A Literature Review: Geometric Methods and Their Applications in Human-Related Analysis

 ,
, 
 and
and
Abstract
1. Introduction
- Geometric methods and their applications in human-related analysis are extensively studied.
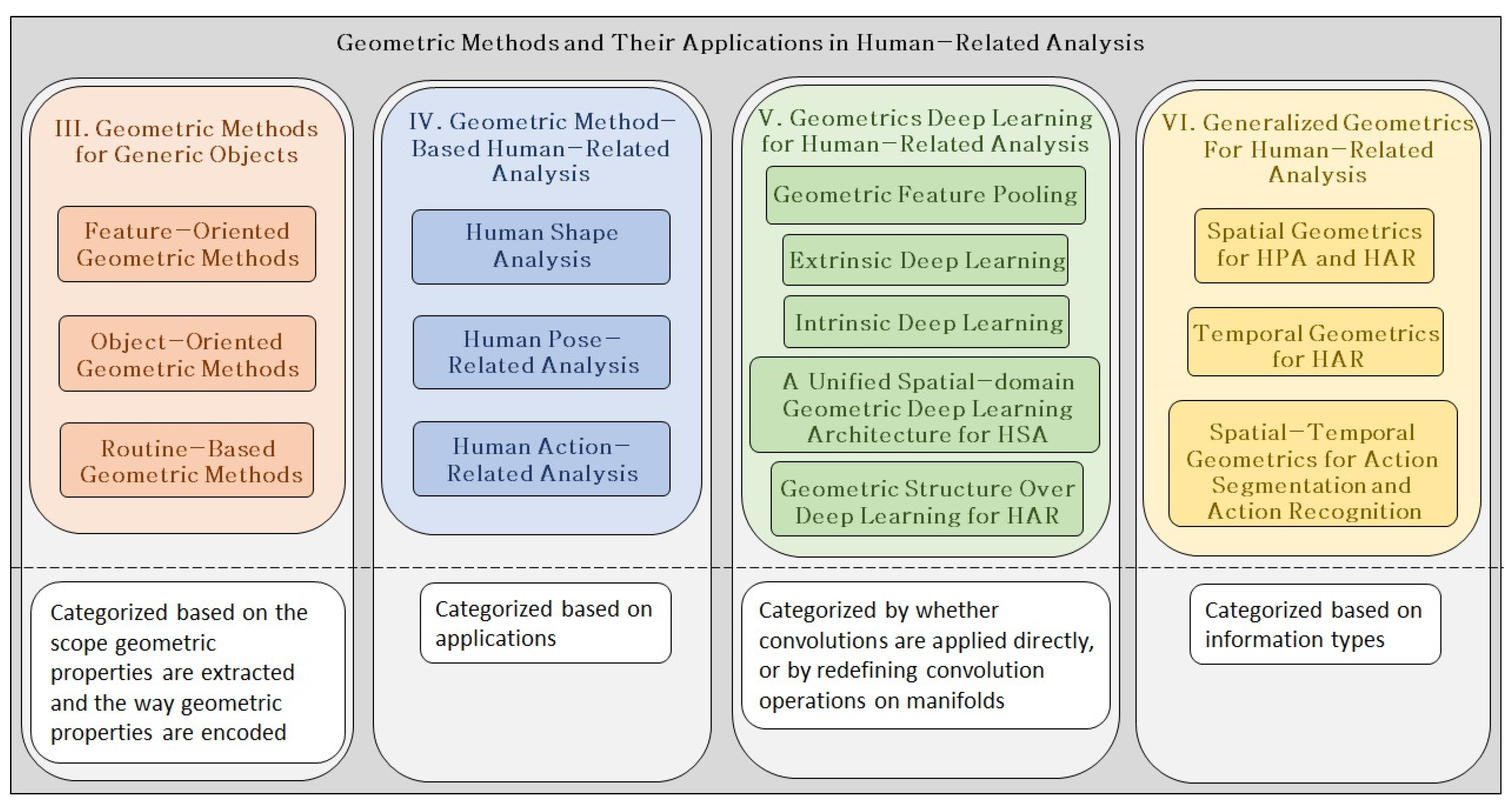
- Geometric methods are studied based on the scope in which they are applied, and we classify them into: feature-oriented geometric methods, object-oriented geometric methods, and routine-based geometric methods.
- Geometric methods and their performances on standard datasets are collected so that researchers who are interested in this topic can identify the state of the art.
2. Basic Geometric Concepts
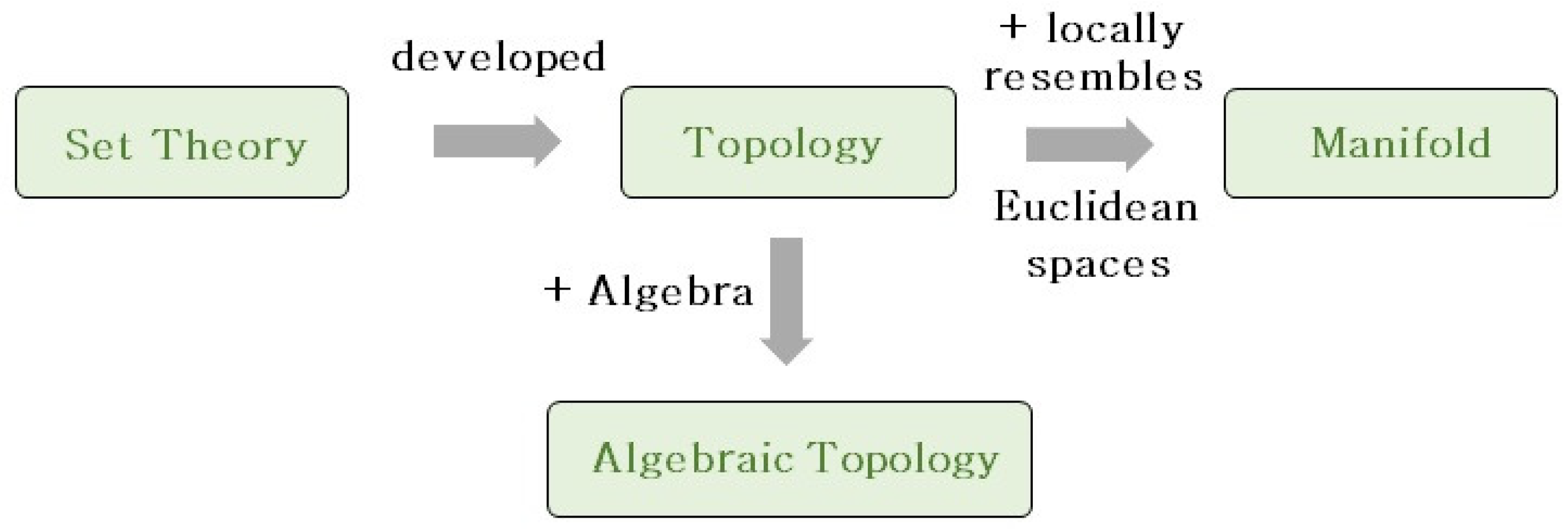
2.1. Set Theory Concepts
2.1.1. Metric
- with equality iff .
- .
- .
2.1.2. Quotient Vector Space
2.2. Topological Concepts
2.2.1. Topology
- x lies in each of its neighborhoods.
- The intersection of two neighborhoods of x is a neighborhood of x.
- If N is a neighborhood of x and if U is a subset of X that contains N, then U is a neighborhood of x.
- If N is a neighborhood of x and if denotes the set , then is a neighborhood of x (the set is called the interior of N).
- The empty set ∅ is in .
- X is in .
- The intersection of a finite number of sets in is also in .
- The union of an arbitrary number of sets in is also in .
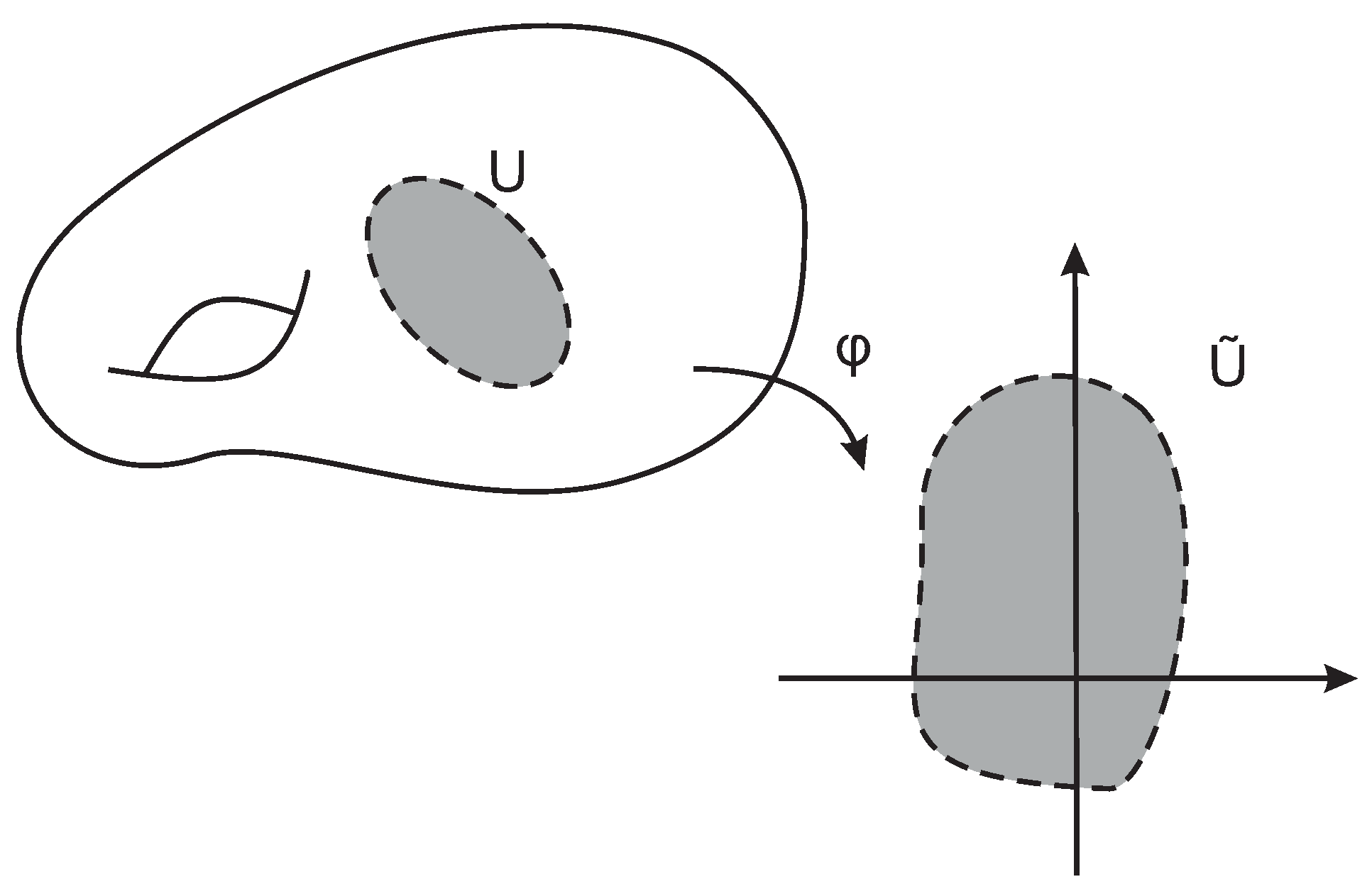
2.2.2. Homeomorphism
2.2.3. Quotient Space
2.3. Algebraic Topology Concepts
2.4. Manifold Concepts
2.4.1. Topological Manifold
- is a Hausdorff space.
