Automatic Detection and Classification of Audio Events for Road Surveillance Applications

 ,
,
Abstract
1. Introduction
2. Methods and Materials
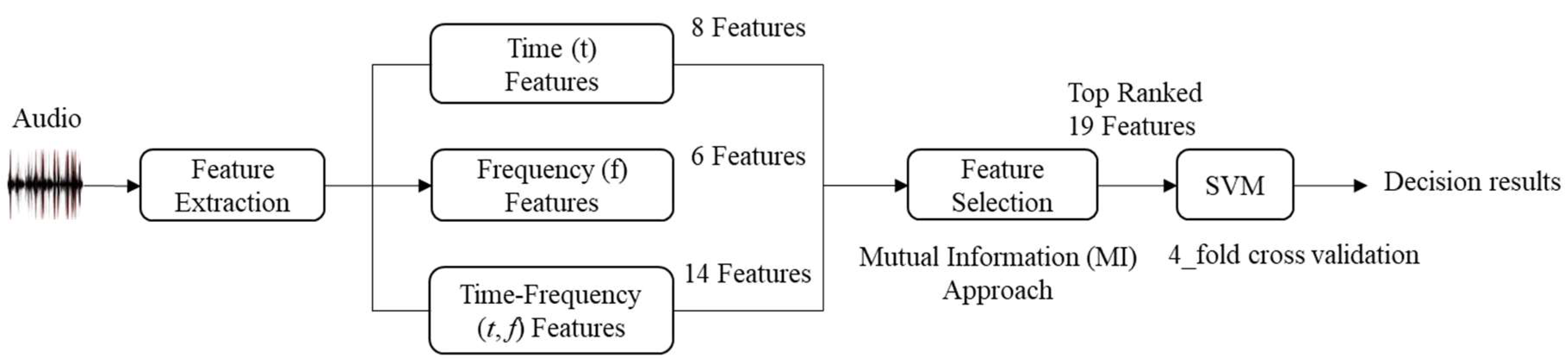
2.1. The Proposed Approach
2.1.1. Extraction of Audio Features
2.1.2. Temporal, Spectral, and Energy Features
2.1.3. Time-Frequency Domain based Approach for Event Detection and Classification
Extraction of Time-Frequency Features
Extension of Temporal and Spectral Features to Joint (t, f)-Domain Features
- The standard Mean of a temporal signal x[n] can be extended to (t, f)-domain as:where represents the TFD matrix of size () associated with the analytic signal y. Similarly, the STD, Skewness, Kurtosis measure and the Coefficient of variation are respectively expressed as,
- The Standard variance:
- The Skewness measure:
- The Kurtosis measure as:
- The Coefficient of Variation:
- The Spectral flux in the (t, f)-domain can be estimated from the TFD matrix of size () using the following expression.
- The Spectral Flatness in the (t, f)-domain is defined as follows.
- The Spectral Entropy in the (t, f)-domain can be expressed as,
- The Instantaneous Frequency (IF) of a mono-component signal corresponds to the peak frequency in the (t, f) plane and given by,
- Similarly, the Instantaneous Amplitude (IA) of a mono-component signal corresponds to the amplitude of the peak frequency in the (t, f) plane and can be expressed as,
- The (t, f) complexity measure, a SVD-based feature is derived from the Shannon entropy of the singular values of the TFD matrix . The TFD matrix is first decomposed into two subspaces given as,where U and V are orthogonal matrixes of order Here is a diagonal matrix and values of are known as the singular values of the TFD matrix.here represents the nth normalized singular value.
