Boosting Depth-Based Face Recognition from a Quality Perspective


 and
and
Abstract
:1. Introduction
- (1)
- We present a large-scale and multi-modality database Extended-Multi-Dim for FR. It has 902 objects which is the largest public RGB-D database, with the high-quality 3D depth data.
- (2)
- We adopt a series of preprocessing methods for the collected databases including labeling 51 landmarks of 3D shapes and labeling 5 landmarks for RGB-D images.
- (3)
- We design a standard experimental protocol for the collected database. Motivated by some conclusions of previous evaluation, we propose some methods based on three strategies to use the information of high-quality depth data to train a better network for low-quality depth-based FR. The results can be as the benchmarks for other researchers.
2. Related Works
2.1. Databases
2.2. Methods
2.2.1. High-Quality Depth-Based FR
2.2.2. Low-Quality Depth-Based FR
2.2.3. Depth Data Enhancement
3. Extended-Multi-Dim Database
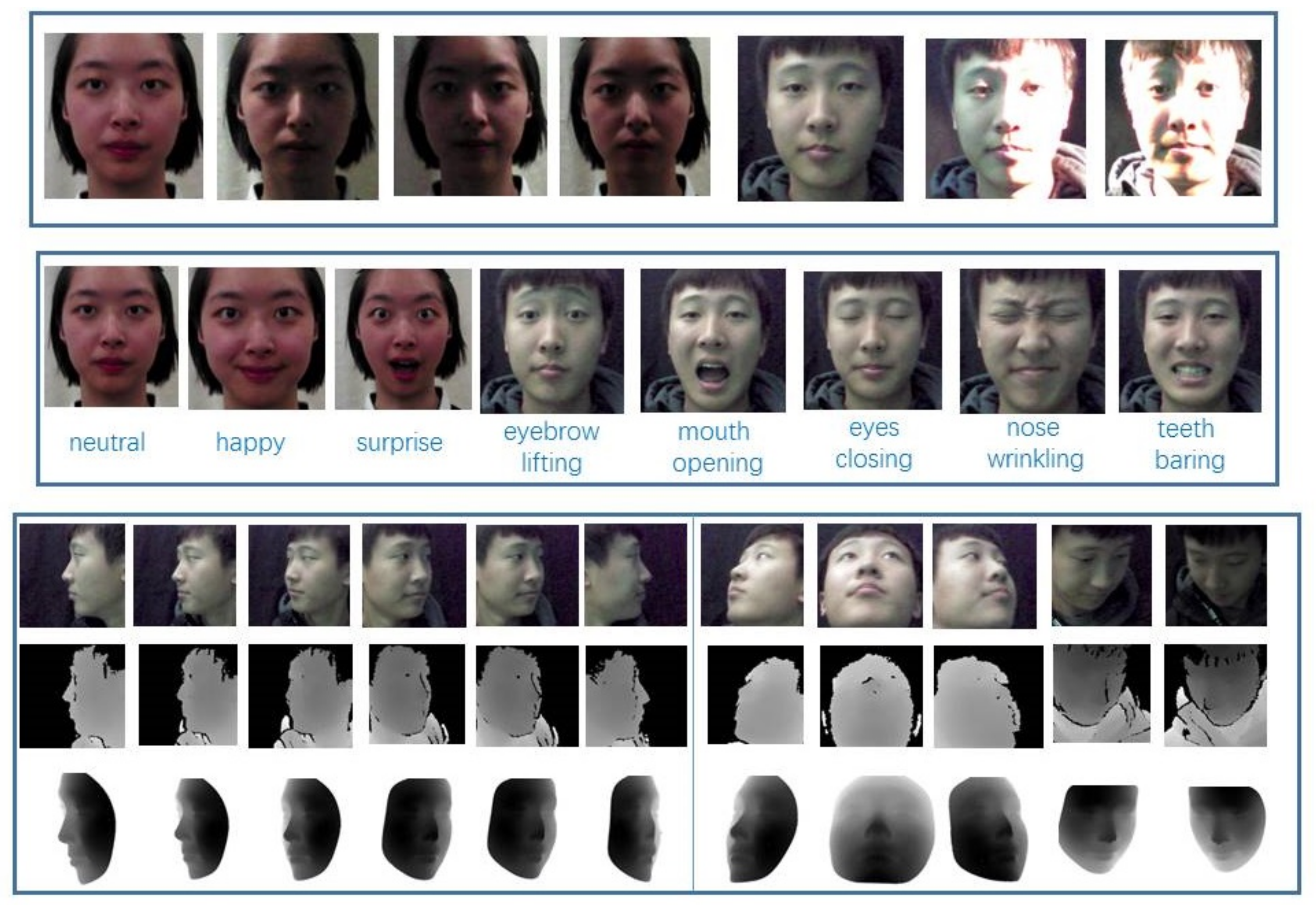
3.1. Acquisition Details
- (1)
- The illumination variations are shown in Table 2.
