Development of Limited-Angle Iterative Reconstruction Algorithms with Context Encoder-Based Sinogram Completion for Micro-CT Applications


 , ,
, ,
Abstract
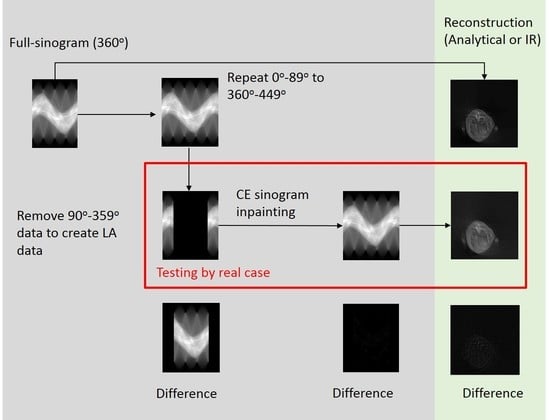
1. Introduction
2. Materials and Methods
2.1. Context-Encoder-Based Sinogram Completion
2.2. Derivation of Image-Quality-Based Stopping-Criteria for IR Reconstruction Algorithms
2.3. Micro-CT System and Experiment Design
2.4. Manipulation of the Limited Angle Sinogram
2.5. Scanning Protocol and Experiment Design
2.6. Performance Evaluation by Physical Phantoms
2.7. Real Animal Application and Dose Evaluation
3. Results and Discussion
3.1. Evaluation of Completed Sinogram by CE
3.2. Numerical Reconstruction Evaluation
3.3. Physical Phantom and Animal Micro-CT Image Evaluation
3.4. Exposure Dose
4. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Prince, J.L.; Willsky, A.S. Constrained sinogram restoration for limited-angle tomography. Opt. Eng. 1990, 29, 535–545. [Google Scholar]
- Choi, J.K.; Dong, B.; Zhang, X. Limited tomography reconstruction via tight frame and simultaneous sinogram extrapolation. J. Comput. Math. 2016, 34, 575–589. [Google Scholar] [CrossRef]
- Ehman, E.C.; Yu, L.; Manduca, A.; Hara, A.K.; Shiung, M.M.; Jondal, D.; Lake, D.S.; Paden, R.G.; Blezek, D.J.; Bruesewitz, M.R. Methods for clinical evaluation of noise reduction techniques in abdominopelvic CT. Radiographics 2014, 34, 849–862. [Google Scholar] [CrossRef] [PubMed]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Candès, E.J.; Wakin, M.B. An introduction to compressive sampling. IEEE Signal Process. Mag. 2008, 25, 21–30. [Google Scholar] [CrossRef]
- Dong, F.; Zhang, H.; Kong, D.-X. Nonlocal total variation models for multiplicative noise removal using split Bregman iteration. Math Comput. Model. 2012, 55, 939–954. [Google Scholar] [CrossRef]
- Sidky, E.Y.; Pan, X. Image reconstruction in circular cone-beam computed tomography by constrained, total-variation minimization. Phys. Med. Biol. 2008, 53, 4777–4807. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Wang, G. Compressed sensing based interior tomography. Phys. Med. Biol. 2009, 54, 2791–2805. [Google Scholar] [CrossRef] [PubMed]
- Xu, Q.; Yu, H.; Mou, X.; Zhang, L.; Hsieh, J.; Wang, G. Low-dose X-ray CT reconstruction via dictionary learning. IEEE Trans. Med. Imaging 2012, 31, 1682–1697. [Google Scholar] [PubMed]
- Chen, H.; Zhang, Y.; Kalra, M.K.; Lin, F.; Chen, Y.; Liao, P.; Zhou, J.; Wang, G. Low-dose CT with a residual encoder-decoder convolutional neural network. IEEE Trans. Med. Imaging 2017, 36, 2524–2535. [Google Scholar] [CrossRef] [PubMed]
- Kelly, B.; Matthews, T.P.; Anastasio, M.A. Deep learning-guided image reconstruction from incomplete data. arXiv preprint, 2017; arXiv:1709.00584. [Google Scholar]
- Adler, J.; Öktem, O. Solving ill-posed inverse problems using iterative deep neural networks. Inverse Probl. 2017, 33, 124007. [Google Scholar] [CrossRef]
- Bian, J.; Siewerdsen, J.H.; Han, X.; Sidky, E.Y.; Prince, J.L.; Pelizzari, C.A.; Pan, X. Evaluation of sparse-view reconstruction from flat-panel-detector cone-beam CT. Phys. Med. Biol. 2010, 55, 6575–6599. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Jin, X.; Li, L.; Wang, G. A limited-angle CT reconstruction method based on anisotropic TV minimization. Phys. Med. Biol. 2013, 58, 2119–2141. [Google Scholar] [CrossRef] [PubMed]
