Deep Spatial-Temporal Joint Feature Representation for Video Object Detection



Abstract
:1. Introduction
2. Related Works
2.1. Still Image Object Detection
2.2. Video Object Detection
2.3. Video Action Detection
2.4. 3D Shape Classification
3. Method
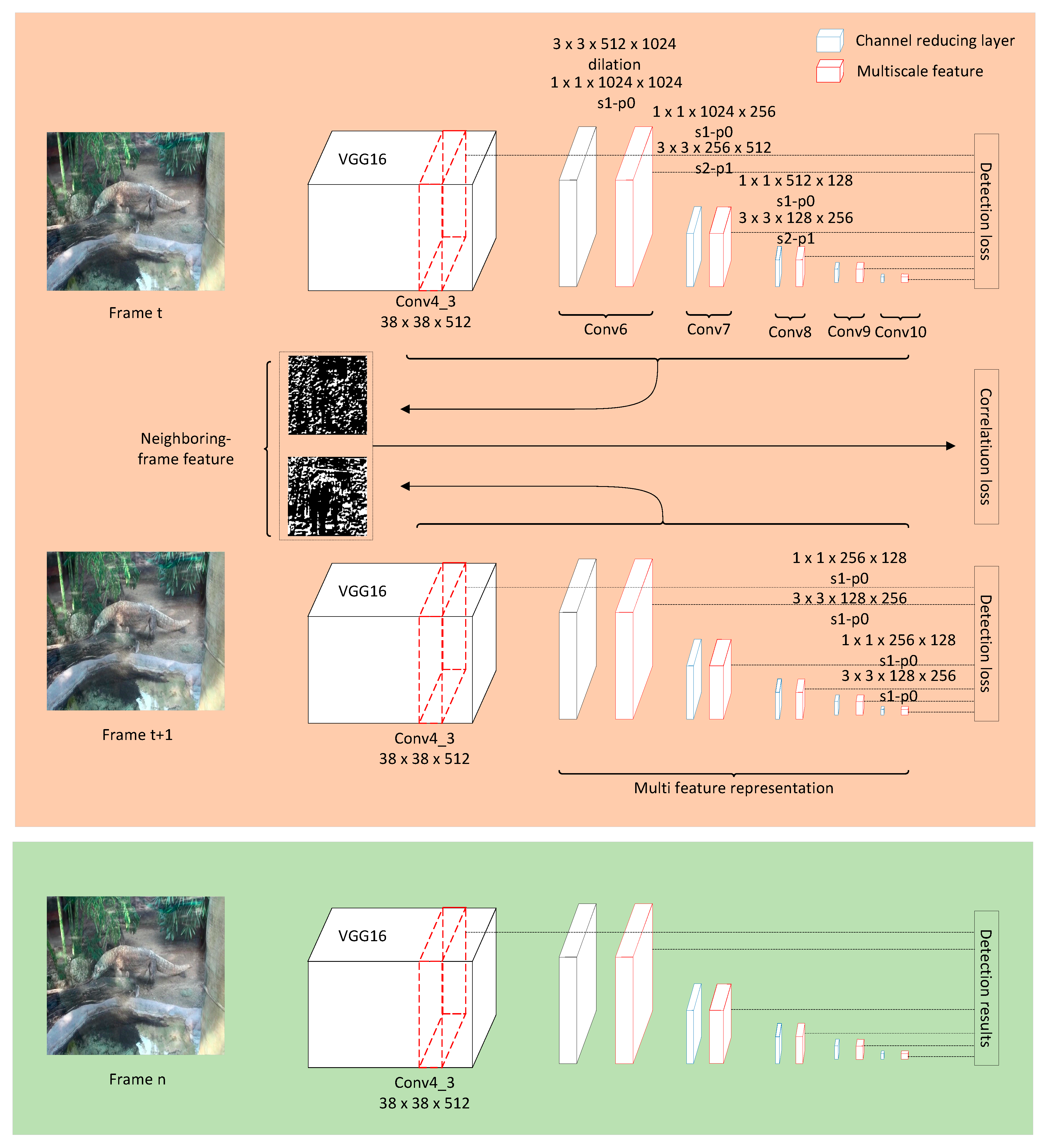
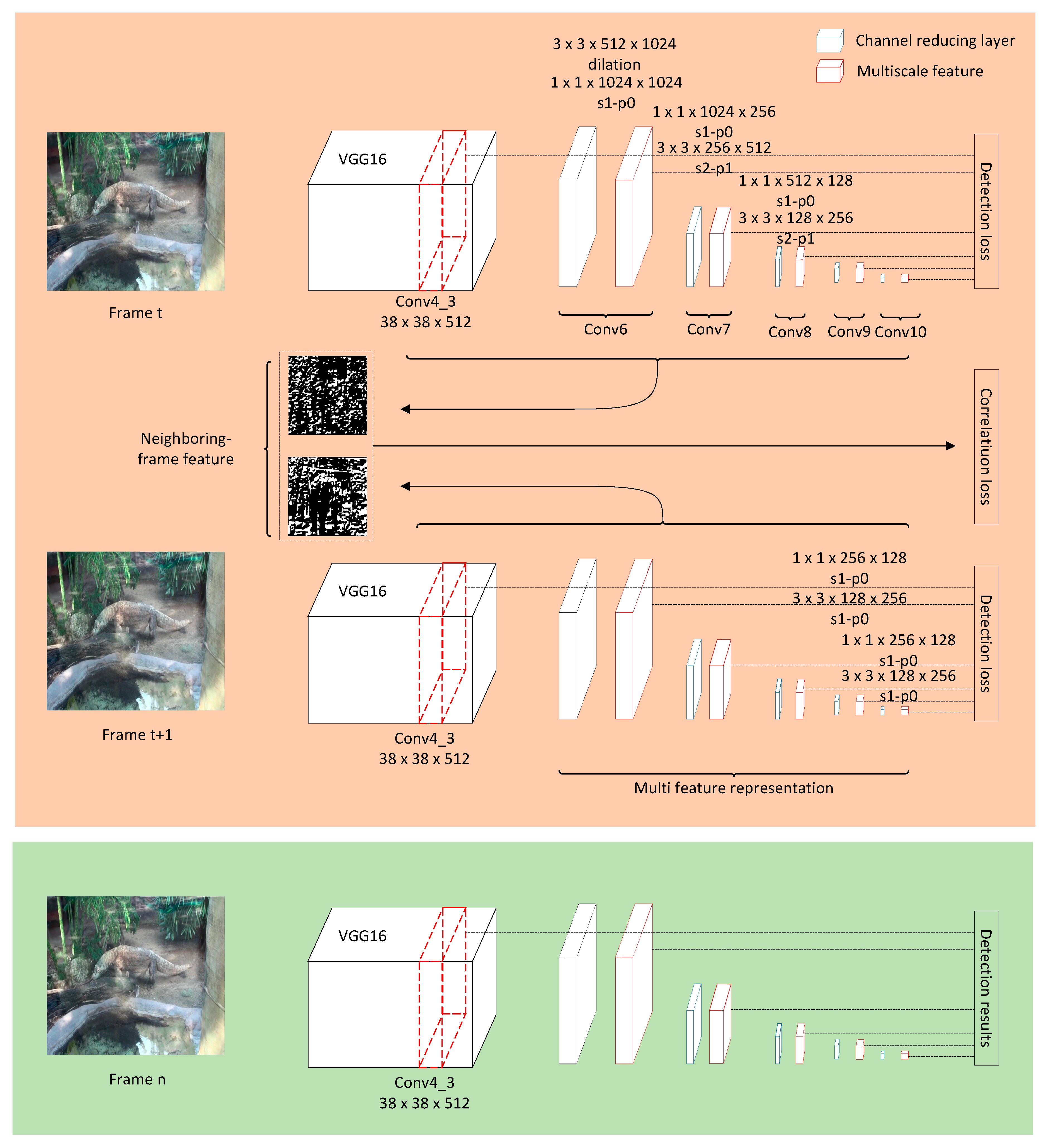
3.1. Network Architecture
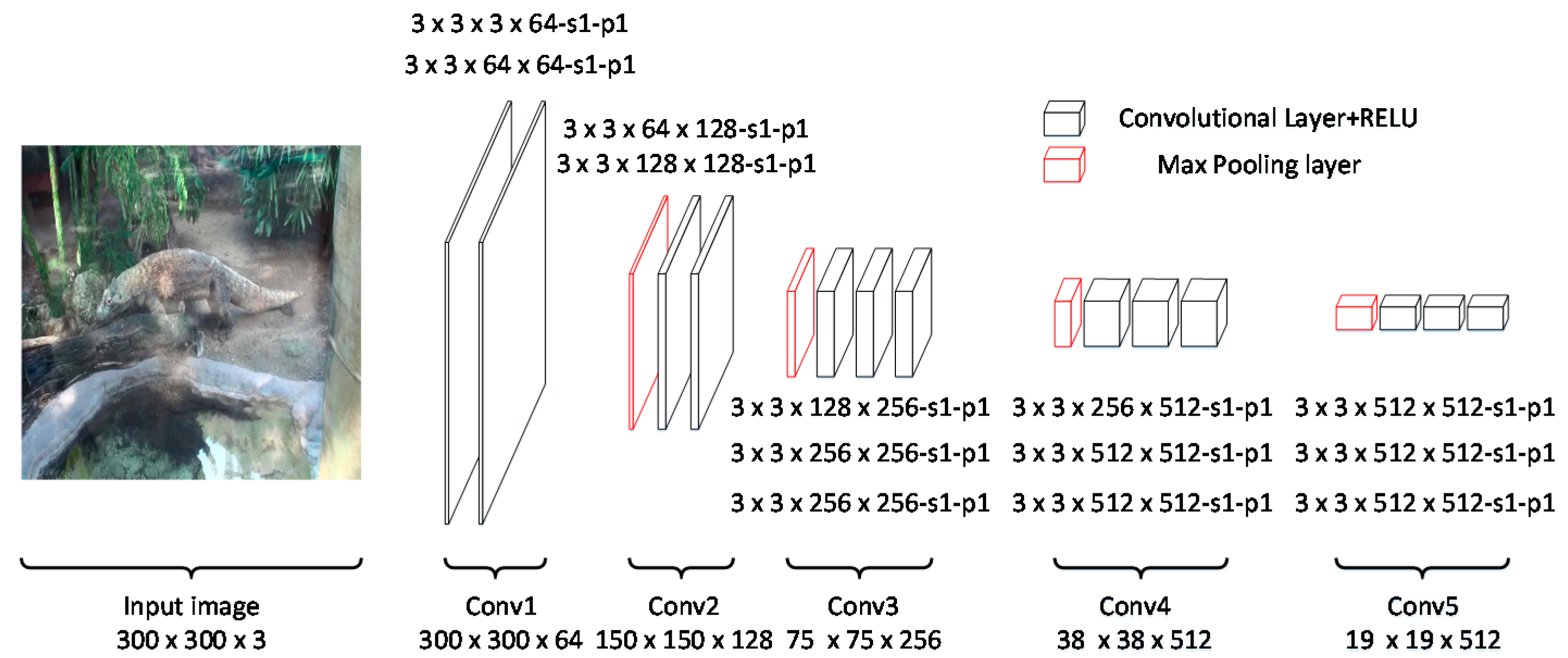
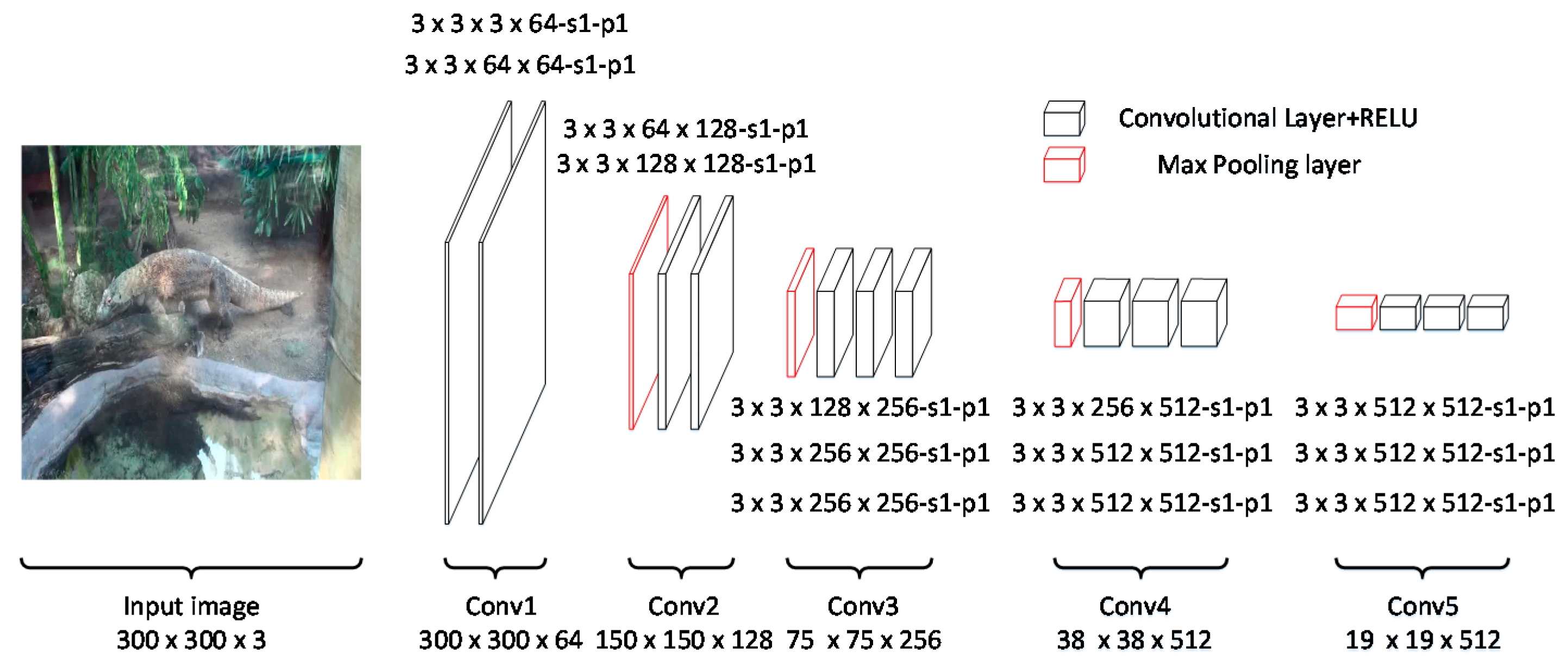
3.1.1. Backbone Network
- (1)
- Input: images with RGB channels.
- (2)
- Convolutional layers: The convolutional layers mainly contain five groups—conv1, conv2, conv3, conv4, and conv5. Conv1 includes two convolutional layers with 64 kernels. Conv2 includes two convolutional layers with kernels. Similar to conv1 and conv2, conv3, conv4, and conv5 include three convolutional layers with 256, 512, and 512 kernels, respectively.
- (3)
- The activation function is rectified linear units [29], and the kernel size of the max pooling layer is .
3.1.2. Multiscale Feature Representation
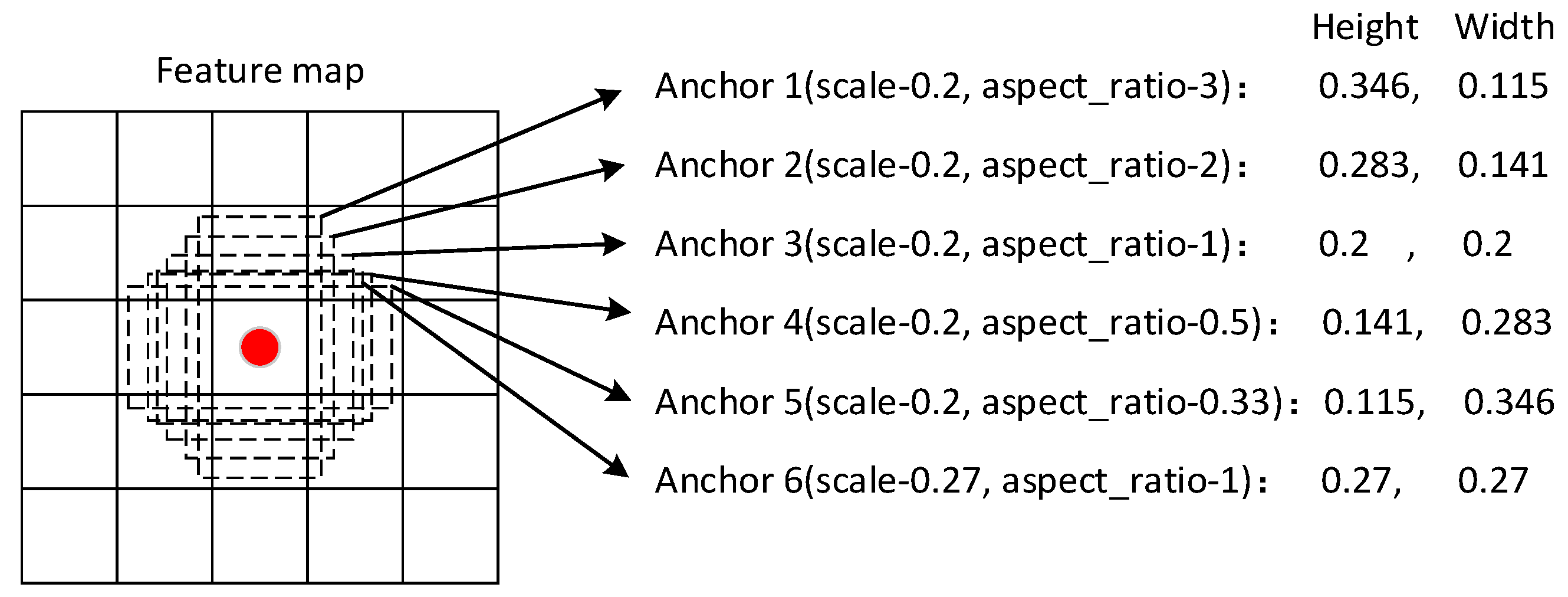
3.1.3. Anchor Generation
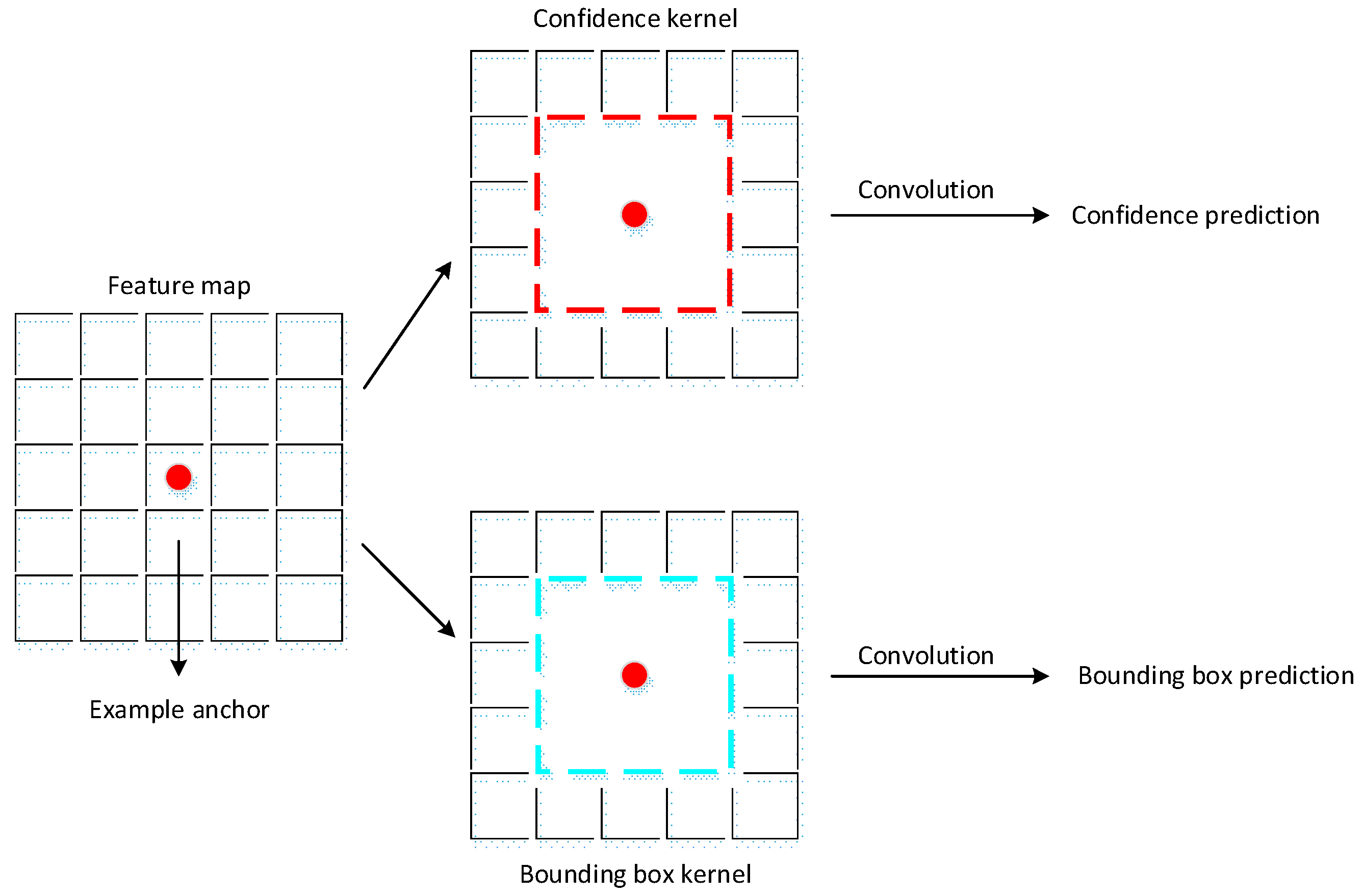
3.1.4. Anchor Prediction
3.1.5. Training Sample Selection
- Use the entire original input image;
- Sample a patch so that the minimum Jaccard overlap with the objects is 0.1, 0.3, 0.5, 0.7, or 0.9;
- Randomly sample a patch.
3.2. Loss Function
3.2.1. Detection Loss
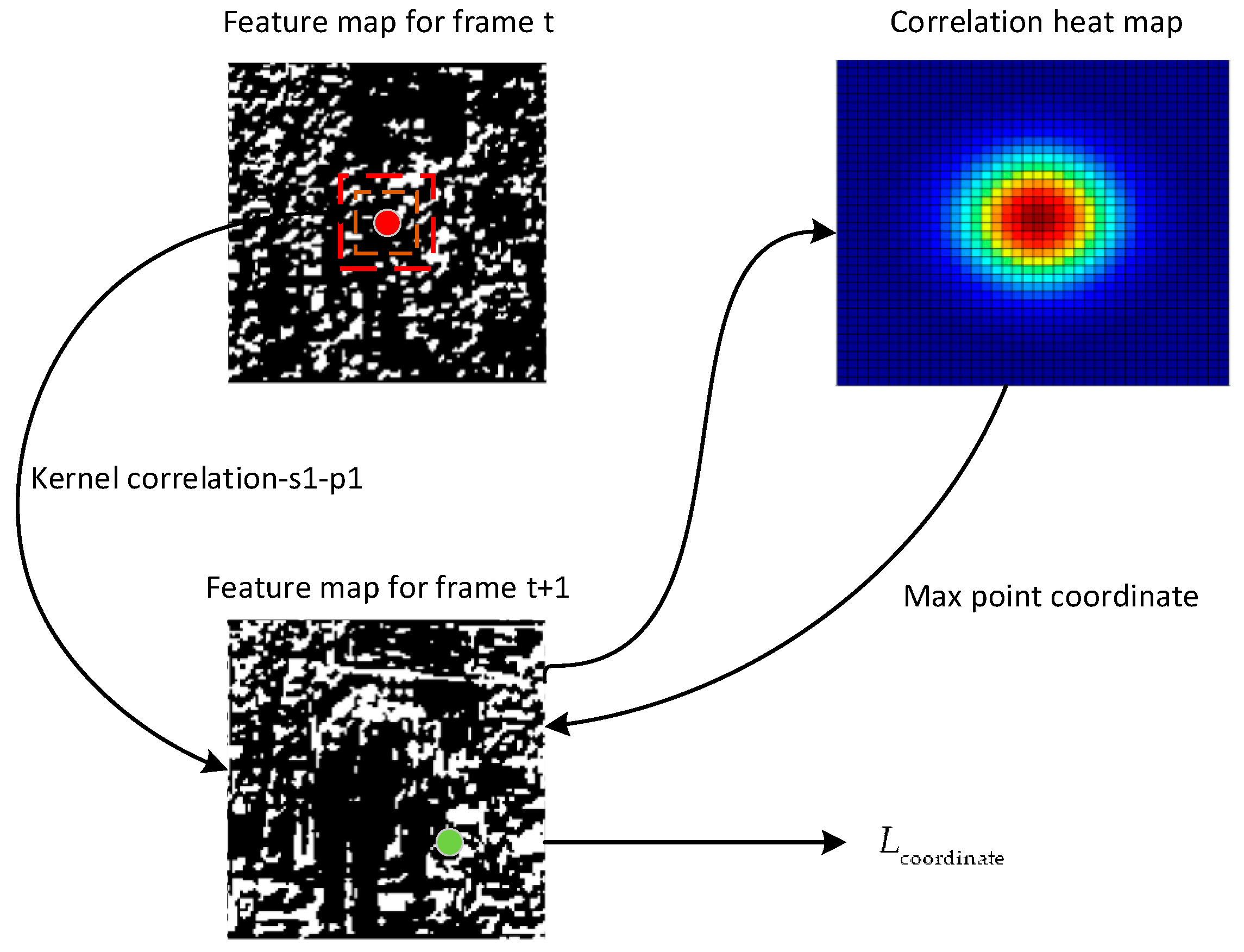
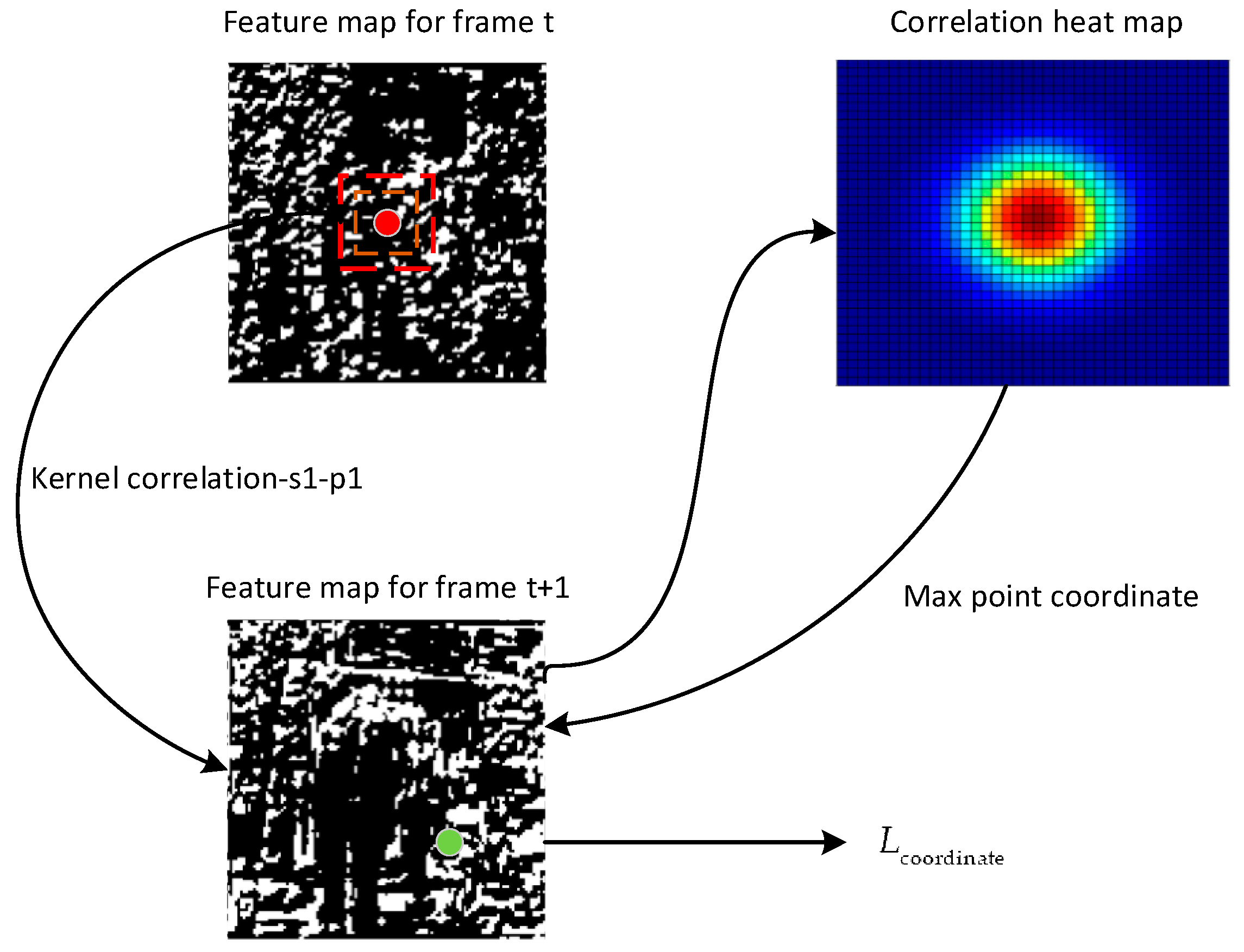
3.2.2. Correlation Loss
4. Experiment and Results
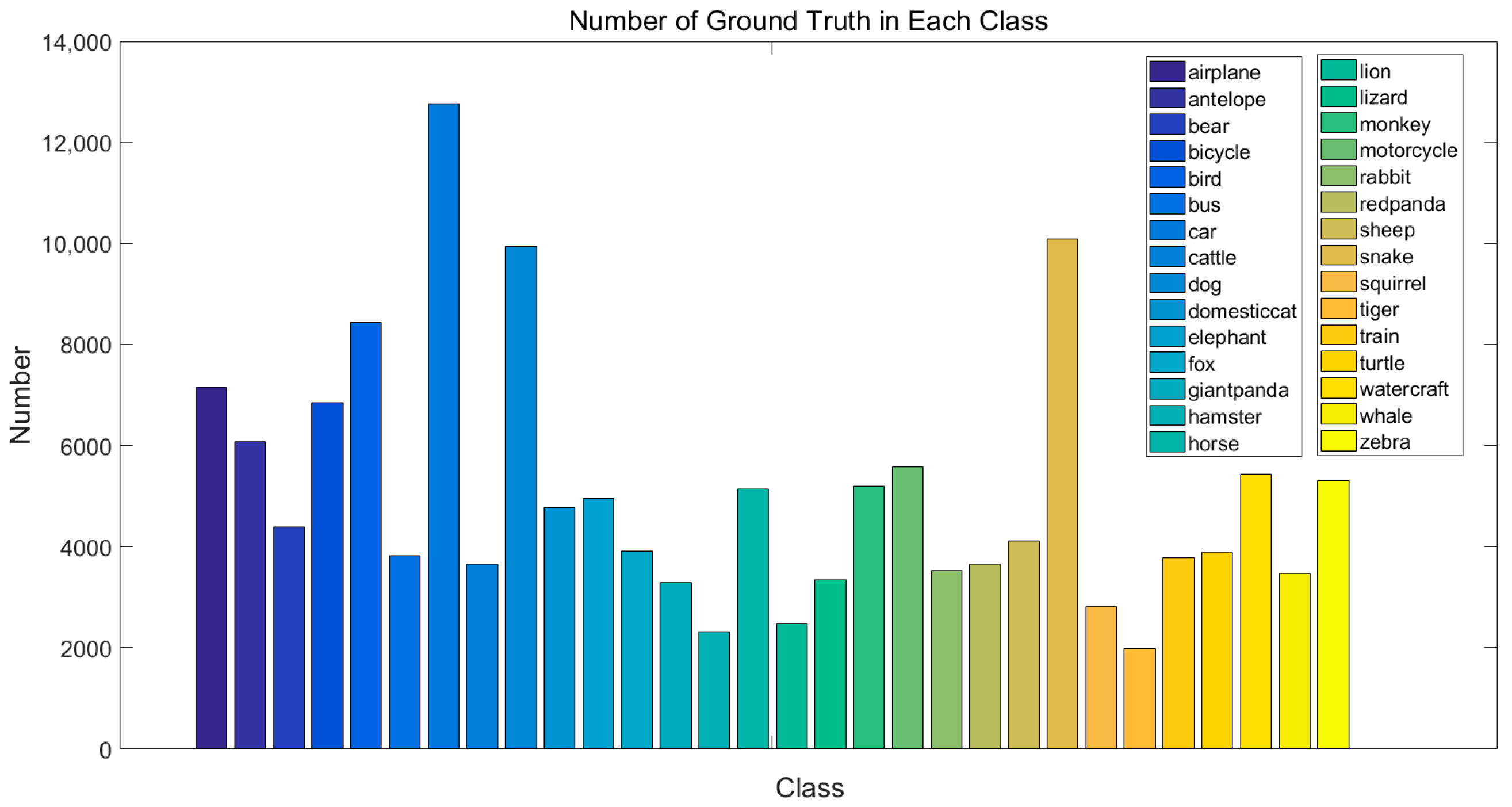
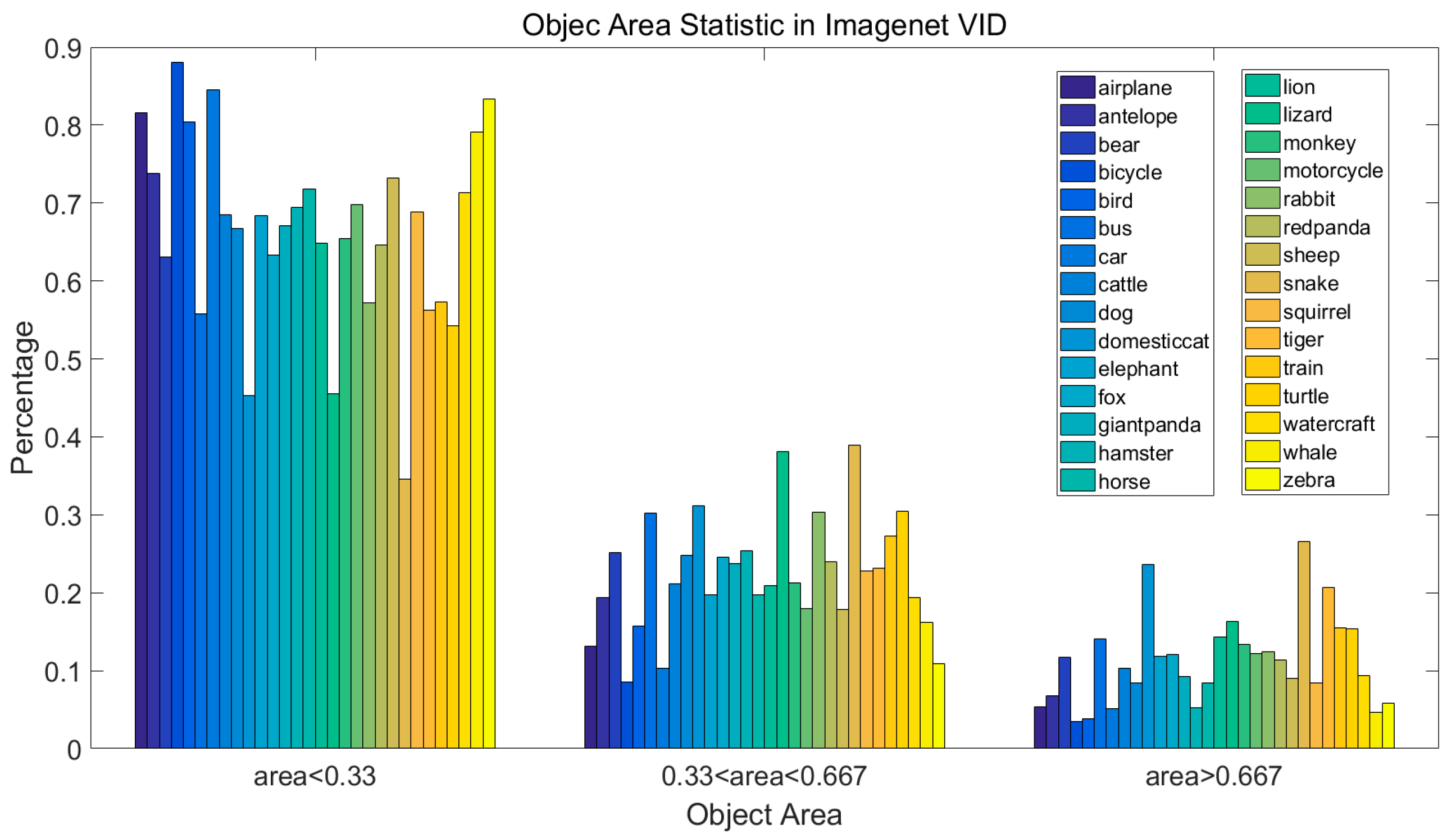
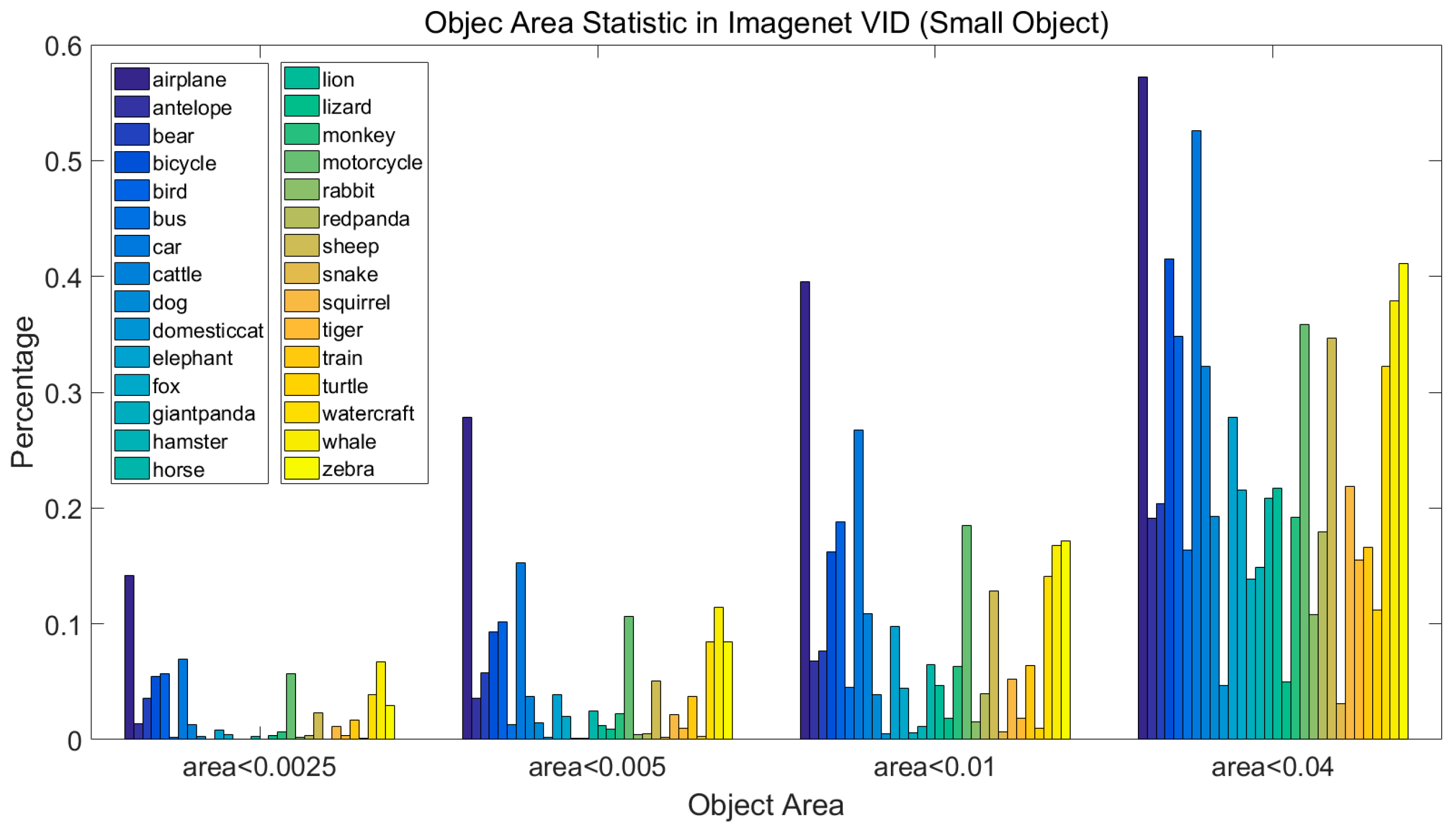
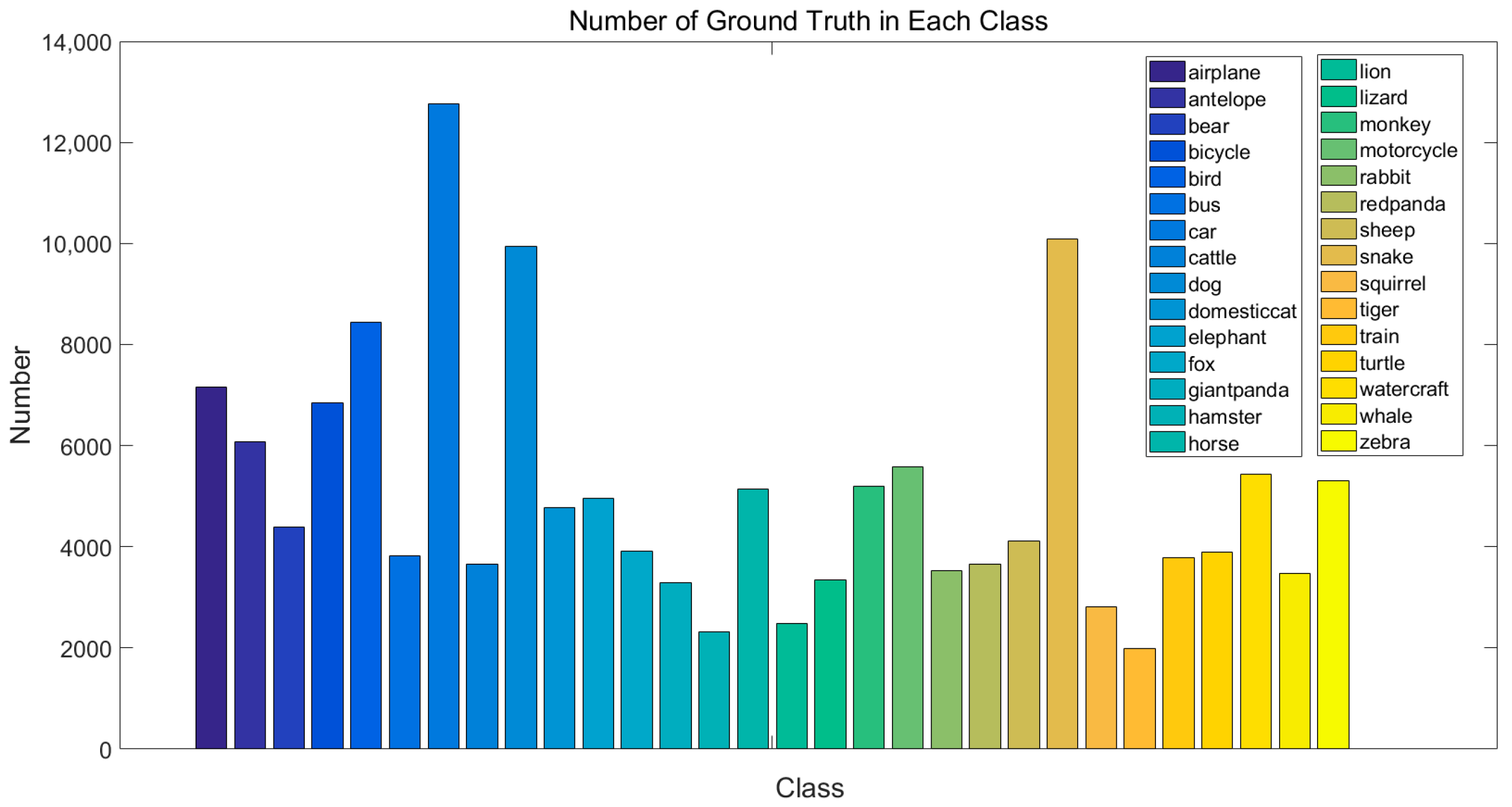
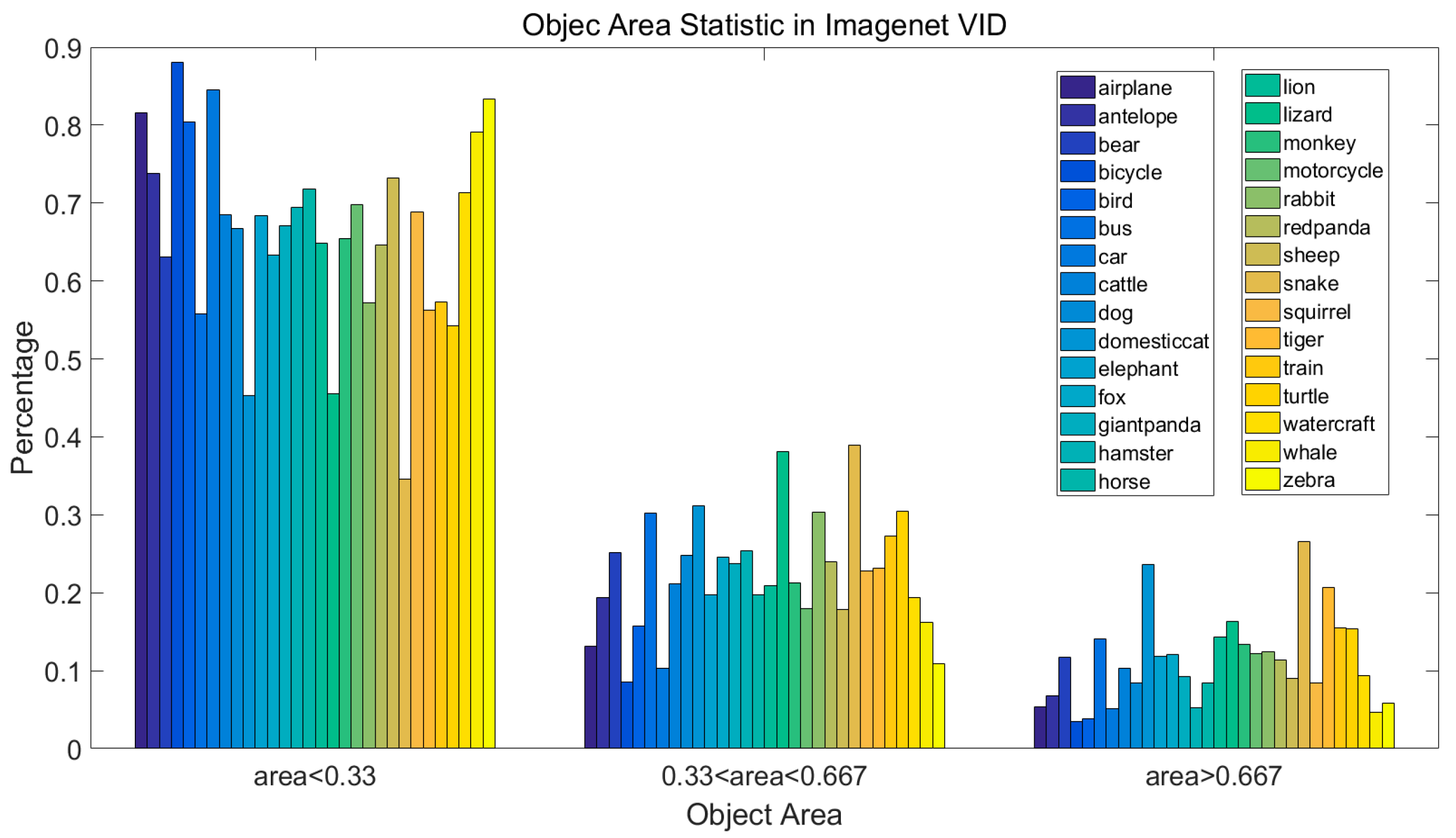
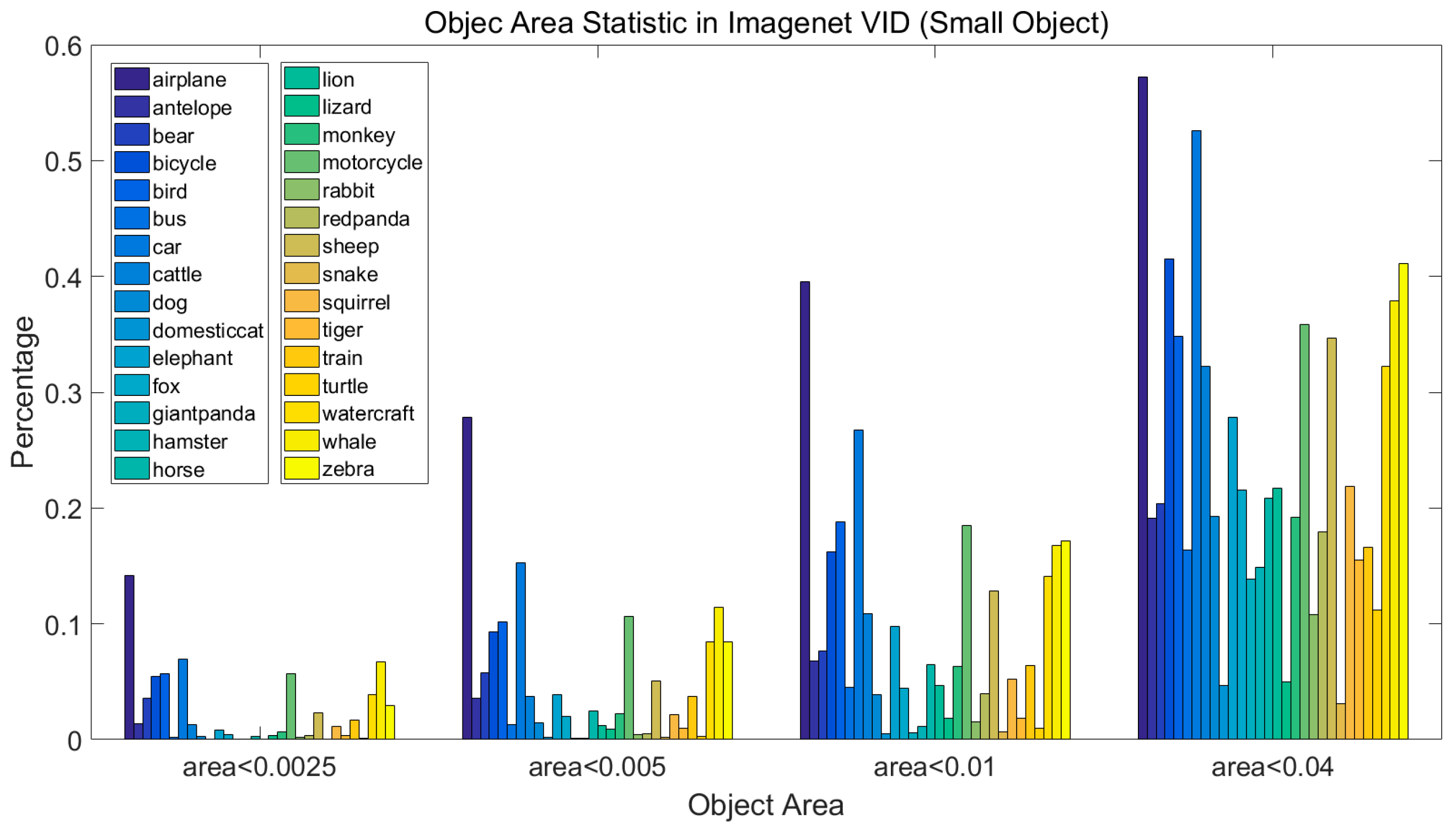
4.1. ImageNet Dataset
4.2. Model Training
