Efficient Interference Estimation with Accuracy Control for Data-Driven Resource Allocation in Cloud-RAN †



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- First, the optimization process in C-RAN requires the measurements of interference in every potential communication link (almost every pair of nodes) in the network, so the number of measurements grows quadratically with the network size.
- Second, due to the shadow fading and background noise, the measured interference will be dynamic over time. Therefore, it requires multiple measurements to ensure the accuracy of measurements in every link.
- Third, the signals fade differently in different channels. Thus, measurements in all channels are also required.
- We reveal the important problem of accurate RSS estimation for data-driven resource allocation and optimization in Cloud-RAN and show the performance gap between theoretical and practical values via trace-driven experiments.
- By taking advantage of the feature of Cloud-RAN, we propose a model-based solution for efficient RSS estimation. It reduces the time cost to the level of , where N is the number of nodes and M is the number of channels.
- We provide an accuracy control method for our solution, which achieves the required accuracy by controlling the number of measuring links. This method could help us to balance the tradeoff between the accuracy and the cost.
- We conduct extensive experiments using real communication traces collected from a wireless network testbed, which shows the efficiency of the proposed solutions.
2. Related Work
2.1. Cloud-RAN
2.2. Wireless Network Optimization
2.3. RSS Estimation
3. Problem Formulation
- Time cost: the number of time slots t to finish all the measurements;
- Measurement overhead: the quantity of the measurements conducted. Note that the measurements could be performed simultaneously, and the measurement overhead should be larger or equal to the time cost;
- Accuracy: the accuracy metric in our algorithm could be divided into link-wise accuracy and network-wide accuracy, respectively. The link-wise accuracy implies that the measurements should be controlled within the confidence . The network-wide accuracy implies that the portion of the measurements is accurate with a certain confidence.
4. Solution
- Firstly, we reduce the total measurement overhead by reducing the number of links and channels that conduct measurements.
- Secondly, we derive the relationship between the number of measurements and the accuracy we could achieve. The accuracy control could help us to balance the tradeoff between the accuracy and measurement overhead.
- Then, based on the results of the previous two steps, we manage to reduce the time cost by distributing the non-conflict measurements into time slots and channels.
4.1. Overhead Reduction
- Measurements in links: First, we reveal that a set of links in the network shares the same (or very close) propagation property via the path loss model, e.g., close path loss exponent. Thus, we only need to perform the measurement over small portion of links for this set. For the whole network, we could select a small portion of links called representative links for measurement, thus reducing the measurement overhead.