- is second countable: there exists a countable basis for the topology of .
- is locally Euclidean of dimension n: for each , we can find an open set containing p, an open set , and a homeomorphism (i.e., a continuous bijective map with the continuous inverse).
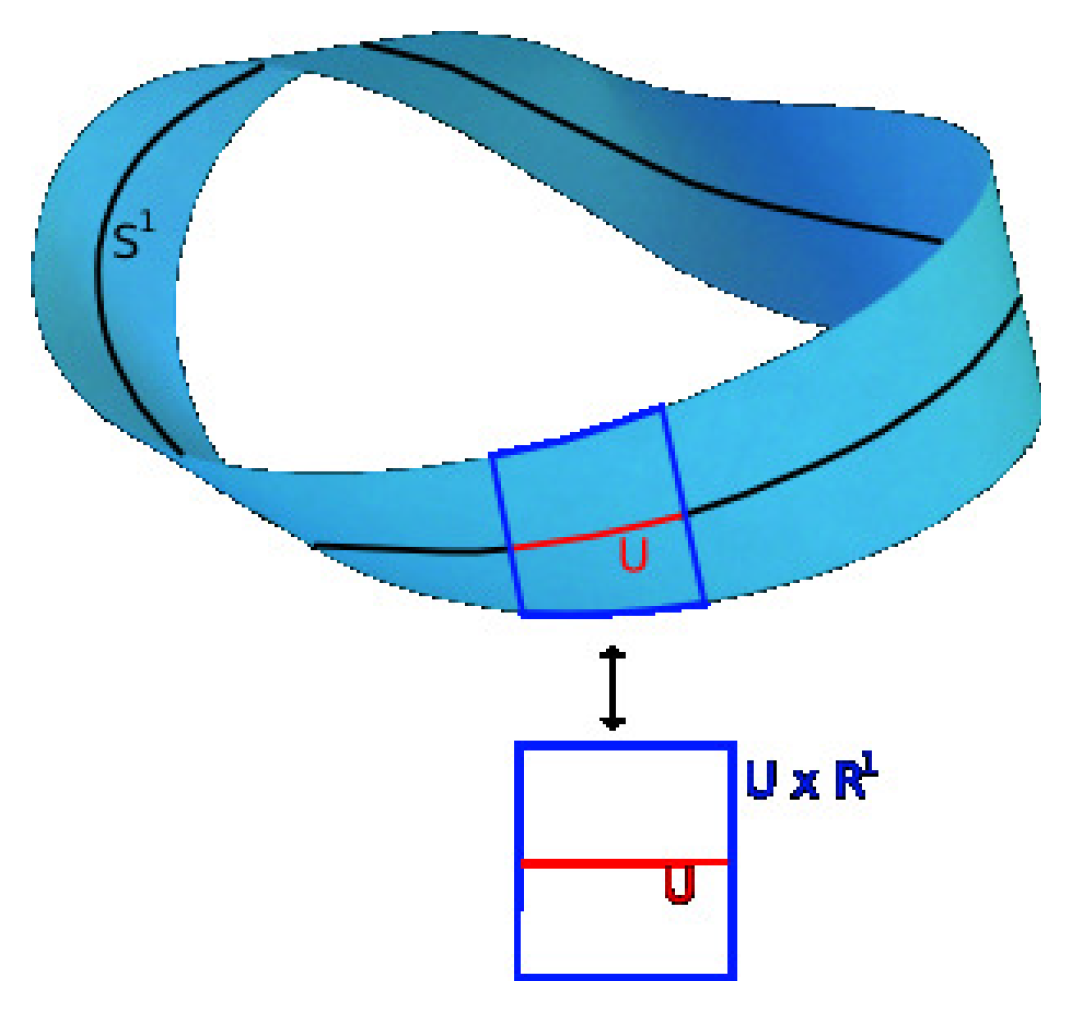
2.4.2. Chart
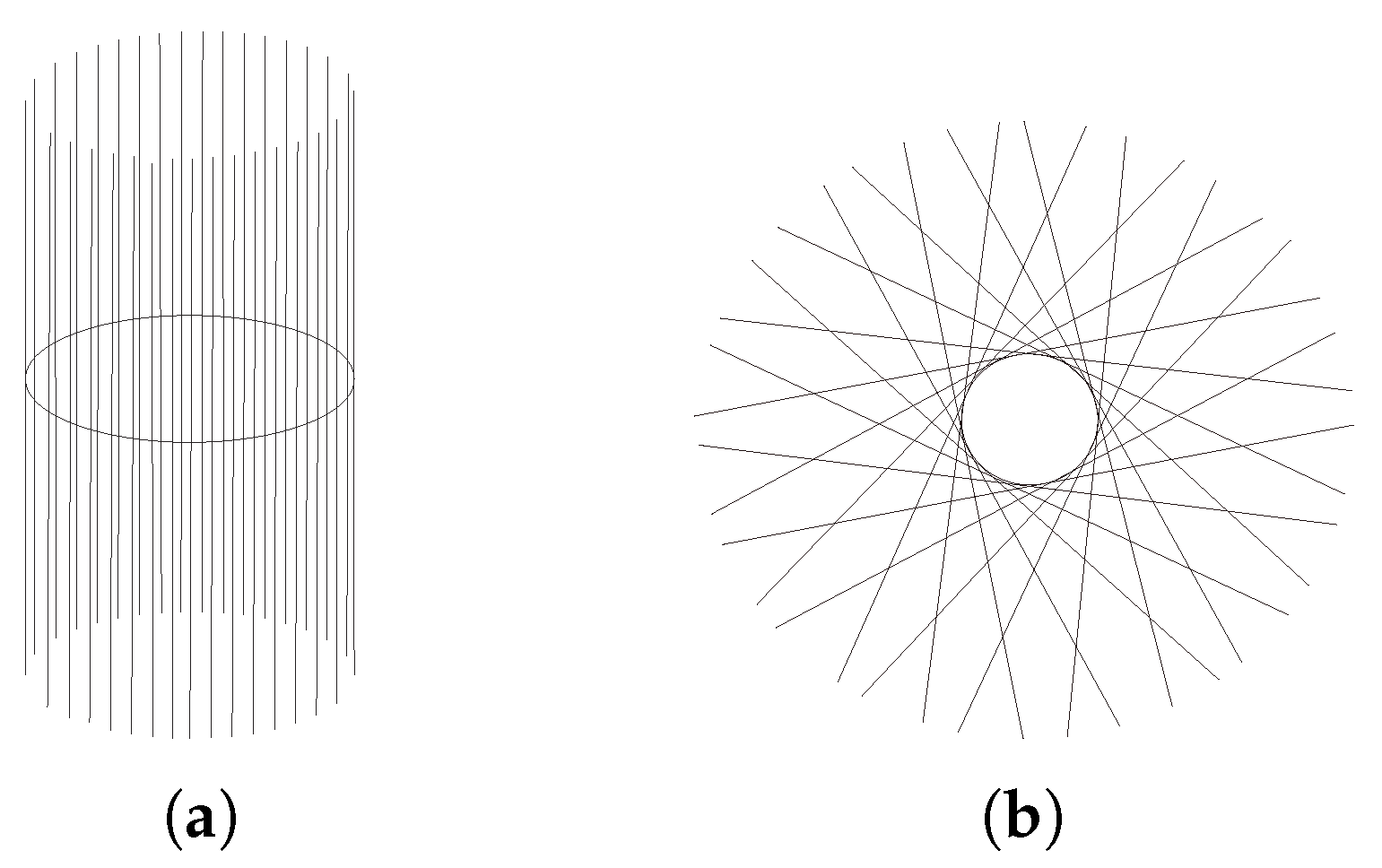
2.4.3. Tangent Space/Tangent Bundle
- .
- .
