Consistent Semantic Annotation of Outdoor Datasets via 2D/3D Label Transfer


Abstract
1. Introduction
- It handles the point cloud representation preferred for natural outdoor scenes (mesh not needed).
- It provides an interface for efficient 2D refinement of annotations (does not rely on a good 3D model).
- It supports frame-to-frame transfer of annotations in video using optical flow.
- Integration with the ROS platform reduces the data preparation time for robotic applications.
2. Related Work
2.1. 2D Images
2.2. 3D Scenes
2.3. 3D to 2D Label Transfer
2.4. 2D to 2D Label Transfer
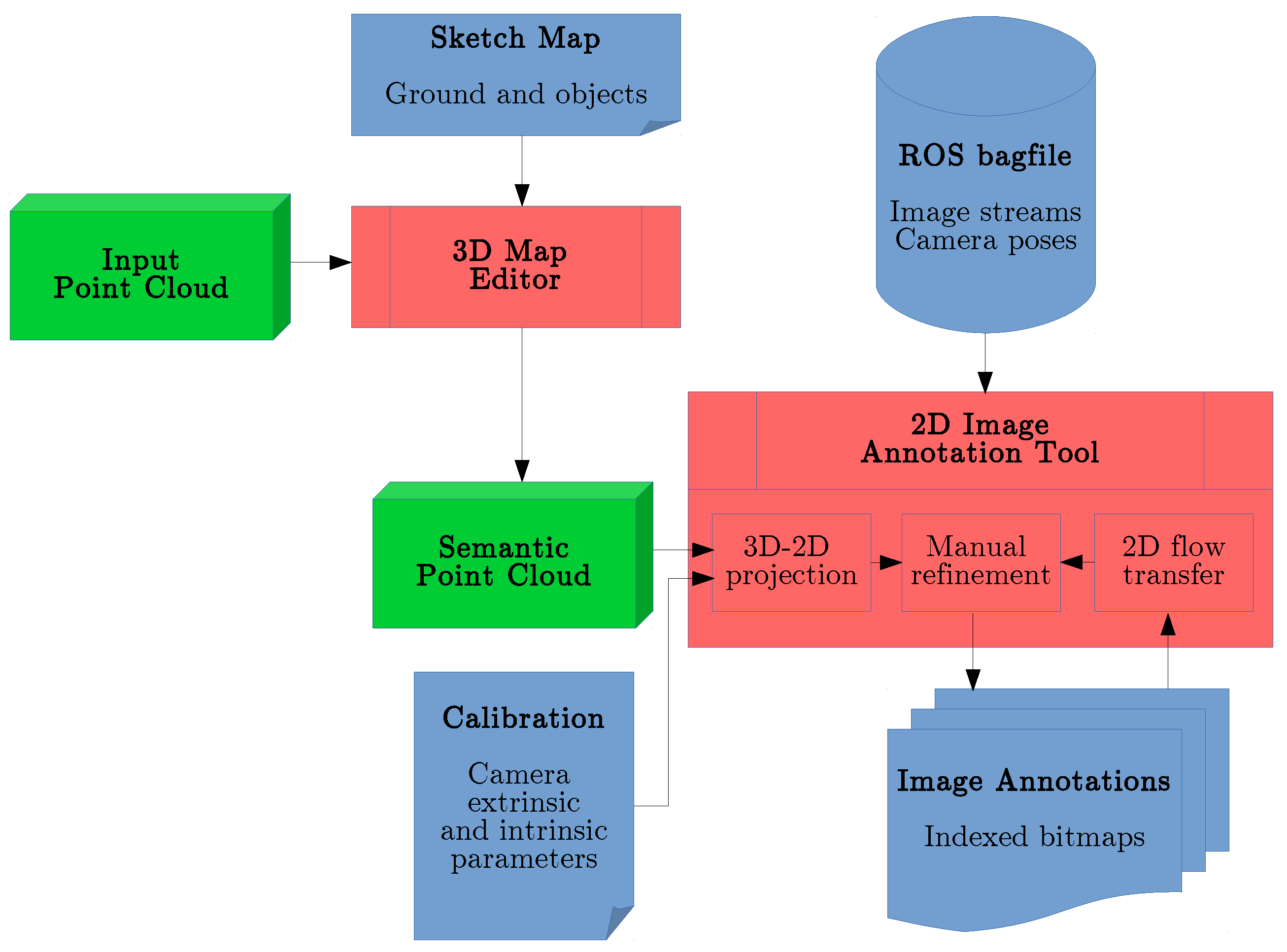
3. Proposed Pipeline
3.1. Input Data Capture
3.1.1. Camera Calibration
3.1.2. Imagery
3.1.3. Point Cloud
3.1.4. Camera Poses
3.2. Semantic Point Cloud
3.2.1. Point Cloud Segmentation
- ground: the horizontal terrain with different types of surfaces, e.g., grass or pavement,
- objects: semantically meaningful parts of the scene, e.g., trees or bushes,
- background: the part of the scene outside of the region of interest.
