Improving Stockline Detection of Radar Sensor Array Systems in Blast Furnaces Using a Novel Encoder–Decoder Architecture


Abstract
1. Introduction
- To present a novel encoder–decoder architecture to improve stockline detection, which learns desired features from noisy data adaptively. We save time and effort compared to traditional hand-crafted denoising processing.
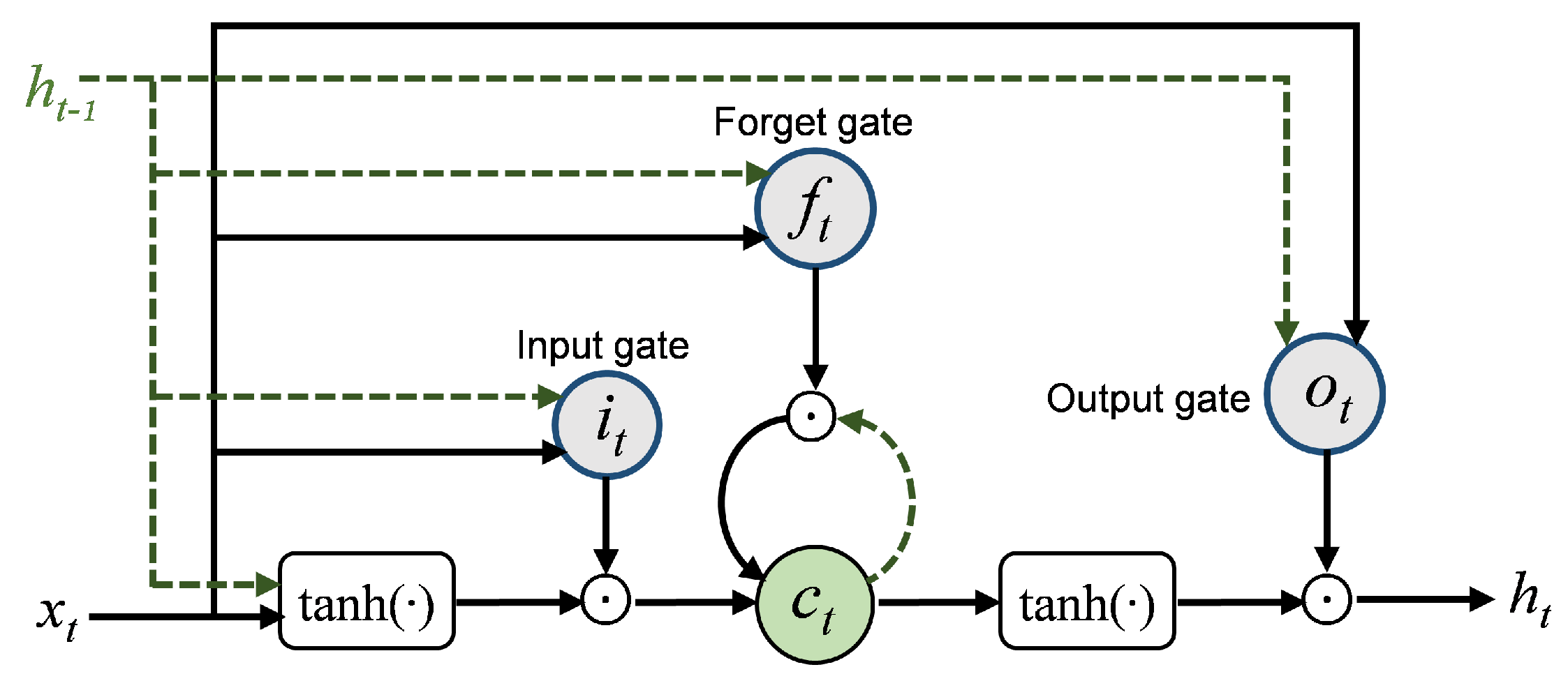
- To present an effective stockline tracking strategy by leveraging the LSTM network to model longer range historical signals. A large tracking capability brings better robustness of noise randomness.
