Faster R-CNN and Geometric Transformation-Based Detection of Driver’s Eyes Using Multiple Near-Infrared Camera Sensors

Abstract
1. Introduction
2. Related Works
3. Contributions
- -
- This study is the first to apply a convolutional neural network (CNN)-based method in an in-vehicle multiple-camera-based environment to attempt to detect the driver’s eyes.
- -
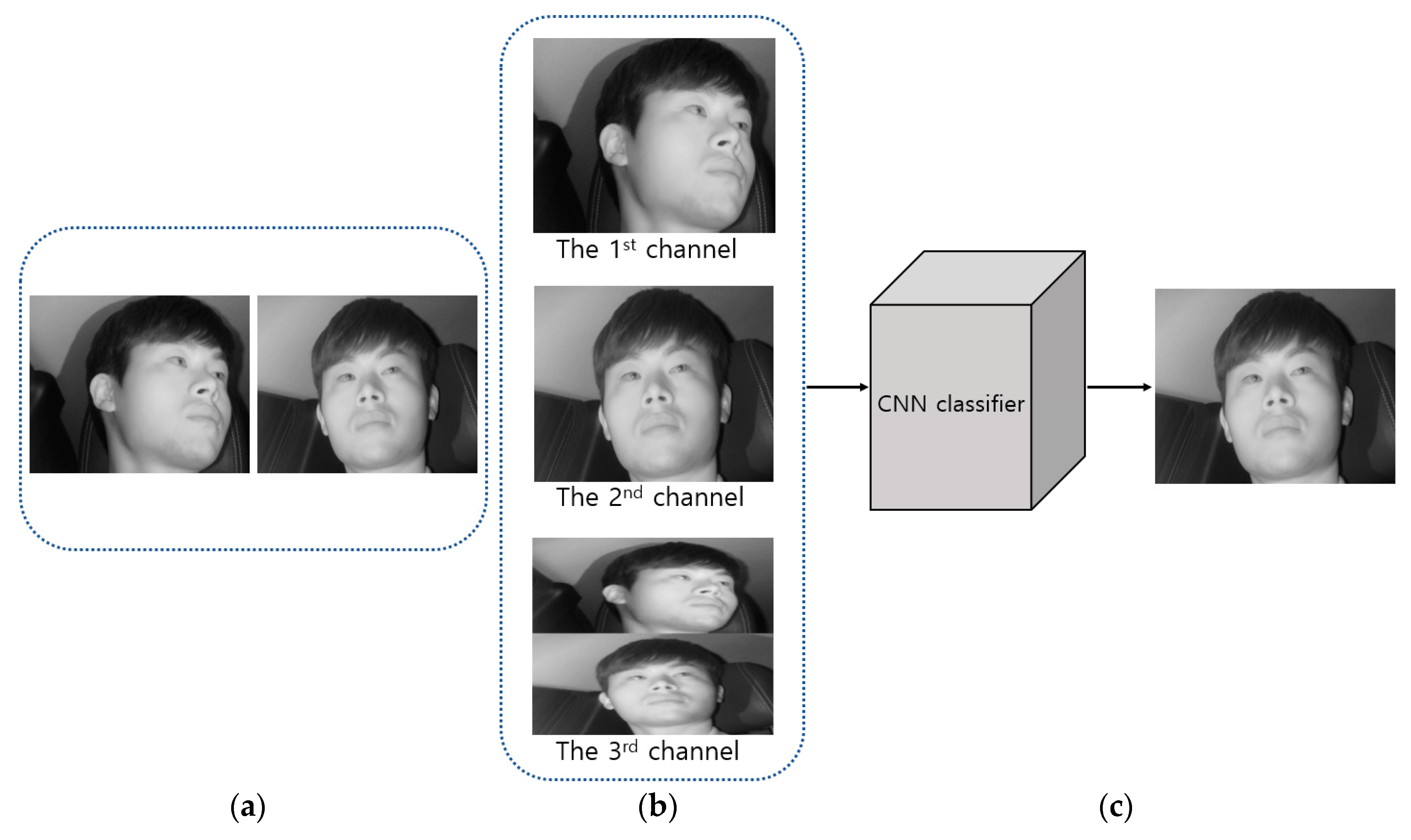
- After composing a three-channel image from the two driver face images obtained using the two cameras from various angles, the image is used as input in the shallow CNN to select a frontal face image. In the selected frontal face image, the eyes barely ever disappear or are covered owing to head rotations of the driver, showing more effective eye detection results
- -
- For the two driver images obtained through the two cameras, faster R-CNN is applied to the frontal face image only rather than to both, and the eye positions of the other image are detected through geometric transformation, thereby preserving eye detection accuracy while reducing processing time.
- -
- The self-built Dongguk Dual Camera-based Driver Database (DDCD-DB1), learned faster R-CNN, and algorithms are released as shown in [31] in order to enable other researchers to perform a fair performance evaluation.
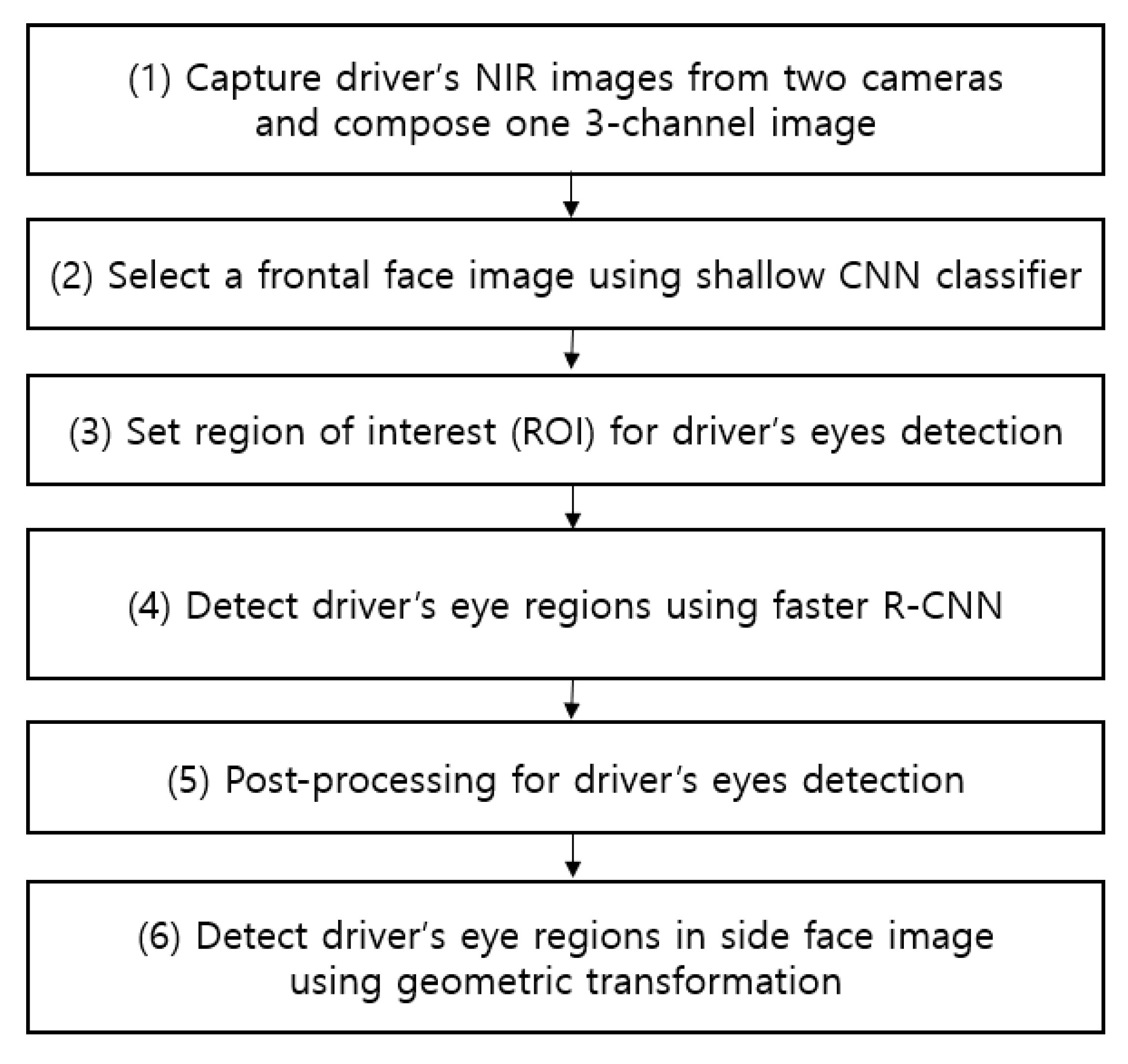
4. Proposed System for Detection of Driver’s Eyes in Vehicle Environments
4.1. Overview of Proposed Method
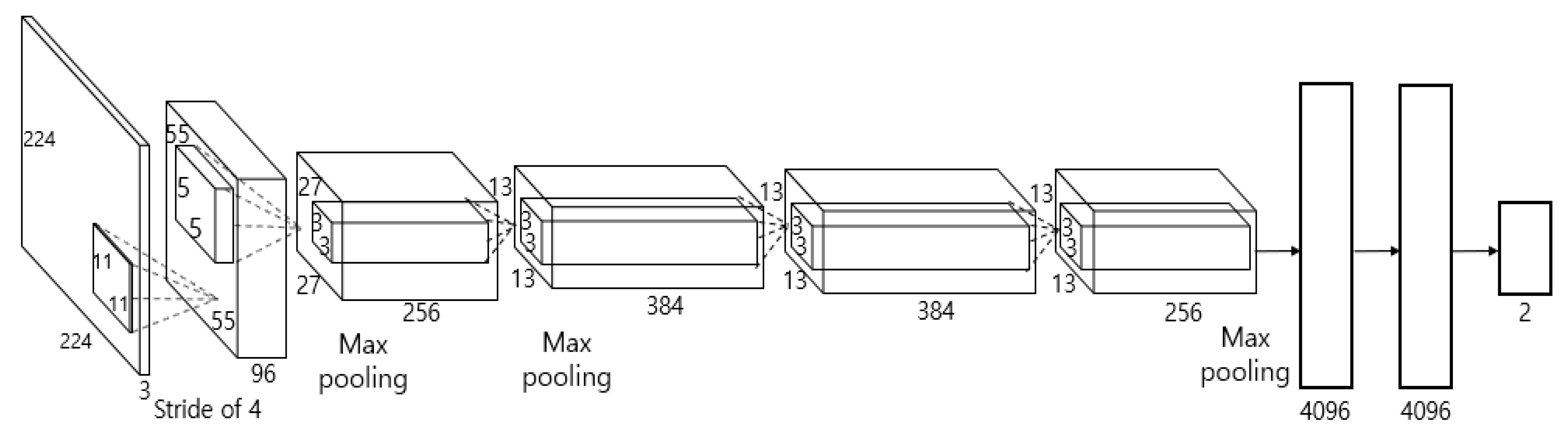
4.2. Classification of Frontal Face Image Using Shallow CNN
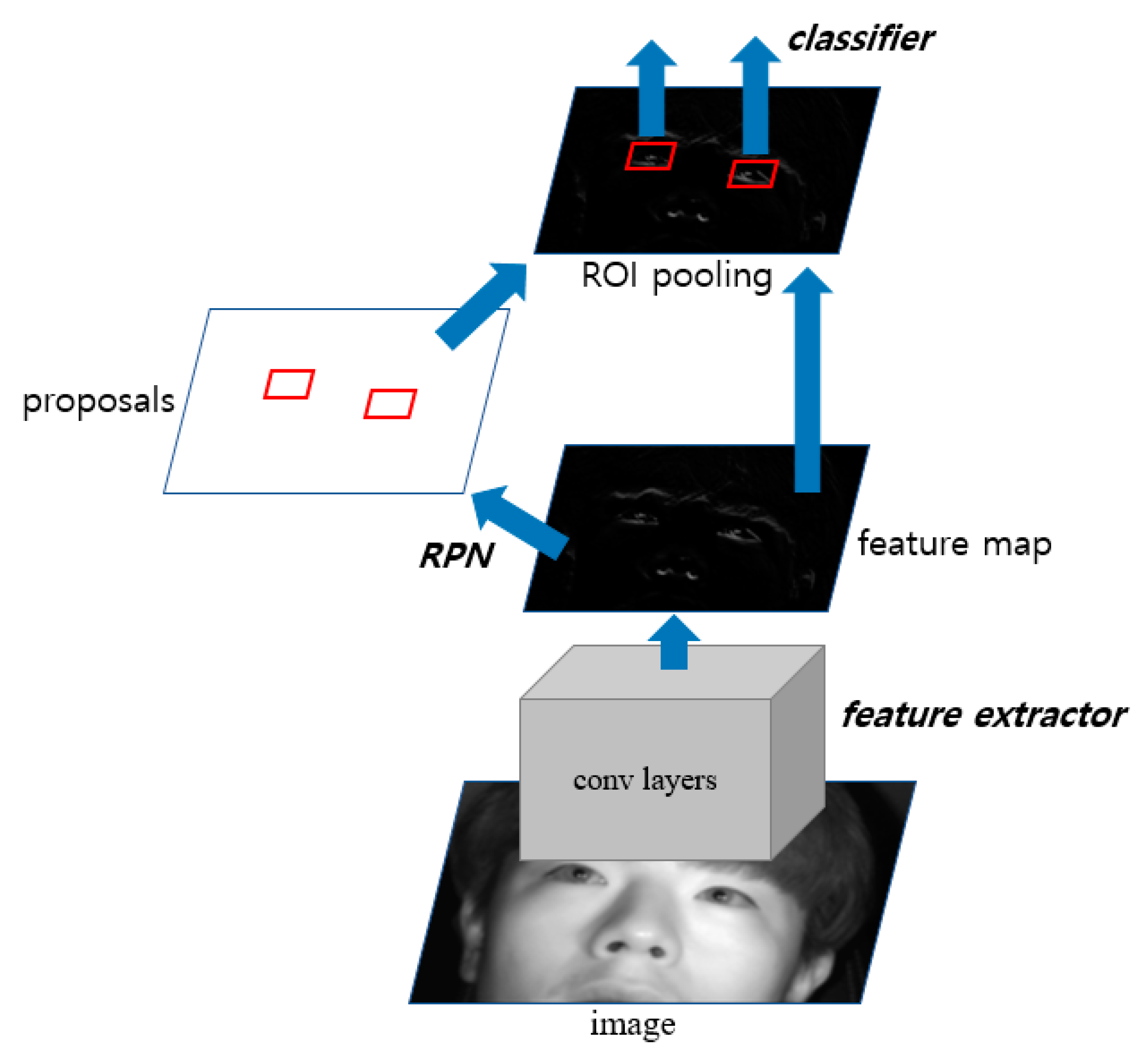
4.3. Eye Detection Using Faster R-CNN
4.3.1. Structure of Faster R-CNN
