Boosting Multi-Vehicle Tracking with a Joint Object Detection and Viewpoint Estimation Sensor

Abstract
1. Introduction
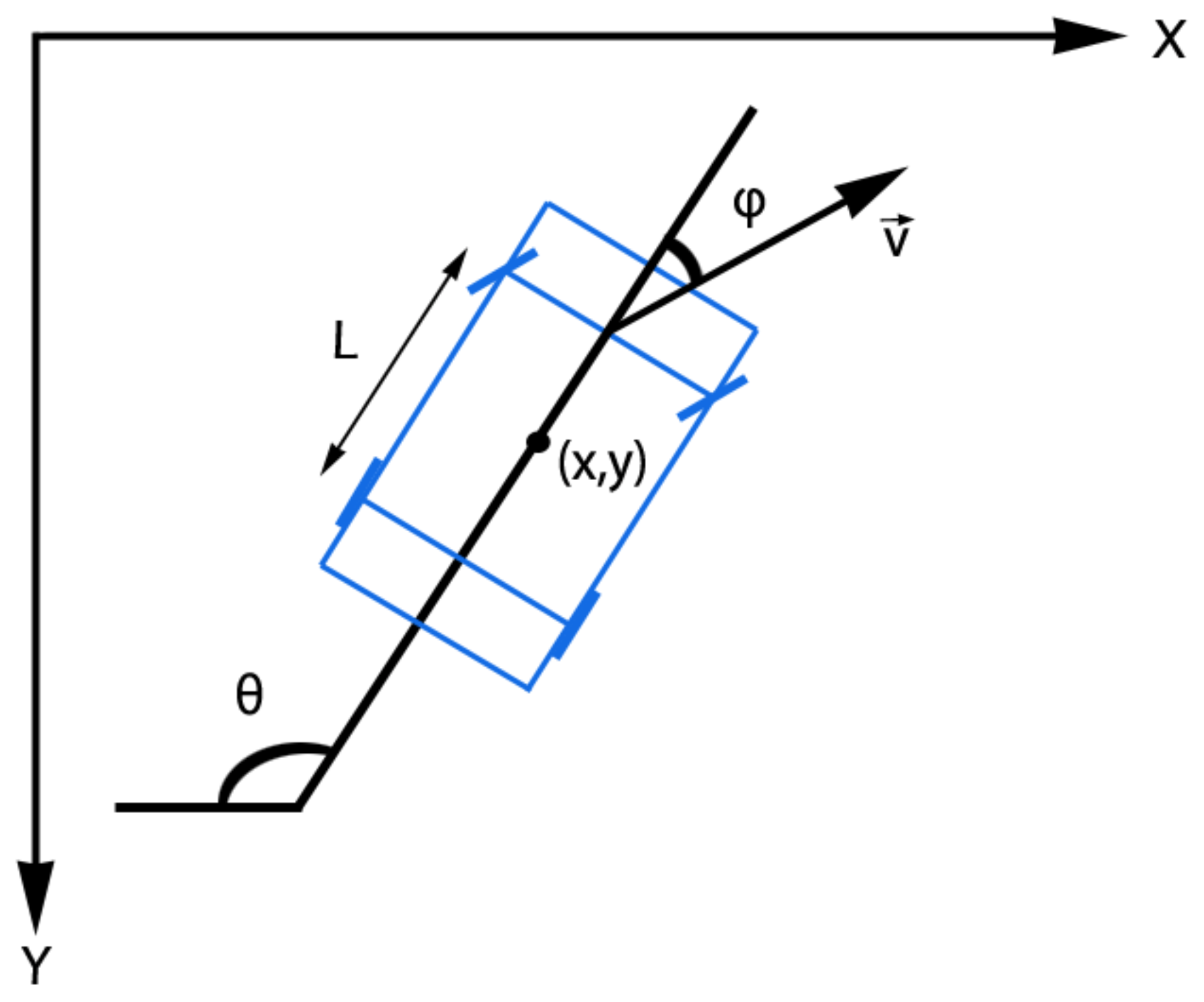
- First, we develop the multi-vehicle tracking approach with a new design for an Extended Kalman Filter (EKF) which is able to simultaneously integrate into the motion model both the position and the viewpoint observations of the objects captured by our sensing solution.
