Single-Board-Computer Clusters for Cloudlet Computing in Internet of Things

 , ,
, ,
Abstract
1. Introduction
- (a)
- A resource-efficient architecture based on single-board computers for cloudlet computing that can bring computing power and low latency to IoT environments at a low cost.
- (b)
- An extensive empirical and simulation analysis that shows Raspberry-Pi clusters can be suitable for realistic IoT data streams.
- (c)
- An extensive analysis and evaluation of the proposed cost-efficient large-scale cloudlet-computing model for data and compute-intensive environments, in terms of scheduling performance and energy consumption, through realistic simulation.
2. Edge Computing Paradigms
2.1. Multi-Access Edge Computing
2.2. Fog Computing
2.3. Cloudlet Computing
3. Single-Board Computers as Micro Data-Center Servers
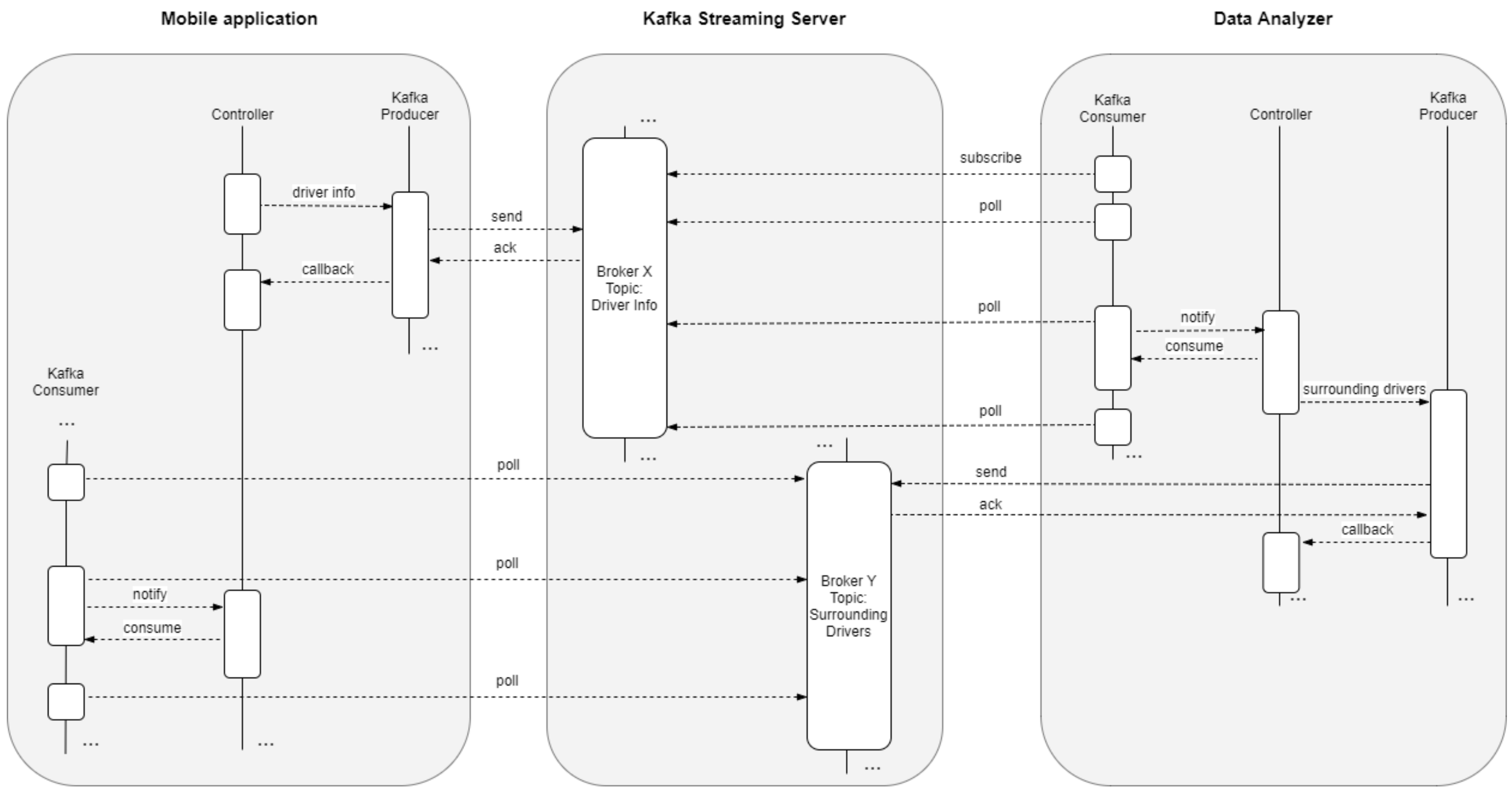
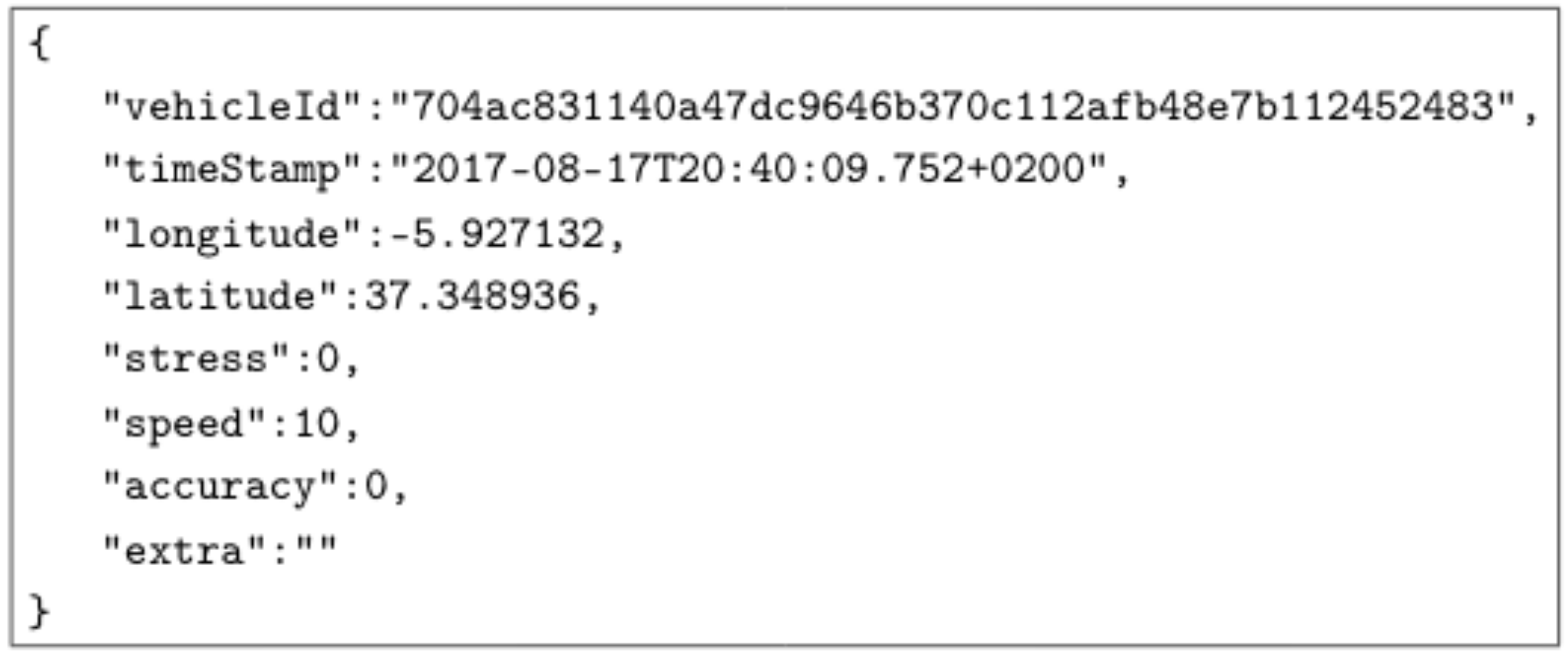
4. Single-Board-Computer Cluster Performance Characterisation at Application Level for IoT Real-Time Streaming Scenarios
- Driver unique identifier;
- Timestamp of the sample;
- Latitude and longitude of the vehicle in that moment;
- Instantaneous driver stress based on the analysis of several factors, such as sudden speed variations, sharp turns, the reading of driver heart rate and previous stress values;
- Instantaneous vehicle speed;
- An estimation of the accuracy of the location; and
- Extra information to make it possible to test different message sizes.
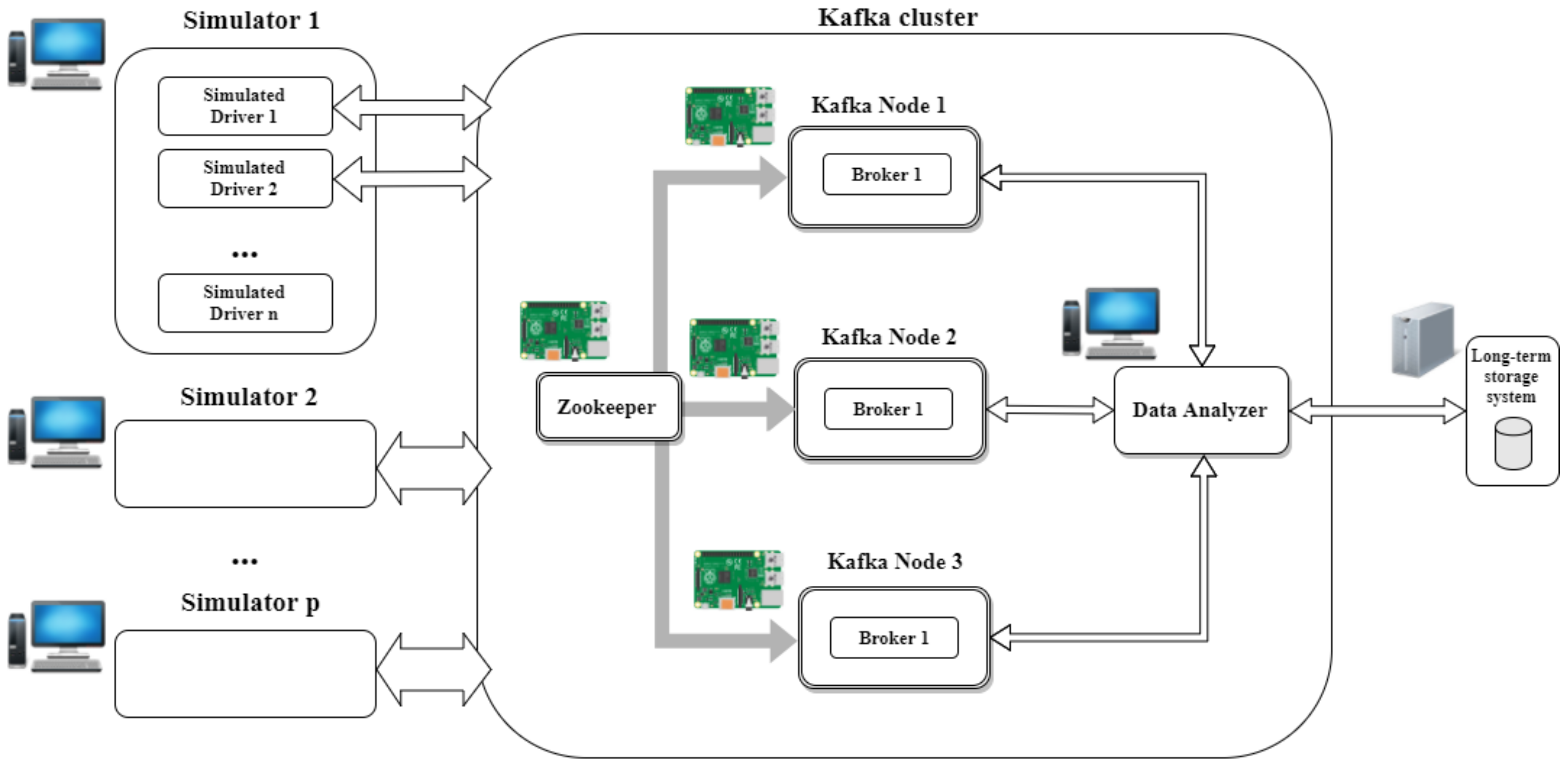
4.1. Experimentation Setup
- A messaging system to capture and publish feeds;
- A transformation tier to manage information, enrich and deliver data; and
- A persistence system, with tools for massive analytics.
