1. Introduction
The efficient processing of sensor data is a central topic in a wide variety of research areas, which is underlined by advances in sensor technology and capabilities, e.g., for odor [
1] and taste recognition [
2] or by advances in visual information processing [
3] as well as by applications in robotics [
4] and sensor networks [
5,
6]. In particular to process data of multiple sensors, the well-known Kalman filter [
7] has evolved into a key component of data fusion algorithms. Multisensor data can directly be transmitted to a data sink that employs a
centralized Kalman filter to process all the accrued sensor readings. Such a simple filter design stands in stark contrast to the communication costs expended to transmit the data. The idea behind
distributed Kalman filter implementations is to use local processing power to combine and condense sensor data locally so that the processing results can be transmitted more efficiently and less frequently. As the local processing results comprise the information from all past observations, the results can be sent to the data sink after arbitrarily many time steps without losing information from the past measurements. As compared to a centralized Kalman filter, distributed implementations not only offer the advantage that the communication load in the network can be reduced significantly but also increase robustness to packet losses and drops. The information in a lost package will automatically be handed in later through a subsequent data transmission.
Most distributed estimation architectures employ local Kalman filters at the sensor nodes. Although the local processing can then be deemed to be optimal in terms of the mean squared estimation error, fusion of the local estimates becomes a challenging task due to correlations between the estimates to be fused [
8,
9,
10]. In particular, a naïve or too simplistic fusion method may render the fusion results inconsistent, i.e., the fusion method reports an estimation error that is too small to account for the actual error. In general, the correlations required to fuse the local estimates optimally are difficult to reconstruct [
11,
12]. In the case of unknown correlations, conservative fusion algorithms, like
Covariance Intersection [
13,
14] or
Ellipsoidal Intersection [
15,
16,
17] and its further development
Inverse Covariance Intersection [
18,
19], can be employed to obtain consistent fusion results. However, these algorithms often provide too conservative assessments of the actual estimation error.
An alternative approach to distributed state estimation has been pursued in [
20,
21,
22,
23]. Here, a distributed implementation of a single centralized Kalman filter has been derived. In doing so, the need to keep track of correlations or to derive conservative bounds can be circumvented. The main advantage of this approach is its optimality with respect to the mean squared estimation error; even optimal fusion algorithms, like the Bar-Shalom/Campo fusion rule, cannot achieve the same estimation quality [
11]. Therefore, this approach constitutes an
optimally distributed Kalman filter (ODKF). An important aspect of this filter is that the local estimates are neither consistent nor unbiased, nor does the error covariance matrix describe the actual estimation error. The local estimates have to be fused in the data sink to obtain a consistent estimate, which is optimal and equal to the result of a centralized Kalman filter. Beside this article, several extensions of this filter have been proposed—assumptions on the available information can be relaxed [
24,
25], it can be implemented in information form [
26], or combinations with ellipsoidal state estimation are possible [
27,
28].
Although communication can take place at arbitrary time steps, a critical drawback of the ODKF is that the data sink requires access to all local estimates in order to compute an estimate, i.e., all nodes have to transmit their estimates to the center node. This limitation has the following two severe implications:
All nodes have to send their data at the same time, and
the central cannot infer any information about the state between the sending times.
Hence, the standard implementation of the ODKF implies transmissions of either all or none of the nodes. As a further consequence, full-rate communication of the nodes is required if the data sink needs an estimate at every time step. In this article, extensions of the ODKF are proposed that can operate under lower communication rates. This is achieved by introducing data-driven transmission strategies [
29,
30]. In particular, the local estimates can asynchronously be transmitted to the data sink. In order to guarantee consistency, bounds on the estimation errors are provided. These bounds are only required in situations when not every local estimate is available at the data sink; the optimal estimate as provided by a central Kalman filter is still obtained each time when all local estimate have been sent to the data sink.
As compared to the standard formulation of the ODKF, the advantage of the proposed extension is that the data sink can now compute an estimate of the state based on a subset of local estimates. This article continues the work in [
31] by introducing an additional criterion for the data-driven transmission strategy, providing more details, and extending the evaluation and discussions.
The paper is structured as follows.
