A Data Quality Control Method for Seafloor Observatories: The Application of Observed Time Series Data in the East China Sea

Abstract
1. Introduction
2. Experimental Seafloor Observatory
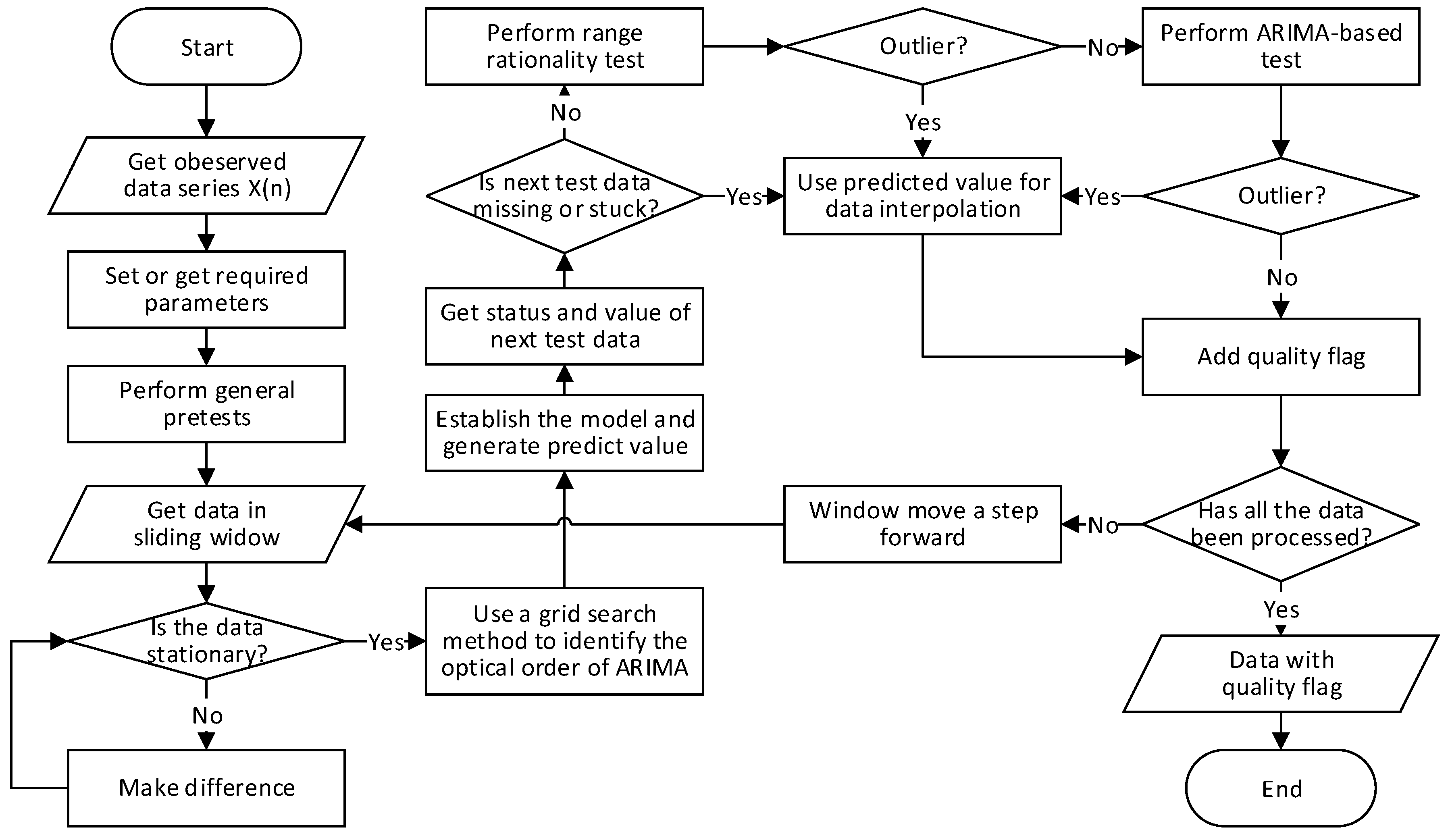
3. Data Quality Control Method
3.1. General Pretest
3.1.1. Redundant Test
3.1.2. Stuck Value Test
3.1.3. Continuity Test
3.2. Data Outlier Detection
3.2.1. Range Rationality Test
3.2.2. ARIMA-Based Test
- Build the ARIMA model with data in the sliding window before the next tested data point.
