1. Introduction
Among the potential applications that may be supported by Vehicular Ad-hoc NETworks (VANETs), video delivery is one of the most resource-demanding. Several application scenarios may require video delivery services in either on-demand or real-time live video streaming, using unicast, multicast or broadcast communications. We may find scenarios where video delivery is required, like the ones related to accidents/rescue assistance, V2X real-time video, context-aware video broadcasts, security surveillance services, driving assistance, etc. However, multimedia streaming over VANETs is a very challenging issue mainly due to the high mobility of vehicles, bandwidth limitations, and the high loss rates typically found in wireless communications. In addition, video transmission requires a high bandwidth with a bounded packet delay, especially when real-time restrictions are mandatory. So, when video suffers from packet losses and/or highly variable packet delays, the user perceived video quality is seriously reduced.
In this work, we analyze the performance of video delivery in a typical VANET urban scenario by means of a simulation framework named Video Delivery Simulation Framework over Vehicular Networks (VDSF-VN) [
1], which allows us to model in detail the different actors involved in a video streaming session. VDSF-VN works with the OMNeT++ simulator [
2], together with the Veins (VEhicles In Network Simulation) framework [
3] to conduct the network simulations, and with SUMO (Simulation of Urban MObility) [
4], as the vehicular traffic simulator.
Inside VDSF-VN, the selected source video sequence is encoded with the High Efficiency Video Coding (HEVC) standard [
5]. In particular, we have developed a tuned version of the HEVC reference software HM (HEVC Test Model) [
6] that it is able to seamlessly work with OMNeT++/Veins/SUMO simulation tools. Also, it has been necessary to develop several software modules, such as a packetizer/depacketizer tool, an RTP packet trace module, etc. All of these software modules are governed from a graphical application, named GatcomVideo, that will significantly improve the usability and automation of the proposed VDSF-VN framework.
Although the simulation framework provides a lot of useful performance metrics (end-to-end delay, goodput, packet delivery ratio, etc.), our main performance metric is the video quality delivered to the user, since it will be used to determine the minimum quality levels that a video delivery application should provide. After analyzing several simulation runs we notice that the received video quality becomes unacceptable when the first interferences appear in the network. So, we proceed to study some coding options implemented in the HEVC video encoder, in order to improve the final video quality delivered to the user.
These options are based on INTRA refresh and tile-based video coding techniques. On the one hand, INTRA refresh technique will help to stop the error propagation produced by a single packet loss in the prediction process of future (next) video frames. So, we have analyzed the performance of several INTRA refresh approaches in order to determine the ones which deliver a higher video quality to the user with an acceptable bit rate overhead. On the other hand, TILE-based coding allows partitioning each video frame in blocks (Tiles), which are completely independent regarding coding/decoding. This may be useful to mitigate the impact of packet losses when compared with no-tiling approaches. When no-tiling approaches (the default coding option) are used, an encoded frame is typically fragmented into several network packets. To decode the frame, all those packets need to be received. If just one packet is lost, the frame is undecodable although the rest of packets had been correctly received. If tiling is used, a frame can be partially decoded (not completely lost) improving the final video quality at the same packet error rate.
A thorough experimental process was developed in order to identify the above mentioned HEVC coding options which offer the best video quality to the user. The simulation results obtained from the experimental tests will show the behavior of the HEVC coding options under different network impairment degrees. This knowledge will provide us with the ability to decide which level of INTRA refreshing is required and how many tiles per frame should be used to guarantee the minimum video quality required by the video delivery application.
The rest of the paper is structured as follows.
Section 2 shows some related works, specifically some techniques and simulation tools used in the literature for improving the video quality perceived by the final user in wireless networks. In
Section 3, we briefly describe the video delivery simulation framework we have used in this work.
Section 4 describes the simulation methodology, the VANET scenario and the video sequence used. The simulation results of the experimental tests are presented and discussed in
Section 5. Finally, conclusions are drawn in
Section 6, along with references to future work.
2. Related Works
Many different techniques have been proposed in the literature to improve video streaming over not reliable medium like the wireless channel, in general, and VANETs, in particular [
7].
Error Concealment (EC) methods try to minimize the impact of packets loss in the perceived quality of the received video sequence [
8,
9,
10]. If any part of an encoded frame is missing, then the entire frame cannot be decoded. These EC methods try to predict the missing parts and correct them by exploiting spatial similarities of the nearby areas, or temporal redundancies in the video sequence [
11]. Spatial prediction can be only used for small areas [
12], whereas the temporal prediction can replace a whole missing frame, replacing it with a previously received frame. This is known as ’Frame Copy Concealment’ [
13]. To make an estimation of the contents of a missing area, different techniques based on Motion Vectors (MV) information can also be used.
Error Resilience (ER) is a group of techniques which aim to provide robustness to video sequences, which are applied at the sender side. One of these is the Feedback Channel (FC), in which the receiver can request the retransmission of some missing part [
14]. Other methods make use of substreams, such as Multiple Description Coding (MDC) [
15] or Layered Coding (LC).There has been a lot of research done to protect video sequences with Forward Error Correction (FEC), also known as Channel Coding [
16]. This technique inserts redundant data, called Error Correction Codes (ECCs), into the encoded video. These ECCs can be used for detecting missing data on the receiver side, and even, to recover them without retransmission, which is not feasible in some scenarios like real-time applications (e.g., live video streaming) [
17]. RaptorQ codes is an example of this kind of mechanism [
18]. FEC can be used in all kind of networks, including VANETs [
19].
Another group of ER techniques are the so-called ’intra refresh’ methods. They encode the bit stream in such a way that it prevents fast quality degradation in the presence of data losses. An inter-coded frame, a frame which it is predicted using other frames as references, although correctly received, can be affected by a reference frame with errors, and it can propagate the error to other inter-frames which use it as reference. A proper insertion of intra-coded frames together with an adequate selection of reference frames may increase the error resilience of an encoded bit stream. So, defining appropriate INTRA refresh encoding modes will make bit streams more robust. There are several works in the literature that exploit these techniques to improve video robustness like the ones found in [
20,
21,
22].
To evaluate the performance of source coding techniques we need a simulation framework to analyze their effects in the final video quality experienced by a VANET user. To measure video quality we will use the Peak Signal-to-Noise Ratio (PSNR) metric. So, the error protection of our encoder will be based on those encoding options which provide a better received video quality, taking into account the bit rate overhead which they typically provide.
There are several simulation frameworks proposed in the literature that follow our requirements, like EvalVid [
23], which allows the video quality evaluation of MPEG4 video transmitted over a real or simulated communication network. Besides measuring several metrics of the underlying network, like loss rate, delay, and jitter, they also support a video quality evaluation of the received video based on the frame-by-frame PSNR calculation. Although no specific network simulator is proposed, authors argue that theoretically any simulator could be used. In this sense, several works have extended EvalVid to include a network simulator. For example, in [
24] EvalVid is integrated with ns-2. In [
25] authors developed a tool named QoE Monitor, which is based on the EvalVid architecture and consists of a new module for the ns-3 simulator. Beside this, this tool can be extended with current video coding standards. In [
26] a simulation framework named Mobile Multi-Media Wireless Sensor Networks (M3WSN) is presented, which is based on EvalVid too. This framework uses the OMNeT++ simulator and Castalia framework [
27].
