Dimensionality Reduction and Subspace Clustering in Mixed Reality for Condition Monitoring of High-Dimensional Production Data †

 , , , ,
, , , ,  , and
, and 
Abstract
1. Introduction
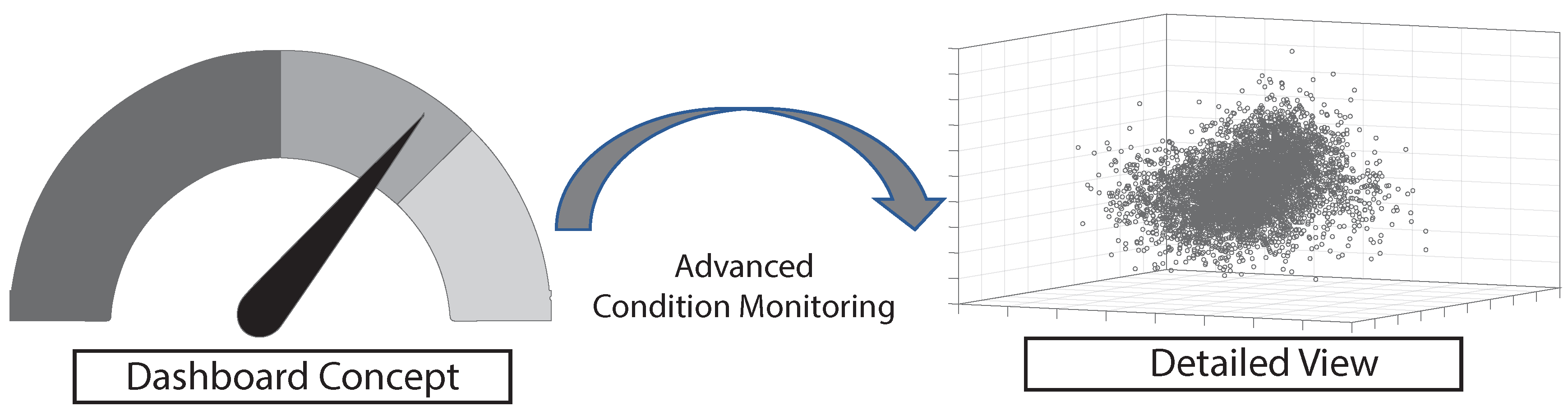
- How can mixed reality be used to allow for quick insights into large datasets?
- How can more than three dimensions be visualized in a comprehensible manner?
- How can recommendations be automatically computed for the purpose to visually analyze industrial production systems more properly?
- Identification of clusters in the reduced dataset.
- Recognition of correlations between variables in the reduced dataset.
- the geometric structure of the objects,
- the configuration of the machine operator,
- measured values from sensors attached to the machine,
- and the quality report of the printed object.
2. Related Work
3. Fundamentals
3.1. Principal Component Analysis
- Subtraction of the average across each dimension
- Calculation of the covariance matrix
- Calculation of the eigenvectors and eigenvalues of the covariance matrix
- Definition of the number of components
- Calculation of the new and reduced dataset
3.2. Subspace Clustering
CLIQUE
4. Prototype
4.1. Dataset
- REQ1: High-dimensional datasets must be displayed in a way that existing clusters can be easily identified.
- REQ2: Data representation must be simplified as the application users are not necessarily data science experts.
- REQ3: A powerful overview feature must be provided to identify the relation between the datasets dimensions.
- REQ4: It must be possible to visualize more than three dimensions as well as to exchange dimensions in the visualization.
- REQ5: To enable REQ4 properly, the computational resources must be explicitly considered and well distributed.
- REQ6: Precise application feedback and easy input possibilities must be provided to accomplish an understandable data analysis workflow.
- REQ7: A recommender system should be provided that supports the decision making while accomplishing the complex process of identifying clusters.
