Robust Face Recognition Using the Deep C2D-CNN Model Based on Decision-Level Fusion

Abstract
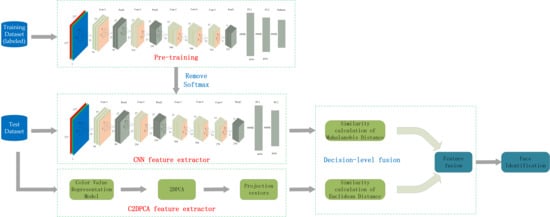
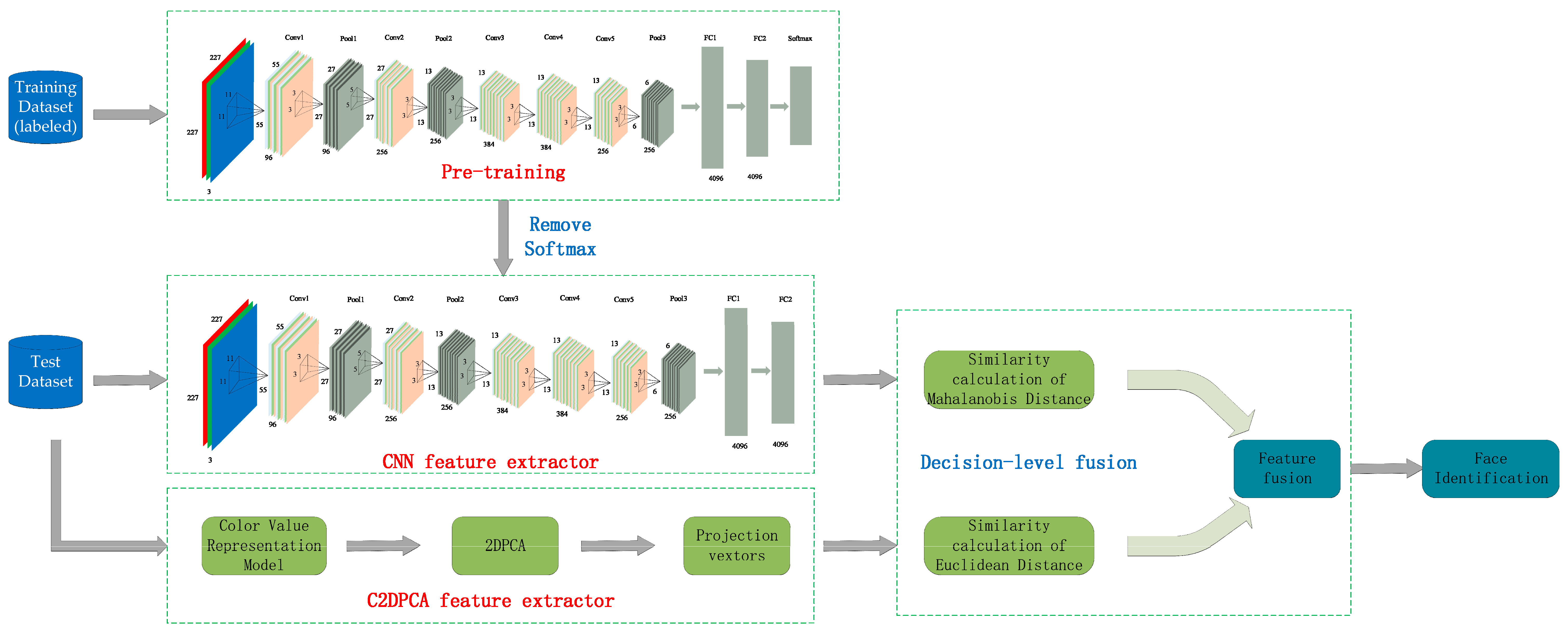
1. Introduction
- We propose a deep face recognition method, C2D-CNN, which combines the two features into the decision-making level, with high-accuracy and low computational cost.
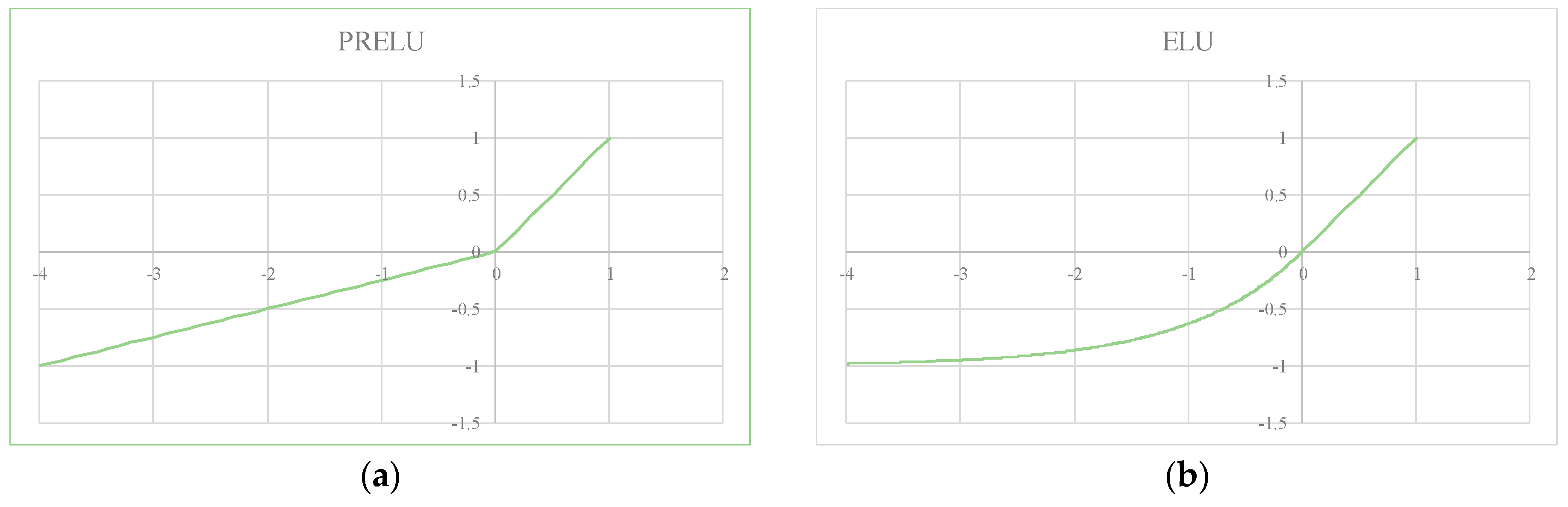
- We investigate a new CNN model. Through careful design, (1) normalization is introduced to accelerate the network convergence and shorten the network pre-training time; (2) a layered activation algorithm is added to improve the non-linear function of the activation function and solve the problem of gradient saturation and gradient diffusion; (3) probabilistic max-pooling is applied to preserve the feature in maximum extent while maintaining feature invariance.