Another example is HEVStream [
28], which is a realistic testbed environment that aims to evaluate HEVC video streaming under different conditions. However, it is hardware-based and we need to use the simulation technique because our target is to evaluate video streaming in vehicular networks.
Despite of the different existing video frameworks (most of them based on the initial EvalVid approach), none of them allows the transmission and quality evaluation of video sequences with the combination of the OMNeT++ simulator, the Veins framework and the SUMO traffic mobility model for vehicular networks. Some analyzed frameworks lack of an updated video codec module, being not trivial to change it with another one, because the packetizer needs to be properly adapted to the intrinsic features of the target bit stream syntax. Also, node mobility models are too simple in most approaches to fit with the particularities of vehicular networks (roads, streets, lanes, stops, traffic lights, etc.). In addition, finally, the different modules of the framework need to be completely integrated in order to launch global simulations specifying the detailed configuration of every module, and performing, on the fly, all the processes, from the video encoding at source node to the decoding process at the receiver end, passing through the network simulation of the video delivery in a realistic vehicular network scenario. These aspects have motivated us to develop the VDSF-VN [
1] simulation framework which it is especially suited for vehicular networks. VDSF-VN is the simulation framework that we use in this work, so we provide a brief introduction of it in the following section.
3. Simulation Framework: VDSF-VN
In
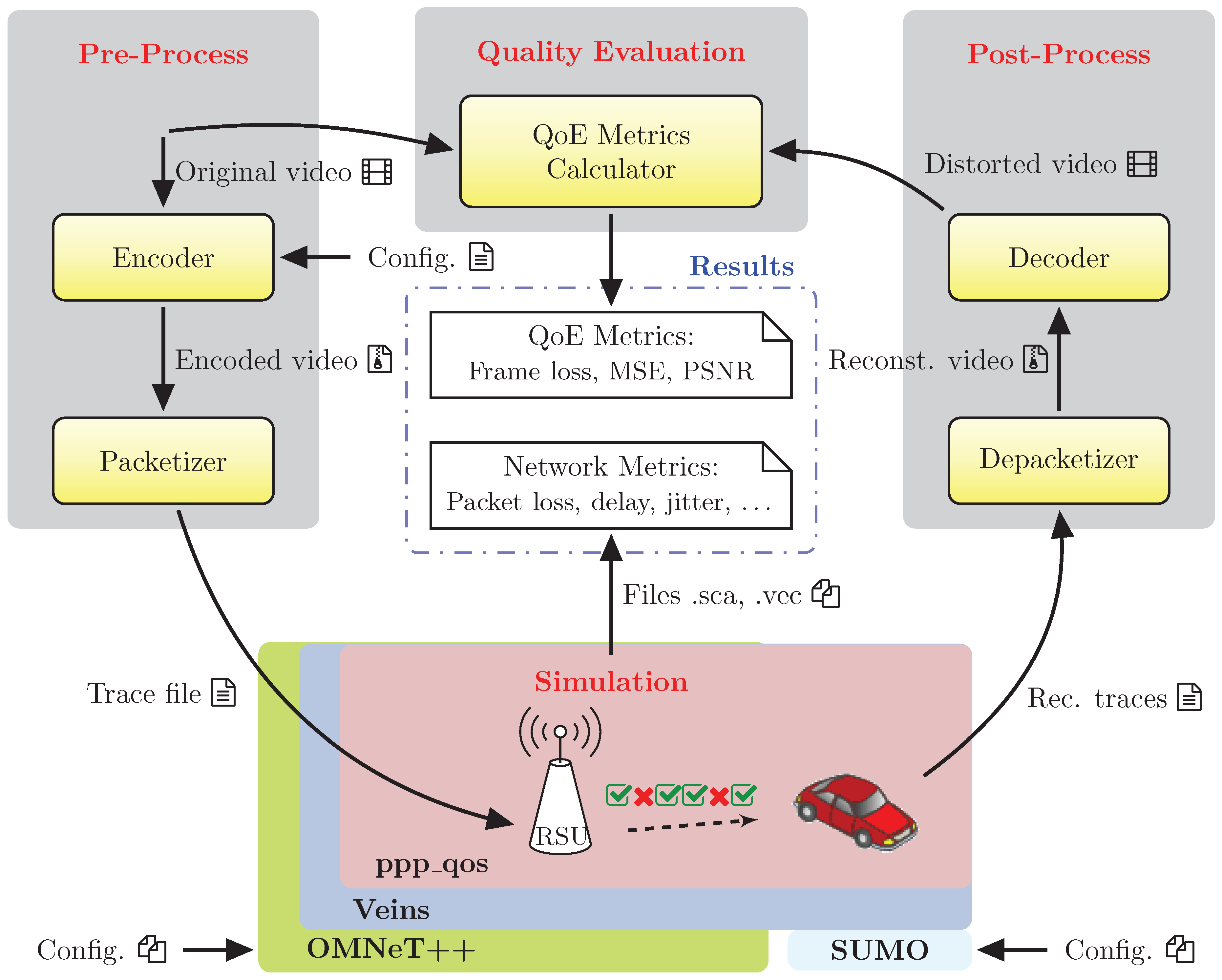
Figure 1, we show the different elements that form the VDSF-VN simulation framework architecture. Some of those elements have to do with the video coding and decoding processes (encoder, packetizer, etc.), whereas some others are related to the simulation process (OMNeT++, Veins and SUMO). Apart from these, a graphical application named “GatcomVideo” was developed which acts as a front-end that manages the whole process. Finally, in order to build the simulation network and configuration files, the “GatcomSUMO” [
29] application was also developed to ease all the configuration duties by means of a Graphical User Interface (GUI).
The VDSF-VN framework coordinates and manages all the necessary tasks involved with this kind of experiments, such as, source video encoding, trace files generation, video decoding tasks, running the simulation sequences and obtaining the desired plots from the simulation statistic results. VDSF-VN was also designed to be multithread-aware, so several tasks or simulation runs may be launched in parallel depending on the available hardware resources.
As depicted in
Figure 1, all of these tasks can be structured in three main steps: (1) pre-process, (2) simulation, and (3) post-process.
Pre-process: This step is in charge of encoding the desired video sequences and then perform the Real-time Transmission Protocol (RTP) packetization of the encoded bit stream and generate the corresponding video trace file. This step is a time-consuming task, because the video encoding requires a great amount of computation and the video sequence may be encoded with different configuration parameter sets.
Simulation: This step includes the actions to prepare the network scenario and run the simulations with OMNeT++, Veins and SUMO. The trace file from the pre-process step is loaded by the video servers to simulate the video broadcasting. During the simulation, the client nodes write the correctly received video packets into an output trace file, which will be used in the post-process step. This is done in an OMNeT++ project named “ppp_qos”, which references the original Veins project, but it is implemented in a separate project for convenience. This project includes the “TraCIDemo11p” application module provided in Veins, which has been extended with: (a) the support of HEVC video trace files, (b) statistics at application level (load, goodput, end-to-end delay), and (c) statistics related to the mobility of the vehicles (the distance between selected pairs of nodes, the number of neighbors during the simulation, etc.). The “ppp_qos” project also extends the MAC layer with many statistics like the Channel Busy Ratio (CBR), that may be local statistics (i.e., per node), global network statistics or statistics grouped by Access Category (AC).
