1. Introduction
Alzheimer’s disease (AD) is the predominant form of dementia in the elderly, and the number of patients is expected to multiply over the next few years [
1]. Alzheimer’s disease, at its earliest stage, involves small-scale alterations in the brain defined by the presence of neurofibrillary tangles and beta-amyloid plaque deposits (A
) [
2]. These alterations result primarily in damage to synapses, followed by degeneration of the axons and, ultimately, atrophy of the dendritic tree and perikaryon and leading to atrophy in specific regions of the brain [
3]. This process especially affects specific areas of the brain such as the right and left hippocampus, temporal gyri, cingulate and precuneus [
4].
It is becoming increasingly apparent that, when a patient is diagnosed with Alzheimer’s disease, the atrophy is already well established in the brain. The earliest clinical presentation of symptoms that can eventually progress to a clinical diagnosis of Alzheimer’s disease is generally classified as mild amnesic cognitive impairment (MCI) [
5]. MCI can be considered a state of clinical impairment, commonly memory loss, beyond that which can be expected for the subject’s age and education without meeting the criteria for classification as dementia. Although not all patients with amnestic MCI will develop AD, cerebral atrophy is already present at this stage [
6]. In mildly Alzheimer’s disease affected individuals, entorhinal volumes have already been reduced by 20–30% and hippocampus volumes by 15–25% [
7]. Estimates of the progression of atrophy in Alzheimer’s disease cases, between 0.8% and 2% per year [
8], suggest that the atrophy process associated with the disease in areas such as the medial temporal lobe must have been active for a period of several years prior to diagnosis or even the presence of symptoms.
The process of degeneration can be visualized through various modalities of medical imaging and has proven to be a valuable biomarker of the stage and potential aggressiveness of the neurodegenerative aspect of Alzheimer’s disease pathology [
9]. As a result, in the last two decades, the use of imaging modalities has gone from being a mere secondary instrument in the diagnosis of Alzheimer’s to one of the main tools. Major advances in neuroimaging have provided opportunities to study neurological-related diseases. Thus, resting-state functional magnetic resonance imaging (fMRI) [
10], imaging the intrinsic functional brain connectivity, or the use of PET radiotracers developed to allow the in vivo visualization of tau aggregates and A
plaques ([
11,
12]), have become relevant biomarkers for Alzheimer’s disease research. However, despite these advances, FDG positron emission tomography (PET) and magnetic resonance imaging (MRI) are still extensively used in AD-related studies, especially the latter, given its wide availability, non-invasive nature and relative absence of patient discomfort. However, early-stage changes in Alzheimer’s disease are subtle and it is difficult to distinguish patterns by conventional radiological evaluation. Therefore, it remains difficult to establish reliable biomarkers for the diagnosis and monitoring of disease progression, especially in the early stages. This has led to the development of numerous automatic methods for the assessment of brain atrophy.
There is a large body of research published on MRI neuroimaging-based computer-aided classification of AD (see [
13] or [
14]). Taking into account the work presented in [
15], these methods can be grouped into three categories, depending on the type of characteristics that are used to assess the structural variation and how they are extracted. Thus, there are methods based on density maps, either using the whole brain as a unit or relying on a parcellation; methods derived from the study of the cortical surface, also in an overall or local way; and methods based only on the examination of specific regions of the brain.
Density mapping methods look for atrophy patterns by using white matter (WM), grey matter (GM), and cerebrospinal fluid (CSF) mapping generated by voxel-based morphometry (VBM) methods [
16]. The direct classification of these features is carried on using either support vector machines (SMV) in [
17] and [
18] or the programming boosting method (LPBM) [
19]. Other works rely on different kinds of feature reduction methods, supervised or unsupervised, in order to reduce the height dimensionality of the feature space. In [
20], WM and GM density map dimensions are reduced by the mean of principal component analysis (PCA) and the result is used to train an SVM based classifier. In [
21], the reduction in the dimensions of GM maps is proposed only using the intensity distribution of voxels of GM maps as features. Another way of feature selection relies on the use of a cerebral partitioning atlas to obtain regional measurements of the anatomical features to question the presence of abnormal tissue areas as in [
22] or [
23].
Methods derived from the cortical surface use subtle changes extracted at the vertex-level from a cortical surface, represented primarily as cortical thickness measurements. As in density mapping methods, these measurements can be used directly [
24] or processed for the reduction of dimensionality. Some examples on the latter category are found in the work presented in [
25] where the cortical surface is modeled using three-dimensional meshes and the cortical thickness is extracted by parametrizing these meshes or the method presented in [
26], where thickness data from the cortical surface data are converted into a frequency domain and the dimensionality is reduced by filtering out high-frequency components.