2. Face Recognition with Color 2-Dimensional Principal Component Analysis-Convolutional Neural Network (C2D-CNN) Model
2.1. Overview of the Proposed Method
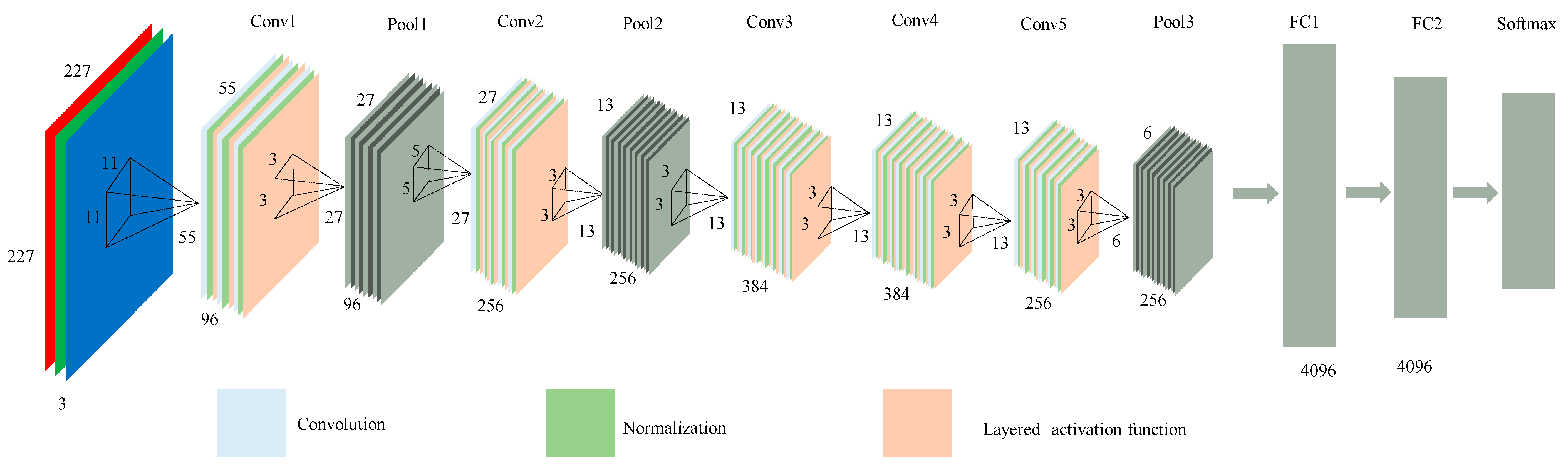
2.2. Feature Extraction with CNN
2.2.1. Forward Propagation of CNN Network
| Algorithm 1 Normalization |
| Input: CNN Network and mini-batch Bx Output: Normalized sample data By |
| 1. Mini-batch mean: |
| 2. Mini-batch variance: |
| 3. Normalized value: |
| 4. Update the global mean: |
| 5. Update the global variance: |
| 6. Update the momentum value φ: |
| 7. Update the momentum value ψ: |
2.2.2. Back Propagation (BP) of CNN Networks
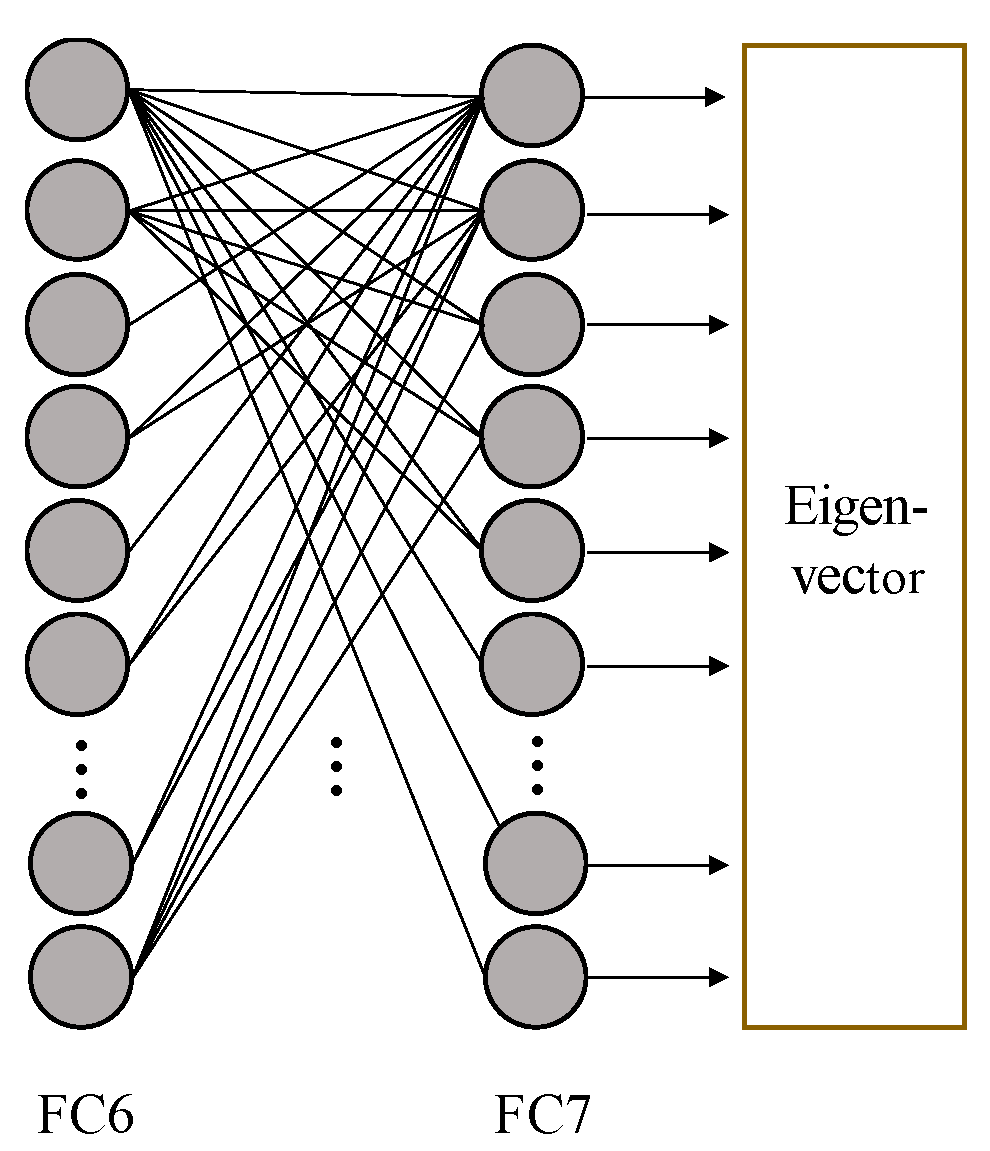
2.2.3. Feature Extraction
2.3. Feature Extraction with Color 2-Dimensional Principal Component Analysis (2DPCA)
2.4. Decision-Level Fusion
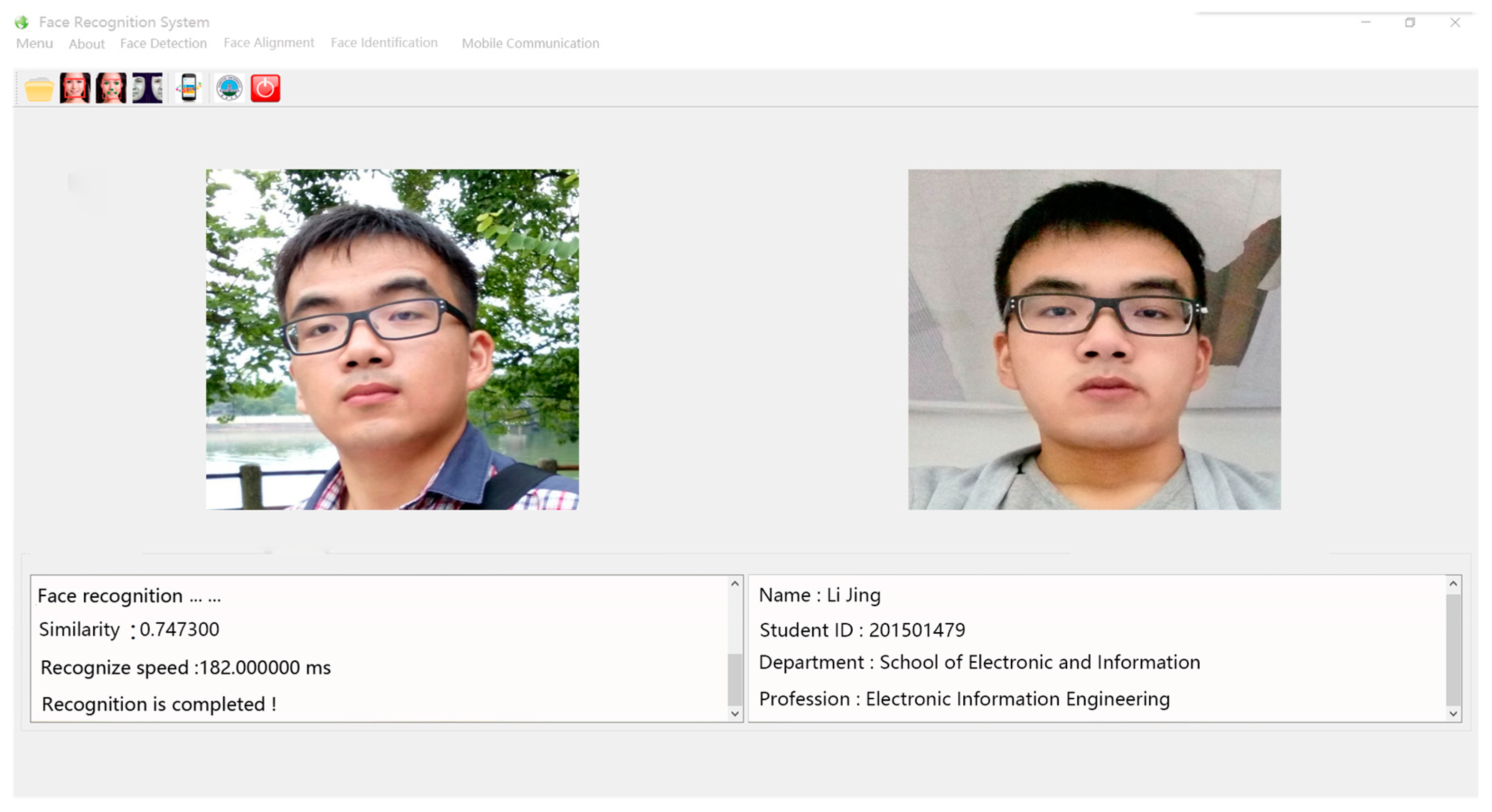
3. Experimental Results and Analysis
3.1. Dataset
3.2. Experiment Setting
3.2.1. Training Details
3.2.2. Data Augmentation Details
3.2.3. Fine-Tuning Details
3.3. Acquisition of Testing Parameter
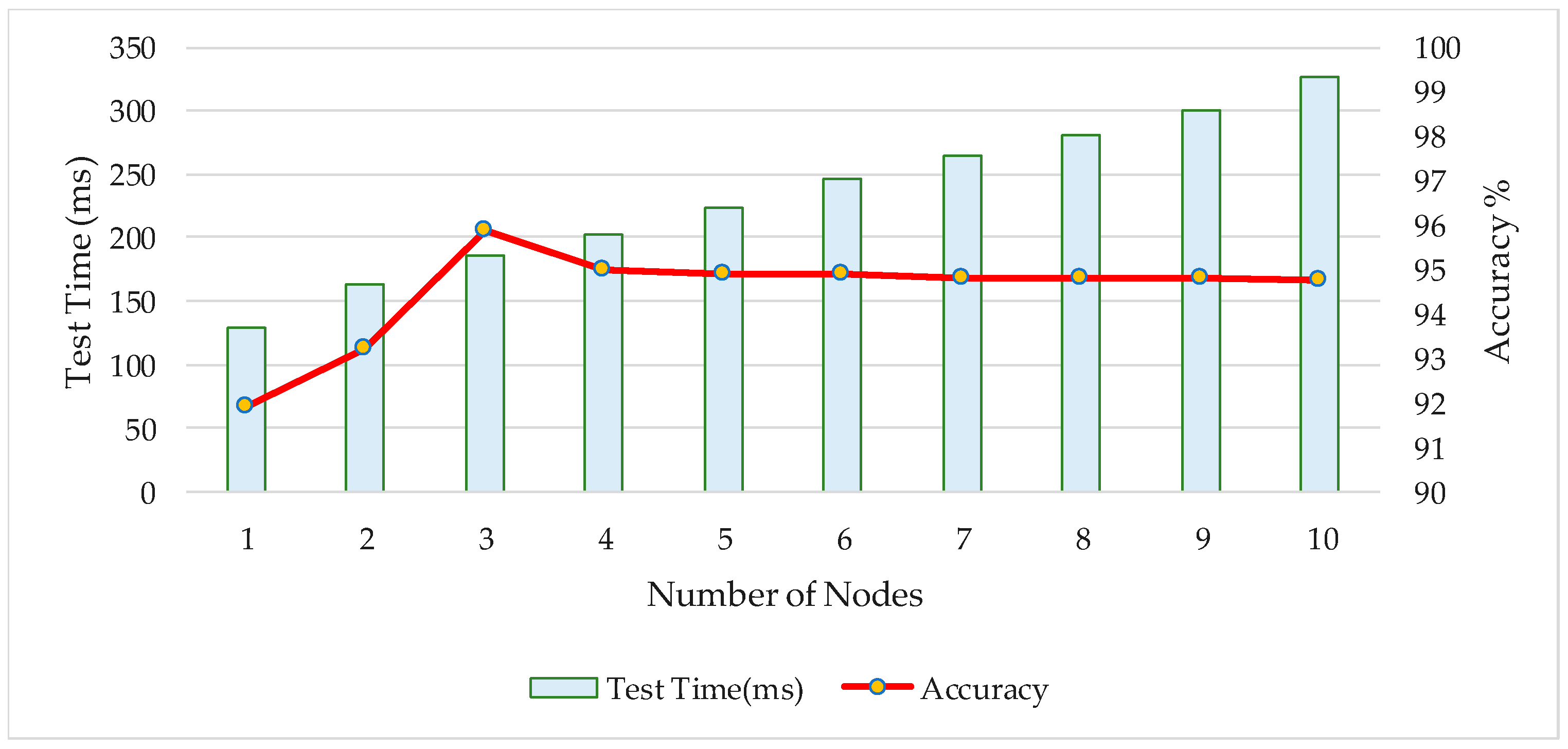
3.3.1. Acquisition of the Optimal Number of Middle-Nodes in Layered Activation Function
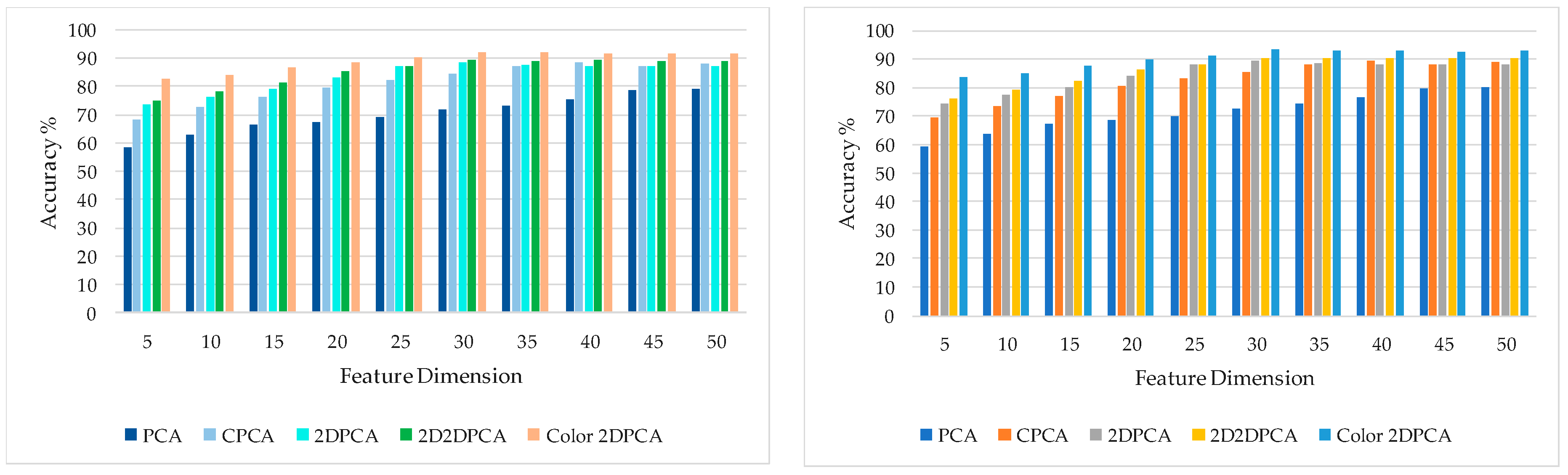
3.3.2. Acquisition of the Optimal Feature Dimension of Color 2DPCA in Different Benchmark Database
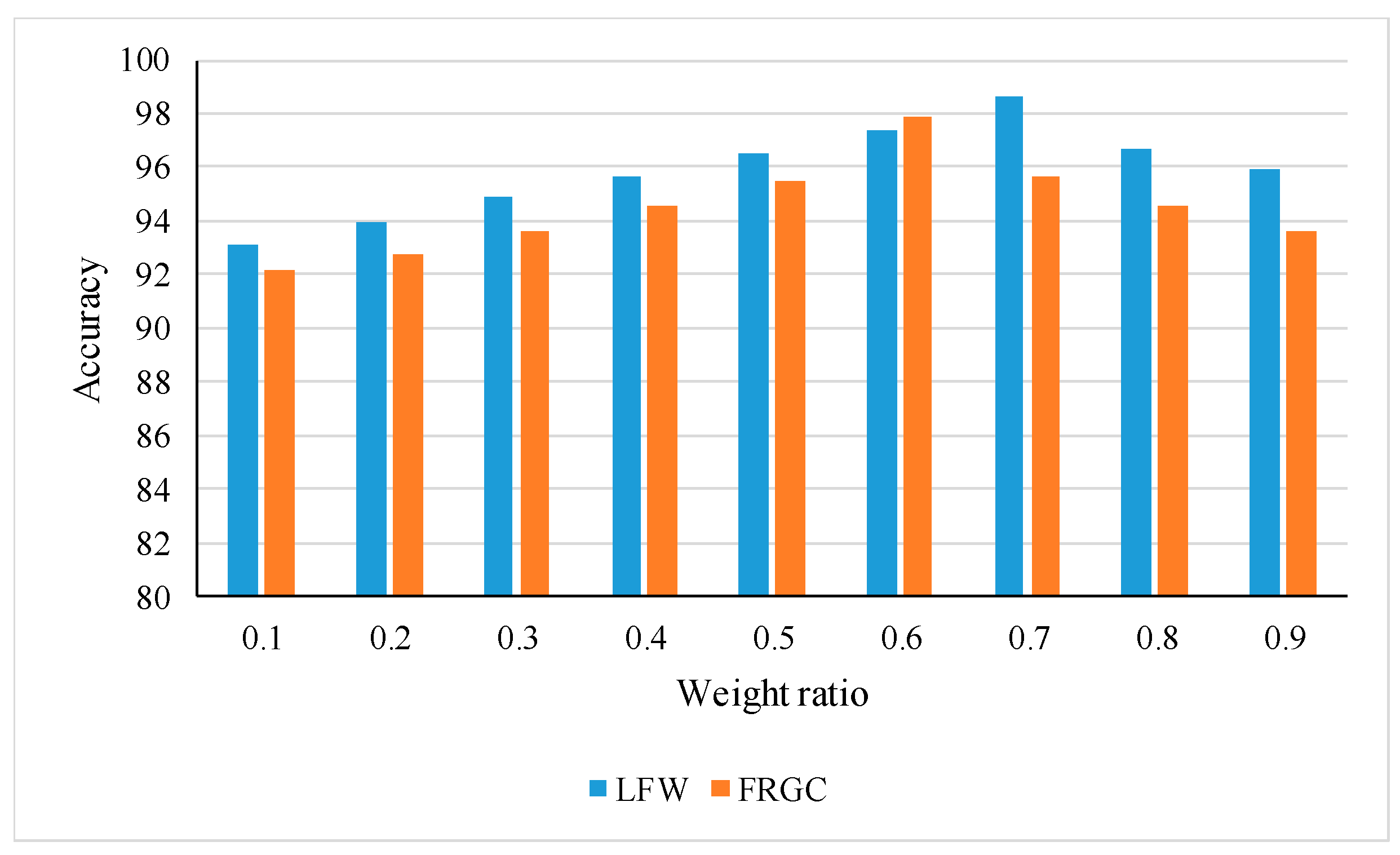
3.3.3. Acquisition of the Optimal Similarity Weight Ratio in Different Benchmark Database
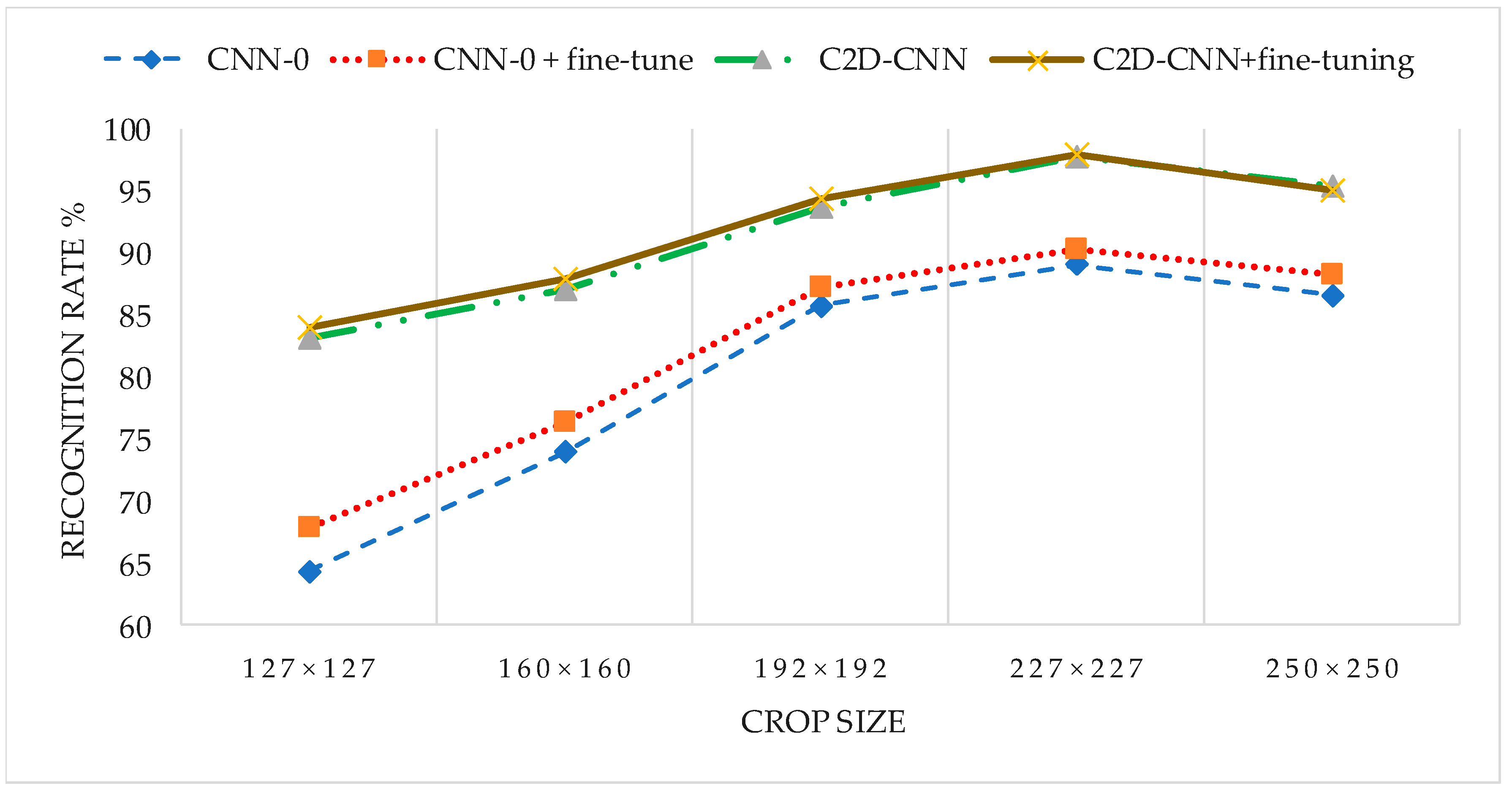
3.3.4. Acquisition of the Optimal Crop Size for Different CNN Models
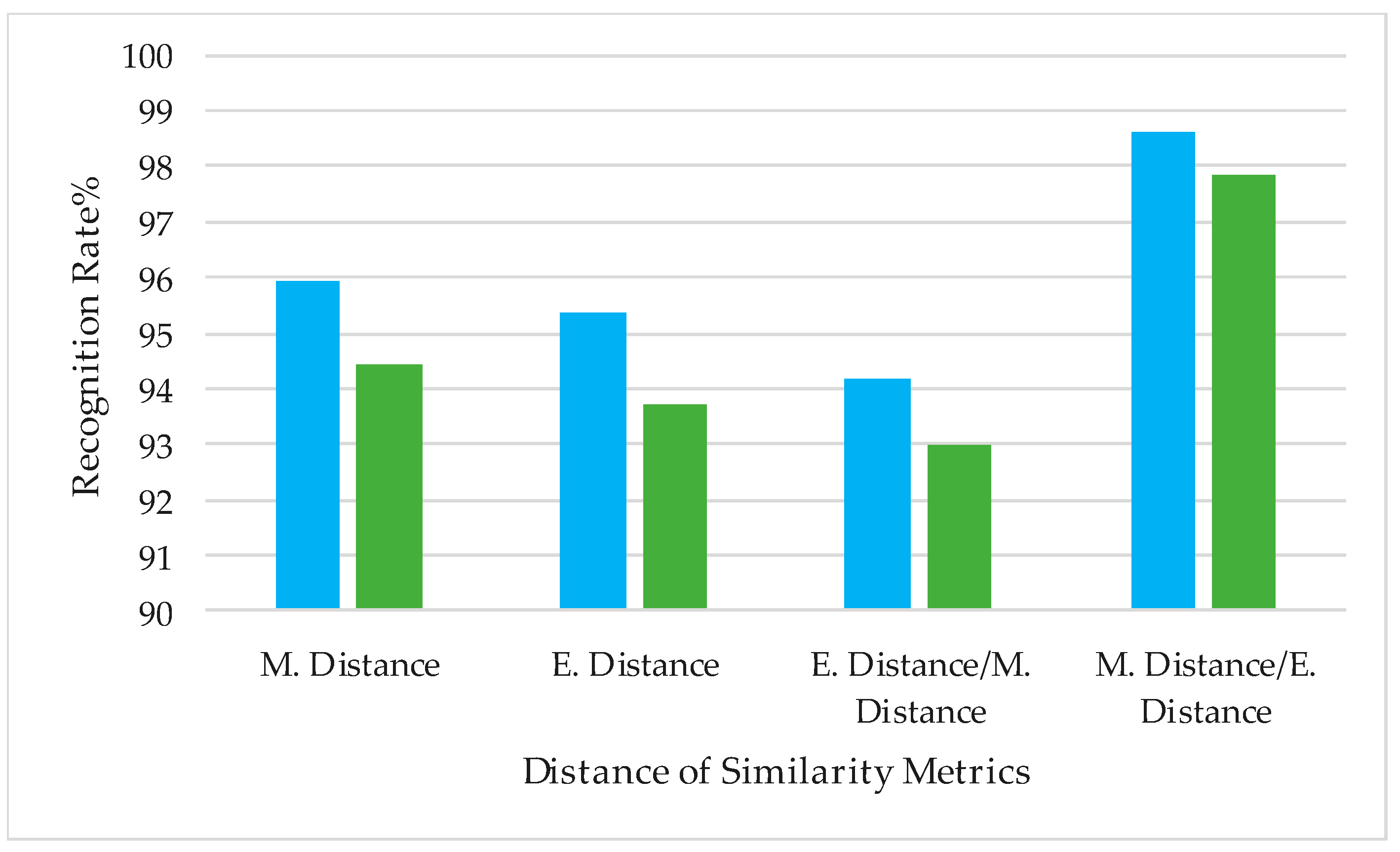
3.3.5. Acquisition of the Optimal Distance Metric Method
3.4. Testing Result and Discussion
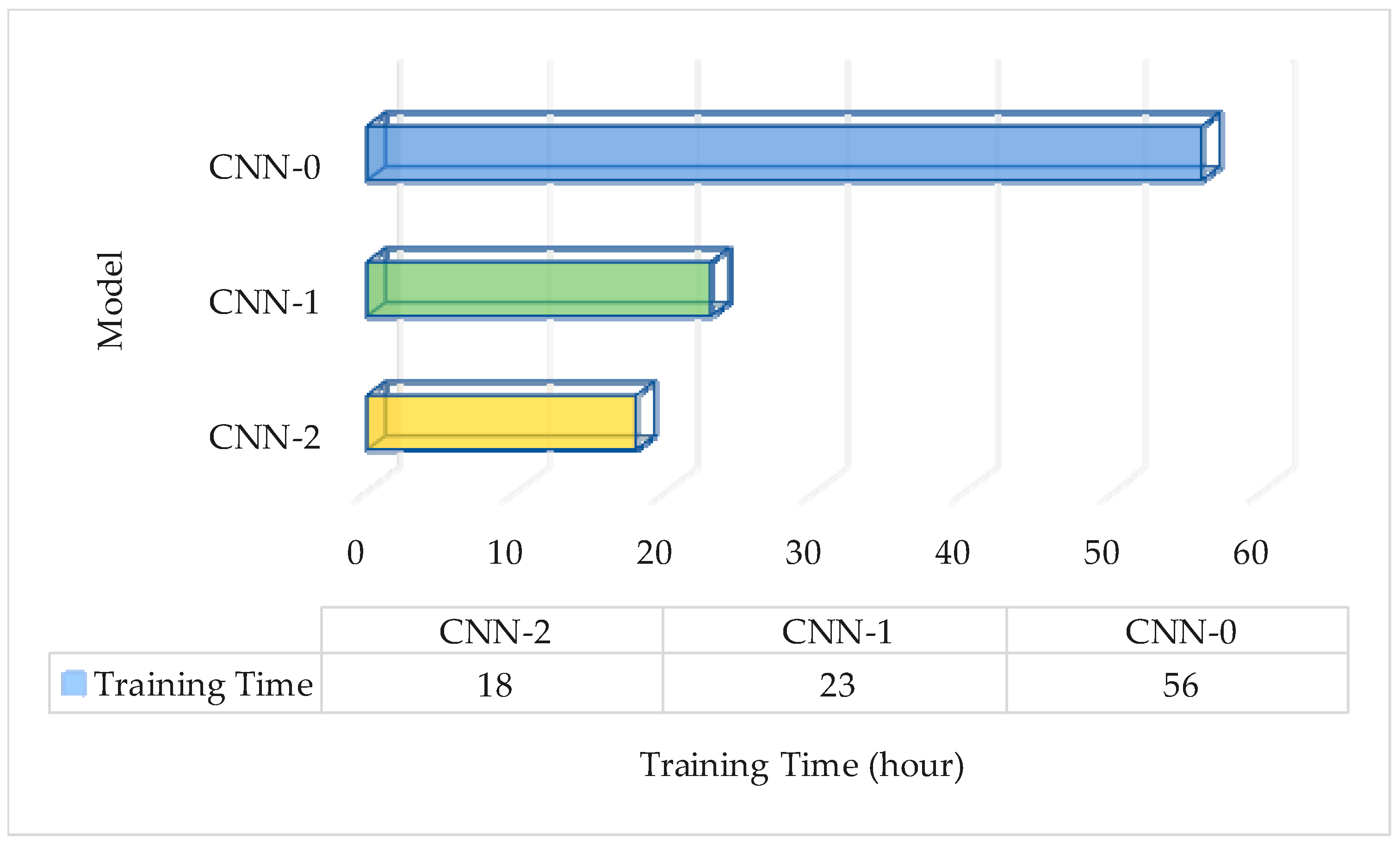
3.4.1. Evaluation of the Performance of Normalization Layer on Training Time
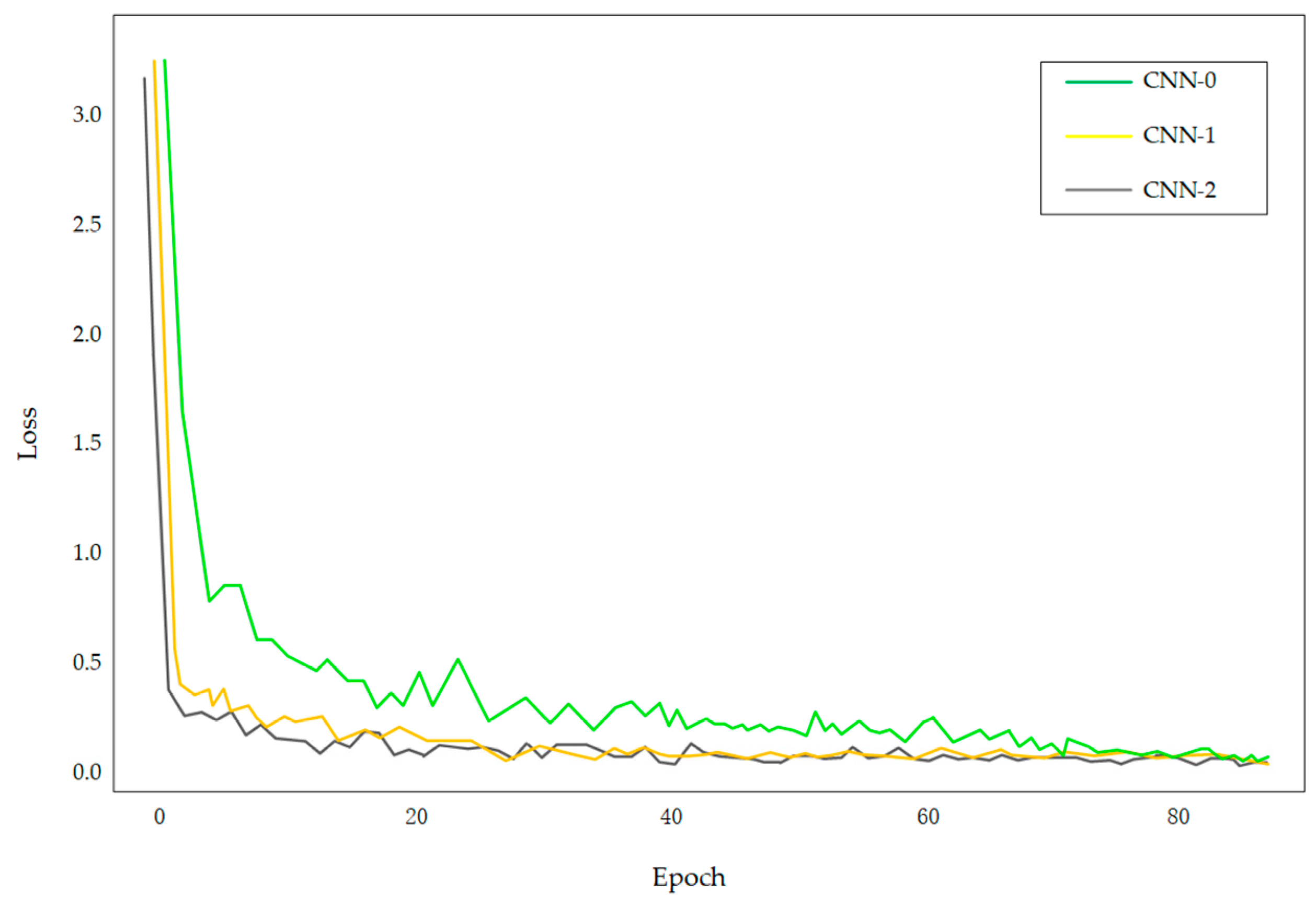
3.4.2. Evaluation of Network Convergence Speed
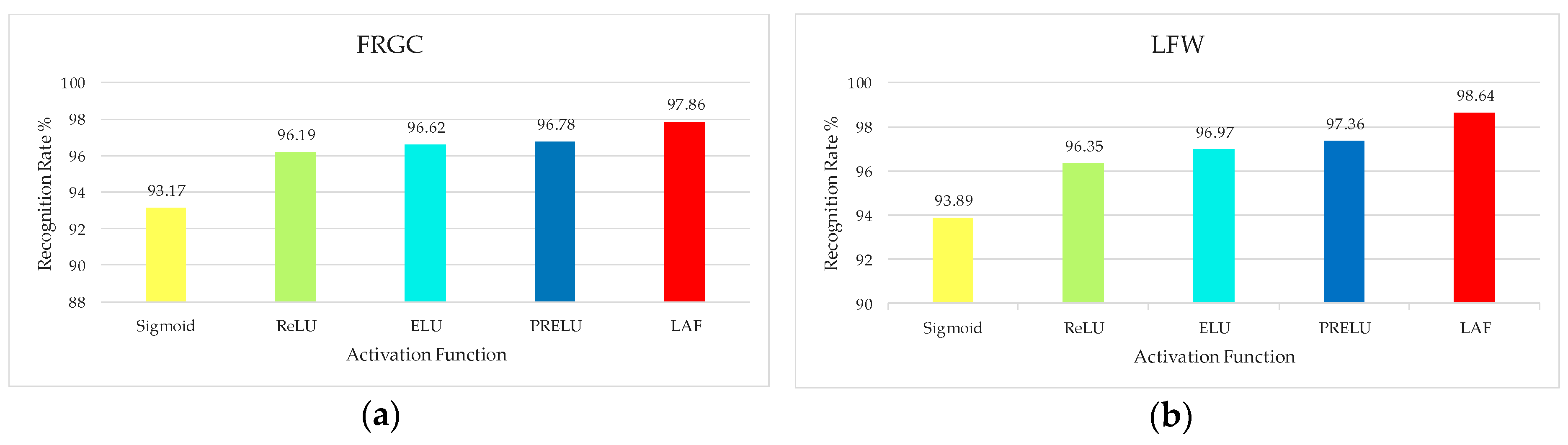
3.4.3. Evaluation of the Performance of Layered Activation Function
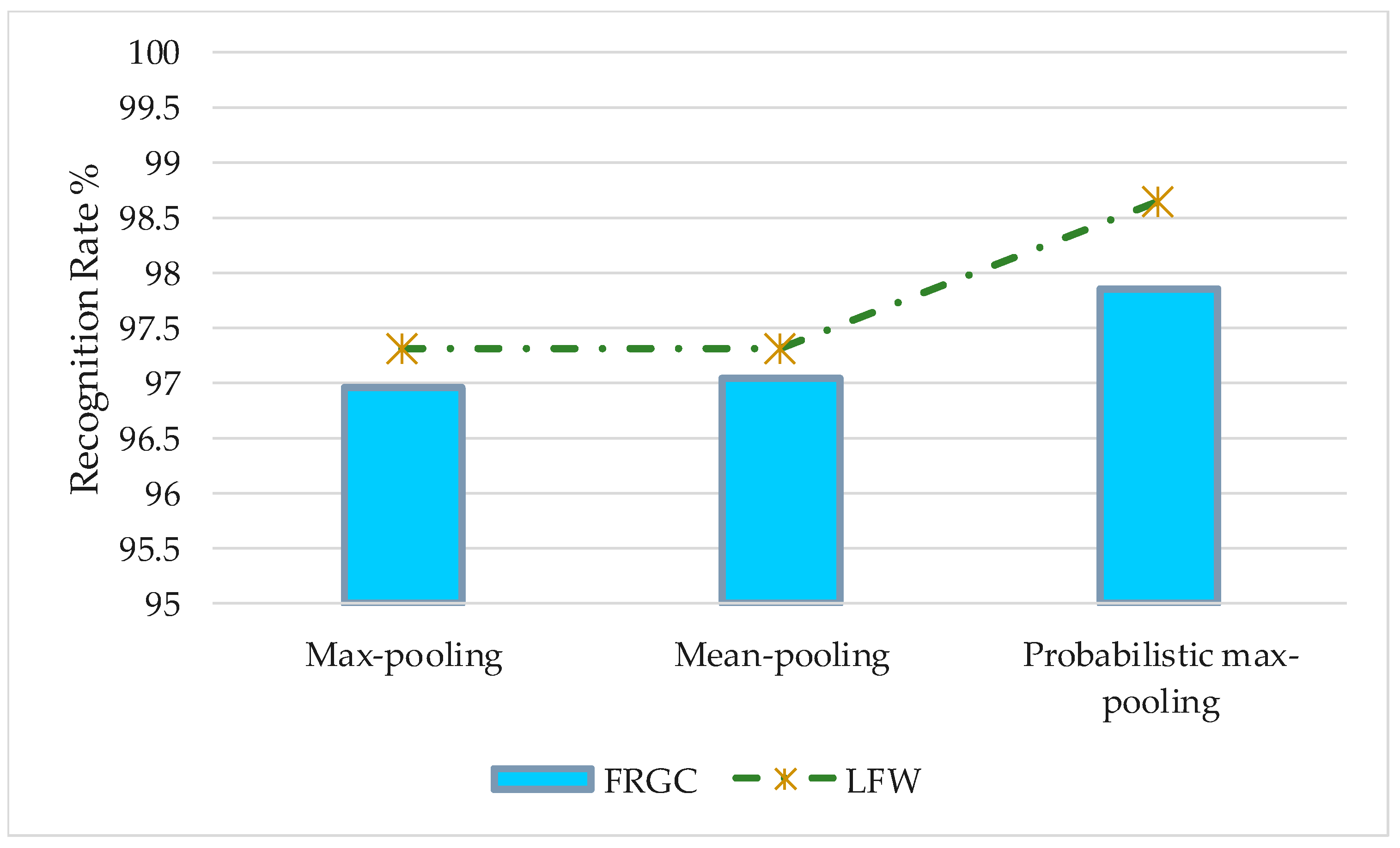
3.4.4. Evaluation of the Performance of the Probabilistic Max-Pooling
3.4.5. Comparison of the Effectiveness of Fine-Tuning and Decision-Level Fusion