Section 2 provides a description of the centralized and the optimally distributed Kalman filter as well as a problem formulation. In
Section 3, the first extension is introduced which enables the data sink to treat missing estimates. In
Section 4 and in
Section 5, we describe the second and the third new distributed algorithm, respectively, which implement data-driven transmission schemes and allow for omitted estimates at the fusion center over multiple time steps. The results of an experimental evaluation are discussed in
Section 6. Finally, the article is concluded in
Section 7.
2. Centralized and Optimally Distributed Kalman Filtering
We consider a sensor network with
N local sensor nodes and a central node, which serves as a data sink and computes an estimate on the state. The true state of the system at time step
k is denoted by
, which evolves according to the discrete-time linear dynamic system
where
is the system matrix and
denotes the process noise, which is assumed to be zero-mean Gaussian noise,
with covariance matrix
. At each time step
k, each sensor
observes the state through the model
where
is the measurement matrix and
the measurement noise, which is assumed to be Gaussian noise with zero mean,
with covariance matrix
. The measurement noise terms of different local sensors are assumed to be mutually uncorrelated. Also, the process and measurement noise terms for different time steps are uncorrelated.
For the
centralized Kalman filter (CKF), each measurement is sent to the data sink, and fused by means of the formulas
These equations correspond to the information form [
32,
33] of the measurement update of the standard Kalman filter.
and
denote the state estimate and the corresponding error covariance matrix after the fusion step, respectively.
and
denote the state estimate and the corresponding error covariance matrix computed by the prediction step of the Kalman filter. The prediction step is carried out at the center node by
where these formulas are also given in the information form [
26,
32]. Since these equations correspond to the standard Kalman filter, the CKF is unbiased and optimal with respect to the minimum mean squared error. In particular, the computed error covariance matrix is equal to the actual estimation error, i.e.,
In [
20,
21,
22,
23], a distributed implementation of the Kalman filter algorithm has been derived, which is algebraically equivalent to the centralized scheme, i.e., which is also unbiased, minimizes the mean squared error, and which fulfills (3). This is achieved by defining a local filtering scheme such that the fusion result is equal to results (1) and (2) of the CKF. We will describe this algorithm—the
optimally distributed Kalman filter (ODKF)—in the following.
The local sensor nodes run modified versions of the Kalman filtering algorithm. They use so called
globalized local states estimates and error covariance matrices (Although, strictly speaking, the local estimate and covariance matrix do not represent consistent estimates of the state, we denote them as local estimates). To initialize the ODKF, the local initial estimates and covariance matrices
at the sensor nodes
, which are usually identical, have to be replaced by the globalized estimates
Since the globalized error covariance matrix is equal for each sensor, the sensor index
i is omitted. This equality also applies to all future time steps. The local prediction step is replaced by the globalized prediction equations
The local filtering steps are globalized by
The processing steps (4) and (5) are computed locally on each sensor node. Hence, measurements are not directly transmitted to the central node—instead, the local estimates are sent to the central node. As the globalized covariance matrix is equal for each node, it can also be computed in the central node.
In order to compute an estimate at an arbitrary time step
k, the central node receives the globalized estimates
from each sensor
i and fuses them according to
denotes the state estimate after the fusion step at the data sink with corresponding error covariance matrix
. From Equations (6) and (7), we can easily accept that
The same equations apply to the fusion of the predicted estimates and error covariance matrices in (4). In [
20], it has been shown that the results are optimal, i.e.,
where
and
are computed by the CKF, i.e., (1) and (2). The disadvantage of the centralized Kalman filter is that each sensor node has to transmit measurements of each time step to the central node. For the ODKF, we observe that communication in past time steps does not influence
and
, i.e., the equalities hold independently of the past communication pattern in the distributed network. As a consequence of (8) and (9), we can see that
is equal to (3)—the ODKF is optimal.
