Speech Emotion Recognition with Heterogeneous Feature Unification of Deep Neural Network


Abstract
1. Introduction
- Different from directly using varieties of acoustic features such as handcrafted features or high-level features for emotion recognition, we propose a hybrid framework which could discover the informative feature representations effectively from the heterogeneous acoustic feature groups to eliminate the redundant and unrelated information.
- After investigating different types of fusion strategy, a fusion network module based on deep neural networks is proposed to fuse the informative feature representations for better results of speech emotion prediction.
- We compare the proposed framework with other prominent methods for acoustic emotion recognition. Extensive experimental results on the emotional dataset show that our framework achieves promising performance which demonstrates the effectiveness of our approach.
2. Related Work
2.1. Acoustic Features Extraction
2.2. Heterogeneous Acoustic Features Processing
2.3. Multiple Acoustic Features Fusion
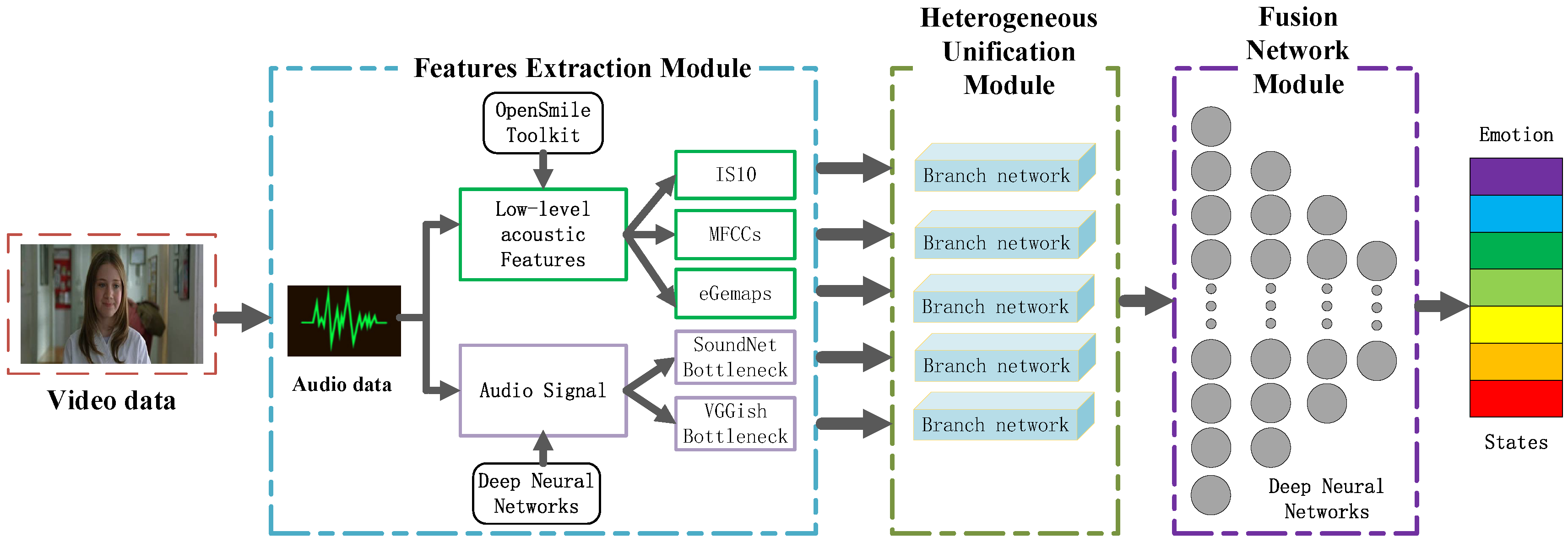
3. Proposed Speech Emotion Recognition Architecture
3.1. Features Extraction Module
3.2. Heterogeneous Unification Module
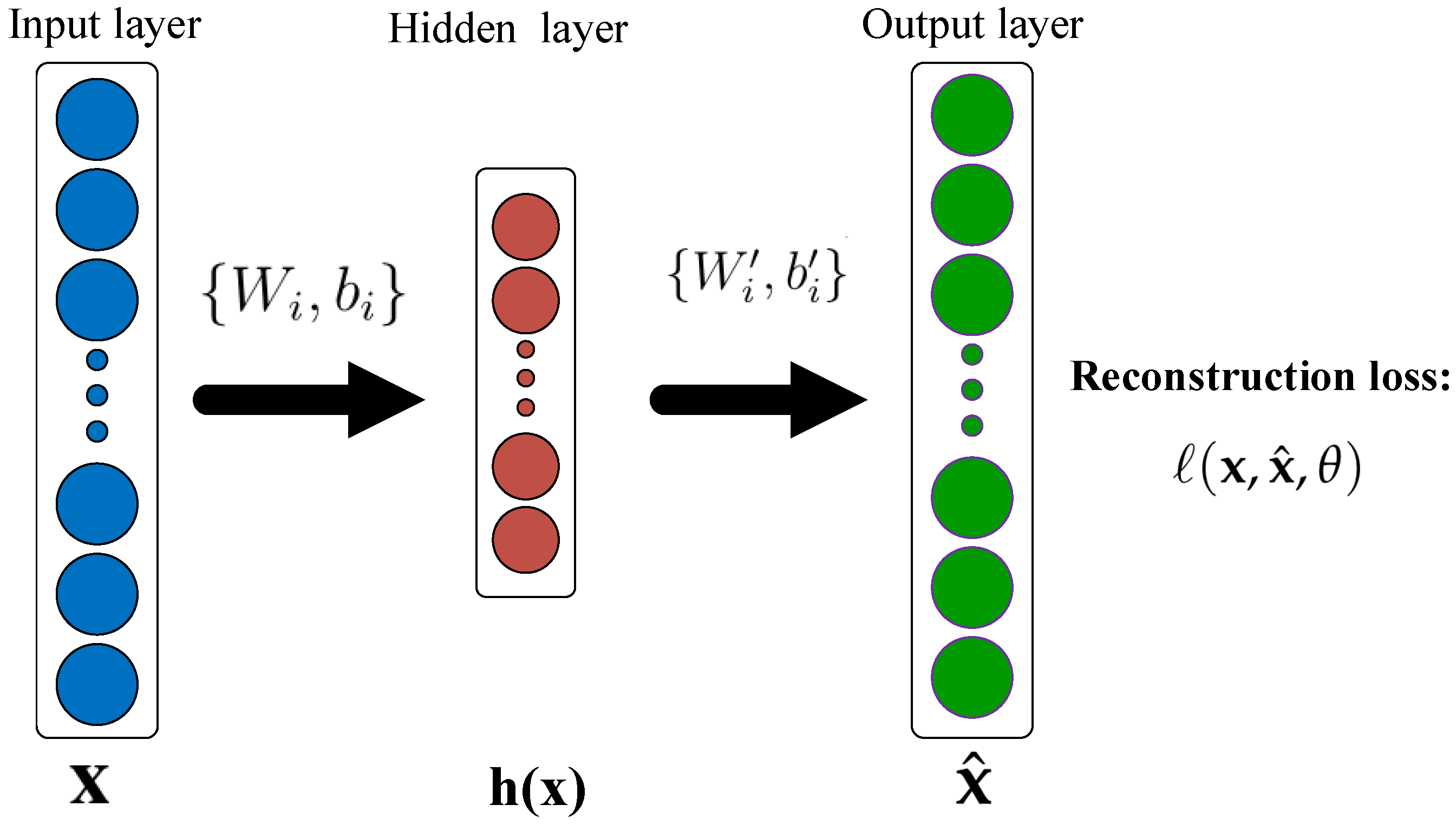
3.2.1. AutoEncoder
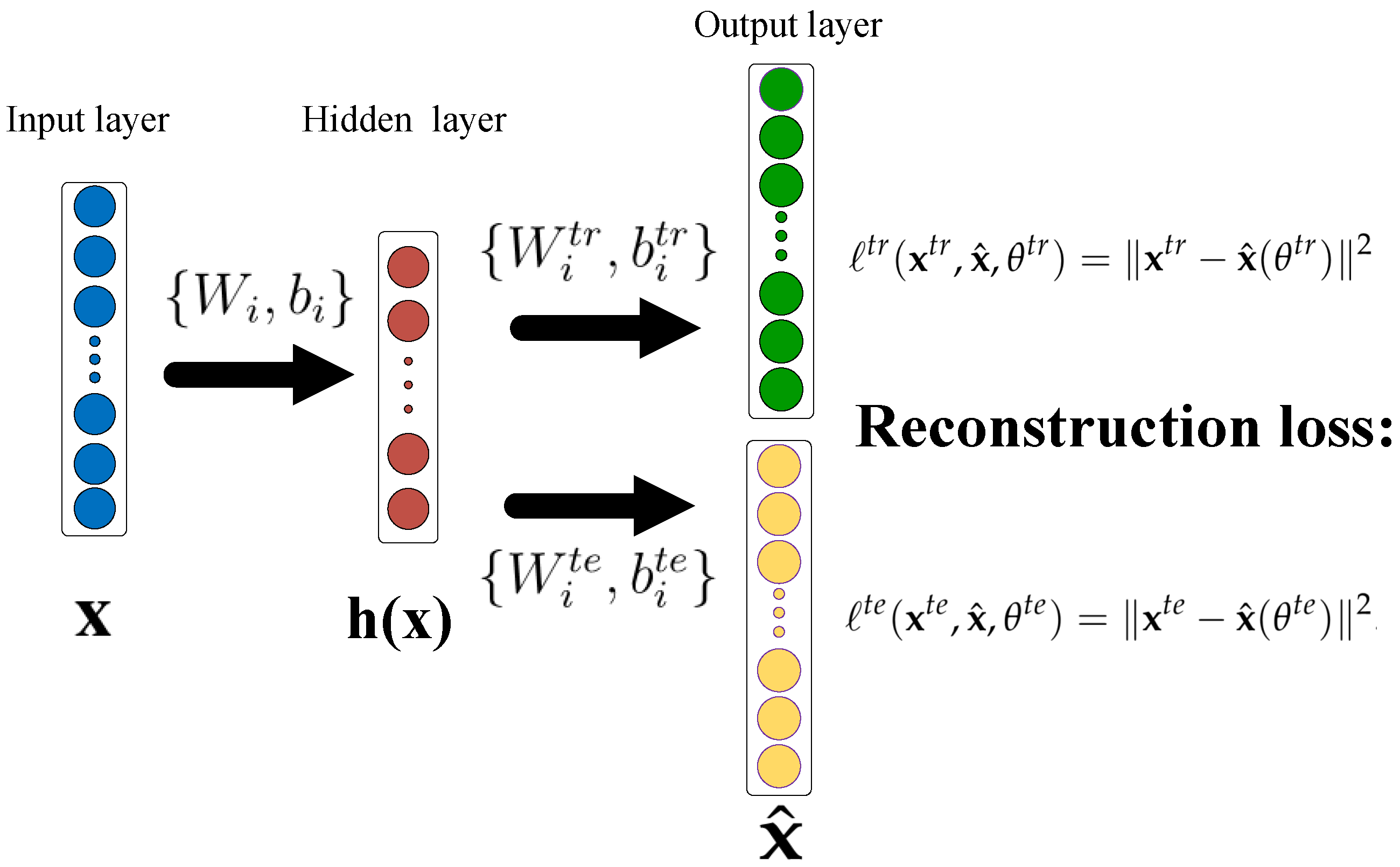
3.2.2. Denoising AutoEncoder
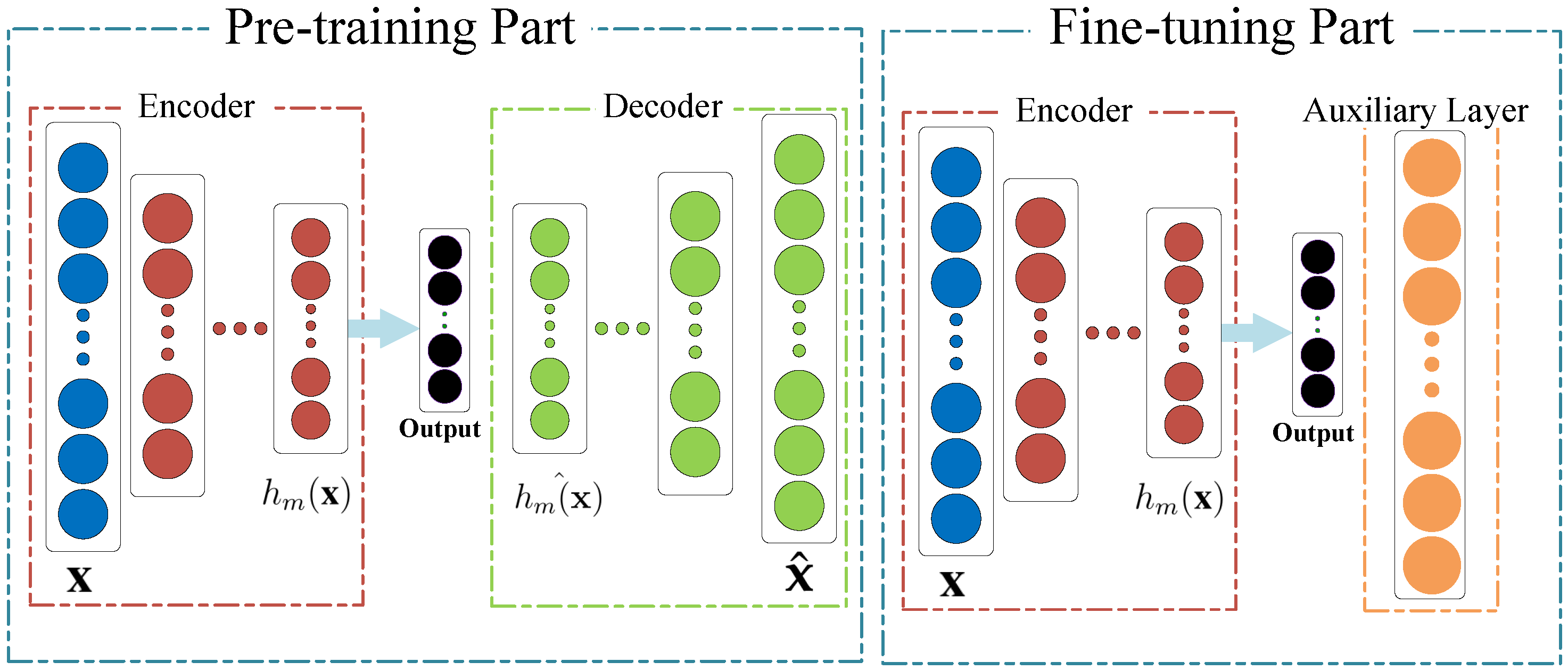
3.2.3. An Improved Shared-Hidden-Layer Autoencoder (SHLA)
3.3. Fusion Network Module
4. Experiment
4.1. Dataset
4.2. Result Analysis and Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Gupta, R.; Malandrakis, N.; Xiao, B.; Guha, T.; Van Segbroeck, M.; Black, M.; Potamianos, A.; Narayanan, S. Multimodal prediction of affective dimensions and depression in human–computer interactions. In Proceedings of the 4th International Workshop on Audio/Visual Emotion Challenge, Orlando, FL, USA, 7 November 2014; pp. 33–40. [Google Scholar]
- Hossain, M.S.; Muhammad, G.; Song, B.; Hassan, M.M.; Alelaiwi, A.; Alamri, A. Audio–visual emotion-aware cloud gaming framework. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 2105–2118. [Google Scholar] [CrossRef]
