Multi-Layer Feature Based Shoeprint Verification Algorithm for Camera Sensor Images


Abstract
1. Introduction
- (i)
- we propose a multi-layer feature-based shoeprint verification algorithm that can be used in forensic practice;
- (ii)
- we introduce a shoeprint partition model (SPM) to analyze shoeprints, which considers foot anatomy and the relationship between shoe and foot, and facilitates analyzing shoeprints accurately in practice;
- (iii)
- we propose an individual identifying characteristics detection method to perform characteristics detection automatically;
- (iv)
- we propose a shoeprint image matching strategy. The shoeprint is divided into nineteen sections. Similarities of each section are computed respectively, and the total similarity between the two images is a weighted sum.
2. Shoeprint Acquisitions and Datasets
3. Methods
3.1. Shoeprint Preprocessing
- (1)
- Shoeprint extraction: An image segmentation technique [24] is used to extract the shoeprint images from the complex backgrounds.
- (2)
- Image registration: In shoeprint verification applications, accurate shoeprint alignment has a determinative effect, and a FFT-based registration algorithm [25] is used to align the shoeprint images.
- (3)
- Shoeprint partition: A shoe partition model (SPM) is proposed to divide shoeprint image into different sections according to the structure of the foot and the relationship between shoe and foot. The SPM is to divide a shoeprint into different sections with a set of landmarks. Firstly, the contour of a shoeprint is represented by an average shape that is trained by using enough shoeprint images with various shapes. Secondly, three points (e.g., the front most point, rearmost point, and leftmost point) are marked interactively. Thirdly the other points of the contour, which are denoted with green dots as shown in Figure 5b, are estimated by using the interpolation method with the average shape and three points. Finally, the subsections are divided according to the predefined model. Each shoeprint is divided into toe section, sole section, instep section, heel section and back of heel section, and each section is further divided into several non-overlapped subsections for further analysis. The total number of subsections is 19.
3.2. Multi-Layer Feature Extraction
3.2.1. Global Layer Feature Extraction
3.2.2. Partial Layer Feature Extraction
3.2.3. Individual Identifying Layer Feature Extraction
3.3. Multi-Layer Feature Matching
3.4. Decision-Making
| Algorithm 1. Shoeprint Image Verification Algorithm |
| Input: A pair of shoeprints . Output: The total similarity score and the verification result. 1. Image preprocessing. 2. Feature extraction. Extract partial layer feature, and individual identifying layer feature, respectively. 3. Feature matching. 4. Calculate similarity of global layer feature. 5. For r = 1, 2, …, 19 6. Calculate similarity of partial layer feature with Equation (19). 7. Calculate similarity of individual identifying layer feature with Equation (20). 8. end For 9. Calculate total similarity score with Equation (21). 10. Judgment. Output verification result, identical or non-identical. |
4. Experiments
4.1. Experiment Configuration
4.1.1. Dataset
- (i)
- Testing set: A testing set is a collection of shoeprint images that need to be verified. The testing set contained 1200 pairs of reference shoeprints in the MUES-SV1KR2R dataset and 256 pairs of crime scene shoeprints in the MUES-SV2HS2S dataset.
- (ii)
- Training set: The training set is a collection of shoeprint images used to train the thresholds. The training set consisted of 300 pairs of reference shoeprint images and 100 pairs of crime scene shoeprint images. One hundred pairs of reference shoeprint images were from the same shoes. Twenty-five pairs of crime scene shoeprints are from the same shoes, and fifty pairs of shoe prints were not of the same class characteristics. Then accord to Equation (24), the optimal and can be achieved by operating shoeprint verification on the training set.