A significant drawback of the ODKF implementation becomes apparent in the following situation. If only
sensors transmit their estimates to the fusion center at time step
k, Equations (6) and (7) become
The resulting ODKF estimate
and error covariance matrix
are different from the centralized estimate
and the error covariance matrix
, which are
In particular, we notice that the covariance matrix (13) differs from the ODKF covariance matrix in (11). A consequence of this mismatch is a possible bias in the fused estimate as discussed, e.g., in [
24]—hence, the ODKF may provide inconsistent estimates in case of missing transmissions. This issue will be addressed in the following sections. Although the CKF does not suffer from inconsistency, (12) and (13) unveil a critical downside of the CKF: Missing measurements at time step
k are lost for all future time steps. By contrast, the local estimates of the ODKF incorporate past measurements, which states the reason why the ODKF may outperform the CKF if we can solve the inconsistency problem of the ODKF.
In this section, the ODKF has been revisited; it provides the same results as the CKF but offers the advantage that transmissions can take place at arbitrary instants of time. However, the ODKF still requires that all nodes send their local estimates at the transmission times to compute (6) and (7). As a consequence, the data sink typically operates at a lower rate than the local nodes as it is idle between transmission times. In the following sections, extensions are provided that enable the nodes to transmit their local estimates asynchronously. The data sink can then operate at the same rate as the sensor nodes, i.e., it is able to provide an estimate at every time step k. By employing data-driven strategies, the communication rate of each node can be significantly lower than 1, where the value 1 corresponds to transmissions at every time step k.
In
Section 3, we develop a consistent ODKF extension than can cope with situations where sensor nodes may send their estimates at every second time step. This algorithm still provides results equal to the CKF. With this algorithm, we are able to reduce the communication rate by half.
Section 4 and
Section 5 introduce a second and third algorithm that can even reach a lower communication rate by applying bounds on the missing pieces of information.
3. Distributed Kalman Filtering with Omitted Estimates
We consider the ODKF algorithm as described in the previous section. At time step
k, only sensor nodes
send their estimates to the fusion center, but the estimates of sensor nodes
are not. In this section, we assume that the data from the nodes
had been available in the fusion center at time step
. Thus, the fusion center can compute the predicted estimates
for time step
k by using (4). In place of the ODKF fusion Equations (6) and (7), the fusion result is now computed by
The resulting estimate
and the error covariance matrix
are equal to the estimate
and the error covariance matrix
computed by a centralized Kalman filter according to (12) and (13). A proof for the equality is provided in
Appendix A.
Since (14) and (15) are equivalent to the CKF, unbiasedness, optimality, and (10) are accordingly inherited from the CKF. We have generalized the original ODKF algorithm such that full-rate communication is not required anymore. The novel fusion algorithm merely requires that if a particular sensor does not communicate with the center at time k, it has sent its data at time , i.e., each sensor has to communicate with the center at least every second time step. Hence, the required communication rate can be reduced by half to .
However, a higher communication rate—and thus, the incorporation of the information contained in additional measurements—will always result in a lower mean squared error (MSE). Thus, we have to deal with the trade-off between a low communication rate and a low MSE. Nevertheless, it is possible to achieve a smaller MSE while keeping the same communication rate by using a data-driven communication strategy and thus, scheduling the data according to the information contained. Valuable results have already been achieved using data-driven communication in distributed sensor networks [
34,
35,
36,
37,
38,
39,
40,
41,
42]. The idea is that each local sensor evaluates the distance between the predicted estimate
and the filtered estimate
. If the distance is large, the measurement
adds much new information to the prediction. Only in this case, the sensor should send its current estimate
to the center node.
It is important to emphasize that the globalized parameters
and
are not unbiased estimates of the actual state. It can be shown [
24] that, in contrast to the difference between the standard Kalman filter estimates,
, the difference
is not zero on average, but may even diverge. Therefore, in order to evaluate the influence of a measurement
, we study the difference between the predicted and updated estimates of the standard Kalman filter, which is related to the weighted difference between the measurement and the prediction, i.e.,
where
denotes the standard Kalman gain. For this purpose, the standard Kalman filtering algorithm has to run in parallel to the globalized version of the Kalman filter at each sensor node. The following data-driven communication strategy can be applied:
where
denotes a scalar parameter. We can achieve any communication rate in range
by varying the parameter
.