3.4.6. Comparison with State-of-the-Art Methods
4. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Abate, A.F.; Nappi, M.; Riccio, D. 2D and 3D face recognition: A survey. Pattern Recognit. Lett. 2007, 28, 1885–1906. [Google Scholar] [CrossRef]
- Kim, D.J.; Sohn, M.K.; Kim, H. Geometric Feature-Based Face Normalization for Facial Expression Recognition. In Proceedings of the 2nd International Conference on Artificial Intelligence, Modelling and Simulation (AIMS), Madrid, Spain, 18–20 November 2014; pp. 172–175. [Google Scholar]
- Ouarda, W.; Trichili, H.; Alimi, A.M. Face recognition based on geometric features using Support Vector Machines. In Proceedings of the 6th International Conference of Soft Computing and Pattern Recognition (SoCPaR), Tunis, Tunisia, 11–14 August 2014; pp. 89–95. [Google Scholar]
- Wei, M.; Ma, B. Face Recognition Based on Randomized Subspace Feature. In Proceedings of the 27th International Conference on Tools with Artificial Intelligence (ICTAI), Vietri sul Mare, Italy, 9–11 November 2015; pp. 668–674. [Google Scholar]
- Chen, C.; Dantcheva, A.; Ross, A. An ensemble of patch-based subspaces for makeup-robust face recognition. Inf. Fusion 2016, 32, 80–92. [Google Scholar] [CrossRef]
- Hanmandlu, M.; Gupta, D.; Vasikarla, S. Face recognition using Elastic bunch graph matching. In Proceedings of the IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 23–25 October 2013; pp. 1–7. [Google Scholar]
- Chen, X.; Zhang, C.; Dong, F.; Zhou, Z. Parallelization of elastic bunch graph matching (EBGM) algorithm for fast face recognition. In Proceedings of the IEEE China Summit & International Conference on Signal and Information Processing, Beijing, China, 6–10 July 2013; pp. 201–205. [Google Scholar]
- Wan, L.; Liu, N.; Huo, H.; Fang, T. Face Recognition with Convolutional Neural Networks and subspace learning. In Proceedings of the 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017; pp. 228–233. [Google Scholar]
- Qi, X.; Liu, C.; Schuckers, S. CNN based key frame extraction for face in video recognition. In Proceedings of the IEEE 4th International Conference on Identity, Security, and Behavior Analysis (ISBA), Singapore, 11–12 January 2018; pp. 1–8. [Google Scholar]
