Distributed Power Allocation for Wireless Sensor Network Localization: A Potential Game Approach


Abstract
:1. Introduction
- (i)
- If we have some prior information of agent nodes, such as the central points and standard deviations of hotspots, the distribution can be modeled as a simple diffusion model [29] or Coefficient of Variation (CoV) of the Voronoi cell area [30]. It is reasonable to collect the prior information by statistical analysis or experience in some practical applications. However, all previous related works did not consider this situation, and their research may not be suitable to achieve a solution.
- (ii)
- If we cannot obtain any prior information about agent nodes in the service area, the distribution probabilities can be estimated by anchor nodes. In this case, two phases will be implemented. In the first phase, each agent node obtains its position by unoptimized power management strategies of anchor nodes. In the next phase, anchor nodes will achieve a trade-off between power consumption and localization accuracy after estimating the distribution of agent nodes. This method may cause unavoidable estimation error compared to the actual situation. The feasibility and preliminaries are the main purpose in our work, and we will perfect this weakness.
- We develop the service area of a WSN localization system to determine power allocation strategies. To the best of our knowledge, this is the first time that the performance of the service area, rather than particular agent nodes, has been considered.
- We propose a power management game to determine power allocation strategies of anchor nodes in a distributed WSN localization system. After designing the potential function, it is proven that the proposed game is a continuous exact potential game, and the better response algorithm can be used to find a -equilibrium point as the end solution.
- We exploit the effects of different distributions of agent nodes on the power allocation strategies when prior distribution information is available. We also derive the estimated distribution of agent nodes to manage power allocation strategies when prior knowledge is unknown. Numerical results show that different equilibrium solutions are achieved, and the performance of the proposed strategies outperforms the uniform strategies and prior power management strategies for particular agent nodes.
2. System Models and Problem Formulation
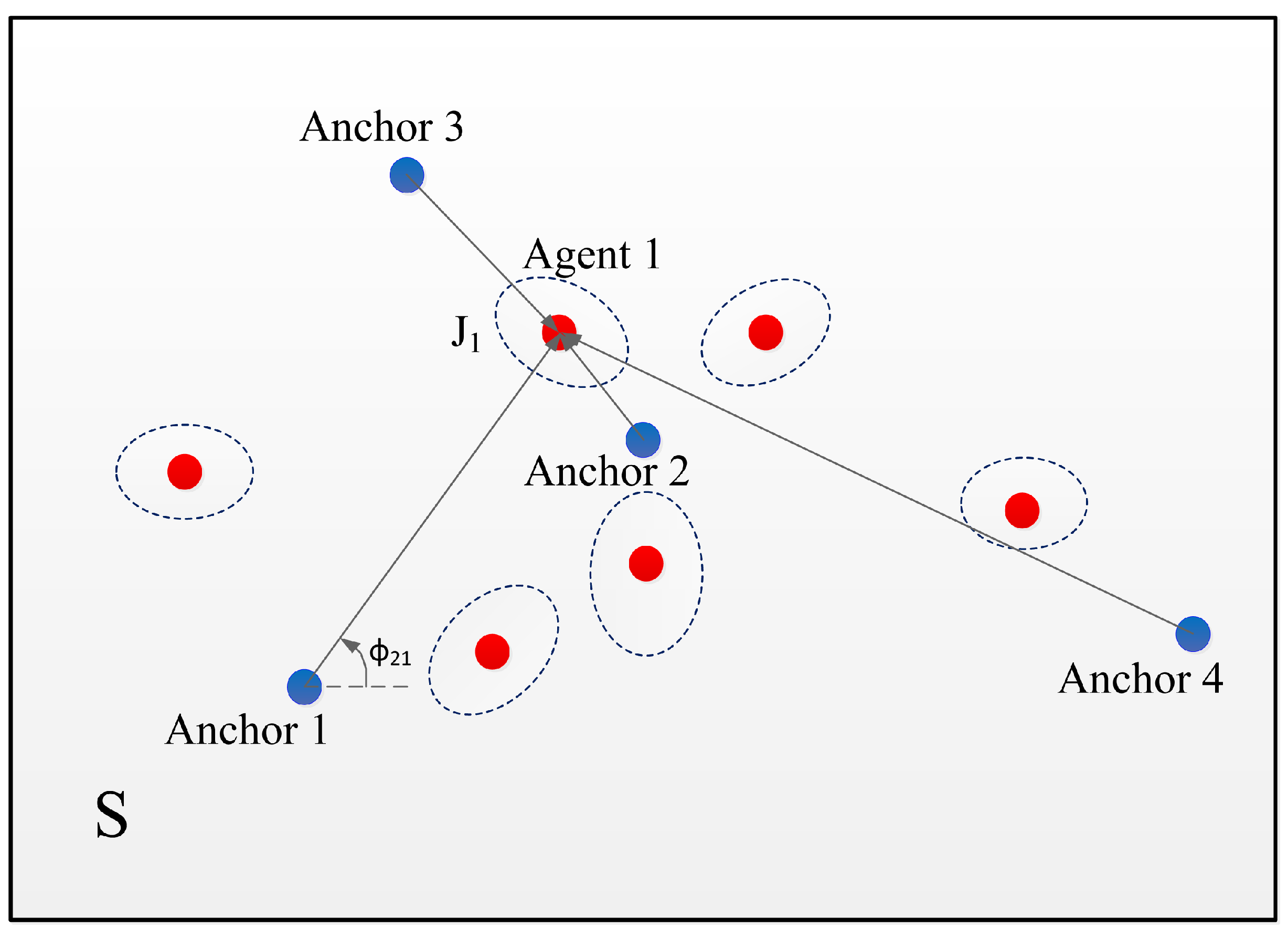
2.1. Network Model
2.2. The SPEB of the Service Area
2.3. Problem Formulation
3. Potential Game for Power Allocation
3.1. Power Allocation Game Framework
3.2. Analysis of NE
- (i)
- Every potential game has at least one pure strategy NE;
- (ii)
- Any global or local maximum of the potential function constitutes a pure strategy NE.
3.3. Achieving the -Equilibrium
| Algorithm 1 Better response-based power allocation algorithm. |
|
3.4. Complexity Analysis
4. Numerical Results
4.1. Scenario Setup
4.2. Performance with Prior Knowledge
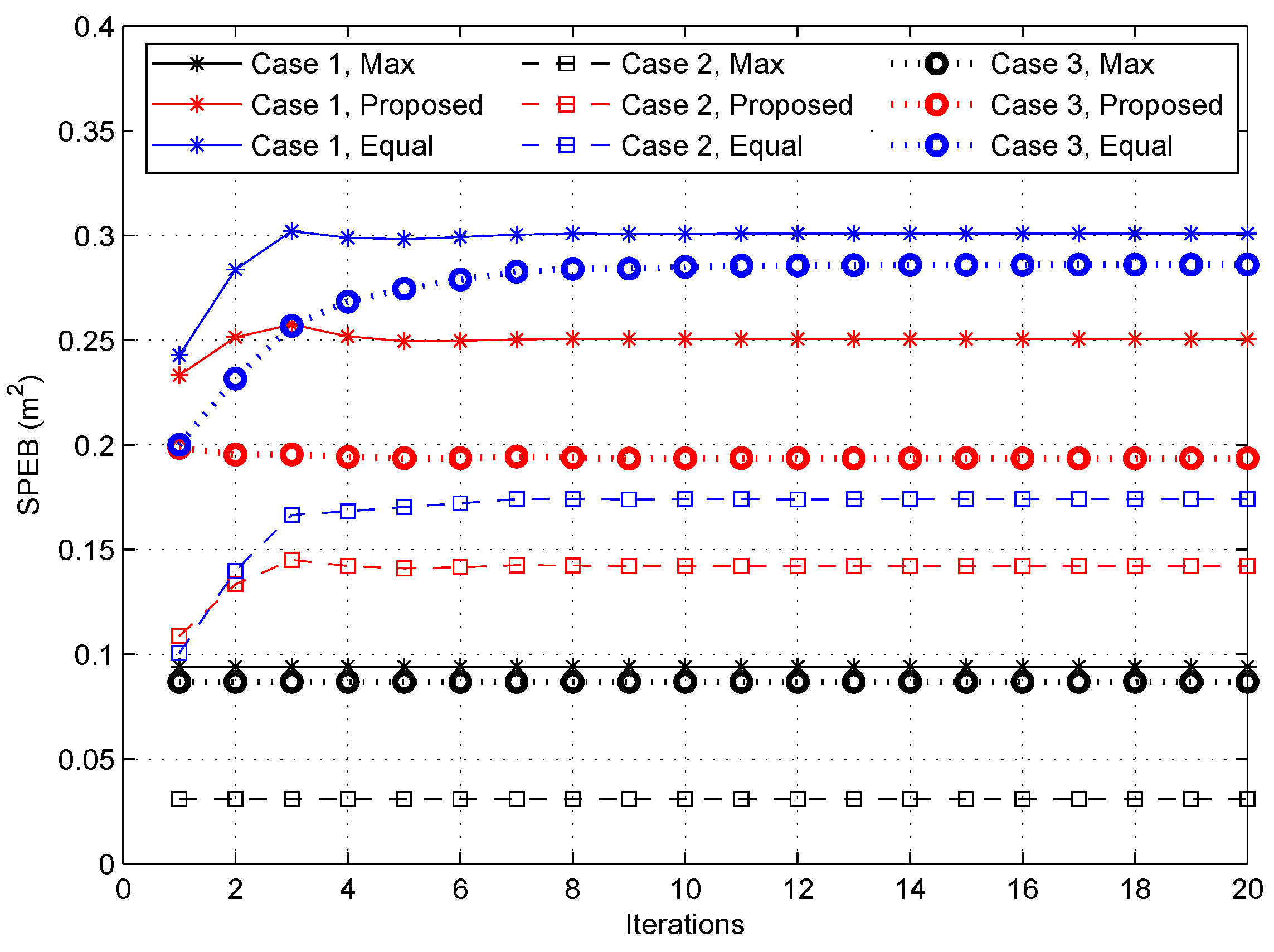
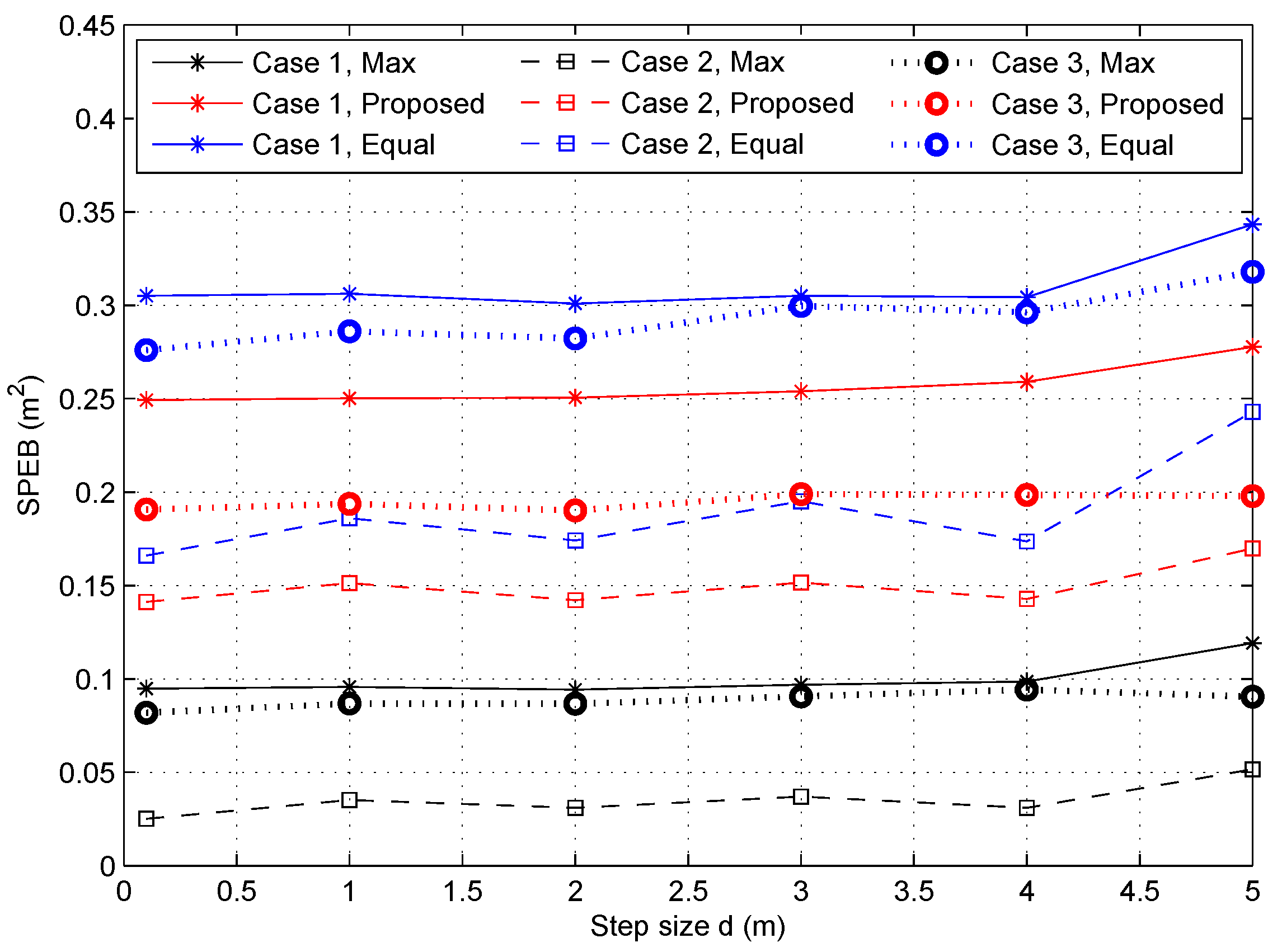
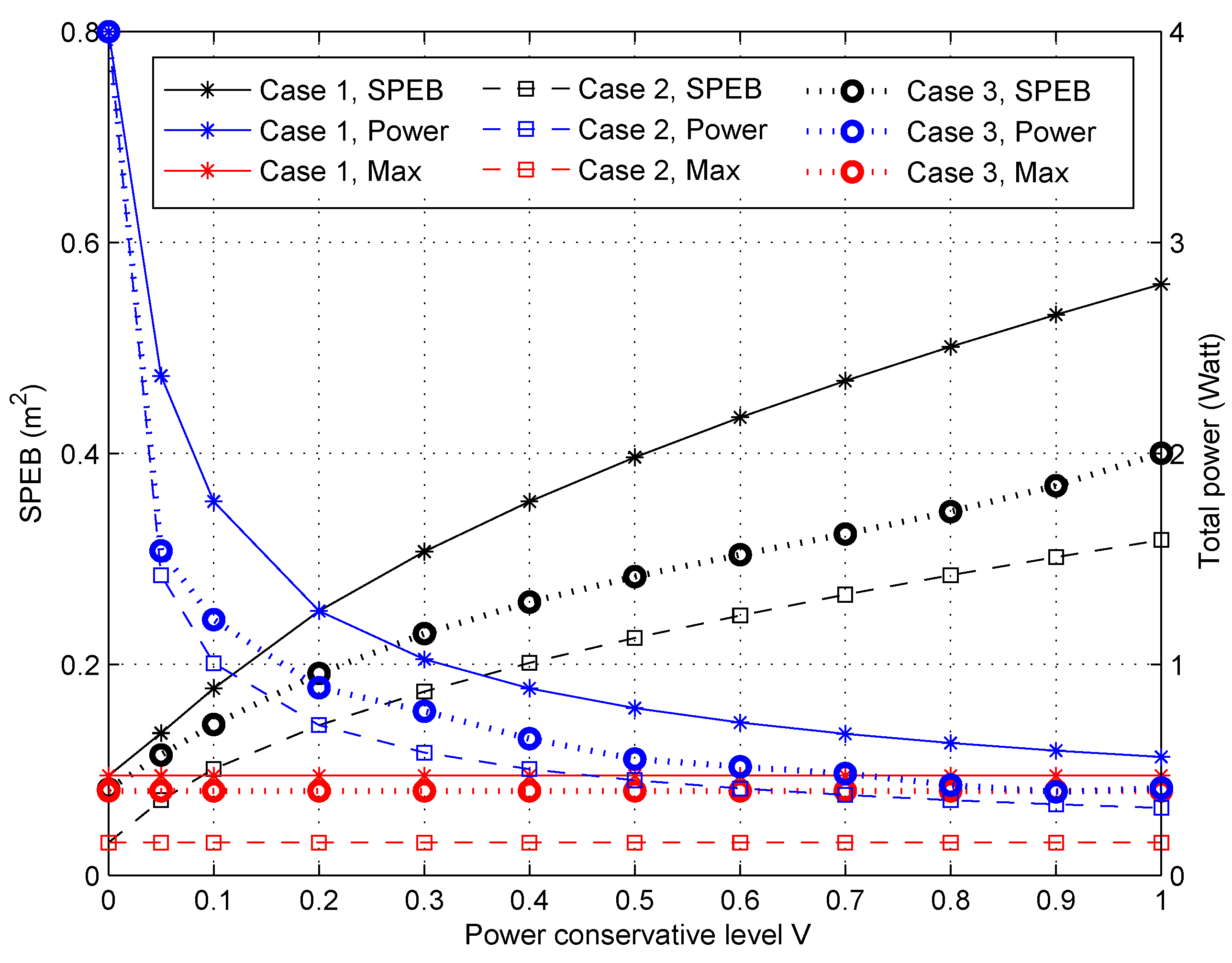
- Case 1: All the agent nodes are uniformly distributed in the service area, which means the probability density function is .