4.3. Testing and Results
4.4. Model Analysis
4.4.1. Number of Anchor Shapes
- Anchor-6: For each pixel in multi-scale feature map, there are six anchor shapes in the multiscale feature map, which contains [1, 2, 3, , ] and an aspect ratio of 1 for a scale of . In our framework, the total number of anchors is 11,640.
- Anchor-4: For each pixel in multi-scale feature map, there are four anchor shapes in the multiscale feature map, which contains [1, 2, ] and an aspect ratio of 1 for a scale of . In our framework, the total number of anchors is 7760.
- Anchor-4 and 6: In this setting, we follow the original SSD setting. In Conv_4_3, Conv9_2, and Conv10_2, there are four anchor shapes in the multiscale feature map, which contains [1, 2, ] and an aspect ratio of 1 for a scale of . Then, in Conv_6_2, Conv7_2, and Conv8_2, there are six anchor shapes in the multiscale feature map, which contains [1, 2, 3, , ] and an aspect ratio of 1 for a scale of . In our framework, the total number of anchors is 8732.
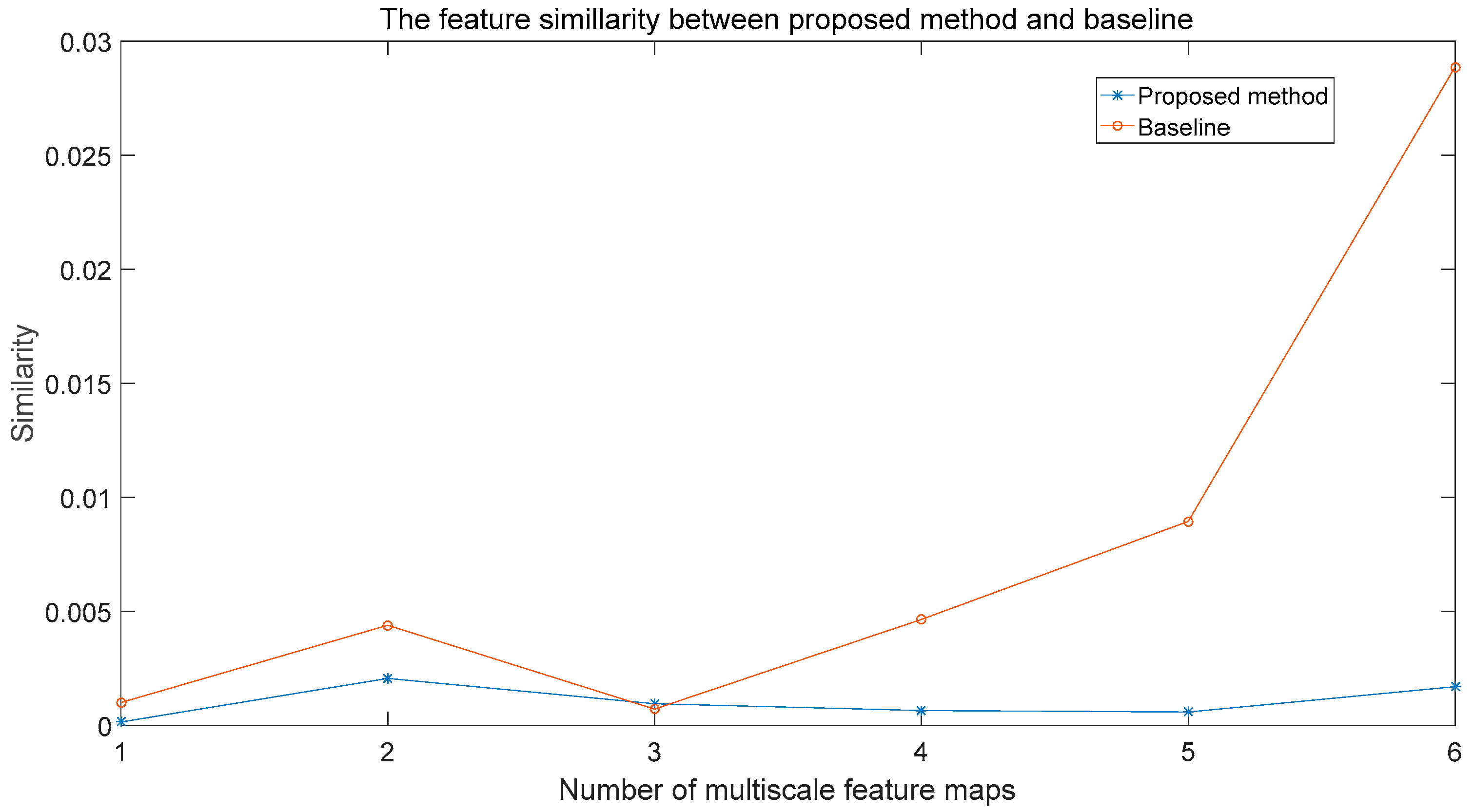
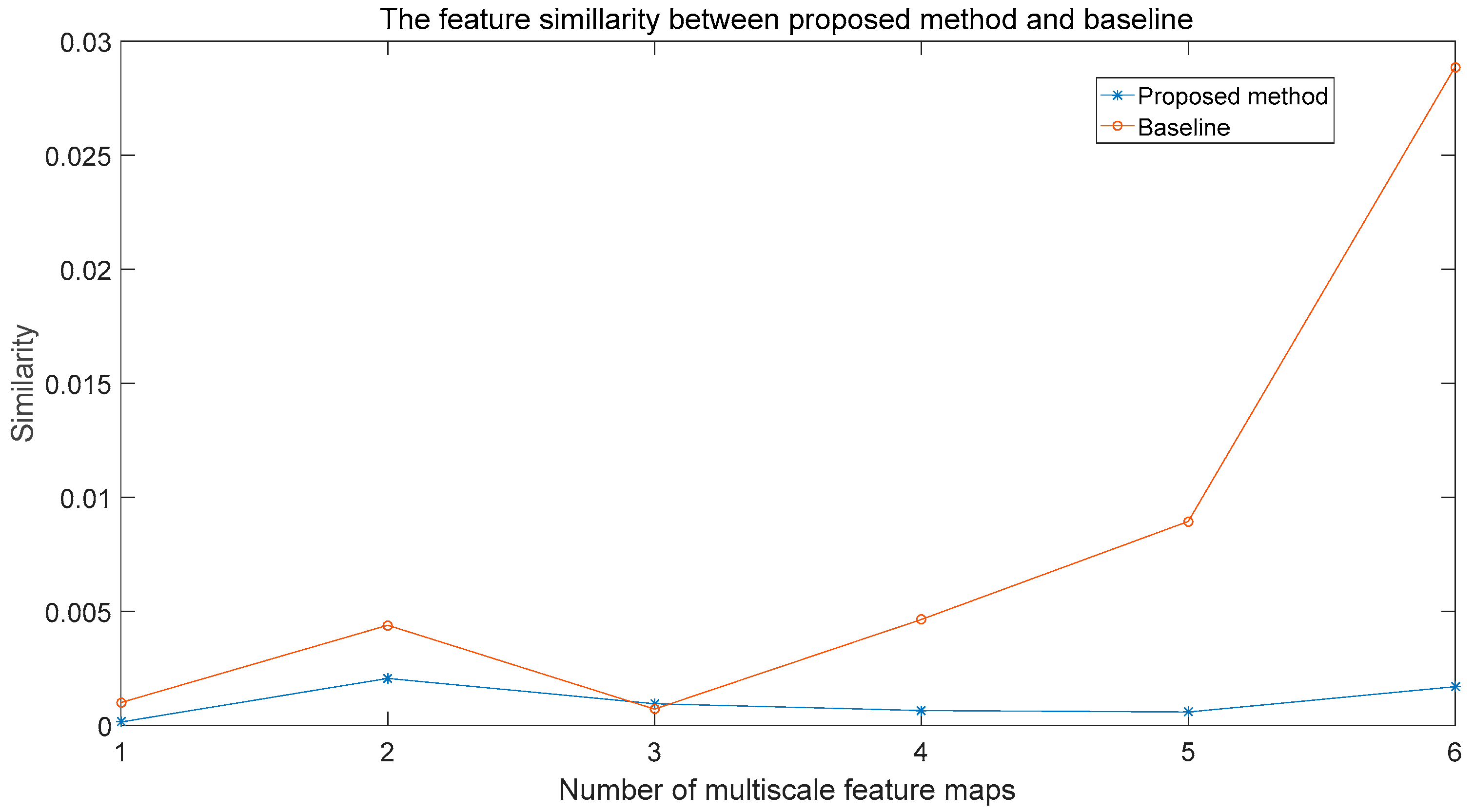
4.4.2. Number of Multi-Scale Feature Maps
- Feature-6: In this setting, we use six feature maps, which are Conv4_3, Conv6_2, Conv7_2, Conv8_2, Conv9_2, and Conv10_2. In our framework, the total number of anchors is 11,640.
- Feature-5: In this setting, we use five feature maps, which are Conv4_3, Conv6_2, Conv7_2, Conv8_2, and Conv9_2. In our framework, the total number of anchors is 11,634.
- Feature-4: In this setting, we use four feature maps, which are Conv4_3, Conv6_2, Conv7_2, and Conv8_2. In our framework, the total number of anchors is 11,580.
- Feature-3: In this setting, we use three feature maps, which are Conv4_3, Conv6_2, and Conv7_2. In our framework, the total number of anchors is 11,430.
