In this section, we first review some relevant concepts related to ontologies that are needed in order to understand our proposed methodology. Then, some related works are also reviewed.
2.1. Ontologies
Ontologies are used to provide structured vocabularies that explain the relations among terms, allowing an unambiguous interpretation of their meaning. Ontologies are formed by concepts (or classes), which are, usually, organized into hierarchies [
12,
13], the ontologies being more complex than taxonomies because they not only consider type-of relations, but they also consider other relations, including part-of or domain-specific relations [
14].
In an ontology, the symbol ⊤ stands for the top concept of the hierarchy, all other concepts being subsets of ⊤. The subsumption relation is usually expressed using the symbol , meaning that the concept A is a subset of the concept B. Concepts can also be specified as logical combinations of other concepts.
The semantics of operators for combining concepts is shown in
Table 1, where
,
R is a relation among concepts,
is the domain of individuals in the model and
I is an interpretation function.
An ontology expresses what individuals, also called objects, belong to which concepts. Moreover, it is possible to declare properties to relate individuals, organizing them into a hierarchy of sub-properties and providing domains and ranges for them. Usually, the domains of properties are concepts, and ranges are either concepts or data types. A declared property can be defined as transitive, symmetric, functional or the inverse of another property (R).
The main advantage of ontologies is that they codify knowledge and make it reusable by people, databases and applications that need to share information [
14,
15]. Due to this, the construction, the integration and the evolution of ontologies have been critical for the Semantic Web [
16,
17,
18]. However, obtaining a high quality ontology largely depends on the availability of well-defined semantics and powerful reasoning tools.
Regarding Semantic Web, a formal language is OWL [
19,
20], which is developed by the World World Wide Web Consortium (W3C): Originally, OWL was designed to represent information about categories of objects and how they are related. OWL inherits characteristics from several representation languages families, including Description Logic (DL) and Frames basically. OWL is built on top of the Resource Description Framework (RDF) and RDF Schema (RDFS). RDF is a data-model for describing resources and relations between them. RDFS describes how to use RDF to describe application and domain-specific vocabularies. It extends the definition for some of the elements of RDF to allow the typing of properties (domain and range) and the creation of subconcepts and subproperties. The major extension over RDFS is that OWL has the ability to impose restrictions on properties for certain classes.
2.2. Related Works
We can find in the literature many works dealing with different aspects of ADL recognition. Within the field of activity recognition, we can distinguish between two main areas of research: activity segmentation and activity classification. Works in the former group try to determine the exact period of time during which the activities are actually taking place [
21,
22]. The proposals of the latter groups are focused on determining the specific type of activity that people are carrying out, building a feature representation from the sequence of sensor events both in online approaches [
9,
23], as well as offline classification from labeled activities [
24]. Usually, both types of approaches are based on the division of the data stream into segments, also called windows or time-slots. Three common segmentation approaches can be found in the literature:
Based on activity: This is a popular segmentation approach, also called explicit, being adopted by a wide range of offline DDA proposals for sensor-based activity recognition because of its excellent results [
25]. Typically, the sensor data stream is divided into segments coinciding with the starting and ending point of time for each activity, whose activation within them provides a straightforward feature representation from binary sensors [
24]. The main disadvantage of this approach is that it is not feasible for online activity recognition because it is not possible to know when the activities are going to start or end.
Based on time: In this approach, the sensor data stream is divided into segments of a given duration [
26]. The main problem of this approach is identifying the optimal length of the segments, since it is critical for the performance of activity recognition [
27]. Initial approaches proposed a fixed time segmentation for evaluating the activation of binary sensor within temporal windows. These approaches usually employed windows of 60 s in length, which provide good performance in daily human activities recognition [
9,
23]. Recent works propose the use of more elaborated methods to identify the optimal size of windows per activity by using statistical analysis: (i) the average length of the activities and the sampling frequency of the sensors [
28]; or (ii) a weighted average by the standard deviation of the activities [
22]. This approach has been also used in activity recognition based on wearable sensor devices [
29].
Based on events: Another approach consists of dividing the sensor data stream based on the changes in sensor events [
30]. The main problem with this approach is separating sensor events, which may correspond to different activities that can be included in the same segment. On the one hand, this approach is adopted by some research works that analyze sensors providing continuous data from wearable devices, such as accelerometers [
10]. On the other hand, the segmentation based on events in binary sensors has been proposed to evaluate activity recognition together with dynamic windowing approaches [
21].
