This section proposes an NN-based PL prediction model trained by a BP algorithm, which corresponds to our first contribution. In the second subsection, this paper expands the offline prediction model to a real-time NN-based PL prediction model, which is our second contribution.
3.1. Typical Empirical Models for Path Loss Prediction
Compared to theoretical modes, empirical models are built upon measured data featuring flexible and accurate prediction performance without requiring prior knowledge. Three empirical models are discussed for comparison purposes in the following: (1) Dual-slope distance-breakpoint PL model; (2) polynomial fitting model, and (3) GG shadowed fading model.
3.1.1. Dual-Slope Distance-Breakpoint Path Loss Model
In a large-scale propagation model, PL is only related to the distance between the transmitter and receiver for a given frequency. Two PL indexes,
and
, are adopted to described the fading slopes in two distinguished regions separated by Fresnel distance. PL index and the variance of slow fading or shadowing can be calculated from measured data using the MMSE criterion. The PL at
, the distance between the Tx and Rx, can be expressed as
where
and
are the variances of slow fading, and
the PL at the reference distance
.
Among them, and are normalized in km and MHz, respectively.
In conventional Line of sight (LoS) models,
is the Fresnel distance to the point where the first Fresnel zone touches the ground, which can be calculated by
, where
and
are antenna heights of the transmitter and receiver, respectively, and
is the wavelength [
9].
The PL model is built up through the steps described below.
- (i)
The relative distances in the training set are rounded to the nearest meter, denoted as , . The corresponding PLs are denoted as .
- (ii)
Take into Equation (4) to calculate the PL at the reference distance .
- (iii)
Calculate the average of PLs at each relative distance , denoted as .
- (iv)
For each reference distance , take into Equation (3) (subject to ) to calculate the optimal and , which leads to the minimum RMSE of and .
- (v)
For each reference distance , take into Equation (3) (subject to ) to calculate the optimal and , which leads to the minimum RMSE of and .
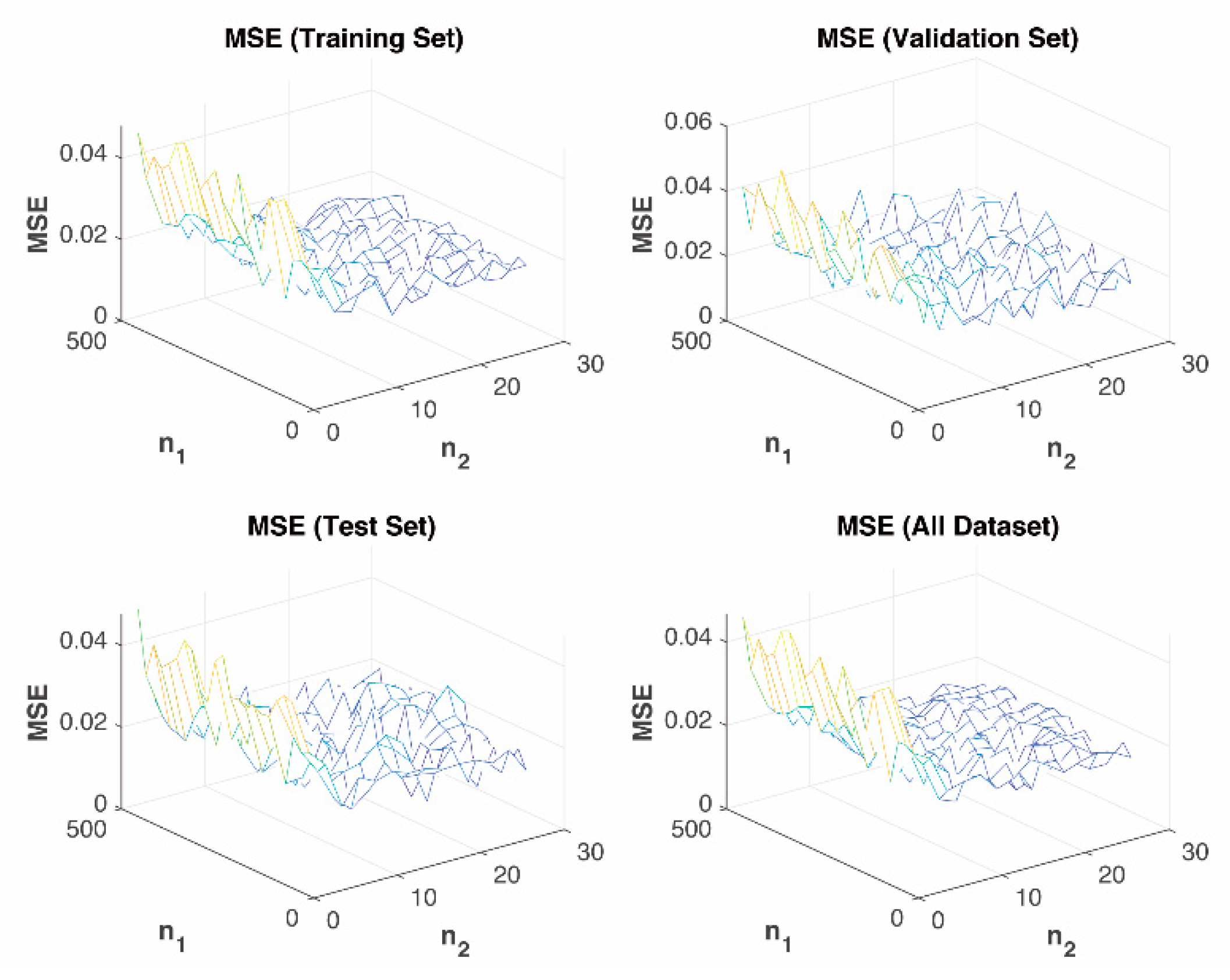
In the PL prediction simulation using the FSPL-based model, six reference values and corresponding PL indexes of and were calculated. The predicted MSE of the prediction models using a training set, validation set, and test set were calculated. Simulation results show that, regardless of the reference distance, the NN-based model outperforms the FSPL-based model in terms of prediction accuracy.
