Dynamic Residual Dense Network for Image Denoising


Abstract
1. Introduction
2. Related Work
2.1. Denoising
2.2. Datasets
3. Methodology
3.1. Architecture of DRDN
3.2. Dynamic Residual Dense Block
3.3. Training Algorithm
| Algorithm 1 REINFORCE |
|
4. Experiments
4.1. Setting
4.2. Local Performance Evaluation
4.3. Evaluation on the Real-world Noise Dataset
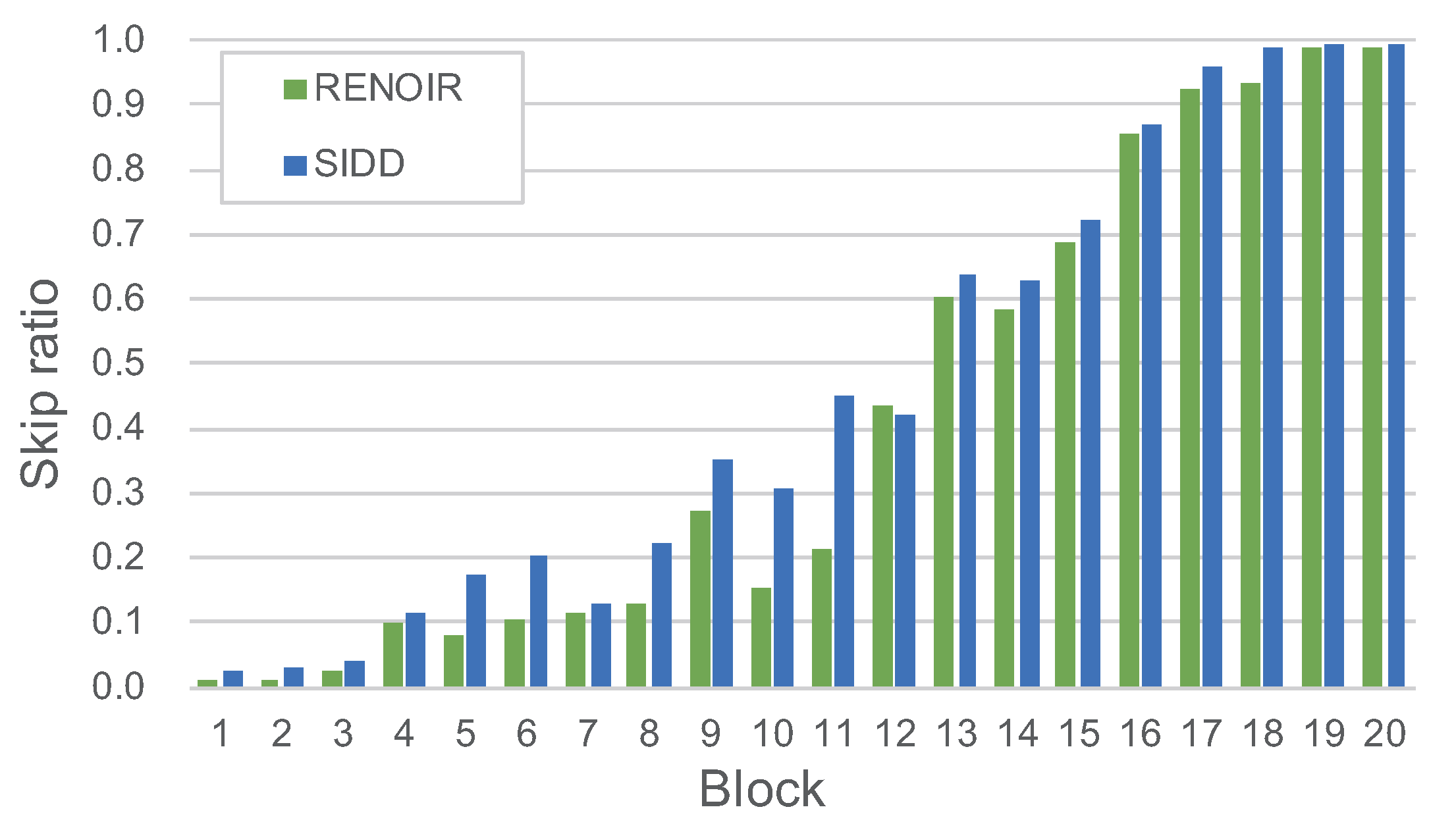
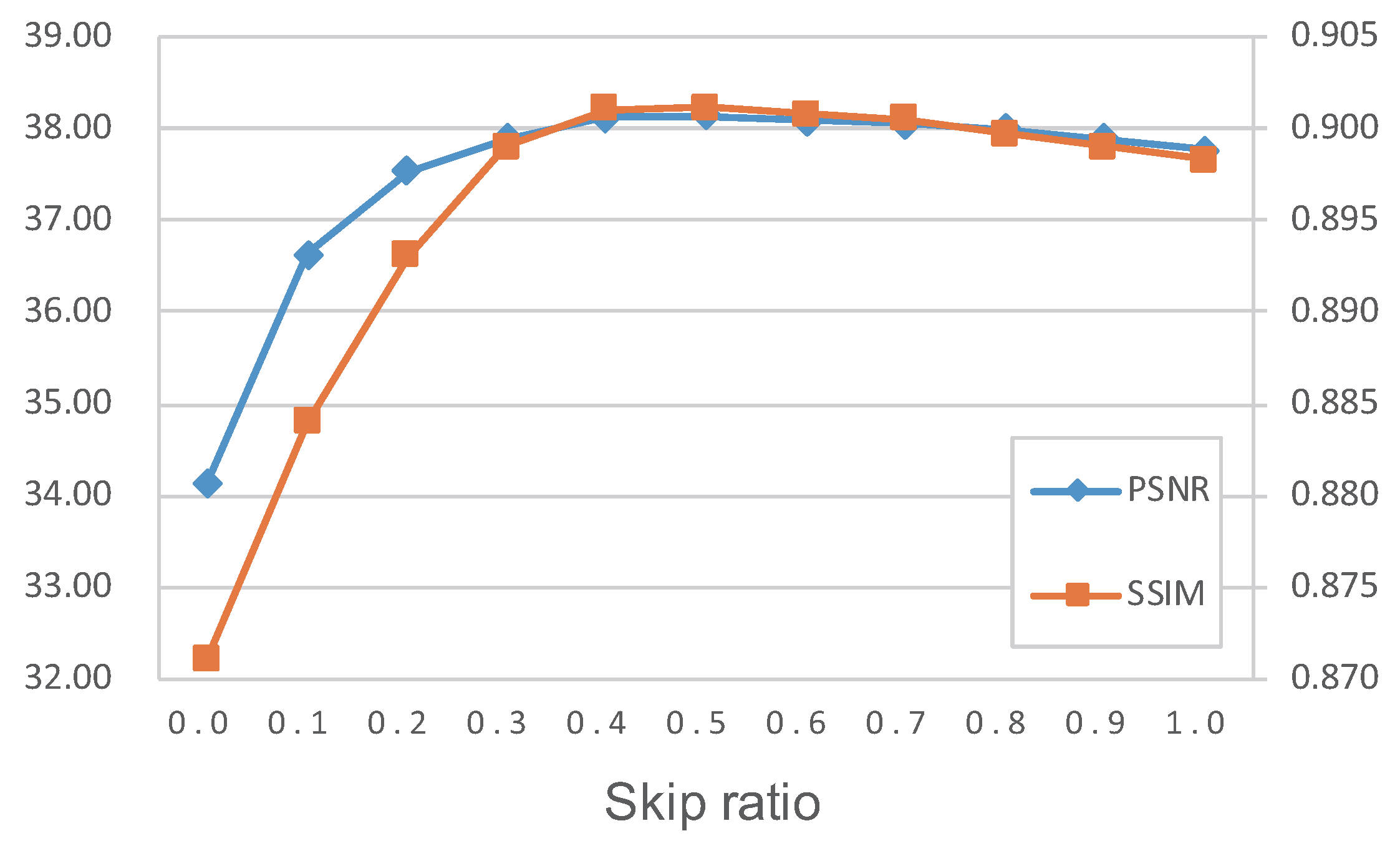
