Characterization and Efficient Management of Big Data in IoT-Driven Smart City Development

Abstract
1. Introduction
- IoT–BD Characterization: In Section 2 we characterize the BD driven by the IoT of a Smart City using the V model. The significance is that no such comprehensive investigations on the characteristics of BD that impact on the choice of data store for smart city development has ever been reported.
- Database Choice: In Section 3 we critically study the features of relational (SQL) and NoSQL databases schemas from the perspective of supporting BD, as characterized in Section 2, and justify MongoDB [10] as a suitable database to manage the IoT-driven BD. We should remark that our investigation, based on the V-model satisfaction, has not been reported in related literature.
- Smart City Development: In Section 4.1 we compare our work with other published works. In Section 4.2 we discuss an abstract architecture for smart city development, currently under implementation [11], and explain the interactions between the data stores and other architectural elements in fulfilling their expected goals.
2. IoT-driven BD
- Technical Sensors: The three types are the following:
- -
- Environmental Sensors: These are used in Environmental Monitoring or Urban Sensing. Some applications are in Meteorology and Weather monitoring, Air Pollution Quality Monitoring, Heat Island Detection, Flood Monitoring, and Nuclear Radiation Safety.
- -
- Mobile Sensors: Wearable ambient Sensors, Mobile, and Sensor Web are different terms to describe the same category. They are used in Ubiquitous Measurement, and Disaster Management.
- -
- Pervasive Sensors: They are used for ubiquitous sensing, and socially aware computing. Applications using this type of sensors are Smart context-aware Environment and Home, Ambient/Active Assisted Living, Pervasive Healthcare, RFID-Based Location and Tracking, and Socially Aware Computing.
- Technical Sensors-Remote Sensors: This type of sensors is mainly for remote sensing, from satellite-based to terrestrial. Applications domains of this type of sensors include “Classic” Airborne and Space-borne Optical System, and Atmosphere/Aerosols.
- Human Sensors: These are of two kinds.
- -
- People as Sensors: Examples of this type of sensors include Citizens as sensors, human sensing, physiological sensors, wearable body sensors, participatory sensors, and Volunteered Geographic Information (VGI). They are primarily used for Flood Monitoring, as Sensing Platform in Smart Cities, and for Physiological Parameters such as saturation, stress levels, and Noise Mapping.
- -
- Collective Sensors: These include Mobile phone sensing, crowd sensing, social sensing, online sensing, and social media. These types are used for Disaster and Incident Management, Mobility Patterns and Transportation, Socio-Physical Context Estimation, Tourism, Epidemiology, and Disease Detection.
2.1. A Classification of “Things” Using the V model of BD
- Volume: We refer to the size of IoT as its volume. IoT comprises of many “things”, some of which may be interconnected, yet may act autonomously. The “interconnectedness” reflects the Vincularity (relationship) among the “things”, i.e., if “things” X and Y are connected, it is obvious that the relationship requires is inherent in it. Not only the number of “things” in IoT will be large, but also the number of the types and size of such relationships.
- Vincularity: This refers to the challenge related to the process of connecting two or more different “things” in order to achieve a complex service. The Vincularity process requires the accuracy of “things” in the fusion.
- Variety: It refers to the heterogeneity of “things” in IoT. Different types of “things” such as sensors, actuators, medical devices, and human actors generate and consume different types of information generated through “things”. They also have different sets of capabilities for storing, processing, and reasoning with data.
- Velocity: It refers to the “streaming” of data at different rates and the ability of sensors/actuators to process them. Periodic data flow, asynchronous functioning ability of “things” in the network, and the unpredictable volume of data flow at different periods add complexity to store and manage data. Because IoT assets will in general be distributed, and processing video and digital images require contextual information [16], the velocity characteristic raises the complexity of real-time streaming of BD.
- Veracity: It refers to the correctness and relevance of data generated by a thing (device or sensor). Some data may have “time constraints” that restricts the utility of data. A “thing” in IoT may be either compromised or damaged. In either case the data is deemed incorrect.
- Validity: It refers to the “relevance” of a “thing” with respect to the achievement of goals. A device may work correctly and emit correct data (veracity is satisfied); however, that may not be necessary to achieve the stated goals. In that case, it is not valid. Please note that a thing that is valid satisfies veracity criterion, but the converse is not true.
- Vitality: It refers to the “criticality” of the thing in IoT. A thing is either being a sensor, an actuator, or a medical device, can be labelled as “mission critical” if the information processed by it is critical. Vitality characteristic implies both veracity and validity; however, the converse is not true.
