Generative adversarial network is a brand-new model that combines generation model with discriminant model. The generation model learns the distribution of the original data and the discriminant model is used to determine whether the generated results are consistent with the original distribution. After adjusting its learning parameters, the original distribution can be best fitted. The birth of generative adversarial network provides a new unsupervised learning method for feature extraction. In the whole model, the samples are constantly trained against each other and the generator parameters are updated from the gradient feedback of the discriminator, which is independent of the distribution of the input data samples. In theory, the model is more universal.
Typical generative models are Autoregressive Model and Variational Autoencoder (VAE), both of which are based on maximum likelihood. The autoregressive model is similar to Markov chain and belongs to the category of sequence generation. It operates on the image at the pixel level [
21]. Variational autoencoder is a probability graph model, which usually includes two parts: encoding and decoding. It mainly constrains the encoding process and forces the decoder to generate reconstructed images [
22]. The characteristic of generative adversarial network is that it does not need to define the distribution function directly and it relies on the initial noise information to fit and generate data. Compared with other generative models, GAN has the following advantages: (1) generating sample data in parallel without changing the boundary conditions; (2) generating function does not have too many restrictions; (3) Compared with VAE, GAN produces better image quality. However, the disadvantage of GAN as a generation model is that the training process of generator is not stable enough and it will be unable to train [
11].
2.1. Structure and Application of Traditional GAN Model
After introducing the basic principles of the discriminant model and the generation model, the next is to expand in detail how the optimization functions of the two models in GAN are solved and eventually how to reach the equilibrium state.
Suppose ,⋯ represents the set of m real samples, z represents the random noise vector and represents the sample distribution of real data. ,⋯ is obtained from m samples sampled from and m noise samples from prior distribution are recorded as .
As shown in
Figure 1, GAN has two main components in structure: one is generating network G, which receives random noise samples z and outputs a set of generated pictures, which are recorded as G(z); the other is discriminant network D, which judges the parameter x from generator or real data and outputs x as the probability of real data, which is recorded as D(x). D is equivalent to a two-classifier. According to the decision probability, the data can be divided into two categories: true and false. On the other hand, D can feed back the difference between the two to generator G through the expression of distance similarly, so that it can fit the real data as much as possible.
Thus, the objective function V(D,G) defined by the model can be expressed as [
11]:
where E(*) denotes the expected value of the distribution function, D(*) denotes the probability of estimating the input sample from the real sample, z denotes the random noise samples and G(z) denotes the pseudo-samples. We can see that this is a minimax problem. In the case of given G, we first maximize V (D, G) and take D, then fix D and minimize V (D, G) to get G. Where, given G, maximized V(D,G) evaluates the difference or distance between the generated sample distribution function and the real sample distribution function.
In order to quantitatively describe the difference value, Jensen-Shannon distance (J-S divergence) is introduced to calculate the distance between two probability distributions. At this time, the GAN objective function is obtained by solving the following formula [
11]:
where
denotes the distribution of real samples,
denotes the distribution of generated samples and JSD (*) denotes the calculation formula of J-S divergence. In fact, it can be proved that the GAN model can converge to special points and the discriminator D and generator G can obtain the optimal solution accordingly. In many cases, the solution process is called the game process of two models and the ideal result may reach the state of Nash Equilibrium.
But sometimes the game result in the GAN model cannot lead to the ideal result, that is, the gradient disappears, which is caused by the distance measurement method defined by J-S divergence. J-S divergence can be obtained from K-L divergence [
23]. For the same random variable
, there are two separate probability distributions
. We can use K-L divergence to measure the difference between the two distributions [
24]:
Due to the asymmetric property of K-L divergence, that is, ≠, there exists meaningless value of K-L divergence. At this time, are inconsistent.
Further, assuming that there are two distributions
and
and the average distribution of the two distributions is
, the J-S divergence between the two distributions can be expressed as the K-L divergence between
and M plus the K-L divergence between
and M divided by 2, that is [
24]:
The range of J-S divergence of any two distributions is 0–log(n) and the maximum log(n) is obtained when the two distributions are far apart and do not overlap at all. log(n) is a constant and the gradient calculated at this point is undoubtedly 0. Therefore, the GAN model represented by J-S divergence has the phenomenon of gradient disappearance.