- Generate a predicted value for the tested data.
- Determine whether the tested data is an outlier through the relative error between the predicted and observed value. The tested data point will be flagged as suspect when this calculated relative error exceeds a pre-defined threshold.
3.3. Data Interpolation
3.3.1. ARIMA Model
3.3.2. Advantages of the ARIMA Model
- The ARIMA model originates from the AR model, MA model, and ARMA model [41]. The models could be transformed into each other by appropriate parameter estimation when facing different datasets. This model fully absorbs the advantages of regression analysis and strengthens the good qualities of moving averages [36].
- The ARIMA model can be applied to a non-stationary time series, which is capable of modeling seafloor observatory data, as it is usually non-stationary.
- The computing complexity is affordable, and the accuracy is relatively high when using the ARIMA model for data interpolation and outlier detection in seafloor observatory data.
3.3.3. Improving and Applying the ARIMA Model
3.4. Quality Control Flag
4. Application of the Method to Xiaoqushan Observatory
- pH data are used to test and verify the outlier detection method, as outliers occur relatively frequently in pH data. The data interpolation method was applied and verified by CTD measurements.
- All test subset data were selected randomly and distributed evenly throughout the year, and each subset has a certain continuity, which could balance the volume and be representative of seafloor observatory data.
- All test subset data are evaluated manually by domain experts. For outlier detection, manually generated quality flags are used for comparison with flags generated by the proposed method. For data interpolation, manually labeled “correct” data are used to evaluate the data interpolation method, and the predicted value was compared with the actual data point.
4.1. Algorithm Design
| Algorithm 1. The data quality control algorithm. | |
| (1) | Dat ← getData() |
| (2) | errThred ← setErrThred() |
| (3) | L ← getWindLen(D, interval) |
| (4) | N ← getStuckThred(D, interval) |
| (5) | T ← setGapThred() |
| (6) | Dat ← delReduntant(Dat) |
| (7) | Dat ← labelStuck(Dat, N) |
| (8) | Dat ← checkContinuity(Dat, T, interval) |
| (9) | while (Dat) do |
| (10) | tbModelDat ← getDatainL(Dat, L) |
| (11) | D ← 0 |
| (12) | while (! isStationary(tbModelDat)) |
| (13) | tbModelDat ← diffData(tbModelDat) |
| (14) | D ← D + 1 |
| (15) | End while |
| (16) | [p, q] ← getBestOrder(tbModelDat, pRange, D, qRange) |
| (17) | Model ← getARIMA(tbModlDat, p, D, q) |
| (18) | predValue ← predict(Model) |
| (19) | [tdatStatus tdatValue] ← getNextTestData(Dat) |
| (20) | If (tdatStatus == missing or tdatStatus == stuck) |
| (21) | Dat ← interpolateData(predValue) |
| (22) | Dat ← setQCFlag() |
| (23) | continue |
| (24) | end if |
| (25) | If (! isInRange(tdatValue, upper, lower)) |
| (26) | Dat ← interpolateData(predValue) |
| (27) | Dat ← setQCFlag() |
| (28) | continue |
| (29) | end if |
| (30) | relErr ← errCalculator(tdatValue, predValue) |
| (31) | if (relErr > errThred) Then |
| (32) | Dat ← interpolateData(predValue) |
| (33) | Dat ← setQCFlag() |
| (34) | end if |
| (35) | end while |
4.2. Application and Verification
4.2.1. Data Outlier Detection
4.2.2. Data Interpolation
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, P. Seafloor observatories: The third platform for earth system observation. Chin. J. Nat. 2007, 29, 125–130. [Google Scholar]
- Abeysirigunawardena, D.; Jeffries, M.; Morley, M.G.; Bui, A.O.V.; Hoeberechts, M. Data quality control and quality assurance practices for Ocean Networks Canada observatories. In Proceedings of the OCEANS 2015—MTS/IEEE Washington, Washington, DC, USA, 19–22 October 2015; pp. 1–8. [Google Scholar]
