1. Introduction
Image classification techniques have been extensively researched in computer vision [
1,
2,
3,
4,
5]. Among them, sparse representation based classification methods [
6] and its variants are frequently proposed and refined due to their effectiveness and efficiency, especially in face recognition [
7,
8,
9]. Rather than using sparse representation (SR), the collaborative representation based classifier was proposed by using collaborative representation (CR), which achieved competitive performances with higher efficiency. The main difference between sparse representation and collaborative representation is the usage of different regularization terms in the minimization formulation, which is
norm for sparse representation and
norm for collaborative representation. Many applications have shown that both methods provide good results in image classification [
5,
10,
11,
12,
13], where they can be further improved for a better recognition performance.
To improve the recognition rate, many works focus on weighting the training samples in different ways. For example, Xu et al. proposed a two-phase test sample sparse representation method [
7] by using sparse representation in the first phase, followed by representation based on previously exploited neighbors of the test sample in the second phase. Timofte et al. imposed weights on the coefficients of collaborative representation [
14] and achieved better performances in face recognition. Similarly, Fan et al. [
8] provided another weights-imposing method, which derives weights of each coefficient from the corresponding training sample by calculating the Gaussian kernel distance between each training sample and test sample. In [
7,
8,
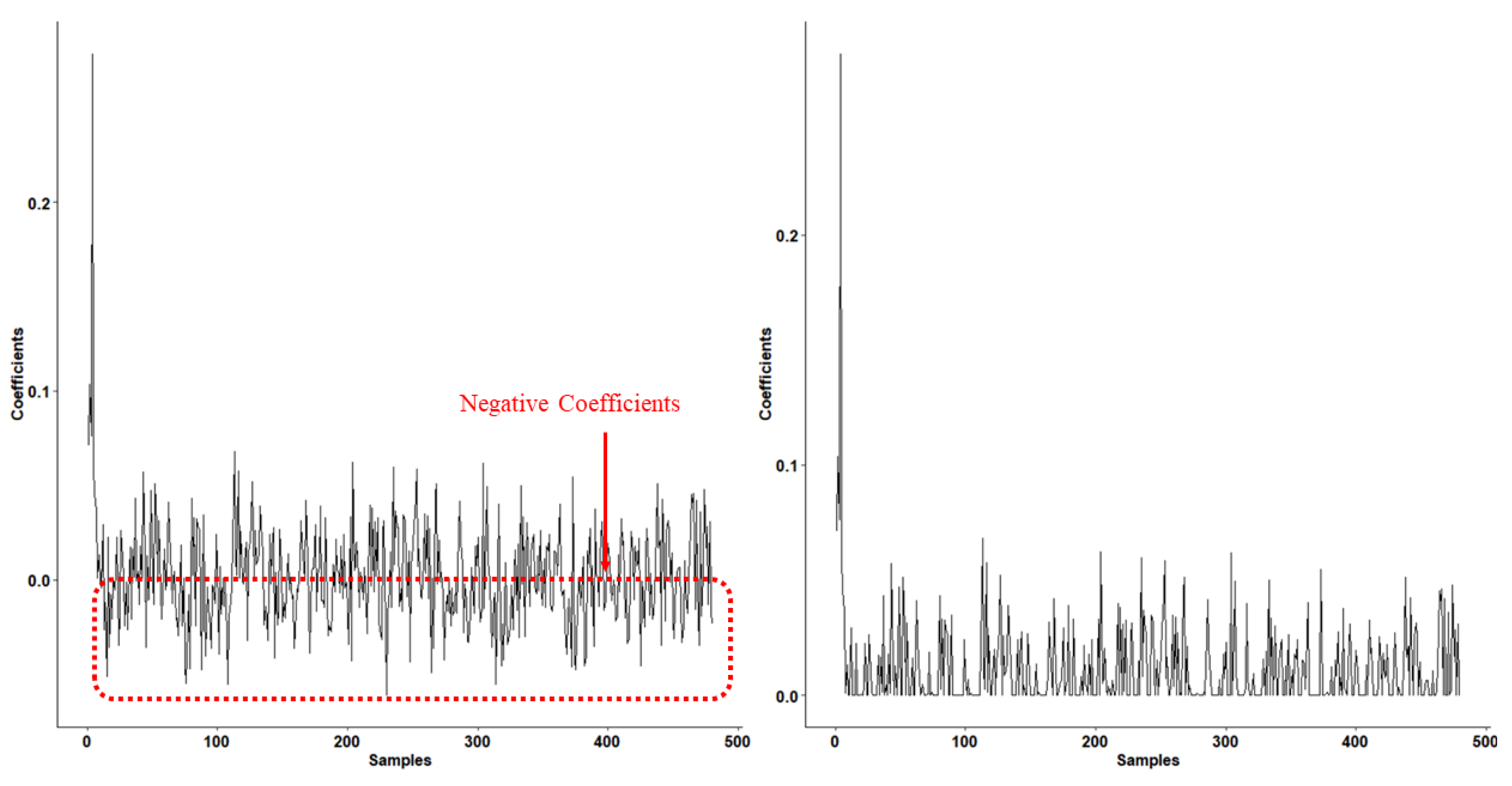
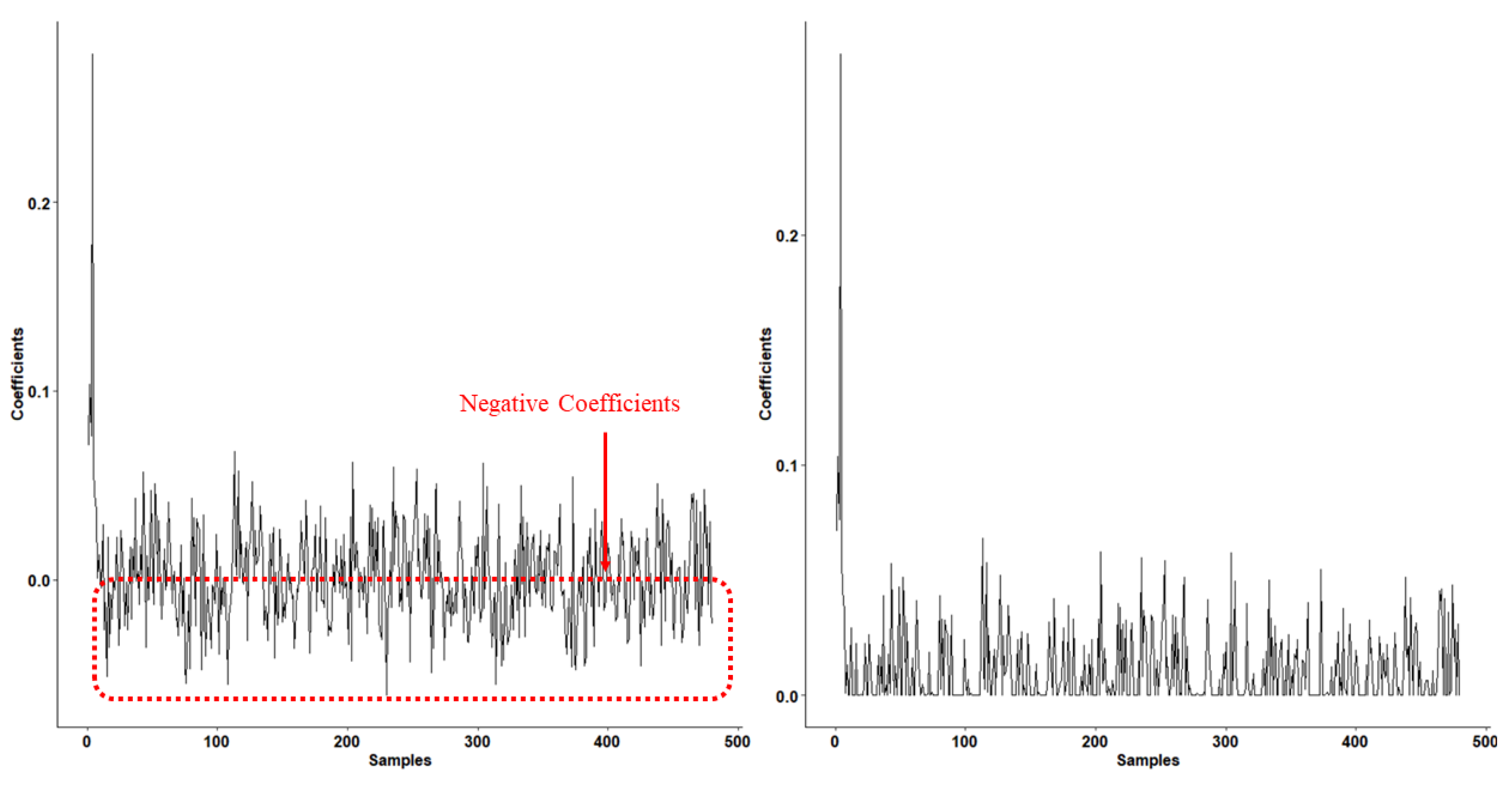
14], the authors intended to seek a weight that can truly help in the classification, indicating that using different training samples may influence the discriminative pattern. Moreover, the negative coefficient implies a negative correlation between the training sample and test sample. Inspired by this idea, and considering the relationship between negative coefficients in the training sample and test samples, we intend to represent the test sample using non-negative representation. Ultimately, this produces a more effective classification [
15,
16,
17].