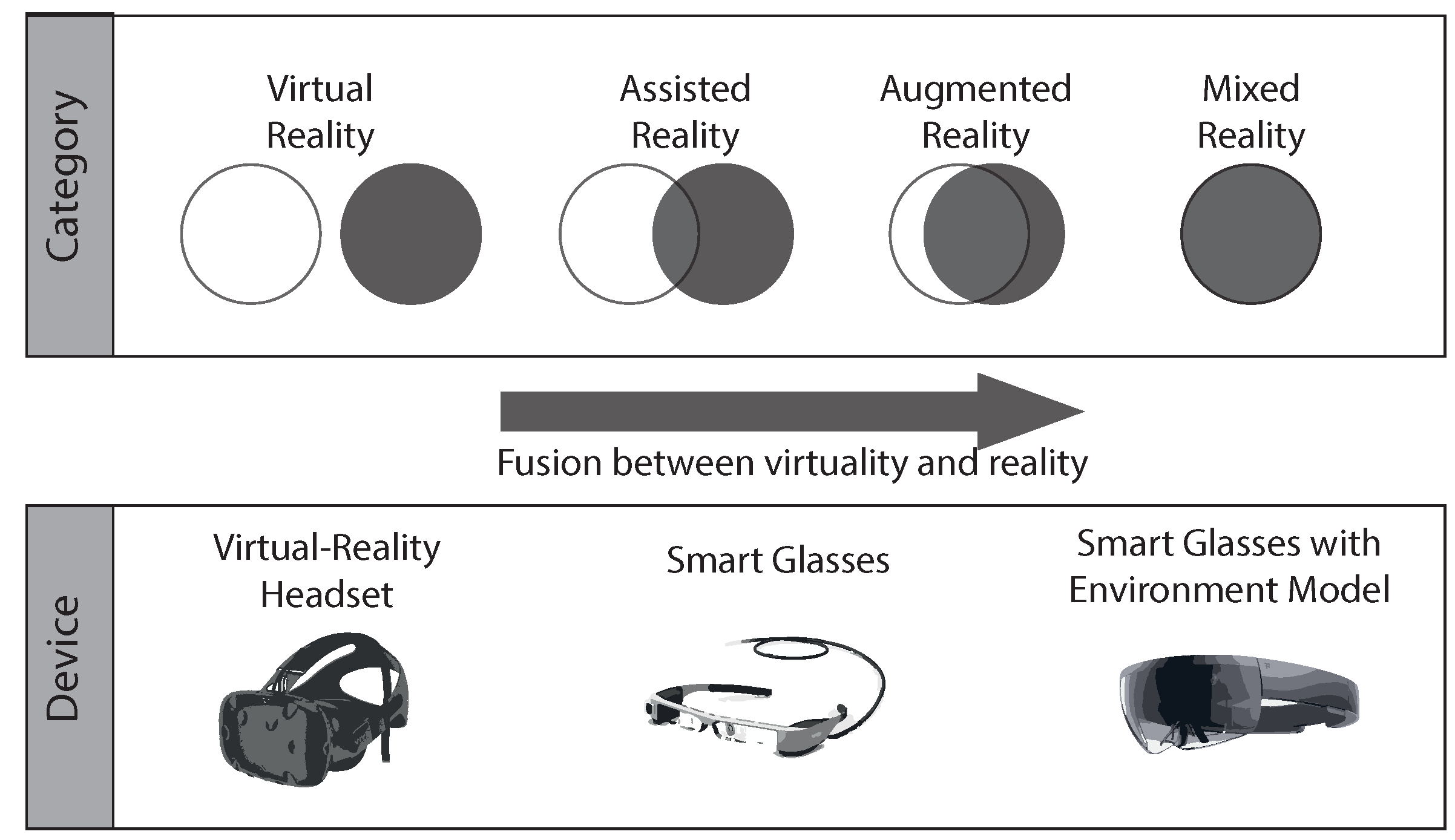
4.2. The HoloLens
4.3. Graphical User Interface
- A negative variance is marked with a red edge.
- A positive variance is displayed with a green edge.
- The strength of a variable connection is visualized based on the opacity of each color, where the covariance intervals [0, 1] and [−1, 0] are mapped to the new opacity value in the range [0, 100%].
