CABE: A Cloud-Based Acoustic Beamforming Emulator for FPGA-Based Sound Source Localization

 , , ,
, , ,  ,
,  and
and 
Abstract
1. Introduction
2. Acoustic Beamforming
2.1. Delay and Sum Beamforming
2.2. Delay and Sum Beamforming with Non-Ideal Microphones
2.3. Computing the Steered Response Power
2.4. Acoustic Beamforming on FPGA–Discrete Sampling
3. Performance Metrics
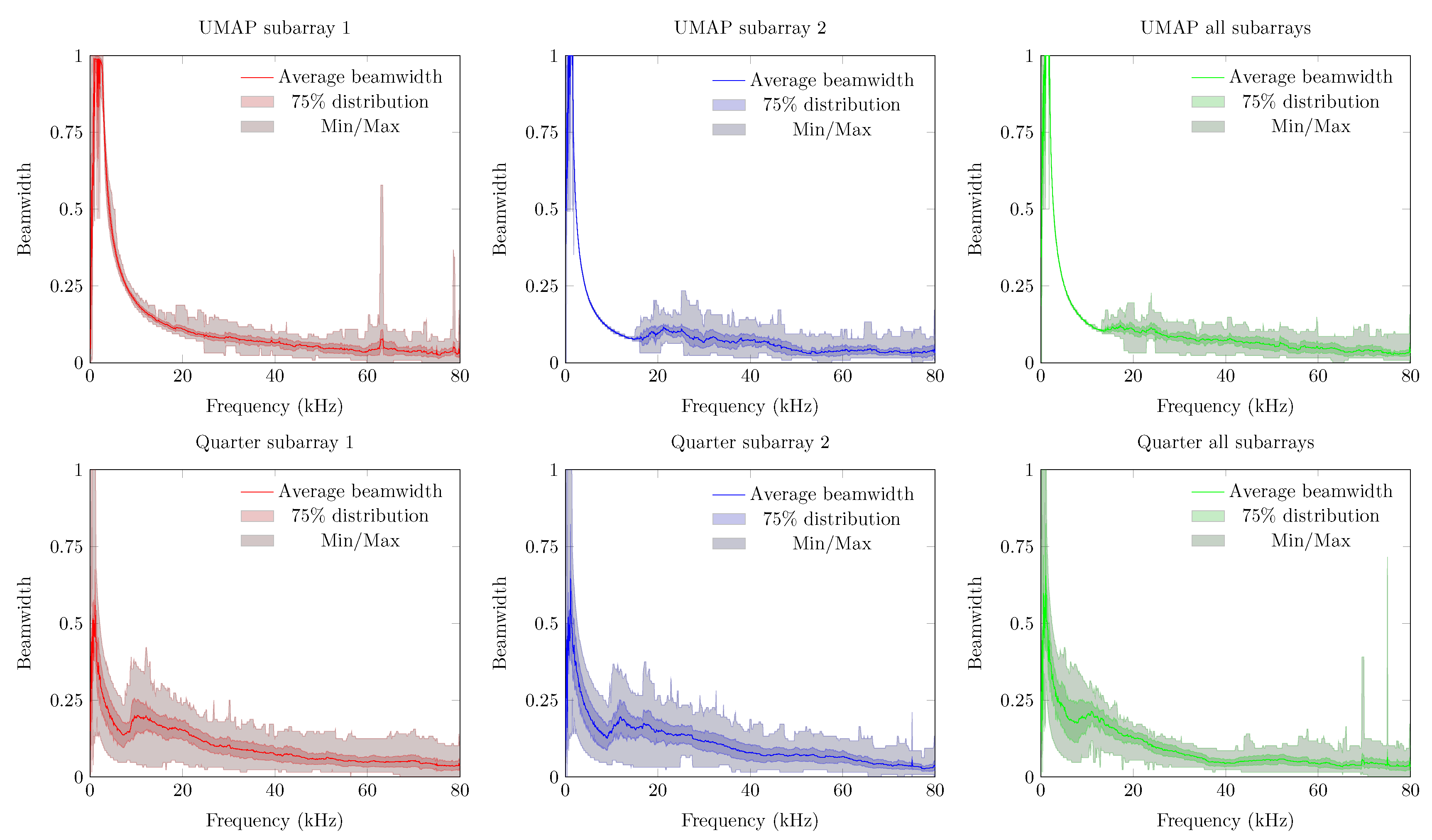
3.1. Beamwidth (BW)
3.2. Peak Side Lobe Level ()
3.3. Integrated Side Lobe Level (ISLL)
3.4. Focal Index (FI)
3.5. Directivity Index (DI)
3.6. Steered Metrics
4. CABE: Cloud-Based Acoustic Beamforming Emulator
4.1. Architectural Overview
4.2. Emulator
- processing input parameters,
- microphone array response computation,
- generating output response files,
- computing metrics,
- generating HDL package.