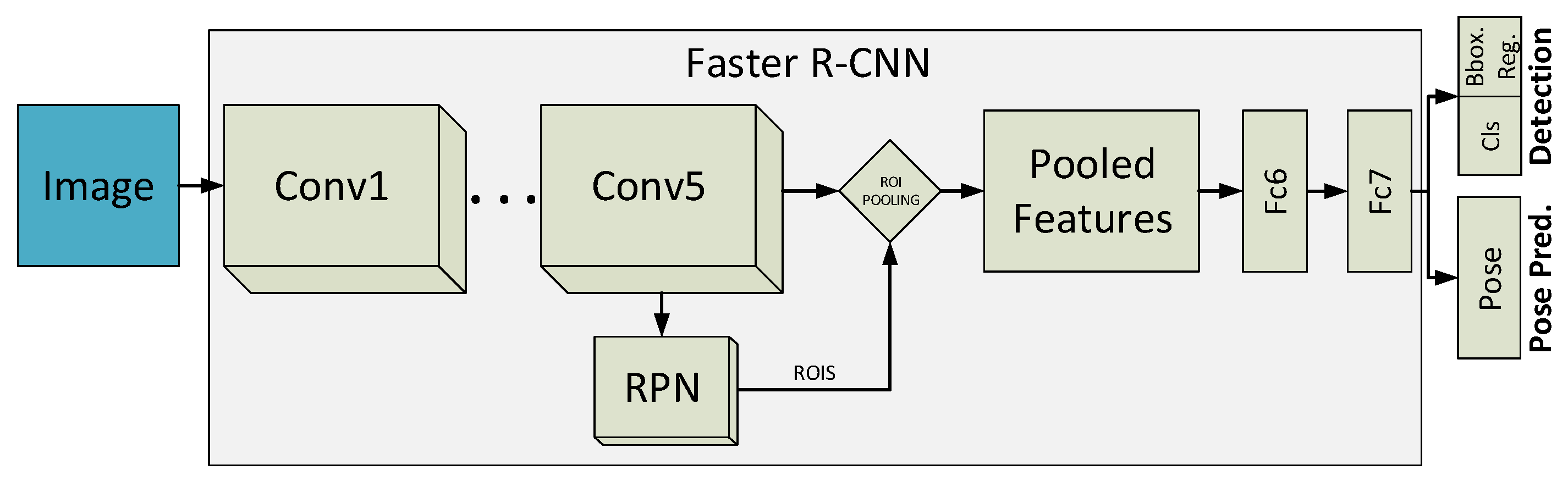
- Second, we introduce two solutions for the simultaneous object detection and pose estimation problem. One consists in a GPU-based implementation of a Histogram of Oriented Gradients (HOG) detector with Support Vector Machines (SVMs) to estimate the viewpoints. For the other, we modify and train the Faster R-CNN deep learning model [16], in order to recover from it not only the object localization but also an estimation of its pose.
- And third, we publicly release a thorough experimental evaluation on the challenging dataset for multi-vehicle tracking and detection, the GRAM Road Traffic Monitoring (GRAM-RTM) database. It has been especially designed for evaluating multi-vehicle tracking approaches within the context of traffic monitoring applications. It comprises more than 700 unique vehicles annotated across more than 40.300 frames of three video sequences. We expect the GRAM-RTM becomes a novel benchmark in vehicle detection and tracking, providing the computer vision and intelligent transportation systems community with a standard set of images, annotations and evaluation procedures for multi-vehicle tracking.
2. Related Work
3. Tracking-By-Detection and Viewpoint Estimation
3.1. Simultaneous Vehicle Detection and Pose Estimation
3.2. Multi-Vehicle Tracking
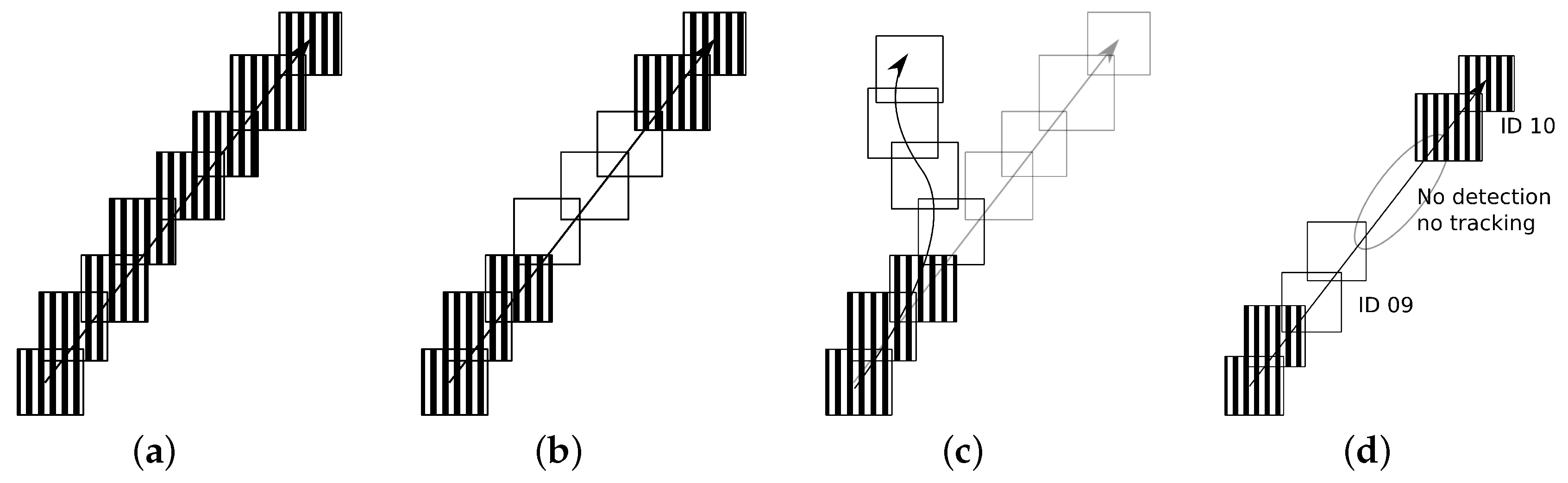
Data Association Algorithm
- Proximity (Algorithm 1—Step 1).
- Appearance similarity (Algorithm 1—Step 2—Lines 1–22).