- The TFD concentration measure of a multicomponent audio signal can be represented as,
- The geometric features such as Convex Hull and Aspect ratio are image descriptors, extracted from a TFD matrix, when considered as an image. These features give the information regarding the geometry of energy concentration regions in the (t, f) plane. The segmentation technique such as water-shed is first applied on the TFD matrix to detect the regions where most of the TFD energy appears, and then a binary segmented image is generated, where represents the number of (t, f) regions. Finally, the geometric features are extracted from the moments of , given by,where n and m = 0, 1, 2, …
2.2. Proposed Feature Selection Scheme
2.3. SVM-Based Classifier
2.4. Data Set and Experiment Setup
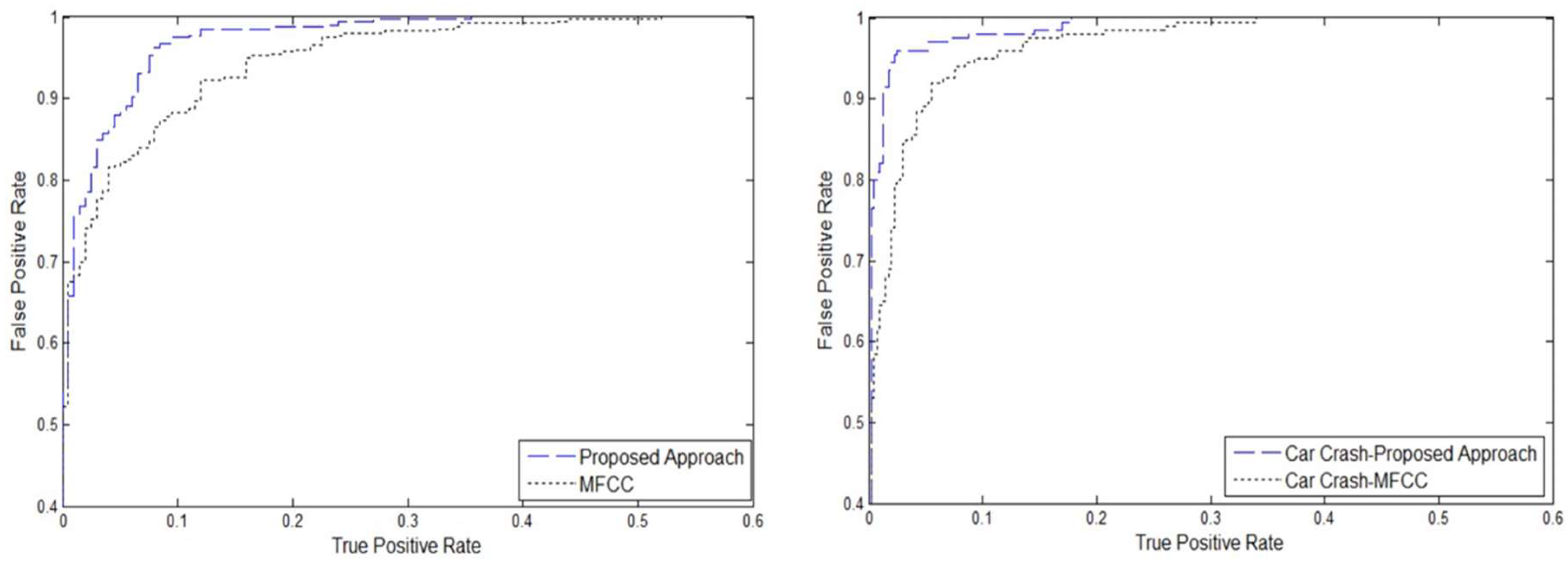
3. Results and Discussions
4. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Ali, H.M.; Alwan, Z.S. Car Accident Detection and Notification System Using Smartphone. Int. J. Comput. Sci. Mob. Comput. 2015, 44, 620–635. [Google Scholar]
- Bener, A. The neglected epidemic: Road traffic accidents in a developing country, State of Qatar. Int. J. Inj. Control Saf. Promot. 2005, 12, 45–47. [Google Scholar] [CrossRef] [PubMed]
- Heron, M. Deaths: Leading Causes for 2014. Natl. Vital Stat Rep. 2016, 65, 1–96. [Google Scholar] [PubMed]
- National Highway Traffic Safety Administration. Traffic Safety Facts 2015: A Compilation of Motor Vehicle Crash Data from the Fatality Analysis Reporting System and the General Estimates System; National Highway Traffic Safety Administration: Washington, DC, USA, 2015.