Post-process: This step is taken to get all the statistics defined at different network levels: Physical, MAC, and Application, with the corresponding plots. To compute the application performance metrics like Frame Loss Rate (FLR) and PSNR, the bit stream needs to be conformed with the received packets and then decoded to obtain the reconstructed video which will be rendered to the user. Many works show that PSNR, under some circumstances, does not properly assess the quality perceived by users. In the literature, we can find quality assessment metrics that better correlates with human perceived quality like MS-SSIM [
30]. These video quality metrics will be incorporated in future versions of VDSF-VN as an optional feature. However, we will use PSNR metric in this work, as most simulation frameworks also use it.
4. Performance Evaluation
This section describes the methodology used in the simulation and the experiments conducted with the proposed VDSF-VN framework for evaluating the video streaming in an urban VANET scenario. Now, we will describe the simulation setup which includes the network scenario, the network simulation parameters, the video source, and the video encoding options.
4.1. Scenario Description
The VDSF-VN framework includes a tool, GatcomSUMO [
29], that allows defining and configuring the network scenario that will be used in the simulation. Different vehicular network scenarios may be designed: regular (mesh, spider, etc.) or irregular (random). It is also possible to import real urban vehicular scenarios from OpenStreetMap [
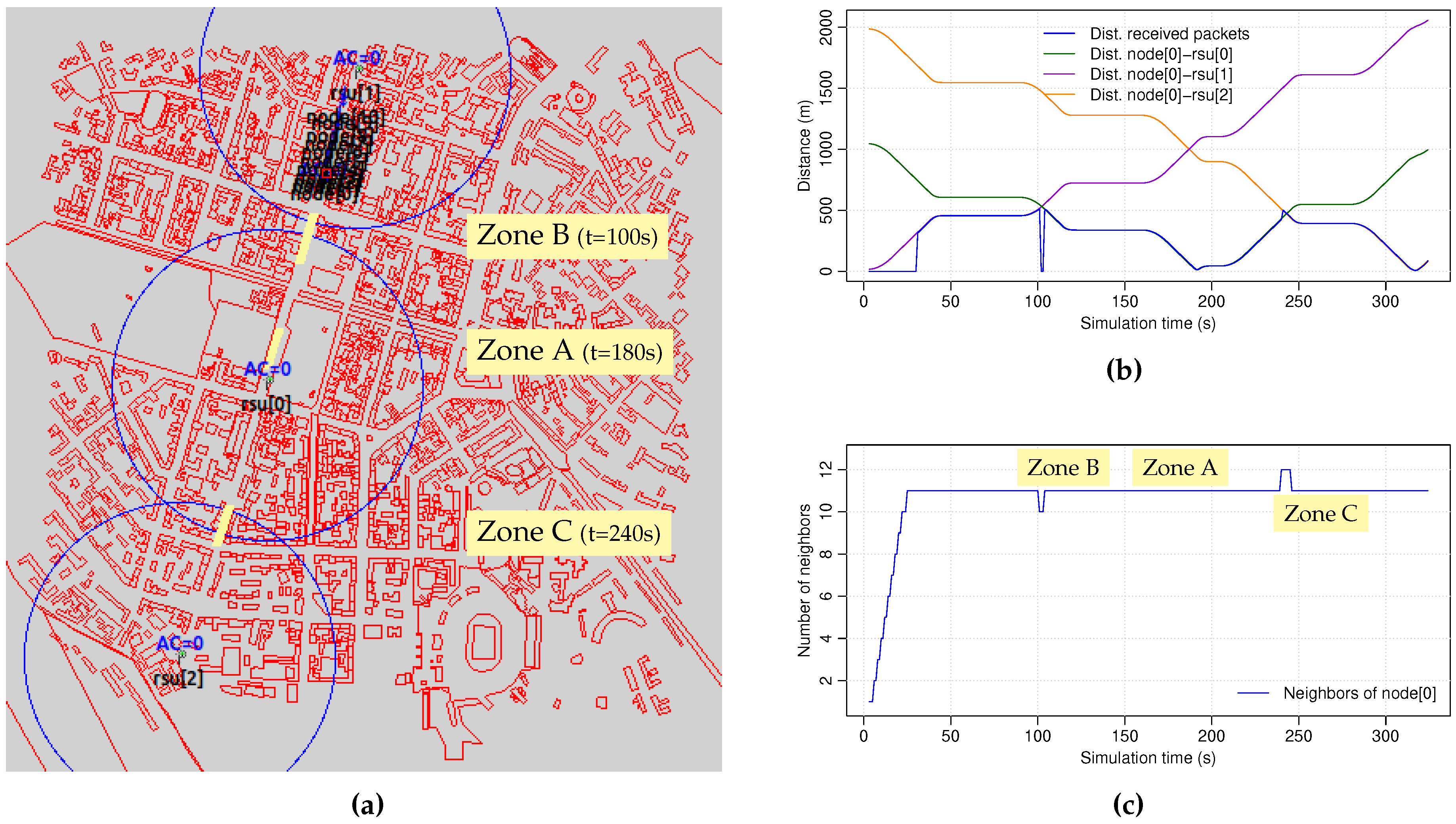
31], so the desired area of a city may be used as our simulation scenario. In this work, we have used a portion of the city of Kiev (Ukraine), which consists of a square area sized 2000×2000 m
2 (
Figure 2a), downloaded from OpenStreetMap and imported into SUMO. The main simulation parameters are summarized in
Table 1.
Three fixed Road Side Units (RSUs) are placed along a central avenue (
rsu[0..2]), which act as video servers delivering the same video sequence in a synchronized and cyclic way. The parameters of the network cards are set with the values shown in
Table 2. The radio transmission range, which is depicted with a blue circle in
Figure 2a, is the default value used in Veins. To get more accurate results, the simulation takes into account the obstacles such as buildings. Specifically, the radio propagation model used is
SimpleObstacleShadowing instead of the
SimplePathLoss model.
On the other hand, several mobile vehicles are defined, which travel together along the simulation time. The first one is the video client (node[0]), which receives the video sequence sent by the video servers. Then, ten vehicles acting as background traffic nodes follow the first one (node[1..10]), and send packets at different bit rates as background traffic load. To represent different levels of network loads, each background traffic node injects packets with a size of 512 bytes in a sequence of the following rates: {0,12,25,50,75} packets per second (pps). Therefore, on average, the total aggregate background traffic is {0,120,250,500,750} pps, respectively.
All the vehicles follow the same fixed route along the avenue, which is defined as a list of edges. This can be done manually, with the help of some utility provided by SUMO like
duarouter, or in a graphical way with the GatcomSUMO application. The maximum speed of the vehicles was fixed to 14 m/s (50 km/h), although their velocity is not constant, as the traffic simulator takes into account intersections, traffic-lights, the presence of other vehicles, etc. SUMO is a microscopic vehicular simulator that slows down or accelerates each vehicle according to the traffic conditions. The mobility model used is the default one in SUMO, that is, a modified version of the Krauss model [
32], which is a car following model. Apart from the mobility model (
carFollowModel) and the maximum speed (
maxSpeed), additional parameters like acceleration (
accel), deceleration (
deccel), or minimum distance to the vehicle ahead (
minGap) are also used.
