Generative vs. Discriminative Recognition Models for Off-Line Arabic Handwriting


Abstract
1. Introduction
2. Previous Works
3. Shape Descriptions Features for Arabic Handwriting Recognition
- Less expensive to extract and to process.
- Capturing the letter’s distinctive shape characteristics.
- Invariant to stroke width and less sensitive to handwriting distortions.
- Easily converted to vectors of observations suitable for sequence classifiers.
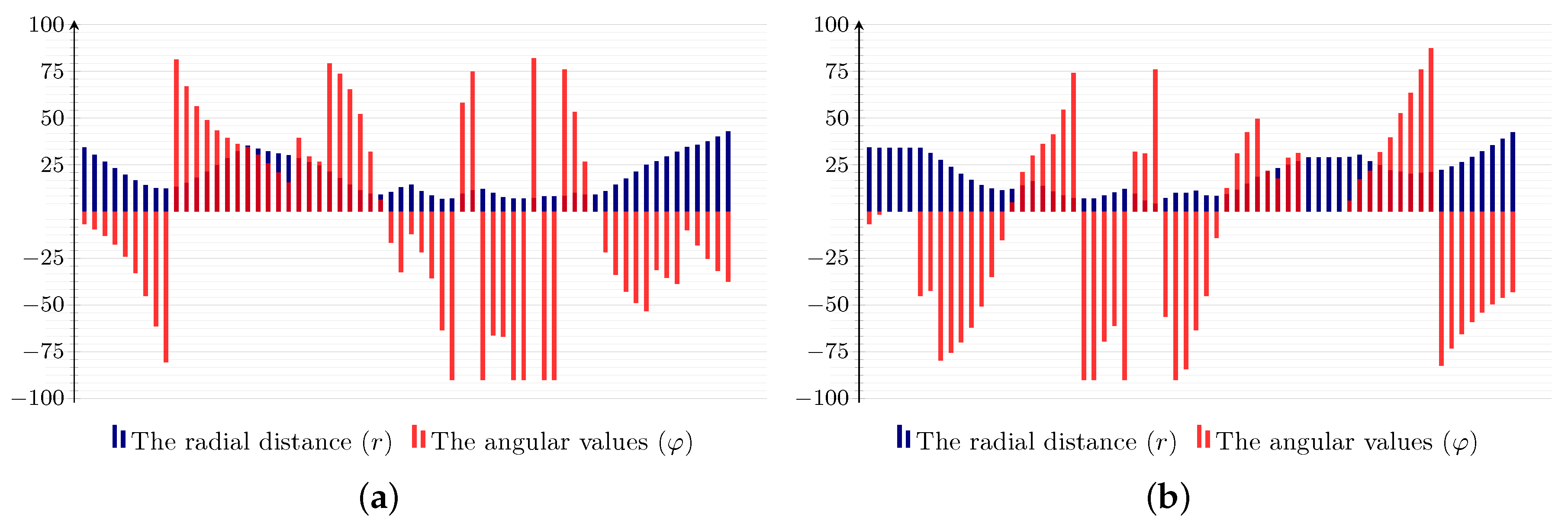
3.1. Extraction of Feature Descriptors
| Algorithm 1: Extraction of feature descriptors. |
 |
3.2. Vector Quantization for Feature Sequences