3.1.2. Polynomial Fitting Model
Polynomial fitting model (PFM) is another commonly used model based on measured data through the least-squares polynomial curve fitting. An approximate curve described by the function of
is drawn from the experimental data where the curve does not need to pass through modeling data exactly. The expression of the approximate curve is
where
is the order of fitting curve, which is selected according to the loss function of the sum of the squares of the errors. It is then adapted to the above polynomial equation. The sum of the distances from each sample point to the fitted curve, representing the sum of squared deviation, is calculated by
The value of that minimizes satisfies the condition that . After simplifying and using the matrix representation, one can have
Equation (7) can be further abbreviated as and the fitting curve can be acquired by .
The polynomial model was established through the following steps.
- (i)
The relative distances in the training set are rounded to the nearest meter, denoted as , , while corresponding PLs are denoted as .
- (ii)
Calculate the average of PLs at each relative distance , denoted as .
- (iii)
Take into Equation (5) to calculate the approximate curve for order .
- (iv)
Calculate the coefficient matrix of using Equation (7) according to the order of .
- (v)
For each order , take into Equation (5) to calculate the optimal , which generates the minimum RMSE of and .
In the simulation of the PFM, fitting orders of were picked, where 24 was selected by Monte Carlo simulation. The predicted MSE of the PFM and NN models based on a training set, validation set, and test set was then calculated. Simulation results validate that for all orders tested, the NN-based model has lower MSE, that is, more accuracy of prediction when compared with the PFM-based model.
