1. Introduction
The wide application of on-board electrical and electronic components and subsystems in modern vehicles increases the instability of the system and promotes the booming of the potential safety hazard. To ensure functional safety, the automobile industry has developed its own standard (ISO26262), which defines the functional safety requirements and life-cycle (management, development, production, service, and decommissioning) management for the safety-related components of automobiles in different phases of the safety lifecycle [
1].
In compliance with the standard, developing a strong on board diagnostic (OBD) system is an effective way. Although the OBD system has made great progress in recognizing the electrical circuit failures, such as the short to ground fault, short to battery fault, and open pin fault, it is still a dead area, which cannot effectively diagnose the fault caused by electric devices’ manufacturer errors or aging, such as the bias fault and drift fault. Furthermore, for the electronic systems of gasoline engine control, it is highly dependent on the availability and accuracy of sensor measurements [
2]. For example, once an intake pressure sensor suffers from a bias or drift fault, suitable gas cannot be supplied for the engine, which will lead to instability of the engine speed, fluctuation of the output torque, deterioration of emissions, and degradation of the vehicle drivability. Therefore, an effective diagnosis method is needed to solve this problem.
Diagnosis methods can generally be classified into model based methods and data driven methods. For decades, many researchers pushed the application of model based methods to design fault diagnosis systems, such as Rizzoni [
3], Blanke [
4], and Ding [
5]. The model based method compares the model output with the system operating value to diagnose faults based on the mathematical model, so its diagnosis accuracy relies on the accuracy of the model. Especially for highly complicated systems, like gasoline engines, it is usually hard to get an accuracy model for the system [
6].
In contrast, data driven methods do not need a mathematical model. Additionally, it only dependss on the measured process data, and can process these massive signals and recognize the health conditions of the machinery automatically [
7,
8]. Moreover, with the recent boom and development of big data, cloud computing, and artificial intelligence technology, it is easier to obtain sufficient high-quality data and high-speed computing components. These offer abundant oil for the development of the data driven method. As such, nowadays, data driven methods have been widely used to design fault diagnosis and fault detection and isolation systems [
9].
Data driven methods mainly adopted in the diagnostic area are the the back propagation (BP) neural network, support vector machine (SVM), and evidence theory. Efforts have been made to study these methods. The BP neural network is a kind of non-logic and non-language artificial intelligence approach based on the connection structure, which has many advantages, such as parallel structure, parallel processing, distributed storage, good error tolerance, self-organization, self-learning, and reasoning. In a previous study [
10], the BP algorithm was used to detect and diagnose faults of a marine engine cooling system. In another study [
11], the intelligent diagnosis of engine faults was realized by using a BP neural network to realize the typical malfunction of a certain truck engine. In another study [
12], a BP neural network was used for recognition of acoustic signals, together with the nearest neighbour classifier and the modified classifier. The authors of [
13] showed that neural networks can be a very useful tool for solving many scientific and practical problems related to the mining industry. Another previous study [
14] contributed to the usage of an artificial neural network as a decisive part in surface roughness prediction. The SVM method was put forward by Vapnik in 1995. It is an effective classification method based on the Vapnik–Chervonenkis (VC) dimension of statistical learning theory and structural risk minimization principle. It can automatically identify the support vector that has a good distinction ability for classification. The authors of [
15] used the support vector machine (SVM) method to effectively recognize the turbocharger fault, analyze the reason for the failures, and realize fault prediction and prevent accidents. Li et al. [
16] applied symbolic dynamic entropy features to extract features of the gearbox signals and applied the support vector machine to recognize health conditions based on the dynamic characteristics of gearbox signals. Evidence theory is an efficient method that is better than traditional probability theory on grasping the unpredictability and uncertainty of the problem. In addition, it provides the method for evidence synthesized methods and can fuse evidence obtained from various evidence sources. A previous study [
17] used the weighted Dempster-Shafer (DS) evidence theory to diagnose engine faults.
When each of them is used separately as a single diagnosis algorithm, the reliability and confidence level of the diagnosis result tends to be low and weak, and there exists the possibility of false diagnosis, especially in highly complicated mechanical systems. Hence, it is necessary to fusion data driven methods to diagnose faults [
18].
The authors of [
19] reviewed the application of multi information fusion in the field of vehicles. A previous study [
20] used the information fusion and classification method to diagnose spark plug faults of an internal combustion engine; for a single application of the artificial neural network, the diagnostic accuracy was 67.46%; for a single application of the least squares support vector machine, the diagnostic accuracy was 65.08%; and, after the use of the evidence theory fusion, the classification accuracy reached 98.56%. In another study [
21], evidence theory was used as a modeling tool, and information was regarded as relevant evidence, which reflects the quality of the engine. A previous study [
22] used the multi information fusion method, which is combined with the artificial neural network and evidence theory, to diagnose faults of a diesel engine. In another paper [
23], the multi information of aero engines and artificial intelligence technology were combined to diagnose sensor faults, gas path faults, and mechanical vibration faults. In another study [
24], by using neural network and evidence theory, the fault diagnosis of the sensor and actuator for an electronic control engine are made. Another study [
25] used the multi information fusion method to diagnose coolant temperature sensor faults and oxygen sensor faults. In a previous study [
26], a method for multi-sensor information fusion based on Dempster-Shafer (DS) evidence theory is discussed for fault diagnosis of the aero-engine gas path.
In this paper, a novel multi information fusion method (which combines the BP neural network, SVM, and evidence theory) is proposed to diagnose electronic systems of gasoline engines. In detail, the bias and drift fault of intake pressure sensors will be regarded as the targets to diagnose and verify the feasibility of the method.
The remainder of the paper is organized as follows: The second section introduces the multi information fusion algorithm, and explains the reason why the multi information fusion algorithm can improve the reliability of diagnosis results. The third section establishes the multi information fusion fault diagnosis model, including the data fusion layer model, feature fusion layer model, and decision fusion layer model, and focuses on the reliability allocation of diagnosis results from the data fusion layer and feature fusion layer. The fourth section describes the experiment process, including the fault simulator development and real vehicle experiment. The fifth section uses the multi information model to analyze the acquired experimental data. The last section summarizes the whole paper and proposes future research.
2. Multi Information Fusion
The basic principle of multi information fusion, also called data fusion, is to simulate the procedure of human processing information, according to certain fusion rules, with complementary information in space and time. It makes full use of the advantages of diversification, obtains valuable decision-making information, and improves the accuracy of results, with the premise of the consistency of data. The feasibility of the multi information fusion method can be proved by information theory.
It is assumed that
on behalf of the engine running state set. Additionally, the engine running state probability is expressed as
. The entropy,
H, of the engine running state,
, indicates the state of uncertainty, as shown in Formula (1).
It is assumed that because
represents the diagnostic information set, and
is known, the condition entropy and the average conditional entropy of engine operating condition can be calculated, according to Formulas (2) and (3).
By computation derivation, it can be inferred that the condition of the engine state would be more than or equal to the conditional entropy. If the engine diagnostic information, X, is known, the uncertainty of the running state, θ, will be improved.
It is assumed that the mutual information of the engine status and diagnostic information reflects the uncertainty relationship between them. The mutual information calculation formula is expressed as (4).
When the case engine diagnostic information is known, the greater the mutual information value, the more determined the engine running state, and the more the diagnostic information,
X, can characterize the running state of the engine. If another engine diagnostic information,
Y, is added, the mutual information calculation formula would be (5).
From Formula (5), it is known that if the fault diagnostic information increases, the fault certainty will be improved further, and the reliability of diagnosis will be enhanced [
27]. Therefore, using the method of multi information fusion can reduce the uncertainty degree effectively and improve the accuracy in the diagnostic process.