Although there are some shortcomings, it still does not affect GAN to play its role in many fields. In practical applications, GAN is mostly used in image field. As a generation model, the advantages of GAN are mainly embodied in avoiding the Markov chain learning mechanism, integrating various loss functions and GAN can still play its own advantages in scenarios where probability density cannot be calculated. For example, in the field of natural language processing, natural sentences can be realized by combining with RNN, such as the generation of poems [
25]. It is more widely used in the field of image. From super resolution [
26] to image restoration [
27] and the emergence of facial attribute operation [
28] in recent years, the application scene of generative adversarial network is constantly expanded and subdivided. In addition, GAN can combine with reinforcement learning. By introducing an unstable punishment-reward mechanism, the existence of adversarial network can promote more high-quality dialogues within the model.
Such applications undoubtedly open up a lot of areas in image processing that have not been involved before. On the other hand, GAN model is constantly improved and optimized.
2.2. GAN Model for Semi-Supervised Classification
The common semi-supervised learning methods include: self-training method, generation model, semi-supervised support vector machine (S3VMs), graph-based algorithm, multi-view algorithm and so on [
29]. The graph-based algorithm maps the data set to a graph and the learning process corresponds to the data node spreading or propagating on the graph. Due to the fact that the solving process is matrix operation, the processing capacity of large-scale data sets is insufficient and the addition of new samples requires the reconstruction of graphs for training, so the applicability of this method is narrow. S3VMs needs to attach category balance as a constraint condition and the objective function is non-convex and difficult to calculate, the main research direction is to seek efficient optimization strategy. The multi-view algorithm requires samples to provide the set of attributes under other views and its applicability is also narrow. However, because the generated model can generate a large number of unlabeled sample data according to random variables, it provides a large number of data for model training to do feature extraction. If these unlabeled data are effectively used, it will undoubtedly improve the performance of the classification model. Among them, GAN is a widely used generation model.
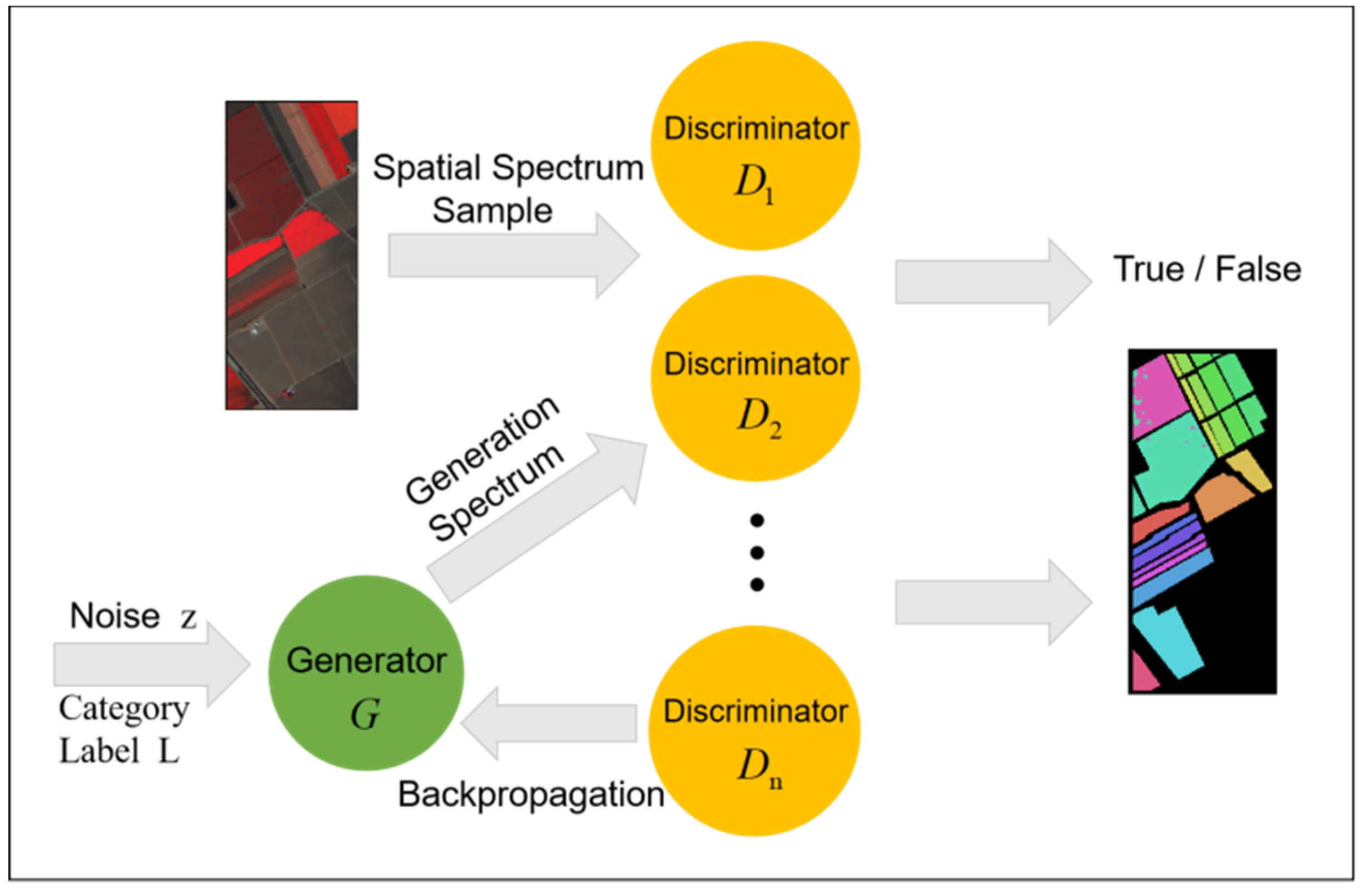