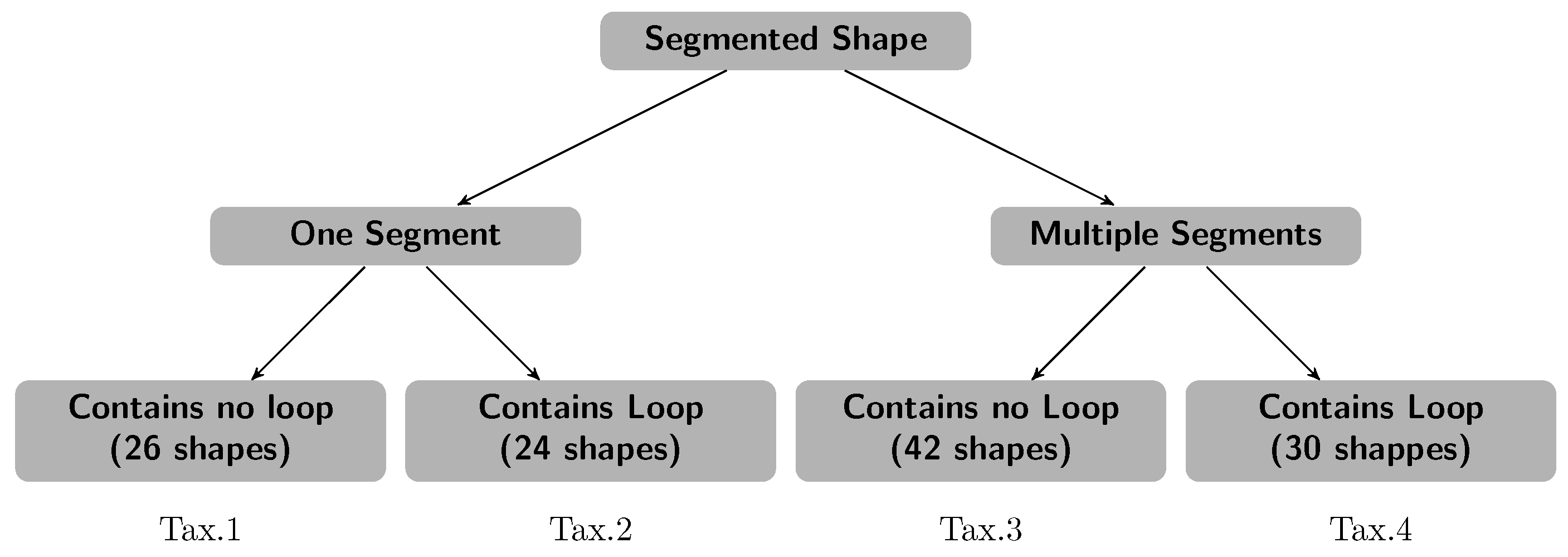
4. Shape-Based Letters’ Taxonomization
5. HMM-Based Recognition of Arabic Handwriting
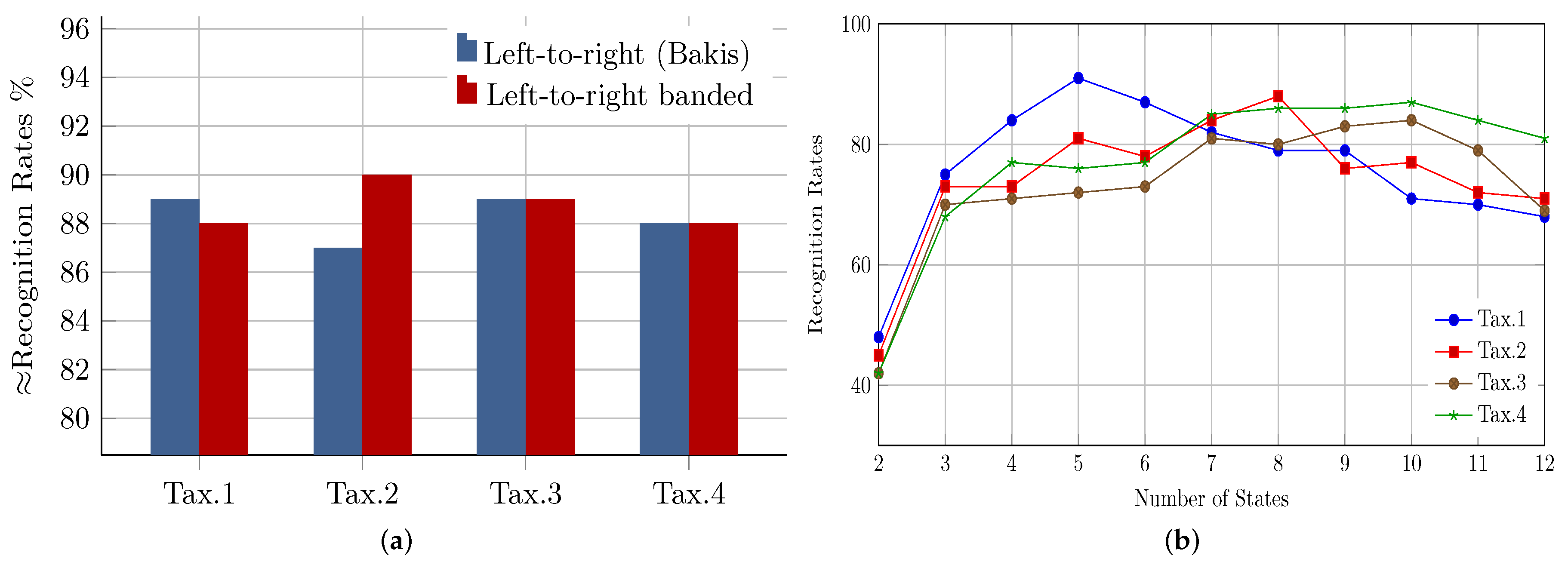
5.1. Topology and Hidden States’ Optimization
5.2. HMM Parameters Initialization
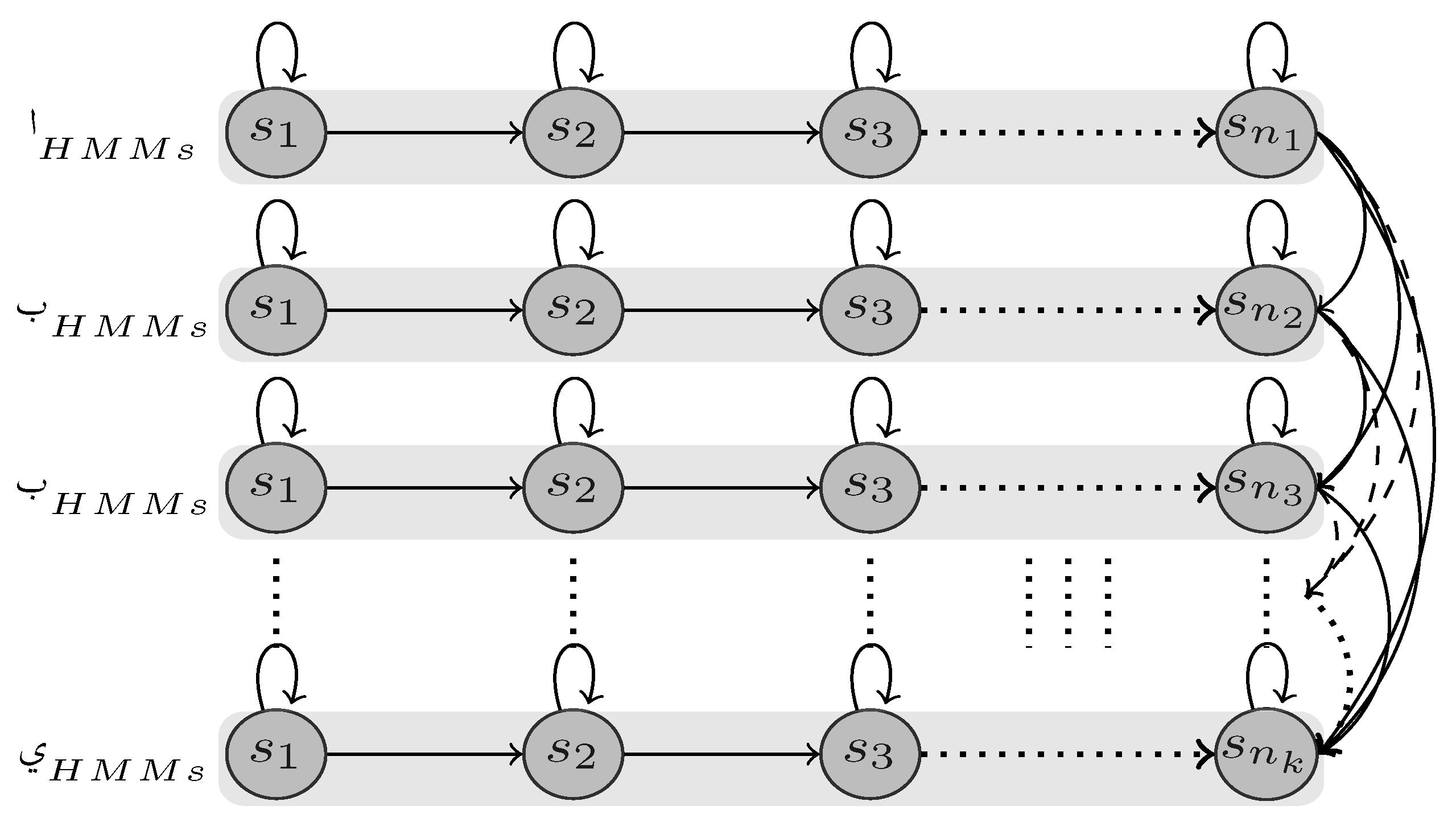
5.3. HMM Models’ Construction
5.4. Threshold Models’ Construction
5.5. HMM-Based Recognition
- . is the highest probability over all reference models, where and are the involved model and its associated most likely path. is the probability of the same observation sequence computed against the reference threshold mode and is the number of models of considered taxonomy.
