Deep Learning-Based Real-Time Multiple-Object Detection and Tracking from Aerial Imagery via a Flying Robot with GPU-Based Embedded Devices


Abstract
:1. Introduction
2. Hardware Development of the Drone Framework
2.1. Technical Specifications of Different Embedded Devices Used for Target Detection and Tracking
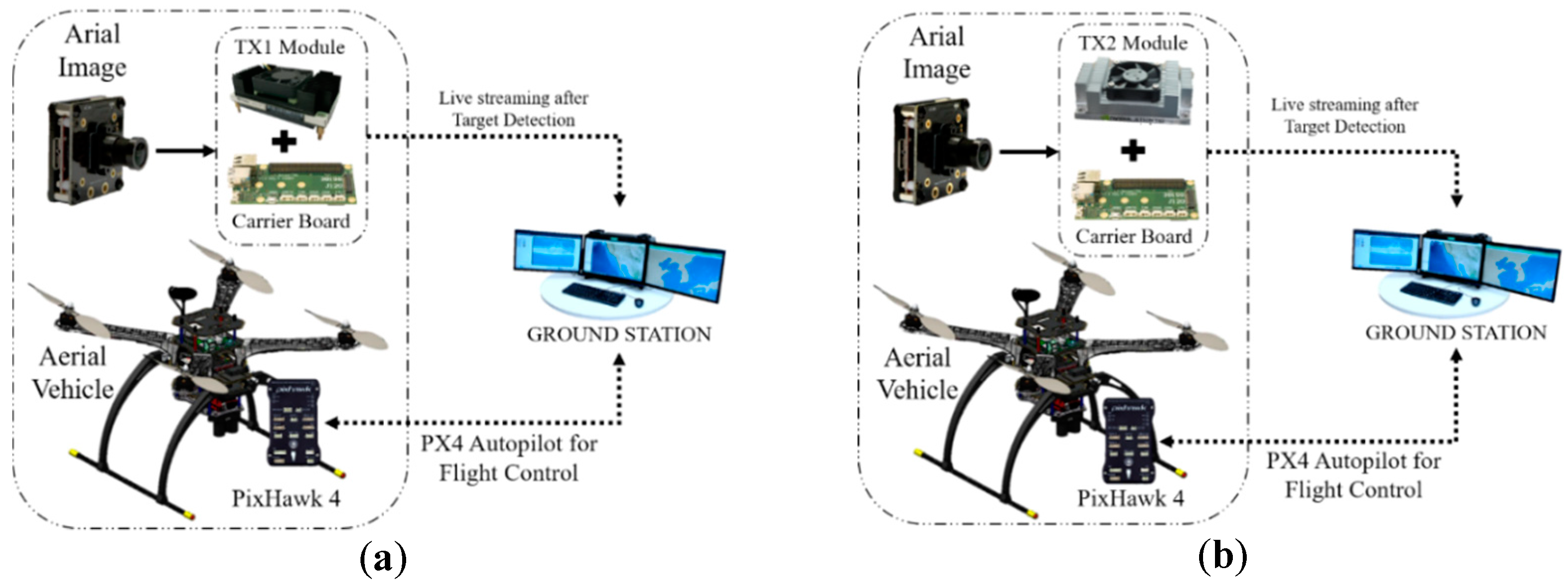
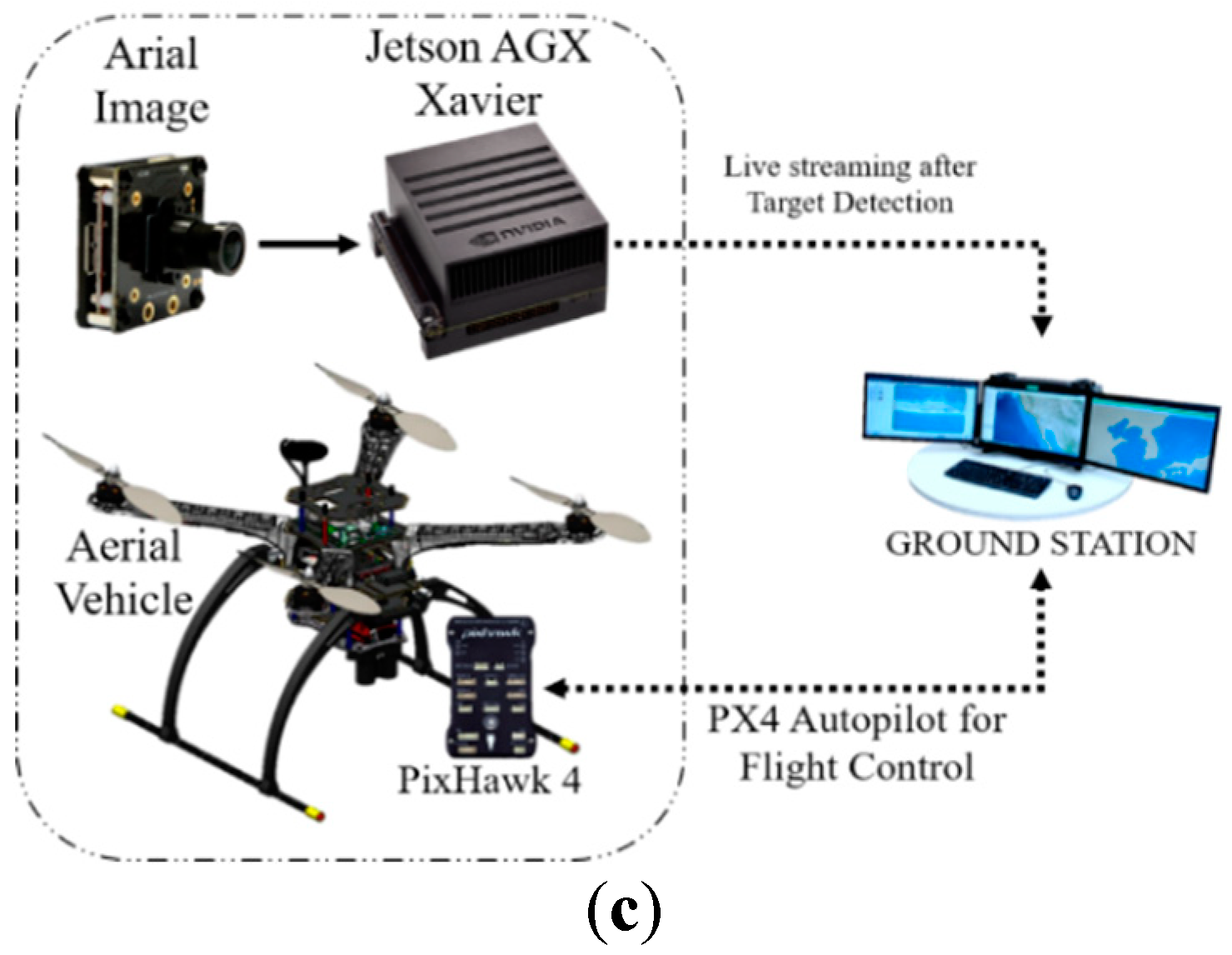
2.1.1. NVidia Jetson Modules (TX1, TX2, and AGX Xavier)
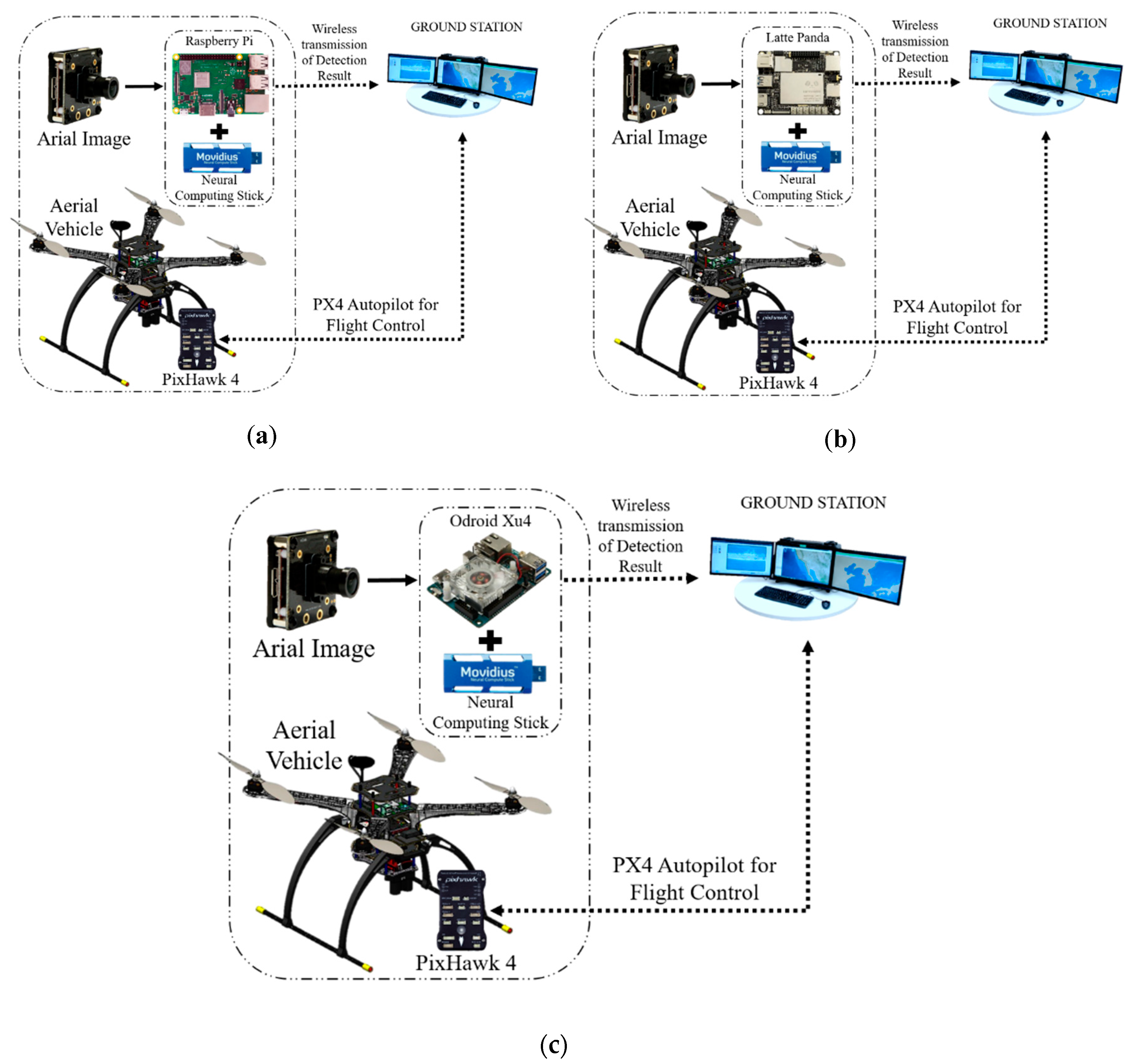
2.1.2. GPU-Constraint Devices (Raspberry Pi 3, Latte Panda, and Odroid Xu4)
2.1.3. Movidius Neural Computing Sticks
- The tool in NCSDK can be used for profiling, tuning, and compiling a DNN model on the host system.
- NCAPI can be used to access the neural computing device hardware to accelerate DNN inferences by prototyping a user application on the host system.