3.2.2. Initialization of 3D Map Geometry
- Object shapes S are initialized as bounding boxes around object cloud segments similar to [17].
- Ground mesh G is initialized using Delaunay Triangulation (DT) of the ground segment. Vertices of the DT are uniformly sampled from ground points.
3.2.3. Assignment of Semantic Labels
3.3. Semantic Image Annotations
3.3.1. Projection of Point Cloud to Image Frames
3.3.2. Transfer of Annotation to the Next Frame
3.3.3. Manual Adjustments of Labels in the Editor
4. Components and User Interface
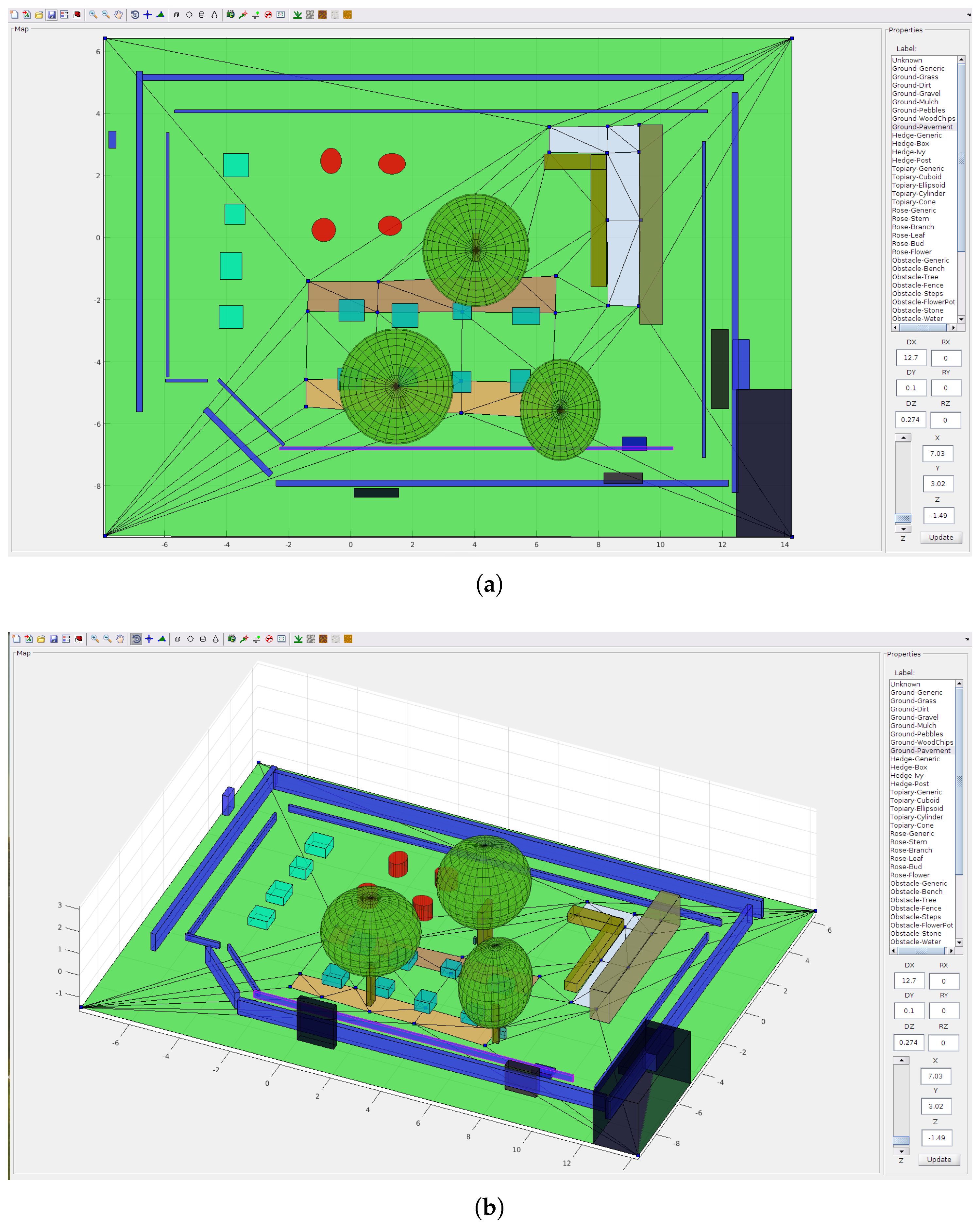
4.1. 3D Semantic Map Editor
- Insert or remove vertices of the ground mesh (control points),
- Move a selected vertex (location X, Y),
- Adjust the elevation (Z ) of a selected vertex or face,
- Insert objects of primitive shapes (spheres, cubes, cylinders, cones),
- Change dimensions of the shapes (diameters DX, DY, DZ)and orientation (rotation angles RX, RY, RZ),
- Assign a semantic label from the list to a selected face of the ground mesh or object.
- Import a segmented point cloud and initialize objects from its components,
- Export a semantic point cloud with labels corresponding to the current 3D map.
4.2. 2D Image Semantic Annotation Tool
- Switch between multiple camera topics and image frames,