3.1.3. Generalized Gamma Shadowed Fading Model
Vehicular channels may experience fast fading as well as shadowing simultaneously. A model that reflects the two types of fading is the GG distribution, of which the Probability Distribution Function (PDF) and Cumulative Distribution Function (CDF) can be written as
where
is the fading parameter,
the shape parameter (typically restricted to
), and
the gamma function. The average power of GG channel,
, is expressed as
where
is the time average of received power. A measurement study shows that
and
vary with distance [
3].
The GG PL model is built up through the steps described below.
- (i)
The relative distances in the training set are rounded to the nearest 5 m, denoted as , . The corresponding PLs are denoted as .
- (ii)
Calculate PDF at the relative distance of the received signal power.
- (iii)
Take and into Equation (8) to calculate the optimal and , which lead to the minimum RMSE of and .
- (iv)
Putting and into Equation (8), we get the estimated PDF and CDF of the received signal power at the relative distance , denoted as and , respectively.
- (v)
The estimated received signal power at the relative distance is .
3.2. A Novel Neural Network-Based Path Loss Prediction Model
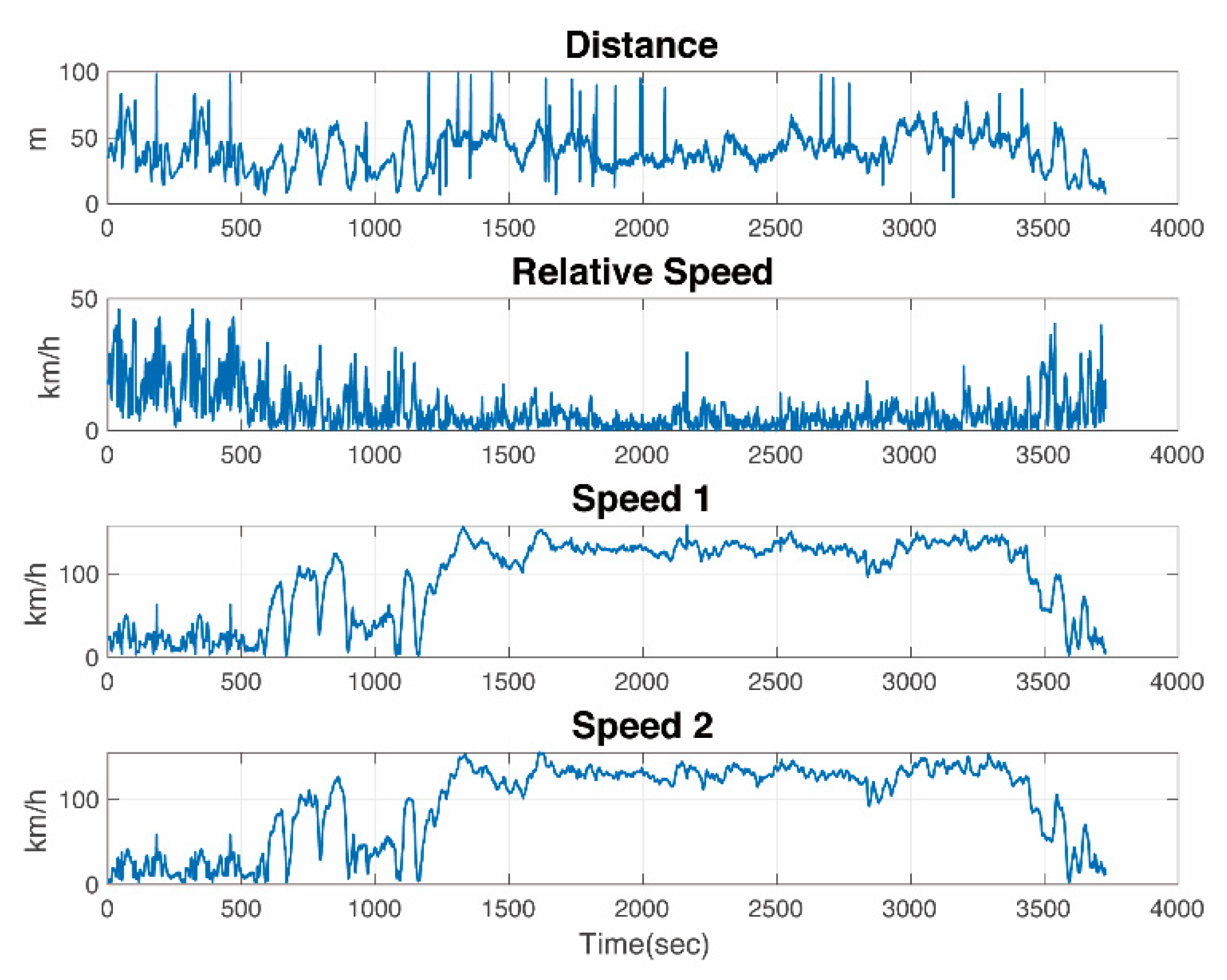
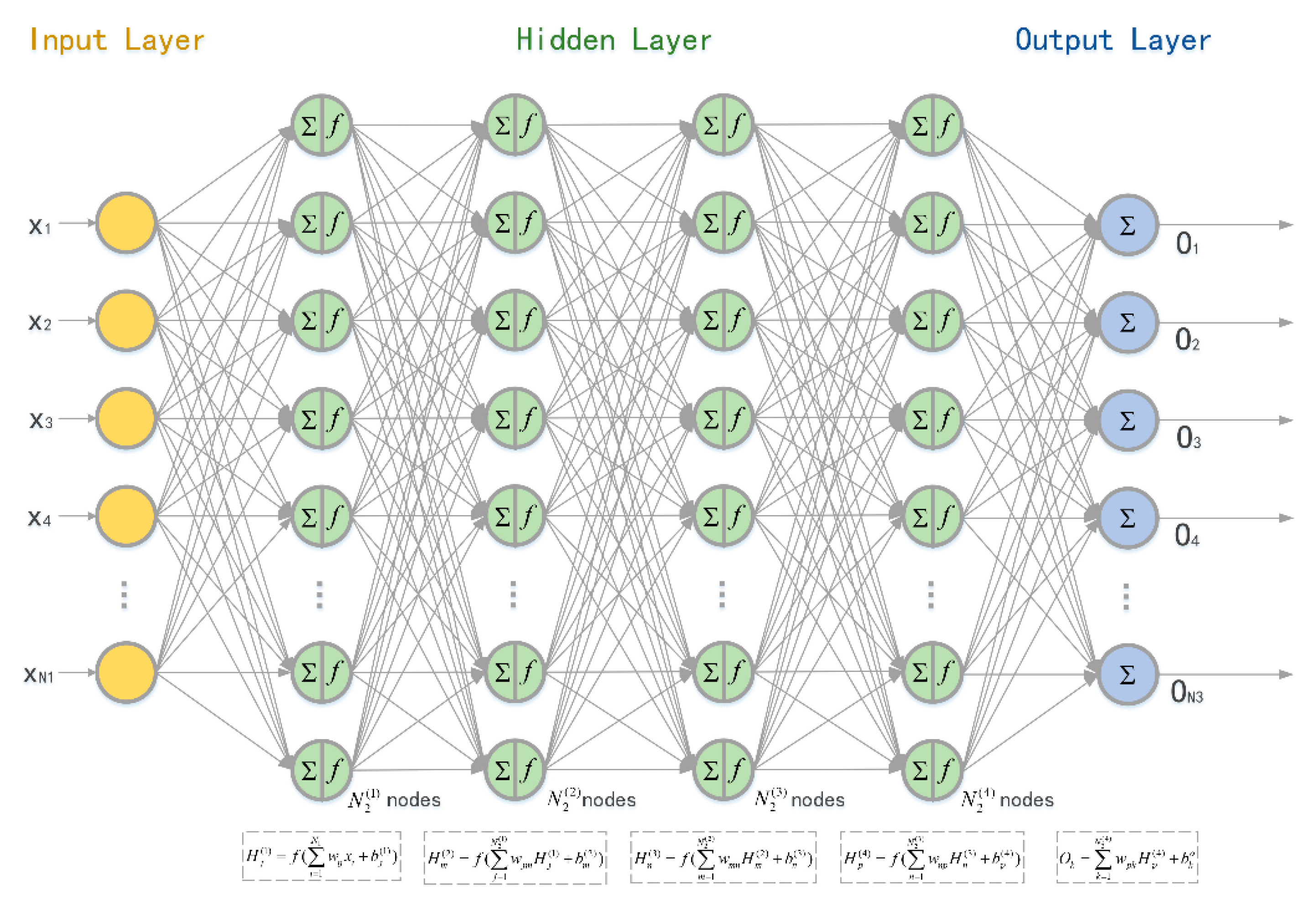
In this subsection, an NN-based PL prediction model is discussed. The input of the NN is the distance between Tx and Rx, gained from onboard GPS sensors, while the PL was calculated from RSSI at Rx. All measurement data came from the above experiments.