By using this communication strategy we can only evaluate the relevance of the measurement to the local estimate
, and not to the fused estimate
. Still, experiments (see
Section 6) will show that by using the data-driven communication strategy instead of random communication, for a fixed communication rate an improvement of the MSE of the fused estimate
can be achieved. However, a drawback of the algorithm is the assumption that if a particular sensor does not communicate with the center at time
k, it has communicated at time
, i.e., each sensor communicates with the center at least every other time step. Thus, communication rates lower than 0.5 cannot be achieved. This will be addressed by the following extensions.
4. Data-Driven Distributed Kalman Filtering with Omitted Estimates over Multiple Time Steps–Version 1
If we want to achieve communication rates lower than 0.5 in the sensor network, we have to allow that a particular sensor does not send its estimates to the fusion center over multiple time steps. In this case, the fusion center has to perform multiple consecutive predictions. Let us assume that the last communication of sensor
i with the center occurred at time
. The predicted estimate for time step
k is computed as shown in the following scheme.
refers to the application of Equation (4). Note that the predicted estimates are now marked with “” instead of “p” to emphasize that possibly multiple prediction steps were applied consecutively. In case that prediction has been performed only once, we have .
In fusion Equation (15). the predictions
are now used for the missing local estimates of the nodes
, i.e.,
The new estimate
can be expressed in terms of the estimate
from (15) as follows:
For the yet to be defined triggering criterion, we consider the distance
The expected estimation error covariance matrix is then given by
Obviously, the expected estimation error cannot be computed exactly at the fusion center, since the difference
is not available. Nevertheless, it is possible to obtain an upper bound on the estimation error, if we alter the communication test (16). We ensure that in case of communication the matrix
is bounded by
. The communication strategy becomes
where
denotes the estimate which has been computed by applying the Kalman filtering prediction step multiple times and
denotes a user-defined symmetric positive definite matrix. For any square matrices
and
,
denotes that
is positive semi-definite.
For the bound, the relationship
holds. Thus, the communication criterion
can be replaced by
, which reduces the computational cost. Assuming that
is an
n-dimensional vector and
an
-matrix, the cost for computing the product
is in
. The computation of the difference
is also in
. The computational cost for computing the eigenvalues of the
-matrix
is in
. All in all, the computational cost for the decision if
is in
. Since the inverse matrix
has to be computed only once beforehand, the cost for computing the product
is in
. Therefore, testing if
only requires
computations. Since
only requires the computation of the Euclidean norm, which is in
, the computational cost of the communication test (19) is in
. The employed relationship (20) is proven in
Appendix B.
As in the previous communication strategy, we have to take into consideration that the globalized estimates
and
are
biased and thus, the difference
may diverge. As a consequence, the matrix
may also diverge. In contrast to the previous fusion algorithm, using the standard Kalman filtering estimates
,
is not a reasonable solution, since the communication strategy is used to get an upper bound on
. An alternative possibility to avoid the divergence of the difference is to
debias the local globalized estimates. A strategy to debias the estimates using
debiasing matrices has been proposed in [
24,
25]. In each prediction and filtering step, each local node computes a new debiasing matrix. This matrix is initialized by
. In the filtering step, the debiasing matrix is computed by
In the prediction step, the debiasing matrix is computed by
is computed by applying Equation (21) multiple times, until the next communication with the center node occurs. By multiplying the inverse of the debiasing matrix with the globalized estimates, we can debias the estimates [
24,
25], i.e.,
It can be easily shown that the same applies to the predicted estimate over multiple time steps, i.e.,
We new define
and then have
Thus, in general the difference
does not diverge. With this result, we adapt (18), and use
to replace the second inequality in (19) by
We can now define the new fusion equations as
where
m is the number of sensors which communicate with the center at time
k and
l is the number of sensors which do not communicate with the center at time
k, but for which
hold. Note that the fusion formulas are equal to (14) and (15) for
, i.e., for the case that each sensor sends its estimate to the center at least every other time step. The resulting estimate is consistent, i.e.,
A proof for the consistency condition (22) is provided in
Appendix C.
