An Indoor Positioning System Based on Static Objects in Large Indoor Scenes by Using Smartphone Cameras


Abstract
1. Introduction
- (1)
- We propose an indoor positioning system by using smartphone cameras, which is designed for large indoor scenes. Previous studies of indoor positioning based on smartphone cameras have their own shortcomings in such large indoor scenes. The system integrates computer vision (CV) and deep learning (DL) algorithms. Common static objects (such as doors and windows) in the indoor scene are used as references for locating purposes, making our method general, and easy to replicate.
- (2)
- We tested our system in a large indoor space with a complicated field of vision—an art museum. Experiments indicated that our method is able to achieve a positioning accuracy within 1 m in such circumstances.
- (3)
- Our method is low-cost, as developers only need to take several photos to the static objects as a sample collection, without any additional infrastructure. It is also easily operated using monocular photography, which means users don’t have to photograph scenes from multiple angles or take a video.
2. Related Works
3. System and Methodology
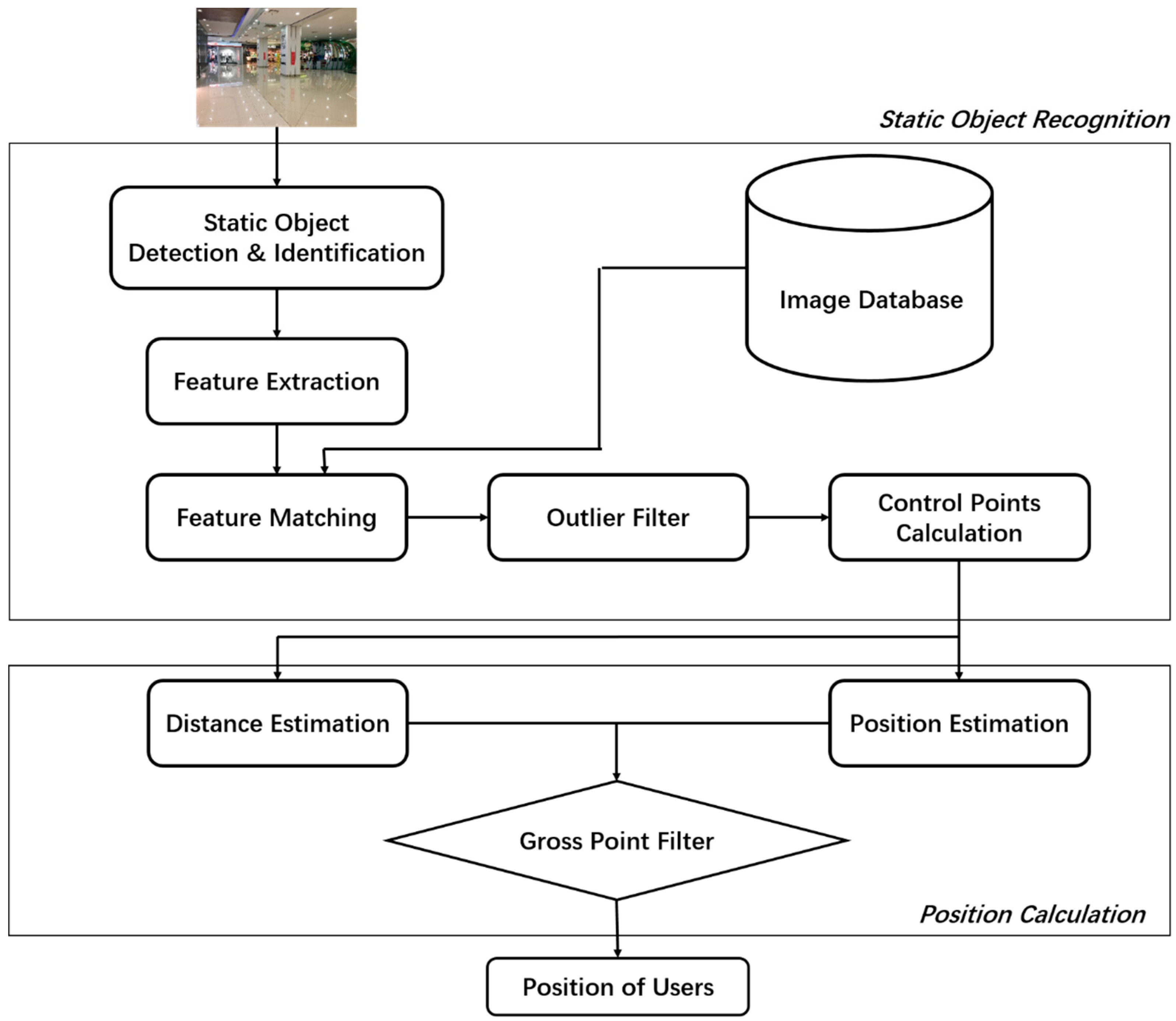
3.1. System Overview
3.2. Static Objects Recognition
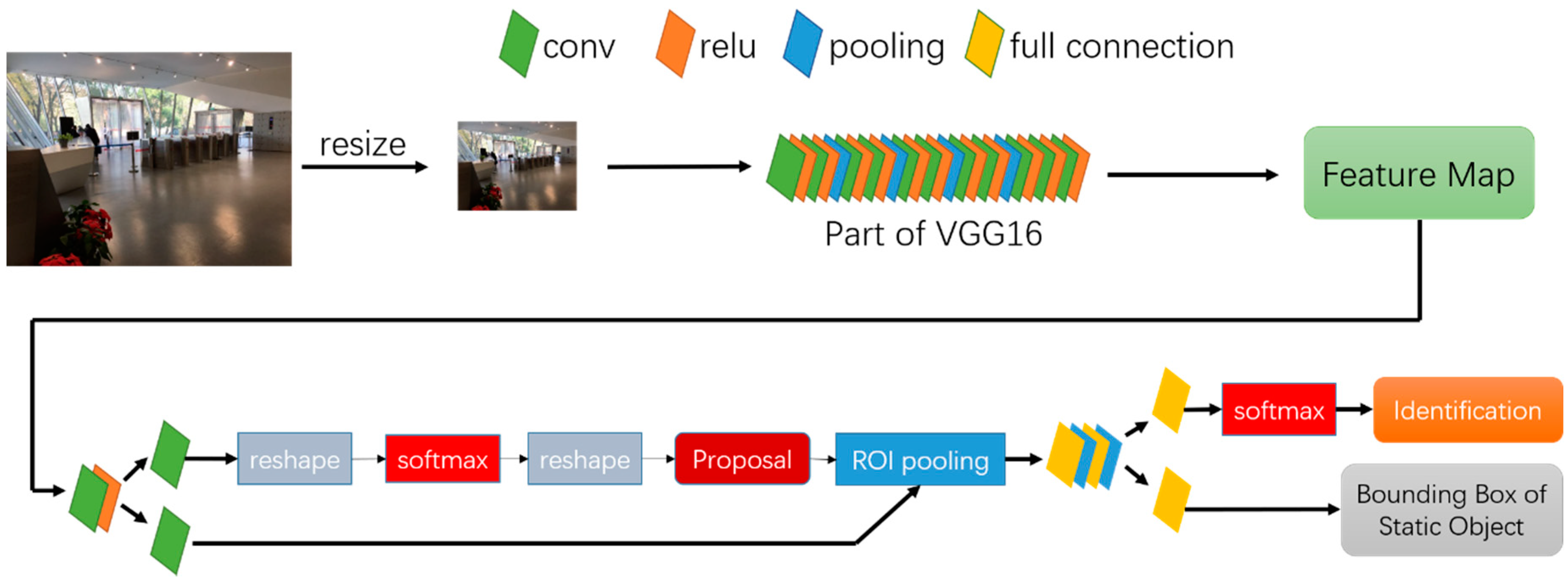
3.2.1. Static Object Detection & Identification
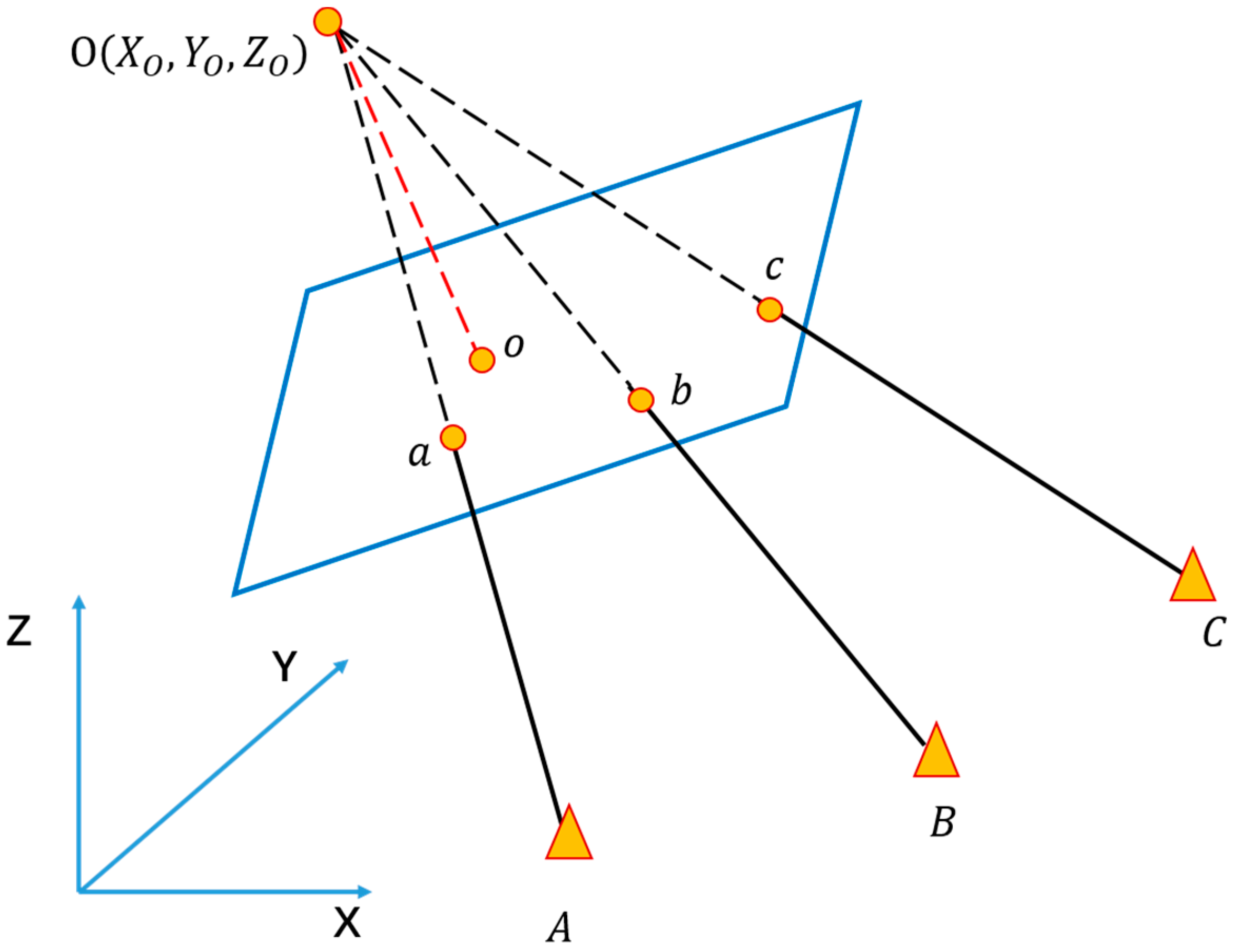
3.2.2. Obtaining Control Points Coordinates
| Algorithm 1. Obtaining Pixel Coordinates of Control Points in Test Images |
| Input: image block of static objects from test image |
| Procedure: |
| (1) Get reference image through identity of static object from database; |
| (2) Extract feature points for both test image block and reference image by SIFT operator [46]; |
| (3) Perform feature matching to get homonymy feature point pairs; |
| (4) Employed RANSAC [47] to remove false matching points; the remaining matching points marked as for test image and for reference image; |
| (5) Calculate homographic matrix by solving formula below:
|
| (6) Estimate pixel coordinates of control points in test images CPT as following formula, is the set of pixel coordinates of control points in reference images:
|
| Output: |
3.3. Position Calculation