The CRC uses
norm to perform classification. As representation coefficients can be derived from an analytic solution to a least square problem, CRC is much more efficient than SRC. Furthermore, the collaborative representation is interpretive as well [
18]. Due to its intrinsic property, CRC has been extensively refined. For instance, Dong et al. used sparse subspace on weighted CRC [
14] to improve the recognition rate for face recognition [
19]. Zeng et al. proposed S*CRC to achieve promising performances by fusing coefficients from sparse representation with the coefficients from collaborative representation [
20]. However, in this work, each test sample is represented twice using SRC and CRC simultaneously, which is time consuming. Zheng et al. selected
k candidate classes before representing a test sample collaboratively, while the
p in the objective function should be defined in advance to obtain optimal results [
21]. In [
14,
18,
19,
20,
21], the authors ignored the relationship between the collaborative coefficient and the test sample. However, we strongly believe that, by considering this relationship, we are able to obtain a higher recognition rate.
The Restricted Linear Unit (ReLU) function [
22] is widely used in deep learning to improve the performance of a deep neural network. Until now, many popular deep neural networks use ReLU as the activation function (e.g., VGG19 [
3]). By using the ReLU function, there is sparse activation, making the network sparser. Similarly, we can apply the ReLU function to enhance the sparsity of CRC, which should improve its performance. Since the sparsity can help the CRC model to perform robust classification [
23], representations mapped by the ReLU function will also achieve promising classification results.
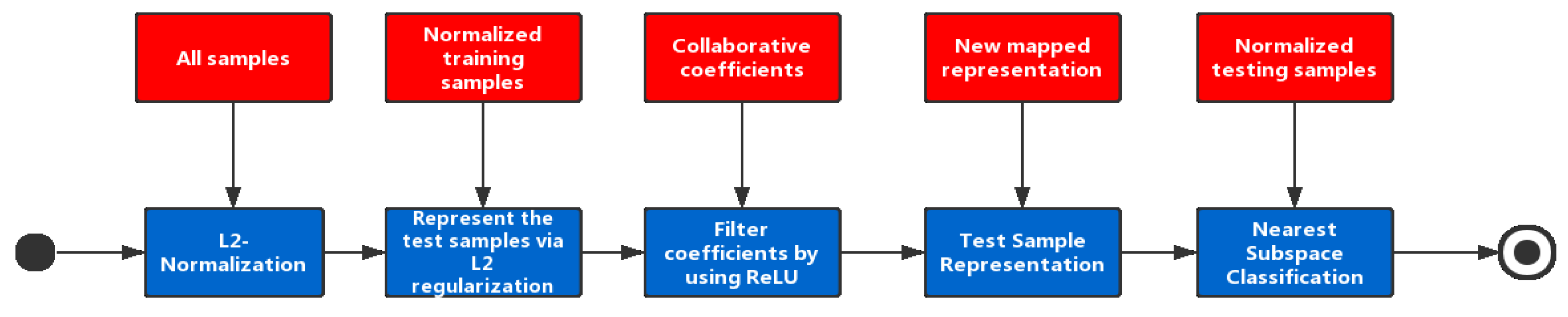
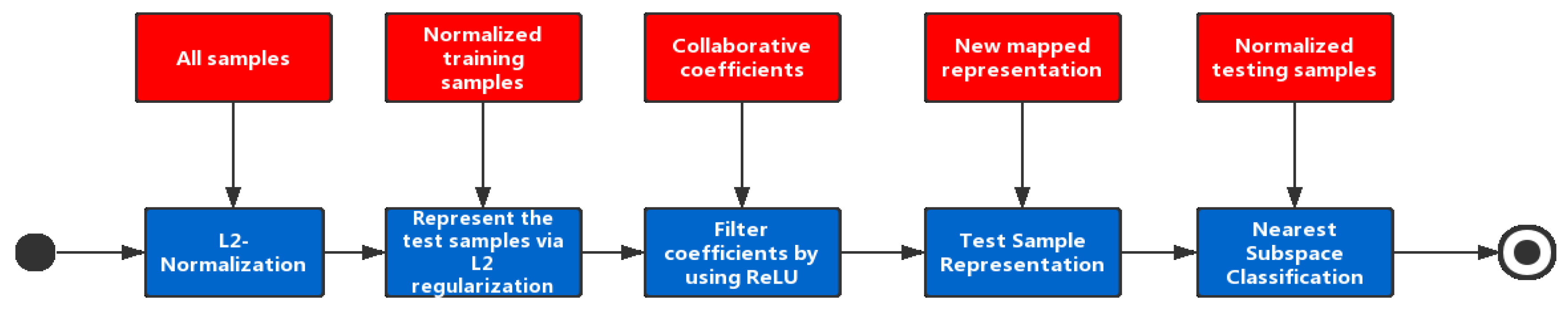
Bringing everything together, this paper proposes a novel collaborative representation based classification method, named Non-negative CRC (NCRC). The system architecture of NCRC can be found in
Figure 1. In the first step, NCRC performs normalization on all samples from a dataset based on
norm. Next, NCRC uses all training samples to calculate the collaborative representation coefficients by representing the test samples collaboratively via
regularization. Afterwards, the ReLU function is utilized to filter these collaborative coefficients and map the negative ones to zero. Then, we use the newly mapped collaborative coefficients to represent the test sample. Finally, to classify each test sample, the nearest subspace classification is performed. Specifically, the residuals between the representation of each class and the test sample are calculated, and we select the class label associated with the minimum residual as the result. The main contributes are:
We propose a novel image classification algorithm using non-negative samples based on the collaborative representation based classifier.