- Measurements in channels: Second, the measurement overhead could be further degraded by only measuring a single channel in each link, as the propagation characteristics in other channels could be derived from the measured channel.
4.1.1. Reduction in Measurement of Links
- Take a small number of measurements in the form of the sequential broadcast of the measurement packet in each node. This number of measurements should be much smaller than the number required to achieve the accuracy requirement, as given in the next subsection;
- Estimate the PLE for each link via linear regression;
- Apply the k-means algorithm to cluster these links into k groups by using the PLEs as the metric, where k is the number of representative links.
- Select the representative links for each group.
4.1.2. Reduction of the Measurements in Channels
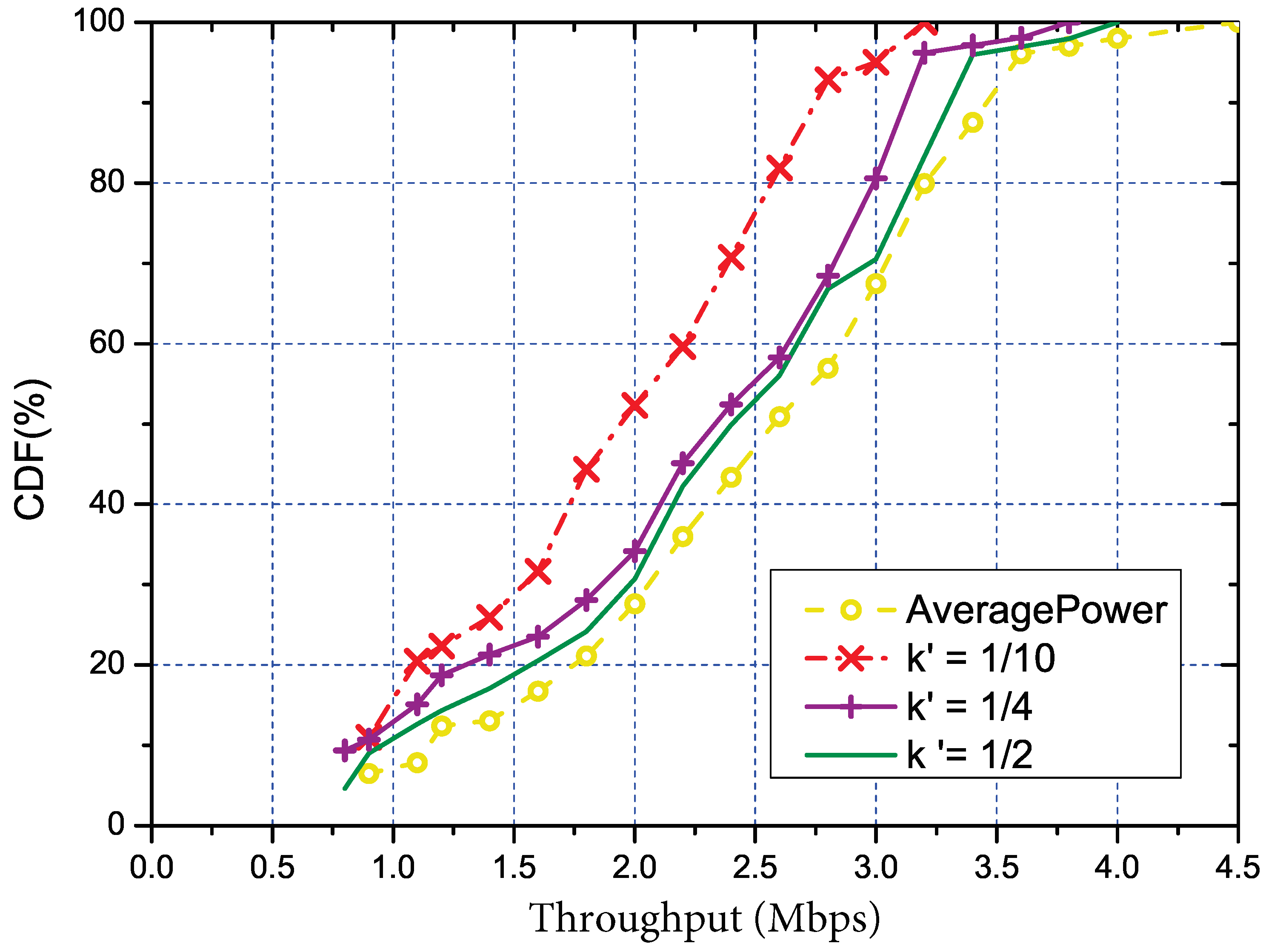
4.2. Accuracy Model and Control Mechanism
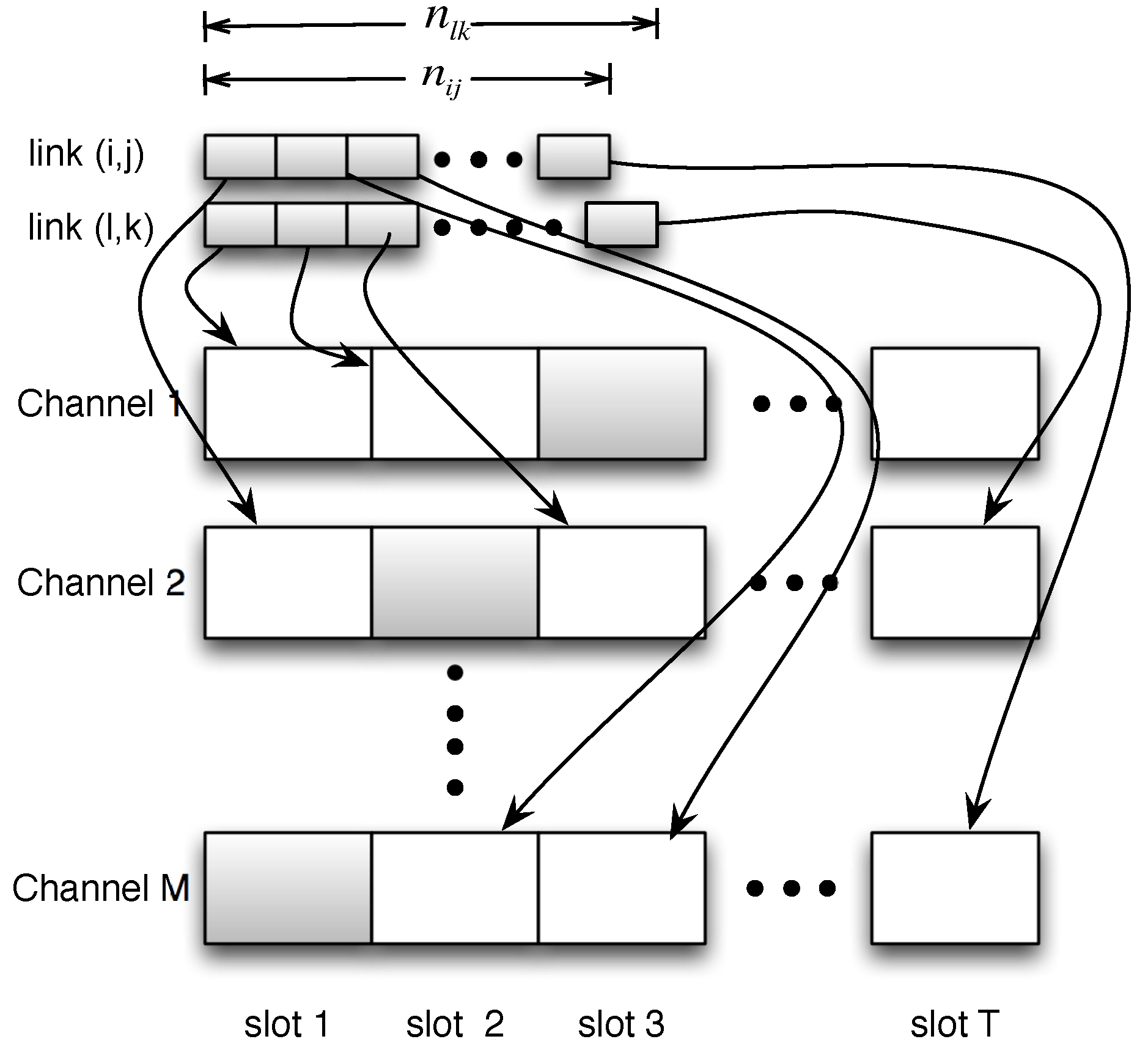
4.3. Time Efficiency
- First, since only representative links are obliged to be measured, we derive the number of broadcasting nodes to cover all the representative links in the node-wise schedule.
- Second, we study how to distribute the measurements into different channels, such that the whole measurement process will end in the earliest time.
5. Evaluation
5.1. Experiment Targets
- The primary target is to evaluate how our solutions impact the SINR-based throughput optimization algorithms.