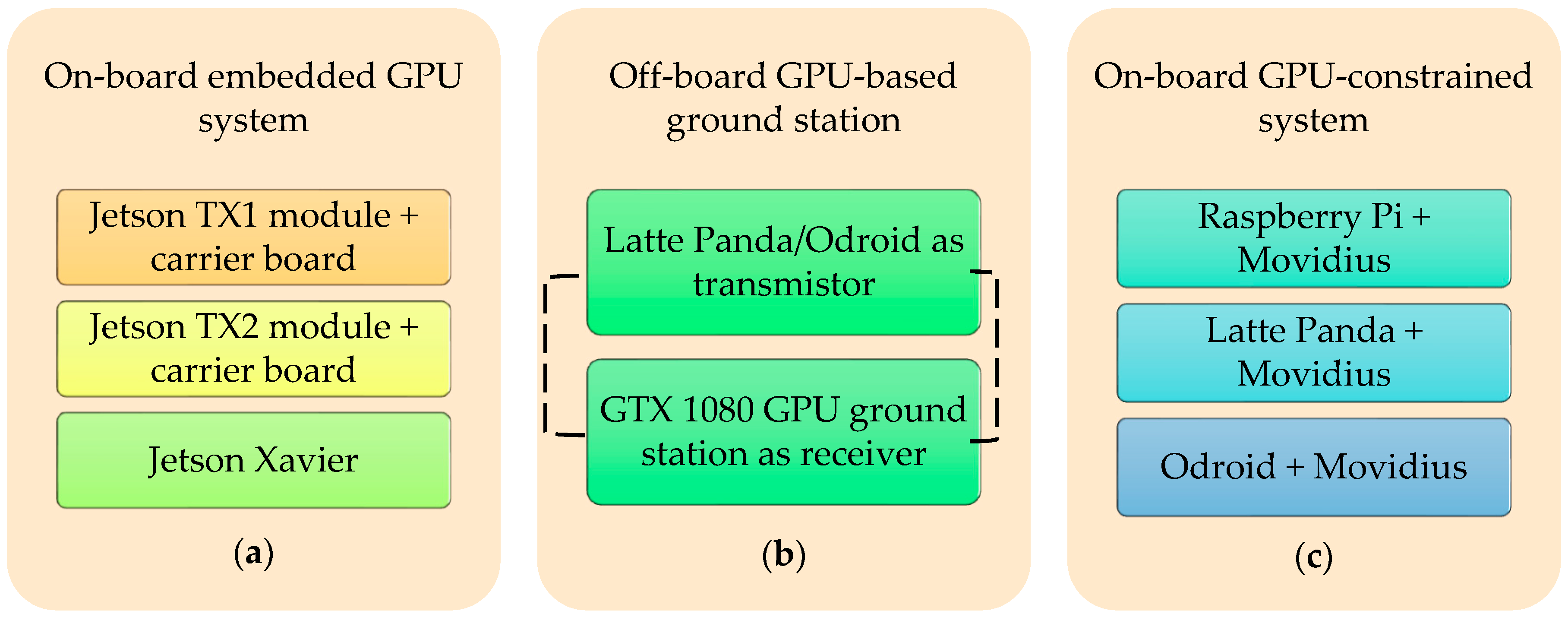
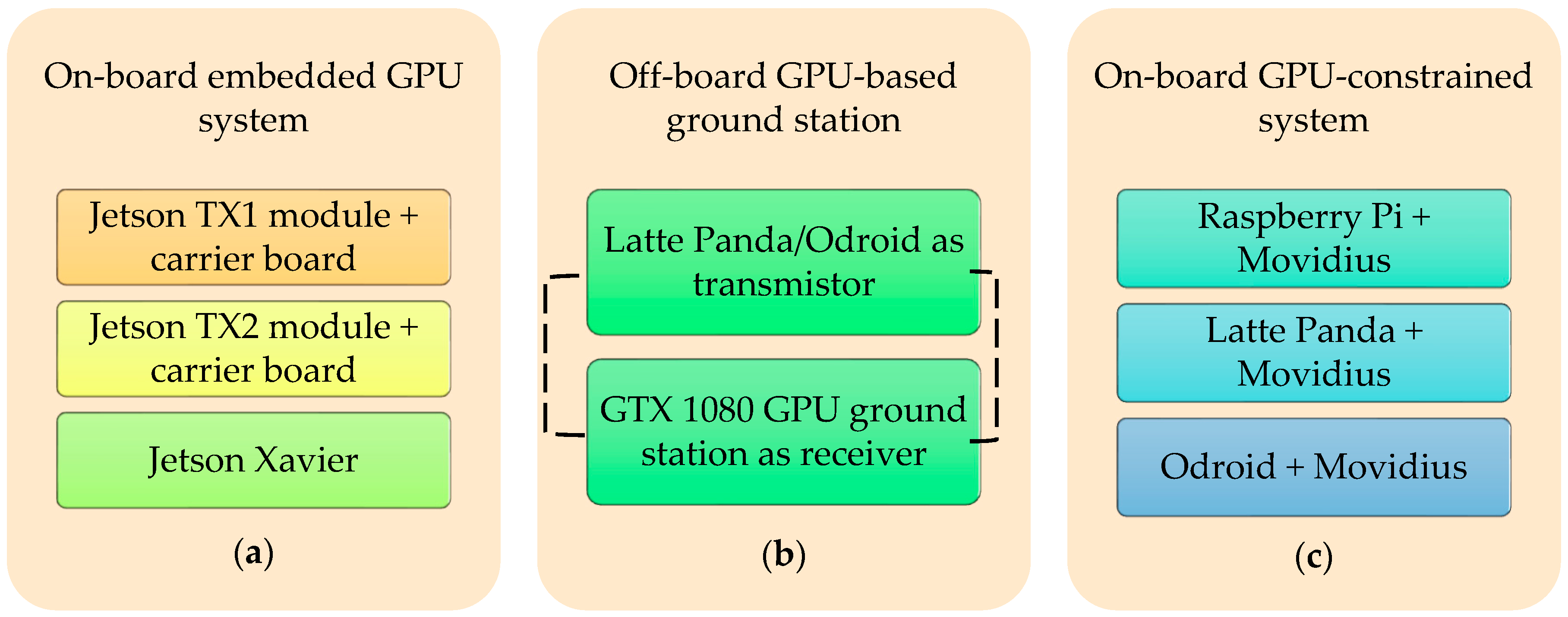
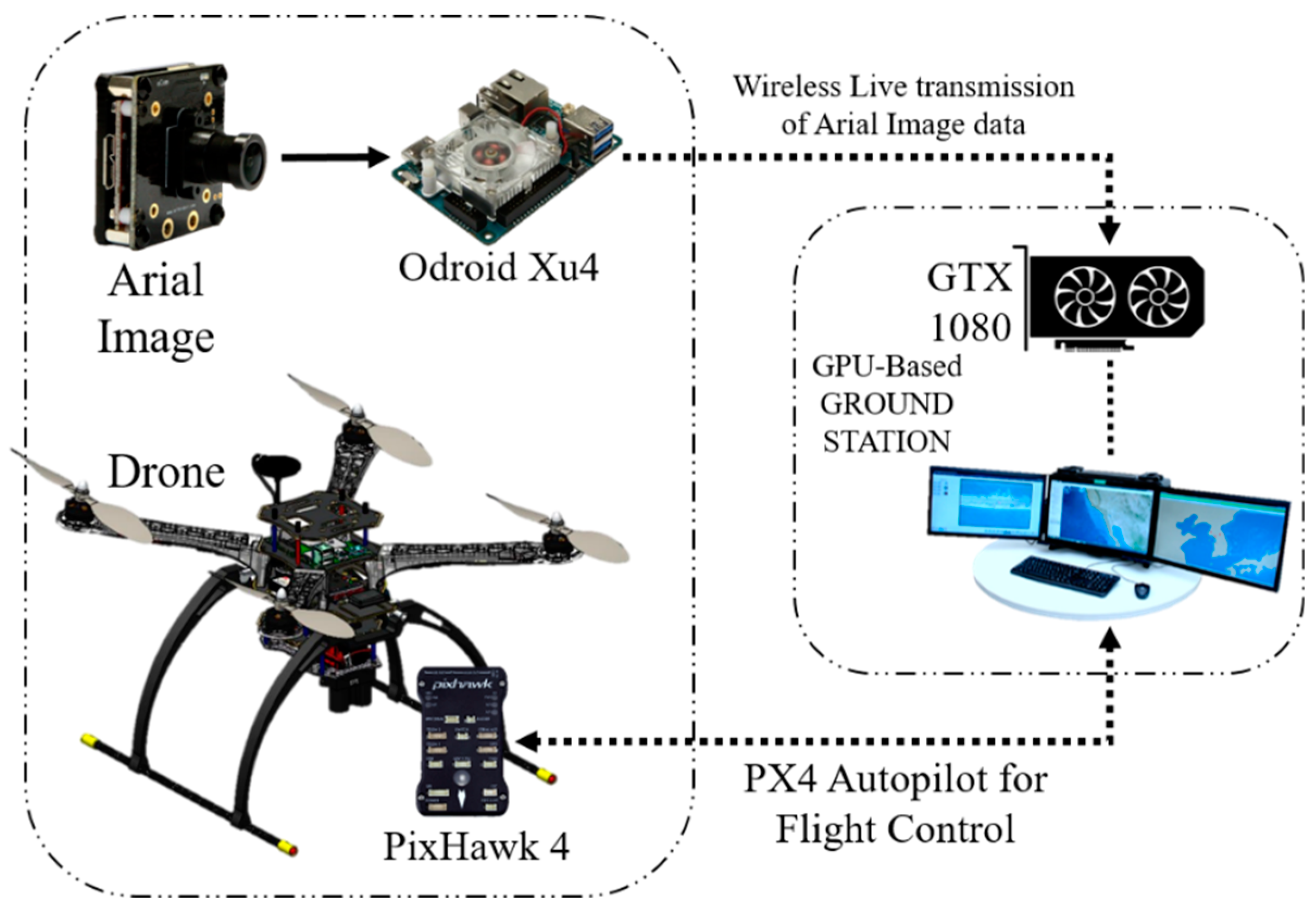
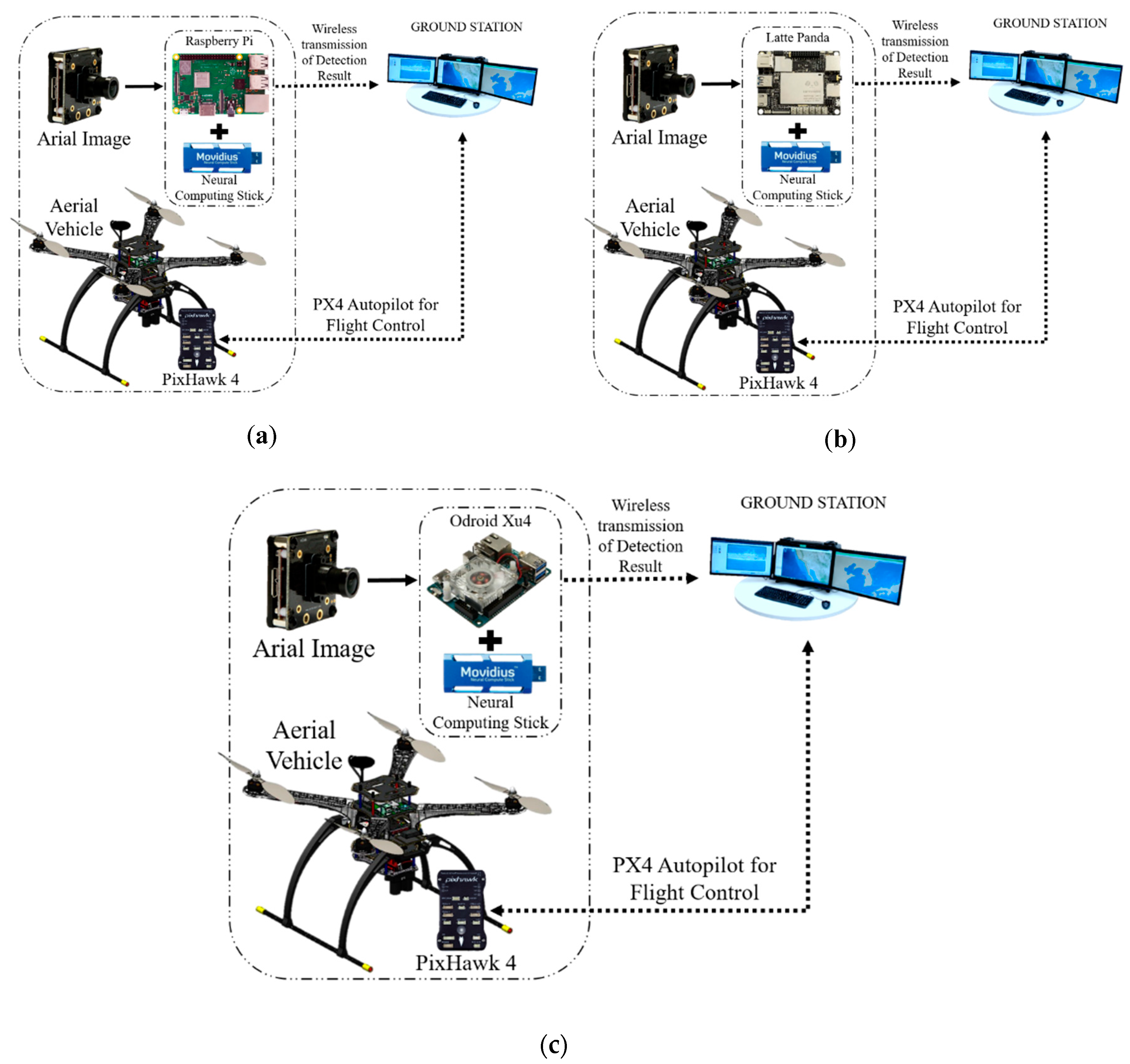
2.2. The Architecture of the Developed Embedded System
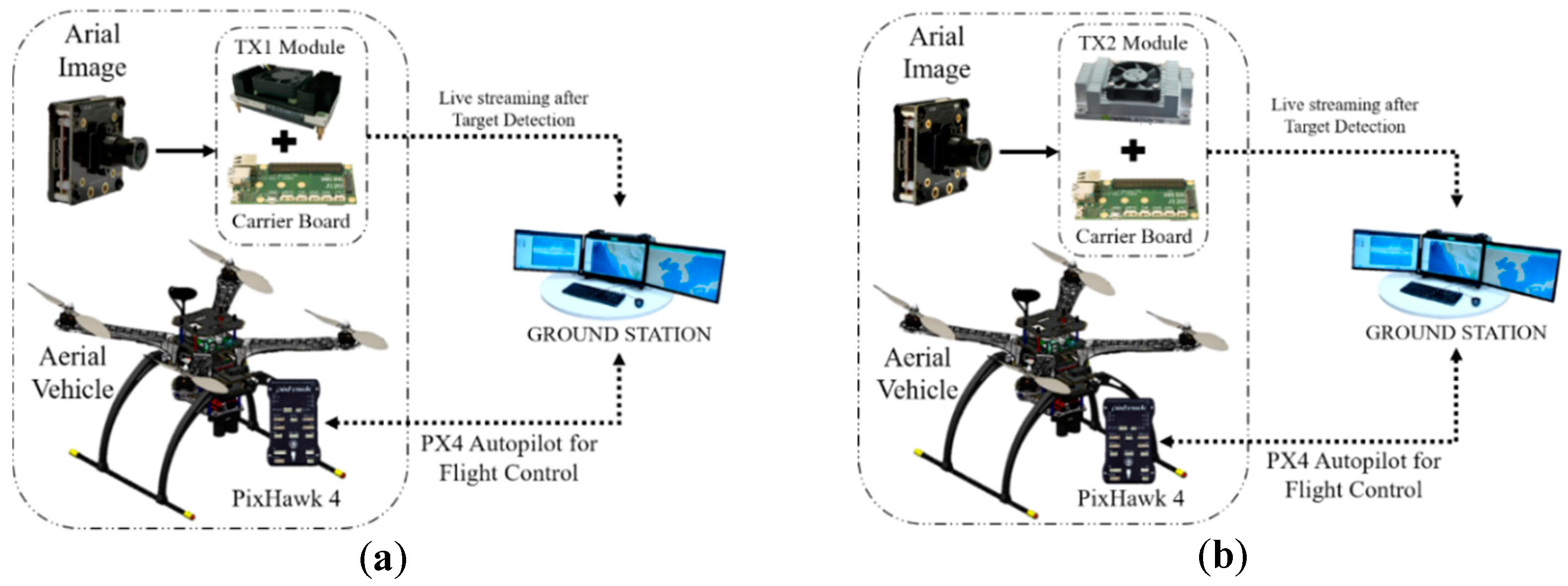
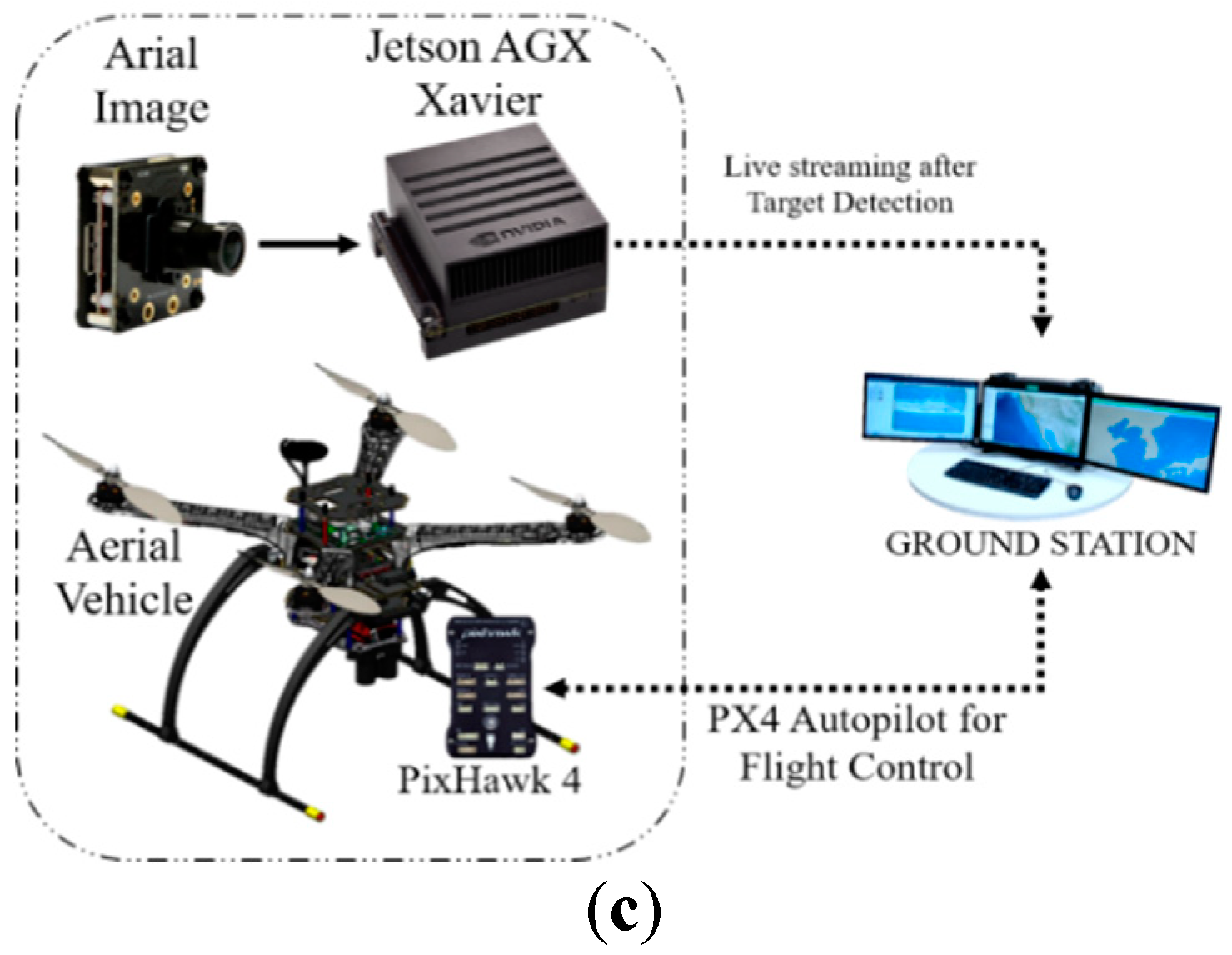
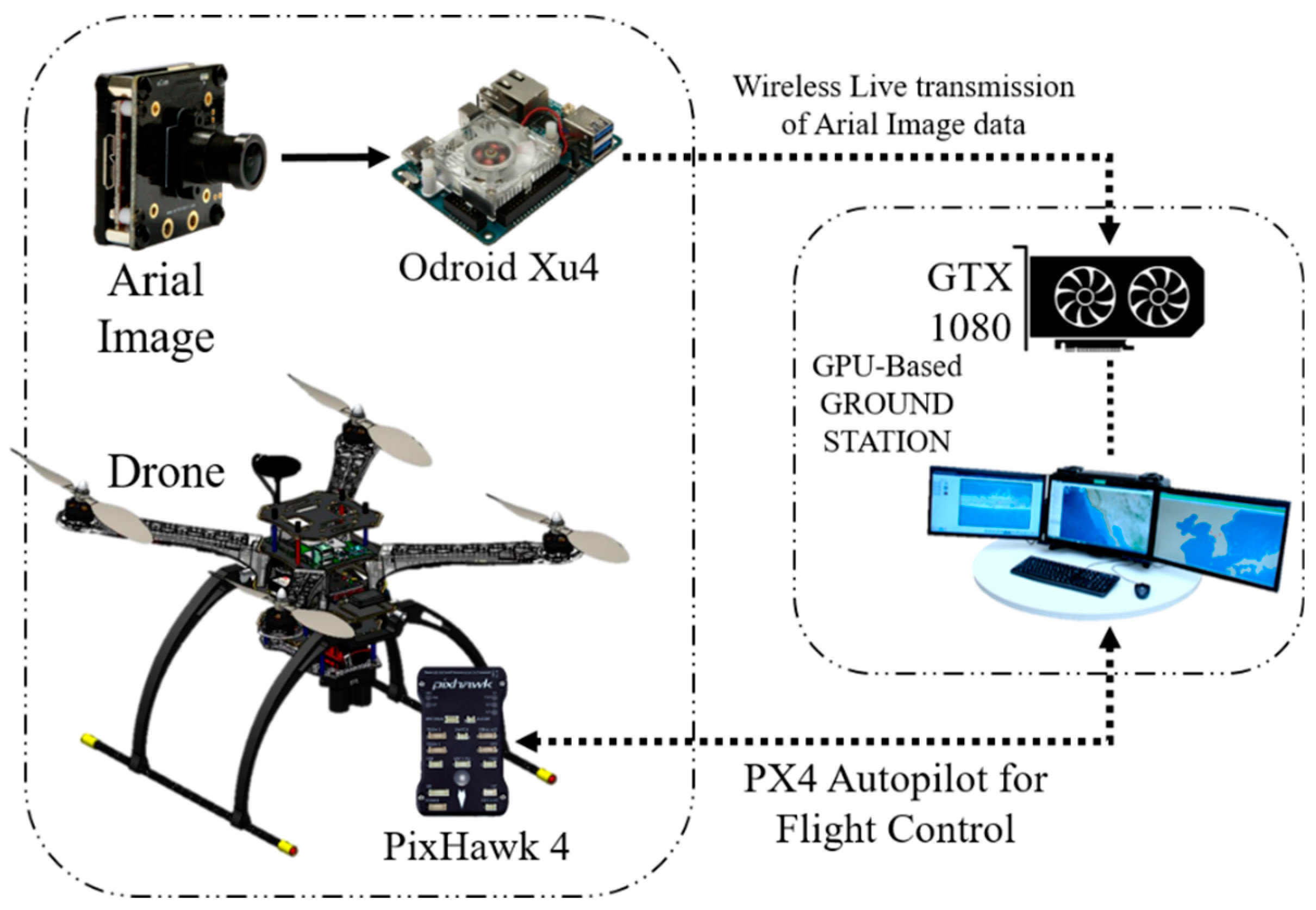
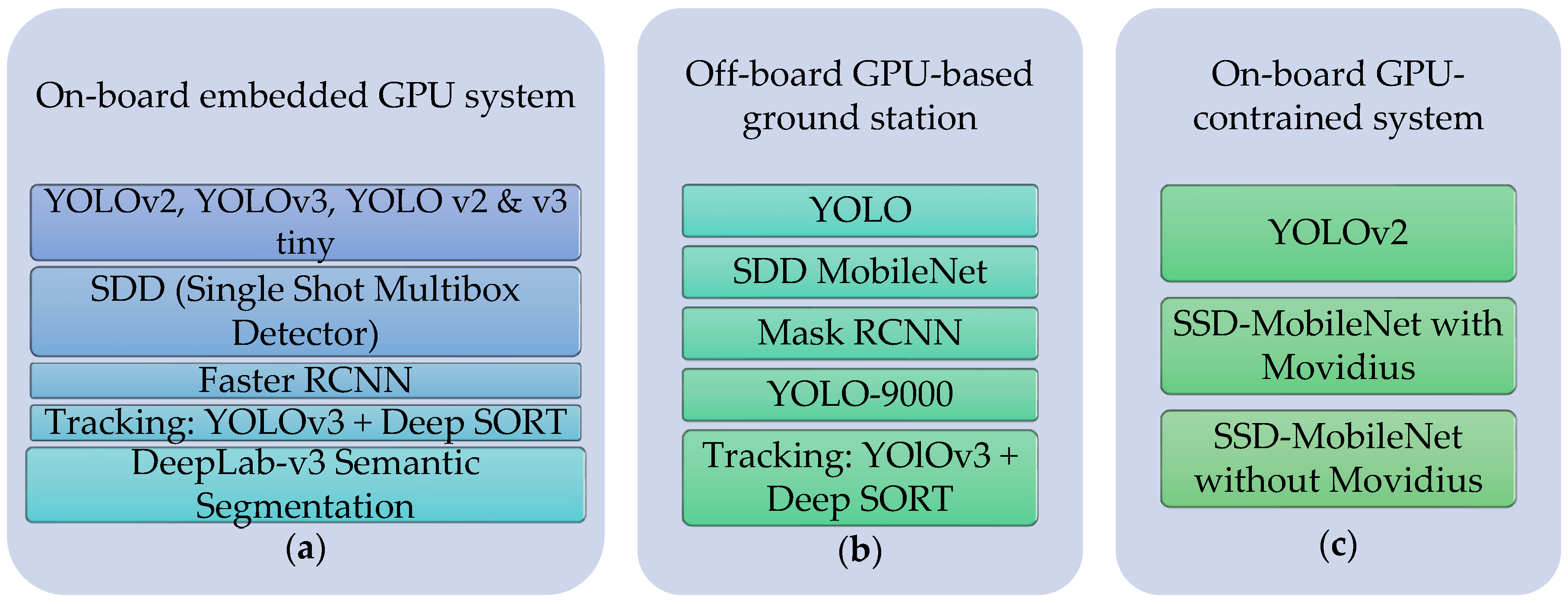
2.2.1. On-Board GPU System
2.2.2. Off-Board GPU-Based Ground Station
2.2.3. On-Board GPU-Constrained System
2.3. Python Socket Server to Send an Image to the GPU-Based Ground Station
3. Implemented Object Detection Algorithm in the Drone System
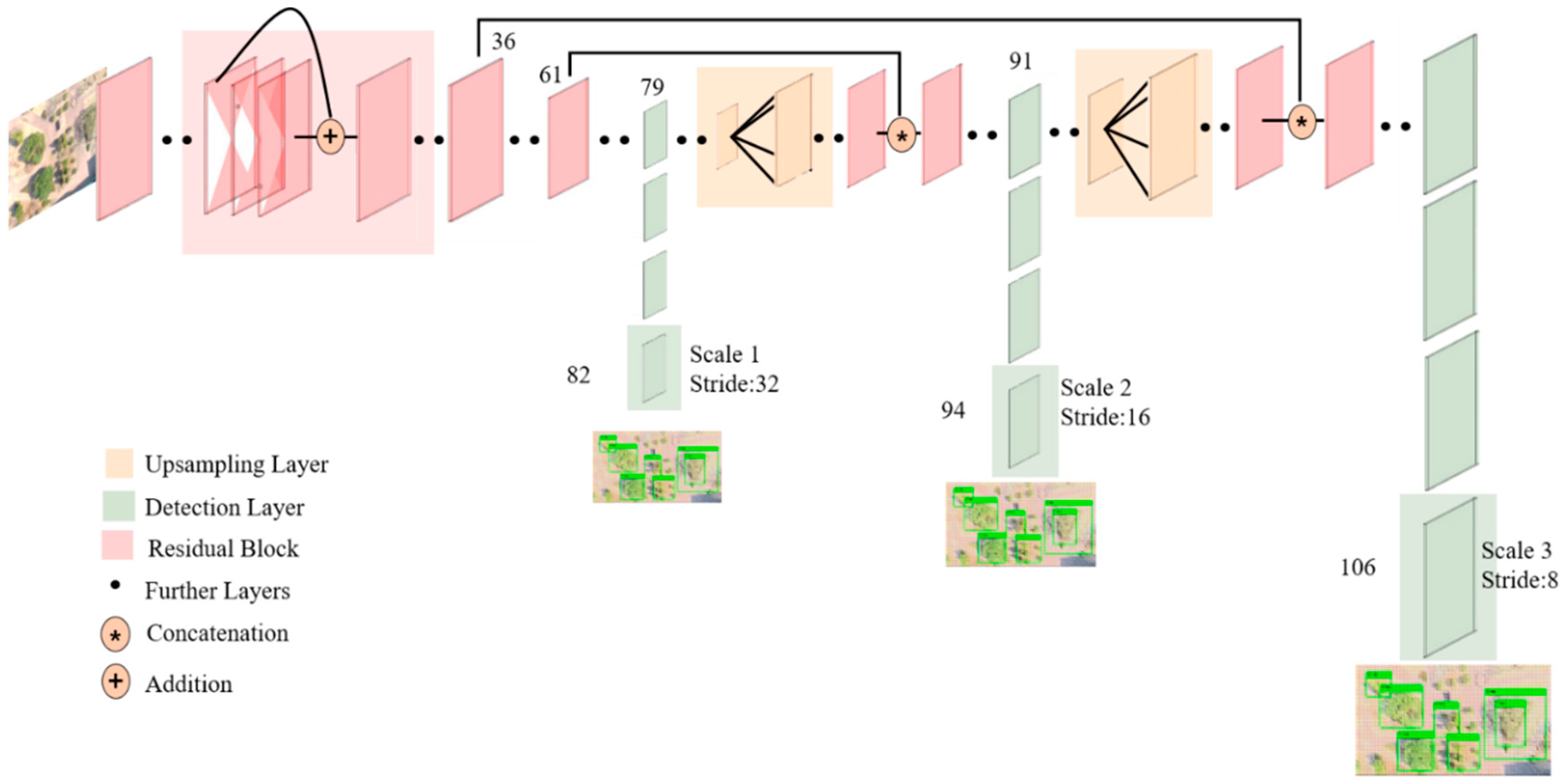
3.1. You Only Look Once: Real-Time Object Detection
3.1.1. YOLOv2
- The fully-connected layers that are responsible for predicting the boundary box were removed.
- One pooling layer was removed to make the spatial output of the network be 13 × 13 instead of 7 × 7.
- The class prediction was moved from the cell level to the boundary box level. Now, each prediction had four parameters for the boundary box [39].