- Detection overlap (Algorithm 1—Step 2—Lines 24–27).
| Algorithm 1 Data Association algorithm. |
Inputs: trackingList → H detectionList Output: trackingList (updated with the new observations) Step 1: Establishing dynamic neighborhood 1 #Establishing dynamic neighborhood 2 for each track in trackingList 3 for each detection in detectionList 4 if overlap(detection, track) #Overlap is measured using the corresponding bounding boxes 5 add detection to track.neighborhood #Detection is added to the track list Step 2: Assigning detections and disambiguation 1 for each track in trackinglist 2 if size(track.neighborhood) = 0 #No vehicle selected 3 track.currentStatus = NULL 4 5 else if size(track.neighborhood) = 1 #Only one vehicle has been selected 6 if appearanceSimilarity(track.neighborhood, #Checking the similarity in terms of appearance 7 track.lastAppearance) < threshold 8 track.currentStatus = track.neighborhood 9 else 10 track.currentStatus = NULL 11 12 else #More than one vehicle has been selected 13 for each neighbor in track.neighborhood 14 if appearanceSimilarity(neighbor, # Disambiguation by appearance similarity 15 track.lastAppearance) > threshold 16 delete neighbor 17 18 if size(track.neighborhood) = 0 19 track.currentStatus = NULL 20 21 else if size(track.neighborhood) = 1 22 track.currentStatus = track.neighborhood 23 24 else #Disambiguation by overlap criteria 25 neighbor = find_max_overlap(track.prediction, 26 track.neighborhood) 27 track.currentStatus = neighbor Step 3: Avoiding more than one track sharing the same detection 1 for each detection in detectionList 2 used = 0 3 list.clean 4 5 for each track in trackingList 6 if track.currentStatus = detection 7 used ++ 8 add track to list 9 10 if used > 1 #If it is used by more than one track ... 11 selected_track = find_max_overlap(detection, list) #…it select the one with maximum overlap 12 13 for each vehicle in list 14 if vehicle not selected_track 15 vehicle.currentStatus = NULL Step 4: Dealing with tracks without detections 1 for each track in trackinglist 2 if track.currentStatus = NULL #Can we associate this empty track to a previous track? 3 if appearanceSimilarity(track.prediction, #We check this situation using the appearance criterion 4 track.lastAppearance) < threshold2 5 track.currentStatus = track.prediction 6 7 else 8 remove track from trackingList #the vehicle is lost |
4. GRAM-RTM Database
4.1. Vehicle Detection
4.2. Vehicle Tracking
4.3. Best Practice: Recommendations on Using The Dataset
5. Results
5.1. Technical Details
5.2. Results