4.5. Evaluation of the YouTube Object (YTO) Dataset
4.5.1. YouTube Object Dataset
4.5.2. Evaluation Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 2012, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Los Alamitos, CA, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 2016, 379–387. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Zhong, J.; Lei, T.; Yao, G. Robust Vehicle Detection in Aerial Images Based on Cascaded Convolutional Neural Networks. Sensors 2017, 17, 2720. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Oh, S.I.; Kang, H.B. Object Detection and Classification by Decision-Level Fusion for Intelligent Vehicle Systems. Sensors 2017, 17, 207. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Xiong, Y.; Dai, J.; Yuan, L.; Wei, Y. Deep feature flow for video recognition. arXiv, 2016; arXiv:1611.07715. [Google Scholar]
- Kang, K.; Li, H.; Yan, J.; Zeng, X.; Yang, B.; Xiao, T.; Zhang, C.; Wang, Z.; Wang, R.; Wang, X. T-CNN: Tubelets with convolutional neural networks for object detection from videos. IEEE Trans. Circuits Systems Video Technol. 2017. [Google Scholar] [CrossRef]
- Han, W.; Khorrami, P.; Paine, T.L.; Ramachandran, P.; Babaeizadeh, M.; Shi, H.; Li, J.; Yan, S.; Huang, T.S. Seq-nms for video object detection. arXiv, 2016; arXiv:1602.08465. [Google Scholar]
- Kang, K.; Ouyang, W.; Li, H.; Wang, X. Object detection from video tubelets with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 817–825. [Google Scholar]
- Lee, B.; Erdenee, E.; Jin, S.; Nam, M.Y.; Jung, Y.G.; Rhee, P.K. Multi-class multi-object tracking using changing point detection. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 68–83. [Google Scholar]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the IEEE CVPR Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 539–546. [Google Scholar]