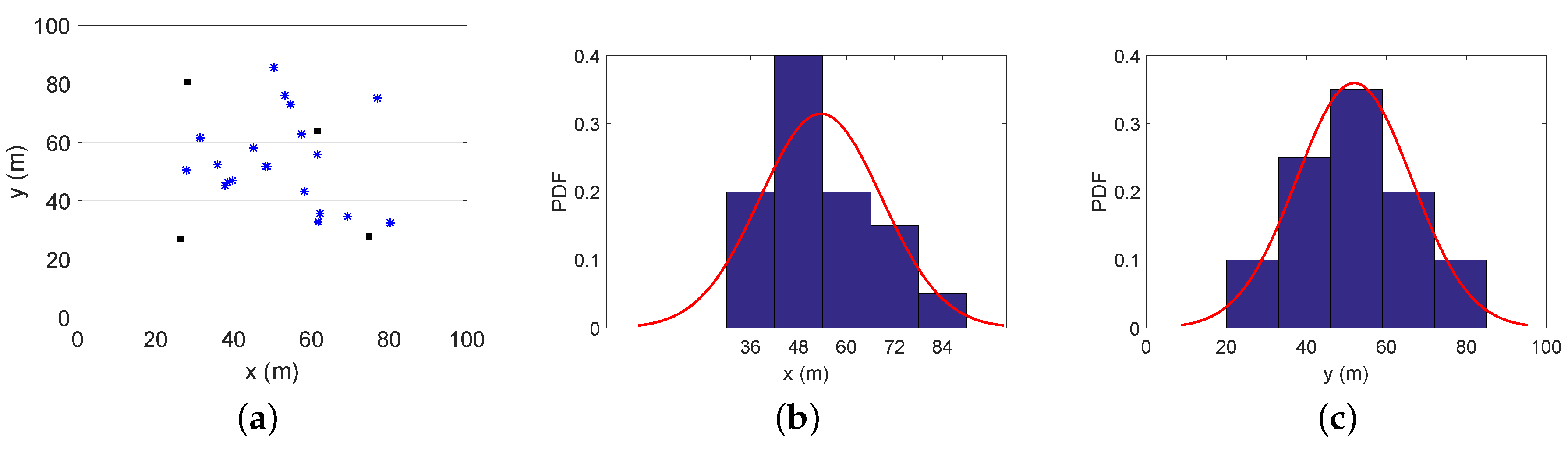
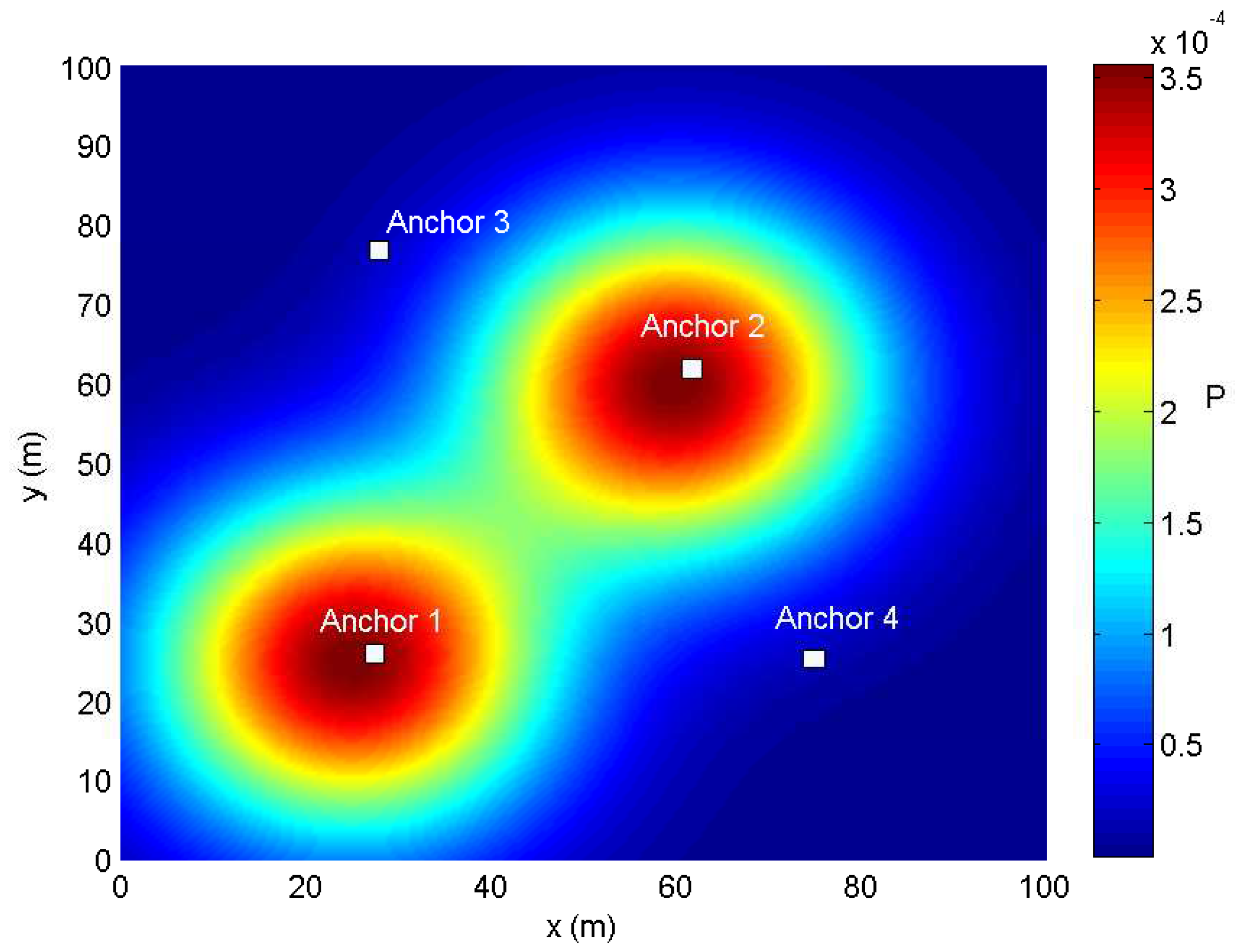
- Case 2: In a general way, agent nodes may focus on some special areas such as a passageway or a seat in an auditorium, called hotspots. However, the outline of special areas and the probability density should be set according to the actual condition. In this paper, the distribution of agent nodes is simply set analogous to the nodes’ placement in sensor networks, which is called as a simple diffusion model in [29]. Then, we consider that there are two special areas as shown in Figure 2, and the probability density function (PDF) of