- . Similarly and are estimated as above except that confirmation models and confirmation threshold model are used instead of their reference counterparts.
- if and , where both refer to the same label (i.e letter) in reference as well as in confirmation models, the label will be assigned to the stroke assuming complete confidence.
- if and , yet point out to different labels, then the label of higher probability is assigned to the stroke, and a substitution error is reported (i.e., ).
- if or , then the label corresponding to the one with probability higher than that of its own threshold model, will be picked as a recognition result, and an insertion error will be reported (i.e., ).
- if and , then the stroke will be rejected and a deletion error will be reported (i.e., ).
6. Linear Chain CRF-Based Recognition of Arabic Handwriting
6.1. CRF Parameter Learning
6.2. Class Label Prediction
7. HCRF for Arabic Handwriting Recognition
8. Experimental Results
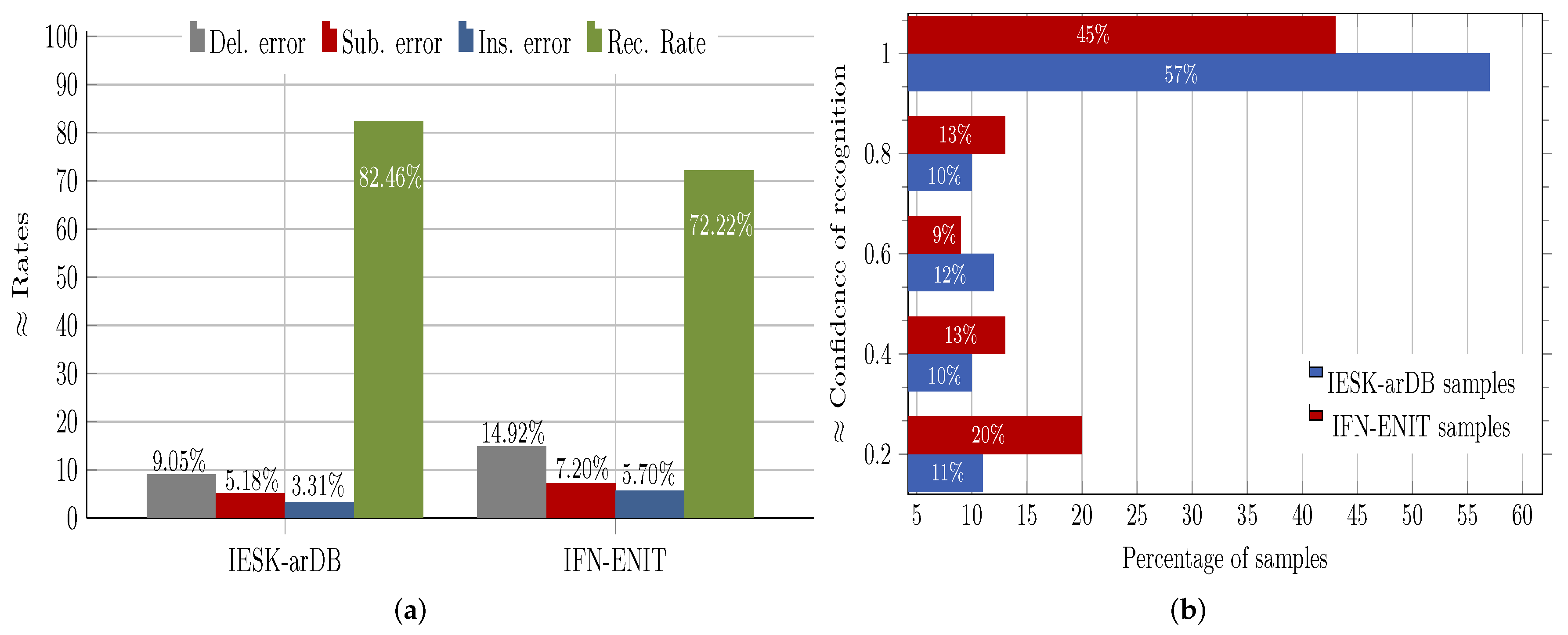
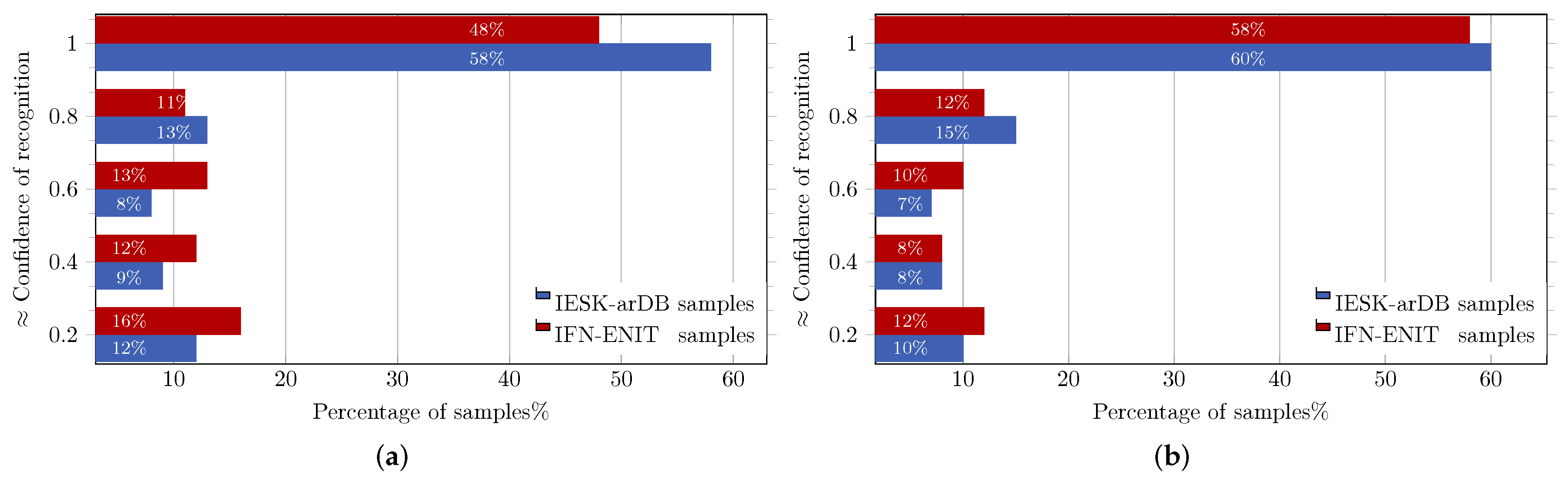
8.1. Evaluation of HMM Recognition Performance
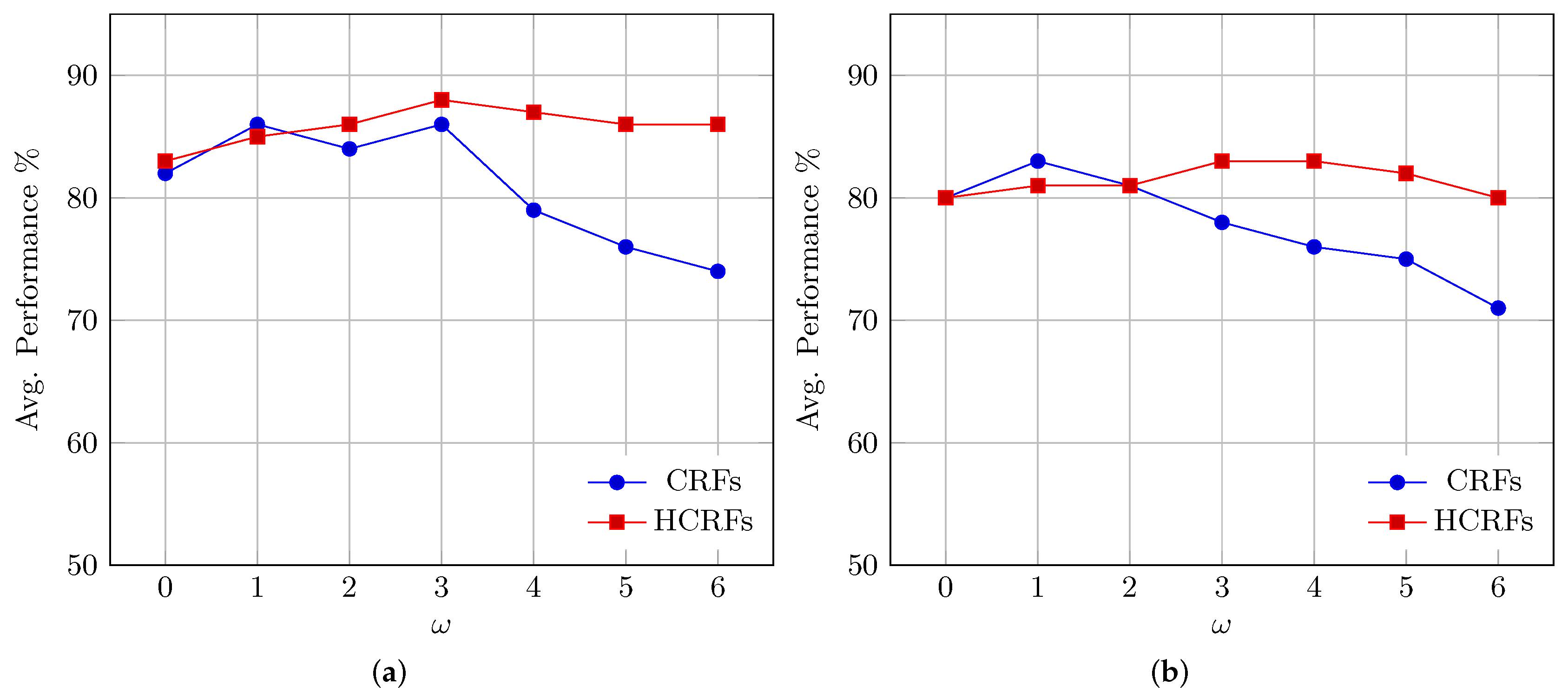
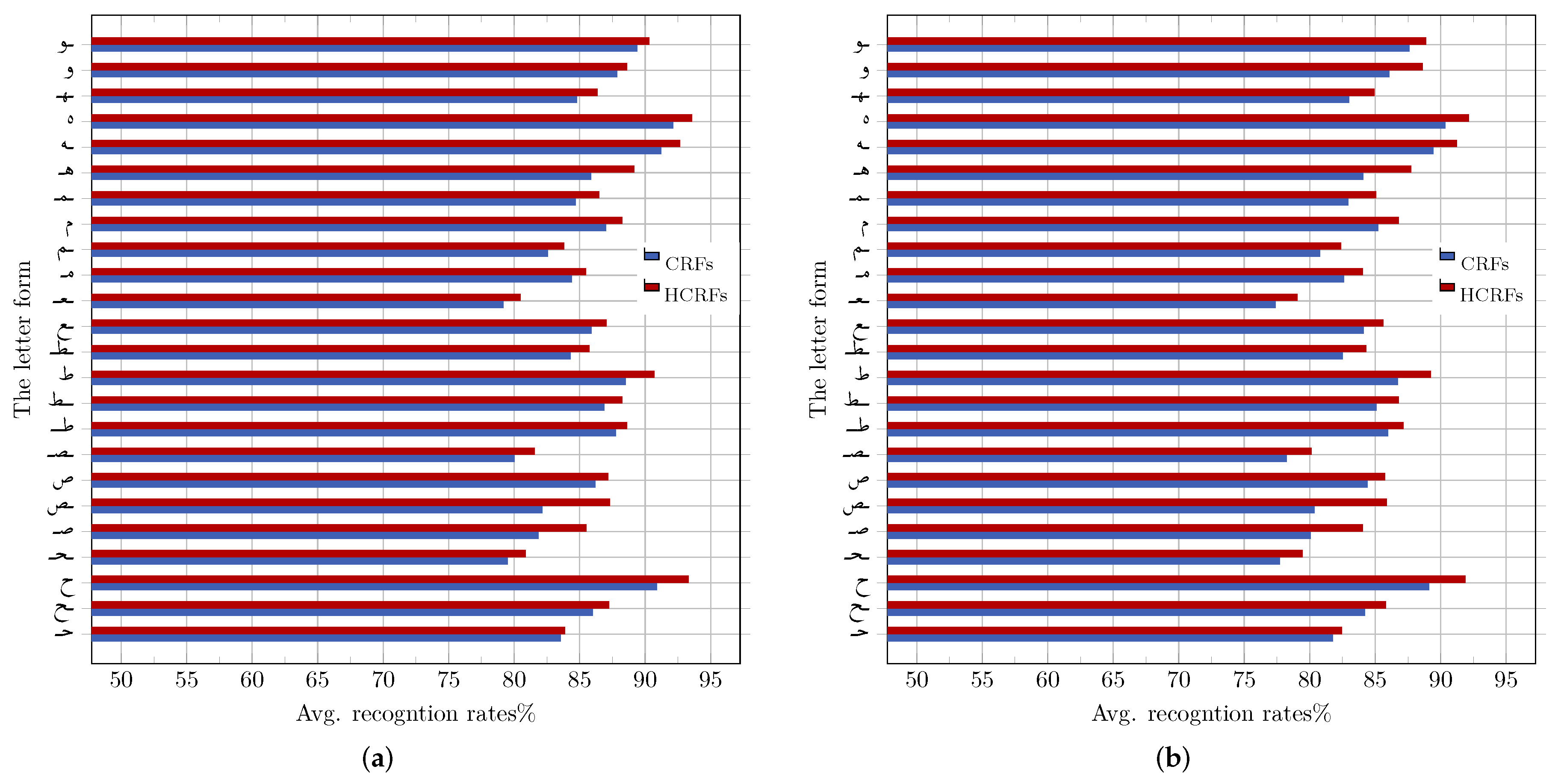
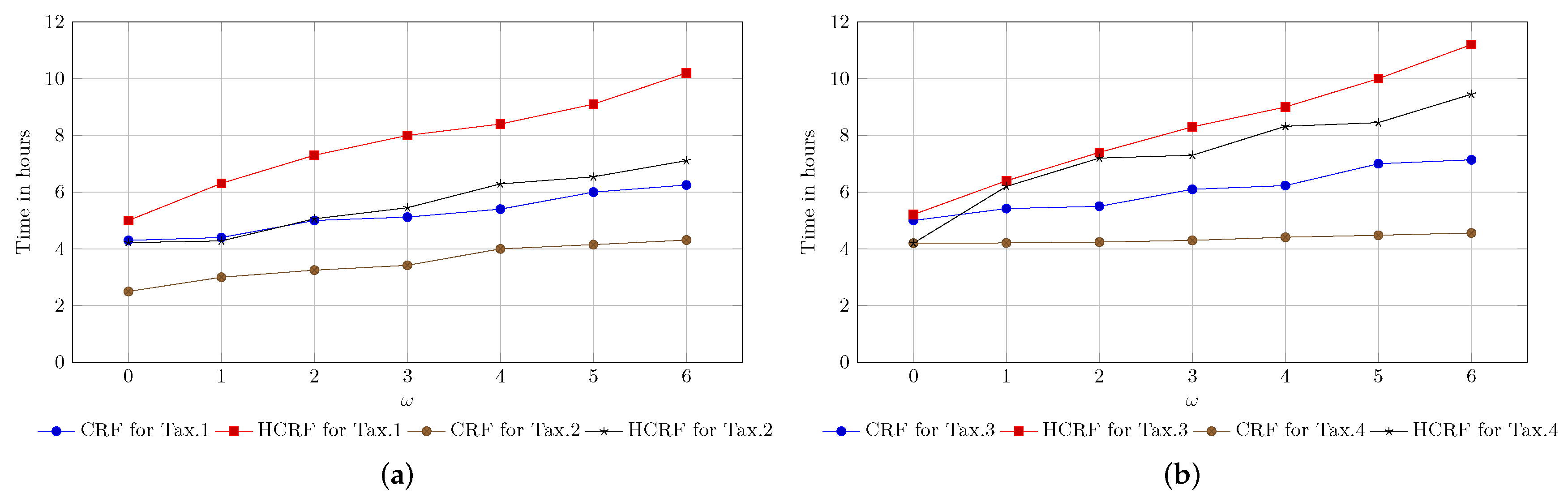
8.2. Performance Evaluation of CRF and HCRF
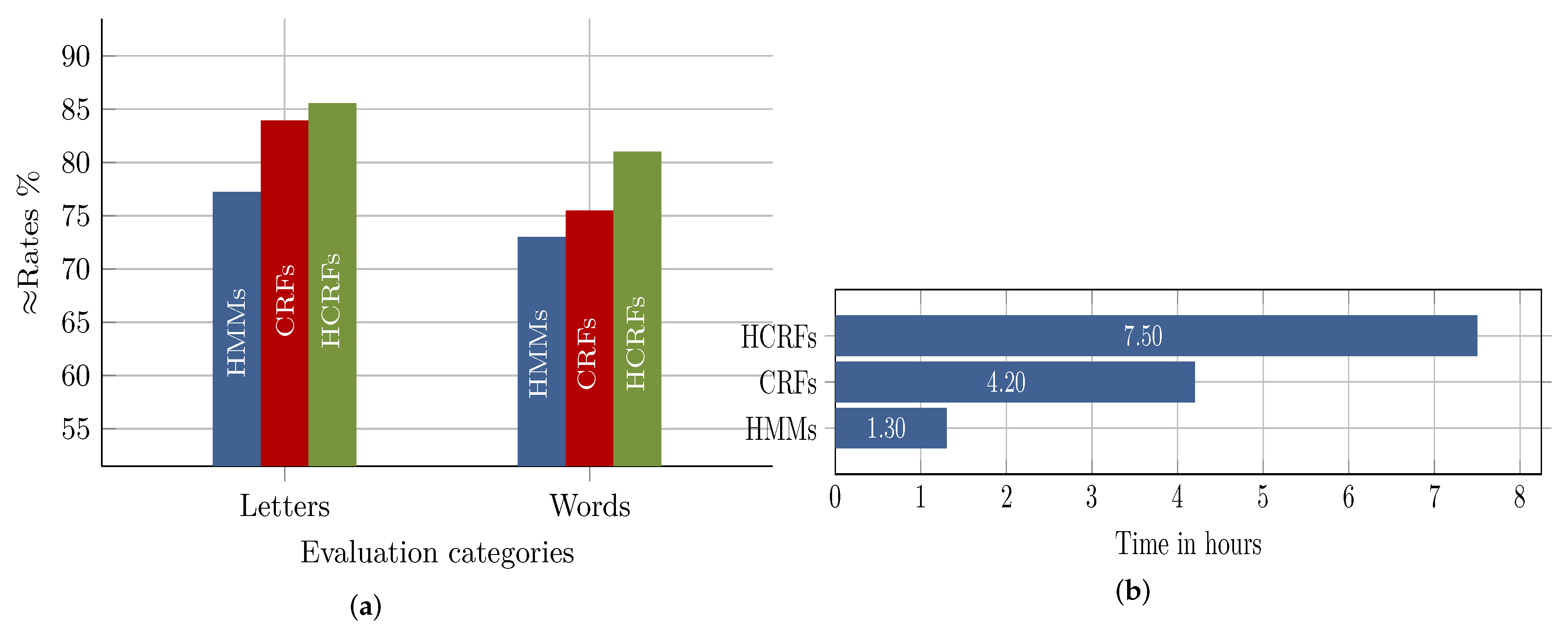
8.3. HMM vs. CRF vs. HCRF
9. Summary and Conclusions
Author Contributions
Conflicts of Interest
References
- Graves, A.; Mohamed, A.; Hinton, G.E. Speech recognition with deep recurrent neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar] [CrossRef]
- Elzobi, M.; Al-Hamadi, A.; Al Aghbari, Z.; Dings, L. IESK-ArDB: A database for handwritten Arabic and an optimized topological segmentation approach. Int. J. Doc. Anal. Recognit. 2012, 1–14. [Google Scholar] [CrossRef]