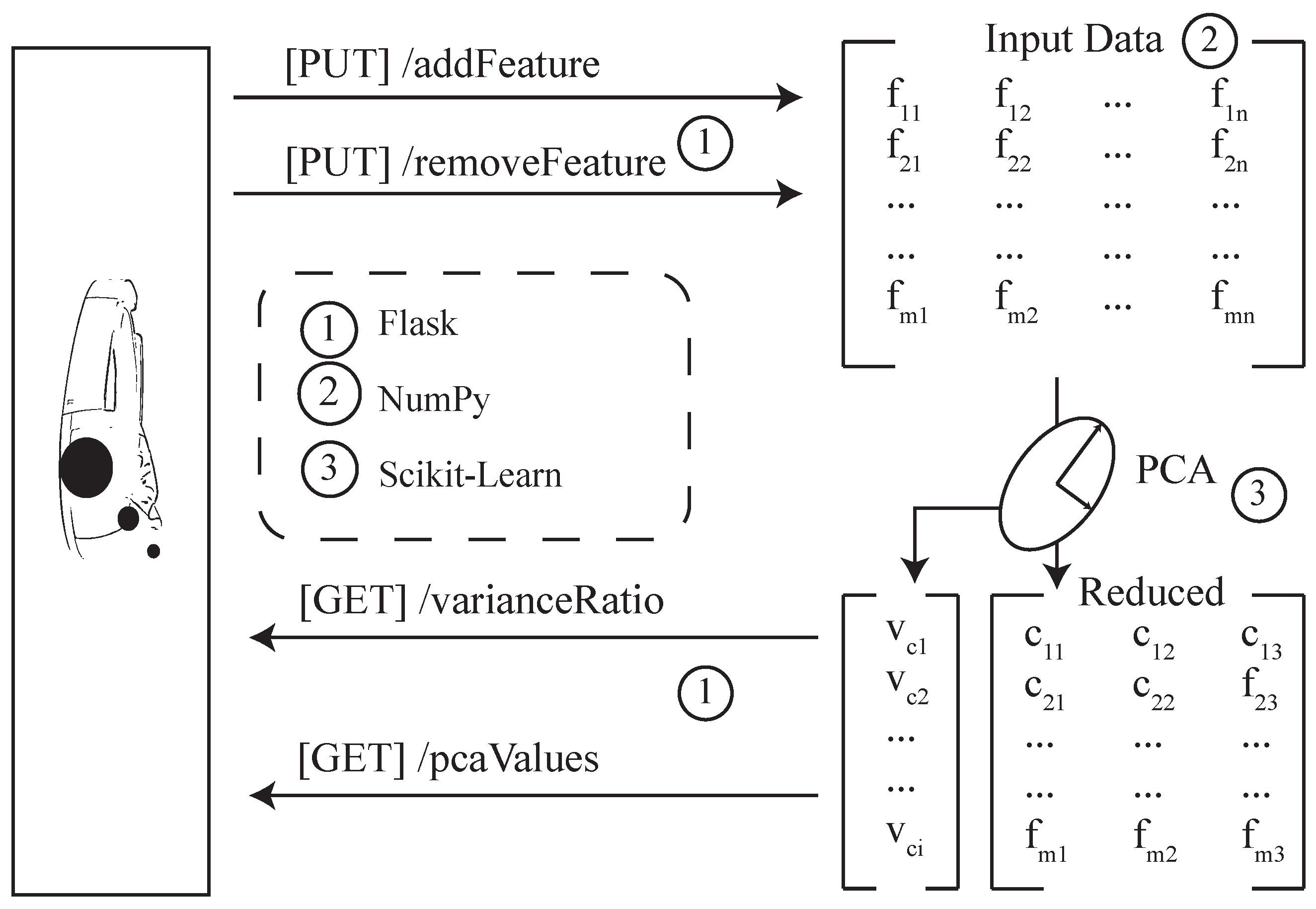
4.4. Backend
4.5. Automated Recommendations
4.5.1. Recommendations for Principal Component Analysis
| Algorithm 1: Recommendation based on information loss. The information Loss is used to remove dimensions from the matrix. |
 |
4.5.2. Recommendations for Subspace Clustering
- What is the largest cluster? This command highlights the clusters that cover the most units and lists all dimensions that are involved.
- How many clusters does {dimension} generate? This command searches the list of clusters and counts occurrences of clusters with respect to the selected dimension.
- What is the densest cluster? This command compares clusters in terms of data points in the cluster and reveals the one with the maximum number of points.
