LCSS-Based Algorithm for Computing Multivariate Data Set Similarity: A Case Study of Real-Time WSN Data

 , ,
, ,  ,
,  , , , and
, , , and
Abstract
1. Introduction
2. Background and Previous Work
3. Proposed Technique: An Overview
3.1. Preprocessing Phase
3.2. Proposed Mechanism
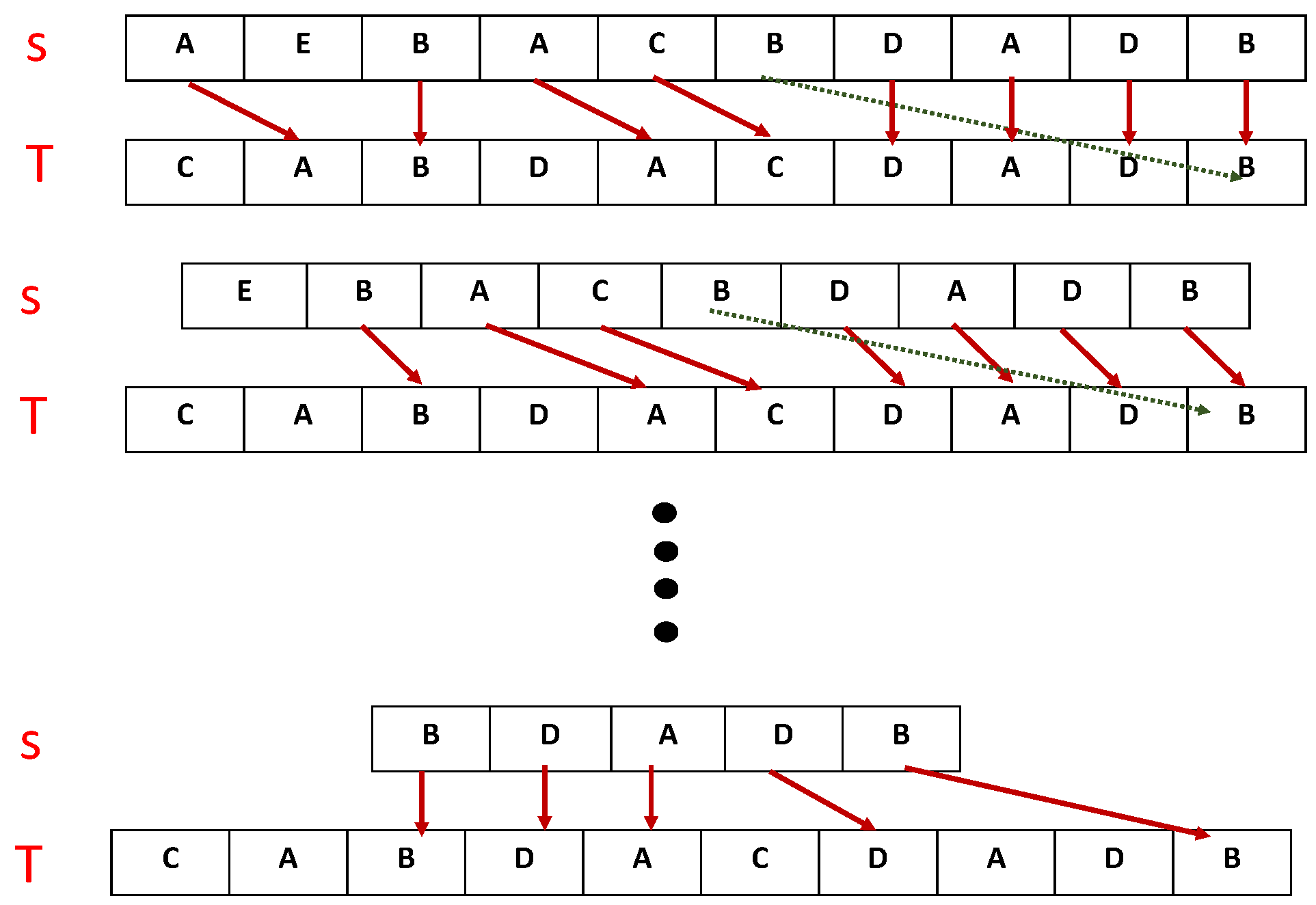
4. Proposed LCSS Calculation Mechanism
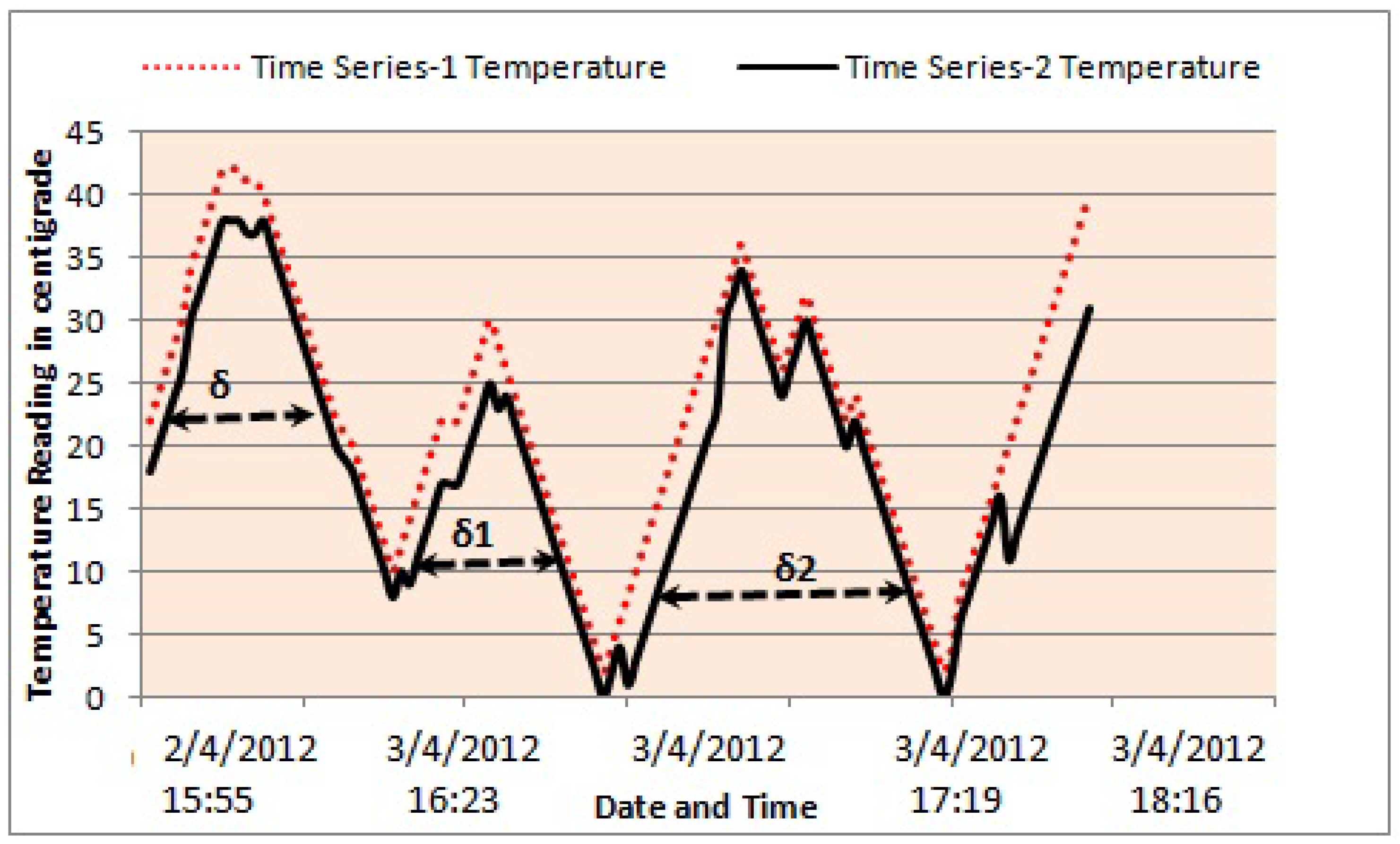
4.1. Proposed Sequential Approach for Multivariate Time Series: Real-Time Data Set of WSN
4.2. Proposed Approach Mathematical Background
4.3. Proposed Multivariate LCSS Algorithm
| Algorithm 1 Multivariate LCSS Calculation Procedure. |
| Require: Multivariate data sets similarity Ensure: Return Longest Common Subsequence
|
5. Complexity Analysis and Results Discussion
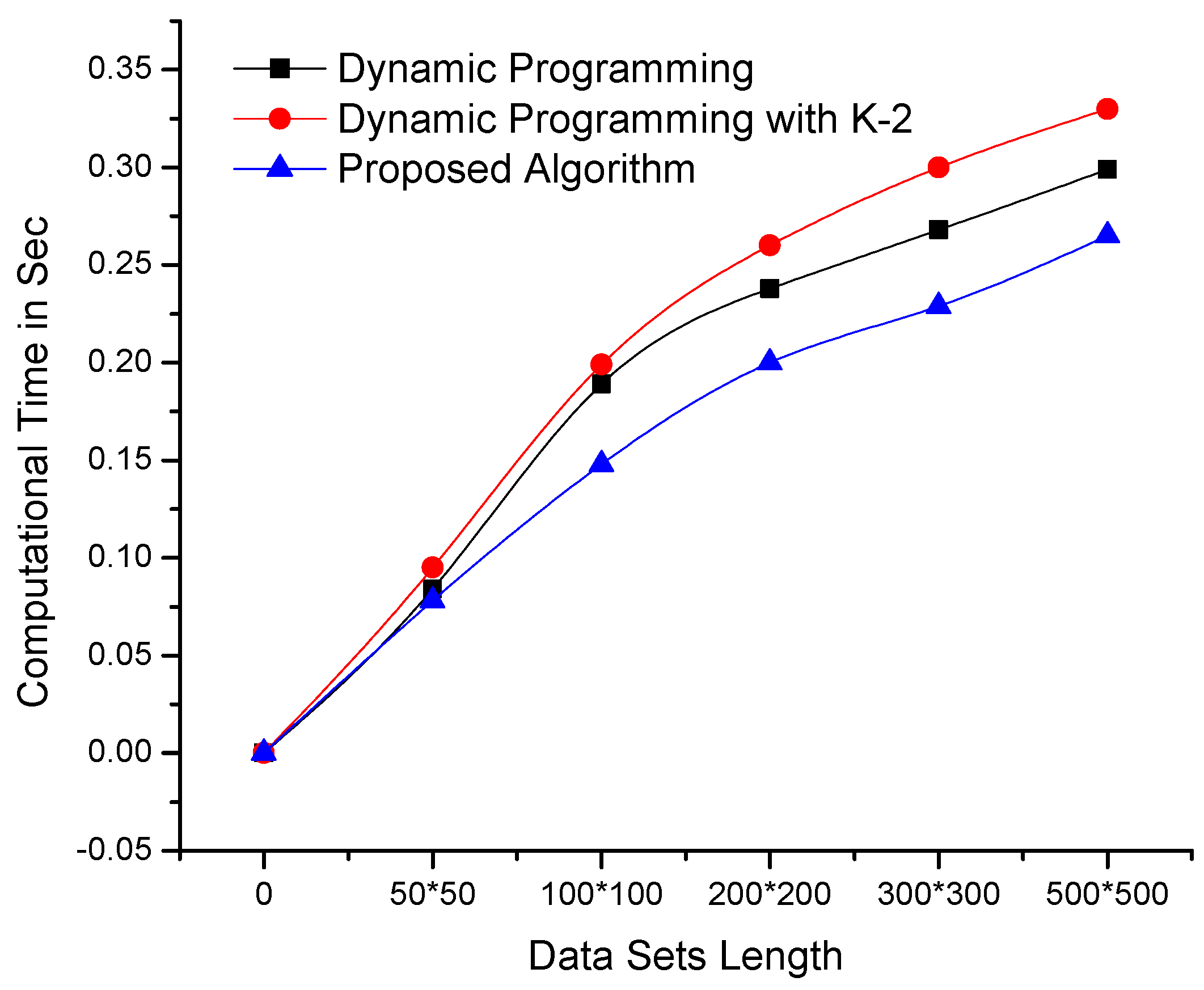
5.1. Proposed Algorithm Complexity Analysis
5.2. Results and Discussion
6. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Polak, A. Why is it hard to beat O(n2) for Longest Common Weakly Increasing Subsequence? Inf. Process. Lett. 2018, 132, 1–5. [Google Scholar] [CrossRef]
- Wang, X.; Mueen, A.; Ding, H.; Trajcevski, G.; Scheuermann, P.; Keogh, E. Experimental comparison of representation methods and distance measures for time series data. Data Min. Knowl. Discov. 2013, 26, 275–309. [Google Scholar] [CrossRef]