4.3.2. Loss Function
4.4. Post-Processing for Eyes Detection
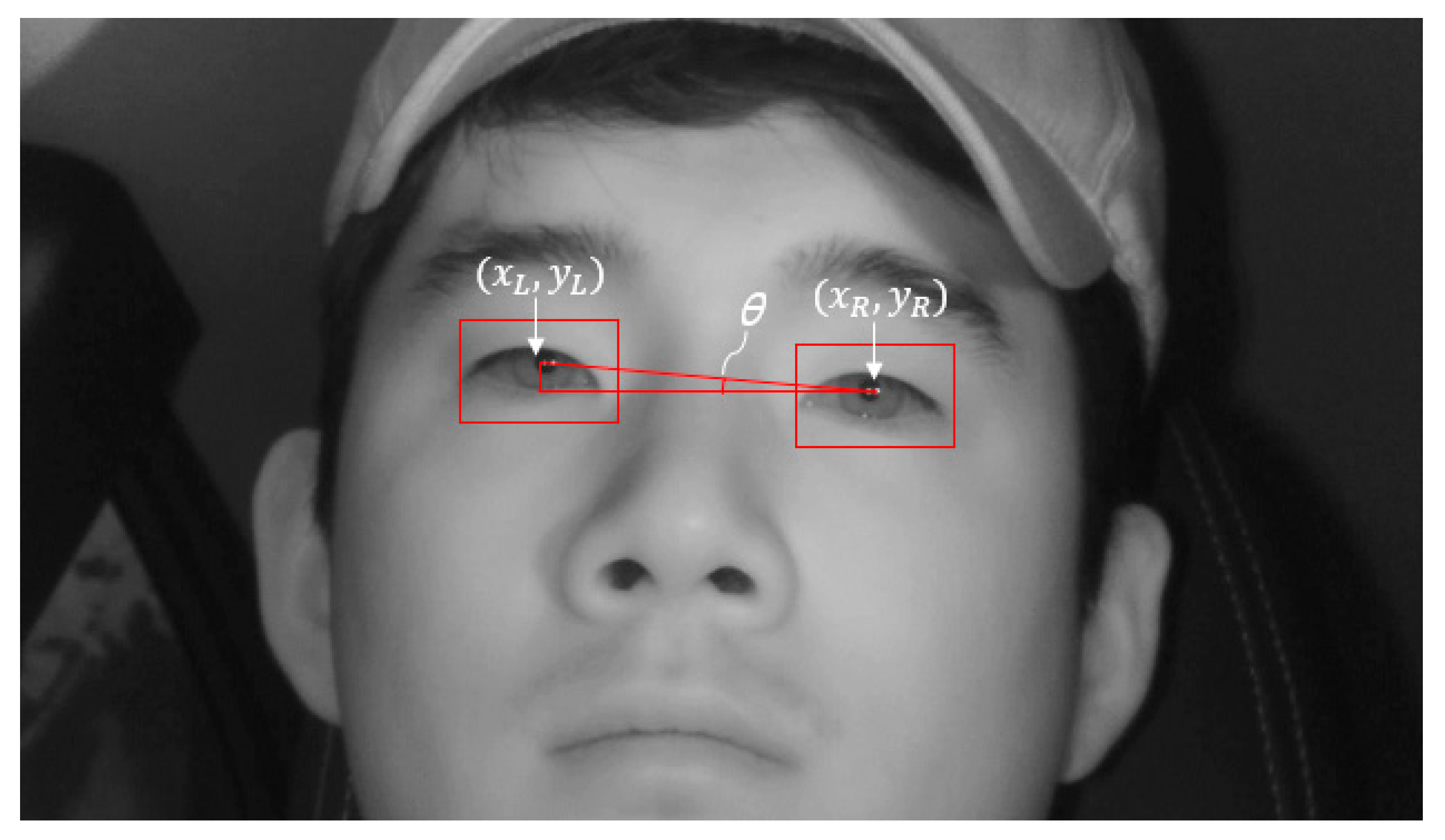
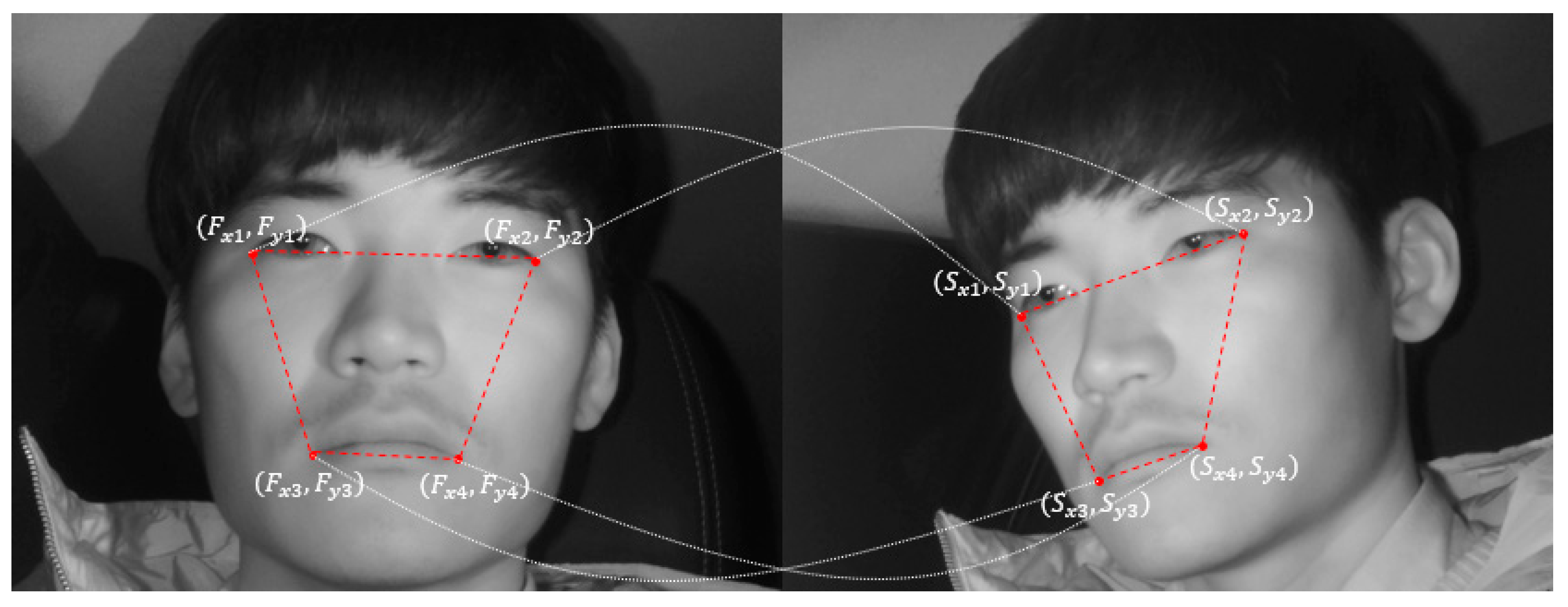
4.5. Detect Driver’s Eyes in Side Face Image Using Geometric Transform Matrix
5. Experimental Results with Analysis
5.1. Experimental Environment
5.2. Performance Evaluation of the Classification of Frontal Face Image Using Shallow CNN
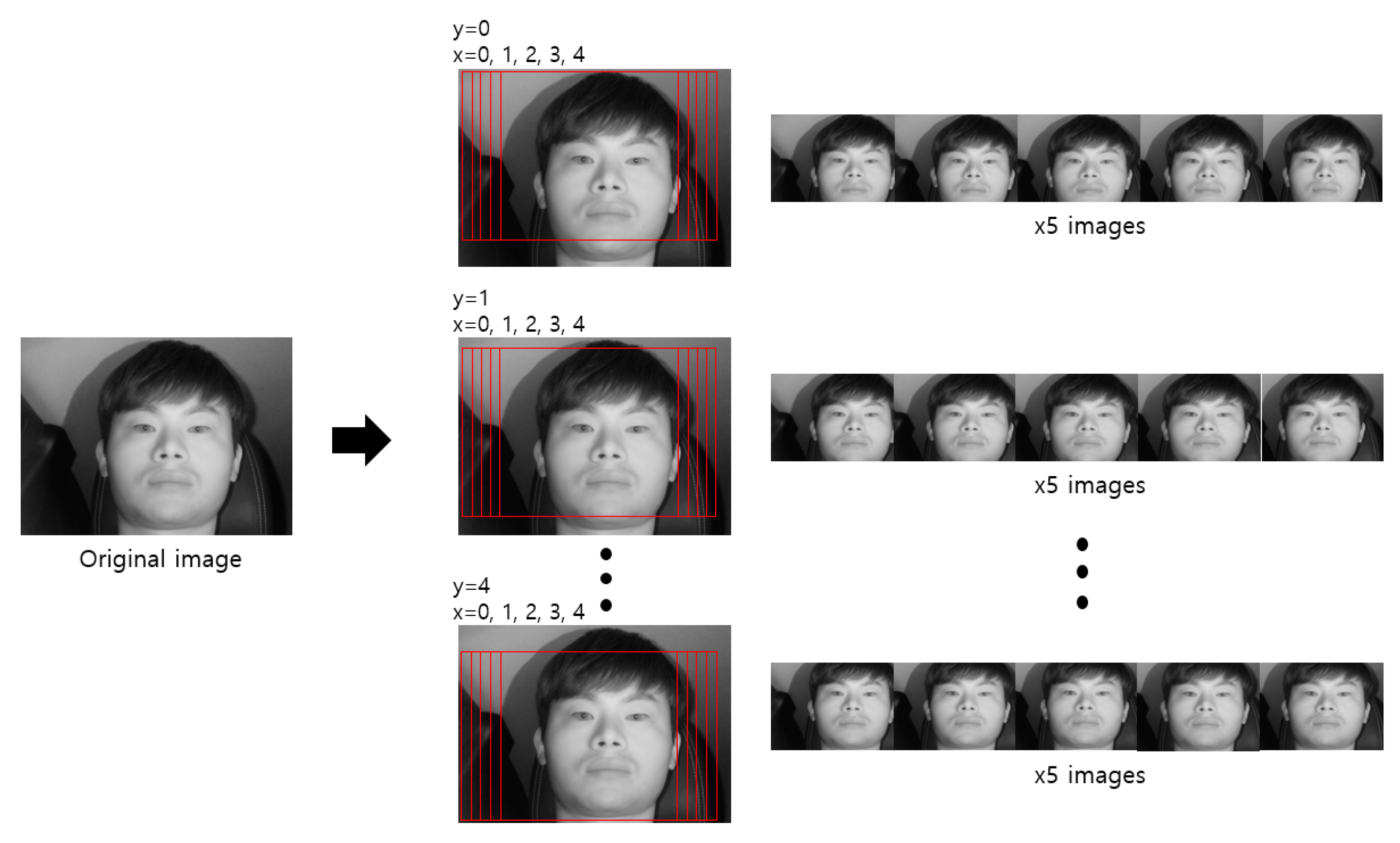
5.2.1. Experimental Data and Training of Shallow CNN
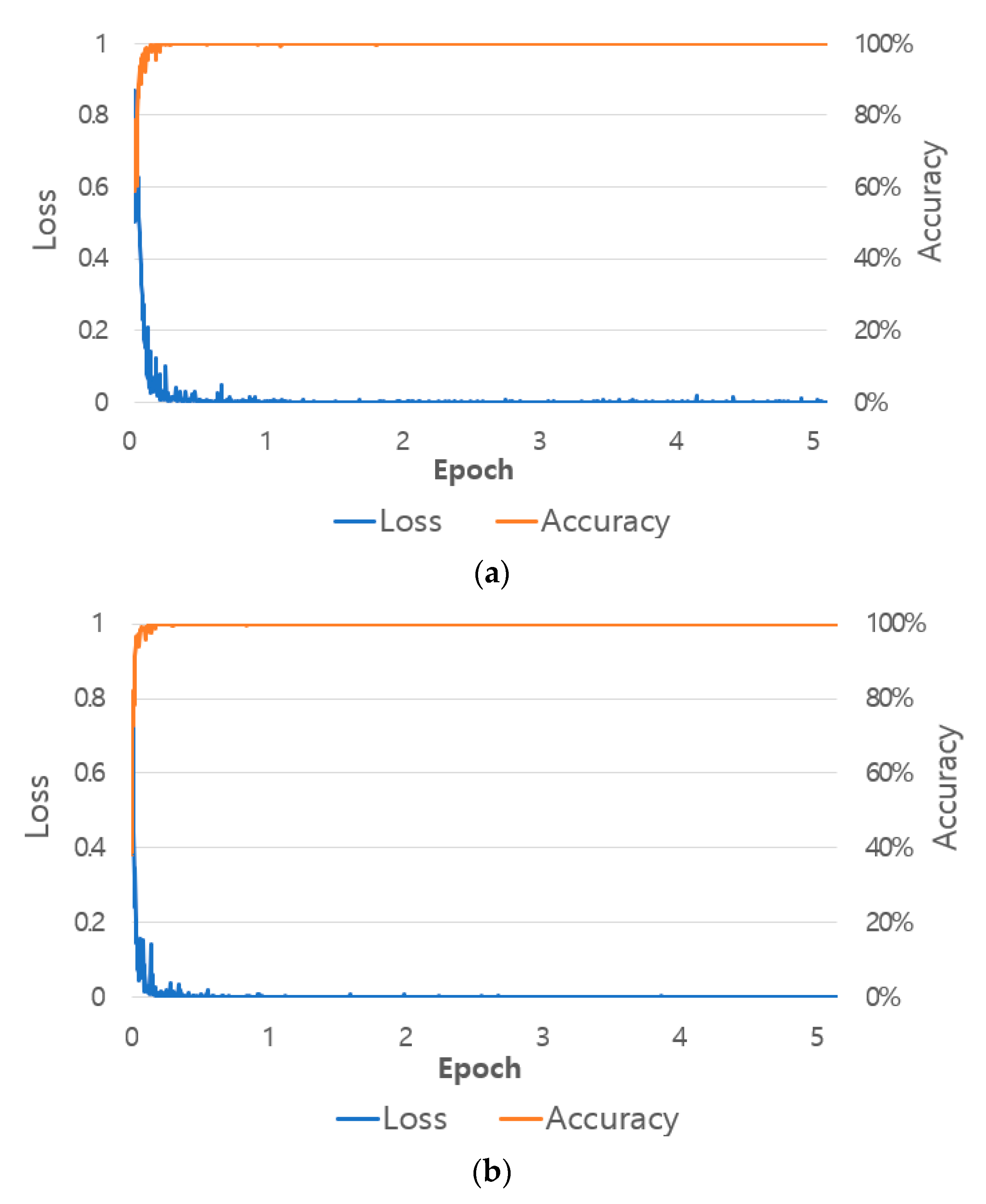
5.2.2. Classification Accuracy with Shallow CNN
5.3. Performance Evaluation of Eye Detection
5.3.1. Experimental Data and Training of Faster R-CNN
5.3.2. Eye Detection Accuracy Obtained Using the Proposed Method
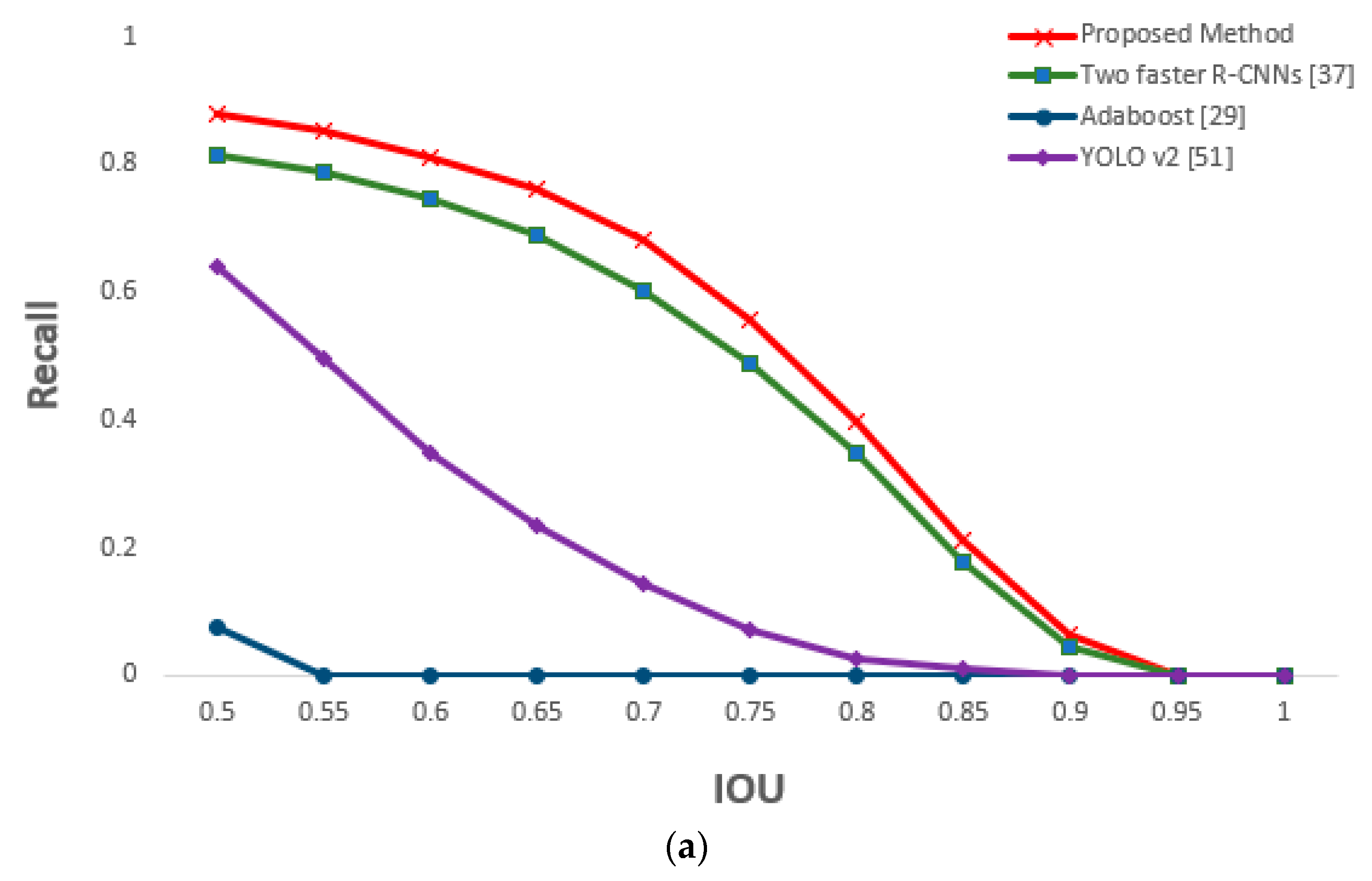
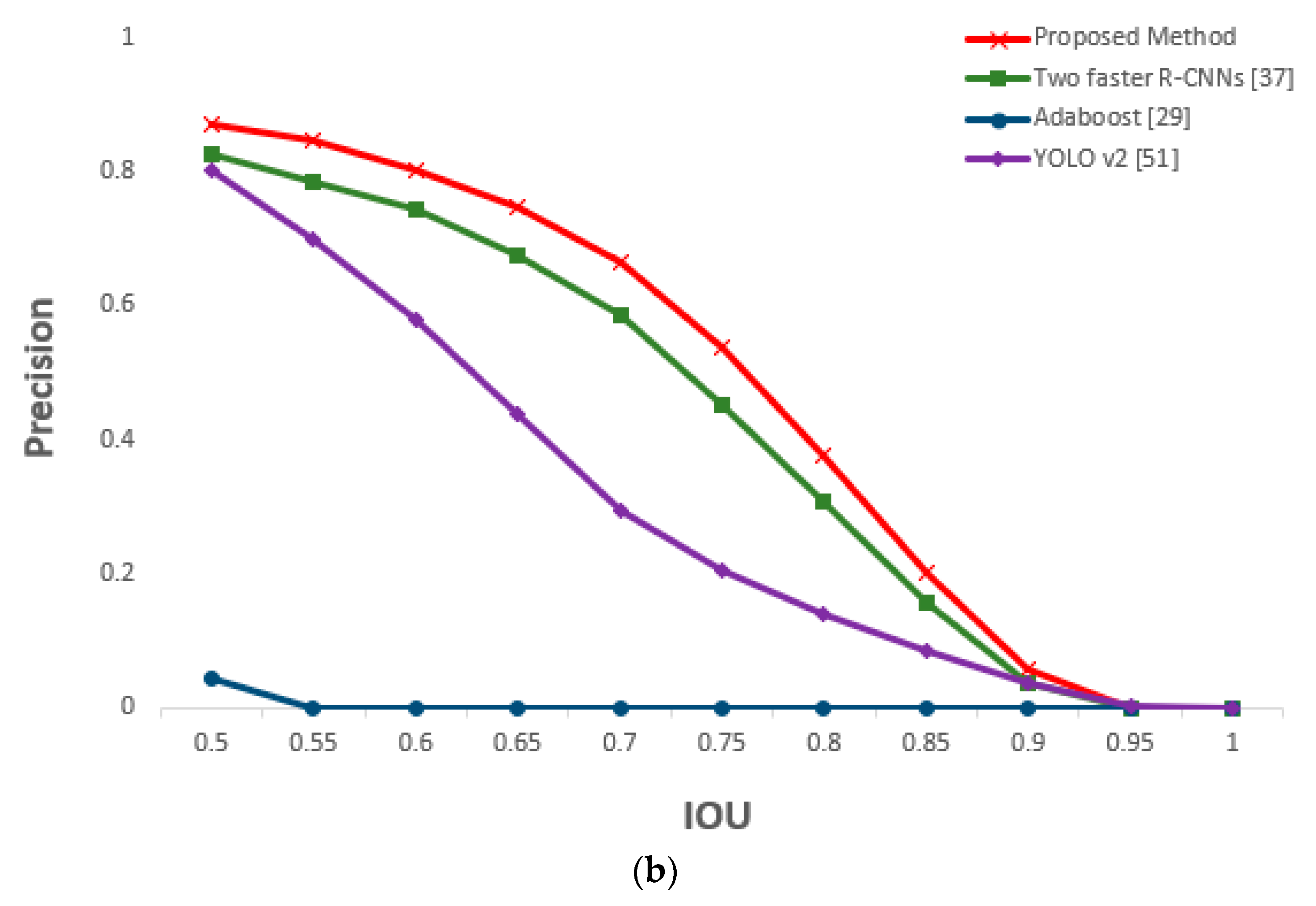
5.3.3. Comparison of Proposed and Previous Methods on Eye Detection
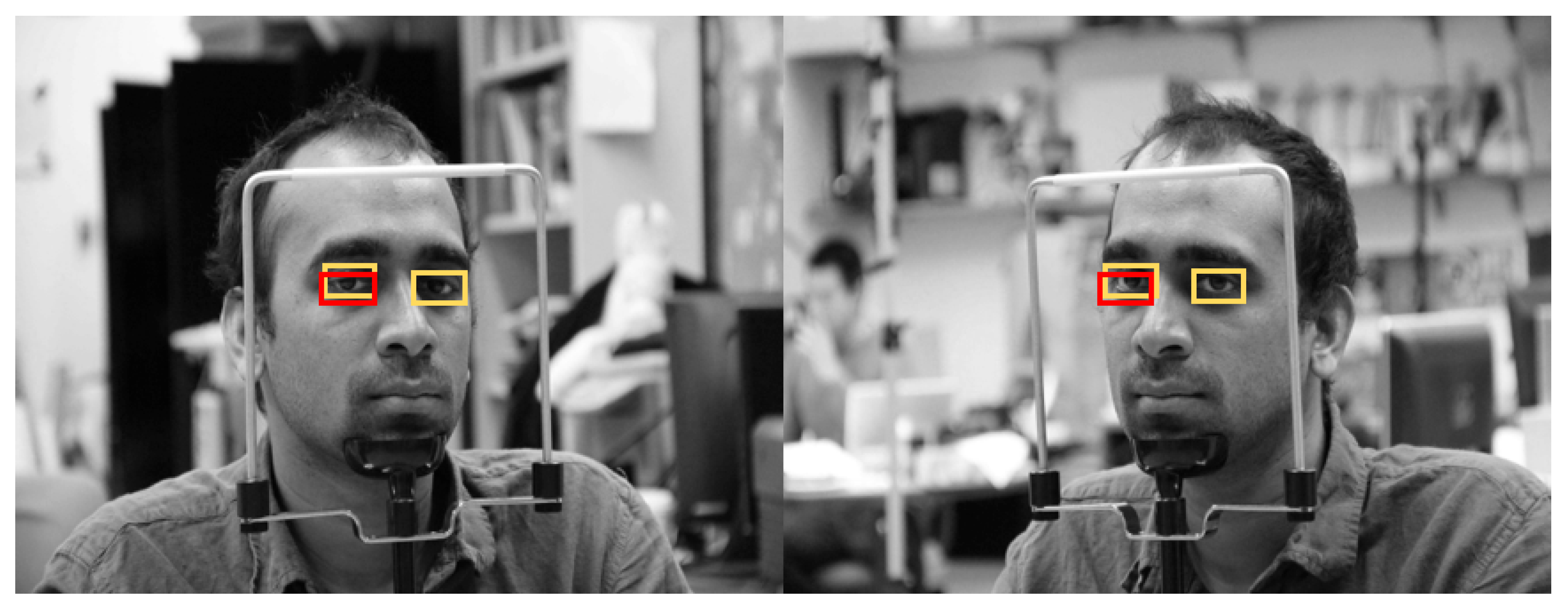
5.4. Performance Evaluations with Open Database
5.4.1. Classification Accuracy of Frontal Face Image Using Shallow CNN
5.4.2. Comparisons of Proposed and Previous Methods on Eye Detection
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Stutts, J.C.; Reinfurt, D.W.; Staplin, L.; Rodgman, E.A. The Role of Driver Distraction in Traffic Crashes; AAA Foundation for Traffic Safety: Washington, DC, USA, May 2001. [Google Scholar]
- Ascone, D.; Lindsey, T.; Varghese, C. An Examination of Driver Distraction as Recorded in NHTSA Databases; Traffic Safety Facts. Report No. DOT HS 811 216; National Highway Traffic Safety Administration: Washington, DC, USA, September 2009.
