The proposed framework provides three components required in high-performance embedded processing solutions: a multithreaded reconfigurable processing architecture, an automated toolchain to deploy edge computing applications using it, and a run-time environment to manage the implemented systems. The ARTICo3 architecture is device agnostic. However, the need for low-level DPR support, which is highly technology-dependent, limits the range of devices that can be used as targets. Only Xilinx devices are supported in the current version of ARTICo3.
3.1. Architecture
ARTICo3 stands for Reconfigurable Architecture to enable Smart Management of Computing Performance, Energy Consumption, and Dependability (Arquitectura Reconfigurable para el Tratamiento Inteligente de Cómputo, Consumo y Confiabilidad in Spanish).
The architecture was originally conceived as a hardware-based alternative for GPU-like embedded computing. Although additional features have been added to this first concept to make it suitable for edge computing in CPSs (e.g., energy-driven execution, fault tolerance, etc.), the underlying hardware structure still resembles GPU devices in the way it exploits parallelism. As a result, for the architecture to be meaningful, applications are required to be a combination of sequential code with data-parallel sections (host code and kernels, respectively). The host code runs in a host processor but, whenever a section with data-level parallelism is reached, the computation is offloaded to the kernels, implemented as hardware accelerators. Moreover, data-independent kernels can be executed concurrently, extending the parallelism to task level.
The key aspect of the ARTICo3 architecture is that it offers the possibility of adjusting hardware resources at run-time to comply with changing requirements of energy consumption, computing performance and fault tolerance. Hence, the working point of the architecture can be altered at run-time from the application code, dynamically adapting its resources to tune it to the best tradeoff solution for a given scenario.
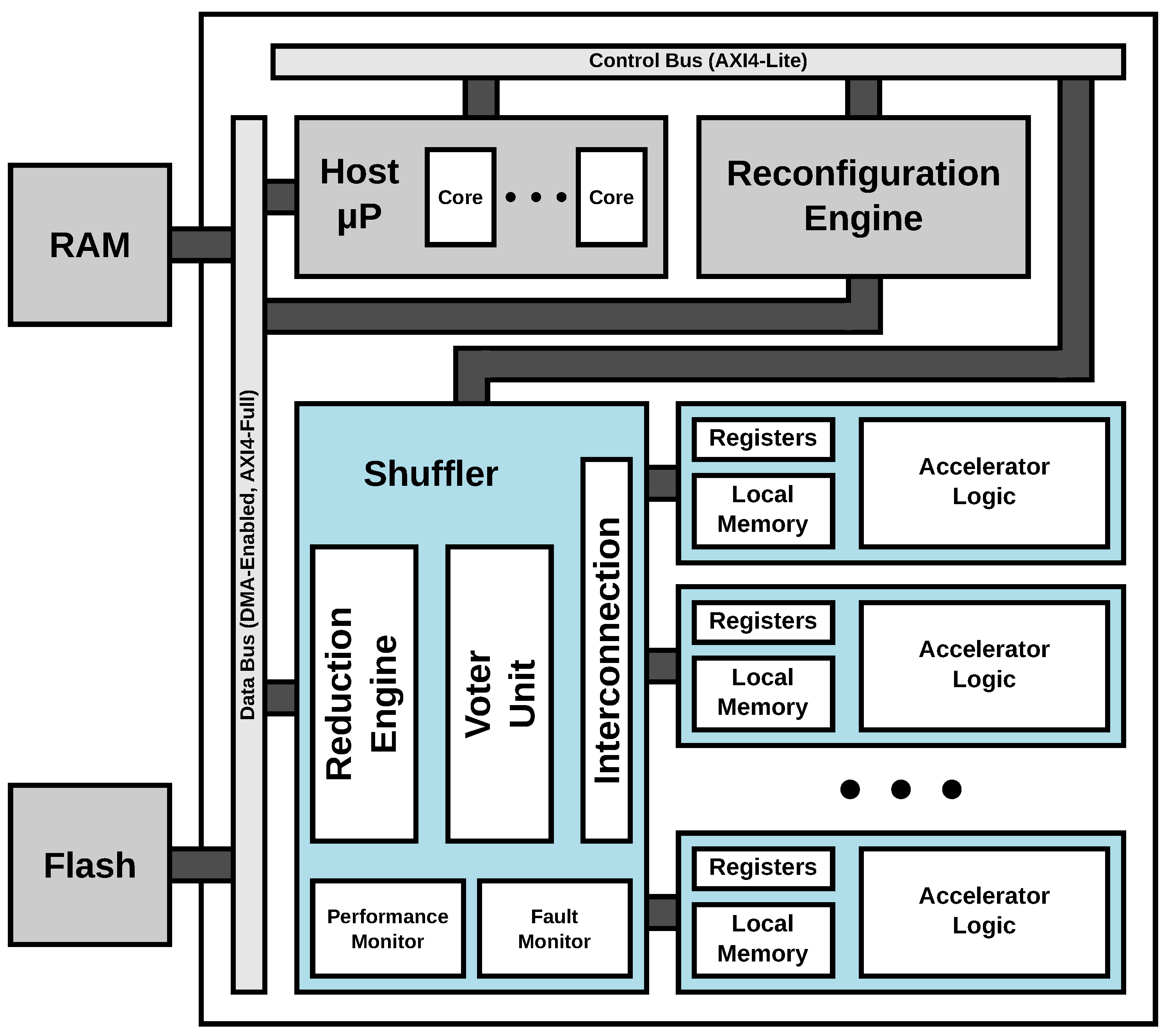
As in most DPR-enabled architectures, ARTICo3 is divided into two different regions: static, which contains the logic resources that are not modified during normal system execution, and dynamic (or reconfigurable), which contains the logic partitions that can be changed at run-time without interfering with the rest of the system. The reconfigurable region is, in turn, divided into several subregions to host different hardware accelerators. The partitioning of the dynamic region follows a slot-based approach, in which accelerators can occupy one or more slots, but where a given slot can only host logic from one hardware accelerator at a given instant. It is important to highlight that, although the static region is completely independent of the device in which the architecture is implemented, the reconfigurable region has strong, low-level technology dependencies: the size of the FPGA or the heterogeneous distribution of logic resources inside the device impose severe restrictions on the amount and size of the reconfigurable partitions.
The communication infrastructure of ARTICo3, optimized for the hierarchical memory approach of the architecture, uses two standard interconnections, one for control purposes (register-based with AXI4-Lite protocol) and another fully dedicated to move data using a burst-capable DMA engine (memory-mapped with AXI4-Full protocol). A gateway module called Data Shuffler acts as a bridge between the twofold bus-based approach of the static region and the reconfigurable hardware accelerators, supporting efficient data transfers between both domains. This bridging functionality is used to mask custom point-to-point (P2P) communication channels behind standard communication interfaces (AXI4 slaves) that can be accessed by any element in the static region (e.g., the host microprocessor for configuration/control purposes, or the master DMA engine for data transfers between external memory and accelerators). This communication infrastructure constrains data transactions between external memory and local accelerator memories to be burst-based and memory-mapped. Application-specific data access patterns can still be implemented, but need to be managed explicitly either in software (the host application prefetches and orders data in the DMA buffers) or in hardware (the user-defined accelerator logic accesses its local memories with the specific pattern, providing additional buffer descriptions as required).
The top-level block diagram of the ARTICo
3 architecture, with the distribution of both static and dynamic partitions, together with the communication infrastructure, is shown in
Figure 2. The ARTICo
3 framework does not impose where the host microprocessor should be: it can be either a soft core implemented in the static partition of the FPGA, or a hard core tightly-coupled with the SRAM-based FPGA fabric.
