Fast Visual Tracking Based on Convolutional Networks

 ,
,
Abstract
1. Introduction
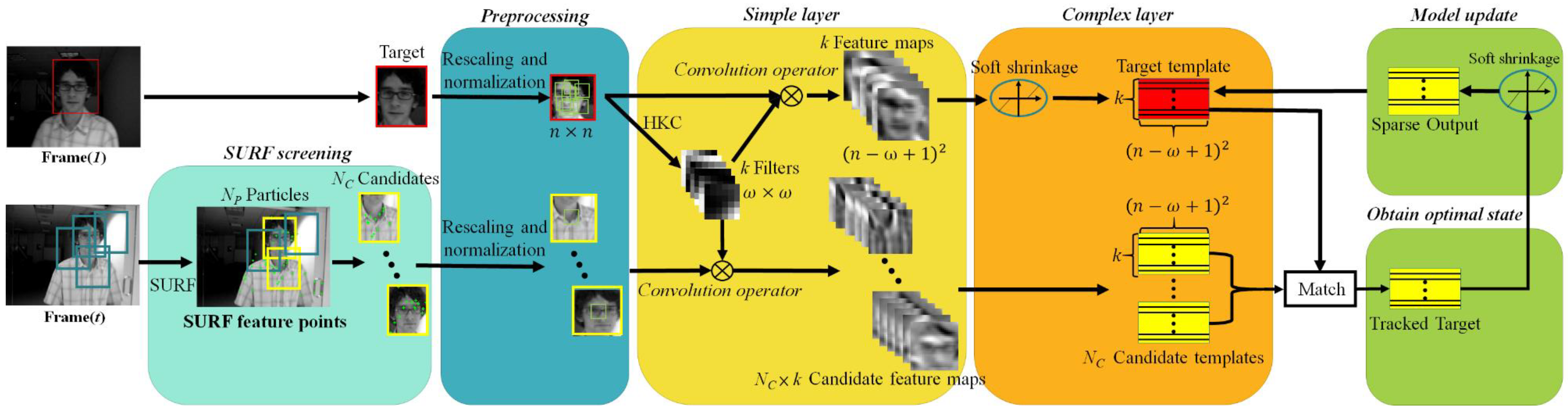
2. Convolutional Network Based Tracker
2.1. Image Representation
2.1.1. Preprocessing
2.1.2. Simple Layer
2.1.3. Complex Layer
2.1.4. Model Update
2.2. Tracking Process
- Sampling N candidate particles .
- Extracting the preprocessed image patch for each particle , subjecting the patch to the simple and complex layer and employing Equations (4) and (5) to obtain the corresponding representation , followed by computing similarity between the target template and representation .
- Estimating the optimal state according to the similarity.
- Extracting background samples to update the corresponding filters set forth in Equation (1), then computing the sparse representation of the target template using Equations (1) and (2) and using Equation (3) to update the target template .
3. Methodology
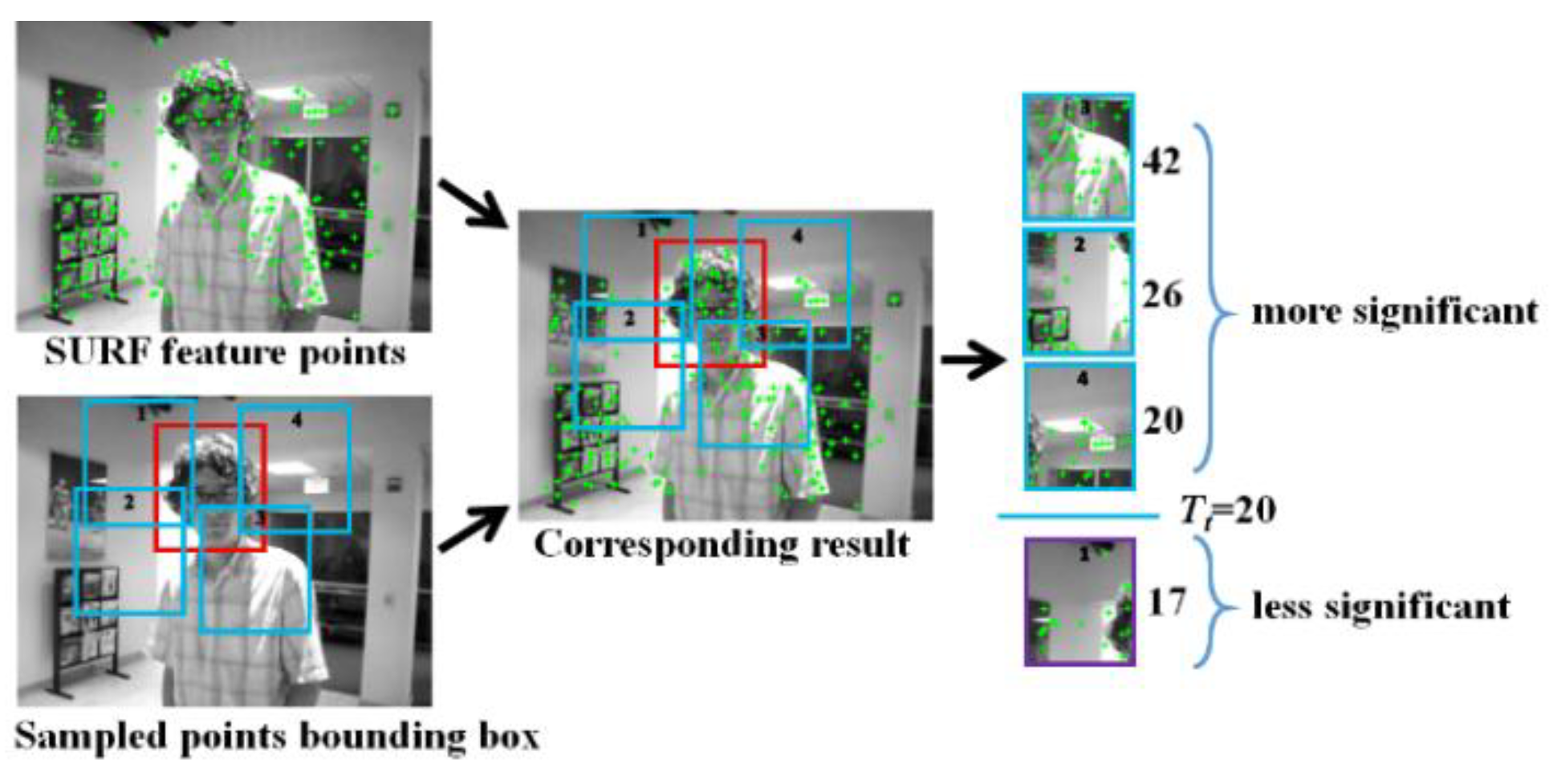
- Every input frame at arbitrary time t (Frame(t)), except the first frame, is subjected to the SURF screening. There are NP particles are sampled from Frame(t), each particle corresponds to a blue bounding box with a randomly selected size. The number of SURF feature points (green prints) covered by each blue bounding box (namely, the particle) is checked to determine if the particle in question is qualified as NC candidates (yellow bounding box).