4.2. Simulation Experiments
- Total number of messages generated;
- Total number of messages sent;
- Total number of messages received successfully by the streaming platform;
- Total number of messages that failed to be sent;
- Total number of messages that could be recovered;
- Total number of messages pending to be sent; and
- Current average drivers delay.
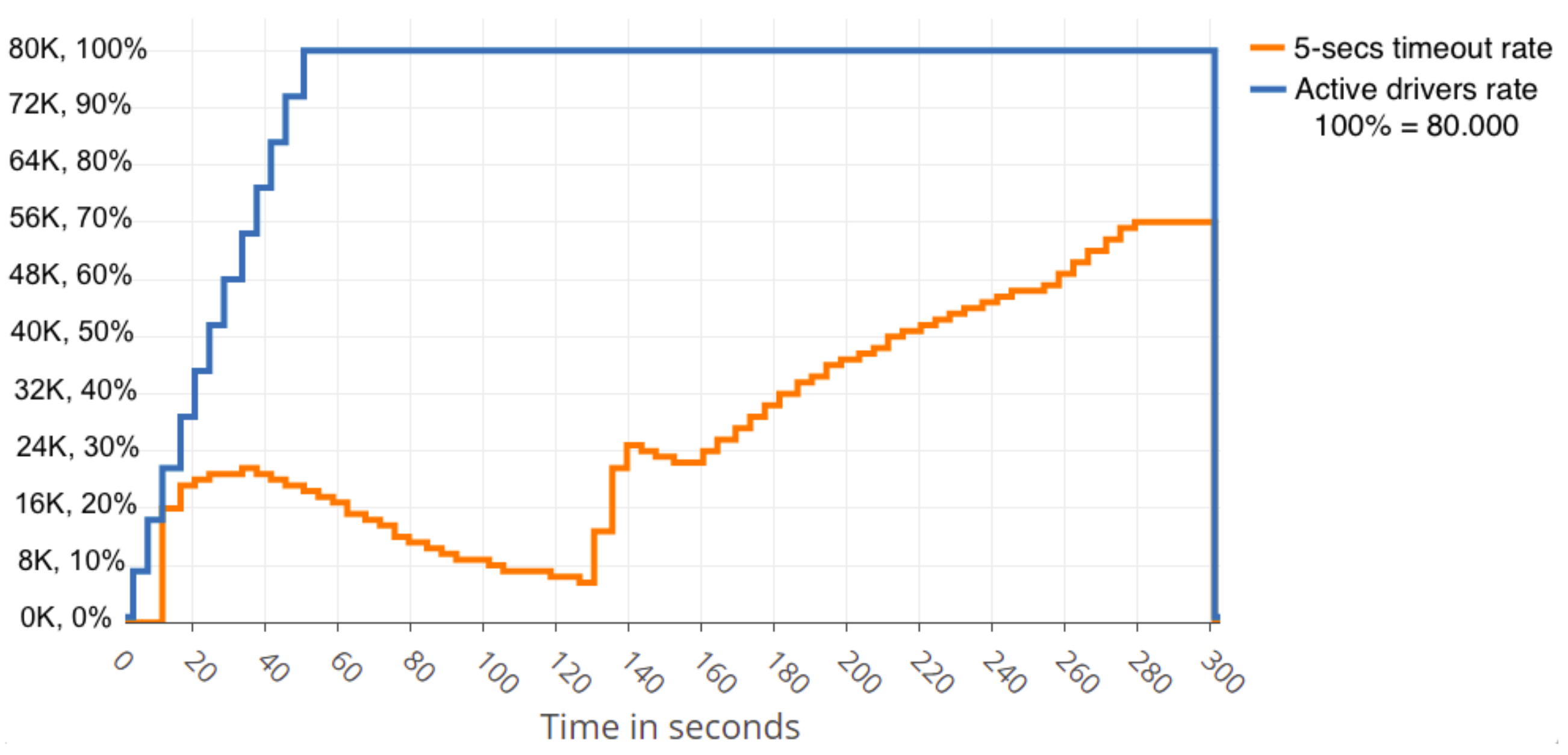
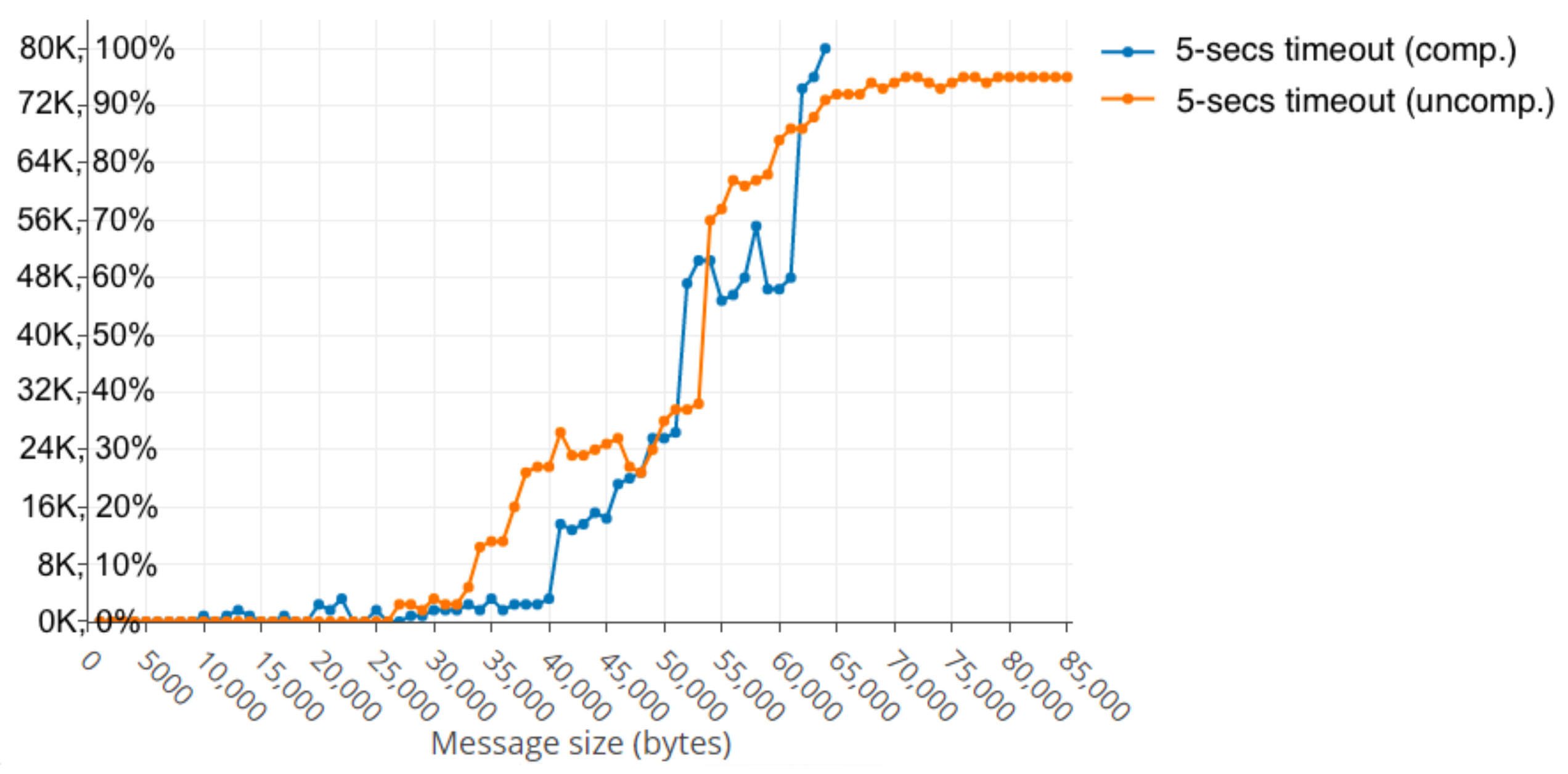
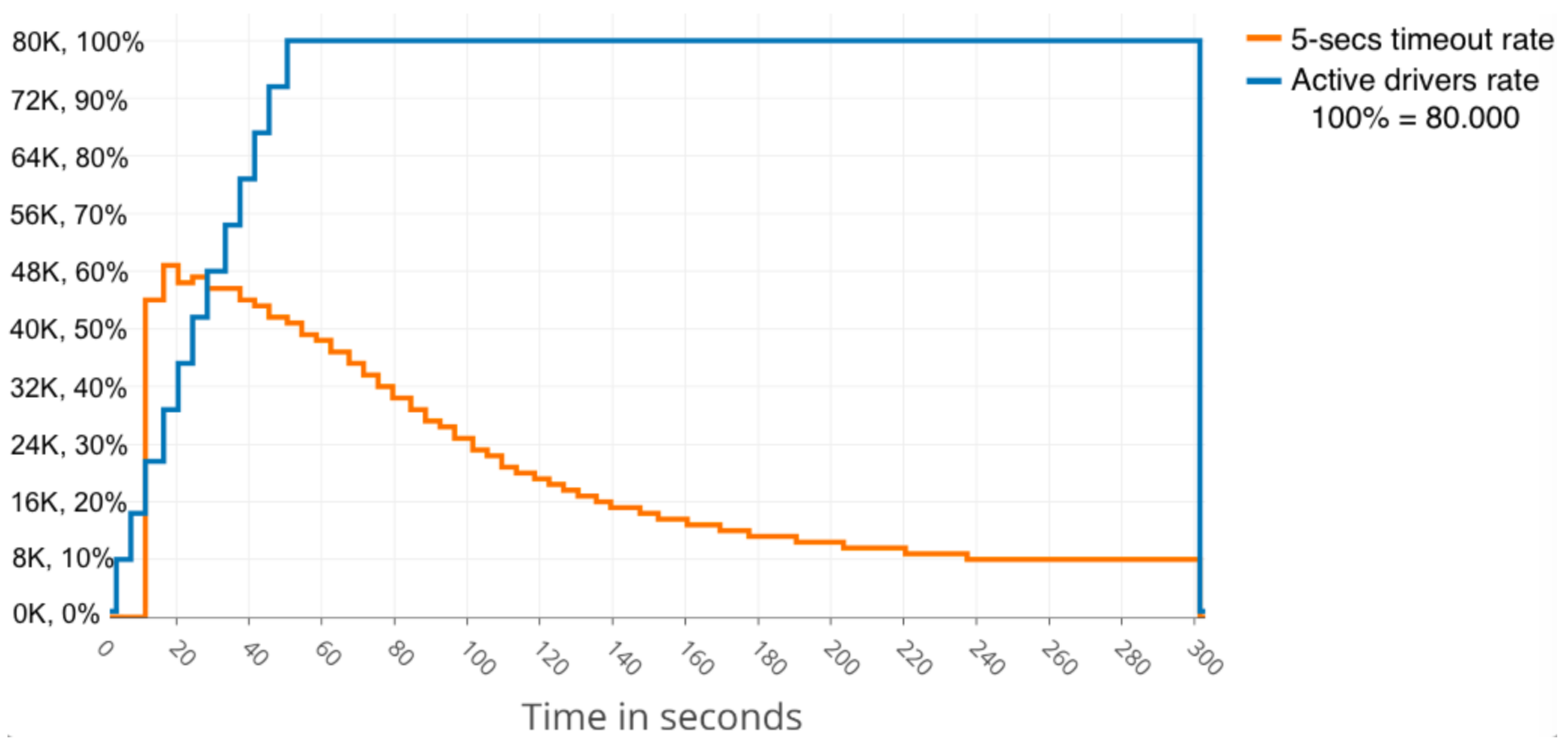
- The impact of the message size sent by the clients on the cluster performance.