3. Engine Fault Diagnostic Model
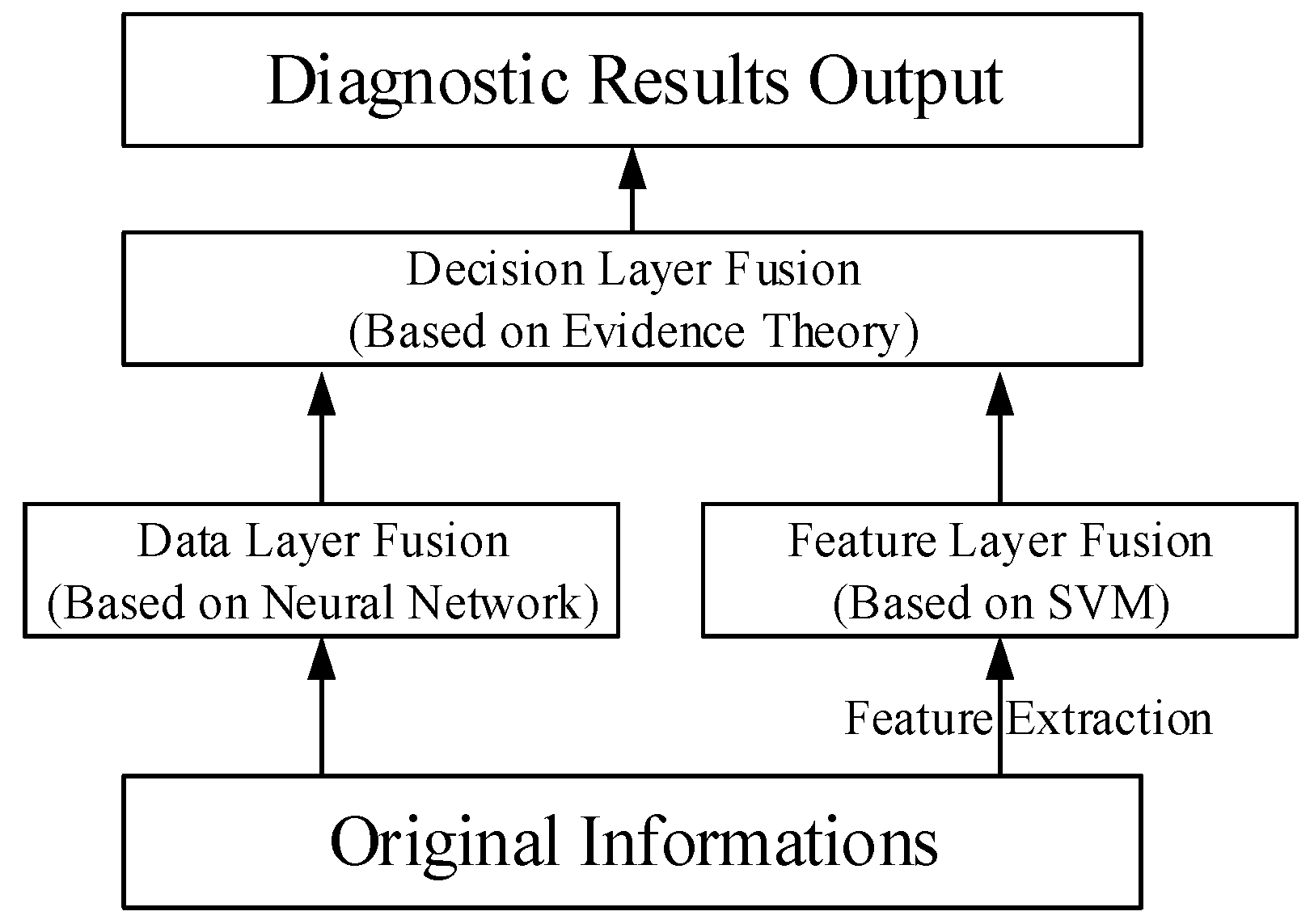
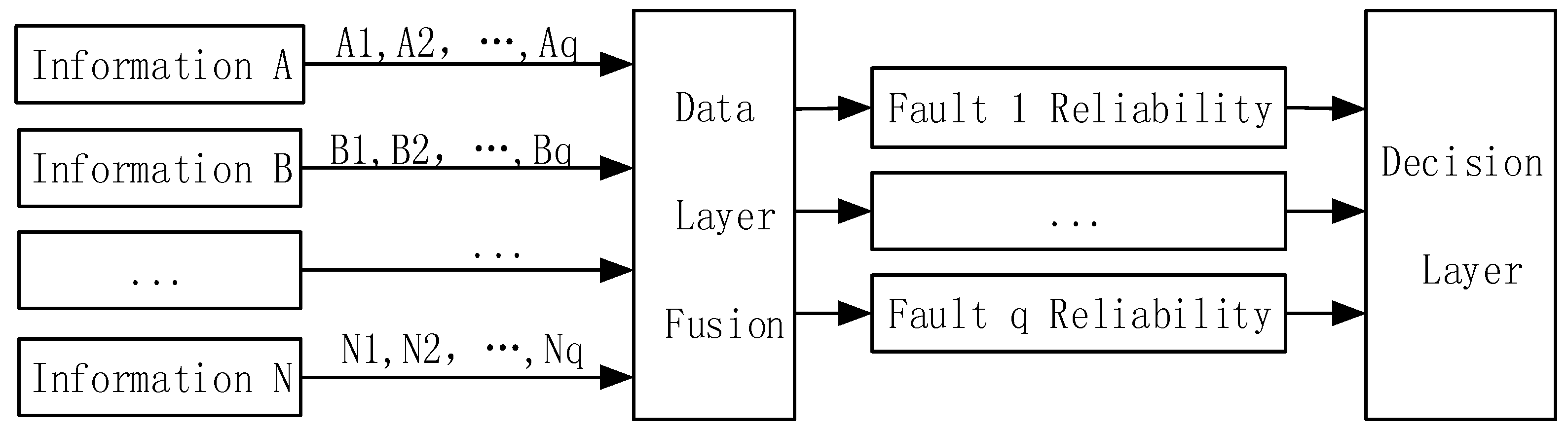
The engine fault diagnosis model based on multi information fusion is built according to the data processing level. The model is composed of the data fusion layer, feature fusion layer, and decision fusion layer, as shown in
Figure 1.
3.1. Data Layer Fusion Model
In essence, engine fault diagnosis is pattern classification through identifying the running state with operating parameters. At the same time, it is the classification of multiple kinds of faults, which is difficult to diagnose through the physic model. Fortunately, the neural network provides a way. The data fusion layer algorithm can use the BP neural network. Because the neural network has a strong ability to identify and classify the associative memory capacity, multiple-input multiple-output models with complex nonlinear relationships can quickly and accurately achieve learning and training.
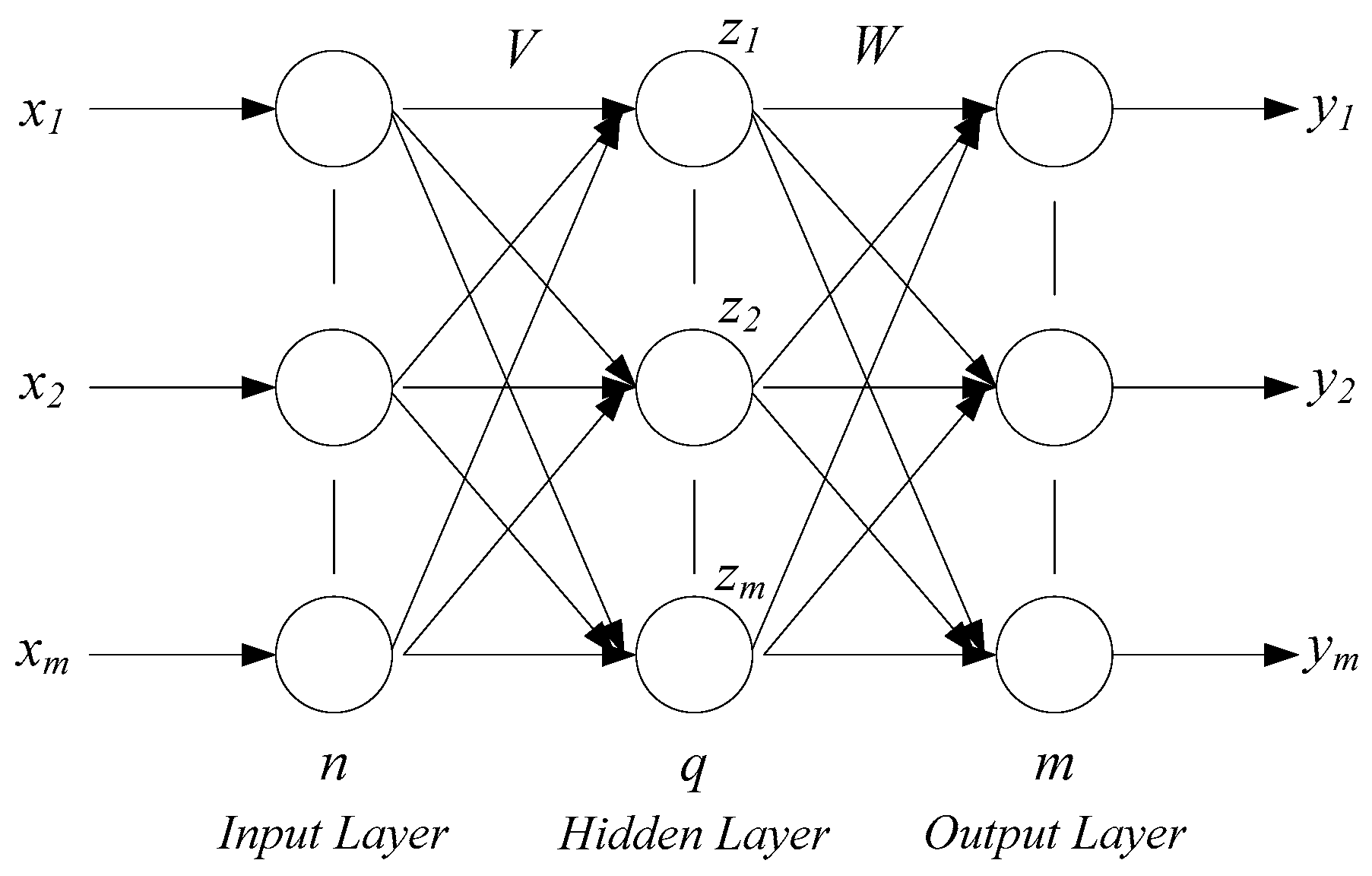
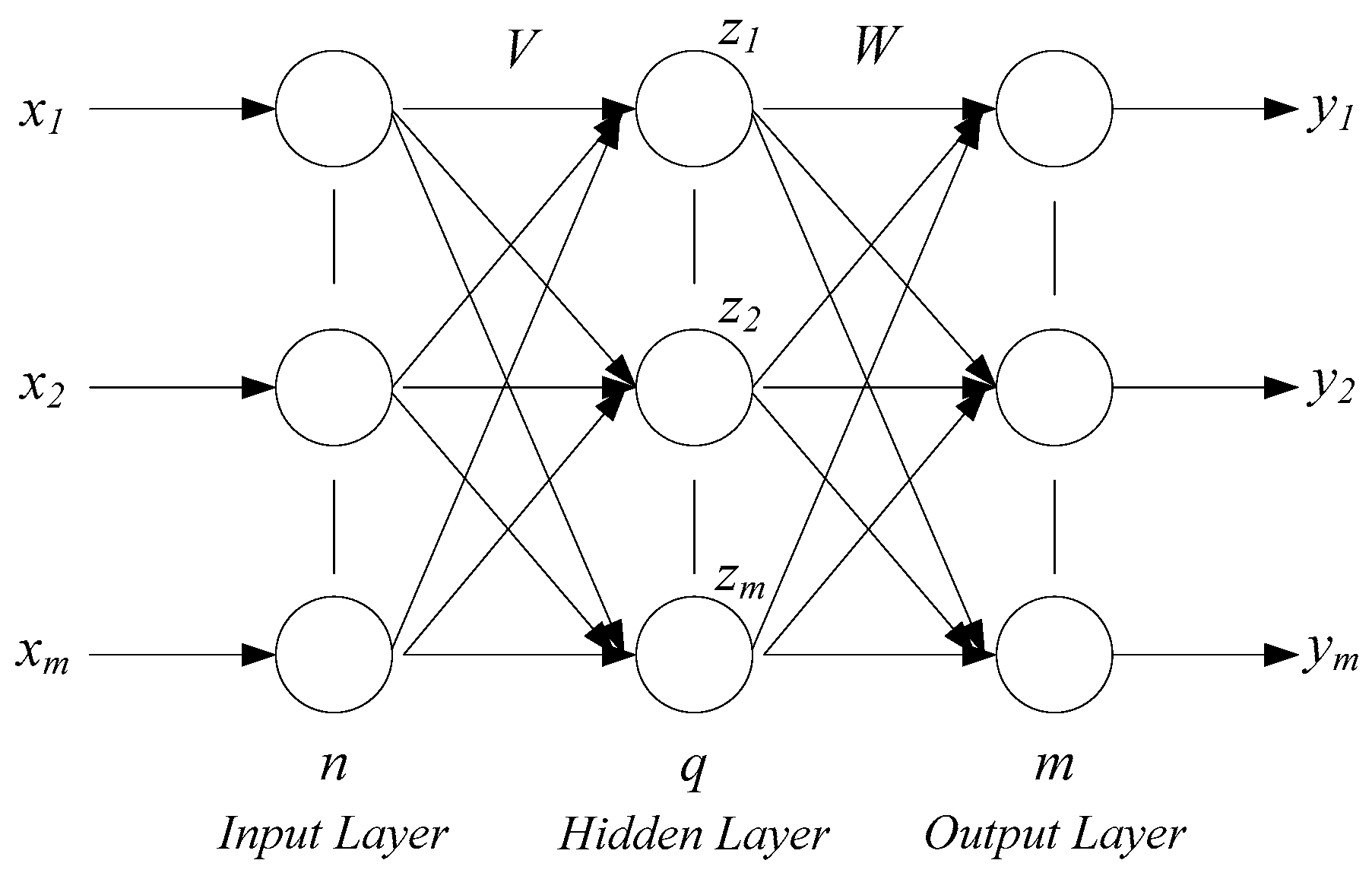
Neural networks usually contain an input layer, hidden layer, and output layer. Its structure diagram is shown in
Figure 2 [
13]. The input layer and output layer are single simple structures, and the number of nodes is determined by the application characteristics. For the layer number of the hidden layer, many researchers have conducted theoretical analysis and have found that if the number of hidden nodes are enough, the single hidden layer structure can simplify nonlinear function approximation. The number of hidden layer nodes mainly relies on experiences and trials. The excitation function of the BP neural network is usually chosen between the sigmoid function and hyperbolic tangent function. The number of output layer nodes mainly relies on the dimension of the expectation output.