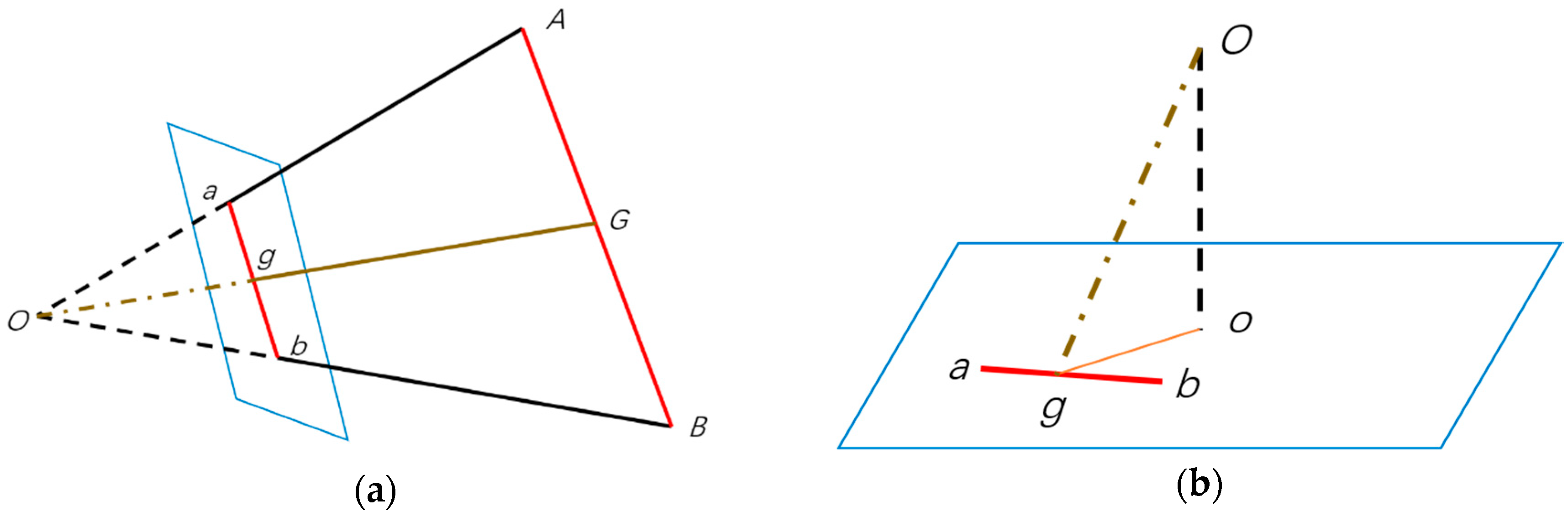
3.3.1. Position Estimation
3.3.2. Distance Estimation
4. Experiments
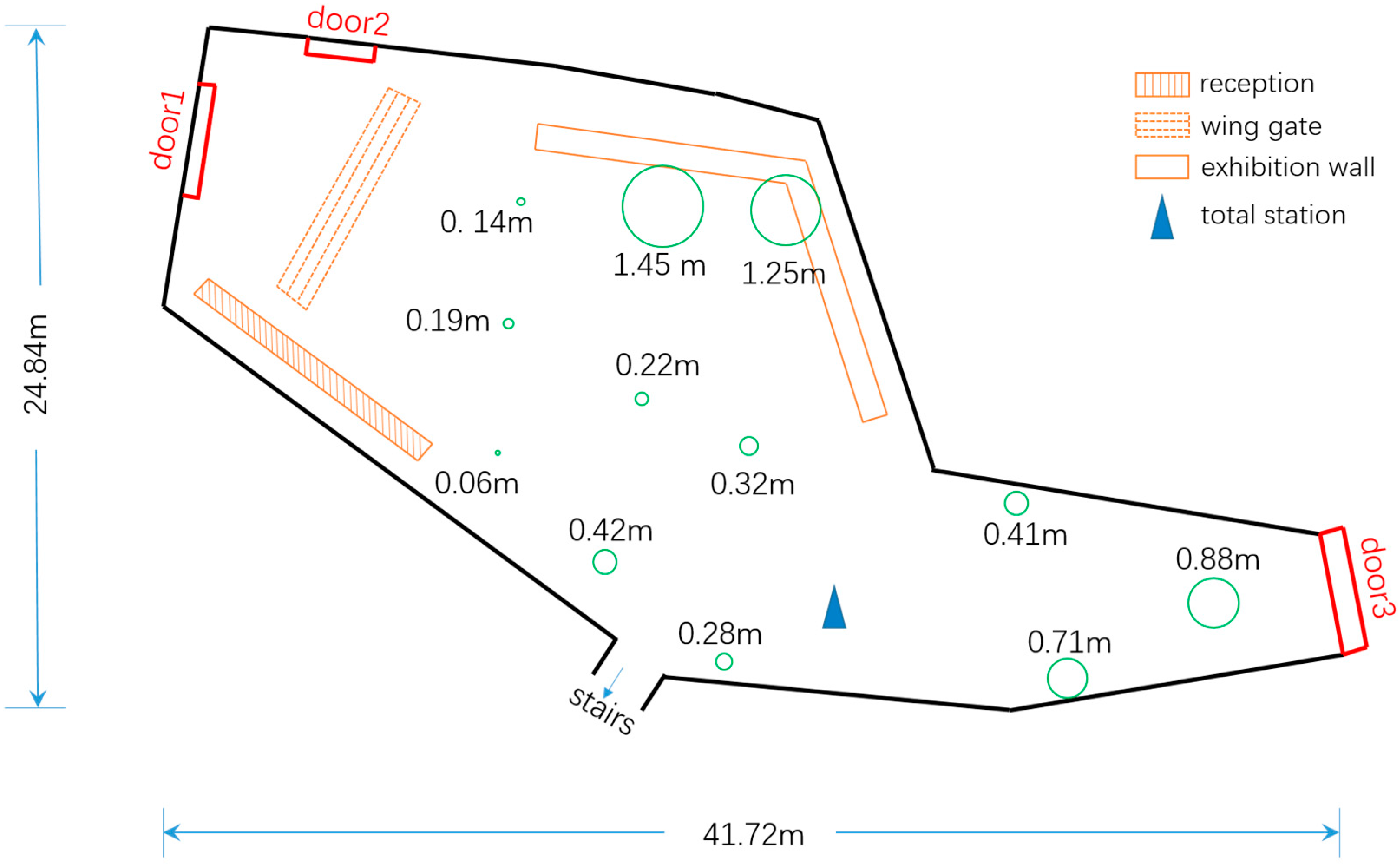
4.1. Experiment Setup
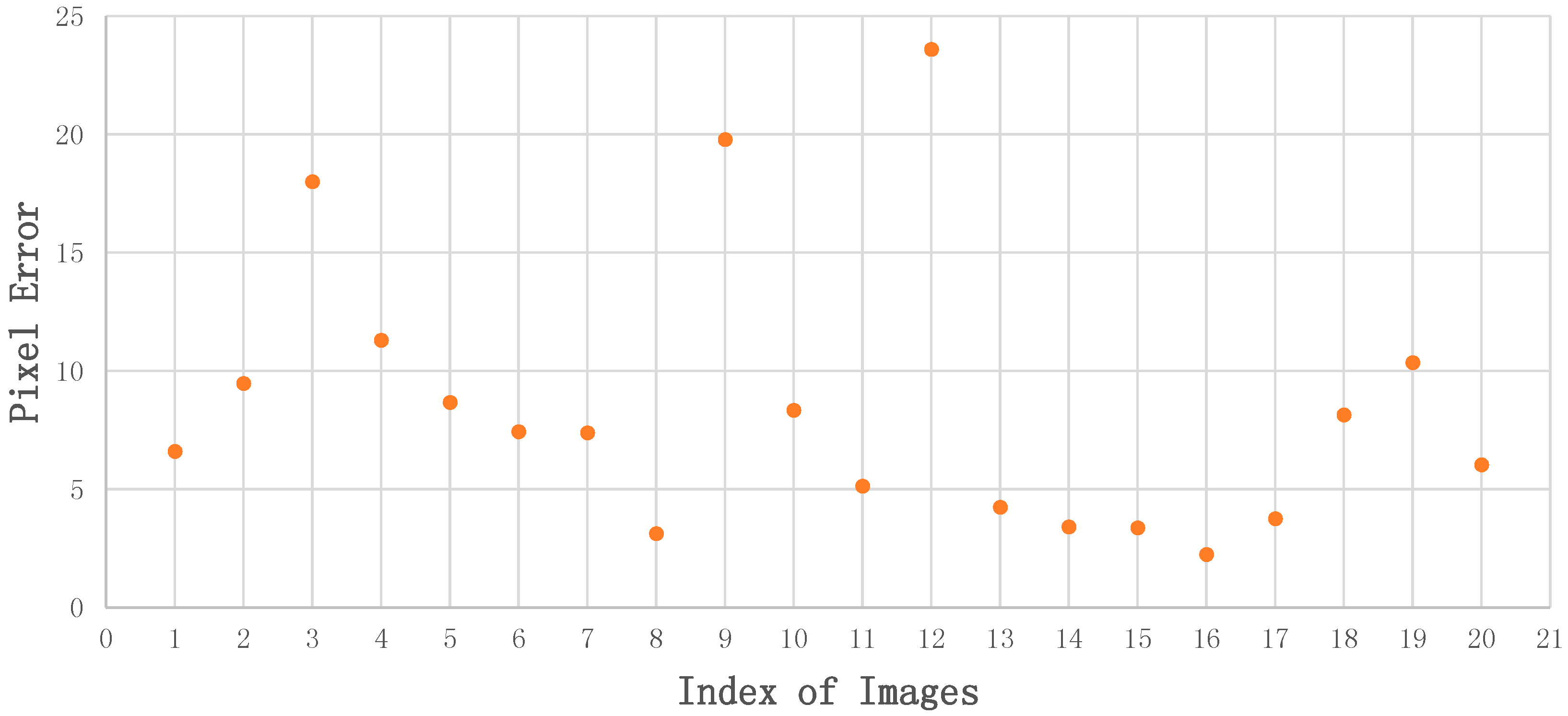
4.2. Performance of Static Object Recognition
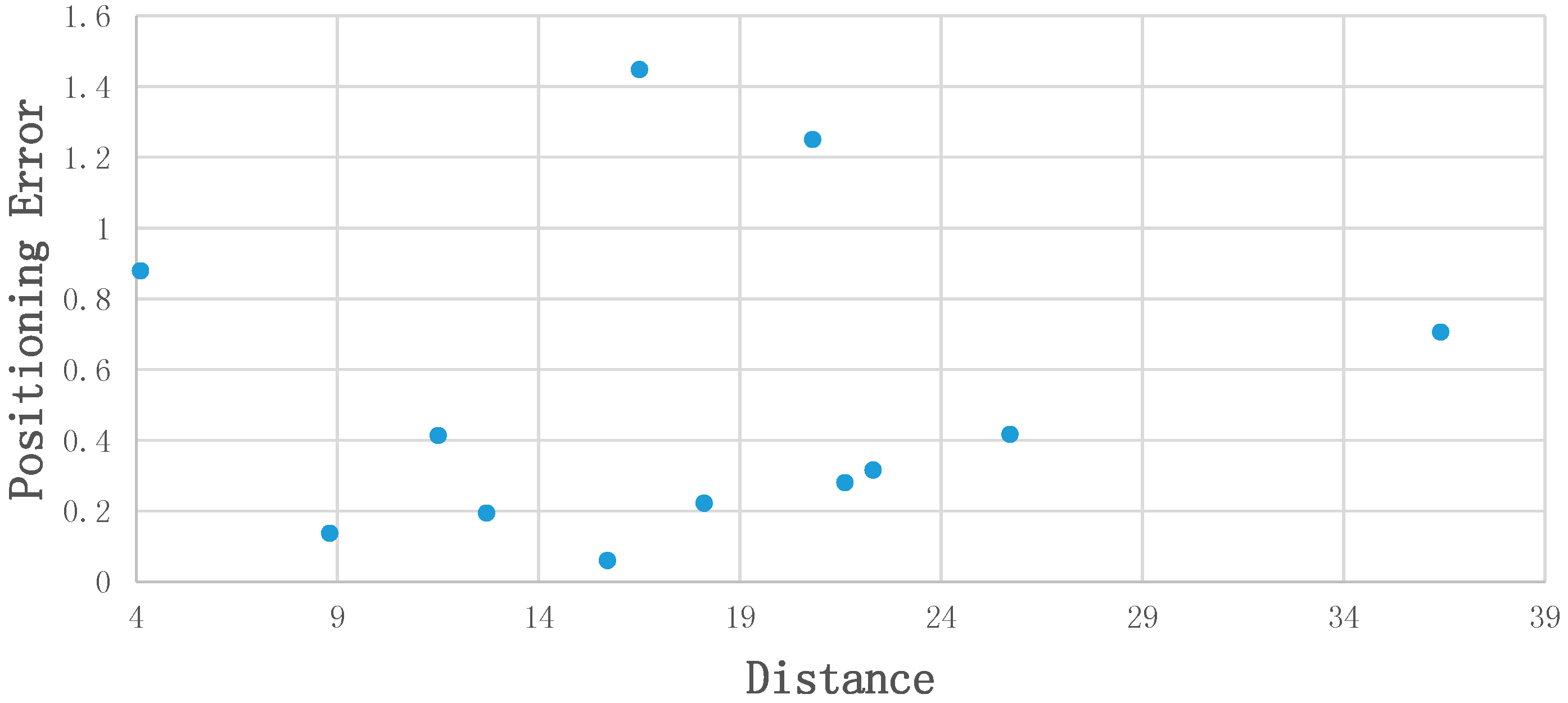
4.3. Positioning Results and Analysis
5. Discussion
5.1. Experimental Difficulties and Criteria for Choosing Static Objects
5.2. Evaluation
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- O’Keefe, J. Place units in the hippocampus of the freely moving rat. Exp. Neurol. 1976, 51, 78–109. [Google Scholar] [CrossRef]
- O’Keefe, J.; Dostrovsky, J. The hippocampus as a spatial map: Preliminary evidence from unit activity in the freely-moving rat. Brain Res. 1971, 34, 171–175. [Google Scholar] [CrossRef]
- Fyhn, M.; Molden, S.; Witter, M.P.; Moser, E.I.; Moser, M.-B. Spatial representation in the entorhinal cortex. Science 2004, 305, 1258–1264. [Google Scholar] [CrossRef] [PubMed]
- Sargolini, F.; Fyhn, M.; Hafting, T.; McNaughton, B.L.; Witter, M.P.; Moser, M.-B.; Moser, E.I. Conjunctive representation of position, direction, and velocity in entorhinal cortex. Science 2006, 312, 758–762. [Google Scholar] [CrossRef] [PubMed]