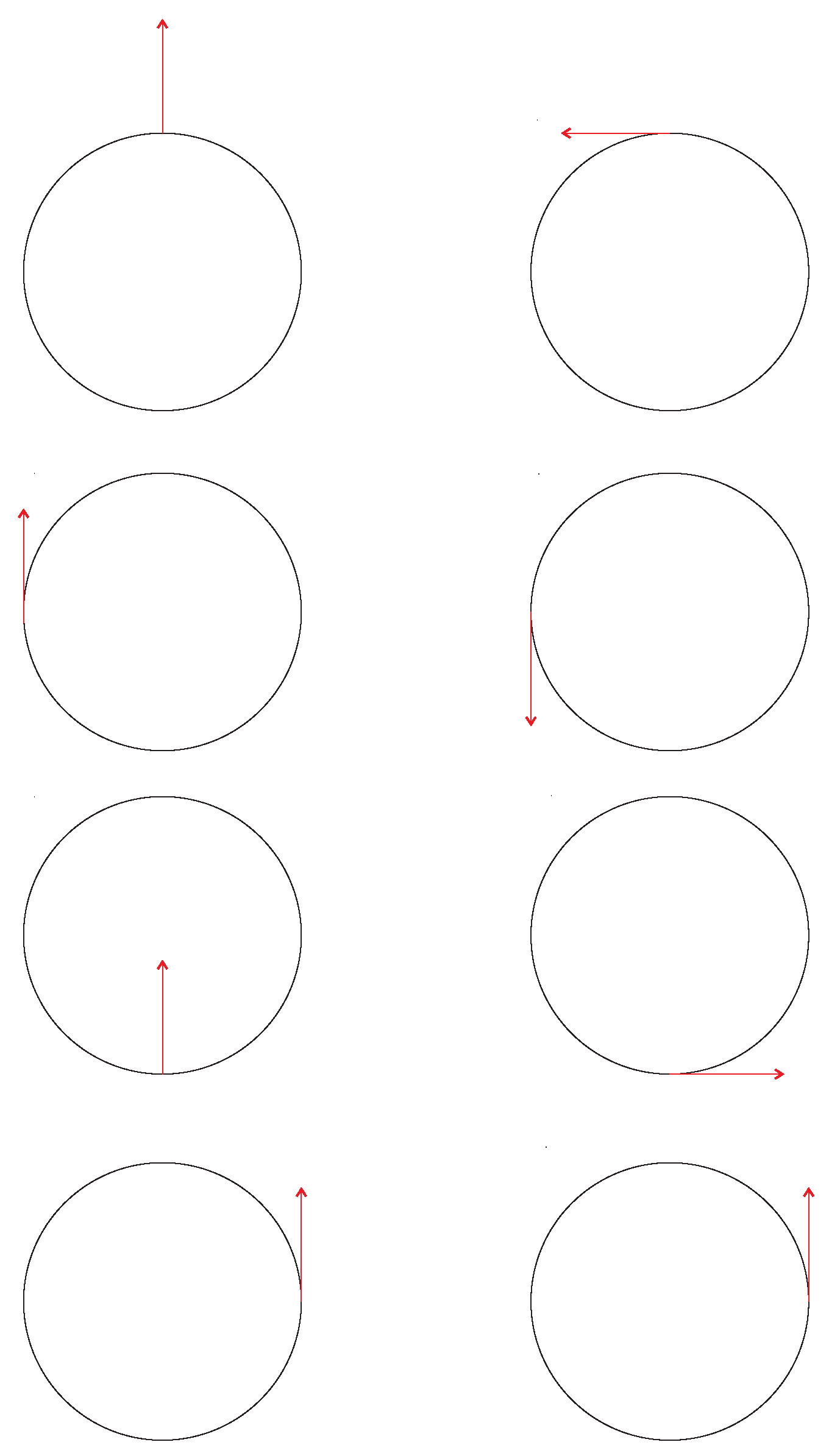
2.4.4. Parallel Transport
2.5. Lie Group and Lie Algebra
- Bilinearity: , for all scalars a, b in F, and all elements x, y, z in .
- Skew-symmetry or alternativity: , which implies for all .
- Jacobi Identity: .
3. Geometric Methods for Generic Objects
3.1. Feature-Oriented Geometric Methods
3.1.1. Distance-Based Methods
3.1.2. Positive Definite Manifold-Based Methods
3.1.3. Kernels over a Manifold
3.1.4. Moduli Space
3.2. Object-Oriented Geometric Methods
3.2.1. Tangent Space-Based Methods
3.2.2. Conformal Geometry-Based Methods
3.2.3. Principal Geodesic Analysis
3.3. Routine-Based Geometric Methods
3.3.1. Dimension Reduction-Based Methods
3.3.2. Graph-Based Methods
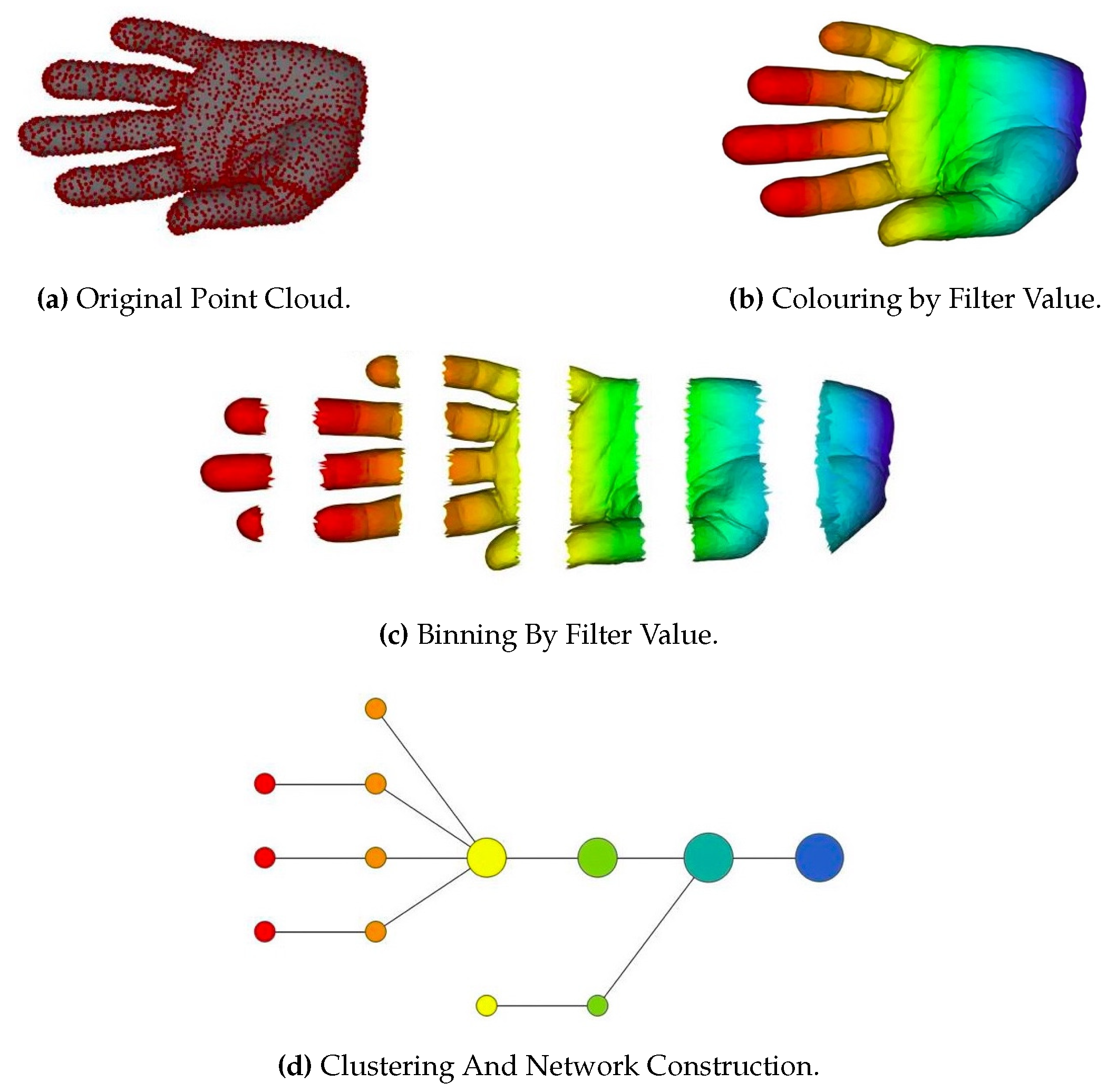
3.3.3. Topological Data Analysis
4. Geometric Method-Based Human-Related Analysis
4.1. Human Shape Analysis
4.1.1. Heat Kernel-Based Methods
4.1.2. Wave Kernel Signature-Based Methods
4.1.3. Learned Spectral Descriptor-Based Methods
4.2. Human Pose-Related Analysis
4.3. Human Action-Related Analysis
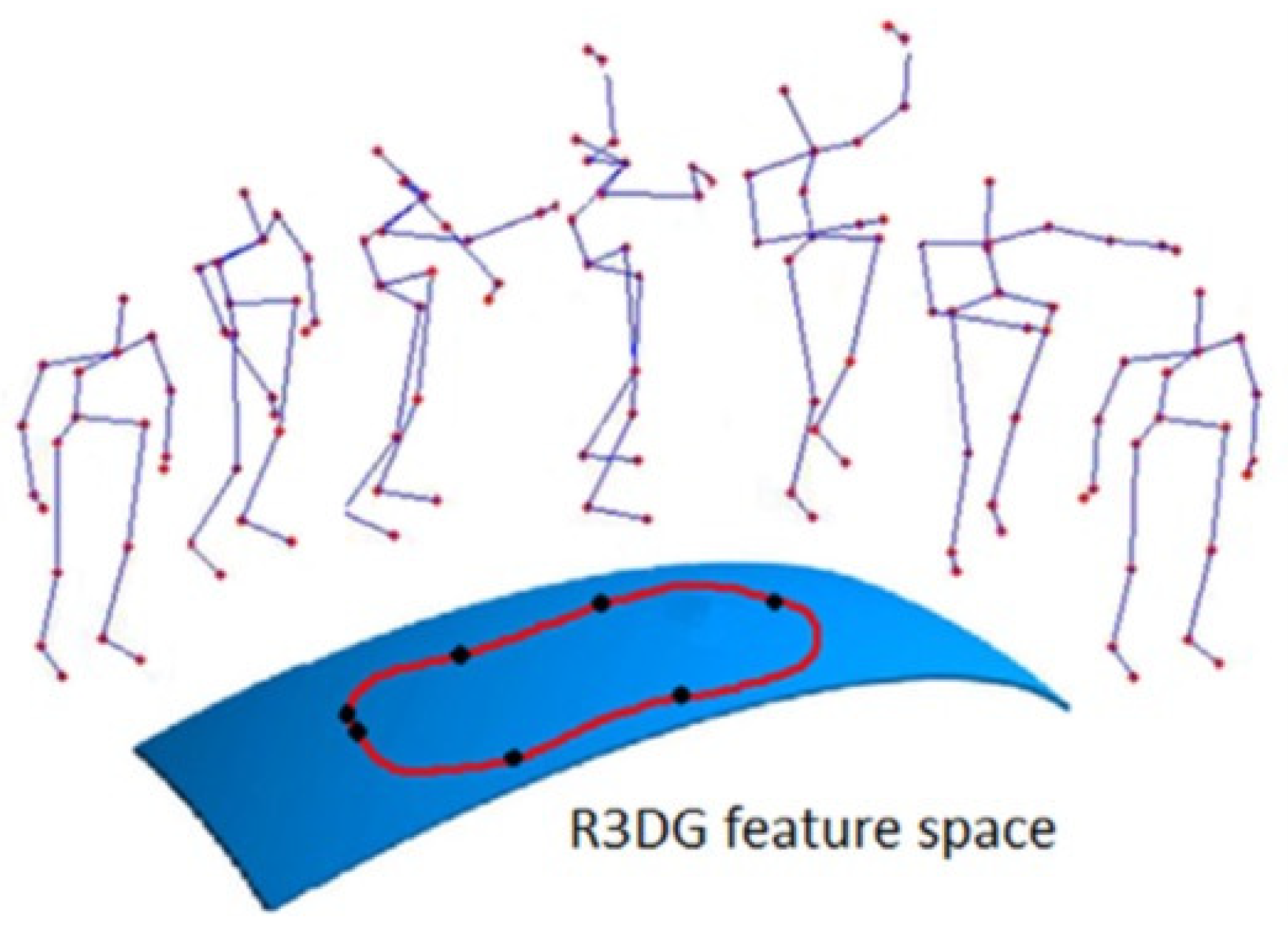
4.3.1. Relative 3D Geometry-Based Methods for Human Action Recognition
4.3.2. Matrix Embedding for 3D Human Action Recognition
4.3.3. Graph-Based Human Action Recognition
4.3.4. Lie Group-Based Human Action Recognition
4.3.5. Dynamic Manifold Warping for Human Action Recognition
5. Geometric Deep Learning for Human-Related Analysis
5.1. Geometric Feature Pooling
5.2. Extrinsic Deep Learning
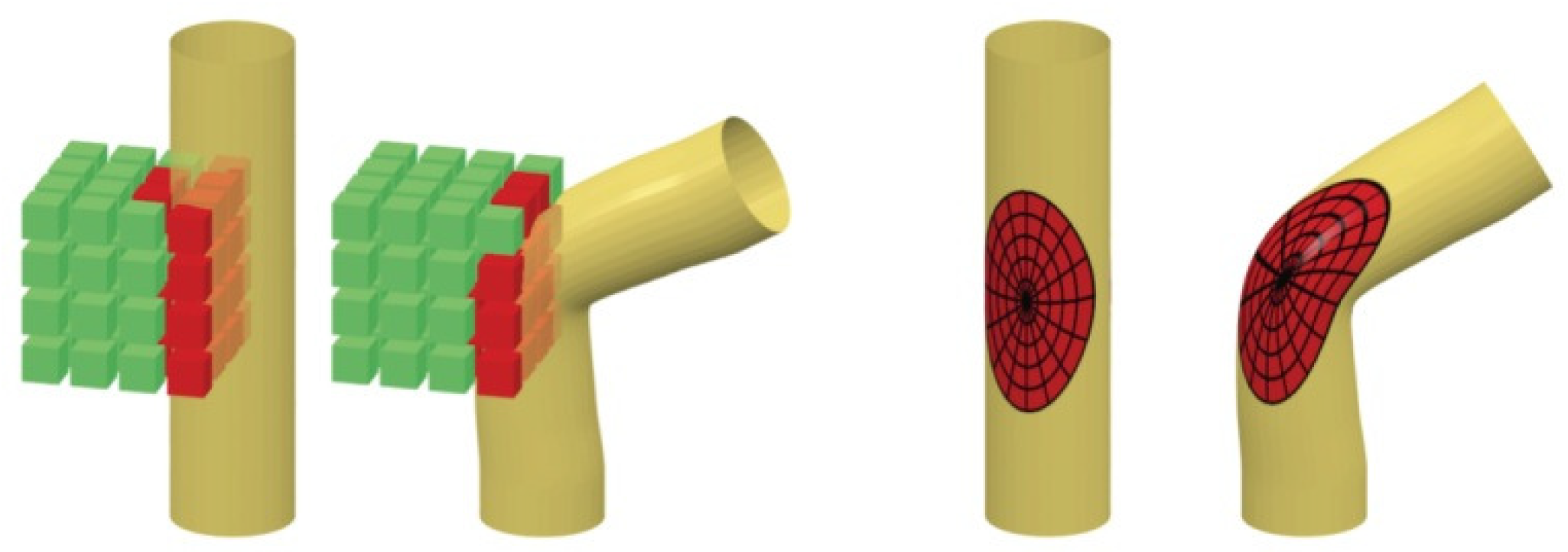
5.2.1. Volumetric CNN for Shape Analysis
5.2.2. Geometric Constrained Extrinsic CNN for Human Shape Analysis
5.3. Intrinsic Deep Learning
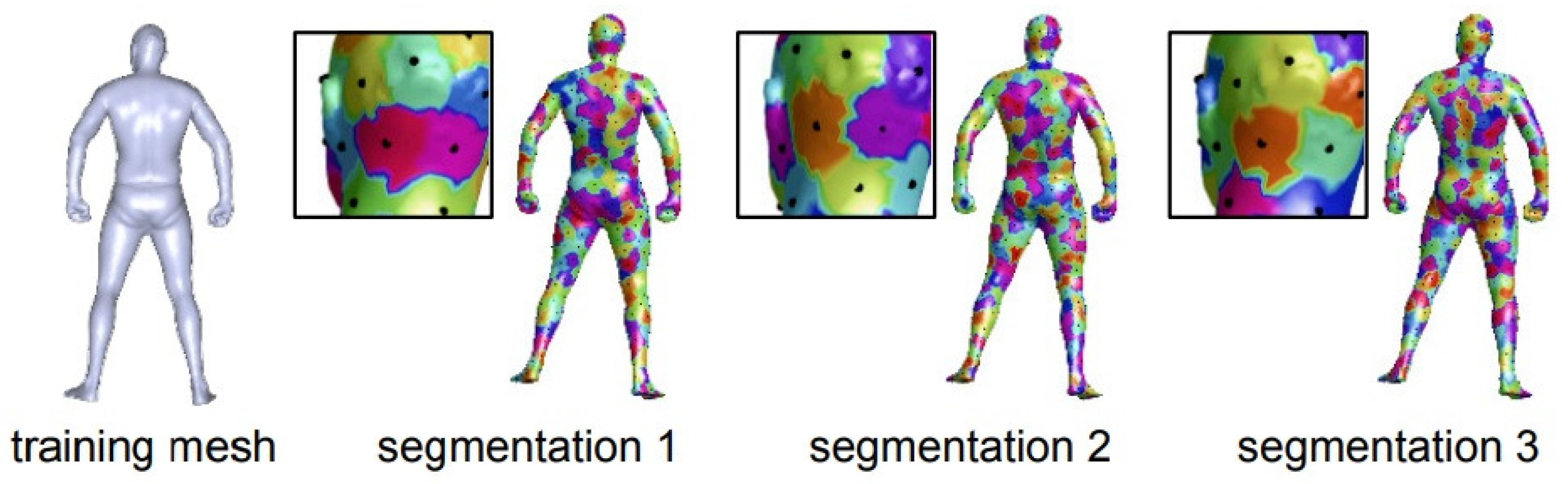
5.3.1. Spatial-Domain Geometric CNN for Human Shape Analysis
5.3.2. Spectral Analysis-Based Intrinsic CNN
Localized Spectral CNN for Human Shape Analysis
5.3.3. Heat Diffusion CNN for Human Shape Analysis
5.4. A Unified Spatial-Domain Geometric Deep Learning Architecture for Human Shape Analysis
5.5. Geometric Structures over Deep Learning for Human Action Recognition
6. Generalized Geometrics for Human-Related Analysis
6.1. Spatial Geometrics for Human Pose-Related Analysis and Human Action-Related Analysis
6.2. Temporal Geometrics for Human Action Recognition