- Kim, J.; Andre, E. Emotion-specific dichotomous classification and feature-level fusion of multichannel biosignals for automatic emotion recognition. In Proceedings of the IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems, Seoul, Korea, 20–22 August 2008; pp. 114–119. [Google Scholar]
- Lee, H.; Shackman, A.J.; Jackson, D.C.; Davidson, R.J. Test-retest reliability of voluntary emotion regulation. Psychophysiology 2010, 46, 874–879. [Google Scholar] [CrossRef] [PubMed]
- Christie, I.C.; Friedman, B.H. Autonomic specificity of discrete emotion and dimensions of affective space: A multivariate approach. Int. J. Psychophysiol. 2004, 51, 143–153. [Google Scholar] [CrossRef] [PubMed]
- Povolny, F.; Matejka, P.; Hradis, M.; Popková, A.; Otrusina, L.; Smrz, P.; Wood, I.; Robin, C.; Lamel, L. Multimodal emotion recognition for AVEC 2016 challenge. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge, Amsterdam, The Netherlands, 16 October 2016; pp. 75–82. [Google Scholar]
- Amiriparian, S.; Freitag, M.; Cummins, N.; Schuller, B. Feature selection in multimodal continuous emotion prediction. In Proceedings of the 2017 Seventh International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW), San Antonio, TX, USA, 23–26 October 2017; pp. 30–37. [Google Scholar]
- Schuller, B. Recognizing affect from linguistic information in 3D continuous space. IEEE Trans. Affect. Comput. 2011, 2, 192–205. [Google Scholar] [CrossRef]
- Jin, Q.; Li, C.; Chen, S.; Wu, H. Speech emotion recognition with acoustic and lexical features. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing, Brisbane, Australia, 19–24 April 2015; pp. 4749–4753. [Google Scholar]
- Glodek, M.; Tschechne, S.; Layher, G.; Schels, M.; Brosch, T.; Scherer, S.; Kächele, M.; Schmidt, M.; Neumann, H.; Palm, G.; et al. Multiple classifier systems for the classification of audio-visual emotional states. In Affective Computing and Intelligent Interaction; Springer: Berlin/Heidelberg, Germany, 2011; pp. 359–368. [Google Scholar]