- Han, X.; Bian, J.; Eaker, D.R.; Kline, T.L.; Sidky, E.Y.; Ritman, E.L.; Pan, X. Algorithm-enabled low-dose micro-CT imaging. IEEE Trans. Med. Imaging 2011, 30, 606–620. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Bovik, A.C. A universal image quality index. IEEE Signal Process. Lett. 2002, 9, 81–84. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Feldkamp, L.; Davis, L.; Kress, J. Practical cone-beam algorithm. J. Opt. Soc. Am. 1984, 1, 612–619. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Sidky, E.Y.; Kao, C.-M.; Pan, X. Accurate image reconstruction from few-views and limited-angle data in divergent-beam CT. J. X-Ray Sci. Technol. 2006, 14, 119–139. [Google Scholar]
- Yan, M. General convergent expectation maximization (EM)-type algorithms for image reconstruction with background emission and poisson noise. Inverse Probl. 2011, 7, 1007–1029. [Google Scholar] [CrossRef]
- Panin, V.; Zeng, G.; Gullberg, G. Total variation regulated EM algorithm [SPECT reconstruction]. IEEE Trans. Nucl. Sci. 1999, 46, 2202–2210. [Google Scholar] [CrossRef]
- Kyriakopoulos, K.G.; Parish, D.J. Compressing computer network measurements using embedded zerotree wavelets. In Proceedings of the AICT’09 Fifth Advanced International Conference on Telecommunications, Venice, Italy, 24–28 May 2009; pp. 188–193. [Google Scholar]
- Tu, S.H.; Chen, Y.C.; Hsiao, T.C.; Jin, S.C.; Chen, J.C. Development of LabVIEW Based Micro Computed Tomography System on Vertical Rotary Gantry. In Proceedings of the 6th European Conference of the International Federation for Medical and Biological Engineering, Dubrovnik, Croatia, 7–11 September 2014; pp. 273–276. [Google Scholar]
- Boll, H.; Bag, S.; Schambach, S.J.; Doyon, F.; Nittka, S.; Kramer, M.; Groden, C.; Brockmann, M.A. High-speed single-breath-hold micro-computed tomography of thoracic and abdominal structures in mice using a simplified method for intubation. J. Comput. Assist. Tomogr. 2010, 34, 783–790. [Google Scholar] [CrossRef] [PubMed]
- Boll, H.; Nittka, S.; Doyon, F.; Neumaier, M.; Marx, A.; Kramer, M.; Groden, C.; Brockmann, M.A. Micro-CT based experimental liver imaging using a nanoparticulate contrast agent: A longitudinal study in mice. PLoS ONE 2011, 6, e25692. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Generator | Discriminator | |
|---|---|---|
| Encoder | Decoder | |
| 3 × 3, d = 2, conv, ↓, LeakyRELU(0.2), BN(0.8) | 34 × 17, d = 16, fully-connected | 3 × 3, d = 64, conv, ↓, LeakyRELU(0.2), BN(0.8) |
| 3 × 3, d = 4, conv, ↓, LeakyRELU(0.2), BN(0.8) | 3 × 3, d = 16, conv, ↑, RELU, BN(0.8) | 3 × 3, d = 128, conv, ↓, LeakyRELU(0.2), BN(0.8) |
| 3 × 3, d = 8, conv, ↓, LeakyRELU(0.2), BN(0.8) | 3 × 3, d = 8, conv, ↑, RELU, BN(0.8) | 3 × 3, d = 128, conv, LeakyRELU(0.2), BN(0.8) |
| 3 × 3, d = 16, conv, ↓, LeakyRELU(0.2), BN(0.8), Drop(0.5) | 3 × 3, d = 4, conv, ↑, RELU, BN(0.8) | 104,448 fully-connected |
| 21,696 fully-connected | 3 × 3, d = 2, conv, ↑, RELU, BN(0.8) | 1 fully-connected, sigmoid |
| 3 × 3, d = 1, tanh | ||
| Pre-Processing Procedure | Dimensions (voxel) | Voxel Size (um) | Sinogram Radial Sampling (degree) |
|---|---|---|---|
| CT reconstructed image | 864 × 864 × 1536 | 69.00 | |
| Slice selection (air region rejection) | 864 × 864 × 500 | 69.00 | |
| Binning 2 × 2 | 432 × 432 × 250 | 138.00 | |
| ROI selection and isotropic air region rejection for training data, with flip, random rotation to do data argumentation) | 380 × 380 × 250 | 138.00 | |
| Forward projection to create sinogram data (replaced by 0 from the 90–359° region and repeated 0–89° information after 360–449°) | 541 × 450 × 250 | 75.00 | 1.00 |
| Resizing of the sinogram to meet the input size of the CE architecture | 544 × 448 × 250 | 74.586 | 1.004 |