- Mikalsen, K.Ø; Bianchi, F.M.; Soguero-Ruiz, C.; Jenssen, R. Time series cluster kernel for learning similarities between multivariate time series with missing data. Pattern Recognit. 2018, 76, 569–581. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Tseng, K.T.; Chan, D.S.; Yang, C.B.; Lo, S.F. Efficient merged longest common subsequence algorithms for similar sequences. Theor. Comput. Sci. 2018, 708, 75–90. [Google Scholar] [CrossRef]
- Li, Y.; Li, H.; Duan, T.; Wang, S.; Wang, Z.; Cheng, Y. A real linear and parallel multiple longest common subsequences (MLCS) algorithm. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1725–1734. [Google Scholar]
- Wang, H. All Common Subsequences. IJCAI 2007, 7, 635–640. [Google Scholar]
- Silva, D.F.; Giusti, R.; Keogh, E.; Batista, G.E. Speeding up similarity search under dynamic time warping by pruning unpromising alignments. Data Min. Knowl. Discov. 2018, 32, 988–1016. [Google Scholar] [CrossRef]
- Chatfield, C. Introduction to Multivariate Analysis; Routledge: New York, NY, USA, 2018. [Google Scholar]
- Breiman, L. Classification and Regression Trees; Routledge: New York, NY, USA, 2017. [Google Scholar]
- Chiu, B.; Keogh, E.; Lonardi, S. Probabilistic discovery of time series motifs. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–27 August 2003; pp. 493–498. [Google Scholar]
- Mueen, A.; Keogh, E.; Zhu, Q.; Cash, S.; Westover, B. Exact discovery of time series motifs. In Proceedings of the 9th SIAM International Conference on Data Mining, Sparks, NV, USA, 30 April–2 May 2009; pp. 473–484. [Google Scholar]