- Wang, Z.Q.; Tashev, I. Learning utterance-level representations for speech emotion and age/gender recognition using deep neural networks. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 5–9 March 2017; pp. 5150–5154. [Google Scholar]
- Cai, G.; Xia, B. Convolutional neural networks for multimedia sentiment analysis. In Natural Language Processing and Chinese Computing; Springer: Berlin/Heidelberg, Germany, 2015; pp. 159–167. [Google Scholar]
- Severyn, A.; Moschitti, A. Twitter sentiment analysis with deep convolutional neural networks. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 959–962. [Google Scholar]
- Wang, Y.; Guan, L. Recognizing human emotional state from audiovisual signals. IEEE Trans. Multimed. 2008, 10, 936–946. [Google Scholar] [CrossRef]
- Zhalehpour, S.; Onder, O.; Akhtar, Z.; Erdem, C.E. BAUM-1: A spontaneous audio-visual face database of affective and mental states. IEEE Trans. Affect. Comput. 2017, 8, 300–313. [Google Scholar] [CrossRef]
- Wang, Y.; Guan, L.; Venetsanopoulos, A.N. Kernel cross-modal factor analysis for information fusion with application to bimodal emotion recognition. IEEE Trans. Multimed. 2012, 14, 597–607. [Google Scholar] [CrossRef]
- Rosas, V.P.; Mihalcea, R.; Morency, L.P. Multimodal sentiment analysis of spanish online videos. IEEE Intell. Syst. 2013, 28, 38–45. [Google Scholar] [CrossRef]
- Baumgärtner, C.; Beuck, N.; Menzel, W. An architecture for incremental information fusion of cross-modal representations. In Proceedings of the 2012 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems, Hamburg, Germany, 13–15 September 2012; pp. 498–503. [Google Scholar]
- Zhang, S.; Zhang, S.; Huang, T.; Gao, W.; Tian, Q. Learning Affective Features With a Hybrid Deep Model for Audio–Visual Emotion Recognition. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 3030–3043. [Google Scholar] [CrossRef]
- Kim, D.H.; Lee, M.K.; Choi, D.Y.; Song, B.C. Multi-modal emotion recognition using semi-supervised learning and multiple neural networks in the wild. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 529–535. [Google Scholar]
