Multi-View Image Denoising Using Convolutional Neural Network


Abstract
:1. Introduction
- A convolutional neural network that takes multiple views (in the form of 3D matrix) as the input and delivers multiple residual images as the output.
- An efficient image fusion approach that integrates multiple denoised 3D focus image stacks into a target denoised image using the disparity map.
- A novel and effective technique that detects and tackles occlusions from the disparity map through morphological transformations.
2. Related Work
2.1. Conventional Image Denoising
2.2. Deep Neural Networks for Single Image Denoising
2.3. Multi-View Image Denoising
3. The Proposed Denoising Network
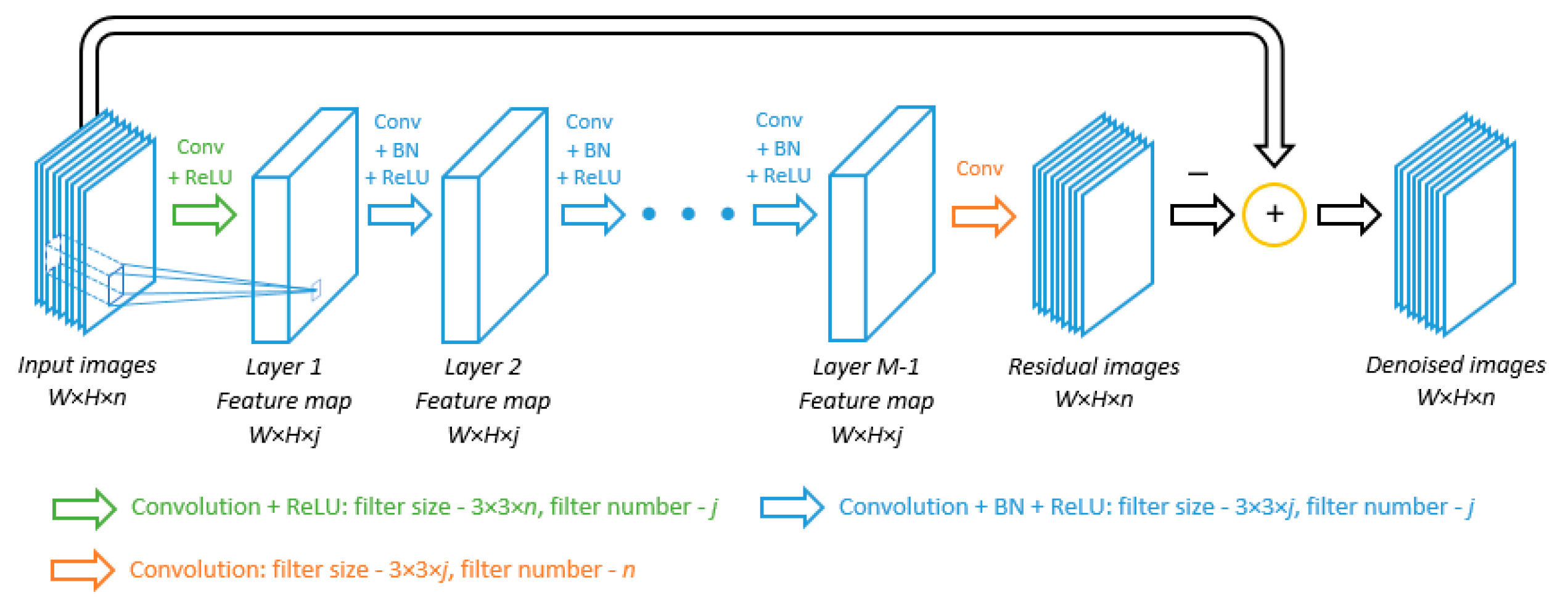
3.1. Network Architecture
3.2. Network Testing: Single Image vs. Multi-View
3.3. Signal Processing Interpretation of MVCNN
3.3.1. General Mechanism of the Denoising Network
3.3.2. Intra-View Correlation
3.3.3. Inter-View Correlation
3.4. Relationship with Previous Works
- The original DnCNN only takes one single image, which is a 2D matrix, as input for grayscale image denoising, while the input of MVCNN usually has a 3D input and output. This changes the filter size in the first convolution layer and the number of filters in the last layer.