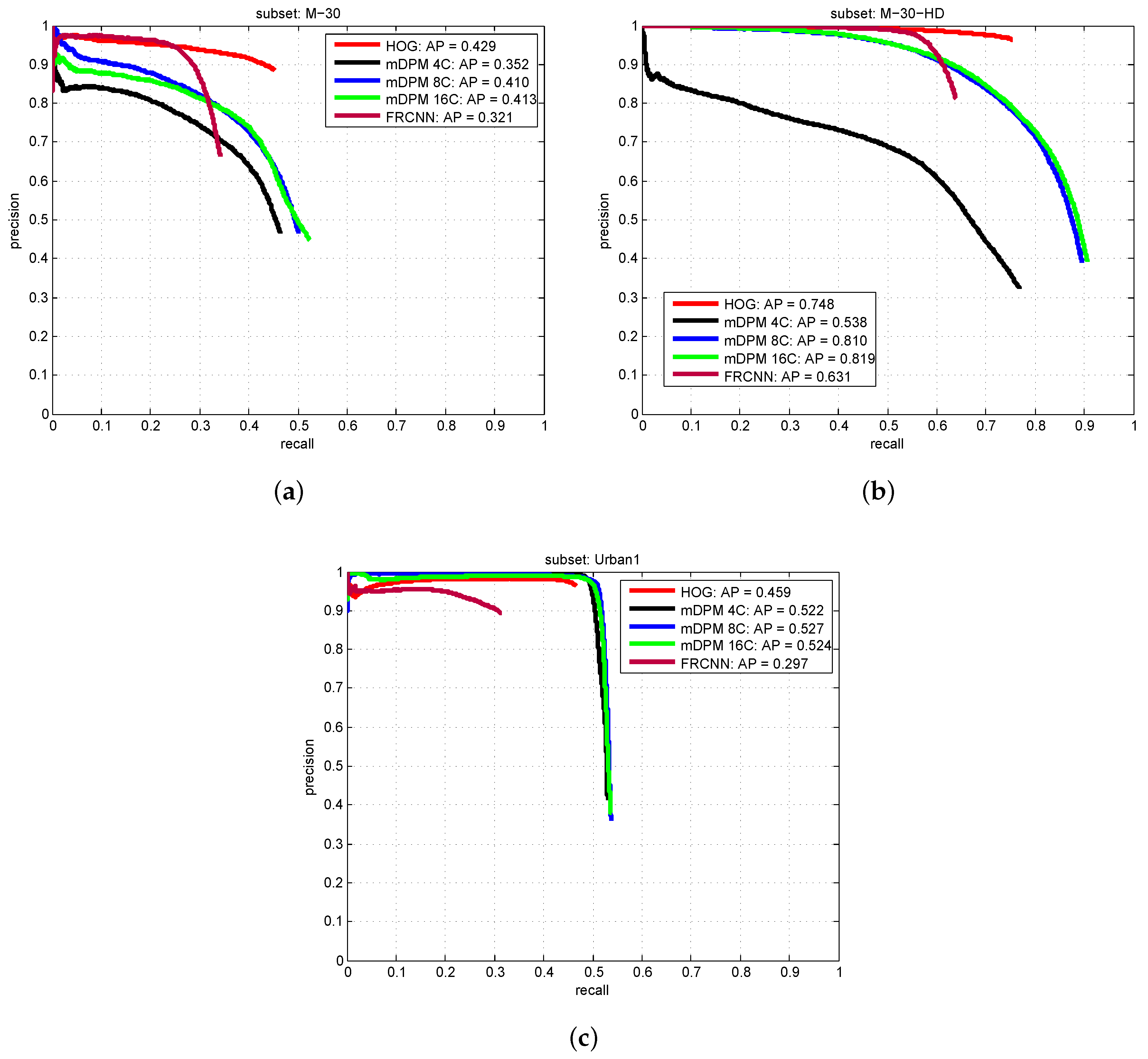
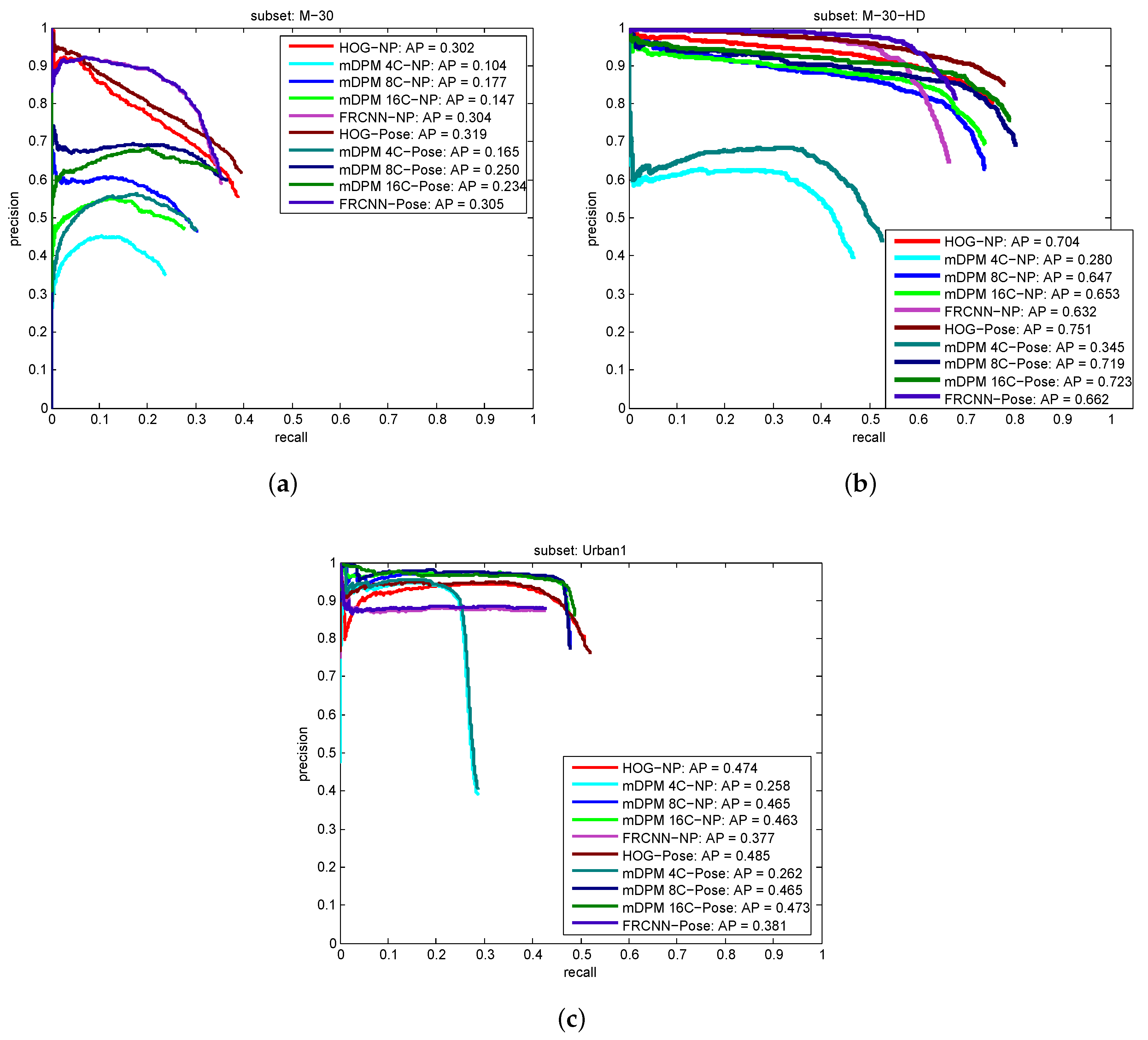
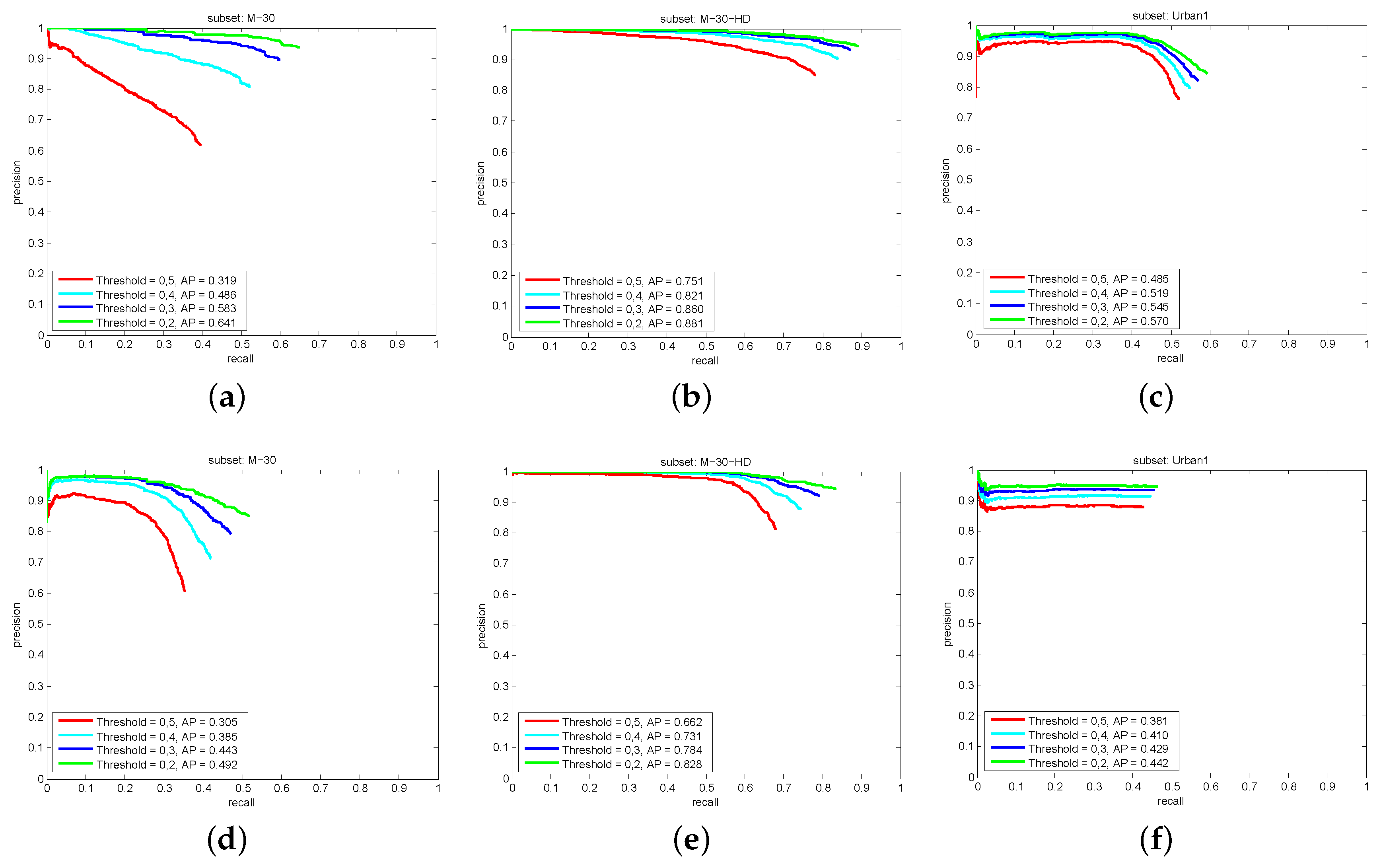
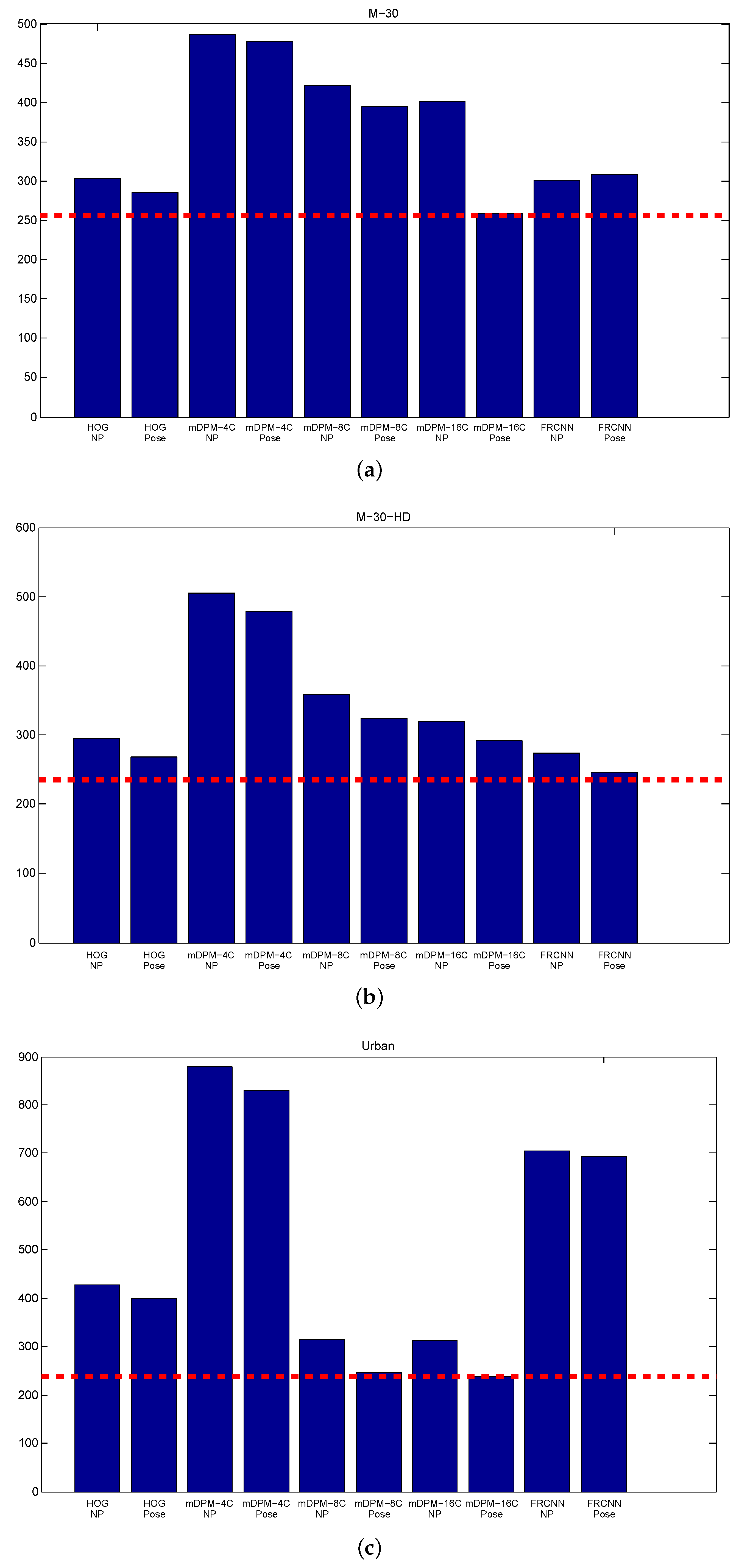
5.2.1. Object Detection Results
5.2.2. Vehicle Tracking Results
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| KF | Kalman Filter |
| EKF | Extended Kalman Filter |
| HOG | Histogram of Oriented Gradients |
| DPM | Deformable Part Model |
| SVM | Support Vector Machine |
| MTT | Multi-Target Tracking |
| GNN | Global Nearest Neighbor |
| RPN | Region Proposal Network |
| MHT | Multiple Hypothesis Tracking |
| CNN | Convolutional Neural Network |
| R-CNN | Regions with CNN features |
References
- Zhu, J.; Yuan, L.; Zheng, Y.; Ewing, R. Stereo Visual Tracking Within Structured Environments for Measuring Vehicle Speed. IEEE TCSVT 2012, 22, 1471–1484. [Google Scholar] [CrossRef][Green Version]
- Markevicius, V.; Navikas, D.; Idzkowski, A.; Andriukaitis, D.; Valinevicius, A.; Zilys, M. Practical Methods for Vehicle Speed Estimation Using a Microprocessor-Embedded System with AMR Sensors. Sensors 2018, 18, 2225. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Ryoo, M.; Riley, M.; Aggarwal, J. Real-Time Illegal Parking Detection in Outdoor Environments Using 1-D Transformation. IEEE TCSVT 2009, 19, 1014–1024. [Google Scholar] [CrossRef]
- Kong, Q.J.; Zhao, Q.; Wei, C.; Liu, Y. Efficient Traffic State Estimation for Large-Scale Urban Road Networks. IEEE Trans. Intell. Transp. Syst. 2013, 14, 398–407. [Google Scholar] [CrossRef]
- Ye, Z.; Wang, L.; Xu, W.; Gao, Z.; Yan, G. Monitoring Traffic Information with a Developed Acceleration Sensing Node. Sensors 2017, 17, 2817. [Google Scholar] [CrossRef]
- Barthélemy, J.; Verstaevel, N.; Forehead, H.; Perez, P. Edge-Computing Video Analytics for Real-Time Traffic Monitoring in a Smart City. Sensors 2019, 19, 2048. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, G.; Wang, Y.; Wu, X.; Ma, Y. A Hybrid Vehicle Detection Method Based on Viola-Jones and HOG + SVM from UAV Images. Sensors 2016, 16, 1325. [Google Scholar] [CrossRef]
- Zhong, J.; Lei, T.; Yao, G. Robust Vehicle Detection in Aerial Images Based on Cascaded Convolutional Neural Networks. Sensors 2017, 17, 2720. [Google Scholar] [CrossRef]
- Wen-Chung, C.; Chih-Wei, C. Online Boosting for Vehicle Detection. IEEE Trans. Syst. Man Cybern. Part B 2010, 40, 892–902. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. PAMI 2010, 32, 1627–1645. [Google Scholar] [CrossRef]
- Herout, A.; Jošth, R.; Juránek, R.; Havel, J.; Hradiš, M.; Zemčík, P. Real-time object detection on CUDA. J. Real-Time Image Process. 2011, 6, 159–170. [Google Scholar] [CrossRef]