- Evanco, W.M. The Impact of Rapid Incident Detection on Freeway Accident Fatalities. Mitretek: McLean, VA, USA, 1996. [Google Scholar]
- White, J.; Thompson, C.; Turner, H.; Dougherty, B.; Schmidt, D.C. WreckWatch: Automatic traffic accident detection and notification with smartphones. Mob. Networks Appl. 2011, 16, 285–303. [Google Scholar] [CrossRef]
- Clark, D.E.; Cushing, B.M. Predicted effect of automatic crash notification on traffic mortality. Accid. Anal. Prev. 2002, 34, 507–513. [Google Scholar] [CrossRef]
- Thompson, C.; White, J.; Dougherty, B.; Albright, A.; Schmidt, D.C. Using smartphones to detect car accidents and provide situational awareness to emergency responders. In Proceedings of the International Conference on Mobile Wireless Middleware, Operating Systems, and Applications, Chicago, IL, USA, 30 June–2 July 2010; Springer: Berlin/Heidelberg, Germany; pp. 29–42. [Google Scholar]
- Champion, H.R.; Augenstein, J.; Blatt, A.J.; Cushing, B.; Digges, K.; Siegel, J.H.; Flanigan, M.C. Automatic Crash Notification and the URGENCY algorithm: its history, value, and use. Adv. Emerg. Nurs. J. 2004, 26, 143–156. [Google Scholar]
- Bouttefroy, P.; Beghdadi, A.; Bouzerdoum, A.; Phung, S. Markov random fields for abnormal behavior detection on highways. In Proceedings of the 2010 2nd European Workshop on Visual Information Processing (EUVIP), Paris, France, 5–6 July 2010. [Google Scholar]
- Bouttefroy, P.L.M.; Bouzerdoum, A.; Phung, S.L.; Beghdadi, A. Vehicle Tracking using Projective Particle Filter. In Proceedings of the 6th IEEE International Conference on Advanced Video and Signal Based Surveillance, Genoa, Italy, 2–4 September 2009. [Google Scholar]
- Bouttefroy, P.L.M.; Bouzerdoum, A.; Phung, S.L.; Beghdadi, A. Abnormal behavior detection using a multi-modal stochastic learning approach. In Proceedings of the 2008 International Conference on Intelligent Sensors, Sensor Networks and Information Processing (ISSNIP 2008), Sydney, Australia, 15–18 December 2008; pp. 121–126. [Google Scholar]
- Foggia, P.; Petkov, N.; Saggese, A.; Strisciuglio, N.; Vento, M. Audio surveillance of roads: A system for detecting anomalous sounds. IEEE Trans Intell. Transp. Syst. 2016, 17, 279–288. [Google Scholar] [CrossRef]
- Crocco, M.; Cristani, M.; Trucco, A.; Murino, V. Audio Surveillance: A Systematic Review. arXiv, 2014; arXiv:1409.7787v1. [Google Scholar]
- Farid, M.S.; Mahmood, A.; Al-Maadeed, S.A. Multi-focus image fusion using Content Adaptive Blurring. Inf. Fusion 2019, 45, 96–112. [Google Scholar] [CrossRef]
- Foggia, P.; Petkov, N.; Saggese, A.; Strisciuglio, N.; Vento, M. Reliable detection of audio events in highly noisy environments. Pattern Recognit. Lett. 2015, 65, 22–28. [Google Scholar] [CrossRef]
- Carletti, V.; Foggia, P.; Percannella, G.; Saggese, A.; Strisciuglio, N.; Vento, M. Audio surveillance using a bag of aural words classifier. In Proceedings of the 2013 10th IEEE International Conference on Advanced Video and Signal Based Surveillance, Krakow, Poland, 27–30 August 2013; pp. 81–86. [Google Scholar]