- Transparently overlay semantic labels on the original image with adjustable opacity (Figure 7f),
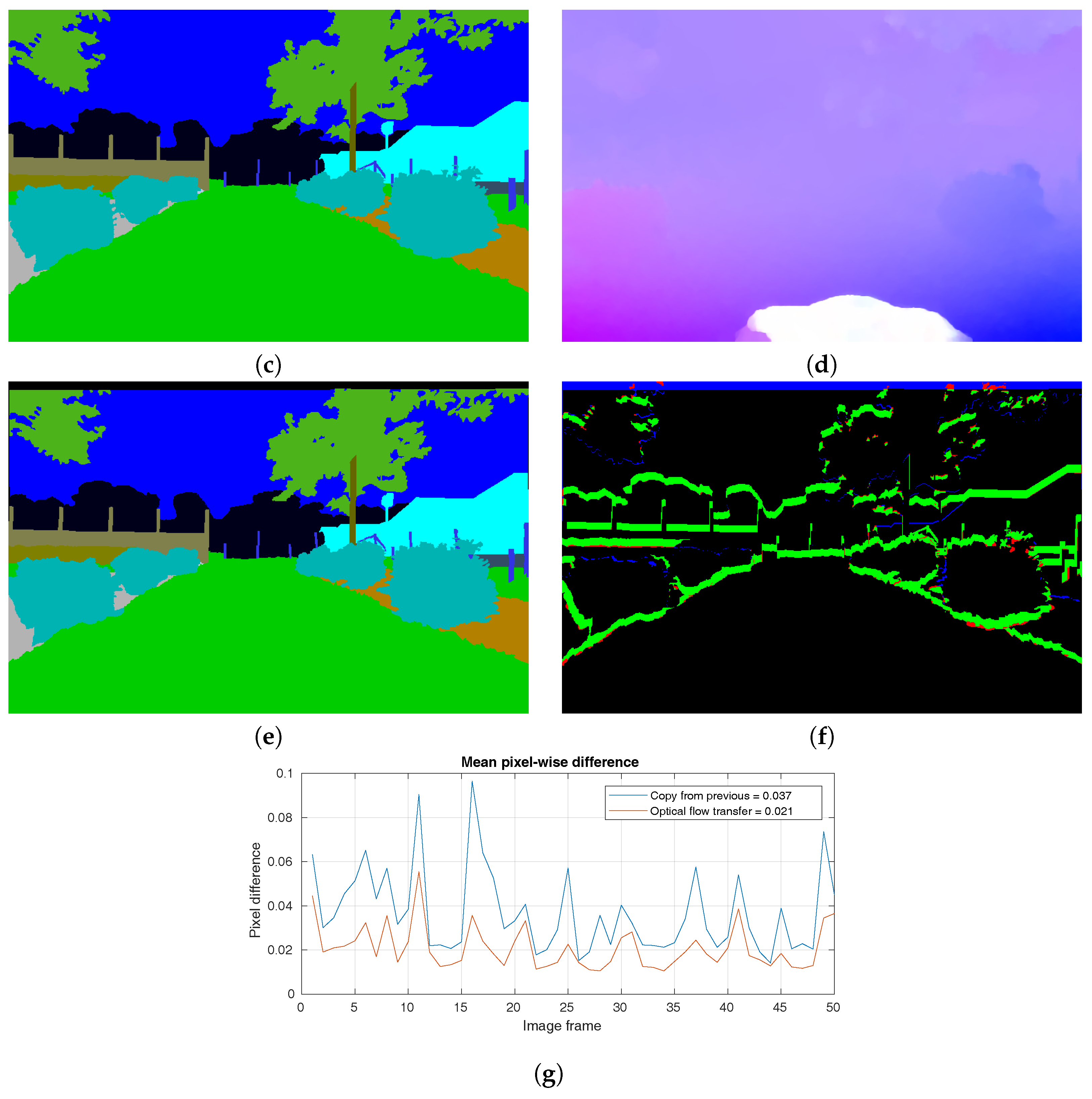
- Initialize the frame from 3D projection (Figure 7c),
- Translate and rotate the current semantic map in the image frame,
- Automatically refine annotation boundaries to align with contours of the original image (super-pixel boundaries [26]),
- Draw user-selected semantic labels with a brush of adjustable size (Figure 7d),
- Draw region boundaries and fill the semantic or image region,
- Transfer labels to the next frame (Figure 9e),
- Export annotations and overlays with the option of label set reduction (top classes only or custom).
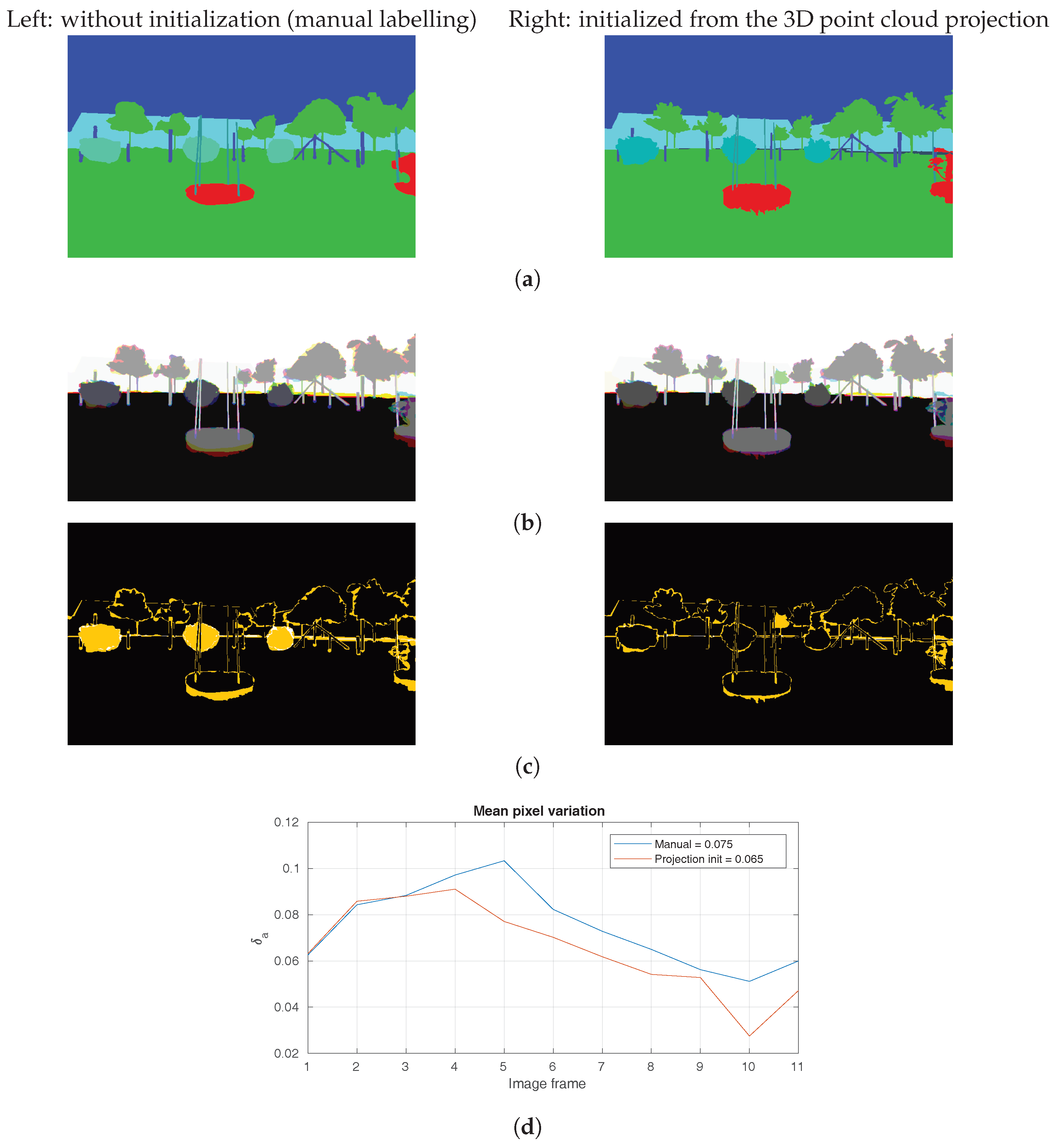
5. Results and Evaluation
- Empty annotation (all manual annotation),
- Projection of the 3D semantic model to the image (3D-2D projection),
- Transferring labels from the previous frame using calculated optical flow (2D flow transfer).
5.1. 3D-2D Projection
- Segmentation inaccurate: variation of object boundaries.
- Under-segmentation: objects or a part missing.
- Semantic class mismatch: different labels assigned to objects or parts.
5.2. 2D Flow Transfer
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| GT | Ground Truth |
| DT | Delaunay Triangulation |
| ROS | Robot Operating System |