- The input image size was changed from 448 × 448 to 416 × 416. This created odd-numbered spatial dimensions (7 × 7 vs. 8 × 8 grid cell). The center of a picture is often occupied by a large object. With an odd number of grid cells, it is more certain where the object belongs [39].
- The last convolution layer was replaced with three 3 × 3 convolutional layers, each outputting 1024 output channels to generate predictions with dimensions of 7 × 7 × 125. Then, a final 1 × 1 convolutional layer was applied to convert the 7 × 7 × 1024 output to 7 × 7 × 125 [39].
3.1.2. YOLOv3
3.1.3. YOLOv2 Tiny and YOLOv3 Tiny
3.1.4. YOLO-9000
- Batch normalization: Batch normalization was used in all convolutional layers, which helped to obtain more than 2% improvement in mAP (mean average precision).
- High-resolution classifier: The classification network was fine-tuned on 448 × 448 images instead of trained with 224 × 224 images. This helped the network perform better at higher resolution. This high-resolution classification network gave an increase of almost 4% mAP.
- Convolutional with anchor boxes: In YOLOv2, anchor boxes are adopted while removing all fully-connected layer. One pooling layer was removed to increase the resolution of the image output. This enabled more boxes to be generated, which improved the recall from 81% (69.5 mAP) to 88% (69.2 mAP) [40].
- Direct location prediction: Prediction becomes easier if the location is constrained or limited. YOLO9000 predicts location coordinates relative to the location of the grid cell, which bounds the ground truth to fall between zero and one. It does not make predictions by using the offset to the center of the bounding box [44].
- Fine-grained features: A pass-through layer was included like ResNet to use fine-grained features for localizing smaller objects.
- Multi-scale training: The same network can predict at different resolutions if a dataset with different resolutions is utilized while training the network. That means that the network can make predictions from a variety of input dimensions.
- Instead of using VGG-16, a custom network of 19 convolutional layers and five max-pooling layers was used. The custom network that used by the YOLO framework is called Darnet-19 [45].