The simulation time is 340 s, which is time enough for all the vehicles to travel from the beginning to the end of the avenue, receiving the video sequences sent by the three RSUs.
Figure 2b shows the distance between the client and the RSUs.
Figure 2c shows the number of neighbors of the client node along the entire simulation, showing that all of the background vehicles are within the communication range of the client car all the time. The plot also shows the instant when the node passes through the three selected zones which represent different network situations: an area where the client node has full coverage of one of the RSUs (Zone A), the shadow area between
rsu[1] and
rsu[0] (Zone B), as well as the overlapping area between
rsu[0] and
rsu[2] (Zone C).
4.2. Video Sequence
The selected video sequence is ’BasketballDrill’, which belongs to the HEVC Common Test Conditions set [
6]. As shown in
Table 3, it has a resolution of 832×480 pixels and a duration of 10 s. The original sequence is 500 frames long at a rate of 50 frames per second (fps), but it was sub-sampled at 25 fps with a length of 250 frames in order to reduce the required network bandwidth.
This video sequence was encoded with the HEVC reference software HM (HEVC Test Model) [
6]. The resulting bit stream consists of a sequence of frames, which can be of three types: I frames (Intra coded), P frames (Predictive coded) and B frames (Bi-directionally predictive coded). A great number of possible encoded bit streams can be generated from a specific raw video sequence depending on the desired HEVC configuration parameters (encoding mode, quantization level, INTRA refreshing, etc.). For example, we can select the main encoding modes provided by the HEVC reference software, namely, All Intra (AI), Low-delay P (LP), Low-delay B (LB), and Random Access (RA), or we can configure other specific encoding modes like the ones that we are going to analyze in this work, shown at
Table 4. AI mode is robust to packet loss, as all the frames of the video sequence are encoded as I frames, that is, without using any other frame as reference. On the contrary, LP mode is less robust than AI because it is sensible to packet losses due to the dependencies between frames. In LP mode, the first frame is encoded as an I frame, and the rest of the frames are encoded as P frames, which use previously encoded frames as reference. So, if losses occurs in previous reference frames we cannot correctly predict the content of the current one since we have no information from the past frames. The error produced in the past affects to the encoding performance of future frames (error propagation). However, LP mode is very efficient regarding compression performance because of the use of motion estimation and compensation. This is the reason we propose a set of encoding modes with different levels of periodic updates (INTRA refresh) which is able to efficiently mitigate the error propagation effects without significant performance degradation.
Another coding parameter to define is the Quantization Parameter (QP), which is used to adjust the compression level. A low QP value implies a soft quantization that will result in larger bit streams with higher video quality. In our experiments, the video quality, measured in terms of PSNR, for all the generated bit streams was fixed to the same value by adjusting the compression level (i.e., the QP value) in each case, targeting to a desired PSNR value of approximately 36 dB.
Apart from the compression mode and QP value, the video encoder accepts many other parameters. For example, HEVC allows splitting a frame into several independent regions (tiles or slices). This will be useful for our purposes since it will provide an extra robustness to video delivery when packet losses start to damage the video packet streaming. However, these partitioning modes lower the encoding performance since spatial correlation is limited to the slice/tile domain, and their use requires extra bit stream signaling information [
33].
As a result, many combinations of parameters need to be considered. In this work, the selected encoding modes, QP values and number of tiles per frame are the following:
Encoding modes (×9): {AI, IPIP, I3P, I7P, I15P, IPx, IPx25pctCTU, LPI4, LP} (see
Table 4).
QP values (×1): the QP value used for each encoding mode was fixed to achieve the desired video quality (PSNR ≈ 36 dB) when using 1 tile per frame (see
Table 5).
Number of tiles per frame (×7): seven values were considered to encode each bit stream: {1, 2, 4, 6, 8, 10, 16}. The size of these partitions can be specified with the number of rows and columns (uniform), or with the number of Coding Tree Units (CTUs) per each row and column (non-uniform). In this work, the following uniform tile patterns were considered: {1×1, 1×2, 2×2, 2×3, 2×4, 2×5, 4×4}, respectively.
So, all of these combinations make a total of 63 different bit streams (9×1×7). As it can be appreciated in
Table 5, the PSNR value of the original encoded video is approximately the same for all of them, whereas each case has a different bit rate value. As an example, the largest bit stream is achieved with AI mode (3.417 Mbps), whereas the smallest one corresponds to LP (0.959 Mbps); the other combinations are intermediate cases.
Once video encoding is done, we proceed to build a trace file from the encoded bit stream [
34]. A trace file is a text file including an ordered list of packets to be transmitted, and is loaded by the video servers before sending it to the clients in the simulation step. Since an encoded frame may be larger than the network Maximum Transmission Unit (MTU), it is necessary to encapsulate it into several packets (packetization). In the trace file, each packet is defined with the following fields: a correlative packet number, the frame type it belongs to (I, P, or B), the playback time (ms), the packet size (bytes), the frame offset of the packet payload, and the total number of fragments of the current frame.
We have modified the HM software to include RTP bit stream packetization [
35]. In addition, it was mandatory to modify the HM decoder in order to get the reconstructed video sequence because the original HM decoder crashes when any piece of information is lost, so we have strengthened the decoder to be robust against packet losses.
At last, once the video sequence is reconstructed we compute, among other application metrics, the PSNR value relating to the original video sequence, which is the most commonly used metric for measuring the video quality.
5. Simulations Results
The purpose of this paper is to find out how different encoding modes affect the video delivery in vehicular networks, that is, to discover which of the generated bit streams achieves the best trade-off between reconstructed video quality and resulting bit rate. So, we start with an evaluation of the different INTRA refresh modes without using tile partitioning (i.e., only one tile per frame). Then we analyze the effect of increasing the number of tiles per frame with the All-Intra (AI) coding mode. In addition, finally we will see in action both INTRA refresh modes and the use of tiles to evaluate their overall behavior on error resilience, video quality and coding bit rate.
Although there are much more metrics available, we have selected the following application layer metrics:
Goodput (GP): the total number of received video packets at the client application layer divided by the application runtime (i.e., from the sending time of the first packet until the time when the last packet is received).
End-to-End (E2E) Delay: the average time each packet requires in order to be delivered to the destination application (running at a particular node).
Jitter: the average E2E delay variation between two consecutive packets received at the destination node.
Packet Delivery Ratio (PDR): the relation between the total number of video packets received by the client with respect to the video packets sent by the server. As all the video servers (RSUs) transmit the same video sequence in a synchronized and cyclic way, in this work, only the number of packets sent by the associated RSUs is considered.
Packet Loss Ratio (PLR): the percentage of lost packets out of the total number of packets of the video sequence.
Tile Loss Ratio (TLR): the percentage of tiles that have not been completely received out of the total number of tiles of the delivered video sequence. In case of using a 1 tile per frame layout (i.e., no-tiling), this value corresponds to the Frame Loss Ratio (FLR).
Peak Signal-to-Noise Ratio (PSNR): the measure of the objective video quality. The PSNR is computed frame-by-frame for the luminance (Y) component as shown in Equation
1, averaged for all the frames. The Mean Squared Error (MSE) is computed for each frame
n by averaging the squared intensity differences between each pixel
of the same original (
) and distorted (
) frame, as shown in Equation
2, where
and
, being
and
the width and height of the frames (in pixels).