- Favali, P.; Beranzoli, L.; De Santis, A. SEAFLOOR OBSERVATORIES: A New Vision of the Earth from the Abyss; Springer: Berlin/Heidelberg, Germany, 2015; ISBN 978-3-642-11373-4. [Google Scholar]
- Campbell, J.L.; Rustad, L.E.; Porter, J.H.; Taylor, J.R.; Dereszynski, E.W.; Shanley, J.B.; Gries, C.; Henshaw, D.L.; Martin, M.E.; Sheldon, W.M.; et al. Quantity is Nothing without Quality: Automated QA/QC for Streaming Environmental Sensor Data. BioScience 2013, 63, 574–585. [Google Scholar] [CrossRef]
- Xu, H.; Zhang, Y.; Xu, C.; Li, J.; Liu, D.; Qin, R.; Luo, S.; Fan, D. Coastal seafloor observatory at Xiaoqushan in the East China Sea. Chin. Sci. Bull. 2011, 56, 2839–2845. [Google Scholar] [CrossRef]
- Yu, Y.; Xu, H.; Xu, C.; Qin, R. A Study of the Remote Control for the East China Sea Seafloor Observation System. J. Atmos. Ocean. Technol. 2012, 29, 1149–1158. [Google Scholar] [CrossRef]
- Xu, H.; Xu, C.; Qin, R.; Zhang, Y.; Chen, H. Coastal seafloor observatory of the East China Sea at Xiaoqushan and its primary observations. In Proceedings of the 2010 AGU Fall Meeting, San Francisco, CA, USA, 13–17 December 2010. [Google Scholar]
- Xu, H.; Xu, C.; Qin, R.; Yu, Y.; Luo, S.; Zhang, Y. The East China Sea Seafloor Observatory and its upgraded project. In Proceedings of the OCEANS’11 MTS/IEEE KONA, Waikoloa, HI, USA, 19–22 September 2011; pp. 1–6. [Google Scholar]
- Barnes, C.R.; Tunnicliffe, V. Building the World’s First Multi-node Cabled Ocean Observatories (NEPTUNE Canada and VENUS, Canada): Science, Realities, Challenges and Opportunities. In Proceedings of the OCEANS 2008—MTS/IEEE Kobe Techno-Ocean, Kobe, Japan, 8–11 April 2008; pp. 1–8. [Google Scholar]
- Barnes, C.R.; Best, M.M.R.; Johnson, F.R.; Pautet, L.; Pirenne, B. Challenges, Benefits, and Opportunities in Installing and Operating Cabled Ocean Observatories: Perspectives from NEPTUNE Canada. IEEE J. Ocean. Eng. 2013, 38, 144–157. [Google Scholar] [CrossRef]
- Heesemann, M.; Insua, T.; Scherwath, M.; Juniper, K.; Moran, K. Ocean Networks Canada: From Geohazards Research Laboratories to Smart Ocean Systems. Oceanography 2014, 27, 151–153. [Google Scholar] [CrossRef]
- Cowles, T.; Delaney, J.; Orcutt, J.; Weller, R. The Ocean Observatories Initiative: Sustained Ocean Observing Across a Range of Spatial Scales. Mar. Technol. Soc. J. 2010, 44, 54–64. [Google Scholar] [CrossRef]
- Smith, M.; Belabbassi, L.; Garzio, L.; Knuth, F.; Lichtenwalner, S.; Kerfoot, J.; Crowley, M.F. Automated quality control procedures for real-time ocean observatories initiative datasets. In Proceedings of the OCEANS 2017—Anchorage, Anchorage, AK, USA, 18–21 September 2017; pp. 1–4. [Google Scholar]
- Vardaro, M.F.; Belabbassi, L.; Garzio, L.; Smith, M.; Knuth, F.; Kerfbot, J.; Lichtenwalner, S.; Crowley, M.F. OOI data quality procedures and tools building on the first year of operations. In Proceedings of the OCEANS 2017–Anchorage, Anchorage, AK, USA, 18–21 September 2017; pp. 1–5. [Google Scholar]
- Best, M.M.R.; Favali, P.; Beranzoli, L.; Blandin, J.; Çağatay, N.M.; Cannat, M.; Dañobeitia, J.J.; Delory, E.; de Miranda, J.M.A.; Del Rio Fernandez, J.; et al. The EMSO-ERIC Pan-European Consortium: Data Benefits and Lessons Learned as the Legal Entity Forms. Mar. Technol. Soc. J. 2016, 50, 8–15. [Google Scholar] [CrossRef]
- Gaillard, F.; Autret, E.; Thierry, V.; Galaup, P.; Coatanoan, C.; Loubrieu, T. Quality Control of Large Argo Datasets. J. Atmos. Ocean. Technol. 2009, 26, 337–351. [Google Scholar] [CrossRef]
- Wong, A.; Keeley, R.; Carval, T.; Argo Data Management Team. Argo Quality Control Manual for CTD and Trajectory Data; Ifremer: Issy-les-Moulineaux, France, 2018.