4.4. Evaluation of the Threshold
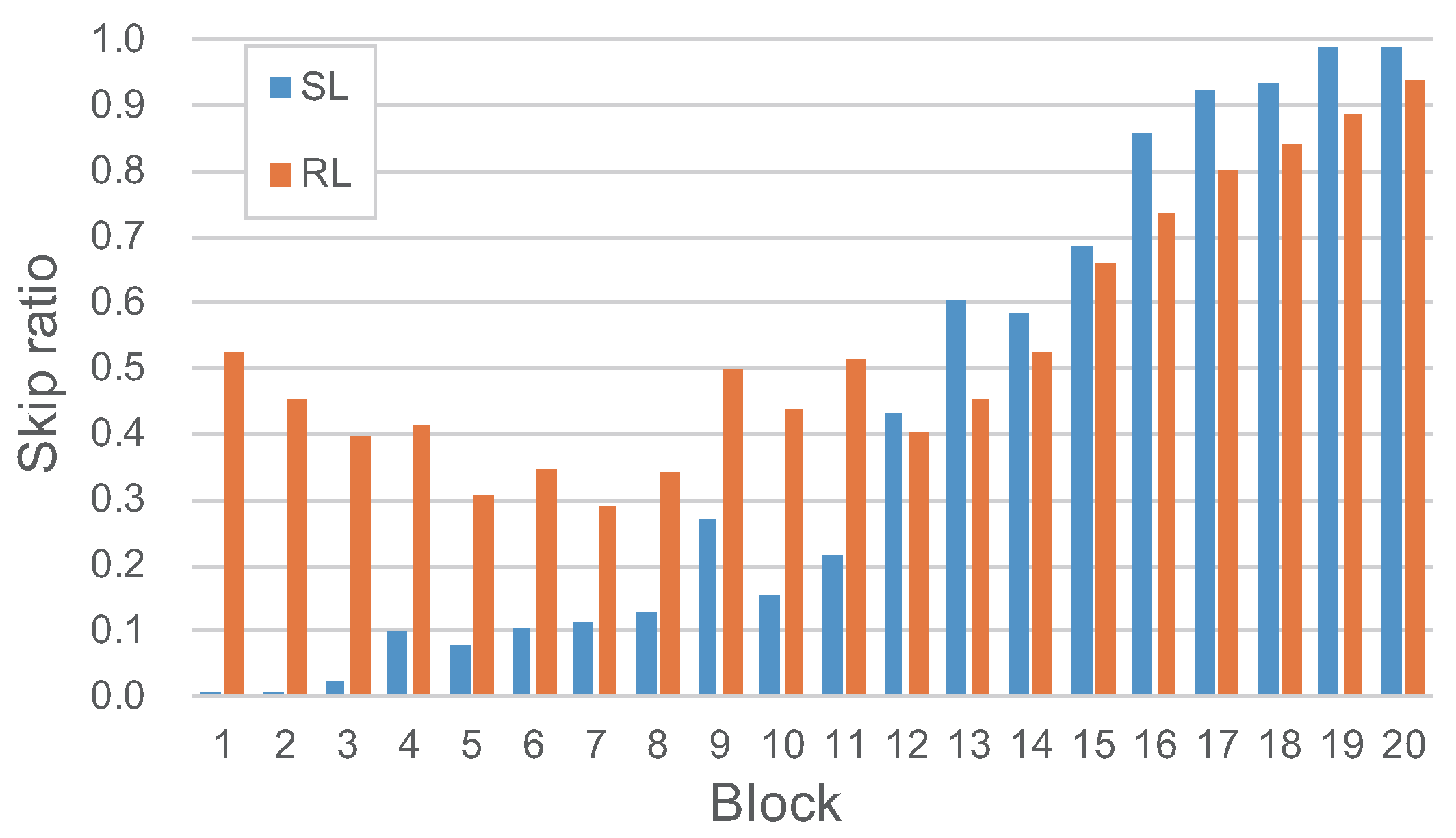
4.5. Results of Reinforcement Learning
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference On Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 8 September 2018; pp. 2472–2481. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 September 2018; pp. 1664–1673. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image super-resolution using dense skip connections. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4799–4807. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 630–645. [Google Scholar]
- Veit, A.; Wilber, M.J.; Belongie, S. Residual networks behave like ensembles of relatively shallow networks. In Advances in Neural Information Processing Systems, Proceedings of the 30th Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; Curran Associates, Inc.: Red Hook, NY, USA; pp. 550–558.