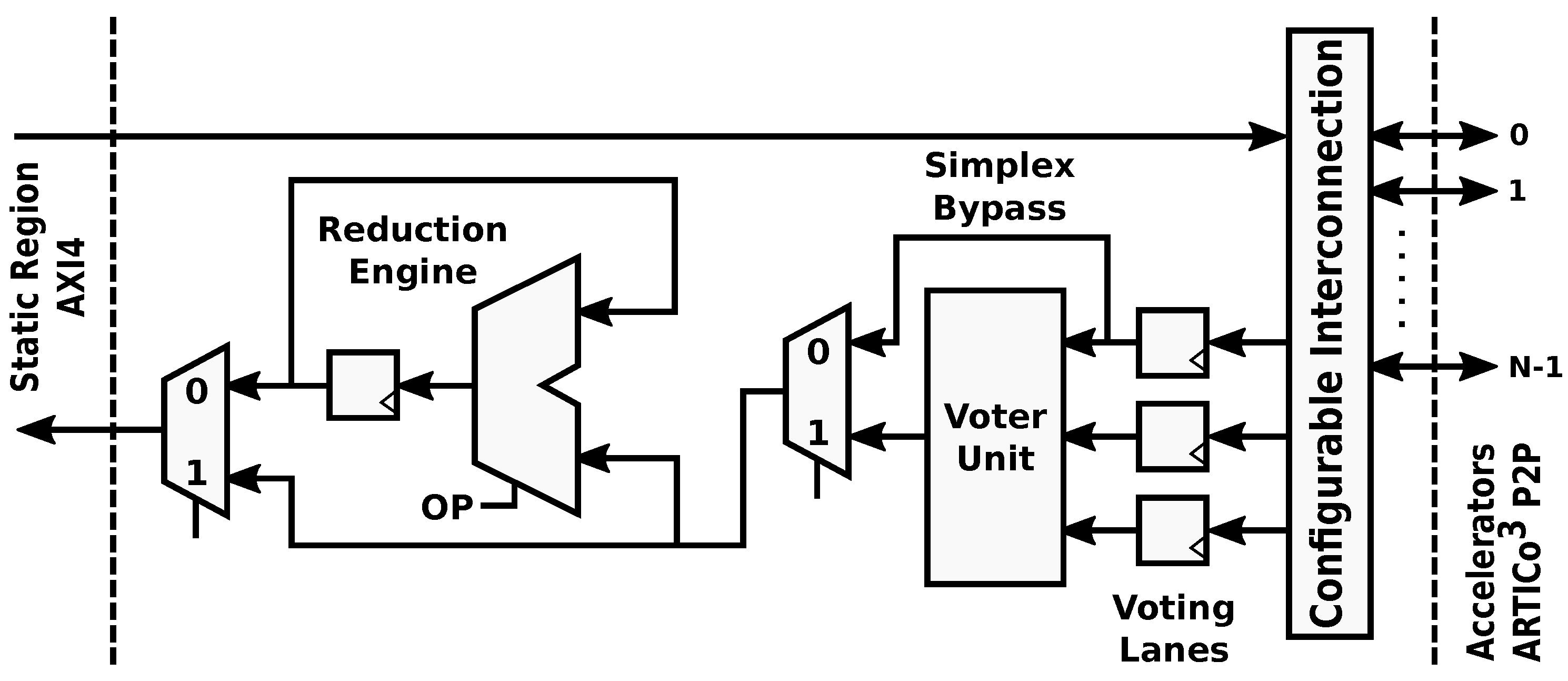
The internal architecture of the Data Shuffler module enables dynamic changes in the datapaths to and from the reconfigurable hardware accelerators. Write and read channels alter their structure to fit a specific processing profile, which is defined by a combination of one or more of the supported transaction modes: parallel mode, redundant mode or reduction mode. Note that the convention used here implies that write operations send data to the accelerators, whereas read operations gather data from the accelerators. The dynamic implementation of the datapath in the Data Shuffler is shown in
Figure 3.
The different transaction modes supported by the architecture and enabled by the Data Shuffler can be summarized as follows:
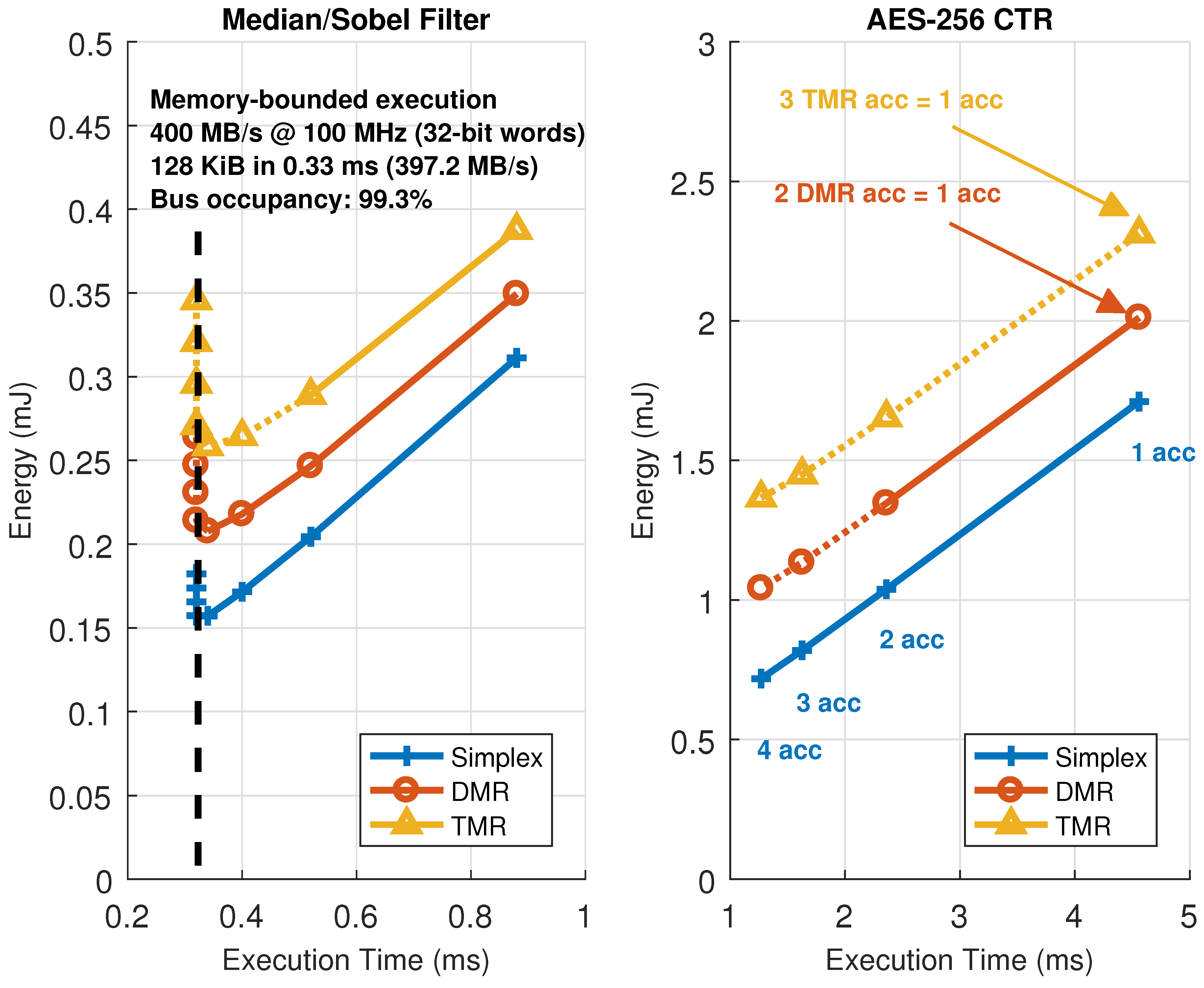
Parallel mode: Different data to different hardware accelerators, SIMD-like approach (parallel execution, even though the bus-based nature of the communication infrastructure forces all transfers to be serialized between Data Shuffler and external memory). Targets computing performance and energy efficiency.