4.3. Processing Input Parameters (Step 1)
4.4. Microphone Array Response Computation (Step 2)
4.4.1. Acoustic Capturing
- In the first step a frequency response shaping on the acoustic signal is applied by means of a convolution filter. This shaping is performed in time domain for easier streaming of samples. The frequency response of each microphone type is converted into FIR coefficients by the frequency sampling method [41].
- The second step consists of converting the output of the frequency shaping function into the right output format proposed by the microphone. Currently supported formats include double precision to mimick analog samples, Pulse Coded Modulation (PCM) and Pulse Density Modulation (PDM). Conversion to PDM format needs to be carefully chosen to match the microphone’s characteristics. Here 4th and 5th order Sigma-Delta Modulation (SDM) converters with an Over Sampling Ratio (OSR) between 15 and 64 are generally used [31,42,43]. The appropriate architectures are designed with the Delsig Matlab toolbox [44].
4.4.2. Delay-and-Sum
4.4.3. Steering Vectors
- Equalpolar Distribution (A): 2D steering vectors in an equal radial pattern on one of the Cartesian planes. A start and stop angle can be provided limiting the “view area” of the microphone array.
- Hypercube Distribution (B and C): 3D steering following a hypercube distrubution. The distribution can be on the cube itself or can be normalized to a unit sphere.
- Hyperplane Distribution (D and E): enables to steer following a grid pattern onto one of the planes of the hypercube method. A normalized pattern can also be used.
- Fibonacci Lattice (F): 3D steering following the Fibonacci lattice distribution [46]. Here only the spherical distribution is available.
4.4.4. Delay-and-Sum between Subarrays
- For each subarray s, the minimum dot product (Equation (37)) between the steering vector and the positions of all microphones is computed. The minimal dot product is indexed in a temporary table. This step is repeated for all steering orientations.