- Liang, Y.; Zhang, Y.; Zeng, X.X. Pose-invariant 3D face recognition using half face. Signal Process. Image Commun. 2017, 57, 84–90. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Y.; Liu, J.; Hao, W. Expression-insensitive 3D face recognition by the fusion of multiple subject-specific curves. Neurocomputing 2018, 275, 1295–1307. [Google Scholar] [CrossRef]
- Dagnes, N.; Vezzetti, E.; Marcolin, F.; Tornincasa, S. Occlusion detection and restoration techniques for 3D face recognition: A literature review. Mach. Vis. Appl. 2018, 1–25. [Google Scholar] [CrossRef]
- Vezzetti, E.; Marcolin, F.; Tornincasa, S. 3D geometry-based automatic landmark localization in presence of facial occlusions. Multimed. Tools Appl. 2017, 14, 1–29. [Google Scholar] [CrossRef]
- Moos, S.; Marcolin, F.; Tornincasa, S.; Vezzetti, E.; Violante, M.G.; Fracastoro, G.; Padula, F. Cleft lip pathology diagnosis and foetal landmark extraction via 3D geometrical analysis. Int. J. Interact. Des. Manuf. 2017, 11, 1–18. [Google Scholar] [CrossRef]
- Moeini, A.; Faez, K.; Moeini, H. Face recognition across makeup and plastic surgery from real-world images. J. Electron. Imaging 2015, 24, 053028. [Google Scholar] [CrossRef]
- Ramalingam, S. Fuzzy interval-valued multi criteria based decision making for ranking features in multi-modal 3D face recognition. Fuzzy Sets Syst. 2018, 337, 25–51. [Google Scholar] [CrossRef]
- Abbad, A.; Abbad, K.; Tairi, H. 3D face recognition: Multi-scale strategy based on geometric and local descriptors. Comput. Electr. Eng. 2017. [Google Scholar] [CrossRef]
- Kim, J.; Han, D.; Hwang, W.; Kim, J. 3D face recognition via discriminative keypoint selection. In Proceedings of the 14th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Jeju, Korea, 28 June–1 July 2017; pp. 477–480. [Google Scholar]
- Soltanpour, S.; Wu, Q.J.; Anvaripour, M. Multimodal 2D-3D face recognition using structural context and pyramidal shape index. In Proceedings of the 6th International Conference on Imaging for Crime Prevention and Detection (ICDP), London, UK, 15–17 July 2015; pp. 1–6. [Google Scholar]
- Wang, X.; Ly, V.; Guo, R.; Kambhamettu, C. 2D-3D face recognition via restricted boltzmann machines. In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014; pp. 574–580. [Google Scholar]