- The number of simultaneous drivers that could be served given a fixed message size.
- The maximum message size that could be served given a fixed number of users.
- The number of drivers that could be served increasing the message production rate given a fixed message size.
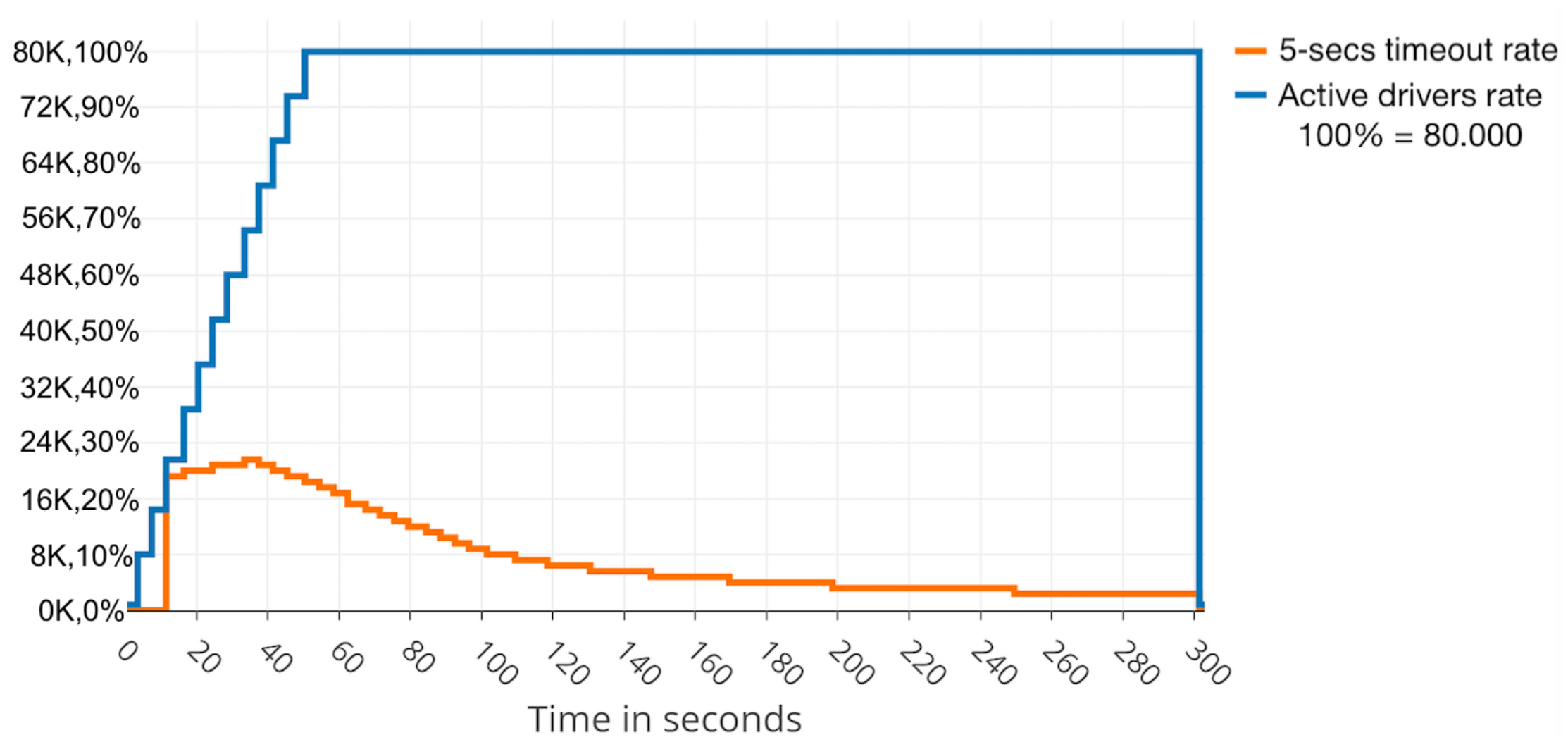
4.3. Experimentation Results
4.3.1. Centralised Cluster Behaviour
4.3.2. Storage Transfer Rate
5. Infrastructure-Level Behaviour of Large-Scale Collaborative SBC-Cloudlets and Cloud Architecture Model
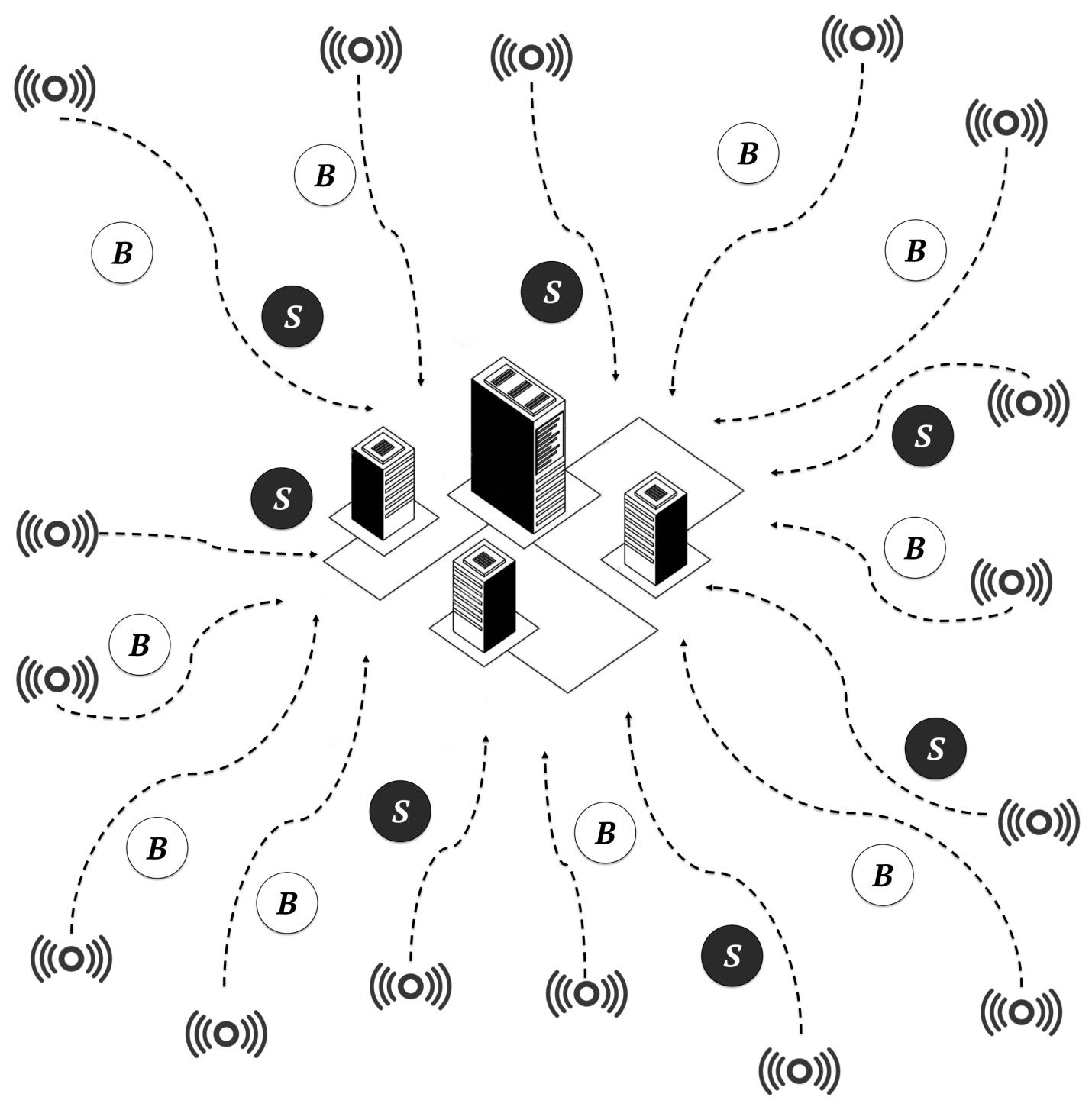
- In the cloud-only scenario, the entire workload was executed by a centralised cloud-Computing data centre composed of 500 high-computing-capacity servers, as shown in Figure 10. This scenario was designed to show the limitations of cloud-only architectures.