4.1.2. Evaluation Metric
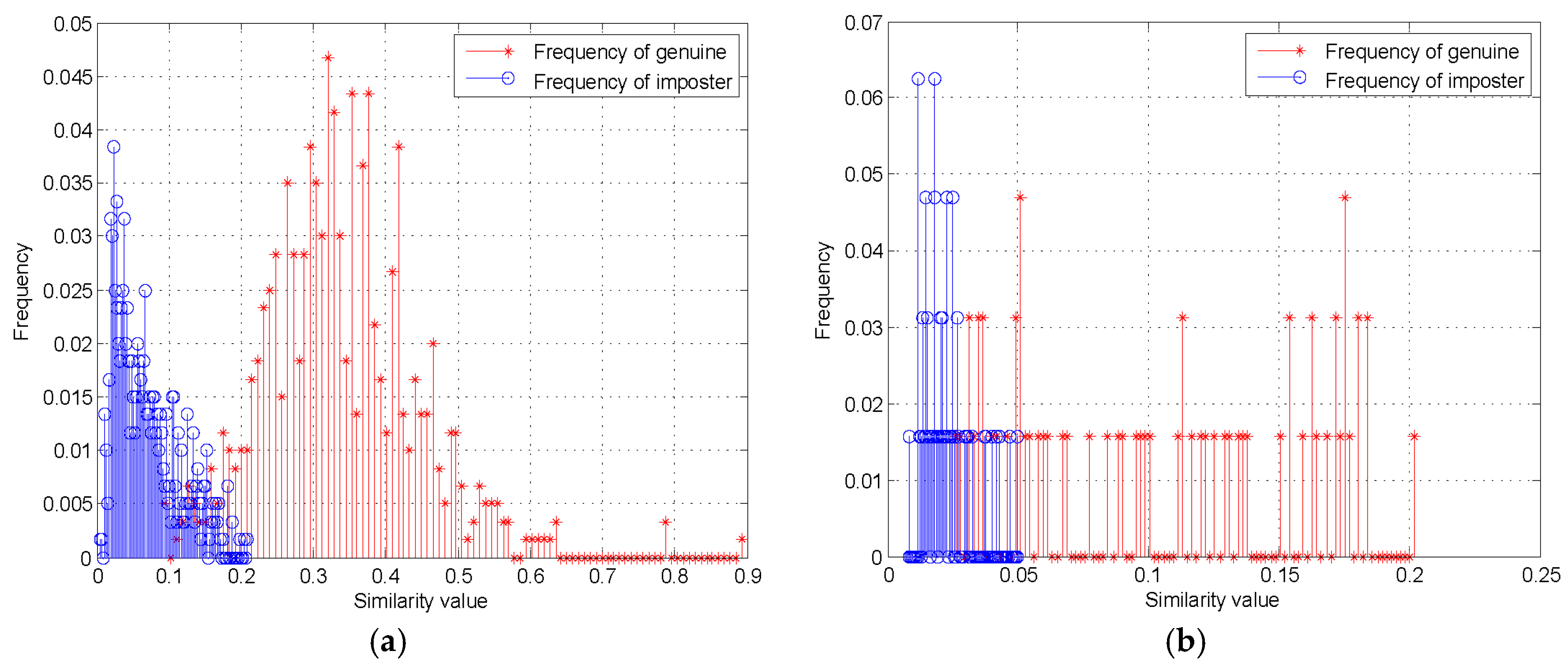
4.2. Performance Evaluation
4.2.1. Performance Evaluation of the Proposed Method
4.2.2. Comparison and Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bodziak, W.J. Footwear Impression Evidence: Detection, Recovery, and Examination; CRC Press: Boca Raton, FL, USA, 2000. [Google Scholar]
- Rida, I.; Bakshi, S.; Proença, H.; Fei, L.; Nait-Ali, A.; Hadid, A. Forensic shoe-print identification: A brief survey. arXiv 2019, arXiv:1901.01431. [Google Scholar]
- Algarni, G.; Amiane, M. A novel technique for automatic shoeprint image retrieval. Forensic Sci. Int. 2008, 181, 10–14. [Google Scholar] [CrossRef] [PubMed]
- Wei, C.H.; Hsin, C.; Gwo, C.Y. Alignment of Core Point for Shoeprint Analysis and Retrieval. In Proceedings of the International Conference on Information Science, Electronics and Electrical Engineering (ISEEE), Sapporo, Japan, 26–28 April 2014; pp. 1069–1072. [Google Scholar] [CrossRef]
- Wang, X.N.; Sun, H.H.; Yu, Q.; Zhang, C. Automatic Shoeprint Retrieval Algorithm for Real Crime Scenes. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 399–413. [Google Scholar] [CrossRef]
- Wang, X.N.; Zhan, C.; Wu, Y.J.; Shu, Y.Y. A manifold ranking based method using hybrid features for crime scene shoeprint retrieval. Multimed. Tools Appl. 2016, 76, 21629–21649. [Google Scholar] [CrossRef]
- Gueham, M.; Bouridane, A.; Crookes, D. Automatic Recognition of Partial Shoeprints Based on Phase-Only Correlation. In Proceedings of the IEEE International Conference on Image Processing, San Antonio, TX, USA, 16–19 September 2007; pp. 441–444. [Google Scholar] [CrossRef]
- Wu, Y.J.; Wang, X.N.; Zhang, T. Crime Scene Shoeprint Retrieval Using Hybrid Features and Neighboring Images. Information 2019, 10, 45. [Google Scholar] [CrossRef]
- de Chazal, P.; Flynn, D.; Reilly, R.B. Automated processing of shoeprint images based on the Fourier transform for use in forensic science. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 341–350. [Google Scholar] [CrossRef]
- Deshmukh, M.P.; Patil, P.M. Automatic shoeprint matching system for crime scene investigation. Int. J. Comput. Sci. Commun. Technol. 2009, 2, 281–287. [Google Scholar]
- Kong, B.; Supancic, J.; Ramanan, D.; Fowlkes, C. Cross-Domain Forensic Shoeprint Matching. In Proceedings of the 28th British Machine Vision Conference (BMVC), London, UK, 4–7 September 2017. [Google Scholar]
