Light Fields for Face Analysis

 ,
,  , ,
, ,
Abstract
1. Introduction
2. Background
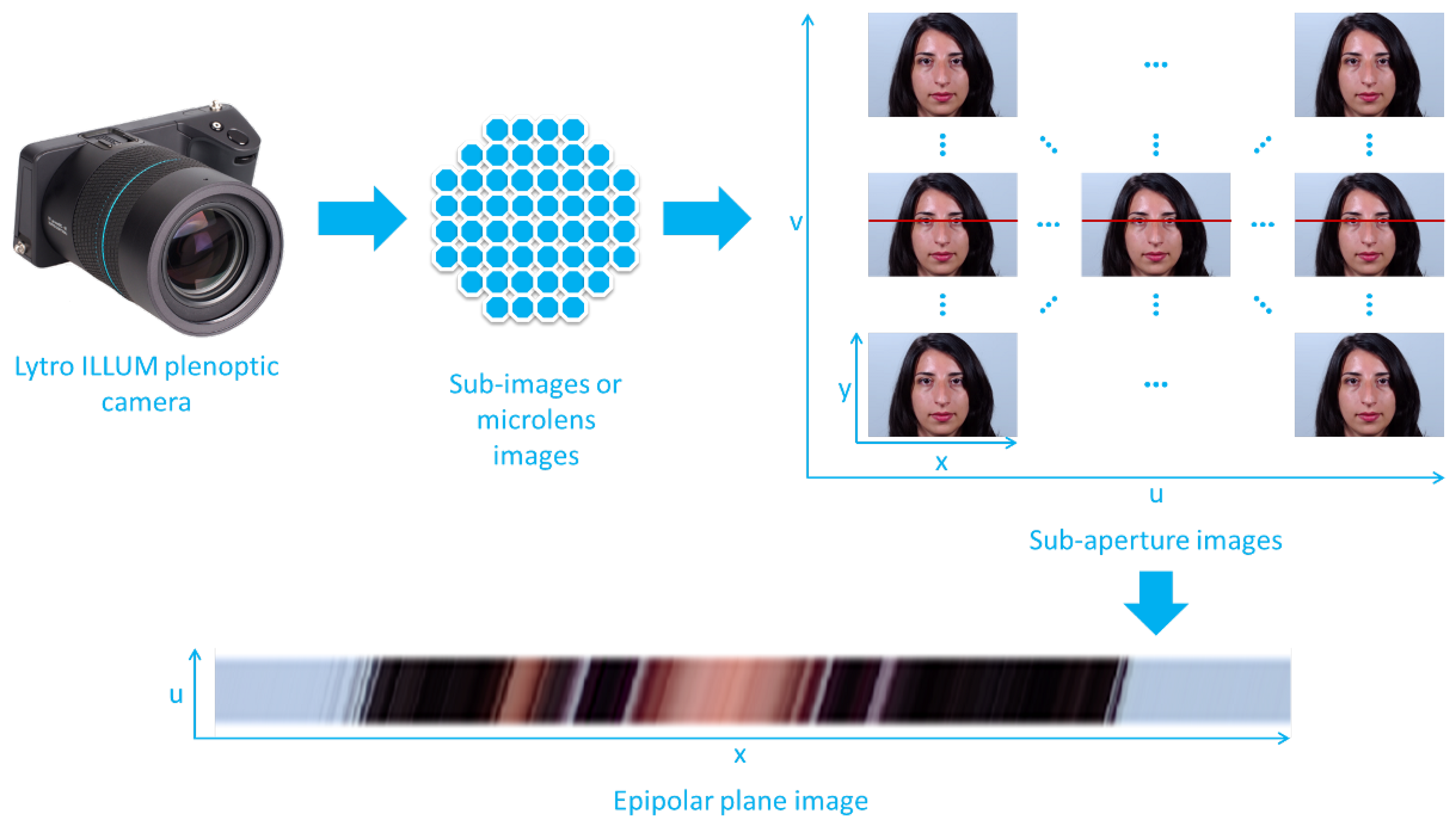
2.1. Light Fields
2.1.1. Epipolar Plane Images
2.1.2. Scene Depth from Light Fields
2.1.3. Refocusing from Light Fields
2.2. Face Analysis
- A posteriori refocusing—As mentioned in Section 2.1, it is possible to refocus a posteriori the captured image at a given depth plane, thus rendering a 2D image where the objects at the selected plane appear in focus. This functionality is not available when using a conventional 2D camera and it can be very useful for face analysis algorithms, allowing improvement of the analysis of a previously out-of-focus region of interest.
- Disparity exploitation—Given a captured light-field image, it is possible to render a set of 2D images corresponding to a set of specified viewpoints. This provides disparity information, with the differences between corresponding points/face components in different viewpoints providing valuable information for face analysis.
- Depth exploitation—As mentioned in Section 2.1, it is possible to estimate depth information from the light-field image. Knowing the distance between face components and the camera, it provides information about the scene geometry, useful for face analysis. An obvious usage of depth information is for presentation attack detection, where depth information can be used to determine if an image is captured from a flat surface (e.g., a screen) or not.
2.3. Databases
- General-purpose light-field databases, which include facial images—These are databases initially developed with different purposes, but also happen to include face images. Metadata about the faces is typically not available, but depending on the purpose of the algorithms being developed, these face images might be interesting to consider. A summary of the available databases is listed in Table 1.
- Light-field face databases—These are databases developed specifically to test face recognition solutions. Therefore, they typically include metadata information, such as the face bounding box and facial component coordinates, the subject gender, age and appearance (facial hair, makeup, haircut, earrings, necklace, scarf, piercings, scars, etc.). There are also databases that focus on specific facial components, such as the iris or the ear, which were derived from light-field face databases, and are also listed in Table 2.
- Light-field face presentation attack detection databases—These databases were specifically developed to test face presentation attack detection solutions. Several types of presentation attack instruments have been considered, such as printed paper, laptop, tablet, and smartphone. Images acquired with a light-field camera of the presentation attack instruments are then tested to check whether the light-field information is helpful in distinguishing a presentation attack from a genuine user presentation (bona fide). The available databases for this category are listed in Table 3.