- Wang, X.; Ly, V.; Guo, G.; Kambhamettu, C. A new approach for 2d-3d heterogeneous face recognition. In Proceedings of the IEEE International Symposium on Multimedia (ISM), Anaheim, CA, USA, 9–11 December 2013; pp. 301–304. [Google Scholar]
- Kakadiaris, I.A.; Toderici, G.; Evangelopoulos, G. 3D-2D face recognition with pose and illumination normalization. Comput. Vision Image Underst. 2017, 154, 137–151. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Swiss, 6–12 September 2014; pp. 184–199. [Google Scholar]
- Cai, H.; Yan, F.; Mikolajczyk, K. Learning weights for codebook in image classification and retrieval. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2320–2327. [Google Scholar]
- Chaib, S.; Yao, H.; Gu, Y.; Amrani, M. Deep feature extraction and combination for remote sensing image classification based on pre-trained CNN models. In Proceedings of the Ninth International Conference on Digital Image Processing (ICDIP), Hongkong, China, 19–22 May 2017; p. 104203D. [Google Scholar]
- Liu, Y.; Li, Y.; Ma, X.; Song, R. Facial Expression Recognition with Fusion Features Extracted from Salient Facial Areas. Sensors 2017, 17, 712. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.; Wang, G.; Zhou, J. Simultaneous feature and dictionary learning for image set based face recognition. IEEE Trans. Image Process. 2017, 26, 4042–4054. [Google Scholar] [CrossRef] [PubMed]
- Hu, G.; Peng, X.; Yang, Y.; Hospedales, T.M.; Verbeek, J. Frankenstein: Learning deep face representations using small data. IEEE Trans. Image Process. 2018, 27, 293–303. [Google Scholar] [CrossRef] [PubMed]
- Oquab, M.; Bottou, L.; Laptev, I. Learning and Transferring Mid-level Image Representations Using Convolutional Neural Networks. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 1717–1724. [Google Scholar]
- Masi, I.; Trần, A.T.; Hassner, T.; L-eksut, J.T.; Medioni, G. Do we really need to collect millions of faces for effective face recognition? In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 579–596. [Google Scholar]
- Campos, V.; Jou, B.; Giro-i-Nieto, X. From pixels to sentiment: Fine-tuning cnns for visual sentiment prediction. Image Vis. Comput. 2017, 65, 15–22. [Google Scholar] [CrossRef]