- Kim, K.W.; Hong, H.G.; Nam, G.P.; Park, K.R. A study of deep CNN-based classification of open and closed eyes using a visible light camera sensor. Sensors 2017, 17, 1534. [Google Scholar] [CrossRef] [PubMed]
- Franchak, J.M.; Kretch, K.S.; Soska, K.C.; Adolph, K.E. Head-mounted eye tracking: A new method to describe infant looking. Child Dev. 2011, 82, 1738–1750. [Google Scholar] [CrossRef]
- Noris, B.; Keller, J.-B.; Billard, A. A wearable gaze tracking system for children in unconstrained environments. Comput. Vis. Image Underst. 2011, 115, 476–486. [Google Scholar] [CrossRef]
- Rantanen, V.; Vanhala, T.; Tuisku, O.; Niemenlehto, P.-H.; Verho, J.; Surakka, V.; Juhola, M.; Lekkala, J. A wearable, wireless gaze tracker with integrated selection command source for human-computer interaction. IEEE Trans. Inf. Technol. Biomed. 2011, 15, 795–801. [Google Scholar] [CrossRef]
- Tsukada, A.; Shino, M.; Devyver, M.; Kanade, T. Illumination-free gaze estimation method for first-person vision wearable device. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Barcelona, Spain, 6–13 November 2011; pp. 2084–2091. [Google Scholar]
- Yoo, D.H.; Chung, M.J. A novel non-intrusive eye gaze estimation using cross-ratio under large head motion. Comput. Vis. Image Underst. 2005, 98, 25–51. [Google Scholar] [CrossRef]
- Shih, S.-W.; Liu, J. A novel approach to 3-D gaze tracking using stereo cameras. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2004, 34, 234–245. [Google Scholar] [CrossRef]
- Lee, H.C.; Lee, W.O.; Cho, C.W.; Gwon, S.Y.; Park, K.R.; Lee, H.; Cha, J. Remote gaze tracking system on a large display. Sensors 2013, 13, 13439–13463. [Google Scholar] [CrossRef]