- (2)
- The volunteers were scanned in the frontal pose without any expression (referred to as NU for short) for a few seconds in both versions.
- (3)
- The subjects were asked to rotate their heads in yaw direction by to (referred to as P1 for short) in version I. Apart from these actions, subject’s head was clockwise around the inverse (referred to as P2 for short) in Version II.
- (4)
- In version I, the participants were asked to perform neutral, happy and surprise expressions in the frontal pose, while in Version II, eyebrow lifting, eyes closing, mouth opening, nose wrinkling and teeth barring were asked to be done by volunteers (referred to as FE for short).
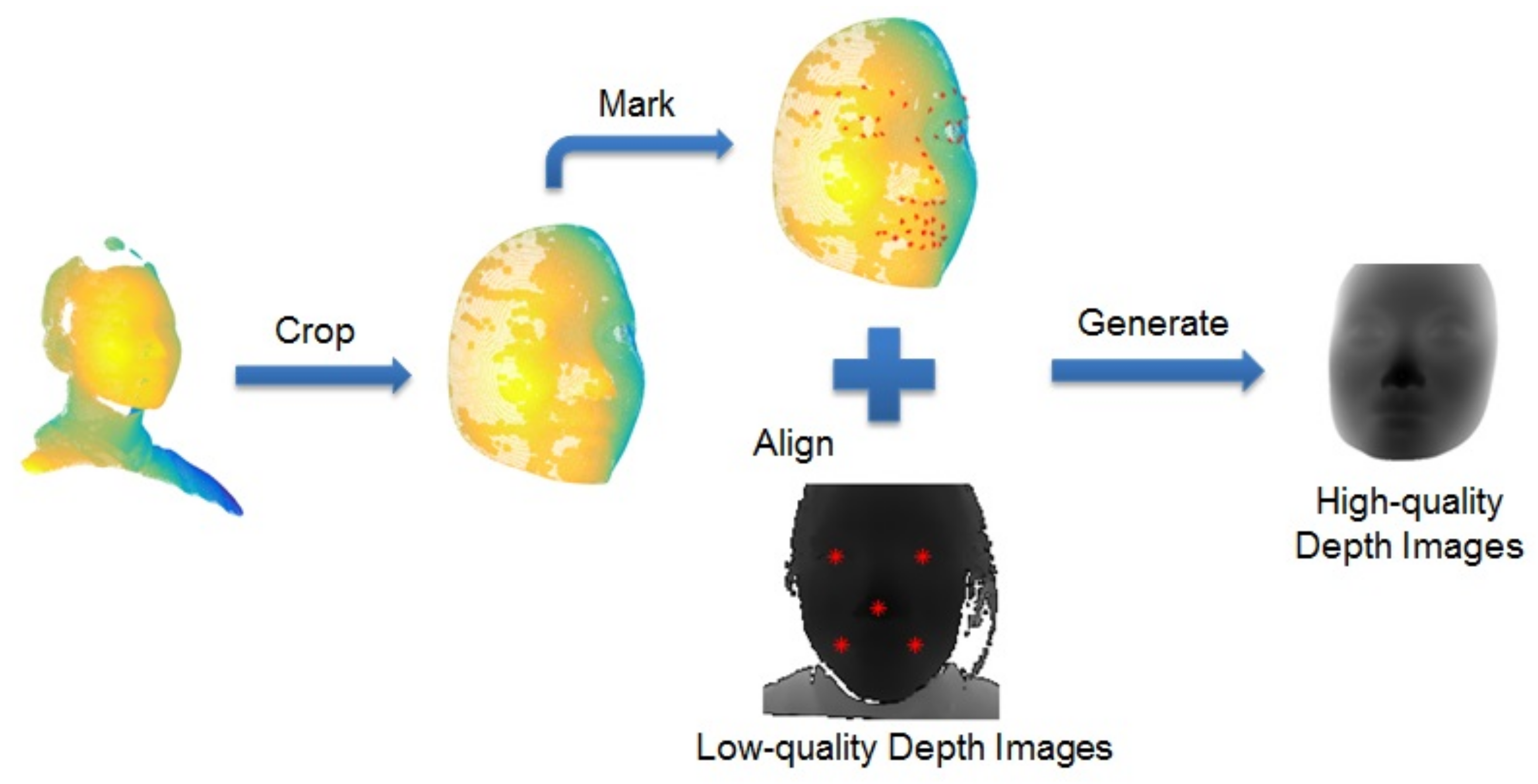
3.2. Data Processing
3.3. Statistics and Protocol
- (1)
- Training set: The training data are all from Version II, and except for 31 subjects with Version I, Version II has 674 subjects. We randomly select 430 subjects of the 674 subjects as training sets. In training models, after shuffling training images, the first 20% images are separated into validation sets.