- Elzobi, M.; Al-Hamadi, A.; Dings, L.; Elmezain, M.; Saeed, A. A Hidden Markov Model-Based Approach with an Adaptive Threshold Model for Off-Line Arabic Handwriting Recognition. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition 2013, Washington, DC, USA, 25–28 August 2013; pp. 945–949. [Google Scholar]
- Sutton, C.; McCallum, A. An Introduction to Conditional Random Fields. Found. Trends Mach. Learn. 2012, 4, 267–373. [Google Scholar] [CrossRef]
- Parvez, M.T.; Mahmoud, S.A. Offline arabic handwritten text recognition: A Survey. ACM Comput. Surv. 2013, 45, 23:1–23:35. [Google Scholar] [CrossRef]
- Ploetz, T.; Fink, G. Markov models for offline handwriting recognition: A survey. Int. J. Doc. Anal. Recognit. 2009, 12, 269–298. [Google Scholar] [CrossRef]
- Lorigo, L.M.; Govindaraju, V. Offline Arabic handwriting recognition: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 712–724. [Google Scholar] [CrossRef] [PubMed]
- Dehghan, M.; Faez, K.; Ahmadi, M.; Shridhar, M. Handwritten Farsi (Arabic) word recognition: A holistic approach using discrete HMM. Pattern Recognit. 2001, 34, 1057–1065. [Google Scholar] [CrossRef]
- Pechwitz, M.; Maergner, V. HMM based approach for handwritten arabic word recognition using the IFN/ENIT—Database. In Proceedings of the Seventh International Conference on Document Analysis and Recognition, Edinburgh, UK, 6 August 2003; pp. 890–894. [Google Scholar] [CrossRef]
- Al-Hajj Mohamad, R.; Likforman-Sulem, L.; Mokbel, C. Combining Slanted-Frame Classifiers for Improved HMM-Based Arabic Handwriting Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 1165–1177. [Google Scholar] [CrossRef] [PubMed]
- Dreuw, P.; Heigold, G.; Ney, H. Confidence- and margin-based MMI/MPE discriminative training for offline handwriting recognition. Int. J. Doc. Anal. Recognit. 2011, 14, 273–288. [Google Scholar] [CrossRef]