6.3. Spatial-Temporal Geometrics for Action Segmentation and Action Recognition
7. Validation Datasets
7.1. 3D Human Datasets
7.1.1. KIDS Dataset
7.1.2. ShapeNet
- (1)
- ShapeNetCore [144], including 55 common object categories (approximately 51,300 unique 3D models), 12 object categories of PASCAL 3D+, and a popular computer vision 3D benchmark dataset.
- (2)
- ShapeNetSem [145], including 12,000 models of 270 categories and annotated with manually-verified category labels, consistent alignments, real-world dimensions, estimates of their material composition at the category level, and estimates of their total volume and weight.
7.1.3. TOSCA High-Resolution Dataset
7.1.4. Human 3.6M
7.1.5. H3D Database
7.1.6. 3D Shape Dataset with Noise
7.1.7. Partial Shape Dataset
7.1.8. SHREC
7.2. 3D Human Action Datasets
7.2.1. CMU Graphics Lab Motion Capture Database
7.2.2. HumanEva Dataset
7.3. RGB-D People Datasets
7.3.1. RGB-D People Datasets
7.3.2. RGB-D Human Tracking Dataset
7.4. RGB-D Human Pose and Posture Datasets
Kinect Gesture Dataset
7.5. RGB-D Human Action and Activity Datasets
7.5.1. Human Daily Activity Dataset
7.5.2. Cornell Activity Datasets
7.5.3. 50 Salads Dataset
7.5.4. UR Fall Detection Dataset
7.5.5. Tum Kitchen Dataset
8. Performances of Related Works
9. Conclusions and Discussions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| Set Theory Symbols | |
| ∼ | A relation |
| The equivalence class x | |
| V/ | The quotient space of V by W, also denoted as V/W |
| Topological Symbols | |
| A topological space | |
| G | A topological group |
| The general linear group | |
| Manifold Symbols | |
| A manifold | |
| The tangent space of at x | |
| The tangent bundle of | |
| The cotangent bundle | |
| The section of the vector bundle | |
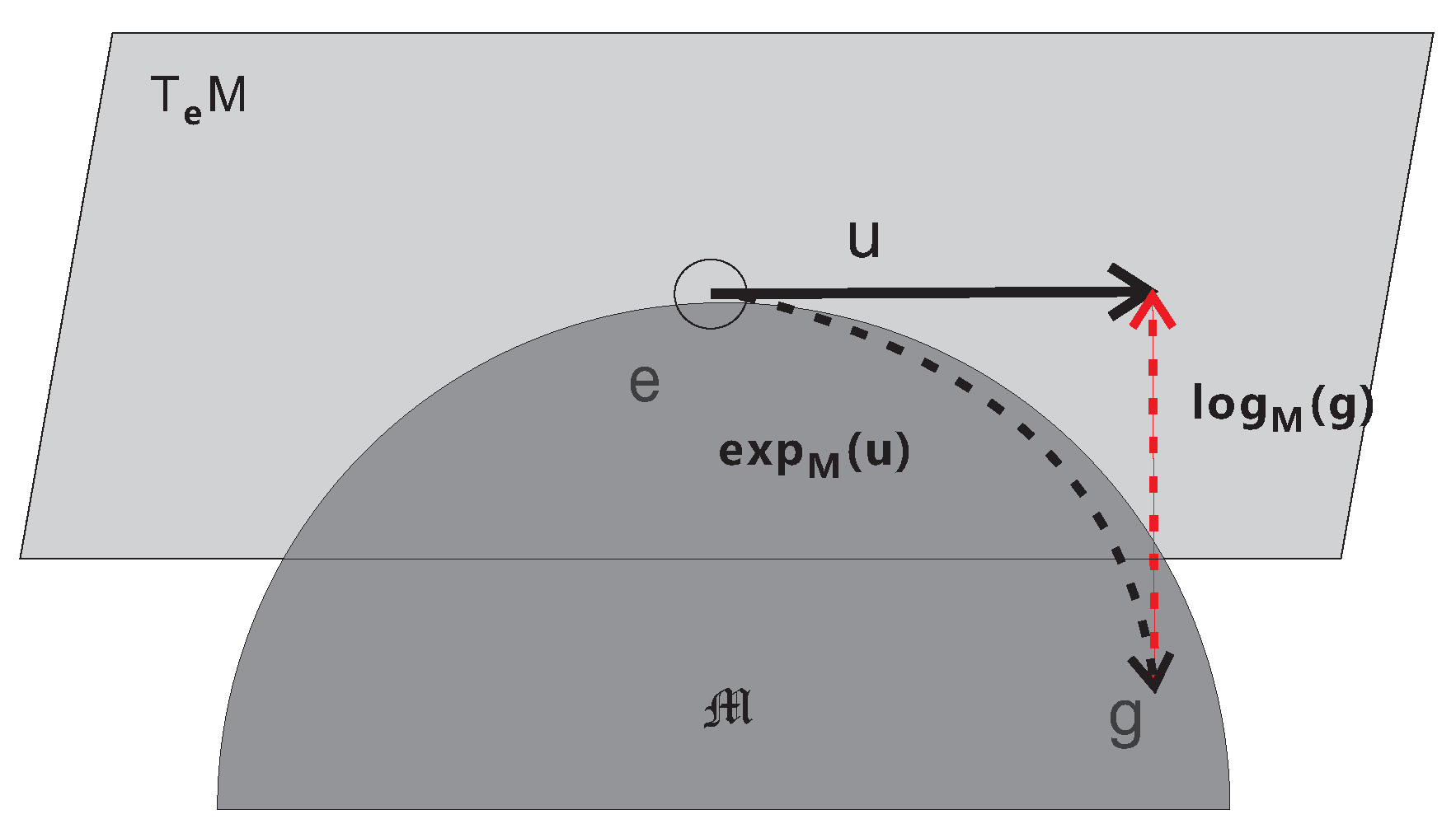
| The exponential map | |
| The inverse exponential map, also denoted as Exp | |
| ∇ | A connection |
| A dual connection | |
| A geodesic, i.e., a curve such that . | |
| , the geodesic distance function determined by g, | |
| A Riemannian manifold equipped with a metric g | |
| A smooth manifold of a pair of a topological manifolds and an atlas on | |
Appendix A. Mathematical Concepts
Appendix A.1. Set Theory Concepts
Appendix A.1.1. Equivalence Relations
- for all .