- Jiang, R.; Al-Maadeed, S.; Bouridane, A.; Crookes, D.; Celebi, M.E. Face Recognition in the Scrambled Domain via Salience-Aware Ensembles of Many Kernels. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1807–1817. [Google Scholar] [CrossRef]
- Foggia, P.; Saggese, A.; Strisciuglio, N.; Vento, M.; Petkov, N. Car crashes detection by audio analysis in crowded roads. In Proceedings of the 2015 12th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Karlsruhe, Germany, 25–28 August 2015. [Google Scholar]
- Di Lascio, R.; Foggia, P.; Percannella, G.; Saggese, A.; Vento, M. A real time algorithm for people tracking using contextual reasoning. Comput. Vis. Image Underst. 2013, 117, 892–908. [Google Scholar] [CrossRef]
- Yan, L.; Zhang, Y.; He, Y.; Gao, S.; Zhu, D.; Ran, B.; Wu, Q. Hazardous Traffic Event Detection Using Markov Blanket and Sequential Minimal Optimization (MB-SMO). Sensors 2016, 16, 1084. [Google Scholar] [CrossRef] [PubMed]
- Saggese, A.; Strisciuglio, A.; Vento, M.; Petkov, N. Time-frequency analysis for audio event detection in real scenarios. In Proceedings of the 2016 13th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Colorado Springs, CO, USA, 23–26 August 2016; pp. 438–443. [Google Scholar]
- Foggia, P.; Saggese, A.; Strisciuglio, A.; Vento, M. Cascade classifiers trained on gammatonegrams for reliably detecting audio events. In Proceedings of the 2014 11th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Seoul, South Korea, 26–29 August 2014; pp. 50–55. [Google Scholar]
- Radhakrishnan, R.; Divakaran, A.; Smaragdis, A. Audio analysis for surveillance applications. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY, USA, 16 October 2005; pp. 158–161. [Google Scholar]
- Vacher, M.; Istrate, D.; Besacier, L. Sound detection and classification for medical telesurvey. In Proceedings of the 2nd Conference on Biomedical Engineering, Innsbruck, Austria, 16–18 February 2004; pp. 395–399. [Google Scholar]
- Clavel, C.; Ehrette, T.; Richard, G. Events detection for an audio-based surveillance system. In Proceedings of the 2005 IEEE International Conference on Multimedia and Expo (ICME 2005), Amsterdam, The Netherlands, 6 July 2005; Volume 2005, pp. 1306–1309. [Google Scholar]
- Valenzise, G.; Gerosa, L.; Tagliasacchi, M.; Antonacci, F.; Sarti, A. Scream and gunshot detection and localization for audio-surveillance systems. In Proceedings of the 2007 IEEE Conference on Advanced Video and Signal Based Surveillance (AVSS 2007), London, UK, 5–7 September 2007; pp. 21–26. [Google Scholar]
- Dufaux, A.; Besacier, L.; Ansorge, M.; Pellandini, F. Automatic Sound Detection and Recognition for Noisy Environment. In Proceedings of the 10th European Signal Processing Conference, Tampere, Finland, 4–8 September 2000; pp. 1–4. [Google Scholar]