The methods of the third category analyse specific regions in the brain. The main approach in these methods implies the use of biomarkers extracted from the hippocampus [
27,
28] as volume and/or shape or textural features. Work on other cerebral areas has been done in [
29], in which a diffeomorphometry study has been carried out in a number of regions, including the right and left hippocampus, thalamus, and lateral ventricles, in order to perform a linear discriminant analysis for AD prediction.
Related to the methods derived from density maps, but based on the use of textural measurements instead of direct measurements, in this work, we propose the extension of the concept of histons [
30] to volumetric images and its use as a textural feature in the classification of T1-weighted MRI images, in order to differentiate Alzheimer’s disease (AD) patients from cognitive normal (CN) patients. Textural methods can identify voxel-intensity patterns and relationships hidden from the unaided human eye [
31]. The histon concept represents a way to visualize information about color regions in an image. Compared to other textural characteristics, a histon is particularly sensitive to subtle variations in color in relation to the space [
32]. The proposed work offers a simple whole-brain descriptor based on the relationship between the voxel probabilities corresponding to gray matter, white matter or cerebrospinal fluid—instead on a unique voxel intensity measurement as in [
33] or [
34]. The partitioning of the MRI image into these three probability volumes allows each of them to be equated to a spectral band and to characterize the MRI volume within the RGB color space.
The rest of the paper is organized as follows:
Section 2 briefly reviews the concepts underlining this work: histons and supervoxels. The materials used and the general pipeline of the presented method are detailed in
Section 3. The experimental results are presented and discussed, in
Section 4, concluding in
Section 5 with the final remarks and possible future work related to the proposed classification method.
3. Materials and Methods
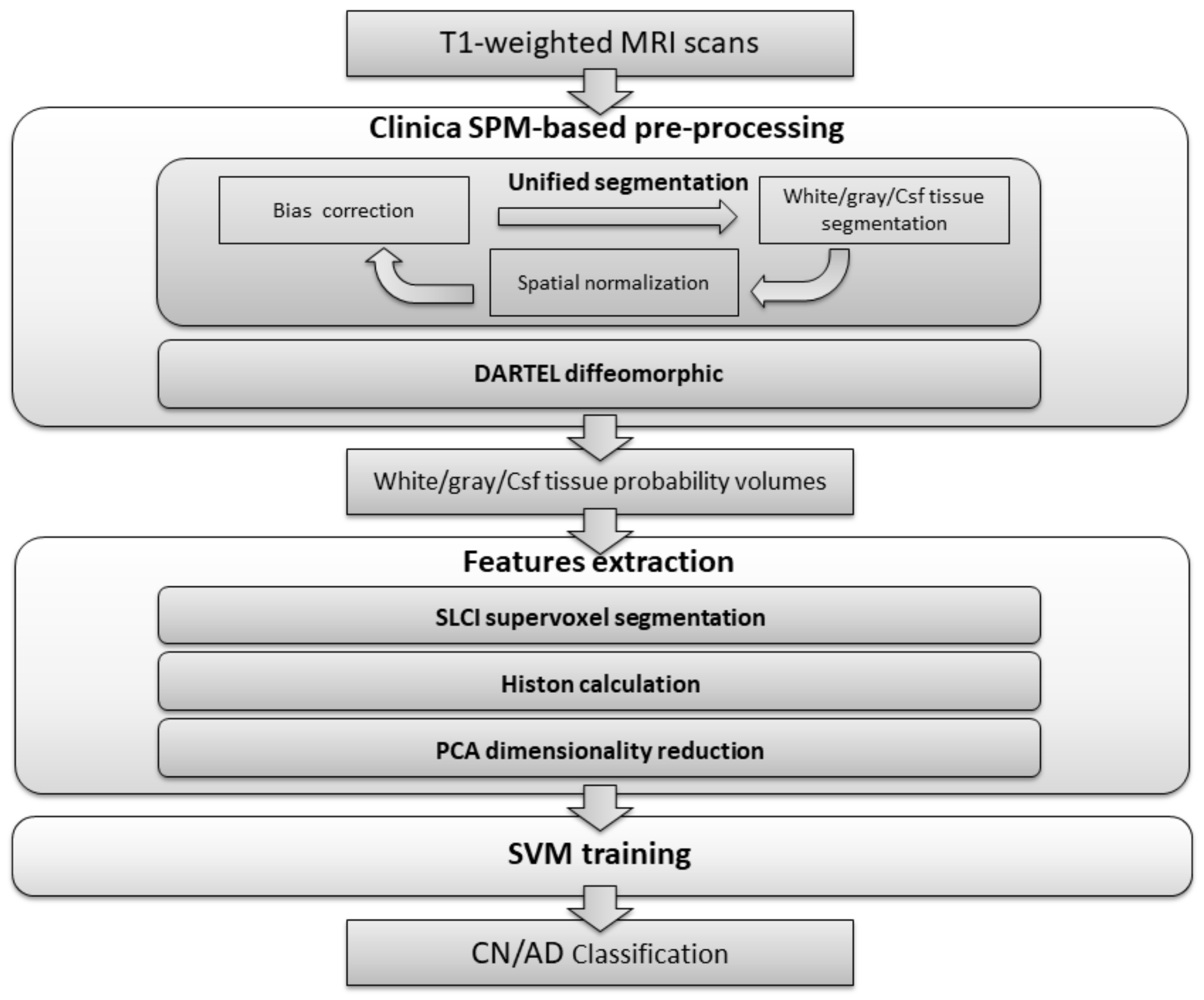
The classification process presented is divided into three stages, as can be seen in
Figure 1. In the first stage, the dataset is processed in order to carry out bias correction and spatial normalization, and to obtain a white matter/grey matter/cerebrospinal fluid segmentation. In the second stage, we calculate a set of histons to be used as a feature vector. To provide a natural neighbourhood for the histon-calculation process, we carry out an over-segmentation using the aggregate volume for GM, WM and CSF. Finally, feature reduction is achieved by means of PCA and the resulting feature vector is used to train an SVM-based classifier.