- Schuller, B.; Batliner, A.; Steidl, S.; Seppi, D. Recognising realistic emotions and affect in speech: State of the art and lessons learnt from the first challenge. Speech Commun. 2011, 53, 1062–1087. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, G.; Huang, Y. Adaptive wavelet packet filter-bank based acoustic feature for speech emotion recognition. In Proceedings of the 2013 Chinese Intelligent Automation Conference, Yangzhou, China, 23–25 August 2013; pp. 359–366. [Google Scholar]
- Tahon, M.; Devillers, L. Towards a small set of robust acoustic features for emotion recognition: Challenges. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 16–28. [Google Scholar] [CrossRef]
- Rong, J.; Chen, Y.P.P.; Chowdhury, M.; Li, G. Acoustic features extraction for emotion recognition. In Proceedings of the 6th IEEE/ACIS International Conference on Computer and Information Science, Melbourne, Australia, 11–13 July 2007; pp. 419–424. [Google Scholar]
- Han, W.; Li, H.; Ruan, H.B.; Ma, L. Review on speech emotion recognition. Ruan Jian Xue Bao 2014, 25, 37–50. [Google Scholar] [CrossRef]
- Huang, J.; Li, Y.; Tao, J.; Yi, J. Multimodal Emotion Recognition with Transfer Learning of Deep Neural Network. ZTE Commun. 2017, 15, 1. [Google Scholar]
- Aytar, Y.; Vondrick, C.; Torralba, A. Soundnet: Learning sound representations from unlabeled video. In Proceedings of the Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; pp. 892–900. [Google Scholar]
- Sun, M.; Zhou, Z.; Hu, Q.; Wang, Z.; Jiang, J. SG-FCN: A Motion and Memory-Based Deep Learning Model for Video Saliency Detection. IEEE Trans. Cybern. 2018. [Google Scholar] [CrossRef] [PubMed]
- Lakomkin, E.; Weber, C.; Magg, S.; Wermter, S. Reusing Neural Speech Representations for Auditory Emotion Recognition. In Proceedings of the Eighth International Joint Conference on Natural Language Processing, Taipei, Taiwan, 27 November–1 December 2017; pp. 423–430. [Google Scholar]