The proposed method enhances the sparsity of CRC by introducing the Restricted Linear Unit (ReLU) function, which increases the sparsity of the coefficients and improves the recognition rate.
The remainder of this paper is organized as follows. In
Section 2, we give a brief overview of the collaborative representation based classifier before introducing our proposed NCRC. In
Section 3, we show extensive experimental results to demonstrate the effectiveness and efficiency of NCRC, while at the same time discussing the superiority of our method. Finally, in
Section 4, we give a conclusion.
3. Experiments
We performed experiments on AR [
28], LFW [
29], MUCT [
30] and the PolyU palmprint [
31] datasets to verify the effectiveness of our method. To show our proposed method’s capability in different image classification tasks, the recognition tasks ranged from human face recognition to palmprint recognition, where the performances were validated by the hand-out method [
32]. For each dataset, we divided them into training and testing to evaluate the result in each iteration. Besides this, we increased the size of the training samples in each iteration. At last, we computed the average accuracy achieved by the proposed method and compared it with other state-of-the-art sparse representation based classifiers (S*CRC [
20] and ProCRC [
18]), the original SRC [
4] and CRC [
24] as well as traditional classifiers such as SVM and KNN. To achieve the optimal results for all classifiers, various parameters were tested. For SRC, CRC, S*CRC, and ProCRC, we used
= 1 ×
, 1 ×
, 1 ×
, 2 ×
, 3 ×
, and 4 ×
. In SVM, we tried different kernel functions, as for KNN (K = 7). All of the experiments were performed on a PC running Windows 10 with a 3.40 GHz CPU and 16 GB RAM running MATLAB R2018a. Below, for the comparison methods, we report the accuracy that was achieved using the optimal parameter. To guarantee the stability of our final results on each dataset, we repeated each experiment 30 times and took the average value as the final result.
3.1. Dataset Description
The AR face database [
28] contains 4000 color images of 126 human faces, where each image is
pixels. Images of the same person are captured in two sessions separated by 14 days. In the experiments, we varied the number of training samples from 4 to 20 images per class, and took remaining samples in each class as the testing samples. Examples of images from this database can be found in
Figure 3.
The LFW face database [
29] contains 13,233 images of 5749 human faces. Among them, 1680 people had more than two images.
Figure 4 depicts some examples from this database. For the experiments, each image consisted of
pixels. We used the number of training samples from 5 to 35 images per class, and employed the remaining samples in each class as the testing samples. In addition, we applied FaceNet to extract the features from the database before feeding it into the classifiers.
The MUCT face [
30] database contains in total 3755 face images collected from 276 people. Each image is given a size of
pixels. These face images were captured by a CCD camera and stored in 24-bit RGB format. Samples from this database are shown in
Figure 5. In the experiments, we adjusted the number of training samples from 1 to 7 in each class and took the remaining samples in each class as the testing samples.
The PolyU palmprint database was created by the Biometric Research Centre, Hong Kong Polytechnic University [
31]. There are 7752 gray-scale images of 386 different palms stored in BMP format.
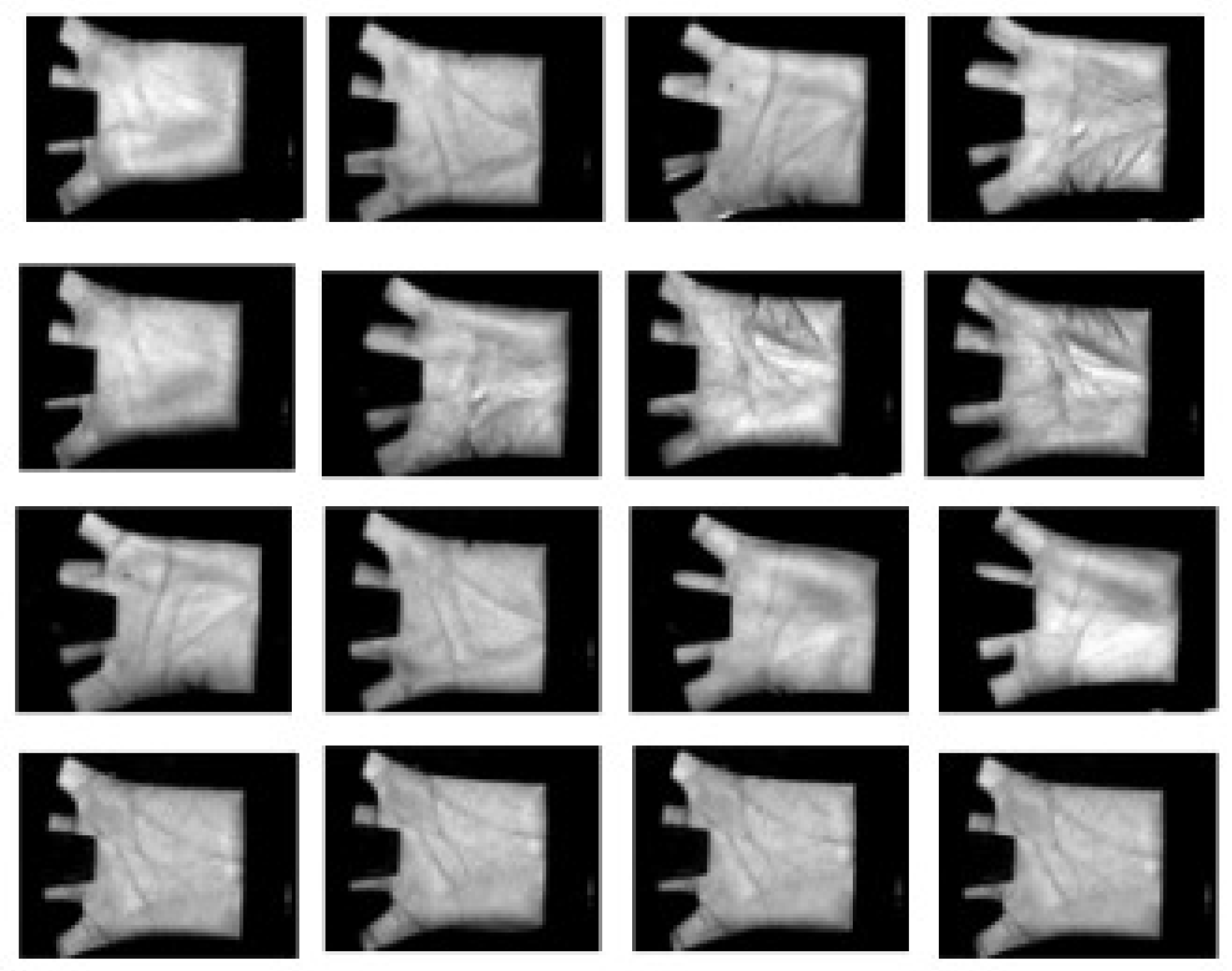
Figure 6 illustrates some examples from this database. For an individual’s palmprint, there are approximately 20 samples collected in two sessions, where each palm image is
pixels. For our experiments, the number of training samples ranged from 1 to 5 images per class, and we used the remaining samples in each class as the testing samples.
The general information of the databases in the experiments is summarized in
Table 1.