- Lin, X.; Li, Z. The similarity of multivariate time series and its application. In Proceedings of the 4th International Conference on Management of e-Commerce and e-Government, Chengdu, China, 23–24 October 2010; pp. 76–81. [Google Scholar]
- Benson, G.; Levy, A.; Shalom, B.R. Longest common subsequence in k length substrings. In Proceedings of the 6th International Conference on Similarity Search and Applications, Galicia, Spain, 2–4 October 2013; pp. 257–265. [Google Scholar]
- Deorowicz, S.; Grabowski, S. Efficient algorithms for the longest common subsequence in k-length substrings. Inf. Process. Lett. 2014, 114, 634–638. [Google Scholar] [CrossRef]
- Sadiq, A.S.; Alkazemi, B.; Mirjalili, S.; Ahmed, N.; Khan, S.; Ali, I.; Pathan, A.S.K.; Ghafoor, K.Z. An Efficient IDS Using Hybrid Magnetic Swarm Optimization in WANETs. IEEE Access 2018, 6, 29041–29053. [Google Scholar] [CrossRef]
- Ueki, Y.; Hendrian, D.; Kurihara, M.; Matsuoka, Y.; Narisawa, K.; Yoshinaka, R.; Bannai, H.; Inenaga, S.; Shinohara, A. Longest common subsequence in at least k length order-isomorphic substrings. In Proceedings of the 43rd International Conference on Current Trends in Theory and Practice of Computer Science, Limerick, Ireland, 16–20 January 2017; pp. 363–374. [Google Scholar]
- Shahabi, C.; Yan, D. Real-time Pattern Isolation and Recognition Over Immersive Sensor Data Streams. In Proceedings of the MMM 2003 9th International Conference on Multi-Media Modeling, Taipei, Taiwan, 7–10 January 2003; pp. 93–113. [Google Scholar]