- Value: Everything in IoT must have “high value”, in the sense that it must contribute to the overall purpose of the IoT. A thing that does not contribute to the goal of IoT has no value and must be ignored or removed. Value of a thing is enhanced only if it is authentic and dependable, where “authenticity” must be certified by an Intelligent Trusted Authority (ITA) of the IoT. Dependability as defined in [14] is “the ability to provide services that can be justifiably be trusted by the client “things” in the IoT”.
- Volatility: Every piece of data must have a specific “lifetime” defined by the system developers depending on where and how it will be used. Volatility characteristic motivates the avoidance of storing meaningless data.
- Visualization: It refers to the management of data presentation. When data is required to be fused or exchanged between two things, where the views on data of the things are not the same a presentation conversion is required. It is important to define the methodology or the proper presentation of the data to the thing requiring the data. The existence of other characteristics will increase the difficulty of meaningful presentation.
- Data Generation: Volume, velocity, variety, vitality, and vincularity are essential V-attributes of data generated by the “things”.
- Data Quality: Veracity, validity, value, and volatility are essential V-attributes for quality of data consumed by the “things”.
- Data Transfer: Vincularity, velocity, validity, volatility, and visualization are essential V-attributes for data exchange/sharing among the “things”.
2.2. A Layer-Centric Dominance of the Vs
3. Database Support for Smart City Development
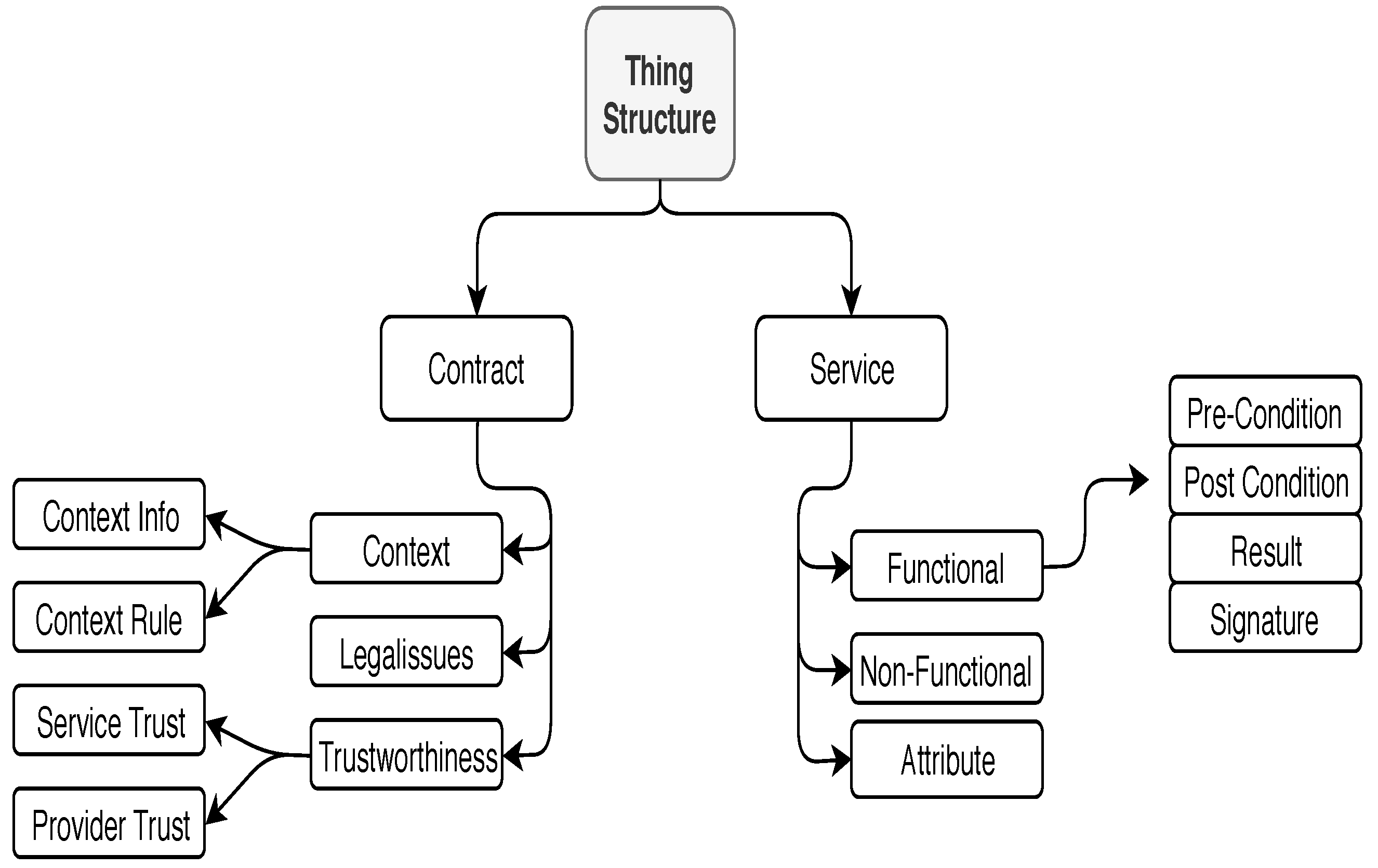
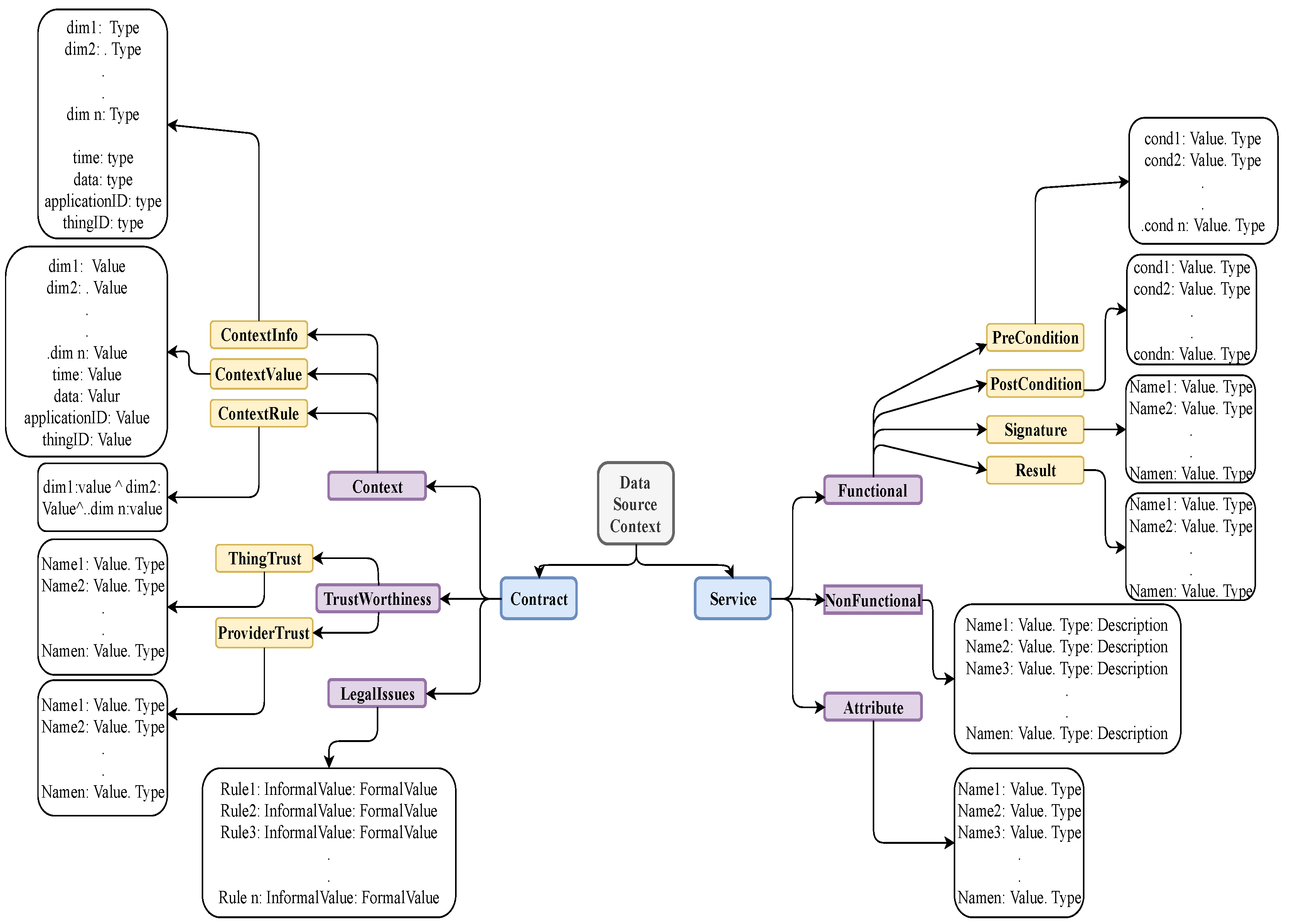
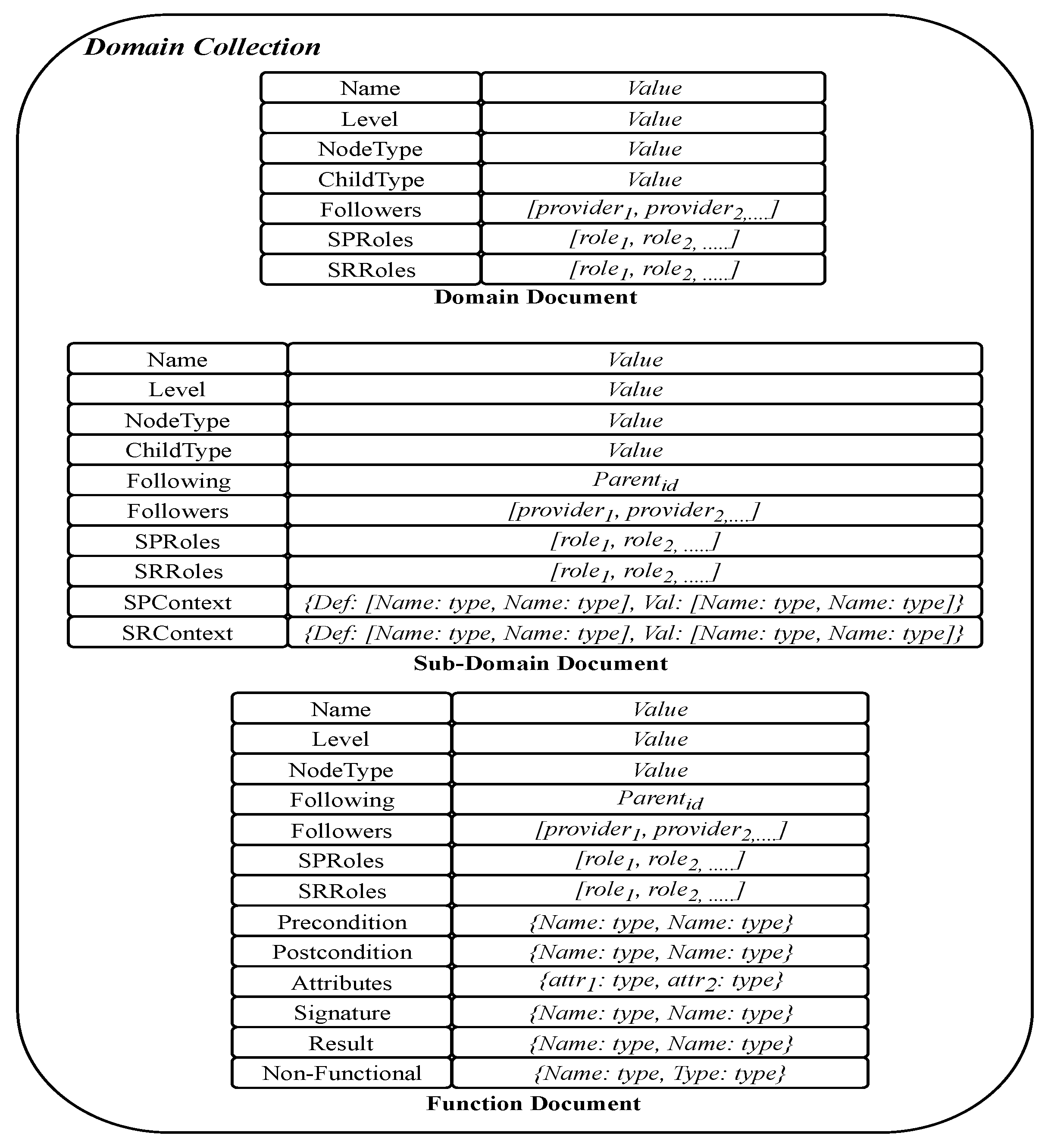
3.1. “Things” Model
Modeling Service Part of “Things”
3.2. Modeling Contract Part of “Things”
3.3. Choice of Database
- Limited Column Family: The columns of Hbase are grouped by Column Families (CFs). Hbase requires the number of CFs to be small. It is better to keep a maximum of three CFs to optimize the performance. If it is necessary to have more than three CFs, it is better not to query more than three at any one time. Because the description of “things” is generic (see Figure 2), and BD applications need responses to complex queries directed at data integrated from different data sources, ideally there should be no limitation on the number of CFs. To be consistent without modeling goal, we want to provide the ability to include as many attributes as are necessary to describe the “thing” in a query. With restrictions, it becomes complex and inefficient to find and rank the “things” to requesters based on their preferences of different attributes. Additionally, Hbase limitation on CF causes an obstacle to achieve BD goals. To be convinced from real-life situations, consider the analysis goal “ find the patient group who take the same set of medications, who live in the same neighborhood and use the same set of clinical facilities”. Clearly the Hbase restriction on CF will make this analysis inefficient.
- Column Qualifiers: In Hbase there is no limitation on the number of column qualifiers. It is better to use column fields as stored information because this increases efficiency. However, Hbase stores the column qualifier key while not limiting the number of column qualifiers. Hence, creating long column qualifiers can be quite costly in terms of storage. This could be an issue in our case as the thing structure is quite rich and creating a qualifier could result in costly storage.
- Veracity, Validity, Value: MongoDB’s distributed architecture separates the analysis processes, such as duplicate detection and machine learning, from querying processes. This helps avoiding long ETL (Extract, Transform, and Load) processes from impacting the operational application, and keeping the data more reliable in its source. As a result, of achieving high Veracity at early level, both Validity and Value of integrated data are enhanced.
- Volume and Variety: Variety not only refers to the different schema integrated from different sources but also to the flexibility in merging them into a single schema without losing any data. The semi-structured schemas are managed in MongoDB “without giving up sophisticated multi-record ACID properties of transactions, schema governance, data access, and rich indexing functionality". This helps to manage both Variety and Veracity characteristics of BD. MongoDB provides support for highly scalable data management for geographically distributed data centers and cloud regions with high level of availability. This basically supports the management of Volume characteristic of BD.
- Vincularity, Velocity, Validity, Volatility: Indexing at multiple levels enable linking of related data at different sources (“things”). Hence, Vincularity characteristic is maintained efficiently. After data integration, validation process could be enhanced through secondary indexes. “Streaming Data Pipeline” feature in MongoDB allows developers to build reactive, real-time apps that can view, filter, and act on data changes as they occur in the database. Combining this feature with the ability to reduction of latency and fast data execution for queries, both Velocity and Volatility characteristic of high data streaming can be managed.
- Visualization: MongoDB uses different methods and visualization tools such as Tableau to efficiently access and display data it stores using standard SQL.
