Traffic Speed Prediction: An Attention-Based Method


Abstract
1. Introduction
- A novel deep learning framework is proposed for short-term traffic speed prediction.
- Temporal clustering is used to improve dataset partition for enhancing performance.
- Two attention mechanisms are introduced to capture important spatio-temporal information.
- The effectiveness of the proposed model is validated in two real-word traffic datasets.
2. Methodology
2.1. Data Partition
| Algorithm 1: Temporal clustering analysis. |
 |
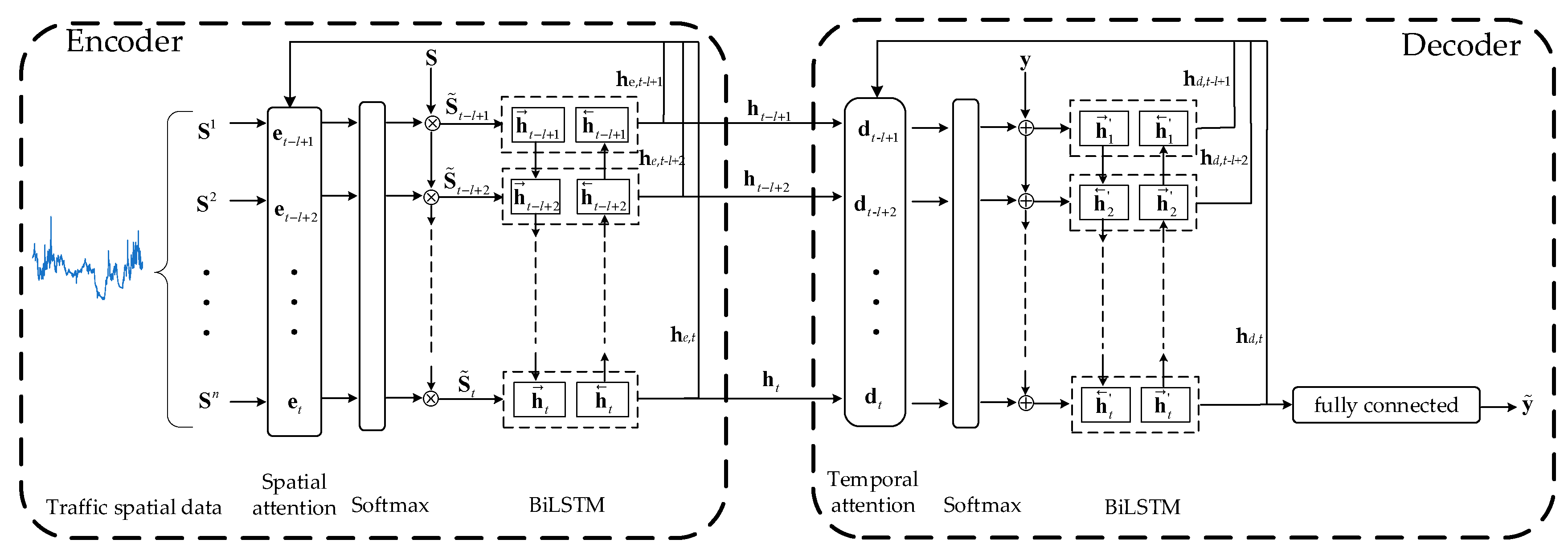
2.2. The Attention Model
2.2.1. The Encoder Module
2.2.2. The Decoder Module
2.3. Model Optimization
3. Results
3.1. Experimental Setup
- Missing data. There are some zero elements in the raw data, which are marked as missing data.
- Outliers. Considering that the speed limits in Hangzhou are usually lower than 80 km/h, we set the maximum traffic speed as 100 km/h, which means that, if a certain record of speed is higher than the threshold, it is marked as an outlier.
- Noisy data. Since it is a real-world traffic speed dataset, dramatic changes should be avoided. Consequently, traffic speeds differing more than 20 km/h between two adjacent time points are considered as noisy data.