| The CE inpainted sinogram | 544 × 448 × 250 | 74.586 | 1.004 |
| Reconstruction to image domain with bilinear interpolation | 864 × 864 × 500 | 68.61 |
| Type of Object (Training) | Random Number Generated Events | Number per Slice | Total Sinograms Generated |
|---|---|---|---|
| Digital cylinder phantom | Number of cylinders (1–4), center of cylinder (initial x, y position), cylinder radius (from 10 to 20 pixel), initial phantom rotated angle (in degrees), reflection (yes/no), reversed rotation (yes/no) | 250 random build per slice | 1.250 |
| 2D Shepp-Logan phantom | Initial phantom rotated angle (in degree), reflection (yes/no), reversed rotation (yes/no) | 250 initial random rotated per slice | 1.250 |
| MOBY digital mouse phantom | Slice number (1-208 in axial direction), initial rotated angle (in degree), reflection (yes/no), reversed rotation (yes/no) | 125 slices from MOBY phantom (208 slices) | 1.250 |
| MINST dataset (Digit numbers 0–9) | Randomly select 125 images per digit | Numbers 0–9, total 10 sets | 1.250 |
| 3D Shepp-Logan phantom | Center 200 from 500 slices (remove air region) | 200 | 200 |
| QRM quality assurance phantom | Select 450 from 500 slices, from 4 phantoms (wire phantom, contrast, water phantom and hydroxyl-appetite) | 450 × 4 phantoms | 1.800 |
| Animal data | Use total 500 slice data from 6 mice (covered from head to pelvic region) | 500 × 6 mice | 3.000 |
| Domain Type | Sinogram Domain | Image Domain | |||||
|---|---|---|---|---|---|---|---|
| Items | LA Figure 5b | CE Figure 5c | FDK (LA) Figure 6b | EM-TV (LA) Figure 6c | FDK (CE) Figure 6d | EM-TV (CE) Figure 6e | EM-TV (CE+IQ) Figure 6f |
| PSNR (dB) | 10.1623 | 40.2738 | 13.9891 | 14.0356 | 24.1986 | 25.1891 | 26.6432 |
| UIQI | 0.3095 | 0.9993 | 0.5066 | 0.5109 | 0.8865 | 0.9023 | 0.9106 |
| SSIM | 0.3095 | 0.9993 | 0.8107 | 0.8123 | 0.9552 | 0.9612 | 0.9813 |
| Acquisition Protocol | Dose Measurement | |
|---|---|---|
| Absorption Dose (mGy) | Effective Dose (μSv) | |
| LA mode | 0.2353 ± 0.30% | 0.1093 ± 0.30% |
| DSFC | 0.9626 ± 0.31% | 0.4470 ± 0.31% |
| LSFC | 0.2005 ± 0.28% | 0.0931 ± 0.28% |
| Dose rate per projection in 1 second | 0.0027 ± 0.31% | 0.0012 ± 0.31% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, S.-C.; Hsieh, C.-J.; Chen, J.-C.; Tu, S.-H.; Chen, Y.-C.; Hsiao, T.-C.; Liu, A.; Chou, W.-H.; Chu, W.-C.; Kuo, C.-W. Development of Limited-Angle Iterative Reconstruction Algorithms with Context Encoder-Based Sinogram Completion for Micro-CT Applications. Sensors 2018, 18, 4458. https://doi.org/10.3390/s18124458
Jin S-C, Hsieh C-J, Chen J-C, Tu S-H, Chen Y-C, Hsiao T-C, Liu A, Chou W-H, Chu W-C, Kuo C-W. Development of Limited-Angle Iterative Reconstruction Algorithms with Context Encoder-Based Sinogram Completion for Micro-CT Applications. Sensors. 2018; 18(12):4458. https://doi.org/10.3390/s18124458
Chicago/Turabian StyleJin, Shih-Chun, Chia-Jui Hsieh, Jyh-Cheng Chen, Shih-Huan Tu, Ya-Chen Chen, Tzu-Chien Hsiao, Angela Liu, Wen-Hsiang Chou, Woei-Chyn Chu, and Chih-Wei Kuo. 2018. "Development of Limited-Angle Iterative Reconstruction Algorithms with Context Encoder-Based Sinogram Completion for Micro-CT Applications" Sensors 18, no. 12: 4458. https://doi.org/10.3390/s18124458
APA StyleJin, S.-C., Hsieh, C.-J., Chen, J.-C., Tu, S.-H., Chen, Y.-C., Hsiao, T.-C., Liu, A., Chou, W.-H., Chu, W.-C., & Kuo, C.-W. (2018). Development of Limited-Angle Iterative Reconstruction Algorithms with Context Encoder-Based Sinogram Completion for Micro-CT Applications. Sensors, 18(12), 4458. https://doi.org/10.3390/s18124458