- Weinberger, K.Q.; Saul, L.K. Distance metric learning for large margin nearest neighbor classification. J. Mach. Learn. Res. 2009, 10, 207–244. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving Object Detection with One Line of Code. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5562–5570. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the IEEE CVPR Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Gkioxari, G.; Malik, J. Finding action tubes. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 759–768. [Google Scholar]
- Peng, X.; Schmid, C. Multi-region two-stream R-CNN for action detection. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 744–759. [Google Scholar]
- Hou, R.; Chen, C.; Shah, M. Tube convolutional neural network (T-CNN) for action detection in videos. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, C.; Stevens, A.; Chen, C.; Pu, Y.; Gan, Z.; Carin, L. Learning Weight Uncertainty with Stochastic Gradient MCMC for Shape Classification. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 5666–5675. [Google Scholar]
- Luciano, L.; Hamza, A.B. Deep learning with geodesic moments for 3D shape classification. Pattern Recognit. Lett. 2017. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Erhan, D.; Szegedy, C.; Toshev, A.; Anguelov, D. Scalable object detection using deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2147–2154. [Google Scholar]
- Hosang, J.; Benenson, R.; Schiele, B. How good are detection proposals, really? arXiv, 2014; arXiv:1406.6962. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Huber, P.J. Robust Estimation of a Location Parameter. Ann. Math. Stat. 1964, 35, 73–101. [Google Scholar] [CrossRef]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Baoxian, W.; Linbo, T.; Jinglin, Y.; Baojun, Z.; Shuigen, W. Visual Tracking Based on Extreme Learning Machine and Sparse Representation. Sensors 2015, 15, 26877–26905. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 850–865. [Google Scholar]