- support vector regression (SVR) [43], which uses linear support vector machine for regression tasks, especially time-series prediction;
- stacked autoencoder (SAE) [21], which encodes the inputs into dense or sparse representations by using multi-layer autoencoders;
- long short-term memory (LSTM) [44], which is an extension of recurrent neural networks (RNNs) and has an input gate, a forget gate, and an output gate so as to deal with the long-term dependency and gradient vanishing/explosion problems;
- the gated recurrent unit (GRU) [44], which has an architecture similar to LSTM but only has two gates, a reset gate, and an update gate, which makes GRU have fewer tensor operations than LSTM;
- the hierarchical attention model (HA), which uses spatial and temporal attention mechanisms to capture spatial and temporal features respectively, but TC is not employed to the input data, and it is different from the proposed TCHA.
3.2. Evaluation Criteria
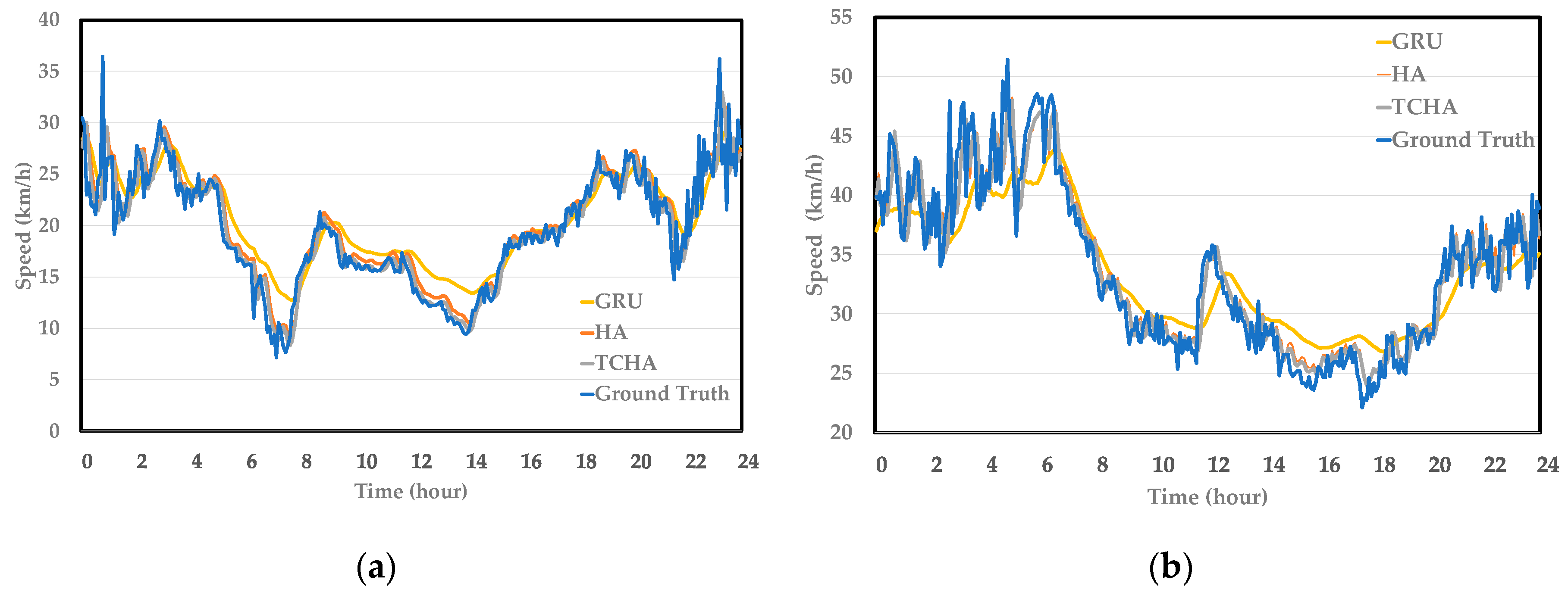
3.3. Experiments Result and Analysis
4. Conclusions
- With the increasement of prediction horizons, the prediction errors become larger.