The weight of the path from the
input layer to the
hidden layer is denoted as
and the weight from the
hidden layer to the
output layer is
. The number of nodes in the input layer, hidden layer, and output layer were
,
, and
, respectively. Thus, we have
,
, and
. The weight vectors of each perceptron were optimized using the back-propagation algorithm. We used the accumulated error BP algorithm and adjusted
and
to minimize the global error
. NN computations, starting from input data and going on to the hidden/output layer weights computations, are shown in
Table 2.
Pseudo-code of NN development is presented as the following.
| Algorithm 1 Developed of Neural Network |
| Input: |
| 1: |
| 2: = [] // NN hyper-parameters including number of hidden layers, nodes of each hidden layers, activation function, learning rate, epochs, training function, learning function, etc. |
| Output: |
| 1: // Predict at each relative distance |
| 2: //RMSE of and |
| 3: // Accuracy of and |
| for in do |
|
|
|
| end for |
|
|
|
|
| return, , |
With the NN developed in Algorithm 1, the prediction model is built up through the steps described below.
- (i)
The relative distances in the training set are rounded to the nearest meter, denoted as , . The corresponding PLs are denoted as .
- (ii)
Randomly divide the dataset into training set, validation set, and test set in proportions of 60%, 15%, and 25%, respectively.
- (iii)
Set NN parameters: number of nodes in each layer , activation function , learning rate , maximum number of epochs to train , sum-squared error goal , back-propagation weight/bias learning function , etc.
- (iv)
Train the NN model with the training set, and then tune the model’s hyper-parameters with the validation set to reduce overfitting.
- (v)
Predict at each relative distance with the NN model from (iv) and then calculate the RMSE of and .
- (vi)
Repeat step (iii)–(v) when the scenario changes to obtain the optimal combination of parameters. In the same scenario, the NN parameters are fixed after the optimal parameters are obtained.
- (vii)
Estimate at each relative distance with The NN model from (vi) and then calculate the RMSE of and .
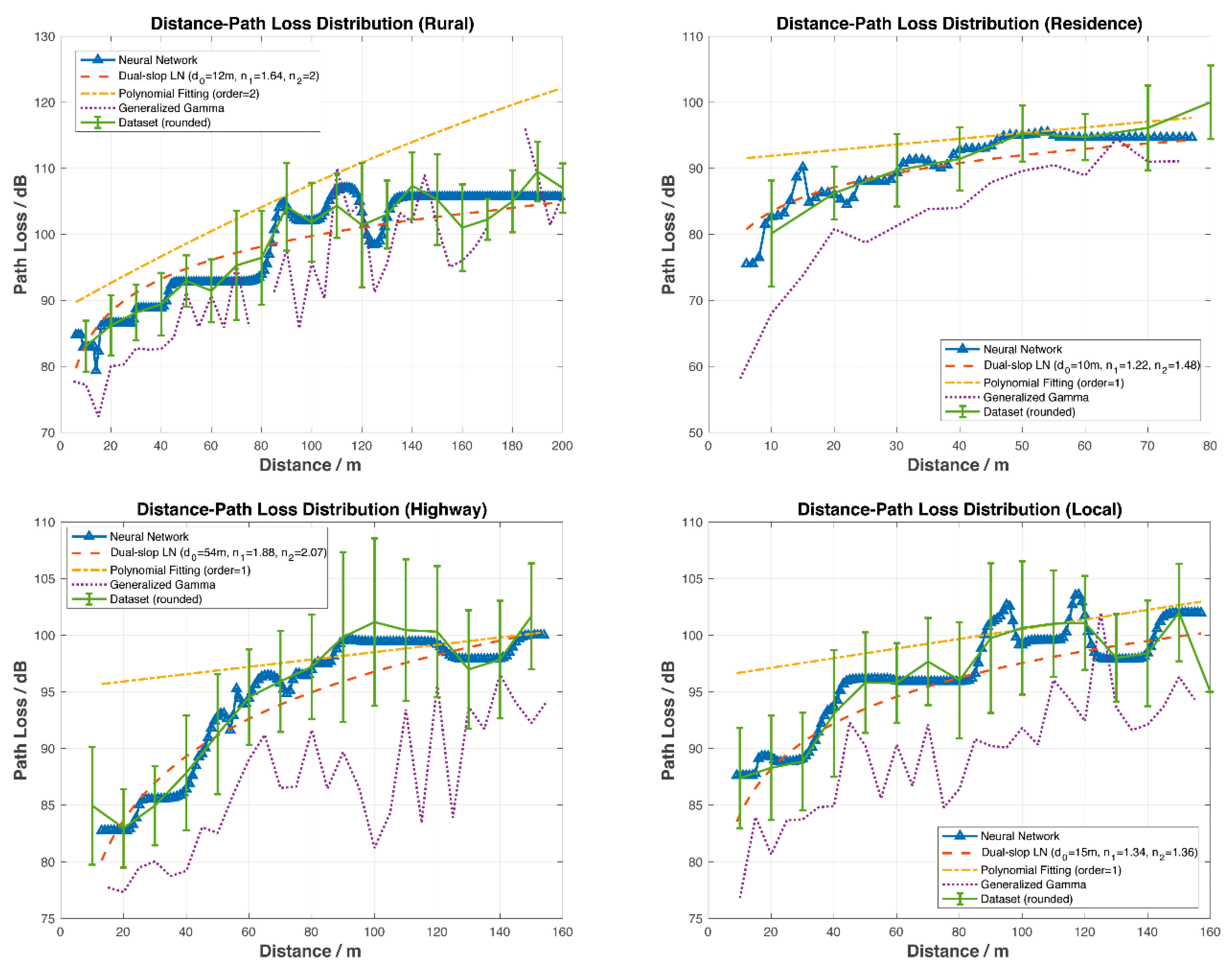
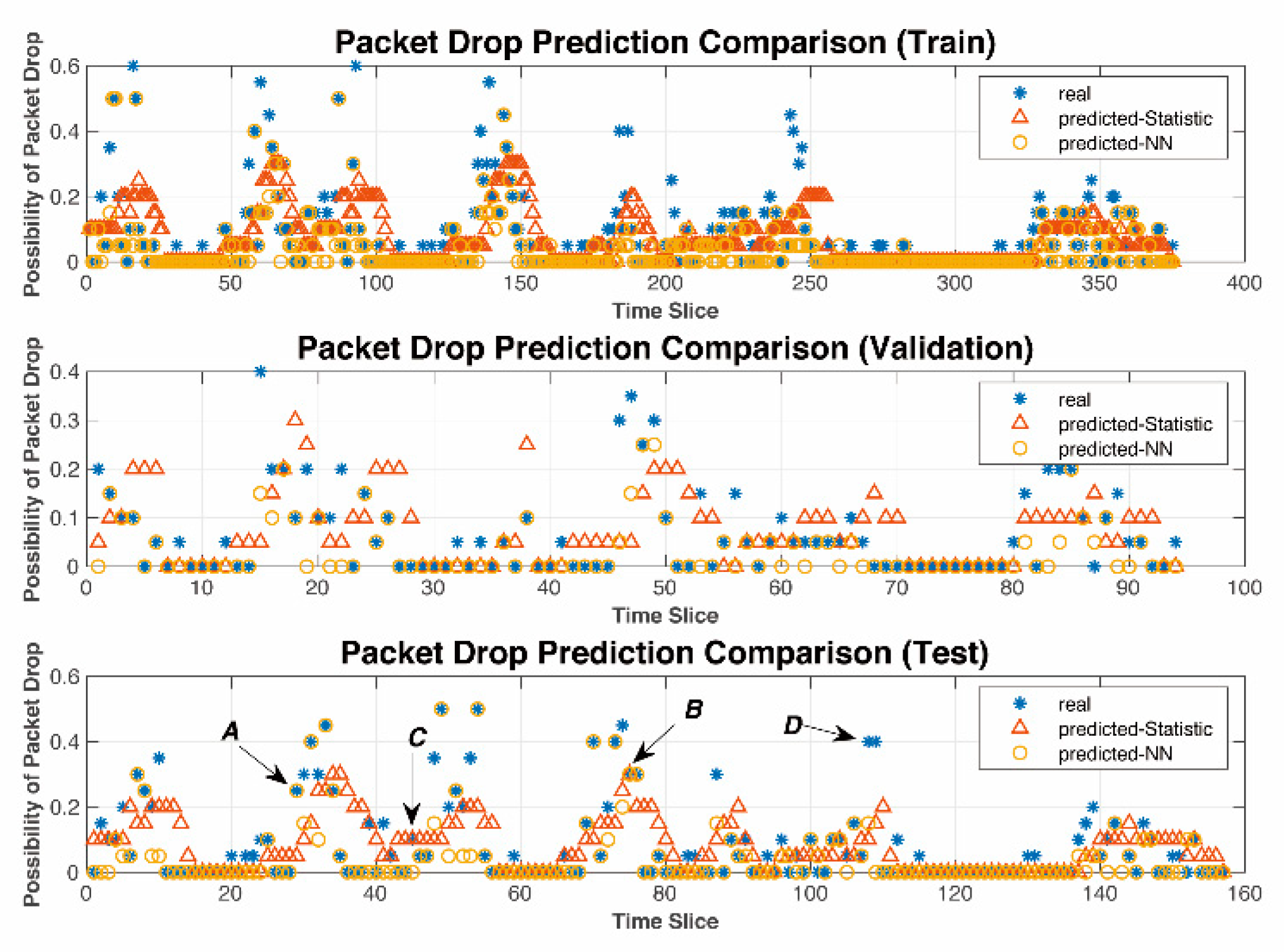
It can be seen clearly from
Figure 4 that the NN model has the lowest MSE, that is, the best accuracy among models. Simulations covered four road scenarios including rural areas, residential areas, local areas, and highways.