- Kong, B.; Supancic, J.; Ramanan, D.; Fowlkes, C. Cross-Domain Image Matching with Deep Feature Maps. Int. J. Comput. Vis. 2019. [Google Scholar] [CrossRef]
- Pavlou, M.; Allinson, N.M. Automated encoding of footwear patterns for fast indexing. Image Vis. Comput. 2009, 27, 402–409. [Google Scholar] [CrossRef]
- Pavlou, M.; Allinson, N.M. Automatic extraction and classification of footwear patterns. In Proceedings of the 7th International Conference on Intelligent Data Engineering and Automated Learning, Burgos, Spain, 20–23 September 2006; pp. 721–728. [Google Scholar] [CrossRef]
- Kortylewski, A.; Albrecht, T.; Vetter, T. Unsupervised Footwear Impression Analysis and Retrieval from Crime Scene Data. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 644–658. [Google Scholar] [CrossRef]
- Kortylewski, A.; Vetter, T. Probabilistic Compositional Active Basis Models for Robust Pattern Recognition. In Proceedings of the 27th British Machine Vision Conference (BMVC), York, UK, 19–22 September 2016. [Google Scholar]
- Kortylewski, A. Model-Based Image Analysis for Forensic Shoe Print Recognition. Ph.D. Thesis, University of Basel, Basel, Switzerland, 2017. [Google Scholar]
- Alizadeh, S.; Kose, C. Automatic Retrieval of Shoeprint Images Using Blocked Sparse Representation. Forensic Sci. Int. 2017, 277, 103–114. [Google Scholar] [CrossRef]
- Richetelli, N.; Lee, M.C.; Lasky, C.A.; Gump, M.E.; Speir, J.A. Classification of footwear outsole patterns using Fourier transform and local interest points. Forensic Sci. Int. 2017, 275, 102–109. [Google Scholar] [CrossRef]
- Wang, H.X.; Fan, J.H.; Li, Y. Research of shoeprint image matching based on SIFT algorithm. J. Comput. Methods Sci. Eng. 2016, 16, 349–359. [Google Scholar] [CrossRef]
- Almaadeed, S.; Bouridane, A.; Crookes, D.; Nibouche, O. Partial shoeprint retrieval using multiple point-of-interest detectors and SIFT descriptors. Integr. Comput. Aided Eng. 2015, 22, 41–58. [Google Scholar] [CrossRef]
- Luostarinen, T.; Lehmussola, A. Measuring the Accuracy of Automatic Shoeprint Recognition Methods. J. Forensic Sci. 2014, 59, 8. [Google Scholar] [CrossRef]
- Yekutieli, Y.; Shor, Y.; Wiesner, S.; Tsach, T. Expert Assisting Computerized System for Evaluating the Degree of Certainty in 2D Shoeprints; The U.S. Department of Justice: Washington, DC, USA, 2012.