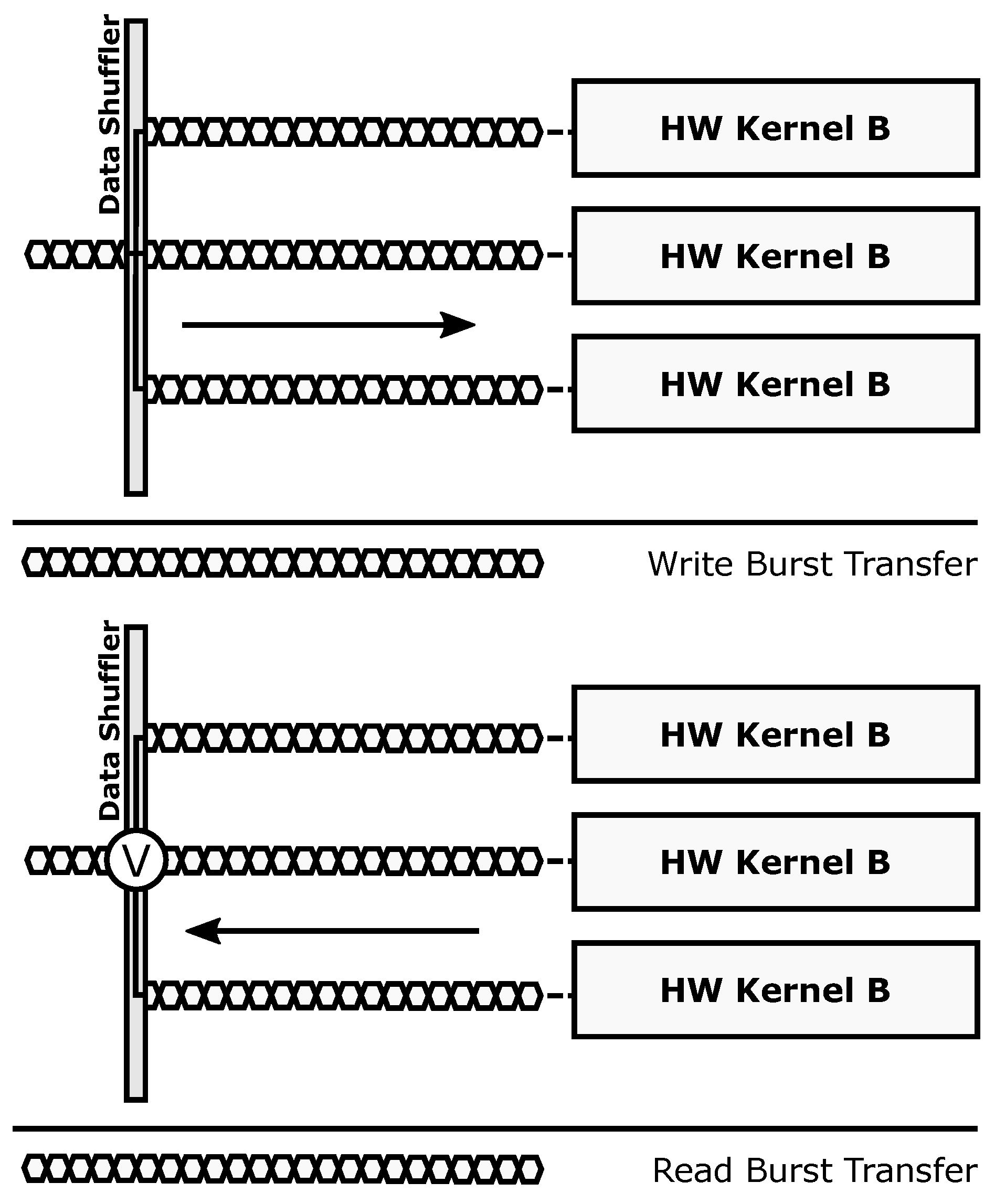
Redundant mode: Same data to different hardware accelerators, majority voting for fault-tolerant execution. Targets dependability.
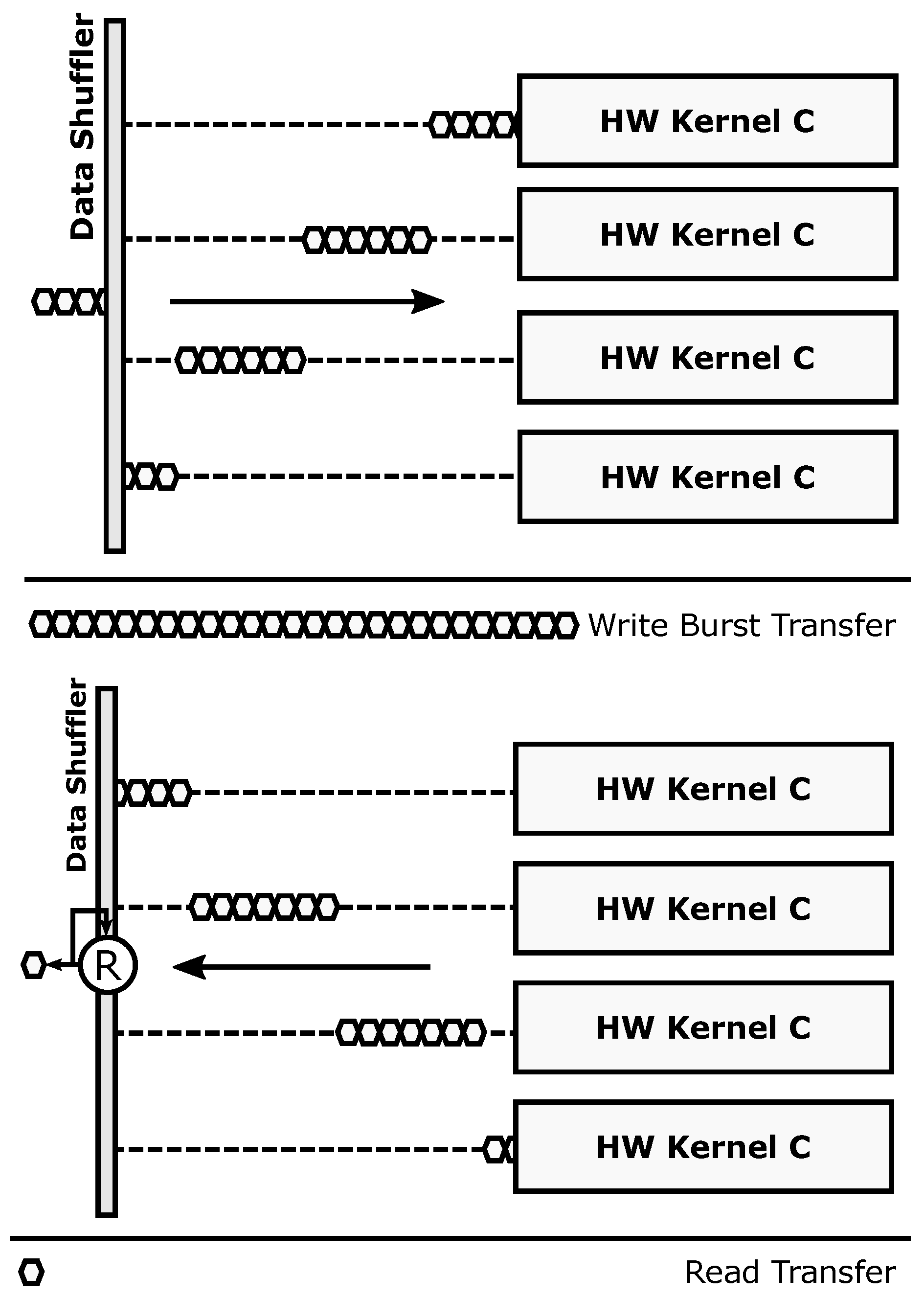
Reduction mode: Different data to one or more hardware accelerators, accumulator-based engine to perform computations taking advantage of data serialization in the bus. Targets computing performance.