- Kumar, P.; Singhal, A.; Mehta, S.; Mittal, A. Real-time moving object detection algorithm on high-resolution videos using GPUs. J. Real-Time Image Process. 2013, 11, 93–109. [Google Scholar] [CrossRef]
- Leibe, B.; Leonardis, A.; Schiele, B. Robust Object Detection with Interleaved Categorization and Segmentation. IJCV 2008, 77, 259–289. [Google Scholar] [CrossRef]
- Sudowe, P.; Leibe, B. Efficient Use of Geometric Constraints for Sliding-Window Object Detection in Video. In Proceedings of the 8th International Conference on Computer Vision Systems, Sophia Antipolis, France, 20–22 September 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 11–20. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2014, arXiv:1311.2524. [Google Scholar]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Lopez-Sastre, R.J.; Tuytelaars, T.; Savarese, S. Deformable Part Models Revisited: A Performance Evaluation for Object Category Pose Estimation. In Proceedings of the ICCV 2011, 1st IEEE Workshop on Challenges and Opportunities in Robot Perception, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Savarese, S.; Fei-Fei, L. 3D generic object categorization, localization and pose estimation. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Sun, M.; Su, H.; Savarese, S.; Fei-Fei, L. A Multi-View Probabilistic Model for 3D Object Classes. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Thomas, A.; Ferrari, V.; Leibe, B.; Tuytelaars, T.; Schiele, B.; Van Gool, L. Towards Multi-View Object Class Detection. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1589–1596. [Google Scholar]
- Pepik, B.; Gehler, P.; Stark, M.; Schiele, B. 3D2PM-3D Deformable Part Models. In Proceedings of the ECCV, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Redondo-Cabrera, C.; López-Sastre, R.J.; Tuytelaars, T. All Together Now: Simultaneous Object Detection and Continuous Pose Estimation Using a Hough Forest with Probabilistic Locally Enhanced Voting. In Proceedings of the BMVC 2014, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Tulsiani, S.; Malik, J. Viewpoints and Keypoints. arXiv 2015, arXiv:1411.6067. [Google Scholar]
- Massa, F.; Marlet, R.; Aubry, M. Crafting a Multi-Task CNN for Viewpoint Estimation. In Proceedings of the BMVC, York, UK, 19–22 September 2016. [Google Scholar]
- Oñoro Rubio, D.; López-Sastre, R.J.; Redondo-Cabrera, C.; Gil-Jiménez, P. The challenge of simultaneous object detection and pose estimation: A comparative study. Image Vis. Comput. 2018, 79, 109–122. [Google Scholar] [CrossRef]