- We also want to quantify the measurement overhead and time cost.
- The link-wise accuracy should be examined.
5.2. Experimental Settings
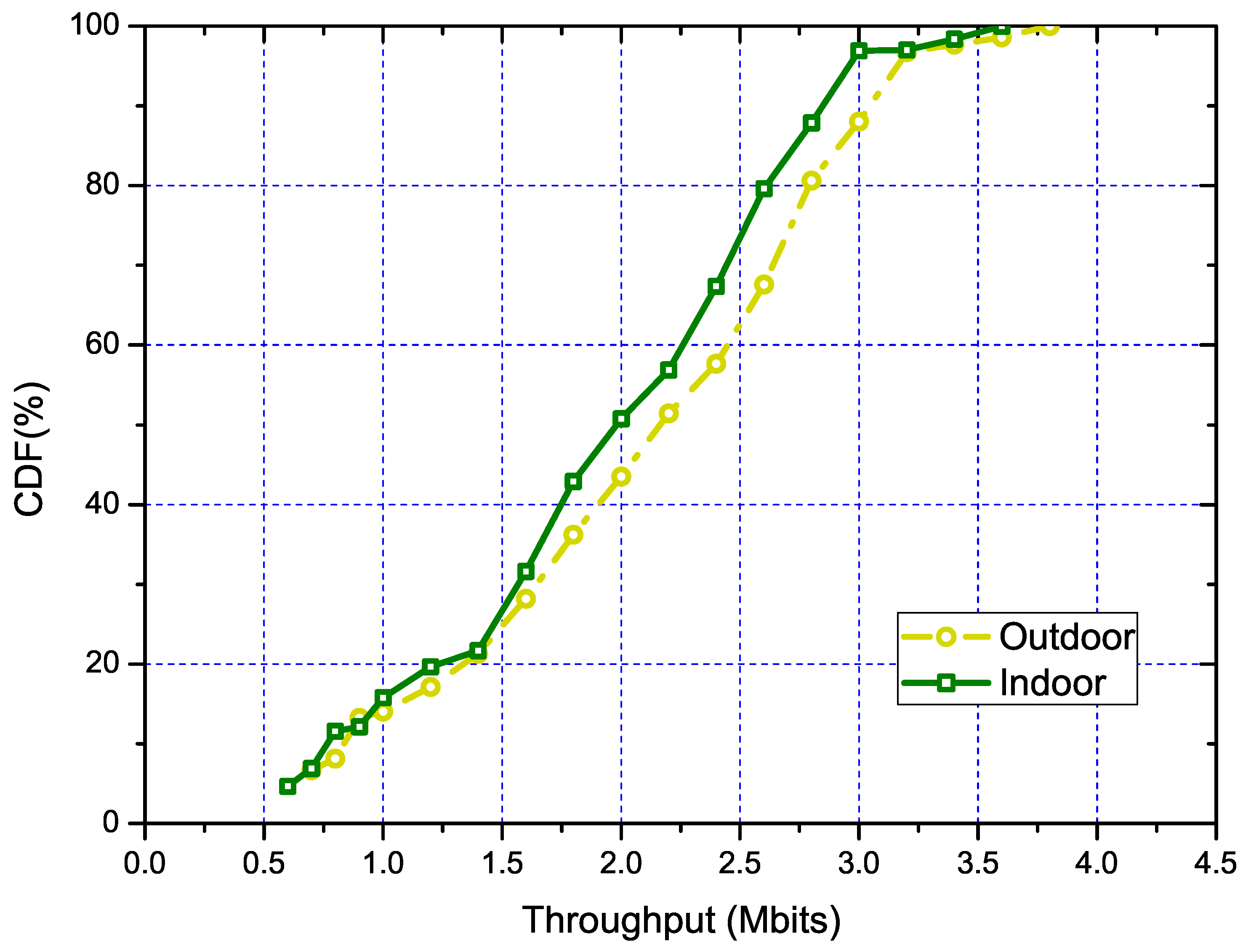
- SWIMdataset: The first one is our data collection from the SWIM platform [33], which mainly consists of 10 wireless nodes running in 802.11a/b/g mode. We collected the RSSI of the broadcasting beacons from each AP. Each node will be activated to broadcast the beacon and tuned to 11 different channels sequentially. Then, a laptop will move to 25 different locations (including the locations of 10 APs) and collect more than 50 beacons in two minutes from one AP in each channel. We also collect the AP ID and channel ID at the same time. This dataset is a representative indoor dataset, while the redundant collected data are very useful to mitigate the interference from the other WiFi access point in the building. A more detailed floor plan and the deployment can be found in [33].
- MetroFidataset: The other is the MetroFi dataset [34], which covers 30,991 measurement locations from 70 APs with known locations and generates more than 200,000 samples. This dataset is basically an outdoor collected dataset. This dataset is collected from a municipal wireless mesh network in Portland, Oregon. The deployers collect signal strength measurements using a battery-powered embedded computer with an external 7-dBi omnidirectional antenna and a GPS device. The collector roams around network to different locations. This dataset can be found in the crawdad database.