3. Face Landmark Detection
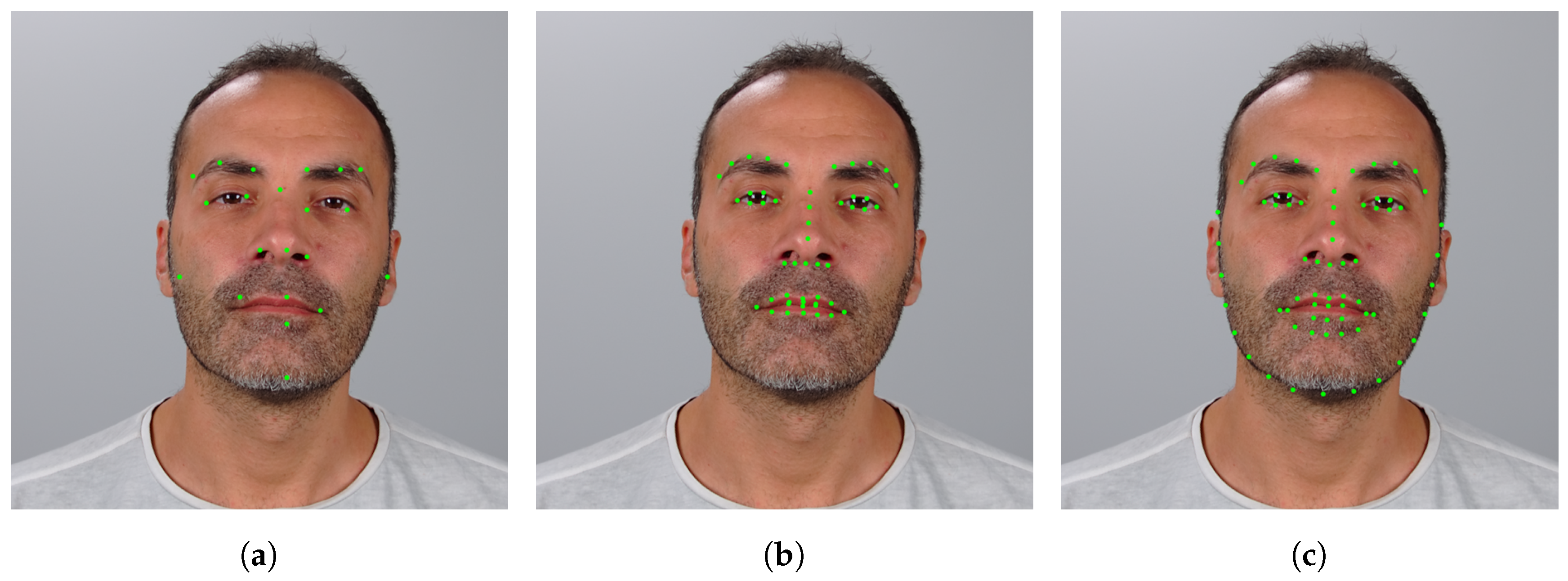
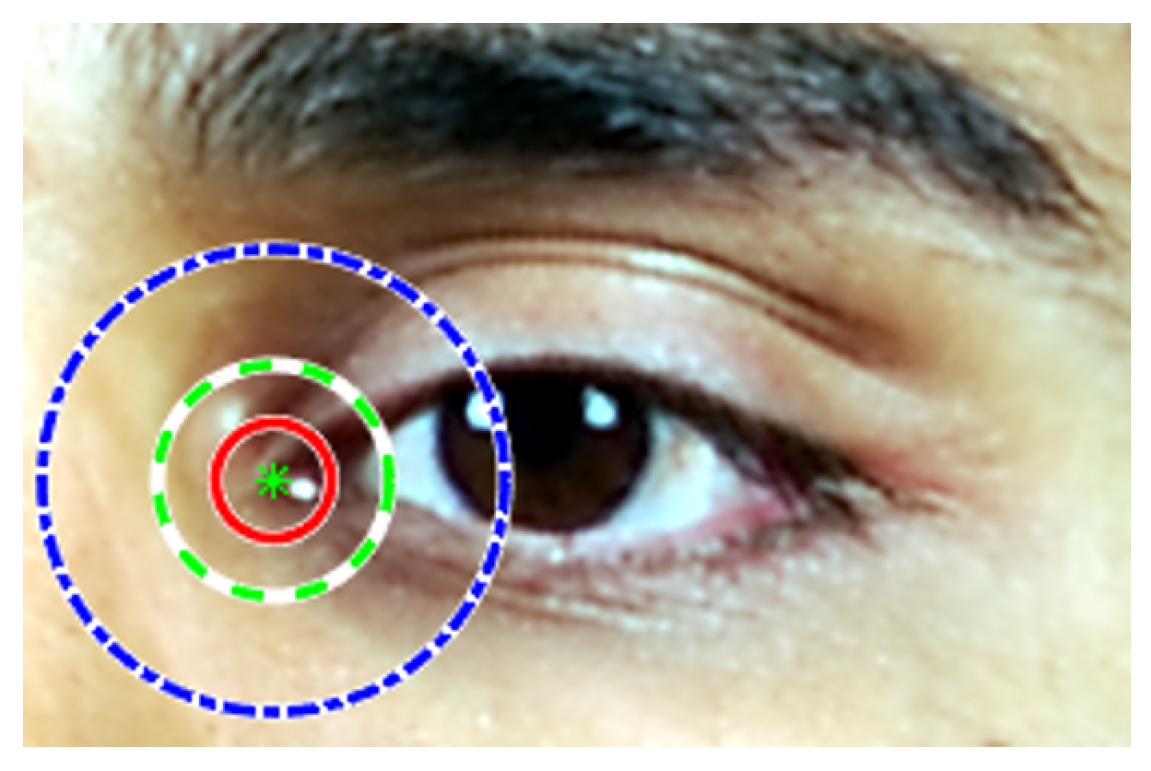
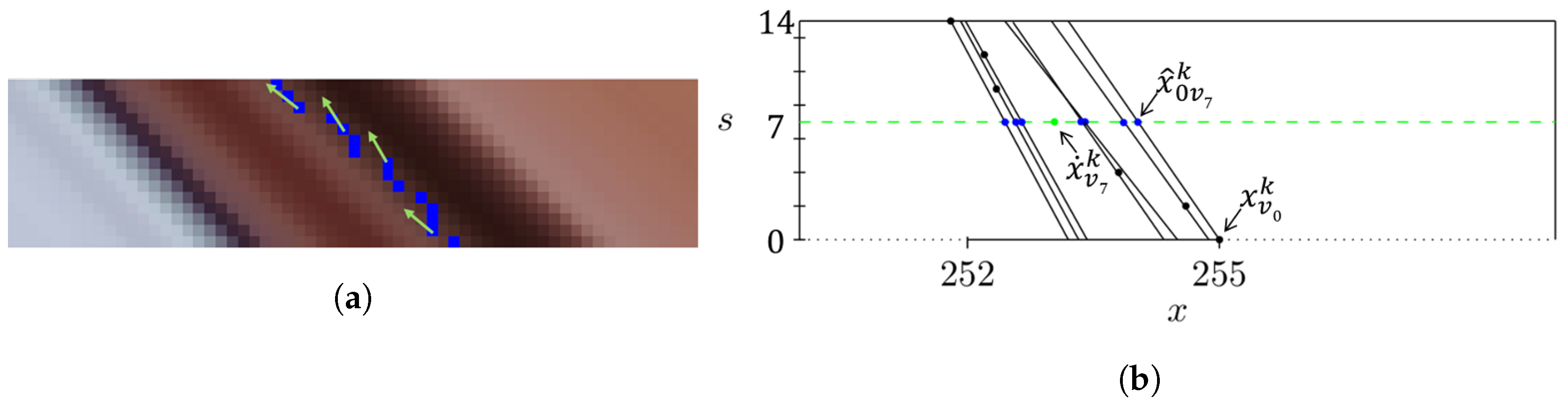
3.1. Facial-Landmark Localization Correction
3.1.1. Coordinates Correction
3.1.2. Results
4. Face Recognition
- IR: Identification Rate at rank 1–The (true-positive) identification rate at rank 1 is the proportion of identification transactions by a user enrolled in the system, for which user’s true identifier is returned in first position in the candidate list. If the rank is omitted in the following, rank 1 is implied.
- EER: Equal Error Rate—value corresponding to
- –
- FMR: False Match Rate—proportion of the completed biometric non-mated comparison trials that result in a false match;
- –
- FNMR: False Non-Match Rate—proportion of the completed biometric mated comparison trials that result in a false non-match.
- ACC: Accuracy—corresponding to the average value of TMR and TNMR;
- –
- TMR: True Match Rate—proportion of the completed biometric mated comparison trials that result in a true match;
- –
- TNMR: True Non-Match Rate—proportion of the completed biometric non-mated comparison trials that result in a true non-match.
