: Cluster-based Under-sampling with Boosting for Imbalanced Classification. arXiv, 2017; arXiv:1712.04356. [Google Scholar]
- Yang, M.; Zheng, H.; Wang, H.; McClean, S. Feature selection and construction for the discrimination of neurodegenerative diseases based on gait analysis. In Proceedings of the 2009 3rd International Conference on Pervasive Computing Technologies for Healthcare, London, UK, 1–3 April 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1–7. [Google Scholar]
- Zheng, H.; Yang, M.; Wang, H.; McClean, S. Machine learning and statistical approaches to support the discrimination of neuro-degenerative diseases based on gait analysis. In Intelligent Patient Management; Springer: Berlin/Heidelberg, Germany, 2009; pp. 57–70. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Sensors | Sensors Type | Method | Validation Methods | Accuracy |
|---|---|---|---|---|---|
| Jean et al., 2008 [36] | In-shoe dynamic foot pressure | Wearable | SVM | 15-fold cross validation | 91.73% |
| Cho et al., 2009 [48] | CCD camera | Non wearable | MDC | Not specified | 95.49% |
| Muniz et al., 2010 [56] | Force platform | Non wearable | LR, PNN, SVM | Bootstrap method | 91–94% |
| Wu and Krishnan 2010 [66] | Force sensors | Wearable | LS-SVM | Leave-one-out | 90.32% |
| Sarbaz et al., 2011 [67] | Force sensors | Wearable | Nearest mean scaled | 70% (train), 30% (test) | 95.6% |
| Daliri 2012 [61] | Force sensors | Wearable | SVM | 50% (train), 50% (test) | 89.33% |
| Lee et al., 2012 [64] | Force sensors | Wearable | NEWFM | 50% (train), 50% (test) | 74–77% |
| Daliri 2013 [65] | Force sensors | Wearable | SVM | 50% (train), 50% (test) | 84–91% |
| Khorasani et al., 2014 [25] | Force sensors | Wearable | HMM with GM | Leave-one-out | 90.3% |
| Dror et al., 2014 [51] | Microsoft 3D camera sensor | Non wearable | SVM | leave-one-out | 100% |
| Dyshel et al., 2015 [52] | Microsoft Kinect For Windows SDK | Non wearable | SVM | 5-fold cross validation | - |
| Su et al., 2015 [59] | Force sensors | Wearable | Threshold-based | 80% (train), 10% | 72% |
| and MLP models | (Valid.), 10% (test) | ||||
| Zeng et al., 2016 [60] | Force sensors | Wearable | RBF NN | 5-fold cross-validation | 96.39% |
| Jane et al., 2016 [69] | Force sensors | Wearable | Q-BTDNN | Cross-validation | 90–92% |
| Ertugrul et al., 2016 [71] | Force sensors | Wearable | BayesNT, NB, LR, MLP, | 10-folds | 87–88% |
| PART, Jrip, RF, and FT | cross-validation | ||||
| Cuzzolin et al., 2017 [68] | IMU sensors | Wearable | HMM | Cross-validation | 85.51% |
| Açici et al., 2017 [72] | Force sensors | Wearable | RF | 10-fold Cross Validation | 74–98% |
| Joshi et al., 2017 [73] | Force sensors | Wearable | SVM | Leave one-out | 90.32% |
| Wu et al., 2017 [74] | Force sensors | Wearable | SVM | Leave one-out | 84.48% |
| Alam et al., 2017 [75] | Force sensors | Wearable | SVM, RF, K-NN, and DT | Leave one-out | 85–95% |
| Bhoi et al., 2017 [77] | Force sensors | Wearable | K-means | - | - |
| Khoury et al., 2018 [76] | Force sensors | Wearable | K-NN, CART, RF, SVM, K-means and GMM | 10-fold Cross Validation | 80–97% |
| Aharonson et al., 2018 [78] | Force sensors and accelerometer | Non wearable | K-means | - | - |
| Haji Ghassemi et al., 2018 [79] | IMU sensors | wearable | GMM | - | - |
| Features References | Extracted Features | Explanation |