- Wu, D.; Chen, R.; Chen, L. Visual positioning indoors: Human eyes vs. smartphone cameras. Sensors 2017, 17, 2645. [Google Scholar] [CrossRef] [PubMed]
- Ruizhi, C.; Liang, C. Indoor Positioning with Smartphones: The State-of-the-art and the Challenges. Acta Geod. Cartogr. Sin. 2017, 46, 1316–1326. [Google Scholar] [CrossRef]
- Youssef, M.; Agrawala, A. The Horus WLAN location determination system. In Proceedings of the 3rd International Conference on Mobile Systems, Applications, and Services, Seattle, WA, USA, 6–8 June 2005; ACM: New York, NY, USA, 2005; pp. 205–218. [Google Scholar]
- Bahl, P.; Padmanabhan, V.N. RADAR: An in-building RF-based user location and tracking system. In Proceedings of the IEEE INFOCOM 2000 Conference on Computer Communications. Nineteenth Annual Joint Conference of the IEEE Computer and Communications Societies (Cat. No.00CH37064), Tel Aviv, Israel, 26–30 March 2000; Volume 2, pp. 775–784. [Google Scholar]
- Vaupel, T.; Seitz, J.; Kiefer, F.; Haimerl, S.; Thielecke, J. Wi-Fi positioning: System considerations and device calibration. In Proceedings of the 2010 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Zurich, Switzerland, 15–17 September 2010; pp. 1–7. [Google Scholar]
- Hansen, R.; Wind, R.; Jensen, C.S.; Thomsen, B. Algorithmic strategies for adapting to environmental changes in 802.11 location fingerprinting. In Proceedings of the 2010 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Zurich, Switzerland, 15–17 September 2010; pp. 1–10. [Google Scholar]
- Teuber, A.; Eissfeller, B. WLAN indoor positioning based on Euclidean distances and fuzzy logic. In Proceedings of the 3rd Workshop on Positioning, Navigation and Communication, Lower Saxony, Germany, 16 March 2006; pp. 159–168. [Google Scholar]
- Haverinen, J.; Kemppainen, A. Global indoor self-localization based on the ambient magnetic field. Rob. Auton. Syst. 2009, 57, 1028–1035. [Google Scholar] [CrossRef]
- Chen, L.; Kuusniemi, H.; Chen, Y.; Pei, L.; Kröger, T.; Chen, R. Information filter with speed detection for indoor Bluetooth positioning. In Proceedings of the 2011 International Conference on Localization and GNSS (ICL-GNSS), Tampere, Finland, 29–30 June 2011; pp. 47–52. [Google Scholar]
- Chen, L.; Kuusniemi, H.; Chen, Y.; Liu, J.; Pei, L.; Ruotsalainen, L.; Chen, R. Constraint Kalman filter for indoor bluetooth localization. In Proceedings of the 2015 23rd European Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2015; pp. 1915–1919. [Google Scholar]
- Chen, L.; Pei, L.; Kuusniemi, H.; Chen, Y.; Kröger, T.; Chen, R. Bayesian fusion for indoor positioning using bluetooth fingerprints. Wirel. Pers. Commun. 2013, 70, 1735–1745. [Google Scholar] [CrossRef]
- Bargh, M.S.; de Groote, R. Indoor localization based on response rate of bluetooth inquiries. In Proceedings of the First ACM International Workshop on Mobile Entity Localization and Tracking in GPS-Less Environments, San Francisco, CA, USA, 19 September 2008; ACM: New York, NY, USA, 2008; pp. 49–54. [Google Scholar]
- He, S.; Chan, S.H.G. INTRI: Contour-Based Trilateration for Indoor Fingerprint-Based Localization. IEEE Trans. Mob. Comput. 2017, 16, 1676–1690. [Google Scholar] [CrossRef]
- Quuppa Company. Available online: http://quuppa.com/company/ (accessed on 10 July 2018).