5. Discussion
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Gilchrist, A. Industry 4.0: The Industrial Internet of Things; Apress: New York, NY, USA, 2016. [Google Scholar]
- Hoppenstedt, B.; Pryss, R.; Stelzer, B.; Meyer-Brötz, F.; Kammerer, K.; Treß, A.; Reichert, M. Techniques and Emerging Trends for State of the Art Equipment Maintenance Systems—A Bibliometric Analysis. Appl. Sci. 2018, 8, 916. [Google Scholar] [CrossRef]
- Chandler, T.; Cordeil, M.; Czauderna, T.; Dwyer, T.; Glowacki, J.; Goncu, C.; Klapperstueck, M.; Klein, K.; Marriott, K.; Schreiber, F.; et al. Immersive analytics. In Proceedings of the 2015 Big Data Visual Analytics (BDVA), Hobart, Australia, 22–25 September 2015; pp. 1–8. [Google Scholar]
- Milgram, P.; Takemura, H.; Utsumi, A.; Kishino, F. Augmented reality: A class of displays on the reality-virtuality continuum. In Telemanipulator and Telepresence Technologies; International Society for Optics and Photonics: Boston, MA, USA, 1995; Volume 2351, pp. 282–293. [Google Scholar]
- Izadi, S.; Kim, D.; Hilliges, O.; Molyneaux, D.; Newcombe, R.; Kohli, P.; Shotton, J.; Hodges, S.; Freeman, D.; Davison, A.; et al. KinectFusion: Real-time 3D reconstruction and interaction using a moving depth camera. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011; pp. 559–568. [Google Scholar]
- Hoppenstedt, B.; Schneider, C.; Pryss, R.; Schlee, W.; Probst, T.; Neff, P.; Simoes, J.; Treß, A.; Reichert, M. HOLOVIEW: Exploring Patient Data in Mixed Reality. In Proceedings of the TRI / TINNET Conference 2018, Regensburg, Germany, 14–16 March 2018. [Google Scholar]
- Gibson, I.; Rosen, D.W.; Stucker, B. Additive Manufacturing Technologies; Springer: New York, NY, USA, 2014; Volume 17. [Google Scholar]
- Hoppenstedt, B.; Reichert, M.; Kammerer, K.; Spiliopoulou, M.; Pryss, R. Towards a Hierarchical Approach for Outlier Detection inIndustrial Production Settings. In Proceedings of the EDBT/ICDT 2019 Workshops, Lisbon, Portugal, 26–29 March 2019. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Van Der Maaten, L.; Postma, E.; Van den Herik, J. Dimensionality reduction: A comparative review. J. Mach. Learn. Res. 2009, 10, 66–71. [Google Scholar]
- Parsons, L.; Haque, E.; Liu, H. Subspace clustering for high dimensional data: A review. Acm Sigk. Explor. Newslett. 2004, 6, 90–105. [Google Scholar] [CrossRef]
- Technologies Uganda. Unity Manual. Available online: http://docs.unity3d.com/Manual/index.html (accessed on 18 February 2019).
- Gracia, A.; González, S.; Robles, V.; Menasalvas, E.; Von Landesberger, T. New insights into the suitability of the third dimension for visualizing multivariate/multidimensional data: A study based on loss of quality quantification. Inf. Vis. 2016, 15, 3–30. [Google Scholar] [CrossRef]
- Raja, D.; Bowman, D.; Lucas, J.; North, C. Exploring the benefits of immersion in abstract information visualization. In Proceedings of the Immersive Projection Technology Workshop, Ames, IA, USA, 13–14 May 2004; pp. 61–69. [Google Scholar]
- Arms, L.; Cook, D.; Cruz-Neira, C. The benefits of statistical visualization in an immersive environment. In Proceedings of the IEEE Virtual Reality (Cat. No. 99CB36316), Houston, TX, USA, 13–17 March 1999; pp. 88–95. [Google Scholar]
- Wagner Filho, J.A.; Rey, M.F.; Freitas, C.; Nedel, L. Immersive analytics of dimensionally-reduced data scatterplots. In Proceedings of the 2nd Workshop on Immersive Analytics, Reutlingen, Germany, 18–22 March 2018. [Google Scholar]
- Sedlmair, M.; Munzner, T.; Tory, M. Empirical guidance on scatterplot and dimension reduction technique choices. IEEE Trans. Vis. Comput. Gr. 2013, 19, 2634–2643. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Self, J.Z.; House, L.; North, C. Be the data: A new approach for lmmersive analytics. In Proceedings of the 2016 Workshop on Immersive Analytics (IA), Greenville, SC, USA, 20 March 2016; pp. 32–37. [Google Scholar]