- Guerrero-Gomez-Olmedo, R.; Lopez-Sastre, R.J.; Maldonado-Bascon, S.; Fernandez-Caballero, A. Vehicle Tracking by Simultaneous Detection and Viewpoint Estimation. In Proceedings of the IWINAC, Mallorca, Spain, 10–14 June 2013. [Google Scholar]
- Yilmaz, A.; Javed, O.; Shah, M. Object tracking: A survey. ACM Comput. Surv. 2006, 38, 1–45. [Google Scholar] [CrossRef]
- Bazzani, L.; Cristani, M.; Murino, V. Collaborative Particle Filters for Group Tracking. In Proceedings of the ICIP, Hong Kong, China, 26–29 September 2010. [Google Scholar]
- Porikli, F.; Pan, P. Regressed Importance Sampling on Manifolds for Efficient Object Tracking. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance, Genova, Italy, 2–4 September 2009. [Google Scholar]
- Shafique, K.; Shah, M. A Non-Iterative Greedy Algorithm for Multi-frame Point Correspondence. IEEE TPAMI 2005, 27, 51–65. [Google Scholar] [CrossRef]
- Shalom, Y.; Fortmann, T. Tracking and Data Association; Academic Press: New York, NY, USA, 1988. [Google Scholar]
- Reid, D. An Algorithm for Tracking Multiple Targets. IEEE Trans. Autom. Control 1979, 24, 843–854. [Google Scholar] [CrossRef]
- Saleemi, I.; Shah, M. Multiframe Many–Many Point Correspondence for Vehicle Tracking in High Density Wide Area Aerial Videos. Int. J. Comput. Vis. 2013, 104, 198–219. [Google Scholar] [CrossRef]
- Porikli, F. Achieving real-time object detection and tracking under extreme conditions. J. Real-Time Image Process. 2006, 1, 33–40. [Google Scholar] [CrossRef]
- Comaniciu, D.; Meer, P. Mean Shift Analysis and Applications. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1197–1203. [Google Scholar]
- Bradski, G.R. Computer Vision Face Tracking For Use in a Perceptual User Interface. Int. Technol. J. 1998, Q2, 1–15. [Google Scholar]
- Huang, L.; Barth, M.J. Real-time Multi-Vehicle Tracking Based on Feature Detection and Color Probability Model. In Proceedings of the Intelligent Vehicles Symposium IEEE, San Diego, CA, USA, 21–24 June 2010; pp. 981–986. [Google Scholar]
- Tamersoy, B.; Aggarwal, J.K. Robust Vehicle Detection for Tracking in Highway Surveillance Videos using Unsupervised Learning. In Proceedings of the 2009 Sixth IEEE International Conference on Advanced Video and Signal Based Surveillance, Genova, Italy, 2–4 September 2009. [Google Scholar]
- Ess, A.; Schindler, K.; Leibe, B.; Van Gool, L. Object detection and tracking for autonomous navigation in dynamic environments. Int. J. Rob. Res. 2010, 29, 1707–1725. [Google Scholar] [CrossRef]