- if and only if .
- and implies .
Appendix A.1.2. Equivalence Class
- The equivalence class of , denoted by , means the set . The sets for all form a partition of the set X.
- The set of equivalence classes under ∼ can be denoted as , and it is referred to as the quotient of X with respect to ∼.
Appendix A.1.3. Covering
Appendix A.2. Topological Concepts
Appendix A.2.1. Closed Sets/Interior and Closure of A Set/Limit Points
Appendix A.2.2. Continuous Function
Appendix A.2.3. Quotient Map
Appendix A.2.4. Metric
- for all , equality holds if and only if .
- for all .
- (Triangle inequality) , for all .
Appendix A.2.5. Hausdorff Space
Appendix A.3. Algebraic Topology Concepts
Appendix A.3.1. Orbit Space
- for all .
- for all and .
Appendix A.3.2. Homotopy
Appendix A.3.3. Fundamental Group
Appendix A.3.4. Homology
Appendix A.3.4.1. Normal Subgroup
Appendix A.3.4.2. Abelian Group
Appendix A.3.4.3. Commutator Subgroup
Appendix A.3.4.4. Homology
Appendix A.4. Manifold Concepts
Appendix A.4.1. Atlas
Appendix A.4.2. Smooth Manifold
Appendix A.4.3. Section
Appendix A.4.4. Vector Bundle/Fiber Bundle
 Here, S is a fixed finite-dimensional real (unless otherwise specified) vector space called the standard fiber or the typical fiber, p is a surjective submersion, and such that .
Here, S is a fixed finite-dimensional real (unless otherwise specified) vector space called the standard fiber or the typical fiber, p is a surjective submersion, and such that .
Appendix A.4.5. The Tangent Bundle Of A Vector Bundle
Appendix A.4.6. Vertical Bundle
Appendix A.4.7. Vector Bundle Homomorphism/Isomorphism
 If is invertible, it is called a vector bundle isomorphism.
If is invertible, it is called a vector bundle isomorphism.Appendix A.4.8. Connection
References
- Dou, M.; Taylor, J.; Fuchs, H.; Fitzgibbon, A.; Izadi, S. 3D Scanning Deformable Objects with a Single RGBD Sensor. In Proceedings of the 2015 Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 493–501. [Google Scholar]
- Li, H.; Vouga, E.; Gudym, A.; Luo, L.; Barron, J.T.; Gusev, G. 3D Self-Portraits. ACM Trans. Graph. 2013, 32, 1–9. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Fox, D.; Seitz, S.M. DynamicFusion: Reconstruction and Tracking of Non-Rigid Scenes in Real-Time. In Proceedings of the 2015 Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 343–352. [Google Scholar]
- Li, H.; Adams, B.; Guibas, L.J.; Pauly, M. Robust Single-View Geometry and Motion Reconstruction. ACM SIGGRAPH Asia 2009, 28, 175. [Google Scholar]
- Tevs, A.; Berner, A.; Wand, M.; Ihrke, I.; Bokeloh, M.; Kerber, J.; Seidel, H.-P. Animation Cartography-Intrinsic Reconstruction of Shape and Motion. ACM Trans. Graph. 2012, 31, 1–15. [Google Scholar] [CrossRef]
- Cetingul, H.; Vidal, R. Intrinsic Mean Shift For Clustering on Stiefel and Grassmann Manifolds. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1896–1902. [Google Scholar]
- Chakraborty, R.; Vemuri, B.C. Recursive Fréchet Mean Computation On Grassmannian and Its Applications to Computer Vision. In Proceedings of the 2015 International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2039–2047. [Google Scholar]
- Salehian, H.; Chakraborty, R.; Ofori, E.; Vaillancourt, D.; Vemuri, B.C. An efficient recursive estimator of the Fréchet mean on hypersphere with applications to Medical Image Analysis. In Proceedings of the 2015 Mathematical Foundations of Computational Anatomy, Munich, Germany, 9 October 2015. [Google Scholar]
- Srivastava, A.; Jermyn, I.; Joshi, S. Riemannian analysis of probability density functions with applications in vision. In Proceedings of the Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8. [Google Scholar]
- Fletcher, P.T.; Joshi, S. Riemannian Geometry for the Statistical Analysis of Diffusion Tensor Data. Signal Process. 2007, 87, 250–262. [Google Scholar] [CrossRef]
- Sra, S.; Cherian, A. Generalized Dictionary Learning for Symmetric Positive Definite Matrices with Application to NN Retrieval. In Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2011; pp. 318–332. [Google Scholar]
- Xie, Y.; Ho, J.; Vemuri, B. On a Nonlinear Generalization of Sparse Coding and Dictionary Learning. In Proceedings of the 2013 International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1480–1488. [Google Scholar]
- Müller, M. Information Retrieval For Music And Motion; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Mining Actionlet Ensemble for Action Recognition with Depth Cameras. In Proceedings of the Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1290–1297. [Google Scholar]
- Hussein, M.E.; Torki, M.; Gowayyed, M.A.; El-Saban, M. Human Action Recognition Using a Temporal Hierarchy of Covariance Descriptors on 3D Joint Locations. Int. Jt. Conf. Artif. Intell. 2013, 86, 639–644. [Google Scholar]
- Goswami, M.; Gu, X.; PrithamPingali, V.; Gu, X. Computing Teichmüller Maps Between Polygons. Found. Comput. Math. 2017, 17, 1–30. [Google Scholar] [CrossRef]
- Litany, O.; Rodolà, E.; Bronstein, A.M.; Bronstein, M.M.; Cremers, D. Non-Rigid Puzzles. Comput. Graph. Forum 2016, 35, 135–143. [Google Scholar] [CrossRef]
- Rodolà, E.; Cosmo, L.; Bronstein, M.M.; Torsello, A.; Cremers, D. Partial Functional Correspondence. Comput. Graph. Forum 2017, 36, 222–236. [Google Scholar] [CrossRef]
- Cosmo, L.; Rodolà, E.; Bronstein, M.; Sahillioǧlu, Y. SHREC’16: Partial Matching of Deformable Shapes. In Proceedings of the International Conference on 3D Vision, Stanford, CA, USA, 25–28 October 2016. [Google Scholar]
- Làhner, Z.; Rodolxax, E.; Bronstein, M.M.; Cremers, D.; Burghard, O.; Cosmo, L.; Dieckmann, A.; Klein, R.; Sahillioglu, Y. SHREC 16: Matching of Deformable Shapes with Topological Noise. In Proceedings of the 2016 International Conference on 3D Vision, Stanford, CA, USA, 25–28 October 2016. [Google Scholar]
- Gu, X.D.; Zeng, W.; Luo, F.; Yau, S.T. Numerical Computation of Surface Conformal Mappings. Comput. Methods Funct. Theory 2012, 11, 747–787. [Google Scholar] [CrossRef]
- Ovsjanikov, M.; Ben-Chen, M.; Solomon, J.; Butscher, A.; Guibas, L.J. Functional Maps: A Flexible Representation of Maps between Shapes. ACM Trans. Graph. 2012, 31, 1–11. [Google Scholar] [CrossRef]
- Rustamov, R.M.; Ovsjanikov, M.; Azencot, O.; Ben-Chen, M.; Chazal, F.; Guibas, L.J. Map-Based Exploration of Intrinsic Shape Differences and Variability. Trans. Graph. 2013, 32, 72. [Google Scholar] [CrossRef]
- Davis, B.C.; Fletcher, P.T.; Bullitt, E.; Joshi, S. Population Shape Regression from Random Design Data. Int. J. Comput. Vis. 2010, 90, 255–266. [Google Scholar] [CrossRef]
- Freifeld, O.; Black, M.J. Lie Bodies: A Manifold Representation of 3D Human Shape. In Proceedings of the 2012 European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Volume 7572, pp. 1–14. [Google Scholar]
- Liu, Z.; Zhang, C.; Tian, Y. 3D-based Deep Convolutional Neural Network for Action Recognition with Depth Sequences. Image Vis. Comput. 2016, 2016, 93–100. [Google Scholar] [CrossRef]
- Wang, P.; Li, W.; Gao, Z.; Zhang, Y.; Tang, C.; Ogunbona, P. Scene Flow to Action Map: A New Representation for RGB-D based Action Recognition with Convolutional Neural Networks. In Proceedings of the 2017 Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 416–425. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D Shapenets: A Deep Representation for Volumetric Shapes. In Proceedings of the 2015 Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Harandi, M.T.; Sanderson, C.; Hartley, R.; Lovell, B.C. Sparse Coding And Dictionary Learning for Symmetric Positive Definite Matrices: A Kernel Approach. In Proceedings of the 2012 European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 216–229. [Google Scholar]
- Li, P.; Wang, Q.; Zuo, W.; Zhang, L. Log-Euclidean Kernels for Sparse Representation and Dictionary Learning. In Proceedings of the 2014 IEEE International Conference on Computer Vision, Paris, France, 27–30 October 2014; pp. 1601–1608. [Google Scholar]
- Armstrong, M.A. Basic Topology; Springer: Berlin/Heidelberg, Germany, 1983. [Google Scholar]
- Hong, Y.; Singh, N.; Kwitt, R.; Niethammer, M. Time-Warped Geodesic Regression. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Boston, MA, USA, 14–18 September 2014; Volume 17, pp. 105–112. [Google Scholar]
- Du, J.; Goh, A.; Kushnarev, S.; Qiu, A. Geodesic Regression on Orientation Distribution Functions with Its Application to an Aging Study. Neuroimage 2014, 87, 416–426. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.J.; Adluru, N.; Collins, M.D.B.; Chung, M.K.; Bendlin, B.; Johnson, S.C. MGLM on Riemannian Manifolds with Applications to Statistical Analysis of Diffusion Weighted Images. In Proceedings of the 2014 Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2705–2712. [Google Scholar]