- Koziana, J.V.; Olson, J.; Anselmo, T.; Lu, W. Automated data quality assurance for marine observations. In Proceedings of the OCEANS 2008, Quebec City, QC, Canada, 15–18 September 2008; pp. 1–6. [Google Scholar]
- Bushnell, M. Quality Assurance/Quality Control of Real-Time Oceanographic Data. In Proceedings of the OCEANS 2016 MTS/IEEE, Monterey, CA, USA, 19–23 September 2016; pp. 1–4. [Google Scholar]
- U.S. Integrated Ocean Observing System. Manual for Real-Time Quality Control of Dissolved Nutrients Data Version 1.1: A Guide to Quality Control and Quality Assurance of Coastal and Dissolved Nutrients Observations; U.S. Integrated Ocean Observing System: Silver Spring, MD, USA, 2018. [CrossRef]
- U.S. Integrated Ocean Observing System. Manual for Real-Time Quality Control of Dissolved Oxygen Observations Version 2.0: A Guide to Quality Control and Quality Assurance for Dissolved Oxygen Observations in Coastal Oceans; U.S. Integrated Ocean Observing System: Silver Spring, MD, USA, 2015.
- U.S. Integrated Ocean Observing System. Manual for Real-Time Quality Control of In-Situ Current Observations Version 2.0: A Guide to Quality Control and Quality Assurance of Acoustic Doppler Current Profiler Observations; U.S. Integrated Ocean Observing System: Silver Spring, MD, USA, 2015.
- U.S. Integrated Ocean Observing System. Manual for Real-Time Quality Control of In-Situ Surface Wave Data Version 2.0: A Guide to Quality Control and Quality Assurance of In-Situ Surface Wave Observations; U.S. Integrated Ocean Observing System: Silver Spring, MD, USA, 2015.
- U.S. Integrated Ocean Observing System. Manual for Real-Time Quality Control of In-Situ Temperature and Salinity Data Version 2.0: A Guide to Quality Control and Quality Assurance of In-Situ Temperature and Salinity Observations; U.S. Integrated Ocean Observing System: Silver Spring, MD, USA, 2015.
- U.S. Integrated Ocean Observing System. Manual for Real-Time Quality Control of Ocean Optics Data Version 1.1: A Guide to Quality Control and Quality Assurance of Coastal and Oceanic Optics Observations; U.S. Integrated Ocean Observing System: Silver Spring, MD, USA, 2017.
- U.S. Integrated Ocean Observing System. Manual for Real-Time Quality Control of Water Level Data Version 2.0: A Guide to Quality Control and Quality Assurance of Water Level Observations; U.S. Integrated Ocean Observing System: Silver Spring, MD, USA, 2016.
- U.S. Integrated Ocean Observing System. Manual for Real-Time Quality Control of Wind Data Version 1.1: A Guide to Quality Control and Quality Assurance of Coastal and Oceanic Wind Observations; U.S. Integrated Ocean Observing System: Silver Spring, MD, USA, 2017.