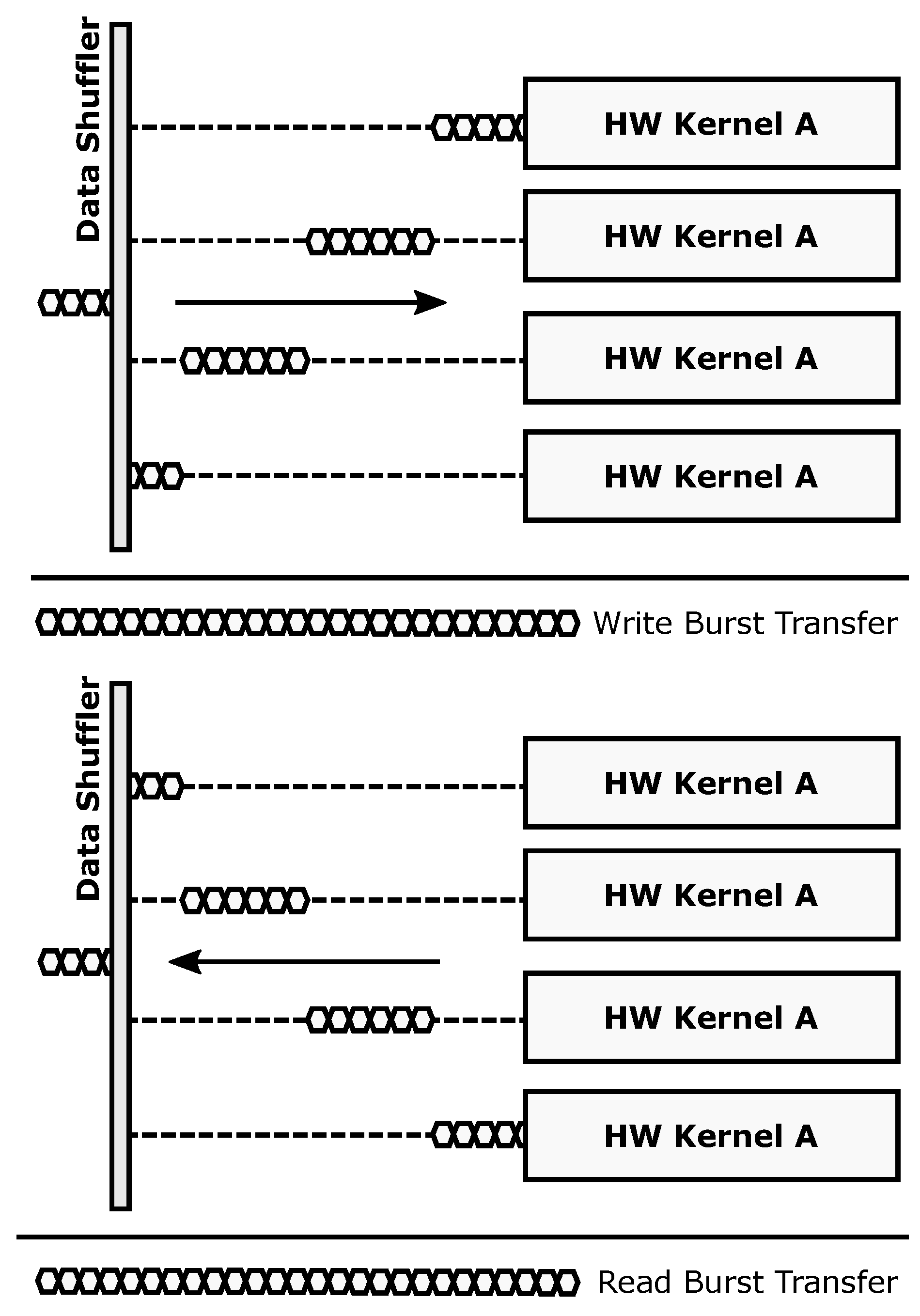
The parallel transaction mode (
Figure 4) is used to take full advantage of data-level parallelism when more than one copy of a given accelerator is present. Burst-based write transactions are split in as many blocks as available accelerators. This process is done on the fly, without incurring additional latency overheads. When using this mode, overlapping periods of memory transactions and data processing occur, since each accelerator starts working as soon as its corresponding data block has been written to its local memory. The resulting burst-based read transaction is composed also on the fly by retrieving data from the accelerators in the same order that was used during the write operation. This mode boosts computing performance using a SIMD-like approach: several copies of a hardware accelerator (same functionality) process different data.
The redundant transaction mode (
Figure 5) is used to enforce fault-tolerant execution, taking advantage of Double or Triple Module Redundancy (DMR and TMR, respectively). Hence, two or three copies of a given accelerator must be present for this mode to be applied. In this mode, burst-based write transactions are issued using a multicast scheme: all the accelerator copies get the same data strictly in parallel. Once the processing is done, a burst-based read transaction is issued, retrieving data also in parallel from all accelerators through a voter unit that decides which result is correct. This unit modifies its behavior according to the required fault-tolerance level, acting as a bypass for compatibility with the parallel mode (i.e., Simplex, no redundancy), a comparator in DMR, and a majority voter in TMR. Notice that the proposed scheme only ensures fault tolerance in the reconfigurable region. The rest of the system, including the Data Shuffler (which can be considered as a single point of failure), is assumed to have been previously hardened, if required, using additional fault tolerance techniques (e.g., configuration memory scrubbers [
43]) that are out of the scope of this paper.
The reduction transaction mode (
Figure 6) can be thought of as an extension of the parallel transaction mode, where the burst-based read operation is forwarded to an accumulator-based reduction engine before reaching the bus-based communication interface. This mode can be used to enhance computing performance by using a memory transaction not only to move data between the reconfigurable and static domains but also to perform a specific computation (addition, maximum, minimum, etc.) on the fly. An example application where the reduction mode can be used is a distributed dot product, where each accelerator computes a partial result and the reduction unit adds them to obtain the final result with no additional access to the external memory. The proposed accumulator-based approach is inherently efficient: on the one hand, only a small area overhead is introduced (an accumulator, an ALU, and its lightweight control logic); on the other hand, certain computations can be performed without adding latency and memory access overheads other than the ones imposed by data serialization in the bus (which are always present when moving data between memories).