The drawback of the presented algorithm is that it needs two parameters and to perform the communication test. Both parameters influence the communication rate. Thus, it is difficult to find the parameters which ensure the desired balance between a small communication rate and a small estimation error. Experiments using the particular dynamic system are needed to find the best combination of both parameters. Thus, we will now present another algorithm which only uses one parameter for the communication strategy.
5. Data-Driven Distributed Kalman Filtering with Omitted Estimates over Multiple Time Steps–Version 2
For the second data-driven algorithm, fusion Equation (15) is now generalized by
The difference to the previous Equation (17) is the covariance matrix
in the second sum. The new estimate
can be expressed in terms of the estimate
from (15) as follows:
In order to define a communication strategy, we consider the difference
which is compared against the matrix
by
denotes a user-defined symmetric positive definite matrix. This time we do not need the Euclidean distance
since the distance between predicted and filtered estimate is included in
. We can now define the new fusion equations as
where
m is the number of sensors which communicate with the center at time
k. With the same arguments as in
Section 4 it can be shown that the resulting estimate is consistent, i.e.,
In the experimental evaluation of the algorithms we will see that although this version of fusing the estimates has the advantage that only one parameter has to be chosen, the estimate of the fused error covariance matrix is not as good as as in the previous version.
6. Simulations and Evaluation
We apply the CKF algorithm as well as the three data-driven ODKF algorithms to a single-target tracking problem. The system state
is a six-dimensional vector with two dimensions for the position, two dimensions for the velocity, and two dimensions for the acceleration. A near-constant acceleration model is used. The system matrix is given by
with the sampling interval
s. The process noise covariance matrix is given by
We have a sensor network consisting of six sensor nodes and one fusion node. Two sensors measure the position, two sensors measure the velocity and two sensors measure the acceleration. The measurement noise covariance matrices are given by
Monte Carlo simulations with 500 independent runs over 100 time steps are performed. Since
is stable and
is detectable the error covariance matrix and the MSE converge to a unique values [
43]. Based on the simulation, actual error covariance matrices and MSE values are computed for each algorithm. Monte Carlo simulations are performed for different average communication rates for each of the three algorithms. For the CKF, communication is performed randomly, but with different average rates. Note that only current measurements are communicated. If the measurement