- At the level of the main array, the delay table is computed by applying Equation (38) on the obtained distances from the subarrays for each of the steering orientations.
4.4.5. Signal Demodulation and Frequency Shaping Function
Analog MEMS and Condenser Microphones
Digital PDM Microphones
Signal Demodulation and Signal Shaping in the Emulator
4.4.6. SRP
4.4.7. Commutative Computations
- Delay and Sum + Filtering for analog based microphones,
- Delay and Sum + CIC + Filtering for PDM based microphones,
- CIC + Filtering + Delay and Sum for PDM based microphones,
- CIC + Filtering + Delay and Decimation and Sum.
4.5. Response Results Output (Step 3)
4.6. Metrics Generator (Step 4)
4.7. HDL Package Generator (Step 5)
4.8. User Web Interface Database and Task Manager
- the database from which the status of each of the emulations can be followed,
- the module which enables the client application to retrieve the necessary configurations and constraints for generating proper emulation files,
- the Task Manager enables to schedule emulations and to communicate with the emulator computers in the back-end and,
- a module keeping track of the required processing time per type of machine and per type of emulation request.
4.9. CABE Client
5. Demonstration of the CABE Platform
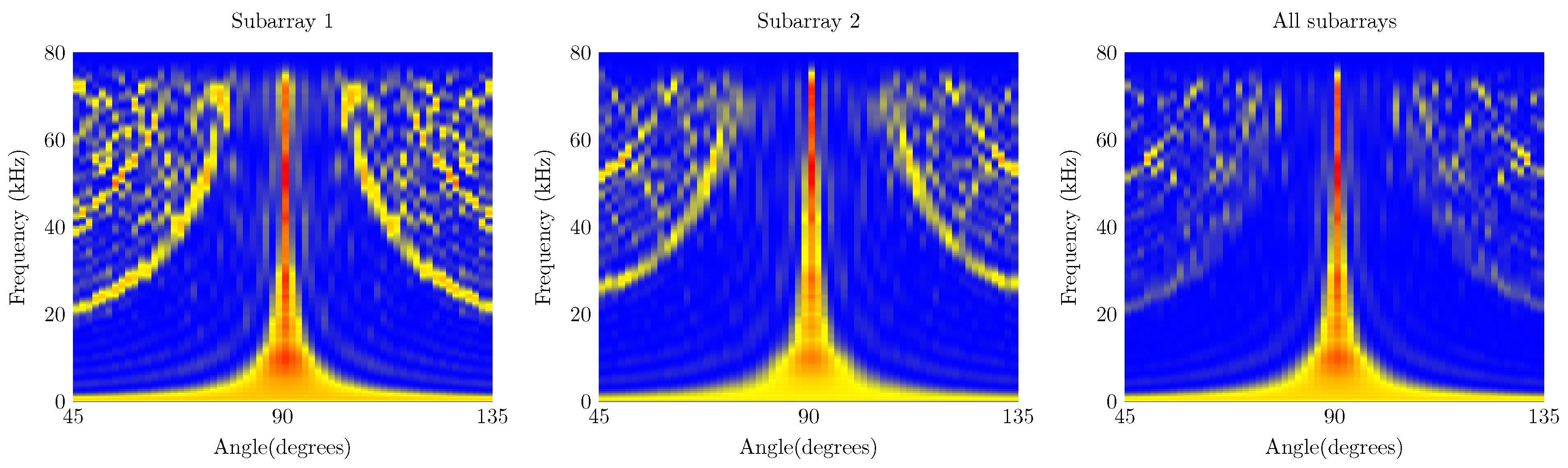
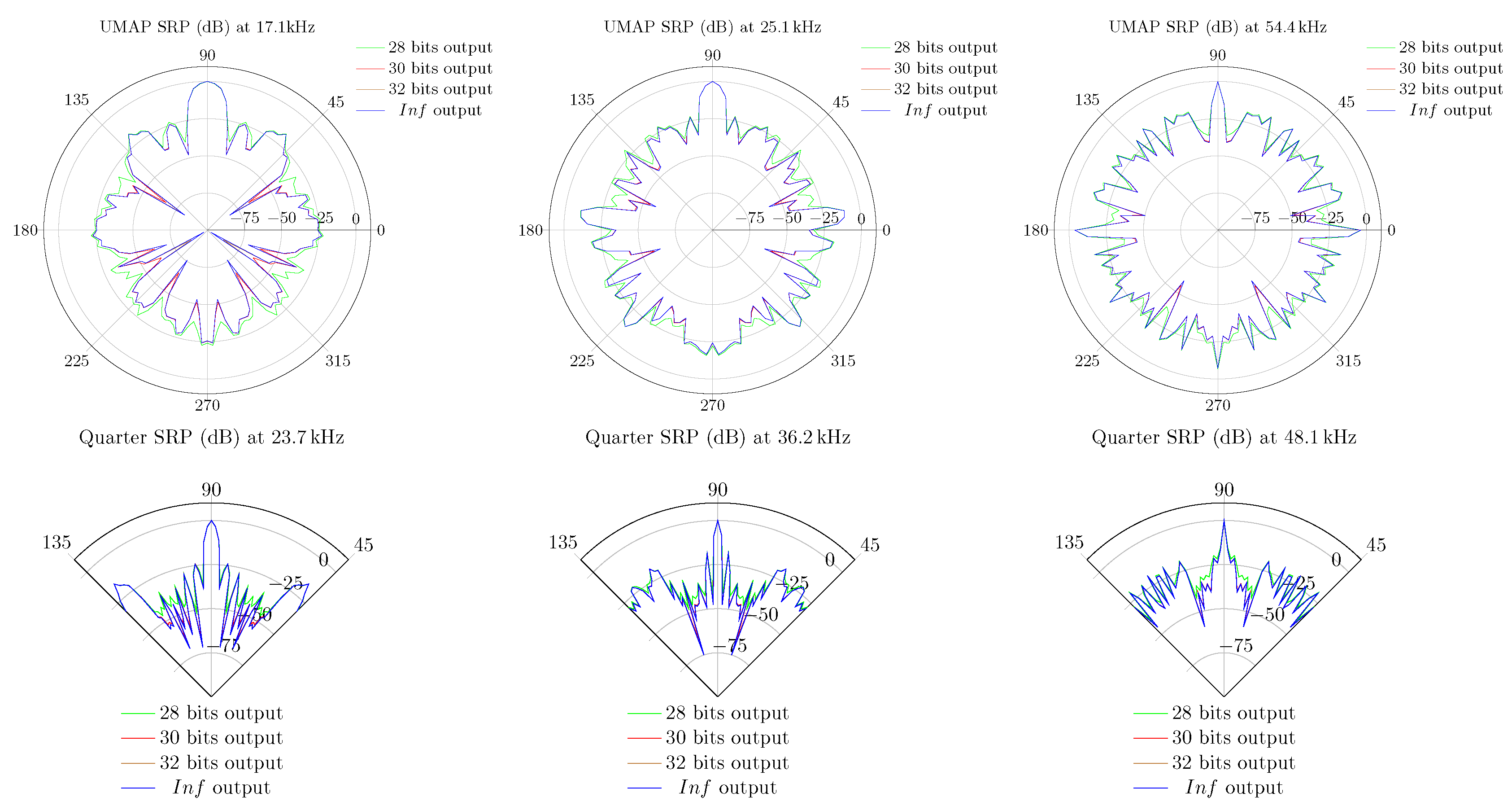
- The first array—the Ultrasonic Multiple Access Positioning (UMAP) array—to be evaluated consists of 12 microphones placed in 2 rings, see diagram in Figure 7. The primary purpose of this array is to evaluate capability of finding an ultrasound source in given AoA. The inner subarray—subarray 1—is composed of 4 microphones located on a radius of 20.32 mm from the center. The outer subarray is composed of the 8 remaining microphones where all microphones are located on a radius of 40.64 mm from the center. Although not provided in the emulation file, the Printed Circuit Board (PCB) provides a hole in the center (Figure 7 Right) so that a speaker or camera can be mounted for additional experiments.