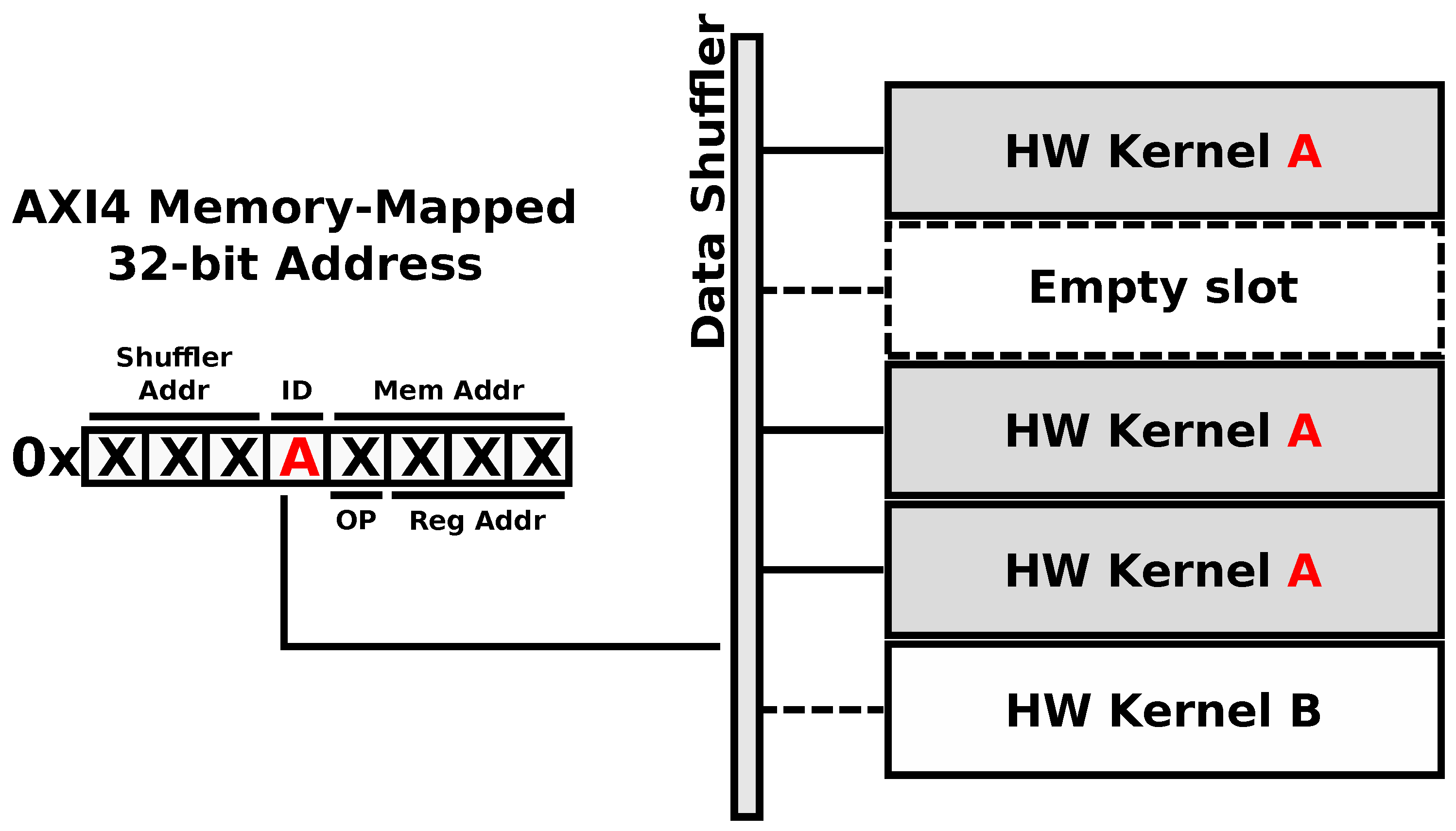
The true power of the ARTICo
3 architecture resides in the method used to access the reconfigurable hardware accelerators, use the different transaction modes and take advantage of the embedded add-on modules (voter unit and reduction engine): the addressing scheme (shown in
Figure 7). Taking advantage of the memory-mapped nature of the static region, hardware accelerators are addressed using a unique identifier, which is inserted in the AXI4 destination address for write transactions or in the AXI4 source address for read transactions. Therefore, addressing is made independent of the relative position of a given accelerator in the dynamic region, since it uses virtual sub-address ranges within the global map of the Data Shuffler to address hardware accelerators. Virtual sub-mappings are transparently managed by the framework, making kernel design agnostic from this process. As a consequence of this
smart addressing scheme, the system can support user-driven task migration without compromising execution integrity in case a reconfigurable slot presents permanent faults (e.g., on-board processing in a satellite might suffer from severe radiation effects). Moreover, the proposed addressing scheme is also used to encode specific operations as part of the transaction addresses. For instance, the destination address in write transactions provides support for multicast commands (e.g., reset all accelerators with a given identifier), whereas the source address in read transactions can be used to encode the operator which is to be used when the reduction mode is enabled.
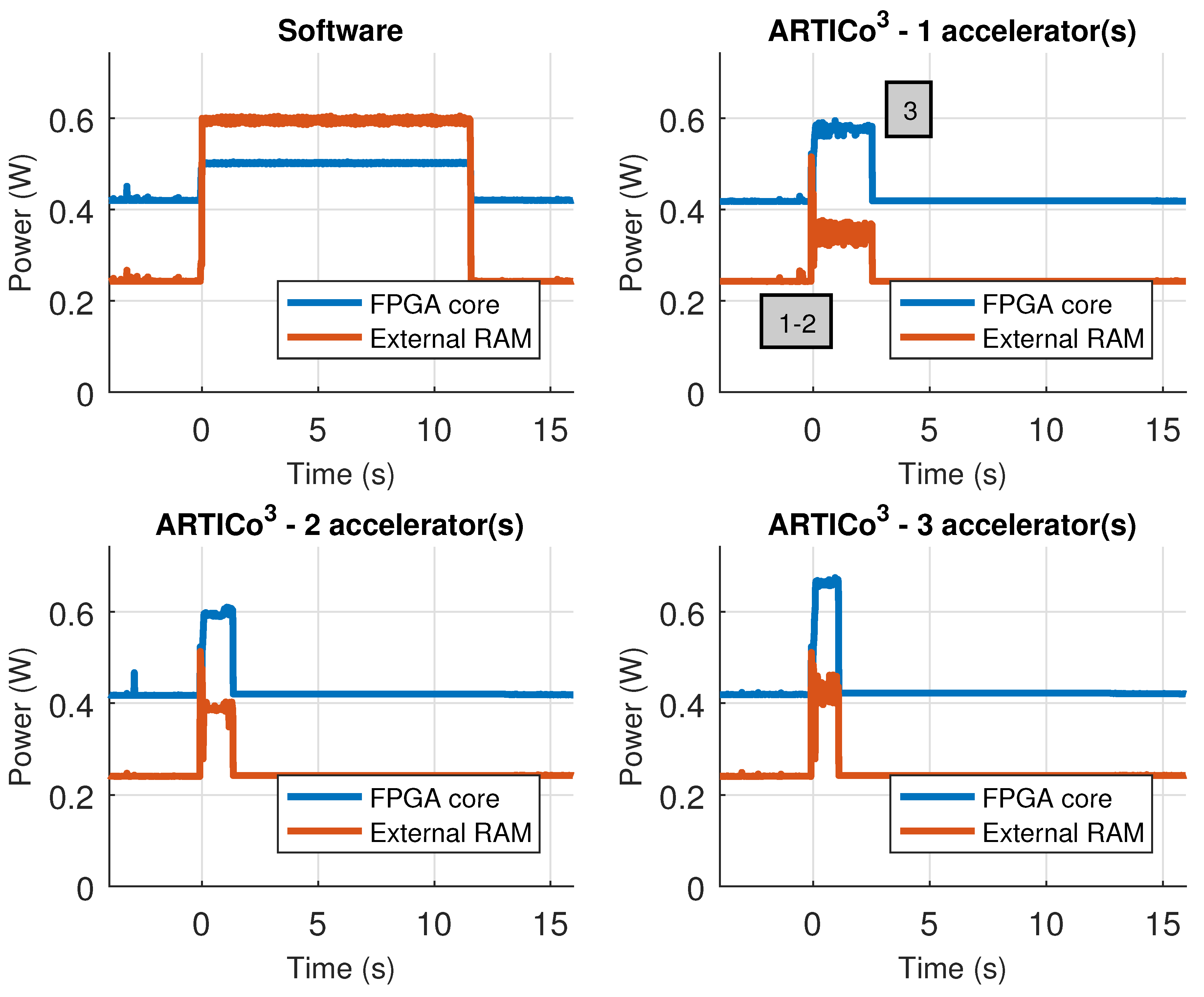
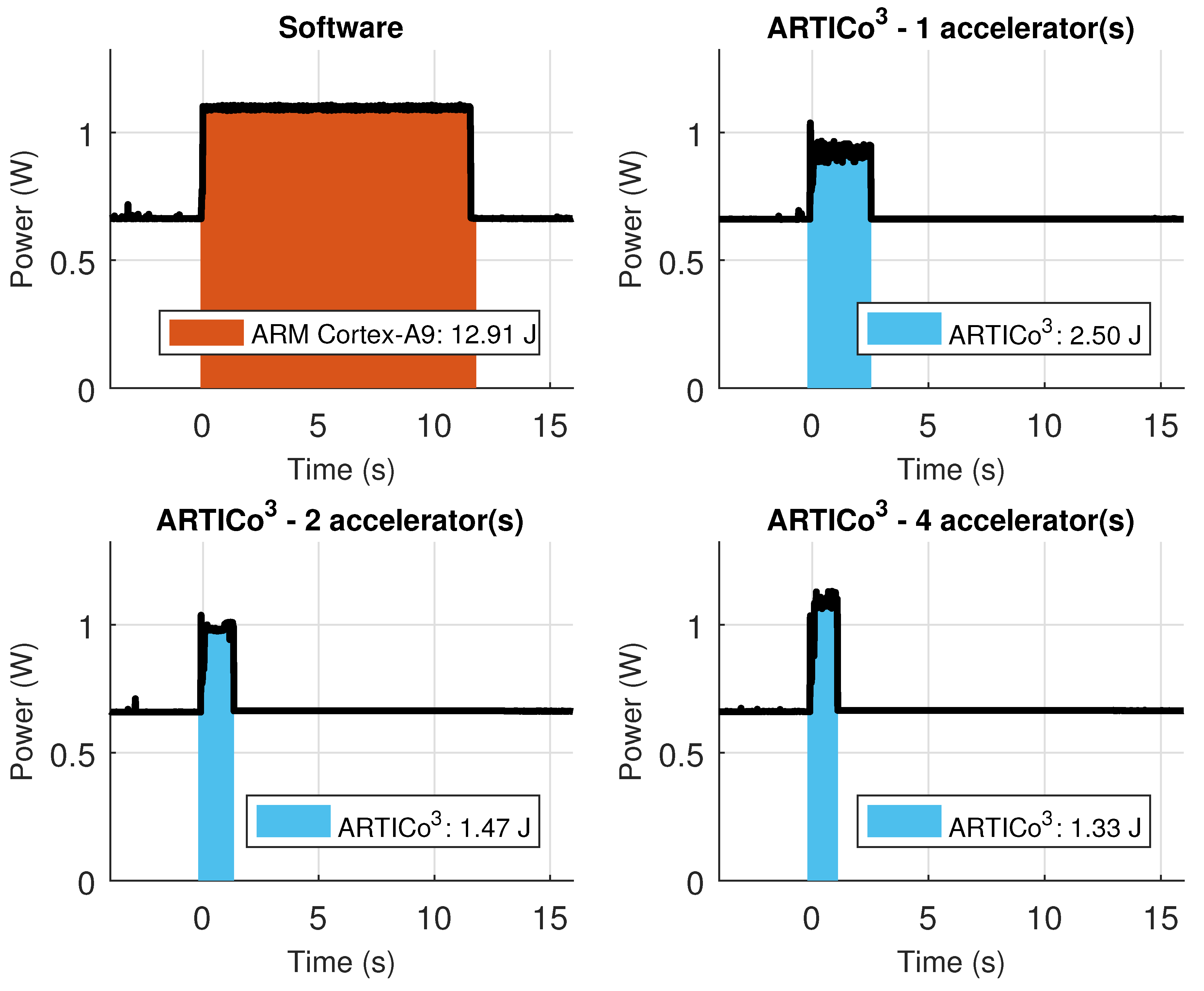