- Zhao, Z.; Han, Y.; Xu, T.; Li, X.; Song, H.; Luo, J. A Reliable and Real-Time Tracking Method with Color Distribution. Sensors 2017, 17, 2303. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Wang, Y.; Dai, J.; Yuan, L.; Wei, Y. Flow-Guided Feature Aggregation for Video Object Detection. arXiv, 2017; arXiv:1703.10025. [Google Scholar]
- Kang, K.; Li, H.; Xiao, T.; Ouyang, W.; Yan, J.; Liu, X.; Wang, X. Object detection in videos with tubelet proposal networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, HI, USA, 21–26 July 2017; p. 7. [Google Scholar]
- Kwak, S.; Cho, M.; Laptev, I.; Ponce, J. Unsupervised Object Discovery and Tracking in Video Collections. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 3173–3181. [Google Scholar]
- Tripathi, S.; Lipton, Z.; Belongie, S.; Nguyen, T. Context Matters: Refining Object Detection in Video with Recurrent Neural Networks. In Proceedings of the British Machine Vision Conference, York, UK, 19–22 September 2016; pp. 44.1–44.12. [Google Scholar]
- Lu, Y.; Lu, C.; Tang, C.K. Online Video Object Detection Using Association LSTM. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2363–2371. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sanya, China, 23–24 October 2010; pp. 249–256. [Google Scholar]
- Ferrari, V.; Schmid, C.; Civera, J.; Leistner, C.; Prest, A. Learning object class detectors from weakly annotated video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3282–3289. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Conv Kernel Size | Feature Map Size | Usage | Options |
|---|---|---|---|---|