The general learning process of the BP neural network is divided into two stages, the calculation results forward transfer and error reverse transmission. In the forward transfer phase, sample data are sent from the input layer to the hidden layer for calculation. Then, the BP neural network obtains the calculation results at the output layer. If the difference between the network calculation results and expected results does not meet the design requirements, the BP network will work in the next stage (error back propagation phase), and otherwise the network training is completed. In the error reverse transfer phase, error is decomposed to each layer of neurons, and the weight factor and threshold factor of each neuron is corrected according to the decomposition value [
12].
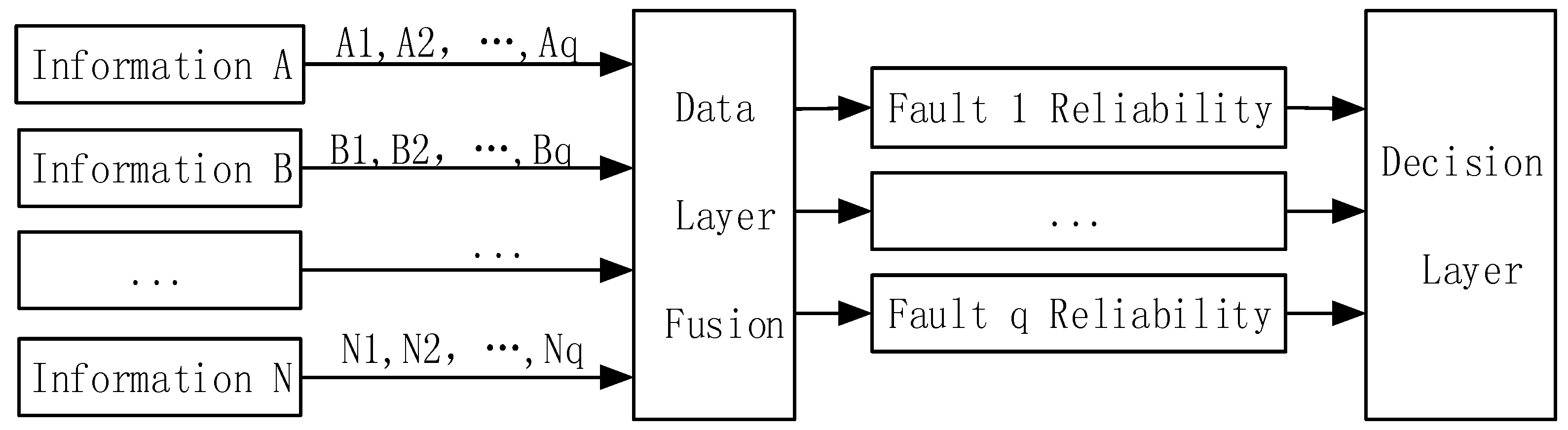
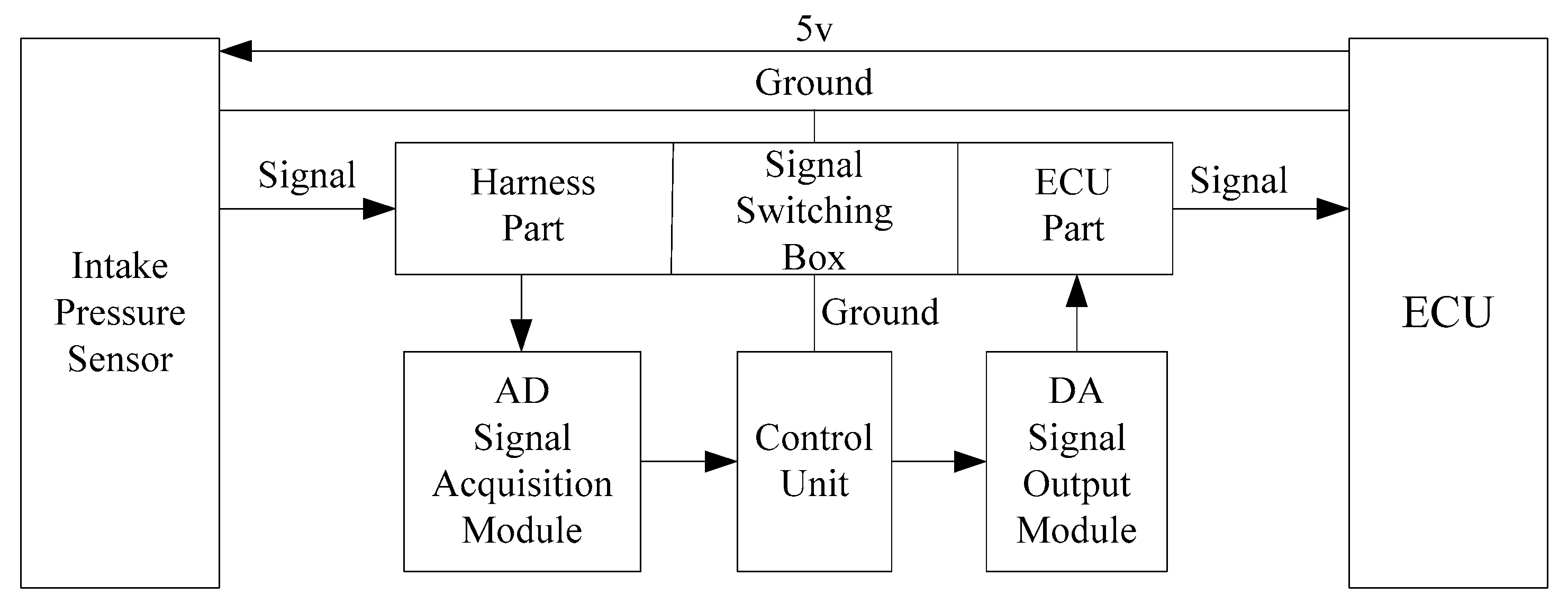
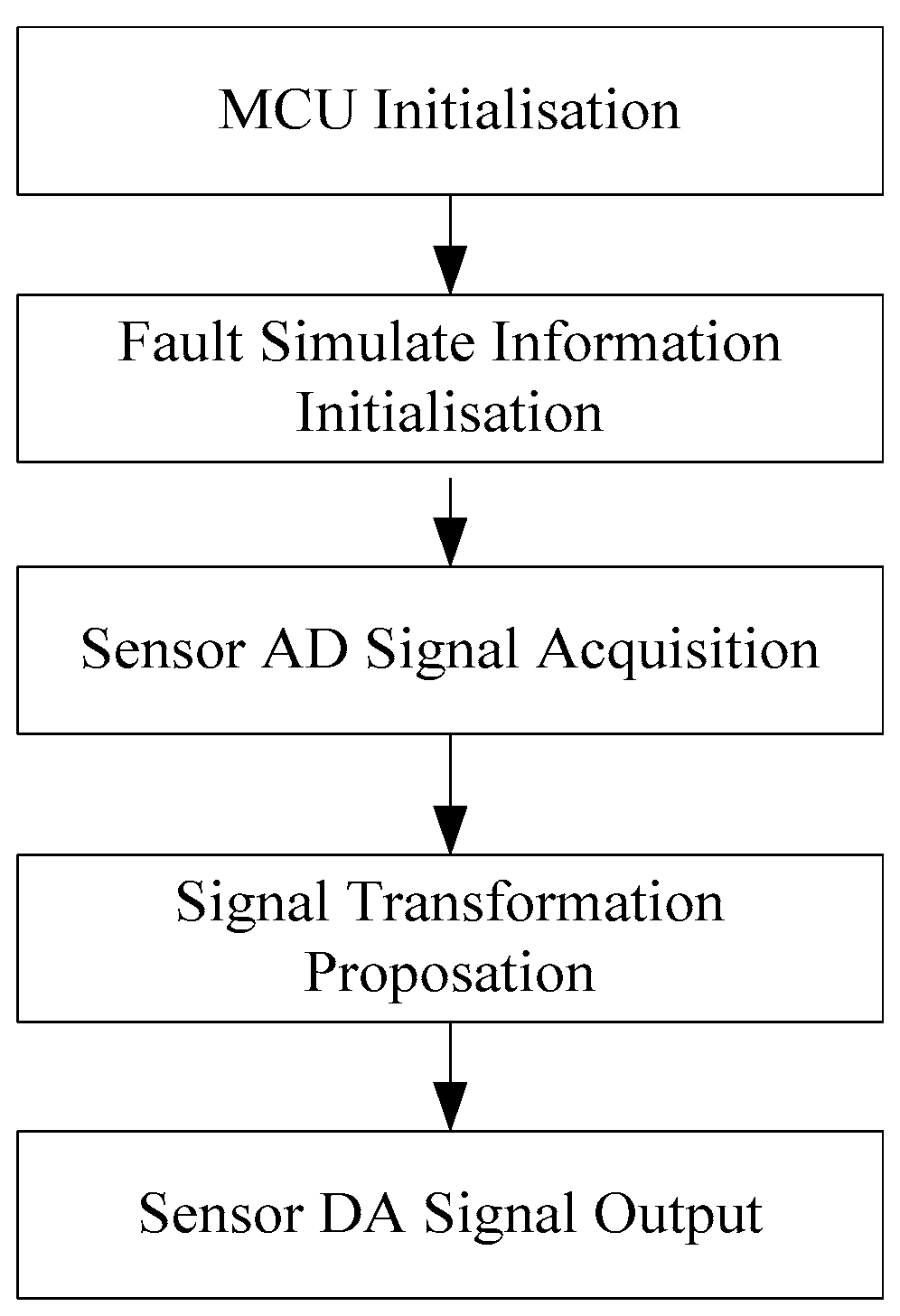
The detailed fault diagnosis process is: Firstly, parameters are sampled with the same engine condition continuously, and ensures the conformity of the acquired parameters in the time aspect. Next, using the normalization method to dispose of the sample parameters, the results are put into the neural network to do the data fusion layer, part of them as training sets and others as test data. Finally, reliability of the diagnosis results is allocated from the data fusion layer, which will be sent to the decision fusion layer to make the final decision. The established data fusion layer model based on the BP neural network is shown in
Figure 3.