- Hierarchical classification: To build a hierarchical prediction, several nodes were inserted. A semantic category was defined for each node at a level. Therefore, different objects in one image can be amalgamated into one label since they were from one higher level semantic label.
- Joint classification and detection: For training a large-scale detector, two types of datasets were used. a traditional classification dataset that contained a large number of categories and a detection dataset [45].
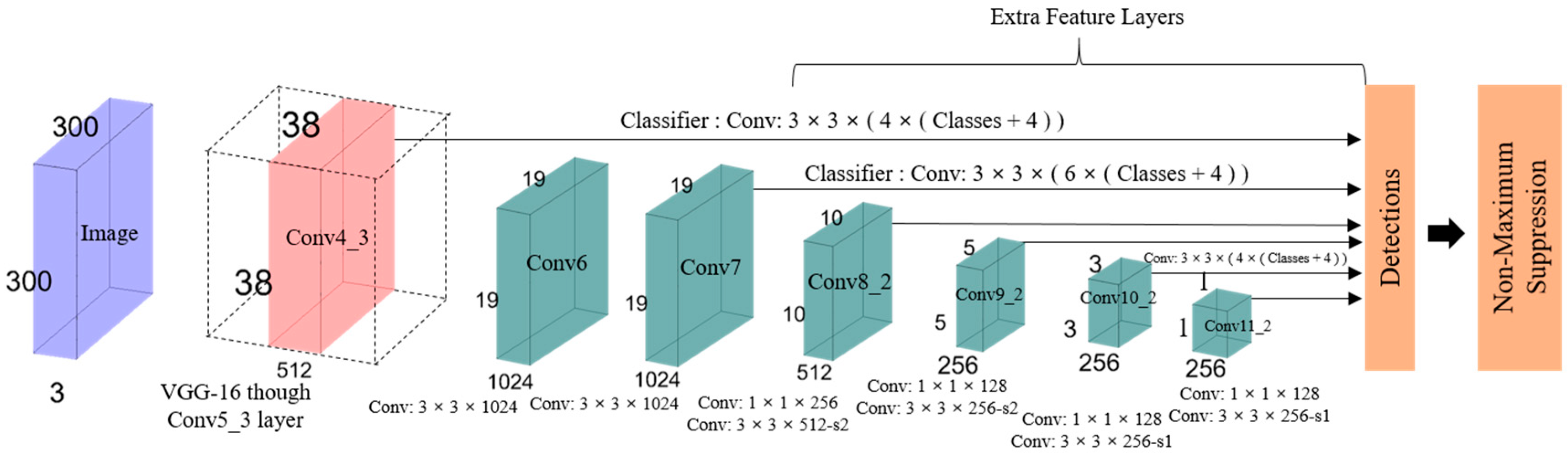
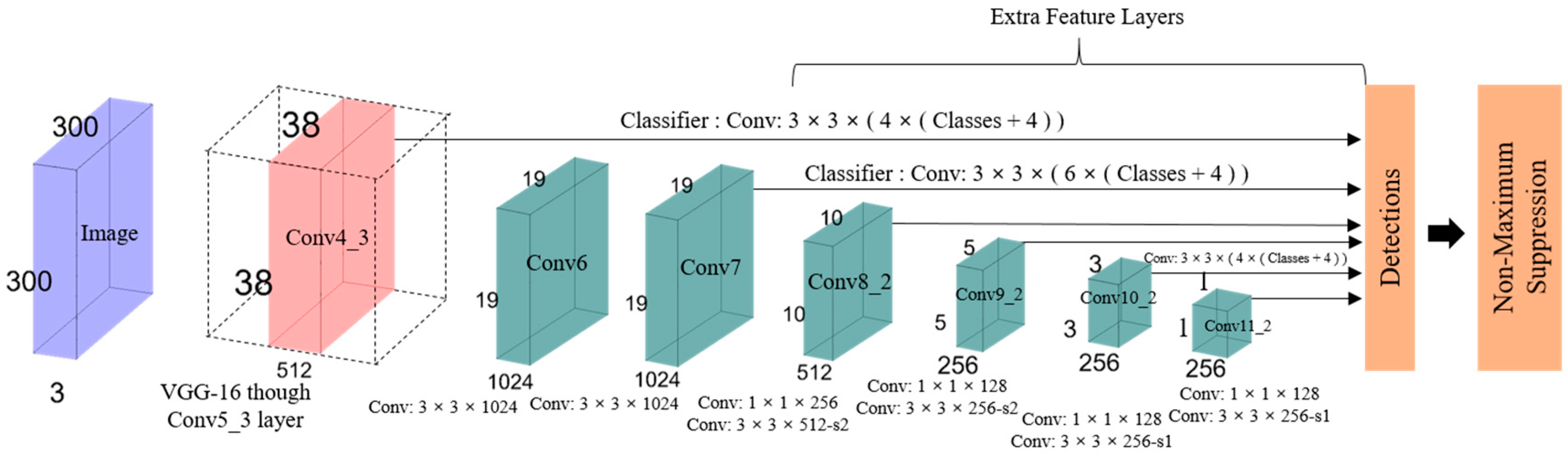
3.2. SSD: Single-Shot MultiBox Detector
- Single shot: The tasks of object localization and classification are executed in a single forward pass of the network.
- Detector: The classification of a detected object is performed by the network, which is called the object detector.