3.2. Experiments on the AR Face Database
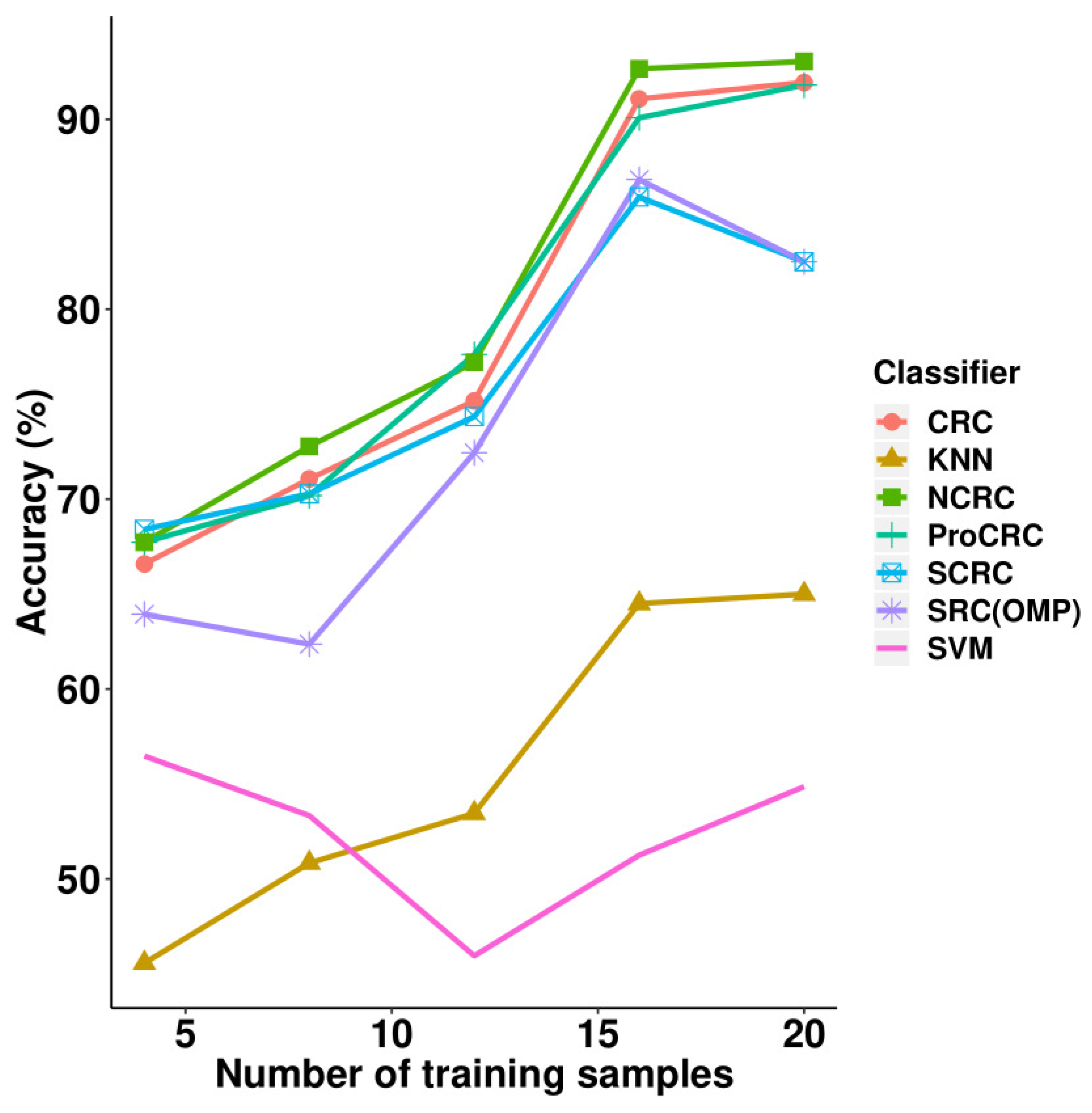
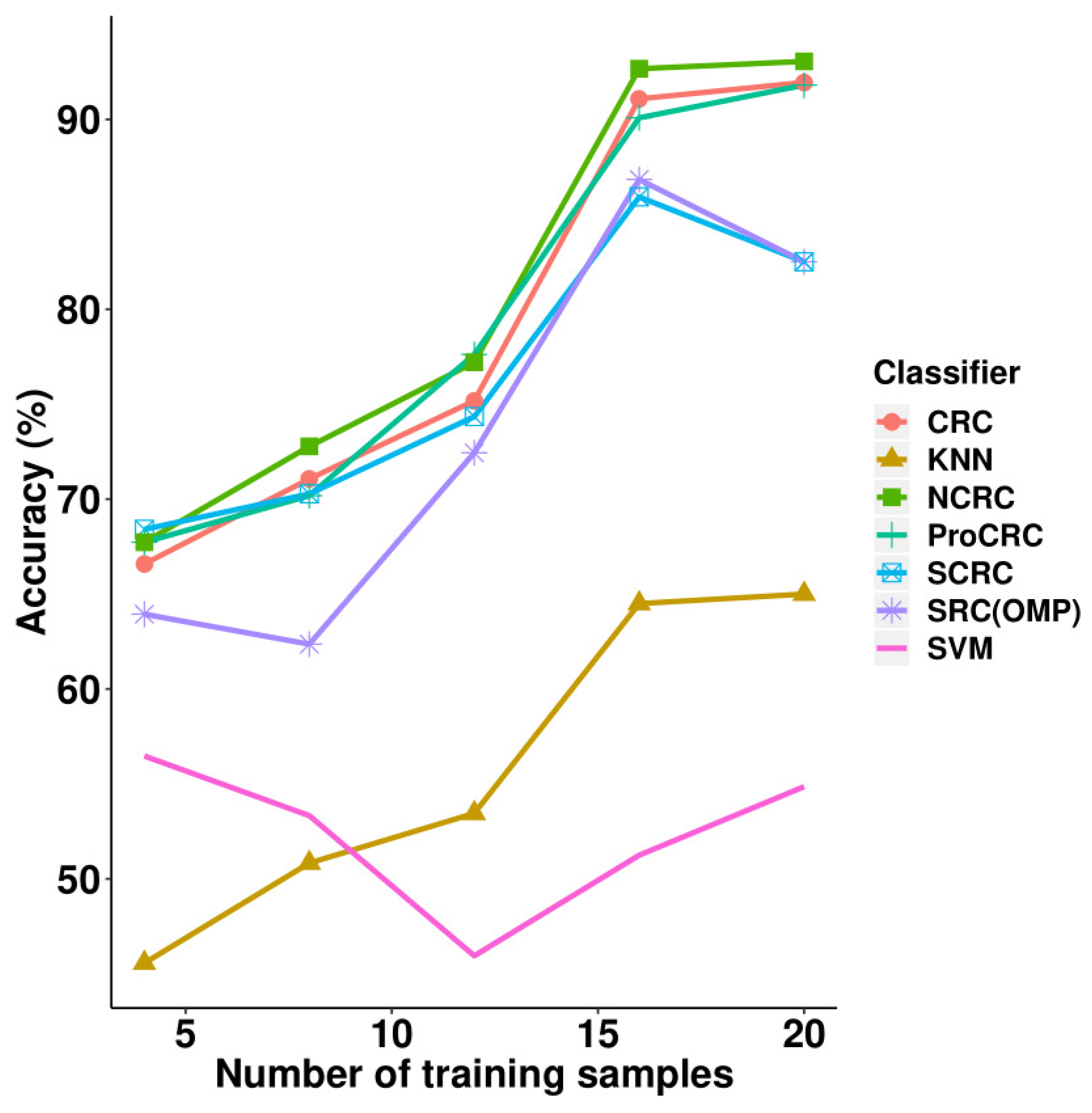
The experimental results on the AR face database can be found in
Table 2 and
Figure 7, where it can be seen that NCRC outperformed other classifiers. The highest recognition rate is 93.06% when using 20 samples per class for training. Compared with CRC, the improvement of NCRC ranges from 0.84% to 2.02%, which shows NCRC enhanced the recognition ability of the original CRC classifier on the AR database. Besides CRC, NCRC also achieved a better result than SRC (82.50%). Furthermore, the proposed method outperformed other variants of SRC and CRC such as S*CRC (82.50%,
) and ProCRC (91.81%,
), as well as traditional classifications including KNN (K = 7) and SVM (polynomial kernel function). For the parameter selection of NCRC, we experimented with
= 1 ×
, 1 ×
, 1 ×
, 2 ×
, 3 ×
, and 4 ×
, respectively (refer to
Table 3) by fixing the number of training samples at 20 (which was used to achieve the highest recognition). According to
Table 3, NCRC obtained the best accuracy when
. In
Table 2, the highest accuracy achieved using each number of samples is marked in bold. In
Table 3, highest accuracy achieved in each parameter
is marked in bold.