3.2. Feature Fusion Layer Model
In the feature fusion layer, firstly, the multidimensional features of the collected information should be extracted and reduced. Then, they will be regarded as input for decision-making in the higher level fusion for fault diagnosis. The feature fusion layer algorithm is the SVM, which is similar to the neural network. SVM uses feature data corresponding directly to the fault mode, and does not need the support of diagnostic rules, which have lower data quantities, but more feature dimensions [
28].
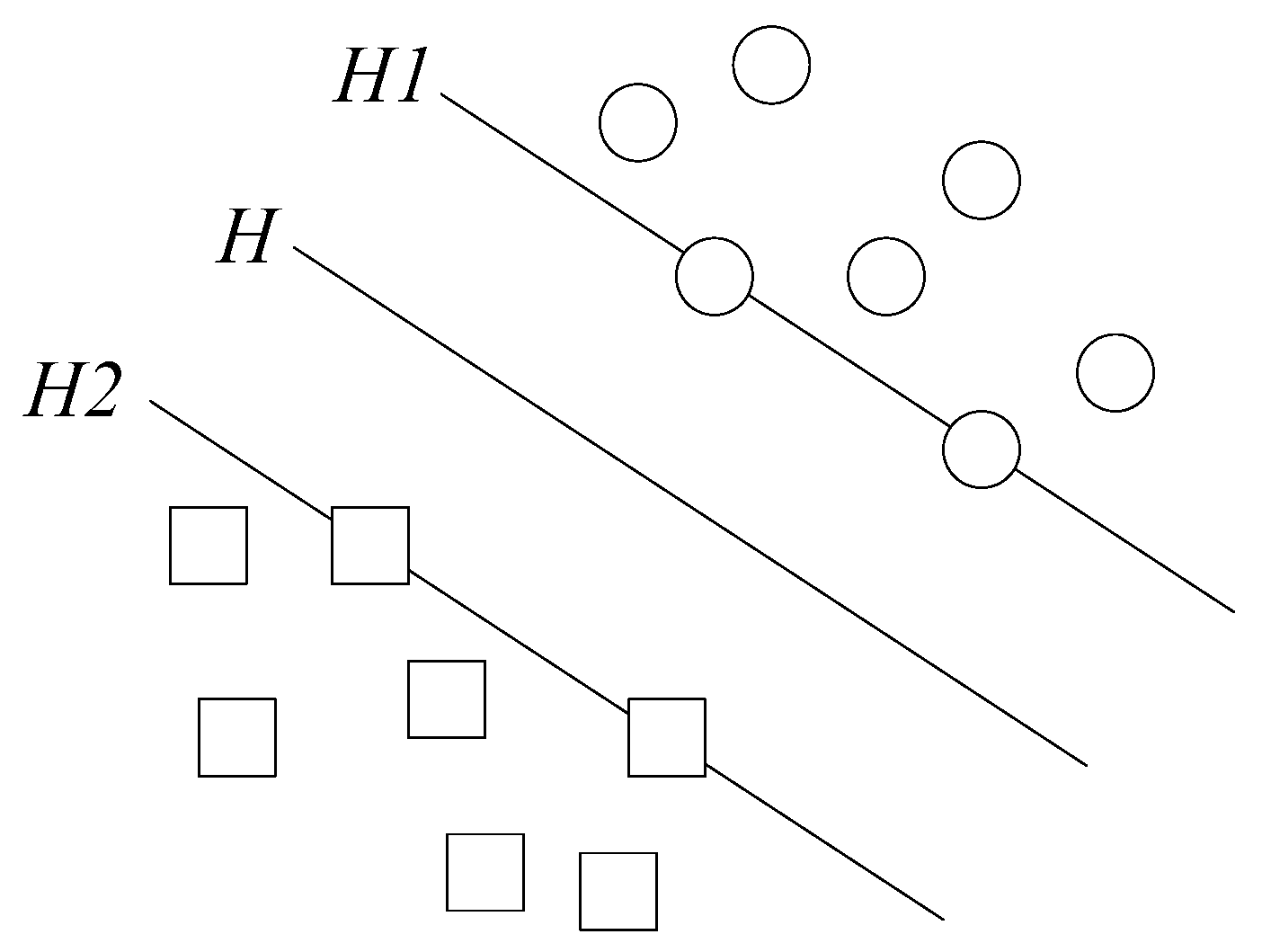
SVM theory assumes that there is a sample set, , . Where, l is the number of samples, D is the number of samples feature, and y is the sample patterns. It is also assumed that there are only two kinds of attribute values, is the hyperplane, H, , y = 1 is the hyperplane, H1, which parallels to the plane of the hyperplane, and the distance between H and H1 is y = 1. , y = −1 is the hyperplane, H2, which parallels to the plane of the hyperplane, and the distance between H and H2 is also y = −1.
If the distance between
H1 and
H2 is maximized, then
H is the optimal hyperplane, and
H1 and
H2 are support vectors of the upper sample data. The classification diagram is shown in
Figure 4, where the square points and dots represent two types of data.
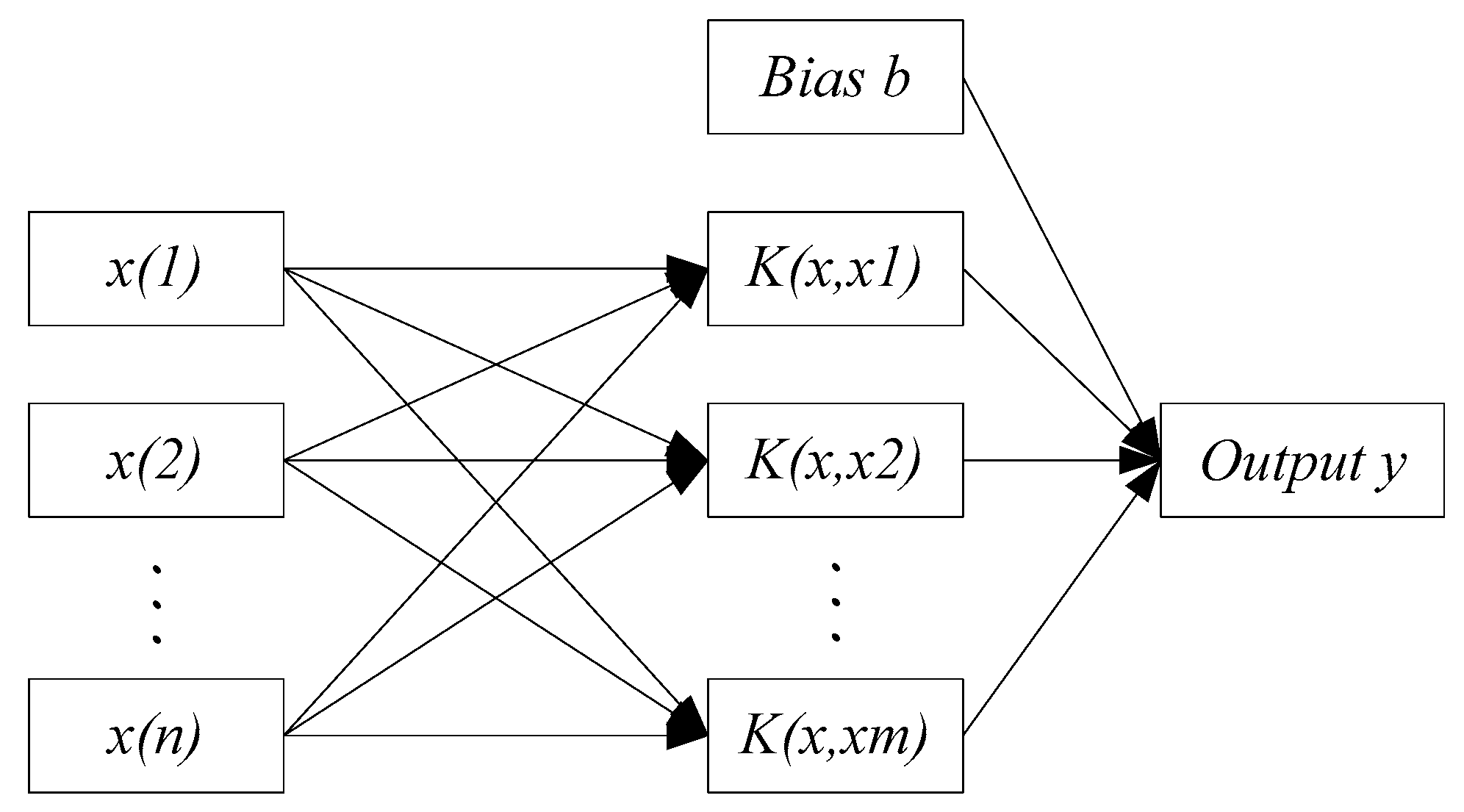
The SVM network structure is shown in
Figure 5.