- Lakmali, B.D.S. Database Correlation for GSM Locationin Outdoor & Indoor Environments. In Proceedings of the 4th International Conference on Information and Automation for Sustainability (ICIAFS), Colombo, Sri Lanka, 12–14 December 2008. [Google Scholar]
- Zhao, Y. Standardization of mobile phone positioning for 3G systems. IEEE Commun. Mag. 2002, 40, 108–116. [Google Scholar] [CrossRef]
- Want, R.; Hopper, A.; Falcao, V.; Gibbons, J. The active badge location system. ACM Trans. Inf. Syst. 1992, 10, 91–102. [Google Scholar] [CrossRef]
- Ward, A.; Jones, A.; Hopper, A. A new location technique for the active office. IEEE Pers. Commun. 1997, 4, 42–47. [Google Scholar] [CrossRef]
- Priyantha, N.B.; Chakraborty, A.; Balakrishnan, H. The cricket location-support system. In Proceedings of the 6th nnual International Conference on Mobile Computing and Networking, Boston, MA, USA, 6–11 August 2011; ACM: New York, NY, USA, 2000; pp. 32–43. [Google Scholar]
- Kim, B.; Kwak, M.; Lee, J.; Kwon, T.T. A multi-pronged approach for indoor positioning with WiFi, magnetic and cellular signals. In Proceedings of the 2014 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Busan, Korea, 27–30 October 2014; pp. 723–726. [Google Scholar]
- Jeon, J.S.; Kong, Y.; Nam, Y.; Yim, K. An Indoor Positioning System Using Bluetooth RSSI with an Accelerometer and a Barometer on a Smartphone. In Proceedings of the 2015 10th International Conference on Broadband and Wireless Computing, Communication and Applications (BWCCA), Krakow, Poland, 4–6 November 2015; pp. 528–531. [Google Scholar]
- Chen, L.H.; Wu, H.K.; Jin, M.H.; Chen, G.H. Intelligent Fusion of Wi-Fi and Inertial Sensor-Based Positioning Systems for Indoor Pedestrian Navigation. IEEE Sens. J. 2014, 14, 4034–4042. [Google Scholar] [CrossRef]
- Li, Y.; Zhuang, Y.; Zhang, P.; Lan, H.; Niu, X.; El-Sheimy, N. An improved inertial/wifi/magnetic fusion structure for indoor navigation. Inf. Fusion 2017, 34, 101–119. [Google Scholar] [CrossRef]
- Liu, M.; Chen, R.; Li, D.; Chen, Y.; Guo, G.; Cao, Z.; Pan, Y. Scene Recognition for Indoor Localization Using a Multi-Sensor Fusion Approach. Sensors 2017, 17, 2847. [Google Scholar] [CrossRef] [PubMed]
- Becker, M.; Ahuja, B. Implementing real-life indoor positioning systems using machine learning approaches. In Proceedings of the 2017 8th International Conference on Information, Intelligence, Systems & Applications (IISA), Larnaca, Cyprus, 27–30 August 2017; pp. 1–6. [Google Scholar]
- Gao, R.; Ye, F.; Wang, T. Smartphone indoor localization by photo-taking of the environment. In Proceedings of the 2014 IEEE International Conference on Communications (ICC), Sydney, Australia, 10–14 June 2014; pp. 2599–2604. [Google Scholar]
- Tian, Y.; Gao, R.; Bian, K.; Ye, F.; Wang, T.; Wang, Y.; Li, X. Towards ubiquitous indoor localization service leveraging environmental physical features. In Proceedings of the IEEE INFOCOM 2014—IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; pp. 55–63. [Google Scholar]
- Shafer, S.; Krumm, J.; Brumitt, B.; Meyers, B.; Czerwinski, M.; Robbins, D. The New EasyLiving Project at Microsoft Research. In Proceedings of the 1998 Joint DARPA/NIST Smart Spaces Workshop, Gaithersburg, MD, USA, 30–31 July 1998; pp. 30–31. [Google Scholar]
- Mautz, R. Indoor Positioning Technologies. Habilitation Thesis, Institute of Geodesy and Photogrammetry, Department of Civil, Environmental and Geomatic Engineering, ETH Zurich, Zurich, Switzerland, 2012. [Google Scholar]
- Hile, H.; Borriello, G. Positioning and orientation in indoor environments using camera phones. IEEE Comput. Graph. Appl. 2008, 28, 32–39. [Google Scholar] [CrossRef]
- Kohoutek, T.K.; Mautz, R.; Donaubauer, A. Real-time indoor positioning using range imaging sensors. In Proceedings of the Real-Time Image and Video Processing 2010, Brussels, Belgium, 4 May 2010; Volume 7724, pp. 1–8. [Google Scholar]