- The second array—the Quarter array—used in the experiments consists of 18 microphones placed in 2 arcs and is shown in Figure 8. This array is designed to help visually impaired people and is mounted on the front head of the person. A transducer mounted on top of the array emits an ultrasound pulse which is reflected by nearby located objects. Measuring acoustic information coming from the back is not desired. Therefore, the array is designed to steer in an aperture angle of a quarter circle, i.e., , in the direction of the convex side. This array consists of 2 subarrays with 9 microphones each. The outer subarray has a radius of 114.3 mm while the inner subarray is arched at 94.3 mm. The shape of the array allows to have a limited number of microphones when covering a limited amount of the steering aperture.
5.1. Frequency Response from a Single Acoustic Emitting Position
- CIC filtering: decimation factor of 15 with a differential delay of 2.
- FIR filter: A compensation filter of 64 taps where the effects of the CIC filter and the microphone characteristics are flattened within a margin of 2 dB in a frequency range between 1 and 65 kHz.
- Halfband filter 2: A filter of order 32 with a cutoff frequency set to 80 kHz.
- A last decimation step which decimates with a factor of 2.
- Optimal (higher) values for the directivity,
- The lowest possible beamwidth,
- The lowest possible (negative) values for and,
- Highest (positive) values for .
5.2. Acoustic Source Emitting from Multiple Positions
5.3. 3D Polar Plot
5.4. Beamforming Using Fixed Point Precision DSP
5.5. Compute-Time of the Emulations
6. Validation of the Emulation Platform
- At first, a clock signal is generated to drive the microphones. The clock the microphones is set at the highest possible clock speed of 4.761 MHz possible (i.e., with a clock divider ratio of 21).
- Secondly, the PDM signals are captured from the microphones. Two microphones share the same PDM multiplexed data line. To retrieve the individual signal from each microphone, this signal is demultiplexed in the FPGA in a ‘left’ and ‘right’ channel by the PDM splitter modules.
- During the last step, the PDM values are stored in a cyclic buffer before being transferred to a computer for later processing. This latter is done via a Universal Asynchronous Receive Transmit (UART) link between the FPGA and a computer.
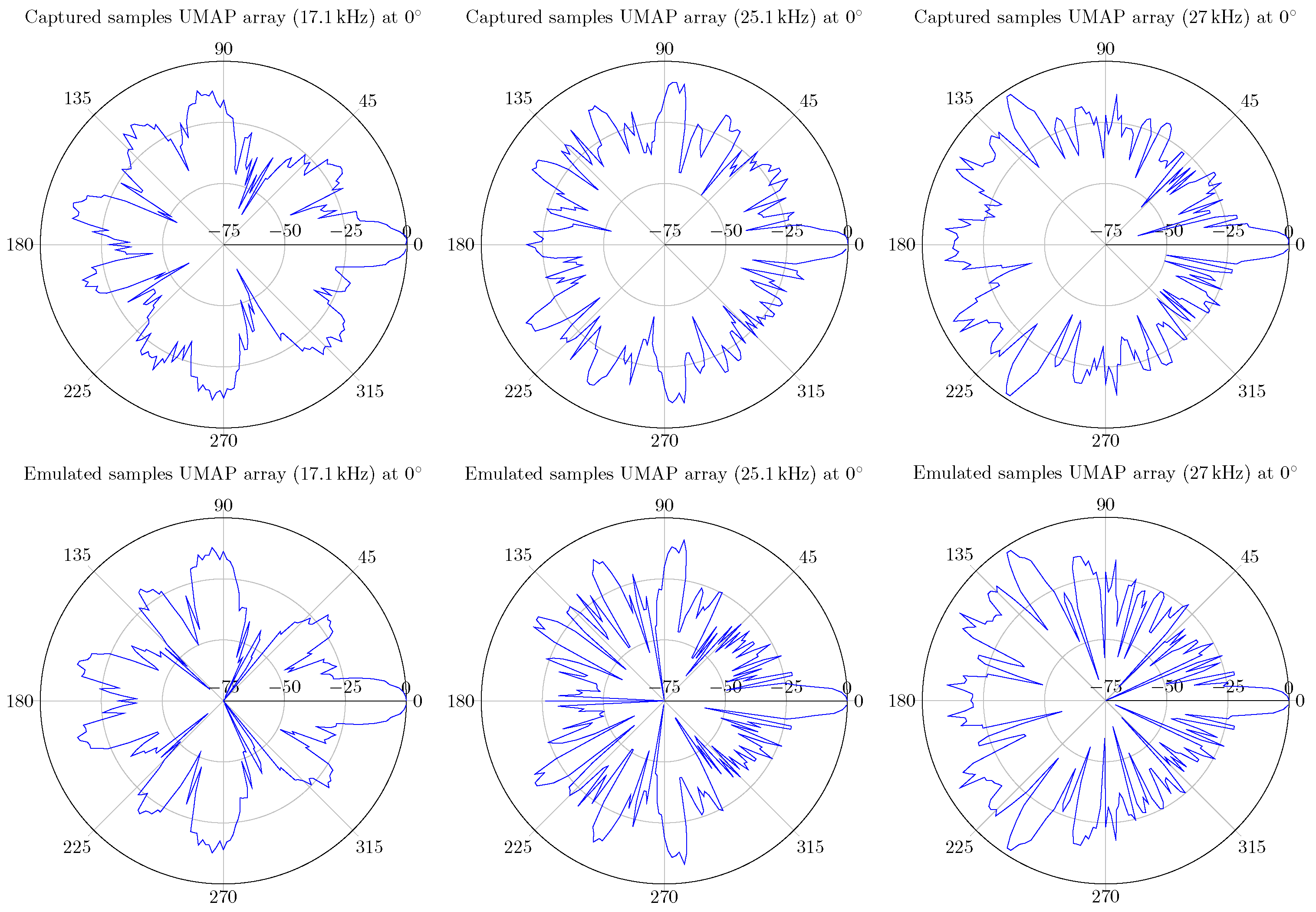
6.1. Validation of the Emulated Microphone Arrays
6.1.1. UMAP Array
6.1.2. Quarter Array
6.2. Compute-Time
6.3. Defining a Microphone Array
- The beamwidth: a thinner beamwidth allows to find a sound source in a smaller angular region. However, a thinner beamwidth also requires more microphones and thus also more processing capabilities.