- Keogh, E.; Chakrabarti, K.; Pazzani, M.; Mehrotra, S. Locally adaptive dimensionality reduction for indexing large time series databases. ACM Sigmod Rec. 2001, 30, 151–162. [Google Scholar] [CrossRef]
- Yang, K.; Shahabi, C. A PCA-based similarity measure for multivariate time series. In Proceedings of the 2nd ACM International Workshop on Multimedia Databases, Washington, DC, USA, 8–13 November 2004; pp. 65–74. [Google Scholar]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM 2011, 58, 11. [Google Scholar] [CrossRef]
- Vlachos, M.; Kollios, G.; Gunopulos, D. Discovering similar multidimensional trajectories. In Proceedings of the 18th International Conference on Data Engineering, San Jose, CA, USA, 26 February–1 March 2002; pp. 673–684. [Google Scholar]
- Duchêne, F.; Garbay, C.; Rialle, V. Similarity measure for heterogeneous multivariate time-series. In Proceedings of the 12th European Signal Processing Conference, Vienna, Austria, 6–10 September 2004; pp. 1605–1608. [Google Scholar]
- Apostolico, A. String editing and longest common subsequences. In Handbook of Formal Languages; Springer: Berlin, Germany, 1997; pp. 361–398. [Google Scholar]
- Sakurai, Y.; Yoshikawa, M.; Faloutsos, C. FTW: Fast similarity search under the time warping distance. In Proceedings of the 24th ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Baltimore, MD, USA, 13–17 June 2005; pp. 326–337. [Google Scholar]
- Rakthanmanon, T.; Campana, B.; Mueen, A.; Batista, G.; Westover, B.; Zhu, Q.; Zakaria, J.; Keogh, E. Searching and mining trillions of time series subsequences under dynamic time warping. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 262–270. [Google Scholar]