- Gavrila, D.M.; Munder, S. Multi-cue Pedestrian Detection and Tracking from a Moving Vehicle. IJCV 2007, 73, 41–59. [Google Scholar] [CrossRef]
- Leibe, B.; Schindler, K.; Cornelis, N.; Van Gool, L. Coupled Object Detection and Tracking from Static Cameras and Moving Vehicles. PAMI 2008, 30, 1683–1698. [Google Scholar] [CrossRef] [PubMed]
- Zhao, D.; Fu, H.; Xiao, L.; Wu, T.; Dai, B. Multi-Object Tracking with Correlation Filter for Autonomous Vehicle. Sensors 2018, 18, 2004. [Google Scholar] [CrossRef]
- Koller, D.; Danilidis, K.; Nagel, H.H. Model-based Object Tracking in Monocular Image Sequences of Road Traffic Scenes. IJCV 1993, 10, 257–281. [Google Scholar]
- Dellaert, F.; Thorpe, C. Robust car tracking using Kalman filtering and Bayesian Templates. In Proceedings of the Intelligent Transportation Systems, Pittsburgh, PA, USA, 6 March 1997. [Google Scholar]
- Niknejad, H.T.; Takeuchi, A.; Mita, S.; McAllester, D.A. On-Road Multivehicle Tracking Using Deformable Object Model and Particle Filter With Improved Likelihood Estimation. IEEE Trans. Intell. Transp. Syst. 2012, 13, 748–758. [Google Scholar] [CrossRef]
- Gu, C.; Ren, X. Discriminative Mixture-of-Templates for Viewpoint Classification. In Proceedings of the ECCV, Crete, Greece, 5–11 September 2010; Volume 6315, pp. 408–421. [Google Scholar]
- Rybski, P.E.; Huber, D.; Morris, D.D.; Hoffman, R. Visual Classification of Coarse Vehicle Orientation using Histogram of Oriented Gradients Features. In Proceedings of the Intelligent Vehicles Symposium, San Diego, CA, USA, 21–24 June 2010; pp. 921–928. [Google Scholar]
- Welch, G.; Bishop, G. An Introduction to the Kalman Filter; Technical Report TR 95-041; University of North Carolina at Chapel Hill: Chapel Hill, NC, USA, 2006. [Google Scholar]
- Cameron, S.; Probert, P. Advanced Guided Vehicles: Aspects of the Oxford AGV Project; World Scientific Publishing Co., Inc.: River Edge, NJ, USA, 1994. [Google Scholar]
- Prisacariu, V.; Reid, I. fastHOG—A Real-time GPU Implementation of HOG; Technical Report 2310/09; Department of Engineering Science, Oxford University: Oxford, UK, 2009. [Google Scholar]
- Milliken, W.F.; Milliken, D.L. Race Car Vehicle Dynamics; SAE International: Warrendale, PA, USA, 1994. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Vondrick, C.; Patterson, D.; Ramanan, D. Efficiently Scaling up Crowdsourced Video Annotation—A Set of Best Practices for High Quality, Economical Video Labeling. IJCV 2013, 101, 184–204. [Google Scholar] [CrossRef]