K is the kernel function, including the linear kernel function, radial basis function, polynomial kernel function, and so on. The established feature fusion layer model based on the support vector machine is shown in
Figure 6.
3.3. Decision Layer Fusion Model
The acquired reliability of diagnosis results from the data layer and feature layer are low, which means that there exists the problem of false diagnosis in some cases. To improve the diagnostic accuracy and reliability, diagnosis results of the data fusion layer and feature fusion layer will be fused to make decisions in the decision fusion layer. In this paper, D-S evidence theory is used as the algorithm for the decision fusion layer.
D-S evidence theory gets the final decision based on the reliability,
m(A), of the evidence through analyzing and synthesizing the evidence. The reliability is the degree of belief for the established proposition,
A. Evidence refers to objective characteristics, personnel subjective experience, and the knowledge that depends on the reliability of the object to be calculated. The essence of the evidence theory is to determine the extent that an unknown object belongs to the identified frame,
(which denotes a set that contains every possible solution of a problem, all the elements of it are mutually exclusive), under the condition of the identification frame determined. Set
is the basic reliability allocation in the recognition framework,
. According to the D-S evidence theory, the support of an arbitrary assumption is presented by an interval. The lower limit of this interval is called the confidence function, which is defined as:
It is assumed that the confidence function,
, is assigned in the same identification framework.
denotes the basic confidence distribution functions in the same recognition frame,
. If
exists, there is a reliability assignment, as shown in Equation (7).
Value
K is the conflict degree, which presents the conflict degree among the evidence, which can be calculated as shown in (8).
The above reliability formula is also called synthetic principle of evidence theory, and the final reliability is obtained by the belief function of each evidence. The evidence combination rule offers a comprehensive combination rule of the multiple independent bodies of evidence, and the law has the nature of association. In the body of evidence synthesis, the combination sequence has no effect on the final synthesis results, so evidence can be in any combination.