4.1. Multi-Focus Based Methods
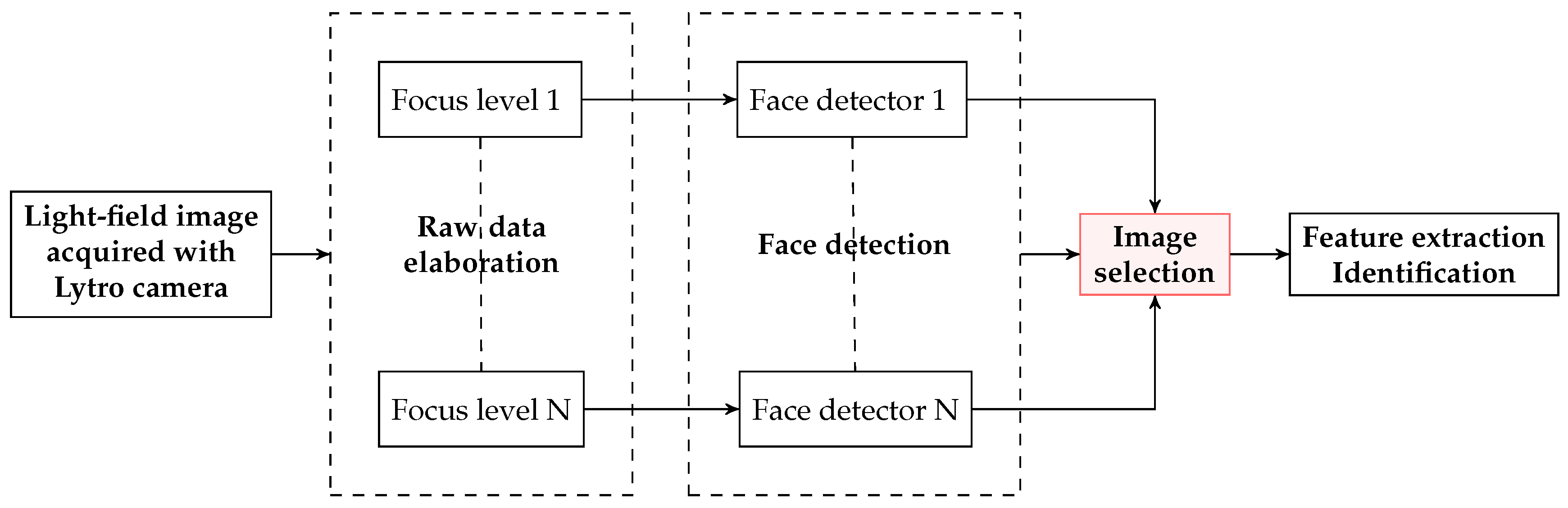
- The 2D images in the database are obtained by rendering the original light-field files at different focusing depths (Figure 10). All images are then processed with the Viola-Jones face detector [48] trained with 2429 face images and 3000 non-face samples. For each capture, the rendered image where the largest number of faces is detected, is chosen to define the facial regions.
- Once the faces are detected and cropped, the best image for each individual is selected according to an energy criterion. The authors chose as energy measure the 2D-Discrete Wavelet Transform (DWT) with Haar wavelet because of its robustness to noise and its content-independent property. The face image with larger energy is chosen.
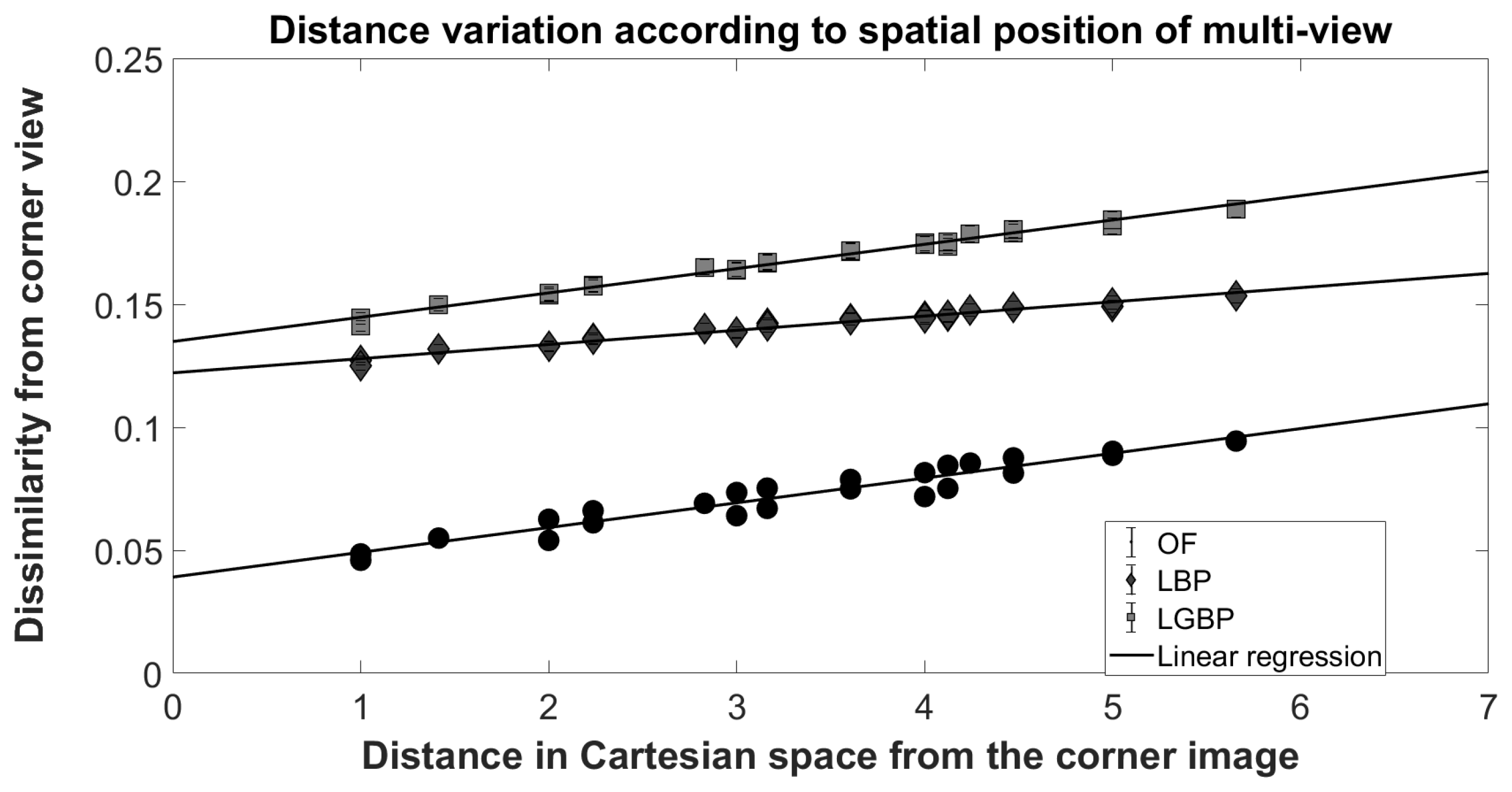
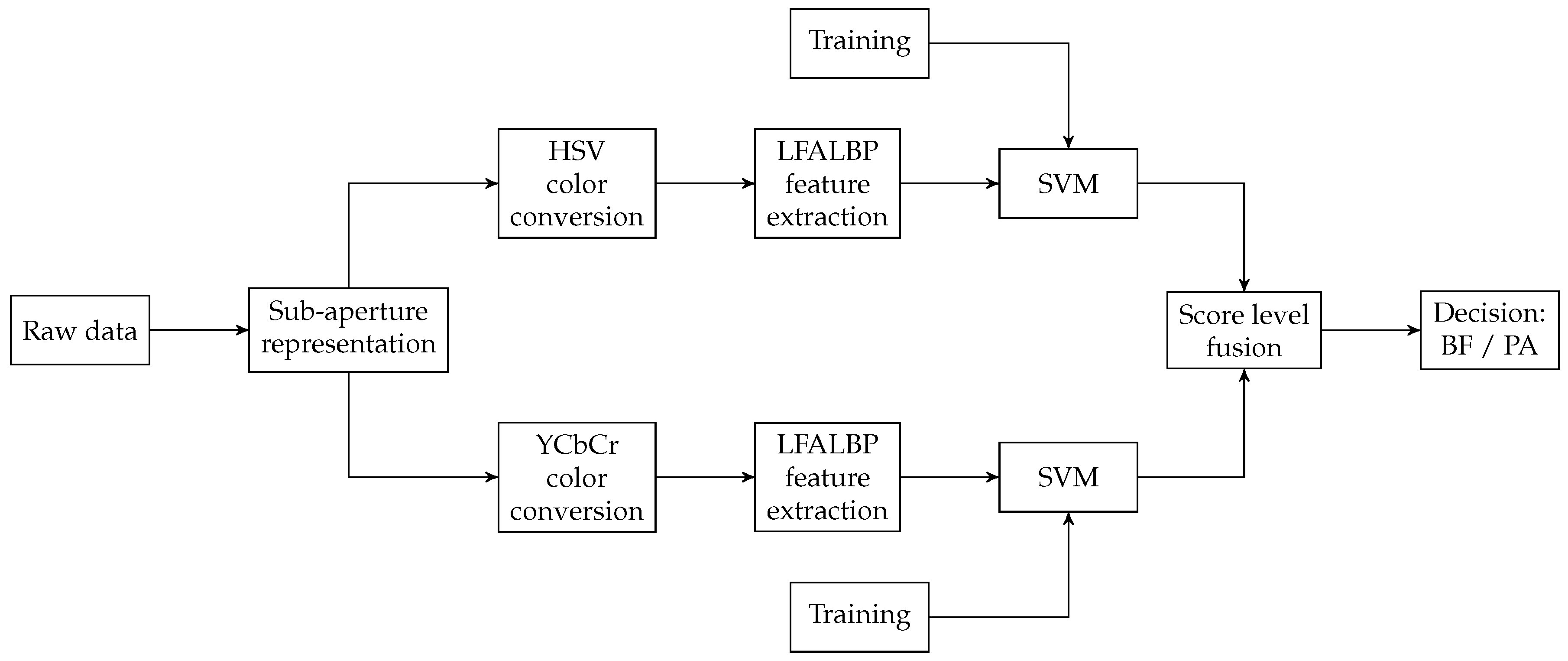
4.2. Sub-Aperture Based Methods