- Su, M.-C.; Wang, K.-C.; Chen, G.-D. An eye tracking system and its application in aids for people with severe disabilities. Biomed. Eng. Appl. Basis Commun. 2006, 18, 319–327. [Google Scholar] [CrossRef]
- Batista, J.P. A real-time driver visual attention monitoring system. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis, Estoril, Portugal, 7–9 June 2005; pp. 200–208. [Google Scholar]
- Vicente, F.; Huang, Z.; Xiong, X.; De la Torre, F.; Zhang, W.; Levi, D. Driver gaze tracking and eyes off the road detection system. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2014–2027. [Google Scholar] [CrossRef]
- Fridman, L.; Lee, J.; Reimer, B.; Victor, T. Owl and lizard: Patterns of head pose and eye pose in driver gaze classification. IET Comput. Vis. 2016, 10, 308–314. [Google Scholar] [CrossRef]
- Smith, P.; Shah, M.; da Vitoria Lobo, N. Determining driver visual attention with one camera. IEEE Trans. Intell. Transp. Syst. 2003, 4, 205–218. [Google Scholar] [CrossRef]
- Smith, P.; Shah, M.; da Vitoria Lobo, N. Monitoring head/eye motion for driver alertness with one camera. In Proceedings of the 15th International Conference on Pattern Recognition, Barcelona, Spain, 3–7 September 2000; pp. 636–642. [Google Scholar]
- Diddi, V.K.; Jamge, S.B. Head pose and eye state monitoring (HEM) for driver drowsiness detection: Overview. Int. J. Innov. Sci. Eng. Technol. 2014, 1, 504–508. [Google Scholar]
- Liang, Y.; Reyes, M.L.; Lee, J.D. Real-time detection of driver cognitive distraction using support vector machines. IEEE Trans. Intell. Transp. Syst. 2007, 8, 340–350. [Google Scholar] [CrossRef]