- Ahmad, I.; Fink, G.A. Class-Based Contextual Modeling for Handwritten Arabic Text Recognition. In Proceedings of the 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 554–559. [Google Scholar] [CrossRef]
- Elzobi, M.; Al-Hamadi, A.; Dings, L.; El-Etriby, S. CRF and HCRF Based Recognition for Off-Line Arabic Handwriting. In Proceedings of the 11th International Symposium on Advances in Visual Computing, Las Vegas, NV, USA, 14–16 December 2015; pp. 337–346. [Google Scholar] [CrossRef]
- Feng, S.; Manmatha, R.; Mccallum, A. Exploring the Use of Conditional Random Field Models and HMM for Historical Handwritten Document Recognition. In Proceedings of the 2nd IEEE International Conference on Document Image Analysis for Libraries (DIAL), Lyon, France, 27–29 April 2006; pp. 30–37. [Google Scholar]
- Hamdani, M.; Shaik, M.A.B.; Doetsch, P.; Ney, H. Investigation of Segmental Conditional Random Fields for large vocabulary handwriting recognition. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 261–265. [Google Scholar] [CrossRef]
- Chen, G.; Li, Y.; Srihari, S.N. Word Recognition with Deep Conditional Random Fields. arXiv, 2016; arXiv:1612.01072v1. [Google Scholar]
- Zhou, X.D.; Wang, D.H.; Tian, F.; Liu, C.L.; Nakagawa, M. Handwritten Chinese/Japanese Text Recognition Using Semi-Markov Conditional Random Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2413–2426. [Google Scholar] [CrossRef] [PubMed]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing; Addison-Wesley: Reading, MA, USA, 1992. [Google Scholar]
- Cheriet, M.; Kharma, N.; Liu, C.L.; Suen, C. Character Recognition Systems: A Guide for Students and Practitioners; Wiley-Interscience: Hoboken, NJ, USA, 2007. [Google Scholar]