- Gorecki, T.; Luczak, M. Multivariate time series classification with parametric derivative dynamic time warping. Expert Syst. Appl. 2015, 2, 2305–2312. [Google Scholar] [CrossRef]
- Shojafar, M.; Pooranian, Z.; Naranjo, P.G.V.; Baccarelli, E. FLAPS: Bandwidth and delay-efficient distributed data searching in Fog-supported P2P content delivery networks. J. Supercomput. 2017, 73, 5239–5260. [Google Scholar] [CrossRef]
- Ramírez-Gallego, S.; Krawczyk, B.; García, S.; Woźniak, M.; Herrera, F. A survey on data preprocessing for data stream mining: Current status and future directions. Neurocomputing 2017, 239, 39–57. [Google Scholar] [CrossRef]
- Khan, R.; Ali, I.; Zakarya, M.; Ahmad, M.; Imran, M.; Shoaib, M. Technology-Assisted Decision Support System for Efficient Water Utilization: A Real-Time Testbed for Irrigation Using Wireless Sensor Networks. IEEE Access 2018, 6, 25686–25697. [Google Scholar] [CrossRef]
- Coordinators, N.R. Database resources of the national center for biotechnology information. Nucleic Acids Res. 2016, 44, D7–D19. [Google Scholar]
- Dua, D.; Karra Taniskidou, E. UCI Machine Learning Repository. 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 18 September 2017).
- Chen, Y.; Keogh, E.; Hu, B.; Begum, N.; Bagnall, A.; Mueen, A.; Batista, G. The UCR Time Series Classification Archive. Available online: http://www.cs.ucr.edu/~eamonn/time_series_data/ (accessed on 18 September 2017).