- Kutila, M.; Jokela, M.; Markkula, G.; Rué, M.R. Driver distraction detection with a camera vision system. In Proceedings of the IEEE International Conference on Image Processing, San Antonio, TX, USA, 16–19 September 2007; pp. 201–204. [Google Scholar]
- Ahlstrom, C.; Kircher, K.; Kircher, A. A gaze-based driver distraction warning system and its effect on visual behavior. IEEE Trans. Intell. Transp. Syst. 2013, 14, 965–973. [Google Scholar] [CrossRef]
- Tawari, A.; Martin, S.; Trivedi, M.M. Continuous head movement estimator for driver assistance: Issues, algorithms, and on-road evaluations. IEEE Trans. Intell. Transp. Syst. 2014, 15, 818–830. [Google Scholar] [CrossRef]
- Tawari, A.; Chen, K.H.; Trivedi, M.M. Where is the driver looking: Analysis of head, eye and iris for robust gaze zone estimation. In Proceedings of the 17th IEEE International Conference on Intelligent Transportation Systems, Qingdao, China, 8–11 October 2014; pp. 988–994. [Google Scholar]
- Bergasa, L.M.; Buenaposada, J.M.; Nuevo, J.; Jimenez, P.; Baumela, L. Analysing driver’s attention level using computer vision. In Proceedings of the 11th International IEEE Conference on Intelligent Transportation Systems, Beijing, China, 12–15 October 2008; pp. 1149–1154. [Google Scholar]
- Ji, Q.; Zhu, Z.; Lan, P. Real-time nonintrusive monitoring and prediction of driver fatigue. IEEE Trans. Veh. Technol. 2004, 53, 1052–1068. [Google Scholar] [CrossRef]
- Nabo, A. Driver Attention—Dealing with Drowsiness and Distraction. IVSS Project Report. Available online: http://smarteye.se/wp-content/uploads/2015/01/Nabo-Arne-IVSS-Report.pdf (accessed on 27 September 2018).