Others: Others works include ad hoc segmentation approaches, such as [
31] or [
32], where a semantic-based segmentation approach for the online sensor streams is proposed.
In our proposal, we include a mixed approach. First, a segmentation based on time is adopted to define the relevant events under a sliding temporal window [
28] for each activity. The optimal size of the sliding temporal window is adapted by a statistical analysis [
22]. Initially, the performance of this time-based segmentation is evaluated at the end of each activity. Secondly, to evaluate our approach under real circumstances, we have performed another experiment in which the segmentation based on events has been used. In this experiment, we try to determine the activity being performed each time a sensor changes its state [
21]. The use of the explicit segmentation based on activity has been discarded because it cannot be used for online activity recognition in a real situation.
Identifying a suitable sensor-based representation for building feature vectors is also an important key factor in the recognition of ADL [
26]. Previous works have been focused on evaluating expert-defined representations of binary sensors, such as raw activation, last activation or change point [
9,
33]. Nevertheless, these representations based on human interpretation hide more complex relationships among sensors. Instead, the proposal presented in this paper automatically generates multiple class expressions, which represent different states of the sensors and sequences of events during the activity. The supervised learning algorithms determine the best representation through a feature selection process. Following, we review some works that also use structured knowledge sources to generate new features for classifying tasks.
A framework that generates new features for a movie recommendation dataset is proposed in [
34]. They use that framework to construct semantics features from YAGO, a general purpose knowledge base that was automatically constructed from Wikipedia, WordNet and other semi-structured web sources. Then, they manually define a set of static queries in SPARQL language that are used to add information to the original dataset, such as its budget, release date, cast, genres, box-office information, etc. Despite being a proposal that is very similar to ours, it is important to note that the set of features in our case is fully automatically generated, without the need for human interaction.
The authors in [
35] also propose the use of ontologies to generate new features. They expand features from the original feature in a breadth first search manner considering the rules for semantically-correct paths defined by Hirst and St-Onge [
36]. Only concepts on outgoing paths from the original entity conforming to these patterns are considered as possible features in the further process. Although they plan to test their proposal with two ontologies, they are actually dealing with the underlying RDF graph of those ontologies. They do not make use of the inference mechanisms of ontologies, nor the formal logic behind them. They just use the user-defined relationships between concepts in the RDF graph in order to relate the original concept to the concepts in its context.
Paulheim [
37] also proposes another technique that employs user-defined relations between concepts in the RDF graph of ontologies for the automatic generation of features. Its main goal is the generation of possible interpretations for statistics using Linked Open Data. The prototype implementation can import arbitrary statistics files and uses DBpedia to generate attributes in a fully-automatic fashion. Furthermore, the author argues that their approach works with any arbitrary SPARQL endpoint providing Linked Open Data. The use of the inference mechanisms of ontologies is also very limited in this work.
The main difference with respect to our proposal is that all previous works propose the use of external knowledge to generate new features, whereas we only consider the information in the original dataset to do so. There are other proposals that also generate new features by just using the data in the dataset. The Latent Dirichlet Allocation (LDA) model is proposed in [
38] to capture the correlation between features and activities by using an offline approach, where both the start and the end labels of the activities are known. Then, they apply the learned classification model for the online recognition of activities. They perform this step by constructing a fixed dimensional feature vector, which is actually composed of two groups of features. One group identifies the basic features in the sliding window, such as the day, the time of the first and the last sensor events, the temporal span of the window, the sensors of the first and the last events and the previous activity. The rest of the features correspond to estimated probability distributions of activities and sensors events. The features are thus generated by using a predefined set of ad hoc rules, the dimension of the feature vector always being the same. In contrast, our proposal uses ontologies to automatically generate features, the final dimension of the feature vector being decided by the user.