- Gu, Y.; Yang, K.; Fu, S.; Chen, S.; Li, X.; Marsic, I. Multimodal Affective Analysis Using Hierarchical Attention Strategy with Word-Level Alignment. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 2018, p. 2225. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335. [Google Scholar] [CrossRef]
- Eyben, F.; Wöllmer, M.; Schuller, B. Opensmile: The munich versatile and fast open-source audio feature extractor. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1459–1462. [Google Scholar]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 689–696. [Google Scholar]
- Patterson, E.K.; Gurbuz, S.; Tufekci, Z.; Gowdy, J.N. CUAVE: A new audio-visual database for multimodal human–computer interface research. In Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing, Orlando, FL, USA, 13–17 May 2002; Volume 2, pp. 2017–2020. [Google Scholar]
- Matthews, I.; Cootes, T.F.; Bangham, J.A.; Cox, S.; Harvey, R. Extraction of visual features for lipreading. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 198–213. [Google Scholar] [CrossRef]
- Srivastava, N.; Salakhutdinov, R.R. Multimodal learning with deep boltzmann machines. In Proceedings of the Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 2222–2230. [Google Scholar]
- Gönen, M.; Alpaydın, E. Multiple kernel learning algorithms. J. Mach. Learn. Res. 2011, 12, 2211–2268. [Google Scholar]
- Nilufar, S.; Ray, N.; Zhang, H. Object detection with DoG scale-space: A multiple kernel learning approach. IEEE Trans. Image Process. 2012, 21, 3744–3756. [Google Scholar] [CrossRef] [PubMed]
- Mansoorizadeh, M.; Charkari, N.M. Multimodal information fusion application to human emotion recognition from face and speech. Multimed. Tools Appl. 2010, 49, 277–297. [Google Scholar] [CrossRef]
- Gu, Y.; Chen, S.; Marsic, I. Deep Multimodal Learning for Emotion Recognition in Spoken Language. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5079–5083. [Google Scholar]
- Missaoui, O.; Frigui, H.; Gader, P. Model level fusion of edge histogram descriptors and gabor wavelets for landmine detection with ground penetrating radar. In Proceedings of the 2010 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Honolulu, HI, USA, 25–30 July 2010; pp. 3378–3381. [Google Scholar]