- Banerjee, M.; Chakraborty, R.; Ofori, E.; Vaillancourt, D.; Vemuri, B.C. Nonlinear Regression On Riemannian Manifolds And Its Applications To Neuro-Image Analysis. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Volume 9349, pp. 719–727. [Google Scholar]
- Singh, N.; Niethammer, M. Splines For Diffeomorphic Image Regression. In Proceedings of the 2014 International Conference on Medical Image Computing and Computer-Assisted Intervention, Boston, MA, USA, 14–18 September 2014; pp. 121–129. [Google Scholar]
- Chakraborty, R.; Banerjee, M.; Crawford, V.; Vemuri, B. An information theoretic formulation of the Dictionary Learning and Sparse Coding Problems on Statistical Manifolds. In Proceedings of the 2016 Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Cherian, A.; Sra, S.; Banerjee, A.; Papanikolopoulos, N. Jensen-Bregman Logdet Divergence with Application to Efficient Similarity Search for Covariance Matrices. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2161–2174. [Google Scholar] [CrossRef] [PubMed]
- Arsigny, V.; Fillard, P.; Pennec, X.; Ayache, N. Logeuclidean Metrics For Fast And Simple Calculus on Diffusion Tensors. Magn. Reson. Med. 2006, 56, 411–421. [Google Scholar] [CrossRef]
- Bhatia, R. Positive Definite Matrices; Princeton University Press: Princeton, NJ, USA, 2009. [Google Scholar]
- Moakher, M.; Batchelor, P. Symmetric Positivedefinite Matrices: From Geometry to Applications and Visualization. In Visualization and Processing of Tensor Fields; Springer: Berlin/Heidelberg, Germany, 2006; pp. 285–298. [Google Scholar]
- Pennec, X.; Fillard, P.; Ayache, N. A Riemannian Framework for Tensor Computing. Int. J. Comput. Vis. 2006, 66, 41–66. [Google Scholar] [CrossRef]
- Jayasumana, S.; Hartley, R.; Salzmann, M.; Li, H.; Harandi, M. Kernel methods on the Riemannian manifold of symmetric positive definite matrices. In Proceedings of the 2013 Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 73–80. [Google Scholar]
- Li, B.; Ayazoglu, M.; Mao, T.; Camps, O.I.; Sznaier, M. Activity Recognition Using Dynamic Subspace Angles. Comput. Vis. Pattern Recognit. 2011, 42, 3193–3200. [Google Scholar]
- Li, B.; Camps, O.I.; Sznaier, M. Cross-view activity recognition using hankelets. Comput. Vis. Pattern Recognit. IEEE 2012, 2012, 1362–1369. [Google Scholar]
- Sivalingam, R.; Boley, D.; Morellas, V.; Papanikolopoulos, N. Tensor sparse coding for positive definite matrices. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 592–605. [Google Scholar] [CrossRef]
- Sra, S. A new metric on the manifold of kernel matrices with application to matrix geometric means. In Proceedings of the 2012 Conference and Workshop on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 144–152. [Google Scholar]
- Wang, Z.; Vemuri, B.C. An affine invariant tensor dissimilarity measure and its applications to tensor-valued image segmentation. In Proceedings of the 2014 Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. I-228–I-233. [Google Scholar]
- Faraki, M.; Harandi, M.T.; Porikli, F. More About Vlad: A Leap from Euclidean to Riemannian Manifolds. In Proceedings of the 2015 Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4951–4960. [Google Scholar]
- Harandi, M.; Salzmann, M.; Porikli, F. Bregman Divergences for Infinite Dimensional Covariance Matrices. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1003–1010. [Google Scholar]
- Harandi, M.; Salzmann, M. Riemannian Coding and Dictionary Learning: Kernels to the Rescue. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3926–3935. [Google Scholar]
- Feragen, A.; Lauze, F.; Hauberg, S. Geodesic Exponential Kernels: When Curvature and Linearity Conflict. In Proceedings of the 2015 Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3032–3042. [Google Scholar]
- Gu, X.D.; Yau, S.-T. Computational Conformal Geometry; Higher Education Press: Beijing, China, 2008. [Google Scholar]
- Boothby, W.M. An Introduction to Differentiable Manifolds and Riemannian Geometry; Academic Press: Cambridge, MA, USA, 1986; Volume 120. [Google Scholar]
- Zhang, M.; Fletcher, P.T. Probabilistic Principal Geodesic Analysis. In Proceedings of the Conference and Workshop on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Fletcher, P.T.; Lu, C.; Pizer, S.M.; Joshi, S. Principal Geodesic Analysis for the Study of Nonlinear Statistics of Shape. IEEE Trans. Med. Imaging 2004, 23, 995–1005. [Google Scholar] [CrossRef]
- Said, S.; Coutry, N.; Bihan, N.; Sangwine, J. Exact Principal Geodesic Analysis for Data On SO(3). In Proceedings of the 2007 Signal Processing Conference, Poznan, Poland, 3–7 September 2007; pp. 1701–1705. [Google Scholar]
- Chakraborty, R.; Seo, D.; Vemuri, B.C. An Efficient Exact-PGA Algorithm for Constant Curvature Manifolds. In Proceedings of the 2016 Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3976–3984. [Google Scholar]
- Sommer, S.; Lauze, F.; Hauberg, S.; Nielsen, M. Manifold Valued Statistics, Exact Principal Geodesic Analysis and the Effect of Linear Approximations. In Proceedings of the 2010 European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 43–56. [Google Scholar]
- Liu, Q.; Cao, X. Action Recognition Using Subtensor Constraint. In Proceedings of the 2012 European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 764–777. [Google Scholar]
- Belkin, M.; Niyogi, P. Laplacian Eigenmaps for Dimensionality Reduction and Data Representation. Neural Comput. 2003, 15, 1373–1396. [Google Scholar] [CrossRef]
- Jenatton, R.; Obozinski, G.; Bach, F. Structured Sparse Principal Component Analysis. J. Mach. Learn. Res. 2009, 9, 131–160. [Google Scholar]
- Mairal, J.; Bach, F.; Ponce, J. Sparse Modeling for Image and Vision Processing. Eprint Arxiv 2014, 8, 85–283. [Google Scholar] [CrossRef]
- Wang, Y.-X.; Zhang, Y.-J. Nonnegative matrix factorization: A comprehensive review. IEEE Trans. Knowl. Data Eng. 2013, 25, 1336–1353. [Google Scholar] [CrossRef]
- Cai, D.; He, X.; Han, J.; Huang, T.S. Graph Regularized Nonnegative Matrix Factorization for Data Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1548–1560. [Google Scholar] [PubMed]
- Du, H.; Zhang, X.; Hu, Q.; Hou, Y. Sparse Representation-Based Robust Face Recognition by Graph Regularized Low-Rank Sparse Representation Recovery. Neurocomputing 2015, 164, 220–229. [Google Scholar] [CrossRef]
- Gao, S.; Tsang, I.-H.; Chia, L.-T. Laplacian Sparse Coding, Hyper-Graph Laplacian Sparse Coding, and Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 92–104. [Google Scholar] [CrossRef]
- Jiang, B.; Ding, C.; Tang, J. Graph-Laplacian PCA: Closed-Form Solution and Robustness. Comput. Vis. Pattern Recognit. 2013, 9, 3492–3498. [Google Scholar]
- Jin, T.; Yu, J.; You, J.; Zeng, K.; Li, C.; Yu, Z. Low-Rank Matrix Factorization with Multiple Hypergraph Regularizers. Pattern Recognit. 2014, 48, 1011–1022. [Google Scholar] [CrossRef]
- Jin, T.; Yu, Z.; Li, L.; Li, C. Multiple Graph Regularized Sparse Coding and Multiple Hypergraph Regularized Sparse Coding for Image Representation. Neurocomputing 2014, 154, 245–256. [Google Scholar] [CrossRef]
- Peng, Y.; Lu, B.-L.; Wang, S. Enhanced Low-Rank Representation Via Sparse Manifold Adaption for Semi-Supervised Learning. Neural Netw. 2015, 65, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Tao, L.; Ip, H.H.; Wang, Y.; Shu, X. Low Rank Approximation with Sparse Integration of Multiple Manifolds for Data Representation. Appl. Intell. 2015, 42, 430–446. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhao, K. Low-Rank Matrix Approximation with Manifold regularization. Pattern Anal. Mach. Intell. 2013, 35, 1717–1729. [Google Scholar] [CrossRef] [PubMed]
- Sibson, R. SLINK: An optimally efficient algorithm for the single-link cluster method. Comput. J. 1973, 16, 30–34. [Google Scholar] [CrossRef]
- Lu, X.; Yao, J.; Tu, J.; Li, K.; Li, L.; Liu, Y. Pairwise Linkage for Point Cloud Segmentation. In Proceedings of the 2016(III-3) ISPRS Annals of Photogrammetry, Remote Sensing and Spatial Information Sciences, Prague, Czech Republic, 12–19 July 2016; pp. 201–208. [Google Scholar]
- Shuman, D.I.; Narang, S.K.; Frossard, P.; Ortega, A.; Vandergheynst, P. The Emerging Field of Signal Processing on Graphs: Extending High-Dimensional Data Analysis to Networks and Other Irregular Domains. IEEE Signal Process. Mag. 2013, 30, 83–98. [Google Scholar] [CrossRef]
- Chazal, F.; Michel, B. An introduction to Topological Data Analysis: fundamental and practical aspects for data scientists. arXiv 2017, arXiv:1710.04019. [Google Scholar]
- Patania, A.; Vaccarino, F.; Petri, G. Topological analysis of data. EPJ Data Sci. 2017, 6, 7. [Google Scholar] [CrossRef]
- Lum, P.; Singh, G.; Lehman, A.; Ishkanov, T.; Vejdemo-Johansson, M.; Alagappan, M.; Carlsson, J.; Carlsson, G. Extracting insights from the shape of complex data using topology. Sci. Rep. 2013, 3, 1236. [Google Scholar] [CrossRef]
- Ovsjanikov, M.; Sun, J.; Guibas, L. Global Intrinsic Symmetries of Shapes. Comput. Graph. Forum 2008. [Google Scholar] [CrossRef]