3.3. Experiments on the LFW Face Database
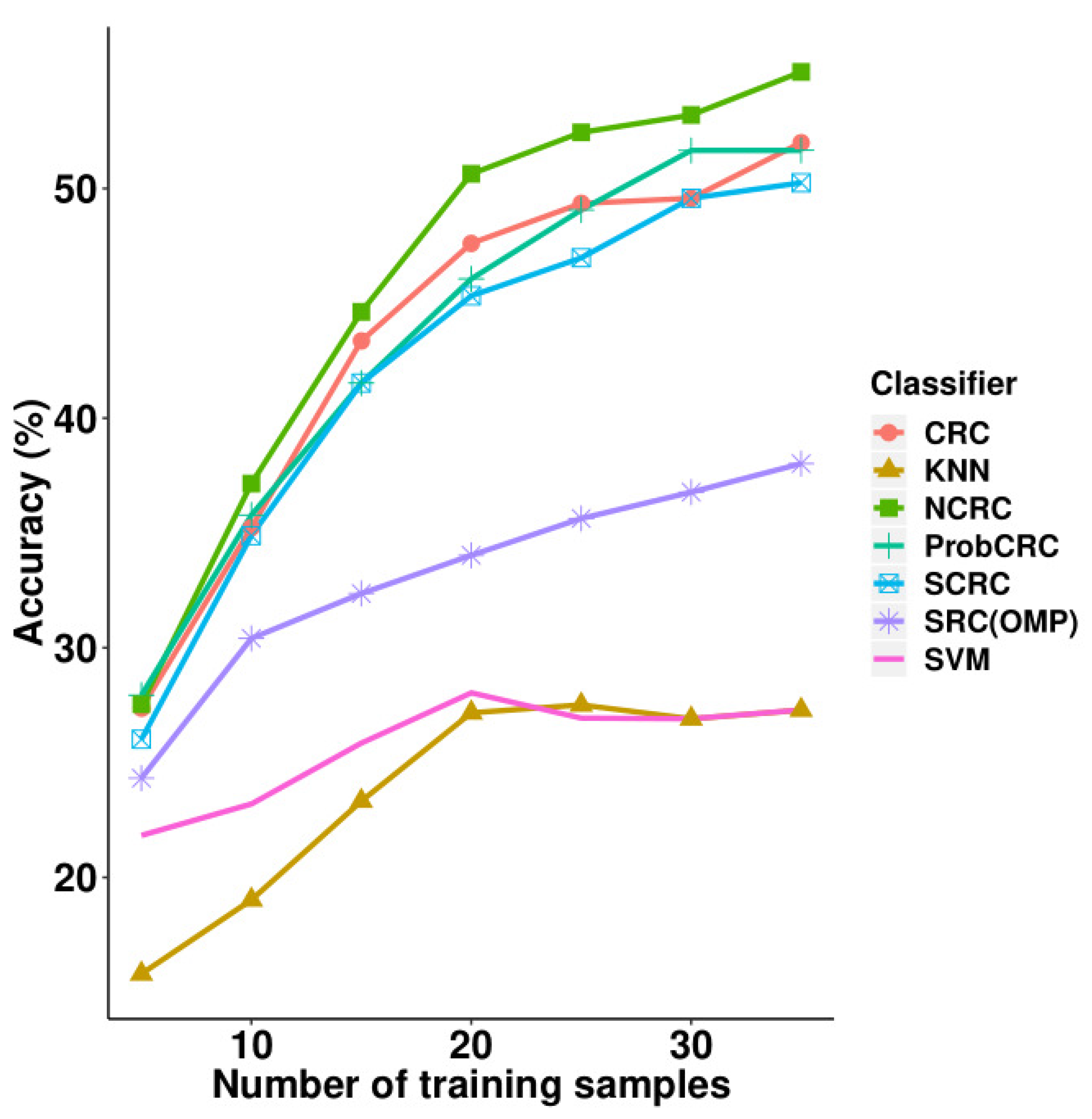
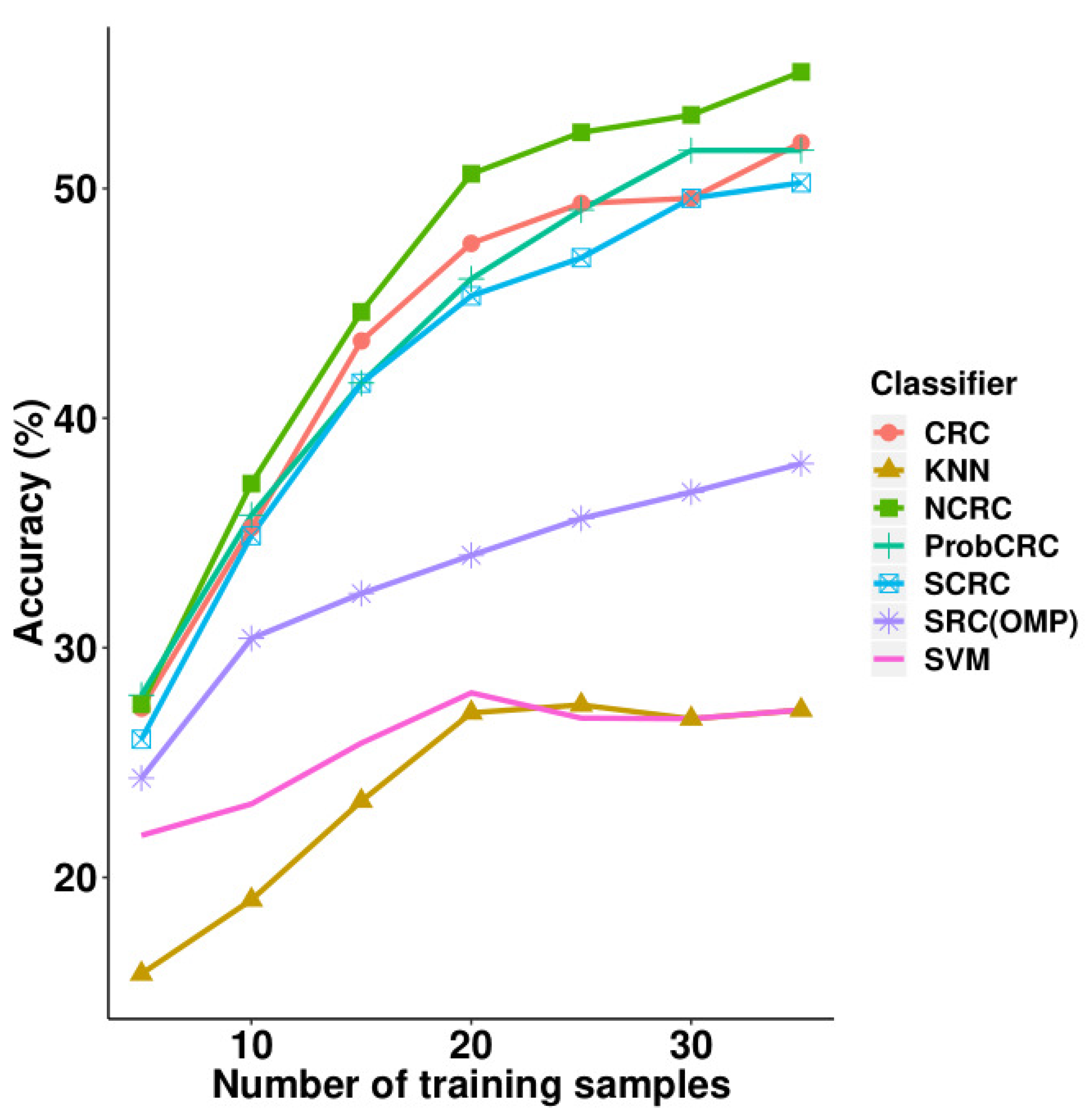
Next, we performed experiments on the LFW face database and compared its results with other classifiers including SRC, CRC, S*CRC, ProCRC, SVM and KNN. These results are illustrated in
Table 4 and
Figure 8, where it can be observed that NCRC performed best using 10–35 training samples. When using five training samples, ProCRC slightly outperformed NCRC by 0.39%. For the parameter selection of NCRC, we experimented with
= 1 ×
, 1 ×
, 1 ×
, 2 ×
, 3 ×
, and 4 ×
(refer to
Table 5) by fixing the number of training samples at 35. The optimal result was obtained when
. Compared with CRC, the improvement of NCRC ranges from 0.17% to 3.62%, which shows NCRC again enhanced the recognition ability of the original CRC. The proposed method using 35 training samples also achieved a better result than SRC (38.02%). Furthermore, NCRC outperformed other variants of SRC and CRC such as S*CRC (50.25%,
), ProCRC (51.66%,
), SVM (28.12%, polynomial kernel function), and KNN (27.29%, K = 7). In
Table 4, the highest accuracy achieved using each number of samples is marked in bold. In
Table 5, highest accuracy achieved in each parameter
is marked in bold.
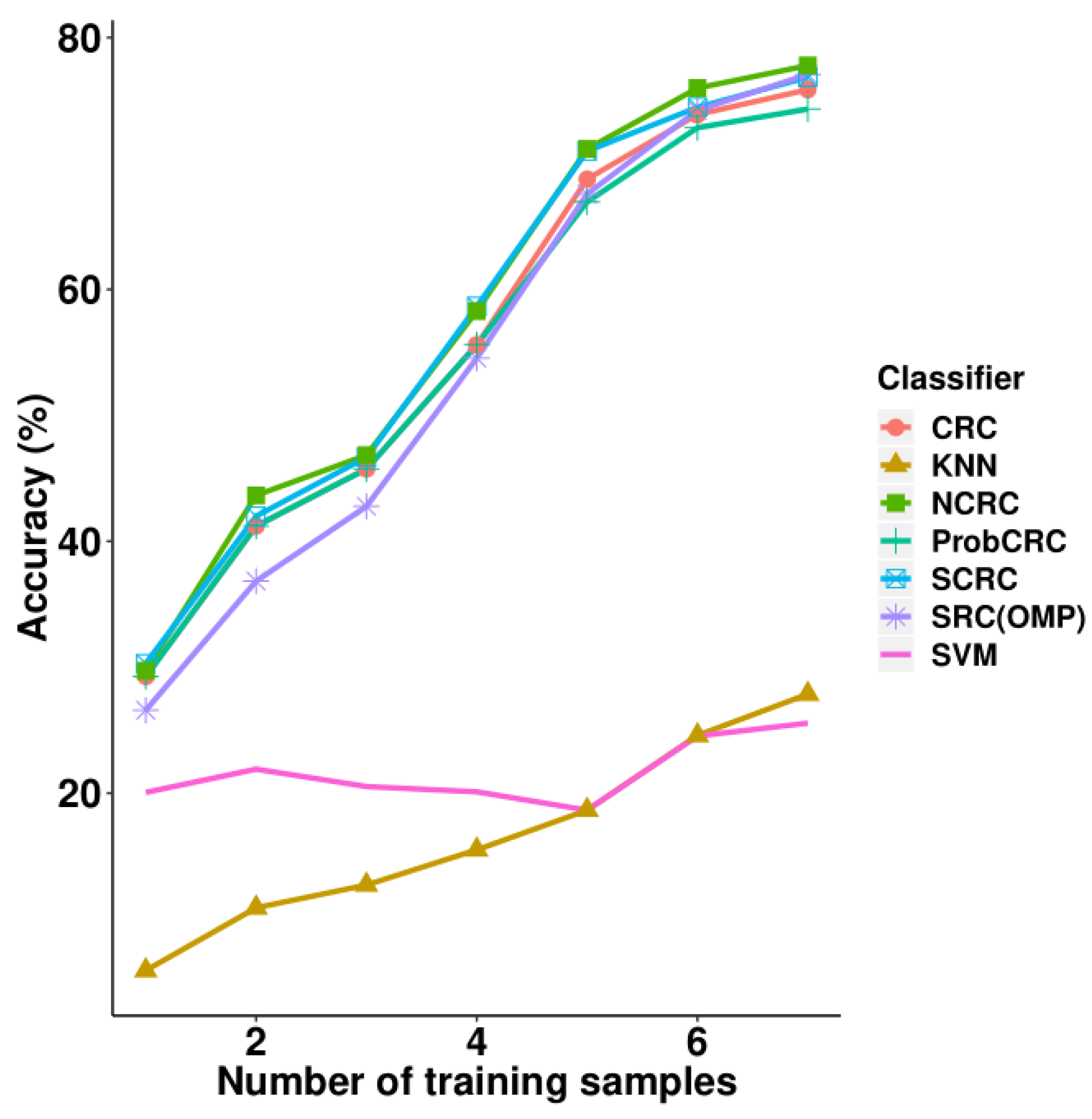
3.4. Experiments on the MUCT Face Database
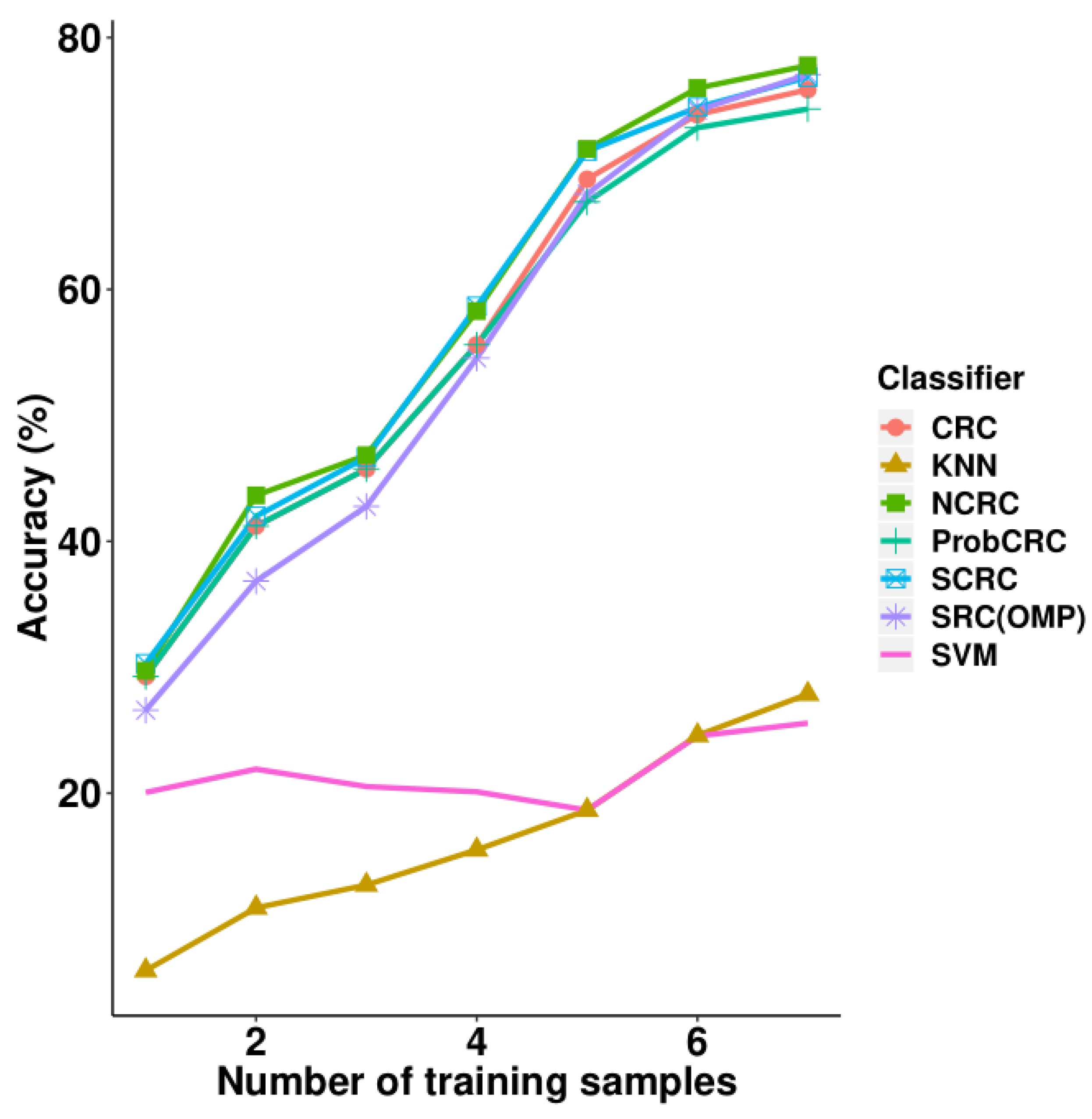
Table 6 and
Figure 9 present the experimental results on the MUCT face database. From the seven different training sample sizes, NCRC attained the highest accuracy using 2–7 samples compared with the other classifiers. Using the same parameter selection progress as presented in