- As the input matrix has more dimension, the number of layers and the number of feature maps also need to be adjusted accordingly. In specifics, the number of feature maps in each layer needs to be increased in order to capture sufficient inter-view correlations and achieve a satisfactory denoising performance. Figure 6 illustrates a denoising example using different numbers of feature maps. Meanwhile, as the number of feature map and number of views increment, the training time also rapidly increases. In order to keep a balance between denoising performance and computational complexity, we choose to slightly decrease the number of layers without sacrificing the performance.
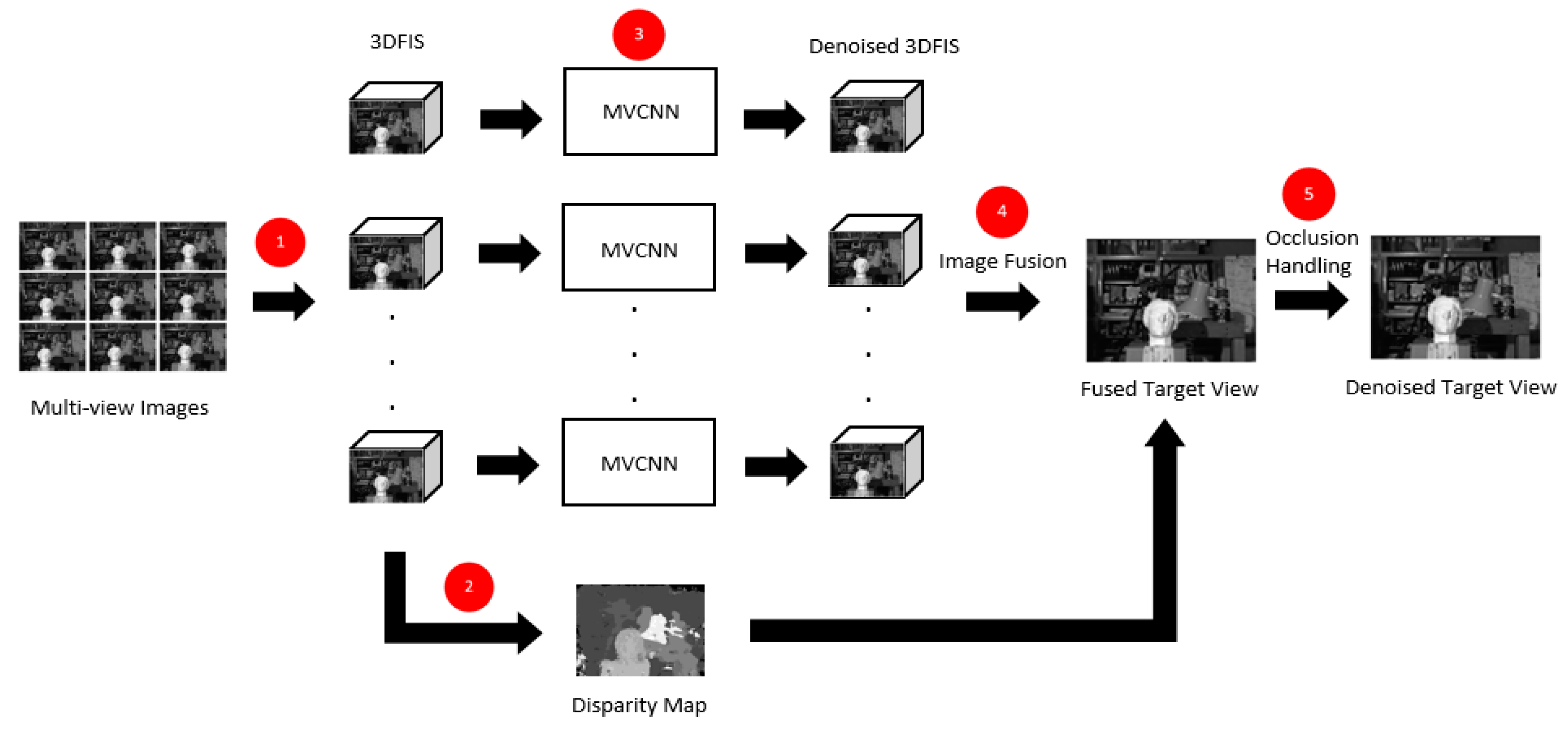
- Simply passing the 3DFIS into the network produces a number of denoised image stacks, which are not the desired final denoised images. Further processing needs to be carried out to integrate these denoised image stacks into denoised images, with careful handling of occlusion. Therefore, a novel image fusion procedure and occlusion handling technique are proposed.