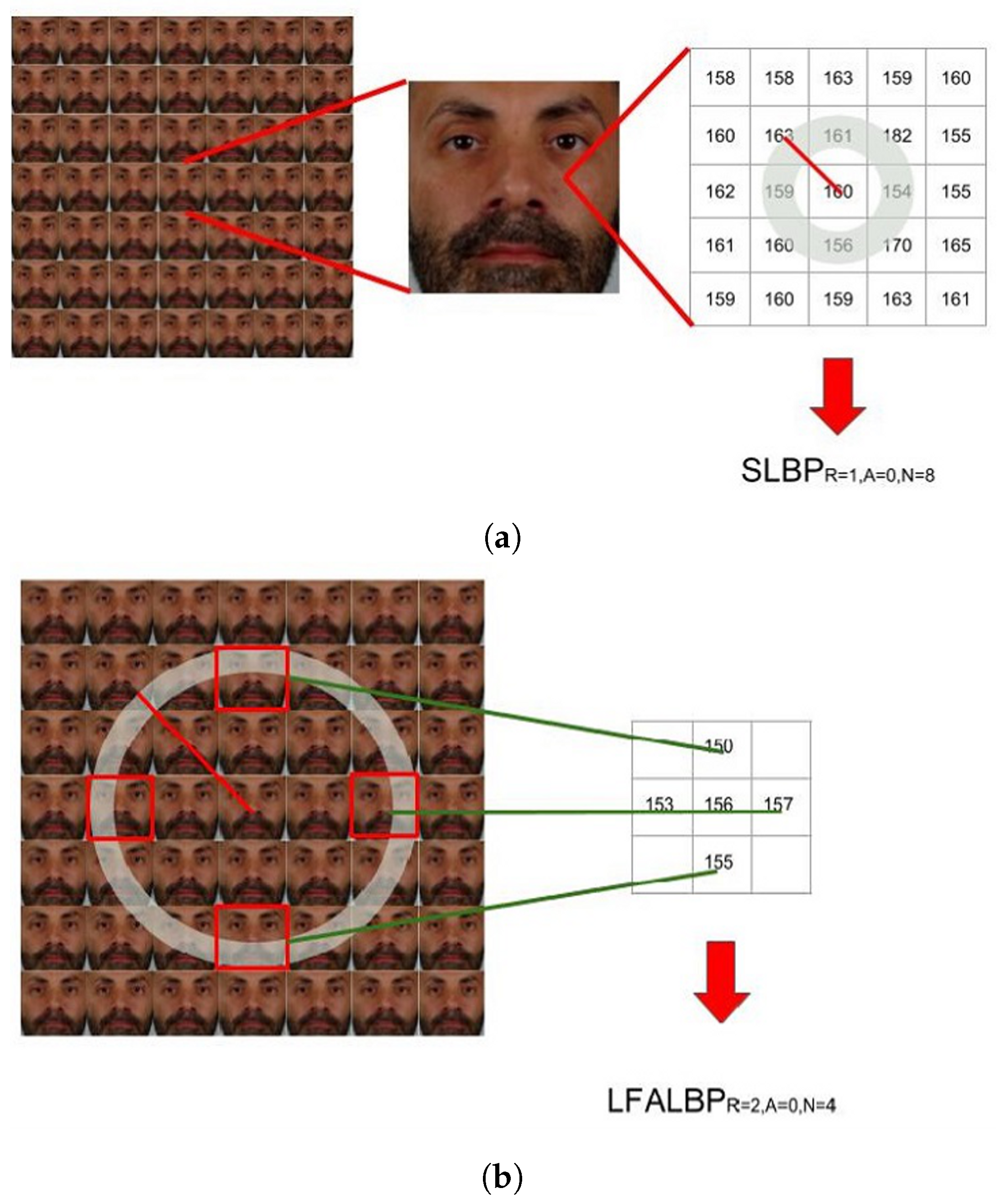
- Spatial Local Binary Pattern (SLBP): the first component is the LBP feature vector extracted from the central view of the considered light-field image;
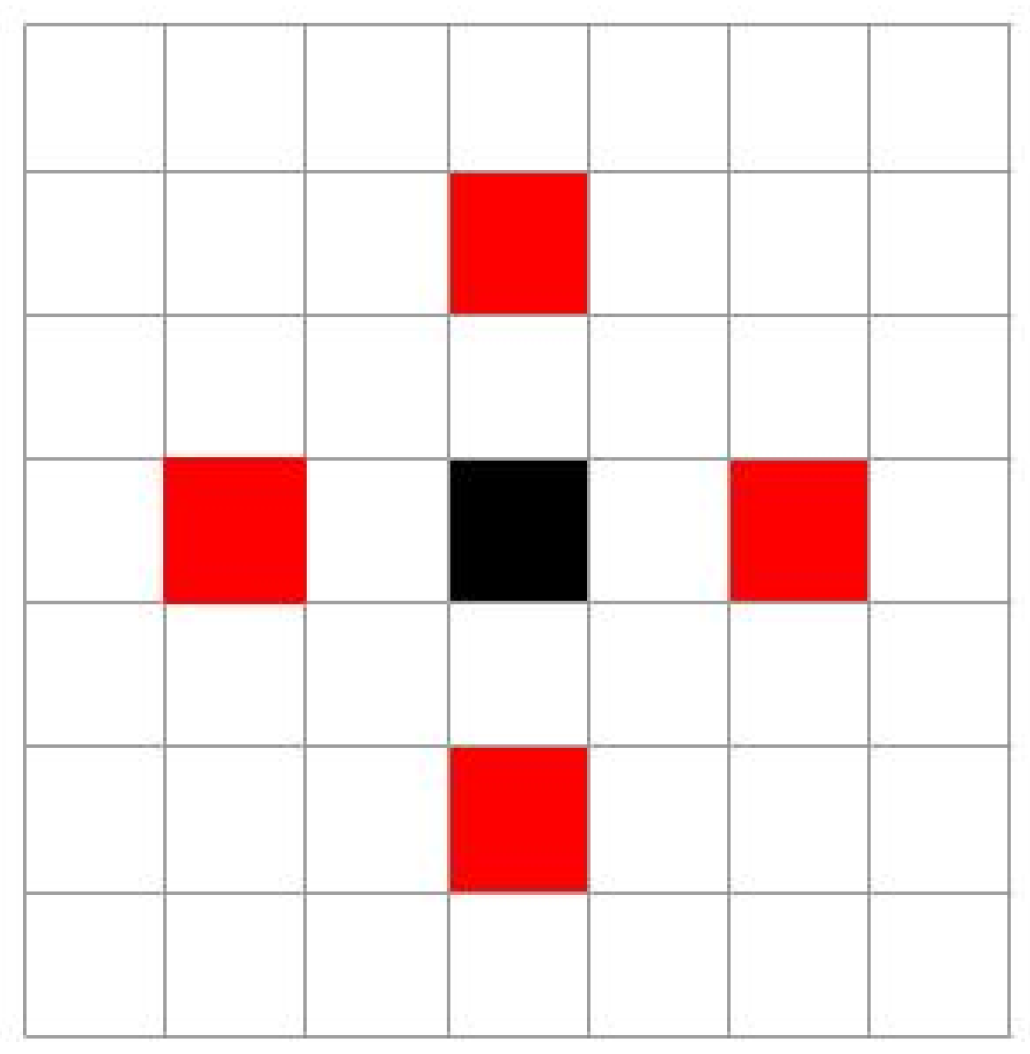
- Light-Field Angular Local Binary Pattern (LFALBP): the second component is a variation of classical LBP customized for light-field images. Let be the reference sample and R the radius representing the distance of the selected adjacent views from the central view. Then, the LFALBP is defined as:whereAngle A indicates the starting angle for the first sub-aperture image to consider in the angular neighborhood, and N indicates the number of views to consider. As in the conventional LBP descriptor, the binary thresholding result obtained by the function is multiplied by the binomial factor, , and the resulting values are summed to get the LFALBP pattern value for each sample position .