The subjects included in this study were obtained from the Open Access Series of Imaging Studies (OASIS-1).
3.1. Dataset: OASIS
The Open Access Series of Imaging Studies (OASIS) [
47] is a project aimed at making MRI data sets of the brain freely available to the scientific community. OASIS is made available from the Washington University Alzheimer’s Disease Research Center, Dr. Randy Buckner at the Howard Hughes Medical Institute (HHMI) at Harvard University, the Neuroinformatics Research Group (NRG) at Washington University School of Medicine, and the Biomedical Informatics Research Network (BIRN).
For this study, the “Cross-sectional MRI Data in Young, Middle-Aged, Non-demented and Demented Older Adults” (OASIS-1) have been selected. This collection is a cross-sectional dataset of 416 individuals of both genders, all right-handed, aged between 18 and 96. The set includes 100 patients (aged over 60) with a clinical diagnosis of Alzheimer’s disease ranging from very mild to moderate. A summary of the demographic characteristics of for the OASIS-1 is shown in
Table 1.
3.2. Clinica Software
In order to work with a standardized pre-processing work-flow, compatible with multiple neuroimaging databases, the volume pre-processing and general dataset management would be carried out using the Clinica software (version 0.1.0). Clinica is a software platform for clinical neuroscience research studies, developed by the ARAMIS Lab at the Institut du Cerveau et de la Moelle épinière (ICM, Brain & Spine Institute) in Paris, using multimodal data (neuroimaging, clinical and cognitive evaluations, genetics, etc.) and, most often, a longitudinal follow-up.
The general image pre-processing process of a T1-weighted MRI image implies tissue segmentation, bias correction and spatial normalization to the Montreal Neurological Institute (MNI) space. The Clinica software wraps the segmentation procedure from SPM (Statistical Parametric Mapping) [
48] that carries out all these processes simultaneously, in a procedure known as “Unified segmentation” [
49].
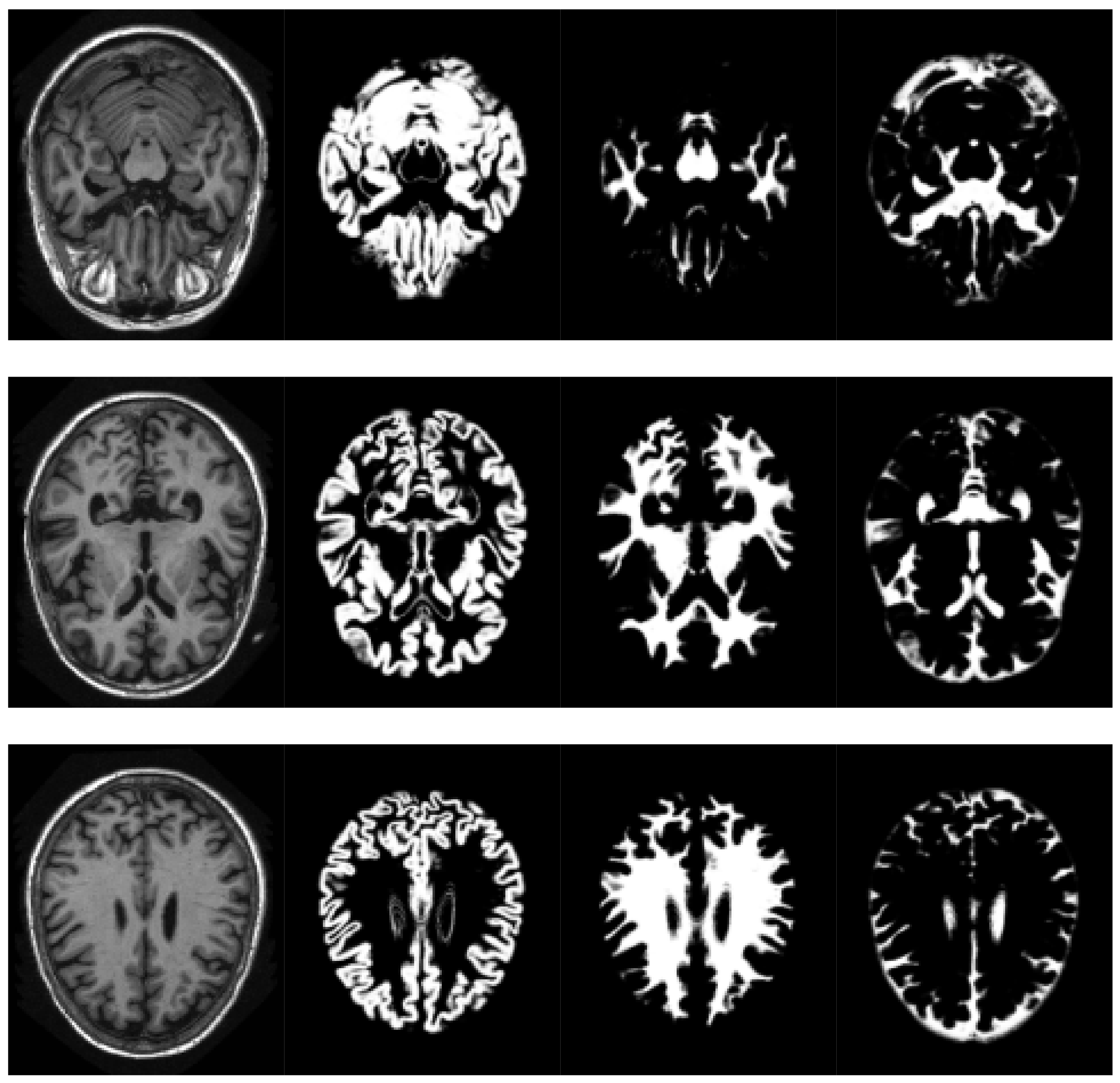
SPM models the brain as a layer of cerebrospinal fluid surrounding the gray and white matter. The prior probability that any voxel contains grey or white matter can be determined using a probabilistic atlas of tissue types. The main idea of this method is to model image intensities as a mixture of k Gaussians, where each Gaussian cluster is modelled by its mean, variance and a known tissue mixing proportion. In the unified model, multiple tissue probability maps are used as a priori information of the tissue classes. The Bayes rule is used to produce the posterior probability of each tissue class. This posterior probability is then combined with the data from the image to determine the final tissue type. Using this approach, two voxels with identical intensities can be identified as different tissues. An example of the results obtained can be seen in