The error bars in
Figure 4 show the relationship between distance and PL, where distances were rounded appropriately depending on the measured dataset.
Figure 4 also illustrates the mean of
and the standard deviation of
of PL at each distance.
Table 3,
Table 4,
Table 5 and
Table 6 indicate statistical characteristics, such as maximum, minimum, mean, and standard deviation, of the measurement data, that is, the dataset used for PL prediction.
The orange dashed line was calculated from the dual-slope model. The breakpoint was set as
= 171.4353 m. The minimum reference distance was set as
and
. Among them, the smallest RMSE, distances and PL indexes are all shown in
Figure 4. As one can see from
Figure 4, the prediction curve of the dual-slope model fits the average of the dataset and is always located within
.
The yellow dash-dot line is gained from the PFM. Cases where the order was
are simulated. Simulation results in
Figure 3 show that, generally speaking, PFM performs better when
k = 1 or
k = 2. The prediction curves were mostly distributed within the range of
, which is not centered around
and is not able to predict the PL accurately.
The purple dotted line was calculated from the GG model. The prediction curve fluctuates, reflecting the trend of PL but in smaller prediction values.
The blue line labelled with triangles was gained from the NN prediction model. The results from the NN model outperform those from the other three models. The prediction curve fits the average of the dataset and always remains within in . For all road scenarios, it shows both the trend and the details of PL. The peaks, such as at 80–90 m in the rural case and at 90–100 m in the local case, etc., were likely caused by up fading, that is, multi-path conditions causing constructive summation of several multi-path components.
For the four scenarios, the corresponding modeling parameters vary.
- ⬤
In the Local case, the optimal parameters of the dual-slope model are 15 m, 1.34, 1.36, and that of the PF model is 1.
- ⬤
In the Residence case, the optimal parameters of the dual-slope model are 10 m, 1.22, 1.48, and that of the PF model is 1.
- ⬤
In the Rural case, the optimal parameters of the dual-slope model are 12 m, 1.64, 2, and that of the PF model is 2.
- ⬤
In the Highway case, the optimal parameters of the dual-slope model are 54 m, 1.88, 2.07, and that of the PF model is 1.
As shown above, the NN PL model achieves the best performance because the NN line is closer to the real data than the other estimations.
The DS breakpoint model is limited by using to approximate the trend. High-order PFM has an accuracy problem at the extremes of the range which results in reduced accuracy. The PF-based model sacrifices accuracy slightly due to the continuity and smoothness of the mathematical model adopted. Moreover, the PF-based model degraded extremely at the edge of the data range. The GG model has more accurate predictions than those from the PF model based on a large dataset, which is not suitable for the proposed real-time PL prediction. In addition, to find the optimal values of and , all training sets are iterated repeatedly. The number of iterations is positively correlated with the accuracies of and . Such processing takes time, which is not acceptable for real-time operation.
However, the NN-based PL prediction model uses a new way to explain relationships within the dataset, which is more in line with the actual channel distribution. It can predict channel parameters for hardware-in-the-loop simulations and modeling for vehicle networks, autonomous driving and networked controlled robotics.
3.3. A Novel Real-Time Neural Network-Based Path Loss Prediction Model
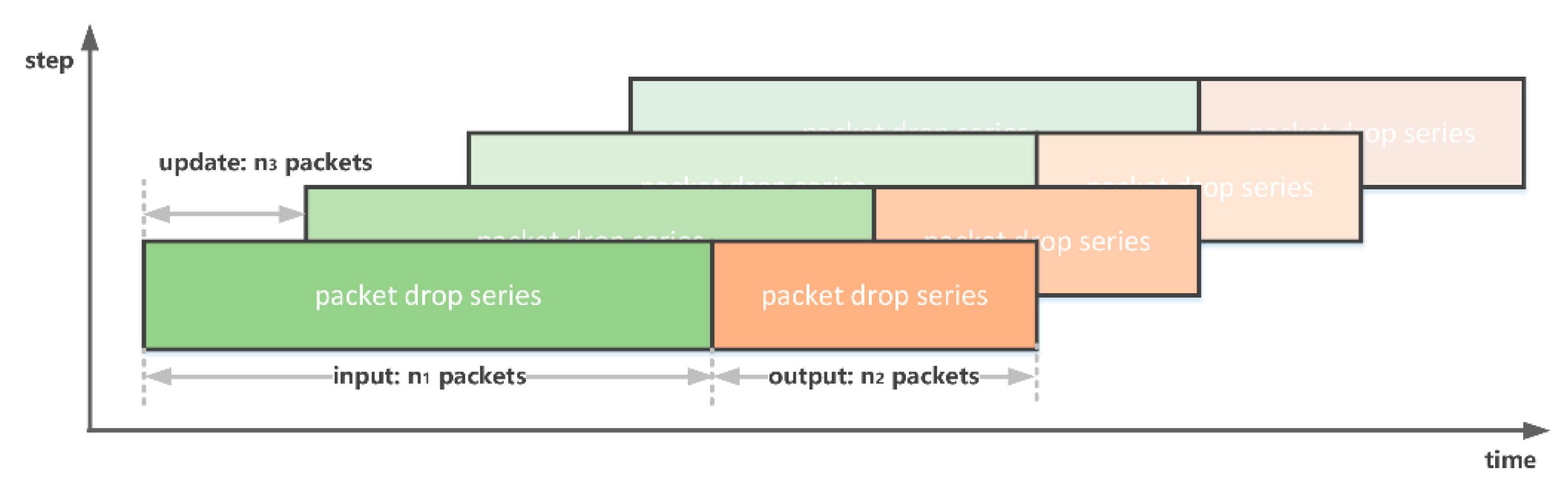
For the applications of vehicle communications and autonomous driving, the channel is time-varying. During the training phase, outdated data will be dropped as appropriate while updating the data.