is not sent to the fusion center at time
k, the information will not be available at the center at any future time.
The first ODKF algorithm (Algorithm 1) from
Section 3 is performed with random communication as well as with data-driven communication. In the latter case, the parameter
is varied to achieve different rates. The second algorithm (Algorithm 2) from
Section 4 and the third algorithm (Algorithm 3) from
Section 5 are performed with data-driven communication. For Algorithm 2 both parameters
and
are varied, for Algorithm 3 the parameter
is varied. The compared methods are:
Algorithm 1: ODKF algorithm from
Section 3 with random and data-driven communication.
Algorithm 2: ODKF algorithm from
Section 4 with data-driven communication and parameters
,
.
Algorithm 3: ODKF algorithm from
Section 5 with data-driven communication and parameter
.
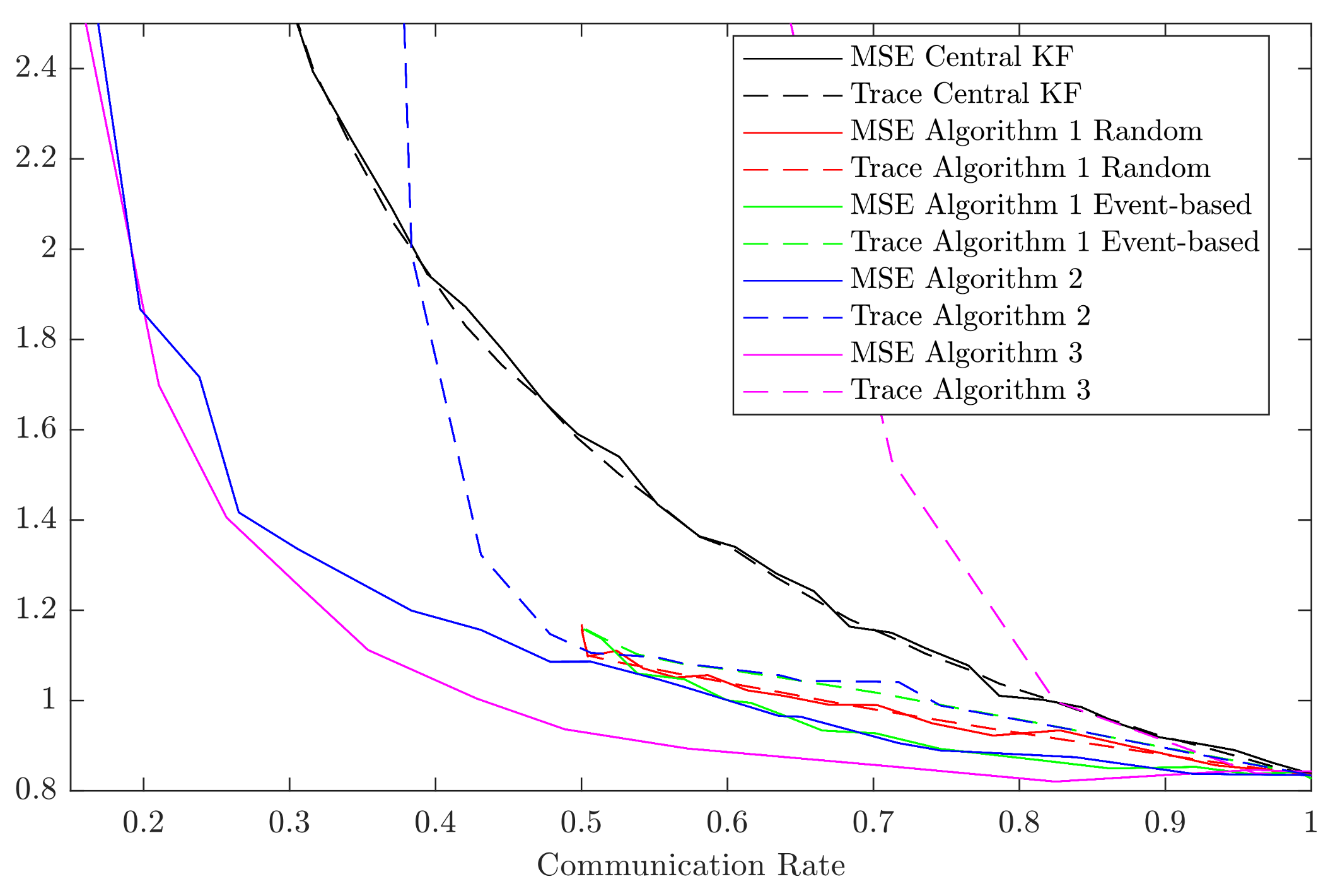
The simulation results are shown in
Figure 1. The MSEs and the traces of the error covariance matrices are depicted relative to the average communication rate in the network. Since for Algorithm 2 different parameter combinations lead to different results, we have only included the results with the smallest error covariance matrices in the plot.
Only for the centralized Kalman filter and for the Algorithm 2 and 3, communication rates lower than 0.5 are given. We can observe that for Algorithm 1 data-driven communication leads to an improved estimate compared to random communication. However, it also leads to a larger trace of the error covariance matrix and thus, to a larger uncertainty reported with the estimate.
We also can observe that for communication rates in range the results of Algorithms 2 and 3 with data-driven communication are almost equal. This can be explained by the fact that Algorithm 2 extends Algorithm 3 share a common triggering criterion, and the fusion formulas for both algorithms are equal if each sensor communicates with the center at least every other time step.
Figure 1 shows that for each of the algorithms the MSE is always smaller than or equal to the trace of the error covariance matrix. This illustrates that the estimators provide consistent results. The traces are good estimates of the MSEs except for low communication rates in Algorithm 3 and very low communication rates in Algorithm 2. Thus, the trace of the error covariance matrices—the uncertainty reported by the estimators—is not significantly larger than the actual uncertainty in most of the cases. Each of the distributed fusion algorithms performs better in terms of the MSE as compared to the centralized algorithm. This can be explained by the fact that in the distributed network the fused estimates contain the information of all past measurements, while in the centralized network only the current measurements are fused.


{kind=link}