Figure 2.
The pipeline then computes a group template by applying the DARTEL (Diffeomorphic Anatomical Registration Through Exponentiated Lie. Algebra [
50]) diffeomorphic method to the T1-weighted MRI image of each subject considered. In computational anatomy, a diffeomorphic system is a system designed to assign metric distances on the space of anatomical images, in order to permit the quantization and comparison of morphometric changes in anatomical structures. Diffeomorphic mapping is a broad term that may actually refer to a number of different algorithms, processes, and methods. DARTEL is based on the idea of producing a bidirectional “flow field” as the core for image “deformation” in the process of image registering.
The DARTEL process begins by taking the parameter produced by a GM/WM/CSF segmentation and aligning it as close as possible to a set of tissue probability maps, by means of rigid transformations. In the next step, from the average of all the images, an initial template is created that is then used for the simultaneous registration of tissues between images. This model is used to compute individual deformations to each of the individual images, and finally the inverse of the deformations are applied and averaged, in order to regenerate the template. This process is repeated several times. When comparing data from a number of scans, all cerebral volumes are required to be in the same 3D space. In this process, it is achieved by normalizing the volumes on the space defined by the Montreal Neurological Institute (MNI) template.
Finally, Clinica provides a modular way of making a classification based on machine learning by combining different inputs, algorithms, and validation strategies. These modules rely on scikit-learn for classification purposes [
51].
3.3. Features Extraction: Supervoxel-Based Histons for Structural MRI Alzheimer Detection
As can be seen in [
52], in the process of unified segmentation, there is a relationship between neuronal degeneration and the presence of voxels with a relatively low probability of it being part of a specific type of tissue. Since Alzheimer’s disease tends to manifest itself as atrophy in specific areas of the brain, in these cases, the process of tissue segmentation will tend to show “ambiguous” areas difficult to classify as one or the other type of tissue, in addition to the decrease in the total volume of white matter and grey matter associated with ageing. In this work, we propose the possibility of exploiting both the decrease in the total volume of GM and WM and the relationship between GM, WM and CSF through the use of histons as a textural volumetric characteristic.