4. Multi-View Denoising Algorithm
4.1. 3D Focus Image Stacks and Disparity Estimation
4.2. Multi-View Denoising Using MVCNN
| Algorithm 1 Multi-view Image Denoising |
| Input: Multi-view images Is,t, maximum candidate disparity value dmax, pre-trained MVCNN, target image number k. |
| Output: Denoised target image Iest. |
| Initialize: Denoised target image Iest = zeros(size(Is,t)), weight matrix W = zeros(size(Is,t)). |
| 1: for d = 1:dmax |
| 2: Construct 3D focus image stacks Fd using Equation (3); |
| 3: Obtain denoised image stacks by applying MVCNN to Fd; |
| 4: end |
| 5: Estimate the disparity map for the target image using Equations (4)-(6); |
| 6: for each pixel (x, y) |
| 7: Find its disparity d(x, y); |
| 8: Obtain a patch P centered at (x, y) in the kth image of image stack , and compute |
| its weight w.r.t. the reference patch Pref as ; |
| 9: Update Iest = Iest + w·P; |
| 10: Update W = W + w; |
| 11: end |
| 12: Compute the denoised target image Iest = Iest/W; |
| 13: Detect and handle occlusion using Algorithm 2. |
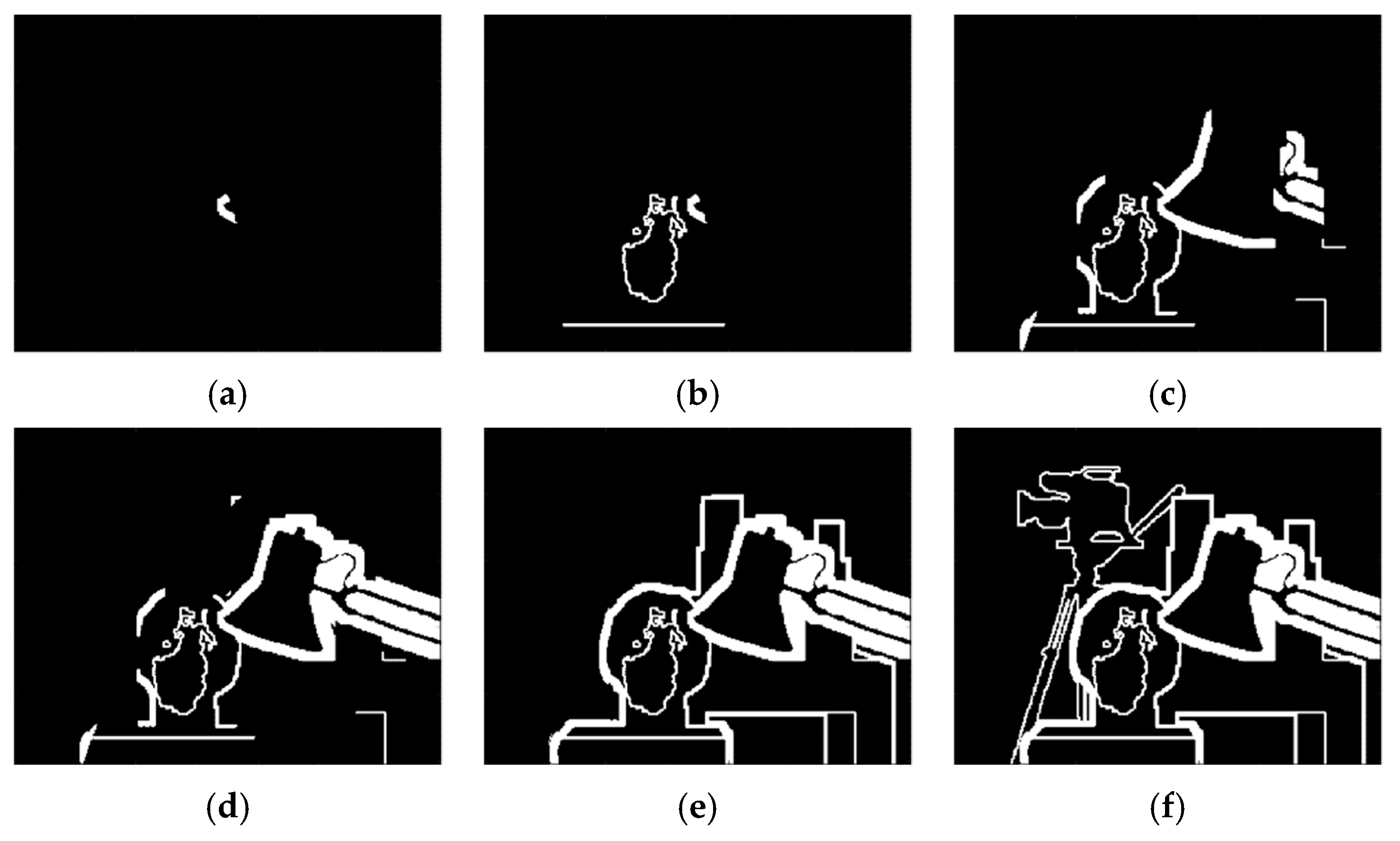
4.3. Occlusion Detection and Handling
| Algorithm 2 Occlusion Detection |
| Input: Disparity map D. |
| Output: Occlusion map O. |
| Initialize: O = zeros(size(D)). |
| 1: for dcur = (dmax – 1):−1:1 |
| 2: Acur = {(x, y): D(x, y) = dcur}; |
| 3: for dprev > dcur |
| 4: SE = (dprev – dcur)(s2 – s1) + 1; |
| 5: Aprev = {(x, y): D(x, y) = dprev}; |
| 6: Adilate = imdilate(Aprev, SE); |
| 7: O = (Acur & Adilate) | O; |
| 8: end |
| 9: end |
5. Experimental Results
5.1. Parameter Settings for Network Training
5.2. Blind Denoising
5.3. Color Image Denoising
5.4. Evaluation of Denoising Performance
5.5. Run Time
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lee, J.S. Refined filtering of image noise using local statistics. Comput. Graph. Image Process. 1981, 15, 380–389. [Google Scholar] [CrossRef]
- Kutoba, A.; Smolic, A.; Magnor, M.; Tanimoto, M.; Chen, T.; Zhang, C. Multiview imaging and 3DTV. IEEE Signal Process. Mag. 2007, 24, 10–21. [Google Scholar]
- Dong, W.; Zhang, L.; Shi, G.; Li, X. Nonlocally centralized sparse representation for image restoration. IEEE Trans. Image Process. 2013, 22, 1620–1630. [Google Scholar] [CrossRef] [PubMed]
- Buades, A.; Coll, B.; Morel, J.M. A non-local algorithm for image denoising. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 60–65. [Google Scholar]