- The experiments are validated on actual industrial BF data. In particular, the experiments are carried out on an intact multi-radar scenario rather than a single radar scenario.
2. Issue Description and Necessity Of Encoder-Decoder Architecture
3. Methodology
3.1. Architecture
3.2. Loss Function
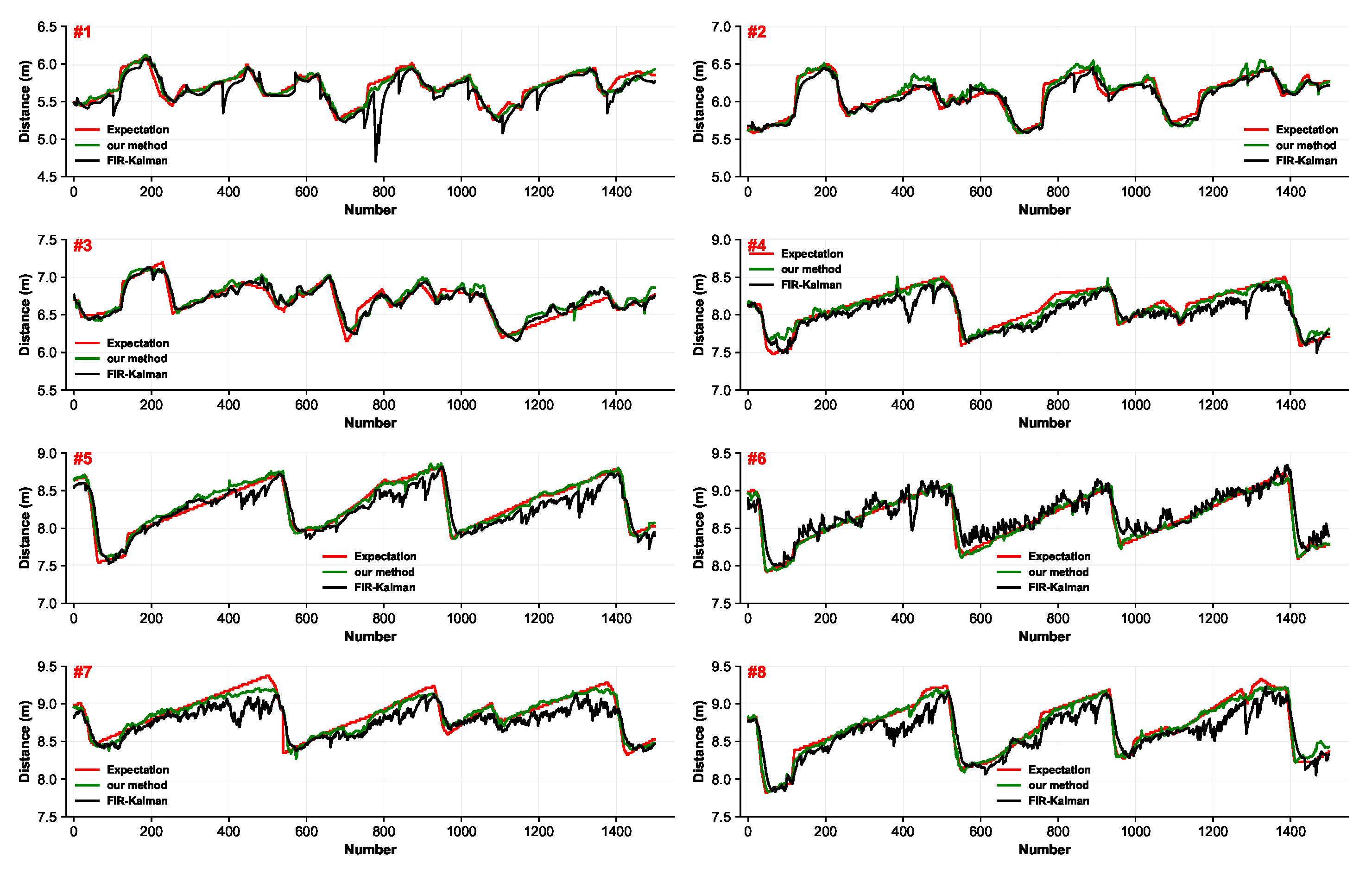
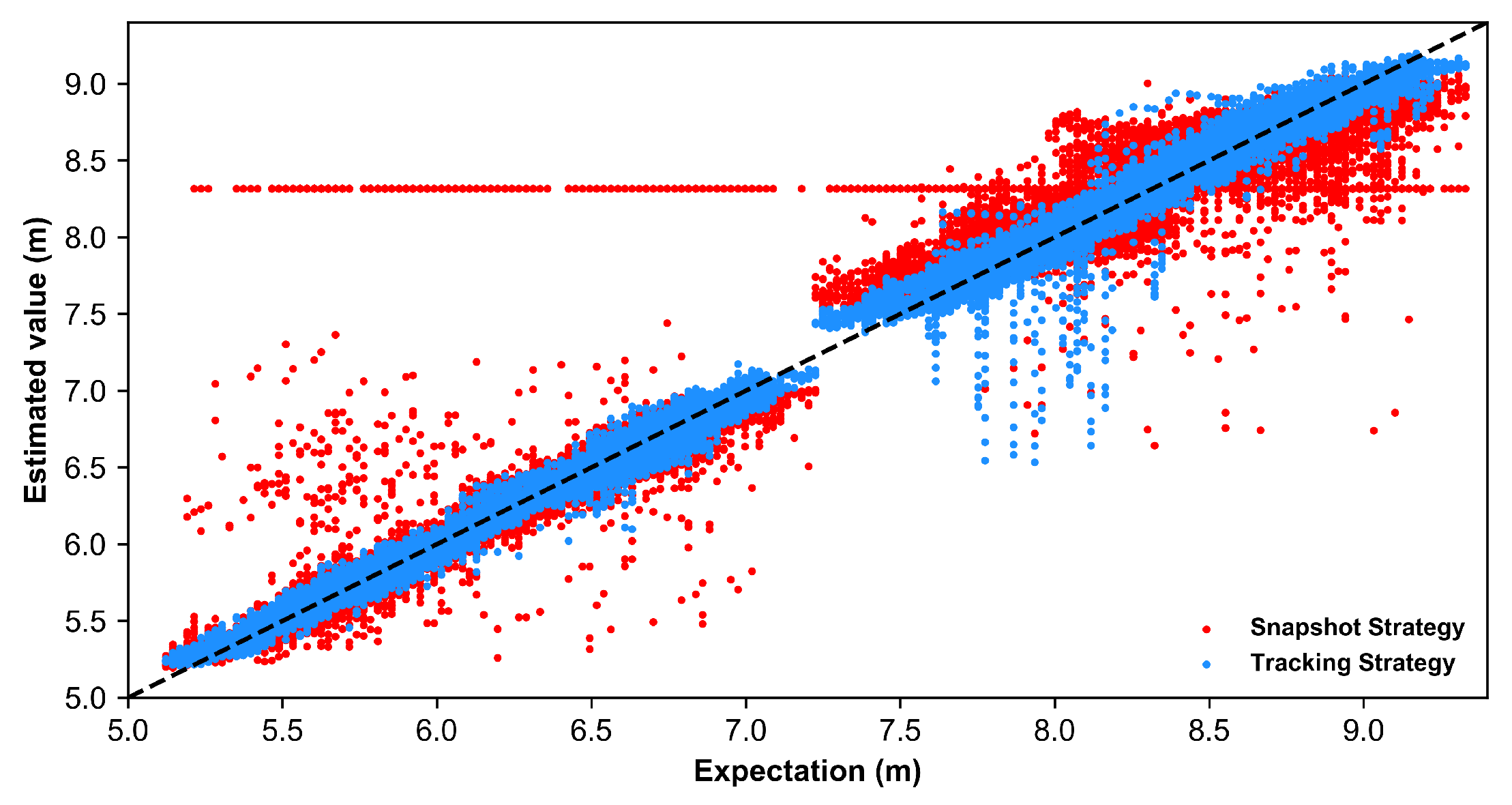
4. Experiment
4.1. Experiment Setup
4.2. Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Guo, Z.; Fu, Z. Current situation of energy consumption and measures taken for energy saving in the iron and steel industry in China. Energy 2010, 35, 4356–4360. [Google Scholar] [CrossRef]
- Zhou, P.; Lv, Y.; Wang, H.; Chai, T. Data-Driven Robust RVFLNs Modeling of a Blast Furnace Iron-Making Process Using Cauchy Distribution Weighted M-Estimation. IEEE Trans. Ind. Electron. 2017, 64, 7141–7151. [Google Scholar] [CrossRef]
- Li, X.L.; Liu, D.X.; Jia, C.; Chen, X.Z. Multi-model control of blast furnace burden surface based on fuzzy SVM. Neurocomputing 2015, 148, 209–215. [Google Scholar] [CrossRef]
- Xu, D.; Li, Z.; Chen, X.; Wang, Z.; Wu, J. A dielectric-filled waveguide antenna element for 3D imaging radar in high temperature and excessive dust conditions. Sensors 2016, 16, 1339. [Google Scholar] [CrossRef] [PubMed]
- Zankl, D.; Schuster, S.; Feger, R.; Stelzer, A.; Scheiblhofer, S.; Schmid, C.M.; Ossberger, G.; Stegfellner, L.; Lengauer, G.; Feilmayr, C.; et al. BLASTDAR—A large radar sensor array system for blast furnace burden surface imaging. IEEE Sens. J. 2015, 15, 5893–5909. [Google Scholar] [CrossRef]
- Zhou, B.; Ye, H.; Zhang, H.; Li, M. Process monitoring of iron-making process in a blast furnace with PCA-based methods. Control. Eng. Pract. 2016, 47, 1–14. [Google Scholar] [CrossRef]