When , there is a conflict of evidence reliability, but there still exists a consistency. It can be processed according to the evidence combination rule to obtain the synthetic results. In the case of K = 1, it means that evidence is completely opposite, and is not in accordance with the evidence rules of evidence synthesis processing. Therefore, it is necessary to calculate the degree of reliability conflict degree and judge whether the fusion diagnosis can be carried out.
The fault diagnostic procedure in the decision fusion layer based on evidence theory is depicted as follows: Firstly, the characteristics of the data fusion layer and feature fusion layer algorithm are united, and the reliability of the data fusion layer and feature fusion layer diagnostic results are allocated. Then, the evidence of the degree of conflict is calculated, and it is determined whether the evidence theory combination rules can be adopted to calculate the reliability of the proposition. Finally, the proposition that has the maximum reliability as output of the decision layer is chosen. In the decision fusion layer, the critical thing is to allocate the reliability of the data fusion layer and diagnosis results of the feature fusion layer.
3.3.1. Reliability Allocation Based on Diagnostic Results of Data Fusion Layer
According to relevance theory, the basic reliability,
, and uncertainty description,
, can be defined as Formulas (9) and (10), as follows.
where,
is the normalized value of the diagnosis results for the BP neural network in the data fusion layer, and
represents the diagnosis procedures aggregate uncertainty. The parameter,
,
,
, can be calculated using (11)–(13).
where,
αi is the difference between the maximum and second largest relevance in evidence,
Ei, of the sub proposition, which reflects the reliability of the sub proposition. In addition, the bigger the
αi, the higher the reliability of the sub proposition in the recognition framework, Θ.
βi is the relevance correlation variance with evidence,
Ei, in the recognition framework, Θ, of other sub propositions (except the sub proposition that has the biggest relevance with evidence,
Ei), which reflects the correlation degree of polymerization for other sub propositions. In addition, the bigger the