- The preprocessing stage rescales and normalizes the target box in Frame(1) as well as the plural candidate boxes in Frame(t) into canonical n × n images, and then in Frame(1) extracts a set of local patches with size of w × w (i.e., multiple w × w patches or subimages in the rescaled and normalized target, w ≦ n). Just like in CNT [3] and in this work, the canonical n is heuristically set to 32, however, both the target box and candidate boxes may have different sizes from each other, thus in the preprocessing stage they are rescaled (corresponding to the “warping” in [3]) to the same size and subjected to L2 normalization. In fact, doing so ensures to achieve the desired effect that one of the NC sets of feature maps in the simple layer well preserves the local structure of the target and delicately overcome the target appearance changes significantly due to illumination changes and scale variations, as well shown in Figure 2 of [3].
- In the simple layer, local patches from rescaled and normalized target in Frame(1) are subjected to the HKC (hierarchical k-means clustering) algorithm [11] to obtain k fixed target filters for convolution(without zero or mirror paddings at the image boundary) with the target to generate k feature maps with size of (n − w + 1)2. On the other hand, target filters (k filters) are convolved with each rescaled and normalized candidate boxes to generate NC sets of feature maps, each set has k feature maps.
- In the complex layer, only the k target feature maps (not the candidate feature maps) are de-noised by soft shrinkage [12]. Subsequently, k simple cell feature maps and NC × k candidate feature maps are stacked to represent the target template and NC candidate templates.