- Making traffic speed prediction during peak hour is challenging.
- Although GRU can be regarded as a simplification of LSTM, it can reach a higher accuracy in most cases.
Author Contributions
Funding
Conflicts of Interest
References
- Vlahogianni, E.I.; Karlaftis, M.G.; Golias, J.C. Short-term traffic forecasting: Where we are and where we’re going. Transp. Res. Part C Emerg. Technol. 2014, 43, 3–19. [Google Scholar] [CrossRef]
- Liu, D.; Wang, M.; Shen, G. A New Combinatorial Characteristic Parameter for Clustering-Based Traffic Network Partitioning. IEEE Access 2019, 7, 40175–40182. [Google Scholar] [CrossRef]
- Chrobok, R. Theory and Application of Advanced Traffic Forecast Methods; University of Duisburg Physics: Duisburg, Germany, 2005. [Google Scholar]
- Fei, X.; Lu, C.C.; Liu, K. A bayesian dynamic linear model approach for real-time short-term freeway travel time prediction. Transp. Res. Part C Emerg. Technol. 2011, 19, 1306–1318. [Google Scholar] [CrossRef]
- Oh, S.; Byon, Y.J.; Jang, K.; Yeo, H. Short-term travel-time prediction on highway: A review on model-based approach. KSCE J. Civ. Eng. 2018, 22, 298–310. [Google Scholar] [CrossRef]
- Williams, B.M.; Hoel, L.A. Modeling and Forecasting Vehicular Traffic Flow as a Seasonal ARIMA Process: Theoretical Basis and Empirical Results. J. Transp. Eng. 2003, 129, 664–672. [Google Scholar] [CrossRef]
- Tran, Q.T.; Ma, Z.; Li, H.; Hao, L.; Trinh, Q.K. A Multiplicative Seasonal ARIMA/GARCH Model in EVN Traffic Prediction. Int. J. Commun. Netw. Syst. Sci. 2015, 8, 43–49. [Google Scholar] [CrossRef]
- Chandra, S.R.; Al-Deek, H. Predictions of freeway traffic speeds and volumes using vector autoregressive models. J. Intell. Transp. Syst. 2009, 13, 53–72. [Google Scholar] [CrossRef]
- Karlaftis, M.G.; Vlahogianni, E.I. Statistical methods versus neural networks in transportation research: Differences, similarities and some insights. Transp. Res. Part C Emerg. Technol. 2011, 19, 387–399. [Google Scholar] [CrossRef]
- Chen, H.; Rakha, H.A.; Sadek, S. Real-time freeway traffic state prediction: A particle filter approach. In Proceedings of the 14th International IEEE Conference on Intelligent Transportation Systems (ITSC), Washington, DC, USA, 5–7 October 2011; pp. 626–631. [Google Scholar]
- Nair, A.S.; Liu, J.-C.; Rilett, L.; Gupta, S. Non-linear analysis of traffic flow. In Proceedings of the IEEE Intelligent Transportation Systems, Oakland, CA, USA, 25–29 August 2001; Volume 68, pp. 681–685. [Google Scholar]
- Van Hinsbergen, C.P.I.J.; Schreiter, T.; Zuurbier, F.S.; Van Lint, J.W.C.; Van Zuylen, H.J. Localized extended kalman filter for scalable real-time traffic state estimation. IEEE Trans. Intell. Transp. Syst. 2012, 13, 385–394. [Google Scholar] [CrossRef]
- Qi, Y.; Ishak, S. A Hidden Markov Model for short term prediction of traffic conditions on freeways. Transp. Res. Part C Emerg. Technol. 2014, 43, 95–111. [Google Scholar] [CrossRef]