- Eyben, F.; Scherer, K.R.; Schuller, B.W.; Sundberg, J.; André, E.; Busso, C.; Devillers, L.Y.; Epps, J.; Laukka, P.; Narayanan, S.S.; et al. The Geneva minimalistic acoustic parameter set (GeMAPS) for voice research and affective computing. IEEE Trans. Affect. Comput. 2016, 7, 190–202. [Google Scholar] [CrossRef]
- Schuller, B.; Steidl, S.; Batliner, A.; Burkhardt, F.; Devillers, L.; Müller, C.; Narayanan, S. The INTERSPEECH 2010 paralinguistic challenge. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Makuhari, Japan, 26–30 September 2010; pp. 2794–2797. [Google Scholar]
- Xu, M.; Duan, L.Y.; Cai, J.; Chia, L.T.; Xu, C.; Tian, Q. HMM-based audio keyword generation. In Proceedings of the Pacific-Rim Conference on Multimedia, Tokyo, Japan, 30 November–3 December 2004; pp. 566–574. [Google Scholar]
- Hossan, M.A.; Memon, S.; Gregory, M.A. A novel approach for MFCC feature extraction. In Proceedings of the 2010 4th International Conference on Signal Processing and Communication Systems, Gold Coast, Australia, 13–15 December 2010; pp. 1–5. [Google Scholar]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.; Gemmeke, J.F.; Jansen, A.; Moore, R.C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN architectures for large-scale audio classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 5–9 March 2017; pp. 131–135. [Google Scholar]
- Zhao, L.; Hu, Q.; Wang, W. Heterogeneous feature selection with multi-modal deep neural networks and sparse group lasso. IEEE Trans. Multimed. 2015, 17, 1936–1948. [Google Scholar] [CrossRef]
- Deng, J.; Frühholz, S.; Zhang, Z.; Schuller, B. Recognizing emotions from whispered speech based on acoustic feature transfer learning. IEEE Access 2017, 5, 5235–5246. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Poria, S.; Chaturvedi, I.; Cambria, E.; Hussain, A. Convolutional MKL based multimodal emotion recognition and sentiment analysis. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining, Barcelona, Spain, 12–15 December 2016; pp. 439–448. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Emotion | Angry | Happy | Neutral | Sad | Total |