Section 3.2 and
Section 3.3 for NCRC, the best
value using 7 training samples was 0.01 (refer to
Table 7). The highest recognition rate is 77.78% when using seven samples per class for training. Compared with CRC, the improvement of NCRC ranges from 0.46% to 2.68%. Furthermore, NCRC also achieved a better result than SRC (77.07%), S*CRC (76.85%,
) and ProCRC (74.32%,
), as well as traditional classifications including KNN (K = 7) and SVM (polynomial kernel function). As for the use of one training sample, S*CRC outperformed NCRC by only 0.58%. In
Table 6, the highest accuracy achieved using each number of samples is marked in bold. In
Table 7, highest accuracy achieved in each parameter
is marked in bold.
3.5. Experiments on the PolyU Palmprint Database
Finally, the experimental results on the PolyU palmprint database can be found in
Table 8. According to this table, the highest average recognition rate with 1–5 training samples on average is 95.04% when using our proposed NCRC classifier, where various
values were tested similar to the other experiments (refer to
Table 9). Compared with CRC, the improvement of NCRC is 0.13% on average, which shows NCRC enhanced the recognition ability of the original CRC classifier on the PolyU palmprint database. When compared to the other classifiers, NCRC also achieved a better result than SRC (95.03%), Furthermore, the proposed method outperformed other variants of SRC and CRC such as S*CRC (94.92%), ProCRC (93.54%), KNN (57.99%), and SVM (86.91%). In