- Wang, J.; Deng, W.; Guo, Y. New Bayesian combination method for short-term traffic flow forecasting. Transp. Res. Part C Emerg. Technol. 2014, 43, 79–94. [Google Scholar] [CrossRef]
- Davis, B.G.A.; Nihan, N.L. Nonparametric regression and short-term freeway traffic forecasting. J. Transp. Eng. 1991, 117, 178–188. [Google Scholar] [CrossRef]
- Oh, S.; Byon, Y.J.; Yeo, H. Improvement of Search Strategy with K-Nearest Neighbors Approach for Traffic State Prediction. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1146–1156. [Google Scholar] [CrossRef]
- Smola, A.J.; Olkopf, B.S.C.H. A tutorial on support vector regression. Stat. Comput 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y. Traffic forecasting using least squares support vector machines. Transportmetrica 2009, 5, 193–213. [Google Scholar] [CrossRef]
- Asif, M.T.; Dauwels, J.; Goh, C.Y.; Oran, A.; Fathi, E.; Xu, M.; Dhanya, M.M.; Mitrovic, N.; Jaillet, P. Spatiotemporal patterns in large-scale traffic speed prediction. IEEE Trans. Intell. Transp. Syst. 2014, 15, 794–804. [Google Scholar] [CrossRef]
- Luo, X.; Li, D.; Zhang, S. Traffic Flow Prediction during the Holidays Based on DFT and SVR. J. Sens. 2019, 2019, 1–10. [Google Scholar] [CrossRef]
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F.Y. Traffic Flow Prediction With Big Data: A Deep Learning Approach. IEEE Trans. Intell. Transp. Syst. 2014, 16, 865–873. [Google Scholar] [CrossRef]
- Ma, X.; Tao, Z.; Wang, Y.; Yu, H.; Wang, Y. Long short-term memory neural network for traffic speed prediction using remote microwave sensor data. Transp. Res. Part C Emerg. Technol. 2015, 54, 187–197. [Google Scholar] [CrossRef]
- Du, S.; Li, T.; Gong, X.; Yu, Z.; Horng, S.-J. A Hybrid Method for Traffic Flow Forecasting Using Multimodal Deep Learning. arXiv 2018, arXiv:1803.02099. [Google Scholar]
- Zhang, S.; Yao, Y.; Hu, J.; Zhao, Y.; Li, S.; Hu, J. Deep autoencoder neural networks for short-term traffic congestion prediction of transportation networks. Sensors 2019, 19, 2229. [Google Scholar] [CrossRef]
- Ran, X.; Shan, Z.; Fang, Y.; Lin, C. A Convolution Component-Based Method with Attention Mechanism for Travel-Time Prediction. Sensors (Basel) 2019, 19, 2063. [Google Scholar] [CrossRef]
- Zeng, X.; Zhang, Y. Development of recurrent neural network considering temporal-spatial input dynamics for freeway travel time modeling. Comput. Civ. Infrastruct. Eng. 2013, 28, 359–371. [Google Scholar] [CrossRef]
- Li, L.; Qin, L.; Qu, X.; Zhang, J.; Wang, Y.; Ran, B. Knowledge-Based Systems Day-ahead traffic flow forecasting based on a deep belief network optimized by the multi-objective particle swarm algorithm. Knowl.-Based Syst. 2019, 172, 1–14. [Google Scholar] [CrossRef]
- Gu, Y.; Lu, W.; Qin, L.; Li, M.; Shao, Z. Short-term prediction of lane-level traffic speeds: A fusion deep learning model. Transp. Res. Part C 2019, 106, 1–16. [Google Scholar] [CrossRef]