|---|---|---|
| 1 | Coefficients of Variations in percentage (%) of Swing Time of the left foot | [28,34] |
| 2 | Coefficient of Variations in duration (s) of the Swing Time of the left foot | [32] |
| 3 | Coefficient of Variations in duration (s) of the Stride Time of the left foot | [28] |
| 4 | Coefficient of Variation in percentage (%) of the Swing Time of the right foot | [28,34] |
| 5 | Coefficient of Variation in duration (s) of the Swing Time of the right foot | [32] |
| 6 | Coefficient of Variation in duration (s) of the Stride Time of the right foot | [28] |
| 7 | Coefficient of Variation of the Short Swing Time | [32] |
| 8 | Coefficient of Variation of the Long Swing Time | [32] |
| 9 | Coefficient of Variation of the Gait Asymmetry | [32] |
| 10 | Mean in percentage (%) of the Swing Time of the left foot | [28,34] |
| 11 | Mean in duration (s) of the Swing Time of the left foot | [32,35,81] |
| 12 | Mean in duration (s) of the Stride Time of the left foot | [28,35,81,82] |
| 13 | Mean in percentage (%) of the Swing Time of the right foot | [28,34] |
| 14 | Mean in duration (s) of the Swing Time of the right foot | [32,35,81] |
| 15 | Mean in duration (s) of the Stride Time of the right foot | [28,35,81,82] |
| 16 | Mean in percentage (%) of the Double Stance Time | [34] |
| 17 | Mean of the Short Swing Time | [32] |
| 18 | Mean of the Long Swing Time | [32] |
| 19 | Mean of the Gait Asymmetry | [32] |
| Sub-Dataset | Features Selection | Supervised | Unsupervised | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Performances | K-NN | CART | RF | NB | SVM | K-Means | GMM | ||
| Yogev et al. | With | Accuracy | 86.05% | 83.72% | 86.05% | 74.42% | 86.05% | 63.72% | 64.77% |
| Without | Accuracy | 82.56% | 80.23% | 84.88% | 72.09% | 82.56% | 53.72% | 61.39% | |
| Hausdorff et al. | With | Accuracy | 90.91% | 84.30% | 87.60% | 77.69% | 90.08% | 55.12% | 65.12% |
| Without | Accuracy | 88.43% | 82.64% | 85.95% | 72.73% | 87.60% | 51.07% | 58.93% | |
| Frenkel-Toledo et al. | With | Accuracy | 81.25% | 79.69% | 82.81% | 79.69% | 82.81% | 57.19% | 65.31% |
| Without | Accuracy | 79.69% | 76.56% | 78.12% | 75% | 81.25% | 53.75% | 57.34% | |
| Sub-Datasets | References of Features | Selected Features |
|---|---|---|
| Yogev et al. | 13 | Mean in percentage (%) of the Swing Time of the right foot |
| 7 | Coefficient of Variation of the Short Swing Time (SSWCV) | |
| 10 | Mean in percentage (%) of the Swing Time of the left foot | |
| 6 | Coefficient of Variation in duration (s) of the Stride Time of the right foot | |
| 11 | Mean in duration (s) of the Swing Time of the left foot | |
| Hausdorff et al. | 7 | Coefficient of Variation of the Short Swing Time (SSWCV) |
| 5 | Coefficient of Variation in duration (s) of the Swing Time of the right foot | |
| 4 | Coefficient of Variation in percentage (%) of the Swing Time of the right foot | |
| 13 | Mean in percentage (%) of the Swing Time of the right foot | |
| 6 | Coefficient of Variation in duration (s) of the Stride Time of the right foot | |
| Frenkel-Toledo et al. | 7 | Coefficient of Variation of the Short Swing Time (SSWCV) |
| 19 | Mean of the Gait Asymmetry | |
| 11 | Mean in duration (s) of the Swing Time of the left foot | |
| 8 | Coefficient of Variation of the Long Swing Time (LSWCV) | |
| 9 | Coefficient of Variation of the Gait Asymmetry |