The foremost task is to identify the number of packets to be used for a training set in a real-time model. Simulation results showed that the number of packets is suggested to be no less than 900. In each prediction period, 900 packets were therefore divided into training set, validation set, and test set in proportions of 60%, 15%, and 25%, respectively.
Window factor, noted by
, is the percentage of the dataset that is updated. Datasets were updated chronologically while the window factor was selected as
. The time window, noted by
, is given by
where,
is the number of packets of the dataset and
the duration of the packet.
The time window can be reduced by shortening the time duration of the packet if necessary.
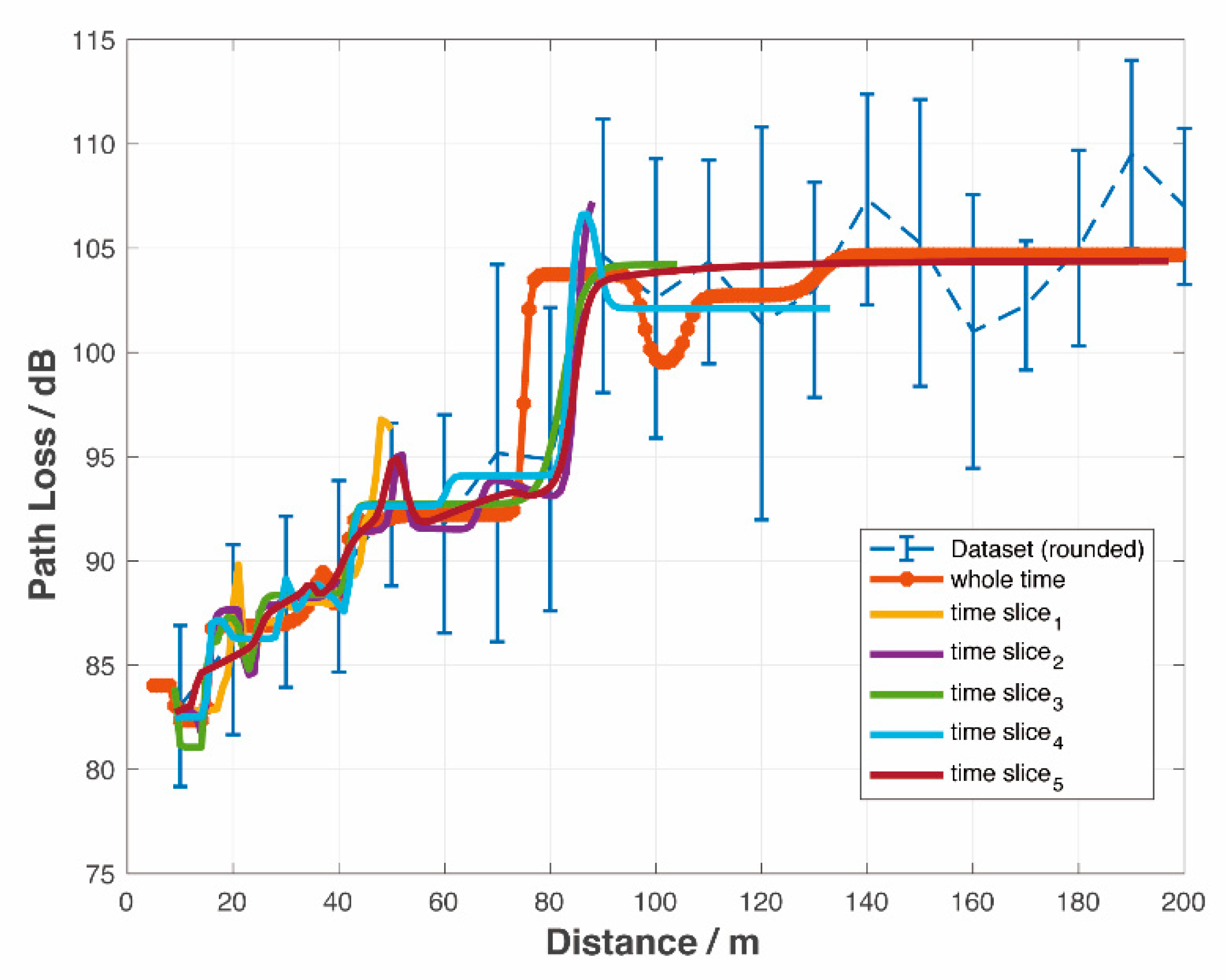
Figure 5 compares the offline and real-time PL prediction model based on the NN. In the offline model, the whole dataset is used, while the real-time model only uses data that is within the coherent window described above.
The coverage areas are different in each slot. The PL prediction for both offline (orange *) and real-time models (colored lines) generated similar results.