- Yu, H.; Wu, Z.; Wang, S.; Wang, Y.; Ma, X. Spatiotemporal recurrent convolutional networks for traffic prediction in transportation networks. Sensors (Switzerland) 2017, 17, 1501. [Google Scholar] [CrossRef]
- Bhaduri, S. Learning phrase representations using RNN encoder-decoder for statistical machine translation. J. Clin. Microbiol. 1990, 28, 828–829. [Google Scholar]
- Zanella, S.; Neviani, A.; Zanoni, E.; Miliozzi, P.; Charbon, E.; Guardiani, C.; Carloni, L.; Sangiovanni-Vincentelli, A. Recurrent models of visual attention. In Proceedings of the Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Luong, M.-T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Qin, Y.; Song, D.; Cheng, H.; Cheng, W.; Jiang, G.; Cottrell, G.W. A dual-stage attention-based recurrent neural network for time series prediction. arXiv 2017, arXiv:1704.02971. [Google Scholar]
- Wu, Y.; Tan, H.; Qin, L.; Ran, B.; Jiang, Z. A hybrid deep learning based traffic flow prediction method and its understanding. Transp. Res. Part C Emerg. Technol. 2018, 90, 166–180. [Google Scholar] [CrossRef]
- Liao, B.; Tang, S.; Yang, S.; Zhu, W.; Wu, F. Multi-Modal Sequence to Sequence Learning with Content Attention for Hotspot Traffic Speed Prediction; Springer International Publishing: Berlin, Germany, 2012; Volume 7674, ISBN 978-3-642-34777-1. [Google Scholar]
- Shen, G.; Chen, C.; Pan, Q.; Shen, S.; Liu, Z. Research on Traffic Speed Prediction by Temporal Clustering Analysis and Convolutional Neural Network with Deformable Kernels. IEEE Access 2018, 6, 51756–51765. [Google Scholar] [CrossRef]
- Xu, J.; Deng, D.; Demiryurek, U.; Shahabi, C.; Van Der Schaar, M. Mining the Situation: Spatiotemporal Traffic. J. Sel. Top. Signal Process. 2015, 9, 702–715. [Google Scholar] [CrossRef]
- Lin, L.I. A Concordance Correlation Coefficient to Evaluate Reproducibility. Biomatrics 1989, 45, 255–268. [Google Scholar] [CrossRef]
- Min, W.; Wynter, L. Real-time road traffic prediction with spatio-temporal correlations. Transp. Res. Part C Emerg. Technol. 2011, 19, 606–616. [Google Scholar] [CrossRef]
- Habtemichael, F.G.; Cetin, M. Short-term traffic flow rate forecasting based on identifying similar traffic patterns. Transp. Res. Part C Emerg. Technol. 2016, 66, 61–78. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional Recurrent Neural Networks. IEEE Trans. Signal Process. 1997, 45, 6757. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, J.; Shi, Q. Short-term traffic speed forecasting hybrid model based on Chaos-Wavelet Analysis-Support Vector Machine theory. Transp. Res. Part C Emerg. Technol. 2013, 27, 219–232. [Google Scholar] [CrossRef]
- Fu, R.; Zhang, Z.; Li, L. Using LSTM and GRU neural network methods for traffic flow prediction. In Proceedings of the 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC), Wuhan, China, 11–13 November 2016; pp. 324–328. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Error Index | Horizon 1 | Horizon 2 | Horizon 3 | Horizon 4 | Horizon 5 |