- Wang, J.; Guo, Y.; Ying, Y.; Liu, Y.; Peng, Q. Fast non-local algorithm for image denoising. In Proceedings of the 2006 International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006; pp. 1429–1432. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G.; Zisserman, A. Non-local sparse models for image restoration. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2272–2279. [Google Scholar]
- Gu, S.; Zhang, L.; Zuo, W.; Feng, X. Weighted nuclear norm minimization with application to image denoising. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2862–2869. [Google Scholar]
- Xu, J.; Zhang, L.; Zuo, W.; Zhang, D.; Feng, X. Patch group based nonlocal self-similarity prior learning for image denoising. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 244–252. [Google Scholar]
- Malfait, M.; Roose, D. Wavelet-based image denoising using a Markov random field a priori model. IEEE Trans. Image Process. 1997, 6, 549–565. [Google Scholar] [CrossRef]
- Roth, S.; Black, M.J. Fields of experts: A framework for learning image priors. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 860–867. [Google Scholar]
- Lan, X.; Roth, S.; Huttenlocher, D.; Black, M.J. Efficient belief propagation with learned higher-order Markov random fields. In Proceedings of the European conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 269–282. [Google Scholar]
- Szeliski, R.; Zabih, R.; Scharstein, D.; Veksler, O.; Kolmogorov, V.; Agarwala, A.; Tappen, M.; Rother, C. A comparative study of energy minimization methods for markov random fields with smoothness-based priors. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1068–1080. [Google Scholar] [CrossRef]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Phys. D Nonlinear Phenom. 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Vogel, C.R.; Oman, M.E. Iterative methods for total variation denoising. SIAM J. Sci. Comput. 1996, 17, 227–238. [Google Scholar] [CrossRef]
- Chambolle, A. An algorithm for total variation minimization and applications. J. Math. Imaging Vision 2004, 20, 89–97. [Google Scholar]
- Beck, A.; Teboulle, M. Fast gradient-based algorithms for constrained total variation image denoising and deblurring problems. IEEE Trans. Image Process. 2009, 18, 2419–2434. [Google Scholar] [CrossRef]
- Yuan, Q.; Zhang, L.; Shen, H. Hyperspectral image denoising employing a spectral-spatial adaptive total variation model. IEEE Trans. Geosci. Remote. Sens. 2012, 50, 3660–3677. [Google Scholar] [CrossRef]