Table 8, the highest average accuracy achieved is marked in bold. In
Table 9, highest accuracy achieved in each parameter
is marked in bold.
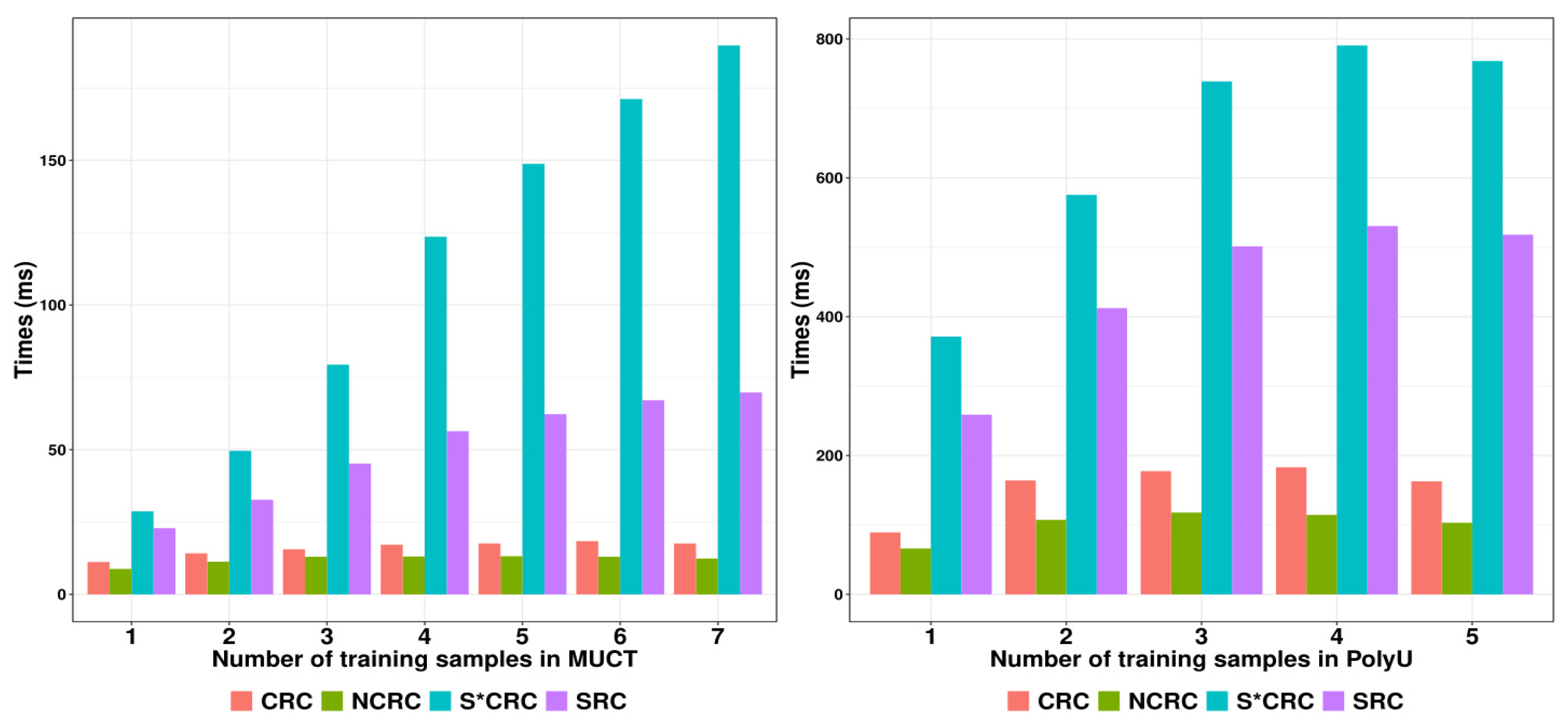
3.6. Comparison of Classification Time
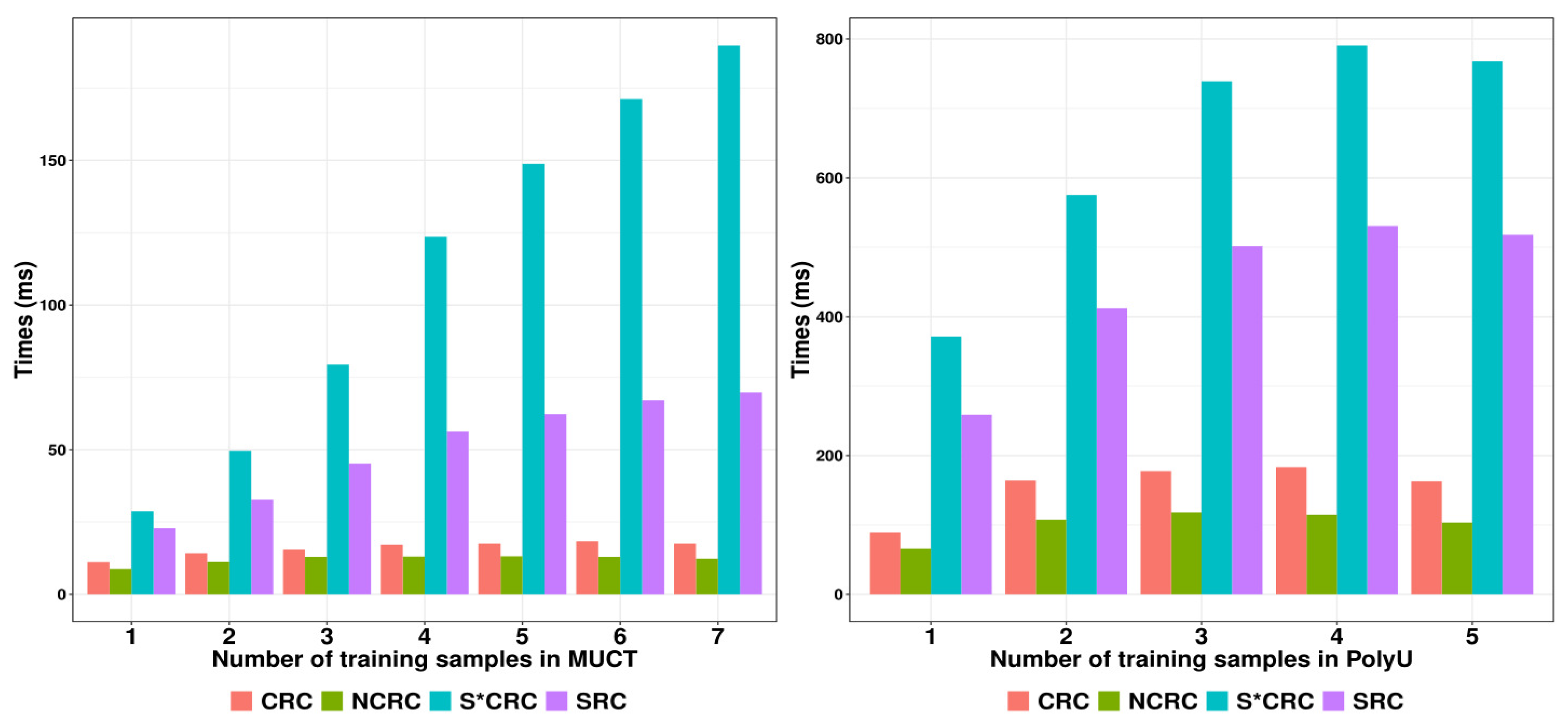
To demonstrate the classification efficiency of the proposed NCRC, we further made comparisons between NCRC and other classifiers in terms of classification time.
Figure 10 shows the classification time of SRC, CRC, S*CRC and NCRC on the MUCT (left) and PolyU (right) databases with an increasing number of training samples. As shown in
Figure 10, NCRC required less classification time compared with the other classifiers, which indicates a higher efficiency for image classification. Even though the classification accuracy of MUCT using S*CRC with one training sample is slightly higher than the result of NCRC (refer to
Table 6), in terms of classification time, NCRC performed (over three times) faster than S*CRC. As a variant of CRC, the ProCRC used less classification time than our proposed method, while its performance on the datasets show inferiority compared with our proposed method. These can be seen in
Table 2,
Table 4,
Table 6 and
Table 8, with NCRC outperforming ProCRC every time except on the LFW database using five training samples, where the difference is only 0.39%.
3.7. Discussion