- Ji, Q.; Yang, X. Real-time eye, gaze, and face pose tracking for monitoring driver vigilance. Real Time Imaging 2002, 8, 357–377. [Google Scholar] [CrossRef]
- D’Orazio, T.; Leo, M.; Guaragnella, C.; Distante, A. A visual approach for driver inattention detection. Pattern Recognit. 2007, 40, 2341–2355. [Google Scholar] [CrossRef]
- King, D.E. Dlib-ml: A machine learning toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; pp. I-511–I-518. [Google Scholar]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Dongguk Dual Camera-based Driver Database (DDCD-DB1) with Faster R-CNN Model and Algorithm. Available online: https:// http://dm.dgu.edu/link.html (accessed on 11 October 2018).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Canziani, A.; Paszke, A.; Culurciello, E. An analysis of deep neural network models for practical applications. arxiv, 2017; arXiv:1605.07678. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- CS231n Convolutional Neural Networks for Visual Recognition. Available online: http://cs231n.github.io/convolutional-networks/#overview (accessed on 27 September 2018).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Choi, J.-S.; Bang, J.W.; Heo, H.; Park, K.R. Evaluation of fear using nonintrusive measurement of multimodal sensors. Sensors 2015, 15, 17507–17533. [Google Scholar] [CrossRef] [PubMed]
- Gao, W.; Cao, B.; Shan, S.; Chen, X.; Zhou, D.; Zhang, X.; Zhao, D. The CAS-PEAL large-scale Chinese face database and baseline evaluations. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2008, 38, 149–161. [Google Scholar]
- Nuevo, J.; Bergasa, L.M.; Jiménez, P. RSMAT: Robust simultaneous modeling and tracking. Pattern Recognit. Lett. 2010, 31, 2455–2463. [Google Scholar] [CrossRef]
- Renault Samsung SM5. Available online: https://en.wikipedia.org/wiki/Renault_Samsung_SM5 (accessed on 6 August 2018).
- GeForce GTX 1070. Available online: https://www.geforce.co.uk/hardware/desktop-gpus/geforce-gtx-1070/specifications (accessed on 27 September 2018).
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Stochastic Gradient Descent. Available online: https://en.wikipedia.org/wiki/Stochastic_gradient_descent (accessed on 14 August 2018).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Li, W.; Zhu, X.; Gong, S. Harmonious attention network for person re-identification. arxiv, 2018; arXiv:1802.08122v1. [Google Scholar]
- Precision and Recall. Available online: https://en.wikipedia.org/wiki/Precision_and_recall (accessed on 25 October 2018).
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arxiv, 2018; arXiv:1804.02767v1. [Google Scholar]
- Smith, B.A.; Yin, Q.; Feiner, S.K.; Nayar, S.K. Gaze locking: Passive eye contact detection for human-object interaction. In Proceedings of the 26th Annual ACM Symposium on User Interface Software and Technology, St. Andrews, UK, 8–11 October 2013; pp. 271–280. [Google Scholar]






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
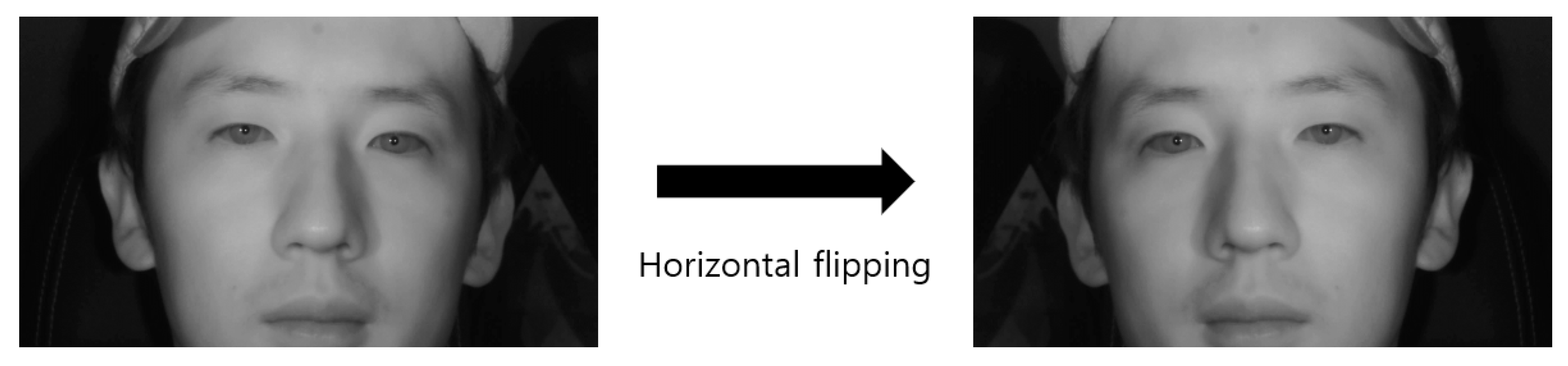{kind=link}
{kind=link}
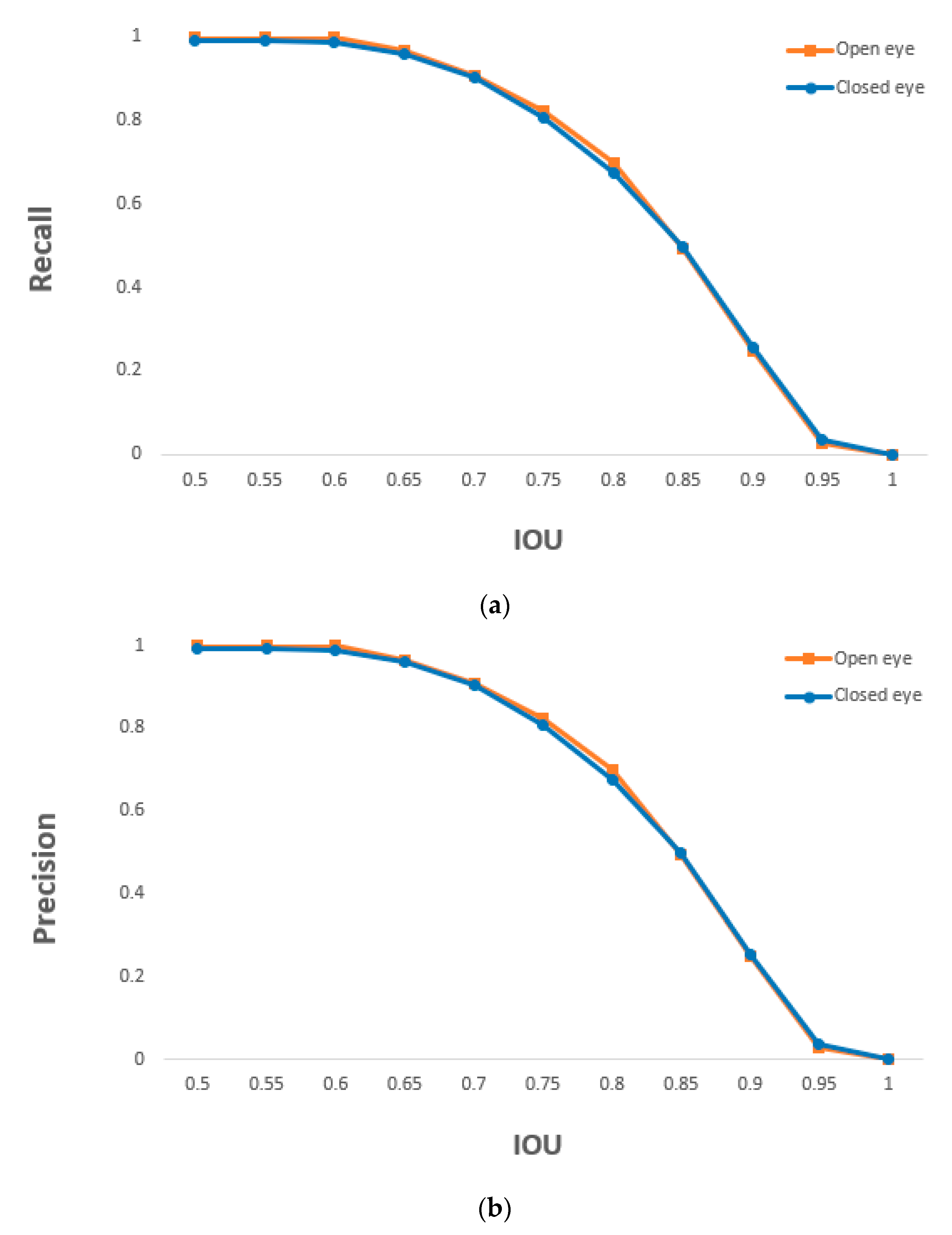{kind=link}
{kind=link}
{kind=link}
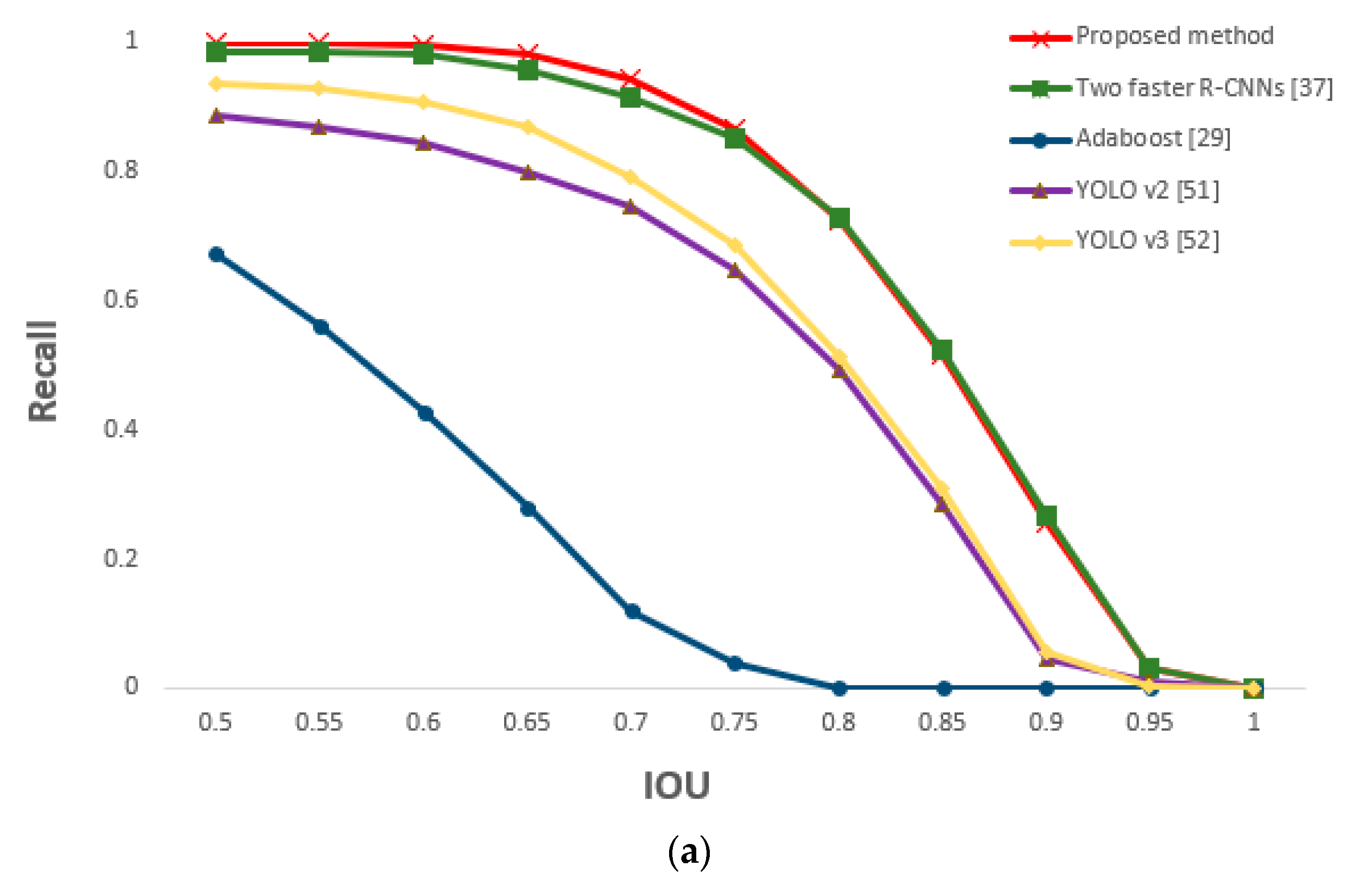{kind=link}
{kind=link}
{kind=link}
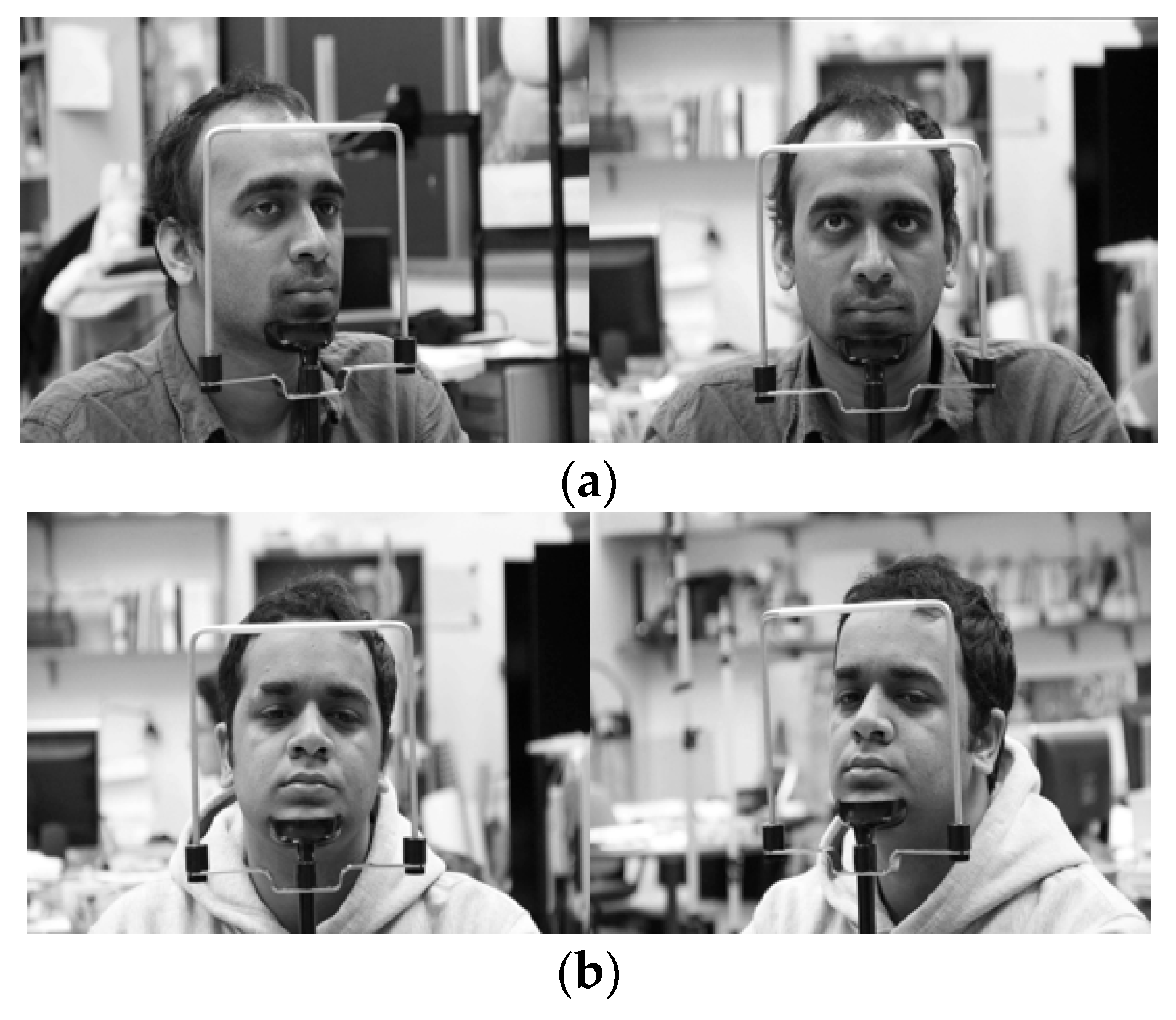{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Methods | Advantage | Disadvantage | ||
|---|---|---|---|---|---|