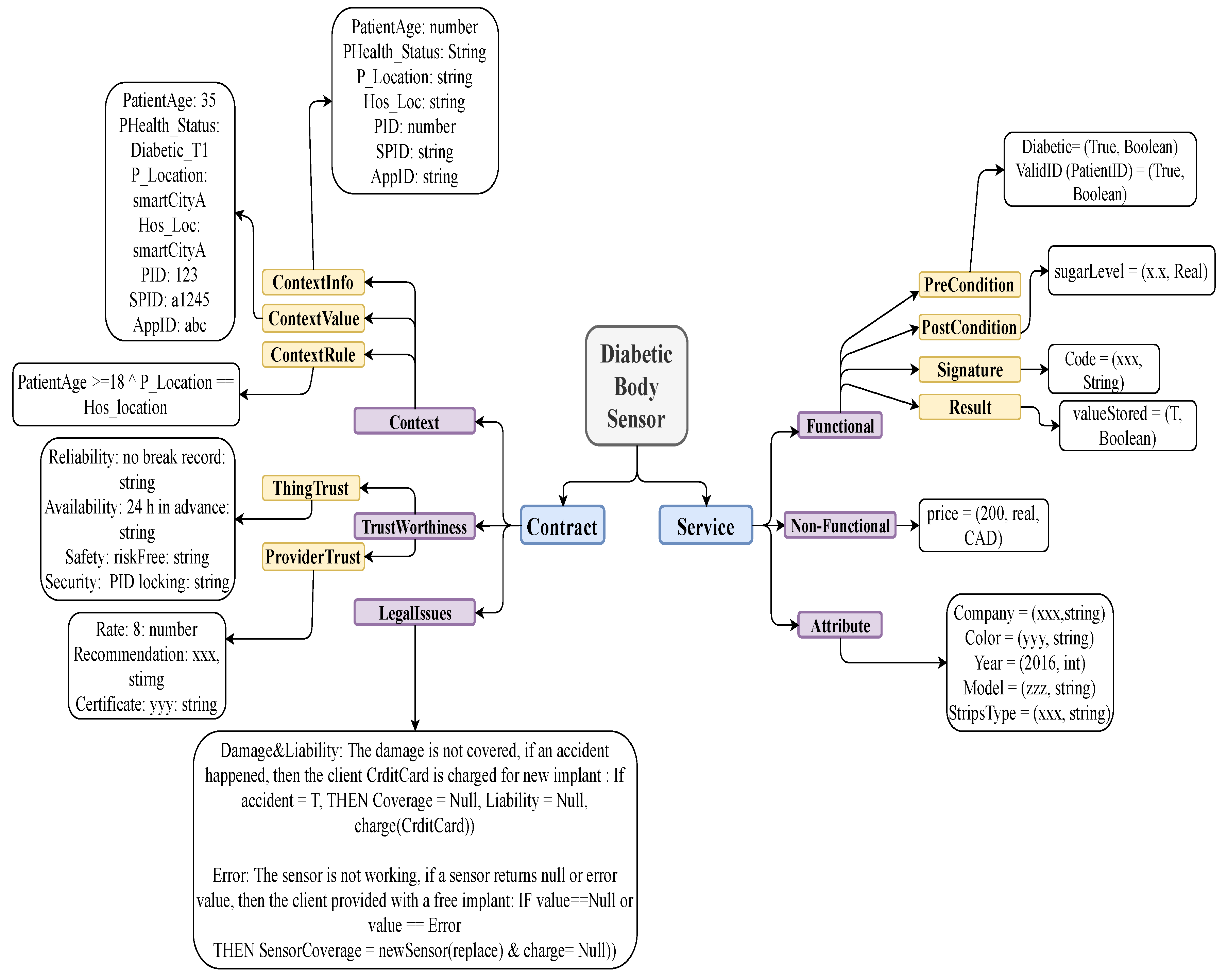
3.4. Things Database: MongoDB Implementation
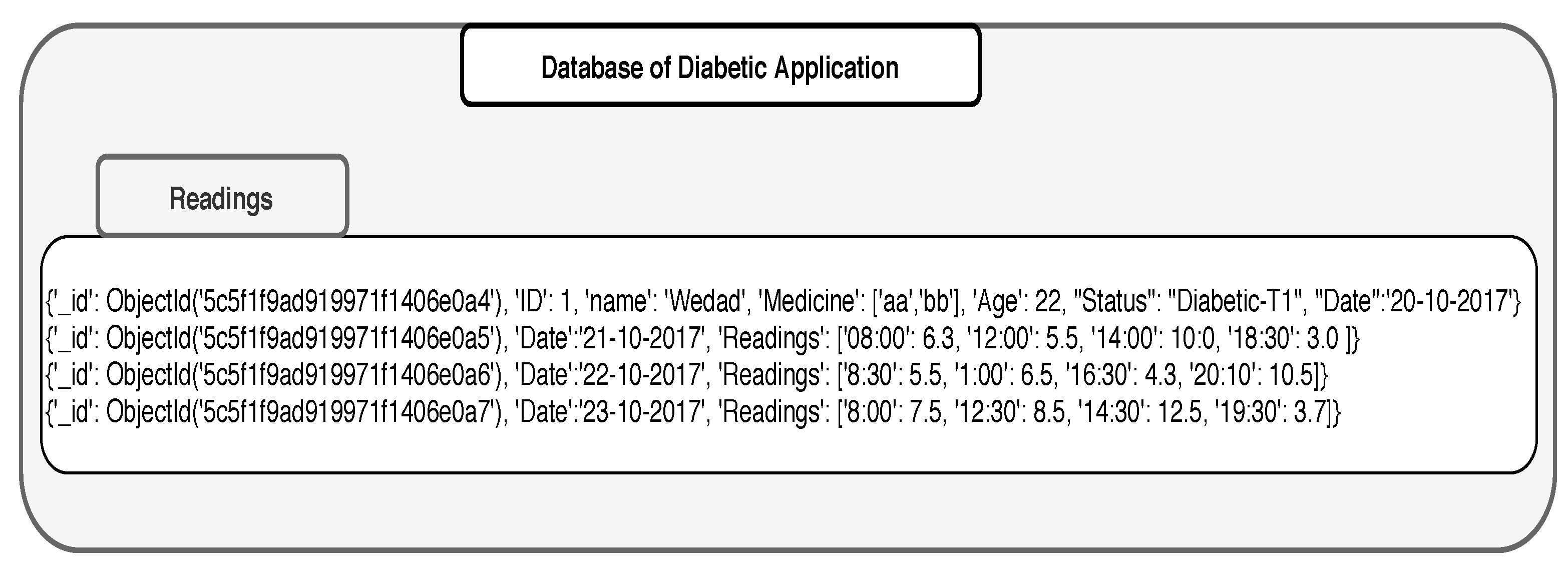
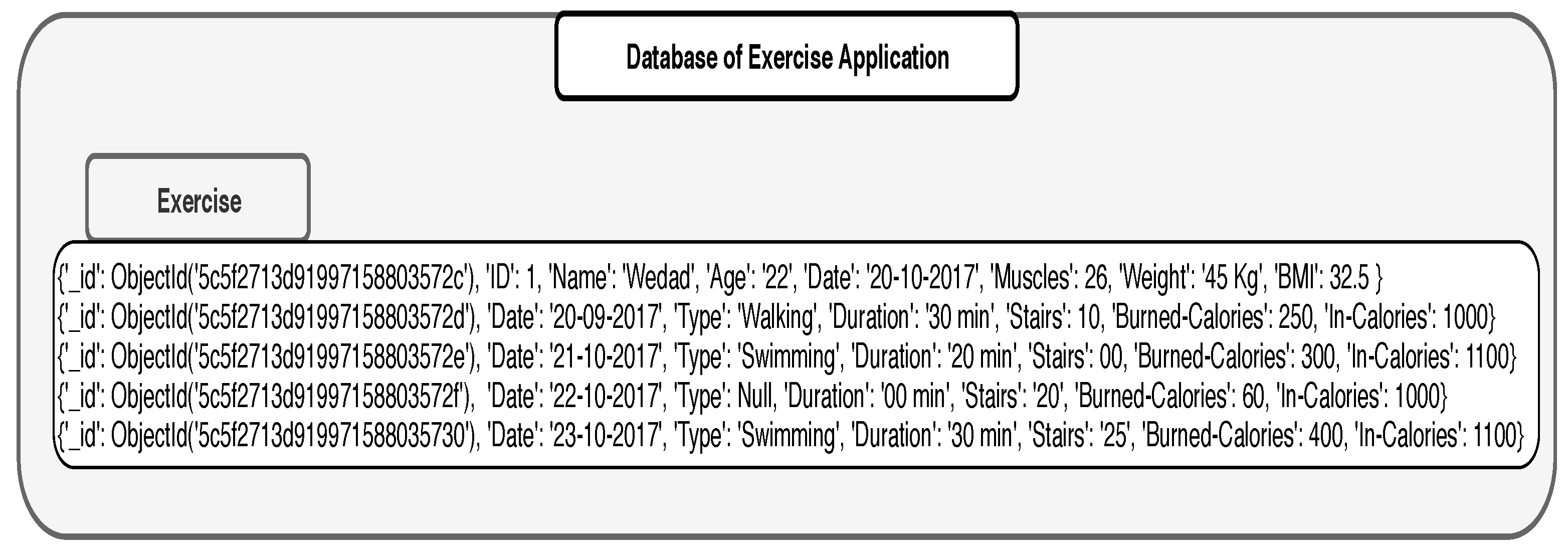
3.5. Data Integration
3.6. An Example of Data Integration in MongoDB
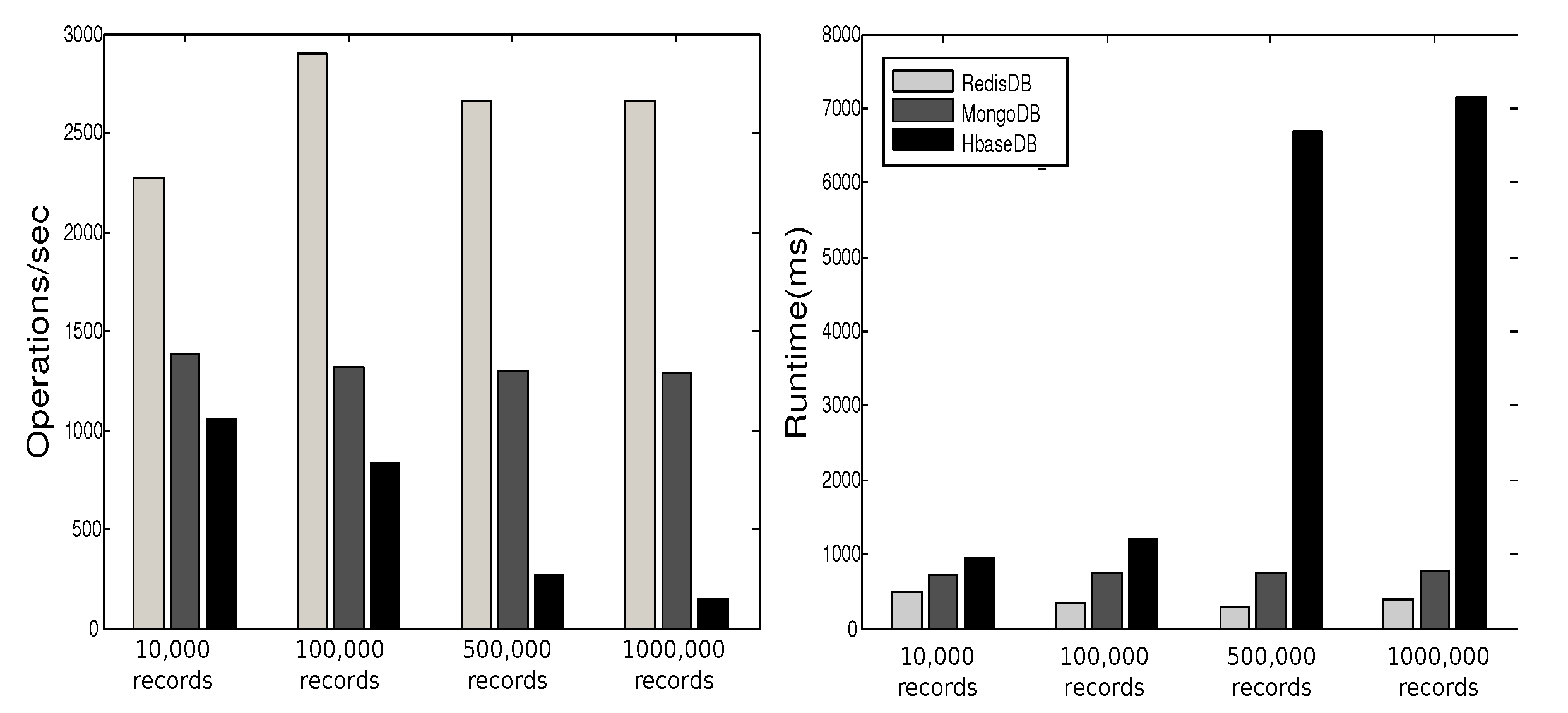
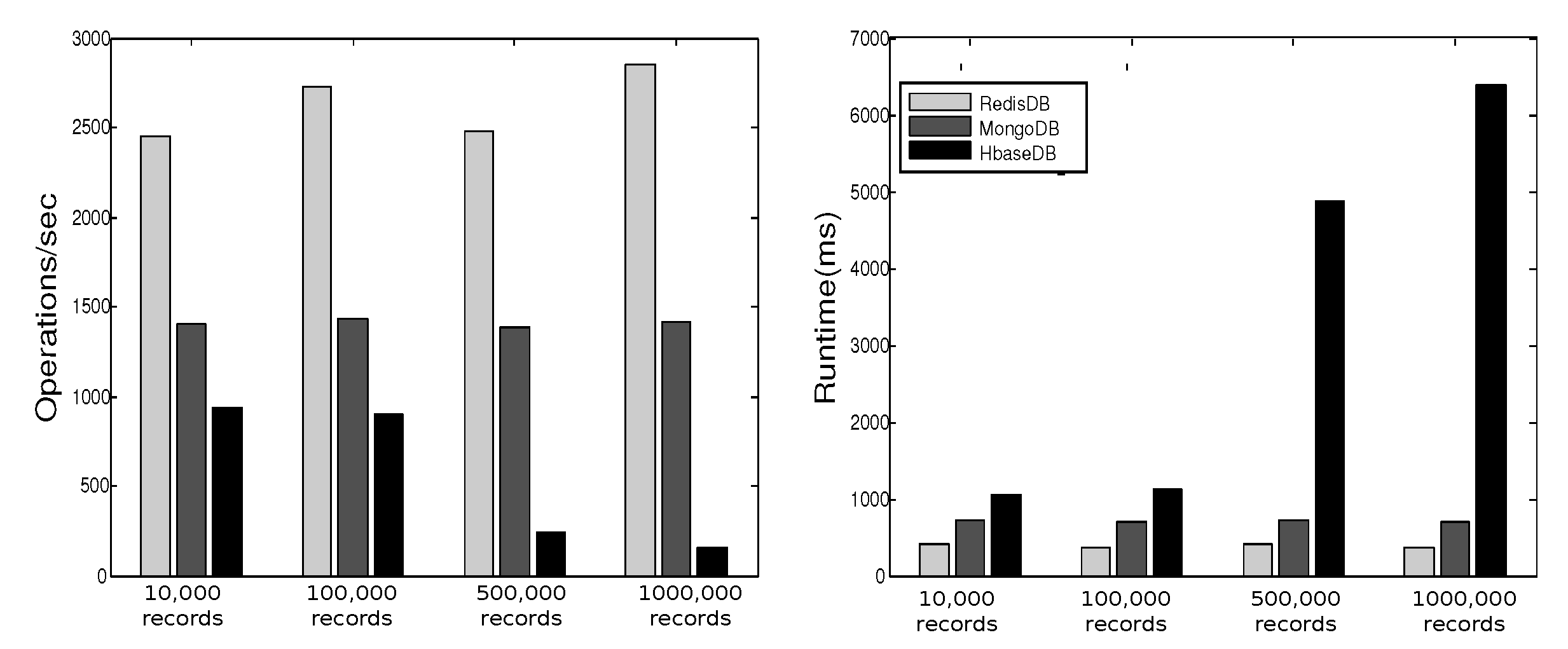
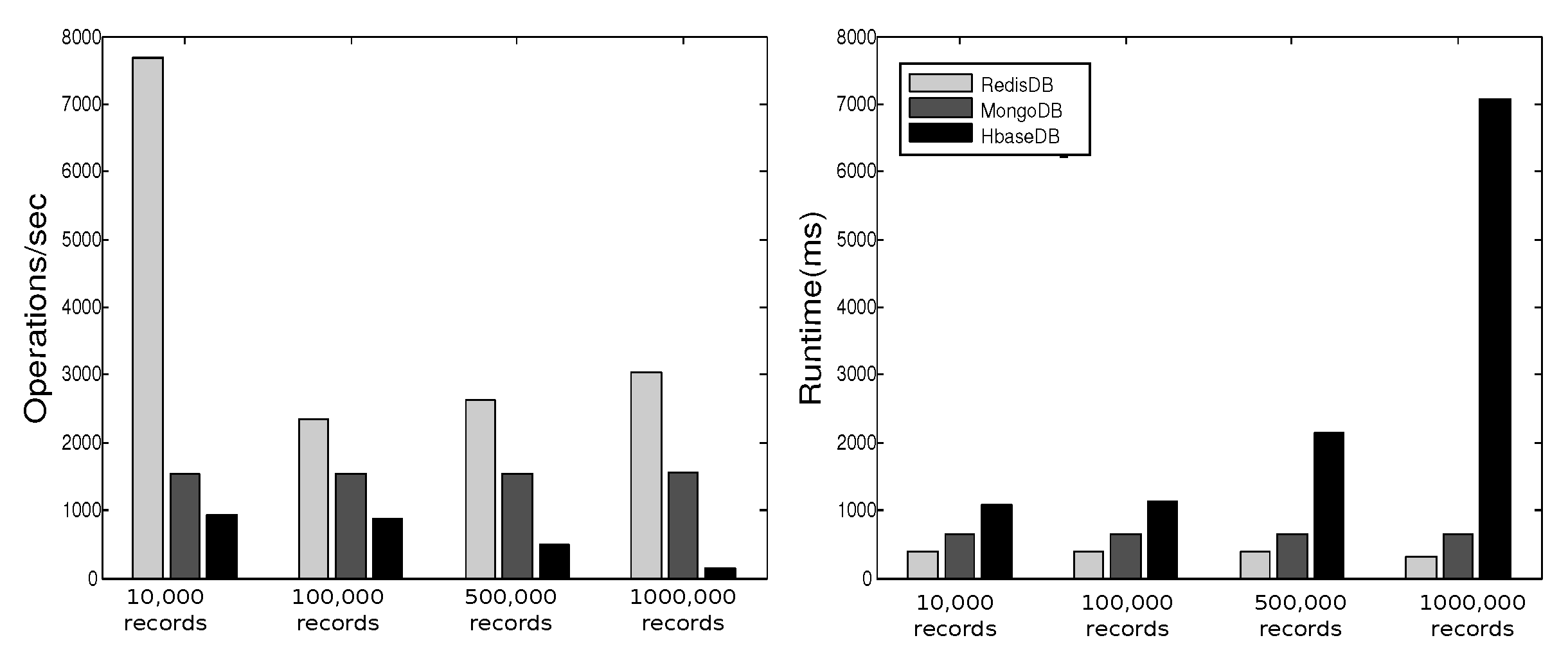
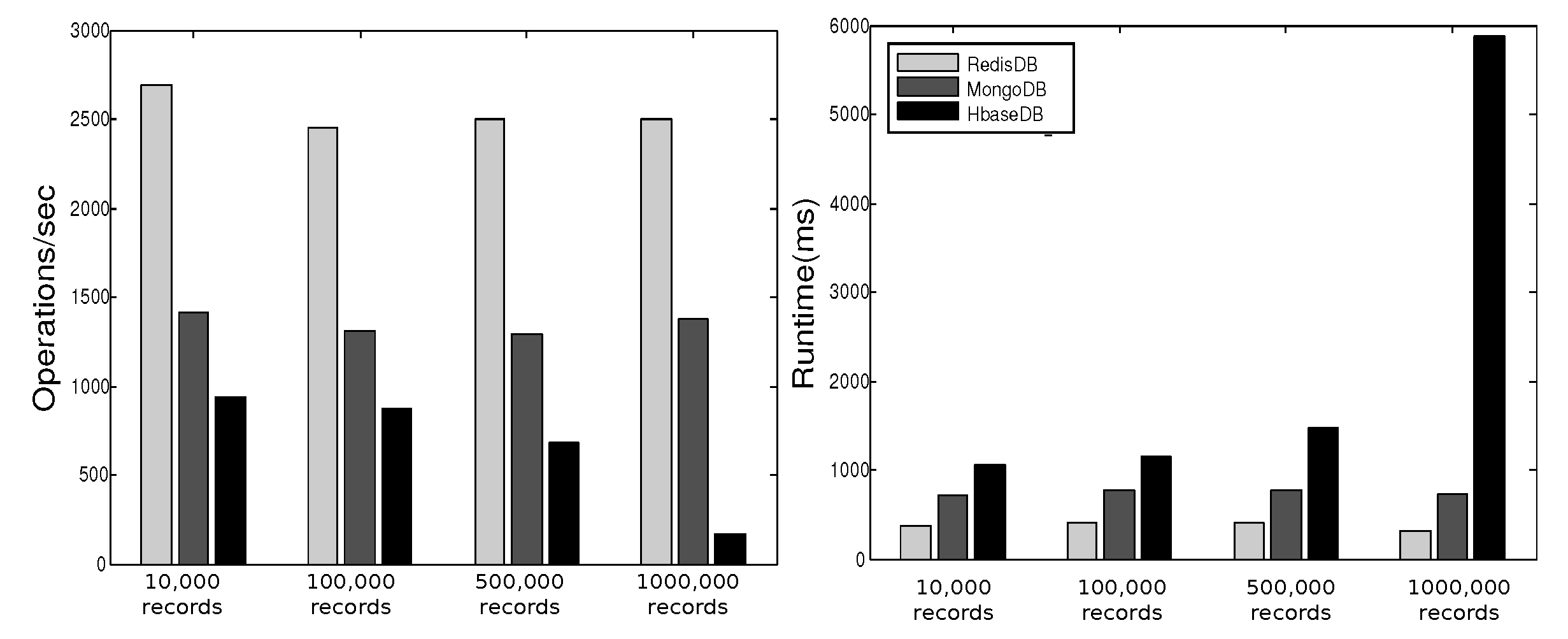