- Gerosa, L.; Valenzise, G.; Tagliasacchi, M.; Antonacci, F.; Sarti, A. Scream and gunshot detection in noisy environments. In Proceedings of the 15th European Signal Processing Conference, Poznan, Poland, 3–7 September 2007; pp. 1216–1220. [Google Scholar]
- Ntalampiras, S.; Potamitis, I.; Fakotakis, N. On Acoustic Surveillance of Hazardous Situations. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2009), Taipei, Taiwan, 19–24 April 2009; pp. 165–168. [Google Scholar]
- Rouas, J.-L.; Louradour, J.; Ambellouis, S. Audio Events Detection in Public Transport Vehicle. In Proceedings of the 2006 IEEE Intelligent Transportation Systems Conference (ITSC ’06), Toronto, ON, Canada, 17–20 September 2006; pp. 733–738. [Google Scholar]
- Ntalampiras, S.; Potamitis, I.; Fakotakis, N. An adaptive framework for acoustic monitoring of potential hazards. Eurasip J. Audio Speech Music Process. 2009, 2009, 594103. [Google Scholar] [CrossRef]
- Conte, D.; Foggia, P.; Percannella, G.; Saggese, A.; Vento, M. An ensemble of rejecting classifiers for anomaly detection of audio events. In Proceedings of the 2012 IEEE Ninth International Conference on Advanced Video and Signal-Based Surveillance (AVSS), Beijing, China, 18–21 September 2012; pp. 76–81. [Google Scholar]
- Boashash, B.; Azemi, G.; Ali Khan, N. Principles of time-frequency feature extraction for change detection in non-stationary signals: Applications to newborn EEG abnormality detection. Pattern Recognit. 2015, 48, 616–627. [Google Scholar] [CrossRef]
- Qian, K.; Zhang, Z.; Ringeval, F.; Schuller, B. Bird sounds classification by large scale acoustic features and extreme learning machine. In Proceedings of the 2015 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Orlando, FL, USA, 14–16 December 2015; pp. 1317–1321. [Google Scholar]
- Giannakopoulos, T.; Pikrakis, A.; Theodoridis, S. A multi-class audio classification method with respect to violent content in movies using Bayesian Networks. In Proceedings of the 2007 IEEE 9th Workshop on Multimedia Signal Processing (MMSP 2007), Crete, Greece, 1–3 October 2007; pp. 90–93. [Google Scholar]
- Boubchir, L.; Al-Maadeed, S.; Bouridane, A. Effectiveness of combined time-frequency image and signal-based features for improving the detection and classification of epileptic seizure activities in EEG signals. In Proceedings of the 2014 International Conference on Control, Decision and Information Technologies (CoDIT), Metz, France, 3–5 November 2014; pp. 673–678. [Google Scholar]
- Boashash, B. Time-Frequency Signal Analysis and Processing: A Comprehensive Reference; Academic Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Hassanpour, H.; Mesbah, M.; Boashash, B. Time-frequency feature extraction of newborn EEC seizure using SVD-based techniques. EURASIP J. Appl. Signal Process. 2004, 2004, 2544–2554. [Google Scholar]
- Boubchir, L.; Daachi, B.; Pangracious, V. A Review of Feature Extraction for EEG Epileptic Seizure Detection and Classification. In Proceedings of the 2017 40th International Conference on Telecommunications and Signal Processing (TSP), Barcelona, Spain, 5–7 July 2017; pp. 456–460. [Google Scholar]