agent nodes’ positions is given by:Here, we set the central point of special areas as (25,25) and (60,60), which are close to two anchor nodes, and the variances are . The is divided by the normalization of the PDF in the service area given by:
- Case 3: For more general situations, agent nodes are non-uniformly distributed as a simple diffusion model, but the central point of the special area is a random distribution in the service area. Different from Case 2, we assume that the central point is , and the PDF of agent nodes’ positions is:where the variances are and c is a two-dimensional uniform distribution in the service area . The is also used to normalize the PDF defined by:
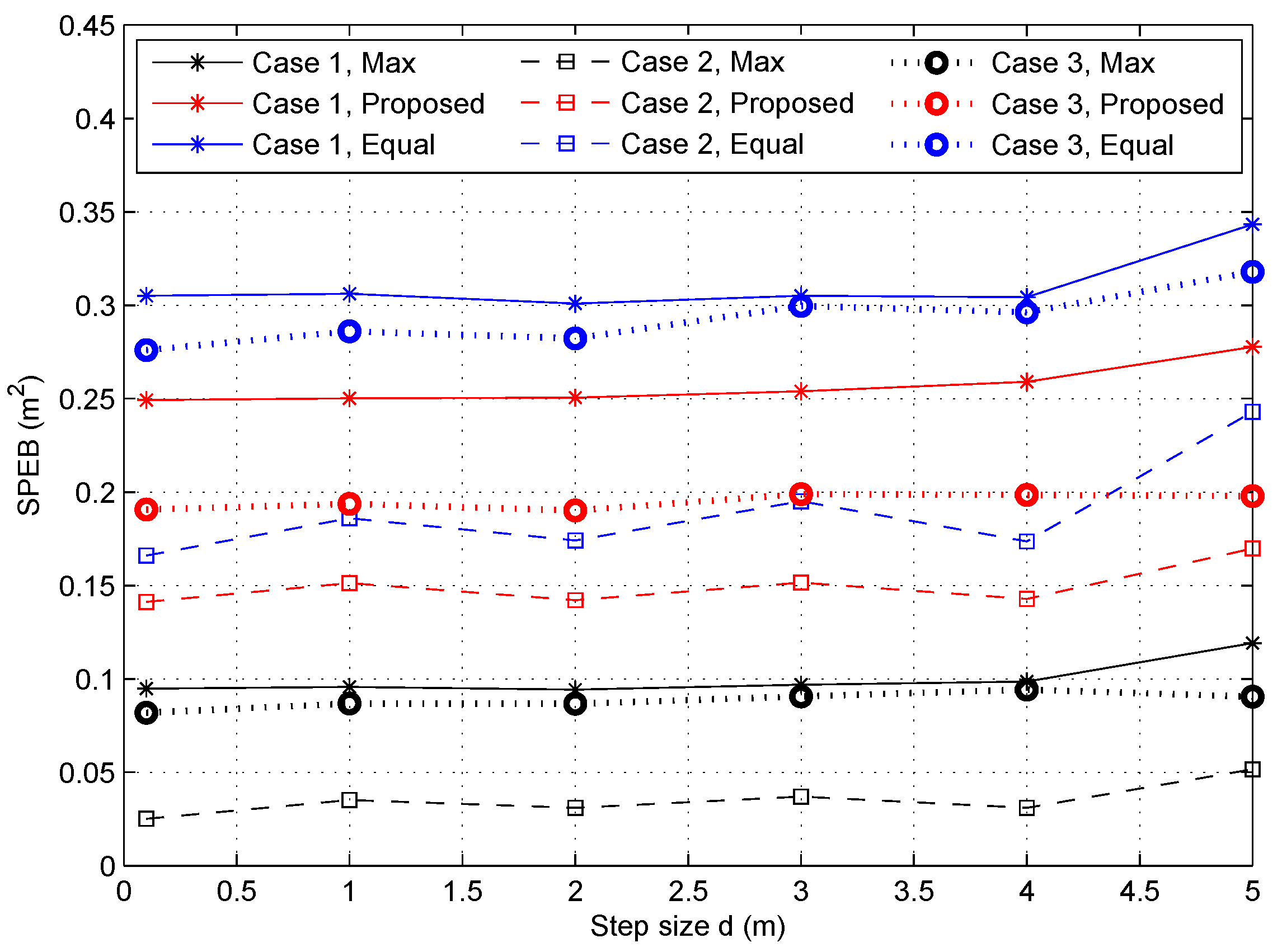
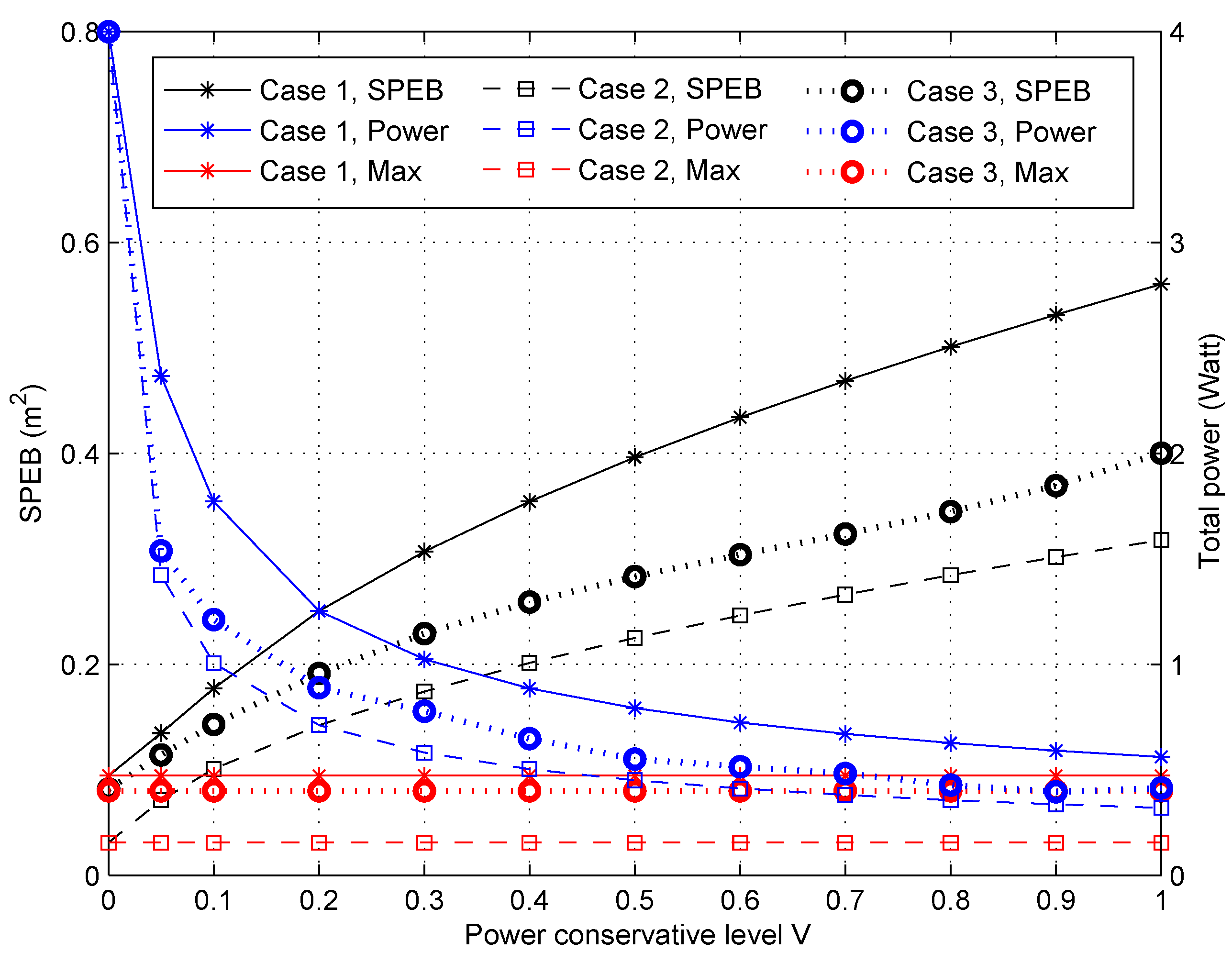
- Max-power: Each anchor node transmits the maximum power, i.e., . This is the practical situation without power optimization;
- The proposed game power allocation: Every anchor node obtains the power allocation strategy through Algorithm 1, i.e., ;
- Equal-power: All anchor nodes adopt the uniform power allocation strategies with the same total power in the proposed game power allocation strategies [16], i.e., .
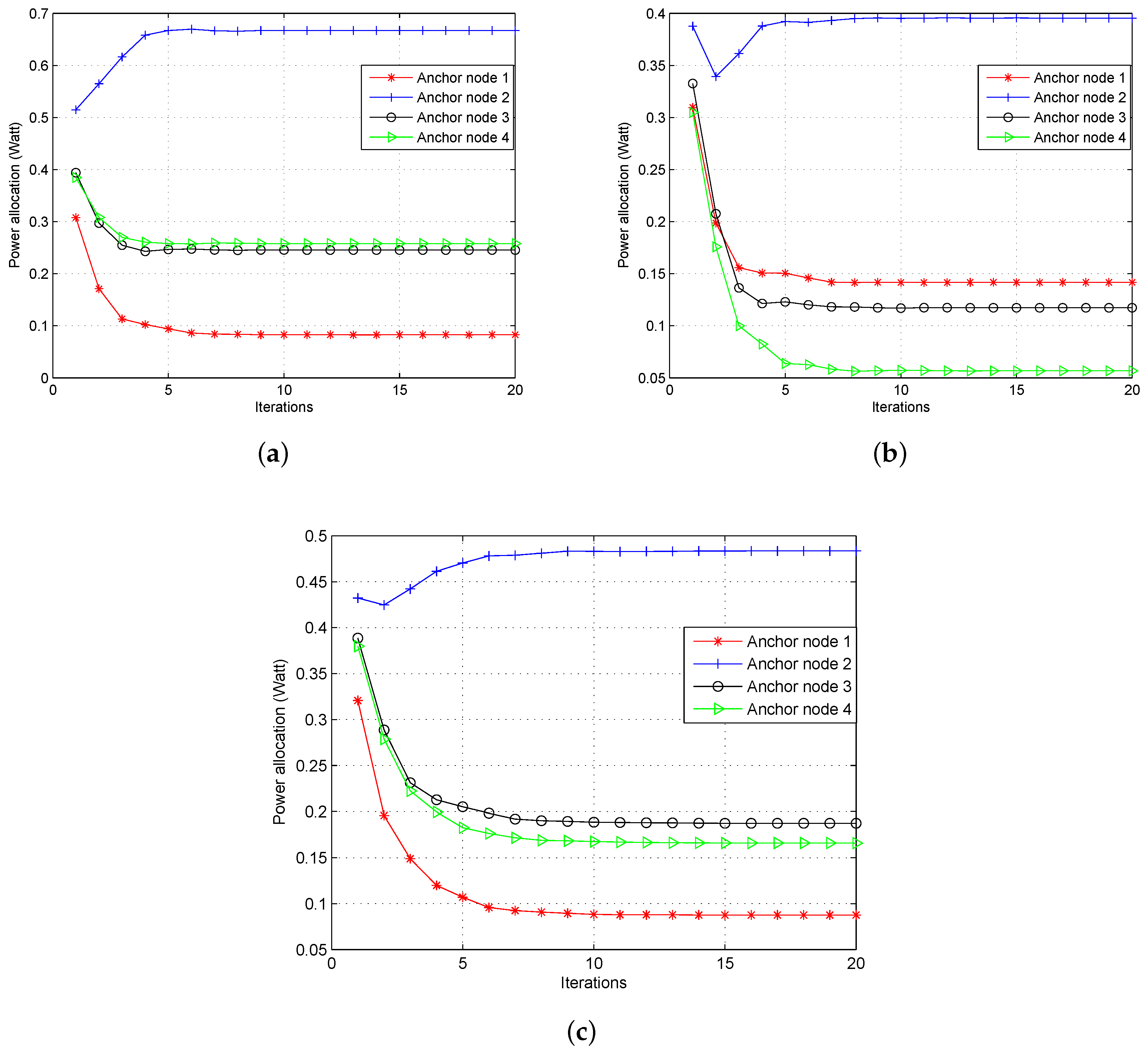
4.2.1. Power Allocation Strategies