- The Directivity: A higher directivity allows to predict with a higher probability the AoA of a sound source for a given microphone array.
- The : in order to be able to find a sound source in a given AoA, a negative must be obtained. More microphones and processing capabilities are required to obtain lower and thus more optimal values.
- The : this metric is related to the beamwidth and the . A positive value of the is to be obtained so that a sound source can be found, where a value of 1 is preferred at the expense of more microphones and processing capabilities.
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Segers, L.; Van Bavegem, D.; De Winne, S.; Braeken, A.; Touhafi, A.; Steenhaut, K. An Ultrasonic Multiple-Access Ranging Core Based on Frequency Shift Keying Towards Indoor Localization. Sensors 2015, 15, 18641–18665. [Google Scholar] [CrossRef] [PubMed]
- Segers, L.; Tiete, J.; Braeken, A.; Touhafi, A. Ultrasonic Multiple-Access Ranging System Using Spread Spectrum and MEMS Technology for Indoor Localization. Sensors 2014, 14, 3172–3187. [Google Scholar] [CrossRef] [PubMed]
- Tiete, J.; Dominguez, F.; Silva, B.D.; Segers, L.; Steenhaut, K.; Touhafi, A. SoundCompass: A Distributed MEMS Microphone Array-Based Sensor for Sound Source Localization. Sensors 2014, 14, 1918–1949. [Google Scholar] [CrossRef] [PubMed]
- Steckel, J. Sonar System Combining an Emitter Array With a Sparse Receiver Array for Air-Coupled Applications. IEEE Sens. 2015, 15, 3446–3452. [Google Scholar] [CrossRef]
- Brandstein, M.S.; Silverman, H.F. A practical methodology for speech source localization with microphone arrays. Comput. Speech Lang. 1997, 11, 91–126. [Google Scholar] [CrossRef]
- Hadad, E.; Marquardt, D.; Pu, W.; Gannot, S.; Doclo, S.; Luo, Z.; Merks, L.; Zhang, T. Comparison of two binaural beamforming approaches for hearing aids. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 236–240. [Google Scholar]
- Steckel, J.; Boen, A.; Peremans, H. Broadband 3-D Sonar System Using a Sparse Array for Indoor Navigation. IEEE Trans. Rob. 2013, 29, 161–171. [Google Scholar] [CrossRef]
- da Silva, B.; Segers, L.; Braeken, A.; Steenhaut, K.; Touhafi, A. A Low-Power FPGA-Based Architecture for Microphone Arrays in Wireless Sensor Networks. In Proceedings of the International Symposium on Applied Reconfigurable Computing, Santorini, Greece, 2–4 May 2018. [Google Scholar]
- da Silva, B.; Braeken, A.; Steenhaut, K.; Touhafi, A. Design Considerations When Accelerating an FPGA-Based Digital Microphone Array for Sound-Source Localization. J. Sens. 2017, 2017, 6782176. [Google Scholar] [CrossRef]
- da Silva, B.; Segers, L.; Segers, Y.; Quevy, Q.; Braeken, A.; Touhafi, A. A Multimode SoC FPGA-Based Acoustic Camera for Wireless Sensor Networks. In Proceedings of the 2018 13th International Symposium on Reconfigurable Communication-centric Systems-on-Chip (ReCoSoC), Lille, France, 9–11 July 2018. [Google Scholar]
- MathWorks. Phased Array System Toolbox. Available online: https://nl.mathworks.com/products/phased-array.html (accessed on 5 June 2018).
- Sun, Y.; Chen, J.; Yuen, C.; Rahardja, S. Indoor Sound Source Localization with Probabilistic Neural Network. IEEE Trans. Ind. Electron. 2017, 65, 6403–6413. [Google Scholar] [CrossRef]
- Sheaffer, J.; Fazenda, B.M. WaveCloud: An Open Source Room Acoustics Simulator Using the Finite Difference Time Domain Method. Available online: http://usir.salford.ac.uk/id/eprint/32804/ (accessed on 15 May 2018).