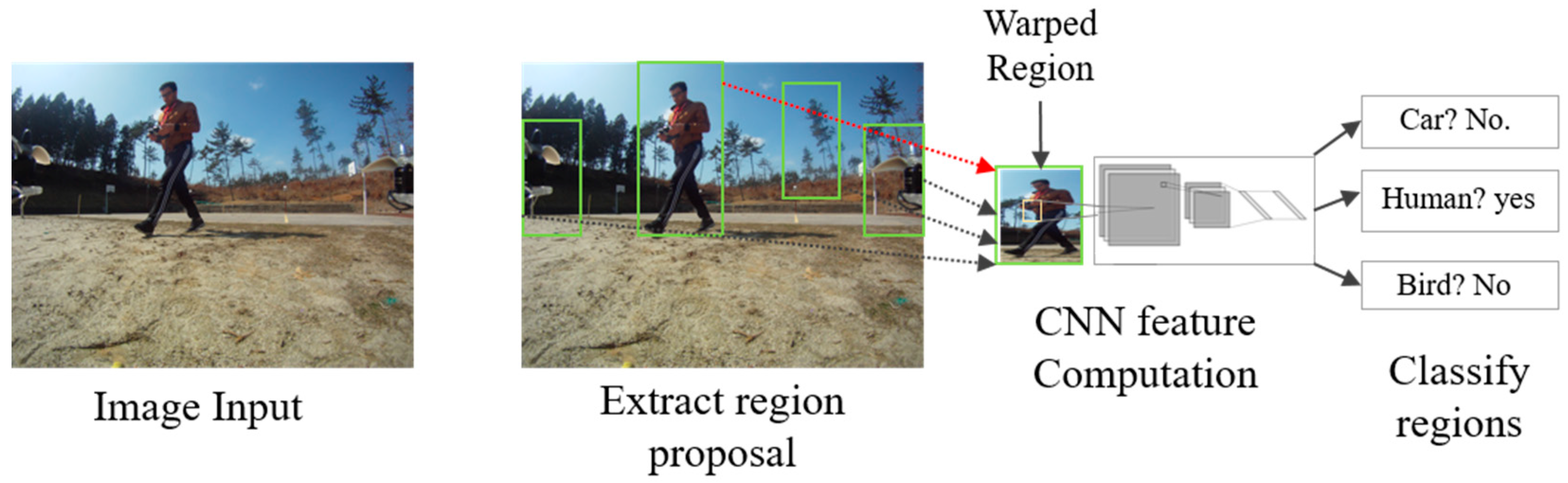
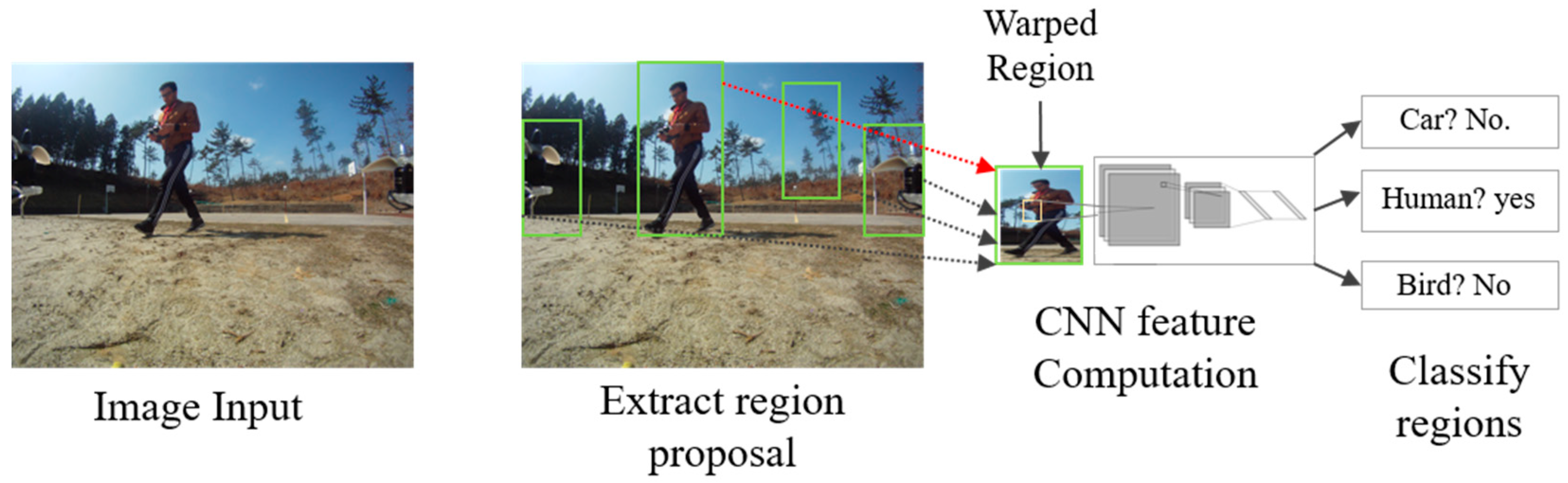
3.3. Region-Based Convolutional Network Method for Object Detection
3.3.1. Faster R-CNN
3.3.2. Mask R-CNN
3.4. DeepLab-v3 Semantic Segmentation
4. Implemented Target Tracking Algorithm in the Drone System
4.1. Deep Sort Using YOLOv3.
| Algorithm 1. Matching cascade. | |
| Input: Track indices , detection indices , maximum age | |
| 1: | Compute cost matrix using Equation (1) |
| 2: | Compute gate matrix using Equation (2) |
| 3: | Initialize the set of matches |
| 4: | Initialize the set of unmatched detections |
| 5: | fordo |
| 6: | Select tracks by age |
| 7: | ← min cost matching |
| 8: | |
| 9: | |
| 10: | end for |
| 11: | return |
4.2. Guiding the UAV toward the Target Using YOLOv2
| Algorithm 2. Following target. | |
| Input: Class for person , area of the bounding box , maximum area = constant, center of the whole image | |
| Output:, | |
| 1: | Look for target |
| 2: | ifthen |
| 3: | if then |
| 4: | Calculate and |
| 5: | |
| 6: | |
| 7: | Repeat Step 5 until , and use for yaw angle |
| 8: | Repeat Step 6 until , and use for forwarding velocity |
| 9: | end if |
| 10: | else |
| 11: | Do nothing |
| 12: | end if |
5. Results
5.1. Detection Results with Classification from the Drone Using the On-Board GPU System
5.2. Detection Results with Classification from the Drone Using the GPU-Based Ground System
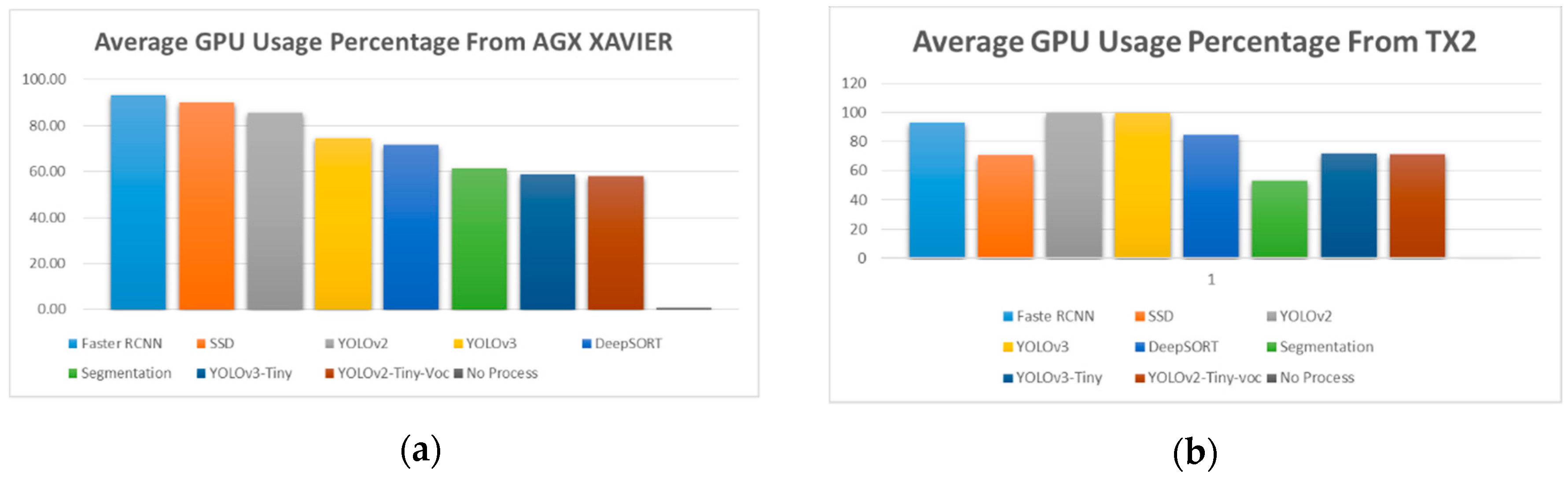
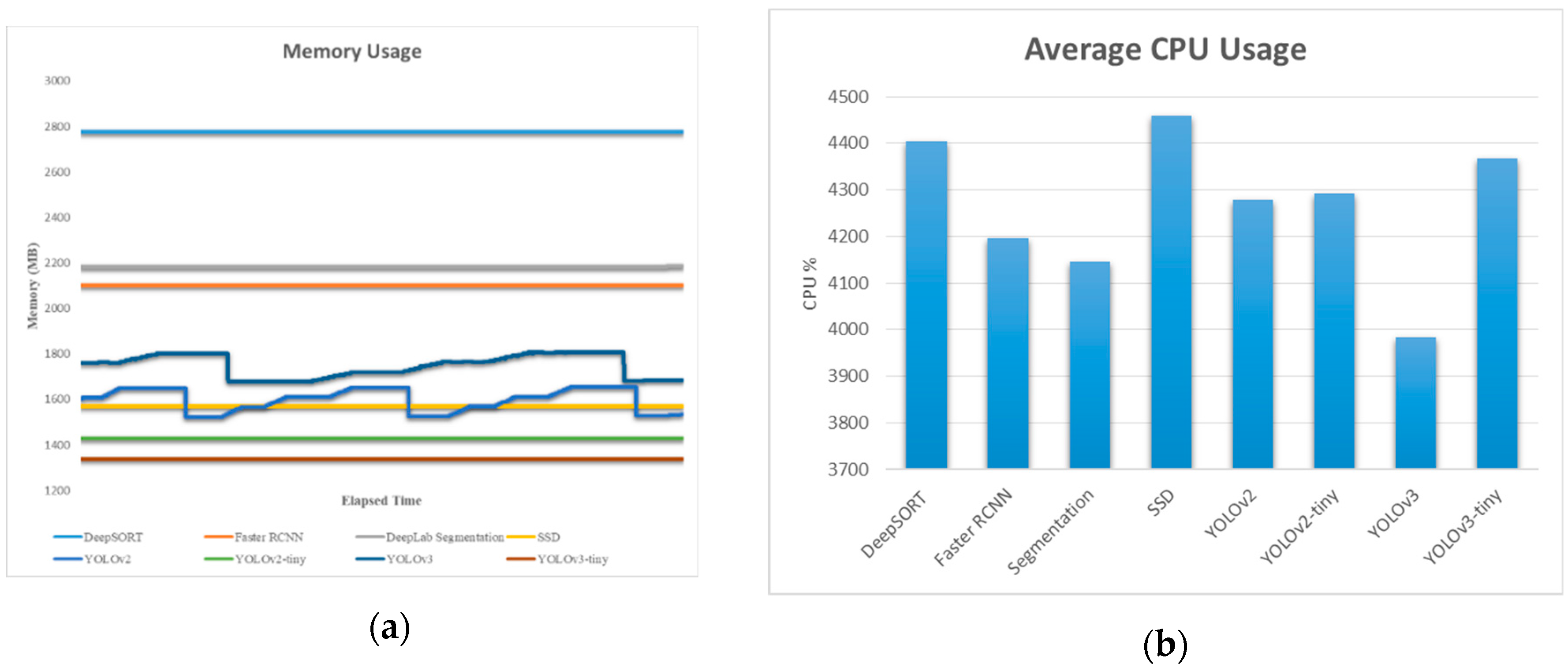
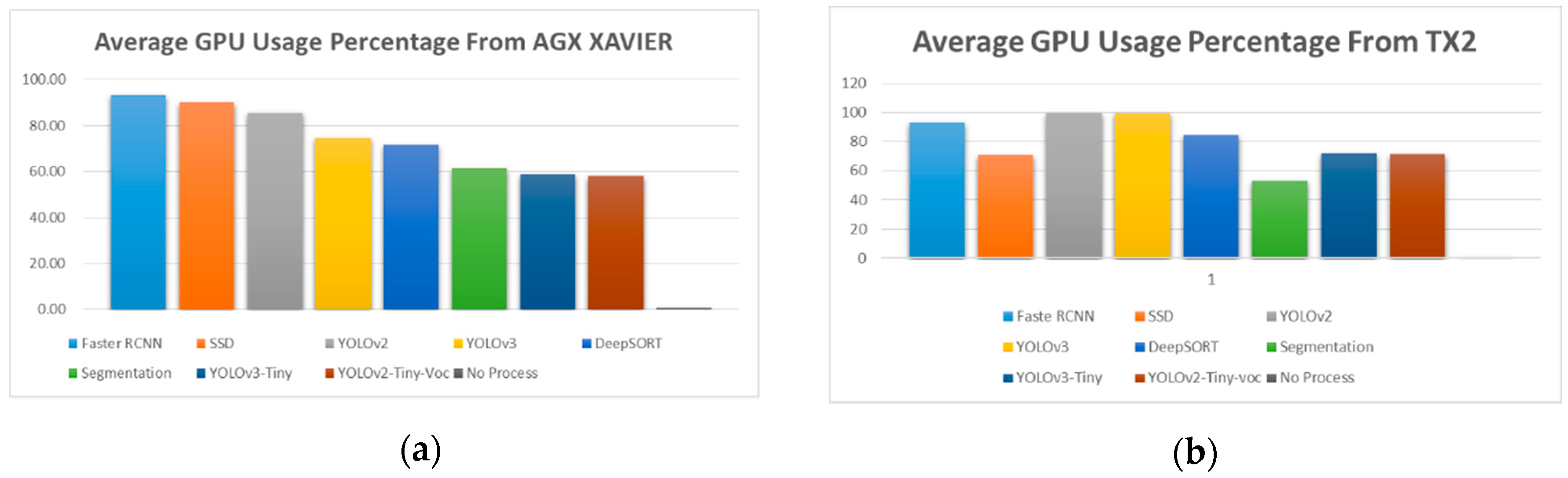
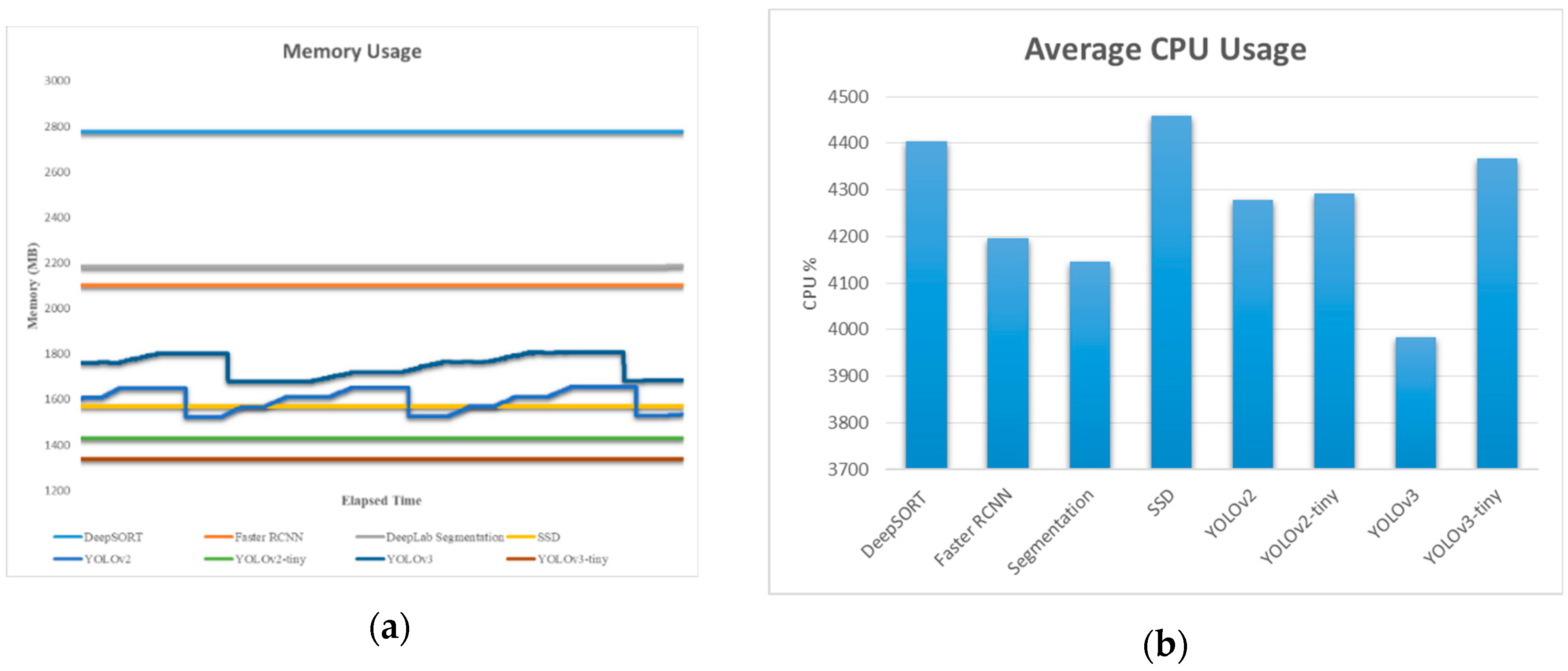
5.3. Performance Results between On-Board and Off-Board System
5.4. Deep SORT Tracking Result Using Xavier and the Off-Board GPU-Based Ground System
5.5. The Object Detection Result of the On-Board GPU-Constrained System
5.6. Performance Results of the On-Board GPU-Constrained System
5.7. Monitored Result of Power Consumption
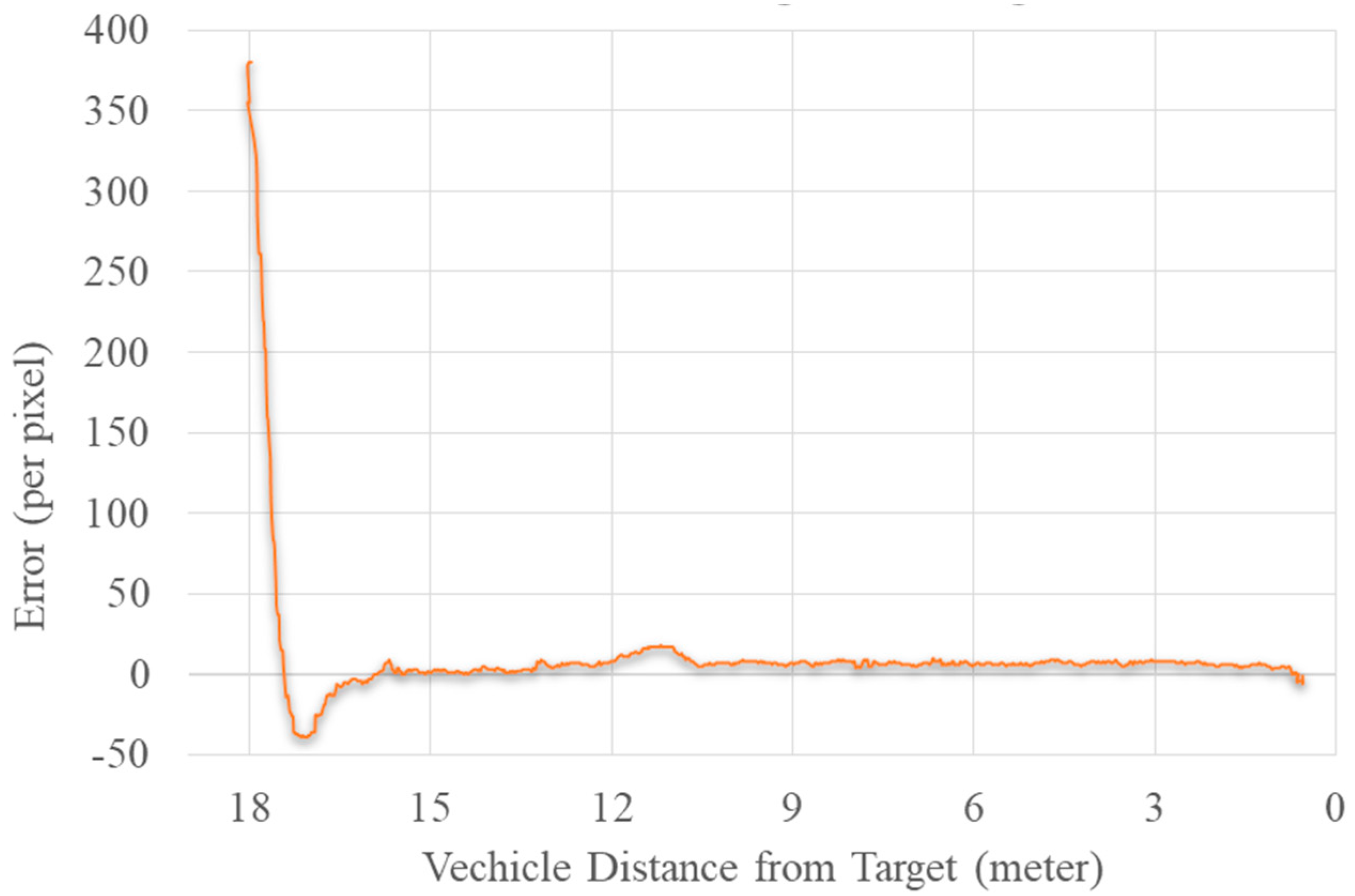
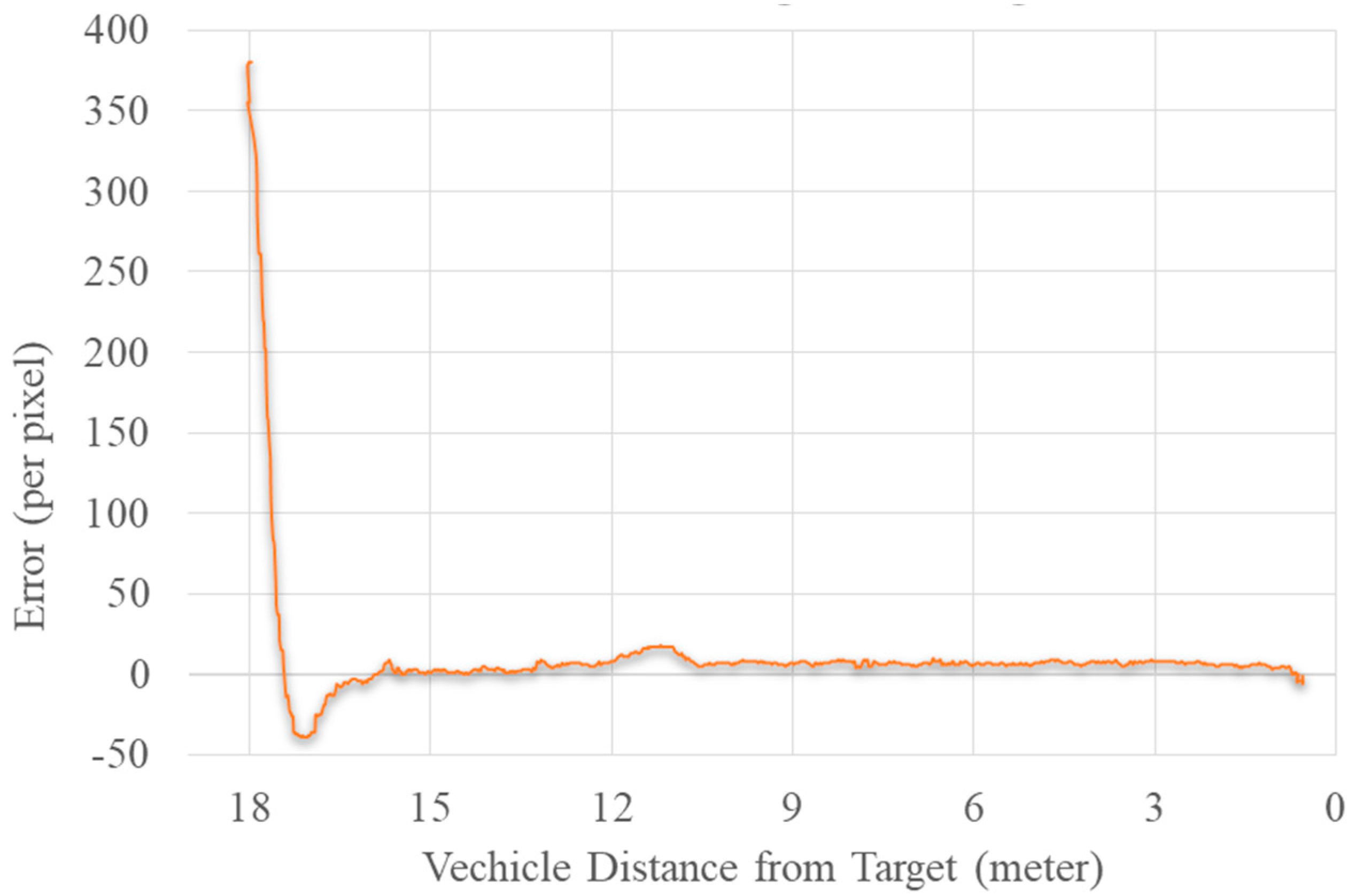
5.8. Guiding the UAV toward the Target
6. Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yoon, Y.; Gruber, S.; Krakow, L.; Pack, D. Autonomous target detection and localization using cooperative unmanned aerial vehicles. In Optimization and Cooperative Control Strategies; Springer: Berlin/Heidelberg, Germany, 2009; pp. 195–205. [Google Scholar]