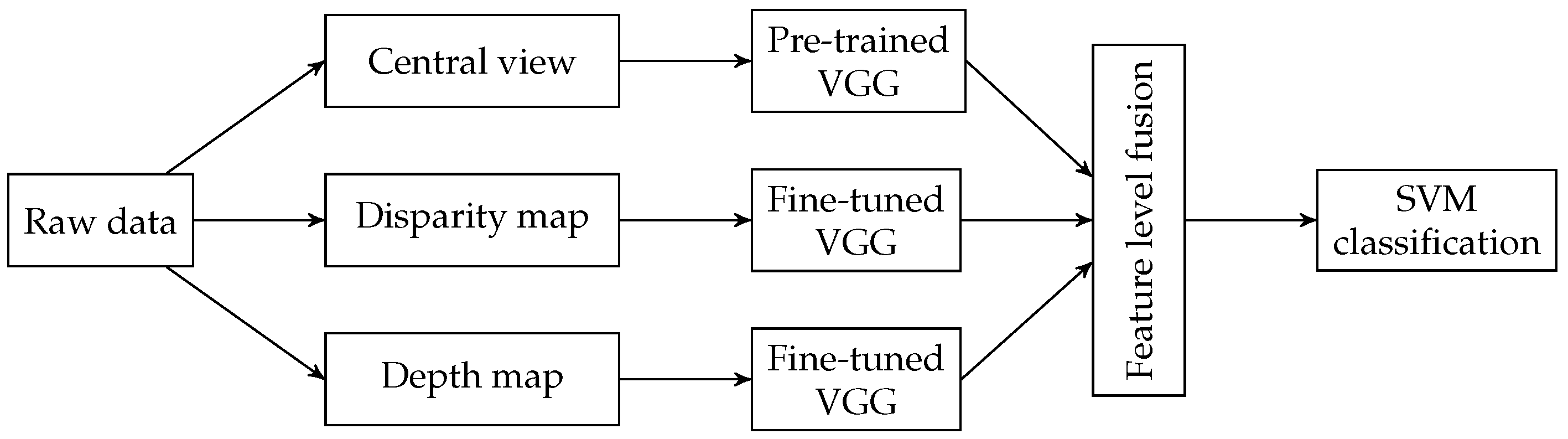
4.3. Deep-Learning Algorithms
- The central view is the input of a pre-trained VGG-Face model;
- The disparity map calculated from the sub-aperture representation is used to fine-tune a second VGG-Face model;
- A third VGG-Face model is fine-tuned using depth maps.
5. Face Presentation Attack Detection
5.1. Taxonomy for Presentation Attack Detection
- presentation attack/attack presentation: presentation to the biometric data capture subsystem with the goal of interfering with the operation of the biometric system
- bona fide presentation: interaction of the biometric capture subject and the biometric data capture subsystem in the fashion intended by the policy of the biometric system
- presentation attack instrument (PAI): biometric characteristic or object used in a presentation attack
- PAI species: class of presentation attack instruments created using a common production method and based on different biometric characteristics
- artefact: artificial object or representation presenting a copy of biometric characteristics or synthetic biometric patterns
- presentation attack detection (PAD): automated determination of a presentation attack
5.2. Metrics for PAD Subsystem Evaluation
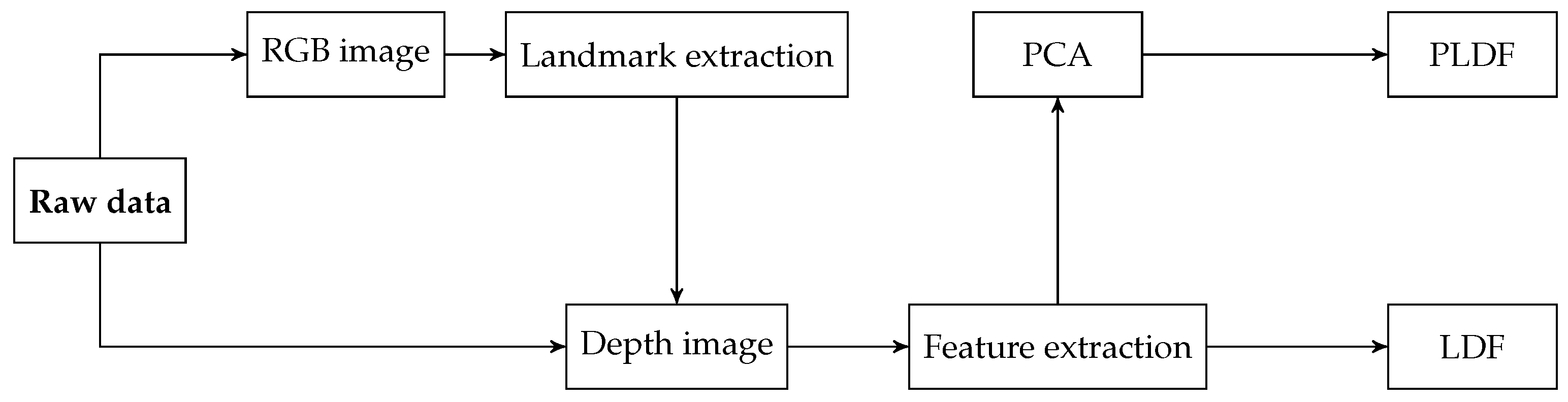
5.3. State-of-the-Art PAD with Light-Field Capture Devices
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gross, R.; Matthews, I.; Baker, S. Eigen light-fields and face recognition across pose. In Proceedings of the Fifth IEEE International Conference on Automatic Face Gesture Recognition, Washington, DC, USA, 21–21 May 2002; pp. 3–9. [Google Scholar]
- Gross, R.; Matthews, I.; Baker, S. Fisher Light-Fields for Face Recognition Across Pose and Illumination. In Proceedings of the German Symposium on Pattern Recognition (DAGM), Zurich, Switzerland, 16–18 September 2002. [Google Scholar]
- Zhou, S.; Chellappa, R. Illuminating light field: Image-based face recognition across illuminations and poses. In Proceedings of the Sixth IEEE International Conference on Automatic Face and Gesture Recognition, Seoul, Korea, 19 May 2004; pp. 229–234. [Google Scholar]
- Gross, R.; Matthews, I.; Baker, S. Appearance-based face recognition and light-fields. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 449–465. [Google Scholar] [CrossRef] [PubMed]
- Raghavendra, R.; Yang, B.; Raja, K.B.; Busch, C. A new perspective—Face recognition with light-field camera. In Proceedings of the 2013 International Conference on Biometrics (ICB), Madrid, Spain, 4–7 June 2013; pp. 1–8. [Google Scholar] [CrossRef]
- Levoy, M.; Hanrahan, P. Light Field Rendering. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 12–17 August 2001; ACM: New York, NY, USA, 1996; pp. 31–42. [Google Scholar]
- Gortler, S.; Grzeszczuk, R.; Szeliski, R.; Cohen, M. The Lumigraph. In Proceedings of the SIGGRAPH, New Orleans, LA, USA, 4–9 August 1996; pp. 43–54. [Google Scholar]
- Wilburn, B.; Joshi, N.; Vaish, V.; Talvala, E.V.; Antunez, E.; Barth, A.; Adams, A.; Horowitz, M.; Levoy, M. High Performance Imaging Using Large Camera Arrays. ACM Trans. Gr. 2005, 24, 765–776. [Google Scholar] [CrossRef]
- Unger, J.; Gustavson, S.; Larsson, P.; Ynnerman, A. Free Form Incident Light Fields. Comput. Gr. Forum 2008. [Google Scholar] [CrossRef]
- Adelson, T.; Wang, J. Single Lens Stereo with a Plenoptic Camera. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 99–106. [Google Scholar] [CrossRef]
- Ng, R.; Levoy, M.; Bredif, M.; Duval, G.; Horowitz, M.; Hanrahan, P. Light field photography with a hand-held plenoptic camera. Stanford Tech Report CTSR 2005-02. 2005, Volume 2, pp. 1–11. Available online: https://graphics.stanford.edu/papers/lfcamera/lfcamera-150dpi.pdf (accessed on 13 June 2019).