- (2)
- The Testing set are divided into A and B parts, where the remaining 275 subjects in Version II make of the Testing set A and the all data in Version I make of the Testing set B. In Sec V, in different experiments, the specific dividing of galleries and probes can be displayed.
- (3)
- Resolved from original videos and face cropping, there are about 299K, 80K, 318K frames in total for training, validation, and Testing sets, respectively. Owing to the huge amount of data and especially the similarity in joint images, when testing, we select one frame out of every 10 frames in Test set A and every 6 frames in Test set B.
4. Proposed Approaches
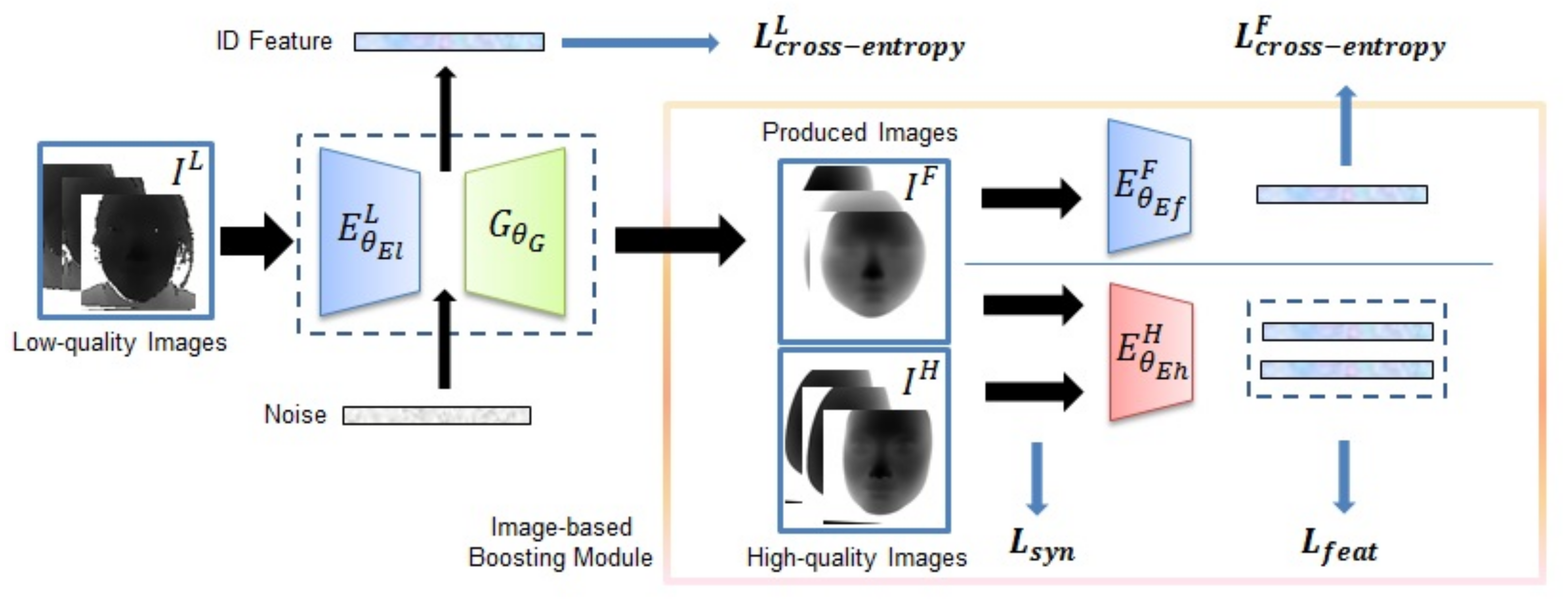
4.1. Image-Based Boosting Strategy
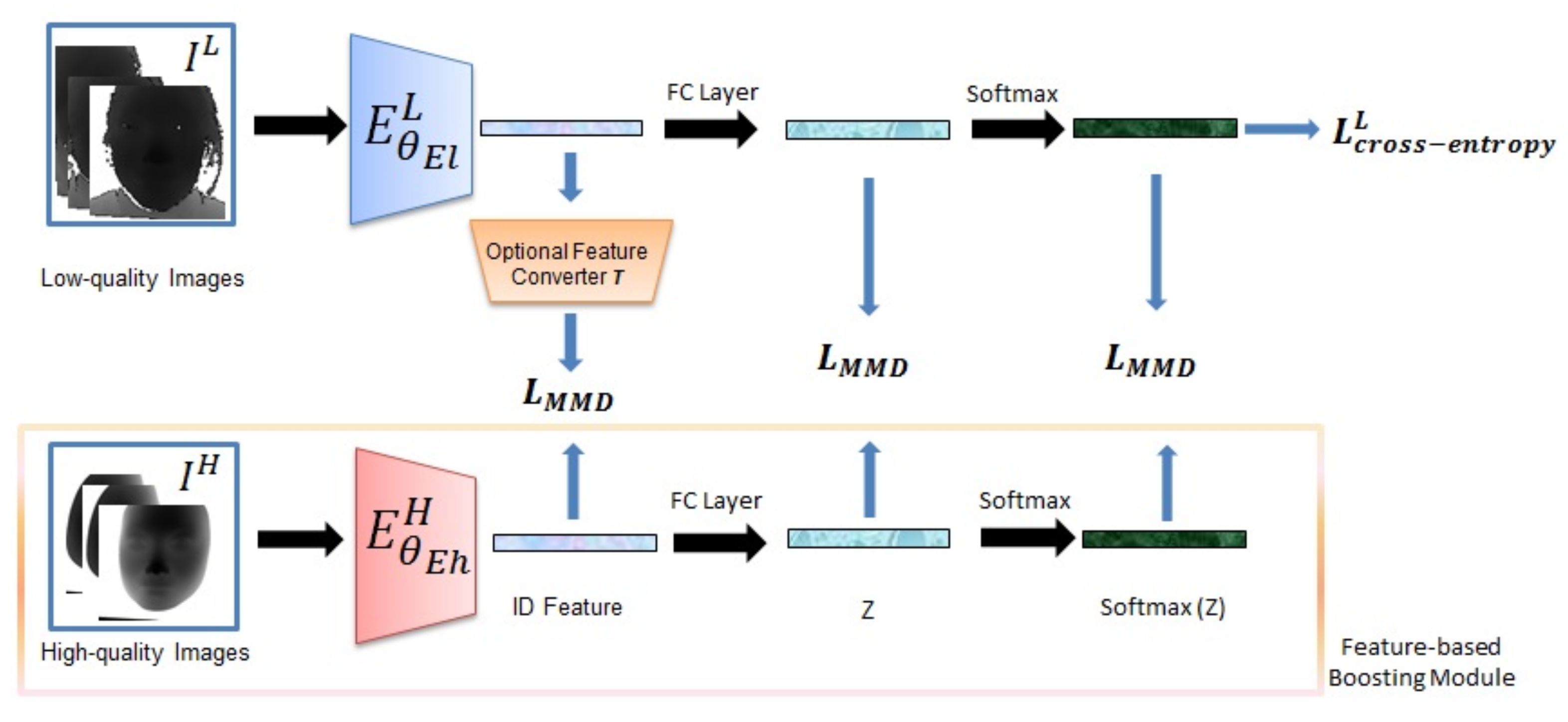
4.2. Feature-Based Boosting Strategy
4.3. Fusion-Based Boosting Strategy
4.4. Backbone Models
5. Experiments and Results
5.1. Experiment Setting
5.1.1. Testing Data Organization
5.1.2. Implementation Details
5.2. Evaluation of Proposed Approaches
5.2.1. The Performance on the Base Models