- Bakker, S.; Van Den Hoven, E.; Antle, A.N. MoSo tangibles: Evaluating embodied learning. In Proceedings of the Fifth International Conference on Tangible, embedded, and Embodied Interaction, Funchal, Portugal, 22–26 January 2011; pp. 85–92. [Google Scholar]
- Evans, G.; Miller, J.; Pena, M.I.; MacAllister, A.; Winer, E. Evaluating the Microsoft HoloLens through an augmented reality assembly application. In Degraded Environments: Sensing, Processing, and Display 2017; International Society for Optics and Photonics: Bellingham, WA, USA, 2017; Volume 10197, p. 101970V. [Google Scholar]
- Donalek, C.; Djorgovski, S.G.; Davidoff, S.; Cioc, A.; Wang, A.; Longo, G.; Norris, J.S.; Zhang, J.; Lawler, E.; Yeh, S.; et al. Immersive and collaborative data visualization using virtual reality platforms. In Proceedings of the 2014 IEEE International Conference on Big Data, Washington, DC, USA, 27–30 October 2014; pp. 609–614. [Google Scholar]
- Hoppenstedt, B.; Schmid, M.; Kammerer, K.; Scholta, J.; Reichert, M.; Pryss, R. Analysis of Fuel Cells Utilizing Mixed Reality and IoT Achievements. In Proceedings of the 6th International Conference on Augmented Reality, Virtual Reality and Computer Graphics (SALENTO AVR 2019), Santa Maria al Bagno, Italy, 24–27 June 2019. [Google Scholar]
- Hoppenstedt, B.; Witte, T.; Ruof, J.; Kammerer, K.; Tichy, M.; Reichert, M.; Pryss, R. Debugging Quadrocopter Trajectories in Mixed Reality. In Proceedings of the 6th International Conference on Augmented Reality, Virtual Reality and Computer Graphics (SALENTO AVR 2019), Santa Maria al Bagno, Italy, 24–27 June 2019. [Google Scholar]
- Hoppenstedt, B.; Kammerer, K.; Reichert, M.; Spiliopoulou, M.; Pryss, R. Convolutional Neural Networks for Image Recognition in Mixed Reality Using Voice Command Labeling. In Proceedings of the 6th International Conference on Augmented Reality, Virtual Reality and Computer Graphics (SALENTO AVR 2019), Santa Maria al Bagno, Italy, 24–27 June 2019. [Google Scholar]
- Liu, H.; Yu, L. Toward integrating feature selection algorithms for classification and clustering. IEEE Trans. Knowl. Data Eng. 2005, 17, 491–502. [Google Scholar]
- Dyer, E.L.; Sankaranarayanan, A.C.; Baraniuk, R.G. Greedy feature selection for subspace clustering. J. Mach. Learn. Res. 2013, 14, 2487–2517. [Google Scholar]
- Dash, M.; Liu, H. Feature selection for clustering. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin, Germany, 2000; pp. 110–121. [Google Scholar]
- Kim, Y.; Street, W.N.; Menczer, F. Feature selection in unsupervised learning via evolutionary search. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2000; pp. 365–369. [Google Scholar]
- Yang, J.; Zhang, D.D.; Frangi, A.F.; Yang, J.y. Two-dimensional PCA: A new approach to appearance-based face representation and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 31–137. [Google Scholar]
- Clausen, C.; Wechsler, H. Color image compression using PCA and backpropagation learning. Pattern Recognit. 2000, 33, 1555–1560. [Google Scholar] [CrossRef]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data clustering: A review. ACM Comput. Surv. (CSUR) 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Indyk, P.; Motwani, R. Approximate nearest neighbors: Towards removing the curse of dimensionality. In Proceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, Dallas, TX, USA, 24–26 May 1998; pp. 604–613. [Google Scholar]
- Aggarwal, C.C.; Wolf, J.L.; Yu, P.S.; Procopiuc, C.; Park, J.S. Fast algorithms for projected clustering. In Proceedings of the ACM SIGMoD Record, Philadelphia, PA, USA, 31 May–3 June 1999; Volume 28, pp. 61–72. [Google Scholar]
- Friedman, J.H.; Meulman, J.J. Clustering objects on subsets of attributes (with discussion). J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2004, 66, 815–849. [Google Scholar] [CrossRef]
- Cheng, C.H.; Fu, A.W.; Zhang, Y. Entropy-based subspace clustering for mining numerical data. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 84–93. [Google Scholar]