4.2.2. The SPEB in Different Power Allocation Strategies
4.2.3. Localization Performance with Respect to Partition Step Size d
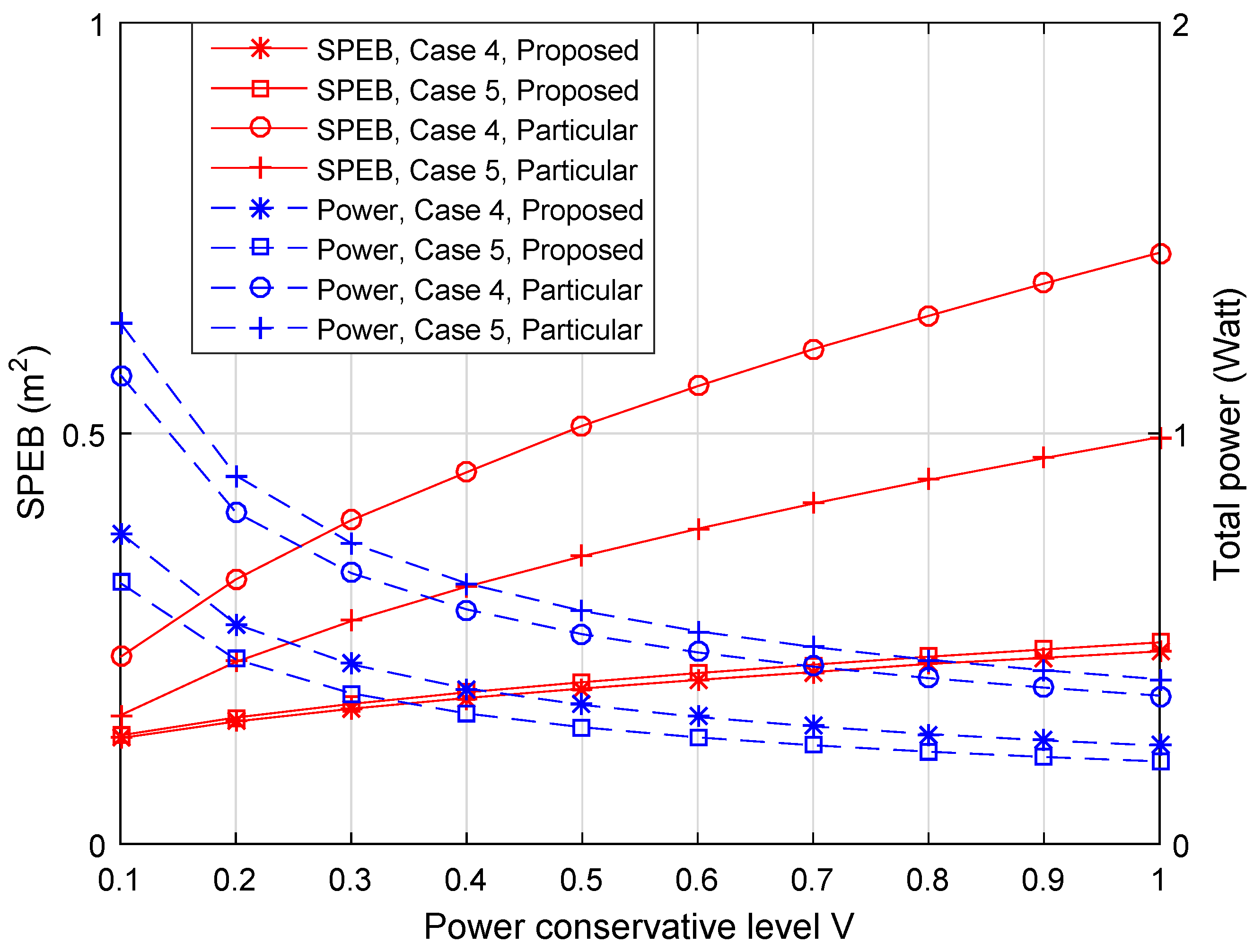
4.2.4. Performance of Different Anchor-Specific Power Conservation Levels
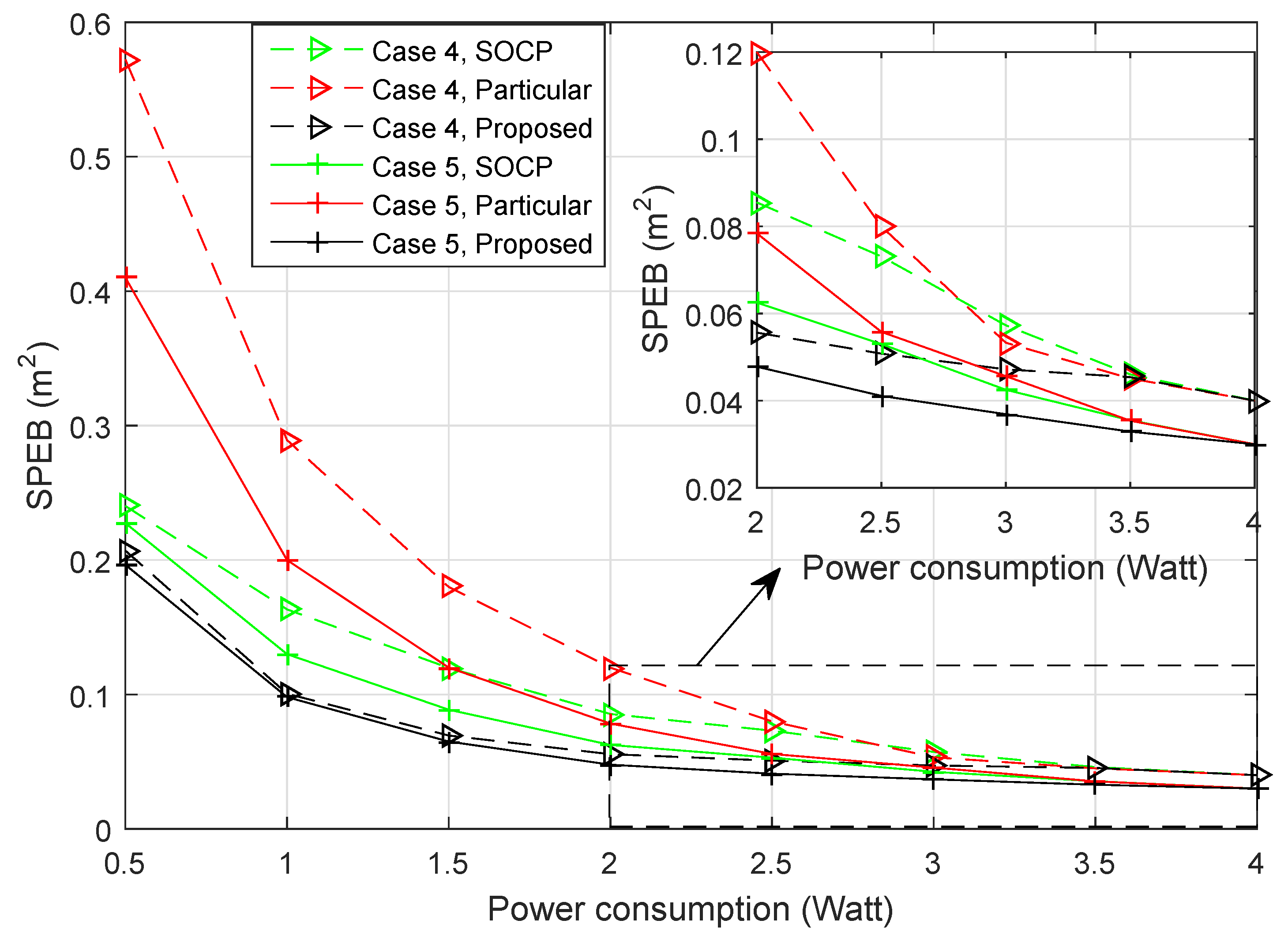
4.3. Performance without Prior Knowledge
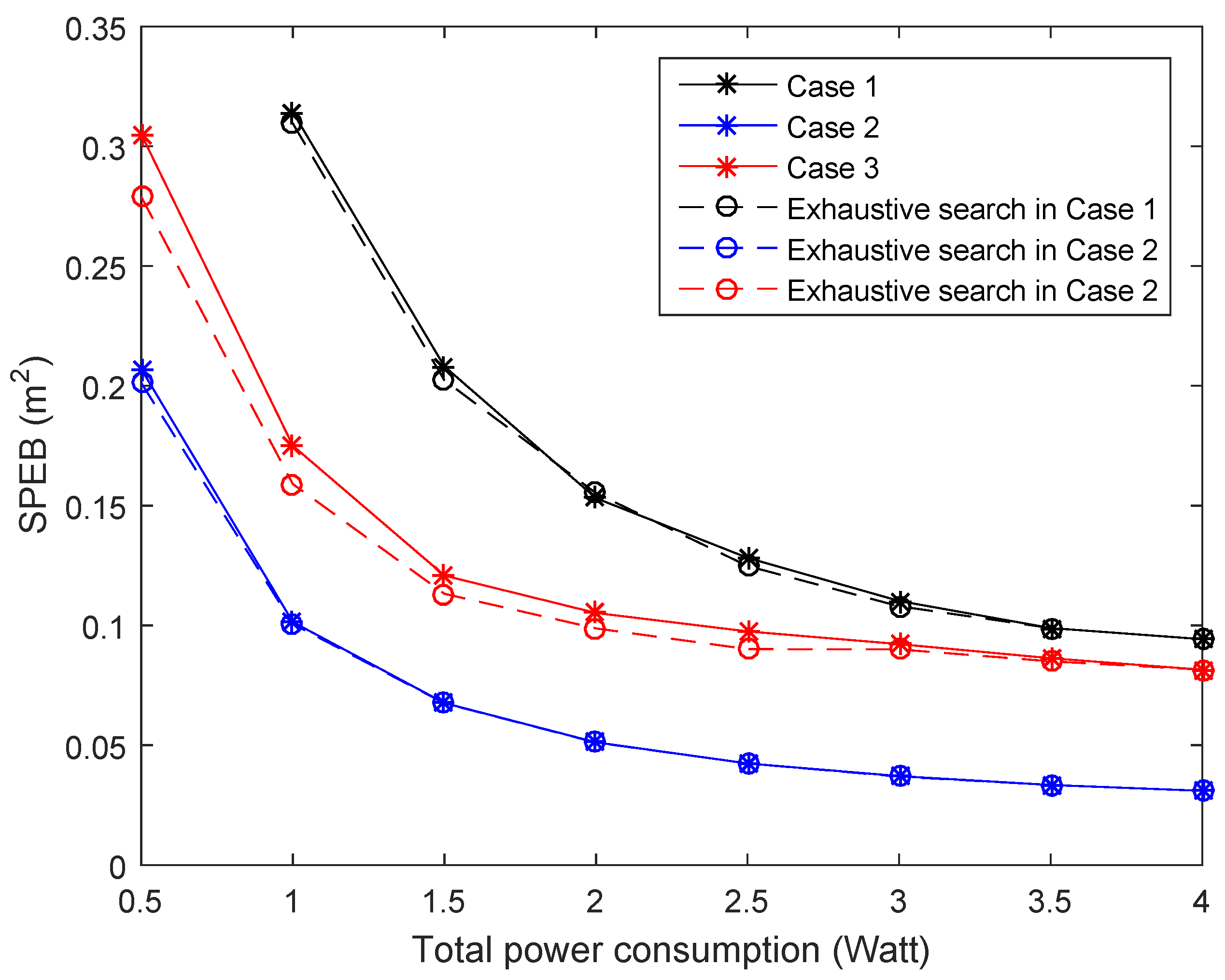
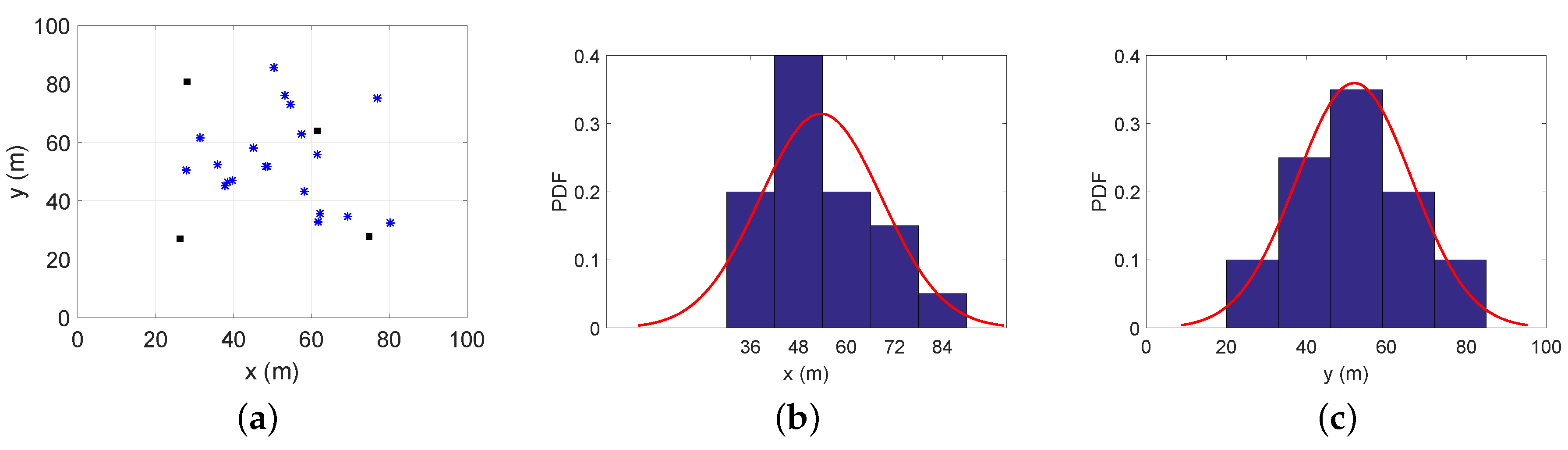
- Case 4: There are 20 agent nodes distributed around the hotspot point (50,50);
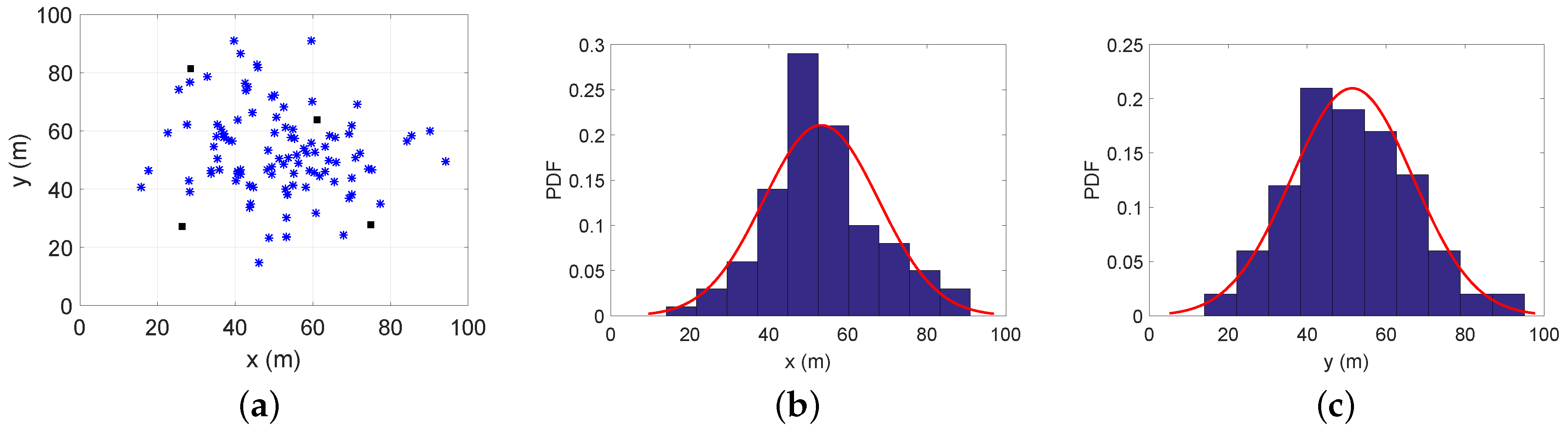
- Case 5: There are 100 agent nodes distributed around the hotspot point (50,50).