- Jonathan Sheaffer. WaveCloud-M: Acoustics FDTD Simulator for Matlab. Available online: http://www.ee.bgu.ac.il/~sheaffer/wavecloud.html (accessed on 15 May 2018).
- SimScale. Home Page. Available online: https://www.simscale.com/ (accessed on 17 May 2018).
- KUAVA. Waveler Cloud. Available online: http://www.kuava.fi/software-solutions/waveller-audio-and-noise-simulation-system/wavecloud.html (accessed on 17 May 2018).
- Segers, L.; da Silva, B.; Braeken, A.; Touhafi, A. Cloud-Based Acoustic Beamforming Emulator for FPGA-Based Sound Source Localization. In Proceedings of the 4th International Conference on Cloud Computing Technologies and Applications (Cloudtech), Brussels, Belgium, 26–28 November 2018. [Google Scholar]
- Taghizadeh, M.; Garner, P.; Bourlard, H. Microphone Array Beampattern Characterization for Hands-Free Speech Applications. In Proceedings of the IEEE 7th Sensor Array and Multichannel Signal Processing Workshop, Hoboken, NJ, USA, 17–20 June 2012; pp. 465–468. [Google Scholar]
- Tashev, I.; Malvar, H.S. A new beamformer design algorithm for microphone arrays. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Brighton, UK, 12–17 May 2005. [Google Scholar]
- Herbordt, W.; Kellermann, W. Computationally efficient frequency-domain robust generalized sidelobe canceller. In Proceedings of the 2005 International Workshop on Acoustic Echo and Noise Control, Eindhoven, The Netherlands, 12–15 September 2005. [Google Scholar]
- Lepauloux, L.; Scalart, P.; Marro, C. Computationally efficient and robust frequency-domain GSC. In Proceedings of the 12th IEEE International Workshop on Acoustic Echo and Noise Control, Tel-Aviv, Israel, 31 August 2010. [Google Scholar]
- Rombouts, G.; Spriet, A.; Moonen, M. Generalized sidelobe canceller based combined acoustic feedback-and noise cancellation. Signal Process. 2008, 88, 571–581. [Google Scholar] [CrossRef]
- Gao, S.; Huang, Y.; Zhang, T.; Wu, X.; Qu, T. A Modified Frequency Weighted MUSIC Algorithm for Multiple Sound Sources Localization. In Proceedings of the 23rd International Conference on Digital Signal Processing (DSP 2018), Shanghai, China, 19–21 November 2018. [Google Scholar]
- Birnie, L.; Abhayapala, T.D.; Chen, H.; Samarasinghe, P.N. Sound Source Localization in a Reverberant Room Using Harmonic Based Music. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019. [Google Scholar]
- Jo, B.; Choi, J.W. Direction of arrival estimation using nonsingular spherical ESPRIT. J. Acoust. Soc. Am. 2018, 143, EL181–EL187. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Huang, Q.; Zhang, L.; Fang, Y. Direction of Arrival Estimation Using Distributed Circular Microphone Arrays. In Proceedings of the 14th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 12–16 August 2018. [Google Scholar]
- Zohourian, M.; Martin, R. GSC-Based Binaural Speaker Separation Preserving Spatial Cues. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Holm, S. Digital Beamforming in Ultrasound Imaging. Available online: https://www.duo.uio.no/handle/10852/9585 (accessed on 13 March 2019).
- Havránek, Z.; Beneš, P.; Klusáček, S. Free-field calibration of MEMS microphone array used for acoustic holography. In Proceedings of the 21st International Congress on Sound and Vibration, Beijing, China, 13 July 2014. [Google Scholar]
- Sant, L.; Gaggl, R.; Bach, E.; Buffa, C.; Sträussnigg, D.; Wiesbauer, A. MEMS Microphones: Concept and Design for Mobile Applications. In Low-Power Analog Techniques, Sensors for Mobile Devices, and Energy Efficient Amplifiers; Springer: Cham, Switzerland, 2019; pp. 155–174. [Google Scholar]
- Hegde, N. Seamlessly Interfacing MEMs Microphones with Blackfin Processors. EE-350 Engineer-to-Engineer Note. Available online: https://www.analog.com/media/en/technical-documentation/application-notes/EE-350rev1.pdf (accessed on 15 January 2018).
- Loibl, M.; Walser, S.; Klugbauer, J.; Feiertag, G.; Siegel, C. Measurement of digital MEMS microphones. GMA/ITG-Fachtagung Sensoren und Messsysteme 2016. Available online: https://www.ama-science.org/proceedings/details/2362 (accessed on 21 June 2018).
- Knowles. Frequency Response and Latency of MEMS Microphones: Theory and Practice. Available online: https://www.knowles.com/docs/default-source/default-document-library/frequency-response-and-latency-of-mems-microphones—theory-and-practice.pdf?sfvrsn=4 (accessed on 16 January 2018).
- Jarman, D. A Brief Introduction to Sigma Delta Conversion. Available online: https://www.renesas.com/eu/en/www/doc/application-note/an9504.pdf (accessed on 18 January 2018).