- Elad, M.; Aharon, M. Image denoising via sparse and redundant representations over learned dictionaries. IEEE Trans. Image Process. 2006, 15, 3736–3745. [Google Scholar] [CrossRef] [PubMed]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311. [Google Scholar] [CrossRef]
- Mairal, J.; Elad, M.; Sapiro, G. Sparse representation for color image restoration. IEEE Trans. Image Process. 2008, 17, 53–69. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Yin, H.; Fang, L. Group-sparse representation with dictionary learning for medical image denoising and fusion. IEEE Trans. Biomed. Eng. 2012, 59, 3450–3459. [Google Scholar] [CrossRef] [PubMed]
- Barbu, A. Learning real-time MRF inference for image denoising. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1574–1581. [Google Scholar]
- Xie, J.; Xu, L.; Chen, E. Image denoising and inpainting with deep neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 341–349. [Google Scholar]
- Schmidt, U.; Roth, S. Shrinkage fields for effective image restoration. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2774–2781. [Google Scholar]
- Chen, Y.; Pock, T. Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1256–1272. [Google Scholar] [CrossRef] [PubMed]
- Burger, H.C.; Schuler, C.J.; Harmeling, S. Image denoising: Can plain neural network compete with BM3D? In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2392–2399. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for cnn based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef]
- Jin, K.H.; McCann, M.T.; Froustey, E.; Unser, M. Deep convolutional neural network for inverse problems in imaging. IEEE Trans. Image Process. 2017, 26, 4509–4522. [Google Scholar] [CrossRef]
- Guo, S.; Yan, Z.; Zhang, K.; Zuo, W.; Zhang, L. Toward convolutional blind denoising of real photographs. arXiv 2018, arXiv:1807.04686. [Google Scholar]
- Zhou, S.; Lou, Z.; Hu, Y.H.; Jiang, H. Multiple view image denoising using 3D focus image stacks. Comput. Vis. Image Underst. 2018, 171, 34–47. [Google Scholar] [CrossRef]
- Zhang, L.; Vaddadi, S.; Jin, H.; Nayar, S. Multiple view image denoising. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1542–1549. [Google Scholar]
- Luo, E.; Chan, S.H.; Pan, S.; Nguyen, T. Adaptive non-local means for multiview image denoising: Search for the right patches via a statistical approach. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, VIC, Australia, 15–18 September 2013; pp. 543–547. [Google Scholar]
- Xue, Z.; Yang, J.; Dai, Q.; Zhang, N. Multi-view image denoising based on graphical model of surface patch. In Proceedings of the 2010 3DTV-Conference: The True Vision - Capture, Transmission and Display of 3D Video, Tampere, Finland, 7–9 June 2010; pp. 1–4. [Google Scholar]