- Kim, J.; Jun, H. Vision-based location positioning using augmented reality for indoor navigation. IEEE Trans. Consum. Electron. 2008, 54, 954–962. [Google Scholar] [CrossRef]
- Werner, M.; Kessel, M.; Marouane, C. Indoor positioning using smartphone camera. In Proceedings of the 2011 International Conference on Indoor Positioning and Indoor Navigation, Guimaraes, Portugal, 21–23 September 2011. [Google Scholar] [CrossRef]
- Möller, A.; Kranz, M.; Huitl, R.; Diewald, S.; Roalter, L. A mobile indoor navigation system interface adapted to vision-based localization. In Proceedings of the 11th International Conference on Mobile and Ubiquitous Multimedia, MUM 2012, Ulm, Germany, 4–6 December 2012; pp. 4:1–4:10. [Google Scholar]
- Mulloni, A.; Wagner, D.; Barakonyi, I.; Schmalstieg, D. Indoor positioning and navigation with camera phones. IEEE Pervasive Comput. 2009, 8, 22–31. [Google Scholar] [CrossRef]
- Ganick, A.; Ryan, D. Light positioning system using digital pulse recognition. U.S. Patent 824,846,7B1, 26 July 2011. [Google Scholar]
- Ruotsalainen, L.; Kuusniemi, H.; Bhuiyan, M.Z.H.; Chen, L.; Chen, R. A two-dimensional pedestrian navigation solution aided with a visual gyroscope and a visual odometer. GPS Solut. 2013, 17, 575–586. [Google Scholar] [CrossRef]
- Ruotsalainen, L. Visual Gyroscope and Odometer for Pedestrian Indoor Navigation with a Smartphone. In Proceedings of the 25th International Technical Meeting of The Satellite Division of the Institute of Navigation (ION GNSS 2012), Nashville, TN, USA, 17–21 September 2012; pp. 2422–2431. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zuxun, Z.; Jianqing, Z. Digital Photogrametry, 2nd ed.; Wuhan Univerty Press: Wuhan, China, 2002. [Google Scholar]
- Keypoints, S.; Lowe, D.G. Distinctive Image Features from. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Van Opdenbosch, D.; Schroth, G.; Huitl, R.; Hilsenbeck, S.; Garcea, A.; Steinbach, E. Camera-based indoor positioning using scalable streaming of compressed binary image signatures. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 2804–2808. [Google Scholar]
- Kawaji, H.; Hatada, K.; Yamasaki, T.; Aizawa, K. Image-based indoor positioning system: Fast image matching using omnidirectional panoramic images. In Proceedings of the 1st ACM International Workshop on Multimodal Pervasive Video Analysis, Firenze, Italy, 29 October 2010; ACM: Firenze, Italy, 2010; pp. 1–4. [Google Scholar]
- Deretey, E.; Ahmed, M.T.; Marshall, J.A.; Greenspan, M. Visual indoor positioning with a single camera using PnP. In Proceedings of the 2015 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Banff, AB, Canada, 13–16 October 2015; pp. 1–9. [Google Scholar]
- Xu, D.; Han, L.; Tan, M.; Li, Y.F. Ceiling-based visual positioning for an indoor mobile robot with monocular vision. IEEE Trans. Ind. Electron. 2009, 56, 1617–1628. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Phase | Static Object | Accurate Precision (AP) |
|---|---|---|
| Training | door1 | 100% |
| door2 | 100% | |
| door3 | 90.9% | |
| mean | 97.0% | |
| Testing | door1/door2/door3 | 100% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, A.; Chen, R.; Li, D.; Chen, Y.; Wu, D. An Indoor Positioning System Based on Static Objects in Large Indoor Scenes by Using Smartphone Cameras. Sensors 2018, 18, 2229. https://doi.org/10.3390/s18072229
Xiao A, Chen R, Li D, Chen Y, Wu D. An Indoor Positioning System Based on Static Objects in Large Indoor Scenes by Using Smartphone Cameras. Sensors. 2018; 18(7):2229. https://doi.org/10.3390/s18072229
Chicago/Turabian StyleXiao, Aoran, Ruizhi Chen, Deren Li, Yujin Chen, and Dewen Wu. 2018. "An Indoor Positioning System Based on Static Objects in Large Indoor Scenes by Using Smartphone Cameras" Sensors 18, no. 7: 2229. https://doi.org/10.3390/s18072229
APA StyleXiao, A., Chen, R., Li, D., Chen, Y., & Wu, D. (2018). An Indoor Positioning System Based on Static Objects in Large Indoor Scenes by Using Smartphone Cameras. Sensors, 18(7), 2229. https://doi.org/10.3390/s18072229