- Morello, E.B.; Lynch, T.P.; Slawinski, D.; Howell, B.; Hughes, D.; Timms, G.P. Quantitative Quality Control (QC) procedures for the Australian National Reference Stations: Sensor Data. In Proceedings of the OCEANS’11 MTS/IEEE KONA, Waikoloa, HI, USA, 19–22 September 2011; pp. 1–7. [Google Scholar]
- Good, S.A.; Martin, M.J.; Rayner, N.A. EN4: Quality controlled ocean temperature and salinity profiles and monthly objective analyses with uncertainty estimates: THE EN4 DATA SET. J. Geophys. Res. Ocean. 2013, 118, 6704–6716. [Google Scholar] [CrossRef]
- Rahman, A.; Smith, D.V.; Timms, G. Multiple classifier system for automated quality assessment of marine sensor data. In Proceedings of the 2013 IEEE Eighth International Conference on Intelligent Sensors, Sensor Networks and Information Processing, Melbourne, VIC, Australia, 2–5 April 2013; pp. 362–367. [Google Scholar]
- Rahman, A.; Smith, D.V.; Timms, G. A Novel Machine Learning Approach toward Quality Assessment of Sensor Data. IEEE Sens. J. 2014, 14, 1035–1047. [Google Scholar] [CrossRef]
- Timms, G.P.; de Souza, P.A.; Reznik, L.; Smith, D.V. Automated Data Quality Assessment of Marine Sensors. Sensors 2011, 11, 9589–9602. [Google Scholar] [CrossRef] [PubMed]
- Smith, D.; Timms, G.; De Souza, P.; D’Este, C. A Bayesian Framework for the Automated Online Assessment of Sensor Data Quality. Sensors 2012, 12, 9476–9501. [Google Scholar] [CrossRef] [PubMed]
- Zare Moayedi, H.; Masnadi-Shirazi, M.A. Arima model for network traffic prediction and anomaly detection. In Proceedings of the 2008 International Symposium on Information Technology, Kuala Lumpur, Malaysia, 26–28 August 2008; pp. 1–6. [Google Scholar]
- Yaacob, A.H.; Tan, I.K.T.; Chien, S.F.; Tan, H.K. ARIMA Based Network Anomaly Detection. In Proceedings of the 2010 Second International Conference on Communication Software and Networks, Singapore, 26–28 February 2010; pp. 205–209. [Google Scholar]
- Yu, Q.; Jibin, L.; Jiang, L. An Improved ARIMA-Based Traffic Anomaly Detection Algorithm for Wireless Sensor Networks. Int. J. Distrib. Sens. Netw. 2016, 12, 9653230. [Google Scholar] [CrossRef]
- Chen, H.; Xu, H.; Yu, Y.; Qin, R.; Xu, C. Design and implementation of a Data Distribution System for Xiaoqushan Submarine Comprehensive Observation and Marine Equipment Test Platform. Comput. Geosci. 2015, 82, 31–37. [Google Scholar] [CrossRef]
- Intergovernmental Oceanographic Commission; Commission of the European Community. Manual of Quality Control Procedures for Validation of Oceanographic Data; UNESCO: Paris, France, 1993; p. 436. [Google Scholar]
- Hawkins, D.M. Identification of Outliers; Springer: Dordrecht, The Netherlands, 1980; ISBN 978-94-015-3996-8. [Google Scholar]
- Box, G.E.; Jenkins, G.M. Time series analysis. Forecasting and control. In Holden-Day Series in Time Series Analysis, Revised ed.; Holden-Day: San Francisco, CA, USA, 1976. [Google Scholar]
- Box, G.E.P.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control, 5th ed.; Wiley Series in Probability and Statistics; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2015; ISBN 978-1-118-67502-1. [Google Scholar]
- Valipour, M.; Banihabib, M.E.; Behbahani, S.M.R. Comparison of the ARMA, ARIMA, and the autoregressive artificial neural network models in forecasting the monthly inflow of Dez dam reservoir. J. Hydrol. 2013, 476, 433–441. [Google Scholar] [CrossRef]
- Wong, A.; Keeley, R.; Carval, T.; Argo Data Management Team. Argo Quality Control Manual. Version 2.9. Available online: http://www.argodatamgt.org/content/download/20685/142877/file/argo-quality-control-manual_version2.9.pdf (accessed on 9 August 2018).