- Gao, C.; Jian, L.; Luo, S. Modeling of the thermal state change of blast furnace hearth with support vector machines. IEEE Trans. Ind. Electron. 2012, 59, 1134–1145. [Google Scholar] [CrossRef]
- Jian, L.; Gao, C. Binary coding SVMs for the multiclass problem of blast furnace system. IEEE Trans. Ind. Electron. 2013, 60, 3846–3856. [Google Scholar] [CrossRef]
- Pettersson, F.; Chakraborti, N.; Saxén, H. A genetic algorithms based multi-objective neural net applied to noisy blast furnace data. Appl. Soft Comput. 2007, 7, 387–397. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, S.; Yin, Y.; Xiao, W.; Zhang, J. A novel online sequential extreme learning machine for gas utilization ratio prediction in blast furnaces. Sensors 2017, 17, 1847. [Google Scholar] [CrossRef]
- Liang, D.; Yu, Y.; Bai, C.; Qiu, G.; Zhang, S. Effect of burden material size on blast furnace stockline profile of bell-less blast furnace. Ironmak. Steelmak. 2009, 36, 217–221. [Google Scholar] [CrossRef]
- Qingwen, H.; Xianzhong, C.; Ping, C. Radar data processing of blast furnace stock-line based on spatio-temporal data association. In Proceedings of the 2015 34th Chinese Control Conference (CCC), Hangzhou, China, 28–30 July 2015; pp. 4604–4609. [Google Scholar]
- Chen, X.; Wei, J.; Xu, D.; Hou, Q.; Bai, Z. 3-Dimension imaging system of burden surface with 6-radars array in a blast furnace. ISIJ Int. 2012, 52, 2048–2054. [Google Scholar] [CrossRef][Green Version]
- Chen, A.; Huang, J.; Qiu, J.; Ke, Y.; Zheng, L.; Chen, X. Signal processing for a FMCW material level measurement system. In Proceedings of the 2016 IEEE 13th International Conference on Signal Processing (ICSP), Chengdu, China, 6–10 November 2016; pp. 244–247. [Google Scholar]