The metrics are collected in both scalar (minimum, maximum, mean, etc.) and vector format. Scalar metrics allow to study the overall performance of the network, whereas the vector data allows studying the evolution of such metrics over the entire simulation. To drastically reduce the huge amount of data needed to store the vector data, some of these metrics are also collected in vector format but averaged every second only; in this way, it is possible to analyze the behavior of the network in any zone defined by two given simulation times.
In this work we have analyzed the selected simulation metrics in 3 different fragments of the whole simulation of 10 s in length each:
Zone A (t = 180..190s): an area where the client node has full coverage of one of the RSUs (rsu[0]).
Zone B (t = 100..110s): a shadow area between two RSUs (rsu[1] and rsu[0]), where none of them are “visible” for the client node.
Zone C (t = 240..250s): an area where the coverage of two RSUs are overlapped (rsu[0] and rsu[2]).
Zones B ad C are not shown, as the percentage of lost packets is too high. The location of the RSUs should be adjusted in Zone B, and a handover mechanism should be used in case of overlapping of the transmission ranges (Zone C). Therefore, only results for Zone A are shown below.
5.1. INTRA Refresh Coding Modes
In this section the effect of different INTRA refresh modes is analyzed. Since we want to determine the potential of INTRA Refresh alone, only one tile per frame is used, that is, the experiments do not use tile partitioning.
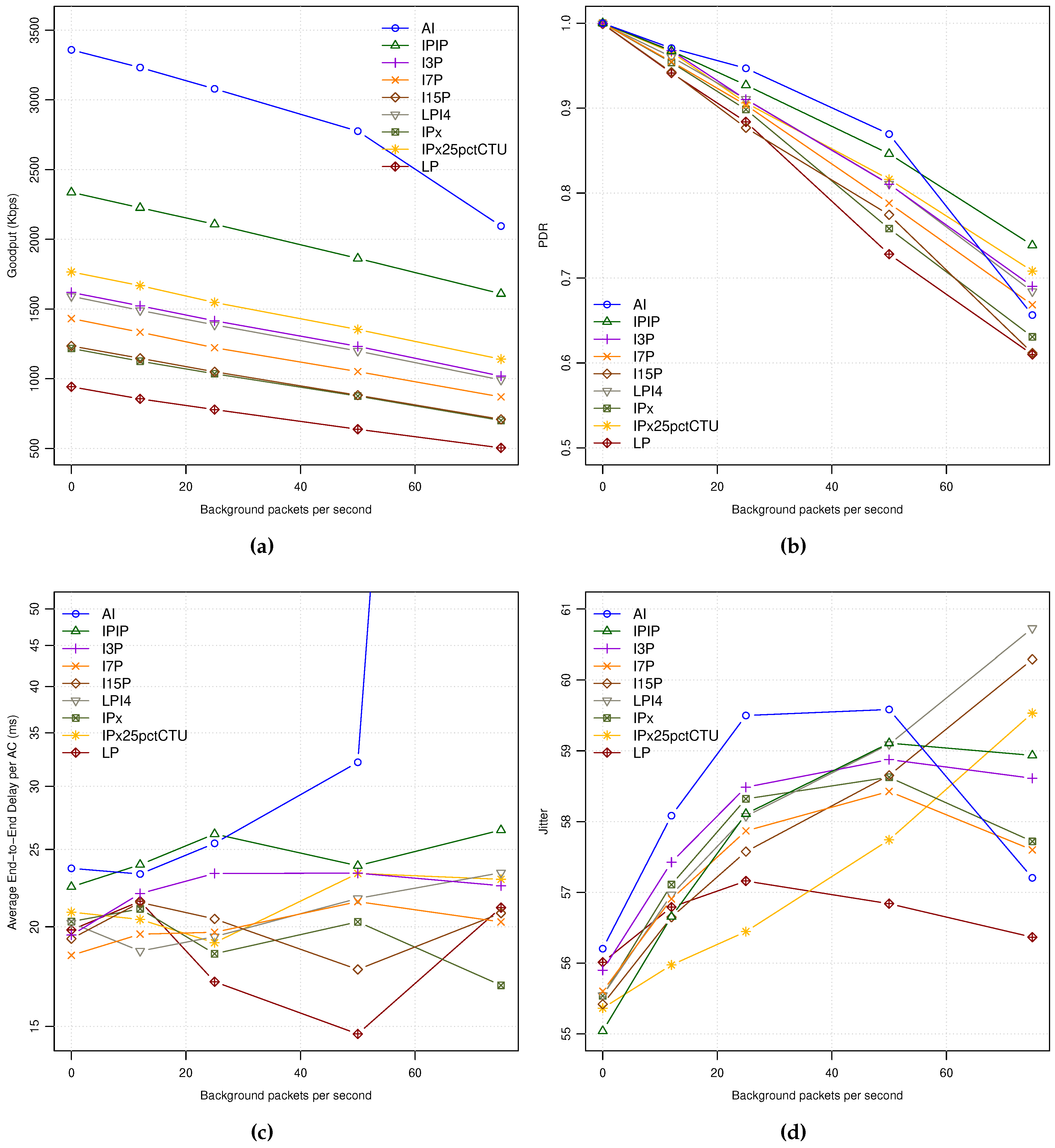
Figure 3a shows the achieved Goodput for each encoding mode under different background traffic loads. As can be seen, it affects to all the encoding modes in a similar way, proportionally to the different encoding bit rates. Only in the case of the maximum background traffic load (75 pps), the AI mode shows an abrupt descent as the network entered in saturation state, being the rest of coding modes with moderate to high network loads depending on their corresponding bit rates.
As can be seen in
Figure 3b, the network Packet Delivery Ratio (PDR) is 1.0 for all the encoding modes when no background traffic is used, meaning that all the packets arrive to their destination. As the background traffic increases, the network PDR decreases for all the encoding modes, being the 50 pps background traffic load a very high network load where more than 15% of packets are lost in all coding modes. Similarly to the previous picture, all the curves are sorted by their consumed bandwidth (see
Table 5).
The End-to-End (E2E) Delay shows similar behavior for all the encoding modes while increasing the background traffic (
Figure 3c). The AI coding mode suffers from network saturation at the highest background traffic load, achieving average delays of up to 6 s (network saturation). The rest of coding modes show two different behaviors: (a) a soft monotonic delay increase for coding modes with the highest bit rates (i.e., IPIP and I3P), and (b) similar packet delays for the rest of modes that require less bandwidth (bit rate). Among the last coding modes we can observe that the ones with lowest bit rates seem to have less delay as background traffic increases. So, as being the coding modes with lowest bit rates they have a lower probability of sending video packets during the control channel period, reducing the average latency and also the jitter, as explained next.
Regarding Jitter,
Figure 3d shows a high average jitter values from 55 milliseconds to more than 60 at high background traffic loads. The main reason for the high jitter observed may be due to the behavior of 802.11p MAC operation, where the time is multiplexed between service and control channels (near the 50% of channel time for each). So, all packets generated during the control channel time period have to wait until the service channel period starts, producing timing distortions in the continuous packet video delivery traffic pattern that seriously affect to Jitter.