- Yu, X.; Yu, Z.; Ramalingam, S. ResNet Sparsifier: Learning Strict Identity Mappings in Deep Residual Networks. arXiv 2018, arXiv:1804.01661. [Google Scholar]
- Lee, C.Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-supervised nets. arXiv 2014, arXiv:1409.5185. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Proceedings of the International Workshop on Deep Learning in Medical Image Analysis and International Workshop on Multimodal Learning for Clinical Decision Support, Granada, Spain, 16–20 September 2018; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Wang, X.; Yu, F.; Dou, Z.Y.; Darrell, T.; Gonzalez, J.E. Skipnet: Learning dynamic routing in convolutional networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 409–424. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image restoration by sparse 3D transform-domain collaborative filtering. In Proceedings of the Algorithms and Systems VI. International Society for Optics and Photonics, San Jose, CA, USA, 1 March 2008; Volume 6812, p. 681207. [Google Scholar]
- Zoran, D.; Weiss, Y. From learning models of natural image patches to whole image restoration. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 479–486. [Google Scholar]
- Gu, S.; Zhang, L.; Zuo, W.; Feng, X. Weighted nuclear norm minimization with application to image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 2862–2869. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Lefkimmiatis, S. Non-local color image denoising with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 3587–3596. [Google Scholar]
- Lefkimmiatis, S. Universal denoising networks: a novel CNN architecture for image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 3204–3213. [Google Scholar]
- Plötz, T.; Roth, S. Neural nearest neighbors networks. arXiv 2018, arXiv:1810.12575. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4539–4547. [Google Scholar]
- Liu, P.; Zhang, H.; Zhang, K.; Lin, L.; Zuo, W. Multi-level wavelet-CNN for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 19–21 June 2018; pp. 773–782. [Google Scholar]
- Guo, S.; Yan, Z.; Zhang, K.; Zuo, W.; Zhang, L. Toward convolutional blind denoising of real photographs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1712–1722. [Google Scholar]
- Chen, C.; Xiong, Z.; Tian, X.; Zha, Z.J.; Wu, F. Real-world Image Denoising with Deep Boosting. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 99, 1. [Google Scholar] [CrossRef] [PubMed]
- Priyanka, S.A.; Wang, Y.K. Fully Symmetric Convolutional Network for Effective Image Denoising. Appl. Sci. 2019, 9, 778. [Google Scholar]
- Roth, S.; Black, M.J. Fields of experts. Int. J. Comput. Vis. 2009, 82, 205. [Google Scholar] [CrossRef]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A Database of Human Segmented Natural Images and Its Application to Evaluating Segmentation Algorithms and Measuring Ecological Statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; pp. 416–423. [Google Scholar]
- Chen, Y.; Pock, T. Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1256–1272. [Google Scholar] [CrossRef] [PubMed]
- Anaya, J.; Barbu, A. RENOIR–A dataset for real low-light image noise reduction. J. Vis. Commun. Image Represent. 2018, 51, 144–154. [Google Scholar] [CrossRef]
- Abdelhamed, A.; Lin, S.; Brown, M.S. A high-quality denoising dataset for smartphone cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 1692–1700. [Google Scholar]
- Nam, S.; Hwang, Y.; Matsushita, Y.; Joo Kim, S. A holistic approach to cross-channel image noise modeling and its application to image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1683–1691. [Google Scholar]