- Gietelink, O.; Ploeg, J.; De Schutter, B.; Verhaegen, M. Development of advanced driver assistance systems with vehicle hardware-in-the-loop simulations. Veh. Syst. Dyn. 2006, 44, 569–590. [Google Scholar] [CrossRef]
- Geronimo, D.; Lopez, A.M.; Sappa, A.D.; Graf, T. Survey of pedestrian detection for advanced driver assistance systems. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1239–1258. [Google Scholar] [CrossRef] [PubMed]
- Ferguson, D.; Darms, M.; Urmson, C.; Kolski, S. Detection, prediction, and avoidance of dynamic obstacles in urban environments. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 1149–1154. [Google Scholar]
- Hirz, M.; Walzel, B. Sensor and object recognition technologies for self-driving cars. Comput.-Aided Des. Appl. 2018, 15, 501–508. [Google Scholar] [CrossRef]
- Pathak, A.R.; Pandey, M.; Rautaray, S. Application of Deep Learning for Object Detection. Procedia Comput. Sci. 2018, 132, 1706–1717. [Google Scholar] [CrossRef]
- Puri, A. A Survey of Unmanned Aerial Vehicles (UAV) for Traffic Surveillance; Department of Computer Science and Engineering, University of South Florida: Tampa, FL, USA, 2005; pp. 1–29. [Google Scholar]
- Hinas, A.; Roberts, J.; Gonzalez, F. Vision-based target finding and inspection of a ground target using a multirotor UAV system. Sensors 2017, 17, 2929. [Google Scholar] [CrossRef] [PubMed]
- Tijtgat, N.; Van Ranst, W.; Goedeme, T.; Volckaert, B.; De Turck, F. Embedded real-time object detection for a UAV warning system. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2110–2118. [Google Scholar]
- Han, S.; Shen, W.; Liu, Z. Deep Drone: Object Detection and Tracking for Smart Drones on Embedded System; Stanford University: Stanford, CA, USA, 2016. [Google Scholar]
- Wang, X. Deep learning in object recognition, detection, and segmentation. Found. Trends® Signal Process. 2016, 8, 217–382. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Nvidia Embedded Systems for Next-Generation Autonomous Machines. NVidia Jetson: The AI Platform for Autonomous Everything. Available online: https://www.nvidia.com/en-gb/autonomous-machines/embedded-systems/ (accessed on 27 February 2019).