- Lumsdaine, A.; Georgiev, T. The focused plenoptic camera. In Proceedings of the IEEE International Conference on Computational Photography, San Francisco, CA, USA, 16–17 April 2009; pp. 1–8. [Google Scholar]
- Bolles, R.C.; Baker, H.H.; Marimont, D.H. Epipolar-plane image analysis: An approach to determining structure from motion. Int. J. Comput. Vis. 1987, 1, 7–55. [Google Scholar] [CrossRef]
- Jeon, H.G.; Park, J.; Choe, G.; Park, J.; Bok, Y.; Tai, Y.W.; So Kweon, I. Accurate depth map estimation from a lenslet light field camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1547–1555. [Google Scholar]
- Huang, C.T. Empirical Bayesian Light-Field Stereo Matching by Robust Pseudo Random Field Modeling. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 552–565. [Google Scholar] [CrossRef] [PubMed]
- Jiang, X.; Le Pendu, M.; Guillemot, C. Depth estimation with occlusion handling from a sparse set of light field views. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 634–638. [Google Scholar]
- Wanner, S.; Goldluecke, B. Variational light field analysis for disparity estimation and super-resolution. IEEE Trans Pattern Anal. Mach. Intell. 2013, 36, 606–619. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Sheng, H.; Li, C.; Zhang, J.; Xiong, Z. Robust depth estimation for light field via spinning parallelogram operator. J. Comput. Vis. Image Underst. 2016, 145, 148–159. [Google Scholar] [CrossRef]
- Corneanu, C.A.; Simón, M.O.; Cohn, J.F.; Guerrero, S.E. Survey on RGB, 3D, Thermal, and Multimodal Approaches for Facial Expression Recognition: History, Trends, and Affect-Related Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1548–1568. [Google Scholar] [CrossRef]
- Chiesa, V.; Dugelay, J. Impact of multi-focused images on recognition of soft biometric traits. In Applications of Digital Image Processing XXXIX; International Society for Optics and Photonics (SPIE): Bellingham, WA, USA, 2016; Volume 9971, p. 99710Q. [Google Scholar]
- Chiesa, V.; Dugelay, J. Kinect vs Lytro in RGB-D Face Recognition. In Proceedings of the 2018 International Conference on Cyberworlds (CW), Singapore, 3–5 October 2018; pp. 345–350. [Google Scholar] [CrossRef]
- Soltanpour, S.; Boufama, B.; Jonathan Wu, Q. A survey of local feature methods for 3D face recognition. Pattern Recognit. 2017, 72, 391–406. [Google Scholar] [CrossRef]
- Ouyang, S.; Hospedales, T.; Song, Y.Z.; Li, X.; Loy, C.; Wang, X. A survey on heterogeneous face recognition: Sketch, infra-red, 3D and low-resolution. Image Vis. Comput. 2016, 56, 28–48. [Google Scholar] [CrossRef]
- Liu, M.; Fo, H.; Wei, Y.; Rehman, Y.; Po, L.; Lo, W. Light field-based face liveness detection with convolutional neural networks. SPIE Electron. Imaging 2019, 28, 013003. [Google Scholar] [CrossRef]
- Vaish, V.; Adams, A. The (New) Stanford Light Field Archive. 2008. Available online: http://lightfield.stanford.edu/lfs.html (accessed on 20 February 2019).
- Řeřábek, M.; Ebrahimi, T. New Light Field Image Dataset. In Proceedings of the 8th International Workshop on Quality of Multimedia Experience (QoMEX), Lisbon, Portugal, 6–8 June 2016. [Google Scholar]
- Raj, A.S.; Lowney, M.; Shah, R.; Wetzstein, G. The Stanford Lytro Light Field Archive. 2016. Available online: http://lightfields.stanford.edu/LF2016.html (accessed on 20 February 2019).