5.2.2. The Performance of the Image-based Boosting Models
5.2.3. The Performance of the Feature-Based Boosting Models
5.2.4. The Performance of the Fusion Models
5.2.5. The Experiment Analysis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Queirolo, C.C.; Silva, L.; Bellon, O.R.P.; Segundo, M.P. 3D Face Recognition Using Simulated Annealing and the Surface Interpenetration Measure. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 206–219. [Google Scholar] [CrossRef] [PubMed]
- Mian, A.S.; Bennamoun, M.; Owens, R.A. An Efficient Multimodal 2D-3D Hybrid Approach to Automatic Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1927–1943. [Google Scholar] [CrossRef] [PubMed]
- Ocegueda, O.; Passalis, G.; Theoharis, T.; Shah, S.K.; Kakadiaris, I.A. UR3D-C: Linear dimensionality reduction for efficient 3D face recognition. In Proceedings of the 2011 IEEE International Joint Conference on Biometrics (IJCB), Washington, DC, USA, 11–13 October 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Perakis, P.; Theoharis, T.; Passalis, G.; Kakadiaris, I.A. Automatic 3D Facial Region Retrieval from Multi-pose Facial Datasets. In Proceedings of the Eurographics Workshop on 3D Object Retrieval, Munich, Germany; 2009; pp. 37–44. [Google Scholar] [CrossRef]
- Yin, S.; Dai, X.; Ouyang, P.; Liu, L.; Wei, S. A Multi-Modal Face Recognition Method Using Complete Local Derivative Patterns and Depth Maps. Sensors 2014, 14, 19561–19581. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Erdogmus, N.; Marcel, S. Spoofing in 2D face recognition with 3D masks and anti-spoofing with Kinect. In Proceedings of the IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 29 September–2 October 2013; pp. 1–6. [Google Scholar]
- Nguyen, D.T.; Pham, T.D.; Baek, N.R.; Park, K.R. Combining Deep and Handcrafted Image Features for Presentation Attack Detection in Face Recognition Systems Using Visible-Light Camera Sensors. Sensors 2018, 18, 699. [Google Scholar] [CrossRef] [PubMed]
- The Introduction for Face-id of iPhone. Available online: https://www.apple.com/iphone/compare/ (accessed on 18 September 2019).