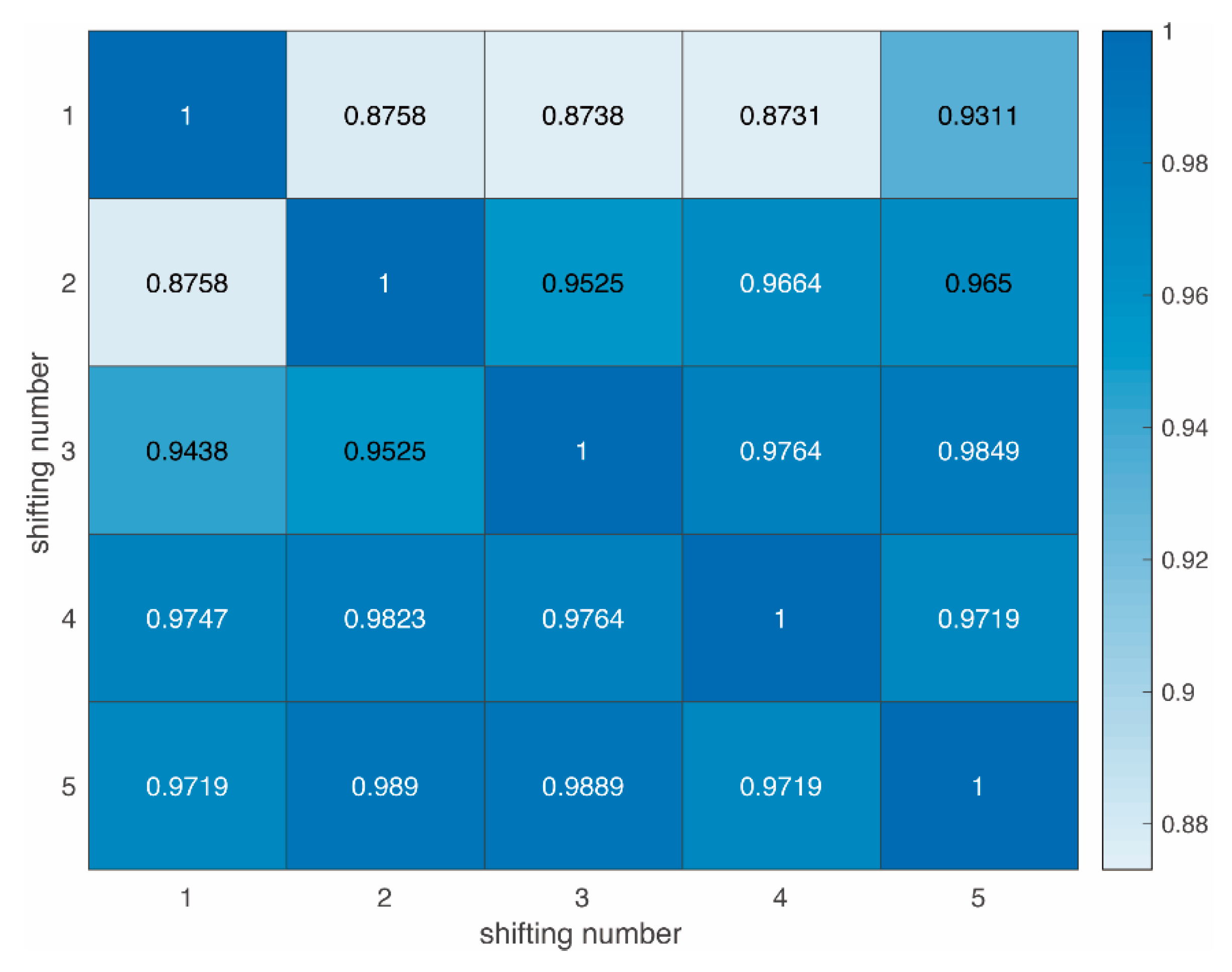
Figure 6 shows the correlation coefficients of 6 real-time PL prediction curves. The dataset adopted is from the rural areas, but can be applicable to others as well. Different areas lead to individual PL curves, but all function well. For simplicity, the following results are based on rural areas only.
The real-time PL prediction curves are defined as
and
in different slots, where
and
in this case. The correlations of PL curves are meaningful and defined as
and
. The correlation coefficient is used as a measure of the linear dependence between them. If a variable has
scalar observations, then the Pearson correlation coefficient is defined as
where
and
are the means and standard deviations of
, respectively, and
and
the means and standard deviations of
.
The cross-correlation matrix can be expressed as
The theory of strict frames (rules) for correlation may be presented as follows:
- ⬤
: the correlation is non-important;
- ⬤
: the correlation is weak;
- ⬤
: the correlation is strong;
- ⬤
: the correlation is very strong.
The correlation coefficients of two consecutive slots are close to one. This result is in line with expectations:
- ⬤
The updated dataset can effectively predict the trend of PL. The PL prediction curves at different slots have coherent shapes and trends at the same distance.
- ⬤
It also varies practically as the environment changes. In some cases, even though Tx and Rx take the same distance, the PL shape predicted demonstrated variations. This is due to changes in the environment where the two vehicles are located, such as obstacles and occlusion.
The real-time PL prediction model was proven to be able to predict not only the trend, but also the local variations in real time.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}