In [
53], we propose the use of super pixel segmentation (using SLIC) as a way of mitigating some of the limitations of the original histon generation method [
44] (histons calculated from a color sphere based on a predefined neighbourhood and colour distance), as a method oriented to the segmentation of multispectral images. In this case, we have extended the original method to MRI volumes.
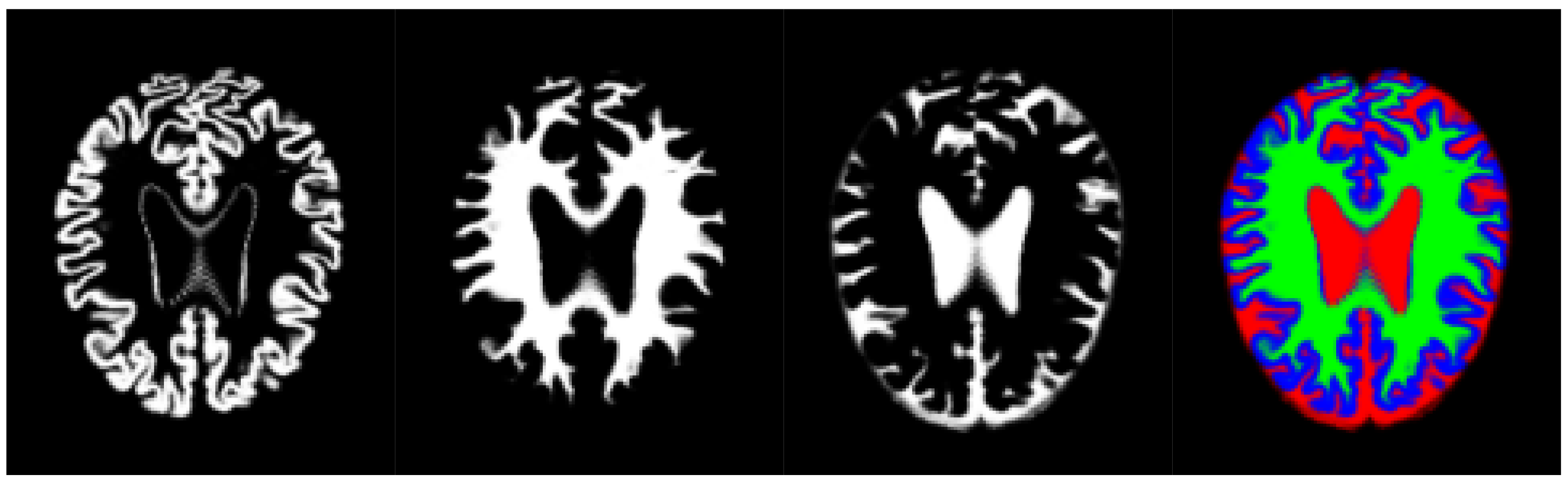
Thus, we have used an aggregation of the probability volumes for GM, WM and CSF to carry out a segmentation using supervoxels. In this respect, for segmentation purposes, the different probability volumes (which are represented as 8-bit intensity maps) can be equated to the spectral bands of a colour volume (see
Figure 3). Using a supervoxel segmentation (over-segmentation), we get a way of characterizing the local similarities within the aggregate volume, obtaining a natural set of neighbourhoods for the generation of histons. Similarly to what can be seen in [
53], the use of supervoxels as a neighbourhood implies the adherence of the neighbourhoods set to the boundaries and features present in the image, so, when a histon is calculated, there is a direct spatial relationship between the voxel tested for its belonging and the color sphere. Furthermore, we can quantify the overall local homogeneity of a volume using the average intensity standard deviation of the supervoxel-defined space since segmentation using supervoxels already produces locally homogeneous areas.
We will associate intensity with the probability of it being GM, WM and CSF in each of the probability volumes. Thus, when calculating a histon, a voxel will be considered to be inside the color sphere if the distance between the mean intensity of its corresponding supervoxel and the intensity of that voxel is less than the mean local deviation of the probability volume in the space defined by the supervoxels, in each of the probability volumes. Let us denote the set of resulting supervoxels in an image segmentation as
, where
is the total number of supervoxels;
represents the centroid of the supervoxel
in the probability volume
, where
is the set of probability volumes
; and
is the number of voxels in that supervoxel. Then, the similarity function
is defined as:
The use of supervoxels as a neighbourhood allows the probability distribution to be represented in a natural and accurate way as a supervoxel represents a real volume within the image, created by taking into account the features present in the image. Thus, the histons will encode the relationships between the probabilities of their being GM, WM and CFS by taking into account their spatial distribution in a volume, based on a natural set of neighbourhoods.