- Zennaro, S.; Munaro, M.; Milani, S.; Zanuttigh, P.; Bernardi, A.; Ghidoni, S.; Menegatti, E. In performance evaluation of the 1st and 2nd generation Kinect for multimedia applications. In Proceedings of the 2015 IEEE International Conference on Multimedia and Expo (ICME), Turin, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Lin, C.; Wang, C.; Chen, H.; Chu, W.; Chen, M.Y. RealSense: directional interaction for proximate mobile sharing using built-in orientation sensors. In Proceedings of the ACM Multimedia Conference, MM ’13, Barcelona, Spain, 21–25 October 2013; pp. 777–780. [Google Scholar] [CrossRef]
- Chowdhury, A.; Ghosh, S.; Singh, R.; Vatsa, M. RGB-D face recognition via learning-based reconstruction. In Proceedings of the 8th IEEE International Conference on Biometrics Theory, Applications and Systems (BTAS), Niagara Falls, NY, USA, 6–9 September 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Li, B.Y.L.; Mian, A.S.; Liu, W.; Krishna, A. Face recognition based on Kinect. Pattern Anal. Appl. 2016, 19, 977–987. [Google Scholar] [CrossRef]
- Min, R.; Kose, N.; Dugelay, J. KinectFaceDB: A Kinect Database for Face Recognition. IEEE Trans. Syst. Man Cybern. Syst. 2014, 44, 1534–1548. [Google Scholar] [CrossRef]
- Liu, H.; He, F.; Zhao, Q.; Fei, X. Matching Depth to RGB for Boosting Face Verification. In Proceedings of the Biometric Recognition—12th Chinese Conference (CCBR), Shenzhen, China, 28–29 October 2017; pp. 127–134. [Google Scholar] [CrossRef]
- Zhang, H.; Han, H.; Cui, J.; Shan, S.; Chen, X. RGB-D Face Recognition via Deep Complementary and Common Feature Learning. In Proceedings of the 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG), Xi’an, China, 15–19 May 2018; pp. 8–15. [Google Scholar] [CrossRef]
- Hayat, M.; Bennamoun, M.; El-Sallam, A.A. An RGB–D based image set classification for robust face recognition from Kinect data. Neurocomputing 2016, 171, 889–900. [Google Scholar] [CrossRef]
- The Introduction for SCU 3D Scanner. Available online: http://www.wisesoft.com.cn/InforDetail.aspx?id=News311d6114-c5cc-43d4-9b65-6798b522d819 (accessed on 18 September 2019).
- Phillips, P.J.; Flynn, P.J.; Scruggs, W.T.; Bowyer, K.W.; Chang, J.; Hoffman, K.; Marques, J.; Min, J.; Worek, W.J. Overview of the Face Recognition Grand Challenge. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; pp. 947–954. [Google Scholar] [CrossRef]
- Venkatesh, Y.V.; Kassim, A.A.; Yuan, J.; Nguyen, T.D. On the simultaneous recognition of identity and expression from BU-3DFE datasets. Pattern Recognition Let. 2012, 33, 1785–1793. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, D.; Wang, Y.; Sun, J. Lock3DFace: A large-scale database of low-cost Kinect 3D faces. In Proceedings of the International Conference on Biometrics (ICB), Halmstad, Sweden, 13–16 June 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Liu, F.; Hu, J.; Sun, J.; Wang, Y.; Zhao, Q. Multi-dim: A multi-dimensional face database towards the application of 3D technology in real-world scenarios. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017; pp. 342–351. [Google Scholar] [CrossRef]
- Hu, Z.; Zhao, Q.; Liu, F. Revisiting Depth-Based Face Recognition from a Quality Perspective. Available online: https://drive.google.com/open?id=1rl19VEg3uh8AmulV-ZgcL78dhgSUEfaq (accessed on 16 April 2019).
- Li, B.Y.L.; Mian, A.S.; Liu, W.; Krishna, A. Using Kinect for face recognition under varying poses, expressions, illumination and disguise. In Proceedings of the 2013 IEEE Workshop on Applications of Computer Vision (WACV), Clearwater Beach, FL, USA, 15–17 January 2013; pp. 186–192. [Google Scholar] [CrossRef]
- Esparza, D.M.C.; Terven, J.R.; Jiménez-Hernández, H.; Herrera-Navarro, A.M. A multiple camera calibration and point cloud fusion tool for Kinect V2. Sci. Comput. Program. 2017, 143, 1–8. [Google Scholar] [CrossRef]
- Goswami, G.; Vatsa, M.; Singh, R. RGB-D Face Recognition With Texture and Attribute Features. IEEE Trans. Inf. Forensics Secur. 2014, 9, 1629–1640. [Google Scholar] [CrossRef]
- Mantecón, T.; del-Blanco, C.R.; Jaureguizar, F.; García, N. Visual Face Recognition Using Bag of Dense Derivative Depth Patterns. IEEE Signal Process. Lett. 2016, 23, 771–775. [Google Scholar] [CrossRef]
- Fanelli, G.; Dantone, M.; Gall, J.; Fossati, A.; Gool, L.V. Random Forests for Real Time 3D Face Analysis. Int. J. Comput. Vis. 2013, 101, 437–458. [Google Scholar] [CrossRef]
- Borghi, G.; Pini, S.; Grazioli, F.; Vezzani, R.; Cucchiara, R. Face Verification from Depth using Privileged Information. In Proceedings of the British Machine Vision Conference 2018 (BMVC), Northumbria University, Newcastle, UK, 3–6 September 2018; p. 303. [Google Scholar]
- Bowyer, K.W.; Chang, K.I.; Flynn, P.J. A survey of approaches and challenges in 3D and multi-modal 3D + 2D face recognition. Comput. Vis. Imag. Underst. 2006, 101, 1–15. [Google Scholar] [CrossRef]
- Mantecón, T.; del-Blanco, C.R.; Jaureguizar, F.; García, N. Depth-based face recognition using local quantized patterns adapted for range data. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 293–297. [Google Scholar] [CrossRef]
- The Tool Librealsense for Dealing with RGB-D Data. Available online: https://github.com/IntelRealSense/librealsense (accessed on 18 September 2019).