- Nagori, V. Fine tuning the parameters of back propagation algorithm for optimum learning performance. In Proceedings of the 2nd International Conference on contemporary Computing and Informatics, Noida, India, 14–17 December 2016; pp. 7–12. [Google Scholar]
- Tzelepi, M.; Tefas, A. Exploiting supervised learning for finetuning deep CNNs in content based image retrieval. In Proceedings of the 23rd International Conference on the Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2918–2923. [Google Scholar]
- Li, Y.; Xie, W.; Li, H. Hyperspectral image reconstruction by deep convolutional neural network for classification. Pattern Recognit. 2016, 63, 371–383. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef] [PubMed]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. J. Mach. Learn. Res. 2010, 9, 249–256. [Google Scholar]
- Shang, W.; Sohn, K.; Almeida, D.; Lee, H. Understanding and improving convolutional neural networks via concatenated rectified linear units. In Proceedings of the International Conference on Machine Learning (ICML), New York, NY, USA, 19–24 June 2016; pp. 2217–2225. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International conference on machine learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Choi, J.Y.; Ro, Y.M.; Plataniotis, K.N. Color local texture features for color face recognition. IEEE Trans. Image Process. 2012, 21, 1366–1380. [Google Scholar] [CrossRef] [PubMed]
- Lu, Z.; Jiang, X.; Kot, A. A novel LBP-based Color descriptor for face recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 1857–1861. [Google Scholar]
- Lu, Z.; Jiang, X.; Kot, A. An effective color space for face recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 849–856. [Google Scholar]
- Lu, Z.; Jiang, X.; Kot, A. A Color Channel Fusion Approach for Face Recognition. IEEE Signal Process. Lett. 2015, 22, 1839–1843. [Google Scholar] [CrossRef]
- Qian, S.; Liu, H.; Liu, C. Adaptive activation functions in convolutional neural networks. Neurocomputing 2017, 272, 204–212. [Google Scholar] [CrossRef]
- Lee, H.; Grosse, R.; Ranganath, R.; Ng, A.Y. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 609–616. [Google Scholar]