- Paudyal, P.; Olsson, R.; Sjöström, M.; Battisti, F.; Carli, M. SMART: A light field image quality dataset. In Proceedings of the 7th International Conference on Multimedia Systems (ICMS), Klagenfurt, Austria, 10–13 May 2016. [Google Scholar]
- Sabater, N.; Boisson, G.; Vandame, B.; Kerbiriou, P.; Babon, F.; Hog, M.; Langlois, T.; Gendrot, R.; Bureller, O.; Schubert, A.; et al. Dataset and Pipeline for Multi-View Light-Field Video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Raghavendra, R.; Raja, K.B.; Yang, B.; Busch, C. GUCLF: A new light field face database. In Proceedings of the 8th Iberoamerican Optics Meeting and 11th Latin American Meeting on Optics, Lasers, and Applications, Porto, Portugal, 22–26 July 2013; Volume 8785, p. 8785. [Google Scholar] [CrossRef]
- Raghavendra, R.; Raja, K.; Busch, C. Exploring the usefulness of light field cameras for Biometrics: An Empirical Study on Face and Iris Recognition. IEEE Trans. Inf. Forensics Secur. 2016, 11, 922–936. [Google Scholar] [CrossRef]
- Sepas-Moghaddam, A.; Chiesa, V.; Correia, P.L.; Pereira, F.; Dugelay, J. The IST-EURECOM Light Field Face Database. In Proceedings of the 2017 5th International Workshop on Biometrics and Forensics (IWBF), Coventry, UK, 4–5 April 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Sepas-Moghaddam, A.; Pereira, F.; Correia, P. Ear recognition in a light field imaging framework: A new perspective. IET Biom. 2018, 7, 224–231. [Google Scholar] [CrossRef]
- Raghavendra, R.; Raja, K.; Busch, C. Presentation Attack Detection for Face Recognition Using Light Field Camera. IEEE Trans. Image Process. 2015, 24, 1060–1074. [Google Scholar] [CrossRef]
- Sepas-Moghaddam, A.; Malhadas, L.; Correia, P.; Pereira, F. Face Spoofing Detection using a Light Field Imaging Framework. IET Biom. 2018, 7, 39–48. [Google Scholar] [CrossRef]
- Sepas-Moghaddam, A.; Pereira, F.; Correia, P. Light Field based Face Presentation Attack Detection: Reviewing, Benchmarking and One Step Further. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1696–1709. [Google Scholar] [CrossRef]
- Sepas-Moghaddam, A.; Pereira, F.; Correia, P. Ear Presentation Attack Detection: Benchmarking Study with First Lenslet Light Field Database. In Proceedings of the 26th European Signal Processing Conference (EUSIPCO 2018), Rome, Italy, 3–7 September 2018. [Google Scholar]
- Çeliktutan, O.; Ulukaya, S.; Sankur, B. A comparative study of face landmarking techniques. EURASIP J. Image Video Process. 2013, 2013, 13. [Google Scholar] [CrossRef]
- Johnston, B.; Chazal, P.D. A review of image-based automatic facial landmark identification techniques. EURASIP J. Image Video Process. 2018, 2018, 86. [Google Scholar] [CrossRef]
- Uřičář, M.; Franc, V.; Thomas, D.; Sugimoto, A.; Hlaváč, V. Multi-view facial landmark detector learned by the Structured Output SVM. Image Vis. Comput. 2016, 47, 45–59. [Google Scholar] [CrossRef]
- Xiong, X.; De la Torre, F. Supervised Descent Method and Its Applications to Face Alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Galdi, C.; Younes, L.; Guillemot, C.; Dugelay, J.L. A new framework for optimal facial landmark localization on light-field images. In Proceedings of the 2018 IEEE Visual Communications and Image Processing (VCIP), Taichung, Taiwan, 9–12 December 2018; pp. 1–4. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar] [CrossRef]
- ISO/IEC JTC1 SC37 Biometrics. ISO/IEC 19795-1:2006. Information Technology—Biometric Performance Testing and Reporting—Part 1: Principles and Framework; International Organization for Standardization and International Electrotechnical Committee: Geneva, Switzerland, 2006. [Google Scholar]
- Gross, R.; Matthews, I.; Cohn, J.; Kanade, T.A. Multi-PIE. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition, Amsterdam, The Netherlands, 17–19 September 2008. [Google Scholar]
- Rauss, P.J.; Phillips, J.; Moon, H.; Rizvi, S.; Hamilton, M.K.; Trent DePersia, A. The FERET (face recognition technology) program. In Proceedings of the 25th Annual AIPR Workshop on Emerging Applications of Computer Vision, Washington, DC, USA, 16–18 October 1996. [Google Scholar] [CrossRef]
- Wibowo, M.E.; Tjondronegoro, D. Face Recognition across Pose on Video Using Eigen Light-Fields. In Proceedings of the 2011 International Conference on Digital Image Computing: Techniques and Applications, Noosa, QLD, Australia, 6–8 December 2011; pp. 536–541. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Field, D.J. Relations between the statistics of natural images and the response properties of cortical cells. J. Opt. Soc. Am. A 1987, 4, 2379–2394. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.; Plataniotis, K.N.; Venetsanopoulos, A.N. Face recognition using kernel direct discriminant analysis algorithms. IEEE Trans. Neural Netw. 2003, 14, 117–126. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust Face Recognition via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Raghavendra, R.; Raja, K.B.; Yang, B.; Busch, C. Improved face recognition at a distance using light field camera and super resolution schemes. In Proceedings of the 6th International Conference on Security of Information and Networks, Aksaray, Turkey, 26–28 November 2013. [Google Scholar]
- Irani, M.; Peleg, S. Improving resolution by image registration. CVGIP Graph. Model. Image Process. 1991, 53, 231–239. [Google Scholar] [CrossRef]
- Stark, H.; Oskoui, P. High-resolution image recovery from image-plane arrays, using convex projections. J. Opt. Soc. Am. A Opt. Image Sci. 1989, 6, 1715–1726. [Google Scholar] [CrossRef]
- Gerchberg, R.W. Super-resolution through Error Energy Reduction. Opt. Acta Int. J. Opt. 1974, 21, 709–720. [Google Scholar] [CrossRef]
- Papoulis, A. A new algorithm in spectral analysis and band-limited extrapolation. IEEE Trans. Circuits Syst. 1975, 22, 735–742. [Google Scholar] [CrossRef]
- Zomet, A.; Rav-Acha, A.; Peleg, S. Robust super-resolution. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; Volume 1. [Google Scholar] [CrossRef]
- Raghavendra, R.; Raja, K.B.; Yang, B.; Busch, C. A novel image fusion scheme for robust multiple face recognition with light-field camera. In Proceedings of the 16th International Conference on Information Fusio, Istanbul, Turkey, 9–12 July 2013; pp. 722–729. [Google Scholar]
- Raghavendra, R.; Raja, K.B.; Yang, B.; Busch, C. Comparative evaluation of super-resolution techniques for multi-face recognition using light-field camera. In Proceedings of the 2013 18th International Conference on Digital Signal Processing (DSP), Santorini, Greece, 1–3 July 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Raja, K.B.; Raghavendra, R.; Alaya Cheikh, F.; Busch, C. Evaluation of fusion approaches for face recognition using light field cameras. In Proceedings of the 2015 Colour and Visual Computing Symposium (CVCS), Gjovik, Norway, 25–26 August 2015. [Google Scholar] [CrossRef]
- Sepas-Moghaddam, A.; Correia, P.L.; Pereira, F. Light field local binary patterns description for face recognition. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3815–3819. [Google Scholar] [CrossRef]
- Chiesa, V.; Dugelay, J.L. On Multi-View Face Recognition Using Lytro Images. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 2250–2254. [Google Scholar] [CrossRef]
- Amos, B.; Ludwiczuk, B.; Satyanarayanan, M. OpenFace: A General-Purpose Face Recognition Library with Mobile Applications; Technical Report, CMU-CS-16-118; CMU School of Computer Science: Pittsburgh, PA, USA, 2016. [Google Scholar]
- Zhang, W.; Shan, S.; Gao, W.; Chen, X.; Zhang, H. Local Gabor binary pattern histogram sequence (LGBPHS): A novel non-statistical model for face representation and recognition. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; Volume 1, pp. 786–791. [Google Scholar] [CrossRef]