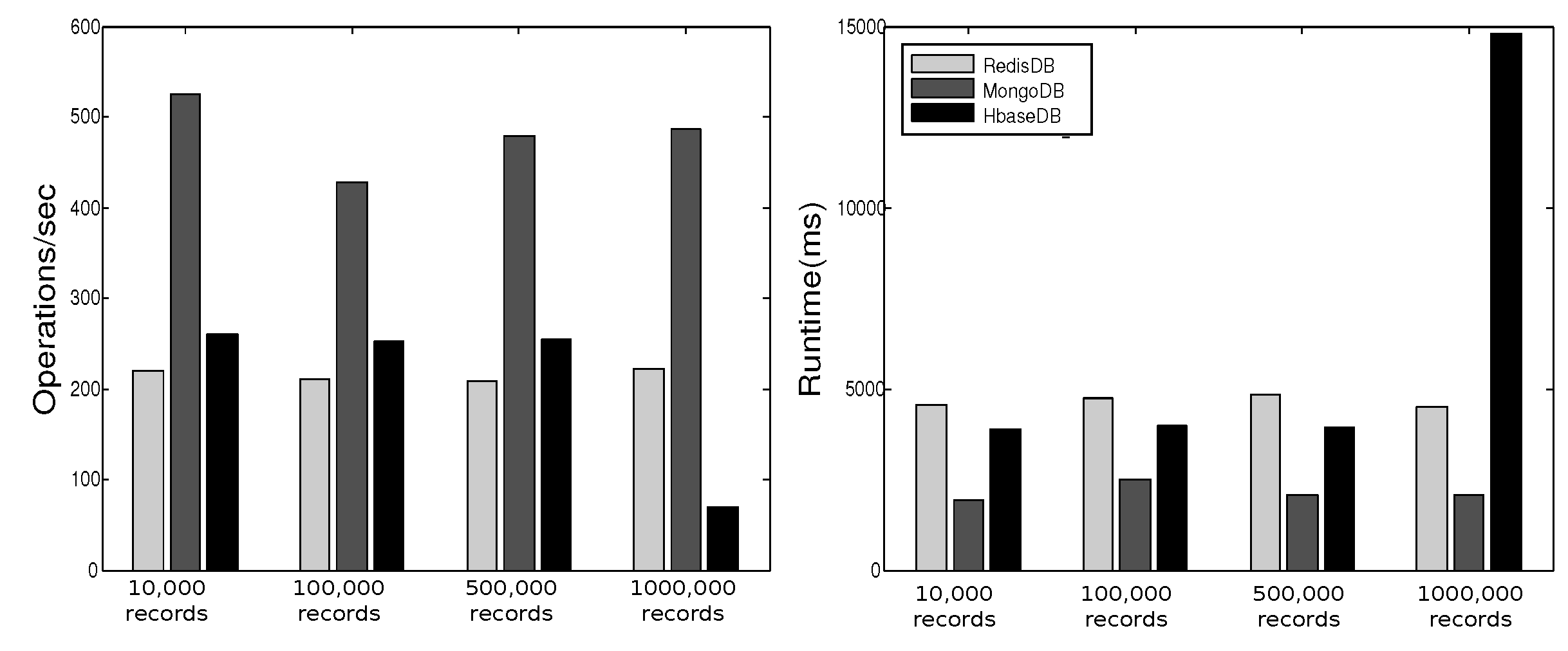
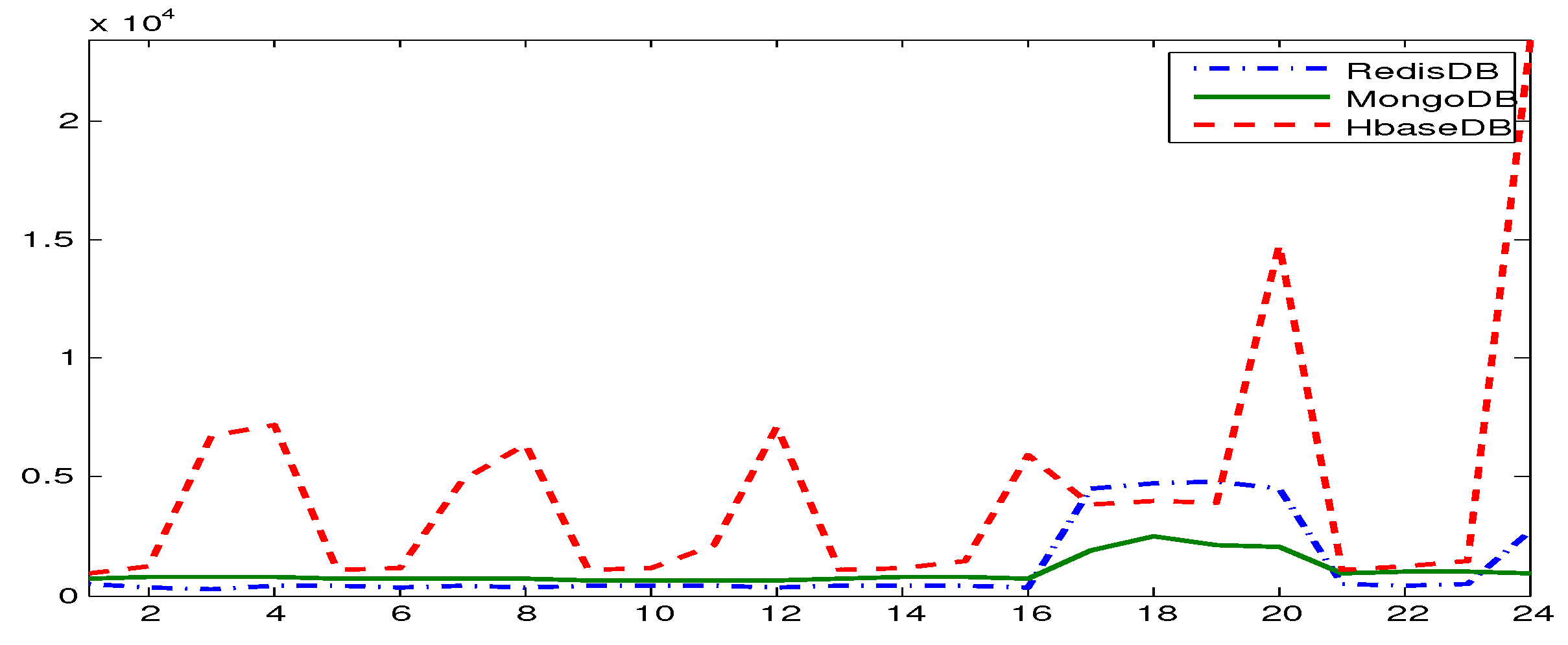
3.7. Experimental Observations–Comparing NoSQL Databases
Observations
- Stable Performance: The performance of a database in YCSB testing shows stable behavior over different workloads.
- Indexing: The database should provide indexing facility for fields of records and/or the document.