- Likforman-Sulem, L.; AlHajj Mohammad, R.; Mokbel, C.; Menasri, F.; Bianne-Bernard, A.L.; Kermorvant, C. Features for HMM-Based Arabic Handwritten Word Recognition Systems. In Guide to OCR for Arabic Scripts; Maergner, V., El Abed, H., Eds.; Springer: London, UK, 2012; pp. 123–143. [Google Scholar]
- Belongie, S.; Malik, J.; Puzicha, J. Shape matching and object recognition using shape contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 509–522. [Google Scholar] [CrossRef]
- Mori, G.; Belongie, S.; Malik, J. Efficient shape matching using shape contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1832–1837. [Google Scholar] [CrossRef] [PubMed]
- Saabni, R.; El-Sana, J. Keywords image retrieval in historical handwritten Arabic documents. J. Electron. Imaging 2013, 22, 013016. [Google Scholar] [CrossRef]
- Liu, C.L.; Nakashima, K.; Sako, H.; Fujisawa, H. Handwritten digit recognition: Investigation of normalization and feature extraction techniques. Pattern Recognit. 2004, 37, 265–279. [Google Scholar] [CrossRef]
- Zhu, Y.; Yu, J.; Jia, C. Initializing K-means Clustering Using Affinity Propagation. In Proceedings of the Ninth International Conference on Hybrid Intelligent Systems, Shenyang, China, 12–14 August 2009; Volume 1, pp. 338–343. [Google Scholar] [CrossRef]
- Dueck, D. Affinity Propagation: Clustering Data by Passing Messages; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Geiger, J.; Schenk, J.; Wallhoff, F.; Rigoll, G. Optimizing the Number of States for HMM-Based On-line Handwritten Whiteboard Recognition. In Proceedings of the 2010 International Conference on Frontiers in Handwriting Recognition (ICFHR), Kolkata, India, 16–18 November 2010; pp. 107–112. [Google Scholar] [CrossRef]