βi, the worse the degree of polymerization.
μi is the relevance mean value (except the sub proposition, which has the biggest relevance with the evidence,
Ei) of other sub propositions.
ωi is the weight factor of the evidence,
Ei. In the application of fault diagnosis, different evidence bodies have different sensitivities to fault, which makes the difference of the characteristic value of the evidence. Therefore, the weight factor is introduced to construct the reliability distribution function to improve the accuracy of decision results.
3.3.2. Reliability Allocation Based on Diagnosis Results of the Feature Fusion Layer
Accordingly, using vote results to allocate reliability is characteristic of the feature fusion layer algorithm, which is based on SVM in the decision fusion layer. In the SVM model, the vote numbers in the one to one classification model are counted, then the whole classification numbers are divided, and the basic probability distribution function of the sub proposition is obtained, as shown in formula (14).
where,
is a type of
,
is the vote numbers in the whole one to one classification model,
n is the total type, and
is the total classification.
6. Conclusions
Based on the analysis of the fault diagnosis methods and multi information fusion theory, this paper studies the application of the multi information fusion method to diagnose sensor faults of an engine electronic control system. The following was accomplished:
The fault diagnostic model and algorithms were studied. Based on the analysis of the characteristics of fault diagnosis and multi information fusion, a fault diagnosis model based on multi information fusion was established according to the data processing level. The model includes the data fusion layer, feature fusion layer, and decision fusion layer. The data fusion algorithm uses the BP artificial neural network, feature fusion algorithm based on the support vector machine, decision fusion algorithm based on evidence theory, and the fusion model structure, and the diagnostic process of each layer in engine fault diagnosis was settled. In the decision fusion model, based on evidence theory, the way of reliability allocation was analyzed by combining data fusion diagnosis results and feature level fusion diagnosis results as evidence.