- Finally, each NC candidate template is matched with the target template in order to find optimal candidate state, which is used to update the target template by Equation (3) in the model update block. Note that the matching can be done by, for example, subtracting the target template from each of the NC candidate templates and selecting one with the minimum result, or through the inner product operation and choosing the one with the greatest similarity, etc.
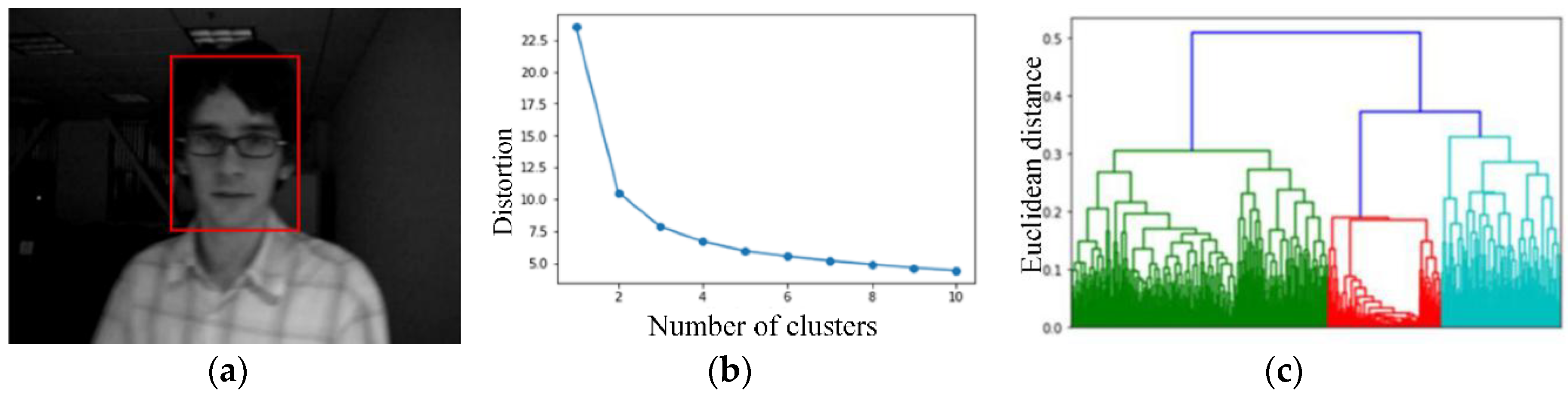
3.1. Adaptive k Value
3.2. SURF Screening
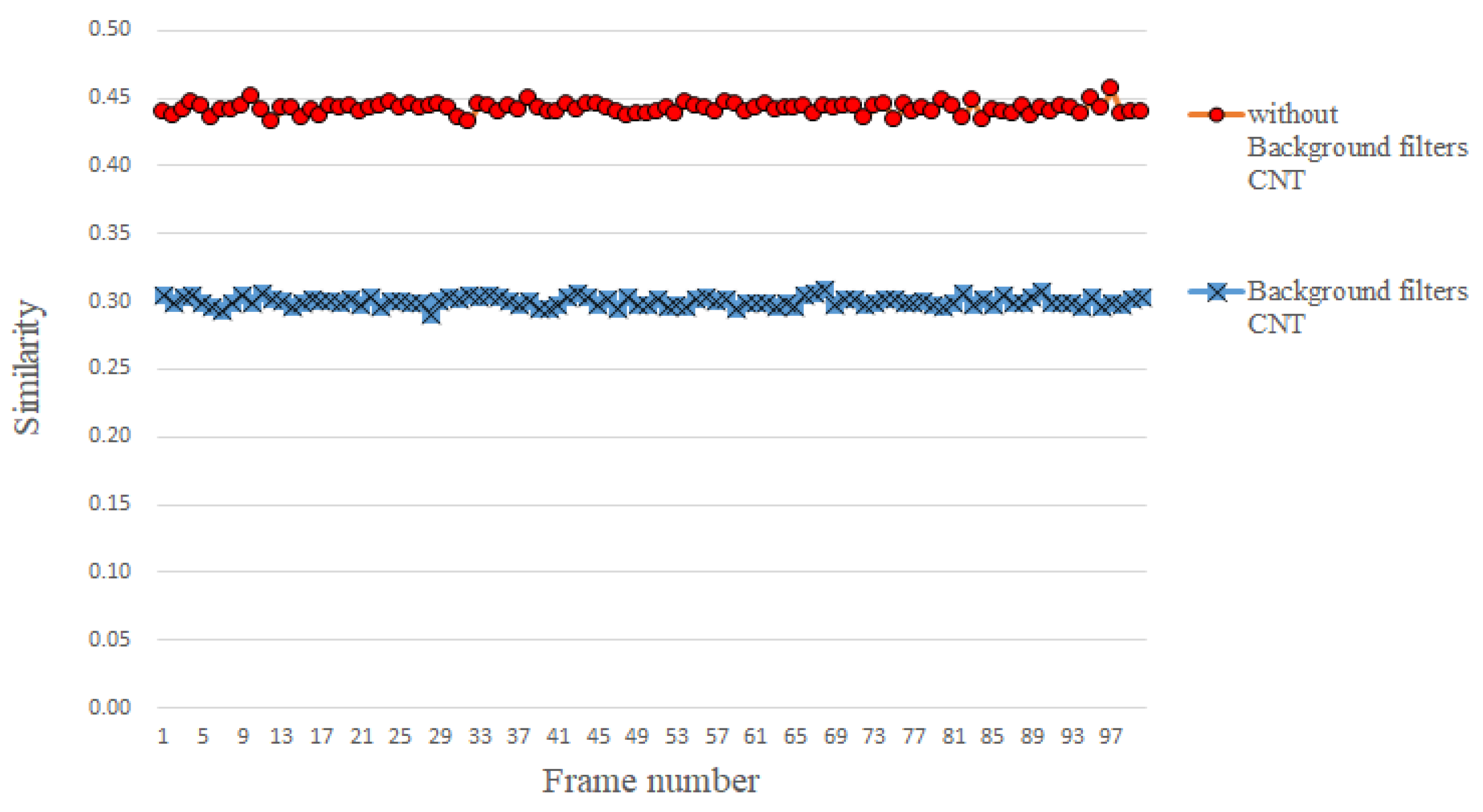
3.3. Abstaining Use of Background Filters
4. Experimental Results
4.1. Experiment Setup
4.2. Evaluation Metrics
4.3. Underwater Tracking
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4293–4302. [Google Scholar]
- Wang, L.; Ouyang, W.; Wang, X.; Lu, H. Stct: Sequentially training convolutional networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1373–1381. [Google Scholar]
- Zhang, K.; Liu, Q.; Wu, Y.; Yang, M.H. Robust visual tracking via convolutional networks without training. IEEE Trans. Image Process. 2016, 25, 1779–1792. [Google Scholar] [CrossRef] [PubMed]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded-up robust features (SURF). Comput. Vis. Image Understand. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Arulampalam, M.S.; Maskell, S.; Gordon, N.; Clapp, T. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar] [CrossRef]
- Gao, J.; Ling, H.; Hu, W.; Xing, J. Transfer learning based visual tracking with Gaussian processes regression. In Proceedings of the 13th European Conference Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 188–203. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Dinh, T.B.; Vo, N.; Medioni, G. Context tracker: Exploring supporters and distracters in unconstrained environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado, CO, USA, 20–25 June 2011; pp. 1177–1184. [Google Scholar]
- Hare, S.; Saffari, A.; Torr, P.H.S. Struck: Structured output tracking with kernels. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 263–270. [Google Scholar]
- Kwon, J.; Lee, K.M. Tracking by sampling trackers. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1195–1202. [Google Scholar]
- Harry, G. Hierarchical K-Means for Unsupervised Learning. Available online: http://www.andrew.cmu.edu/user/hgifford/projects/k_means.pdf (accessed on 20 July 2018).