We conducted experiments ranging from face to palmprint recognition, where it has been well proven that our proposed method achieved promising performances as well as efficient classification times. Here, we are able to reach the following inferences from the experiments:
For face recognition, NCRC tends to achieve better results when the number of training samples is increased compared with SRC and CRC. Here, the highest improvement reaches 17.3% on the LFW database. Furthermore, NCRC (AR: 93.06%; LFW: 55.32%; and MUCT: 77.78%) is even more effective in terms of accuracy than S*CRC (AR: 82.50%; LFW: 50.25%; and MUCT: 76.85%) and ProCRC (AR: 91.81%; LFW: 51.66%; and MUCT: 74.32%), which are refined classifiers based on SRC (AR: 82.50%; LFW: 38.02%; and MUCT: 77.07%) and CRC (AR: 91.94%; LFW: 52.00%; and MUCT: 75.86%).
When it comes to palmprint recognition, NCRC (95.04%) also shows competitive recognition rates on average, reaching its highest improvement of 1.5% over other state-of-the-art sparse representation methods such as SRC (95.03%), CRC (94.91%), S*CRC (94.92%), and ProCRC (93.54%). This indicates that our proposed method is not only effective in face recognition, but also other image classification tasks.
Besides the recognition rate, NCRC (MUCT: 12.1 ms) consumed less time in classification compared with SRC (MUCT: 50.9 ms), CRC (MUCT: 16.0 ms) and S*CRC (MUCT: 113 ms) implying its efficiency in image classification. Although ProCRC performed faster than NCRC, in terms of the recognition rate, the proposed method outperformed all classifiers on average.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}