5.3. Experiments Results
5.3.1. Performance of Overall Solution
5.3.2. Performance of the Overhead Reduction
5.3.3. Performance of Accuracy Control
5.3.4. Performance of Measurement Scheduling
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Langar, R.; Secci, S.; Boutaba, R.; Pujolle, G. An Operations Research Game Approach for Resource and Power Allocation in Cooperative Femtocell Networks. IEEE Trans. Mob. Comput. 2015, 14, 675–687. [Google Scholar] [CrossRef]
- Li, W.; Zhao, Y.; Lu, S.; Chen, D. Mechanisms and challenges on mobility-augmented service provisioning for mobile cloud computing. IEEE Commun. Mag. 2015, 53, 89–97. [Google Scholar] [CrossRef]
- Chih-Lin, I.; Rowell, C.; Han, S.; Xu, Z.; Li, G.; Pan, Z. Toward green and soft: A 5G perspective. IEEE Commun. Mag. 2014, 52, 66–73. [Google Scholar]
- Goussevskaia, O.; Oswald, Y.A.; Wattenhofer, R. Complexity in geometric SINR. In Proceedings of the ACM MobiHoc, Montreal, QC, Canada, 9–14 September 2007; pp. 100–109. [Google Scholar]
- Bhatia, R.; Kodialam, M. On Power Efficient Communication over Multi-hop Wireless Networks: Joint Routing, Scheduling and Power Control. In Proceedings of the IEEE INFOCOM, Hong Kong, China, 7–11 March 2004. [Google Scholar]
- Shi, Y.; Hou, Y.; Kompella, S.; Sherali, H.D. Maximizing capacity in multihop cognitive radio networks under the SINR model. IEEE Trans. Mob. Comput. 2011, 10, 954–967. [Google Scholar] [CrossRef]
- Zhao, Y.; Wu, J.; Lu, S. Efficient SINR Estimating with Accuracy Control in Large Scale Cognitive Radio Networks. In Proceedings of the 2011 IEEE 17th International Conference on Parallel and Distributed Systems (ICPADS), Tainan, Taiwan, 7–9 December 2011; pp. 549–556. [Google Scholar]
- Zhou, X.; Zhang, Z.; Wang, G.; Yu, X.; Zhao, B.Y.; Zheng, H. Practical conflict graphs for dynamic spectrum distribution. In Proceedings of the ACM SIGMETRICS, Pittsburgh, PA, USA, 17–21 June 2013; pp. 5–16. [Google Scholar]
- Lin, Y.; Shao, L.; Zhu, Z.; Wang, Q.; Sabhikhi, R.K. Wireless network cloud: Architecture and system requirements. IBM J. Res. Dev. 2010, 54, 4:1–4:12. [Google Scholar] [CrossRef]
- Mobile, C. C-RAN: The Road Towards Green RAN; China Mobile Research Institute: Beijing, China, 2011; Volume 2. [Google Scholar]
- Checko, A.; Christiansen, H.L.; Yan, Y.; Scolari, L.; Kardaras, G.; Berger, M.S.; Dittmann, L. Cloud RAN for mobile networks—A technology overview. IEEE Commun. Surv. Tutor. 2015, 17, 405–426. [Google Scholar] [CrossRef]
- Ponzini, F.; Giorgi, L.; Bianchi, A.; Sabella, R. Centralized radio access networks over wavelength-division multiplexing: A plug-and-play implementation. IEEE Commun. Mag. 2013, 9, 94–99. [Google Scholar] [CrossRef]
- Grieger, M.; Boob, S.; Fettweis, G. Large scale field trial results on frequency domain compression for uplink joint detection. In Proceedings of the 2012 IEEE Globecom Workshops, Anaheim, CA, USA, 3–7 December 2012; pp. 1128–1133. [Google Scholar]
- Flanagan, T. Creating cloud Base Stations with TI’s KeyStone Multicore Architecture; Texas Instruments White Paper; Texas Instruments: Dallas, TX, USA, 2011. [Google Scholar]
- Yang, M.; Li, Y.; Jin, D.; Su, L.; Ma, S.; Zeng, L. OpenRAN: A software-defined ran architecture via virtualization. In Proceedings of the ACM SIGCOMM Computer Communication Review, Hong Kong, China, 12–16 August 2013; Volume 43, pp. 549–550. [Google Scholar]
- Gudipati, A.; Perry, D.; Li, L.E.; Katti, S. SoftRAN: Software defined radio access network. In Proceedings of the Second ACM SIGCOMM Workshop on Hot Topics in Software Defined Networking, Hong Kong, China, 16 August 2013; pp. 25–30. [Google Scholar]
- Zhou, S.; Zhao, T.; Niu, Z.; Zhou, S. Software-defined hyper-cellular architecture for green and elastic wireless access. IEEE Commun. Mag. 2016, 54, 12–19. [Google Scholar] [CrossRef]
- Semasinghe, P.; Hossain, E.; Zhu, K. An evolutionary game for distributed resource allocation in self-organizing small cells. IEEE Trans. Mob. Comput. 2015, 14, 274–287. [Google Scholar] [CrossRef]