However, the architecture not only includes an optimized datapath and a smart addressing scheme, but it also features embedded Performance Monitoring Counters (PMCs) to enable self-awareness, and could also be extended by attaching additional sensor interfaces to enable environment-awareness (a common scenario in CPSs, where sensing physical variables is fundamental). There is a number of common PMCs for all implementations, measuring useful performance metrics such as execution times per accelerator, bus utilization (memory bandwidth), or fault tolerance metrics such as the number of errors found per slot (this report comes from the voter unit). In addition, some implementations also feature power consumption self-measurement (provided that the required instrumentation infrastructure is available). As a result, the architecture provides an infrastructure to get relevant information that can be used to make sensible decisions on whether to change the current working point. Nevertheless, closing this feedback loop is out of the scope of this paper, and is assumed to be managed from user applications.
3.2. Toolchain
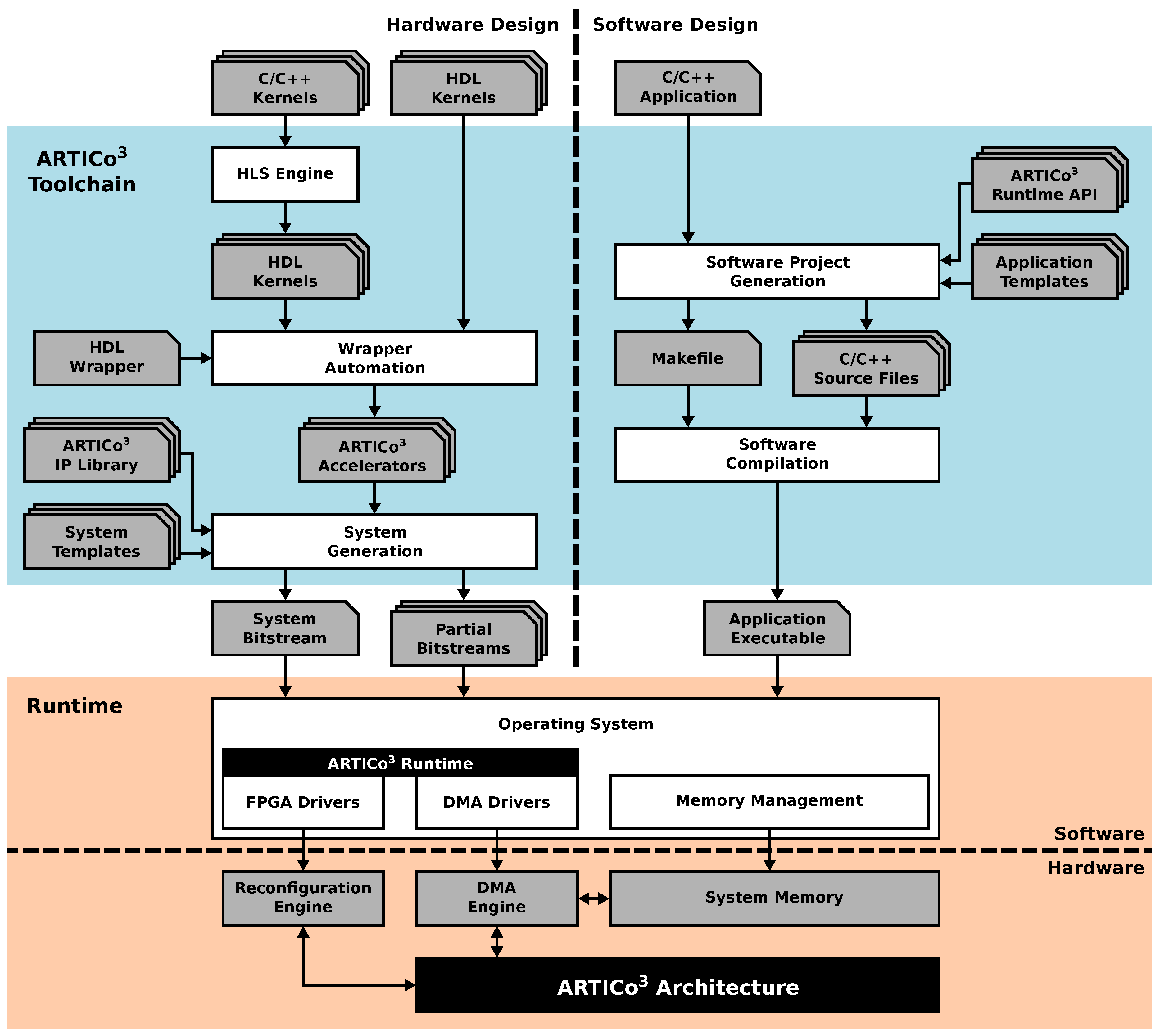
The ARTICo3 architecture provides a good starting point for edge computing in CPSs. However, FPGA-based systems, especially when enhanced by DPR, have been traditionally restricted to Academia due to their inherent complexity at both design and run time. To make the design of ARTICo3-based systems accessible to wider range of embedded system designers, an automated toolchain has been developed with two main objectives: on the one hand, to encapsulate user-defined hardware accelerators in a standard wrapper and automatically glue them to the rest of the hardware system; and, on the other hand, to generate the required binaries for software and hardware execution. Note that the hardware/software partitioning of the application is a step that needs to be done beforehand, either manually or using an automated tool. The ARTICo3 toolchain assumes independent hardware and software descriptions are provided as inputs. The components to enable a transparent use of ARTICo3 at run time, which are also required to make the framework accessible, are covered in the next section.