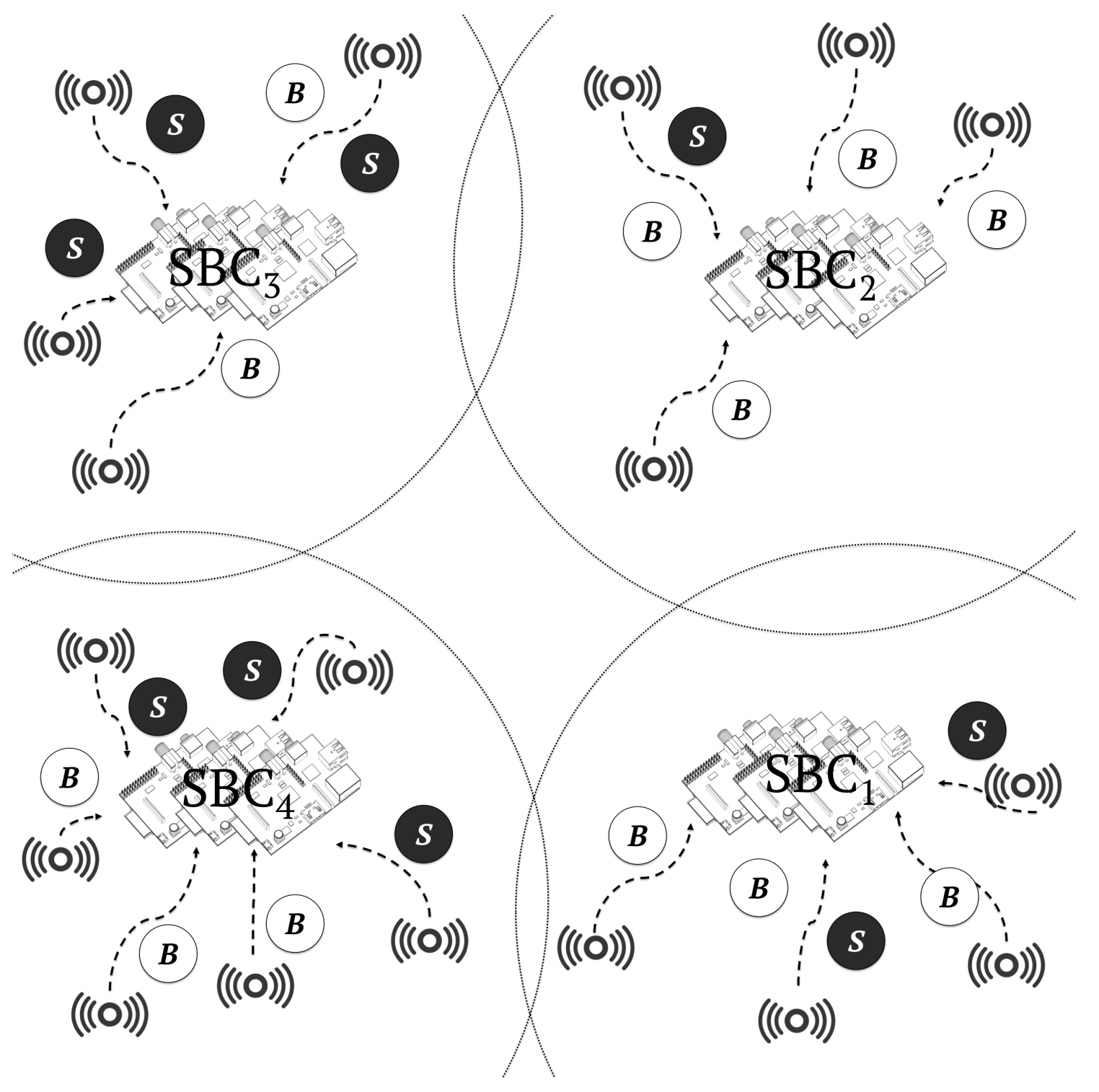
- In the cloudlet-SBC only scenario, the entire workload was executed by four cloudlets composed of 500 SBCs each, as shown in Figure 11. This scenario was designed to show the limitations of cloudlet-only architectures.
- In the cloudlet-CC + cloud scenario, 40% of the workload was distributed among four cloudlets composed of 60 high-end servers and 60% to a centralised data centre composed of 500 servers, respectively. This scenario showed the current less-cost-efficient cloudlet infrastructures that we aimed to improve, in terms of both costs and energy efficiency.
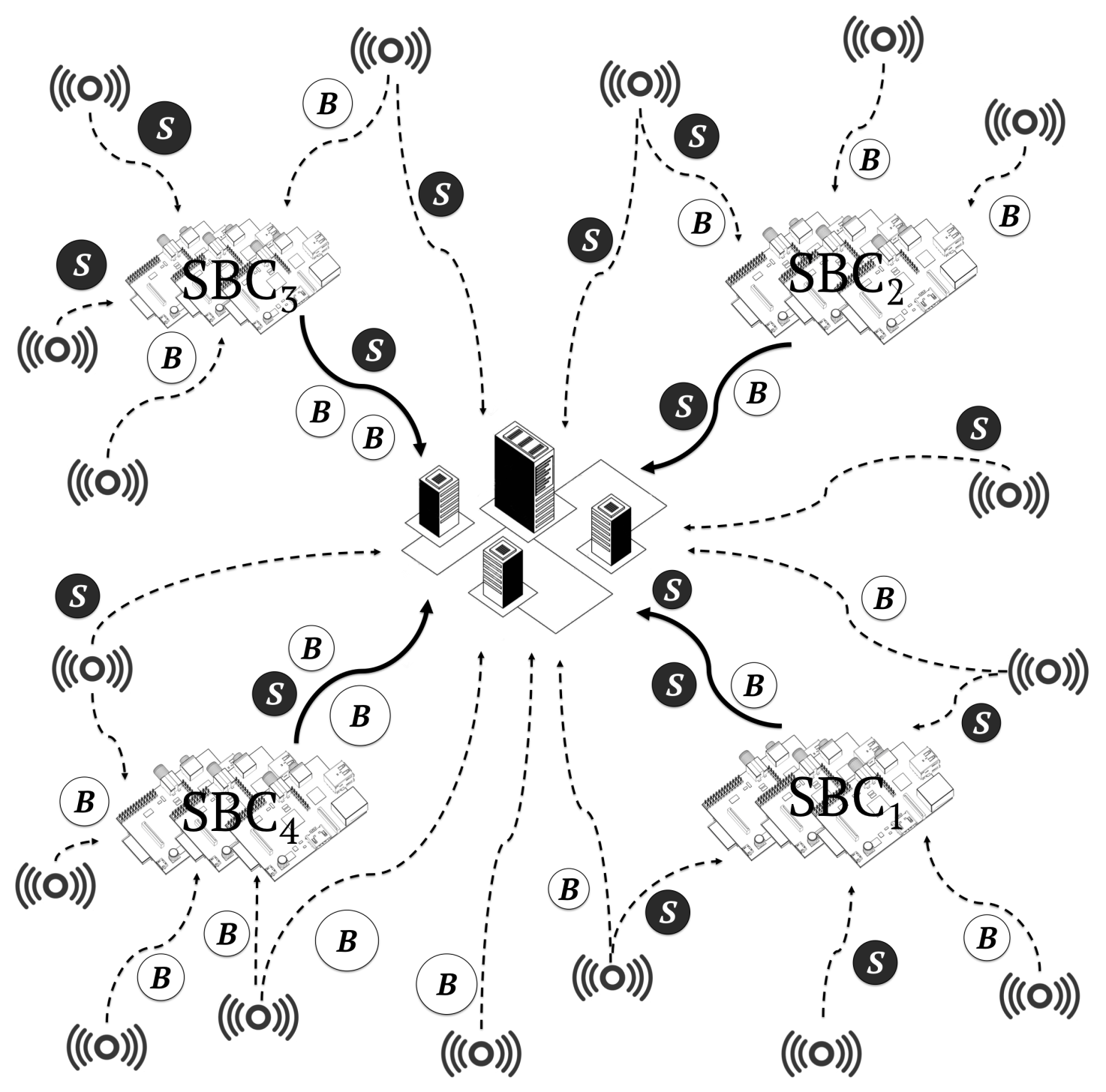
- In the cloudlet-SBC + cloud scenario, 40% of the workload was distributed among four cloudlets composed of 500 SBCs and 60% to a centralised data centre composed of 500 servers, respectively. Figure 12 shows this architecture. This is the architecture model that we propose in this work.
5.1. Performance and Energy Models
5.2. Simulation Tool
5.3. Workload
- (a)
- Batch jobs perform a computing-intensive workload and then finish. MapReduce jobs are an example of a Batch job.
- (b)
- Service jobs represent long-running jobs with no determined end. Long-running services, such as databases, streaming engines, and web servers, are representative Service jobs.
- (a)
- Data-intensive workloads consist of jobs composed of tasks that lightly process large amounts of data. Batch jobs in this workload require large amounts of bandwidth and data, but low computing capacity.
- (b)
- Compute-intensive workload have jobs composed of tasks that perform complex computations. Batch jobs in this workload require high computing capacity, while they do not require long data transmissions.