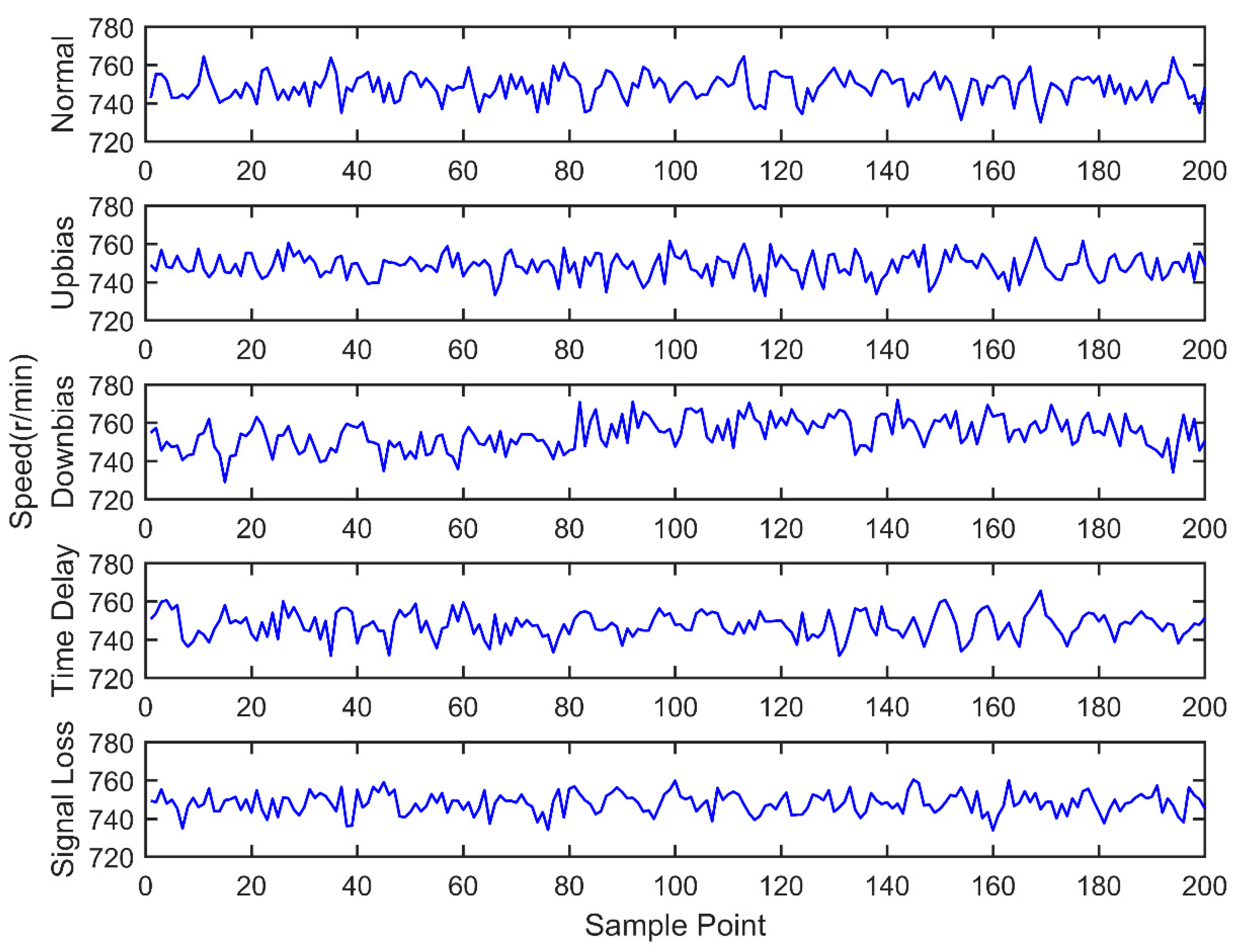
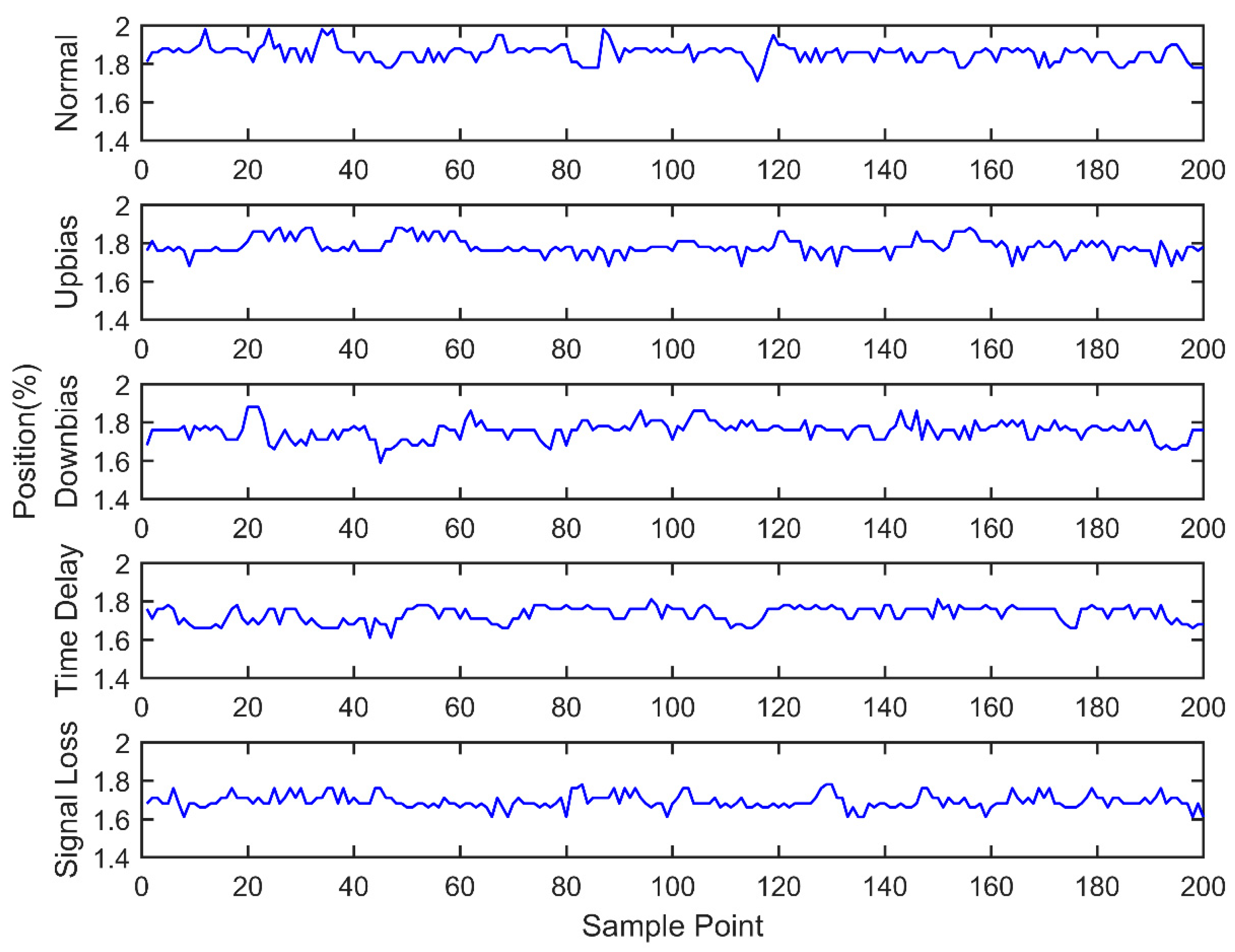
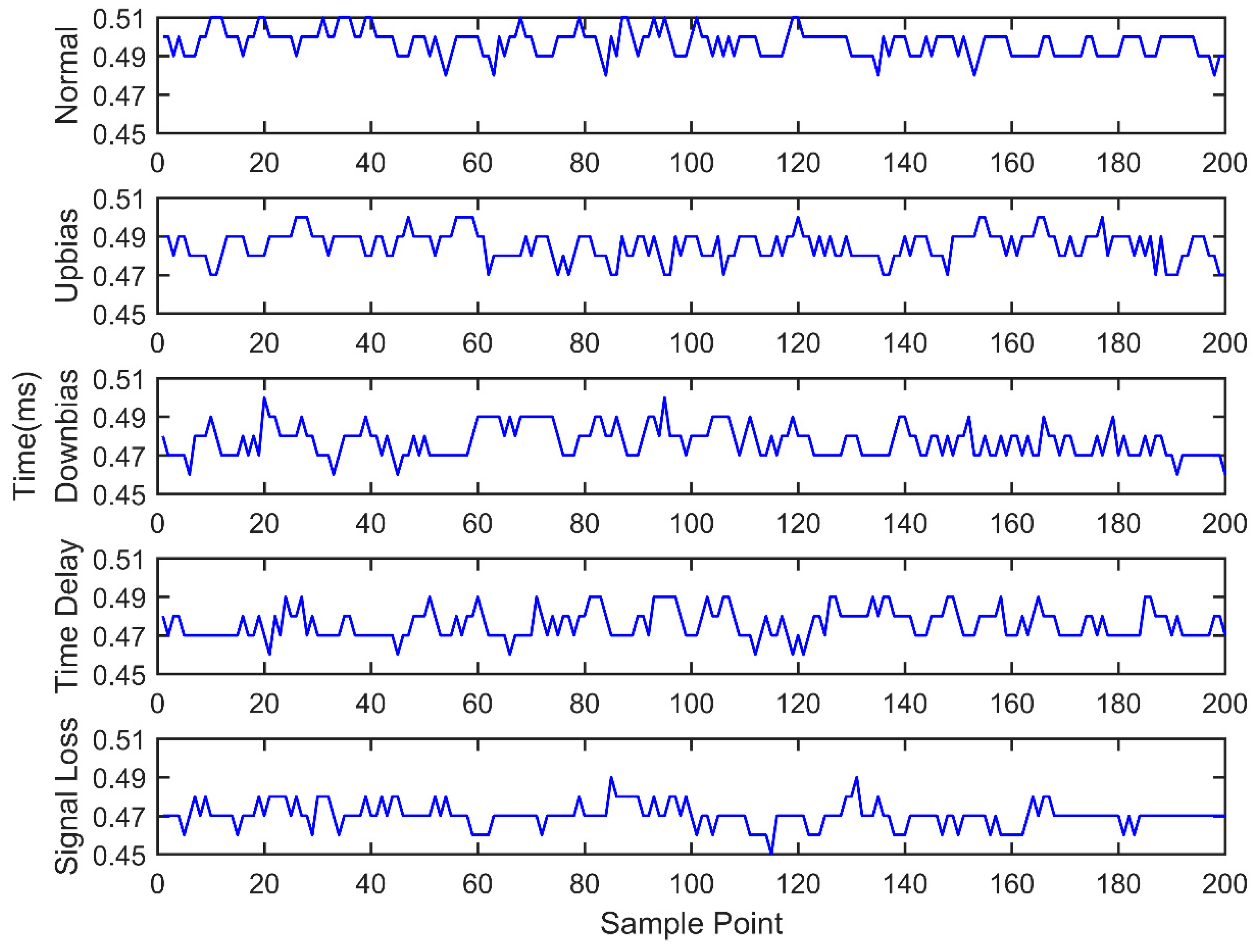
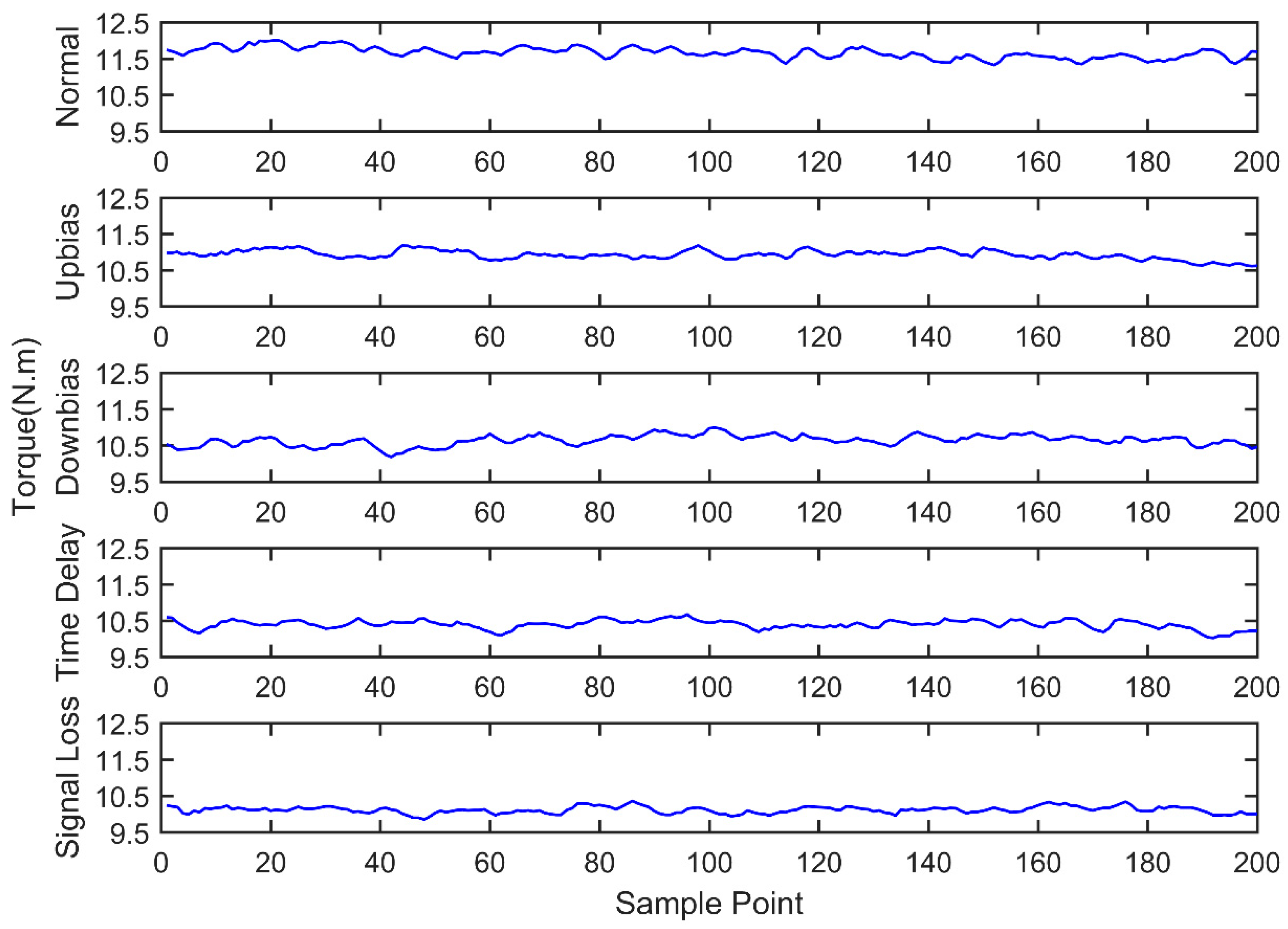
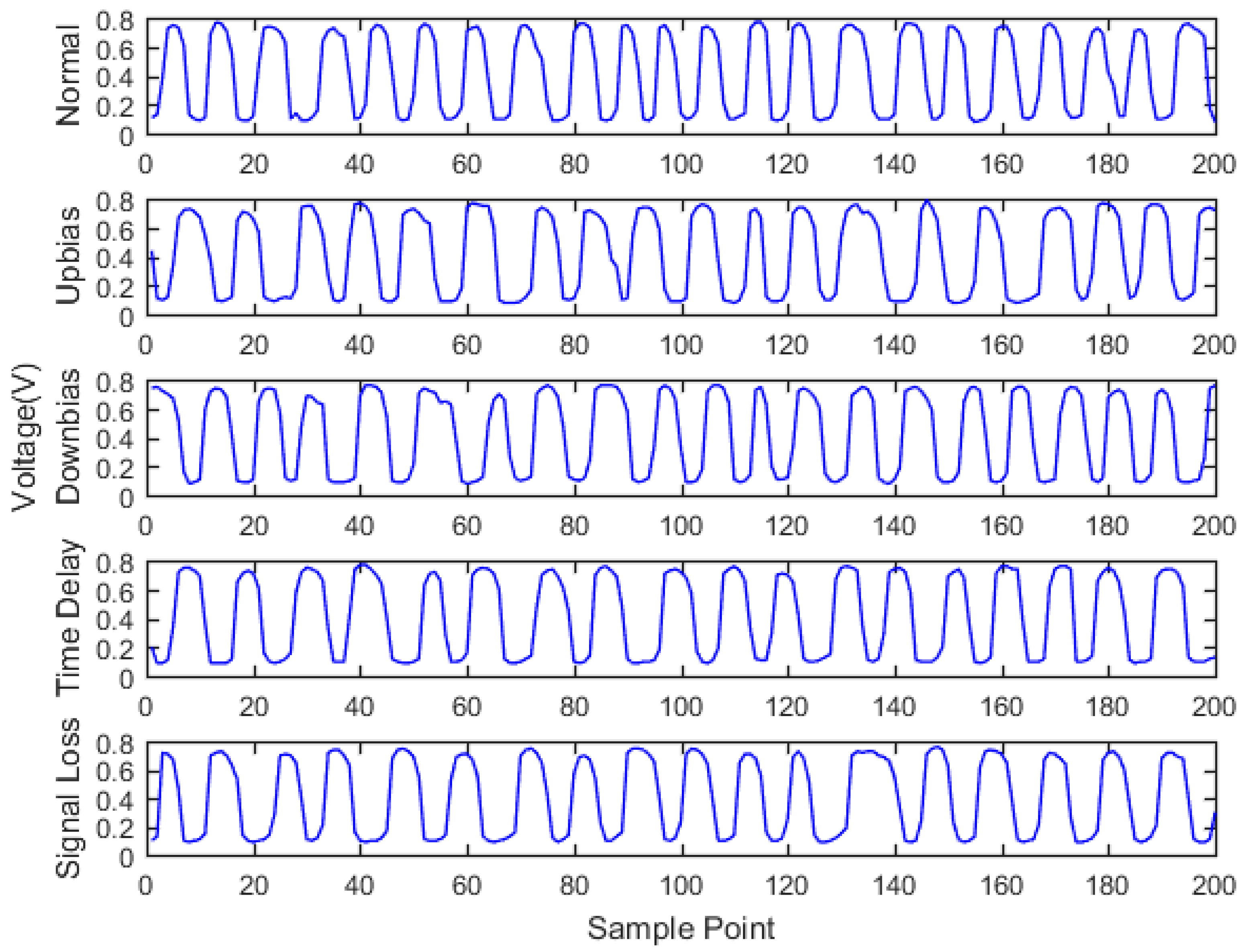
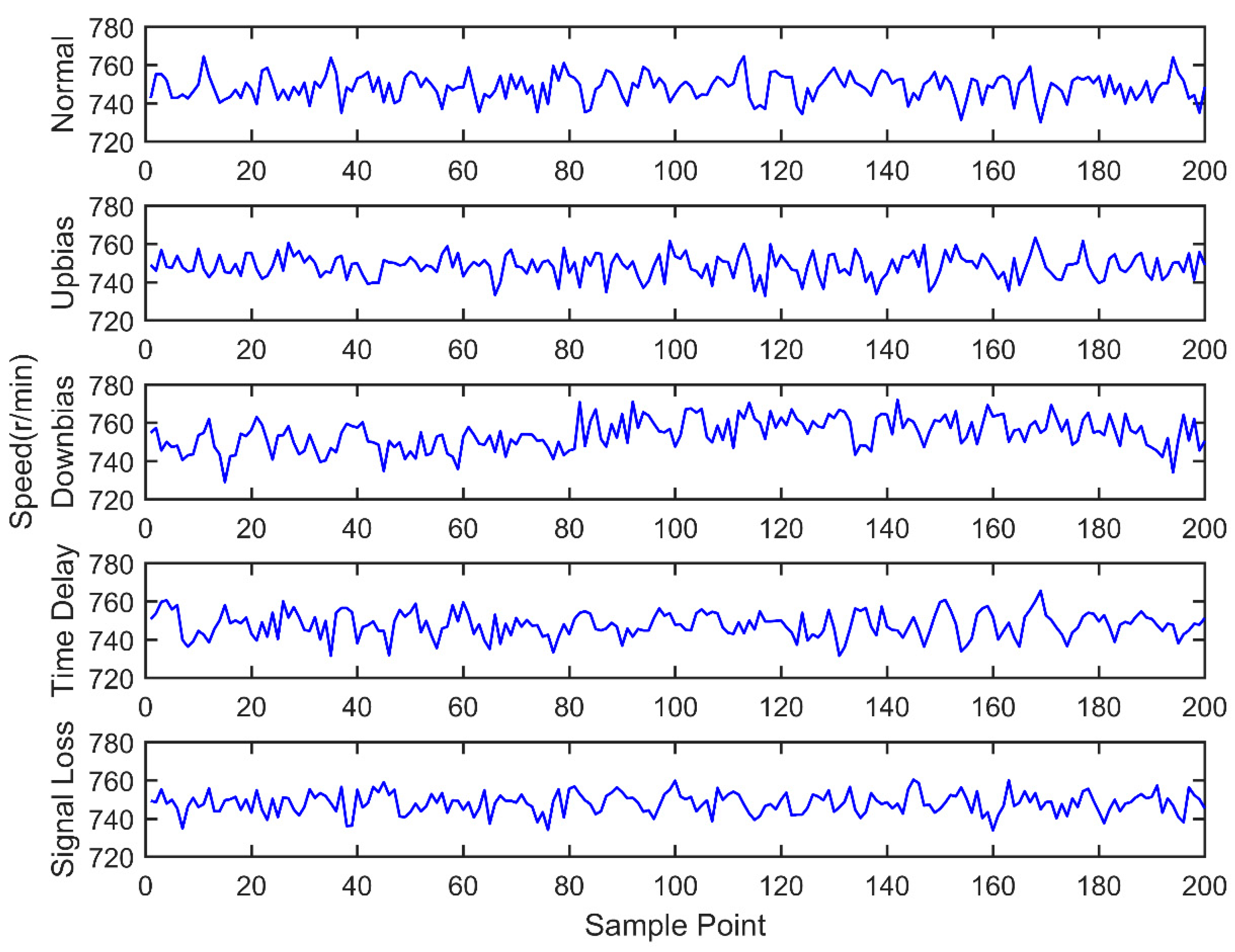
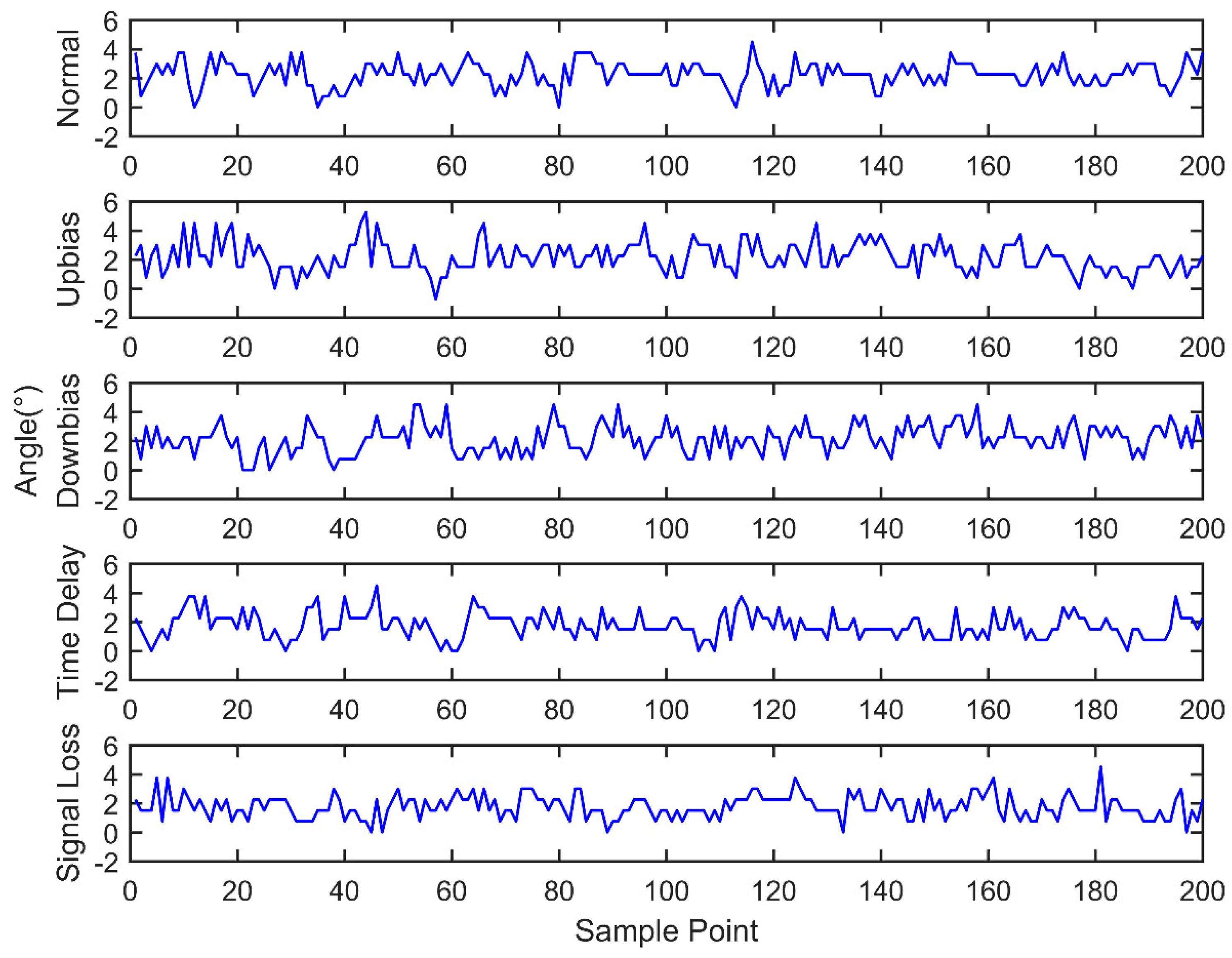
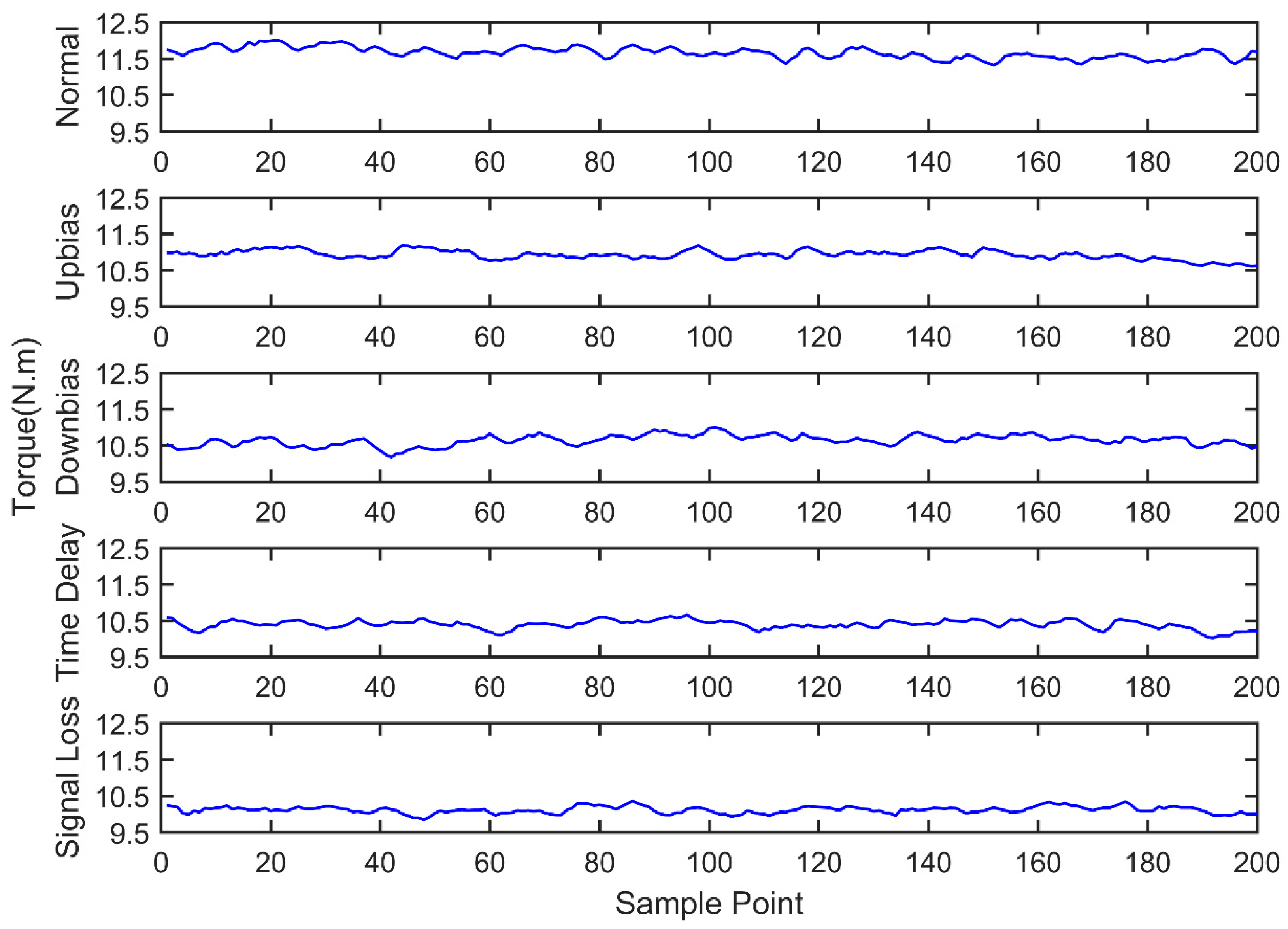
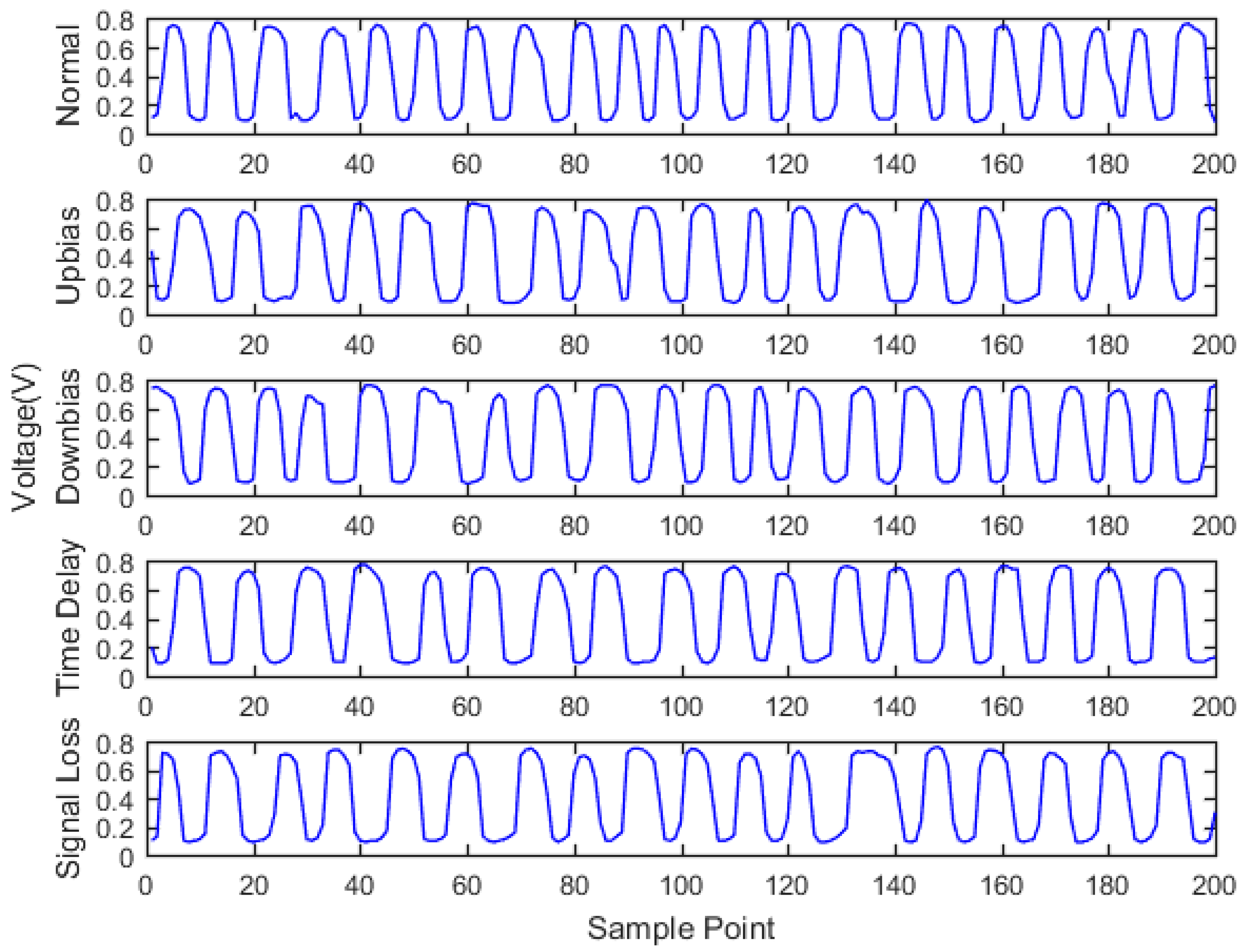
Engine sensor fault analysis and simulator development were carried out. Based on the summary of the main simulation methods and combining the studied fault types of the electronic control system, a fault simulator was developed. The fault simulator consists of a signal switching box, AD signal acquisition module, main control unit, and DA signal output module. Under the CodeWarrior integrated development environment, fault simulator software was developed. The developed fault simulator can simulate both bias fault and drift fault of the sensor with the deal of voltage up bias, down bias, and delay.
Sensor fault diagnosis with multi information fusion was completed. Real vehicle was selected as the experimental platform. Fault diagnosis was carried out by multi information fusion with data acquired from a CAN bus. In the data layer, engine data was used to diagnosis with the BP neural network directly; in the feature layer, feature vectors were extracted from original data with the time domain method. The accuracy and training time were compared in the two fusion layers. In the decision layer, the fault diagnosis was based on evidence theory, which combines the data fusion layer and feature fusion layer results as the evidence. Diagnostic results showed that the multi information fusion method can diagnose the faults of engine electronic control systems effectively, and clearly improves the accuracy and reliability.
With the rapid development of remote diagnosis technology, car networking technology, big data technology, and promotion of T-box devices, it is easy to collect numerous process data of vehicles. However, automobile manufacturers are faced with a problem of how to use them to get what we want. For example, how to prognose the critical fault in time by analyzing the data to further ensure function safety. It is worthwhile to be researched, therefore, this will be the subject of future research.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}