- Kester, W. ADC Architectures III: Sigma–Delta ADC Basics. Available online: https://www.analog.com/media/en/training-seminars/tutorials/MT-022.pdf (accessed on 17 January 2018).
- Janssen, E.; van Roermund, A. Basics of Sigma-Delta Modulation. In Look-Ahead Based Sigma-Delta Modulation. Analog Circuits and Signal Processing; Springer: Dordrecht, The Netherlands, 2011; pp. 5–28. [Google Scholar]
- Kelly, M.R.; Amuso, V.J.; Eddins, D.A.; Borkholder, D.A. The focal index as a singular metric for beamforming effectiveness. J. Acous. Soc. Am. 2014, 136, 2654–2664. [Google Scholar] [CrossRef] [PubMed]
- Sun, H.; Yan, S.; Svensson, U.P. Robust minimum sidelobe beamforming for spherical microphone arrays. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 1045–1051. [Google Scholar] [CrossRef]
- Caorsi, S.; Lommi, A.; Massa, A.; Pastorino, M. Peak sidelobe level reduction with a hybrid approach based on GAs and difference sets. IEEE Trans. Antennas Propag. 2004, 52, 1116–1121. [Google Scholar] [CrossRef]
- YAML. YAML Ain’t Markup Language. Available online: https://yaml.org (accessed on 1 October 2018).
- Ammar, A.; Julboub, M.; Elmghairbi, A. Digital Filter Design (FIR) Using Frequency Sampling Method. Available online: http://bulletin.zu.edu.ly/issue_n15_3/Contents/E_04.pdf (accessed on 19 December 2018).
- Knowles. Digital Zero-Height SiSonic Microphone with Multi-Mode and Ultrasonic Support. Available online: https://www.mouser.be/datasheet/2/218/-746191.pdf (accessed on 3 October 2017).
- Analog Devices. Ultralow Noise Microphone withBottom Port and PDM Digital Output. Available online: http://www.analog.com/media/en/technical-documentation/obsolete-data-sheets/ADMP521.pdf (accessed on 8 December 2016).
- Richard Schreier. Delta Sigma Toolbox. Available online: https://nl.mathworks.com/matlabcentral/fileexchange/19-delta-sigma-toolbox (accessed on 9 May 2018).
- Yazkurt, U.; Dundar, G.; Talay, S.; Beilleau, N.; Aboushady, H.; de Lamarre, L. Scaling Input Signal Swings of Overloaded Integrators in Resonator-based Sigma-Delta Modulators. In Proceedings of the 2006 13th IEEE International Conference on Electronics, Circuits and Systems, Nice, France, 10–13 December 2006. [Google Scholar]
- Gonzalez, A. Measurement of areas on a sphere using Fibonacci and latitude–longitude lattices. Math. Geosci. 2010, 42, 49–64. [Google Scholar] [CrossRef]
- da Silva, B.; Braeken, A.; Touhafi, A. FPGA-Based Architectures for Acoustic Beamforming with Microphone Arrays: Trends, Challenges and Research Opportunities. Computers 2018, 7, 41. [Google Scholar] [CrossRef]
- Abdeen, A.; Ray, L. Design and performance of a real-time acoustic beamforming system. In Proceedings of the 2013 IEEE Sensors, Baltimore, MD, USA, 3–6 November 2013. [Google Scholar]
- Netti, A.; Diodati, G.; Camastra, F.; Quaranta, V. FPGA implementation of a real-time filter and sum beamformer for acoustic antenna. In Proceedings of the INTER-NOISE and NOISE-CON Congress and Conference Proceedings, San Francisco, CA, USA, 9–12 August 2015. [Google Scholar]
- Zimmermann, B.; Studer, C. FPGA-based real-time acoustic camera prototype. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010. [Google Scholar]
- Hogenauer, E. An economical class of digital filters for decimation and interpolation. IEEE Trans. Acoust. Speech Signal Process. 1981, 29, 155–162. [Google Scholar] [CrossRef]
- Hafizovic, I.; Nilsen, C.I.C.; Kjolerbakken, M.; Jahr, V. Design and implementation of a MEMS microphone array system for real-time speech acquisition. Appl. Acoust. 2012, 73, 132–143. [Google Scholar] [CrossRef]
- Zwyssig, E.; Lincoln, M.; Renals, S. A digital microphone array for distant speech recognition. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010. [Google Scholar]
- Perrodin, F.; Nikolic, J.; Busset, J.; Siegwart, R. Design and calibration of large microphone arrays for robotic applications. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 4596–4601. [Google Scholar]
- da Silva, B.; Segers, L.; Braeken, A.; Touhafi, A. Design Exploration and Performance Strategies Towards Power-Efficient FPGA-based Architectures for Sound Source Localization. J. Sens. 2019, 2019. [Google Scholar] [CrossRef]
- Xilinx. Zynq-7000 SoC. Available online: https://www.xilinx.com/products/silicon-devices/soc/zynq-7000.html (accessed on 10 July 2018).