5.4. Experimentation Results
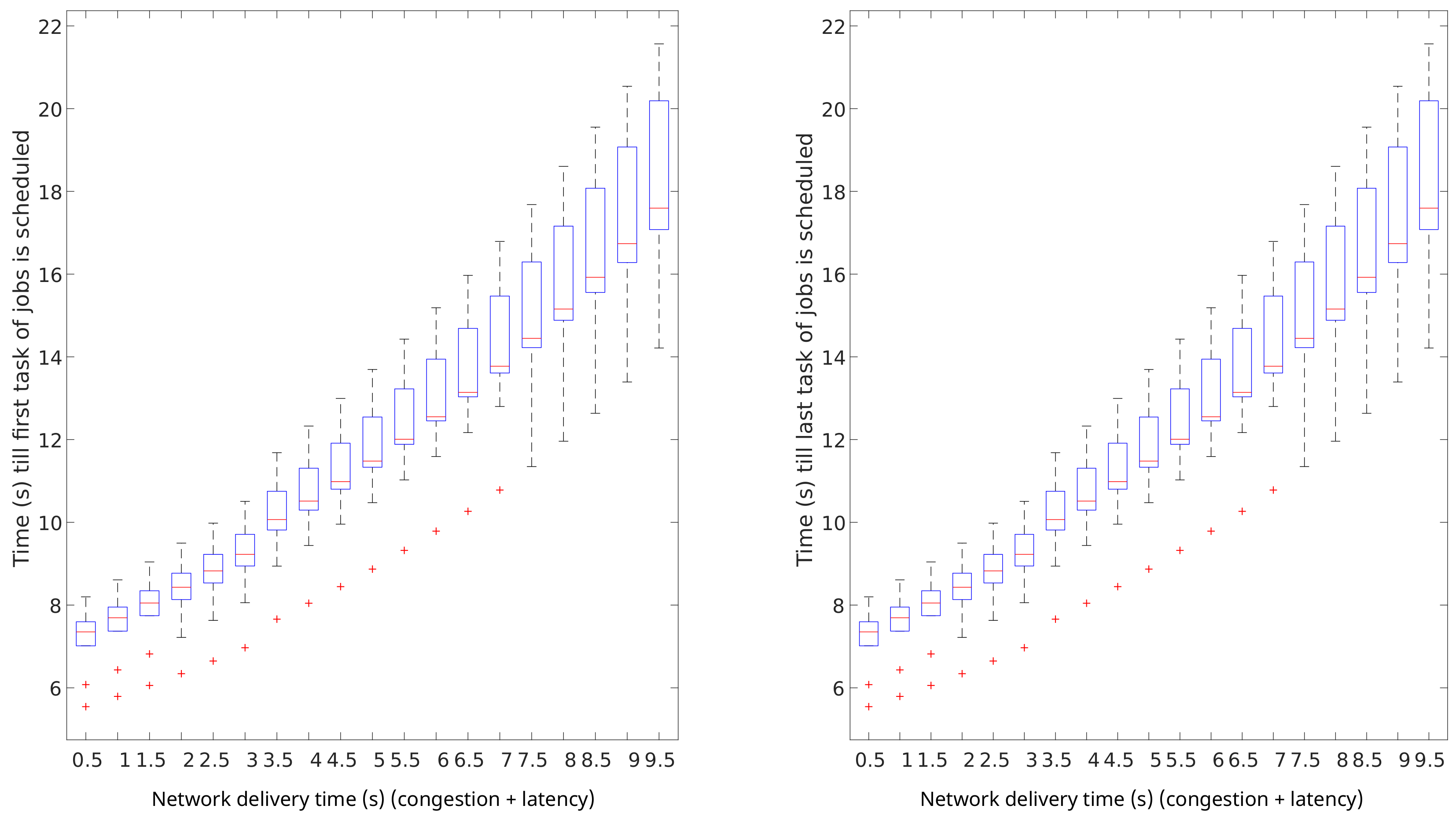
- Network delivery time impacts heavily on the makespan of data-intensive workloads, and has a minor impact in terms of scheduling performance. The scheduling performance is represented by the job queue times. The results of this analysis are graphically shown in Figure 13. In this figure, the impact of a range of values for on queue times are presented. It can be noticed that the network delivery time impacts negatively in terms of queue times linearly. Furthermore, when very high values are present, makes the system performance more unpredictable.
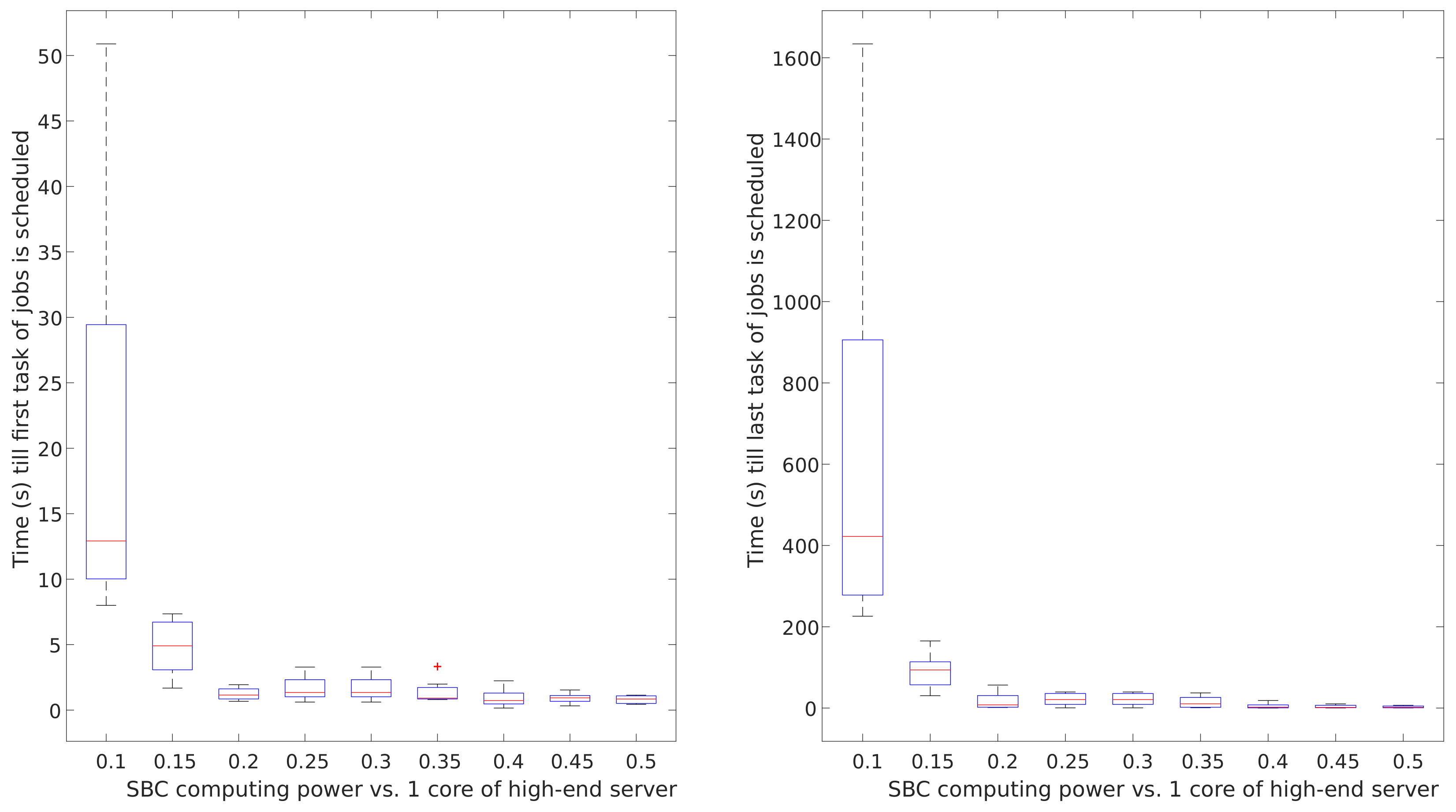
- Impact of the computing power of SBCs on queue times in SBC clusters was compared to the computing power of one core in typical cloud-computing servers. The results of this analysis are graphically shown in Figure 14. It can be noticed that the computing capacity is the key factor to achieve short queue times in prototypical IoT scenarios if compute-intensive workloads are under consideration. This analysis shows that SBCs may provide predictable performance results if the computing capacity of the SBC raises to 30% of that of one core of current typical cloud-computing servers. With the required improvements, SBCs can become an optimal candidate for edge-computing nodes.
- was set to 150 ms and to 100 ms. A range of values for was considered for cloud facilities, while took a value of 10 ms for cloudlet clusters.
- The computing power of SBCs was set to 20% of one core of a cloud server.
- The number and duration of tasks were similar for both experiment sets, while was set to 1 for cloud servers, and 0.2 for Single-Board Computers.
- was set to 110 W and to 50 W per cloud CPU. respectively. was set to 15 W and to 8 W per SBC.
6. Conclusions and Future Work
- Cost and resource-efficient cloudlet Computing architecture model based on single-board-computer clusters.
- Analysis on single board computers, such as Raspberry Pi 3, can successfully execute real-time realistic IoT workloads, such as the presented traffic-system scenario.
- Evaluation of results in terms of performance, energy consumption and acquisition costs of the proposed model compared to the architectures found in the literature, both for data and compute-intensive scenarios.
- Validation of the obtained results in a real infrastructure.
- Development of full architecture cost model, including operations, maintenance and network costs.
- Improvements on the simulation tool to consider more complex networking topologies.
- Improvements on the simulation tool to consider more complex scheduling algorithms between cooperative cloudlets and cloud-computing infrastructures.
- Analysis on the impact of resource-managing frameworks in the proposed model.
- Analysis on the impact of energy-efficiency policies in the proposed model.
- Evaluation of cost models for the proposed architecture using productive analysis models, such as Data Envelopment Analysis [67].