- Fields Querying: The database operation should give the ability to query specific fields of the record and/or the document.
- Hierarchical Structure: This is necessary to support embedding or linking among entities.
- Easy Usage: The database must have an easy-to-use user interface ease that allows configuration, installation, and coding.
4. Database Support for Smart City Realization
4.1. Related Work
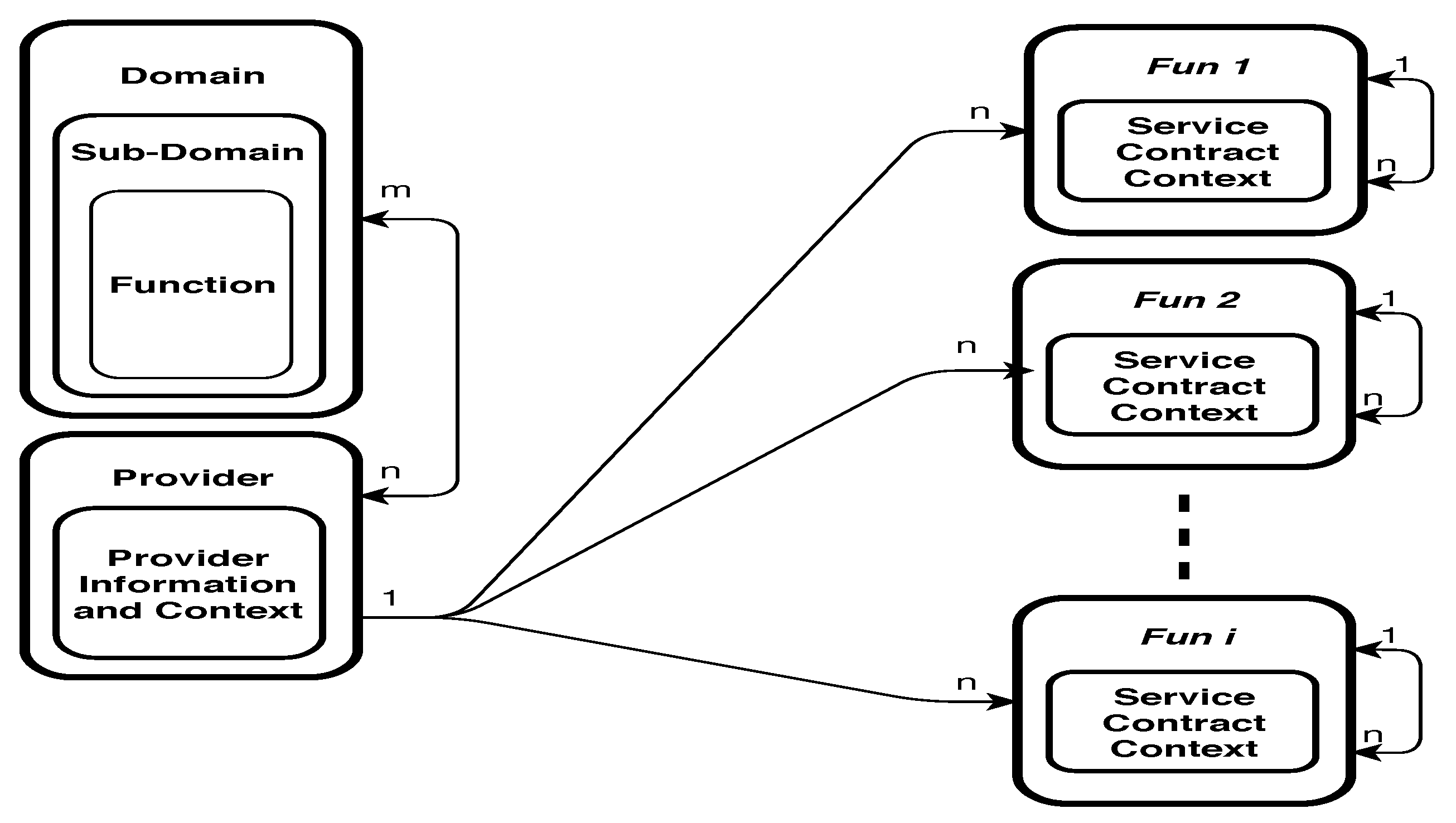