| MRF | Markov Random Field |
| CRF | Conditional Random Field |
| WVGA | Wide Video Graphics Array |
| YAML | Yet Another Markup Language |
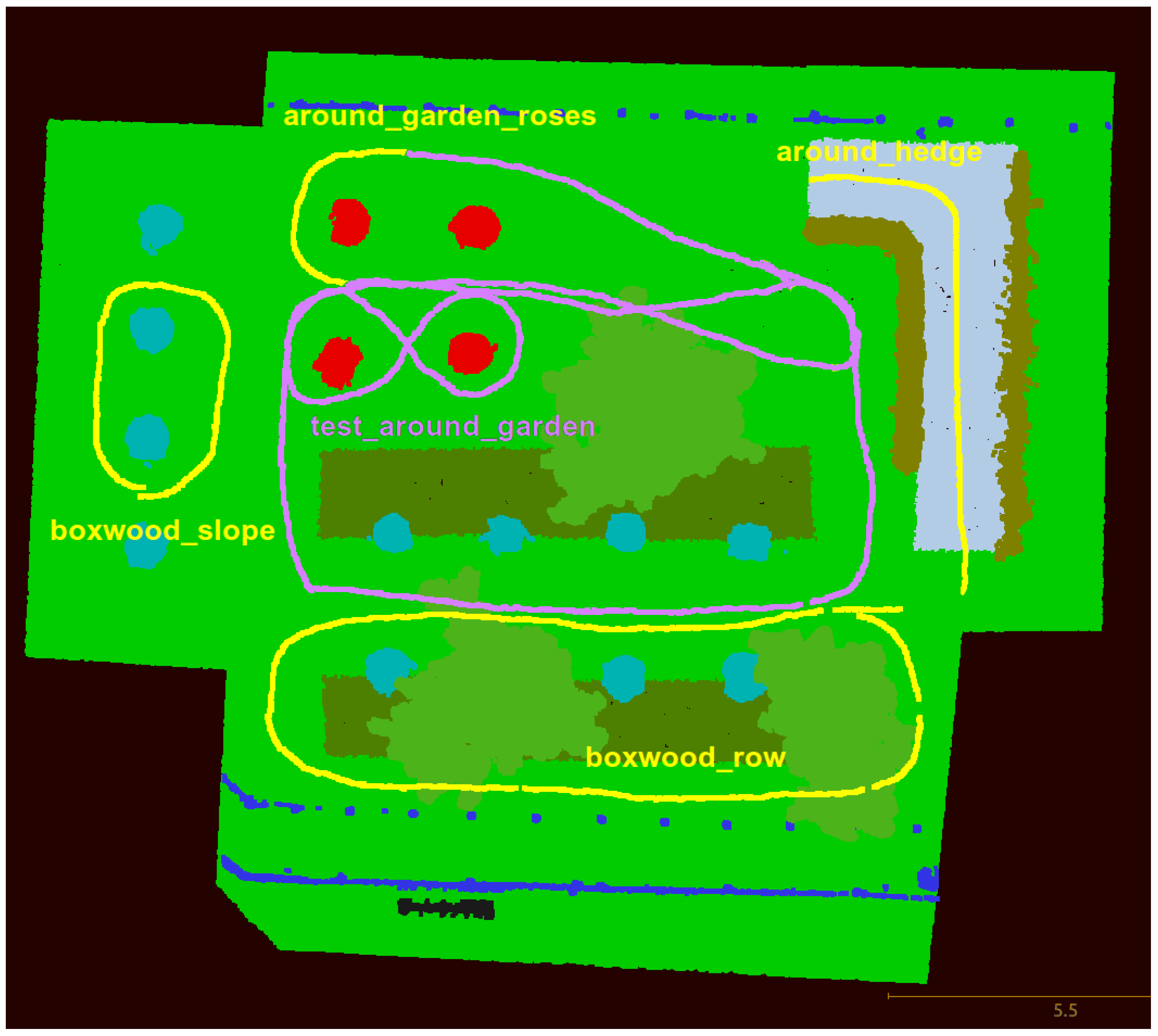
Appendix A. 3DRMS2017 Garden Dataset

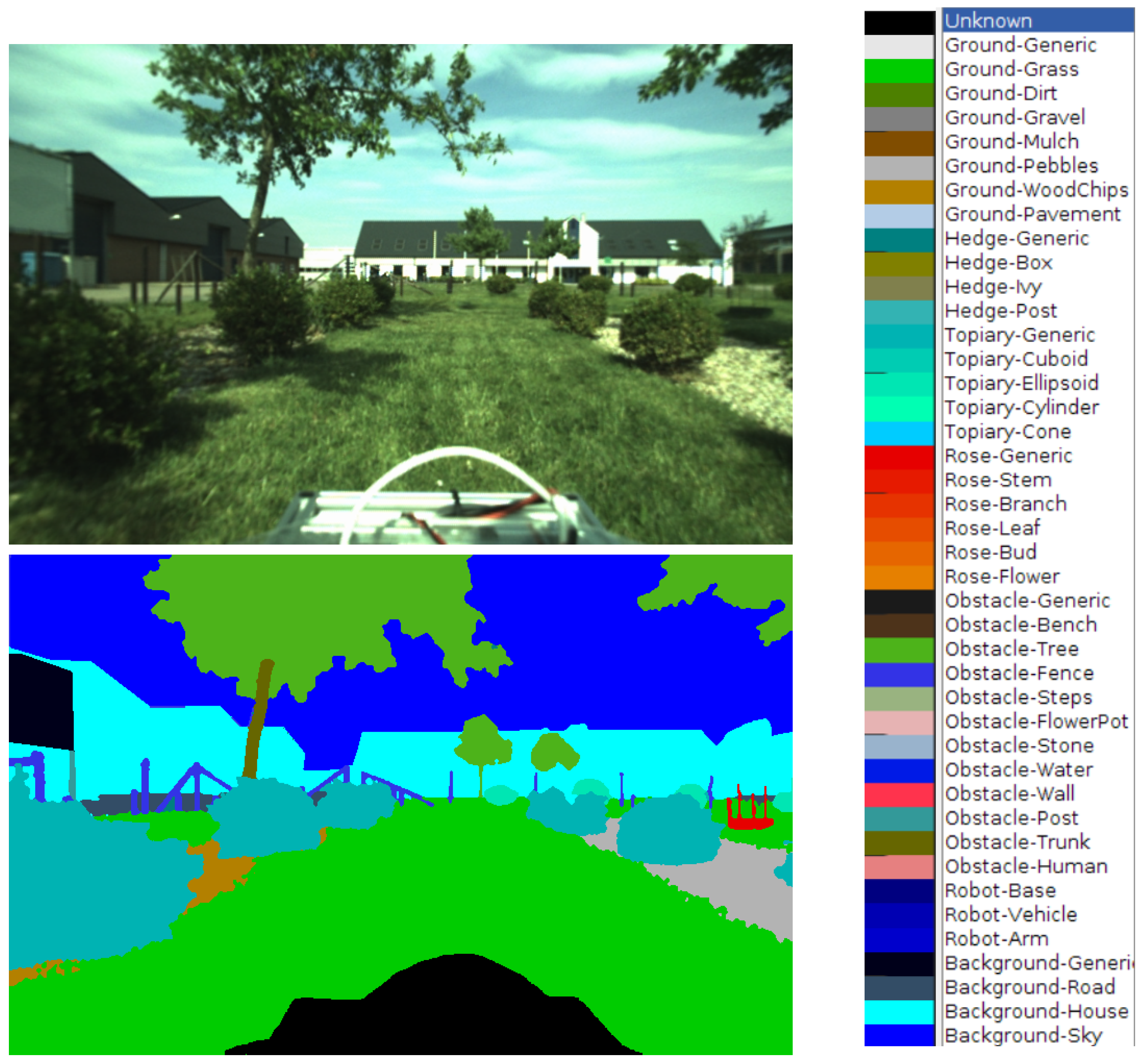
Appendix A.1. Calibrated Images

Appendix A.2. Semantic Image Annotations
- Grass (light green)
- Ground (brown)
- Pavement (grey)
- Hedge (ochre)
- Topiary (cyan)
- Rose (red)
- Obstacle (blue)
- Tree (dark green)
- Background (black)

Appendix A.3. Semantic Point Cloud

References
- Oram, P. WordNet: An Electronic Lexical Database; Fellbaum, C., Ed.; MIT Press: Cambridge, MA, USA, 1998; p. 423. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. arXiv, 2015; arXiv:1512.03012. [Google Scholar]
- Boom, B.J.; Huang, P.X.; He, J.; Fisher, R.B. Supporting ground-truth annotation of image datasets using clustering. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR 2012), Tsukuba, Japan, 11–15 November 2012; pp. 1542–1545. [Google Scholar]
- Papadopoulos, D.P.; Uijlings, J.R.R.; Keller, F.; Ferrari, V. Extreme clicking for efficient object annotation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 854–863. [Google Scholar] [CrossRef]