Author Contributions
Funding
Conflicts of Interest
References
- Neirotti, P.; De Marco, A.; Cagliano, A.C.; Mangano, G.; Scorrano, F. Current trends in Smart City initiatives: Some stylised facts. Cities 2014, 38, 25–36. [Google Scholar] [CrossRef]
- Ji, Z.; Ganchev, I.; O’Droma, M.; Zhao, L.; Zhang, X. A cloud-based car parking middleware for IoT-based smart cities: design and implementation. Sensors 2014, 14, 22372–22393. [Google Scholar] [CrossRef] [PubMed]
- Bockermann, C. A Survey of the Stream Processing Landscape; Lehrstuhl Fork Unstliche Intelligenz Technische Universit: Dortmund, Germany, 2014. [Google Scholar]
- Evans, D. The internet of things: How the next evolution of the internet is changing everything. Cisco White Pap. 2011, 1, 1–11. [Google Scholar]
- Zhang, B.; Mor, N.; Kolb, J.; Chan, D.S.; Lutz, K.; Allman, E.; Wawrzynek, J.; Lee, E.; Kubiatowicz, J. The cloud is not enough: Saving iot from the cloud. In Proceedings of the 7th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 15), Santa Clara, CA, USA, 6–7 July 2015. [Google Scholar]
- Satyanarayanan, M.; Bahl, P.; Caceres, R.; Davies, N. The case for vm-based cloudlets in mobile computing. IEEE Pervasive Comput. 2009, 8, 14–23. [Google Scholar] [CrossRef]
- Cloutier, M.; Paradis, C.; Weaver, V. A raspberry pi cluster instrumented for fine-grained power measurement. Electronics 2016, 5, 61. [Google Scholar] [CrossRef]
- Al Nuaimi, E.; Al Neyadi, H.; Mohamed, N.; Al-Jaroodi, J. Applications of big data to smart cities. J. Int. Serv. Appl. 2015, 6, 25. [Google Scholar] [CrossRef]
- Kolozali, S.; Bermudez-Edo, M.; Davar, N.F.; Barnaghi, P.; Gao, F.; Ali, M.I.; Mileo, A.; Fischer, M.; Iggena, T.; Kuemper, D.; et al. Observing the Pulse of a City: A Smart City Framework for Real-time Discovery, Federation, and Aggregation of Data Streams. IEEE Int. Things J. 2019, 6, 2651–2668. [Google Scholar] [CrossRef]
- Pérez, J.A.; Álvarez, J.A.; Fernández-Montes, A.; Ortega, J.A. Service-oriented device integration for ubiquitous ambient assisted living environments. In Proceedings of the International Work-Conference on Artificial Neural Networks, Salamanca, Spain, 10–12 June 2009; pp. 843–850. [Google Scholar]
- Gazis, V. A Survey of Standards for Machine-to-Machine and the Internet of Things. IEEE Commun. Surv. Tutor. 2017, 19, 482–511. [Google Scholar] [CrossRef]
- Cherniack, M.; Balakrishnan, H.; Balazinska, M.; Carney, D.; Cetintemel, U.; Xing, Y.; Zdonik, S.B. Scalable Distributed Stream Processing. CIDR 2003, 3, 257–268. [Google Scholar]
- Barga, R.S.; Goldstein, J.; Ali, M.; Hong, M. Consistent streaming through time: A vision for event stream processing. arXiv 2006, arXiv:cs/0612115. [Google Scholar]
- Shahzadi, S.; Iqbal, M.; Dagiuklas, T.; Qayyum, Z.U. Multi-access edge computing: Open issues, challenges and future perspectives. Cloud Comput. 2017, 6, 30. [Google Scholar] [CrossRef]
- Escamilla-Ambrosio, P.J.; Rodríguez-Mota, A.; Aguirre-Anaya, E.; Acosta-Bermejo, R.; Salinas-Rosales, M. Distributing Computing in the Internet of Things: Cloud, Fog and Edge Computing Overview. In NEO 2016: Results of the Numerical and Evolutionary Optimization Workshop NEO 2016 and the NEO Cities 2016 Workshop Held on September 20–24, 2016 in Tlalnepantla, Mexico; Maldonado, Y., Trujillo, L., Schütze, O., Riccardi, A., Vasile, M., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 87–115. [Google Scholar] [CrossRef]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A survey on mobile edge computing: The communication perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef]
- Beck, M.T.; Maier, M. Mobile edge computing: Challenges for future virtual network embedding algorithms. In Proceedings of the Eighth International Conference on Advanced Engineering Computing and Applications in Sciences (ADVCOMP 2014), Rome, Italy, 24–28 August 2014; Volume 1, p. 3. [Google Scholar]
- Chen, X.; Jiao, L.; Li, W.; Fu, X. Efficient multi-user computation offloading for mobile-edge cloud computing. IEEE/ACM Trans. Netw. 2016, 24, 2795–2808. [Google Scholar] [CrossRef]
- Mao, Y.; Zhang, J.; Letaief, K.B. Dynamic computation offloading for mobile-edge computing with energy harvesting devices. IEEE J. Sel. Areas Commun. 2016, 34, 3590–3605. [Google Scholar] [CrossRef]
- Tan, Z.; Yu, F.R.; Li, X.; Ji, H.; Leung, V.C. Virtual resource allocation for heterogeneous services in full duplex-enabled SCNs with mobile edge computing and caching. IEEE Trans. Veh. Technol. 2018, 67, 1794–1808. [Google Scholar] [CrossRef]
- Patel, M.; Naughton, B.; Chan, C.; Sprecher, N.; Abeta, S.; Neal, A.; Hu, Y.; Thornton, C.; Ramos, J.R.; Musiol, T.; et al. Mobile-Edge Computing Introductory Technical White Paper. In White Paper, Mobile-Edge Computing (MEC) Industry Initiative; ETSI: Sophia Antipolis, France, 2014; pp. 1089–7801. [Google Scholar]
- Mirkhanzadeh, B.; Shakeri, A.; Shao, C.; Razo, M.; Tacca, M.; Galimberti, G.M.; Martinelli, G.; Cardani, M.; Fumagalli, A. An SDN-enabled multi-layer protection and restoration mechanism. Opt. Switch. Netw. 2018, 30, 23–32. [Google Scholar] [CrossRef]
- Li, H.; Shou, G.; Hu, Y.; Guo, Z. Mobile edge computing: Progress and challenges. In Proceedings of the 2016 4th IEEE International Conference on Mobile Cloud Computing, Services, and Engineering (MobileCloud), Oxford, UK, 29 March–1 April 2016; pp. 83–84. [Google Scholar]
- Bonomi, F.; Milito, R.; Zhu, J.; Addepalli, S. Fog Computing and Its Role in the Internet of Things. In Proceedings of the First Edition of the MCC Workshop on Mobile Cloud Computing; ACM: New York, NY, USA, 2012; pp. 13–16. [Google Scholar] [CrossRef]
- Stojmenovic, I.; Wen, S. The Fog computing paradigm: Scenarios and security issues. In Proceedings of the 2014 Federated Conference on Computer Science and Information Systems, Warsaw, Poland, 7–10 September 2014; pp. 1–8. [Google Scholar] [CrossRef]
- Gribaudo, M.; Iacono, M.; Jakobik, A.; Kolodziej, J. Performance Optimisation Of Edge Computing Homeland Security Support Applications. In Proceedings of the 32nd European Conference on Modelling and Simulation, European Council for Modeling and Simulation, Wilhelmshaven, Germany, 22–25 May 2018; pp. 440–446. [Google Scholar]
- Fernández-Caramés, T.; Fraga-Lamas, P.; Suárez-Albela, M.; Vilar-Montesinos, M. A Fog Computing and Cloudlet Based Augmented Reality System for the Industry 4.0 Shipyard. Sensors 2018, 18, 1798. [Google Scholar] [CrossRef]
- Chen, Y.S.; Tsai, Y.T. A mobility management using follow-me cloud-cloudlet in fog-computing-based RANs for smart cities. Sensors 2018, 18, 489. [Google Scholar] [CrossRef]
- Tang, B.; Chen, Z.; Hefferman, G.; Wei, T.; He, H.; Yang, Q. A Hierarchical Distributed Fog Computing Architecture for Big Data Analysis in Smart Cities. In Proceedings of the ASE BigData & SocialInformatics 2015; ACM: New York, NY, USA, 2015; pp. 28:1–28:6. [Google Scholar] [CrossRef]
- Bahl, V. Emergence of Micro Datacenter (Cloudlets/Edges) for Mobile Computing. 2017. Available online: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/11/Micro-Data-Centers-mDCs-for-Mobile-Computing-1.pdf (accessed on 9 July 2019).