| Performances | Supervised | Unsupervised | |||||
|---|---|---|---|---|---|---|---|
| K-NN | CART | RF | NB | SVM | K-Means | GMM | |
| Accuracy | 86.05% | 83.72% | 86.05% | 74.42% | 86.05% | 63.72% | 64.77% |
| Precision | 84.89% | 82.86% | 85.07% | 74.73% | 84.90% | 64.34% | 62.63% |
| Recall | 86.34% | 81.94% | 85.07% | 76.45% | 85.71% | 65.31% | 62.91% |
| F-measure | 85.61% | 82.40% | 85.07% | 75.58% | 85.30% | 64.82% | 62.77% |
| Performances | Supervised | Unsupervised | |||||
|---|---|---|---|---|---|---|---|
| K-NN | CART | RF | NB | SVM | K-Means | GMM | |
| Accuracy | 90.91% | 84.30% | 87.60% | 77.69% | 90.08% | 55.12% | 65.12% |
| Precision | 85.35% | 82.34% | 89.41% | 70.64% | 89.31% | 52.58% | 57.95% |
| Recall | 88.35% | 64.96% | 71.48% | 78.54% | 78.96% | 53.91% | 61.29% |
| F-measure | 86.83% | 72.62% | 79.45% | 74.38% | 83.82% | 53.24% | 59.57% |
| Performances | Supervised | Unsupervised | |||||
|---|---|---|---|---|---|---|---|
| K-NN | CART | RF | NB | SVM | K-Means | GMM | |
| Accuracy | 81.25% | 79.69% | 82.81% | 79.69% | 82.81% | 57.19% | 65.31% |
| Precision | 81.43% | 79.56% | 83.10% | 79.69% | 82.81% | 61.07% | 64.95% |
| Recall | 81.67% | 79.36% | 82.22% | 79.95% | 83.10% | 59.23% | 64.62% |
| F-measure | 81.55% | 79.46% | 82.65% | 79.82% | 82.96% | 60.14% | 64.78% |
| Obtained Classes | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Supervised | Unsueprvised | ||||||||||||||
| K-NN | CART | RF | NB | SVM | K-Means | GMM | |||||||||
| Healthy | PD | Healthy | PD | Healthy | PD | Healthy | PD | Healthy | PD | Healthy | PD | Healthy | PD | ||
| True | Healthy | 87.50% | 12.50% | 75.00% | 25.00% | 81.25% | 18.75% | 84.38% | 15.62% | 84.38% | 15.62% | 71.53% | 28.47% | 55.63% | 44.37% |
| Classes | PD | 14.81% | 85.19% | 11.11% | 88.89% | 11.11% | 88.89% | 31.48% | 68.52% | 12.96% | 87.04% | 40.91% | 59.09% | 29.81% | 70.19% |
| Obtained Classes | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Supervised | Unsueprvised | ||||||||||||||
| K-NN | CART | RF | NB | SVM | K-Means | GMM | |||||||||
| Healthy | PD | Healthy | PD | Healthy | PD | Healthy | PD | Healthy | PD | Healthy | PD | Healthy | PD | ||
| True | Healthy | 84.00% | 16.00% | 32.00% | 68.00% | 44.00% | 56.00% | 80.00% | 20.00% | 60.00% | 40.00% | 51.84% | 48.16% | 54.76% | 45.24% |
| Classes | PD | 7.29% | 92.71% | 2.08% | 97.92% | 1.04% | 98.96% | 22.92% | 77.08% | 2.08% | 97.92% | 44.02% | 55.98% | 32.19% | 67.81% |
| Obtained Classes | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Supervised | Unsueprvised | ||||||||||||||
| K-NN | CART | RF | NB | SVM | K-Means | GMM | |||||||||
| Healthy | PD | Healthy | PD | Healthy | PD | Healthy | PD | Healthy | PD | Healthy | PD | Healthy | PD | ||
| True | Healthy | 86.21% | 13.79% | 75.86% | 24.14% | 75.86% | 24.14% | 82.76% | 17.24% | 86.21% | 13.79% | 80.97% | 19.03% | 57.24% | 42.76% |
| Classes | PD | 22.86% | 77.14% | 17.14% | 82.86% | 11.43% | 88.57% | 22.86% | 77.14% | 20.00% | 80.00% | 62.51% | 37.49% | 28.00% | 72.00% |
| Reference | Gait Parameters Features | Classifiers | Accuracy |
|---|---|---|---|
| Sarbaz et al., 2011 [67] | Time-domain features | Nearest mean scaled classifier | 95.6% |
| Daliri 2012 [61] | Time domain features | SVM | 89.33% |
| Lee et al., 2012 [64] | frequency domain features | NEWFM | 74–77% |