- Zimmermann, M.; Bunke, H. Hidden Markov Model Length Optimization for Handwriting Recognition Systems. In Proceedings of the Eighth International Workshop on Frontiers in Handwriting Recognition (IWFHR’02); IEEE Computer Society: Washington, DC, USA, 2002. [Google Scholar]
- Elmezain, M.; Al-Hamadi, A.; Appenrodt, J.; Michaelis, B. A Hidden Markov Model-based continuous gesture recognition system for hand motion trajectory. In Proceedings of the 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar] [CrossRef]
- Al-Ohali, Y.; Cheriet, M.; Suen, C. Introducing termination probabilities to HMM. In Proceedings of the 16th International Conference on Pattern Recognition, Quebec, QC, Canada, 11–15 August 2002; Volume 3, pp. 319–322. [Google Scholar] [CrossRef]
- Rabiner, L. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Elmezain, M.; Hamadi, A.; Michaelis, B. Hand Gesture Spotting and Recognition Using HMM and CRF in Color Image Sequences. Ph.D. Thesis, Otto-von-Guericke-Universitaet, Magdeburg, Germany, 2010. [Google Scholar]
- Willett, D.; Worm, A.; Neukirchen, C.; Rigoll, G. Confidence Measures For HMM-Based Speech Recognition. In Proceedings of the 5th International Conference on Spoken Language Processing (ICSLP 98), Sydney, Australia, 30 November–4 December 1998; pp. 3241–3244. [Google Scholar]
- Lee, H.K.; Kim, J. An HMM-based threshold model approach for gesture recognition. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 961–973. [Google Scholar] [CrossRef]
- Chen, M.Y.; Kundu, A.; Zhou, J. Off-line handwritten word recognition using a hidden Markov model type stochastic network. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 481–496. [Google Scholar] [CrossRef]
- Wikipedia. Word Error Rate—Wikipedia, The Free Encyclopedia, 2014. Available online: https://en.wikipedia.org/wiki/Word_error_rate (accessed on 6 January 2015).