The generation of custom hardware accelerators in ARTICo
3 is very flexible, since developers can choose whether to use low-level HDL descriptions of the algorithms to be accelerated, or use HLS from high-level C/C++ code (the current version of the ARTICo
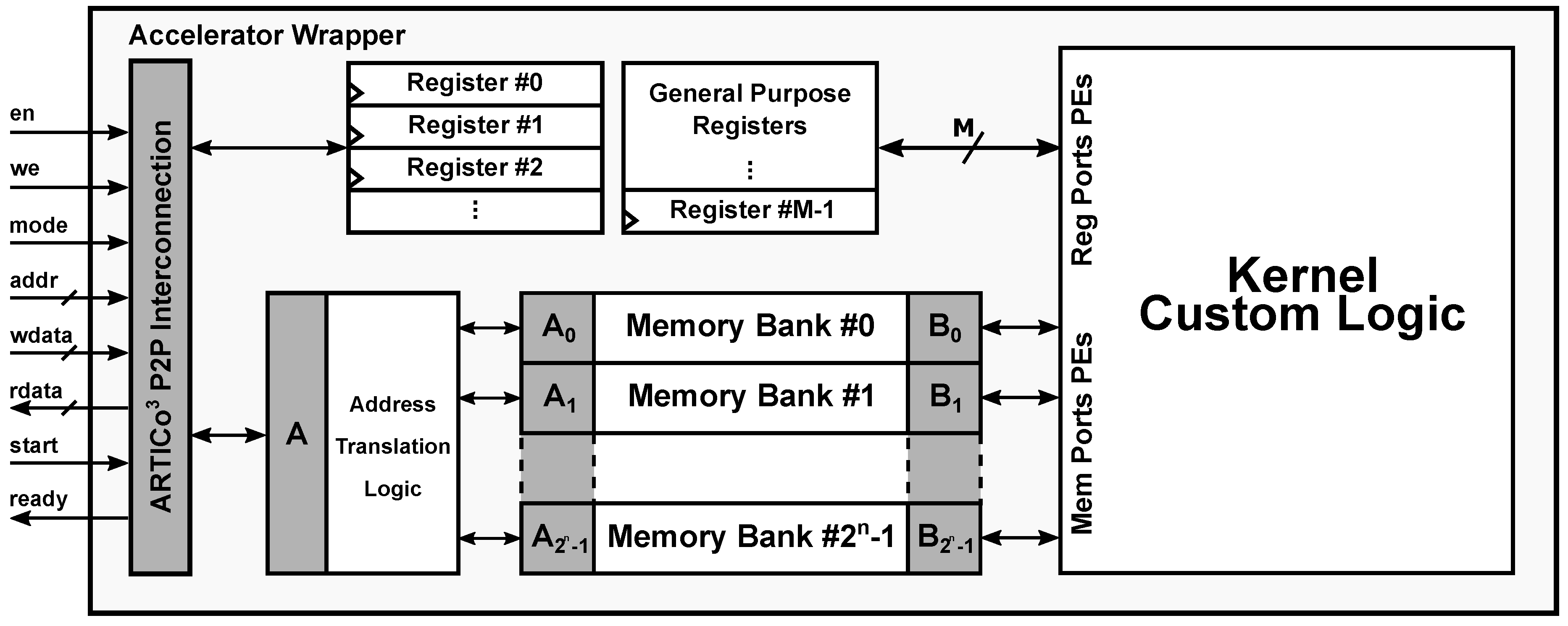
3 toolchain only supports Vivado HLS). Either way, the resulting HDL code is then instantiated in a standard wrapper, which provides not only a fixed interface to be directly pluggable in the Data Shuffler, but also a configurable number of memory banks and registers (see
Figure 8). The toolchain parses and customizes this wrapper for each kernel that has to be implemented. Hence, the key aspect of the toolchain is that it encapsulates hardware-accelerated functionality within a common wrapper that has a fixed interface with the rest of the architecture, but whose internal structure is specifically tailored for each application. This customization process, together with the generation of DPR-compatible implementations, is performed transparently and without direct user intervention.
The ARTICo3 kernel wrapper provides direct connection between user logic and the Data Shuffler using a custom P2P protocol. This protocol relies on enabled read/write memory-mapped operations (enable en, write enable we, address addr, write data wdata, and read data rdata), a mode signal to select the target from memory or registers, two additional control signals to start the accelerator and check whether the processing has finished (start and ready), and, finally, the clock and reset signals.
Local memory inside ARTICo3 accelerators is specified using two parameters: total size, and number of partitions (or banks) in which it has to be split. This approach increases the potential parallelism that can be exploited by providing as many access ports as necessary, while at the same time keeping all the banks as a uniform memory map for the communication infrastructure (i.e., the DMA engine only sees a continuous memory map for each accelerator, even if more than one bank is present).
Once the accelerators have been generated (i.e., once an HDL description for them is available), the toolchain generates the whole hardware system to be implemented inside the FPGA by using peripheral libraries (either provided by Xilinx or included in the toolchain itself). This process has two different stages: first, a high-level block diagram is generated by instantiating all required modules and connecting them together; second, the block diagram is synthesized, placed and routed, generating FPGA configuration files for both static and dynamic regions (full and partial bitstreams, respectively). In parallel, the toolchain also generates the required software project by combining the user files (where the main application is defined) with the API to access the underlying ARTICo3 runtime library, creating a customized Makefile to transparently build the application executable.
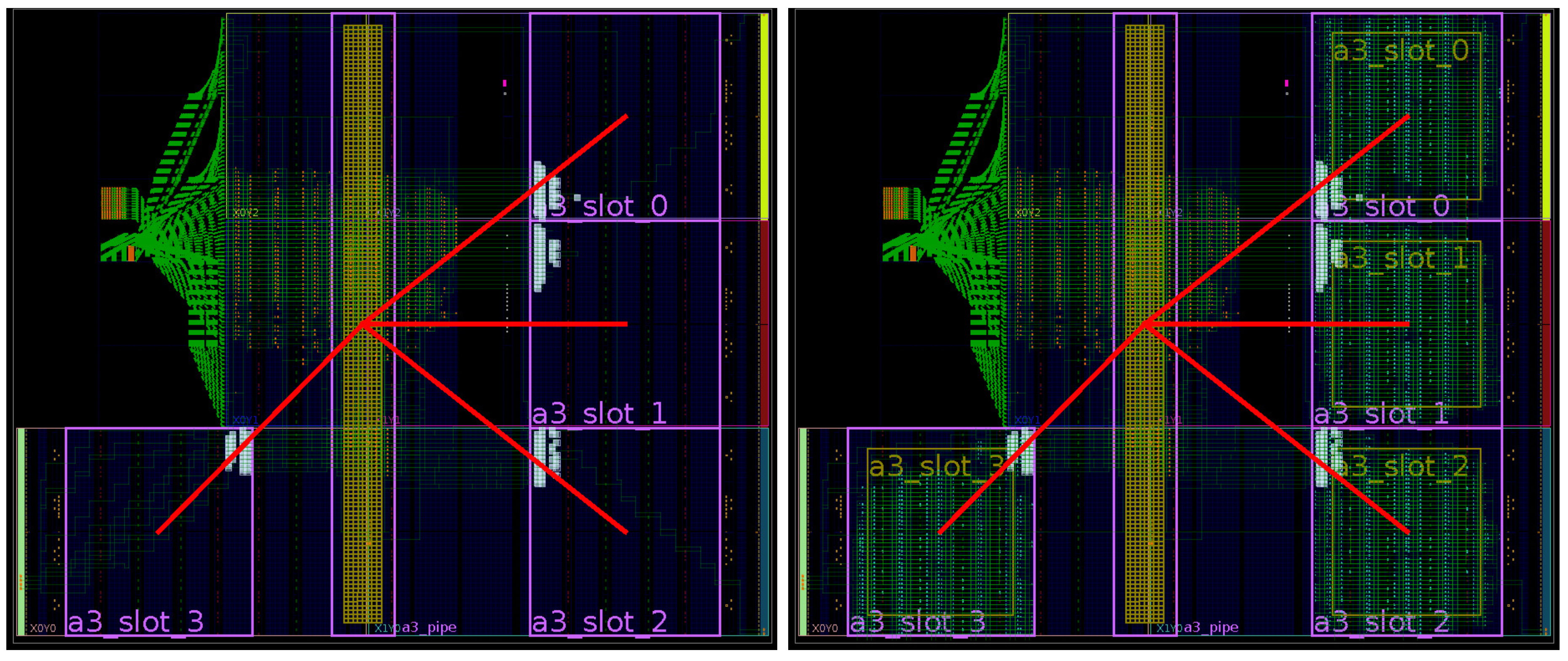
As a result, the toolchain produces output binaries for both hardware and software components without user intervention. This automated methodology greatly increases productivity by reducing development time and error occurrences, especially when compared to legacy design methodologies that were mainly handmade. For example,
Figure 9 and
Figure 10 show ARTICo
3-based systems in two different devices that were manually generated and routed using legacy Xilinx tools (ISE), whereas
Figure 11 shows the outcome of the toolchain (which uses current Xilinx Vivado tools) for another device. Although they are functionally equivalent, development time went down, on average, from almost a week to a couple of hours (these figures are based on the authors’ experience on designing reconfigurable systems). The main reason for this is that low-level technology and device dependencies are transparently handled by the toolchain, hiding them from the developer, who can now implement DPR-enabled systems with no extra effort.