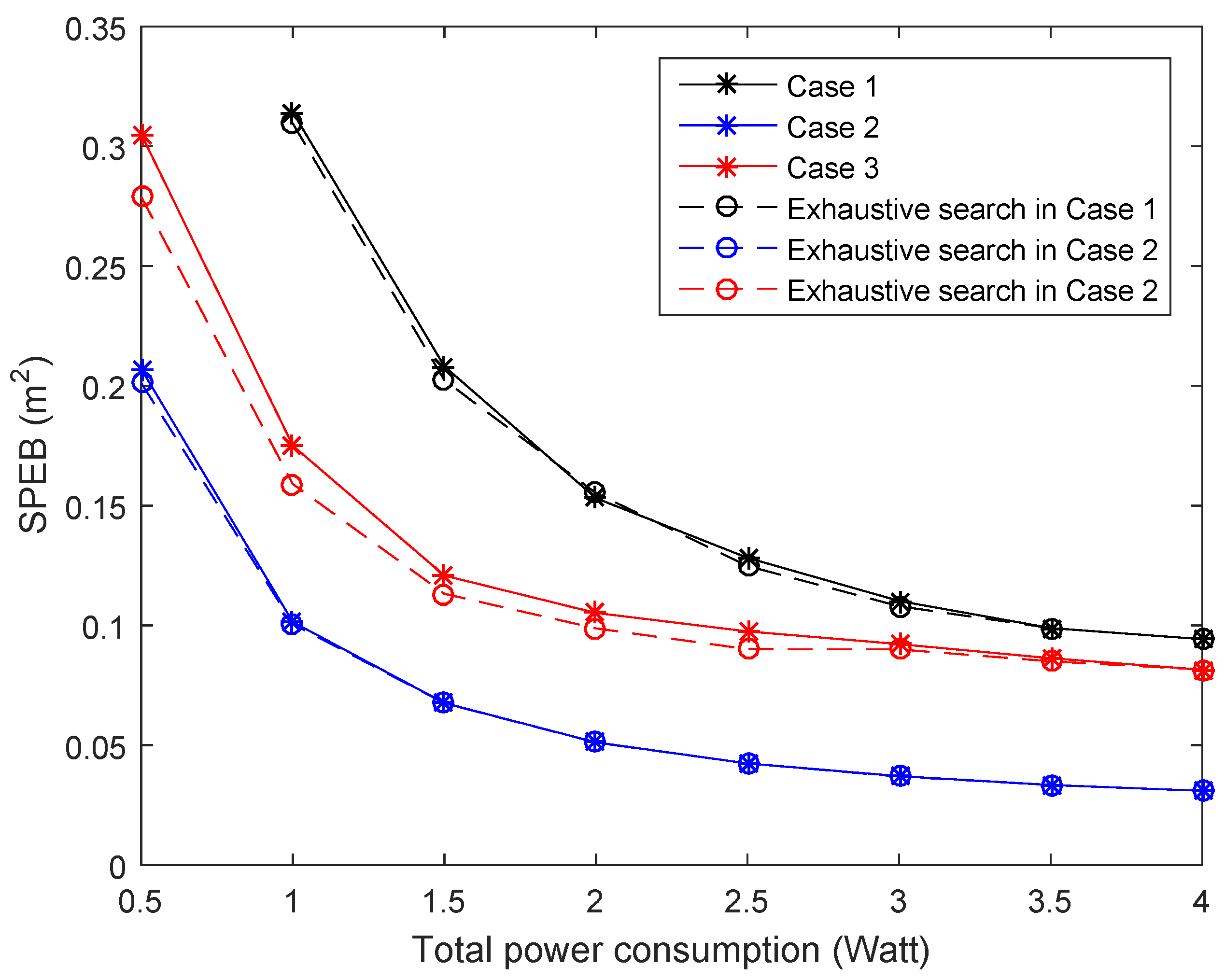
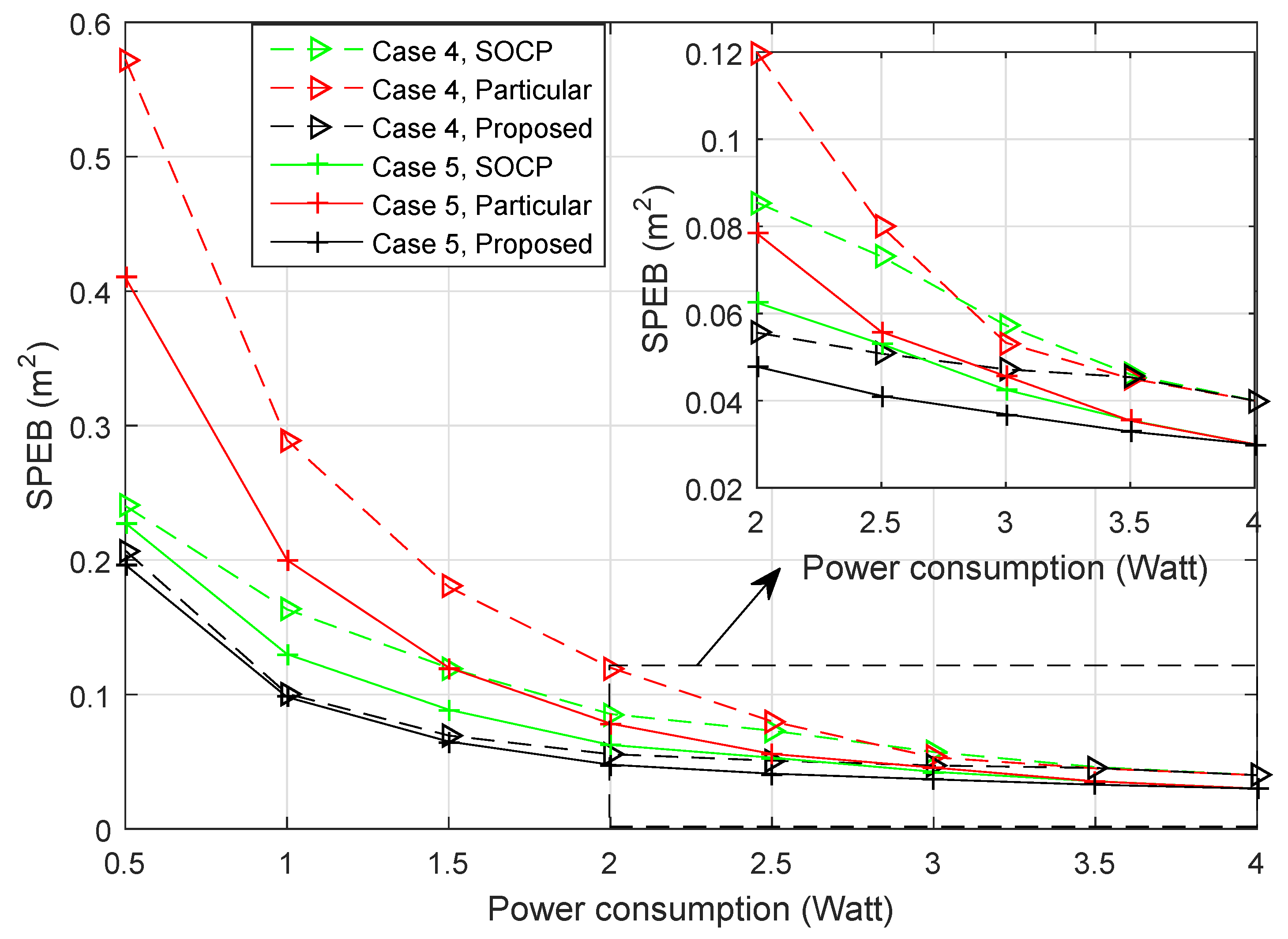
- Second-order cone program (SOCP): The power allocation problem was transformed into second-order cone programs in [15]. While the strategies only considered particular agent nodes, due to multiple agent nodes being distributed in the service area, we get the power allocation strategy for every agent node and the average SPEB for all agent nodes at the same time. For example, for the particular Agent Node 1, anchor nodes will obtain a power allocation strategy, and the average SPEB for all agent nodes can be calculated with this strategy. Then, we choose the strategy with the least average SPEB to compare with proposed strategies.
- The game strategies for particular agents: When only a particular agent is considered, the power allocation strategies also can be obtained by a potential game approach. Different from the proposed approach, the optimal objective is given by:With the similar proof method and solving algorithm of the proposed approach, we can get the power allocation strategies for . Here, we also choose the strategy with the least average SPEB to compare with different strategies.
- The proposed strategy for the estimation distribution: When the distribution of agent nodes is estimated, each anchor node obtains the power allocation strategy through the proposed Algorithm 1.