- Beigy, H.; Meybodi, M.R. Adaptation of Parameters of BP Algorithm Using Learning Automata. In Proceedings of the Sixth Brazilian Symposium on Neural Networks, Rio de Janeiro, Brazil, 22–25 November 2000; pp. 24–31. [Google Scholar]
- Kline, D.M.; Berardi, V.L. Revisiting squared-error and cross-entropy functions for training neural network classifiers. Neural Comput. Appl. 2005, 14, 310–318. [Google Scholar] [CrossRef]
- Xuelong, L.; Yanwei, P.; Yuan, Y. L1-norm-based 2DPCA. IEEE Trans. Syst. Man Cybern. 2010, 40, 1170–1175. [Google Scholar] [CrossRef] [PubMed]
- Moore, B. Principal component analysis in linear systems: Controllability, observability, and model reduction. IEEE Trans. Autom. Cont. 1981, 26, 17–32. [Google Scholar] [CrossRef]
- Xinguang, X.; Yang, J.; Qiuping, C. Color face recognition by PCA-like approach. Neurocomputing 2015, 152, 231–235. [Google Scholar] [CrossRef]
- Saxena, S.; Verbeek, J. Heterogeneous face recognition with CNNs. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 483–491. [Google Scholar]
- Lu, Z.; Jiang, X.; Kot, A. Feature fusion with covariance matrix regularization in face recognition. Signal Process. 2018, 144, 296–305. [Google Scholar] [CrossRef]
- Perlibakas, V. Distance measures for PCA-based face recognition. Pattern Recognit. Lett. 2004, 25, 711–724. [Google Scholar] [CrossRef]
- Xu, A.; Jin, X.; Jiang, Y.; Guo, P. Complete two-dimensional PCA for face recognition. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR), Hong Kong, China, 20–24 August 2006; pp. 481–484. [Google Scholar]
- Huang, G.B.; Ramesh, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments; No. 2. Technical Report 07-49; University of Massachusetts: Amherst, MA, USA, 2007; Volume 1. [Google Scholar]
- Phillips, P.J.; Flynn, P.J.; Scruggs, T. Overview of the Face Recognition Grand Challenge. In Proceedings of the Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 947–954. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CNN-0 | CNN-1 | CNN-2 | |
|---|---|---|---|
| Learning rates | 0.01 | 0.05 | 0.05 |
| Dropout | 0.5 | --- | --- |
| Weight decay | 0.001 | 0.001 | 0.001 |
| Momentum | 0.9 | 0.9 | 0.9 |
| No. of epochs | 80 | 25 | 20 |