GAN is basically used in the field of unsupervised learning after it was proposed but it was not found that there is research value in semi-supervised learning until later. GAN is a semi-supervised learning method when a small number of tags and multi-classifiers are added to it. However, the output of the original discriminator is true or false (0 or 1), which is a binary classification problem. In order to apply GAN to semi-supervised classification and realize hyperspectral image classification, we have made some changes based on the original GAN structure, that is, adding a layer of softmax to the top of the discriminator as the classifier. At this time, the discriminator output is
, which corresponds to the label category.
is a generalized form of Logistic, which is modeled by polynomial distribution, so it can combine different types of classifiers together to form multiple classifiers. Assuming that the original sample has many categories, the number of categories is counted as c. The samples generated by the generator are classified into category c + 1, so when training semi-supervised GAN model, softmax classifier also adds an output neuron, which is used to represent the probability that the discriminator model determines the input is false, namely, category c + 1. It can be seen that the GAN model can classify the labeled original data and the unlabeled generated samples at the same time and the training samples are much larger than the original data. Therefore, semi-supervised GAN can be applied to the case of small samples to improve the accuracy of classification algorithm. The specific semi-supervised GAN structure is shown in
Figure 2, in which the category label L is added to the input to match the classification results at the output.
Because the output of the discriminator is no longer the probability of judging true or false, the loss function is different at this time. Semi-supervised GAN loss function has two parts, one is supervised learning loss function, the other is unsupervised loss function. The final loss function is obtained by adding the two functions together [
12].
Let
, the loss function of unsupervised learning can be simplified as follows:
where c is the number of categories,
is the data distribution of each category and
represents the probability of being false. It can be seen that the loss function
of unsupervised learning can actually be expressed as the loss function of GAN in formula (1). In the training process, for labeled samples, the cross-entropy loss is calculated, while for unlabeled samples, the two loss functions need to be minimized simultaneously.