The feature vector obtained consists of 768 components (a different histon for each probability volume, each with 256 levels).
Working with high-dimensional feature vectors makes a classifier prone to over-fitting by choosing the wrong dimension as a discriminatory feature. To decrease the high dimensionality represented by the aggregate histon vector, principal component analysis (PCA) is used. PCA [
54] aims to transform a set of original variables into a new set of variables, a linear combination of the original ones, called principal components (PCs), without losing any information. For a standardized dataset, the principal components can be calculated as the normalized eigenvectors of the covariance matrix of the original variables and can be sorted by the amount of variation found in the data they explain. From a geometrical point of view, each component can be viewed as the maximizing direction of the variance of the samples, uncorrelated to previous components, when they are projected onto the component itself. The number of components extracted is equal to the number of variables being analysed, so only a subset of them are generally used in the classification. Usually, only the first few components account for meaningful amounts of variance, and the rest will tend to represent only trivial amounts of variance.
3.4. SVM Classifier
To carry out the categorization of the T1-weighted MRI volumes, in order to separate Alzheimer’s disease patients and cognitive normal patients, the Support Vector Machine (SVM) [
55] has been selected to train the classifier, as it generally yields good results and is remarkably robust to model bias or model variance [
56].
SVM is a general supervised learning method able to carry out binary group separation. An SVM belongs to the category of linear classifiers, as the classification is carried out by finding the plane or (depending on the dimensionality of the problem) hyperplane that better differentiates the two classes. The idea is to obtain what is called a maximum margin on each side of the hyperplane by selecting an equidistant separation hyperplane from the closest samples of each class. Only the data that define the borders (the support vectors) of those margins are considered. The search for the separation hyperplane in these spaces, normally of very high dimension, will be implicitly made using the so-called kernel functions. From an algorithmic point of view, the problem of optimizing the geometric margin represents a quadratic optimization problem with linear constraints that can be solved using standard quadratic programming techniques.
4. Results
The experiments were carried out in a subset of the T1-weighted MRI transversal image part of the OASIS-1 dataset, using all the subjects aged 60 and over. To assess the differences in demographic and clinical characteristics between groups (AD and CN), we used a Student’s
t-test for age and MMSE (Mini-Mental State Examination) and Pearson’s chi-square test for gender. The significance level was set at 0.05. Significant differences between controls and patients were found for the MMSE, and gender. The gender differences between groups, as well as the general large variability in age of the dataset, are factors that can result in a bias in the classification results. Taking this into account, a second reduced dataset will be used, their subjects selected randomly under the criteria of minimizing gender differences between groups and, as far as possible, discarding outliers to decrease standard deviation of the age. A summary of the subject’s demographics and dementia status for the population of both subsets is detailed in
Table 2. Segmentation and feature extraction is carried out with our own implementation of SLIC on MATLAB (MATLAB and Statistics Toolbox Release 2017b, The MathWorks, Inc., Natick, MA, USA), feature reduction and classification is carried out using R.
4.1. Validation Strategy
In order to obtain unbiased estimates of the performances, following the recommendations presented in [
57], each dataset is randomly split ten times into two groups: training sets and testing sets (80/20%). The split division process preserves the distribution of age and gender. Each training set is used to train a classifier, and their corresponding testing sets are used for evaluation purposes. The training sets obtained from the aged 60 and over dataset are also used to determine the optimal kernel for the SVM classifier. Individual demographic information for each split can be seen in
Appendix A.
As performance measurement, we report the accuracy (), negative prediction value (), positive prediction value (), sensitivity (), specificity (), F-score () and balanced accuracy (), where P is the total number of Alzheimer’s disease patients in the dataset, F is the cognitive normal patients in the dataset, true positives () are the correctly classifies Alzheimer’s disease patient volumes, true negatives () are the correctly classified number of cognitive normal volumes, false positives () represent uncorrected classified volumes as cognitive normal patients and () are cognitive normals classified as Alzheimer’s disease patients.
For comparison purposes, the results provided by the machine learning-based classification modules are used as a baseline, following the lines proposed in [
58]. In this specific case, DARTEL-modulated gray matter probability maps obtained from the T1-weighted MRI images are used to calculate a linear kernel using the Gram matrix from the feature vectors of the subjects provided (all the voxels in the volume). This kernel is used as input for a generic SVM whose cost parameter is optimized to improve the balanced accuracy by means of an exhaustive grid search. This process is repeated on both aged over 60 and reduced datasets, for each split.