- Raspberry Pi 3. Available online: www.raspberrypi.org/products/ (accessed on 27 February 2019).
- LattePanda 4G/64G. Available online: www.lattepanda.com/products/3.html (accessed on 27 February 2019).
- Hardkernel Co., Ltd: ODROID-XU4 User Manual. Available online: magazine.odroid.com/odroid-xu4/ (accessed on 27 February 2019).
- Intel Intel® MovidiusTM Neural Compute Stick. Available online: https://movidius.github.io/ncsdk/ncs.html (accessed on 27 February 2019).
- Nvidia GeForce GTX 1080. Available online: http://www.geforce.co.uk/hardware/10series/geforce-gtx-1080/ (accessed on 27 February 2019).
- Nvidia Meet Jetson, the Platform for AI at the Edge. Available online: https://developer.nvidia.com/embedded-computing (accessed on 3 March 2019).
- Jetson TX1 Module. Available online: https://developer.nvidia.com/embedded/buy/jetson-tx1 (accessed on 3 March 2019).
- Jetson TX2. Available online: www.nvidia.com/en-gb/autonomous-machines/embedded-systems/jetson-tx2/ (accessed on 3 March 2019).
- NVidia JETSON AGX XAVIER: The AI Platform for Autonomous Machines. Available online: www.nvidia.com/en-us/autonomous-machines/jetson-agx-xavier/ (accessed on 3 March 2019).
- Jetson AGX Xavier Developer Kit. Available online: developer.nvidia.com/embedded/buy/jetson-agx-xavier-devkit (accessed on 3 March 2019).
- NVidia Jetson AGX Xavier Delivers 32 TeraOps for New Era of AI in Robotics. Available online: devblogs.nvidia.com/nvidia-jetson-agx-xavier-32-teraops-ai-robotics/ (accessed on 3 March 2019).
- Raspberry Pi. Available online: en.wikipedia.org/wiki/Raspberry_Pi (accessed on 3 March 2019).
- What is a Raspberry Pi? Available online: opensource.com/resources/raspberry-pi (accessed on 3 March 2019).
- Raspbian. Available online: www.raspberrypi.org/downloads/raspbian/ (accessed on 4 March 2019).
- Latte Panda 4G/64G. Available online: www.lattepanda.com/products/3.html (accessed on 4 March 2019).
- Lubuntu: Welcome to the Next Universe. Available online: lubuntu.me (accessed on 3 March 2019).
- ODROID-XU4. Available online: wiki.odroid.com/odroid-xu4/odroid-xu4 (accessed on 4 March 2019).
- ODROID-XU4 Manual. Available online: magazine.odroid.com/odroid-xu4 (accessed on 4 March 2019).
- NCSDK Documentation. Available online: movidius.github.io/ncsdk/ (accessed on 4 March 2019).
- Adding AI to the Raspberry Pi with the Movidius Neural Compute Stick. Available online: www.bouvet.no/bouvet-deler/adding-ai-to-edge-devices-with-the-movidius-neural-compute-stick (accessed on 4 March 2019).
- Rhodes, B.; Goerzen, J. Foundations of Python Network Programming; Springer: Berlin, Germany, 2014; ISBN 9781430230038. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019. [Google Scholar] [CrossRef] [PubMed]
- Hui, J. Real-Time Object Detection with YOLO, YOLOv2 and Now YOLOv3. Available online: medium.com/@jonathan_hui/real-time-object-detection-with-YOLO-YOLOv2-28b1b93e2088 (accessed on 24 February 2019).
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Kathuria, A. What’s new in YOLO v3? Available online: towardsdatascience.com/YOLO-v3-object-detection-53fb7d3bfe6b (accessed on 24 February 2019).
- Redmon, J. Darknet: Open Source Neural Networks in C 2013. 2016. [Google Scholar]
- Tsang, S.-H. Review: YOLOv2 & YOLO9000—You Only Look Once (Object Detection). Available online: towardsdatascience.com/review-YOLOv2-YOLO9000-you-only-look-once-object-detection-7883d2b02a65 (accessed on 24 February 2019).
- Li, J. Reading Note: YOLO9000: Better, Faster, Stronger. Available online: joshua19881228.github.io/2017-01-11-YOLO9000/ (accessed on 24 February 2019).
- Gao, H. Understand Single Shot MultiBox Detector (SSD) and Implement It in Pytorch. Available online: medium.com/@smallfishbigsea/understand-ssd-and-implement-your-own-caa3232cd6ad (accessed on 25 February 2019).
- Forson, E. Understanding SSD MultiBox—Real-Time Object Detection in Deep Learning. Available online: towardsdatascience.com/understanding-ssd-multibox-real-time-object-detection-in-deep learning-495ef744fab (accessed on 25 February 2019).
- Szegedy, C.; Reed, S.; Erhan, D.; Anguelov, D.; Ioffe, S. Scalable, high-quality object detection. arXiv 2014, arXiv:1412.1441. [Google Scholar]
- Szegedy, C.; Toshev, A.; Erhan, D. Deep neural networks for object detection. Adv. Neural Inf. Process. Syst. 2013, 26, 2553–2561. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Uijlings, J.R.R.; Van De Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Parthasarathy, D. A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN. Available online: blog.athelas.com/a-brief-history-of-cnns-in-image-segmentation-from-r-cnn-to-mask-r-cnn-34ea83205de4 (accessed on 24 February 2019).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Qi, H.; Zhang, Z.; Xiao, B.; Hu, H.; Cheng, B.; Wei, Y.; Dai, J. Deformable convolutional networks–coco detection and segmentation challenge 2017 entry. In Proceedings of the ICCV COCO Challenge Workshop, Venice, Italy, 28 October 2017; Volume 2, p. 6. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Zheng, L.; Bie, Z.; Sun, Y.; Wang, J.; Su, C.; Wang, S.; Tian, Q. Mars: A video benchmark for large-scale person re-identification. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 868–884. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System | Patch Size/Stride | Output Size |
|---|---|---|
| UAV | Configuration type | X-configuration |
| Dimension (including propeller) | ) | |
| Durance | 20 min | |
| Payload (total) | 2.5 kg | |
| Altitude | 300 m | |
| Camera (oCam: 5-MP USB 3.0 Camera) | Dimension | ) |
| Weight | 35 g | |
| Resolution | 1920 × 1080@30 fps |
| TX1 1 | TX2 2 | AGX XAVIER 3 | |
|---|---|---|---|
| GPU | NVidia Maxwell™ GPU with 256 NVidia® CUDA® Cores | NVidia Pascal™ architecture with 256 NVidia CUDA cores | 512-core Volta GPU with Tensor Cores |
| DL Accelerator | None | None | (2x) NVDLA Engine |
| CPU | Quad-core ARM® Cortex®-A57 MPCore Processor | Dual-core Denver 2 64-bit CPU and quad-core ARM A57 complex | 8-Core ARM v8.2 64-bit CPU, 8-MB L2 + 4 MB L3 |
| MEMORY | 4 GB LPDDR4 Memory | 8 GB 128-bit LPDDR4 | 16 GB 256-bit LPDDR4x | 137 GB/s |
| STORAGE | 16 GB eMMC 5.1 Flash Storage | 32 GB eMMC 5.1 | 32 GB eMMC 5.1 |
| VIDEO ENCODE | 4K @ 30 | 2 4K @ 30 (HEVC) | 8 4K @ 60 (HEVC) |
| VIDEO DECODE | 4K @ 30 | 2 4K @ 30, 12-bit support | 12 4K @ 30 12-bit support |
| JetPack Support | Jetpack 2.0~3.3 | Jetpack 3.0~3.3 | JetPack 4.1.1 |
| Raspberry Pi 3 1 | Latte Panda 2 | Odroid Xu4 3 | |
|---|---|---|---|
| CPU | 1.2 GHz 64-bit quad-core ARMv8 CPU | Intel Cherry Trail Z8350 Quad Core 1.44-GHz Boost 1.92 GHz | Samsung Exynos5422 Cortex™-A15 2 GHz and Cortex™-A7 Octa core CPUs |
| GPU | Broadcom video core 4 | Intel HD Graphics, 12 EUs @ 200–500 MHz | Mali-T628 MP6 |
| MEMORY | 1 GB | 4 GB DDRL3L | 2-Gbyte LPDDR3 RAM PoP stacked |
| STORAGE | Support MicroSD | 64 GB eMMC | Supports eMMC5.0 HS400 and/or micro SD |
| Name | Patch Size/Stride | Output Size |
|---|---|---|
| Conv 1 | ||
| Conv 2 | ||
| Max Pool 3 | ||
| Residual 4 | ||
| Residual 5 | ||
| Residual 6 | ||
| Residual 7 | ||
| Residual 8 | ||
| Residual 9 | ||
| Dense 10 | 128 | |
| Batch and normalization | 128 |
| TX1 | TX2 | Xavier AGX | GPU-Based Ground Station: Gtx 1080 | |
|---|---|---|---|---|
| YOLOv2 | 2.9 FPS | 7 FPS | 26~30 FPS | 28 FPS |
| YOLOv2 tiny voc | 6~7 FPS | 15~16 FPS | 29 FPS | 30+ FPS |
| YOLOv3 | --- | 3 FPS | 16~18 FPS | 15.6 FPS |
| YOLOv3 tiny | 9~10 FPS | 12 FPS | 30 FPS | 30+ FPS |
| SSD | 8 FPS | 11~12 FPS | 35~48 FPS | 32 FPS |
| DeepLab-v3 Semantic Segmentation | -- | 2.2~2.5 FPS | 10 FPS | 15~16 FPS |
| Faster R-CNN | 0.9 FPS | 1.3 FPS | -- | |
| Mask R-CNN | -- | -- | -- | 2~3 FPS |
| YOLOv3 + Deep SORT | -- | 2.20 FPS | 10 FPS | 13 FPS |
| Systems | YOLO | SSD Mobile Net |
|---|---|---|
| Movidius NCS + Raspberry Pi | 1 FPS | 5 FPS |
| Movidius NCS + Latte Panda | 1.8 FPS | 5.5~ 5.7 FPS |
| Movidius NCS + Odroid | 2.10 FPS | 7~8 FPS |
| Just Odroid without Movidius NCS | -- | 1.4 FPS |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hossain, S.; Lee, D.-j. Deep Learning-Based Real-Time Multiple-Object Detection and Tracking from Aerial Imagery via a Flying Robot with GPU-Based Embedded Devices. Sensors 2019, 19, 3371. https://doi.org/10.3390/s19153371
Hossain S, Lee D-j. Deep Learning-Based Real-Time Multiple-Object Detection and Tracking from Aerial Imagery via a Flying Robot with GPU-Based Embedded Devices. Sensors. 2019; 19(15):3371. https://doi.org/10.3390/s19153371
Chicago/Turabian StyleHossain, Sabir, and Deok-jin Lee. 2019. "Deep Learning-Based Real-Time Multiple-Object Detection and Tracking from Aerial Imagery via a Flying Robot with GPU-Based Embedded Devices" Sensors 19, no. 15: 3371. https://doi.org/10.3390/s19153371
APA StyleHossain, S., & Lee, D.-j. (2019). Deep Learning-Based Real-Time Multiple-Object Detection and Tracking from Aerial Imagery via a Flying Robot with GPU-Based Embedded Devices. Sensors, 19(15), 3371. https://doi.org/10.3390/s19153371