| Conv4_3 | Detection for scale 1 | s-1, p-1 | ||
| Conv6_1 | Enlarge receptive field | dilation | ||
| Conv6_2 | Detection for scale 2 | s-1, p-0 | ||
| Conv7_1 | Reduce channels | s-1, p-0 | ||
| Conv7_2 | Detection for scale 3 | s-2, p-1 | ||
| Conv8_1 | Reduce channels | s-1, p-0 | ||
| Conv8_2 | Detection for scale 4 | s-2, p-1 | ||
| Conv9_1 | Reduce channels | s-1, p-0 | ||
| Conv9_2 | Detection for scale 5 | s-1, p-0 | ||
| Conv10_1 | Reduce channels | s-1, p-0 | ||
| Conv10_2 | Detection for scale 6 | s-1, p-0 |
| Feature | Feature Map Size | Anchor Height | Anchor Width | Number |
|---|---|---|---|---|
| Conv4_3 | 0.0707, 0.0577, 0.1414 0.1732, 0.1000, 0.1414 | 0.1414, 0.1732, 0.0707 0.0577, 0.1000, 0.1414 | 8864 | |
| Conv6_2 | 0.1414, 0.1155, 0.2828 0.3464, 0.2000, 0.2784 | 0.2828, 0.3464, 0.1414 0.1155, 0.2000, 0.2784 | 2166 | |
| Conv7_2 | 0.2740, 0.2237, 0.5480 0.6712, 0.3875, 0.4720 | 0.5480, 0.6712, 0.2740 0.2237, 0.3875, 0.4720 | 600 | |
| Conv8_2 | 0.4066, 0.3320, 0.8132 0.9959, 0.5750, 0.6621 | 0.8132, 0.9959, 0.4066 0.3320, 0.5750, 0.6621 | 150 | |
| Conv9_2 | 0.5392, 0.4402, 1.0783 1.3207, 0.7625, 0.8511 | 1.0783, 1.3207, 0.5392 0.4402, 0.7625, 0.8511 | 54 | |
| Conv10_2 | 0.6718, 0.5485, 1.3435 1.6454, 0.9500, 1.0395 | 1.3435, 1.6454, 0.6718 0.5485, 0.9500, 1.0395 | 6 |
| Feature | Feature Map Size | Confidence Kernel | Location Kernel |
|---|---|---|---|
| Conv4_3 | |||
| Conv6_2 | |||
| Conv7_2 | |||
| Conv8_2 | |||
| Conv9_2 | |||
| Conv10_2 |
| Class | [8] | [5] | [15] | [39] | Baseline | Our | [13] |
|---|---|---|---|---|---|---|---|
| Airplane | 64.5 | 82.1 | 72.7 | 84.6 | 79.3 | 81.2 | 83.7 |
| Antelope | 71.4 | 78.4 | 75.5 | 78.1 | 73.2 | 73.5 | 85.7 |
| Bear | 42.6 | 66.5 | 42.2 | 72.0 | 65.0 | 70.2 | 84.4 |
| Bicycle | 36.4 | 65.6 | 39.5 | 67.2 | 72.5 | 72.3 | 74.5 |