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks. arXiv 2016, arXiv:1604.02878. [Google Scholar]
- The Introduction for Geomagic Studio. Available online: http://www.globenewswire.com/news-release/2013/02/27/526691/10023310/en/3D-Systems-Completes-the-Acquisition-of-Geomagic.html (accessed on 18 September 2019).
- The Introduction for CloudCompare. Available online: https://www.danielgm.net/cc/ (accessed on 18 September 2019).
- Tran, L.; Yin, X.; Liu, X. Disentangled Representation Learning GAN for Pose-Invariant Face Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1283–1292. [Google Scholar] [CrossRef]
- An, Z.; Deng, W.; Yuan, T.; Hu, J. Deep Transfer Network with 3D Morphable Models for Face Recognition. In Proceedings of the 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG), Xi’an, China, 15–19 May 2018; pp. 416–422. [Google Scholar] [CrossRef]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Schölkopf, B.; Smola, A.J. A Kernel Two-Sample Test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Huang, Z.; Wang, N. Like What You Like: Knowledge Distill via Neuron Selectivity Transfer. arXiv 2017, arXiv:1707.01219. [Google Scholar]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Learning Face Representation from Scratch. arXiv 2014, arXiv:1411.7923. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 417–425. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Ma, Y.; Klabjan, D. Convergence Analysis of Batch Normalization for Deep Neural Nets. arXiv 2017, arXiv:1705.08011. [Google Scholar]
- Clevert, D.; Unterthiner, T.; Hochreiter, S. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Giannini, F.; Laveglia, V.; Rossi, A.; Zanca, D.; Zugarini, A. Neural Networks for Beginners. A fast implementation in Matlab, Torch, TensorFlow. arXiv 2017, arXiv:1703.05298. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, M.; Liu, R.; Abe, N.; Uchida, H.; Matsunami, T.; Yamada, S. Discover the Effective Strategy for Face Recognition Model Compression by Improved Knowledge Distillation. In Proceedings of the 2018 IEEE International Conference on Image Processing(ICIP), Athens, Greece, 7–10 October 2018; pp. 2416–2420. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Databases | No. of Subjects | Devices | Resolution | Precision () | Rank-1 Identification Rate Using | ||
|---|---|---|---|---|---|---|---|
| Depth | RGB | Depth+RGB | |||||
| FRGC v2 [18] | 466 | Vivid 910 | 60K | [1] | – | – | |
| BU-3DFE [19] | 100 | 3dMD | 8K | [3] | – | – | |
| Lock3DFace [20] | 509 | Kinect II | 20K | [15] | % [15] | % [15] | |
| RGBD-W [22] | 2239 | RealSense | 45K | – | |||
| IIIT-D [25] | 106 | Kinect I | 13K | 2–4 [9] | [11] | [15] | [11] |
| CurtinFaces [12] | 52 | Kinect I | 13K | 2–4 | [12] | [12] | [12] |