- Elad, M.; Figueiredo, M.A.T.; Ma, Y. On the role of sparse and redundant representations in image processing. Proc. IEEE 2010, 98, 972–982. [Google Scholar] [CrossRef]
- Raina, R.; Battle, A.; Lee, H.; Packer, B.; Ng, A.Y. Self-taught learning: Transfer learning from unlabeled data. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 20–24 June 2007; pp. 759–766. [Google Scholar]
- Kang, Z.; Landry, S.J. An eye movement analysis algorithm for a multielement target tracking task: Maximum transition-based agglomerative hierarchical clustering. IEEE Trans. Hum.-Mach. Syst. 2015, 45, 13–24. [Google Scholar] [CrossRef]
- Shen, J.; Hao, X.; Liang, Z.; Liu, Y.; Wang, W.; Shao, L. Real-Time Superpixel Segmentation by DBSCAN Clustering Algorithm. IEEE Trans. Image Proc. 2016, 25, 5933–5942. [Google Scholar] [CrossRef] [PubMed]
- Salazar, A.M.; de Diego, I.M.; Conde, C.; Pardos, E.C. Evaluation of Keypoint Descriptors Applied in the Pedestrian Detection in Low Quality Images. IEEE Lat. Am. Trans. 2016, 14, 1401–1407. [Google Scholar] [CrossRef]
- Wu, Y.; Lim, J.; Yang, M.H. Online object tracking: A benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 25–27 June 2013; pp. 2411–2418. [Google Scholar]
- Ross, D.A.; Lim, J.; Lin, R.-S.; Yang, M.-H. Incremental learning for robust visual tracking. Int. J. Comput. Vis. 2008, 77, 125–141. [Google Scholar] [CrossRef]
- Yiming, X.; Shigeru, T.; Fengjun, D. Fundamental study on ecosystem in East China Sea by an integrated model of low and high trophic levels. In Proceedings of the OCEANS 2016—Shanghai, Shanghai, China, 10–13 April 2016; pp. 1–5. [Google Scholar]
- Shortis, M. Calibration Techniques for Accurate Measurements by Underwater Camera Systems. Sensors 2015, 15, 30810–30826. [Google Scholar] [CrossRef] [PubMed]
- Morita, N.; Nogami, H.; Higurashi, E.; Sawada, R. Grasping Force Control for a Robotic Hand by Slip Detection Using Developed Micro Laser Doppler Velocimeter. Sensors 2018, 18, 326. [Google Scholar] [CrossRef] [PubMed]
- Duraibabu, D.B.; Leen, G.; Toal, D.; Newe, T.; Lewis, E.; Dooly, G. Underwater Depth and Temperature Sensing Based on Fiber Optic Technology for Marine and Fresh Water Applications. Sensors 2017, 17, 1228. [Google Scholar] [CrossRef] [PubMed]
- Shaoqing, R.; Kaiming, H.; Ross, G.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 6, 1137–1149. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fast-CNT | CNT | |
|---|---|---|
| CPU | Intel i7 7700K 4.20 GHz | |
| Video resolution | 1280 × 960 Downsized to 320 × 240 | |
| Number of Particles | 200 | 600 |
| k value | 8 | 100 |
| SURF Screening | Disabled | Disabled |
| Background Filters | Disabled | Enabled |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, R.-J.; Tsao, C.-Y.; Kuo, Y.-P.; Lai, Y.-C.; Liu, C.C.; Tu, Z.-W.; Wang, J.-H.; Chang, C.-C. Fast Visual Tracking Based on Convolutional Networks. Sensors 2018, 18, 2405. https://doi.org/10.3390/s18082405
Huang R-J, Tsao C-Y, Kuo Y-P, Lai Y-C, Liu CC, Tu Z-W, Wang J-H, Chang C-C. Fast Visual Tracking Based on Convolutional Networks. Sensors. 2018; 18(8):2405. https://doi.org/10.3390/s18082405
Chicago/Turabian StyleHuang, Ren-Jie, Chun-Yu Tsao, Yi-Pin Kuo, Yi-Chung Lai, Chi Chung Liu, Zhe-Wei Tu, Jung-Hua Wang, and Chung-Cheng Chang. 2018. "Fast Visual Tracking Based on Convolutional Networks" Sensors 18, no. 8: 2405. https://doi.org/10.3390/s18082405
APA StyleHuang, R.-J., Tsao, C.-Y., Kuo, Y.-P., Lai, Y.-C., Liu, C. C., Tu, Z.-W., Wang, J.-H., & Chang, C.-C. (2018). Fast Visual Tracking Based on Convolutional Networks. Sensors, 18(8), 2405. https://doi.org/10.3390/s18082405