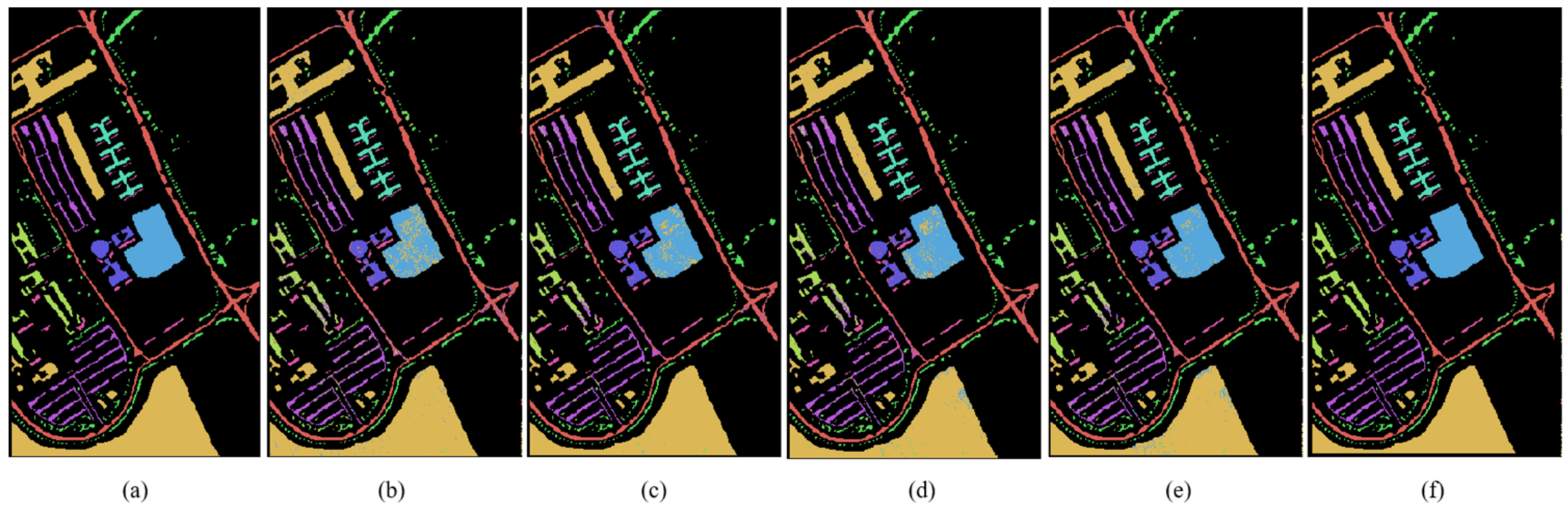
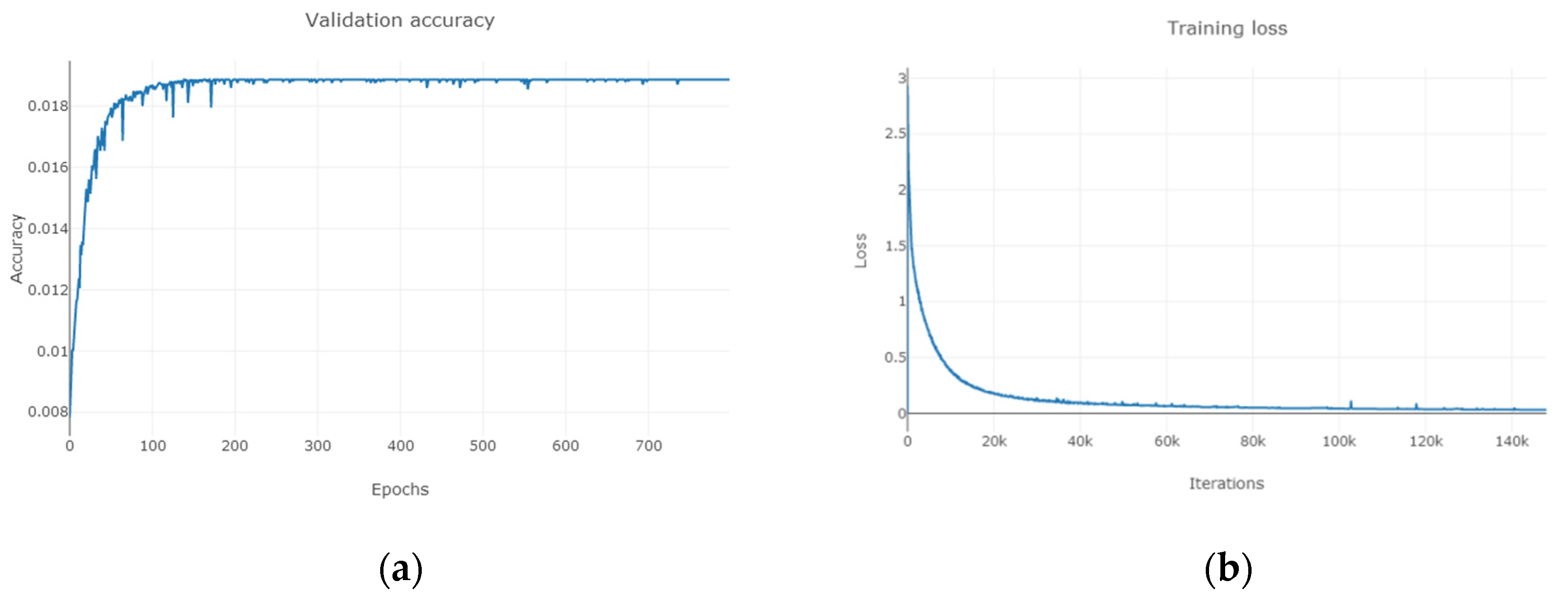
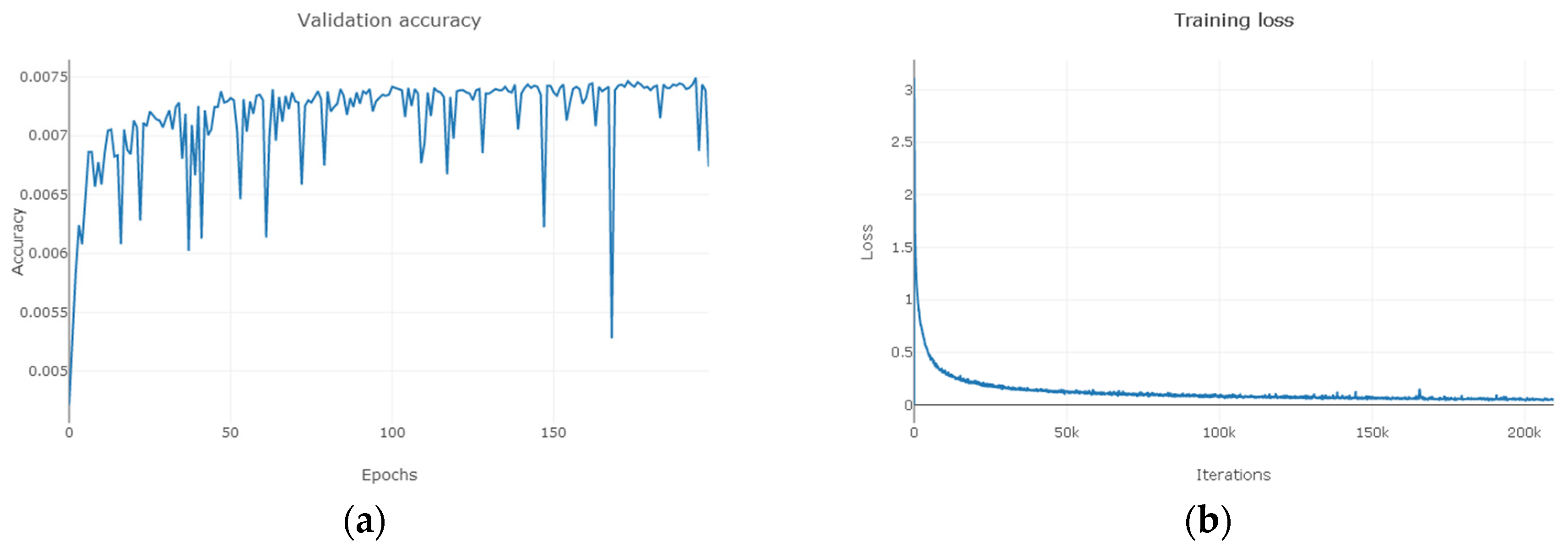
Semi-supervised learning method can expand the data set, improve the generalization ability of the model through a large number of unlabeled data sets and learn the hidden features in unlabeled samples. It is suitable for scenarios where labeled data is missing. Before GAN was not used in the semi-supervised field, these unlabeled data were basically real data available. After the appearance of semi-supervised GAN, these unlabeled data can be synthesized manually, which solves some problems that cannot be handled because of the small number of original samples. Generative adversarial network can be used not only in image and speech generation but also in other image classification areas where depth model is good at. This is the basis of hyperspectral image classification in this paper.

 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}