- Rother, C.; Kolmogorov, V.; Blake, A. “GrabCut”: Interactive Foreground Extraction Using Iterated Graph Cuts. ACM Trans. Graph. 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Hua, B.S.; Yu, L.F.; Yeung, S.K. A Robust 3D-2D Interactive Tool for Scene Segmentation and Annotation. arXiv, 2017; arXiv:1610.05883. [Google Scholar] [CrossRef] [PubMed]
- Papadopoulos, D.P.; Uijlings, J.R.R.; Keller, F.; Ferrari, V. We Do Not Need No Bounding-Boxes: Training Object Class Detectors Using Only Human Verification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas Valley, NV, USA, 26 June–1 July 2016; pp. 854–863. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Deng, J.; Russakovsky, O.; Krause, J.; Bernstein, M.S.; Berg, A.; Fei-Fei, L. Scalable Multi-label Annotation. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’14), Toronto, ON, Canada, 26 April–1 May 2014; ACM: New York, NY, USA, 2014; pp. 3099–3102. [Google Scholar] [CrossRef]
- Giordano, D.; Palazzo, S.; Spampinato, C. A diversity-based search approach to support annotation of a large fish image dataset. Multimed. Syst. 2016, 22, 725–736. [Google Scholar] [CrossRef]
- Salvo, R.D.; Spampinato, C.; Giordano, D. Generating reliable video annotations by exploiting the crowd. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–9 March 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Yu, F.; Zhang, Y.; Song, S.; Seff, A.; Xiao, J. LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop. arXiv, 2015; arXiv:1506.03365. [Google Scholar]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A Database and Web-Based Tool for Image Annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Valentin, J.; Vineet, V.; Cheng, M.M.; Kim, D.; Shotton, J.; Kohli, P.; Niessner, M.; Criminisi, A.; Izadi, S.; Torr, P. SemanticPaint: Interactive 3D Labeling and Learning at Your Fingertips. ACM Trans. Graph. 2015, 34, 154:1–154:17. [Google Scholar] [CrossRef]
- Sattler, T.; Brox, T.; Pollefeys, M.; Fisher, R.B.; Tylecek, R. 3D Reconstruction meets Semantics—Reconstruction Challenge. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. SEMANTIC3D.NET: A new large-scale point cloud classification benchmark. arXiv, 2017; arXiv:1704.03847. [Google Scholar] [CrossRef]
- Xie, J.; Kiefel, M.; Sun, M.T.; Geiger, A. Semantic Instance Annotation of Street Scenes by 3D to 2D Label Transfer. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas Valley, NV, USA, 26 June–1 July 2016; pp. 3688–3697. [Google Scholar] [CrossRef]
- Schöps, T.; Schönberger, J.L.; Galliani, S.; Sattler, T.; Schindler, K.; Pollefeys, M.; Geiger, A. A Multi-view Stereo Benchmark with High-Resolution Images and Multi-camera Videos. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2538–2547. [Google Scholar] [CrossRef]