- Yue, H.; Sun, X.; Yang, J.; Wu, F. Image denoising by exploring external and internal correlations. IEEE Trans. Image Process. 2015, 24, 1967–1982. [Google Scholar] [CrossRef] [PubMed]
- Miyata, M.; Kadoma, K.; Hamamoto, T. Fast multiple-view denoising based on image reconstruction by plane sweeping. In Proceedings of the 2014 IEEE Visual Communications and Image Processing Conference, Valletta, Malta, 7–10 December 2014; pp. 462–465. [Google Scholar]
- Collins, R.T. A space-sweep approach to true multi-image matching. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 18–20 June 1996; pp. 358–363. [Google Scholar]
- Chen, J.; Hou, J.; Chau, L.P. Light field denoising via anisotropic parallax analysis in a CNN framework. IEEE Signal Process. Lett. 2018, 25, 1403–1407. [Google Scholar] [CrossRef]
- Fujita, S.; Takahashi, K.; Fujii, T. How should we handle 4D light fields with CNNs? In Proceedings of the 25th IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018; pp. 2600–2604. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Song, K.; Chung, T.; Oh, Y.; Kim, C.S. Error concealment of multi-view video sequences using inter-view and intra-view correlations. J. Vis. Commun. Image Represent. 2009, 20, 281–292. [Google Scholar] [CrossRef]
- Jing, X.Y.; Hu, R.; Zhu, Y.P.; Wu, S.; Liang, C.; Yang, J.Y. Intra-view and inter-view supervised correlation analysis for multi-view feature learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; Volume 14, pp. 1882–1889. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Accurate image super-resolution using very deep convolution networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition; 2016; pp. 1637–1645. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland; pp. 391–407. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 23, 1222–1239. [Google Scholar] [CrossRef]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Vedaldi, A.; Lenc, K. Matconvnet: Convolutional neural networks for matlab. In Proceedings of the 23rd ACM international conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 689–692. [Google Scholar]
- Middlebury Multi-View Stereo Datasets. Available online: http://vision.middlebury.edu/stereo/data/ (accessed on 1 March 2019).
- The (New) Stanford Light Field Archive. Available online: http://lightfield.stanford.edu/lfs.html (accessed on 1 March 2019).