| Daliri 2013 [65] | Time domain features | SVM | 84–91% |
| Khorasani et al., 2014 [25] | Raw gait data | HMM with GM | 90.3% |
| Ertugrul et al., 2016 [71] | Entropy, Energy, Correlation, Coefficient of Variation, Skewness and Kurtosis | BayesNT, NB, LR, MLP, PART, Jrip, RF, and FT | 87–88% |
| Wu et al., 2017 [74] | ApEn, NSE, STC | SVM | 84.48% |
| Jane et al., 2016 [69] | Left and right vGRF signals | Q-BTDNN | 90–92% |
| Alam et al., 2017 [75] | Time and Frequency domain | SVM | 85–95% |
| Açici et al., 2017 [72] | Time and Frequency domain | RF | 74–98% |
| Khoury et al., 2018 [76] | CDTW-Distance | K-NN, CART, RF, SVM, K-means, and GMM | 82–97% |
| Proposed methodology | Time domain features | K-NN, CART, RF, SVM, K-means, and GMM | 80–91% |
| Performances | Supervised | Unsupervised | |||||
|---|---|---|---|---|---|---|---|
| K-NN | CART | RF | NB | SVM | K-Means | GMM | |
| Accuracy | 92.86% | 82.14% | 85.71% | 78.57% | 89.29% | 73.21% | 66.79% |
| Precision | 92.82% | 82.14% | 85.64% | 78.46% | 89.58% | 77.89% | 68.19% |
| Recall | 92.82% | 82.31% | 85.64% | 78.46% | 88.97% | 71.62% | 65.46% |
| F-measure | 92.82% | 82.83% | 85.64% | 78.46% | 89.28% | 74.62% | 66.88% |
| Performances | Supervised | Unsupervised | |||||
|---|---|---|---|---|---|---|---|
| K-NN | CART | RF | NB | SVM | K-Means | GMM | |
| Accuracy | 83.33% | 73.33% | 76.67% | 70% | 80 % | 69.33% | 64.67% |
| Precision | 83.43% | 73.76% | 76.79% | 70.83% | 80.54 % | 69.39% | 64.88% |
| Recall | 83.33% | 73.33% | 76.67% | 70% | 80% | 69.33% | 64.67% |
| F-measure | 83.41% | 73.54% | 76.73% | 70.41% | 80.27% | 69.36% | 64.77% |
| Performances | Supervised | Unsupervised | |||||
|---|---|---|---|---|---|---|---|
| K-NN | CART | RF | NB | SVM | K-Means | GMM | |
| Accuracy | 87.10% | 80.65% | 87.10% | 83.87% | 90.32% | 57.42% | 65.16% |
| Precision | 87.08% | 80.63% | 87.82% | 85.31% | 90.55% | 58.52% | 65.94% |
| Recall | 87.08% | 80.63% | 86.88% | 83.54% | 90.21% | 57.88% | 64.73% |
| F-measure | 87.08% | 80.62% | 87.35% | 84.42% | 90.38% | 58.20% | 65.33% |
| Performances | Supervised | Unsupervised | |||||
|---|---|---|---|---|---|---|---|
| K-NN | CART | RF | NB | SVM | K-Means | GMM | |
| Accuracy | 90% | 80% | 83.33% | 76.67% | 86.67% | 75.33% | 69.33% |
| Precision | 90.18% | 80.54% | 83.48% | 76.79% | 87.33% | 76% | 69.62% |
| Recall | 90% | 80% | 83.33% | 76.67% | 86.67% | 75.33% | 69.33% |
| F-measure | 90.09% | 80.27% | 83.41% | 76.73% | 87.00% | 75.66% | 69.47% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khoury, N.; Attal, F.; Amirat, Y.; Oukhellou, L.; Mohammed, S. Data-Driven Based Approach to Aid Parkinson’s Disease Diagnosis. Sensors 2019, 19, 242. https://doi.org/10.3390/s19020242
Khoury N, Attal F, Amirat Y, Oukhellou L, Mohammed S. Data-Driven Based Approach to Aid Parkinson’s Disease Diagnosis. Sensors. 2019; 19(2):242. https://doi.org/10.3390/s19020242
Chicago/Turabian StyleKhoury, Nicolas, Ferhat Attal, Yacine Amirat, Latifa Oukhellou, and Samer Mohammed. 2019. "Data-Driven Based Approach to Aid Parkinson’s Disease Diagnosis" Sensors 19, no. 2: 242. https://doi.org/10.3390/s19020242
APA StyleKhoury, N., Attal, F., Amirat, Y., Oukhellou, L., & Mohammed, S. (2019). Data-Driven Based Approach to Aid Parkinson’s Disease Diagnosis. Sensors, 19(2), 242. https://doi.org/10.3390/s19020242