- Chunming, L.; Rui, H.; Zhaohua, D.; Gatenby, J.C.; Metaxas, D.N.; Gore, J.C. A Level Set Method for Image Segmentation in the Presence of Intensity Inhomogeneities with Application to MRI. IEEE Trans. Image Process. 2011, 20, 2007–2016. [Google Scholar] [CrossRef]
- Reddy, B.S.; Chatterji, B.N. An FFT-based technique for translation, rotation, and scale-invariant image registration. IEEE Trans. Image Process. 1996, 5, 1266–1271. [Google Scholar] [CrossRef]
- Mikolajczyk, K.; Schmid, C. A Performance Evaluation of Local Descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar] [CrossRef]
- Mikolajczyk, K.; Tuytelaars, T.; Schmid, C.; Zisserman, A.; Matas, J.; Schaffalitzky, F.; Kadir, T.; Gool, L.V. A Comparison of Affine Region Detectors. Int. J. Comput. Vis. 2005, 65, 43–72. [Google Scholar] [CrossRef]
- Harris, C.; Stephens, M. A Combined Corner and Edge Detector. In Proceedings of the 4th Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; pp. 147–151. [Google Scholar] [CrossRef]
- de Araújo, S.A.; Kim, H.Y. Ciratefi: An RST-invariant template matching with extension to color images. Integr. Comput. Aided Eng. 2011, 18, 75–90. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- el Hannani, A.; Petrovska-Delacrétaz, D.; Fauve, B. Text-independent Speaker Verification. In Guide to Biometric Reference Systems and Performance Evaluation; Petrovska-Delacrétaz, D., Chollet, G., Dorizzi, B., Eds.; Springer: London, UK, 2009; pp. 167–211. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Gool, L.V. SURF: Speeded up robust features. In Proceedings of the 9th European Conference on Computer Vision (ECCV), Berlin/Heidelberg, Germany, 7–13 May 2006; pp. 404–417. [Google Scholar] [CrossRef]
- Yang, G.; Xiao, R.; Yin, Y. Finger Vein Recognition Based on Personalized Weight Maps. Sensors 2013, 13, 12093–12112. [Google Scholar] [CrossRef]
- Xi, X.; Yang, G.; Yin, Y. Finger Vein Recognition with Personalized Feature Selection. Sensors 2013, 13, 11243–11259. [Google Scholar] [CrossRef]
- Ma, X.; Jing, X.; Huang, H. A Novel Palm Vein Recognition Scheme Based on an Adaptive Gabor Filter. IET Biom. 2016, 6, 325–333. [Google Scholar] [CrossRef]
- Shi, J.; Tomasi, C. Good features to track. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 593–600. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subsection Index | Section of Shoeprint | Weight Order |
|---|---|---|
| 1, 2, 3 | Toe | 3 |
| 4, 5, 6, 7, 8, 9 | Sole | 1 |
| 13, 14, 15, 16 | Heel | 2 |
| 17, 18, 19 | Back of Heel | 4 |
| 10, 11, 12 | Instep | 5 |
| Method for Shoeprint Verification | Performance (EER), % | Computation Time, s |
|---|---|---|
| Harris_HOG | 11.1 | 2.1 |
| Harris_NCC | 9.8 | 3.1 |
| Shi-Tomasi_HOG | 11.2 | 9.7 |
| Shi-Tomasi_NCC | 8.5 | 10.0 |
| SURF | 22.4 | 14.7 |
| Ours | 3.2 | 280.6 |
| Method for Shoeprint Verification | Performance (EER), % | Computation Time, s |
|---|---|---|
| Harris_HOG | 34.4 | 2.1 |
| Harris_NCC | 37.5 | 3.2 |
| Shi-Tomasi_HOG | 20.3 | 10.4 |
| Shi-Tomasi_NCC | 31.3 | 11.0 |
| SURF | 34.3 | 15.2 |
| Ours | 10.9 | 293.3 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Wu, Y.; Zhang, T. Multi-Layer Feature Based Shoeprint Verification Algorithm for Camera Sensor Images. Sensors 2019, 19, 2491. https://doi.org/10.3390/s19112491
Wang X, Wu Y, Zhang T. Multi-Layer Feature Based Shoeprint Verification Algorithm for Camera Sensor Images. Sensors. 2019; 19(11):2491. https://doi.org/10.3390/s19112491
Chicago/Turabian StyleWang, Xinnian, Yanjun Wu, and Tao Zhang. 2019. "Multi-Layer Feature Based Shoeprint Verification Algorithm for Camera Sensor Images" Sensors 19, no. 11: 2491. https://doi.org/10.3390/s19112491
APA StyleWang, X., Wu, Y., & Zhang, T. (2019). Multi-Layer Feature Based Shoeprint Verification Algorithm for Camera Sensor Images. Sensors, 19(11), 2491. https://doi.org/10.3390/s19112491