- Liu, C.; Yuen, J.; Torralba, A. Nonparametric Scene Parsing via Label Transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2368–2382. [Google Scholar] [CrossRef] [PubMed]
- Gould, S.; Zhao, J.; He, X.; Zhang, Y. Superpixel Graph Label Transfer with Learned Distance Metric. In Proceedings of the European Conference on Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014, Part III; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 632–647. [Google Scholar]
- Furgale, P.; Rehder, J.; Siegwart, R. Unified temporal and spatial calibration for multi-sensor systems. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 1280–1286. [Google Scholar] [CrossRef]
- Schönberger, J.L.; Frahm, J.M. Structure-from-Motion Revisited. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas Valley, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Girardeau-Montaut, D. CloudCompare—3D Point Cloud and Mesh Processing Software, version 2.9.1; Open Source Project; Telecom ParisTechs: Paris, France, 2017. [Google Scholar]
- Zhang, W.; Qi, J.; Wan, P.; Wang, H.; Xie, D.; Wang, X.; Yan, G. An Easy-to-Use Airborne LiDAR Data Filtering Method Based on Cloth Simulation. Remote Sens. 2016, 8, 501. [Google Scholar] [CrossRef]
- Revaud, J.; Weinzaepfel, P.; Harchaoui, Z.; Schmid, C. EpicFlow: Edge-Preserving Interpolation of Correspondences for Optical Flow. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Susstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Manual | 3D-2D Projection | 2D Flow Transfer | Frames |
|---|---|---|---|---|
| Random annotation (effort) | 42 min | 40 min | 562 | |
| Multi-user variation (consistency) | 7.5% pixels | 6.5% pixels | 30 | |
| Consecutive sequence (effort) | 20 min | 11 min | 180 | |
| Refinement needed (area) | 3.7% pixels | 2.1% pixels | 50 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tylecek, R.; Fisher, R.B. Consistent Semantic Annotation of Outdoor Datasets via 2D/3D Label Transfer. Sensors 2018, 18, 2249. https://doi.org/10.3390/s18072249
Tylecek R, Fisher RB. Consistent Semantic Annotation of Outdoor Datasets via 2D/3D Label Transfer. Sensors. 2018; 18(7):2249. https://doi.org/10.3390/s18072249
Chicago/Turabian StyleTylecek, Radim, and Robert B. Fisher. 2018. "Consistent Semantic Annotation of Outdoor Datasets via 2D/3D Label Transfer" Sensors 18, no. 7: 2249. https://doi.org/10.3390/s18072249
APA StyleTylecek, R., & Fisher, R. B. (2018). Consistent Semantic Annotation of Outdoor Datasets via 2D/3D Label Transfer. Sensors, 18(7), 2249. https://doi.org/10.3390/s18072249