- Malmberg, D.; Hahlin, P.; Nilsson, E. Microwave technology in steel and metal industry, an overview. ISIJ Int. 2007, 47, 533–538. [Google Scholar] [CrossRef]
- Gomes, F.S.; Côco, K.F.; Salles, J.L.F. Multistep forecasting models of the liquid level in a blast furnace hearth. IEEE Trans. Autom. Sci. Eng. 2017, 14, 1286–1296. [Google Scholar] [CrossRef]
- Brännbacka, J.; Saxen, H. Novel model for estimation of liquid levels in the blast furnace hearth. Chem. Eng. Sci. 2004, 59, 3423–3432. [Google Scholar] [CrossRef]
- Wei, J.; Chen, X.; Kelly, J.; Cui, Y. Blast furnace stockline measurement using radar. Ironmak. Steelmak. 2015, 42, 533–541. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, long short-term memory, fully connected deep neural networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 4580–4584. [Google Scholar]
- Trigeorgis, G.; Ringeval, F.; Brueckner, R.; Marchi, E.; Nicolaou, M.A.; Schuller, B.; Zafeiriou, S. Adieu features? end-to-end speech emotion recognition using a deep convolutional recurrent network. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5200–5204. [Google Scholar]
- Chen, Z.; Zhao, R.; Zhu, Q.; Masood, M.K.; Soh, Y.C.; Mao, K. Building occupancy estimation with environmental sensors via CDBLSTM. IEEE Trans. Ind. Electron. 2017, 64, 9549–9559. [Google Scholar] [CrossRef]
- Stove, A.G. Linear FMCW radar techniques. In IEE Proceedings F (Radar and Signal Processing); IET: London, UK, 1992; Volume 139, pp. 343–350. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Kendall, A.; Cipolla, R. Geometric loss functions for camera pose regression with deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5974–5983. [Google Scholar]
- Kendall, A.; Gal, Y. What uncertainties do we need in bayesian deep learning for computer vision? In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 5574–5584. [Google Scholar]