- OpenGL. Home Page. Available online: https://www.opengl.org/ (accessed on 13 February 2019).
- Geuzaine, C. GL2PS: An OpenGL to PostScript printing library. Available online: http://geuz.org/gl2ps (accessed on 12 February 2019).
- Carvalho, F.R.; Tiete, J.; Touhafi, A.; Steenhaut, K. ABox: New method for evaluating wireless acoustic-sensor networks. Appl. Acoust. 2014, 79, 81–91. [Google Scholar] [CrossRef]
- Air Ultrasonic Ceramic Transducers. 250ST/R160. Available online: http://www.farnell.com/datasheets/1914801.pdf (accessed on 13 September 2016).
- Make Your Idea Real. Home Page. Available online: http://www.myirtech.com/ (accessed on 12 July 2018).
- Make Your Idea Real. Z-turn Board. Available online: http://www.myirtech.com/list.asp?id=502 (accessed on 12 July 2018).





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Machine Type | Number of Cores | CPU Model | CPU Frequency (GHz) | RAM (GB) |
|---|---|---|---|---|
| Virtual server 1 | 8 (16 hyper threaded) | Intel Xeon®E5530 CPU | 2.4 | 12 |
| Virtual server 2 | 8 | Intel Xeon®Gold 5118 CPU | 2.3 | 16 |
| Virtual server 3 | 8 | Intel Xeon®Gold 5118 CPU | 2.3 | 16 |
| Virtual server 4 | 4 | Intel Xeon®Gold 5118 CPU | 2.3 | 16 |
| Emulation Configuration | Machine | Completion Time (s) |
|---|---|---|
| UMAP subarray 1, aessp | Virtual server 2/3 | 309 |
| UMAP subarray 2, aessp | Virtual server 1 | 602 |
| UMAP all subarrays, aessp | Virtual server 2/3 | 487 |
| Quarter subarray 1, aessp | Virtual server 2/3 | 396 |
| Quarter subarray 2, aessp | Virtual server 1 | 558 |
| Quarter all subarrays, aessp | Virtual server 2/3 | 549 |
| UMAP subarray 1, aesmp | Virtual server 1 | 25,089 |
| UMAP subarray 2, aesmp | Virtual server 4 | 22,241 |
| UMAP all subarrays, aesmp | Virtual server 2/3 | 19,152 |
| Quarter subarray 1, aesmp () | Virtual server 2/3 | 17,803 |
| Quarter subarray 2, aesmp () | Virtual server 4 | 29,659 |
| Quarter all subarrays, aesmp () | Virtual server 2/3 | 24,838 |
| Quarter subarray 1, aesmp () | Virtual server 2/3 | 13,744 |
| Quarter subarray 2, aesmp () | Virtual server 2/3 | 14,103 |
| Quarter all subarrays, aesmp () | Virtual server 1 | 28,638 |
| Emulation Configuration | Completion Time Capturing (s) | Completion Time Simulation (s) |
|---|---|---|
| UMAP 17.1 kHz | 4 (Virtual server 2/3) | 11 (Virtual server 1) |
| UMAP 25.1 kHz | 6 (Virtual server 1) | 8 (Virtual server 2/3) |
| UMAP 27 kHz | 4 (Virtual server 2/3) | 8 (Virtual server 4) |
| Quarter 20 kHz | 4 (Virtual server 2/3) | 15 (Virtual server 1) |
| Quarter 23.7 kHz | 4 (Virtual server 4) | 12 (Virtual server 2/3) |
| Quarter 36.2 kHz | 5 (Virtual server 2/3) | 12 (Virtual server 4) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Segers, L.; Vandendriessche, J.; Vandervelden, T.; Lapauw, B.J.; da Silva, B.; Braeken, A.; Touhafi, A. CABE: A Cloud-Based Acoustic Beamforming Emulator for FPGA-Based Sound Source Localization. Sensors 2019, 19, 3906. https://doi.org/10.3390/s19183906
Segers L, Vandendriessche J, Vandervelden T, Lapauw BJ, da Silva B, Braeken A, Touhafi A. CABE: A Cloud-Based Acoustic Beamforming Emulator for FPGA-Based Sound Source Localization. Sensors. 2019; 19(18):3906. https://doi.org/10.3390/s19183906
Chicago/Turabian StyleSegers, Laurent, Jurgen Vandendriessche, Thibaut Vandervelden, Benjamin Johan Lapauw, Bruno da Silva, An Braeken, and Abdellah Touhafi. 2019. "CABE: A Cloud-Based Acoustic Beamforming Emulator for FPGA-Based Sound Source Localization" Sensors 19, no. 18: 3906. https://doi.org/10.3390/s19183906
APA StyleSegers, L., Vandendriessche, J., Vandervelden, T., Lapauw, B. J., da Silva, B., Braeken, A., & Touhafi, A. (2019). CABE: A Cloud-Based Acoustic Beamforming Emulator for FPGA-Based Sound Source Localization. Sensors, 19(18), 3906. https://doi.org/10.3390/s19183906