- Ovsjanikov, M.; Mérigot, Q.; Mémoli, F.; Guibas, L.J. One Point Isometric Matching with the Heat Kernel. Comput. Graph. Forum 2010, 29, 1555–1564. [Google Scholar] [CrossRef]
- Solomon, J.; Ben-Chen, M.; Butscher, A.; Guibas, L. Discovery of Intrinsic Primitives on Triangle Meshes. Comput. Graph. Forum 2011, 30, 365–374. [Google Scholar] [CrossRef]
- Corman, E.; Ovsjanikov, M. Functional Characterization of Deformation Fields. ACM Trans. Graph. 2019, 38, 8:1–8:19. [Google Scholar] [CrossRef]
- Raviv, D.; Bronstein, A.M.; Bronstein, M.M.; Kimmel, R. Full and Partial Symmetries of Non-rigid Shapes. Int. J. Comput. Vis. 2010, 89, 18–39. [Google Scholar] [CrossRef]
- Bronstein, A.M.; Bronstein, M.M.; Kimmel, R. Topology-Invariant Similarity of Nonrigid Shapes. Int. J. Comput. Vis. 2008, 81, 281. [Google Scholar] [CrossRef]
- Smeets, D.; Hermans, J.; Vandermeulen, D.; Suetens, P. Isometric Deformation Invariant 3D Shape Recognition. Pattern Recognit. 2012, 45, 2817–2831. [Google Scholar] [CrossRef]
- Shamir, A. A survey on Mesh Segmentation Techniques. Comput. Graph. Forum 2008, 27, 1539–1556. [Google Scholar] [CrossRef]
- Loncaric, S. A Survey of Shape Analysis Techniques. Pattern Recognit. 1998, 31, 983–1001. [Google Scholar] [CrossRef]
- Laga, H. A Survey on Non-Rigid 3D Shape Analysis; Academic Press Library in Signal Processing; Academic Press: Cambridge, MA, USA, 2018; Volume 6, pp. 261–304. [Google Scholar]
- Tangelder, J.W.H.; Veltkamp, R.C. A Survey of Content Based 3D Shape Retrieval Methods. Multimed. Tools Appl. 2008, 39, 441. [Google Scholar] [CrossRef]
- Coifman, R.R.; Lafon, S. Diffusion Maps. Appl. Comput. Harmon. Anal. 2006, 21, 5–30. [Google Scholar] [CrossRef]
- Sun, J.; Ovsjanikov, M.; Guibas, L.J. A Concise and Provably Informative Multi-Scale Signature Based on Heat Diffusion. Comput. Graph. Forum 2009, 28, 1383–1392. [Google Scholar] [CrossRef]
- Aubry, M.; Schlickewei, U.; Cremers, D. The Wave Kernel Signature: A Quantum Mechanical Approach to Shape Analysis. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Barcelona, Spain, 6–13 November 2011; pp. 1626–1633. [Google Scholar]
- Rodolà, E.; Bulò, S.R.; Windheuser, T.; Vestner, M.; Cremers, D. Dense Non-Rigid Shape Correspondence Using Random Forests. In Proceedings of the 2014 Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 4177–4184. [Google Scholar]
- Litman, R.; Bronstein, A.M. Learning Spectral Descriptors for Deformable Shape Correspondence. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 170–180. [Google Scholar] [CrossRef] [PubMed]
- Galoppo, N.; Otaduy, M.A.; Moss, W.; Sewall, J.; Curtis, S.; Lin, M.C. Controlling Deformable Material with Dynamic Morph Targets. In Proceedings of the ACM Siggraph Symposium on Interactived Graphics and Games, New Orleans, LA, USA, 4–6 August 2009; pp. 39–47. [Google Scholar]
- Hahn, F.; Thomaszewski, B.; Coros, S.; Sumner, R.W.; Cole, F.; Meyer, M.; Derose, T.; Gross, M. Subspace Clothing Simulation Using Adaptive Bases. ACM Trans. Graph. 2014, 33, 105. [Google Scholar] [CrossRef]
- Teng, Y.; Meyer, M.; Derose, T.; Kim, T. Subspace Condensation: Full Space Adaptivity for Subspace Deformations. ACM Trans. Graph. 2015, 34, 76:1–76:9. [Google Scholar] [CrossRef]
- Kry, P.G.; James, D.L.; Pai, D.K. EigenSkin: Real Time Large Deformation Character Skinning in Hardware. In Proceedings of the 2002 Symposium on Computer Animation, San Antonio, TX, USA, 21–22 July 2002; pp. 153–160. [Google Scholar]
- Barbič, J.; James, D.L. Real-time Subspace Integration For St. Venant-Kirchhoff Deformable Models. ACM Trans. Graph. 2005, 24, 982–990. [Google Scholar] [CrossRef]
- Tycowicz, C.V.; Schulz, C.; Seidel, H.-P.; Hildebrandt, K. An Efficient Construction of Reduced Deformable Objects. SIGGRAPH Asia 2013, 32, 213. [Google Scholar] [CrossRef]
- Xu, H.; Barbic, J. Pose-Space Subspace Dynamics. ACM Trans. Graph. 2016, 35, 1–14. [Google Scholar] [CrossRef]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. R3DG features: Relative 3D geometry-based skeletal representations for human action recognition. Comput. Vis. Image Underst. 2016, 152, 155–166. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, Y.; Gou, M.; Sznaier, M.; Camps, O. Efficient Temporal Sequence Comparison and Classification Using Gram Matrix Embeddings on a Riemannian Manifold. In Proceedings of the 2016 Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4498–4507. [Google Scholar]
- Çeliktutan, O.; Wolf, C.; Sankur, B.; Lombardi, E. Real-Time Exact Graph Matching with Application in Human Action Recognition. In Human Behavior Understanding; Springer: Berlin/Heidelberg, Germany, 2012; pp. 17–28. [Google Scholar]
- Gaur, U.; Zhu, Y.; Song, B.; Roy-Chowdhury, A. A “String of Feature Graphs” Model For Recognition of Complex Activities in Natural Videos. In Proceedings of the 2011 International Conference on Computer Vision, Tokyo, Japan, 25–27 May 2011; pp. 2595–2602. [Google Scholar]
- Wang, L.; Sahbi, H. Directed Acyclic Graph Kernels for Action Recognition. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3168–3175. [Google Scholar]
- Wang, P.; Yuan, C.; Hu, W.; Li, B.; Zhang, Y. Graph Based Skeleton Motion Representation and Similarity Measurement for Action Recognition. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 370–385. [Google Scholar]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human Action Recognition by Representing 3D Skeletons as Points in a Lie Group. In Proceedings of the 2014 Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 588–595. [Google Scholar]
- Vemulapalli, R.; Chellappa, R. Rolling Rotations for Recognizing Human Actions from 3D Skeletal Data. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4471–4479. [Google Scholar]
- Gong, D.; Medioni, G. Dynamic Manifold Warping for View Invariant Action Recognition. In Proceedings of the 2011 International Conference on Computer Vision, Tokyo, Japan, 25–27 May 2011; Volume 23, pp. 571–578. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. Int. Conf. Neural Inf. Process. Syst. 2012, 60, 1097–1105. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 2014, 1. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network For Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Saito, S.; Li, T.; Li, H. Real-Time Facial Segmentation and Performance Capture from RGB Input. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 244–261. [Google Scholar]
- Olszewski, K.; Lim, J.J.; Saito, S.; Li, H. High-fidelity facial and speech animation for VR HMDs. ACM Trans. Graph. 2016, 35, 221. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Springenberg, J.T.; Brox, T. Learning to Generate Chairs With Convolutional Neural Networks. In Proceedings of the 2015 Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1538–1546. [Google Scholar]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; Vandergheynst, P. Geometric Deep Learning: Going beyond Euclidean Data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef]
- Masci, J.; Rodolà, E.; Boscaini, D.; Bronstein, M.M.; Li, H. Geometric deep learning. In Proceedings of the SIGGRAPH ASIA 2016 Courses, Macao, 5–8 December 2016. [Google Scholar]
- Boscaini, D.; Masci, J.; Rodolà, E.; Bronstein, M. Learning Shape Correspondence with Anisotropic Convolutional Neural Networks. In Proceedings of the Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3189–3197. [Google Scholar]
- Li, T.; Meng, Z.; Ni, B.; Shen, J.; Wang, M. Robust geometric ℓp-norm feature pooling for image classification and action recognition. Image Vis. Comput. 2016, 55, 64–76. [Google Scholar] [CrossRef]
- Song, S.; Xiao, J. Deep Sliding Shapes for a Modal 3D Object Detection in RGB-D Images. In Proceedings of the 2016 Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 808–816. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition. In Proceedings of the Conference on Intelligent Robots and Systems IEEE, Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Zeng, A.; Song, S.; Nißeer, M.; Fisher, M.; Xiao, J. 3DMatch: Learning the Matching of Local 3D Geometry in Range Scans. In Proceedings of the 2017 Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Yumer, M.E.; Mitra, N.J. Learning Semantic Deformation Flows with 3D Convolutional Networks. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Wei, L.; Huang, Q.; Ceylan, D.; Vouga, E.; Li, H. Dense Human Body Correspondences Using Convolutional Networks. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 1544–1553. [Google Scholar]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral Networks and Locally Connected Networks on Graphs. In Proceedings of the International Conference on Learning Representations (ICLR2014), CBLS, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Masci, J.; Boscaini, D.; Bronstein, M.M.; Vandergheynst, P. Geodesic Convolutional Neural Networks on Riemannian Manifolds. In Proceedings of the 2015 IEEE Workshop on 3D Representation and Recognition, Santiago, Chile, 17 December 2015; pp. 832–840. [Google Scholar]