- Xu, J.; Li, H.; Liang, Z.; Zhang, D.; Zhang, L. Real-world noisy image denoising: A new benchmark. arXiv 2018, arXiv:1804.02603. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Saxe, A.M.; McClelland, J.L.; Ganguli, S. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. arXiv 2013, arXiv:1312.6120. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image restoration. arXiv 2018, arXiv:1812.10477. [Google Scholar]
- Plotz, T.; Roth, S. Benchmarking denoising algorithms with real photographs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 1586–1595. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar]
- Zhou, Y.; Jiao, J.; Huang, H.; Wang, Y.; Wang, J.; Shi, H.; Huang, T. When AWGN-based Denoiser Meets Real Noises. arXiv 2019, arXiv:1904.03485. [Google Scholar]
- Yu, K.; Wang, X.; Dong, C.; Tang, X.; Loy, C.C. Path-Restore: Learning Network Path Selection for Image Restoration. arXiv 2019, arXiv:1904.10343. [Google Scholar]
- Chen, Y.; Yu, W.; Pock, T. On learning optimized reaction diffusion processes for effective image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5261–5269. [Google Scholar]
- Xu, J.; Zhang, L.; Zhang, D.; Feng, X. Multi-channel weighted nuclear norm minimization for real color image denoising. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1096–1104. [Google Scholar]
- Xu, J.; Zhang, L.; Zhang, D. A trilateral weighted sparse coding scheme for real-world image denoising. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 20–36. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method | PSNR | SSIM | Params (M) | FLOPs (G) | Latency (s) |
|---|---|---|---|---|---|---|
| RENOIR | RDN+ | 38.17 | 0.9013 | 5.47 | 105.5 | 0.63 |
| DRDN | 38.12 | 0.9010 | 5.59 | 61.18 | 0.49 | |
| SIDD | RDN+ | 39.55 | 0.9399 | 5.47 | 105.5 | 0.63 |
| DRDN | 39.60 | 0.9401 | 5.59 | 53.00 | 0.42 |
| Method | PSNR | SSIM | Blind/Non-Blind |
|---|---|---|---|
| EPLL [13] | 33.51 | 0.8244 | Non-blind |
| TNRD [42] | 33.65 | 0.8306 | Non-blind |
| BM3D [12] | 34.51 | 0.8507 | Non-blind |
| MCWNNM [43] | 37.38 | 0.9294 | Non-blind |
| FFDNet+ [39] | 37.61 | 0.9415 | Non-blind |
| DnCNN+ [15] | 37.90 | 0.9430 | Blind |
| TWSC [44] | 37.96 | 0.9416 | Non-blind |
| CBDNet [21] | 38.06 | 0.9421 | Blind |
| PD [40] | 38.40 | 0.9452 | Blind |
| Path-Restore [41] | 39.00 | 0.9542 | Blind |
| DRDN | 39.40 | 0.9524 | Blind |
| Dataset | Metric | EPLL [13] | BM3D [12] | TNRD [42] | DnCNN [15] | TWSC [44] | DRDN |
|---|---|---|---|---|---|---|---|
| Nam | PSNR | 33.66 | 35.19 | 36.61 | 33.86 | 37.81 | 38.45 |
| SSIM | 0.8591 | 0.8580 | 0.9463 | 0.8635 | 0.9586 | 0.9626 | |
| PolyU | PSNR | 36.17 | 37.40 | 38.17 | 36.08 | 38.60 | 38.96 |
| SSIM | 0.9216 | 0.9526 | 0.9640 | 0.9161 | 0.9685 | 0.9691 |
| Method | PSNR | SSIM | FLOPs |
|---|---|---|---|
| DRDN+SL | 38.12 | 0.9010 | 61.18 |
| DRDB+RL | 38.03 | 0.9003 | 48.75 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, Y.; Zhu, Y.; Du, X. Dynamic Residual Dense Network for Image Denoising. Sensors 2019, 19, 3809. https://doi.org/10.3390/s19173809
Song Y, Zhu Y, Du X. Dynamic Residual Dense Network for Image Denoising. Sensors. 2019; 19(17):3809. https://doi.org/10.3390/s19173809
Chicago/Turabian StyleSong, Yuda, Yunfang Zhu, and Xin Du. 2019. "Dynamic Residual Dense Network for Image Denoising" Sensors 19, no. 17: 3809. https://doi.org/10.3390/s19173809
APA StyleSong, Y., Zhu, Y., & Du, X. (2019). Dynamic Residual Dense Network for Image Denoising. Sensors, 19(17), 3809. https://doi.org/10.3390/s19173809