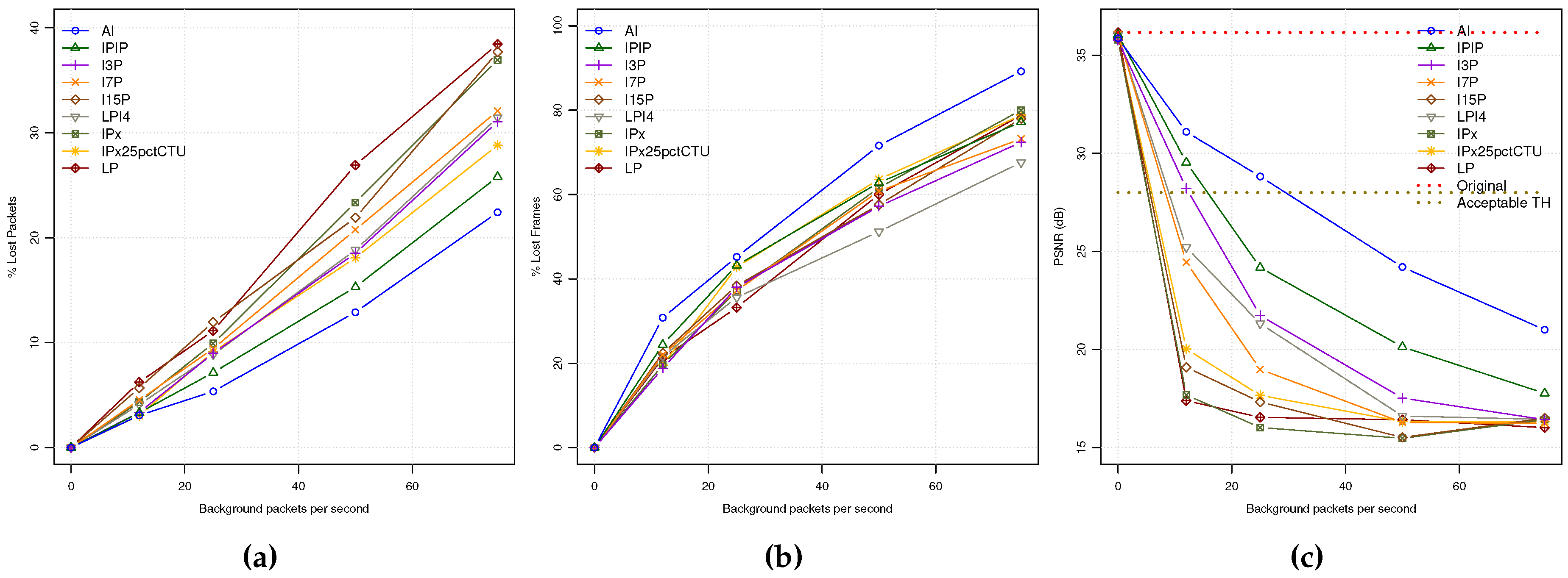
In
Figure 4a,b, the PLR and FLR application metrics are shown. The PLR follows a behavior coherent with the PDR plot described before: the higher the coding mode bit rate, the lower the PLR value. However, when analyzing the FLR, we can observe that the number of lost frames is inversely proportional to the coding mode bit rates under similar network load conditions. This is due to the bit stream packetization process that produces a higher number of packets per encoded frame for coding modes with higher bit rates. So, the probability of losing one frame is higher, producing more frame losses. In
Figure 4c, the PSNR values for all the encoding modes of a video sequence received in Zone A are plotted. As can be seen, the highest video quality is achieved by the AI coding mode followed by IPIP and I3P coding modes. However, as background traffic increases, the PSNR values fall down under unacceptable quality levels (below 28 dBs) for most video contents. On the other hand, LP and IPx have the worst PSNR values; when the first packet losses appear, the video is degraded, being unable to stop error propagation due to their poor INTRA refresh capabilities.
These results demonstrate the benefits of using INTRA refresh encoding modes for improving the reconstructed video quality. However, the price we have to pay for is the increased bit rates, which can cause a greater loss of packets when the network gets saturated.
5.2. Tile Partitioning for the All-Intra Coding Mode
After analyzing the INTRA refresh coding modes with their pros and cons, we proceed to study another error resilience technique that may efficiently work together with INTRA refresh. We propose the use of frame partitioning that allow fragmenting each frame into independently encoded/decoded tiles. The idea is to significantly reduce the number of frame losses. In this section we will study the effect of using 1, 2, 4, 6, 8, 10 and 16 tiles per frame with the AI coding mode.
As it was explained in the introduction section, using tiles introduces an overhead in the bit stream as required signaling in form of headers, so higher bit streams are produced. From
Table 6, the use of tiles for the AI coding mode increase the bit rate from 0.6% to 6.8% when using 2 and 16 tiles, respectively. With respect to the reconstructed video quality, we can see that using tiles has no effect.
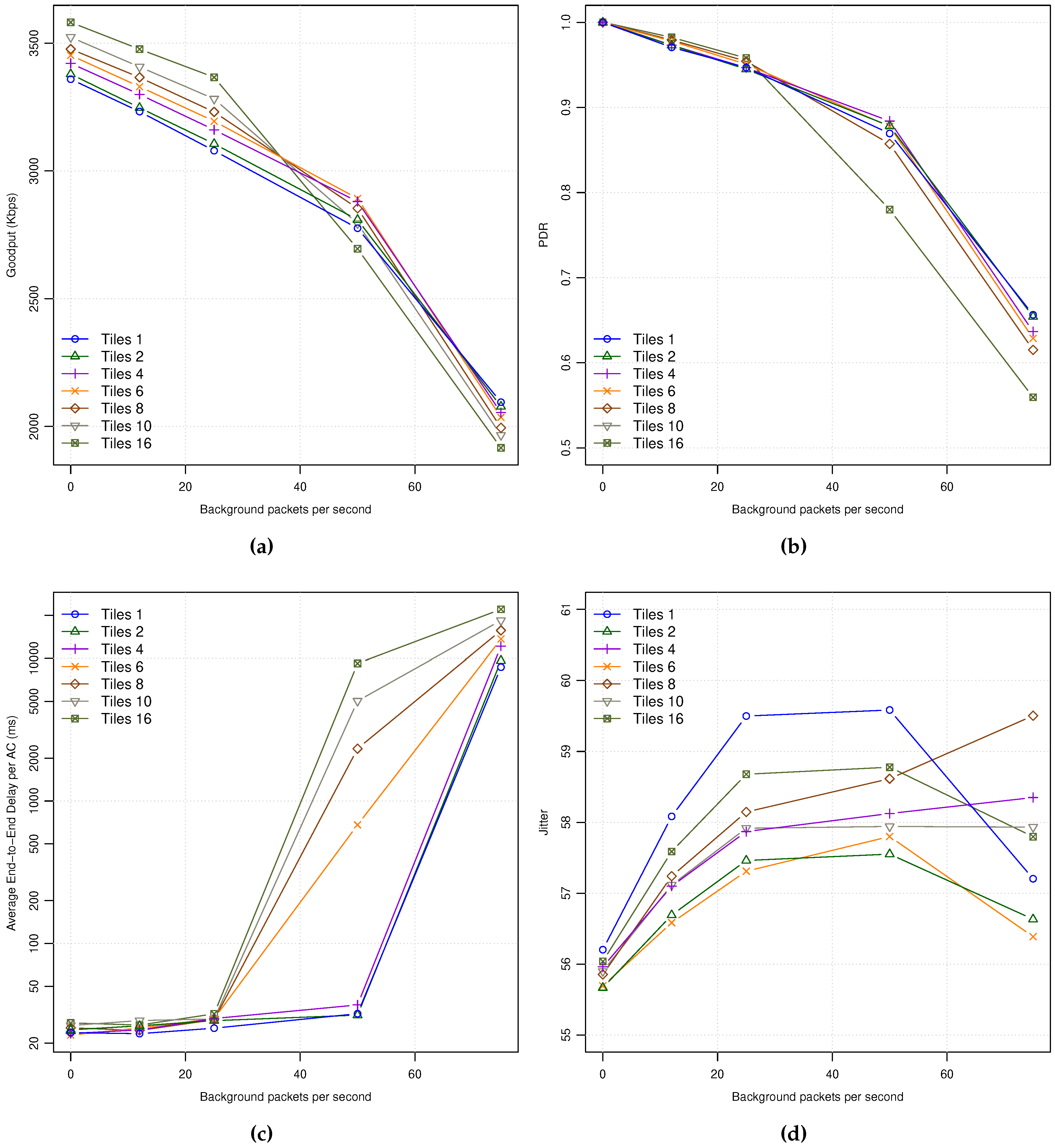
In
Figure 5, we show the simulation results with the same network metrics used in previous experiments.