- Bay, S.D.; Kibler, D.; Pazzani, M.J.; Smyth, P. The UCI KDD archive of large data sets for data mining research and experimentation. ACM SIGKDD Explor. Newsl. 2000, 2, 81–85. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date and Time | Temperature °C | Humidity %RH | Soil Moisture (kHz) |
|---|---|---|---|
| 15 April 2011 22:00 | 35 | 92 | 780 |
| 15 April 2011 22:15 | 39 | 82 | 778 |
| 15 April 2011 22:30 | 36 | 87 | 776 |
| 15 April 2011 22:45 | 35 | 91 | 774 |
| 15 April 2011 23:00 | 37 | 85 | 772 |
| 15 April 2011 23:15 | 36 | 87 | 772 |
| 15 April 2011 23:30 | 38 | 83 | 770 |
| 15 April 2011 23:45 | 35 | 90 | 767 |
| 15 April 2011 00:00 | 38 | 82 | 762 |
| 15 April 2011 00:15 | 36 | 86 | 756 |
| Date and Time | Temperature °C | Humidity %RH | Soil Moisture (kHz) |
|---|---|---|---|
| 16 April 2011 2:00 | 37 | 85 | 782 |
| 16 April 2011 2:15 | 35 | 92 | 780 |
| 16 April 2011 2:30 | 36 | 87 | 776 |
| 16 April 2011 2:45 | 38 | 84 | 775 |
| 16 April 2011 3:00 | 35 | 91 | 774 |
| 16 April 2011 3:15 | 37 | 85 | 772 |
| 16 April 2011 3:30 | 38 | 83 | 770 |
| 16 April 2011 3:45 | 35 | 90 | 767 |
| 17 April 2011 0:00 | 38 | 81 | 762 |
| 17 April 2011 0:15 | 36 | 86 | 756 |
| Data Sets | Computational Time (Seconds) | ||
|---|---|---|---|
| DP-Based Algorithm | DP-Based Algorithm | Proposed Algorithm | |
| with k-2 | |||
| Hobolink-500 | 1.1091 | 1.1880 | 0.9220 |
| Amex-500 | 0.625 | 0.8060 | 0.5470 |
| Robotic-300 | 0.2810 | 0.3170 | 0.2650 |
| Haptitus-500 | 0.4220 | 0.4561 | 0.3910 |
| Twopattern-500 | 1.1720 | 1.2138 | 0.7810 |
| Bacteria-700 | 1.3910 | 1.7430 | 1.0470 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, R.; Ali, I.; Altowaijri, S.M.; Zakarya, M.; Ur Rahman, A.; Ahmedy, I.; Khan, A.; Gani, A. LCSS-Based Algorithm for Computing Multivariate Data Set Similarity: A Case Study of Real-Time WSN Data. Sensors 2019, 19, 166. https://doi.org/10.3390/s19010166
Khan R, Ali I, Altowaijri SM, Zakarya M, Ur Rahman A, Ahmedy I, Khan A, Gani A. LCSS-Based Algorithm for Computing Multivariate Data Set Similarity: A Case Study of Real-Time WSN Data. Sensors. 2019; 19(1):166. https://doi.org/10.3390/s19010166
Chicago/Turabian StyleKhan, Rahim, Ihsan Ali, Saleh M. Altowaijri, Muhammad Zakarya, Atiq Ur Rahman, Ismail Ahmedy, Anwar Khan, and Abdullah Gani. 2019. "LCSS-Based Algorithm for Computing Multivariate Data Set Similarity: A Case Study of Real-Time WSN Data" Sensors 19, no. 1: 166. https://doi.org/10.3390/s19010166
APA StyleKhan, R., Ali, I., Altowaijri, S. M., Zakarya, M., Ur Rahman, A., Ahmedy, I., Khan, A., & Gani, A. (2019). LCSS-Based Algorithm for Computing Multivariate Data Set Similarity: A Case Study of Real-Time WSN Data. Sensors, 19(1), 166. https://doi.org/10.3390/s19010166