| Single-camera-based | A single camera is used to detect driver’s eye region [12,13,14,15,16,17] | Relatively faster processing speed owing to low computational cost compared with the multiple-camera-based method | - Vulnerable to the driver’s head movements and rotations | ||
| - Low detection reliability owing to the use of image information from only one camera | |||||
| Multiple-camera-based | Non-training-based method | Using commercial eye tracker [18,19,20] | - High detection reliability achieved by combining image information from two cameras - Driver allowed to freely move his head - Provides relatively high image resolution even when the driver moves his head | Possible to measure gaze direction through eye detection | Use of expensive commercial eye-tracker |
| Facial-feature-points-based method [22,23] | Possible to simply detect eye region during facial feature point detection | Additional process of face detection or facial landmarks detection is required | |||
| Bright-and-dark pupil-based method [24,26] | - Possible to detect eyes in various environments with nearby light using NIR illuminator | - Eye detection is difficult if movements are severe, glasses are worn, or distance from camera is far | |||
| - Faster eye detection possible through simple computation process | - NIR illuminator device is large, making application in actual vehicle environment difficult | ||||
| Training-based method | Hough transform and neural network [27] | - Effective eye validation through training method | - Large amount of data required for training | ||
| - Experiment conducted for only the front camera of the two cameras - As the training-based method is used only in detected eye validation, improvement of detection performance is limited | |||||
| Faster R-CNN & geometric-transformation-based method (proposed method) | - Miniature NIR camera and illuminator used to detect eyes in various nearby lighting conditions | - Large amount of data and time used for training of faster R-CNN | |||
| - Improves processing speed by solving the problem of high computational cost in multiple-camera-based method | |||||
| - Superior eye detection performance through the application of CNN-based method | |||||
| Layer Type | Number of Filters | Size of Output (Height × Width × Channel) | Size of Kernel | Number of Strides | Number of Paddings |
|---|---|---|---|---|---|
| Input layer | 800 × 1400 × 3 | ||||
| 1_1st CL | 64 | 800 × 1400 × 64 | 3 × 3 × 3 | 1 × 1 | 1 × 1 |
| 1_2nd CL | 64 | 800 × 1400 × 64 | 3 × 3 × 64 | 1 × 1 | 1 × 1 |
| Max pooling layer | 1 | 400 × 700 × 64 | 2 × 2 × 1 | 2 × 2 | 0 × 0 |
| 2_1st CL | 128 | 400 × 700 × 128 | 3 × 3 × 64 | 1 × 1 | 1 × 1 |
| 2_2nd CL | 128 | 400 × 700 × 128 | 3 × 3 × 128 | 1 × 1 | 1 × 1 |
| Max pooling layer | 1 | 200 × 350 × 128 | 2 × 2 × 1 | 2 × 2 | 0 × 0 |
| 3_1st CL | 256 | 200 × 350 × 256 | 3 × 3 × 128 | 1 × 1 | 1 × 1 |
| 3_2nd CL | 256 | 200 × 350 × 256 | 3 × 3 × 256 | 1 × 1 | 1 × 1 |
| 3_3rd CL | 256 | 200 × 350 × 256 | 3 × 3 × 256 | 1 × 1 | 1 × 1 |
| Max pooling layer | 1 | 100 × 175 × 256 | 2 × 2 × 1 | 2 × 2 | 0 × 0 |
| 4_1st CL | 512 | 100 × 175 × 512 | 3 × 3 × 256 | 1 × 1 | 1 × 1 |
| 4_2nd CL | 512 | 100 × 175 × 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 |
| 4_3rd CL | 512 | 100 × 175 × 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 |
| Max pooling layer | 1 | 50 × 88 × 512 | 2 × 2 × 1 | 2 × 2 | 0 × 1 |
| 5_1st CL | 512 | 50 × 88 × 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 |