- Sepas-Moghaddam, A.; Correia, P.; Nasrollahi, K.; Moeslund, T.; Pereira, F. Light Field Based Face Recognition via a Fused Deep Representation. In Proceedings of the 2018 IEEE 28th International Workshop on Machine Learning for Signal Processing (MLSP), Aalborg, Denmark, 17–20 September 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sepas-Moghaddam, A.; Haque, M.A.; Correia, P.L.; Nasrollahi, K.; Moeslund, T.B.; Pereira, F. A Double-Deep Spatio-Angular Learning Framework for Light Field based Face Recognition. IEEE Trans. Circuits Syst. Video Technol. 2019. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- ISO/IEC JTC1 SC37 Biometrics. ISO/IEC 30107-1. Information Technology–Biometric Presentation Attack Detection—Part 1: Framework; International Organization for Standardization: Geneva, Switzerland, 2016. [Google Scholar]
- ISO/IEC JTC1 SC37 Biometrics. ISO/IEC 2382-37:2017 Information Technology–Vocabulary—Part 37: Biometrics; International Organization for Standardization: Geneva, Switzerland, 2017. [Google Scholar]
- ISO/IEC JTC1 SC37 Biometrics. ISO/IEC 30107-3. Information Technology–Biometric Presentation Attack Detection—Part 3: Testing and Reporting; International Organization for Standardization: Geneva, Switzerland, 2017. [Google Scholar]
- Ramachandra, R.; Busch, C. Presentation Attack Detection Methods for Face Recognition Systems: A Comprehensive Survey. ACM Comput. Surv. 2017, 50, 8:1–8:37. [Google Scholar] [CrossRef]
- Kim, S.; Ban, Y.; Lee, S. Face liveness detection using a light field camera. Sensors 2014, 14, 22471–22499. [Google Scholar] [CrossRef]
- Ji, Z.; Zhu, H.; Wang, Q. LFHOG: A discriminative descriptor for live face detection from light field image. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1474–1478. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Chiesa, V.; Dugelay, J.L. Advanced face presentation attack detection on light field images. In Proceedings of the 17th International Conference of the Biometrics Special Interest Group, BIOSIG, Darmstadt, Germany, 26–28 September 2018. [Google Scholar]
- Bhattacharjee, S.; Mohammadi, A.; Marcel, S. Spoofing Deep Face Recognition with Custom Silicone Masks. In Proceedings of the 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS), Redondo Beach, CA, USA, 22–25 October 2018; pp. 1–8. [Google Scholar]
- Shao, L.; Han, J.; Xu, D.; Shotton, J. Special issue on computer vision for RGB-D sensors: Kinect and its applications. IEEE Trans. Cybern. 2012, 42, 1295–1296. [Google Scholar] [CrossRef] [PubMed]
- Riou, C.; Colicchio, B.; Lauffenburger, J.P.; Cudel, C. Interests of refocused images calibrated in depth with a multi-view camera for control by vision. In Thirteenth International Conference on Quality Control by Artificial Vision 2017; International Society for Optics and Photonics: Bellingham, Washington, DC, USA, 2017; Volume 10338, p. 1033807. [Google Scholar]
- Gendre, L.; Bazeille, S.; Bigué, L.; Cudel, C. Interest of polarimetric refocused images calibrated in depth for control by vision. In Unconventional Optical Imaging; International Society for Optics and Photonics: Bellingham, Washington, DC, USA, 2018; Volume 10677, p. 106771W. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Year | Image Acquisition | Spatial Resolution | Images with Faces | Content Variations |
|---|---|---|---|---|---|
| The (New) Stanford Light-Field Archive [25] | 2008 | Camera array | 1 (students behind bushes) | Pose; distance; multiple people; occlusion; outdoor | |
| EPFL Light-Field Image Dataset [26] | 2016 | Lytro Illum | 18 (category: people) | Pose; distance; multiple people; outdoor | |
| Stanford Lytro Light-Field Archive [27] | 2016 | Lytro Illum | 17 (category: people) | Pose; distance; multiple people; occlusion; outdoor | |
| SMART [28] | 2016 | Lytro Illum | 1 (person) | Close-up, one person; reflection; indoor | |
| Technicolor Light-Field dataset [29] | 2017 | camera rig | Several | Pose; distance; indoor |
| Name | Year | Image Acquisition | Image Type | Spatial Resolution | Test Subjects | Content Variations |
|---|---|---|---|---|---|---|
| GUCLF [30] | 2013 | 2D camera; Lytro | 2D; 2D rendered | ; | 25 | Pose; distance; illumination, multiple people; indoor; outdoor |
| LFC-MFD [31] | 2016 | 2D camera; Lytro | 2D; 2D rendered | ; | 112 | Pose; distance; illumination, multiple people; indoor; outdoor |
| IST-EURECOM LFFD [32] | 2017 | Lytro Illum | 4D light field; 2D rendered; 2D depth map | ; ; | 100 | Multiple sessions, pose, illumination, expression, occlusion |
| LFC-VID [31] | 2016 | Lytro | 2D rendered | 55 (iris) | Distance range: 9–15 inches; indoor | |
| LLFEDB [33] | 2018 | Lytro Illum | 4D light field; 2D rendered | ; | 67 (ear) | Multiple sessions, pose, illumination, occlusion |
| Name | Year | Image Acquisition | Image Type | Spatial Resolution | Test Subjects/Images | Attack Instruments |
|---|---|---|---|---|---|---|
| GUC-LiFFAD Database [34] | 2015 | Lytro | 2D rendered (various depth/focus) | 80 subjects/80 bona fide images; 2400 2D attack images | Printed paper: laser + inkjet, tablet | |
| LLFFSD [35,36] | 2018 | Lytro Illum | 4D light field; 2D rendered; 2D depth map | ; ; | 50 subjects/100 bona fide images; 600 attack images | Printed paper, wrapped printed paper, laptop, tablet, smartphone 1, smartphone 2 |
| LLFEADB [37] | 2018 | Lytro Illum | 4D light field; 2D rendered | ; | 67 subjects/268 bona fide images; 1072 attack images | Laptop, tablet, smartphone 1, smartphone 2 |
| Neutral Frontal Face | Action Mouth Open | Pose Up Looking | Pose Half-Profile Left | |||||
|---|---|---|---|---|---|---|---|---|
| Original | Corrected | Original | Corrected | Original | Corrected | Original | Corrected | |
| P(%) | 97.81 | 98.11 | 95.70 | 96.37 | 91.80 | 92.66 | 77.68 | 79.13 |
| Ref. | Year | Feature Extractor | Classifier | LF DB | 2D Baseline | LF Perf. | Gain |
|---|---|---|---|---|---|---|---|
| [5] | 2013 | WE; LBP; LG | SRC | GUCLF | 75.53% IR | 79.10% IR | 3.57% |
| [53] | 2013 | SR; LBP | SRC | GUCLF | - | 53.62% IR | - |
| [59] | 2013 | LE; LBP; LG | SRC | GUCLF | - | 75.12% IR | - |
| [60] | 2013 | LBP | SRC | GUCLF | - | 60.56% IR | - |
| [61] | 2015 | LP; LBP | SRC | GUCLF | - | 4.14% EER | - |
| Ref. | Year | Feature Extractor | Classifier | LF DB | 2D Baseline | LF Perf. | Gain |
|---|---|---|---|---|---|---|---|
| [62] | 2017 | LFLBP | NN | LFFD | 89.1% IR | 92.1% IR | 3% |
| [63] | 2018 | OF | LFFD | 99.27% ACC | 99.80% ACC | 0.53% |
| Ref. | Year | Feature Extractor | Classifier | LF DB | 2D Baseline | LF Perf. | Gain |
|---|---|---|---|---|---|---|---|
| [66] | 2018 | VGG-Face | SVM | LFFD | 96.8% IR | 98.1% IR | 1.3% |
| [68] | 2018 | VGG-Face + LSTM | SoftMax | LFFD | 92.90% IR | 98.60% IR | 5.7% |
| Ref. | Year | Feature Extractor | Classifier | LF DB | LF Perf. |
|---|---|---|---|---|---|
| [74] | 2014 | EF + RD | SVM | Private | 0.89–4.22% HTER |
| [34] | 2015 | FV + DR | SVM | GUC-LiFFAD | 4.01–5.27% HTER |
| [75] | 2016 | LFHOG | SVM | Private | 99.75% ACC |
| [35] | 2018 | + | SVM | IST LLFFSD | 0.33–2.85% HTER |
| [36] | 2018 | HDG | SVM | IST LLFFSD | 0–0.45% BPCER @ 1%APCER |
| [77] | 2018 | LDF; PLDF | SVM | IST LLFFSD | 0–0.8% HTER |
| [24] | 2019 | CNN | SVM | Private | 0.028% HTER |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Galdi, C.; Chiesa, V.; Busch, C.; Lobato Correia, P.; Dugelay, J.-L.; Guillemot, C. Light Fields for Face Analysis. Sensors 2019, 19, 2687. https://doi.org/10.3390/s19122687
Galdi C, Chiesa V, Busch C, Lobato Correia P, Dugelay J-L, Guillemot C. Light Fields for Face Analysis. Sensors. 2019; 19(12):2687. https://doi.org/10.3390/s19122687
Chicago/Turabian StyleGaldi, Chiara, Valeria Chiesa, Christoph Busch, Paulo Lobato Correia, Jean-Luc Dugelay, and Christine Guillemot. 2019. "Light Fields for Face Analysis" Sensors 19, no. 12: 2687. https://doi.org/10.3390/s19122687
APA StyleGaldi, C., Chiesa, V., Busch, C., Lobato Correia, P., Dugelay, J.-L., & Guillemot, C. (2019). Light Fields for Face Analysis. Sensors, 19(12), 2687. https://doi.org/10.3390/s19122687