Performance of Different Strategies
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Han, G.; Jiang, J.; Zhang, C.; Duong, T.Q.; Guizani, M.; Karagiannidis, G.K. A survey on mobile anchor node assisted localization in wireless sensor networks. IEEE Commun. Surv. Tutor. 2016, 18, 2220–2243. [Google Scholar] [CrossRef]
- Sayed, A.H.; Tarighat, A.; Khajehnouri, N. Network-based wirelesslocation: Challenges faced in developing techniques for accurate wireless location information, IEEE Signal Process. Mag. 2005, 22, 24–40. [Google Scholar] [CrossRef]
- Gezici, S.; Tian, Z.; Giannakis, G.B.; Kobayashi, H.; Molisch, A.F.; Poor, H.V.; Sahinoglu, Z. Localization via ultra-wideband radios: A look at positioning aspects for future sensor networks. IEEE Signal Process. Mag. 2005, 22, 70–84. [Google Scholar] [CrossRef]
- Santos, F. Localization in wireless sensor networks. ACM J. 2008, 5, 1–19. [Google Scholar]
- Wymeersch, H.; Lien, J.; Win, M.Z. Cooperative localization in wireless networks. Proc. IEEE 2009, 97, 427–450. [Google Scholar] [CrossRef]
- Guvenc, I.; Chong, C.C. A survey on TOA based wireless localization and NLOS mitigation techniques. IEEE Commun. Surv. Tutor. 2009, 11, 107–124. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, Z.; Wang, X.; Jian, L. Location, localization, and localizability. J. Comput. Sci. Technol. 2010, 25, 274–297. [Google Scholar] [CrossRef]
- Win, M.Z.; Conti, A.; Mazuelas, S.; Shen, Y.; Gifford, W.M.; Dardari, D.; Chiani, M. Network localization and navigation via cooperation. IEEE Commun. Mag. 2011, 49, 56–62. [Google Scholar] [CrossRef]
- Zeng, Y.; Cao, J.; Hong, J.; Zhang, S.; Xie, L. Secure localization and location verification in wireless sensor networks: A survey. J. Supercomput. 2013, 64, 685–701. [Google Scholar] [CrossRef]
- Wu, Y.; Chen, W. An intelligent target localization in wireless sensor networks. In Proceedings of the International Conference on Intelligent Green Building and Smart Grid, Taipei, Taiwan, 23–25 April 2014; pp. 1–4. [Google Scholar]
- Dai, W.; Shen, Y.; Win, M.Z. On the minimum number of active anchors for optimal localization. In Proceedings of the IEEE Global Telecommunications Conference, Anaheim, CA, USA, 3–7 December 2012; pp. 4951–4956. [Google Scholar]
- Shen, Y.; Win, M.Z. Fundamental limits of wideband localization—Part I: A general framework. IEEE Trans. Inf. Theory 2010, 56, 4956–4980. [Google Scholar] [CrossRef]
- Dai, W.; Shen, Y.; Win, M.Z. A Computational Geometry Framework for Efficient Network Localization. IEEE Trans. Inf. Theory 2018, 64, 1317–1339. [Google Scholar] [CrossRef]
- Li, W.W.-L.; Shen, Y.; Zhang, Y.J.; Win, M.Z. Robust power allocation for energy-efficient location-aware networks. IEEE/ACM Trans. Netw. 2013, 21, 1918–1930. [Google Scholar] [CrossRef]
- Shen, Y.; Dai, W.; Win, M.Z. Power optimization for network localization. IEEE/ACM Trans. Netw. 2014, 22, 1337–1350. [Google Scholar] [CrossRef]
- Dai, W.; Shen, Y.; Win, M.Z. Distributed power allocation for cooperative wireless network localization. IEEE J. Sel. Areas Commun. 2015, 33, 28–40. [Google Scholar] [CrossRef]
- Dai, W.; Shen, Y.; Win, M.Z. Energy-efficient network navigation algorithms. IEEE J. Sel. Areas Commun. 2015, 33, 1418–1430. [Google Scholar] [CrossRef]
- Chen, J.; Dai, W.; Shen, Y.; Lau, V.K.N.; Win, M.Z. Power management for cooperative localization: A game theoretical approach. IEEE Trans. Signal Process. 2016, 64, 6517–6532. [Google Scholar] [CrossRef]
- Gharehshiran, O.N.; Krishnamurthy, V. Coalition formation for bearings-only localization in sensor networks—A cooperative game approach. IEEE Trans. Signal Process. 2010, 58, 4322–4338. [Google Scholar] [CrossRef]
- Bejar, B.; Belanovic, P.; Zazo, S. Cooperative localization in wireless sensor networks using coalitional game theory. In Proceedings of the European Signal Processing Conference, Aalborg, Denmark, 23–27 August 2010; pp. 1459–1463. [Google Scholar]
- Ghassemi, F.; Krishnamurthy, V. A cooperative game-theoretic measurement allocation algorithm for localization in unattended ground sensor networks. In Proceedings of the IEEE International Conference on Information Fusion, Cologne, Germany, 30 June–3 July 2008; pp. 1–7. [Google Scholar]
- He, H.; Subramanian, A.; Shen, X.; Varshney, P.K. A coalitional game for distributed estimation in wireless sensor networks. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 4574–4578. [Google Scholar]
- Zhao, Z.; Zhang, R.; Cheng, X.; Yang, L.; Jiao, B. Network formation games for the link selection of cooperative localization in wireless networks. In Proceedings of the IEEE International Conference on Communications, Sydney, Australia, 10–14 June 2014; pp. 4577–4582. [Google Scholar]
- Moragrega, A.; Closas, P.; Ibars, C. Supermodular game for power control in TOA-based positioning. IEEE Trans. Signal Process. 2013, 61, 3246–3259. [Google Scholar] [CrossRef]
- Chen, J.; Dai, W.; Shen, Y.; Lau, V.K.N.; Win, M.Z. Power management game for cooperative localization in asynchronous networks. In Proceedings of the IEEE International Conference on Communications, London, UK, 8–12 June 2015; pp. 1506–1511. [Google Scholar]
- Chen, J.; Dai, W.; Shen, Y.; Lau, V.K.N.; Win, M.Z. Resource management games for distributed network localization. IEEE J. Sel. Areas Commun. 2017, 35, 317–329. [Google Scholar] [CrossRef]
- Ke, M.; Wang, Y.; Li, M.; Gao, F.; Du, Z. Distributed power allocation for cooperative localization: A potential game approach. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017; pp. 616–621. [Google Scholar]
- Ke, M.; Xu, Y.; Anpalagan, A.; Liu, D.; Zhang, Y. Distributed TOA-Based Positioning in Wireless Sensor Networks: A Potential Game Approach. IEEE Commun. Lett. 2018, 22, 316–319. [Google Scholar] [CrossRef]
- Ishizuka, M.; Aida, M. Performance study of node placement in sensor networks. In Proceedings of the 24th International Conference on Distributed Computing Systems Workshops, Tokyo, Japan, 26 March 2004; pp. 598–603. [Google Scholar]
- Mirahsan, M.; Schoenen, R.; Yanikomeroglu, H. HetHetNets: Heterogeneous traffic distribution in heterogeneous wireless cellular networks. IEEE J. Sel. Areas Commun. 2015, 33, 2252–2265. [Google Scholar] [CrossRef]
- Shen, Y.; Wymeersch, H.; Win, M.Z. Fundamental limits of wideband localization—Part II: Cooperative networks. IEEE Trans. Inf. Theory 2010, 56, 4981–5000. [Google Scholar] [CrossRef]
- Lin, Z.; Fu, M.; Diao, Y. Distributed self localization for relative position sensing networks in 2D space. IEEE Trans. Signal Process. 2015, 63, 3751–3761. [Google Scholar] [CrossRef]
- Lã, Q.D.; Chew, Y.H.; Soong, B.H. Potential Game Theory: Applications in Radio Resource Allocation; Springer: Berlin, Germany, 2016. [Google Scholar]
- Xu, Y.; Wang, J.; Wu, Q.; Anpalagan, A.; Yao, Y.D. Opportunistic spectrum access in cognitive radio networks: Global optimization using local interaction games. IEEE J. Sel. Top. Signal Process. 2012, 6, 180–194. [Google Scholar] [CrossRef]
- Marden, J.R.; Arslan, G.; Shamma, J.S. Joint strategy fictitious play with inertia for potential games. IEEE Trans. Autom. Control 2009, 54, 208–220. [Google Scholar] [CrossRef]
- Corts, A.; Martnez, S. Self-triggered best-response dynamics for continuous games. IEEE Trans. Autom. Control 2015, 60, 1115–1120. [Google Scholar] [CrossRef]
- Ahmadi, H.; Farhang, A.; Marchetti, N.; MacKenzie, A. A game theoretic approach for pilot contamination avoidance in massive MIMO. IEEE Wirel. Commun. Lett. 2016, 5, 12–15. [Google Scholar] [CrossRef]
- Winner II Interim Channel Models. IST-4-027756 WINNER II D1.1.2v1.2. Available online: http://www. ist-winner. org/WINNER2-Deliverables (accessed on 2 May 2018).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Step | Computation | Operation | Size | Cost |
|---|---|---|---|---|---|
| 1 | Step 4 | 3 sums, 2 products, 2 divisions, 1 square root | N | ||
| 2 | Step 4 | 4 products | N | ||
| 3 | Step 4 | products | N | ||
| sums | N | ||||
| 4 | Step 4 | matrix inverse (2 × 2) | N | ||
| 2 sums | N | ||||
| 5 | Step 4 | 2 products | N | ||
| (N-1) sums | 1 | ||||
| 6 | Step 5 | 2 sums | 1 | ||
| 7 | Step 5 | sum (Nos. 3 to 5) * |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ke, M.; Li, D.; Tian, S.; Zhang, Y.; Tong, K.; Xu, Y. Distributed Power Allocation for Wireless Sensor Network Localization: A Potential Game Approach. Sensors 2018, 18, 1480. https://doi.org/10.3390/s18051480
Ke M, Li D, Tian S, Zhang Y, Tong K, Xu Y. Distributed Power Allocation for Wireless Sensor Network Localization: A Potential Game Approach. Sensors. 2018; 18(5):1480. https://doi.org/10.3390/s18051480
Chicago/Turabian StyleKe, Mingxing, Ding Li, Shiwei Tian, Yuli Zhang, Kaixiang Tong, and Yuhua Xu. 2018. "Distributed Power Allocation for Wireless Sensor Network Localization: A Potential Game Approach" Sensors 18, no. 5: 1480. https://doi.org/10.3390/s18051480
APA StyleKe, M., Li, D., Tian, S., Zhang, Y., Tong, K., & Xu, Y. (2018). Distributed Power Allocation for Wireless Sensor Network Localization: A Potential Game Approach. Sensors, 18(5), 1480. https://doi.org/10.3390/s18051480