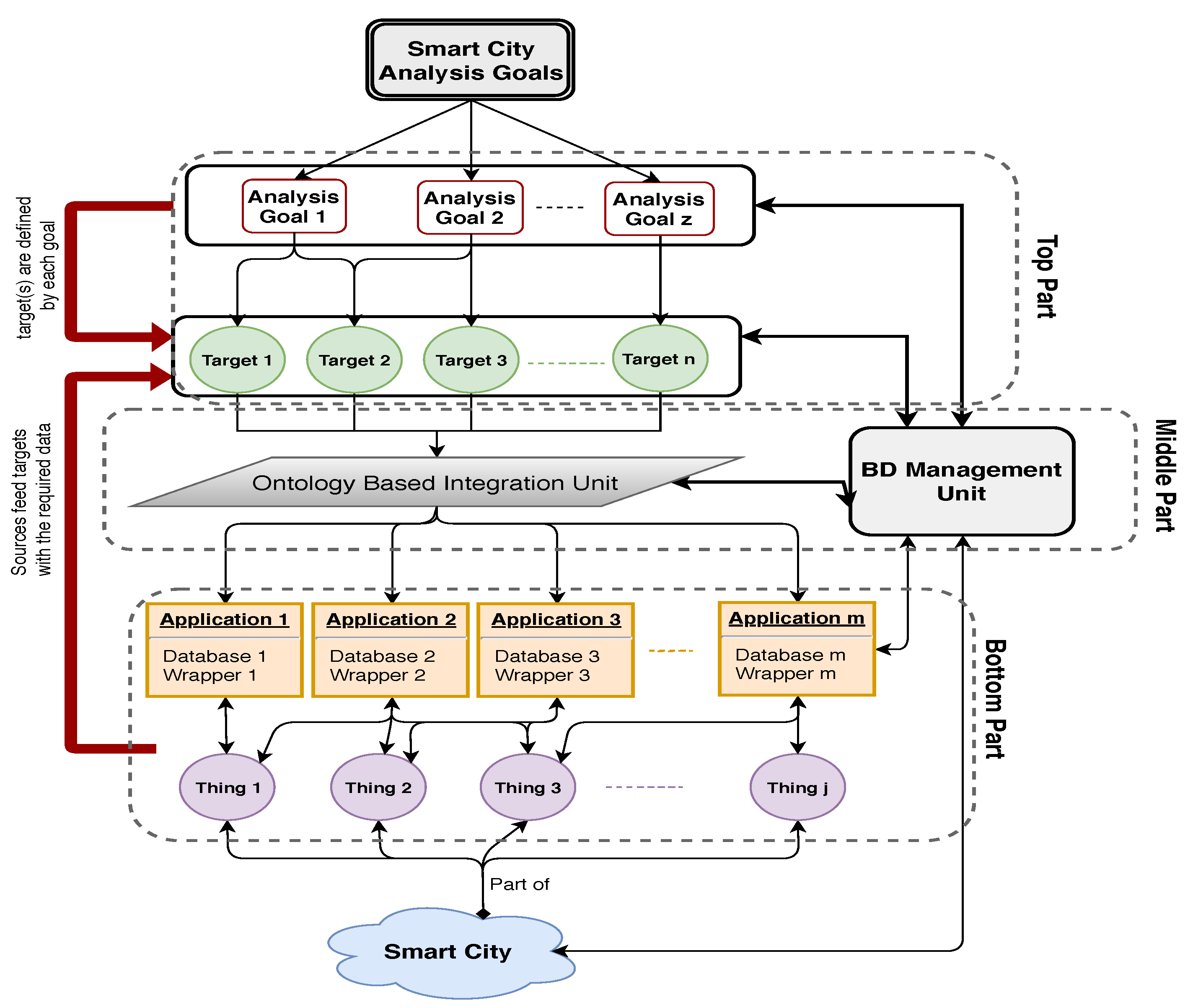
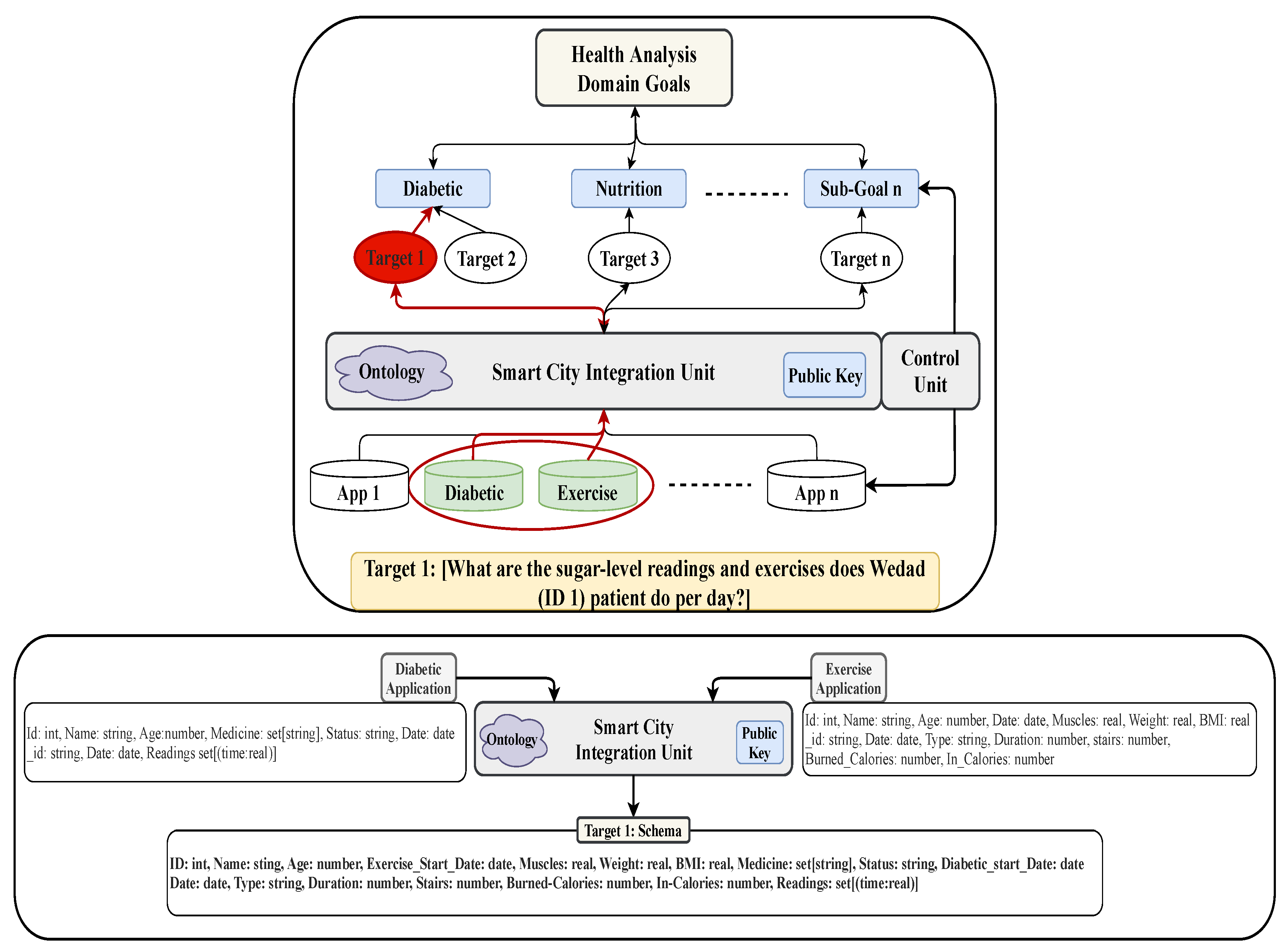
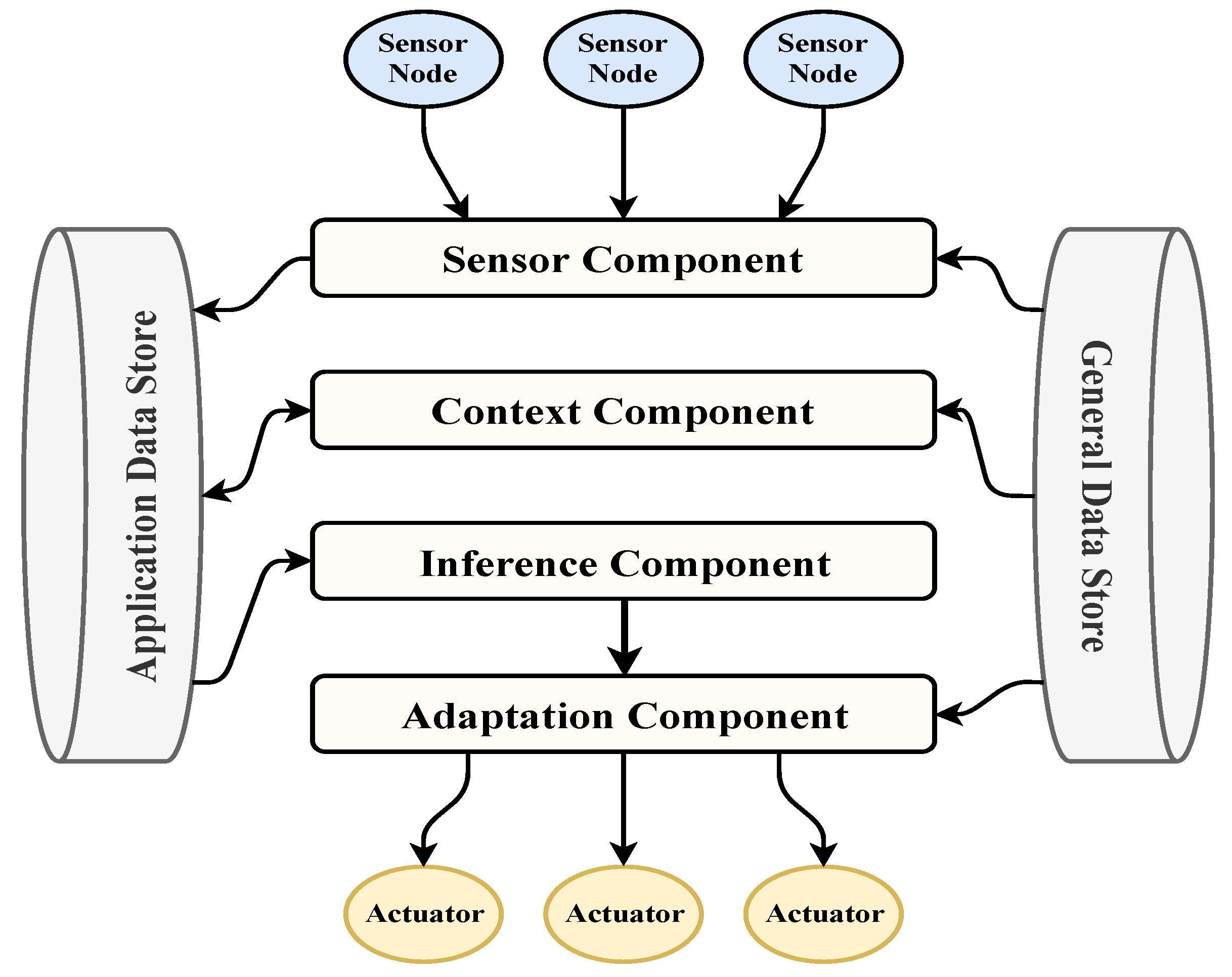
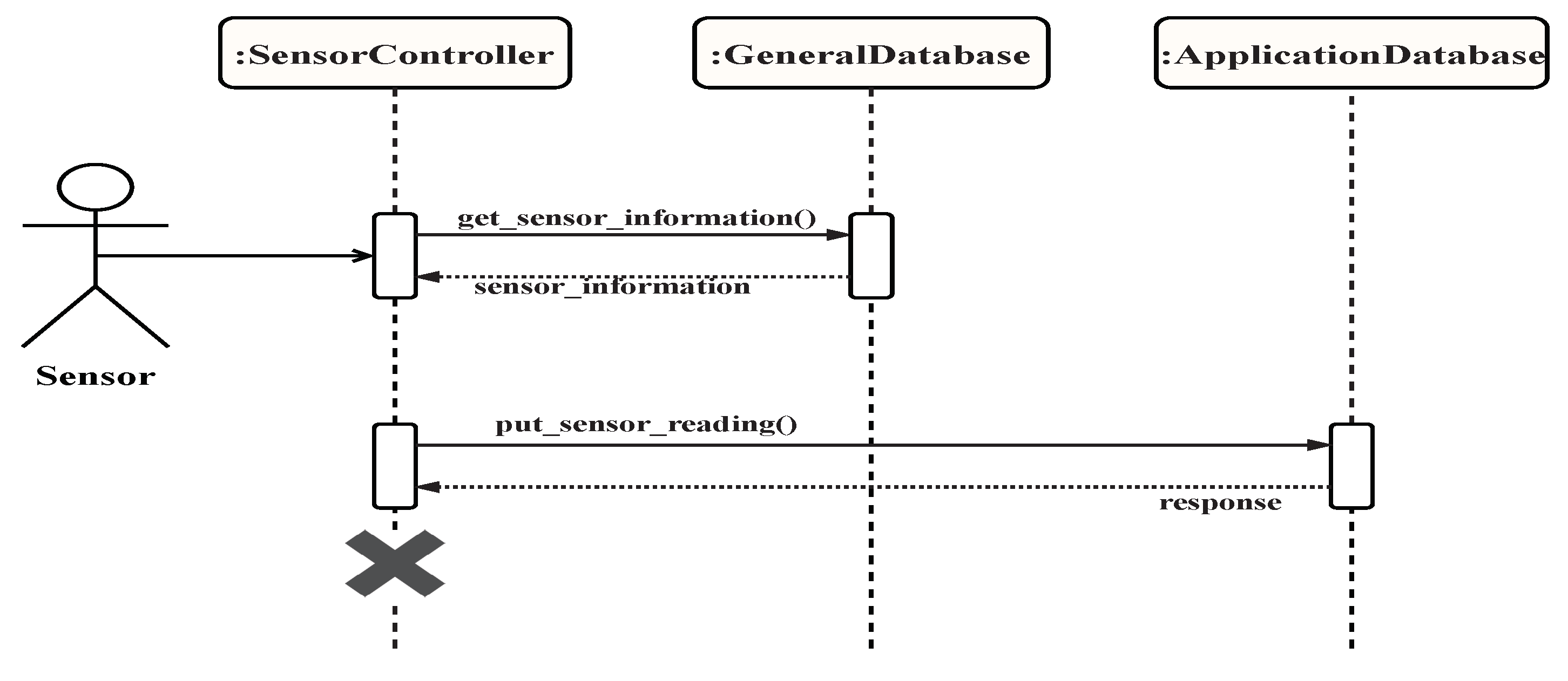
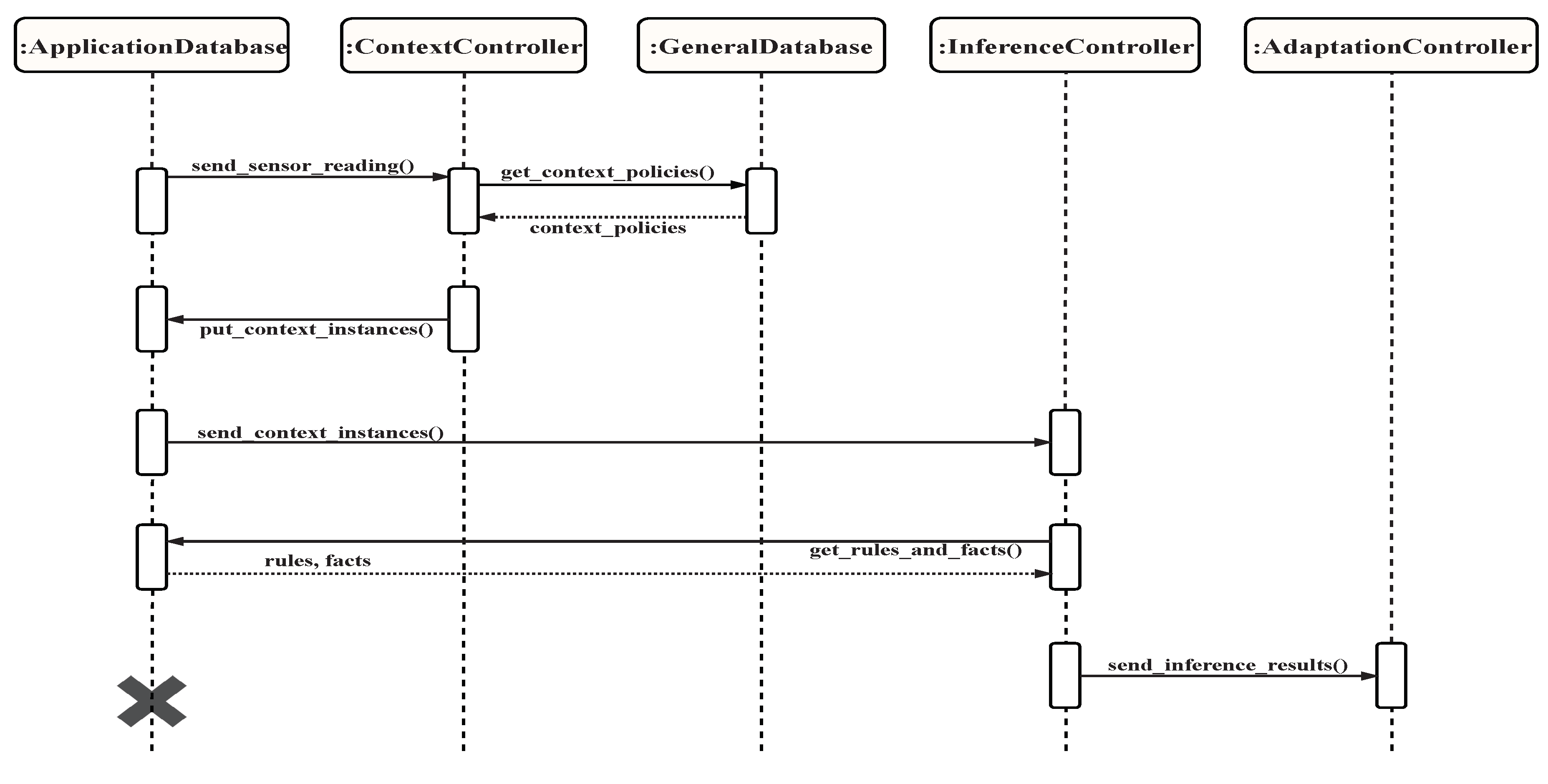
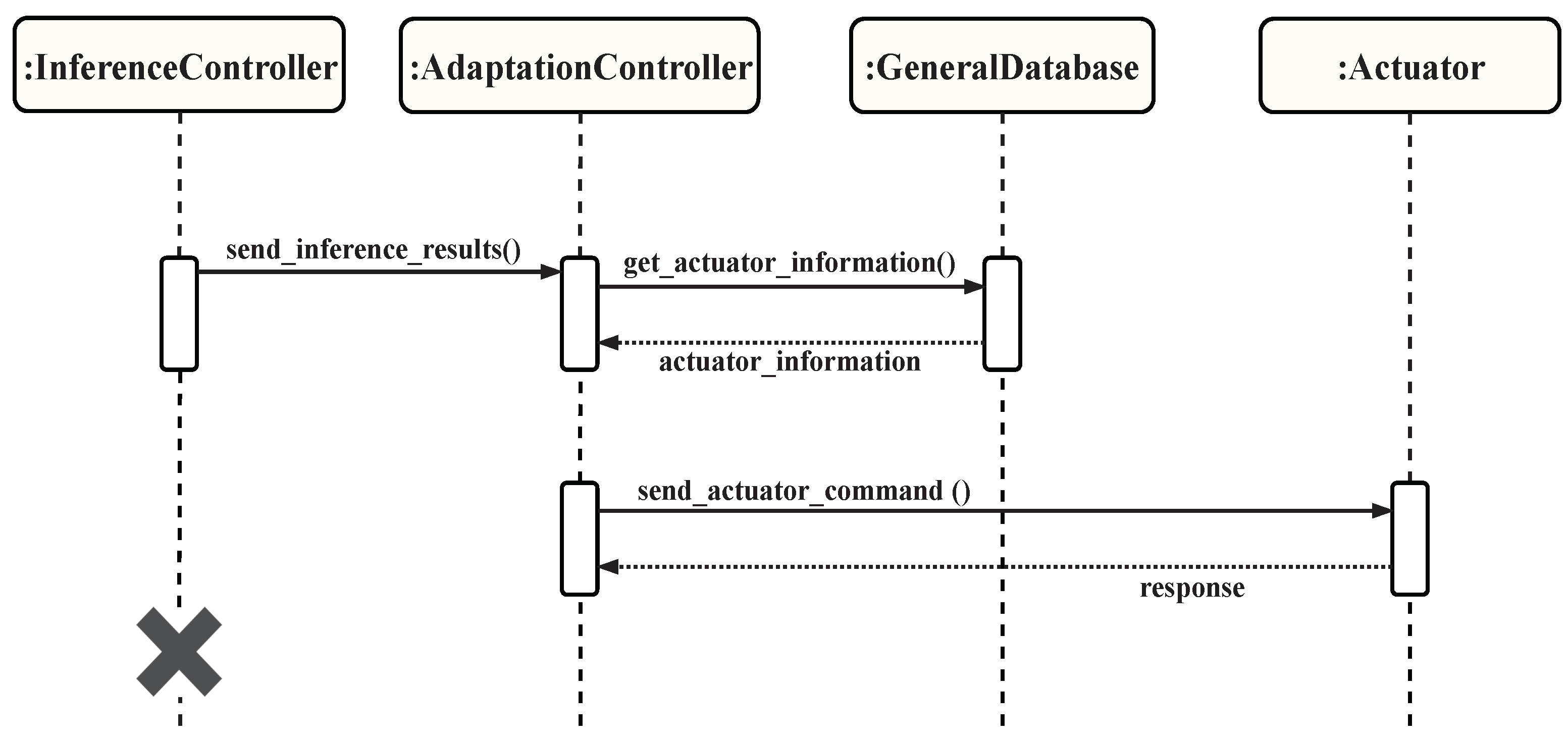
4.2. The Proposed Smart City Development Architecture
4.2.1. Input Stage
4.2.2. Process Stage
4.2.3. Output Stage
4.3. Analysis
5. Conclusions
- Some Collections may scale down. This is because of the decision we made for clustering the “things” based on their common functionality. Some collections of “things” might have only few records in it, because not too many SPs may publish such a service. Also, when the SP of an existing “things” ceases to sustain providing a service, it may be deleted from the system. Consequently, there is a possibility that a collection may end up being empty.