- Chen, C.; Lee, D. A joint design of distributed QoS scheduling and power control for wireless networks. In Proceedings of the IEEE INFOCOM, Barcelona, Spain, 23–29 April 2006. [Google Scholar]
- Zhu, K.; Hossain, E.; Niyato, D. Pricing, spectrum sharing, and service selection in two-tier small cell networks: A hierarchical dynamic game approach. IEEE Trans. Mob. Comput. 2014, 13, 1843–1856. [Google Scholar] [CrossRef]
- Liu, W.; Luo, X.; Liu, Y.; Liu, J.; Liu, M.; Shi, Y.Q. Localization Algorithm of Indoor Wi-Fi Access Points Based on Signal Strength Relative Relationship and Region Division. Comput. Mater. Contin. 2018, 55, 71. [Google Scholar]
- Zhao, X.; Razoumov, L.; Greenstein, L.J. Path Loss Estimation Algorithms and Results for RF Sensor Networks. In Proceedings of the IEEE Vehicular Technology Conference (VTC), Los Angeles, CA, USA, 26–29 September 2004. [Google Scholar]
- Benvenuto, N.; Santucci, F. A Least Squares Path-Loss Estimation Approach to Handover Algorithms. IEEE Trans. Veh. Technol. 1999, 48, 437–447. [Google Scholar] [CrossRef]
- Mao, G.; Anderson, B.D.O.; Fidan, B. Path Loss Exponent Estimation for Wireless Sensor Network Localization. Comput. Netw. 2007, 51, 2467–2483. [Google Scholar] [CrossRef]
- Nie, Q.; Weng, J.; Xu, X.; Feng, B. Defining Embedding Distortion for Intra Prediction Mode-based Video Steganography. Comput. Mater. Contin. 2018, 55, 59–70. [Google Scholar]
- Andrews, M.; Dinitz, M. Maximizing capacity in arbitrary wireless networks in the SINR model: Complexity and game theory. In Proceedings of the IEEE INFOCOM, Rio de Janeiro, Brazil, 19–25 April 2009; pp. 1332–1340. [Google Scholar]
- Zhao, Y.; Wu, J.; Lu, S. Throughput Maximization in Cognitive Radio Based Wireless Mesh Networks. In Proceedings of the Military Communications Conference (Milcom), Baltimore, MD, USA, 7–10 November 2011; pp. 260–265. [Google Scholar]
- Propagation Data and Prediction Methods for the Planning of Indoor Radiocomm. Systems and Radio Local Area Networks in the Frequency Range 900 MHz to 100 GHz; Rec. ITU-R P.1238-9; ITU-R Recommendations: Geneva, Switzerland, 2012.
- Jain, R. The Art of Computer Systems Performance Analysis; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1991. [Google Scholar]
- Garey, M.; Johnson, D. Computers and Intractability: A Guide to the Theory of NP-completeness; W.H. Freeman and Company: New York, NY, USA, 1979. [Google Scholar]
- Kuhn, F.; Wattenhofer, R. Constant-time distributed dominating set approximation. Distrib. Comput. 2005, 17, 303–310. [Google Scholar] [CrossRef]
- Zhang, J.; Mouratidis, K.; Pang, H. Heuristic algorithms for balanced multi-way number partitioning. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- SWIM Platform. Available online: http://cs.nju.edu.cn/lwz/swim/SWIM.html (accessed on 26 April 2011).
- Phillips, C.; Senior, R.; Sicker, D.; Grunwald, D. Robust Coverage and Performance Testing for Large Area Networks. In International Conference on Access Networks; Springer: Berlin/Heidelberg, Germany, 2008; pp. 457–469. [Google Scholar]
- Zhao, Y.; Li, W.; Wu, J.; Lu, S. Quantized conflict graphs for wireless network optimization. In Proceedings of the IEEE INFOCOM, Hong Kong, China, 26 April–1 May 2015; pp. 2218–2226. [Google Scholar]









© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Wu, J.; Li, W.; Lu, S. Efficient Interference Estimation with Accuracy Control for Data-Driven Resource Allocation in Cloud-RAN. Sensors 2018, 18, 3000. https://doi.org/10.3390/s18093000
Zhao Y, Wu J, Li W, Lu S. Efficient Interference Estimation with Accuracy Control for Data-Driven Resource Allocation in Cloud-RAN. Sensors. 2018; 18(9):3000. https://doi.org/10.3390/s18093000
Chicago/Turabian StyleZhao, Yanchao, Jie Wu, Wenzhong Li, and Sanglu Lu. 2018. "Efficient Interference Estimation with Accuracy Control for Data-Driven Resource Allocation in Cloud-RAN" Sensors 18, no. 9: 3000. https://doi.org/10.3390/s18093000
APA StyleZhao, Y., Wu, J., Li, W., & Lu, S. (2018). Efficient Interference Estimation with Accuracy Control for Data-Driven Resource Allocation in Cloud-RAN. Sensors, 18(9), 3000. https://doi.org/10.3390/s18093000