- Goil, S.; Nagesh, H.; Choudhary, A. MAFIA: Efficient and scalable subspace clustering for very large data sets. In Proceedings of the 5th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 443–452. [Google Scholar]
- Agrawal, R.; Gehrke, J.; Gunopulos, D.; Raghavan, P. Automatic Subspace Clustering of High Dimensional Data for Data Mining Applications; ACM: New York, NY, USA, 1998; Volume 27. [Google Scholar]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference Very Large Data Bases, VLDB, Santiago, Chile, 12–15 September 1994; Volume 1215, pp. 487–499. [Google Scholar]
- Schlee, W.; Pryss, R.C.; Probst, T.; Schobel, J.; Bachmeier, A.; Reichert, M.; Langguth, B. Measuring the moment-to-moment variability of tinnitus: The TrackYourTinnitus smart phone app. Front. Aging Neurosci. 2016, 8, 294. [Google Scholar] [CrossRef] [PubMed]
- Probst, T.; Pryss, R.; Langguth, B.; Schlee, W. Emotional states as mediators between tinnitus loudness and tinnitus distress in daily life: Results from the “TrackYourTinnitus” application. Sci. Rep. 2016, 6, 20382. [Google Scholar] [CrossRef] [PubMed]
- Pryss, R.; Probst, T.; Schlee, W.; Schobel, J.; Langguth, B.; Neff, P.; Spiliopoulou, M.; Reichert, M. Prospective crowdsensing versus retrospective ratings of tinnitus variability and tinnitus–stress associations based on the TrackYourTinnitus mobile platform. Int. J. Data Sci. Anal. 2018, 5, 1–12. [Google Scholar] [CrossRef]
- Lavalle, S. Sensor Fusion: Keeping It Simple. Available online: https://developer.oculus.com/blog/sensor-fusion-keeping-it-simple/ (accessed on 18 February 2019).
- Peña, J.M. Reading dependencies from covariance graphs. Int. J. Approx. Reason. 2013, 54, 216–227. [Google Scholar] [CrossRef]
- Grinberg, M. Flask Web Development: Developing Web Applications with Python; O’Reilly Media, Inc.: Newton, MA, USA, 2018. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Van Der Walt, S.; Colbert, S.C.; Varoquaux, G. The NumPy array: A structure for efficient numerical computation. Comput. Sci. Eng. 2011, 13, 22. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; AAAI Press: Santiago, Chile; pp. 226–231. [Google Scholar]
- Hoppenstedt, B.; Probst, T.; Reichert, M.; Schlee, W.; Kammerer, K.; Spiliopoulou, M.; Schobel, J.; Zimoch, M.; Felnhofer, A.; Kothgassner, O.; et al. Applicability of Immersive Analytics in Mixed Reality: Usability Study. IEEE Access 2019, 7, 71921–71932. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Jobs | 215 |
| Mean of Number of Layers | 411,425 |
| Variance of Number of Layers | 57,828 |
| Data Format | XML |
| Inertial Measurement Unit (IMU) | 1 |
| Environmental Recognition Camera | 4 |
| Depth Sensor | 1 |
| RGB Camera | 2MP*1 |
| Mixed-Reality Capture | 1 |
| Microphone | 4(2*2) |
| Ambient Light Sensor | 1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hoppenstedt, B.; Reichert, M.; Kammerer, K.; Probst, T.; Schlee, W.; Spiliopoulou, M.; Pryss, R. Dimensionality Reduction and Subspace Clustering in Mixed Reality for Condition Monitoring of High-Dimensional Production Data. Sensors 2019, 19, 3903. https://doi.org/10.3390/s19183903
Hoppenstedt B, Reichert M, Kammerer K, Probst T, Schlee W, Spiliopoulou M, Pryss R. Dimensionality Reduction and Subspace Clustering in Mixed Reality for Condition Monitoring of High-Dimensional Production Data. Sensors. 2019; 19(18):3903. https://doi.org/10.3390/s19183903
Chicago/Turabian StyleHoppenstedt, Burkhard, Manfred Reichert, Klaus Kammerer, Thomas Probst, Winfried Schlee, Myra Spiliopoulou, and Rüdiger Pryss. 2019. "Dimensionality Reduction and Subspace Clustering in Mixed Reality for Condition Monitoring of High-Dimensional Production Data" Sensors 19, no. 18: 3903. https://doi.org/10.3390/s19183903
APA StyleHoppenstedt, B., Reichert, M., Kammerer, K., Probst, T., Schlee, W., Spiliopoulou, M., & Pryss, R. (2019). Dimensionality Reduction and Subspace Clustering in Mixed Reality for Condition Monitoring of High-Dimensional Production Data. Sensors, 19(18), 3903. https://doi.org/10.3390/s19183903