- Boubchir, L.; Touati, Y.; Daachi, B.; Cherif, A.A. EEG error potentials detection and classification using time-frequency features for robot reinforcement learning. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 1761–1764. [Google Scholar]
- Khan, N.A.; Ali, S. Classification of EEG signals using adaptive Time-Frequency distributions. Metrol. Meas. Syst. 2016, 23, 251–260. [Google Scholar] [CrossRef]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information: Criteria of Max-Dependency, Max-Relevance, and Min-Redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.; Lin, C. LIBSVM: A Library for Support Vector Machines. ACM Trans. Intell. Syst. Technol. 2013, 2, 1–39. [Google Scholar] [CrossRef]
- Rajpoot, K.; Rajpoot, N. SVM optimization for hyperspectral colon tissue cell classification. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Saint-Malo, Brittany, 26–29 September 2004; pp. 829–837. [Google Scholar]
- Souli, S.; Lachiri, Z. Audio sounds classification using scattering features and support vectors machines for medical surveillance. Appl. Acoust. 2018, 130, 270–282. [Google Scholar] [CrossRef]
- Young, S.; Evermann, G.; Gales, M.; Hain, T.; Kershaw, D.; Liu, X.; Moore, G.; Odell, J.; Ollason, D.; Povey, D.; et al. The HTK Book (for HTK Version 3.4.1); Microsoft Corporation: Washington, WA, USA, 2002. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Temporal Features | Spectral Features |
|---|---|
| The of a time domain audio signal is given by, | The can be estimated by taking the sum of absolute difference of the Fourier transforms (FTs) of the signal, |
| The of a time-domain is given as, | here is the FT of the frame of the time-domain signal. |
| The can be expressed as, | |
| The of time-domain is represented as, | |
| where | |
| The of a time domain signal is given as, | The is defined as the geometric means of the FT of a signal normalized by its arithmetic mean |
| The of a time-domain signal is given as, | here is the FT of the analytic associate of a real signal, and is the length of signal . |
| The can be expressed as, | |
| of a time-domain signal ca be represented as, | |
| where represents a threshold. | |
| The of a time-domain signal can be represented as, | can be represented as, |
| where and represents is a sign function | Maximum power of the frequency bands can be represented as, |
| Class | # Events | Duration (s) |
|---|---|---|
| CC | 200 | 326.3 |
| TS | 200 | 522.5 |
| BN | - | 2737 |
| Time and Frequency Features | Time-Frequency Features | Selected Features |
|---|---|---|
| Mean (t) | Mean (t, f) | Variance (t, f) |
| Variance (t) | Variance (t, f) | Coefficient of Variation (t, f) |
| Skewness (t) | Coefficient of Variation (t, f) | Skewness (t, f) |
| Coefficient of Variation (t) | Skewness (t, f) | Flatness (t, f) |