| Eurecom [13] | 52 | Kinect I | 13K | 2–4 | [13] | [13] | [15] |
| Variations | 01 | 02 | 03 | 04 |
|---|---|---|---|---|
| Version id | (The conditions of each light in each variation.) | |||
| version I | All off. | L2 on. | L1 on | L3 and L4 on. |
| version II | All off | L2 on. | L1 and L2 on. | – |
| Source | # Obj. | # Videos | # Ori. img. | # Crop. Samp. img. | |
|---|---|---|---|---|---|
| Training | Version II | 430 | 1290 | ||
| Testing A | Version II | 275 | 825 | ||
| Testing B | Version I | 228 | 912 |
| Conv1.x | Conv2.x | Conv3.x | Conv4.x | Conv5.x | ||
|---|---|---|---|---|---|---|
| CASIA-Net | 320 | |||||
| ResNet-18 | (max pool.) | 512 |
| Datasets | # Objects. | # Images. | Variations |
|---|---|---|---|
| Gallery-A | 275 | 275 | N, |
| Probe-A-NU | 275 | N, | |
| Probe-A-PS1 | 275 | N, , | |
| Probe-A-PS2 | 275 | N, , | |
| Probe-A-FE | 275 | N, , E | |
| Gallery-B | 228 | 228 | N, |
| Probe-B | 228 | N, , E, |
| Network | Quality | Pro.-A-NU | Pro.-A-FE | Pro.-A-PS1 | Pro.-A-PS2 | Pro.-A-Avg |
|---|---|---|---|---|---|---|
| CASIA-Net | High | |||||
| Low | ||||||
| ResNet-18 | High | |||||
| Low |
| Methods | Pro.-A-NU | Pro.-A-FE | Pro.-A-PS1 | Pro.-A-PS2 | Pro.-A-Avg | |
|---|---|---|---|---|---|---|
| CASIA-Net | Baseline | |||||
| ResNet-18 | Baseline | |||||
| Methods | Pro.-A-NU | Pro.-A-FE | Pro.-A-PS1 | Pro.-A-PS2 | Pro.-A-Avg | |
|---|---|---|---|---|---|---|
| CASIA-Net | Baseline | |||||
| Equ-(5) | ||||||
| Equ-(6) | ||||||
| Equ-(7) | ||||||
| Equ-(7) | ||||||
| ResNet-18 | Baseline | |||||
| Equ-(5) | ||||||
| Equ-(6) | ||||||
| Equ-(7) | ||||||
| Equ-(7) |
| Methods | Pro.-A-NU | Pro.-A-FE | Pro.-A-PS1 | Pro.-A-PS2 | Pro.-A-Avg | Pro.-B | |
|---|---|---|---|---|---|---|---|
| CASIA-Net | Baseline | ||||||
| Equ-(4) + (6) | |||||||
| Equ-(4) + | |||||||
| Equ-+(6) | |||||||
| ResNet-18 | Baseline | ||||||
| Equ-(4) + (6) | |||||||
| Equ-(4) + | |||||||
| Equ-+(6) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Z.; Gui, P.; Feng, Z.; Zhao, Q.; Fu, K.; Liu, F.; Liu, Z. Boosting Depth-Based Face Recognition from a Quality Perspective. Sensors 2019, 19, 4124. https://doi.org/10.3390/s19194124
Hu Z, Gui P, Feng Z, Zhao Q, Fu K, Liu F, Liu Z. Boosting Depth-Based Face Recognition from a Quality Perspective. Sensors. 2019; 19(19):4124. https://doi.org/10.3390/s19194124
Chicago/Turabian StyleHu, Zhenguo, Penghui Gui, Ziqing Feng, Qijun Zhao, Keren Fu, Feng Liu, and Zhengxi Liu. 2019. "Boosting Depth-Based Face Recognition from a Quality Perspective" Sensors 19, no. 19: 4124. https://doi.org/10.3390/s19194124
APA StyleHu, Z., Gui, P., Feng, Z., Zhao, Q., Fu, K., Liu, F., & Liu, Z. (2019). Boosting Depth-Based Face Recognition from a Quality Perspective. Sensors, 19(19), 4124. https://doi.org/10.3390/s19194124