- Khan, K.A.; Wang, Q.; Luo, C.; Wang, X.; Grecos, C. Comparative study of internet cloud and cloudlet over wireless mesh networks for real-time applications. In Proceedings of the International Society for Optics and Photonics, Brussels, Belgium, 13–17 April 2014; Volume 9139, p. 91390K. [Google Scholar]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Int. Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Whaiduzzaman, M.; Gani, A.; Naveed, A. Pefc: Performance enhancement framework for cloudlet in mobile cloud computing. In Proceedings of the 2014 IEEE International Symposium on Robotics and Manufacturing Automation (ROMA), Kuala Lumpur, Malaysia, 15–16 December 2014; pp. 224–229. [Google Scholar]
- Jararweh, Y.; Tawalbeh, L.; Ababneh, F.; Dosari, F. Resource efficient mobile computing using cloudlet infrastructure. In Proceedings of the 2013 IEEE 9th International Conference on Mobile Ad-hoc and Sensor Networks, Dalian, China, 11–13 December 2013; pp. 373–377. [Google Scholar]
- Khan, K.A.; Wang, Q.; Grecos, C. Experimental framework of integrated cloudlets and wireless mesh networks. In Proceedings of the 2012 20th Telecommunications Forum (TELFOR), Belgrade, Serbia, 20–22 November 2012; pp. 190–193. [Google Scholar]
- Rawadi, J.; Artail, H.; Safa, H. Providing local cloud services to mobile devices with inter-cloudlet communication. In Proceedings of the MELECON 2014-2014 17th IEEE Mediterranean Electrotechnical Conference, Beirut, Lebanon, 13–16 April 2014; pp. 134–138. [Google Scholar]
- Ceselli, A.; Premoli, M.; Secci, S. Cloudlet network design optimization. In Proceedings of the 2015 IFIP Networking Conference (IFIP Networking), Toulouse, France, 20–22 May 2015; pp. 1–9. [Google Scholar]
- Gai, K.; Qiu, M.; Zhao, H.; Tao, L.; Zong, Z. Dynamic energy-aware cloudlet-based mobile cloud computing model for green computing. J. Netw. Comput. Appl. 2016, 59, 46–54. [Google Scholar] [CrossRef]
- Niyato, D.; Wang, P.; Joo, P.C.H.; Han, Z.; Kim, D.I. Optimal energy management policy of a mobile cloudlet with wireless energy charging. In Proceedings of the 2014 IEEE International Conference on Smart Grid Communications (SmartGridComm), Venice, Italy, 3–6 November 2014; pp. 728–733. [Google Scholar]
- Miori, L.; Sanin, J.; Helmer, S. A Platform for Edge Computing Based on Raspberry Pi Clusters. In Proceedings of the British International Conference on Databases, London, UK, 10–12 July 2017; pp. 153–159. [Google Scholar]
- D’Amore, M.; Baggio, R.; Valdani, E. A Practical Approach to Big Data in Tourism: A Low Cost Raspberry Pi Cluster. In Information and Communication Technologies in Tourism 2015; Springer: Berlin, Germany, 2015; pp. 169–181. [Google Scholar]
- Johnston, S.J.; Basford, P.J.; Perkins, C.S.; Herry, H.; Tso, F.P.; Pezaros, D.; Mullins, R.D.; Yoneki, E.; Cox, S.J.; Singer, J. Commodity single board computer clusters and their applications. Future Gener. Comput. Syst. 2018, 89, 201–212. [Google Scholar] [CrossRef]
- Tso, F.P.; White, D.R.; Jouet, S.; Singer, J.; Pezaros, D.P. The glasgow raspberry pi cloud: A scale model for cloud computing infrastructures. In Proceedings of the 2013 IEEE 33rd International Conference on Distributed Computing Systems Workshops, Philadelphia, PA, USA, 8–11 July 2013; pp. 108–112. [Google Scholar]
- Kruger, M.J. Building a Parallella Board Cluster. Bachelor’s Thesis, Rhodes University, Grahamstown, South Africa, 2015. [Google Scholar]
- Saffran, J.; Garcia, G.; Souza, M.A.; Penna, P.H.; Castro, M.; Góes, L.F.; Freitas, H.C. A low-cost energy-efficient Raspberry Pi cluster for data mining algorithms. In Proceedings of the European Conference on Parallel Processing, Grenoble, France, 24–26 August 2016; pp. 788–799. [Google Scholar]
- Qureshi, B.; Koubâa, A. On Energy Efficiency and Performance Evaluation of Single Board Computer Based Clusters: A Hadoop Case Study. Electronics 2019, 8, 182. [Google Scholar] [CrossRef]
- Maksimović, M.; Vujović, V.; Davidović, N.; Milošević, V.; Perišić, B. Raspberry Pi as Internet of things hardware: Performances and constraints. Des. Issues 2014, 3, 8. [Google Scholar]
- Qureshi, B.; Koubaa, A. Power Efficiency of a SBC Based Hadoop Cluster. In Proceedings of the International Conference on Smart Cities, Infrastructure, Technologies and Applications, Jeddah, Saudi Arabia, 27–29 November 2017; pp. 52–60. [Google Scholar]
- Qureshi, B.; Koubaa, A. On Performance of Commodity Single Board Computer-Based Clusters: A Big Data Perspective. In Smart Infrastructure and Applications: Foundations for Smarter Cities and Societies; Mehmood, R., See, S., Katib, I., Chlamtac, I., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 349–375. [Google Scholar] [CrossRef]
- Kaewkasi, C.; Srisuruk, W. Optimizing performance and power consumption for an ARM-based big data cluster. In Proceedings of the TENCON 2014—2014 IEEE Region 10 Conference, Bangkok, Thailand, 22–25 October 2014; pp. 1–6. [Google Scholar]
- Wilcox, E.; Jhunjhunwala, P.; Gopavaram, K.; Herrera, J. Pi-crust: A Raspberry Pi Cluster Implementation; Technical Report; Texas A&M University: College Station, TX, USA, 2015. [Google Scholar]
- Hamilton, J. Cooperative expendable micro-slice servers (CEMS): Low cost, low power servers for internet-scale services. In Proceedings of the Conference on Innovative Data Systems Research (CIDR’09), Asilomar, CA, USA, 4–7 January 2009. [Google Scholar]
- Fernández-Rodríguez, J.Y.; Álvarez-García, J.A.; Fisteus, J.A.; Luaces, M.R.; Magaña, V.C. Benchmarking real-time vehicle data streaming models for a Smart City. Inf. Syst. 2017. [Google Scholar] [CrossRef]
- Brinkhoff, T. A framework for generating network-based moving objects. GeoInformatica 2002, 6, 153–180. [Google Scholar] [CrossRef]
- Behrisch, M.; Bieker, L.; Erdmann, J.; Krajzewicz, D. SUMO—Simulation of urban mobility: An overview. In Proceedings of the SIMUL 2011, The Third International Conference on Advances in System Simulation, Barcelona, Spain, 23–28 October 2011. [Google Scholar]
- Gupta, H.; Vahid Dastjerdi, A.; Ghosh, S.K.; Buyya, R. iFogSim: A toolkit for modeling and simulation of resource management techniques in the Internet of Things, Edge and Fog computing environments. Softw. Pract. Exp. 2017, 47, 1275–1296. [Google Scholar] [CrossRef]
- Lopes, M.M.; Higashino, W.A.; Capretz, M.A.; Bittencourt, L.F. Myifogsim: A simulator for virtual machine migration in fog computing. In Proceedings of the 10th International Conference on Utility and Cloud Computing, Austin, TX, USA, 5–8 December 2017; pp. 47–52. [Google Scholar]
- Naas, M.I.; Boukhobza, J.; Parvedy, P.R.; Lemarchand, L. An extension to ifogsim to enable the design of data placement strategies. In Proceedings of the 2018 IEEE 2nd International Conference on Fog and Edge Computing (ICFEC), Washington, DC, USA, 1–3 May 2018; pp. 1–8. [Google Scholar]
- Calheiros, R.N.; Ranjan, R.; Beloglazov, A.; De Rose, C.A.; Buyya, R. CloudSim: A toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms. Softw. Pract. Exp. 2011, 41, 23–50. [Google Scholar] [CrossRef]