|---|---|---|---|---|---|
| Utterances | 1103 | 1636 | 1708 | 1084 | 5531 |
| Duration (min) | 83.0 | 126.0 | 111.1 | 99.3 | 419.4 |
| Classifiers | KNN | LR | RF | SVM |
|---|---|---|---|---|
| Angry | 0.56 | 0.64 | 0.66 | 0.65 |
| Happy | 0.71 | 0.73 | 0.77 | 0.79 |
| Neutral | 0.38 | 0.39 | 0.46 | 0.45 |
| Sad | 0.58 | 0.62 | 0.64 | 0.69 |
| Total | 0.55 | 0.59 | 0.63 | 0.64 |
| Features | IS10 | MFCCs | eGemaps | SoundNet | VGGish |
|---|---|---|---|---|---|
| Angry | 0.39 | 0.33 | 0.43 | 0.47 | 0.49 |
| Happy | 0.53 | 0.51 | 0.57 | 0.59 | 0.63 |
| Neutral | 0.21 | 0.21 | 0.24 | 0.29 | 0.3 |
| Sad | 0.42 | 0.37 | 0.43 | 0.48 | 0.51 |
| Total | 0.38 | 0.35 | 0.41 | 0.45 | 0.48 |
| Approaches | Angry | Happy | Neutral | Sad | Total |
|---|---|---|---|---|---|
| Lakomkin [29] | 0.59 | 0.72 | 0.37 | 0.59 | 0.58 |
| Gu [30] | - | - | - | - | 0.62 |
| ours + shla | 0.65 | 0.79 | 0.45 | 0.69 | 0.64 |
| Methods | Angry | Happy | Neutral | Sad | Total |
|---|---|---|---|---|---|
| ours-H | 0.53 | 0.64 | 0.33 | 0.56 | 0.51 |
| ours-F | 0.61 | 0.74 | 0.41 | 0.62 | 0.59 |
| ours + dae | 0.63 | 0.79 | 0.45 | 0.66 | 0.63 |
| ours + shla | 0.65 | 0.79 | 0.45 | 0.69 | 0.64 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, W.; Wang, Z.; Jin, J.S.; Han, X.; Li, C. Speech Emotion Recognition with Heterogeneous Feature Unification of Deep Neural Network. Sensors 2019, 19, 2730. https://doi.org/10.3390/s19122730
Jiang W, Wang Z, Jin JS, Han X, Li C. Speech Emotion Recognition with Heterogeneous Feature Unification of Deep Neural Network. Sensors. 2019; 19(12):2730. https://doi.org/10.3390/s19122730
Chicago/Turabian StyleJiang, Wei, Zheng Wang, Jesse S. Jin, Xianfeng Han, and Chunguang Li. 2019. "Speech Emotion Recognition with Heterogeneous Feature Unification of Deep Neural Network" Sensors 19, no. 12: 2730. https://doi.org/10.3390/s19122730
APA StyleJiang, W., Wang, Z., Jin, J. S., Han, X., & Li, C. (2019). Speech Emotion Recognition with Heterogeneous Feature Unification of Deep Neural Network. Sensors, 19(12), 2730. https://doi.org/10.3390/s19122730