- Boscaini, D.; Masci, J.; Melzi, S.; Bronstein, M.M.; Castellani, U.; Vandergheynst, P. Learning Class-Specific Descriptors for Deformable Shapes Using Localized Spectral Convolutional Networks. Comput. Graph. Forum 2015, 34, 13–23. [Google Scholar] [CrossRef]
- Shuman, D.I.; Ricaud, B.; Vandergheynst, P. Vertex-Frequency Analysis on Graphs. Appl. Comput. Harmon. Anal. 2016, 40, 260–291. [Google Scholar] [CrossRef]
- Andreux, M.; Rodolà, E.; Aubry, M.; Cremers, D. Anisotropic Laplace-Beltrami Operators for Shape Analysis. In Proceedings of the Sixth Workshop on Non-Rigid Shape Analysis and Deformable Image Alignment (NORDIA), Zurich, Switzerland, 12 September 2014. [Google Scholar]
- Monti, F.; Boscaini, D.; Masci, J.; Rodolà, E.; Svoboda, J.; Bronstein, M. Geometric deep learning on graphs and manifolds using mixture model CNNs. In Proceedings of the 2017 Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, C.; Liu, J.; He, Z.; Zhai, Y.; Hu, Q.; Huang, Y. Convolutional Neural Random Fields for Action Recognition. Pattern Recognit. 2016, 59, 213–224. [Google Scholar] [CrossRef]
- Du, L.; Chen, H.; Mei, S.; Wang, Q. Real-time human action recognition using individual body part locations and local joints structure. In Proceedings of the ACM SIGGRAPH Conference on Virtual-Reality Continuum and Its Applications in Industry, Zhuhai, China, 3–4 December 2016; pp. 293–298. [Google Scholar]
- Vinagre, M.; Aranda, J.; Casals, A. A New Relational Geometric Feature for Human Action Recognition. In Informatics in Control, Automation and Robotics; Springer: Berlin/Heidelberg, Germany, 2015; pp. 263–278. [Google Scholar]
- Li, C.; Wang, P.; Wang, S.; Hou, Y.; Li, W. Skeleton-based Action Recognition Using LSTM and CNN. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo Workshops, Hong Kong, China, 10–14 July 2017; pp. 585–590. [Google Scholar]
- Wu, C.; Zhang, J.; Savarese, S.; Saxena, A. Watch-n-patch: Unsupervised understanding of actions and relations. In Proceedings of the 2015 Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4362–4370. [Google Scholar]
- Leonardos, S.; Zhou, X.; Daniilidis, K. Articulated Motion Estimation from a Monocular Image Sequence Using Spherical Tangent Bundles. In Proceedings of the IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016; pp. 587–593. [Google Scholar]
- Lea, C.; Reiter, A.; Vidal, R.; Hager, G.D. Segmental Spatiotemporal CNNs For Fine-Grained Action Segmentation. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 36–52. [Google Scholar]
- Ke, Q.; An, S.; Bennamoun, M.; Sohel, F.; Boussaid, F. SkeletonNet: Mining Deep Part Features for 3D Action Recognition. IEEE Signal Process. Lett. 2017. [Google Scholar] [CrossRef]
- Veeriah, V.; Zhuang, N.; Qi, G. Differential Recurrent Neural Networks for Action Recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Región Metropolitana, Chile, 11–18 December 2015; pp. 4041–4049. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-Temporal LSTM with Trust Gates for 3D Human Action Recognition. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 816–833. [Google Scholar]
- Liu, M.; Chen, C.; Liu, H. Learning informative pairwise joints with energy-based temporal pyramid for 3D action recognition. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo, Hong Kong, China, 10–14 July 2017; pp. 901–906. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. arXiv, 2015; arXiv:1512.03012. [Google Scholar]
- Savva, M.; Chang, A.X.; Hanrahan, P. Semantically-Enriched 3D Models for Common-sense Knowledge. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Bronstein, A.M.; Bronstein, M.M.; Kimmel, R. Numerical Geometry of Non-Rigid Shapes; Springer: New York, NY, USA, 2008; ISBN 978-0-387-73300-5. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1325–1339. [Google Scholar] [CrossRef]
- Ionescu, C.; Li, F.; Sminchisescu, C. Latent Structured Models for Human Pose Estimation. Int. Conf. Comput. Vis. 2011, 58, 2220–2227. [Google Scholar]
- Bourdev, L.; Malik, J. Poselets: Body Part Detectors Trained Using 3D Human Pose Annotations. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1365–1372. [Google Scholar]
- Spinello, L.; Arras, K.O. People Detection in RGB-D Data. In Proceedings of the International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 3838–3843. [Google Scholar]
- Luber, M.; Spinello, L.; Arras, K.O. People Tracking in RGB-D Data with On-line Boosted Target Models. In Proceedings of the International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 3844–3849. [Google Scholar]
- Song, S.; Xiao, J. Tracking Revisited Using RGBD Camera: Unified Benchmark and Baselines. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 233–240. [Google Scholar]
- Stein, S.; McKenna, S.J. Combining Embedded Accelerometers with Computer Vision for Recognizing Food Preparation Activities. In Proceedings of the ACM International Joint Conference on Pervasive and Ubiquitous Computing, Zurich, Switzerland, 8–12 September 2013; pp. 729–738. [Google Scholar]
- Kwolek, B.; Kepski, M. Human Fall Detection on Embedded Platform Using Depth Maps and Wireless Accelerometer. Comput. Methods Programs Biomed. 2014, 117, 489–501. [Google Scholar] [CrossRef]





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Applications | Year | Methods | Validation Datasets | Accuracy (%) or Error (cm) |
|---|---|---|---|---|
| Human Shape Analysis | 2016 | Dense correspondence-based method [126] | FAUST | 2–2.35 cm |
| CMUMocap | ||||
| Human Pose Related | 2017 | SkeletonNet [140] | NTURGB+D | |
| Analysis | SBUKinect interaction | |||
| 2011 | Spatio temporal manifold model-based method [111] | Mocap | ||
| 2012 | Bi-lingual Hankelets [45] | IXMAS | ||
| 2012 | Graph matching-based method [105] | KTH | ||
| 2013 | Directed acyclic graph kernel-based method [107] | UCFSport | ||
| 2014 | Fully-convolutional network-based method [113] | PASCAL VOC 2011 | ||
| MSRAction3D | ||||
| 2014 | Lie group-based method [109] | UTKinect-Action | ||
| Florence3D-Action | ||||
| 2014 | Shape matching-based method [94] | TOSCA | ||
| 2015 | Deep deconvolution network-based method [114] | PASCAL VOC 2012 | ||
| KTH-1 | ||||
| 2015 | Differential recurrent neural network-based method | KTH-2 | ||
| [141] | MSR Action3D | |||
| 2016 | 3D DCNN-based method [26] | MSR Action3D | ||
| Weizmann | ||||
| 2016 | Convolutional neural random fields [133] | Youtube | ||
| UCF50 | ||||
| WBJR | ||||
| NTURGB+D | ||||
| SBUInteraction | ||||
| 2016 | Enhanced-LSTM-based method [142] | UT-Kinect | ||
| Berkeley MHAD | ||||
| MSRAction3D | ||||
| HDM05 | ||||
| Human action related | 2016 | Gram matrix-based method [104] | MSR-Action3D | |
| Analysis | MHAD | |||
| UTKinect | ||||
| MSR Action3D | ||||
| 2016 | Local joint structure and body part locations | UTKinect-Action | ||
| Feature-based method [134] | Florence3D-Action | |||
| MSR Action3D | ||||
| 2016 | Motionlet-graph-based method [108] | Florence 3D Actions | ||
| UTKinect Action | ||||
| Florence3D | ||||
| G3D | ||||
| 2016 | Relative 3D geometry-based method [103] | MSR Action3D | ||
| MSRPairs | ||||
| UTKinect-Action | ||||
| Florence3D | ||||
| 2016 | Rolling map-based method [110] | MSRPairs | ||
| G3D | ||||
| 2016 | Segmental spatiotemporal CNN-based method [139] | 50 Salads | ||
| JIGSAWS | ||||
| 2017 | LSTM and CNN-based method [136] | NTU RGB+D | ||
| 2017 | Geometric feature pooling-based method [136] | HOIactivity dataset | ||
| 2017 | Scene flow to action map [27] | ChaLearn LAP IsoGD | ||
| Multi-modal and multi-view and interactive dataset | ||||
| 2017 | Spatiotemporal feature-based method [143] | MSRAction3D | ||
| UTKinect-Action |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, W.; Zhang, B.; Wang, C.; Yue, H.; Li, C.; Xing, L.; Qiao, Y.; Zhang, W.; Gong, F. A Literature Review: Geometric Methods and Their Applications in Human-Related Analysis. Sensors 2019, 19, 2809. https://doi.org/10.3390/s19122809
Gong W, Zhang B, Wang C, Yue H, Li C, Xing L, Qiao Y, Zhang W, Gong F. A Literature Review: Geometric Methods and Their Applications in Human-Related Analysis. Sensors. 2019; 19(12):2809. https://doi.org/10.3390/s19122809
Chicago/Turabian StyleGong, Wenjuan, Bin Zhang, Chaoqi Wang, Hanbing Yue, Chuantao Li, Linjie Xing, Yu Qiao, Weishan Zhang, and Faming Gong. 2019. "A Literature Review: Geometric Methods and Their Applications in Human-Related Analysis" Sensors 19, no. 12: 2809. https://doi.org/10.3390/s19122809
APA StyleGong, W., Zhang, B., Wang, C., Yue, H., Li, C., Xing, L., Qiao, Y., Zhang, W., & Gong, F. (2019). A Literature Review: Geometric Methods and Their Applications in Human-Related Analysis. Sensors, 19(12), 2809. https://doi.org/10.3390/s19122809