| Bird | 18.8 | 66.1 | 25 | 68 | 70.9 | 71.5 | 73.8 |
| Bus | 62.4 | 77.2 | 64.1 | 80.1 | 76.8 | 78.6 | 75.7 |
| Car | 37.3 | 52.3 | 36.3 | 54.7 | 49.2 | 50.1 | 57.1 |
| Cattle | 47.6 | 49.1 | 51.1 | 61.2 | 63.8 | 65.3 | 58.7 |
| Dog | 15.6 | 57.1 | 24.4 | 61.6 | 56.6 | 60.4 | 72.3 |
| Dc_cat | 49.5 | 72.0 | 48.6 | 78.9 | 72.6 | 70.1 | 69.2 |
| Elephant | 66.9 | 68.1 | 65.6 | 71.6 | 78.9 | 82.6 | 80.2 |
| Fox | 66.3 | 76.8 | 73.9 | 83.2 | 85.6 | 85.9 | 83.4 |
| Giant_panda | 58.2 | 71.8 | 61.7 | 78.1 | 79.8 | 81.2 | 80.5 |
| Hamster | 74.1 | 89.7 | 82.4 | 91.5 | 86.5 | 87.5 | 93.1 |
| Horse | 25.5 | 65.1 | 30.8 | 66.8 | 73.5 | 75.2 | 84.2 |
| Lion | 29 | 20.1 | 34.4 | 21.6 | 46.5 | 47.8 | 67.8 |
| Lizard | 68.7 | 63.8 | 54.2 | 74.4 | 69.4 | 71.5 | 80.3 |
| Monkey | 1.9 | 34.7 | 1.6 | 36.6 | 52.6 | 50.3 | 54.8 |
| Motorcycle | 50.8 | 74.1 | 61.0 | 76.3 | 70.8 | 72.5 | 80.6 |
| Rabbit | 34.2 | 45.7 | 36.6 | 51.4 | 59.1 | 61.8 | 63.7 |
| Red_panda | 29.4 | 55.8 | 19.7 | 70.6 | 67.8 | 71.9 | 85.7 |
| Sheep | 59.0 | 54.1 | 55.0 | 64.2 | 38.7 | 40.0 | 60.5 |
| Snake | 43.7 | 57.2 | 38.9 | 61.2 | 59.2 | 62.3 | 72.9 |
| Squirrel | 1.8 | 29.8 | 2.6 | 42.3 | 83.4 | 85.1 | 52.7 |
| Tiger | 33.0 | 81.5 | 42.8 | 84.8 | 76.8 | 78.1 | 89.7 |
| Train | 56.6 | 72.0 | 54.6 | 78.1 | 69.3 | 71.2 | 81.3 |
| Turtle | 66.1 | 74.4 | 66.1 | 77.2 | 72.9 | 74.5 | 73.7 |
| Watercraft | 61.1 | 55.7 | 69.2 | 61.5 | 63.4 | 65.6 | 69.5 |
| Whale | 24.1 | 43.2 | 26.5 | 66.9 | 46.8 | 51.8 | 33.5 |
| Zebra | 64.2 | 89.4 | 68.6 | 88.5 | 74.9 | 75.2 | 90.2 |
| mAP | 45.3 | 63.0 | 47.5 | 68.4 | 67.9 | 69.5 | 73.8 |
| Settings | Anchor-6 | Anchor-4 | Anchor-4 and 6 |
|---|---|---|---|
| Anchor number | 11,640 | 7760 | 8732 |
| Detection speed | 32 fps | 51 fps | 46 fps |
| Mean AP | 69.5 | 67.9 | 68.3 |