4.2. SVM Parameters and Kernel Selection
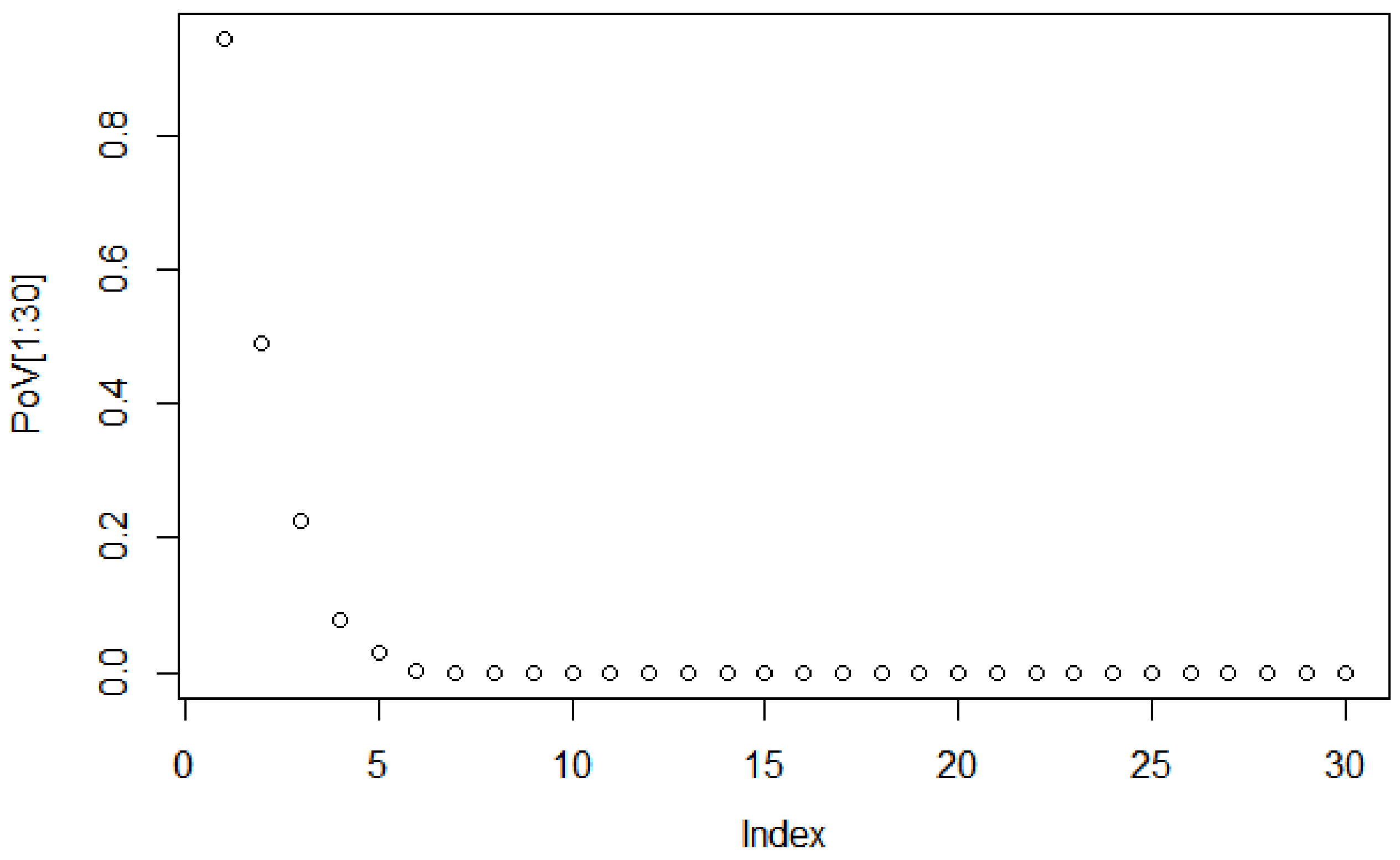
To decide the suitable size of the PCA-based dimensionality reduction, the scree graph method is used. The scree graph [
59] shows the the eigenvalues of the covariance against number of principal components. The scree test is used to decide on the size of the feature vector via visual analysis, by looking for a “break” between the components with relatively large eigenvalues and those with small eigenvalues. When the curve bends displaying an “elbow”, it is assumed that the variance explained will not increase significantly with the addition of mere eigenvectors.
Figure 4 shows the scree graph, plotting the variance explained in terms of the first 30 main components of the dataset analysed. As can be seen, the elbow occurs between the 5th and 6th principal components; therefore, the first five components appear to be enough to describe the variance in the data.
Since we do not know the specific characteristics of the processed dataset and, therefore, we do not know which is the most appropriate kernel, generic linear, polynomial and radial kernels for the SVM classifier are tested. We apply a 10-fold cross-validation methodology, repeating the folding experiment 10 times for a total of 100 iterations of the algorithm for each of the training subsets of the dataset of subjects aged 60 and over.