- Kliazovich, D.; Bouvry, P.; Khan, S.U. GreenCloud: A packet-level simulator of energy-aware cloud computing data centers. J. Supercomput. 2012, 62, 1263–1283. [Google Scholar] [CrossRef]
- Fernández-Cerero, D.; Fernández-Montes, A.; Jakóbik, A.; Kołodziej, J.; Toro, M. SCORE: Simulator for cloud optimization of resources and energy consumption. Simul. Model. Pract. Theory 2018, 82, 160–173. [Google Scholar] [CrossRef]
- Fernández-Cerero, D.; Jakóbik, A.; Fernández-Montes, A.; Kołodziej, J. GAME-SCORE: Game-based energy-aware cloud scheduler and simulator for computational clouds. Simul. Model. Pract. Theory 2018, 93, 3–20. [Google Scholar] [CrossRef]
- Fernández-Cerero, D.; Jakóbik, A.; Grzonka, D.; Kołodziej, J.; Fernández-Montes, A. Security supportive energy-aware scheduling and energy policies for cloud environments. J. Parallel Distrib. Comput. 2018, 119, 191–202. [Google Scholar] [CrossRef]
- MacGillivray, C.; Turner, V.; Clarke, R.; Feblowitz, J.; Knickle, K.; Lamy, L.; Xiang, M.; Siviero, A.; Cansfield, M. IDC future scape: Worldwide internet of things 2017 predictions. In Proceedings of the IDC Web Conference, Framingham, MA, USA, 12 January 2016. [Google Scholar]
- Fernández-Cerero, D.; Fernández-Montes, A.; Ortega, J.A. Energy policies for data-center monolithic schedulers. Expert Syst. Appl. 2018, 110, 170–181. [Google Scholar] [CrossRef]
- Abdul-Rahman, O.A.; Aida, K. Towards understanding the usage behavior of Google cloud users: The mice and elephants phenomenon. In Proceedings of the IEEE International Conference on Cloud Computing Technology and Science (CloudCom), Singapore, 15–18 December 2014; pp. 272–277. [Google Scholar]
- Fernández-Cerero, D.; Fernández-Montes, A.; Velasco, F. Productive Efficiency of Energy-Aware Data Centers. Energies 2018, 11, 2053. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Multi-Access Edge | Fog | Cloudlet |
|---|---|---|---|
| Cloud-providers integration | Medium | Medium | Easy |
| Distance | Close | Close | Close |
| Availability | Average | High | High |
| Latency | Low | Low | Low |
| Acquisition Cost | Medium | Low | High |
| Energy consumption | Low | Low | Medium |
| Reliability | Medium | High | Medium |
| Measure | Without Compression | LZ4 Compression |
|---|---|---|
| Avg. network upload bandwidth | 8.7 MB/s | 8.6 MB/s |
| Avg. network download bandwidth | 8.1 MB/s | 4.4 MB/s |
| Avg. CPU usage | 38.2% | 42.7% |
| Avg. memory usage | 90.1% | 91.3% |
| Avg. swap usage | 42.6% | 40.5% |
| Avg. core temperature | 56.2 °C | 57.8 °C |
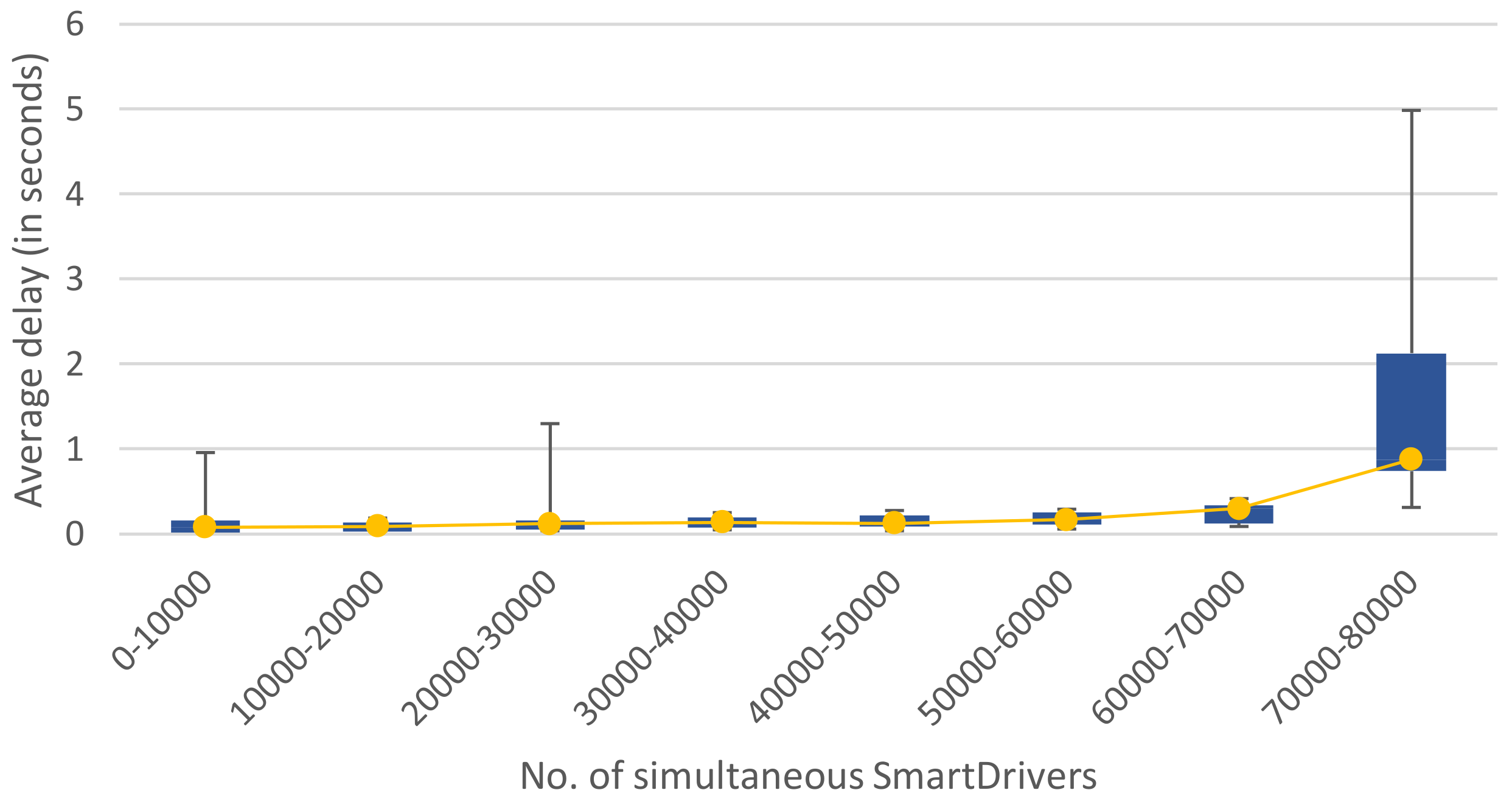
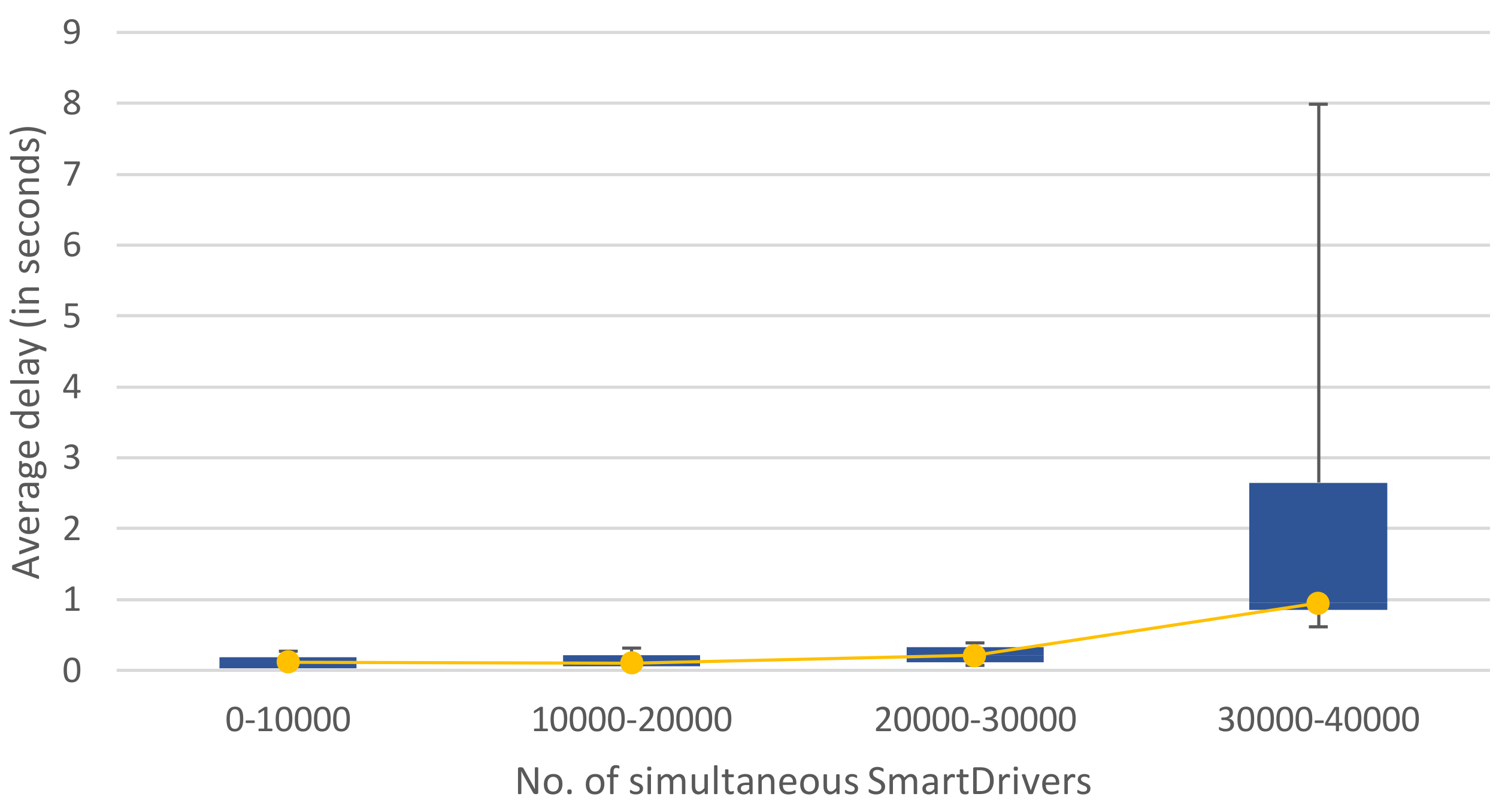
| Simultaneous Drivers | Highest Slow Responses Rate | Highest Delay |
|---|---|---|
| 10,000 | 0% | 0.6 s |
| 20,000 | 3% | 0.7 s |
| 30,000 | 18% | 0.9 s |
| 35,000 | 47% | 1.6 s |
| 40,000 | 77% | 1.8 s |
| 60,000 | 95% | 2.7 s |
| 80,000 | 96% | 4.1 s |
| Raspberry Pi 2 | Raspberry Pi 3 | FIWARE | |
|---|---|---|---|
| Max | 4.8 MB/s | 9.7 MB/s | 69.6 MB/s |
| Min | 3.0 MB/s | 7.2 MB/s | 54.8 MB/s |
| Avg | 4.0 MB/s | 5.4 MB/s | 61.4 MB/s |
| Scenario | Resource | (s) | (s) | Makespan (s) | MWh | Cost | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| (ms) | Occ. (%) | B | S | B | S | B | S | cons. | (M$) | |
| Isolated | ||||||||||
| Cloud | 50 | 20.80 | 5.70 | 5.56 | 5.70 | 5.56 | 99.21 | 2003.19 | 9.73 | 1.20 |
| Cloud | 150 | 21.00 | 5.61 | 5.33 | 5.61 | 5.33 | 114.66 | 1985.85 | 9.75 | 1.20 |
| Cloud | 300 | 21.11 | 6.26 | 5.33 | 6.26 | 5.33 | 142.27 | 1980.65 | 9.76 | 1.20 |
| HE-Cloudlets | 10 | 22.46 | 0.91 | 0.77 | 3.21 | 2.46 | 88.24 | 2058.18 | 4.77 | 0.60 |
| SBC-Cloudlets | 10 | 18.26 | 0.87 | 0.77 | 1.85 | 1.46 | 95.90 | 1996.77 | 1.03 | 0.07 |
| Collaborative | ||||||||||
| Cloud + | 50 | 19.18 | 1.71 | 1.38 | 2.10 | 1.82 | 90.62 | 1979.64 | 14.47 | 1.80 |
| HE-Cloudlets | 10 | 17.52 | ||||||||
| Cloud + | 150 | 19.22 | 1.72 | 1.39 | 2.11 | 1.59 | 90.62 | 1979.64 | 14.48 | 1.80 |
| HE-Cloudlets | 10 | 17.70 | ||||||||
| Cloud + | 300 | 19.18 | 1.73 | 1.41 | 2.12 | 1.60 | 90.62 | 1979.64 | 14.48 | 1.80 |
| HE-Cloudlets | 10 | 18.45 | ||||||||
| Cloud + | 50 | 19.24 | 1.69 | 1.46 | 1.74 | 1.95 | 93.62 | 2019.96 | 10.72 | 1.27 |
| SBC-Cloudlets | 10 | 14.11 | ||||||||
| Cloud + | 150 | 19.19 | 1.70 | 1.47 | 1.75 | 1.72 | 93.62 | 2019.96 | 10.72 | 1.27 |
| SBC-Cloudlets | 10 | 14.68 | ||||||||
| Cloud | 300 | 19.23 | 1.72 | 1.49 | 1.76 | 1.74 | 93.62 | 2019.96 | 10.73 | 1.27 |
| SBC-Cloudlets | 10 | 15.13 | ||||||||
| Scenario | Resource | (s) | (s) | Makespan (s) | MWh | Cost | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| (ms) | occ. (%) | B | S | B | S | B | S | cons. | (M$) | |
| Isolated | ||||||||||
| Cloud | 50 | 20.82 | 5.19 | 5.18 | 5.19 | 5.18 | 98.61 | 2008,41 | 9.72 | 1.20 |
| Cloud | 150 | 20.82 | 5.23 | 5.22 | 5.23 | 5.22 | 98.61 | 2008.41 | 9.72 | 1.20 |
| Cloud | 300 | 20.82 | 5.29 | 5.28 | 5.29 | 5.28 | 98.60 | 2008.41 | 9.72 | 1.20 |
| HE-Cloudlets | 10 | 22.32 | 0.88 | 0.85 | 2.96 | 3.32 | 91.56 | 2051.33 | 4.73 | 0.60 |
| SBC-Cloudlets | 10 | 34.37 | 3.02 | 3.23 | 62.05 | 69.94 | 575.97 | 2066.43 | 1.67 | 0.07 |
| Collaborative | ||||||||||
| Cloud + | 50 | 19.21 | 1.75 | 1.42 | 2.09 | 1.64 | 90.62 | 1979.64 | 14.47 | 1.80 |
| HE-Cloudlets | 10 | 17.42 | ||||||||
| Cloud + | 150 | 19.27 | 1.76 | 1.43 | 2.10 | 1.65 | 90.62 | 1979.64 | 14.48 | 1.80 |
| HE-Cloudlets | 10 | 17.65 | ||||||||
| Cloud + | 300 | 19.28 | 1.78 | 1.44 | 2.11 | 1.67 | 90.62 | 1979.64 | 14.48 | 1.80 |
| HE-Cloudlets | 10 | 18.07 | ||||||||
| Cloud + | 50 | 19.24 | 1.81 | 1.43 | 6.41 | 6.37 | 241.46 | 2002.00 | 10.84 | 1.27 |
| SBC-Cloudlets | 10 | 21.32 | ||||||||
| Cloud + | 150 | 19.29 | 1.82 | 1.44 | 6.42 | 6.38 | 241.45 | 2002.00 | 10.84 | 1.27 |
| SBC-Cloudlets | 10 | 21.34 | ||||||||
| Cloud | 300 | 19.34 | 1.84 | 1.46 | 6.44 | 6.39 | 241.46 | 2002.00 | 10.85 | 1.27 |
| SBC-Cloudlets | 10 | 21.42 | ||||||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fernández-Cerero, D.; Fernández-Rodríguez, J.Y.; Álvarez-García, J.A.; Soria-Morillo, L.M.; Fernández-Montes, A. Single-Board-Computer Clusters for Cloudlet Computing in Internet of Things. Sensors 2019, 19, 3026. https://doi.org/10.3390/s19133026
Fernández-Cerero D, Fernández-Rodríguez JY, Álvarez-García JA, Soria-Morillo LM, Fernández-Montes A. Single-Board-Computer Clusters for Cloudlet Computing in Internet of Things. Sensors. 2019; 19(13):3026. https://doi.org/10.3390/s19133026
Chicago/Turabian StyleFernández-Cerero, Damián, Jorge Yago Fernández-Rodríguez, Juan A. Álvarez-García, Luis M. Soria-Morillo, and Alejandro Fernández-Montes. 2019. "Single-Board-Computer Clusters for Cloudlet Computing in Internet of Things" Sensors 19, no. 13: 3026. https://doi.org/10.3390/s19133026
APA StyleFernández-Cerero, D., Fernández-Rodríguez, J. Y., Álvarez-García, J. A., Soria-Morillo, L. M., & Fernández-Montes, A. (2019). Single-Board-Computer Clusters for Cloudlet Computing in Internet of Things. Sensors, 19(13), 3026. https://doi.org/10.3390/s19133026