Figure 5a shows the Goodput for the different tile layouts. As expected, at low background traffic levels the curves are sorted by their corresponding bit rate. However, when background traffic increases with values greater or equal than 50 pps, and we use a high number of tiles per frame, the trend is inverted. Again, this is because the network begins to be saturated, and this situation affects more to the video sequences that require more bandwidth. The same behavior can be observed in the PDR metric shown in
Figure 5b.
As shown in
Figure 5c, the average E2E delay keeps similar values for all the tile number configurations at low to moderate background traffic levels, showing always slightly higher delay values when (a) increasing the number of tiles, and (b) the background traffic level increases. Notice that at 50 pps background traffic loads, only the configurations of up to 4 tiles maintain the same behavior than the one explained before at lower background traffic levels, being a symptom of entering network saturation for the AI encoding mode.
Figure 5d shows the average jitter varying the number of tiles per frame. As it can be seen, the experienced jitter is always lower on average than the one obtained with just one tile, observing better response when using a low number of tiles per frame (from 2 to 6).
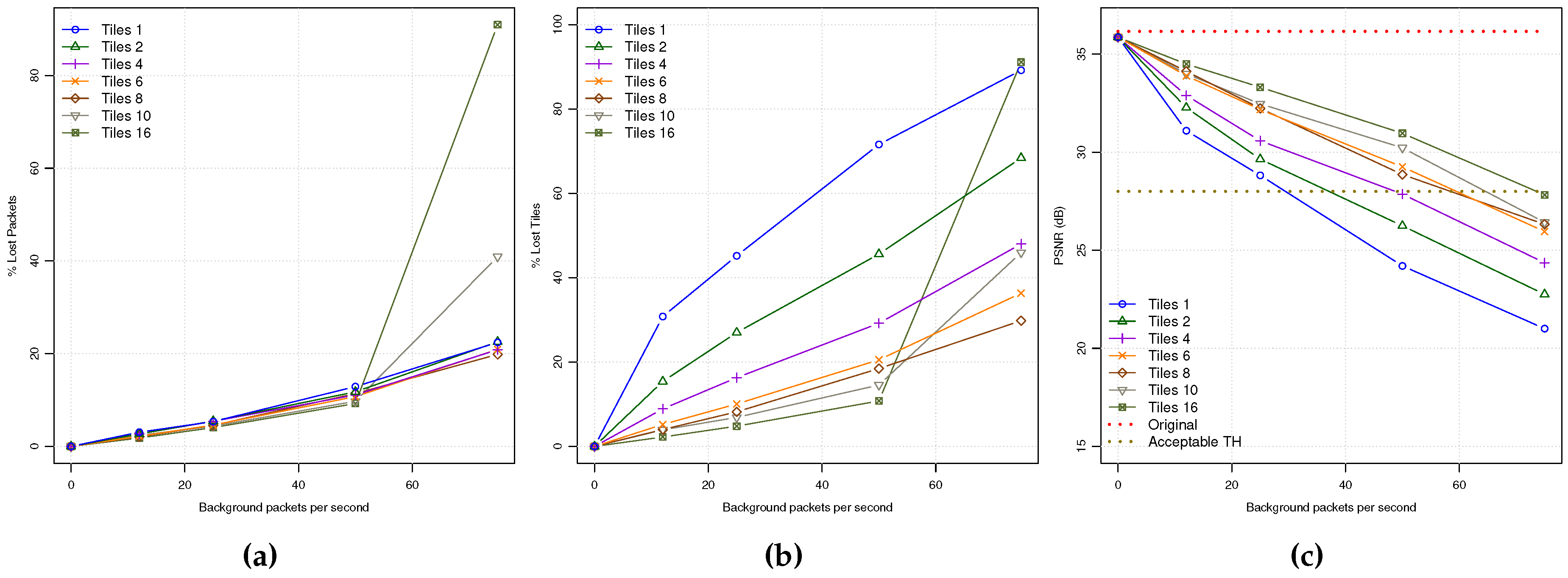
From
Figure 6a, we may observe a lineal increase of PLR up to the network saturation point, where a higher number of tiles always produce a lower PLR. However, in
Figure 6b the TLR metric shows an interesting behavior, achieving lower TLR values when the number of tiles per frame increases. As a consequence, the video quality of the received video will be better as shown in
Figure 6c. So, we can conclude that when the number of tiles per frame increases, the error resilience of the video stream also increases, obtaining acceptable video quality levels from low to moderate background traffic levels. Taking into account that the more tiles per frame the more overhead in the bit stream, several tiles of 4 or 6 would be a good trade-off.