| Kurtosis (t) | Kurtosis (t, f) | Spectral Entropy (t, f) |
| Energy Entropy (t) | Flatness (t, f) | Spectral Flux (t, f) |
| Zero Crossing Rate (t) | Renyi Entropy (t, f) | Instantaneous Amplitude (t, f) |
| Short-Time Energy (t) | Spectral Flux (t, f) | SVD-based Feature (t, f) |
| Flatness (f) | Instantaneous Frequency (t, f) | TFD Concentration Measure (t, f) |
| Spectral Entropy (f) | Instantaneous Amplitude (t, f) | Aspect Ratio (t, f) |
| Spectral Roll-off (f) | SVD-based Features (t, f) | Flatness (f) |
| Spectral Centroid (f) | TFD Concentration Measure (t, f) | Spectral Entropy (f) |
| Spectral Flux (f) | Area or Convex Hull (t, f) | Spectral Flux (f) |
| Maximum power | Aspect Ratio (t, f) | Spectral Centroid (f) |
| of the frequency bands (f) | Spectral Roll-off (f) | |
| Skewness (t) | ||
| Kurtosis (t) | ||
| Energy Entropy (t) | ||
| Short-Time Energy (t) |
| (a) Proposed Approach | (b) MFCC Features [47] | ||||||
|---|---|---|---|---|---|---|---|
| Predicted Class | |||||||
| TS | CC | BN | TS | CC | BN | ||
| True Class | TS | 94% | 3% | 3% | 85.5% | 5% | 9% |
| CC | 1.5% | 96% | 2.5% | 0% | 92.5% | 7.5% | |
| BN | 8% | 2% | 90% | 5.5% | 8.5% | 86% | |
| (c) Temporal and Spectral Features [13] | (d) MFCC Features (BoW) [13] | ||||||
| Predicted Class | |||||||
| TS | CC | BN | TS | CC | BN | ||
| TS | 75.0% | 0.5% | 24.5% | 71% | 0.5% | 28.5% | |
| CC | 0% | 89% | 11% | 1% | 89.5% | 9.5% | |
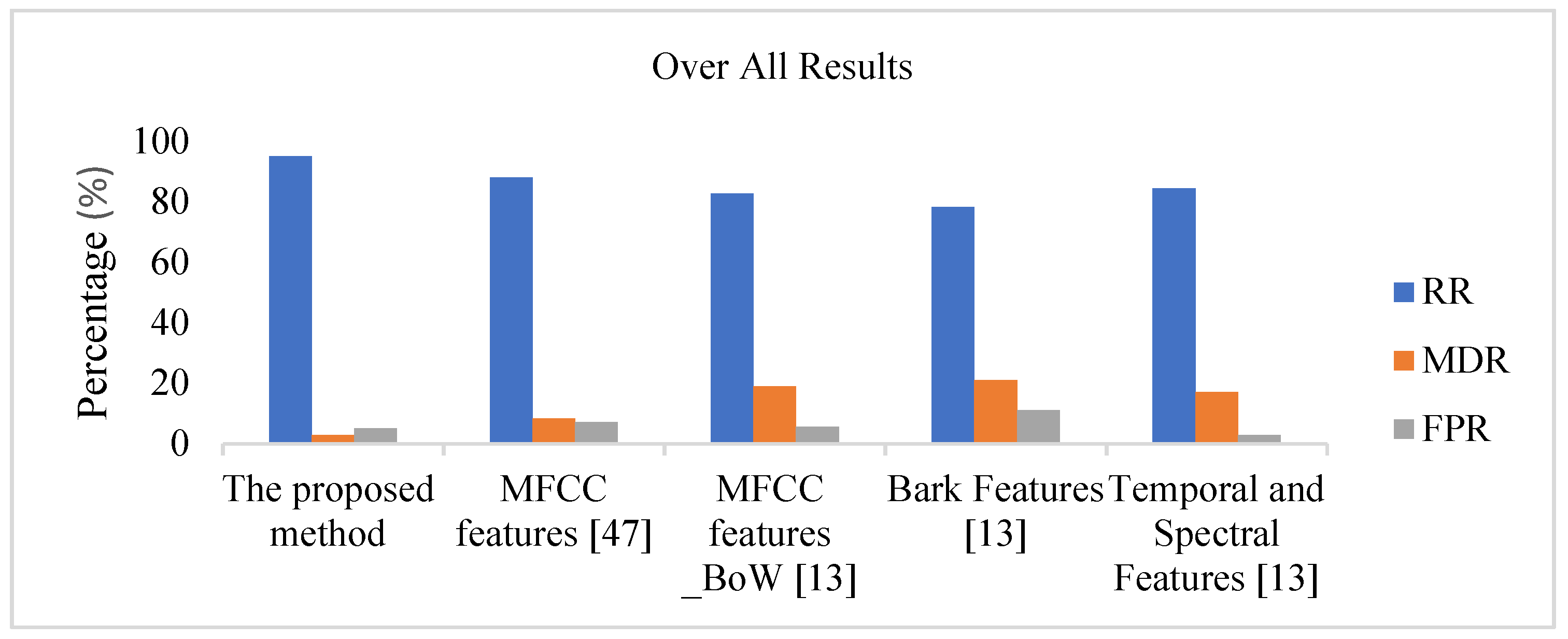
| Methods | RR (%) | MDR (%) | FPR (%) | AUC (%) |
|---|---|---|---|---|
| Bark Features [13] | 78.20 | 21 | 10.96 | 86 |
| MFCC Features_BoW [13] | 82.65 | 19 | 5.48 | 90 |
| Temporal and Spectral | 84.5 | 17.75 | 2.85 | 80 |
| Features [13] | ||||
| MFCC Features [47] | 88 | 8.25 | 7 | 96.72 |
| Proposed Approach | 95 | 2.75 | 5 | 98.32 |
| Features | RR (%) |
|---|---|
| Temporal | 61 |
| Spectral | 81.5 |
| Time-Frequency | 84 |
| Joint set of Features | 93 |
| Proposed set of features | 95 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almaadeed, N.; Asim, M.; Al-Maadeed, S.; Bouridane, A.; Beghdadi, A. Automatic Detection and Classification of Audio Events for Road Surveillance Applications. Sensors 2018, 18, 1858. https://doi.org/10.3390/s18061858
Almaadeed N, Asim M, Al-Maadeed S, Bouridane A, Beghdadi A. Automatic Detection and Classification of Audio Events for Road Surveillance Applications. Sensors. 2018; 18(6):1858. https://doi.org/10.3390/s18061858
Chicago/Turabian StyleAlmaadeed, Noor, Muhammad Asim, Somaya Al-Maadeed, Ahmed Bouridane, and Azeddine Beghdadi. 2018. "Automatic Detection and Classification of Audio Events for Road Surveillance Applications" Sensors 18, no. 6: 1858. https://doi.org/10.3390/s18061858
APA StyleAlmaadeed, N., Asim, M., Al-Maadeed, S., Bouridane, A., & Beghdadi, A. (2018). Automatic Detection and Classification of Audio Events for Road Surveillance Applications. Sensors, 18(6), 1858. https://doi.org/10.3390/s18061858