- We may need to Iterate Collections. If there was a user request that requires some operation to be repeatedly applied to more than one thing, then we need to go through different collections to apply that operation. Consequently, substantial amount of work will have to be done to satisfy such user requests. It is also possible that maintenance operations might require going through some collections more frequently than others.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Albino, V.; Berardi, U.; Dangelico, R.M. Smart Cities: Definitions, Dimensions, Performance, and Initiatives. J. Urban Technol. 2015, 22, 3–21. [Google Scholar] [CrossRef]
- Caragliu, A.; Bo, C.D.; Nijkamp, P. Smart Cities in Europe. J. Urban Technol. 2011, 18, 65–82. [Google Scholar] [CrossRef]
- Harrison, C.; Eckman, B.; Hamilton, R.; Hartswick, P.; Kalagnanam, J.; Paraszczak, J.; Williams, P. Foundations for Smarter Cities. IBM J. Res. Dev. 2010, 54, 1–16. [Google Scholar] [CrossRef]
- Marsal, L.; Colomer, J.; Meléndez, J. Lessons in urban monitoring taken from sustainable and livable cities to better address the Smart Cities initiative. Technol. Forecast. Soc. Chang. 2014, 90, 611–622. [Google Scholar] [CrossRef]
- Qin, Y.; Sheng, Q.Z. Big Data Analysis and IoT. In Encyclopedia of Big Data Technologies; Sakr, S., Zomaya, A., Eds.; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Bačić, Ž.; Jogun, T.; Majicć, I. Integrated Sensor Systems for Smart Cities. Tehniĉki vjesnik 2018, 25, 277–284. [Google Scholar]
- Brock, D.L. The Electronic Product Code (EPC): A Naming Scheme for Physical Objects; White Paper, Technical Report MIT-AUTOID-WH-002.pdf; MIT Auto-ID Center: Cambridge, MA, USA, 2001. [Google Scholar]
- Union, I.T. ITU Internet Reports 2005: The Internet of Things; International Telecommunication Union Workshop Report: Geneva, Switzerland, 2005. [Google Scholar]
- Washburn, D.; Sindhu, U.; Balaouras, S.; Dines, R.A.; Hayes, N.M.; Nelson, L.E. Helping CIOs Understand “Smart City” Initiatives: Defining the Smart City, Its Drivers, and the Role of the CIO; Technical Report; Forrester Research, Inc.: Cambridge, MA, USA, 2010. [Google Scholar]
- Alsaig, A.; Alsaig, A.; Mohammed, M.; Alagar, V. Storing and managing context and context history. Context-Aware Syst. Appl. 2014, 128, 35–46. [Google Scholar]
- Chammaa, Z. Smart City Architecture Design by Integrating Context Awareness and Reasoning. Master’s Thesis, Concordia University, Montreal, QC, Canada, 2019. [Google Scholar]
- Ashton, K. The Internet of Things: Things in the real world, things matter more than ideas. RFID J. 2009, 4986. [Google Scholar]
- Uckelmann, D.; Harrison, M.; Michahelles, F. An Architecture Approach Towards the Future of Internet of Thing. In Architecture of Internet of Things; Springer: Berlin, Germany, 2011; pp. 1–2. [Google Scholar]
- Wan, K.; Alagar, V. Integrating Context-awareness and Trustworthiness in IoT Descriptions. In Proceedings of the 2013 IEEE International Conference on Green Computing and Communications and IEEE Internet of Things and IEEE Cyber, Physical and Social Computing, Beijing, China, 20–23 August 2013; pp. 1168–1174. [Google Scholar]
- Alsaig, A.; Alagar, V.; Ormandjieva, O. A Critical Analysis of the V-Model of Big Data. In Proceedings of the 2018 17th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/12th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE), New York, NY, USA, 1–3 August 2018; pp. 1809–1813. [Google Scholar]
- Hernández Aguilar, A.; Bonilla-Robles, J.C.; Zavala Díaz, J.C.; Ochoa, A. Real-time video image processing through GPUs and CUDA and its future implementation in real problems in a Smart City. Int. J. Comb. Optim. Prob. Inform. 2019, 10, 33–49. [Google Scholar]
- Firouzi, F.; Rahmani, A.; Mankodiya, K.; Badaroglu, M.; Merrett, G.; Wong, P.; Farahani, B. Internet-of-Things and big data for smarter healthcare: From device to architecture, applications and analytics. Future Gener. Comput. Syst. 2018, 78, 583–586. [Google Scholar] [CrossRef]
- Javier Ferrández-Pastor, F.; Mora, H.; Jimeno-Morenilla, A.; Volckaert, B. Deployment of IoT Edge and Fog Computing Technologies to Develop Smart Building Services. Sustainability 2018, 10, 3832. [Google Scholar] [CrossRef]
- Gandomi, A.; Haider, M. Beyond the hype: Big data concepts, methods, and analytics. Int. J. Inf. Manag. 2015, 35, 137–144. [Google Scholar] [CrossRef]
- Ibrahim, N.I. Specification, Composition and Provision of Trustworthy Context-Dependent Services. Ph.D. Thesis, Concordia University, Montreal, QC, Canada, 2012. [Google Scholar]
- Hassan, M.; Desouky, A.E.; Elghamrawy, S.; Sarhan, A. Big Data Challenges and Opportunities in Healthcare Informatics and Smart Hospitals. In Security in Smart Cities: Models, Applications, and Challenges; Springer International Publishing: Cham, Switzerland, 2019; pp. 3–26. [Google Scholar]
- Dameri, R.P. Smart City Implementation; In Progress in IS; Springer: Genoa, Italy, 2017. [Google Scholar]
- Carlson, J.L. Redis in Action; Manning Publications Co.: Greenwich, CT, USA, 2013. [Google Scholar]
- George, L. HBase: The Definitive Guide: Random Access to Your Planet-Size Data; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2011. [Google Scholar]
- Banker, K. MongoDB in Action; Manning Publications Co.: Greenwich, CT, USA, 2011. [Google Scholar]
- Paper, A.M.W. Unlocking Operational Intelligence from the Data Lake; Technical Report; MongoDB: New York, NY, USA, 2018. [Google Scholar]
- Alsaig, A. Context-Aware Service Registry: Modeling and Implementation. Ph.D. Thesis, Concordia University, Montreal, QC, Canada, 2013. [Google Scholar]
- Barata, M.; Bernardino, J.; Furtado, P. YCSB and TPC-H: Big Data and Decision Support Benchmarks. In Proceedings of the IEEE International Congress on Big Data, Anchorage, AK, USA, 27 June–2 July 2014; pp. 800–801. [Google Scholar]
- Avalon. Comparing NoSQL Databases with YCSB Standard Benchmark; Technical Report; Avalon Consulting, LLC: Frisco, TX, USA, 2016. [Google Scholar]
- Abraamova, V.; Bernardino, J.; Furtado, P. Experimental Evaluation of NoSQL Databases. Int. J. Database Manag. Syst. (IJDMS) 2014, 6, 1–16. [Google Scholar] [CrossRef]
- Tang, E.; Fan, Y. Performance Comparison between Five NoSQL Databases. In Proceedings of the 7th International Conference on Cloud Computing and Big Data, Macau, China, 16–18 November 2016; pp. 105–109. [Google Scholar]
- Prasad, S.; Shah, N. NextGen Data Persistence Pattern in Healthcare: Polyglot Persistence. In Proceedings of the 2013 Fourth International Conference on Computing, Communications and Networking Technologies (ICCCNT), Tiruchengode, India, 4–6 July 2013; pp. 1–8. [Google Scholar]
- Cooper, B.; Silberstein, A.; Tam, E.; Ramakrishnan, R.; Sears, R. Benchmarking cloud serving systems with YCSB. In Proceedings of the 1st ACM Symposium on Cloud Computing, Indianapolis, IN, USA, 10–11 June 2010; pp. 143–154. [Google Scholar]
- Redmond, E.; Wilson, J.; Carter, J. Seven Databases in Seven Weeks: A Guide to Modern Databases and the NoSQL Movement; Pragmatic Bookshelf: Raleigh, NC, USA, 2012. [Google Scholar]
- Fahy, P.; Clarke, S. CASS-Middleware for Mobile Context-Aware Applications. MobiSys. 2004. Available online: https://www.sigmobile.org/mobisys/2004/context_awareness/papers/cass12f.pdf (accessed on 28 May 2019).
- Salber, D.; Dey, A.K.; Abowd, G.D. The Context Toolkit: Aiding the Development of Context-enabled Applications. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Pittsburgh, PA, USA, 15–20 May 1999; pp. 434–441. [Google Scholar] [CrossRef]
- Hnaide, S.A. A Framework for Developing Context-Aware Systems. Master’s Thesis, Concordia University, Montreal, QC, Canada, 2011. [Google Scholar]
- Miraoui, M.; El-etriby, S.; Abid, A.Z.; Tadj, C. Agent-Based Context-Aware Architecture for a Smart Living Room. Int. J. Smart Home 2016, 10, 39–54. [Google Scholar] [CrossRef]
- Chen, H.L. An Intelligent Broker Architecture for Pervasive Context-Aware Systems. Ph.D. Thesis, University of Maryland, College Park, MD, USA, 2004. [Google Scholar]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Workload | Operations Combination | Ratio |
|---|---|---|
| (A) | Read/Update | 50:50 |
| (B) | Read/update | 95:5 |
| (C) | Read/update | 100:0 |
| (D) | Read/update/insert | 95:0:5 |
| (E) | Scan/insert | 95:5 |
| (F) | Read/Read-Update | 50/50 |
| Redis | MongoDB | Hbase | |
|---|---|---|---|
| Stable Performance | Yes | Yes | No |
| Indexing | No | Yes | No |
| Fields Querying | Partial | Partial | Yes |
| Hierarchical Structure | No | Yes | Partial |
| Usage easiness | Yes | Yes | Partial |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsaig, A.; Alagar, V.; Chammaa, Z.; Shiri, N. Characterization and Efficient Management of Big Data in IoT-Driven Smart City Development. Sensors 2019, 19, 2430. https://doi.org/10.3390/s19112430
Alsaig A, Alagar V, Chammaa Z, Shiri N. Characterization and Efficient Management of Big Data in IoT-Driven Smart City Development. Sensors. 2019; 19(11):2430. https://doi.org/10.3390/s19112430
Chicago/Turabian StyleAlsaig, Alaa, Vangalur Alagar, Zaki Chammaa, and Nematollaah Shiri. 2019. "Characterization and Efficient Management of Big Data in IoT-Driven Smart City Development" Sensors 19, no. 11: 2430. https://doi.org/10.3390/s19112430
APA StyleAlsaig, A., Alagar, V., Chammaa, Z., & Shiri, N. (2019). Characterization and Efficient Management of Big Data in IoT-Driven Smart City Development. Sensors, 19(11), 2430. https://doi.org/10.3390/s19112430