We can also find in the literature many ontologies for the description of ADLs [
5,
39,
40,
41]. However, most of them have been designed to be as expressive as possible, defining a huge amount of classes and properties. This makes it more difficult for our methodology to find relevant class expressions, since the search space grows exponentially. The ontology proposed in [
40], for example, contains one hundred and sixty-five predefined activities and thirty-three different types of predefined events (“atomic activities”). It also incorporates other types of entities that are specific to the dataset, such as the person performing the activity and his or her posture. Furthermore, all properties are flat, i.e., without any characteristic (inverse, functional, etc.), because the reasoning about the order of events is done in an external rules system. The same applies to the ontology proposed in [
5], where there are properties to associate a sensor with the object in which it is located and even its manufacturer. Their authors distinguish between simple and compound activities, and they are organized into hierarchies. There are also dozens of activities and properties already predefined in the ontology that do not correspond to the activities in the datasets of the experiment described in
Section 4.2. The ontology proposed in [
41] is oriented towards the development of an ADL monitoring system that can interact with the users through mobile networks. It includes concepts and properties to implement a message service between the user and the monitoring system.
The ontology proposed in [
42] is the most similar to the one used in the experiment of this work, described in a later section. It defines some concepts that are not needed in the experiment, such as the type of the sensor or its location. However, the main problem with this ontology is its inefficiency. It has been designed for KDA approaches, and it encodes some complex class expressions that take much time to compute. Even if those concepts are removed (they are defined for a specific dataset), an exploratory analysis shows that the time required to determine the instances of some of its concepts ranges from seven minutes to ten hours, whereas the entire process takes no more than a few seconds, in most cases, when using the proposed ontology.
The system proposed in [
31] requires human intervention. This includes initial inputs of domain knowledge, manual specification of the seed ontological activity models and human validation and update of learned activities at the end of each single iteration. The quality of the results depends on the quality of the rules created ad hoc for the dataset. Only some phases are completely automatic. They employ a small, private dataset, although they plan to test their approach using some publicly available activity datasets.
The methodology proposed in this paper also shares some characteristics with Class Expression Learning (CEL) techniques. The algorithms for CEL are mainly used in the field of ontology engineering [
43]. They can be used to suggest new class descriptions that are relevant to the problem while the ontologies are being developed. The objective of CEL algorithms is to determine new class descriptions for concepts that may be used to classify individuals in an ontology according to some criterion. More formally, given a class