| 5_2nd CL | 512 | 50 × 88 × 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 |
| 5_3rd CL | 512 | 50 × 88 × 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 |
| Layer Type | Number of Filters | Size of Output | Size of Kernel | Number of Strides | Number of Paddings |
|---|---|---|---|---|---|
| [5_3rd CL] Input layer | 50 × 88 × 512 | ||||
| 6th CL (ReLU) | 512 | 50 × 88 × 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 |
| Classification CL (Softmax) | 18 | 50 × 88 × 18 | 1 × 1 × 512 | 1 × 1 | 0 × 0 |
| [6th CL] Regression CL | 36 | 50 × 88 × 36 | 1 × 1 × 512 | 1 × 1 | 0 × 0 |
| Layer Type | Size of Output |
|---|---|
| [5_3rd CL] [RPN proposal region] Input layer | 50 × 88 × 512 (height × width × depth) 300 × 4 (ROI coordinate *) |
| ROI pooling layer | 7 × 7 × 512 (height × width × depth) × 300 |
| 1st FCL (ReLU) (Dropout) | 4096 × 300 |
| 2nd FCL (ReLU) (Dropout) | 4096 × 300 |
| Classification FCL (Softmax) | 3 × 300 |
| [2nd FCL] Regression FCL | 4 × 300 |
| Two-Fold Cross Validation | Training | Testing |
|---|---|---|
| 1st fold validation | 75,975 (3039 25) images from 13 people | 3149 images from 13 people |
| 2nd fold validation | 78,725 (3149 25) images from 13 people | 3039 images from 13 people |
| Accuracy | 1st Fold Validation | 2nd Fold Validation | Average |
|---|---|---|---|
| Our shallow CNN | 99.42 | 100 | 99.71 |
| Two-Fold Cross Validation | Kinds of Images | Training (Augmented Images) |
|---|---|---|
| 1st fold validation | Open eye images | 8974 (4487 2) |
| Closed eye images | 9248 (4624 2) | |
| Total | 18,222 (9111 2) | |
| 2nd fold validation | Open eye images | 10,272 (5136 2) |
| Closed eye images | 9004 (4502 2) | |
| Total | 19,276 (9638 2) |
| Class | Recall | Precision |
|---|---|---|
| Open eye | 0.9989 | 1 |
| Closed eye | 0.9906 | 0.9916 |
| Method | Recall | Precision | Processing Time (Unit: ms) |
|---|---|---|---|
| AdaBoost [29] | 0.67 | 0.17 | 65 |
| YOLO v2 [51] | 0.89 | 0.92 | 40 |
| YOLO v3 [52] | 0.93 | 0.94 | 62 |
| Two faster R-CNNs [37] (without shallow CNN) | 0.98 | 0.99 | 236 |
| Proposed method | 0.99 | 1 | 121 |
| 1st Fold Validation | 2nd Fold Validation | Average | |
|---|---|---|---|
| Accuracy | 99.23 | 98.87 | 99.05 |
| Method | Recall | Precision | Processing Time (Unit: ms) |
|---|---|---|---|
| AdaBoost [29] | 0.07 | 0.04 | 67 |
| YOLO v2 [51] | 0.64 | 0.80 | 41 |
| Two faster R-CNNs [37] (without shallow CNN) | 0.81 | 0.82 | 235 |
| Proposed method | 0.88 | 0.87 | 126 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, S.H.; Yoon, H.S.; Park, K.R. Faster R-CNN and Geometric Transformation-Based Detection of Driver’s Eyes Using Multiple Near-Infrared Camera Sensors. Sensors 2019, 19, 197. https://doi.org/10.3390/s19010197
Park SH, Yoon HS, Park KR. Faster R-CNN and Geometric Transformation-Based Detection of Driver’s Eyes Using Multiple Near-Infrared Camera Sensors. Sensors. 2019; 19(1):197. https://doi.org/10.3390/s19010197
Chicago/Turabian StylePark, Sung Ho, Hyo Sik Yoon, and Kang Ryoung Park. 2019. "Faster R-CNN and Geometric Transformation-Based Detection of Driver’s Eyes Using Multiple Near-Infrared Camera Sensors" Sensors 19, no. 1: 197. https://doi.org/10.3390/s19010197
APA StylePark, S. H., Yoon, H. S., & Park, K. R. (2019). Faster R-CNN and Geometric Transformation-Based Detection of Driver’s Eyes Using Multiple Near-Infrared Camera Sensors. Sensors, 19(1), 197. https://doi.org/10.3390/s19010197