|---|---|---|---|---|---|---|
| SVR | MAE | 3.1410 | 3.2829 | 3.4212 | 3.5746 | 3.7013 |
| RMSE | 4.4425 | 4.5538 | 4.6558 | 4.7810 | 4.8937 | |
| MRE | 0.1670 | 0.1750 | 0.1830 | 0.1925 | 0.2004 | |
| SAE | MAE | 2.2477 | 2.8831 | 3.0239 | 3.1550 | 3.2762 |
| RMSE | 3.0273 | 3.6742 | 3.8646 | 4.0222 | 4.1691 | |
| MRE | 0.1226 | 0.1627 | 0.1695 | 0.1761 | 0.1823 | |
| LSTM | MAE | 2.4501 | 2.7280 | 2.8957 | 3.0512 | 3.1998 |
| RMSE | 3.2971 | 3.5613 | 3.7749 | 3.9642 | 4.1405 | |
| MRE | 0.1283 | 0.1464 | 0.1553 | 0.1635 | 0.1715 | |
| GRU | MAE | 2.1859 | 2.5738 | 2.7458 | 2.9019 | 3.0501 |
| RMSE | 2.9850 | 3.4393 | 3.6518 | 3.8358 | 4.0064 | |
| MRE | 0.1166 | 0.1378 | 0.1464 | 0.1544 | 0.1621 | |
| HA | MAE | 1.6259 | 2.0841 | 2.3489 | 2.5223 | 2.7112 |
| RMSE | 2.3756 | 3.0004 | 3.2993 | 3.5420 | 3.7166 | |
| MRE | 0.0768 | 0.1029 | 0.1163 | 0.1259 | 0.1374 | |
| TCHA | MAE | 1.5051 | 2.0017 | 2.1689 | 2.3892 | 2.7127 |
| RMSE | 2.3040 | 2.8217 | 3.1351 | 3.4294 | 3.7481 | |
| MRE | 0.0681 | 0.0984 | 0.1063 | 0.1182 | 0.1366 |
| Algorithm | Error Index | Horizon 1 | Horizon 2 | Horizon 3 | Horizon 4 | Horizon 5 |
|---|---|---|---|---|---|---|
| SVR | MAE | 4.9455 | 5.0361 | 5.1511 | 5.2186 | 5.2512 |
| RMSE | 6.4193 | 6.4726 | 6.5692 | 6.6283 | 6.6590 | |
| MRE | 0.1496 | 0.1525 | 0.1558 | 0.1577 | 0.1586 | |
| SAE | MAE | 3.5900 | 3.6890 | 3.8020 | 4.7404 | 4.9129 |
| RMSE | 4.2695 | 4.4256 | 4.5911 | 6.0130 | 6.2097 | |
| MRE | 0.1163 | 0.1191 | 0.1223 | 0.1428 | 0.1482 | |
| LSTM | MAE | 3.1010 | 3.2402 | 3.6749 | 3.7564 | 4.0615 |
| RMSE | 4.0861 | 4.2574 | 4.6404 | 4.7457 | 5.0561 | |
| MRE | 0.0935 | 0.0977 | 0.1143 | 0.1167 | 0.1280 | |
| GRU | MAE | 2.8053 | 2.9635 | 3.2987 | 3.5628 | 3.6247 |
| RMSE | 3.8097 | 4.0104 | 4.2109 | 4.4912 | 4.6136 | |
| MRE | 0.0826 | 0.0872 | 0.1022 | 0.1112 | 0.1221 | |
| HA | MAE | 1.8842 | 2.7023 | 2.9582 | 3.1797 | 3.3378 |
| RMSE | 2.5605 | 3.6264 | 3.9319 | 4.1614 | 4.3393 | |
| MRE | 0.0554 | 0.0806 | 0.0887 | 0.0960 | 0.1012 | |
| TCHA | MAE | 1.7686 | 2.4112 | 2.7111 | 2.9115 | 3.0833 |
| RMSE | 2.4271 | 3.3031 | 3.6741 | 3.9253 | 4.1050 | |
| MRE | 0.0518 | 0.0706 | 0.0802 | 0.0865 | 0.0916 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, D.; Tang, L.; Shen, G.; Han, X. Traffic Speed Prediction: An Attention-Based Method. Sensors 2019, 19, 3836. https://doi.org/10.3390/s19183836
Liu D, Tang L, Shen G, Han X. Traffic Speed Prediction: An Attention-Based Method. Sensors. 2019; 19(18):3836. https://doi.org/10.3390/s19183836
Chicago/Turabian StyleLiu, Duanyang, Longfeng Tang, Guojiang Shen, and Xiao Han. 2019. "Traffic Speed Prediction: An Attention-Based Method" Sensors 19, no. 18: 3836. https://doi.org/10.3390/s19183836
APA StyleLiu, D., Tang, L., Shen, G., & Han, X. (2019). Traffic Speed Prediction: An Attention-Based Method. Sensors, 19(18), 3836. https://doi.org/10.3390/s19183836