| Batch _size | 512 | 512 | 512 |
| Pooling method | Max-pooling | Max-pooling | Probabilistic max-pooling |
| Activation function | ReLU | ReLU | LAF |
| other | --- | Batch Normalization | Normalization |
| CNN-2 | Color 2DPCA | |
|---|---|---|
| Input | Color face images | Color face images |
| Output dimensions | 4096 | 30 |
| Matching strategy | Mahalanobis distance | Euclidean distance |
| Weight ratio | Depending on the sample database | |
| CNN-0 | CNN-2 | |
|---|---|---|
| Learning rates | Conv1-FC2: 0.005 Softmax: 0.02 | Conv1-FC2: 0.02 Softmax: 0.05 |
| Dropout | 0.5 | --- |
| Weight decay | 0.001 | 0.001 |
| Momentum | 0.9 | 0.9 |
| No. of epochs | 60 | 20 |
| Batch _size | 512 | 512 |
| Pooling method | Max-pooling | Probabilistic max-pooling |
| Activation function | ReLU | LAF |
| other | --- | Normalization |
| Crop Size | Accuracy % | |||
|---|---|---|---|---|
| CNN-0 | CNN-0 + Fine-Tune | CNN-2 | CNN-2 + Fine-Tune | |
| 127 × 127 | 64.32 | 67.96 | 83.24 | 84.01 |
| 160 × 160 | 73.94 | 76.31 | 87.14 | 87.97 |
| 192 × 192 | 85.75 | 87.19 | 93.77 | 94.37 |
| 227 × 227 | 89.12 | 90.23 | 97.86 | 98.02 |
| 250 × 250 | 86.63 | 88.27 | 95.34 | 95.15 |
| Method | Rank-1 (%) | DIR@1% FAR (%) |
|---|---|---|
| COST-S1 | 56.7 | 25.0 |
| COTS-S1 + S2 | 66.5 | 35.0 |
| DeepFace | 64.9 | 44.50 |
| WSTFusion | 82.5 | 61.90 |
| Our Method | 91.98 | 63.34 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Qiu, T.; Wen, C.; Xie, K.; Wen, F.-Q. Robust Face Recognition Using the Deep C2D-CNN Model Based on Decision-Level Fusion. Sensors 2018, 18, 2080. https://doi.org/10.3390/s18072080
Li J, Qiu T, Wen C, Xie K, Wen F-Q. Robust Face Recognition Using the Deep C2D-CNN Model Based on Decision-Level Fusion. Sensors. 2018; 18(7):2080. https://doi.org/10.3390/s18072080
Chicago/Turabian StyleLi, Jing, Tao Qiu, Chang Wen, Kai Xie, and Fang-Qing Wen. 2018. "Robust Face Recognition Using the Deep C2D-CNN Model Based on Decision-Level Fusion" Sensors 18, no. 7: 2080. https://doi.org/10.3390/s18072080
APA StyleLi, J., Qiu, T., Wen, C., Xie, K., & Wen, F.-Q. (2018). Robust Face Recognition Using the Deep C2D-CNN Model Based on Decision-Level Fusion. Sensors, 18(7), 2080. https://doi.org/10.3390/s18072080