5.3. Global Evaluation
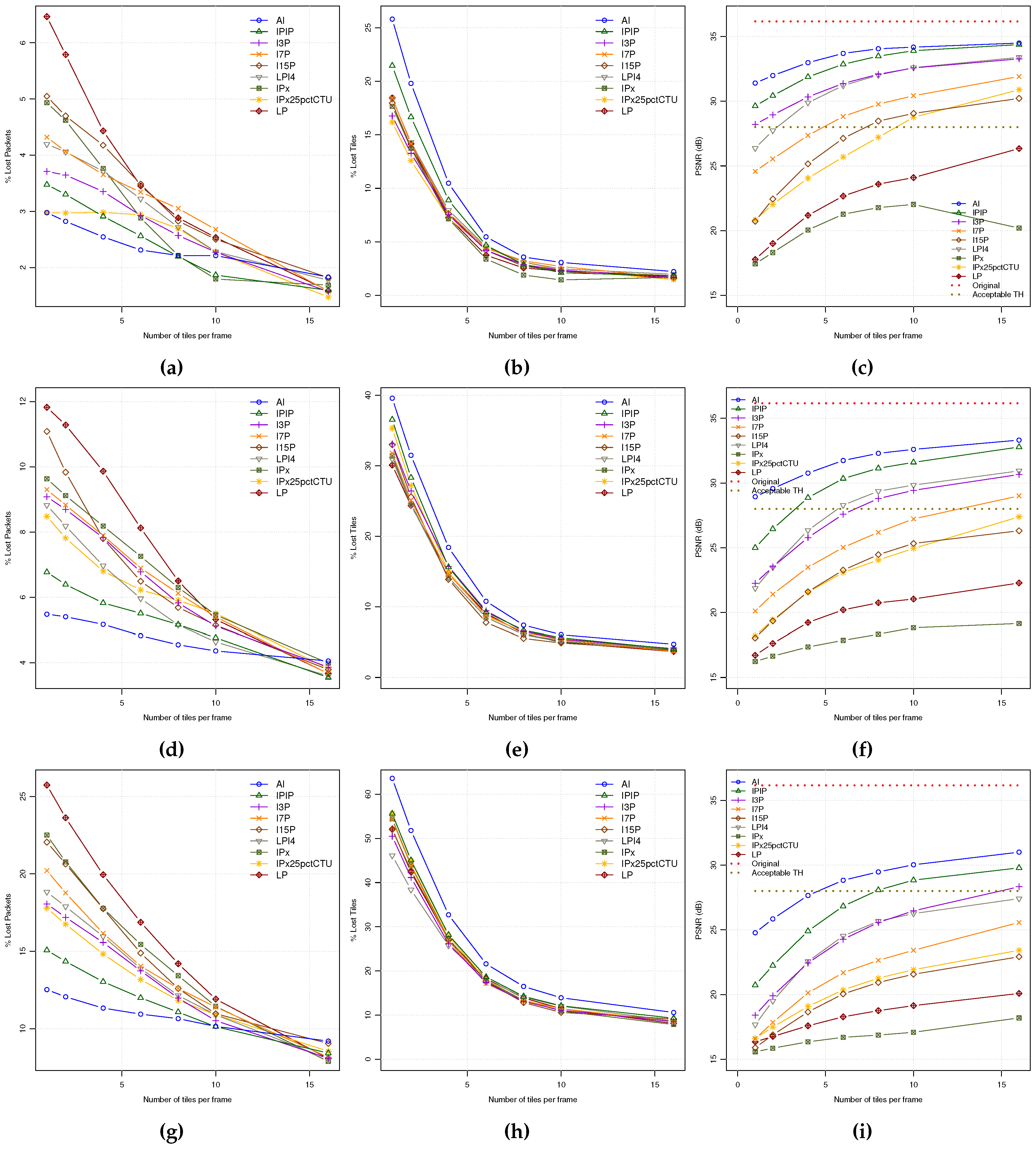
Now, we are going to analyze the combined effect of both INTRA refresh coding modes and tiles. So, we will show the PLR, TLR and PSNR metrics for all the encoding modes as a function of the number of tiles for every coding mode for a particular background traffic level. From the previous experiments, only 12, 25, and 50 pps background traffic levels will be explored in
Figure 7, since at higher traffic loads the video quality levels are unacceptable.
As it can be seen in
Figure 7, there is a general behavior from low to moderate-high background traffic loads where, as the number of tiles increases (a) the PLR decreases, especially fast with the lowest bit rate coding modes (LP coding mode reduces PLR to the half by using 6 tiles); (b) the TLR also decreases at the same pace for all the coding modes, significantly reducing TLR six times for 12 pps background traffic load; and (c) the resulting PSNR also shows improvements as the number of tiles increases for all coding modes. At the other hand, when the background traffic load increases, both PLR and TLR also increases, following the same pattern as depicted before. As a consequence, the PSNR video quality decreases in general (e.g., IPIP coding mode using 6 tiles reduces PSNR in 2.5 dBs when going from 12 pps to 25 pps network load). If we define a threshold for minimum accepted video quality in 28 dBs, AI, IPIP, I3P and LPI4 will be the only coding modes that keep over that quality threshold when working with a frame partitioning of 4 tiles and low network loads (12 pps). The I7P coding mode could belong to the selected group when using 6 tiles per frame. The rest of coding modes will not satisfy the minimum quality requirement. At moderate network loads (25 pps), only AI and IPIP will be above the defined video quality threshold for 4 tiles per frame, discarding all the rest of modes. In addition, finally, at high network loads (close to saturation) only the AI coding mode will be the one that remains over the quality threshold with 6 tiles. If the number of tiles were not an issue, the IPIP coding mode could be also selected using at least 8 tiles per frame.
From this study, we may conclude that the coding modes with higher "intra refresh" degree are the ones that better stand up in front of packet losses, but they are the ones that higher network bandwidth will require. On the other hand, when using tiles, the behavior is very similar for all the coding modes, resulting in PSNR improvements. However, the consequence of using a higher number of tiles, as for high intra refreshing coding modes, is also a bit stream size increase. So, a trade-off should be defined between error resilience and bandwidth (network resources), what should be finally determined by the application requirements. We may propose a selection criteria of using a frame partitioning in no more than 6 tiles (no significant improvements are found beyond), and the coding mode that, remaining over the application quality threshold, requires the lowest bit rate.
6. Conclusions
In this work, we have introduced VDSF-VN, a simulation framework based on the OMNeT++ network simulator, the Veins framework and the SUMO mobility traffic simulator, which was designed to study and evaluate the robustness of a video delivery stream in vehicular ad-hoc network scenarios. Using the proposed simulation framework we analyzed different coding options, available at HEVC video encoder, to improve the robustness of the resulting video stream when it is faced with error-prone network scenarios like urban vehicular networks. We have tested different INTRA refresh coding modes and frame partitioning schemes by means of tiling, so we can determine the configurations that better performance and robustness provide at different network loads.
The experimental results show that error resilience improves as the INTRA refresh level increases. So, the best coding mode would be AI followed by IPIP, I3P, and LPI4. Notice that these encoding modes require high bit rates with respect the others, so a trade-off between error resilience and final bit rate should be defined, which strongly depends on the application requirements and the available network resources. With respect to frame partitioning, we have observed that the use of tiles has a positive impact when combined with INTRA refresh coding modes. So, acceptable video quality levels are achieved from low to moderate background traffic loads, reinforcing the properties of the INTRA refresh coding modes. Again, a trade-off should be applied since the use of tiles increases the bit stream, so the recommendation is not to use more than 6 tiles per frame since when using more tiles the improvements are, in general, negligible.
The main conclusion is that by using different INTRA refresh options combined with appropriate tile coding we will improve the protection of video streaming in VANET urban scenarios, allowing to keep acceptable video quality at high packet loss rates. We can use these error resilience techniques at encoding/decoding sides to protect the video streams. However, we need to explore additional techniques, like channel coding (FEC), the use of QoS at MAC level, and efficient error concealment, which, combined with the ones proposed here, minimize the introduced bit stream overhead and maximize the final error resilience. The final goal is focused to provide robust and efficient video streams which are able to fight against moderate to high packet network error conditions, keeping the video quality over the threshold demanded by the application. As future work, we are planning to use the available MAC QoS features, and later we will extend our error resilience architecture with packet-based FEC proposals, and advanced error concealment strategies.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}