The ARTICo3 toolchain, which is made up of Python and TCL scripts, is highly modular, relying on common constructs that are particularized for each individual implementation (system templates for hardware generation, and application templates for software generation). This is also a key aspect, since it makes adding new devices to the ones supported by the toolchain, or changing the peripherals present for an already existing device, really easy.
3.3. Run-Time
As it was already introduced in the previous section, providing designers with the capabilities to transparently generate ARTICo3-based reconfigurable systems from high-level algorithmic descriptions is not enough to make the whole framework accessible to embedded system designers with no prior experience in hardware design. In addition, it is also necessary to provide a common interface to link the automatically generated hardware platforms with the user applications, usually written in any programming language (e.g., C/C++), that will use the proposed processing architecture.
To achieve this, a concurrent run-time environment has been also developed. This run-time environment has been implemented as a user-space extension of the application code, relying on a Linux-based OS. Although Linux may not seem the best approach for certain type of embedded systems (e.g., safety-critical applications where specialized OSs are used instead), it shows several advantages. On the one hand, its multitasking capabilities can be exploited to manage different kernels concurrently; and, on the other hand, it is widely used, and developer-friendly.
User applications interact with the ARTICo
3 architecture and accelerators by means of a runtime library written in C code, which is accessible through a minimal API. The runtime library includes functions to initialize and clean the system, perform DPR to load accelerators, change the working point of the architecture, manage memory buffers between application and accelerators, run kernels with a given workload, etc.
Table 2 shows the function calls available in the ARTICo
3 runtime API.
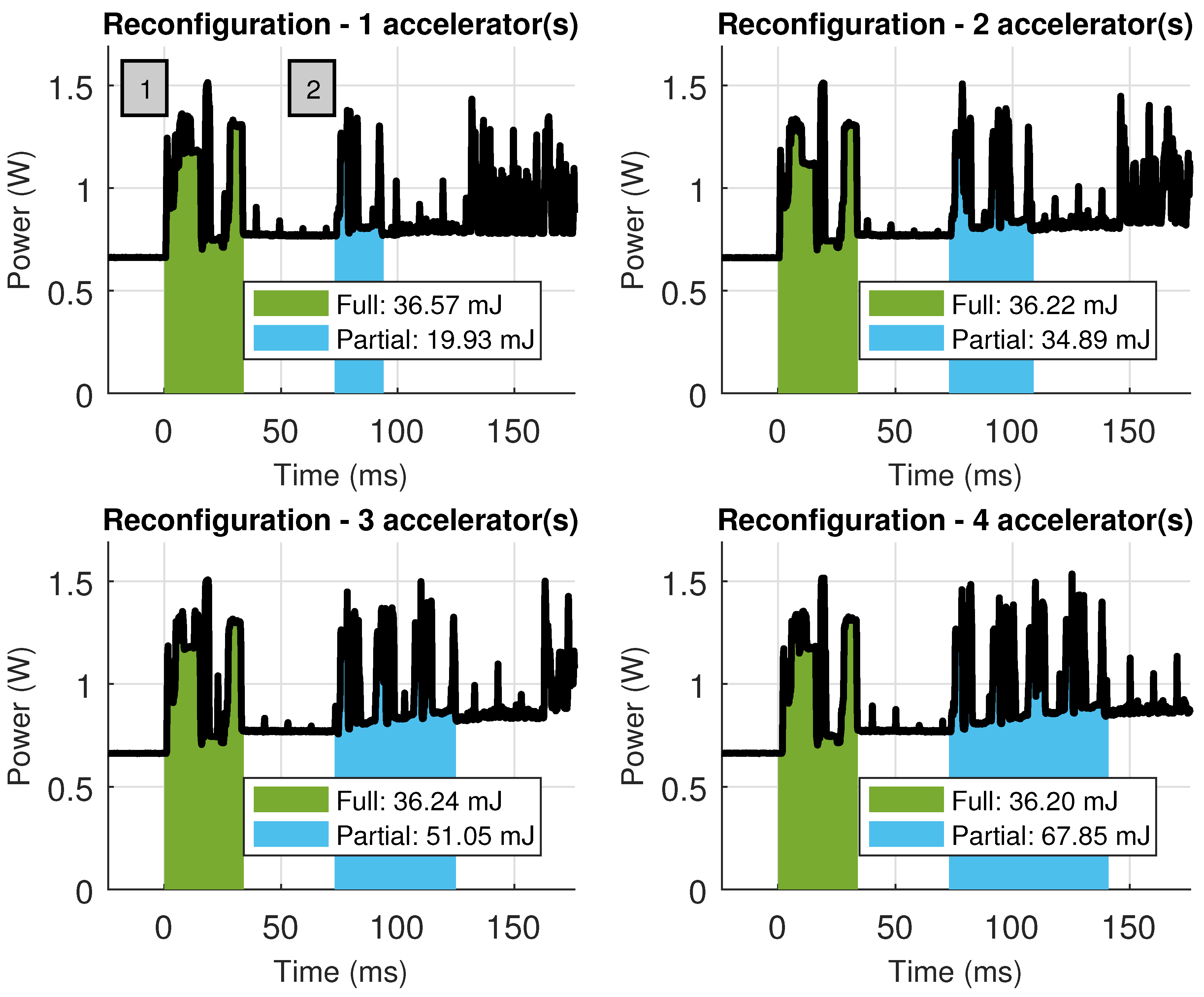
The ARTICo3 run-time environment automates and hides from the user two processes: FPGA reconfiguration and parallel-driven execution management (i.e., workload scheduling over a given number of accelerators using variable-size DMA transfers between external and local memories). However, users are expected to actively and explicitly decide how many accelerators need to be loaded for a given kernel and how to configure them using artico3_load (this function performs DPR transparently). Moreover, users are also in charge of allocating as many shared buffers (between external and local memories) as required by the application/kernels using artico3_alloc. Once everything has been set up, users can call artico3_kernel_execute to start kernel execution. This function takes advantage of the data-independent ARTICo3 execution model to automatically sequence all processing rounds (global work) over the available hardware accelerators of a kernel (each of which can process a certain amount of local work). The sequencing process sends data to the accelerators (DMA send transfer), waits for them to finish and then gets the obtained results back (DMA receive transfer) until all processing rounds have finished. The ARTICo3 run-time environment creates an independent scheduling/sequencing thread for each kernel that is enqueued for processing. Host code can then continue its execution in parallel to the accelerators until it needs to wait for any of the sequencing threads to finish, which can be done by calling the function artico3_kernel_wait.

 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}