- Honauer, K.; Johannsen, O.; Kondermann, D.; Goldluecke, B. A dataset and evaluation methodology for depth estimation on 4D light fields. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Cham, Switzerland, 2016; pp. 19–34. [Google Scholar]
- Maggioni, M.; Boracchi, G.; Foi, A.; Egiazarian, K. Video denoising, deblocking, and enhancement through separable 4-D nonlocal spatiotemporal transforms. IEEE Trans. Image Process. 2012, 21, 3952–3966. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Color image denoising via sparse 3D collaborative filtering with grouping constraint in luminance-chrominance space. In Proceedings of the IEEE International Conference on Image Processing, San Antonio, TX, USA, 16–19 September 2007; Volume 1, pp. 313–316. [Google Scholar]
- Golub, G.H.; van Loan, C.F. Matrix Computations; JHU Press: Baltimore, MD, USA, 2012; Volume 3. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BM3D [6] | WNNM [8] | DnCNN [28] | Miyata et al. [37] | VBM4D [58] | Zhou et al. [32] | MVCNN | MVCNN-B | |
|---|---|---|---|---|---|---|---|---|
| σ = 15 | ||||||||
| Bicycle | 29.44 | 29.72 | 30.21 | 29.90 | 31.56 | 31.32 | 32.10 | 31.33 |
| Dishes | 31.49 | 32.34 | 32.56 | 31.03 | 33.65 | 33.54 | 35.00 | 34.78 |
| Knights | 30.97 | 31.80 | 31.91 | 30.73 | 33.51 | 33.00 | 34.15 | 33.72 |
| Medieval | 32.17 | 32.55 | 32.64 | 31.22 | 33.92 | 34.26 | 35.92 | 35.07 |
| Sideboard | 29.32 | 30.61 | 29.70 | 29.91 | 31.48 | 31.50 | 32.70 | 32.20 |
| Tarot | 28.20 | 28.71 | 29.25 | 27.96 | 30.27 | 30.58 | 30.32 | 29.96 |
| Tsukuba | 32.77 | 33.14 | 33.34 | 30.35 | 32.64 | 34.34 | 35.48 | 34.96 |
| σ = 25 | ||||||||
| Bicycle | 26.72 | 26.92 | 27.51 | 26.60 | 28.93 | 28.60 | 30.15 | 29.32 |
| Dishes | 28.55 | 29.29 | 29.73 | 26.94 | 30.75 | 30.46 | 32.89 | 32.19 |
| Knights | 27.71 | 28.56 | 28.59 | 26.99 | 30.42 | 29.97 | 32.02 | 31.25 |
| Medieval | 30.19 | 30.58 | 30.44 | 27.20 | 31.73 | 31.37 | 33.31 | 32.70 |
| Sideboard | 26.31 | 27.43 | 26.60 | 26.47 | 28.62 | 28.77 | 30.63 | 29.83 |
| Tarot | 24.87 | 25.30 | 25.99 | 25.16 | 27.43 | 27.93 | 28.15 | 28.01 |
| Tsukuba | 29.65 | 30.28 | 30.09 | 26.65 | 29.66 | 30.89 | 32.31 | 32.04 |
| σ = 35 | ||||||||
| Bicycle | 24.93 | 25.24 | 25.69 | 24.15 | 27.24 | 26.93 | 28.68 | 27.88 |
| Dishes | 26.36 | 27.35 | 27.47 | 24.31 | 28.66 | 28.32 | 31.00 | 30.28 |
| Knights | 25.51 | 26.53 | 26.30 | 24.42 | 28.23 | 27.75 | 29.96 | 29.35 |
| Medieval | 28.77 | 29.18 | 28.90 | 24.63 | 30.23 | 29.36 | 31.16 | 31.07 |