Adjusting the parameters in an SVM classifier represents a compromise between achieving the model that best fits the training set and maintaining the classifier ability to generalize to new data (see [
60]). A process of parameter optimization (model fitting) can lead to a hyperplane too focused on classifying each element of the training set correctly, resulting in a loss of generalization properties. While this does not have to result in an overfitting problem, it is a possibility that should be taken into account, so no optimization step is carried out on the presented models. The default parameters for the SVM in R are used ( 1 for the cost parameter,
for the gamma parameter and 3 for the degree parameter). From the results presented in
Table 3, we will select a linear kernel to carry out the rest of the experiments, as it represents an improvement all the performance measurements evaluated.
4.3. Classification
Table 4 shows the means of the results obtained with the dataset of subjects aged 60 and over (upper table) as well as with the reduced subset (lower table) using both the Clinica baseline and the proposed histon-based feature classification methods. Individual evaluation results for each split can be located in
Appendix B.
To assess whether the proposed method performs significantly better than the Clinica baseline classifier, we used McNemar’s chi-square tests. The use of histons as features represents an improvement in all the proposed evaluation metrics (McNemar test
p < 0.05 for all splits, except split 5). As can be appreciated from both the confusion matrix (see
Table 4, upper row) and the negative and positive prediction values (NPV and PPV), the errors of classification in the Clinica baseline have a slight bias towards false negatives, whereas, for the proposed method, errors are mainly associated with false positives. It should be noted the remarkable differences between the results presented in
Table 3 and
Table 4 for the aged 60 and over dataset. This is the result of the different evaluation strategies between the two cases. Cross-validation not only has a pessimistic bias (see [
57]), but the cross-validation folds are completely random, not respecting the age or gender distribution of the original dataset.
As expected, using the reduced dataset without the bias imposed by significant differences in gender between AD and CN groups and less variability in age, the results improve for both the Clinica baseline and the proposed method, as can be seen in
Table 4 (lower table). In this case, the proposed method provides better results for all evaluation metrics compared to the results with the aged 60 and over dataset. The distribution of errors does not differ from the previous scenario (see
Table 5, lower row). In this case, we can not claim significance for the results using the McNemar test.It should be noted that the McNemar’s chi-square test may be inadequate for small sample sizes [
61].
5. Conclusions
In this study, we propose the use of histons as a textural characteristic to carry out the categorization of T1-weighted MRI volumes, in order to separate Alzheimer’s disease and cognitive normal patients. Specifically, Clinica software is used to carry out a preprocessing stage: tissue segmentation, bias correction and spatial normalization to MNI space. After the normalization stage, we perform an over-segmentation using the aggregate volume for gray matter, white matter and cerebrospinal fluid, in order to provide a natural set of neighbourhoods for the histon-calculation process. Then, a subset of the vectors features is selected using PCA. Finally, we train SVM classifiers using the reduced features.
The use of a volume-based histon aims to exploit the relationship between gray matter, white matter and cerebrospinal fluid. For this purpose, the method for histon calculation presented in [
53] has been extended to volumetric images. The concept of histons represents a mean for visualization of color information for the evaluation of similar color regions in an image. Compared to other textural features, a histon is especially sensitive to subtle variations of color in relation to space, particularly when we provide a natural set of neighbourhoods for its creation through the use of supervoxels. This allows for quantifying the colour variations associated with neuronal degeneration on a RGB interpretation of an aggregation of the probability volumes for GM, WM and CSF.
Experimental results, on both the aged 60 and over and the reduced subset, have demonstrated a significant improvement in performance for AD versus CN classification compared to the direct voxel classification of the T1-weighted MRI volumes (baseline provided by Clinica). Although given the differences in age, gender, impairment and/or image quality between study populations it is impossible to make a direct comparison, in general, we can affirm that the results obtained are comparable to or better than those of similar textural methods (see [
33,
62] or [
34]). On the other hand, the current implementation of the method, where histons are calculated on the whole brain, does not assert specific spatial patterns of cerebral degeneration associated with Alzheimer’s disease. This may limit the method’s ability to discriminate in the presence of cerebral atrophy associated with other pathologies, or even in very elderly patients.
The use of a standardized work-flow, provided by Clinica, represents an important step towards the reproducibility of this research and its comparability with future developments. However, it should be noted that this pre-processing step can be computationally expensive, especially if large datasets are considered.
The remarkable results obtained with the method proposed suggest the extension of the study to other cases, such as discrimination between cognitive normal and mild cognitive disorder or to predict the evolution from mild cognitive disorder to Alzheimer’s disease, as well as to the expansion and refinement of the study group by extending it to other databases. In the future, it is planned to improve the discrimination capacity of the textural feature presented by applying it only to specific areas of the brain.

 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}