- Wang, Q.; Chen, F.; Xu, W.; Yang, M. An Experimental Comparison of Online Object Tracking Algorithms. In Proceedings of the SPIE: Image and Signal Processing (SPIE 2011), Prague, Czech Republic, 19–21 September 2011. [Google Scholar]
- Hoiem, D.; Chodpathumwan, Y.; Dai, Q. Diagnosing Error in Object Detectors. In Computer Vision—ECCV 2012, Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Spring: Berlin/Heidelberg, Germany, 2012; Volume 7574, pp. 340–353. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. arXiv 2014, arXiv:1408.5093. [Google Scholar]
- Xiang, Y.; Mottaghi, R.; Savarese, S. Beyond PASCAL: A Benchmark for 3D Object Detection in the Wild. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tracking-by-Detection | Integration of Pose Estimations | Pose Estimation Modifies the Motion Model | |
|---|---|---|---|
| [6,41,42,43,44] | √ | × | × |
| [47] | √ | √ | × |
| Ours | √ | √ | √ |
| M-30 | M-30-HD | Urban1 | |
|---|---|---|---|
| Frames | 7520 | 9390 | 23435 |
| Resolution | |||
| Vehicles annotated | 256 | 235 | 237 |
| Categories | car, truck, van, big-truck | ||
| Frontal | Left | Rear | Right | |
|---|---|---|---|---|
| HOG window | (54,39) | (50,19) | (54,39) | (50,19) |
| HOG descriptor | (6,4) | (7,3) | (6,4) | (7,3) |
| Frontal | Left | Rear | Right | |
|---|---|---|---|---|
| HOG window | (63,45) | (50,19) | (63,45) | (50,19) |
| HOG descriptor | (7,5) | (7,3) | (7,5) | (7,3) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
López-Sastre, R.J.; Herranz-Perdiguero, C.; Guerrero-Gómez-Olmedo, R.; Oñoro-Rubio, D.; Maldonado-Bascón, S. Boosting Multi-Vehicle Tracking with a Joint Object Detection and Viewpoint Estimation Sensor. Sensors 2019, 19, 4062. https://doi.org/10.3390/s19194062
López-Sastre RJ, Herranz-Perdiguero C, Guerrero-Gómez-Olmedo R, Oñoro-Rubio D, Maldonado-Bascón S. Boosting Multi-Vehicle Tracking with a Joint Object Detection and Viewpoint Estimation Sensor. Sensors. 2019; 19(19):4062. https://doi.org/10.3390/s19194062
Chicago/Turabian StyleLópez-Sastre, Roberto J., Carlos Herranz-Perdiguero, Ricardo Guerrero-Gómez-Olmedo, Daniel Oñoro-Rubio, and Saturnino Maldonado-Bascón. 2019. "Boosting Multi-Vehicle Tracking with a Joint Object Detection and Viewpoint Estimation Sensor" Sensors 19, no. 19: 4062. https://doi.org/10.3390/s19194062
APA StyleLópez-Sastre, R. J., Herranz-Perdiguero, C., Guerrero-Gómez-Olmedo, R., Oñoro-Rubio, D., & Maldonado-Bascón, S. (2019). Boosting Multi-Vehicle Tracking with a Joint Object Detection and Viewpoint Estimation Sensor. Sensors, 19(19), 4062. https://doi.org/10.3390/s19194062