| Sideboard | 24.32 | 25.25 | 24.63 | 23.94 | 26.49 | 26.95 | 28.95 | 28.17 |
| Tarot | 22.74 | 23.33 | 23.81 | 23.00 | 25.36 | 26.03 | 26.99 | 26.60 |
| Tsukuba | 27.56 | 28.48 | 27.69 | 24.20 | 27.54 | 28.69 | 29.32 | 29.51 |
| σ = 50 | ||||||||
| Bicycle | 22.86 | 23.44 | 23.84 | 21.34 | 25.39 | 24.96 | 26.28 | 26.26 |
| Dishes | 24.18 | 25.37 | 25.41 | 21.50 | 26.37 | 26.05 | 27.90 | 27.89 |
| Knights | 23.14 | 24.41 | 24.08 | 21.61 | 25.81 | 25.25 | 26.92 | 26.94 |
| Medieval | 26.57 | 27.68 | 26.43 | 21.79 | 28.31 | 27.30 | 28.93 | 29.00 |
| Sideboard | 22.09 | 23.12 | 22.70 | 20.94 | 24.03 | 24.89 | 26.03 | 26.25 |
| Tarot | 20.53 | 21.42 | 21.83 | 20.34 | 22.96 | 23.87 | 25.03 | 24.83 |
| Tsukuba | 25.07 | 26.66 | 25.01 | 21.62 | 25.14 | 25.95 | 26.83 | 26.69 |
| CBM3D [59] | CDnCNN [28] | CVBM3D [59] | MVCNN-C | |
|---|---|---|---|---|
| Bicycle | 28.26 | 29.23 | 30.45 | 30.51 |
| Dishes | 30.73 | 31.89 | 33.16 | 33.74 |
| Knights | 29.96 | 30.89 | 32.74 | 32.40 |
| Medieval | 31.01 | 31.45 | 33.41 | 33.26 |
| Sideboard | 27.69 | 28.63 | 29.73 | 30.82 |
| Tarot | 26.87 | 28.15 | 28.66 | 28.95 |
| Tsukuba | 31.13 | 31.64 | 31.40 | 32.68 |
| Average | 29.38 | 30.27 | 31.36 | 31.77 |
| BM3D [6] | WNNM [8] | DnCNN [28] | Miyata et al. [37] | VBM4D [58] | Zhou et al. [32] | MVCNN | |
|---|---|---|---|---|---|---|---|
| Bicycle | 0.5 | 76.1 | 0.040 | 2.74 | 18.8 | 93.1 | 1.73 |
| Dishes | 0.6 | 76.3 | 0.044 | 2.70 | 18.6 | 99.6 | 1.82 |
| Knights | 0.5 | 75.5 | 0.045 | 2.68 | 17.5 | 94.4 | 2.08 |
| Medieval | 0.6 | 75.9 | 0.040 | 2.57 | 18.1 | 94.6 | 1.88 |
| Sideboard | 0.5 | 75.3 | 0.040 | 2.73 | 17.4 | 90.4 | 1.70 |
| Tarot | 0.4 | 78.5 | 0.048 | 3.48 | 17.6 | 94.1 | 1.73 |
| Tsukuba | 1.0 | 134.1 | 0.050 | 4.49 | 38.6 | 170.7 | 2.62 |
| Average | 0.58 | 84.53 | 0.044 | 3.06 | 20.94 | 105.27 | 1.94 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, S.; Hu, Y.-H.; Jiang, H. Multi-View Image Denoising Using Convolutional Neural Network. Sensors 2019, 19, 2597. https://doi.org/10.3390/s19112597
Zhou S, Hu Y-H, Jiang H. Multi-View Image Denoising Using Convolutional Neural Network. Sensors. 2019; 19(11):2597. https://doi.org/10.3390/s19112597
Chicago/Turabian StyleZhou, Shiwei, Yu-Hen Hu, and Hongrui Jiang. 2019. "Multi-View Image Denoising Using Convolutional Neural Network" Sensors 19, no. 11: 2597. https://doi.org/10.3390/s19112597
APA StyleZhou, S., Hu, Y.-H., & Jiang, H. (2019). Multi-View Image Denoising Using Convolutional Neural Network. Sensors, 19(11), 2597. https://doi.org/10.3390/s19112597