- Diederik, P.; Kingma, J.B. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI’16), Savannah, GA, USA, 2–4 November 2016; Volume 16, pp. 265–283. [Google Scholar]
- Bishop, G.; Welch, G. An introduction to the Kalman filter. Proc. Siggraph Course 2001, 8, 59. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Radar ID | Normal | Distorted | Total |
|---|---|---|---|
| 1# | 61,904 | 1157 | 63,061 |
| 2# | 61,267 | 1794 | 63,061 |
| 3# | 61,715 | 1346 | 63,061 |
| 4# | 50,490 | 12,571 | 63,061 |
| 5# | 53,599 | 9462 | 63,061 |
| 6# | 52,150 | 10,911 | 63,061 |
| 7# | 52,719 | 10,342 | 63,061 |
| 8# | 53,839 | 9222 | 63,061 |
| Radar ID | 1# | 2# | 3# | 4# | 5# | 6# | 7# | 8# |
|---|---|---|---|---|---|---|---|---|
| Window Length | 64 | 96 | 264 | 136 | 136 | 128 | 184 | 104 |
| Radar ID | PS (w/o Denoising) | FIR-PS | FIR-Kalman-PS | CNN | LSTM | CNN-LSTM (Ours) |
|---|---|---|---|---|---|---|
| 1# | 0.2575 | 0.0825 | 0.0733 | 0.1153 | 0.1675 | 0.0320 |
| 2# | 0.7230 | 0.0621 | 0.0502 | 0.1751 | 0.1952 | 0.0434 |
| 3# | 0.5422 | 0.0898 | 0.0583 | 0.2403 | 0.1938 | 0.0520 |
| 4# | 5.1153 | 0.1330 | 0.0892 | 0.1986 | 0.2304 | 0.0645 |
| 5# | 5.1069 | 0.1030 | 0.0778 | 0.1434 | 1.1906 | 0.0418 |
| 6# | 1.4011 | 0.1629 | 0.0938 | 0.1741 | 0.2822 | 0.0318 |
| 7# | 5.8221 | 0.1433 | 0.1032 | 0.2010 | 0.2044 | 0.0414 |
| 8# | 0.9030 | 0.1301 | 0.1132 | 0.1601 | 0.2967 | 0.0385 |
| Average | 2.8097 | 0.1133 | 0.0824 | 0.1760 | 0.3451 | 0.0432 |
| Radar ID | PS (w/o Denoising) | FIR-PS | FIR-Kalman-PS | CNN | LSTM | CNN-LSTM (Ours) |
|---|---|---|---|---|---|---|
| 1# | 0.8002 | 0.2776 | 0.1130 | 0.2770 | 0.2082 | 0.0423 |
| 2# | 3.2089 | 0.1321 | 0.0640 | 0.2900 | 0.2384 | 0.0564 |
| 3# | 1.3763 | 0.1445 | 0.0738 | 0.2997 | 0.2458 | 0.0675 |
| 4# | 5.1337 | 0.2300 | 0.1145 | 0.2666 | 0.2853 | 0.0869 |