- U.S. Integrated Ocean Observing System. Manual for the Use of Real-Time Oceanographic Data Quality Control Flags; Version 1.1; U.S. Integrated Ocean Observing System: Silver Spring, MD, USA, 2017.
- Intergovernmental Oceanographic Commission. GTSPP Real-Time Quality Control Manual; Manuals and Guides 22; UNESCO: Paris, France, 2010. [Google Scholar]
- Makridakis, S.; Hibon, M.; Moser, C. Accuracy of Forecasting: An Empirical Investigation. J. R. Stat. Soc. Ser. A Gen. 1979, 142, 97–145. [Google Scholar] [CrossRef]
- Seo, S. A Review and Comparison of Methods for Detecting Outliers in Univariate Data Sets. Ph.D. Thesis, University of Pittsburgh, Pittsburgh, PA, USA, 2006. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensors | Main Measurement Parameters | Data Collection Intervals (s) |
|---|---|---|
| ADCP | depth, current velocity and direction | 10 |
| CTD | temperature, salinity, depth | 10 |
| CO2 Pro | CO2 | 6 |
| Hydrolab DS 5 | PH, chlorophyll-a | 8 |
| PBR Tide-Wave Recorder | depth | 1 |
| Magnetometer | magnetic data | 1 |
| OBS-3+ | turbidity | 10 |
| Ocean Bottom Seismometer | earth motion data | 0.01 |
| Quality Flag | Description |
|---|---|
| 1 | Good data, passed all tests. |
| 2 | Data quality control procedures are not performed. |
| 3 | Suspect data, failed the ARIMA model-based test. |
| 4 | Bad data, failed the range rationality test. |
| 5 | Stuck value data. |
| 7 | Interpolated single data point by the ARIMA method. |
| 8 | Interpolated successive multi data points by the ARIMA method. |
| 9 | Missing data. |
| Actual Data Status | Tested Results | |
|---|---|---|
| Abnormal | Normal | |
| Abnormal | True Positive (TP) | False Negative (FN) |
| Normal | False Positive (FP) | True Negative (TN) |
| Methods | TP | FN | FP | TN | Precision | Recall | F1 |
|---|---|---|---|---|---|---|---|
| ARIMA | 414 | 27 | 16 | 9543 | 0.9628 | 0.9388 | 0.9506 |
| 3sd method | 192 | 249 | 11 | 9548 | 0.9458 | 0.4354 | 0.5963 |
| 2sd method | 281 | 160 | 153 | 9406 | 0.6475 | 0.6372 | 0.6423 |
| Single-Point Interpolation | Successive Multipoint Interpolation | |||||
|---|---|---|---|---|---|---|
| Temperature | Conductivity | Pressure | Temperature | Conductivity | Pressure | |
| MAPE | 0.0015% | 0.0075% | 0.0226% | 0.0241% | 0.0798% | 0.0973% |
| MAE | 0.0002 | 0.0020 | 0.0032 | 0.0034 | 0.0220 | 0.0140 |
| RMSE | 0.0023 | 0.0060 | 0.0049 | 0.0114 | 0.0687 | 0.0190 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Qin, R.; Xu, H.; Sadiq, S.; Yu, Y. A Data Quality Control Method for Seafloor Observatories: The Application of Observed Time Series Data in the East China Sea. Sensors 2018, 18, 2628. https://doi.org/10.3390/s18082628
Zhou Y, Qin R, Xu H, Sadiq S, Yu Y. A Data Quality Control Method for Seafloor Observatories: The Application of Observed Time Series Data in the East China Sea. Sensors. 2018; 18(8):2628. https://doi.org/10.3390/s18082628
Chicago/Turabian StyleZhou, Yusheng, Rufu Qin, Huiping Xu, Shazia Sadiq, and Yang Yu. 2018. "A Data Quality Control Method for Seafloor Observatories: The Application of Observed Time Series Data in the East China Sea" Sensors 18, no. 8: 2628. https://doi.org/10.3390/s18082628
APA StyleZhou, Y., Qin, R., Xu, H., Sadiq, S., & Yu, Y. (2018). A Data Quality Control Method for Seafloor Observatories: The Application of Observed Time Series Data in the East China Sea. Sensors, 18(8), 2628. https://doi.org/10.3390/s18082628