- Sminchisescu, C.; Kanaujia, A.; Li, Z.; Metaxas, D. Conditional models for contextual human motion recognition. In Proceedings of the Tenth IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005; Volume 2, pp. 1808–1815. [Google Scholar] [CrossRef]
- Lafferty, J. Conditional Random Fields: Probabilistic Models for Segmenting And Labeling Sequence Data; Morgan Kaufmann: Burlington, MA, USA 2001; pp. 282–289. [Google Scholar]
- Liu, D.C.; Nocedal, J. On the Limited Memory BFGS Method for Large Scale Optimization. Math. Program. 1989, 45, 503–528. [Google Scholar] [CrossRef]
- Ng, A.Y.; Jordan, M.I. On Discriminative vs. Generative classifiers: A comparison of logistic regression and naive Bayes. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2001), Vancouver, BC, Canada, 3–8 December 2001. [Google Scholar]
- Morency, L.P.; Quattoni, A.; Christoudias, C.M.; Wang, S. Hidden-state Conditional Random Field Library. Available online: http://pt.sourceforge.jp/projects/sfnet_hcrf/ (accessed on 19 August 2018).
- Abed, H.E.; Margner, V. The IFN/ENIT-database—A tool to develop Arabic handwriting recognition systems. In Proceedings of the 2007 9th International Symposium on Signal Processing and Its Applications, Sharjah, UAE, 12–15 February 2007; pp. 1–4. [Google Scholar] [CrossRef]
- Mozaffari, S.; Soltanizadeh, H. ICDAR 2009 Handwritten Farsi/Arabic Character Recognition Competition. In Proceedings of the 2009 10th International Conference on Document Analysis and Recognition, Barcelona, Spain, 26–29 July 2009; pp. 1413–1417. [Google Scholar]
- Shaalan, K.; Attia, M.; Pecina, P.; Samih, Y.; van Genabith, J. Arabic Word Generation and Modelling for Spell Checking. In Proceedings of the Eight International Conference on Language Resources and Evaluation (LREC’12); Chair, N.C.C., Choukri, K., Declerck, T., Dogan, M.U., Maegaard, B., Mariani, J., Moreno, A., Odijk, J., Piperidis, S., Eds.; European Language Resources Association (ELRA): Istanbul, Turkey, 2012. [Google Scholar]
- Dinges, L.; Al-Hamadi, A.; Elzobi, M. An Approach for Arabic Handwriting Synthesis Based on Active Shape Models. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition (ICDAR), Washington, DC, USA, 25–28 August 2013; pp. 1260–1264. [Google Scholar] [CrossRef]
- Bluche, T.; Louradour, J.; Messina, R. Scan, Attend and Read: End-to-End Handwritten Paragraph Recognition with MDLSTM Attention. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1050–1055. [Google Scholar] [CrossRef]
- Moysset, B.; Bluche, T.; Knibbe, M.; Benzeghiba, M.F.; Messina, R.; Louradour, J.; Kermorvant, C. The A2iA Multi-lingual Text Recognition System at the Second Maurdor Evaluation. In Proceedings of the 2014 14th International Conference on Frontiers in Handwriting Recognition, Heraklion, Greece, 1–4 September 2014; pp. 297–302. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Inputs | Results | |
|---|---|---|
| Recognized Letter | Confidence Value () | |
 |  | 1 − (0.5 × 0 + 0.5 × 0 + 0)/5 = 1.00 |
 |  | 1 − (0.5 × 0 + 0.5 × 0 + 0)/6 = 1.00 |
 |  | 1 − (0.5 × 1 + 0.5 × 1 + 1)/5 = 0.60 |
 |  | 1 − (0.5 × 1 + 0.5 × 0 + 0)/7 = 0.93 |
| Dataset | CRF’ Rec. Rates % | HCRF’ Rec. Rates % | ||||||
|---|---|---|---|---|---|---|---|---|
| Tax.1 | Tax.2 | Tax.3 | Tax.4 | Tax.1 | Tax.2 | Tax.3 | Tax.4 | |
| IESK-arDB | ||||||||
| IFN-ENIT | ||||||||
| Avg.% | ||||||||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elzobi, M.; Al-Hamadi, A. Generative vs. Discriminative Recognition Models for Off-Line Arabic Handwriting. Sensors 2018, 18, 2786. https://doi.org/10.3390/s18092786
Elzobi M, Al-Hamadi A. Generative vs. Discriminative Recognition Models for Off-Line Arabic Handwriting. Sensors. 2018; 18(9):2786. https://doi.org/10.3390/s18092786
Chicago/Turabian StyleElzobi, Moftah, and Ayoub Al-Hamadi. 2018. "Generative vs. Discriminative Recognition Models for Off-Line Arabic Handwriting" Sensors 18, no. 9: 2786. https://doi.org/10.3390/s18092786
APA StyleElzobi, M., & Al-Hamadi, A. (2018). Generative vs. Discriminative Recognition Models for Off-Line Arabic Handwriting. Sensors, 18(9), 2786. https://doi.org/10.3390/s18092786