| Settings | Feature-6 | Feature-5 | Feature-4 | Feature-3 |
|---|---|---|---|---|
| Anchor number | 11,640 | 11,634 | 11,580 | 11,430 |
| Detection speed | 32 fps | 32 fps | 32 fps | 33 fps |
| Mean AP | 69.5 | 69.3 | 69.1 | 66.8 |
| Class | [40] | [22] | [41] | [42] | [15] | Base | Our |
|---|---|---|---|---|---|---|---|
| Airplane | 56.5 | 76.6 | 76.1 | 78.9 | 94.1 | 80.2 | 85.2 |
| Bird | 66.4 | 89.5 | 87.6 | 90.9 | 69.7 | 79.5 | 83.6 |
| Boat | 58.0 | 57.6 | 62.1 | 65.9 | 88.2 | 75.8 | 79.5 |
| Car | 76.8 | 65.5 | 80.7 | 84.8 | 79.3 | 86.9 | 90.7 |
| Cat | 39.9 | 43.0 | 62.4 | 65.2 | 76.6 | 76.5 | 78.9 |
| Cow | 69.3 | 53.4 | 78.0 | 81.4 | 18.6 | 82.3 | 87.4 |
| Dog | 50.4 | 55.8 | 58.7 | 61.9 | 89.6 | 67.3 | 71.7 |
| Horse | 56.3 | 37.0 | 81.8 | 83.2 | 89.0 | 85.2 | 88.1 |
| Moterbike | 53.0 | 24.6 | 41.5 | 43.9 | 87.3 | 58.6 | 65.8 |
| Train | 31.0 | 62.0 | 58.2 | 61.3 | 75.3 | 71.7 | 77.8 |
| Mean AP | 55.7 | 56.5 | 68.7 | 72.1 | 76.8 | 76.4 | 80.8 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, B.; Zhao, B.; Tang, L.; Han, Y.; Wang, W. Deep Spatial-Temporal Joint Feature Representation for Video Object Detection. Sensors 2018, 18, 774. https://doi.org/10.3390/s18030774
Zhao B, Zhao B, Tang L, Han Y, Wang W. Deep Spatial-Temporal Joint Feature Representation for Video Object Detection. Sensors. 2018; 18(3):774. https://doi.org/10.3390/s18030774
Chicago/Turabian StyleZhao, Baojun, Boya Zhao, Linbo Tang, Yuqi Han, and Wenzheng Wang. 2018. "Deep Spatial-Temporal Joint Feature Representation for Video Object Detection" Sensors 18, no. 3: 774. https://doi.org/10.3390/s18030774
APA StyleZhao, B., Zhao, B., Tang, L., Han, Y., & Wang, W. (2018). Deep Spatial-Temporal Joint Feature Representation for Video Object Detection. Sensors, 18(3), 774. https://doi.org/10.3390/s18030774