C, the goal of CEL algorithms is to determine a class description
A such that
. Given a set of positive and negative examples of individuals in an ontology, the learning problem consists of finding a new class expression or concept such that most of the positive examples are instances of that concept, whereas the negative instances are not.
The main difference with respect to our proposal is that the result of CEL algorithms is always a DL class expression, whereas the result of the proposed methodology is a set of DL class expressions, which do not always describe positive instances. Sometimes, the features of negative instances provide valuable information to the classification model. In our case, the entire set of generated class expressions is treated as features. The classifier may combine the DL class expressions as necessary, without the need to produce the result in the form of logical axioms that describe positive instances. This is the reason why the classifiers based on our proposal perform better than the CEL algorithms. In addition, the rigidity of DL makes the classification model less tolerant to conflicting and incoherent situations due to faulty sensing hardware or communication problems [
44].




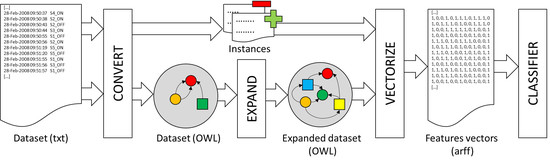
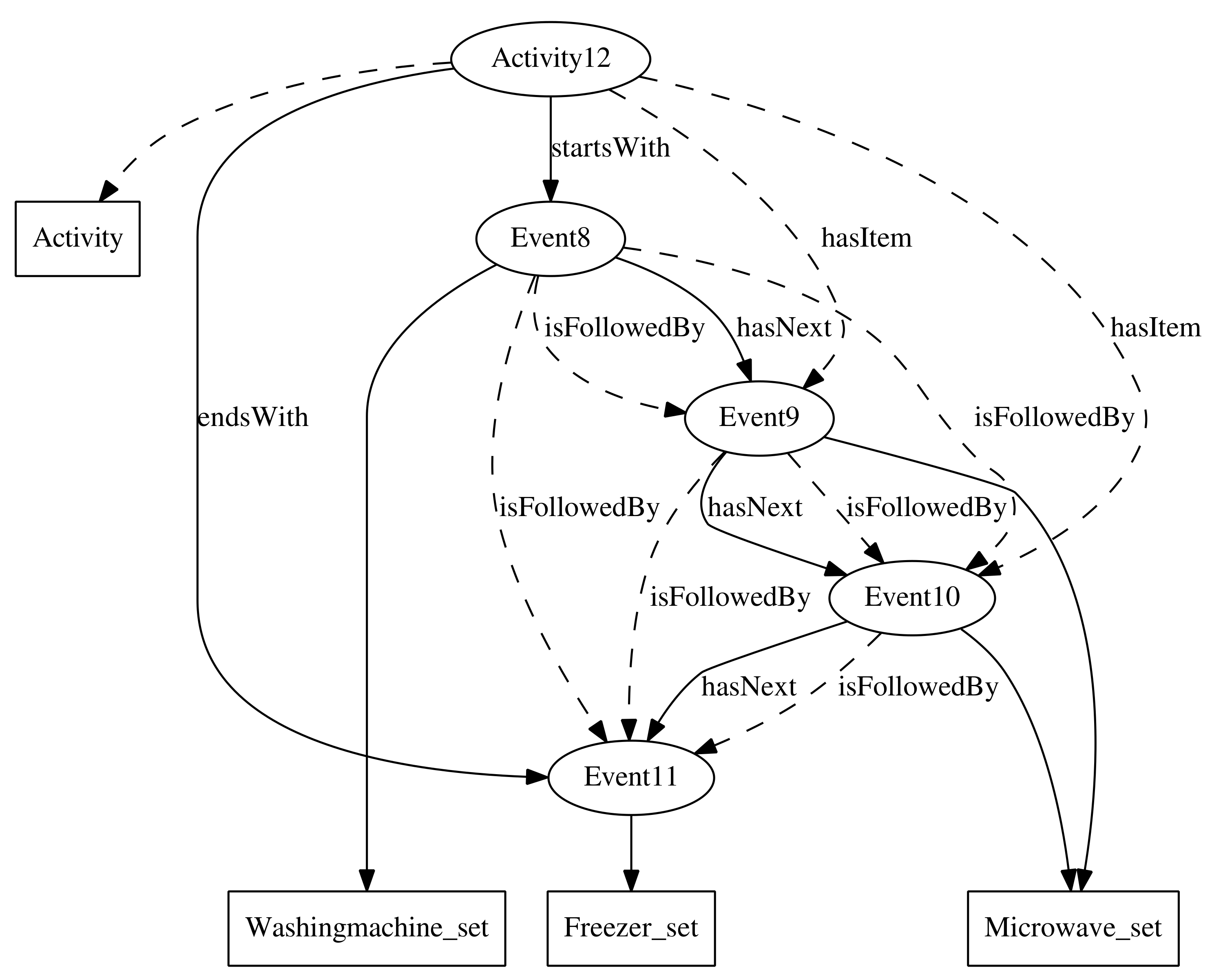
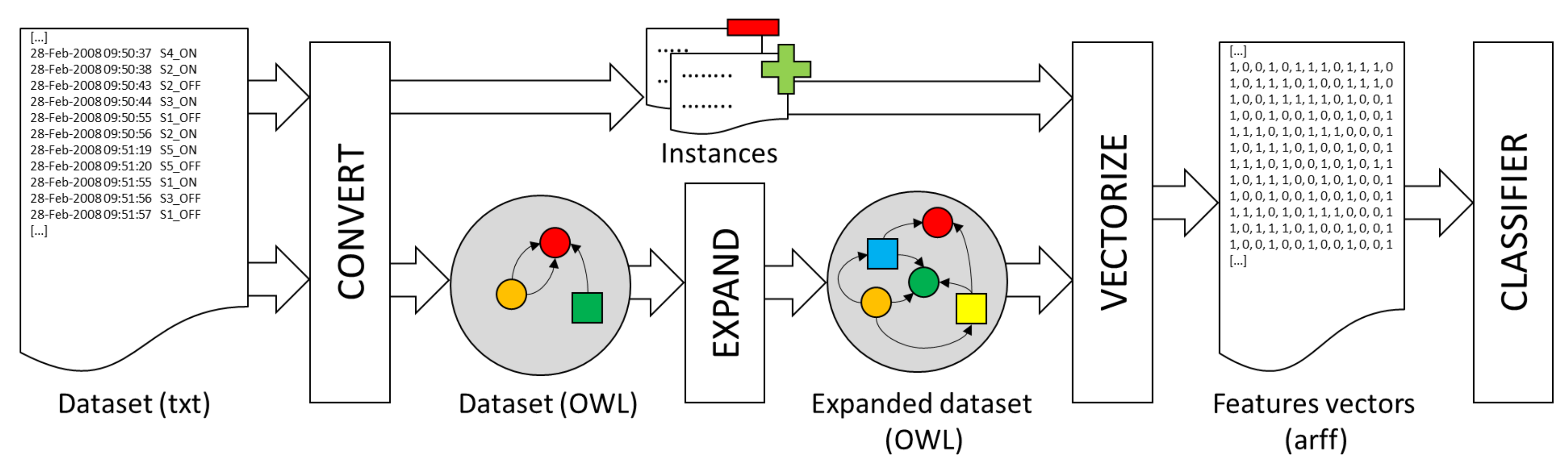
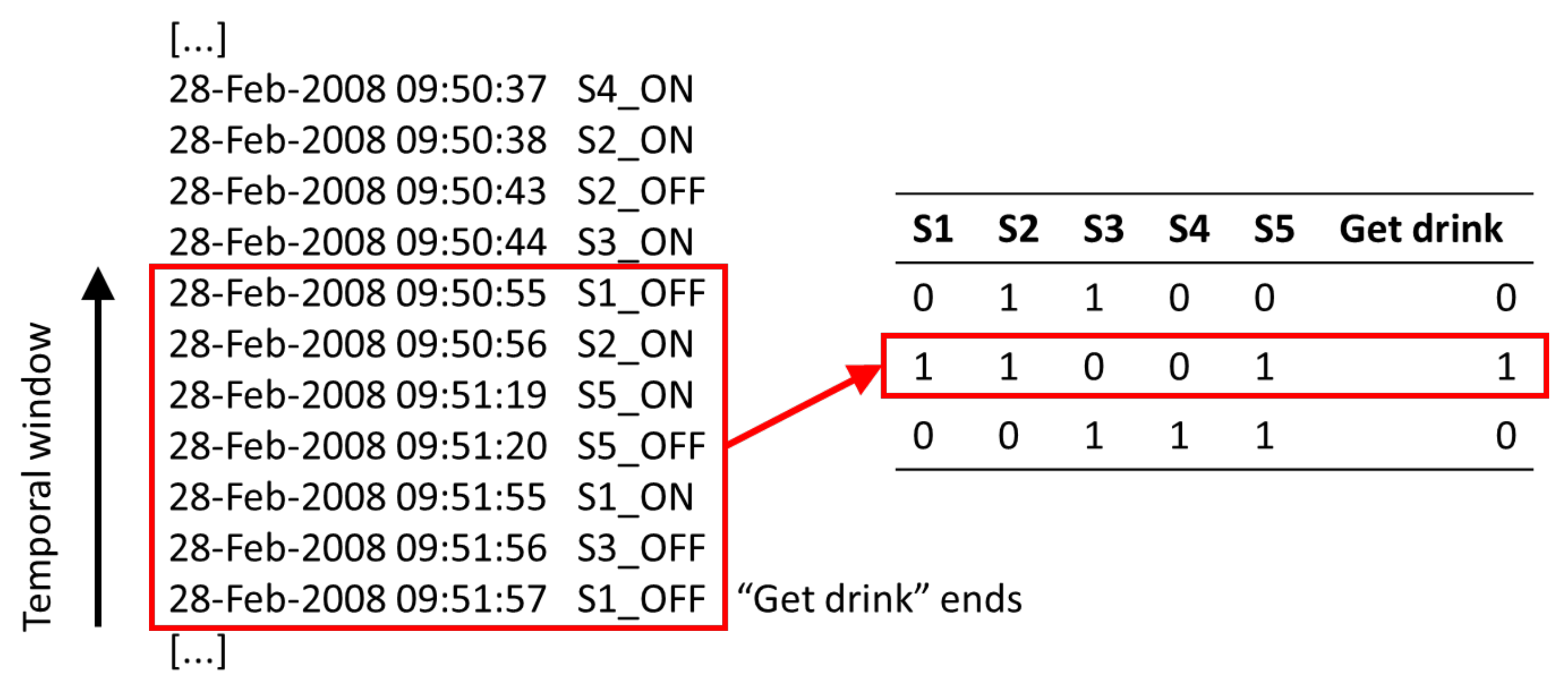

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}