| 5# | 5.2721 | 0.2191 | 0.1033 | 0.2264 | 1.5000 | 0.0588 |
| 6# | 2.7862 | 0.3662 | 0.1235 | 0.2645 | 0.3404 | 0.0427 |
| 7# | 5.8500 | 0.2282 | 0.1317 | 0.2907 | 0.2509 | 0.0559 |
| 8# | 2.0667 | 0.2994 | 0.1438 | 0.2547 | 0.3605 | 0.0540 |
| Average | 3.5598 | 0.2371 | 0.1084 | 0.2712 | 0.4287 | 0.0581 |
| Radar ID | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| 1# | 98.33% | 98.36% | 99.98% | 99.16% |
| 2# | 98.84% | 98.97% | 99.86% | 99.42% |
| 3# | 97.97% | 98.14% | 99.81% | 98.97% |
| 4# | 94.48% | 96.08% | 97.67% | 96.87% |
| 5# | 89.07% | 88.05% | 99.99% | 93.64% |
| 6# | 95.83% | 95.41% | 99.81% | 97.56% |
| 7# | 95.62% | 96.14% | 98.85% | 97.48% |
| 8# | 97.08% | 96.88% | 99.90% | 98.37% |
| Average | 95.90% | 96.00% | 99.48% | 97.68% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Liu, Y.; Zhang, M.; Chen, X.; Li, J. Improving Stockline Detection of Radar Sensor Array Systems in Blast Furnaces Using a Novel Encoder–Decoder Architecture. Sensors 2019, 19, 3470. https://doi.org/10.3390/s19163470
Liu X, Liu Y, Zhang M, Chen X, Li J. Improving Stockline Detection of Radar Sensor Array Systems in Blast Furnaces Using a Novel Encoder–Decoder Architecture. Sensors. 2019; 19(16):3470. https://doi.org/10.3390/s19163470
Chicago/Turabian StyleLiu, Xiaopeng, Yan Liu, Meng Zhang, Xianzhong Chen, and Jiangyun Li. 2019. "Improving Stockline Detection of Radar Sensor Array Systems in Blast Furnaces Using a Novel Encoder–Decoder Architecture" Sensors 19, no. 16: 3470. https://doi.org/10.3390/s19163470
APA StyleLiu, X., Liu, Y., Zhang, M., Chen, X., & Li, J. (2019). Improving Stockline Detection of Radar Sensor Array Systems in Blast Furnaces Using a Novel Encoder–Decoder Architecture. Sensors, 19(16), 3470. https://doi.org/10.3390/s19163470